Human-level Control Through Deep Reinforcement Learning (Deep Q Network) Peidong Wang 11/13/2015
|
|
|
- Hortense Hudson
- 6 years ago
- Views:
Transcription
1 Human-level Control Through Deep Reinforcement Learning (Deep Q Network) Peidong Wang 11/13/2015
2 Content Demo Framework Remarks Experiment Discussion
3 Content Demo Framework Remarks Experiment Discussion
4 Demo
5 Demo
6 Content Demo Framework Remarks Experiment Discussion
7 Framework Figure from: Volodymyr Mnih, Koray Kavukcuoglu, David Silver, et al, Human-level control through deep reinforcement learning [J], Nature, Vol. 518: , February
8 Framework Deep ConvolutionalNeural Networks (CNN) Q (Reinforcement) The network is used to approximate the Q* function. In another word, each dimensionof the output corresponds to the Q value of a certain action.
9 Framework Q Function What is Q? It is also called action-value function in a Markov Decision Process. The expected reward given observation s, action a and a certain strategy π at time t. Q π (s,a) = E[R t s t = s,a t = a] What is Q*? The maximal expected reward given observation s and action a over strategy π at time t. * Q(, sa) = maxe[ R s = sa, = a, π ] π t t t
10 Framework Q Function What is R? The sum of the discounted rewards. t' t γ What is r? Can be assigned manually. In ourapplication, itisthe re-scaled score in a game. R t T = t' = t r t'
11 Framework Bellman Equation Note that the formula of R involvest, which is the time-step when the game terminates. So that calculating Q* directly may not work. The Q* function obeys an important identity known as the Bellman Equation. Q(, sa) = E [ r+γ maxq( s', a') sa, ] * * s' a' In reinforcement learning, the formula above is usually used in an iterative manner. Q + ( sa, ) = E [ r+γ maxq( s', a') sa, ] i 1 s' i a'
12 Framework Parameterization Having the iterativelymannered Q* function, we can learn the optimal strategy for each sequence separately. But we need a general model to incorporatemultiple sequences. So that the Q* function needs to be parameterized by a function approximator. * Q( sa, ; θ) Q ( sa, ) Typically, the function approximator should be linear.deep Q Network, however, uses a deep neural network.
13 Framework Objective Function Now we knowthat DeepQ Network uses CNN as its model and Q values as its output. And the inputpatterns are of course extracted from the game images. If we have the objective function and the parameter update method, we get all we need to train a model. The objectivefunction is the mean-squared error between Q* (in the Bellman Equationform) and current CNN output. L( θ ) = E [(E [ y s, a] Q( s, a; θ )) ] = E [( y Q( s, a; θ )) ] + E [V[ y]] 2 2 i i s, a, r s' i s, a, r, s' i s, a, r s' y = r+γ max Q( s', a'; θ ) a' i
14 Framework Objective Function The objectivefunction is worth seeing for a second time. L( θ ) = E [(E [ y s, a] Q( s, a; θ )) ] = E [( y Q( s, a; θ )) ] + E [V[ y]] 2 2 i i s, a, r s' i s, a, r, s' i s, a, r s' y = r+γ max Q( s', a'; θ ) a' i Note that ina Deep Q Network, the targets dependonthe parameters, which are network weights in this case. This is in contrast with supervised learning, where the targets are fixed beforelearningbegins.
15 Framework Parameter Update Now we get the objective function. How should we update parameters to minimize it? Differentiating the objective function with respect to the parameters. L( θ ) = E [( r+ γ max Q( s ', a '; θ ) Q( s, a ; θ )) Q( s, a ; θ )] θ i i s, a, r, s' a ' i i θi i Rather than computingthe full expectation in the above gradient, it is often more computational expedient to use stochastic gradient descent.
16 Content Demo Framework Remarks Experiment Discussion
17 Remarks Many othertricks are exploited in the practical Deep Q Network. Experience replay Periodicalweights update Error term clip ε-greedy action selection Image preprocessing Frame skipping
18 Remarks Back to the slide about parameterization, Q* function is typically parameterized using a linear approximator in reinforcement learning. Thereasonis that when usinga nonlinearfunctionapproximator like a neural network, the system tends to be unstable or even to diverge. There are several causes. The observationsin a sequence are correlated. Small updates to Q may significantly change the policy and therefore change the data distribution. The outputvaluesand target valuesare correlated.
19 Remarks Experience Replay For each iteration,a tuple < (s t ), a t, r t, (s t+1 )> is observed and stored in set D. At the network weights update step, randomly pick up a tuple in D as the training data. This method breaks the correlations in the sequence of observations.
20 Remarks Periodical Weights Updtate Use a separate networkq& to generate the targets. After every C updates we clone the network Q to the network Q& and use Q& to generate targets for the followingc updates to Q. This method adds a delay between the time an update to Q is made and the time the updateaffects the targets.
21 Content Demo Framework Remarks Experiment Discussion
22 Experiment Experiment Setting Data: Atari 2600 games (210 * 160 color video at 60Hz) Training: A total of 50 million frames (around 38 days of game experience). Testing: Play each game 30 times for up to 5 min each time with different initial random conditionsand an ε-greedy policy with ε = 0.05.
23 Experiment Result Presentation: Compare the performance with human players. The human performance is the average reward achieved from around 20 episodes of each game lasting a maximum of 5 min each, following around 2 h of practice playing each game. A random agent is also proposed. The random agent chooses an action at 10Hz, which is every sixth frame, repeating its last action on intervening frames. 10Hz is about the fastest that a human player can select the fire button.
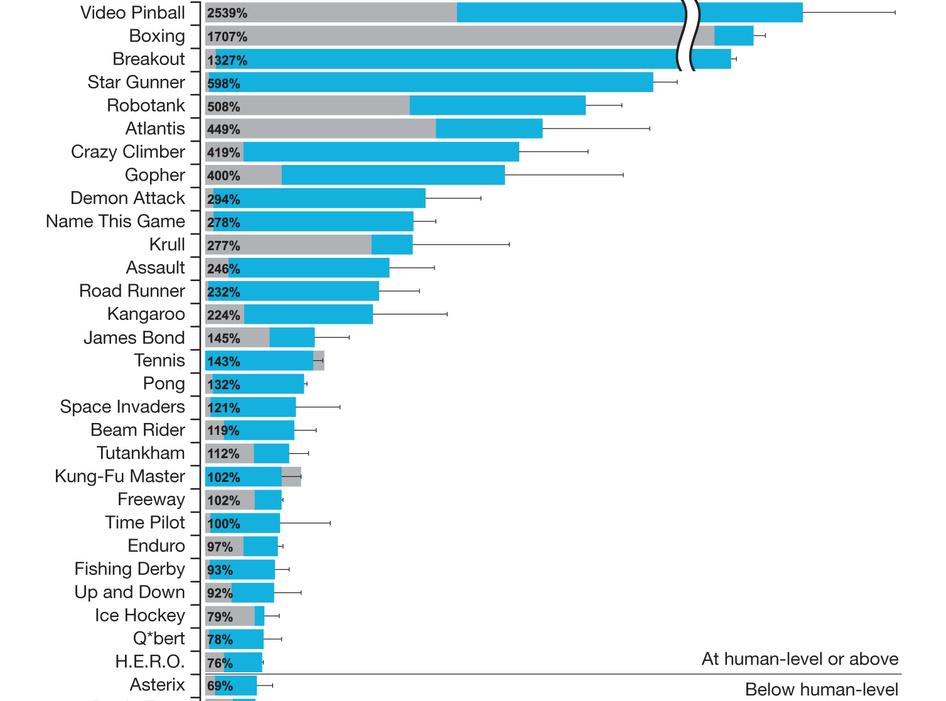
24 Experiment
25 Experiment
26 Experiment The above two figures are from Volodymyr Mnih, Koray Kavukcuoglu, David Silver, et al, Human-level control through deep reinforcement learning [J], Nature, Vol. 518: , February html The values shown in the figure are the normalized performances of Deep Q Network, which is calculated as 100 (DQN score random play score)/(human score random play score).
