Data Informatics. Seon Ho Kim, Ph.D.
|
|
|
- Edgar Martin
- 5 years ago
- Views:
Transcription
1 Data Informatics Seon Ho Kim, Ph.D.
2 Clustering Overview
3 Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements, etc.) are accompanied by labels indicating the class of the observations New data is classified based on the training set Unsupervised learning (clustering) The class labels of training data is unknown Given a set of measurements, observations, etc. with the aim of establishing the existence of classes or clusters in the data
4 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Clustering is the process of organizing objects into groups whose members are similar in some way. Discover new categories in an unsupervised manner (no sample category labels provided).
5
6 Ch. 16 A data set with clear cluster structure How would you design an algorithm for finding the three clusters in this case?
7 Hierarchy isn t clustering but is the kind of output you want from clustering (30) agriculture biology physics CS space dairy crops botany cell forestry agronomy evolution magnetism relativity AI HCI courses craft missions
8 Why clustering? A few good reasons... Simplifications Pattern detection Useful in data concept construction Unsupervised learning process
9 Where to use clustering? Data mining, information retrieval, text mining, Web analysis, marketing, medical diagnostic, etc. Marketing: Help marketers discover distinct groups in their customer bases, and then use this knowledge to develop targeted marketing programs Land use: Identification of areas of similar land use in an earth observation database Insurance: Identifying groups of motor insurance policy holders with a high average claim cost City-planning: Identifying groups of houses according to their house type, value, and geographical location Earth-quake studies: Observed earth quake epicenters should be clustered along continent faults
10 Which method should I use? Type of attributes in data Scalability to larger dataset Ability to work with irregular data Time cost Complexity Data order dependency Result presentation
11 Major Existing clustering methods Distance-based: based on connectivity and density functions Hierarchical: create a hierarchical decomposition of the set of data (or objects) using some criterion Partitioning: construct various partitions and then evaluate them by some criterion Probabilistic: a model is hypothesized for each of the clusters
12 Clustering Algorithms Hierarchical algorithms Bottom-up, agglomerative Top-down, divisive Flat algorithms Usually start with a random (partial) partitioning Refine it iteratively K means clustering (Model based clustering)
13 Hard vs. soft clustering Hard clustering: each sample belongs to exactly one cluster More common and easier to do Soft clustering: a sample can belong to more than one cluster. Makes more sense for applications like creating browsable hierarchies You may want to put a pair of sneakers in two clusters: (i) sports apparel and (ii) shoes You can only do that with a soft clustering approach.
14 Clustering Algorithms Start with a collection of n objects each represented by a p - dimensional feature vector x i, i=1, n. The goal is to divide these n objects into k clusters so that objects within a clusters are more similar than objects between clusters. k is usually unknown. Popular methods: hierarchical, k-means, SOM (Self Organizing Map), mixture models, etc.
15 Sec Issues for clustering Representation for clustering Object representation Vector space? Normalization? Need a notion of similarity/distance How many clusters? Fixed a priori? Completely data driven? Avoid trivial clusters - too large or small
16 Hierarchical Clustering
17 Hierarchical Clustering Build a tree-based hierarchical taxonomy (dendrogram) from a set of unlabeled examples. animal vertebrate fish reptile amphib. mammal invertebrate worm insect crustacean Recursive application of a standard clustering algorithm can produce a hierarchical clustering.
18 Aglommerative vs. Divisive Clustering Multilevel clustering: level 1 has n clusters à level n has one cluster. Aglommerative (bottom-up) methods start with each example in its own cluster and iteratively combine them to form larger and larger clusters. starts with singleton and merge clusters. Divisive (partitional, top-down) separate all examples immediately into clusters. starts with one sample and split clusters.
19 Hierarchical Clustering Dendrogram Venn Diagram of Clustered Data
20 Nearest Neighbor Algorithm Nearest Neighbor Algorithm is an agglomerative approach (bottom-up). Starts with n nodes (n is the size of our sample), merges the 2 most similar nodes at each step, and stops when the desired number of clusters is reached.
21 Nearest Neighbor, Level 2, k = 7 clusters.
22 Nearest Neighbor, Level 3, k = 6 clusters.
23 Nearest Neighbor, Level 4, k = 5 clusters.
24 Nearest Neighbor, Level 5, k = 4 clusters.
25 Nearest Neighbor, Level 6, k = 3 clusters.
26 Nearest Neighbor, Level 7, k = 2 clusters.
27 Nearest Neighbor, Level 8, k = 1 cluster.
28 Hierarchical Clustering Calculate the similarity between all possible combinations of two profiles Keys Similarity Clustering Two most similar clusters are grouped together to form a new cluster Calculate the similarity between the new cluster and all remaining clusters. Until there is only one cluster
29 Cluster Similarity Assume a similarity function that determines the similarity of two instances: sim(x,y). a similarity measure or similarity function is a real-valued function that quantifies the similarity between two objects. Although no single definition of a similarity measure exists, usually similarity measures are in some sense the inverse of distance metrics. How to compute similarity of two clusters each possibly containing multiple instances? Single Link: Similarity of two most similar members. Complete Link: Similarity of two least similar members. Group Average: Average similarity between members.
