ECS 234: Data Analysis: Clustering ECS 234
|
|
|
- Sharyl Clark
- 5 years ago
- Views:
Transcription

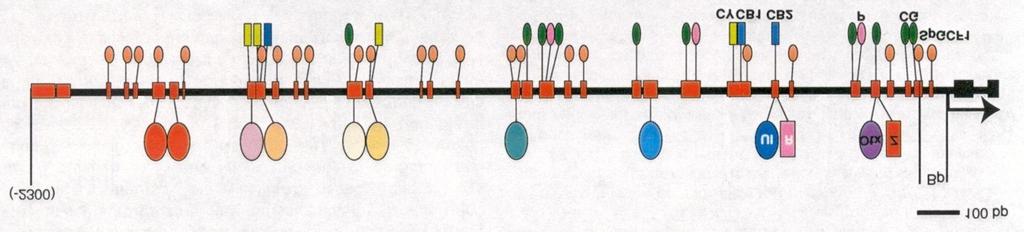
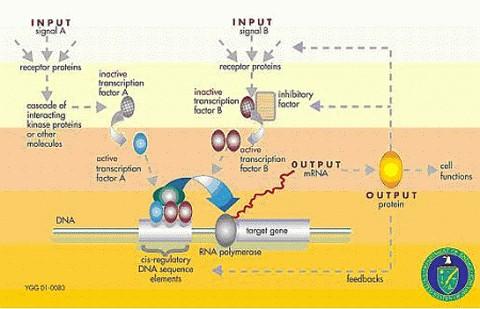
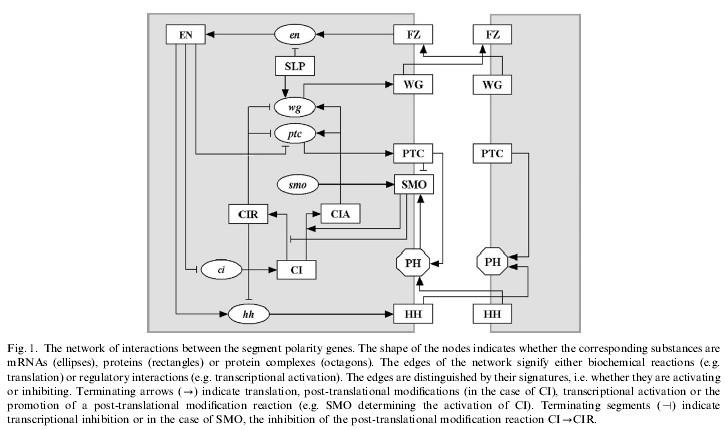

1 : Data Analysis: Clustering
2 What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed problem!

3 Cluster These
4
5 Impossibility of Clustering Scale-invariance: meters vs inches Richness: all partitions as possible solutions Consistency: increasing distances between clusters and decreasing distances within clusters should yield the same solution No function exists that satisfies all three. Kleinberg, NIPS 2002
6 Clustering Microarray Data Clustering reveals similar expression patterns, in particular in time-series expression data Guilt-by-association: a gene of unknown function has the same function as a similarly expressed gene of known function Genes of similar expression might be similarly regulated
7 Clustering Approaches Parametric Non-Parametric (Hierarchical) Reconstructive Graph Models Agglomerative Divisive K-Means Corrupted K-Medoids Clique Single Link Divisive Set Partitioning Average Link (PAM) Hard Clustering Soft Clustering Gaussian Mixture Models Fuzzy C-Means SOM Bayesian Models Complete Link Ward Method Generative Biclustering Plaid Models Multi-feature
8 How To Choose the Right Clustering? Data Type Independent Experiments (e.g. knockouts) Dependent experiments (e.g. time series) Parametric vs. non-parametric clustering Quality of Clustering Software Availability Features of the Methods Computing averages (sometimes impossible or too slow) Stability analysis Properties of the clusters Speed Memory
9 Clustering Meta-Procedure 1. Compare the similarity of all pairs of objects 2. Group the most similar ones together into clusters 3. Reason about the resulting groups of clusters
10 Distance Measures, d(x,y) Certain properties are expected from distance measures 1. d(x,y)=0 d(x,y)>0, x y 1. d(x,y)=d(y,x) d(x,y) d(x,z)+d(z,y) the triangle inequality If properties 1-4 are satisfied, the distance measure is a metric
 Equidistant points from a center, for different norms p=1 p=2 p=3")
11 The Lp norm d ( x, y ) = p x1 y1 p + + xn yn p p = 2, Euclidean Dist. p =, Manhattan Dist.(downtown Davis distance) Equidistant points from a center, for different norms p=1 p=2 p=3 p=4 p=20
12 Pearson Correlation Coefficient (Normalized vector dot product) r ( x, y ) = k ( xk 2 k xk y k ( xk ) 2 k n x yk k k Not a metric! k n )( yk 2 k ( yk ) 2 k n ) Good for comparing expression profiles because it is insensitive to scaling (but data should be normally distributed, e.g. log expression)!
