Pradip Bose Tom Conte IEEE Computer May 1998
|
|
|
- Edward Knight
- 6 years ago
- Views:
Transcription


1 Performance Analysis and Its Impact on Design Pradip Bose Tom Conte IEEE Computer May 1998

2
3 Performance Evaluation Architects should not write checks that designers cannot cash. Do architects know their bank balance? What all do architects need to know to estimate their bank balance? Technology parameters and constraints Performance, power and area of conceived designs When do designers need to know this?
4 Typical Design Process Application Analysis Teams Lead architects consider bounds of potential designs Performance team creates performance model Performance architects create test cases Performance architects test the model Architects choose a microarchitecture based on the perf model results Design team implements the microarchitecture
 CPI = Infinite-Cache-CPI + FCE FCE = Finite")

5 Bose-Conte paper Read the paper and Sidebars New terminology Path length = Instrn Count Separable Components (Phil Emma) CPI = Infinite-Cache-CPI + FCE FCE = Finite Cache Effect = miss penalty X miss rate = cycles per miss X misses per instruction Infinite Cache CPI = E_busy + E_idle E_busy = useful work; E_idle due to pipeline stalls

6
7 Performance Validation Generating Performance Test Cases Early test cases can be randomly generated After failing tests are below a certain threshold, use focused test cases Handwritten tests to exercise particular parts of microarchitecture model Latency tests and block cost estimation Cycle counts of individual instructions Multi-level cache hit and miss latencies for load/store instructions Pipeline latencies for back-to-back dependent instructions
8 Performance Validation Cost estimation for large basic blocks based on program dependence graphs Best and Worst case timings for a block of instructions can be used as test cases Bandwidth tests Test upper bounds Test Resource limits
9 Performance Signature Dictionary Apart from specs for cycle count, and Steady state loop performance, we may Derive more elaborate performance signatures Signatures are plots of various quantities that follow a characteristic pattern for a given test case Eg: Periodic pattern of pipeline state transitions for a loop test case, or Pattern or cycle-by-cycle machine state changes
10 Machine State Signature Hash the full pipeline flow state (which describes all instructions in flight) into a compact encoding Fig 2 pg 48 Signature dictionary? A collection of performance test cases along with their corresponding signatures Dictionary can include cycle counts and CPI metrics Any mismatch automatically flags problems Performance test benches???
11 Cycle by Cycle Validation of a 4- wide Superscalar Pipeline with 2- Load/Store Units
12 Inacuracies in Traces-Trace Distortion Another important concept discussed in Bose-Conte paper Instrumentation can cause distortion Example: mtrace is a software tracing tool used within IBM for performance validation This tool is 60 times slower than PPC601 Tool collects I- and D- address (user and kernel) In AIX, a clock interrupt occurs 100 times per second to wake scheduler
13 Trace Distortion Contd In AIX, a clock interrupt occurs 100 times per second to wake scheduler In an m-trace instrumented run, the clock interrupt would occur 6000 times per simulated second The AIX decrementer has to be slowed down by a factor of 60 to get bona-fide traces
14 Assignment 1 B Due Thursday 25 midnight 1. Read Black and Shen paper. Summarize potential modeling errors, abstraction errors and specification errors in Lab 1. You can answer the modeling errors in a mirrored fashion to next question. 2. Read the concept of alpha, beta, gamma tests in Black and Shen and the concept of Performance Signatures Dictionary as in Bose-Conte paper and create a performance signatures dictionary for detecting the modeling errors in the cache design in Lab 1.
15 Performance Signature Dictionary Example This is just an example not particularly good. I am looking forward to seeing your creativity. Be creative Test Objective Test Case Expected Output Cycles Block Size (L1) Associativity (L1) LRU (L1) Cache Size (L1) Block Size (L2)..
16 Analysis of Redundancy and Application Balance in the SPEC CPU 2006 Benchmark Suite ISCA 2007 Phansalkar, Joshi and John

17
18 Motivation Many benchmarks are similar Running more benchmarks that are similar will not provide more information but necessitates more effort One could construct a good benchmark suite by choosing representative programs from similar clusters Advantages: Reduces experimentation effort
19 Benchmark Reduction Measure properties of programs (say K properties) Microarchitecture independent properties Microarchitecture dependent properties Display benchmarks in a K-dimensional space Workload space consists of clusters of benchmarks Choose one benchmark per cluster
20 Example Workload/Benchmark space Distributions x x x x x
21 Benchmark Reduction Measure properties of programs (say K properties) Microarchitecture independent properties Microarchitecture dependent properties Derive principal components that capture most of the variability between the programs Workload space consists of clusters of benchmarks in the principal component space Choose one benchmark per cluster
22 Principal Components Analysis Remove correlation between program characteristics Principal Components (PC) are linear combination of original characteristics Var(PC1) > Var(PC2) >... Reduce No. of variables PC2 is less important to explain variation. Throw away PCs with negligible variance PC1 a 11 PC2 a PC3 a x1 a x1 a x1 a x 2 x x a a a x x3... x3... Variable 1 Source:moss.csc.ncsu.edu/pact02/slides/eeckhout_135.ppt
23 Clustering Clustering algorithms K-means clustering Hierarchical clustering
24 1. Select K, e.g.: K=3 2. Randomly select K cluster centers K-means Clustering 4. Move cluster centers 3. Assign benchmarks to cluster centers 5. Repeat steps 3 and 4 until convergence
25 Hierarchical Clustering Iteratively join clusters 1. Initialize with 1 benchmark/cluster Joining clusters Complete linkage 2. Join two closest clusters Closeness determined by linkage strategy Other linkage strategies exist with qualitatively the same results 3. Repeat step 2 until one cluster remains WWC-7 25
26 Distance between clusters Euclidian Distance - the way the crow flies; sq root of (a^2 +b^2); Manhattan Distance The way cars go in manhattan; a+b Centroid of clusters Distance from centroid of one cluster to another centroid Longest distance from any element of one cluster to another
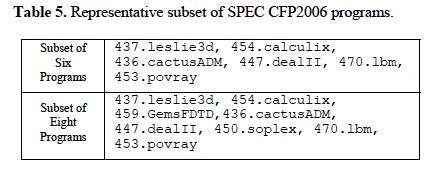
27 BENCHMARK SUITE CREATION Dendrogram for illustrating Similarity Single Linkage distanc k=4 400.perlbench, 462.libquantum,473.astar,483.xalancbmk k=6 400.perlbench, 471.omnetpp, 429.mcf, 462.libquantum, 473.astar, 483.xalancbmk 27 9/18/2014
28 Software Packages to do Similarity Analysis STATISTICA R MATLAB PCA K-means clustering Dendrogram generation
29
30