27 Content Demo Framework Remarks Experiment Discussion
28 Discussion Deep Q Network combinesreinforcementlearning with deep neural networks. So that the model doesn t needfixed labels and is expressive enough to approximate nonlinear Q* function. Deep Q Network shows that by viewing neural networks as tools for function approximating and embeddingthem into otherlearning methods, we may get betterlearning machines. The ideas in Deep Q Network may be used in robust speech recognition, where we can continuously modify our model through interaction with the environment.
29 Appendix 1: Source Program The sourceprogram of Deep Q Network is provided on the website. Hardware settings A Linux server whose operating system uses apt-get command (I used a server which has been installedubuntu). The program can be run both on GPUs and CPUs. Software settings Need to install tools like LuaJIT, Torch 7.0, nngraph, Xitari and AleWrap. Need to download Atari game files. Scripts Changes of scripts are mainly in run_gpu/run_cpu in the root folder and train_agent.lua in the DQN folder.
30 Appendix 2: Reinforcement Learning For a quick start on Reinforcement Learning, you can use materials by David Silver on For a detailed study, you may read ReinforcementLearning: An Introduction by Richard S. Sutton and Andrew G. Barto. The online version is on
31 Thank You!
Introduction to Deep Q-network
 Introduction to Deep Q-network Presenter: Yunshu Du CptS 580 Deep Learning 10/10/2016 Deep Q-network (DQN) Deep Q-network (DQN) An artificial agent for general Atari game playing Learn to master 49 different
Introduction to Deep Q-network Presenter: Yunshu Du CptS 580 Deep Learning 10/10/2016 Deep Q-network (DQN) Deep Q-network (DQN) An artificial agent for general Atari game playing Learn to master 49 different
Slides credited from Dr. David Silver & Hung-Yi Lee
 Slides credited from Dr. David Silver & Hung-Yi Lee Review Reinforcement Learning 2 Reinforcement Learning RL is a general purpose framework for decision making RL is for an agent with the capacity to
Slides credited from Dr. David Silver & Hung-Yi Lee Review Reinforcement Learning 2 Reinforcement Learning RL is a general purpose framework for decision making RL is for an agent with the capacity to
A Brief Introduction to Reinforcement Learning
 A Brief Introduction to Reinforcement Learning Minlie Huang ( ) Dept. of Computer Science, Tsinghua University aihuang@tsinghua.edu.cn 1 http://coai.cs.tsinghua.edu.cn/hml Reinforcement Learning Agent
A Brief Introduction to Reinforcement Learning Minlie Huang ( ) Dept. of Computer Science, Tsinghua University aihuang@tsinghua.edu.cn 1 http://coai.cs.tsinghua.edu.cn/hml Reinforcement Learning Agent
10703 Deep Reinforcement Learning and Control
 10703 Deep Reinforcement Learning and Control Russ Salakhutdinov Machine Learning Department rsalakhu@cs.cmu.edu Policy Gradient I Used Materials Disclaimer: Much of the material and slides for this lecture
10703 Deep Reinforcement Learning and Control Russ Salakhutdinov Machine Learning Department rsalakhu@cs.cmu.edu Policy Gradient I Used Materials Disclaimer: Much of the material and slides for this lecture
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound. Lecture 12: Deep Reinforcement Learning
: Multimodal Learning with Vision, Language and Sound. Lecture 12: Deep Reinforcement Learning") Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 12: Deep Reinforcement Learning Types of Learning Supervised training Learning from the teacher Training data includes
Topics in AI (CPSC 532L): Multimodal Learning with Vision, Language and Sound Lecture 12: Deep Reinforcement Learning Types of Learning Supervised training Learning from the teacher Training data includes
When Network Embedding meets Reinforcement Learning?
 When Network Embedding meets Reinforcement Learning? ---Learning Combinatorial Optimization Problems over Graphs Changjun Fan 1 1. An Introduction to (Deep) Reinforcement Learning 2. How to combine NE
When Network Embedding meets Reinforcement Learning? ---Learning Combinatorial Optimization Problems over Graphs Changjun Fan 1 1. An Introduction to (Deep) Reinforcement Learning 2. How to combine NE
Introduction to Reinforcement Learning. J. Zico Kolter Carnegie Mellon University
 Introduction to Reinforcement Learning J. Zico Kolter Carnegie Mellon University 1 Agent interaction with environment Agent State s Reward r Action a Environment 2 Of course, an oversimplification 3 Review:
Introduction to Reinforcement Learning J. Zico Kolter Carnegie Mellon University 1 Agent interaction with environment Agent State s Reward r Action a Environment 2 Of course, an oversimplification 3 Review:
arxiv: v1 [cs.cv] 2 Sep 2018
![arxiv: v1 [cs.cv] 2 Sep 2018](/thumbs/85/92128474.jpg "arxiv: v1 [cs.cv] 2 Sep 2018") Natural Language Person Search Using Deep Reinforcement Learning Ankit Shah Language Technologies Institute Carnegie Mellon University aps1@andrew.cmu.edu Tyler Vuong Electrical and Computer Engineering
Natural Language Person Search Using Deep Reinforcement Learning Ankit Shah Language Technologies Institute Carnegie Mellon University aps1@andrew.cmu.edu Tyler Vuong Electrical and Computer Engineering
Deep Q-Learning to play Snake
 Deep Q-Learning to play Snake Daniele Grattarola August 1, 2016 Abstract This article describes the application of deep learning and Q-learning to play the famous 90s videogame Snake. I applied deep convolutional
Deep Q-Learning to play Snake Daniele Grattarola August 1, 2016 Abstract This article describes the application of deep learning and Q-learning to play the famous 90s videogame Snake. I applied deep convolutional
CS 234 Winter 2018: Assignment #2
 Due date: 2/10 (Sat) 11:00 PM (23:00) PST These questions require thought, but do not require long answers. Please be as concise as possible. We encourage students to discuss in groups for assignments.
Due date: 2/10 (Sat) 11:00 PM (23:00) PST These questions require thought, but do not require long answers. Please be as concise as possible. We encourage students to discuss in groups for assignments.
Deep Reinforcement Learning
 Deep Reinforcement Learning 1 Outline 1. Overview of Reinforcement Learning 2. Policy Search 3. Policy Gradient and Gradient Estimators 4. Q-prop: Sample Efficient Policy Gradient and an Off-policy Critic
Deep Reinforcement Learning 1 Outline 1. Overview of Reinforcement Learning 2. Policy Search 3. Policy Gradient and Gradient Estimators 4. Q-prop: Sample Efficient Policy Gradient and an Off-policy Critic
Accelerating Reinforcement Learning in Engineering Systems
 Accelerating Reinforcement Learning in Engineering Systems Tham Chen Khong with contributions from Zhou Chongyu and Le Van Duc Department of Electrical & Computer Engineering National University of Singapore
Accelerating Reinforcement Learning in Engineering Systems Tham Chen Khong with contributions from Zhou Chongyu and Le Van Duc Department of Electrical & Computer Engineering National University of Singapore
10703 Deep Reinforcement Learning and Control
 10703 Deep Reinforcement Learning and Control Russ Salakhutdinov Machine Learning Department rsalakhu@cs.cmu.edu Policy Gradient II Used Materials Disclaimer: Much of the material and slides for this lecture
10703 Deep Reinforcement Learning and Control Russ Salakhutdinov Machine Learning Department rsalakhu@cs.cmu.edu Policy Gradient II Used Materials Disclaimer: Much of the material and slides for this lecture
TD LEARNING WITH CONSTRAINED GRADIENTS
 TD LEARNING WITH CONSTRAINED GRADIENTS Anonymous authors Paper under double-blind review ABSTRACT Temporal Difference Learning with function approximation is known to be unstable. Previous work like Sutton
TD LEARNING WITH CONSTRAINED GRADIENTS Anonymous authors Paper under double-blind review ABSTRACT Temporal Difference Learning with function approximation is known to be unstable. Previous work like Sutton
Neural Episodic Control. Alexander pritzel et al (presented by Zura Isakadze)
") Neural Episodic Control Alexander pritzel et al. 2017 (presented by Zura Isakadze) Reinforcement Learning Image from reinforce.io RL Example - Atari Games Observed States Images. Internal state - RAM.