13 Hierarchical Clustering Input: Data Points, x1,x2,,xn Output:Tree Cluster Merging Cost the data points are leaves Branching points indicate similarity between sub-trees Horizontal cut in the tree produces data clusters
14 General Algorithm 1. Place each element in its own cluster, Ci={xi} Compute (update) the merging cost between every pair of elements in the set of clusters to find the two cheapest to merge clusters Ci, Cj, Merge Ci and Cj in a new cluster Cij which will be the parent of Ci and Cj in the result tree. Go to (2) until there is only one set remaining Cluster Merging Cost Maximum iterations: n-1
15 Different Types of Algorithms Based on The Merging Cost d ( x, y ) Single Link, x min C, y C i j 1 Average Link, Ci Cj x C y C d ( x, y ) i j Complete Link, max d ( x, y ) x C, y C i j Others (Ward method-least squares)
16 Characteristics of Hierarchical Clustering Greedy Algorithms suffer from local optima, and build a few big clusters A lot of guesswork involved: Number of clusters Cutoff coefficient Size of clusters Average Link is fast and not too bad: biologically meaningful clusters are retrieved

17
18 K-Means Input: Data Points, Number of Clusters (K) Output: K clusters Algorithm: Starting from k-centroids assign data points to them based on proximity, updating the centroids iteratively Select K initial cluster centroids, c1, c2, c3,..., ck Assign each element x to nearest centroid 1. For each cluster, re-compute its centroid by averaging the data points in it 2. Go to (2) until convergence is achieved
19 K-means Clustering The intended clusters are found. Ouyang et al.
20 K-Means Properties Must know the number of clusters before hand Sensitive to perturbations Clusters formed ad hoc with no indication of relationships among them Results depend on initial choice for centers In general, betters average link clustering
21 Properties of K-means Clustering Relocate a point The intended clusters are not found.
22 Self Organizing Maps Clustering Input: Data Points, SOM Topology (K nodes and a distance function) Output: K clusters, (near clusters are similar) Algorithm: Starting with a simple topology (connected nodes) iteratively move the nodes closer to the data Select initial topology Select a random data point P Move all the nodes towards P by varying amounts Go to (2) until convergence is achieved.
