Clustering. Lecture 6, 1/24/03 ECS289A
|
|
|
- Darcy Gilbert
- 6 years ago
- Views:
Transcription
1 Clustering Lecture 6, 1/24/03
2 What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed problem!
3 Cluster These
4
5 Clustering Approaches Agglomerative Single Link Average Link Non-Parametric (Hierarchical) Complete Link Hard Clustering Soft Clustering Divisive Divisive Set Partitioning Ward Method K-Means Reconstructive K-Medoids (PAM) Parametric Graph Models Corrupted Clique Biclustering Multi-feature Generative Gaussian Mixture Models SOM Bayesian Models Fuzzy C-Means Plaid Models

6 Clustering Microarray Data Clustering reveals similar expression patterns, in particular in time-series expression data Guilt-by-association: a gene of unknown function has the same function as a similarly expressed gene of known function Genes of similar expression might be similarly regulated
7 How To Choose the Right Clustering? Data Type: Single array measurement? Series of experiments Quality of Clustering Code Availability Features of the Methods Computing averages (sometimes impossible or too slow) Sensitivity to Perturbation and other indices Properties of the clusters Speed Memory
8 Distance Measures, d(x,y) Certain properties are expected from distance measures 1. d(x,y)=0 2. d(x,y)>0, x y 3. d(x,y)=d(y,x) 4. d(x,y) d(x,z)+d(z,y) the triangle inequality If properties 1-4 are satisfied, the distance measure is a metric
 Equidistant points from a center, for different norms p=1 p=2 p=3")
9 The L p norm p p p d ( x, y) = x1 y1 + + xn yn p = 2, Euclidean Dist. p =, Manhattan Dist.(downtown Davis distance) Equidistant points from a center, for different norms p=1 p=2 p=3 p=4 p=20
10 Pearson Correlation Coefficient ) ) ( )( ) ( ( ), ( n y y n x x n y x y x y x r k k k k k k k k k k k k k k k = (Normalized vector dot product) Good for comparing expression profiles because it is insensitive to scaling (but data should be normally distributed, e.g. log expression)! Not a metric!
11 Hierarchical Clustering Input: Data Points, x 1,x 2,,x n Output:Tree the data points are leaves Branching points indicate similarity between sub-trees Horizontal cut in the tree produces data clusters Cluster Merging Cost
12 General Algorithm 1. Place each element in its own cluster, C i ={x i } 2. Compute (update) the merging cost between every pair of elements in the set of clusters to find the two cheapest to merge clusters C i, C j, 3. Merge C i and C j in a new cluster C ij which will be the parent of C i and C j in the result tree. 4. Go to (2) until there is only one set remaining Cluster Merging Cost Maximum iterations: n-1
13 Different Types of Algorithms Based on The Merging Cost Single Link, x min d( x, y) C, y i C j Average Link, 1 Cj Ci x C i y C j d( x, y) Complete Link, max x C, y i C j d( x, y) Others (Ward method-least squares)
14 Characteristics of Hierarchical Clustering Greedy Algorithms suffer from local optima, and build a few big clusters A lot of guesswork involved: Number of clusters Cutoff coefficient Size of clusters Average Link is fast and not too bad: biologically meaningful clusters are retrieved

15
16 Optimize a given function Combinatorial Optimization Problems Enumerable space Given a finite number of objects Find an object which maximizes/minimizes a function min i d ( x i, x)
17 K-Means Input: Data Points, Number of Clusters (K) Output: K clusters Algorithm: Starting from k-centroids assign data points to them based on proximity, updating the centroids iteratively 1. Select K initial cluster centroids, c 1, c 2, c 3,..., c k 2. Assign each element x to nearest centroid 3. For each cluster, re-compute its centroid by averaging the data points in it 4. Go to (2) until convergence is achieved
18 K-means Clustering The intended clusters are found. Ouyang et al.
19 K-Means Properties Must know the number of clusters before hand Sensitive to perturbations Clusters formed ad hoc with no indication of relationships among them Results depend on initial choice for centers In general, betters average link clustering
20 Properties of K-means Clustering Relocate a point The intended clusters are not found.
21 Self Organizing Maps Clustering Input: Data Points, SOM Topology (K nodes and a distance function) Output: K clusters, (near clusters are similar) Algorithm: Starting with a simple topology (connected nodes) iteratively move the nodes closer to the data 1. Select initial topology 2. Select a random data point P 3. Move all the nodes towards P by varying amounts 4. Go to (2) until convergence is achieved.