Neural Episodic Control Alexander pritzel et al. 2017 (presented by Zura Isakadze) Reinforcement Learning Image from reinforce.io RL Example - Atari Games Observed States Images. Internal state - RAM.
Knowledge Transfer for Deep Reinforcement Learning with Hierarchical Experience Replay
 Knowledge Transfer for Deep Reinforcement Learning with Hierarchical Experience Replay Haiyan (Helena) Yin, Sinno Jialin Pan School of Computer Science and Engineering Nanyang Technological University
Knowledge Transfer for Deep Reinforcement Learning with Hierarchical Experience Replay Haiyan (Helena) Yin, Sinno Jialin Pan School of Computer Science and Engineering Nanyang Technological University
Convolutional Restricted Boltzmann Machine Features for TD Learning in Go
 ConvolutionalRestrictedBoltzmannMachineFeatures fortdlearningingo ByYanLargmanandPeterPham AdvisedbyHonglakLee 1.Background&Motivation AlthoughrecentadvancesinAIhaveallowed Go playing programs to become
ConvolutionalRestrictedBoltzmannMachineFeatures fortdlearningingo ByYanLargmanandPeterPham AdvisedbyHonglakLee 1.Background&Motivation AlthoughrecentadvancesinAIhaveallowed Go playing programs to become
GUNREAL: GPU-accelerated UNsupervised REinforcement and Auxiliary Learning
 GUNREAL: GPU-accelerated UNsupervised REinforcement and Auxiliary Learning Koichi Shirahata, Youri Coppens, Takuya Fukagai, Yasumoto Tomita, and Atsushi Ike FUJITSU LABORATORIES LTD. March 27, 2018 0 Deep
GUNREAL: GPU-accelerated UNsupervised REinforcement and Auxiliary Learning Koichi Shirahata, Youri Coppens, Takuya Fukagai, Yasumoto Tomita, and Atsushi Ike FUJITSU LABORATORIES LTD. March 27, 2018 0 Deep
Distributed Deep Q-Learning
 Distributed Deep Q-Learning Kevin Chavez 1, Hao Yi Ong 1, and Augustus Hong 1 Abstract We propose a distributed deep learning model to successfully learn control policies directly from highdimensional
Distributed Deep Q-Learning Kevin Chavez 1, Hao Yi Ong 1, and Augustus Hong 1 Abstract We propose a distributed deep learning model to successfully learn control policies directly from highdimensional
Combining Deep Reinforcement Learning and Safety Based Control for Autonomous Driving
 Combining Deep Reinforcement Learning and Safety Based Control for Autonomous Driving Xi Xiong Jianqiang Wang Fang Zhang Keqiang Li State Key Laboratory of Automotive Safety and Energy, Tsinghua University
Combining Deep Reinforcement Learning and Safety Based Control for Autonomous Driving Xi Xiong Jianqiang Wang Fang Zhang Keqiang Li State Key Laboratory of Automotive Safety and Energy, Tsinghua University
arxiv: v2 [cs.lg] 16 May 2017
![arxiv: v2 [cs.lg] 16 May 2017](/thumbs/93/114062849.jpg "arxiv: v2 [cs.lg] 16 May 2017") EFFICIENT PARALLEL METHODS FOR DEEP REIN- FORCEMENT LEARNING Alfredo V. Clemente Department of Computer and Information Science Norwegian University of Science and Technology Trondheim, Norway alfredvc@stud.ntnu.no
EFFICIENT PARALLEL METHODS FOR DEEP REIN- FORCEMENT LEARNING Alfredo V. Clemente Department of Computer and Information Science Norwegian University of Science and Technology Trondheim, Norway alfredvc@stud.ntnu.no
Applications of Reinforcement Learning. Ist künstliche Intelligenz gefährlich?
 Applications of Reinforcement Learning Ist künstliche Intelligenz gefährlich? Table of contents Playing Atari with Deep Reinforcement Learning Playing Super Mario World Stanford University Autonomous Helicopter
Applications of Reinforcement Learning Ist künstliche Intelligenz gefährlich? Table of contents Playing Atari with Deep Reinforcement Learning Playing Super Mario World Stanford University Autonomous Helicopter
Reinforcement Learning (INF11010) Lecture 6: Dynamic Programming for Reinforcement Learning (extended)
 Lecture 6: Dynamic Programming for Reinforcement Learning (extended)") Reinforcement Learning (INF11010) Lecture 6: Dynamic Programming for Reinforcement Learning (extended) Pavlos Andreadis, February 2 nd 2018 1 Markov Decision Processes A finite Markov Decision Process
Reinforcement Learning (INF11010) Lecture 6: Dynamic Programming for Reinforcement Learning (extended) Pavlos Andreadis, February 2 nd 2018 1 Markov Decision Processes A finite Markov Decision Process
ADAPTIVE TILE CODING METHODS FOR THE GENERALIZATION OF VALUE FUNCTIONS IN THE RL STATE SPACE A THESIS SUBMITTED TO THE FACULTY OF THE GRADUATE SCHOOL
 ADAPTIVE TILE CODING METHODS FOR THE GENERALIZATION OF VALUE FUNCTIONS IN THE RL STATE SPACE A THESIS SUBMITTED TO THE FACULTY OF THE GRADUATE SCHOOL OF THE UNIVERSITY OF MINNESOTA BY BHARAT SIGINAM IN
ADAPTIVE TILE CODING METHODS FOR THE GENERALIZATION OF VALUE FUNCTIONS IN THE RL STATE SPACE A THESIS SUBMITTED TO THE FACULTY OF THE GRADUATE SCHOOL OF THE UNIVERSITY OF MINNESOTA BY BHARAT SIGINAM IN
arxiv: v1 [cs.ai] 18 Apr 2017
![arxiv: v1 [cs.ai] 18 Apr 2017](/thumbs/90/102214606.jpg "arxiv: v1 [cs.ai] 18 Apr 2017") Investigating Recurrence and Eligibility Traces in Deep Q-Networks arxiv:174.5495v1 [cs.ai] 18 Apr 217 Jean Harb School of Computer Science McGill University Montreal, Canada jharb@cs.mcgill.ca Abstract
Investigating Recurrence and Eligibility Traces in Deep Q-Networks arxiv:174.5495v1 [cs.ai] 18 Apr 217 Jean Harb School of Computer Science McGill University Montreal, Canada jharb@cs.mcgill.ca Abstract
Deep Reinforcement Learning for Pellet Eating in Agar.io
 Deep Reinforcement Learning for Pellet Eating in Agar.io Nil Stolt Ansó 1, Anton O. Wiehe 1, Madalina M. Drugan 2 and Marco A. Wiering 1 1 Bernoulli Institute, Department of Artificial Intelligence, University
Deep Reinforcement Learning for Pellet Eating in Agar.io Nil Stolt Ansó 1, Anton O. Wiehe 1, Madalina M. Drugan 2 and Marco A. Wiering 1 1 Bernoulli Institute, Department of Artificial Intelligence, University
Reinforcement Learning for Traffic Optimization
 Matt Stevens Christopher Yeh MSLF@STANFORD.EDU CHRISYEH@STANFORD.EDU Abstract In this paper we apply reinforcement learning techniques to traffic light policies with the aim of increasing traffic flow
Matt Stevens Christopher Yeh MSLF@STANFORD.EDU CHRISYEH@STANFORD.EDU Abstract In this paper we apply reinforcement learning techniques to traffic light policies with the aim of increasing traffic flow
Reinforcement Learning (2)
") Reinforcement Learning (2) Bruno Bouzy 1 october 2013 This document is the second part of the «Reinforcement Learning» chapter of the «Agent oriented learning» teaching unit of the Master MI computer course.