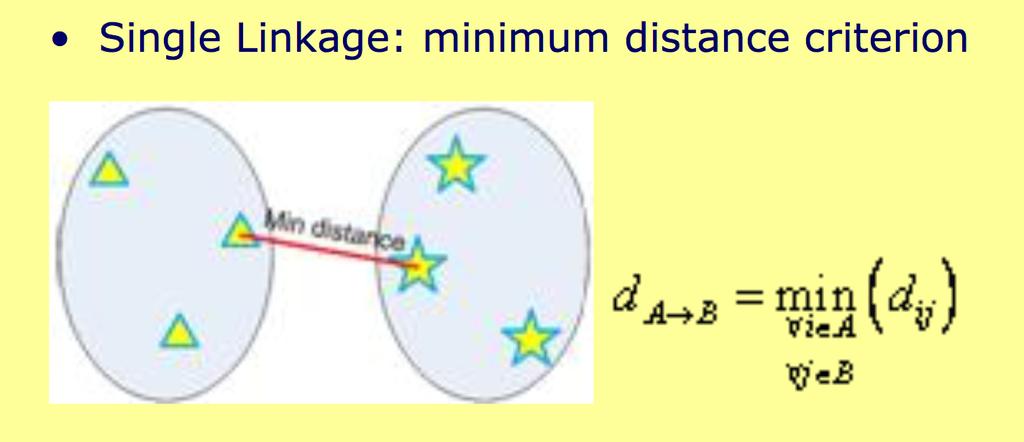
30 Clustering Single Linkage + + C 2 Dissimilarity between two clusters = Minimum dissimilarity between the members of two clusters C 1 Tend to generate long chains
31 Clustering Complete Linkage + + C 2 Dissimilarity between two clusters = Maximum dissimilarity between the members of two clusters C 1 Tend to generate clumps
32 Clustering Average Linkage + + C 2 Dissimilarity between two clusters = Averaged distances of all pairs of objects (one from each cluster). C 1
33 Clustering Average Group Linkage + + C 2 Dissimilarity between two clusters = Distance between two cluster means. C 1
34 Single Link Agglomerative Clustering Use maximum similarity of pairs: sim( c i, c j ) = max x c, y i c j sim( x, y) Can result in straggly (long and thin) clusters due to chaining effect. Appropriate in some domains, such as clustering islands.