 = Distance between N and N p f i ( N ) = Position of node N at iteration i τ is the learning rate (decreases with d and")
23 f i + 1 ( N ) = f i ( N ) + τ (d ( N, N p ), i )( P f i ( N )) Initial Topology N = Node; P = Random point P; N p = Node closest to P d ( N, N p ) = Distance between N and N p f i ( N ) = Position of node N at iteration i τ is the learning rate (decreases with d and I)
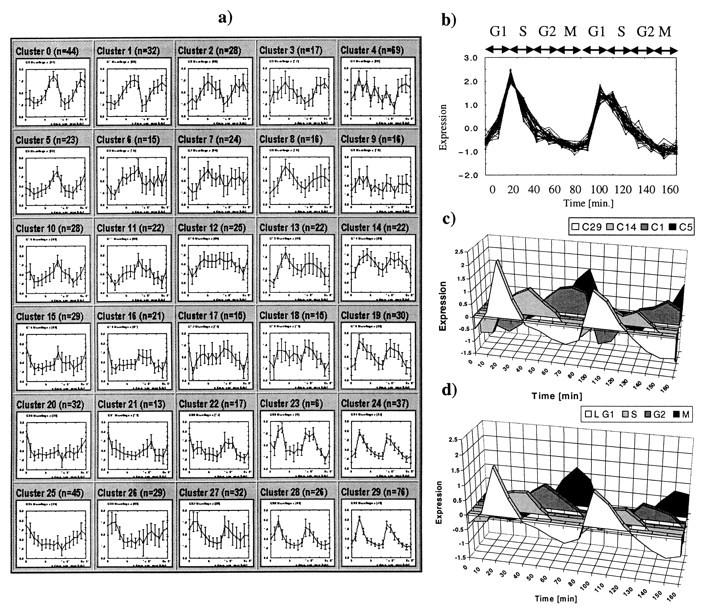
24 Results
25 SOM Properties Neighbouring clusters are similar Element on the borders belong to both clusters Very robust Works for short profile data too

26 What if the number of clusters is not known? Elbow criterion: look for a clustering that explains most of the variance or stability in data with the fewest clusters Information theoretic: maximize (or minimize) some Information Criterion (like BIC or AIC or MDL) Within/between cluster distance/separation: silhouettes
27 Note on Missing Values Microarray experiments often have missing values, as a result of experimental error, values out of bound, spot reading error, batch errors, etc. Many clustering algorithms (all of the ones presented here) are sensitive to missing data Filling in the holes: All 0s Average Better: weighted K-nearest neighbor, or SVD based methods (SVDimpute, KNNimpute) Troyanskaya et al (AVAILABLE FOR DOWNLOAD) Robust Do better than average

28 Cluster Visualization How to see the clusters effectively? Present gene expressions in different colors Plot similar genes close to each other R GeneXPress Expander CytoScape
29 Algorithm Comparison and Cluster Validation Paper: Chen et al Data: embryonic stem cells expression data Results: evaluated advantages and weaknesses of algorithms w/respect to both internal and external quality measures Used known and developed novel indices to measure clustering efficacy
30 Algorithms Compared Average Link Hierarchical Clustering, K-Means and PAM, and SOM, two different neighborhood radii R=0 (theoretically approaches K-Means) R=1 Compared them for different numbers of clusters
31 Clustering Quality Indices Homogeneity and Separation Homogeneity is calculated as the average distance between each gene expression profile and the center of the cluster it belongs to Separation is calculated as the weighted average distance between cluster centers H reflects the compactness of the clusters while S reflects the overall distance between clusters Decreasing H or increasing S suggest an improvement in the clustering results
32 Results: K-Means and PAM scored identically SOM_r0 very close to both above All three beat ALHC SOM_r1 worst
33 Silhouette Width A composite index reflecting the compactness and separation of the clusters, and can be applied to different distance metrics A larger value indicates a better overall quality of the clusters Results: All had low scores indicating underlying blurriness of the data K-Means, PAM, SOM_r0 very close All three slightly better than ALHC SOM_r1 had the lowest score
34 Redundant Scores (external validation) Almost every microarray data set has a small portion of duplicates, i.e. redundant genes (check genes) A good clustering algorithm should cluster the redundant genes expressions in the same clusters with high probability DRRS (difference of redundant separation scores) between control and redundant genes was used as a measure of cluster quality High DRRS suggests the redundant genes are more likely to be clustered together than randomly chosen genes Results: - K-means consistently better than ALHC - PAM and SOM_r0 close to the above - SOM_r1 was consistently the worst
35 WADP Measure of Robustness If the input data deviate slightly from their current value, will we get the same clustering? Important in Microarray expression data analysis because of constant noise Experiment: each gene expression profile was perturbed by adding to it a random vector of the same dimension values for the random vector generated from a Gaussian distr. (mean zero, and stand. dev.=0.01) data was renormalized and clustered WADP Cluster discrepancy: measure of inconsistent clusterings after noise. WADP=0 is perfect.