Reinforcement Learning (2) Bruno Bouzy 1 october 2013 This document is the second part of the «Reinforcement Learning» chapter of the «Agent oriented learning» teaching unit of the Master MI computer course.
Neural Networks and Tree Search
 Mastering the Game of Go With Deep Neural Networks and Tree Search Nabiha Asghar 27 th May 2016 AlphaGo by Google DeepMind Go: ancient Chinese board game. Simple rules, but far more complicated than Chess
Mastering the Game of Go With Deep Neural Networks and Tree Search Nabiha Asghar 27 th May 2016 AlphaGo by Google DeepMind Go: ancient Chinese board game. Simple rules, but far more complicated than Chess
Simulated Transfer Learning Through Deep Reinforcement Learning
 Through Deep Reinforcement Learning William Doan Griffin Jarmin WILLRD9@VT.EDU GAJARMIN@VT.EDU Abstract This paper encapsulates the use reinforcement learning on raw images provided by a simulation to
Through Deep Reinforcement Learning William Doan Griffin Jarmin WILLRD9@VT.EDU GAJARMIN@VT.EDU Abstract This paper encapsulates the use reinforcement learning on raw images provided by a simulation to
Adaptive Building of Decision Trees by Reinforcement Learning
 Proceedings of the 7th WSEAS International Conference on Applied Informatics and Communications, Athens, Greece, August 24-26, 2007 34 Adaptive Building of Decision Trees by Reinforcement Learning MIRCEA
Proceedings of the 7th WSEAS International Conference on Applied Informatics and Communications, Athens, Greece, August 24-26, 2007 34 Adaptive Building of Decision Trees by Reinforcement Learning MIRCEA
CME 213 SPRING Eric Darve
 CME 213 SPRING 2017 Eric Darve MPI SUMMARY Point-to-point and collective communications Process mapping: across nodes and within a node (socket, NUMA domain, core, hardware thread) MPI buffers and deadlocks
CME 213 SPRING 2017 Eric Darve MPI SUMMARY Point-to-point and collective communications Process mapping: across nodes and within a node (socket, NUMA domain, core, hardware thread) MPI buffers and deadlocks
arxiv: v1 [cs.db] 22 Mar 2018
![arxiv: v1 [cs.db] 22 Mar 2018](/thumbs/84/89504805.jpg "arxiv: v1 [cs.db] 22 Mar 2018") Learning State Representations for Query Optimization with Deep Reinforcement Learning Jennifer Ortiz, Magdalena Balazinska, Johannes Gehrke, S. Sathiya Keerthi + University of Washington, Microsoft, Criteo
Learning State Representations for Query Optimization with Deep Reinforcement Learning Jennifer Ortiz, Magdalena Balazinska, Johannes Gehrke, S. Sathiya Keerthi + University of Washington, Microsoft, Criteo
Deep Reinforcement Learning in Large Discrete Action Spaces
 Gabriel Dulac-Arnold*, Richard Evans*, Hado van Hasselt, Peter Sunehag, Timothy Lillicrap, Jonathan Hunt, Timothy Mann, Theophane Weber, Thomas Degris, Ben Coppin DULACARNOLD@GOOGLE.COM Google DeepMind
Gabriel Dulac-Arnold*, Richard Evans*, Hado van Hasselt, Peter Sunehag, Timothy Lillicrap, Jonathan Hunt, Timothy Mann, Theophane Weber, Thomas Degris, Ben Coppin DULACARNOLD@GOOGLE.COM Google DeepMind
arxiv: v1 [stat.ml] 1 Sep 2017
![arxiv: v1 [stat.ml] 1 Sep 2017](/thumbs/72/67041160.jpg "arxiv: v1 [stat.ml] 1 Sep 2017") Mean Actor Critic Kavosh Asadi 1 Cameron Allen 1 Melrose Roderick 1 Abdel-rahman Mohamed 2 George Konidaris 1 Michael Littman 1 arxiv:1709.00503v1 [stat.ml] 1 Sep 2017 Brown University 1 Amazon 2 Providence,
Mean Actor Critic Kavosh Asadi 1 Cameron Allen 1 Melrose Roderick 1 Abdel-rahman Mohamed 2 George Konidaris 1 Michael Littman 1 arxiv:1709.00503v1 [stat.ml] 1 Sep 2017 Brown University 1 Amazon 2 Providence,
Pascal De Beck-Courcelle. Master in Applied Science. Electrical and Computer Engineering
 Study of Multiple Multiagent Reinforcement Learning Algorithms in Grid Games by Pascal De Beck-Courcelle A thesis submitted to the Faculty of Graduate and Postdoctoral Affairs in partial fulfillment of
Study of Multiple Multiagent Reinforcement Learning Algorithms in Grid Games by Pascal De Beck-Courcelle A thesis submitted to the Faculty of Graduate and Postdoctoral Affairs in partial fulfillment of
Planning and Control: Markov Decision Processes
 CSE-571 AI-based Mobile Robotics Planning and Control: Markov Decision Processes Planning Static vs. Dynamic Predictable vs. Unpredictable Fully vs. Partially Observable Perfect vs. Noisy Environment What
CSE-571 AI-based Mobile Robotics Planning and Control: Markov Decision Processes Planning Static vs. Dynamic Predictable vs. Unpredictable Fully vs. Partially Observable Perfect vs. Noisy Environment What
Natural Actor-Critic. Authors: Jan Peters and Stefan Schaal Neurocomputing, Cognitive robotics 2008/2009 Wouter Klijn
 Natural Actor-Critic Authors: Jan Peters and Stefan Schaal Neurocomputing, 2008 Cognitive robotics 2008/2009 Wouter Klijn Content Content / Introduction Actor-Critic Natural gradient Applications Conclusion
Natural Actor-Critic Authors: Jan Peters and Stefan Schaal Neurocomputing, 2008 Cognitive robotics 2008/2009 Wouter Klijn Content Content / Introduction Actor-Critic Natural gradient Applications Conclusion
Markov Decision Processes. (Slides from Mausam)
") Markov Decision Processes (Slides from Mausam) Machine Learning Operations Research Graph Theory Control Theory Markov Decision Process Economics Robotics Artificial Intelligence Neuroscience /Psychology
Markov Decision Processes (Slides from Mausam) Machine Learning Operations Research Graph Theory Control Theory Markov Decision Process Economics Robotics Artificial Intelligence Neuroscience /Psychology
Markov Decision Processes and Reinforcement Learning
 Lecture 14 and Marco Chiarandini Department of Mathematics & Computer Science University of Southern Denmark Slides by Stuart Russell and Peter Norvig Course Overview Introduction Artificial Intelligence
Lecture 14 and Marco Chiarandini Department of Mathematics & Computer Science University of Southern Denmark Slides by Stuart Russell and Peter Norvig Course Overview Introduction Artificial Intelligence
Apprenticeship Learning for Reinforcement Learning. with application to RC helicopter flight Ritwik Anand, Nick Haliday, Audrey Huang
 Apprenticeship Learning for Reinforcement Learning with application to RC helicopter flight Ritwik Anand, Nick Haliday, Audrey Huang Table of Contents Introduction Theory Autonomous helicopter control
Apprenticeship Learning for Reinforcement Learning with application to RC helicopter flight Ritwik Anand, Nick Haliday, Audrey Huang Table of Contents Introduction Theory Autonomous helicopter control
Representations and Control in Atari Games Using Reinforcement Learning