31
32 Are features of equal weight? Need for Normalizing Data feature 1 feature 2 bench bench bench bench bench bench bench bench Variance 1 > Mean 1 Variance 2 << Mean 2 Feature 1 numeric values << Feature 2 numeric val Compute distance from 0 to bench 4, and 0 to bench 8 Feature 1 has low effect on distance
33 Unit normal distribution 1sigma=68.27% 2 sigma=95.45% 3 sigma=99.73%
34 Normalizing Data (Transforming to Unit-Normal) The converted data is also called standard score. How do you convert to a distribution with mean = 0 and std dev = 1?
35 With normalized data, bench8 is far from bench 4 Normalizing Data feature 1 feature 2 norm feat 1 norm feat 2 bench bench bench bench bench bench bench bench Convert to a distribution with mean = 0 and std dev = 1
36 Mahalanobis distance Mahalanobis distance How many standard deviations away a point P is from the mean of a distribution If all axes are scaled to have unit variance, Mahalanobis distance = Euclidian distance
37

38

39

40
41

42
43 BENCHMARK SUITE CREATION Dendrogram for illustrating Similarity Single Linkage distanc k=4 400.perlbench, 462.libquantum,473.astar,483.xalancbmk k=6 400.perlbench, 471.omnetpp, 429.mcf, 462.libquantum, 473.astar, 483.xalancbmk 43 9/18/2014
44
45