36 Results: SOM_r1 clusters are the most robust of all K-means and ALHC were high through all cluster numbers PAM and SOM_r1 were better for small number of clusters
37 Comparison of Cluster Size and Consistency
38 Comparison of Cluster Content How similar are two clusterings in all the methods? WADP Other measures of similarity based on co-clusteredness of elements Rand index Adjusted Rand Jaccard
39 Clustering: Conclusions K-means outperforms ALHC SOM_r0 is almost K-means and PAM Tradeoff between robustness and cluster quality: SOM_r1 vs SOM_r0, based on the topological neighborhood Whan should we use which? Depends on what we know about the data Hierarchical data ALHC Cannot compute mean PAM General quantitative data - K-Means Need for robustness SOM_r1 Soft clustering: Fuzzy C-Means Clustering genes and experiments - Biclustering
40 Biclustering Problem with clustering: Clustering the same genes under different subsets of conditions can result in very different clusterings Additional Motivation sometimes only subset of genes are interesting and one wants to cluster those Genes expressed differentially in different conditions and pathways Proposed solutions: cluster simultaneously the genes and the conditions
41 Clustering conditions Clustering Genes Biclustering The biclustering methods look for submatrices in the expression matrix which show coordinated differential expression of subsets of genes in subsets of conditions. The biclusters are also statistically significant. Clustering is a global similarity method, while biclustering is a local one.
42 Biclustering Methods Biclustering Coupled Two-way Clustering Iterative Signature Algorithm SAMBA Spectral Biclustering Plaid Models
43 Other Dimension Reduction Techniques All (including clustering) are based on the premise that not all genes (or experiments) show different behavior, so groups of similar genes (experiments) are sought Principal Component Analysis Identifies the underlying classes or base genes of the data representing most variability (best separating the genes) All other genes expressions are linear combination of those Classes are built around a few top base genes Typically used for 2D or 3D data visualization and seeding k-means Independent Component Analysis Similar as PCA but here the base components are required to be statistically independent Non-zero Matrix Factorization
44 Expander example
Clustering. Lecture 6, 1/24/03 ECS289A
 Clustering Lecture 6, 1/24/03 What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
Clustering Lecture 6, 1/24/03 What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
Hierarchical Clustering
 What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Measure of Distance. We wish to define the distance between two objects Distance metric between points:
 Measure of Distance We wish to define the distance between two objects Distance metric between points: Euclidean distance (EUC) Manhattan distance (MAN) Pearson sample correlation (COR) Angle distance
Measure of Distance We wish to define the distance between two objects Distance metric between points: Euclidean distance (EUC) Manhattan distance (MAN) Pearson sample correlation (COR) Angle distance
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Cluster Analysis for Microarray Data
 Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
Cluster Analysis for Microarray Data Seventh International Long Oligonucleotide Microarray Workshop Tucson, Arizona January 7-12, 2007 Dan Nettleton IOWA STATE UNIVERSITY 1 Clustering Group objects that
High throughput Data Analysis 2. Cluster Analysis
 High throughput Data Analysis 2 Cluster Analysis Overview Why clustering? Hierarchical clustering K means clustering Issues with above two Other methods Quality of clustering results Introduction WHY DO
High throughput Data Analysis 2 Cluster Analysis Overview Why clustering? Hierarchical clustering K means clustering Issues with above two Other methods Quality of clustering results Introduction WHY DO
10701 Machine Learning. Clustering
 171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
9/29/13. Outline Data mining tasks. Clustering algorithms. Applications of clustering in biology
 9/9/ I9 Introduction to Bioinformatics, Clustering algorithms Yuzhen Ye (yye@indiana.edu) School of Informatics & Computing, IUB Outline Data mining tasks Predictive tasks vs descriptive tasks Example
9/9/ I9 Introduction to Bioinformatics, Clustering algorithms Yuzhen Ye (yye@indiana.edu) School of Informatics & Computing, IUB Outline Data mining tasks Predictive tasks vs descriptive tasks Example
Cluster Analysis. Angela Montanari and Laura Anderlucci
 Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
5/15/16. Computational Methods for Data Analysis. Massimo Poesio UNSUPERVISED LEARNING. Clustering. Unsupervised learning introduction
 Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Computational Methods for Data Analysis Massimo Poesio UNSUPERVISED LEARNING Clustering Unsupervised learning introduction 1 Supervised learning Training set: Unsupervised learning Training set: 2 Clustering
Foundations of Machine Learning CentraleSupélec Fall Clustering Chloé-Agathe Azencot
 Foundations of Machine Learning CentraleSupélec Fall 2017 12. Clustering Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning objectives
Foundations of Machine Learning CentraleSupélec Fall 2017 12. Clustering Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning objectives
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Part I. Hierarchical clustering. Hierarchical Clustering. Hierarchical clustering. Produces a set of nested clusters organized as a
 Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Exploratory data analysis for microarrays
 Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Dimension reduction : PCA and Clustering
 Dimension reduction : PCA and Clustering By Hanne Jarmer Slides by Christopher Workman Center for Biological Sequence Analysis DTU The DNA Array Analysis Pipeline Array design Probe design Question Experimental
Dimension reduction : PCA and Clustering By Hanne Jarmer Slides by Christopher Workman Center for Biological Sequence Analysis DTU The DNA Array Analysis Pipeline Array design Probe design Question Experimental
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Distances, Clustering! Rafael Irizarry!
 Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
MSA220 - Statistical Learning for Big Data
 MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
Clustering k-mean clustering
 Clustering k-mean clustering Genome 373 Genomic Informatics Elhanan Borenstein The clustering problem: partition genes into distinct sets with high homogeneity and high separation Clustering (unsupervised)
Clustering k-mean clustering Genome 373 Genomic Informatics Elhanan Borenstein The clustering problem: partition genes into distinct sets with high homogeneity and high separation Clustering (unsupervised)
Clustering Gene Expression Data: Acknowledgement: Elizabeth Garrett-Mayer; Shirley Liu; Robert Tibshirani; Guenther Walther; Trevor Hastie
 Clustering Gene Expression Data: Acknowledgement: Elizabeth Garrett-Mayer; Shirley Liu; Robert Tibshirani; Guenther Walther; Trevor Hastie Data from Garber et al. PNAS (98), 2001. Clustering Clustering
Clustering Gene Expression Data: Acknowledgement: Elizabeth Garrett-Mayer; Shirley Liu; Robert Tibshirani; Guenther Walther; Trevor Hastie Data from Garber et al. PNAS (98), 2001. Clustering Clustering
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
Clustering and Dissimilarity Measures. Clustering. Dissimilarity Measures. Cluster Analysis. Perceptually-Inspired Measures
 Clustering and Dissimilarity Measures Clustering APR Course, Delft, The Netherlands Marco Loog May 19, 2008 1 What salient structures exist in the data? How many clusters? May 19, 2008 2 Cluster Analysis
Clustering and Dissimilarity Measures Clustering APR Course, Delft, The Netherlands Marco Loog May 19, 2008 1 What salient structures exist in the data? How many clusters? May 19, 2008 2 Cluster Analysis
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
10601 Machine Learning. Hierarchical clustering. Reading: Bishop: 9-9.2
 161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
161 Machine Learning Hierarchical clustering Reading: Bishop: 9-9.2 Second half: Overview Clustering - Hierarchical, semi-supervised learning Graphical models - Bayesian networks, HMMs, Reasoning under
Chapter DM:II. II. Cluster Analysis
 Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Gene expression & Clustering (Chapter 10)
") Gene expression & Clustering (Chapter 10) Determining gene function Sequence comparison tells us if a gene is similar to another gene, e.g., in a new species Dynamic programming Approximate pattern matching
Gene expression & Clustering (Chapter 10) Determining gene function Sequence comparison tells us if a gene is similar to another gene, e.g., in a new species Dynamic programming Approximate pattern matching
Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Stat 321: Transposable Data Clustering
 Stat 321: Transposable Data Clustering Art B. Owen Stanford Statistics Art B. Owen (Stanford Statistics) Clustering 1 / 27 Clustering Given n objects with d attributes, place them (the objects) into groups.