 Representations and Control in Atari Games Using Reinforcement Learning by Yitao Liang Class of 2016 A thesis submitted in partial fulfillment of the requirements for the honor in Computer Science May
Representations and Control in Atari Games Using Reinforcement Learning by Yitao Liang Class of 2016 A thesis submitted in partial fulfillment of the requirements for the honor in Computer Science May
10-701/15-781, Fall 2006, Final
 -7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
-7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
Reinforcement Learning: A brief introduction. Mihaela van der Schaar
 Reinforcement Learning: A brief introduction Mihaela van der Schaar Outline Optimal Decisions & Optimal Forecasts Markov Decision Processes (MDPs) States, actions, rewards and value functions Dynamic Programming
Reinforcement Learning: A brief introduction Mihaela van der Schaar Outline Optimal Decisions & Optimal Forecasts Markov Decision Processes (MDPs) States, actions, rewards and value functions Dynamic Programming
Unsupervised Learning. CS 3793/5233 Artificial Intelligence Unsupervised Learning 1
 Unsupervised CS 3793/5233 Artificial Intelligence Unsupervised 1 EM k-means Procedure Data Random Assignment Assign 1 Assign 2 Soft k-means In clustering, the target feature is not given. Goal: Construct
Unsupervised CS 3793/5233 Artificial Intelligence Unsupervised 1 EM k-means Procedure Data Random Assignment Assign 1 Assign 2 Soft k-means In clustering, the target feature is not given. Goal: Construct
arxiv: v1 [cs.ai] 18 May 2018
![arxiv: v1 [cs.ai] 18 May 2018](/thumbs/94/120786151.jpg "arxiv: v1 [cs.ai] 18 May 2018") Hierarchical Reinforcement Learning with Deep Nested Agents arxiv:1805.07008v1 [cs.ai] 18 May 2018 Marc W. Brittain Department of Aerospace Engineering Iowa State University Ames, IA 50011 mwb@iastate.edu
Hierarchical Reinforcement Learning with Deep Nested Agents arxiv:1805.07008v1 [cs.ai] 18 May 2018 Marc W. Brittain Department of Aerospace Engineering Iowa State University Ames, IA 50011 mwb@iastate.edu
Machine Learning Techniques at the core of AlphaGo success
 Machine Learning Techniques at the core of AlphaGo success Stéphane Sénécal Orange Labs stephane.senecal@orange.com Paris Machine Learning Applications Group Meetup, 14/09/2016 1 / 42 Some facts... (1/3)
Machine Learning Techniques at the core of AlphaGo success Stéphane Sénécal Orange Labs stephane.senecal@orange.com Paris Machine Learning Applications Group Meetup, 14/09/2016 1 / 42 Some facts... (1/3)
arxiv: v1 [cs.lg] 6 Nov 2018
![arxiv: v1 [cs.lg] 6 Nov 2018](/thumbs/89/100747523.jpg "arxiv: v1 [cs.lg] 6 Nov 2018") Quasi-Newton Optimization in Deep Q-Learning for Playing ATARI Games Jacob Rafati 1 and Roummel F. Marcia 2 {jrafatiheravi,rmarcia}@ucmerced.edu 1 Electrical Engineering and Computer Science, 2 Department
Quasi-Newton Optimization in Deep Q-Learning for Playing ATARI Games Jacob Rafati 1 and Roummel F. Marcia 2 {jrafatiheravi,rmarcia}@ucmerced.edu 1 Electrical Engineering and Computer Science, 2 Department
CS221 Final Project: Learning Atari
 CS221 Final Project: Learning Atari David Hershey, Rush Moody, Blake Wulfe {dshersh, rmoody, wulfebw}@stanford December 11, 2015 1 Introduction 1.1 Task Definition and Atari Learning Environment Our goal
CS221 Final Project: Learning Atari David Hershey, Rush Moody, Blake Wulfe {dshersh, rmoody, wulfebw}@stanford December 11, 2015 1 Introduction 1.1 Task Definition and Atari Learning Environment Our goal
Algorithms for Solving RL: Temporal Difference Learning (TD) Reinforcement Learning Lecture 10
 Reinforcement Learning Lecture 10") Algorithms for Solving RL: Temporal Difference Learning (TD) 1 Reinforcement Learning Lecture 10 Gillian Hayes 8th February 2007 Incremental Monte Carlo Algorithm TD Prediction TD vs MC vs DP TD for control:
Algorithms for Solving RL: Temporal Difference Learning (TD) 1 Reinforcement Learning Lecture 10 Gillian Hayes 8th February 2007 Incremental Monte Carlo Algorithm TD Prediction TD vs MC vs DP TD for control:
Monte Carlo Tree Search PAH 2015
 Monte Carlo Tree Search PAH 2015 MCTS animation and RAVE slides by Michèle Sebag and Romaric Gaudel Markov Decision Processes (MDPs) main formal model Π = S, A, D, T, R states finite set of states of the
Monte Carlo Tree Search PAH 2015 MCTS animation and RAVE slides by Michèle Sebag and Romaric Gaudel Markov Decision Processes (MDPs) main formal model Π = S, A, D, T, R states finite set of states of the
Large Scale Distributed Deep Networks
 Large Scale Distributed Deep Networks Yifu Huang School of Computer Science, Fudan University huangyifu@fudan.edu.cn COMP630030 Data Intensive Computing Report, 2013 Yifu Huang (FDU CS) COMP630030 Report
Large Scale Distributed Deep Networks Yifu Huang School of Computer Science, Fudan University huangyifu@fudan.edu.cn COMP630030 Data Intensive Computing Report, 2013 Yifu Huang (FDU CS) COMP630030 Report
arxiv: v1 [cs.lg] 15 Jun 2016
![arxiv: v1 [cs.lg] 15 Jun 2016](/thumbs/90/104317325.jpg "arxiv: v1 [cs.lg] 15 Jun 2016") Deep Reinforcement Learning with Macro-Actions arxiv:1606.04615v1 [cs.lg] 15 Jun 2016 Ishan P. Durugkar University of Massachusetts, Amherst, MA 01002 idurugkar@cs.umass.edu Stefan Dernbach University
Deep Reinforcement Learning with Macro-Actions arxiv:1606.04615v1 [cs.lg] 15 Jun 2016 Ishan P. Durugkar University of Massachusetts, Amherst, MA 01002 idurugkar@cs.umass.edu Stefan Dernbach University
Generalized Inverse Reinforcement Learning
 Generalized Inverse Reinforcement Learning James MacGlashan Cogitai, Inc. james@cogitai.com Michael L. Littman mlittman@cs.brown.edu Nakul Gopalan ngopalan@cs.brown.edu Amy Greenwald amy@cs.brown.edu Abstract
Generalized Inverse Reinforcement Learning James MacGlashan Cogitai, Inc. james@cogitai.com Michael L. Littman mlittman@cs.brown.edu Nakul Gopalan ngopalan@cs.brown.edu Amy Greenwald amy@cs.brown.edu Abstract
4.12 Generalization. In back-propagation learning, as many training examples as possible are typically used.
 1 4.12 Generalization In back-propagation learning, as many training examples as possible are typically used. It is hoped that the network so designed generalizes well. A network generalizes well when
1 4.12 Generalization In back-propagation learning, as many training examples as possible are typically used. It is hoped that the network so designed generalizes well. A network generalizes well when
A Series of Lectures on Approximate Dynamic Programming
 A Series of Lectures on Approximate Dynamic Programming Dimitri P. Bertsekas Laboratory for Information and Decision Systems Massachusetts Institute of Technology Lucca, Italy June 2017 Bertsekas (M.I.T.)