46

47
48

49
50
51 Memory Characteristic space
52

53

54

55

56 We will discuss this after Plackett and Burman method Yi et al in a few weeks
Microarchitecture Overview. Performance
 Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 15, 2007 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 15, 2007 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
Main Memory Supporting Caches
 Main Memory Supporting Caches Use DRAMs for main memory Fixed width (e.g., 1 word) Connected by fixed-width clocked bus Bus clock is typically slower than CPU clock Cache Issues 1 Example cache block read
Main Memory Supporting Caches Use DRAMs for main memory Fixed width (e.g., 1 word) Connected by fixed-width clocked bus Bus clock is typically slower than CPU clock Cache Issues 1 Example cache block read
Course web site: teaching/courses/car. Piazza discussion forum:
 Announcements Course web site: http://www.inf.ed.ac.uk/ teaching/courses/car Lecture slides Tutorial problems Courseworks Piazza discussion forum: http://piazza.com/ed.ac.uk/spring2018/car Tutorials start
Announcements Course web site: http://www.inf.ed.ac.uk/ teaching/courses/car Lecture slides Tutorial problems Courseworks Piazza discussion forum: http://piazza.com/ed.ac.uk/spring2018/car Tutorials start
Security-Aware Processor Architecture Design. CS 6501 Fall 2018 Ashish Venkat
 Security-Aware Processor Architecture Design CS 6501 Fall 2018 Ashish Venkat Agenda Common Processor Performance Metrics Identifying and Analyzing Bottlenecks Benchmarking and Workload Selection Performance
Security-Aware Processor Architecture Design CS 6501 Fall 2018 Ashish Venkat Agenda Common Processor Performance Metrics Identifying and Analyzing Bottlenecks Benchmarking and Workload Selection Performance
Basics of Performance Engineering
 ERLANGEN REGIONAL COMPUTING CENTER Basics of Performance Engineering J. Treibig HiPerCH 3, 23./24.03.2015 Why hardware should not be exposed Such an approach is not portable Hardware issues frequently
ERLANGEN REGIONAL COMPUTING CENTER Basics of Performance Engineering J. Treibig HiPerCH 3, 23./24.03.2015 Why hardware should not be exposed Such an approach is not portable Hardware issues frequently
Clustering and Dimensionality Reduction
 Clustering and Dimensionality Reduction Some material on these is slides borrowed from Andrew Moore's excellent machine learning tutorials located at: Data Mining Automatically extracting meaning from
Clustering and Dimensionality Reduction Some material on these is slides borrowed from Andrew Moore's excellent machine learning tutorials located at: Data Mining Automatically extracting meaning from
Chapter 5A. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5A Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) Fast, expensive Dynamic RAM (DRAM) In between Magnetic disk Slow, inexpensive Ideal memory Access time of SRAM
Chapter 5A Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) Fast, expensive Dynamic RAM (DRAM) In between Magnetic disk Slow, inexpensive Ideal memory Access time of SRAM
MEMORY HIERARCHY BASICS. B649 Parallel Architectures and Programming
 MEMORY HIERARCHY BASICS B649 Parallel Architectures and Programming BASICS Why Do We Need Caches? 3 Overview 4 Terminology cache virtual memory memory stall cycles direct mapped valid bit block address
MEMORY HIERARCHY BASICS B649 Parallel Architectures and Programming BASICS Why Do We Need Caches? 3 Overview 4 Terminology cache virtual memory memory stall cycles direct mapped valid bit block address
Profiling: Understand Your Application
 Profiling: Understand Your Application Michal Merta michal.merta@vsb.cz 1st of March 2018 Agenda Hardware events based sampling Some fundamental bottlenecks Overview of profiling tools perf tools Intel
Profiling: Understand Your Application Michal Merta michal.merta@vsb.cz 1st of March 2018 Agenda Hardware events based sampling Some fundamental bottlenecks Overview of profiling tools perf tools Intel
Portland State University ECE 587/687. Caches and Memory-Level Parallelism
 Portland State University ECE 587/687 Caches and Memory-Level Parallelism Revisiting Processor Performance Program Execution Time = (CPU clock cycles + Memory stall cycles) x clock cycle time For each
Portland State University ECE 587/687 Caches and Memory-Level Parallelism Revisiting Processor Performance Program Execution Time = (CPU clock cycles + Memory stall cycles) x clock cycle time For each
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Memory Technology. Caches 1. Static RAM (SRAM) Dynamic RAM (DRAM) Magnetic disk. Ideal memory. 0.5ns 2.5ns, $2000 $5000 per GB
 Dynamic RAM (DRAM) Magnetic disk. Ideal memory. 0.5ns 2.5ns, $2000 $5000 per GB") Memory Technology Caches 1 Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per GB Ideal memory Average access time similar
Memory Technology Caches 1 Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per GB Ideal memory Average access time similar
Analyzing and Improving Clustering Based Sampling for Microprocessor Simulation
 Analyzing and Improving Clustering Based Sampling for Microprocessor Simulation Yue Luo, Ajay Joshi, Aashish Phansalkar, Lizy John, and Joydeep Ghosh Department of Electrical and Computer Engineering University
Analyzing and Improving Clustering Based Sampling for Microprocessor Simulation Yue Luo, Ajay Joshi, Aashish Phansalkar, Lizy John, and Joydeep Ghosh Department of Electrical and Computer Engineering University
Workload Characterization Techniques
 Workload Characterization Techniques Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides are available on-line at: http://www.cse.wustl.edu/~jain/cse567-08/
Workload Characterization Techniques Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides are available on-line at: http://www.cse.wustl.edu/~jain/cse567-08/
Program design and analysis
 Program design and analysis Optimizing for execution time. Optimizing for energy/power. Optimizing for program size. Motivation Embedded systems must often meet deadlines. Faster may not be fast enough.
Program design and analysis Optimizing for execution time. Optimizing for energy/power. Optimizing for program size. Motivation Embedded systems must often meet deadlines. Faster may not be fast enough.
ECS 234: Data Analysis: Clustering ECS 234
 : Data Analysis: Clustering What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
: Data Analysis: Clustering What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
Portland State University ECE 587/687. Caches and Memory-Level Parallelism
 Portland State University ECE 587/687 Caches and Memory-Level Parallelism Copyright by Alaa Alameldeen, Zeshan Chishti and Haitham Akkary 2017 Revisiting Processor Performance Program Execution Time =
Portland State University ECE 587/687 Caches and Memory-Level Parallelism Copyright by Alaa Alameldeen, Zeshan Chishti and Haitham Akkary 2017 Revisiting Processor Performance Program Execution Time =
LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY
 LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY Abridged version of Patterson & Hennessy (2013):Ch.5 Principle of Locality Programs access a small proportion of their address space at any time Temporal
LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY Abridged version of Patterson & Hennessy (2013):Ch.5 Principle of Locality Programs access a small proportion of their address space at any time Temporal
CS450/650 Notes Winter 2013 A Morton. Superscalar Pipelines
 CS450/650 Notes Winter 2013 A Morton Superscalar Pipelines 1 Scalar Pipeline Limitations (Shen + Lipasti 4.1) 1. Bounded Performance P = 1 T = IC CPI 1 cycletime = IPC frequency IC IPC = instructions per
CS450/650 Notes Winter 2013 A Morton Superscalar Pipelines 1 Scalar Pipeline Limitations (Shen + Lipasti 4.1) 1. Bounded Performance P = 1 T = IC CPI 1 cycletime = IPC frequency IC IPC = instructions per
INSTRUCTION LEVEL PARALLELISM
 INSTRUCTION LEVEL PARALLELISM Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 2 and Appendix H, John L. Hennessy and David A. Patterson,
INSTRUCTION LEVEL PARALLELISM Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 2 and Appendix H, John L. Hennessy and David A. Patterson,
Techniques for Efficient Processing in Runahead Execution Engines
 Techniques for Efficient Processing in Runahead Execution Engines Onur Mutlu Hyesoon Kim Yale N. Patt Depment of Electrical and Computer Engineering University of Texas at Austin {onur,hyesoon,patt}@ece.utexas.edu
Techniques for Efficient Processing in Runahead Execution Engines Onur Mutlu Hyesoon Kim Yale N. Patt Depment of Electrical and Computer Engineering University of Texas at Austin {onur,hyesoon,patt}@ece.utexas.edu
Cache Optimization. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Cache Optimization Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Cache Misses On cache hit CPU proceeds normally On cache miss Stall the CPU pipeline
Cache Optimization Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Cache Misses On cache hit CPU proceeds normally On cache miss Stall the CPU pipeline
CS377P Programming for Performance Single Thread Performance Out-of-order Superscalar Pipelines
 CS377P Programming for Performance Single Thread Performance Out-of-order Superscalar Pipelines Sreepathi Pai UTCS September 14, 2015 Outline 1 Introduction 2 Out-of-order Scheduling 3 The Intel Haswell
CS377P Programming for Performance Single Thread Performance Out-of-order Superscalar Pipelines Sreepathi Pai UTCS September 14, 2015 Outline 1 Introduction 2 Out-of-order Scheduling 3 The Intel Haswell
Resource-Conscious Scheduling for Energy Efficiency on Multicore Processors
 Resource-Conscious Scheduling for Energy Efficiency on Andreas Merkel, Jan Stoess, Frank Bellosa System Architecture Group KIT The cooperation of Forschungszentrum Karlsruhe GmbH and Universität Karlsruhe
Resource-Conscious Scheduling for Energy Efficiency on Andreas Merkel, Jan Stoess, Frank Bellosa System Architecture Group KIT The cooperation of Forschungszentrum Karlsruhe GmbH and Universität Karlsruhe
Performance Prediction using Program Similarity
 Performance Prediction using Program Similarity Aashish Phansalkar Lizy K. John {aashish, ljohn}@ece.utexas.edu University of Texas at Austin Abstract - Modern computer applications are developed at a
Performance Prediction using Program Similarity Aashish Phansalkar Lizy K. John {aashish, ljohn}@ece.utexas.edu University of Texas at Austin Abstract - Modern computer applications are developed at a
Agenda. Cache-Memory Consistency? (1/2) 7/14/2011. New-School Machine Structures (It s a bit more complicated!)
 7/14/2011. New-School Machine Structures (It s a bit more complicated!)") 7/4/ CS 6C: Great Ideas in Computer Architecture (Machine Structures) Caches II Instructor: Michael Greenbaum New-School Machine Structures (It s a bit more complicated!) Parallel Requests Assigned to
7/4/ CS 6C: Great Ideas in Computer Architecture (Machine Structures) Caches II Instructor: Michael Greenbaum New-School Machine Structures (It s a bit more complicated!) Parallel Requests Assigned to
Compiler Optimisation 2014 Course Project
 Compiler Optimisation 2014 Course Project Michael O Boyle Chris Margiolas January 2014 Course Work Based on GCC compiler One piece of course work: 25 % of course mark Set today and due Thursday 4pm February
Compiler Optimisation 2014 Course Project Michael O Boyle Chris Margiolas January 2014 Course Work Based on GCC compiler One piece of course work: 25 % of course mark Set today and due Thursday 4pm February
Donn Morrison Department of Computer Science. TDT4255 Memory hierarchies
 TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
UCB CS61C : Machine Structures
 inst.eecs.berkeley.edu/~cs61c UCB CS61C : Machine Structures Lecture 36 Performance 2010-04-23 Lecturer SOE Dan Garcia How fast is your computer? Every 6 months (Nov/June), the fastest supercomputers in
inst.eecs.berkeley.edu/~cs61c UCB CS61C : Machine Structures Lecture 36 Performance 2010-04-23 Lecturer SOE Dan Garcia How fast is your computer? Every 6 months (Nov/June), the fastest supercomputers in
Outline. Emerging Trends. An Integrated Hardware/Software Approach to On-Line Power- Performance Optimization. Conventional Processor Design
 Outline An Integrated Hardware/Software Approach to On-Line Power- Performance Optimization Sandhya Dwarkadas University of Rochester Framework: Dynamically Tunable Clustered Multithreaded Architecture
Outline An Integrated Hardware/Software Approach to On-Line Power- Performance Optimization Sandhya Dwarkadas University of Rochester Framework: Dynamically Tunable Clustered Multithreaded Architecture
Chapter 03. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 03 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 3.3 Comparison of 2-bit predictors. A noncorrelating predictor for 4096 bits is first, followed
Chapter 03 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 3.3 Comparison of 2-bit predictors. A noncorrelating predictor for 4096 bits is first, followed
Cache Memory COE 403. Computer Architecture Prof. Muhamed Mudawar. Computer Engineering Department King Fahd University of Petroleum and Minerals
 Cache Memory COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline The Need for Cache Memory The Basics
Cache Memory COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline The Need for Cache Memory The Basics
Lecture: Benchmarks, Pipelining Intro. Topics: Performance equations wrap-up, Intro to pipelining
 Lecture: Benchmarks, Pipelining Intro Topics: Performance equations wrap-up, Intro to pipelining 1 Measuring Performance Two primary metrics: wall clock time (response time for a program) and throughput