22 f ( N) = f ( N) + ( d( N, N ), i)( P f ( N 1 i p i τ i+ )) Initial Topology N = Node; P = Random point P; N d ( N, N p ) = Distance between N and N = Node f i ( N ) = Position of node N at iteration i τ is the learning rate (decreases with d and I) p p closest to P
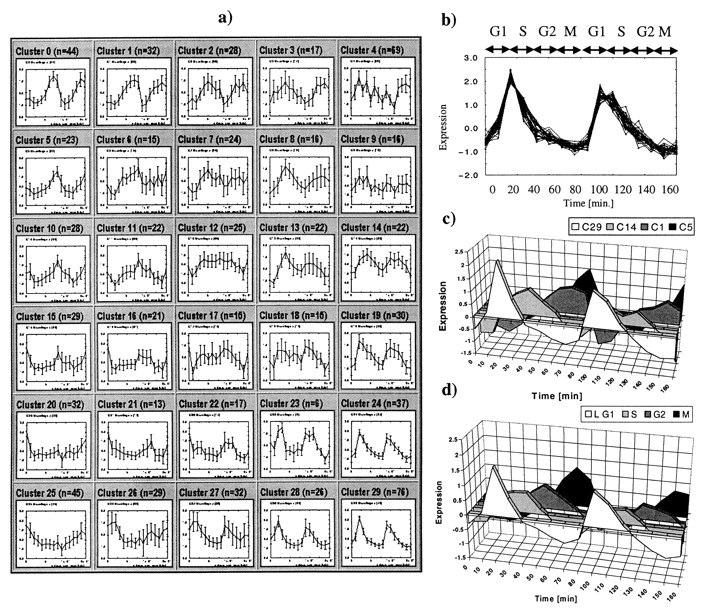
23 Results
24 Properties Neighboring clusters are similar Element on the borders belong to both clusters Very robust Works for short profile data too

25 Cluster Presentation How to see the clusters effectively? Present gene expressions in different colors Plot similar genes close to each other Eisen s TreeView: minimize the sum of distances between clustered neighboring genes (2 n-1 possible sub-tree flips, but can be done in polynomial time by dynamic programming)
26 Note on Missing Values Microarray experiments often have missing values, as a result of experimental error, values out of bound, spot reading error, batch errors, etc. Many clustering algorithms (all of the ones presented here) are sensitive to missing data Filling in the holes: All 0s Average Better: weighted K-nearest neighbor, or SVD based methods (SVDimpute, KNNimpute) Troyanskaya et al Robust Do better than average
27 Algorithm Comparison and Cluster Validation Paper: Chen et al Data: embryonic stem cells expression data Results: evaluated advantages and weaknesses of algorithms w/respect to both internal and external quality measures Used known and developed novel indices to measure clustering efficacy
28 Algorithms Compared Average Link Hierarchical Clustering, K-Means and PAM, and SOM, two different neighborhood radii R=0 (theoretically approaches K-Means) R=1 Compared them for different numbers of clusters
29 Clustering Quality Indices Homogeneity and Separation Homogeneity is calculated as the average distance between each gene expression profile and the center of the cluster it belongs to Separation is calculated as the weighted average distance between cluster centers H reflects the compactness of the clusters while S reflects the overall distance between clusters Decreasing H or increasing S suggest an improvement in the clustering results
30 Results: K-Means and PAM scored identically SOM_r0 very close to both above All three beat ALHC SOM_r1 worst
31 Silhouette Width A composite index reflecting the compactness and separation of the clusters, and can be applied to different distance metrics A larger value indicates a better overall quality of the clusters Results: All had low scores indicating underlying blurriness of the data K-Means, PAM, SOM_r0 very close All three slightly better than ALHC SOM_r1 had the lowest score
32 Redundant Scores (external validation) Almost every microarray data set has a small portion of duplicates, i.e. redundant genes (check genes) A good clustering algorithm should cluster the redundant genes expressions in the same clusters with high probability DRRS (difference of redundant separation scores) between control and redundant genes was used as a measure of cluster quality High DRRS suggests the redundant genes are more likely to be clustered together than randomly chosen genes Results: - K-means consistently better than ALHC - PAM and SOM_r0 close to the above - SOM_r1 was consistently the worst
33 WADP Measure of Robustness If the input data deviate slightly from their current value, will we get the same clustering? Important in Microarray expression data analysis because of constant noise Experiment: each gene expression profile was perturbed by adding to it a random vector of the same dimension values for the random vector generated from a Gaussian distr. (mean zero, and stand. dev.=0.01) data was renormalized and clustered WADP Cluster discrepancy: measure of inconsistent clusterings after noise. WADP=0 is perfect.