Stat 321: Transposable Data Clustering Art B. Owen Stanford Statistics Art B. Owen (Stanford Statistics) Clustering 1 / 27 Clustering Given n objects with d attributes, place them (the objects) into groups.
University of Florida CISE department Gator Engineering. Clustering Part 5
 Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
Clustering. RNA-seq: What is it good for? Finding Similarly Expressed Genes. Data... And Lots of It!
 RNA-seq: What is it good for? Clustering High-throughput RNA sequencing experiments (RNA-seq) offer the ability to measure simultaneously the expression level of thousands of genes in a single experiment!
RNA-seq: What is it good for? Clustering High-throughput RNA sequencing experiments (RNA-seq) offer the ability to measure simultaneously the expression level of thousands of genes in a single experiment!
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Unsupervised Learning Partitioning Methods
 Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
CHAPTER-6 WEB USAGE MINING USING CLUSTERING
 CHAPTER-6 WEB USAGE MINING USING CLUSTERING 6.1 Related work in Clustering Technique 6.2 Quantifiable Analysis of Distance Measurement Techniques 6.3 Approaches to Formation of Clusters 6.4 Conclusion
CHAPTER-6 WEB USAGE MINING USING CLUSTERING 6.1 Related work in Clustering Technique 6.2 Quantifiable Analysis of Distance Measurement Techniques 6.3 Approaches to Formation of Clusters 6.4 Conclusion
EECS730: Introduction to Bioinformatics
 EECS730: Introduction to Bioinformatics Lecture 15: Microarray clustering http://compbio.pbworks.com/f/wood2.gif Some slides were adapted from Dr. Shaojie Zhang (University of Central Florida) Microarray
EECS730: Introduction to Bioinformatics Lecture 15: Microarray clustering http://compbio.pbworks.com/f/wood2.gif Some slides were adapted from Dr. Shaojie Zhang (University of Central Florida) Microarray
Hierarchical clustering
 Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
INF 4300 Classification III Anne Solberg The agenda today:
 INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
How do microarrays work
 Lecture 3 (continued) Alvis Brazma European Bioinformatics Institute How do microarrays work condition mrna cdna hybridise to microarray condition Sample RNA extract labelled acid acid acid nucleic acid
Lecture 3 (continued) Alvis Brazma European Bioinformatics Institute How do microarrays work condition mrna cdna hybridise to microarray condition Sample RNA extract labelled acid acid acid nucleic acid
Clustering. Partition unlabeled examples into disjoint subsets of clusters, such that:
 Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A
 MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering
 Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
10. Clustering. Introduction to Bioinformatics Jarkko Salojärvi. Based on lecture slides by Samuel Kaski
 10. Clustering Introduction to Bioinformatics 30.9.2008 Jarkko Salojärvi Based on lecture slides by Samuel Kaski Definition of a cluster Typically either 1. A group of mutually similar samples, or 2. A
10. Clustering Introduction to Bioinformatics 30.9.2008 Jarkko Salojärvi Based on lecture slides by Samuel Kaski Definition of a cluster Typically either 1. A group of mutually similar samples, or 2. A
Clustering Techniques
 Clustering Techniques Bioinformatics: Issues and Algorithms CSE 308-408 Fall 2007 Lecture 16 Lopresti Fall 2007 Lecture 16-1 - Administrative notes Your final project / paper proposal is due on Friday,
Clustering Techniques Bioinformatics: Issues and Algorithms CSE 308-408 Fall 2007 Lecture 16 Lopresti Fall 2007 Lecture 16-1 - Administrative notes Your final project / paper proposal is due on Friday,
SGN (4 cr) Chapter 11
 Chapter 11") SGN-41006 (4 cr) Chapter 11 Clustering Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology February 25, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006 (4 cr) Chapter
SGN-41006 (4 cr) Chapter 11 Clustering Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology February 25, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006 (4 cr) Chapter
Machine Learning and Data Mining. Clustering (1): Basics. Kalev Kask