Lecture: Benchmarks, Pipelining Intro Topics: Performance equations wrap-up, Intro to pipelining 1 Measuring Performance Two primary metrics: wall clock time (response time for a program) and throughput
The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350):
:") The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350): Motivation for The Memory Hierarchy: { CPU/Memory Performance Gap The Principle Of Locality Cache $$$$$ Cache Basics:
The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350): Motivation for The Memory Hierarchy: { CPU/Memory Performance Gap The Principle Of Locality Cache $$$$$ Cache Basics:
The Memory Hierarchy. Cache, Main Memory, and Virtual Memory (Part 2)
") The Memory Hierarchy Cache, Main Memory, and Virtual Memory (Part 2) Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Cache Line Replacement The cache
The Memory Hierarchy Cache, Main Memory, and Virtual Memory (Part 2) Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Cache Line Replacement The cache
Microarchitecture Overview. Performance
 Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 18, 2005 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 18, 2005 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
Chapter 2: Memory Hierarchy Design Part 2
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Two-Level Address Storage and Address Prediction
 Two-Level Address Storage and Address Prediction Enric Morancho, José María Llabería and Àngel Olivé Computer Architecture Department - Universitat Politècnica de Catalunya (Spain) 1 Abstract. : The amount
Two-Level Address Storage and Address Prediction Enric Morancho, José María Llabería and Àngel Olivé Computer Architecture Department - Universitat Politècnica de Catalunya (Spain) 1 Abstract. : The amount
Page 1. Multilevel Memories (Improving performance using a little cash )
") Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
Memory Hierarchy: The motivation
 Memory Hierarchy: The motivation The gap between CPU performance and main memory has been widening with higher performance CPUs creating performance bottlenecks for memory access instructions. The memory
Memory Hierarchy: The motivation The gap between CPU performance and main memory has been widening with higher performance CPUs creating performance bottlenecks for memory access instructions. The memory
Dimension reduction : PCA and Clustering
 Dimension reduction : PCA and Clustering By Hanne Jarmer Slides by Christopher Workman Center for Biological Sequence Analysis DTU The DNA Array Analysis Pipeline Array design Probe design Question Experimental
Dimension reduction : PCA and Clustering By Hanne Jarmer Slides by Christopher Workman Center for Biological Sequence Analysis DTU The DNA Array Analysis Pipeline Array design Probe design Question Experimental
A Fast Instruction Set Simulator for RISC-V
 A Fast Instruction Set Simulator for RISC-V Maxim.Maslov@esperantotech.com Vadim.Gimpelson@esperantotech.com Nikita.Voronov@esperantotech.com Dave.Ditzel@esperantotech.com Esperanto Technologies, Inc.
A Fast Instruction Set Simulator for RISC-V Maxim.Maslov@esperantotech.com Vadim.Gimpelson@esperantotech.com Nikita.Voronov@esperantotech.com Dave.Ditzel@esperantotech.com Esperanto Technologies, Inc.
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
ProfileMe: Hardware-Support for Instruction-Level Profiling on Out-of-Order Processors
 ProfileMe: Hardware-Support for Instruction-Level Profiling on Out-of-Order Processors Jeffrey Dean Jamey Hicks Carl Waldspurger William Weihl George Chrysos Digital Equipment Corporation 1 Motivation
ProfileMe: Hardware-Support for Instruction-Level Profiling on Out-of-Order Processors Jeffrey Dean Jamey Hicks Carl Waldspurger William Weihl George Chrysos Digital Equipment Corporation 1 Motivation
Improving Cache Performance
 Improving Cache Performance Tuesday 27 October 15 Many slides adapted from: and Design, Patterson & Hennessy 5th Edition, 2014, MK and from Prof. Mary Jane Irwin, PSU Summary Previous Class Memory hierarchy
Improving Cache Performance Tuesday 27 October 15 Many slides adapted from: and Design, Patterson & Hennessy 5th Edition, 2014, MK and from Prof. Mary Jane Irwin, PSU Summary Previous Class Memory hierarchy
DEMM: a Dynamic Energy-saving mechanism for Multicore Memories
 DEMM: a Dynamic Energy-saving mechanism for Multicore Memories Akbar Sharifi, Wei Ding 2, Diana Guttman 3, Hui Zhao 4, Xulong Tang 5, Mahmut Kandemir 5, Chita Das 5 Facebook 2 Qualcomm 3 Intel 4 University
DEMM: a Dynamic Energy-saving mechanism for Multicore Memories Akbar Sharifi, Wei Ding 2, Diana Guttman 3, Hui Zhao 4, Xulong Tang 5, Mahmut Kandemir 5, Chita Das 5 Facebook 2 Qualcomm 3 Intel 4 University
Improving Cache Performance
 Improving Cache Performance Computer Organization Architectures for Embedded Computing Tuesday 28 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition,
Improving Cache Performance Computer Organization Architectures for Embedded Computing Tuesday 28 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition,
Measure of Distance. We wish to define the distance between two objects Distance metric between points:
 Measure of Distance We wish to define the distance between two objects Distance metric between points: Euclidean distance (EUC) Manhattan distance (MAN) Pearson sample correlation (COR) Angle distance
Measure of Distance We wish to define the distance between two objects Distance metric between points: Euclidean distance (EUC) Manhattan distance (MAN) Pearson sample correlation (COR) Angle distance
ECE7995 (6) Improving Cache Performance. [Adapted from Mary Jane Irwin s slides (PSU)]
![ECE7995 (6) Improving Cache Performance. [Adapted from Mary Jane Irwin s slides (PSU)]](/thumbs/72/68075397.jpg "ECE7995 (6) Improving Cache Performance. [Adapted from Mary Jane Irwin s slides (PSU)]") ECE7995 (6) Improving Cache Performance [Adapted from Mary Jane Irwin s slides (PSU)] Measuring Cache Performance Assuming cache hit costs are included as part of the normal CPU execution cycle, then CPU
ECE7995 (6) Improving Cache Performance [Adapted from Mary Jane Irwin s slides (PSU)] Measuring Cache Performance Assuming cache hit costs are included as part of the normal CPU execution cycle, then CPU
Mesocode: Optimizations for Improving Fetch Bandwidth of Future Itanium Processors
 : Optimizations for Improving Fetch Bandwidth of Future Itanium Processors Marsha Eng, Hong Wang, Perry Wang Alex Ramirez, Jim Fung, and John Shen Overview Applications of for Itanium Improving fetch bandwidth
: Optimizations for Improving Fetch Bandwidth of Future Itanium Processors Marsha Eng, Hong Wang, Perry Wang Alex Ramirez, Jim Fung, and John Shen Overview Applications of for Itanium Improving fetch bandwidth
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Accurate Statistical Approaches for Generating Representative Workload Compositions