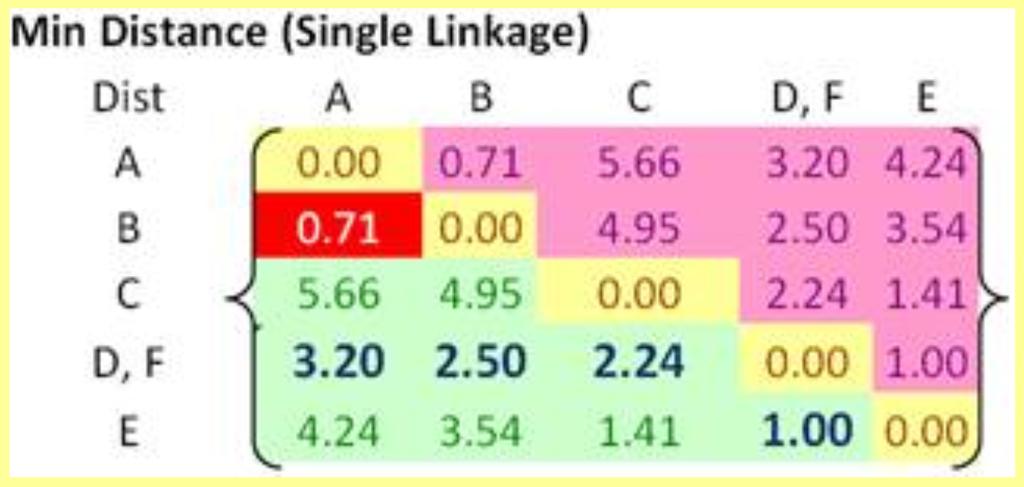
35 Example Combine D and F!
36 Now, how to calculate new distances?
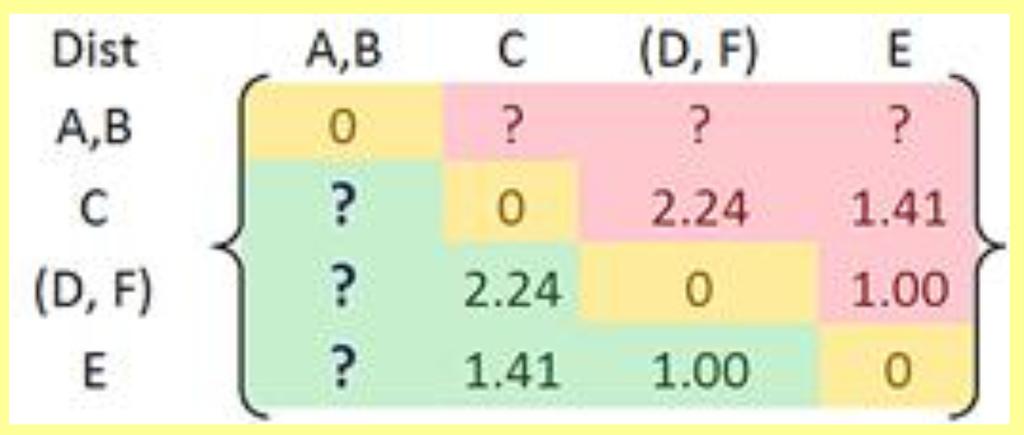
37
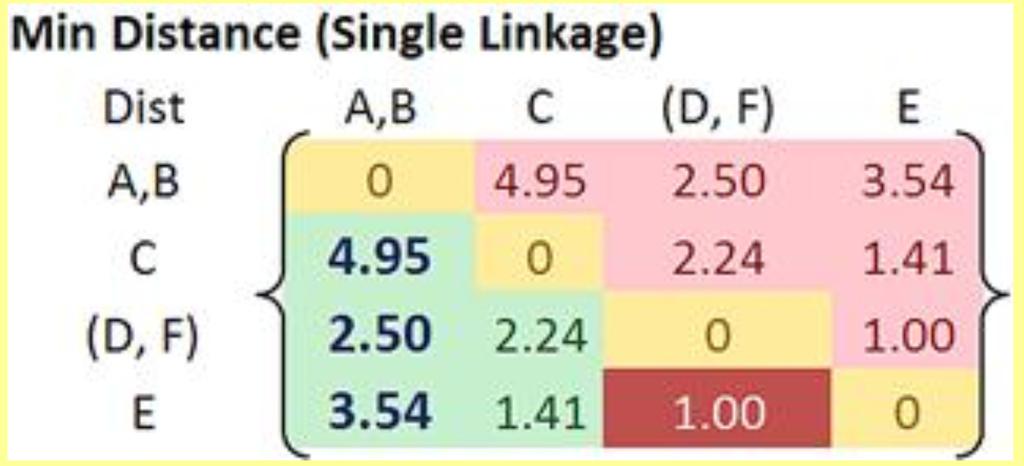
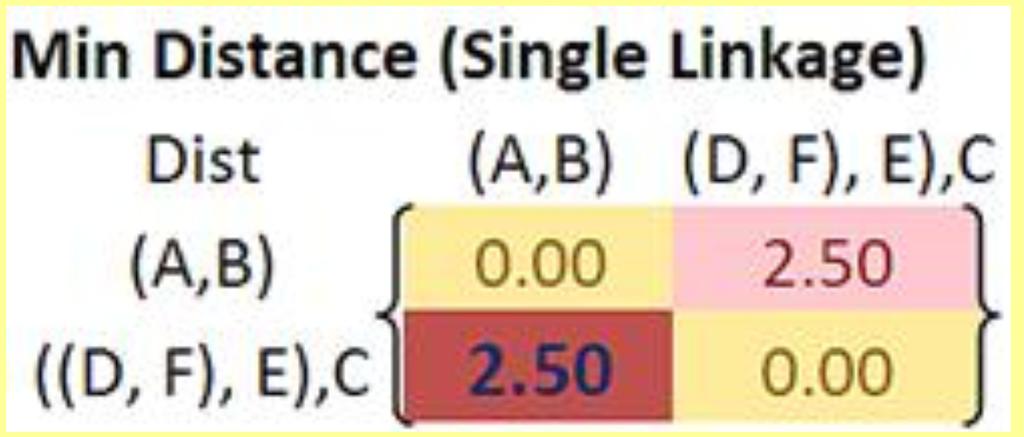
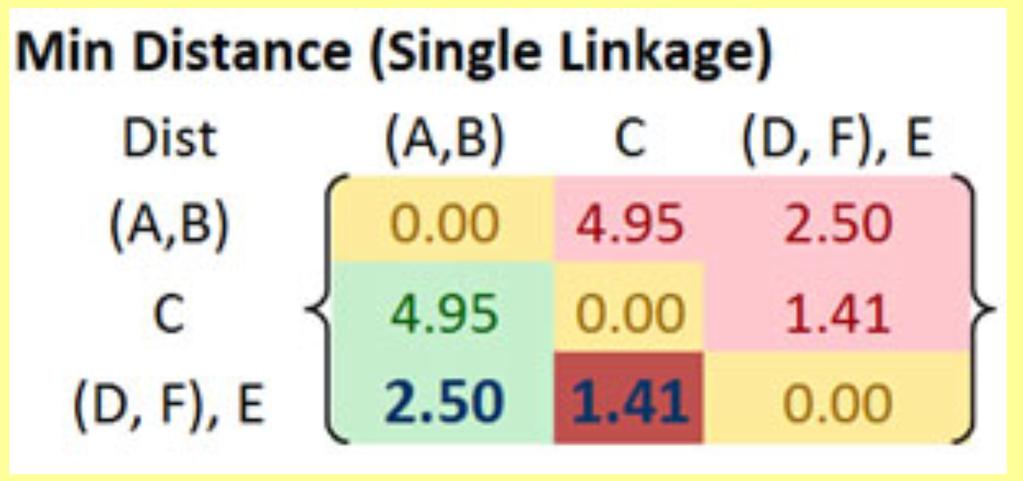
38
39 Complete Link Agglomerative Clustering Use minimum similarity of pairs: sim( c i, c j ) = x c min, y i c j sim( x, y) Makes more tight, spherical clusters that are typically preferable.