: Basics. Kalev Kask") Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Segmentation Computer Vision Spring 2018, Lecture 27
 Segmentation http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 218, Lecture 27 Course announcements Homework 7 is due on Sunday 6 th. - Any questions about homework 7? - How many of you have
Segmentation http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 218, Lecture 27 Course announcements Homework 7 is due on Sunday 6 th. - Any questions about homework 7? - How many of you have
Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering
 Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering Clustering Algorithms Contents K-means Hierarchical algorithms Linkage functions Vector quantization SOM Clustering Formulation
Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering Clustering Algorithms Contents K-means Hierarchical algorithms Linkage functions Vector quantization SOM Clustering Formulation
A Review on Cluster Based Approach in Data Mining
 A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
An Unsupervised Approach for Combining Scores of Outlier Detection Techniques, Based on Similarity Measures
 An Unsupervised Approach for Combining Scores of Outlier Detection Techniques, Based on Similarity Measures José Ramón Pasillas-Díaz, Sylvie Ratté Presenter: Christoforos Leventis 1 Basic concepts Outlier
An Unsupervised Approach for Combining Scores of Outlier Detection Techniques, Based on Similarity Measures José Ramón Pasillas-Díaz, Sylvie Ratté Presenter: Christoforos Leventis 1 Basic concepts Outlier
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Introduction to Mobile Robotics
 Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Function approximation using RBF network. 10 basis functions and 25 data points.
 1 Function approximation using RBF network F (x j ) = m 1 w i ϕ( x j t i ) i=1 j = 1... N, m 1 = 10, N = 25 10 basis functions and 25 data points. Basis function centers are plotted with circles and data
1 Function approximation using RBF network F (x j ) = m 1 w i ϕ( x j t i ) i=1 j = 1... N, m 1 = 10, N = 25 10 basis functions and 25 data points. Basis function centers are plotted with circles and data
Data Mining Algorithms
 for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Unsupervised Learning and Data Mining
 Unsupervised Learning and Data Mining Unsupervised Learning and Data Mining Clustering Supervised Learning ó Decision trees ó Artificial neural nets ó K-nearest neighbor ó Support vectors ó Linear regression
Unsupervised Learning and Data Mining Unsupervised Learning and Data Mining Clustering Supervised Learning ó Decision trees ó Artificial neural nets ó K-nearest neighbor ó Support vectors ó Linear regression
Classification. Vladimir Curic. Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University
 Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering. SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic
 Clustering SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic Clustering is one of the fundamental and ubiquitous tasks in exploratory data analysis a first intuition about the
Clustering SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic Clustering is one of the fundamental and ubiquitous tasks in exploratory data analysis a first intuition about the
Multivariate Analysis
 Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Using Machine Learning to Optimize Storage Systems
 Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
CS Introduction to Data Mining Instructor: Abdullah Mueen
 CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
Machine Learning for Signal Processing Clustering. Bhiksha Raj Class Oct 2016
 Machine Learning for Signal Processing Clustering Bhiksha Raj Class 11. 13 Oct 2016 1 Statistical Modelling and Latent Structure Much of statistical modelling attempts to identify latent structure in the
Machine Learning for Signal Processing Clustering Bhiksha Raj Class 11. 13 Oct 2016 1 Statistical Modelling and Latent Structure Much of statistical modelling attempts to identify latent structure in the
Chapter 6 Continued: Partitioning Methods