A Series of Lectures on Approximate Dynamic Programming Dimitri P. Bertsekas Laboratory for Information and Decision Systems Massachusetts Institute of Technology Lucca, Italy June 2017 Bertsekas (M.I.T.)
SEMANTIC COMPUTING. Lecture 8: Introduction to Deep Learning. TU Dresden, 7 December Dagmar Gromann International Center For Computational Logic
 SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
Recurrent Neural Networks. Nand Kishore, Audrey Huang, Rohan Batra
 Recurrent Neural Networks Nand Kishore, Audrey Huang, Rohan Batra Roadmap Issues Motivation 1 Application 1: Sequence Level Training 2 Basic Structure 3 4 Variations 5 Application 3: Image Classification
Recurrent Neural Networks Nand Kishore, Audrey Huang, Rohan Batra Roadmap Issues Motivation 1 Application 1: Sequence Level Training 2 Basic Structure 3 4 Variations 5 Application 3: Image Classification
Deep-Reinforcement Learning Multiple Access for Heterogeneous Wireless Networks
 Deep-Reinforcement Learning Multiple Access for Heterogeneous Wireless Networks Yiding Yu, Taotao Wang, Soung Chang Liew arxiv:1712.00162v1 [cs.ni] 1 Dec 2017 Abstract This paper investigates the use of
Deep-Reinforcement Learning Multiple Access for Heterogeneous Wireless Networks Yiding Yu, Taotao Wang, Soung Chang Liew arxiv:1712.00162v1 [cs.ni] 1 Dec 2017 Abstract This paper investigates the use of
Applying the Episodic Natural Actor-Critic Architecture to Motor Primitive Learning
 Applying the Episodic Natural Actor-Critic Architecture to Motor Primitive Learning Jan Peters 1, Stefan Schaal 1 University of Southern California, Los Angeles CA 90089, USA Abstract. In this paper, we
Applying the Episodic Natural Actor-Critic Architecture to Motor Primitive Learning Jan Peters 1, Stefan Schaal 1 University of Southern California, Los Angeles CA 90089, USA Abstract. In this paper, we
Common Subspace Transfer for Reinforcement Learning Tasks
 Common Subspace Transfer for Reinforcement Learning Tasks ABSTRACT Haitham Bou Ammar Institute of Applied Research Ravensburg-Weingarten University of Applied Sciences, Germany bouammha@hs-weingarten.de
Common Subspace Transfer for Reinforcement Learning Tasks ABSTRACT Haitham Bou Ammar Institute of Applied Research Ravensburg-Weingarten University of Applied Sciences, Germany bouammha@hs-weingarten.de
Performance Comparison of Sarsa(λ) and Watkin s Q(λ) Algorithms
 and Watkin s Q(λ) Algorithms") Performance Comparison of Sarsa(λ) and Watkin s Q(λ) Algorithms Karan M. Gupta Department of Computer Science Texas Tech University Lubbock, TX 7949-314 gupta@cs.ttu.edu Abstract This paper presents a
Performance Comparison of Sarsa(λ) and Watkin s Q(λ) Algorithms Karan M. Gupta Department of Computer Science Texas Tech University Lubbock, TX 7949-314 gupta@cs.ttu.edu Abstract This paper presents a
Reinforcement Learning in Discrete and Continuous Domains Applied to Ship Trajectory Generation
 POLISH MARITIME RESEARCH Special Issue S1 (74) 2012 Vol 19; pp. 31-36 10.2478/v10012-012-0020-8 Reinforcement Learning in Discrete and Continuous Domains Applied to Ship Trajectory Generation Andrzej Rak,
POLISH MARITIME RESEARCH Special Issue S1 (74) 2012 Vol 19; pp. 31-36 10.2478/v10012-012-0020-8 Reinforcement Learning in Discrete and Continuous Domains Applied to Ship Trajectory Generation Andrzej Rak,
Deep Reinforcement Learning for Urban Traffic Light Control
 Deep Reinforcement Learning for Urban Traffic Light Control Noé Casas Department of Artificial Intelligence Universidad Nacional de Educación a Distancia This dissertation is submitted for the degree of
Deep Reinforcement Learning for Urban Traffic Light Control Noé Casas Department of Artificial Intelligence Universidad Nacional de Educación a Distancia This dissertation is submitted for the degree of
Knowledge-Defined Networking: Towards Self-Driving Networks
 Knowledge-Defined Networking: Towards Self-Driving Networks Albert Cabellos (UPC/BarcelonaTech, Spain) albert.cabellos@gmail.com 2nd IFIP/IEEE International Workshop on Analytics for Network and Service
Knowledge-Defined Networking: Towards Self-Driving Networks Albert Cabellos (UPC/BarcelonaTech, Spain) albert.cabellos@gmail.com 2nd IFIP/IEEE International Workshop on Analytics for Network and Service
CSE 547: Machine Learning for Big Data Spring Problem Set 2. Please read the homework submission policies.
 CSE 547: Machine Learning for Big Data Spring 2019 Problem Set 2 Please read the homework submission policies. 1 Principal Component Analysis and Reconstruction (25 points) Let s do PCA and reconstruct
CSE 547: Machine Learning for Big Data Spring 2019 Problem Set 2 Please read the homework submission policies. 1 Principal Component Analysis and Reconstruction (25 points) Let s do PCA and reconstruct
Residual Advantage Learning Applied to a Differential Game
 Presented at the International Conference on Neural Networks (ICNN 96), Washington DC, 2-6 June 1996. Residual Advantage Learning Applied to a Differential Game Mance E. Harmon Wright Laboratory WL/AAAT
Presented at the International Conference on Neural Networks (ICNN 96), Washington DC, 2-6 June 1996. Residual Advantage Learning Applied to a Differential Game Mance E. Harmon Wright Laboratory WL/AAAT
GPU-BASED A3C FOR DEEP REINFORCEMENT LEARNING
 GPU-BASED A3C FOR DEEP REINFORCEMENT LEARNING M. Babaeizadeh,, I.Frosio, S.Tyree, J. Clemons, J.Kautz University of Illinois at Urbana-Champaign, USA NVIDIA, USA An ICLR 2017 paper A github project GPU-BASED
GPU-BASED A3C FOR DEEP REINFORCEMENT LEARNING M. Babaeizadeh,, I.Frosio, S.Tyree, J. Clemons, J.Kautz University of Illinois at Urbana-Champaign, USA NVIDIA, USA An ICLR 2017 paper A github project GPU-BASED
Deterministic Policy Gradient Based Robotic Path Planning with Continuous Action Spaces
 Deterministic Policy Gradient Based Robotic Path Planning with Continuous Action Spaces Somdyuti Paul and Lovekesh Vig TCS Research, New Delhi, India Email : { somdyuti.p2 lovekesh.vig}@tcs.com Abstract
Deterministic Policy Gradient Based Robotic Path Planning with Continuous Action Spaces Somdyuti Paul and Lovekesh Vig TCS Research, New Delhi, India Email : { somdyuti.p2 lovekesh.vig}@tcs.com Abstract
Neural Network Neurons
 Neural Networks Neural Network Neurons 1 Receives n inputs (plus a bias term) Multiplies each input by its weight Applies activation function to the sum of results Outputs result Activation Functions Given
Neural Networks Neural Network Neurons 1 Receives n inputs (plus a bias term) Multiplies each input by its weight Applies activation function to the sum of results Outputs result Activation Functions Given
Markov Decision Processes (MDPs) (cont.)