40 Computational Complexity In the first iteration, all HAC methods need to compute similarity of all pairs of n individual instances which is O(n 2 ). In each of the subsequent n-2 merging iterations, it must compute the distance between the most recently created cluster and all other existing clusters. In order to maintain an overall O(n 2 ) performance, computing similarity to each other cluster must be done in constant time.
41 Computing Cluster Similarity After merging c i and c j, the similarity of the resulting cluster to any other cluster, c k, can be computed by: Single Link: sim (( ci c j ), ck ) = max( sim( ci, ck ), sim( c j, ck )) Complete Link: sim (( ci c j ), ck ) = min( sim( ci, ck ), sim( c j, ck ))
42 Group Average Agglomerative Clustering Use average similarity across all pairs within the merged cluster to measure the similarity of two clusters. sim( c i, c j ) = c i c j 1 ( c i c 1) Compromise between single and complete link. Averaged across all ordered pairs in the merged cluster instead of unordered pairs between the two clusters to encourage tight clusters. j!!!! x ( c c ) y ( c c ): y x i j i j!! sim( x, y)
43 Computing Group Average Similarity Assume cosine similarity and normalized vectors with unit length. Always maintain sum of vectors in each cluster. Compute similarity of clusters in constant time: = c j x c j x s!!! ) ( 1) )( ( ) ( )) ( ) ( ( )) ( ) ( ( ), ( = j i j i j i j i j i j i c c c c c c c s c s c s c s c c sim!!!!
44 Non-Hierarchical Clustering Typically must provide the number of desired clusters, k. Randomly choose k instances as seeds, one per cluster. Form initial clusters based on these seeds. Iterate, repeatedly reallocating instances to different clusters to improve the overall clustering. Stop when clustering converges or after a fixed number of iterations.
45 K-Means Assumes instances are real-valued vectors. Clusters based on centroids, center of gravity, or mean of points in a cluster, c:! µ(c) = 1! x c! IcI is the number of data points in cluster c Reassignment of instances to clusters is based on distance to the current cluster centroids. x c
46 Distance Metrics Euclidian distance (L 2 norm): m!! L2 ( x, y) = ( x i yi ) i= 1 L 1 norm: m!! L1 ( x, y) = x i y i i= 1 Cosine Similarity (transform to a distance by subtracting from 1):!! x y 1!! x y 2
47 K-Means Algorithm Let d be the distance measure between instances. Select k random instances {s 1, s 2, s k } as seeds. Until clustering converges or other stopping criterion: For each instance x i : Assign x i to the cluster c j such that d(x i, s j ) is minimal. (Update the seeds to the centroid of each cluster) For each cluster c j s j = m(c j ) // recalculate centroids
48 K Means Example (K=2) Pick seeds Reassign clusters Compute centroids Reasssign clusters x x x x Compute centroids Reassign clusters Converged!
49 Sec Termination conditions Several possibilities, e.g., A fixed number of iterations. Partition unchanged. Centroid positions don t change.
50 Sec Convergence Why should the K-means algorithm ever reach a fixed point? A state in which clusters don t change. K-means is a special case of a general procedure known as the Expectation Maximization (EM) algorithm. EM is known to converge. Number of iterations could be large. But in practice usually isn t
51 Time Complexity Assume computing distance between two instances is O(m) where m is the dimensionality of the vectors. Reassigning clusters: O(kn) distance computations, or O(knm). Computing centroids: Each instance vector gets added once to some centroid: O(nm). Assume these two steps are each done once for I iterations: O(Iknm). Linear in all relevant factors, assuming a fixed number of iterations, more efficient than O(n 2 ) HAC.
52 A Simple example showing the implementation of k-means algorithm (using K=2)
")
53 Step 1: Initialization: Randomly we choose following two centroids (k=2) for two clusters. In this case the 2 centroid are: m1=(1.0,1.0) and m2=(5.0,7.0).

54 Step 2: Thus, we obtain two clusters containing: {1,2,3} and {4,5,6,7}. Their new centroids are:
 and m2 = (3.9,5.")
55 Step 3: Now using these centroids we compute the Euclidean distance of each object, as shown in table. Therefore, the new clusters are: {1,2} and {3,4,5,6,7} Next centroids are: m1=(1.25,1.5) and m2 = (3.9,5.1)

56 Step 4: The clusters obtained are: {1,2} and {3,4,5,6,7} Therefore, there is no change in the cluster. Thus, the algorithm comes to a halt here and final result consist of 2 clusters {1,2} and {3,4,5,6,7}.
57 PLOT
58 (with K=3) Step 1 Step 2
59 PLOT
60 Getting the k right How to select k? Try different k, looking at the change in the average distance to centroid as k increases Average falls rapidly until right k, then changes little Average distance to centroid k Best value of k
61 Example: Picking k Too few; many long distances to centroid. x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x
62 Example: Picking k Just right; distances rather short. x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x
63 Example: Picking k Too many; little improvement in average distance. x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x
64 Strengths: Strengths of k-means Simple: easy to understand and to implement Efficient: Time complexity: O(tkn), where n is the number of data points, k is the number of clusters, and t is the number of iterations. Since both k and t are small. k-means is considered a linear algorithm. K-means is the most popular clustering algorithm. Note that: it terminates at a local optimum if SSE is used. The global optimum is hard to find due to complexity.