 Accurate Statistical Approaches for Generating Representative Workload Compositions Lieven Eeckhout, Rashmi Sundareswara, Joshua J. Yi, David J. Lilja and Paul Schrater ELIS Department, Ghent University,
Accurate Statistical Approaches for Generating Representative Workload Compositions Lieven Eeckhout, Rashmi Sundareswara, Joshua J. Yi, David J. Lilja and Paul Schrater ELIS Department, Ghent University,
ECE 30 Introduction to Computer Engineering
 ECE 0 Introduction to Computer Engineering Study Problems, Set #9 Spring 01 1. Given the following series of address references given as word addresses:,,, 1, 1, 1,, 8, 19,,,,, 7,, and. Assuming a direct-mapped
ECE 0 Introduction to Computer Engineering Study Problems, Set #9 Spring 01 1. Given the following series of address references given as word addresses:,,, 1, 1, 1,, 8, 19,,,,, 7,, and. Assuming a direct-mapped
Perceptron Learning for Reuse Prediction
 Perceptron Learning for Reuse Prediction Elvira Teran Zhe Wang Daniel A. Jiménez Texas A&M University Intel Labs {eteran,djimenez}@tamu.edu zhe2.wang@intel.com Abstract The disparity between last-level
Perceptron Learning for Reuse Prediction Elvira Teran Zhe Wang Daniel A. Jiménez Texas A&M University Intel Labs {eteran,djimenez}@tamu.edu zhe2.wang@intel.com Abstract The disparity between last-level
Computer Organization and Structure. Bing-Yu Chen National Taiwan University
 Computer Organization and Structure Bing-Yu Chen National Taiwan University Large and Fast: Exploiting Memory Hierarchy The Basic of Caches Measuring & Improving Cache Performance Virtual Memory A Common
Computer Organization and Structure Bing-Yu Chen National Taiwan University Large and Fast: Exploiting Memory Hierarchy The Basic of Caches Measuring & Improving Cache Performance Virtual Memory A Common
Calibration of Microprocessor Performance Models
 Calibration of Microprocessor Performance Models Bryan Black and John Paul Shen Department of Electrical and Computer Engineering Carnegie Mellon University Pittsburgh PA, 15213 {black,shen}@ece.cmu.edu
Calibration of Microprocessor Performance Models Bryan Black and John Paul Shen Department of Electrical and Computer Engineering Carnegie Mellon University Pittsburgh PA, 15213 {black,shen}@ece.cmu.edu
Chapter 7-1. Large and Fast: Exploiting Memory Hierarchy (part I: cache) 臺大電機系吳安宇教授. V1 11/24/2004 V2 12/01/2004 V3 12/08/2004 (minor)
 臺大電機系吳安宇教授. V1 11/24/2004 V2 12/01/2004 V3 12/08/2004 (minor)") Chapter 7-1 Large and Fast: Exploiting Memory Hierarchy (part I: cache) 臺大電機系吳安宇教授 V1 11/24/2004 V2 12/01/2004 V3 12/08/2004 (minor) 臺大電機吳安宇教授 - 計算機結構 1 Outline 7.1 Introduction 7.2 The Basics of Caches
Chapter 7-1 Large and Fast: Exploiting Memory Hierarchy (part I: cache) 臺大電機系吳安宇教授 V1 11/24/2004 V2 12/01/2004 V3 12/08/2004 (minor) 臺大電機吳安宇教授 - 計算機結構 1 Outline 7.1 Introduction 7.2 The Basics of Caches
Evaluating STT-RAM as an Energy-Efficient Main Memory Alternative
 Evaluating STT-RAM as an Energy-Efficient Main Memory Alternative Emre Kültürsay *, Mahmut Kandemir *, Anand Sivasubramaniam *, and Onur Mutlu * Pennsylvania State University Carnegie Mellon University
Evaluating STT-RAM as an Energy-Efficient Main Memory Alternative Emre Kültürsay *, Mahmut Kandemir *, Anand Sivasubramaniam *, and Onur Mutlu * Pennsylvania State University Carnegie Mellon University
Clustering. Lecture 6, 1/24/03 ECS289A
 Clustering Lecture 6, 1/24/03 What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
Clustering Lecture 6, 1/24/03 What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
CS 61C: Great Ideas in Computer Architecture. Cache Performance, Set Associative Caches
 CS 61C: Great Ideas in Computer Architecture Cache Performance, Set Associative Caches Instructor: Justin Hsia 7/09/2012 Summer 2012 Lecture #12 1 Great Idea #3: Principle of Locality/ Memory Hierarchy
CS 61C: Great Ideas in Computer Architecture Cache Performance, Set Associative Caches Instructor: Justin Hsia 7/09/2012 Summer 2012 Lecture #12 1 Great Idea #3: Principle of Locality/ Memory Hierarchy
Clustering. Robert M. Haralick. Computer Science, Graduate Center City University of New York
 Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
The bottom line: Performance. Measuring and Discussing Computer System Performance. Our definition of Performance. How to measure Execution Time?
 The bottom line: Performance Car to Bay Area Speed Passengers Throughput (pmph) Ferrari 3.1 hours 160 mph 2 320 Measuring and Discussing Computer System Performance Greyhound 7.7 hours 65 mph 60 3900 or
The bottom line: Performance Car to Bay Area Speed Passengers Throughput (pmph) Ferrari 3.1 hours 160 mph 2 320 Measuring and Discussing Computer System Performance Greyhound 7.7 hours 65 mph 60 3900 or
Parallel Programming. Parallel algorithms Combinatorial Search
 Parallel Programming Parallel algorithms Combinatorial Search Some Combinatorial Search Methods Divide and conquer Backtrack search Branch and bound Game tree search (minimax, alpha-beta) 2010@FEUP Parallel
Parallel Programming Parallel algorithms Combinatorial Search Some Combinatorial Search Methods Divide and conquer Backtrack search Branch and bound Game tree search (minimax, alpha-beta) 2010@FEUP Parallel
Clustering, cont. Genome 373 Genomic Informatics Elhanan Borenstein. Some slides adapted from Jacques van Helden
 Clustering, cont Genome 373 Genomic Informatics Elhanan Borenstein Some slides adapted from Jacques van Helden Improving the search heuristic: Multiple starting points Simulated annealing Genetic algorithms
Clustering, cont Genome 373 Genomic Informatics Elhanan Borenstein Some slides adapted from Jacques van Helden Improving the search heuristic: Multiple starting points Simulated annealing Genetic algorithms
CSE 255 Lecture 5. Data Mining and Predictive Analytics. Dimensionality Reduction
 CSE 255 Lecture 5 Data Mining and Predictive Analytics Dimensionality Reduction Course outline Week 4: I ll cover homework 1, and get started on Recommender Systems Week 5: I ll cover homework 2 (at the
CSE 255 Lecture 5 Data Mining and Predictive Analytics Dimensionality Reduction Course outline Week 4: I ll cover homework 1, and get started on Recommender Systems Week 5: I ll cover homework 2 (at the
Threshold-Based Markov Prefetchers
 Threshold-Based Markov Prefetchers Carlos Marchani Tamer Mohamed Lerzan Celikkanat George AbiNader Rice University, Department of Electrical and Computer Engineering ELEC 525, Spring 26 Abstract In this
Threshold-Based Markov Prefetchers Carlos Marchani Tamer Mohamed Lerzan Celikkanat George AbiNader Rice University, Department of Electrical and Computer Engineering ELEC 525, Spring 26 Abstract In this
Chapter 2: Memory Hierarchy Design Part 2
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Midterm Examination CS540-2: Introduction to Artificial Intelligence
 Midterm Examination CS540-2: Introduction to Artificial Intelligence March 15, 2018 LAST NAME: FIRST NAME: Problem Score Max Score 1 12 2 13 3 9 4 11 5 8 6 13 7 9 8 16 9 9 Total 100 Question 1. [12] Search