34 Results: SOM_r1 clusters are the most robust of all K-means and ALHC were high through all cluster numbers PAM and SOM_r1 were better for small number of clusters
35 Comparison of Cluster Size and Consistency
36 Comparison of Cluster Content How similar are two clusterings in all the methods? WADP Other measures of similarity based on co-clusteredness of elements Rand index Adjusted Rand Jaccard
37 Conclusions K-means outperforms ALHC SOM_r0 is almost K-means and PAM Tradeoff between robustness and cluster quality: SOM_r1 vs SOM_r0, based on the topological neighborhood Whan should we use which? Depends on what we know about the data Hierarchical data ALHC Cannot compute mean PAM General quantitative data - K-Means Need for robustness SOM_r1 Soft clustering: Fuzzy C-Means Clustering genes and experiments - Biclustering
38 References Eisen et al., Cluster analysis and display of genome-wide expression patterns, PNAS, v. 95, Tamayo et al., Interpreting patterns of gene expression with self organizing maps, PNAS, v. 96, Chen G, et al., Cluster analysis of microarray gene expression data, Statistica Sinica, 12: Troyanskaya et al., Missing value estimation methods for DNA microarrays, Bioinformatics 2001 Jun;17(6):520-5
ECS 234: Data Analysis: Clustering ECS 234
 : Data Analysis: Clustering What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
: Data Analysis: Clustering What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Measure of Distance. We wish to define the distance between two objects Distance metric between points:
 Measure of Distance We wish to define the distance between two objects Distance metric between points: Euclidean distance (EUC) Manhattan distance (MAN) Pearson sample correlation (COR) Angle distance
Measure of Distance We wish to define the distance between two objects Distance metric between points: Euclidean distance (EUC) Manhattan distance (MAN) Pearson sample correlation (COR) Angle distance
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Distances, Clustering! Rafael Irizarry!
 Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Exploratory data analysis for microarrays
 Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
9/29/13. Outline Data mining tasks. Clustering algorithms. Applications of clustering in biology
 9/9/ I9 Introduction to Bioinformatics, Clustering algorithms Yuzhen Ye (yye@indiana.edu) School of Informatics & Computing, IUB Outline Data mining tasks Predictive tasks vs descriptive tasks Example
9/9/ I9 Introduction to Bioinformatics, Clustering algorithms Yuzhen Ye (yye@indiana.edu) School of Informatics & Computing, IUB Outline Data mining tasks Predictive tasks vs descriptive tasks Example
Clustering Gene Expression Data: Acknowledgement: Elizabeth Garrett-Mayer; Shirley Liu; Robert Tibshirani; Guenther Walther; Trevor Hastie
 Clustering Gene Expression Data: Acknowledgement: Elizabeth Garrett-Mayer; Shirley Liu; Robert Tibshirani; Guenther Walther; Trevor Hastie Data from Garber et al. PNAS (98), 2001. Clustering Clustering
Clustering Gene Expression Data: Acknowledgement: Elizabeth Garrett-Mayer; Shirley Liu; Robert Tibshirani; Guenther Walther; Trevor Hastie Data from Garber et al. PNAS (98), 2001. Clustering Clustering
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Clustering k-mean clustering
 Clustering k-mean clustering Genome 373 Genomic Informatics Elhanan Borenstein The clustering problem: partition genes into distinct sets with high homogeneity and high separation Clustering (unsupervised)
Clustering k-mean clustering Genome 373 Genomic Informatics Elhanan Borenstein The clustering problem: partition genes into distinct sets with high homogeneity and high separation Clustering (unsupervised)
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Cluster Analysis for Microarray Data
 Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Cluster Analysis. Angela Montanari and Laura Anderlucci
 Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
10701 Machine Learning. Clustering
 171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
Gene expression & Clustering (Chapter 10)
") Gene expression & Clustering (Chapter 10) Determining gene function Sequence comparison tells us if a gene is similar to another gene, e.g., in a new species Dynamic programming Approximate pattern matching