 (cont.)") Markov Decision Processes (MDPs) (cont.) Machine Learning 070/578 Carlos Guestrin Carnegie Mellon University November 29 th, 2007 Markov Decision Process (MDP) Representation State space: Joint state x
Markov Decision Processes (MDPs) (cont.) Machine Learning 070/578 Carlos Guestrin Carnegie Mellon University November 29 th, 2007 Markov Decision Process (MDP) Representation State space: Joint state x
Hierarchical Reinforcement Learning for Robot Navigation
 Hierarchical Reinforcement Learning for Robot Navigation B. Bischoff 1, D. Nguyen-Tuong 1,I-H.Lee 1, F. Streichert 1 and A. Knoll 2 1- Robert Bosch GmbH - Corporate Research Robert-Bosch-Str. 2, 71701
Hierarchical Reinforcement Learning for Robot Navigation B. Bischoff 1, D. Nguyen-Tuong 1,I-H.Lee 1, F. Streichert 1 and A. Knoll 2 1- Robert Bosch GmbH - Corporate Research Robert-Bosch-Str. 2, 71701
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 22, 2016 Course Information Website: http://www.stat.ucdavis.edu/~chohsieh/teaching/ ECS289G_Fall2016/main.html My office: Mathematical Sciences
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 22, 2016 Course Information Website: http://www.stat.ucdavis.edu/~chohsieh/teaching/ ECS289G_Fall2016/main.html My office: Mathematical Sciences
arxiv: v2 [cs.ai] 21 Sep 2017
![arxiv: v2 [cs.ai] 21 Sep 2017](/thumbs/82/86250689.jpg "arxiv: v2 [cs.ai] 21 Sep 2017") Learning to Drive using Inverse Reinforcement Learning and Deep Q-Networks arxiv:161203653v2 [csai] 21 Sep 2017 Sahand Sharifzadeh 1 Ioannis Chiotellis 1 Rudolph Triebel 1,2 Daniel Cremers 1 1 Department
Learning to Drive using Inverse Reinforcement Learning and Deep Q-Networks arxiv:161203653v2 [csai] 21 Sep 2017 Sahand Sharifzadeh 1 Ioannis Chiotellis 1 Rudolph Triebel 1,2 Daniel Cremers 1 1 Department
Deep Learning with Tensorflow AlexNet
 Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
CS 687 Jana Kosecka. Reinforcement Learning Continuous State MDP s Value Function approximation
 CS 687 Jana Kosecka Reinforcement Learning Continuous State MDP s Value Function approximation Markov Decision Process - Review Formal definition 4-tuple (S, A, T, R) Set of states S - finite Set of actions
CS 687 Jana Kosecka Reinforcement Learning Continuous State MDP s Value Function approximation Markov Decision Process - Review Formal definition 4-tuple (S, A, T, R) Set of states S - finite Set of actions
An Artificial Agent for Anatomical Landmark Detection in Medical Images
 An Artificial Agent for Anatomical Landmark Detection in Medical Images Florin C Ghesu 1,2, Bogdan Georgescu 1, Tommaso Mansi 1, Dominik Neumann 1, Joachim Hornegger 2, and Dorin Comaniciu 1 1 Medical
An Artificial Agent for Anatomical Landmark Detection in Medical Images Florin C Ghesu 1,2, Bogdan Georgescu 1, Tommaso Mansi 1, Dominik Neumann 1, Joachim Hornegger 2, and Dorin Comaniciu 1 1 Medical
Learning Combinatorial Optimization Algorithms over Graphs
 Learning Combinatorial Optimization Algorithms over Graphs arxiv:704.0665v [cs.lg] 5 Apr 207 Hanjun Dai, Elias B. Khalil, Yuyu Zhang, Bistra Dilkina, Le Song College of Computing, Georgia Institute of
Learning Combinatorial Optimization Algorithms over Graphs arxiv:704.0665v [cs.lg] 5 Apr 207 Hanjun Dai, Elias B. Khalil, Yuyu Zhang, Bistra Dilkina, Le Song College of Computing, Georgia Institute of
Value Iteration. Reinforcement Learning: Introduction to Machine Learning. Matt Gormley Lecture 23 Apr. 10, 2019
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Reinforcement Learning: Value Iteration Matt Gormley Lecture 23 Apr. 10, 2019 1
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Reinforcement Learning: Value Iteration Matt Gormley Lecture 23 Apr. 10, 2019 1
arxiv: v1 [cs.lg] 7 Dec 2018
![arxiv: v1 [cs.lg] 7 Dec 2018](/thumbs/93/112089949.jpg "arxiv: v1 [cs.lg] 7 Dec 2018") A new multilayer optical film optimal method based on deep q-learning A.Q. JIANG, 1,* OSAMU YOSHIE, 1 AND L.Y. CHEN 2 1 Graduate school of IPS, Waseda University, Fukuoka 8080135, Japan 2 Department of
A new multilayer optical film optimal method based on deep q-learning A.Q. JIANG, 1,* OSAMU YOSHIE, 1 AND L.Y. CHEN 2 1 Graduate school of IPS, Waseda University, Fukuoka 8080135, Japan 2 Department of
Deep Reinforcement Learning for Active Breast Lesion Detection from DCE-MRI
 Deep Reinforcement Learning for Active Breast Lesion Detection from DCE-MRI Gabriel Maicas Gustavo Carneiro Andrew P. Bradley Jacinto C. Nascimento Ian Reid ACVT, School of Computer Science, The University
Deep Reinforcement Learning for Active Breast Lesion Detection from DCE-MRI Gabriel Maicas Gustavo Carneiro Andrew P. Bradley Jacinto C. Nascimento Ian Reid ACVT, School of Computer Science, The University
Gradient Descent. Wed Sept 20th, James McInenrey Adapted from slides by Francisco J. R. Ruiz
 Gradient Descent Wed Sept 20th, 2017 James McInenrey Adapted from slides by Francisco J. R. Ruiz Housekeeping A few clarifications of and adjustments to the course schedule: No more breaks at the midpoint
Gradient Descent Wed Sept 20th, 2017 James McInenrey Adapted from slides by Francisco J. R. Ruiz Housekeeping A few clarifications of and adjustments to the course schedule: No more breaks at the midpoint
Deep Learning of Visual Control Policies
 ESANN proceedings, European Symposium on Artificial Neural Networks - Computational Intelligence and Machine Learning. Bruges (Belgium), 8-3 April, d-side publi., ISBN -9337--. Deep Learning of Visual
ESANN proceedings, European Symposium on Artificial Neural Networks - Computational Intelligence and Machine Learning. Bruges (Belgium), 8-3 April, d-side publi., ISBN -9337--. Deep Learning of Visual
Problem characteristics. Dynamic Optimization. Examples. Policies vs. Trajectories. Planning using dynamic optimization. Dynamic Optimization Issues
 Problem characteristics Planning using dynamic optimization Chris Atkeson 2004 Want optimal plan, not just feasible plan We will minimize a cost function C(execution). Some examples: C() = c T (x T ) +
Problem characteristics Planning using dynamic optimization Chris Atkeson 2004 Want optimal plan, not just feasible plan We will minimize a cost function C(execution). Some examples: C() = c T (x T ) +
Using Reinforcement Learning to Optimize Storage Decisions Ravi Khadiwala Cleversafe
 Using Reinforcement Learning to Optimize Storage Decisions Ravi Khadiwala Cleversafe Topics What is Reinforcement Learning? Exploration vs. Exploitation The Multi-armed Bandit Optimizing read locations
Using Reinforcement Learning to Optimize Storage Decisions Ravi Khadiwala Cleversafe Topics What is Reinforcement Learning? Exploration vs. Exploitation The Multi-armed Bandit Optimizing read locations
Lightweight Multi Car Dynamic Simulator for Reinforcement Learning