Midterm Examination CS540-2: Introduction to Artificial Intelligence March 15, 2018 LAST NAME: FIRST NAME: Problem Score Max Score 1 12 2 13 3 9 4 11 5 8 6 13 7 9 8 16 9 9 Total 100 Question 1. [12] Search
Addressing End-to-End Memory Access Latency in NoC-Based Multicores
 Addressing End-to-End Memory Access Latency in NoC-Based Multicores Akbar Sharifi, Emre Kultursay, Mahmut Kandemir and Chita R. Das The Pennsylvania State University University Park, PA, 682, USA {akbar,euk39,kandemir,das}@cse.psu.edu
Addressing End-to-End Memory Access Latency in NoC-Based Multicores Akbar Sharifi, Emre Kultursay, Mahmut Kandemir and Chita R. Das The Pennsylvania State University University Park, PA, 682, USA {akbar,euk39,kandemir,das}@cse.psu.edu
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Track Join. Distributed Joins with Minimal Network Traffic. Orestis Polychroniou! Rajkumar Sen! Kenneth A. Ross
 Track Join Distributed Joins with Minimal Network Traffic Orestis Polychroniou Rajkumar Sen Kenneth A. Ross Local Joins Algorithms Hash Join Sort Merge Join Index Join Nested Loop Join Spilling to disk
Track Join Distributed Joins with Minimal Network Traffic Orestis Polychroniou Rajkumar Sen Kenneth A. Ross Local Joins Algorithms Hash Join Sort Merge Join Index Join Nested Loop Join Spilling to disk
CPSC 340: Machine Learning and Data Mining. Outlier Detection Fall 2016
 CPSC 340: Machine Learning and Data Mining Outlier Detection Fall 2016 Admin Assignment 1 solutions will be posted after class. Assignment 2 is out: Due next Friday, but start early! Calculus and linear
CPSC 340: Machine Learning and Data Mining Outlier Detection Fall 2016 Admin Assignment 1 solutions will be posted after class. Assignment 2 is out: Due next Friday, but start early! Calculus and linear
Spring 2014 Midterm Exam Review
 mr 1 When / Where Spring 2014 Midterm Exam Review mr 1 Monday, 31 March 2014, 9:30-10:40 CDT 1112 P. Taylor Hall (Here) Conditions Closed Book, Closed Notes Bring one sheet of notes (both sides), 216 mm
mr 1 When / Where Spring 2014 Midterm Exam Review mr 1 Monday, 31 March 2014, 9:30-10:40 CDT 1112 P. Taylor Hall (Here) Conditions Closed Book, Closed Notes Bring one sheet of notes (both sides), 216 mm
LRU. Pseudo LRU A B C D E F G H A B C D E F G H H H C. Copyright 2012, Elsevier Inc. All rights reserved.
 LRU A list to keep track of the order of access to every block in the set. The least recently used block is replaced (if needed). How many bits we need for that? 27 Pseudo LRU A B C D E F G H A B C D E
LRU A list to keep track of the order of access to every block in the set. The least recently used block is replaced (if needed). How many bits we need for that? 27 Pseudo LRU A B C D E F G H A B C D E
CSE 258 Lecture 5. Web Mining and Recommender Systems. Dimensionality Reduction
 CSE 258 Lecture 5 Web Mining and Recommender Systems Dimensionality Reduction This week How can we build low dimensional representations of high dimensional data? e.g. how might we (compactly!) represent
CSE 258 Lecture 5 Web Mining and Recommender Systems Dimensionality Reduction This week How can we build low dimensional representations of high dimensional data? e.g. how might we (compactly!) represent
Lecture notes for CS Chapter 2, part 1 10/23/18
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
High throughput Data Analysis 2. Cluster Analysis
 High throughput Data Analysis 2 Cluster Analysis Overview Why clustering? Hierarchical clustering K means clustering Issues with above two Other methods Quality of clustering results Introduction WHY DO
High throughput Data Analysis 2 Cluster Analysis Overview Why clustering? Hierarchical clustering K means clustering Issues with above two Other methods Quality of clustering results Introduction WHY DO
Profiling and Workflow
 Profiling and Workflow Preben N. Olsen University of Oslo and Simula Research Laboratory preben@simula.no September 13, 2013 1 / 34 Agenda 1 Introduction What? Why? How? 2 Profiling Tracing Performance
Profiling and Workflow Preben N. Olsen University of Oslo and Simula Research Laboratory preben@simula.no September 13, 2013 1 / 34 Agenda 1 Introduction What? Why? How? 2 Profiling Tracing Performance
Final Lecture. A few minutes to wrap up and add some perspective
 Final Lecture A few minutes to wrap up and add some perspective 1 2 Instant replay The quarter was split into roughly three parts and a coda. The 1st part covered instruction set architectures the connection
Final Lecture A few minutes to wrap up and add some perspective 1 2 Instant replay The quarter was split into roughly three parts and a coda. The 1st part covered instruction set architectures the connection
Reduction of Control Hazards (Branch) Stalls with Dynamic Branch Prediction
 Stalls with Dynamic Branch Prediction") ISA Support Needed By CPU Reduction of Control Hazards (Branch) Stalls with Dynamic Branch Prediction So far we have dealt with control hazards in instruction pipelines by: 1 2 3 4 Assuming that the branch
ISA Support Needed By CPU Reduction of Control Hazards (Branch) Stalls with Dynamic Branch Prediction So far we have dealt with control hazards in instruction pipelines by: 1 2 3 4 Assuming that the branch
and data combined) is equal to 7% of the number of instructions. Miss Rate with Second- Level Cache, Direct- Mapped Speed
 is equal to 7% of the number of instructions. Miss Rate with Second- Level Cache, Direct- Mapped Speed") 5.3 By convention, a cache is named according to the amount of data it contains (i.e., a 4 KiB cache can hold 4 KiB of data); however, caches also require SRAM to store metadata such as tags and valid
5.3 By convention, a cache is named according to the amount of data it contains (i.e., a 4 KiB cache can hold 4 KiB of data); however, caches also require SRAM to store metadata such as tags and valid
10/19/17. You Are Here! Review: Direct-Mapped Cache. Typical Memory Hierarchy
 CS 6C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 3 Instructors: Krste Asanović & Randy H Katz http://insteecsberkeleyedu/~cs6c/ Parallel Requests Assigned to computer eg, Search
CS 6C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 3 Instructors: Krste Asanović & Randy H Katz http://insteecsberkeleyedu/~cs6c/ Parallel Requests Assigned to computer eg, Search
UCB CS61C : Machine Structures
 inst.eecs.berkeley.edu/~cs61c UCB CS61C : Machine Structures Lecture 38 Performance 2008-04-30 Lecturer SOE Dan Garcia How fast is your computer? Every 6 months (Nov/June), the fastest supercomputers in
inst.eecs.berkeley.edu/~cs61c UCB CS61C : Machine Structures Lecture 38 Performance 2008-04-30 Lecturer SOE Dan Garcia How fast is your computer? Every 6 months (Nov/June), the fastest supercomputers in
Clustering. Partition unlabeled examples into disjoint subsets of clusters, such that:
 Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