Gene expression & Clustering (Chapter 10) Determining gene function Sequence comparison tells us if a gene is similar to another gene, e.g., in a new species Dynamic programming Approximate pattern matching
Giri Narasimhan. CAP 5510: Introduction to Bioinformatics. ECS 254; Phone: x3748
 CAP 5510: Introduction to Bioinformatics Giri Narasimhan ECS 254; Phone: x3748 giri@cis.fiu.edu www.cis.fiu.edu/~giri/teach/bioinfs07.html 3/3/08 CAP5510 1 Gene g Probe 1 Probe 2 Probe N 3/3/08 CAP5510
CAP 5510: Introduction to Bioinformatics Giri Narasimhan ECS 254; Phone: x3748 giri@cis.fiu.edu www.cis.fiu.edu/~giri/teach/bioinfs07.html 3/3/08 CAP5510 1 Gene g Probe 1 Probe 2 Probe N 3/3/08 CAP5510
Clustering. RNA-seq: What is it good for? Finding Similarly Expressed Genes. Data... And Lots of It!
 RNA-seq: What is it good for? Clustering High-throughput RNA sequencing experiments (RNA-seq) offer the ability to measure simultaneously the expression level of thousands of genes in a single experiment!
RNA-seq: What is it good for? Clustering High-throughput RNA sequencing experiments (RNA-seq) offer the ability to measure simultaneously the expression level of thousands of genes in a single experiment!
Foundations of Machine Learning CentraleSupélec Fall Clustering Chloé-Agathe Azencot
 Foundations of Machine Learning CentraleSupélec Fall 2017 12. Clustering Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning objectives
Foundations of Machine Learning CentraleSupélec Fall 2017 12. Clustering Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning objectives
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
EECS730: Introduction to Bioinformatics
 EECS730: Introduction to Bioinformatics Lecture 15: Microarray clustering http://compbio.pbworks.com/f/wood2.gif Some slides were adapted from Dr. Shaojie Zhang (University of Central Florida) Microarray
EECS730: Introduction to Bioinformatics Lecture 15: Microarray clustering http://compbio.pbworks.com/f/wood2.gif Some slides were adapted from Dr. Shaojie Zhang (University of Central Florida) Microarray
Clustering Techniques
 Clustering Techniques Bioinformatics: Issues and Algorithms CSE 308-408 Fall 2007 Lecture 16 Lopresti Fall 2007 Lecture 16-1 - Administrative notes Your final project / paper proposal is due on Friday,
Clustering Techniques Bioinformatics: Issues and Algorithms CSE 308-408 Fall 2007 Lecture 16 Lopresti Fall 2007 Lecture 16-1 - Administrative notes Your final project / paper proposal is due on Friday,
Hierarchical Clustering
 What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
5/15/16. Computational Methods for Data Analysis. Massimo Poesio UNSUPERVISED LEARNING. Clustering. Unsupervised learning introduction
 Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
CHAPTER-6 WEB USAGE MINING USING CLUSTERING
 CHAPTER-6 WEB USAGE MINING USING CLUSTERING 6.1 Related work in Clustering Technique 6.2 Quantifiable Analysis of Distance Measurement Techniques 6.3 Approaches to Formation of Clusters 6.4 Conclusion
CHAPTER-6 WEB USAGE MINING USING CLUSTERING 6.1 Related work in Clustering Technique 6.2 Quantifiable Analysis of Distance Measurement Techniques 6.3 Approaches to Formation of Clusters 6.4 Conclusion
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
10. Clustering. Introduction to Bioinformatics Jarkko Salojärvi. Based on lecture slides by Samuel Kaski
 10. Clustering Introduction to Bioinformatics 30.9.2008 Jarkko Salojärvi Based on lecture slides by Samuel Kaski Definition of a cluster Typically either 1. A group of mutually similar samples, or 2. A
10. Clustering Introduction to Bioinformatics 30.9.2008 Jarkko Salojärvi Based on lecture slides by Samuel Kaski Definition of a cluster Typically either 1. A group of mutually similar samples, or 2. A
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
Data Mining Algorithms
 for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
10601 Machine Learning. Hierarchical clustering. Reading: Bishop: 9-9.2
 161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
High throughput Data Analysis 2. Cluster Analysis
 High throughput Data Analysis 2 Cluster Analysis Overview Why clustering? Hierarchical clustering K means clustering Issues with above two Other methods Quality of clustering results Introduction WHY DO
High throughput Data Analysis 2 Cluster Analysis Overview Why clustering? Hierarchical clustering K means clustering Issues with above two Other methods Quality of clustering results Introduction WHY DO