65 Strengths: Strengths of k-means Simple: easy to understand and to implement Efficient: Time complexity: O(tkn), where n is the number of data points, k is the number of clusters, and t is the number of iterations. Since both k and t are small. k-means is considered a linear algorithm. K-means is the most popular clustering algorithm. Note that: it terminates at a local optimum if SSE is used. The global optimum is hard to find due to complexity.
66 Strengths: Strengths of k-means Simple: easy to understand and to implement Efficient: Time complexity: O(tkn), where n is the number of data points, k is the number of clusters, and t is the number of iterations. Since both k and t are small. k-means is considered a linear algorithm. K-means is the most popular clustering algorithm. Note that: it terminates at a local optimum if SSE is used. The global optimum is hard to find due to complexity.
67 Weaknesses of k-means The algorithm is only applicable if the mean is defined. For categorical data, k-mode - the centroid is represented by most frequent values. The user needs to specify k. The algorithm is sensitive to outliers Outliers are data points that are very far away from other data points. Outliers could be errors in the data recording or some special data points with very different values.
68 Weaknesses of k-means: Problems with outliers
69 Weaknesses of k-means: To deal with outliers One method is to remove some data points in the clustering process that are much further away from the centroids than other data points. To be safe, we may want to monitor these possible outliers over a few iterations and then decide to remove them. Another method is to perform random sampling. Since in sampling we only choose a small subset of the data points, the chance of selecting an outlier is very small. Assign the rest of the data points to the clusters by distance or similarity comparison, or classification
70 Weaknesses of k-means (cont ) The algorithm is sensitive to initial seeds.
71 Weaknesses of k-means (cont ) If we use different seeds: good results There are some methods to help choose good seeds
72 Weaknesses of k-means (cont ) The k-means algorithm is not suitable for discovering clusters that are not hyper-ellipsoids (or hyper-spheres). +
73 K-means summary Despite weaknesses, k-means is still the most popular algorithm due to its simplicity, efficiency and other clustering algorithms have their own lists of weaknesses. No clear evidence that any other clustering algorithm performs better in general although they may be more suitable for some specific types of data or applications. Comparing different clustering algorithms is a difficult task. No one knows the correct clusters!
74 Cluster Evaluation: hard problem The quality of a clustering is very hard to evaluate because We do not know the correct clusters Some methods are used: User inspection Study centroids, and spreads Rules from a decision tree. For text documents, one can read some documents in clusters.
75 Cluster evaluation: ground truth We use some labeled data (for classification) Assumption: Each class is a cluster. After clustering, a confusion matrix is constructed. From the matrix, we compute various measurements, entropy, purity, precision, recall and F-score. Let the classes in the data D be C = (c 1, c 2,, c k ). The clustering method produces k clusters, which divides D into k disjoint subsets, D 1, D 2,, D k.
76 About ground truth evaluation Commonly used to compare different clustering algorithms. A real-life data set for clustering has no class labels. Thus although an algorithm may perform very well on some labeled data sets, no guarantee that it will perform well on the actual application data at hand. The fact that it performs well on some label data sets does give us some confidence of the quality of the algorithm. This evaluation method is said to be based on external data or information.
77 Evaluation based on internal information Intra-cluster cohesion (compactness): Cohesion measures how near the data points in a cluster are to the cluster centroid. Sum of squared error (SSE) is a commonly used measure. Inter-cluster separation (isolation): Separation means that different cluster centroids should be far away from one another. In most applications, expert judgments are still the key.
78 Holes in data space All the clustering algorithms only group data. Clusters only represent one aspect of the knowledge in the data. Another aspect that we have not studied is the holes. A hole is a region in the data space that contains no or few data points. Reasons: insufficient data in certain areas, and/or certain attribute-value combinations are not possible or seldom occur.
79 Holes are useful too Although clusters are important, holes in the space can be quite useful too. For example, in a disease database we may find that certain symptoms and/or test values do not occur together, or when a certain medicine is used, some test values never go beyond certain ranges. Discovery of such information can be important in medical domains because it could mean the discovery of a cure to a disease or some biological laws.
80 Data regions and empty regions Given a data space, separate data regions (clusters) and empty regions (holes, with few or no data points). Use a supervised learning technique, i.e., decision tree induction, to separate the two types of regions. Due to the use of a supervised learning method for an unsupervised learning task, an interesting connection is made between the two types of learning paradigms.
81 Clustering Summary Clustering is has a long history and still active There are a huge number of clustering algorithms More are still coming every year. We only introduced several main algorithms. There are many others, e.g., density based algorithm, sub-space clustering, scale-up methods, neural networks based methods, fuzzy clustering, co-clustering, etc. Clustering is hard to evaluate, but very useful in practice. This partially explains why there are still a large number of clustering algorithms being devised every year. Clustering is highly application dependent and to some extent subjective.