 1 Lightweight Multi Car Dynamic Simulator for Reinforcement Learning Abhijit Majumdar, Patrick Benavidez and Mo Jamshidi Department of Electrical and Computer Engineering The University of Texas at San
1 Lightweight Multi Car Dynamic Simulator for Reinforcement Learning Abhijit Majumdar, Patrick Benavidez and Mo Jamshidi Department of Electrical and Computer Engineering The University of Texas at San
Deep Learning and Its Applications
 Convolutional Neural Network and Its Application in Image Recognition Oct 28, 2016 Outline 1 A Motivating Example 2 The Convolutional Neural Network (CNN) Model 3 Training the CNN Model 4 Issues and Recent
Convolutional Neural Network and Its Application in Image Recognition Oct 28, 2016 Outline 1 A Motivating Example 2 The Convolutional Neural Network (CNN) Model 3 Training the CNN Model 4 Issues and Recent
Boosted Deep Q-Network
 Boosted Deep Q-Network Boosted Deep Q-Network Bachelor-Thesis von Jeremy Eric Tschirner aus Kassel Tag der Einreichung: 1. Gutachten: Prof. Dr. Jan Peters 2. Gutachten: M.Sc. Samuele Tosatto Boosted Deep
Boosted Deep Q-Network Boosted Deep Q-Network Bachelor-Thesis von Jeremy Eric Tschirner aus Kassel Tag der Einreichung: 1. Gutachten: Prof. Dr. Jan Peters 2. Gutachten: M.Sc. Samuele Tosatto Boosted Deep
Machine Learning in WAN Research
 Machine Learning in WAN Research Mariam Kiran mkiran@es.net Energy Sciences Network (ESnet) Lawrence Berkeley National Lab Oct 2017 Presented at Internet2 TechEx 2017 Outline ML in general ML in network
Machine Learning in WAN Research Mariam Kiran mkiran@es.net Energy Sciences Network (ESnet) Lawrence Berkeley National Lab Oct 2017 Presented at Internet2 TechEx 2017 Outline ML in general ML in network
Reinforcement Learning for Appearance Based Visual Servoing in Robotic Manipulation
 Reinforcement Learning for Appearance Based Visual Servoing in Robotic Manipulation UMAR KHAN, LIAQUAT ALI KHAN, S. ZAHID HUSSAIN Department of Mechatronics Engineering AIR University E-9, Islamabad PAKISTAN
Reinforcement Learning for Appearance Based Visual Servoing in Robotic Manipulation UMAR KHAN, LIAQUAT ALI KHAN, S. ZAHID HUSSAIN Department of Mechatronics Engineering AIR University E-9, Islamabad PAKISTAN
Cross-modal Bidirectional Translation via Reinforcement Learning
 Cross-modal Bidirectional Translation via Reinforcement Learning Jinwei Qi and Yuxin Peng Institute of Computer Science and Technology, Peking University, Beijing 100871, China pengyuxin@pku.edu.cn Abstract
Cross-modal Bidirectional Translation via Reinforcement Learning Jinwei Qi and Yuxin Peng Institute of Computer Science and Technology, Peking University, Beijing 100871, China pengyuxin@pku.edu.cn Abstract
Reinforcement Learning and Shape Grammars
 Reinforcement Learning and Shape Grammars Technical report Author Manuela Ruiz Montiel Date April 15, 2011 Version 1.0 1 Contents 0. Introduction... 3 1. Tabular approach... 4 1.1 Tabular Q-learning...
Reinforcement Learning and Shape Grammars Technical report Author Manuela Ruiz Montiel Date April 15, 2011 Version 1.0 1 Contents 0. Introduction... 3 1. Tabular approach... 4 1.1 Tabular Q-learning...
CS885 Reinforcement Learning Lecture 9: May 30, Model-based RL [SutBar] Chap 8
![CS885 Reinforcement Learning Lecture 9: May 30, Model-based RL [SutBar] Chap 8](/thumbs/90/103880210.jpg "CS885 Reinforcement Learning Lecture 9: May 30, Model-based RL [SutBar] Chap 8") CS885 Reinforcement Learning Lecture 9: May 30, 2018 Model-based RL [SutBar] Chap 8 CS885 Spring 2018 Pascal Poupart 1 Outline Model-based RL Dyna Monte-Carlo Tree Search CS885 Spring 2018 Pascal Poupart
CS885 Reinforcement Learning Lecture 9: May 30, 2018 Model-based RL [SutBar] Chap 8 CS885 Spring 2018 Pascal Poupart 1 Outline Model-based RL Dyna Monte-Carlo Tree Search CS885 Spring 2018 Pascal Poupart
Modern Methods of Data Analysis - WS 07/08
 Modern Methods of Data Analysis Lecture XV (04.02.08) Contents: Function Minimization (see E. Lohrmann & V. Blobel) Optimization Problem Set of n independent variables Sometimes in addition some constraints
Modern Methods of Data Analysis Lecture XV (04.02.08) Contents: Function Minimization (see E. Lohrmann & V. Blobel) Optimization Problem Set of n independent variables Sometimes in addition some constraints
Go in numbers 3,000. Years Old
 Go in numbers 3,000 Years Old 40M Players 10^170 Positions The Rules of Go Capture Territory Why is Go hard for computers to play? Brute force search intractable: 1. Search space is huge 2. Impossible
Go in numbers 3,000 Years Old 40M Players 10^170 Positions The Rules of Go Capture Territory Why is Go hard for computers to play? Brute force search intractable: 1. Search space is huge 2. Impossible
CS535 Big Data Fall 2017 Colorado State University 10/10/2017 Sangmi Lee Pallickara Week 8- A.
 CS535 Big Data - Fall 2017 Week 8-A-1 CS535 BIG DATA FAQs Term project proposal New deadline: Tomorrow PA1 demo PART 1. BATCH COMPUTING MODELS FOR BIG DATA ANALYTICS 5. ADVANCED DATA ANALYTICS WITH APACHE
CS535 Big Data - Fall 2017 Week 8-A-1 CS535 BIG DATA FAQs Term project proposal New deadline: Tomorrow PA1 demo PART 1. BATCH COMPUTING MODELS FOR BIG DATA ANALYTICS 5. ADVANCED DATA ANALYTICS WITH APACHE
Reinforcement Learning and Optimal Control. ASU, CSE 691, Winter 2019
 Reinforcement Learning and Optimal Control ASU, CSE 691, Winter 2019 Dimitri P. Bertsekas dimitrib@mit.edu Lecture 1 Bertsekas Reinforcement Learning 1 / 21 Outline 1 Introduction, History, General Concepts
Reinforcement Learning and Optimal Control ASU, CSE 691, Winter 2019 Dimitri P. Bertsekas dimitrib@mit.edu Lecture 1 Bertsekas Reinforcement Learning 1 / 21 Outline 1 Introduction, History, General Concepts
Project Whitepaper: Reinforcement Learning Language
 Project Whitepaper: Reinforcement Learning Language Michael Groble (michael.groble@motorola.com) September 24, 2006 1 Problem Description The language I want to develop for this project is one to specify
Project Whitepaper: Reinforcement Learning Language Michael Groble (michael.groble@motorola.com) September 24, 2006 1 Problem Description The language I want to develop for this project is one to specify
ICRA 2012 Tutorial on Reinforcement Learning I. Introduction
 ICRA 2012 Tutorial on Reinforcement Learning I. Introduction Pieter Abbeel UC Berkeley Jan Peters TU Darmstadt Motivational Example: Helicopter Control Unstable Nonlinear Complicated dynamics Air flow
ICRA 2012 Tutorial on Reinforcement Learning I. Introduction Pieter Abbeel UC Berkeley Jan Peters TU Darmstadt Motivational Example: Helicopter Control Unstable Nonlinear Complicated dynamics Air flow
Perceptron: This is convolution!
 Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image