University of Florida CISE department Gator Engineering. Clustering Part 5
 Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Missing Data Estimation in Microarrays Using Multi-Organism Approach
 Missing Data Estimation in Microarrays Using Multi-Organism Approach Marcel Nassar and Hady Zeineddine Progress Report: Data Mining Course Project, Spring 2008 Prof. Inderjit S. Dhillon April 02, 2008
Missing Data Estimation in Microarrays Using Multi-Organism Approach Marcel Nassar and Hady Zeineddine Progress Report: Data Mining Course Project, Spring 2008 Prof. Inderjit S. Dhillon April 02, 2008
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A
 MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
CS Introduction to Data Mining Instructor: Abdullah Mueen
 CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Statistics 202: Data Mining. c Jonathan Taylor. Clustering Based in part on slides from textbook, slides of Susan Holmes.
 Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Clustering. Robert M. Haralick. Computer Science, Graduate Center City University of New York
 Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Hierarchical Clustering
 Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Introduction to Clustering
 Introduction to Clustering Ref: Chengkai Li, Department of Computer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) What is Cluster Analysis? Finding groups of
Introduction to Clustering Ref: Chengkai Li, Department of Computer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) What is Cluster Analysis? Finding groups of
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Slides From Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Part I. Hierarchical clustering. Hierarchical Clustering. Hierarchical clustering. Produces a set of nested clusters organized as a
 Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Machine Learning for Signal Processing Clustering. Bhiksha Raj Class Oct 2016
 Machine Learning for Signal Processing Clustering Bhiksha Raj Class 11. 13 Oct 2016 1 Statistical Modelling and Latent Structure Much of statistical modelling attempts to identify latent structure in the
Machine Learning for Signal Processing Clustering Bhiksha Raj Class 11. 13 Oct 2016 1 Statistical Modelling and Latent Structure Much of statistical modelling attempts to identify latent structure in the
Stat 321: Transposable Data Clustering
 Stat 321: Transposable Data Clustering Art B. Owen Stanford Statistics Art B. Owen (Stanford Statistics) Clustering 1 / 27 Clustering Given n objects with d attributes, place them (the objects) into groups.
Stat 321: Transposable Data Clustering Art B. Owen Stanford Statistics Art B. Owen (Stanford Statistics) Clustering 1 / 27 Clustering Given n objects with d attributes, place them (the objects) into groups.
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Dimension reduction : PCA and Clustering
 Dimension reduction : PCA and Clustering By Hanne Jarmer Slides by Christopher Workman Center for Biological Sequence Analysis DTU The DNA Array Analysis Pipeline Array design Probe design Question Experimental
Dimension reduction : PCA and Clustering By Hanne Jarmer Slides by Christopher Workman Center for Biological Sequence Analysis DTU The DNA Array Analysis Pipeline Array design Probe design Question Experimental
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
How do microarrays work
 Lecture 3 (continued) Alvis Brazma European Bioinformatics Institute How do microarrays work condition mrna cdna hybridise to microarray condition Sample RNA extract labelled acid acid acid nucleic acid
Lecture 3 (continued) Alvis Brazma European Bioinformatics Institute How do microarrays work condition mrna cdna hybridise to microarray condition Sample RNA extract labelled acid acid acid nucleic acid
Unsupervised Learning Hierarchical Methods
 Unsupervised Learning Hierarchical Methods Road Map. Basic Concepts 2. BIRCH 3. ROCK The Principle Group data objects into a tree of clusters Hierarchical methods can be Agglomerative: bottom-up approach
Unsupervised Learning Hierarchical Methods Road Map. Basic Concepts 2. BIRCH 3. ROCK The Principle Group data objects into a tree of clusters Hierarchical methods can be Agglomerative: bottom-up approach
What is Unsupervised Learning?