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Clustering. Partition unlabeled examples into disjoint subsets of clusters, such that:
 Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
Clustering CE-324: Modern Information Retrieval Sharif University of Technology
 Clustering CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch. 16 What
Clustering CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch. 16 What
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Road map. Basic concepts
 Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Text Clustering Prof. Chris Clifton 19 October 2018 Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti Document clustering Motivations Document
CS47300: Web Information Search and Management Text Clustering Prof. Chris Clifton 19 October 2018 Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti Document clustering Motivations Document
CS490W. Text Clustering. Luo Si. Department of Computer Science Purdue University
 CS490W Text Clustering Luo Si Department of Computer Science Purdue University [Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti] Clustering Document clustering Motivations Document
CS490W Text Clustering Luo Si Department of Computer Science Purdue University [Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti] Clustering Document clustering Motivations Document
Administrative. Machine learning code. Supervised learning (e.g. classification) Machine learning: Unsupervised learning" BANANAS APPLES
 Machine learning: Unsupervised learning BANANAS APPLES") Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
Information Retrieval and Organisation
 Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
Clustering algorithms
 Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Big Data Analytics! Special Topics for Computer Science CSE CSE Feb 9
 Big Data Analytics! Special Topics for Computer Science CSE 4095-001 CSE 5095-005! Feb 9 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Clustering I What
Big Data Analytics! Special Topics for Computer Science CSE 4095-001 CSE 5095-005! Feb 9 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Clustering I What
What to come. There will be a few more topics we will cover on supervised learning
 Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
 http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Informa(on Retrieval
 Introduc*on to Informa(on Retrieval Clustering Chris Manning, Pandu Nayak, and Prabhakar Raghavan Today s Topic: Clustering Document clustering Mo*va*ons Document representa*ons Success criteria Clustering
Introduc*on to Informa(on Retrieval Clustering Chris Manning, Pandu Nayak, and Prabhakar Raghavan Today s Topic: Clustering Document clustering Mo*va*ons Document representa*ons Success criteria Clustering
Lecture 15 Clustering. Oct
 Lecture 15 Clustering Oct 31 2008 Unsupervised learning and pattern discovery So far, our data has been in this form: x 11,x 21, x 31,, x 1 m y1 x 12 22 2 2 2,x, x 3,, x m y We will be looking at unlabeled
Lecture 15 Clustering Oct 31 2008 Unsupervised learning and pattern discovery So far, our data has been in this form: x 11,x 21, x 31,, x 1 m y1 x 12 22 2 2 2,x, x 3,, x m y We will be looking at unlabeled
Informa(on Retrieval
 Introduc*on to Informa(on Retrieval CS276: Informa*on Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Lecture 12: Clustering Today s Topic: Clustering Document clustering Mo*va*ons Document
Introduc*on to Informa(on Retrieval CS276: Informa*on Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Lecture 12: Clustering Today s Topic: Clustering Document clustering Mo*va*ons Document
Clustering Results. Result List Example. Clustering Results. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Presenting Results Clustering Clustering Results! Result lists often contain documents related to different aspects of the query topic! Clustering is used to
Information Retrieval INFO 4300 / CS 4300! Presenting Results Clustering Clustering Results! Result lists often contain documents related to different aspects of the query topic! Clustering is used to
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
Hierarchical Clustering
 Hierarchical Clustering Build a tree-based hierarchical taxonomy (dendrogram) from a set animal of documents. vertebrate invertebrate fish reptile amphib. mammal worm insect crustacean One approach: recursive
Hierarchical Clustering Build a tree-based hierarchical taxonomy (dendrogram) from a set animal of documents. vertebrate invertebrate fish reptile amphib. mammal worm insect crustacean One approach: recursive
Unsupervised learning, Clustering CS434
 Unsupervised learning, Clustering CS434 Unsupervised learning and pattern discovery So far, our data has been in this form: We will be looking at unlabeled data: x 11,x 21, x 31,, x 1 m x 12,x 22, x 32,,
Unsupervised learning, Clustering CS434 Unsupervised learning and pattern discovery So far, our data has been in this form: We will be looking at unlabeled data: x 11,x 21, x 31,, x 1 m x 12,x 22, x 32,,
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Administrative. Machine learning code. Machine learning: Unsupervised learning
 Machine learning: Unsupervised learning http://www.youtube.com/watch?v=or_-y-eilqo David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
Machine learning: Unsupervised learning http://www.youtube.com/watch?v=or_-y-eilqo David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
k-means demo Administrative Machine learning: Unsupervised learning" Assignment 5 out
 Machine learning: Unsupervised learning" David Kauchak cs Spring 0 adapted from: http://www.stanford.edu/class/cs76/handouts/lecture7-clustering.ppt http://www.youtube.com/watch?v=or_-y-eilqo Administrative
Machine learning: Unsupervised learning" David Kauchak cs Spring 0 adapted from: http://www.stanford.edu/class/cs76/handouts/lecture7-clustering.ppt http://www.youtube.com/watch?v=or_-y-eilqo Administrative