so Mechanism for Internet Services
 Twinkle: A Fast Resource Provisioning so Mechanism for Internet Services Professor Zhen Xiao Dept. of Computer Science Peking University xiaozhen@pku.edu.cn Joint work with Jun Zhu and Zhefu Jiang Motivation
Twinkle: A Fast Resource Provisioning so Mechanism for Internet Services Professor Zhen Xiao Dept. of Computer Science Peking University xiaozhen@pku.edu.cn Joint work with Jun Zhu and Zhefu Jiang Motivation
Review: Computer Organization
 Review: Computer Organization Cache Chansu Yu Caches: The Basic Idea A smaller set of storage locations storing a subset of information from a larger set. Typically, SRAM for DRAM main memory: Processor
Review: Computer Organization Cache Chansu Yu Caches: The Basic Idea A smaller set of storage locations storing a subset of information from a larger set. Typically, SRAM for DRAM main memory: Processor
Performance. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Performance Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Defining Performance (1) Which airplane has the best performance? Boeing 777 Boeing
Performance Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Defining Performance (1) Which airplane has the best performance? Boeing 777 Boeing
Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1)
") Department of Electr rical Eng ineering, Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering,
Department of Electr rical Eng ineering, Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering,
Lecture 27: Review. Reading: All chapters in ISLR. STATS 202: Data mining and analysis. December 6, 2017
 Lecture 27: Review Reading: All chapters in ISLR. STATS 202: Data mining and analysis December 6, 2017 1 / 16 Final exam: Announcements Tuesday, December 12, 8:30-11:30 am, in the following rooms: Last
Lecture 27: Review Reading: All chapters in ISLR. STATS 202: Data mining and analysis December 6, 2017 1 / 16 Final exam: Announcements Tuesday, December 12, 8:30-11:30 am, in the following rooms: Last
Memory hier ar hier ch ar y ch rev re i v e i w e ECE 154B Dmitri Struko Struk v o
 Memory hierarchy review ECE 154B Dmitri Strukov Outline Cache motivation Cache basics Opteron example Cache performance Six basic optimizations Virtual memory Processor DRAM gap (latency) Four issue superscalar
Memory hierarchy review ECE 154B Dmitri Strukov Outline Cache motivation Cache basics Opteron example Cache performance Six basic optimizations Virtual memory Processor DRAM gap (latency) Four issue superscalar
ECEC 355: Cache Design
 ECEC 355: Cache Design November 28, 2007 Terminology Let us first define some general terms applicable to caches. Cache block or line. The minimum unit of information (in bytes) that can be either present
ECEC 355: Cache Design November 28, 2007 Terminology Let us first define some general terms applicable to caches. Cache block or line. The minimum unit of information (in bytes) that can be either present
Automatic clustering of similar VM to improve the scalability of monitoring and management in IaaS cloud infrastructures
 Automatic clustering of similar to improve the scalability of monitoring and management in IaaS cloud infrastructures C. Canali R. Lancellotti University of Modena and Reggio Emilia Department of Engineering
Automatic clustering of similar to improve the scalability of monitoring and management in IaaS cloud infrastructures C. Canali R. Lancellotti University of Modena and Reggio Emilia Department of Engineering
indicates problems that have been selected for discussion in section, time permitting.
 Page 1 of 17 Caches indicates problems that have been selected for discussion in section, time permitting. Problem 1. The diagram above illustrates a blocked, direct-mapped cache for a computer that uses
Page 1 of 17 Caches indicates problems that have been selected for discussion in section, time permitting. Problem 1. The diagram above illustrates a blocked, direct-mapped cache for a computer that uses
Linearly Compressed Pages: A Main Memory Compression Framework with Low Complexity and Low Latency
 Linearly Compressed Pages: A Main Memory Compression Framework with Low Complexity and Low Latency Gennady Pekhimenko, Vivek Seshadri, Yoongu Kim, Hongyi Xin, Onur Mutlu, Todd C. Mowry Phillip B. Gibbons,
Linearly Compressed Pages: A Main Memory Compression Framework with Low Complexity and Low Latency Gennady Pekhimenko, Vivek Seshadri, Yoongu Kim, Hongyi Xin, Onur Mutlu, Todd C. Mowry Phillip B. Gibbons,
Bias Scheduling in Heterogeneous Multi-core Architectures
 Bias Scheduling in Heterogeneous Multi-core Architectures David Koufaty Dheeraj Reddy Scott Hahn Intel Labs {david.a.koufaty, dheeraj.reddy, scott.hahn}@intel.com Abstract Heterogeneous architectures that
Bias Scheduling in Heterogeneous Multi-core Architectures David Koufaty Dheeraj Reddy Scott Hahn Intel Labs {david.a.koufaty, dheeraj.reddy, scott.hahn}@intel.com Abstract Heterogeneous architectures that
Compiler Optimisation
 Compiler Optimisation 2 Coursework Hugh Leather IF 1.18a hleather@inf.ed.ac.uk Institute for Computing Systems Architecture School of Informatics University of Edinburgh 2018 Course work Based on GCC compiler
Compiler Optimisation 2 Coursework Hugh Leather IF 1.18a hleather@inf.ed.ac.uk Institute for Computing Systems Architecture School of Informatics University of Edinburgh 2018 Course work Based on GCC compiler
Wait of a Decade: Did SPEC CPU 2017 Broaden the Performance Horizon?
 Wait of a Decade: Did SPEC CPU 2017 Broaden the Performance Horizon? Reena Panda, Shuang Song, Joseph Dean, Lizy K. John The University of Texas at Austin reena.panda@utexas.edu, songshuang1990@utexas.edu,
Wait of a Decade: Did SPEC CPU 2017 Broaden the Performance Horizon? Reena Panda, Shuang Song, Joseph Dean, Lizy K. John The University of Texas at Austin reena.panda@utexas.edu, songshuang1990@utexas.edu,
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Exploring the limits of prefetching
 Exploring the limits of prefetching P. G. Emma A. Hartstein T. R. Puzak V. Srinivasan We formulate a new approach for evaluating a prefetching algorithm. We first carry out a profiling run of a program
Exploring the limits of prefetching P. G. Emma A. Hartstein T. R. Puzak V. Srinivasan We formulate a new approach for evaluating a prefetching algorithm. We first carry out a profiling run of a program
The Application Slowdown Model: Quantifying and Controlling the Impact of Inter-Application Interference at Shared Caches and Main Memory
 The Application Slowdown Model: Quantifying and Controlling the Impact of Inter-Application Interference at Shared Caches and Main Memory Lavanya Subramanian* Vivek Seshadri* Arnab Ghosh* Samira Khan*
The Application Slowdown Model: Quantifying and Controlling the Impact of Inter-Application Interference at Shared Caches and Main Memory Lavanya Subramanian* Vivek Seshadri* Arnab Ghosh* Samira Khan*