 Clustering What is Unsupervised Learning? Unlike in supervised learning, in unsupervised learning, there are no labels We simply a search for patterns in the data Examples Clustering Density Estimation
Clustering What is Unsupervised Learning? Unlike in supervised learning, in unsupervised learning, there are no labels We simply a search for patterns in the data Examples Clustering Density Estimation
K-Means Clustering. Sargur Srihari
 K-Means Clustering Sargur srihari@cedar.buffalo.edu 1 Topics in Mixture Models and EM Mixture models K-means Clustering Mixtures of Gaussians Maximum Likelihood EM for Gaussian mistures EM Algorithm Gaussian
K-Means Clustering Sargur srihari@cedar.buffalo.edu 1 Topics in Mixture Models and EM Mixture models K-means Clustering Mixtures of Gaussians Maximum Likelihood EM for Gaussian mistures EM Algorithm Gaussian
Analyzing ICAT Data. Analyzing ICAT Data
 Analyzing ICAT Data Gary Van Domselaar University of Alberta Analyzing ICAT Data ICAT: Isotope Coded Affinity Tag Introduced in 1999 by Ruedi Aebersold as a method for quantitative analysis of complex
Analyzing ICAT Data Gary Van Domselaar University of Alberta Analyzing ICAT Data ICAT: Isotope Coded Affinity Tag Introduced in 1999 by Ruedi Aebersold as a method for quantitative analysis of complex
Unsupervised Learning Partitioning Methods
 Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Clustering. Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
MSA220 - Statistical Learning for Big Data
 MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
Comparisons and validation of statistical clustering techniques for microarray gene expression data. Outline. Microarrays.
 Comparisons and validation of statistical clustering techniques for microarray gene expression data Susmita Datta and Somnath Datta Presented by: Jenni Dietrich Assisted by: Jeffrey Kidd and Kristin Wheeler
Comparisons and validation of statistical clustering techniques for microarray gene expression data Susmita Datta and Somnath Datta Presented by: Jenni Dietrich Assisted by: Jeffrey Kidd and Kristin Wheeler
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Clustering. Chapter 10 in Introduction to statistical learning
 Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
CLUSTERING IN BIOINFORMATICS
 CLUSTERING IN BIOINFORMATICS CSE/BIMM/BENG 8 MAY 4, 0 OVERVIEW Define the clustering problem Motivation: gene expression and microarrays Types of clustering Clustering algorithms Other applications of
CLUSTERING IN BIOINFORMATICS CSE/BIMM/BENG 8 MAY 4, 0 OVERVIEW Define the clustering problem Motivation: gene expression and microarrays Types of clustering Clustering algorithms Other applications of
Clustering gene expression data
 Clustering gene expression data 1 How Gene Expression Data Looks Entries of the Raw Data matrix: Ratio values Absolute values Row = gene s expression pattern Column = experiment/condition s profile genes
Clustering gene expression data 1 How Gene Expression Data Looks Entries of the Raw Data matrix: Ratio values Absolute values Row = gene s expression pattern Column = experiment/condition s profile genes
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Hierarchical Clustering
 Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Finding Clusters 1 / 60
 Finding Clusters Types of Clustering Approaches: Linkage Based, e.g. Hierarchical Clustering Clustering by Partitioning, e.g. k-means Density Based Clustering, e.g. DBScan Grid Based Clustering 1 / 60
Finding Clusters Types of Clustering Approaches: Linkage Based, e.g. Hierarchical Clustering Clustering by Partitioning, e.g. k-means Density Based Clustering, e.g. DBScan Grid Based Clustering 1 / 60
Statistical Analysis of Metabolomics Data. Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte
 Statistical Analysis of Metabolomics Data Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte Outline Introduction Data pre-treatment 1. Normalization 2. Centering,
Statistical Analysis of Metabolomics Data Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte Outline Introduction Data pre-treatment 1. Normalization 2. Centering,
University of Florida CISE department Gator Engineering. Clustering Part 4
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
k-means A classical clustering algorithm
 k-means A classical clustering algorithm Devert Alexandre School of Software Engineering of USTC 30 November 2012 Slide 1/65 Table of Contents 1 Introduction 2 Visual demo Step by step Voronoi diagrams
k-means A classical clustering algorithm Devert Alexandre School of Software Engineering of USTC 30 November 2012 Slide 1/65 Table of Contents 1 Introduction 2 Visual demo Step by step Voronoi diagrams
Clustering. k-mean clustering. Genome 559: Introduction to Statistical and Computational Genomics Elhanan Borenstein
 Clustering k-mean clustering Genome 559: Introduction to Statistical and Computational Genomics Elhanan Borenstein A quick review The clustering problem: homogeneity vs. separation Different representations
Clustering k-mean clustering Genome 559: Introduction to Statistical and Computational Genomics Elhanan Borenstein A quick review The clustering problem: homogeneity vs. separation Different representations
Hierarchical clustering
 Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Clustering Color/Intensity. Group together pixels of similar color/intensity.