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Unsupervised Learning I: K-Means Clustering
 Unsupervised Learning I: K-Means Clustering Reading: Chapter 8 from Introduction to Data Mining by Tan, Steinbach, and Kumar, pp. 487-515, 532-541, 546-552 (http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf)
Unsupervised Learning I: K-Means Clustering Reading: Chapter 8 from Introduction to Data Mining by Tan, Steinbach, and Kumar, pp. 487-515, 532-541, 546-552 (http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf)
Cluster Analysis. CSE634 Data Mining
 Cluster Analysis CSE634 Data Mining Agenda Introduction Clustering Requirements Data Representation Partitioning Methods K-Means Clustering K-Medoids Clustering Constrained K-Means clustering Introduction
Cluster Analysis CSE634 Data Mining Agenda Introduction Clustering Requirements Data Representation Partitioning Methods K-Means Clustering K-Medoids Clustering Constrained K-Means clustering Introduction
DD2475 Information Retrieval Lecture 10: Clustering. Document Clustering. Recap: Classification. Today
 Sec.14.1! Recap: Classification DD2475 Information Retrieval Lecture 10: Clustering Hedvig Kjellström hedvig@kth.se www.csc.kth.se/dd2475 Data points have labels Classification task: Finding good separators
Sec.14.1! Recap: Classification DD2475 Information Retrieval Lecture 10: Clustering Hedvig Kjellström hedvig@kth.se www.csc.kth.se/dd2475 Data points have labels Classification task: Finding good separators
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Flat Clustering. Slides are mostly from Hinrich Schütze. March 27, 2017
 Flat Clustering Slides are mostly from Hinrich Schütze March 7, 07 / 79 Overview Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? / 79 Outline Recap Clustering:
Flat Clustering Slides are mostly from Hinrich Schütze March 7, 07 / 79 Overview Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? / 79 Outline Recap Clustering:
Clustering Part 1. CSC 4510/9010: Applied Machine Learning. Dr. Paula Matuszek
 CSC 4510/9010: Applied Machine Learning 1 Clustering Part 1 Dr. Paula Matuszek Paula.Matuszek@villanova.edu Paula.Matuszek@gmail.com (610) 647-9789 What is Clustering? 2 Given some instances with data:
CSC 4510/9010: Applied Machine Learning 1 Clustering Part 1 Dr. Paula Matuszek Paula.Matuszek@villanova.edu Paula.Matuszek@gmail.com (610) 647-9789 What is Clustering? 2 Given some instances with data:
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering
 INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
Clustering. Informal goal. General types of clustering. Applications: Clustering in information search and analysis. Example applications in search
 Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16)
") CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16) Michael Hahsler Southern Methodist University These slides are largely based on the slides by Hinrich Schütze Institute for
CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16) Michael Hahsler Southern Methodist University These slides are largely based on the slides by Hinrich Schütze Institute for
CS 2750: Machine Learning. Clustering. Prof. Adriana Kovashka University of Pittsburgh January 17, 2017
 CS 2750: Machine Learning Clustering Prof. Adriana Kovashka University of Pittsburgh January 17, 2017 What is clustering? Grouping items that belong together (i.e. have similar features) Unsupervised:
CS 2750: Machine Learning Clustering Prof. Adriana Kovashka University of Pittsburgh January 17, 2017 What is clustering? Grouping items that belong together (i.e. have similar features) Unsupervised:
Data Mining. Dr. Raed Ibraheem Hamed. University of Human Development, College of Science and Technology Department of Computer Science
 Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
5/15/16. Computational Methods for Data Analysis. Massimo Poesio UNSUPERVISED LEARNING. Clustering. Unsupervised learning introduction
 Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Machine Learning. Unsupervised Learning. Manfred Huber
 Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
10701 Machine Learning. Clustering
 171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
Clustering in Ratemaking: Applications in Territories Clustering
 Clustering in Ratemaking: Applications in Territories Clustering Ji Yao, PhD FIA ASTIN 13th-16th July 2008 INTRODUCTION Structure of talk Quickly introduce clustering and its application in insurance ratemaking
Clustering in Ratemaking: Applications in Territories Clustering Ji Yao, PhD FIA ASTIN 13th-16th July 2008 INTRODUCTION Structure of talk Quickly introduce clustering and its application in insurance ratemaking
Cluster Analysis: Agglomerate Hierarchical Clustering
 Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 6: Flat Clustering Wiltrud Kessler & Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 0-- / 83
Introduction to Information Retrieval http://informationretrieval.org IIR 6: Flat Clustering Wiltrud Kessler & Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 0-- / 83
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Slides From Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
COSC 6397 Big Data Analytics. Fuzzy Clustering. Some slides based on a lecture by Prof. Shishir Shah. Edgar Gabriel Spring 2015.
 COSC 6397 Big Data Analytics Fuzzy Clustering Some slides based on a lecture by Prof. Shishir Shah Edgar Gabriel Spring 215 Clustering Clustering is a technique for finding similarity groups in data, called
COSC 6397 Big Data Analytics Fuzzy Clustering Some slides based on a lecture by Prof. Shishir Shah Edgar Gabriel Spring 215 Clustering Clustering is a technique for finding similarity groups in data, called
COSC 6339 Big Data Analytics. Fuzzy Clustering. Some slides based on a lecture by Prof. Shishir Shah. Edgar Gabriel Spring 2017.