 Chapter 6 Continued: Partitioning Methods Partitioning methods fix the number of clusters k and seek the best possible partition for that k. The goal is to choose the partition which gives the optimal
Chapter 6 Continued: Partitioning Methods Partitioning methods fix the number of clusters k and seek the best possible partition for that k. The goal is to choose the partition which gives the optimal
Clustering Lecture 3: Hierarchical Methods
 Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
STATS306B STATS306B. Clustering. Jonathan Taylor Department of Statistics Stanford University. June 3, 2010
 STATS306B Jonathan Taylor Department of Statistics Stanford University June 3, 2010 Spring 2010 Outline K-means, K-medoids, EM algorithm choosing number of clusters: Gap test hierarchical clustering spectral
STATS306B Jonathan Taylor Department of Statistics Stanford University June 3, 2010 Spring 2010 Outline K-means, K-medoids, EM algorithm choosing number of clusters: Gap test hierarchical clustering spectral
Missing Data Estimation in Microarrays Using Multi-Organism Approach
 Missing Data Estimation in Microarrays Using Multi-Organism Approach Marcel Nassar and Hady Zeineddine Progress Report: Data Mining Course Project, Spring 2008 Prof. Inderjit S. Dhillon April 02, 2008
Missing Data Estimation in Microarrays Using Multi-Organism Approach Marcel Nassar and Hady Zeineddine Progress Report: Data Mining Course Project, Spring 2008 Prof. Inderjit S. Dhillon April 02, 2008
Clustering. Informal goal. General types of clustering. Applications: Clustering in information search and analysis. Example applications in search
 Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
What is Unsupervised Learning?
 Clustering What is Unsupervised Learning? Unlike in supervised learning, in unsupervised learning, there are no labels We simply a search for patterns in the data Examples Clustering Density Estimation
Clustering What is Unsupervised Learning? Unlike in supervised learning, in unsupervised learning, there are no labels We simply a search for patterns in the data Examples Clustering Density Estimation
Giri Narasimhan. CAP 5510: Introduction to Bioinformatics. ECS 254; Phone: x3748
 CAP 5510: Introduction to Bioinformatics Giri Narasimhan ECS 254; Phone: x3748 giri@cis.fiu.edu www.cis.fiu.edu/~giri/teach/bioinfs07.html 3/3/08 CAP5510 1 Gene g Probe 1 Probe 2 Probe N 3/3/08 CAP5510
CAP 5510: Introduction to Bioinformatics Giri Narasimhan ECS 254; Phone: x3748 giri@cis.fiu.edu www.cis.fiu.edu/~giri/teach/bioinfs07.html 3/3/08 CAP5510 1 Gene g Probe 1 Probe 2 Probe N 3/3/08 CAP5510
K-Means Clustering. Sargur Srihari
 K-Means Clustering Sargur srihari@cedar.buffalo.edu 1 Topics in Mixture Models and EM Mixture models K-means Clustering Mixtures of Gaussians Maximum Likelihood EM for Gaussian mistures EM Algorithm Gaussian
K-Means Clustering Sargur srihari@cedar.buffalo.edu 1 Topics in Mixture Models and EM Mixture models K-means Clustering Mixtures of Gaussians Maximum Likelihood EM for Gaussian mistures EM Algorithm Gaussian
Hierarchical Clustering
 Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Behavioral Data Mining. Lecture 18 Clustering
 Behavioral Data Mining Lecture 18 Clustering Outline Why? Cluster quality K-means Spectral clustering Generative Models Rationale Given a set {X i } for i = 1,,n, a clustering is a partition of the X i
Behavioral Data Mining Lecture 18 Clustering Outline Why? Cluster quality K-means Spectral clustering Generative Models Rationale Given a set {X i } for i = 1,,n, a clustering is a partition of the X i
Clustering. Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Lecture 5 Finding meaningful clusters in data. 5.1 Kleinberg s axiomatic framework for clustering
 CSE 291: Unsupervised learning Spring 2008 Lecture 5 Finding meaningful clusters in data So far we ve been in the vector quantization mindset, where we want to approximate a data set by a small number
CSE 291: Unsupervised learning Spring 2008 Lecture 5 Finding meaningful clusters in data So far we ve been in the vector quantization mindset, where we want to approximate a data set by a small number