 Clustering Color/Intensity Group together pixels of similar color/intensity. Agglomerative Clustering Cluster = connected pixels with similar color. Optimal decomposition may be hard. For example, find
Clustering Color/Intensity Group together pixels of similar color/intensity. Agglomerative Clustering Cluster = connected pixels with similar color. Optimal decomposition may be hard. For example, find
Mining di Dati Web. Lezione 3 - Clustering and Classification
 Mining di Dati Web Lezione 3 - Clustering and Classification Introduction Clustering and classification are both learning techniques They learn functions describing data Clustering is also known as Unsupervised
Mining di Dati Web Lezione 3 - Clustering and Classification Introduction Clustering and classification are both learning techniques They learn functions describing data Clustering is also known as Unsupervised
Unsupervised Learning and Data Mining
 Unsupervised Learning and Data Mining Unsupervised Learning and Data Mining Clustering Supervised Learning ó Decision trees ó Artificial neural nets ó K-nearest neighbor ó Support vectors ó Linear regression
Unsupervised Learning and Data Mining Unsupervised Learning and Data Mining Clustering Supervised Learning ó Decision trees ó Artificial neural nets ó K-nearest neighbor ó Support vectors ó Linear regression
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Multivariate Analysis
 Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Data Mining: Concepts and Techniques. Chapter March 8, 2007 Data Mining: Concepts and Techniques 1
 Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
University of California, Berkeley
 University of California, Berkeley U.C. Berkeley Division of Biostatistics Working Paper Series Year 2002 Paper 105 A New Partitioning Around Medoids Algorithm Mark J. van der Laan Katherine S. Pollard
University of California, Berkeley U.C. Berkeley Division of Biostatistics Working Paper Series Year 2002 Paper 105 A New Partitioning Around Medoids Algorithm Mark J. van der Laan Katherine S. Pollard
Supervised vs unsupervised clustering
 Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
Review: Identification of cell types from single-cell transcriptom. method
 Review: Identification of cell types from single-cell transcriptomes using a novel clustering method University of North Carolina at Charlotte October 12, 2015 Brief overview Identify clusters by merging
Review: Identification of cell types from single-cell transcriptomes using a novel clustering method University of North Carolina at Charlotte October 12, 2015 Brief overview Identify clusters by merging
Cluster Analysis. Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX April 2008 April 2010
 Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
What is Cluster Analysis?
 Cluster Analysis What is Cluster Analysis? Finding groups of objects (data points) such that the objects in a group will be similar (or related) to one another and different from (or unrelated to) the
Cluster Analysis What is Cluster Analysis? Finding groups of objects (data points) such that the objects in a group will be similar (or related) to one another and different from (or unrelated to) the
Clustering analysis of gene expression data
 Clustering analysis of gene expression data Chapter 11 in Jonathan Pevsner, Bioinformatics and Functional Genomics, 3 rd edition (Chapter 9 in 2 nd edition) Human T cell expression data The matrix contains
Clustering analysis of gene expression data Chapter 11 in Jonathan Pevsner, Bioinformatics and Functional Genomics, 3 rd edition (Chapter 9 in 2 nd edition) Human T cell expression data The matrix contains