 COSC 6339 Big Data Analytics Fuzzy Clustering Some slides based on a lecture by Prof. Shishir Shah Edgar Gabriel Spring 217 Clustering Clustering is a technique for finding similarity groups in data, called
COSC 6339 Big Data Analytics Fuzzy Clustering Some slides based on a lecture by Prof. Shishir Shah Edgar Gabriel Spring 217 Clustering Clustering is a technique for finding similarity groups in data, called
Unsupervised Learning. Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team
 Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211
 PV: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv IIR 6: Flat Clustering Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University, Brno Center
PV: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv IIR 6: Flat Clustering Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University, Brno Center
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
Data Mining: Concepts and Techniques. Chapter March 8, 2007 Data Mining: Concepts and Techniques 1
 Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
Clustering. Shishir K. Shah
 Clustering Shishir K. Shah Acknowledgement: Notes by Profs. M. Pollefeys, R. Jin, B. Liu, Y. Ukrainitz, B. Sarel, D. Forsyth, M. Shah, K. Grauman, and S. K. Shah Clustering l Clustering is a technique
Clustering Shishir K. Shah Acknowledgement: Notes by Profs. M. Pollefeys, R. Jin, B. Liu, Y. Ukrainitz, B. Sarel, D. Forsyth, M. Shah, K. Grauman, and S. K. Shah Clustering l Clustering is a technique
Introduction to Mobile Robotics
 Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Unsupervised Learning
 Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 16: Flat Clustering Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2009.06.16 1/ 64 Overview
Introduction to Information Retrieval http://informationretrieval.org IIR 16: Flat Clustering Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2009.06.16 1/ 64 Overview
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Hierarchical Clustering
 Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
CS7267 MACHINE LEARNING
 S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
Supervised and Unsupervised Learning (II)
") Supervised and Unsupervised Learning (II) Yong Zheng Center for Web Intelligence DePaul University, Chicago IPD 346 - Data Science for Business Program DePaul University, Chicago, USA Intro: Supervised
Supervised and Unsupervised Learning (II) Yong Zheng Center for Web Intelligence DePaul University, Chicago IPD 346 - Data Science for Business Program DePaul University, Chicago, USA Intro: Supervised
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 9: Data Mining (4/4) March 9, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 9: Data Mining (4/4) March 9, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
Kapitel 4: Clustering
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Unsupervised Learning Partitioning Methods
 Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Unsupervised Learning. Supervised learning vs. unsupervised learning. What is Cluster Analysis? Applications of Cluster Analysis
 7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
7 Supervised learning vs unsupervised learning Unsupervised Learning Supervised learning: discover patterns in the data that relate data attributes with a target (class) attribute These patterns are then
Association Rule Mining and Clustering
 Association Rule Mining and Clustering Lecture Outline: Classification vs. Association Rule Mining vs. Clustering Association Rule Mining Clustering Types of Clusters Clustering Algorithms Hierarchical:
Association Rule Mining and Clustering Lecture Outline: Classification vs. Association Rule Mining vs. Clustering Association Rule Mining Clustering Types of Clusters Clustering Algorithms Hierarchical:
INF4820, Algorithms for AI and NLP: Hierarchical Clustering
 INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
Clustering Part 3. Hierarchical Clustering
 Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Classification & Clustering. Hadaiq Rolis Sanabila
 Classification & Clustering Hadaiq Rolis Sanabila hadaiq@cs.ui.ac.id Natural Language Processing and Text Mining Pusilkom UI 22 26 Maret 2016 CLASSIFICATION 2 Categorization/Classification Given: A description
Classification & Clustering Hadaiq Rolis Sanabila hadaiq@cs.ui.ac.id Natural Language Processing and Text Mining Pusilkom UI 22 26 Maret 2016 CLASSIFICATION 2 Categorization/Classification Given: A description
What is Cluster Analysis? COMP 465: Data Mining Clustering Basics. Applications of Cluster Analysis. Clustering: Application Examples 3/17/2015
 // What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
// What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
Data Exploration with PCA and Unsupervised Learning with Clustering Paul Rodriguez, PhD PACE SDSC
 Data Exploration with PCA and Unsupervised Learning with Clustering Paul Rodriguez, PhD PACE SDSC Clustering Idea Given a set of data can we find a natural grouping? Essential R commands: D =rnorm(12,0,1)
Data Exploration with PCA and Unsupervised Learning with Clustering Paul Rodriguez, PhD PACE SDSC Clustering Idea Given a set of data can we find a natural grouping? Essential R commands: D =rnorm(12,0,1)
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Unsupervised Learning and Data Mining
 Unsupervised Learning and Data Mining Unsupervised Learning and Data Mining Clustering Supervised Learning ó Decision trees ó Artificial neural nets ó K-nearest neighbor ó Support vectors ó Linear regression
Unsupervised Learning and Data Mining Unsupervised Learning and Data Mining Clustering Supervised Learning ó Decision trees ó Artificial neural nets ó K-nearest neighbor ó Support vectors ó Linear regression
Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme
 Entscheidungsunterstützungssysteme") Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme Why do we need to find similarity? Similarity underlies many data science methods and solutions to business problems. Some
Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme Why do we need to find similarity? Similarity underlies many data science methods and solutions to business problems. Some
PAM algorithm. Types of Data in Cluster Analysis. A Categorization of Major Clustering Methods. Partitioning i Methods. Hierarchical Methods
 Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest)
") Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Clustering Lecture 3: Hierarchical Methods
 Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced