DeepVoting: A Robust and Explainable Deep Network for Semantic Part Detection under Partial Occlusion
|
|
|
- Arron Wade
- 5 years ago
- Views:
Transcription


1 CBMM Memo No. 083 Jun 19, 018 DeepVoting: A Robust and Explainable Deep Network for Semantic Part Detection under Partial Occlusion Zhishuai Zhang 1, Cihang Xie 1, Jianyu Wang, Lingxi Xie 1, Alan L. Yuille 1 * denotes equal contribution, denotes corresponding author 1: Johns Hopkins University : Baidu Research USA Abstract In this paper, we study the task of detecting semantic parts of an object, e.g., a wheel of a car, under partial occlusion. We propose that all models should be trained without seeing occlusions while being able to transfer the learned knowledge to deal with occlusions. This setting alleviates the difficulty in collecting an exponentially large dataset to cover occlusion patterns and is more essential. In this scenario, the proposal-based deep networks, like RCNN-series, often produce unsatisfactory results, because both the proposal extraction and classification stages may be confused by the irrelevant occluders. To address this, [5] proposed a voting mechanism that combines multiple local visual cues to detect semantic parts. The semantic parts can still be detected even though some visual cues are missing due to occlusions. However, this method is manually-designed, thus is hard to be optimized in an end-to-end manner. In this paper, we present DeepVoting, which incorporates the robustness shown by [5] into a deep network, so that the whole pipeline can be jointly optimized. Specifically, it adds two layers after the intermediate features of a deep network, e.g., the pool-4 layer of VGGNet. The first layer extracts the evidence of local visual cues, and the second layer performs a voting mechanism by utilizing the spatial relationship between visual cues and semantic parts. We also propose an improved version DeepVoting+ by learning visual cues from context outside objects. In experiments, DeepVoting achieves significantly better performance than several baseline methods, including Faster-RCNN, for semantic part detection under occlusion. In addition, DeepVoting enjoys explainability as the detection results can be diagnosed via looking up the voting cues.




2 This material is based upon work supported by the Center for Brains, Minds and Machines (CBMM), funded by NSF STC award CCF
3 DeepVoting: A Robust and Explainable Deep Network for Semantic Part Detection under Partial Occlusion Zhishuai Zhang 1 Cihang Xie 1 Jianyu Wang Lingxi Xie 1( ) Alan L. Yuille 1 Johns Hopkins University 1 Baidu Research USA {zhshuai.zhang, cihangxie306, wjyouch, xc, alan.l.yuille}@gmail.com Abstract In this paper, we study the task of detecting semantic parts of an object, e.g., a wheel of a car, under partial occlusion. We propose that all models should be trained without seeing occlusions while being able to transfer the learned knowledge to deal with occlusions. This setting alleviates the difficulty in collecting an exponentially large dataset to cover occlusion patterns and is more essential. In this scenario, the proposal-based deep networks, like RCNN-series, often produce unsatisfactory results, because both the proposal extraction and classification stages may be confused by the irrelevant occluders. To address this, [5] proposed a voting mechanism that combines multiple local visual cues to detect semantic parts. The semantic parts can still be detected even though some visual cues are missing due to occlusions. However, this method is manually-designed, thus is hard to be optimized in an end-to-end manner. In this paper, we present DeepVoting, which incorporates the robustness shown by [5] into a deep network, so that the whole pipeline can be jointly optimized. Specifically, it adds two layers after the intermediate features of a deep network, e.g., the pool-4 layer of VGGNet. The first layer extracts the evidence of local visual cues, and the second layer performs a voting mechanism by utilizing the spatial relationship between visual cues and semantic parts. We also propose an improved version DeepVoting+ by learning visual cues from context outside objects. In experiments, DeepVoting achieves significantly better performance than several baseline methods, including Faster-RCNN, for semantic part detection under occlusion. In addition, Deep- Voting enjoys explainability as the detection results can be diagnosed via looking up the voting cues. 1. Introduction Deep networks have been successfully applied to a wide range of vision tasks, in particular object detection [7, 0, The first three authors contributed equally to this work. 19, 13, 9]. Recently, object detection is dominated by a family of proposal-based approaches [7, 0], which first generates a set of object proposals for an image, followed by a classifier to predict objects score for each proposal. However, semantic part detection, despite its importance, has been much less studied. A semantic part is a fraction of an object which has semantic meaning and can be verbally described, such as a wheel of a car or a chimney of a train. Detecting semantic parts is a human ability, which enables us to recognize or parse an object at a finer scale. In the real world, semantic parts of an object are frequently occluded, which makes detection much harder. In this paper, we investigate semantic part detection especially when these semantic parts are partially or fully occluded. We use the same datasets as in [5], i.e., the VehicleSemanticPart dataset and the VehicleOcclusion dataset. Some typical semantic part examples are shown in Figure 1. Note that, the VehicleOcclusion dataset is a synthetic occlusion dataset, where the target object is randomly superimposed with two, three or four irrelevant objects (named occluders) and the occlusion ratios of the target object is constrained. To the best of our knowledge, VehicleOcclusion is the only public occlusion dataset that provides accurate occlusion annotations of semantic parts like the occlusion ratio and number of occluders. This allows us to evaluate different methods under different occlusion difficulty levels. One intuitive solution of dealing with occlusion is to train a model on the dataset that covers different occlusion cases. However, it is extremely difficult yet computationally intractable to collect a dataset that covers occlusion patterns of different numbers, appearances and positions. To overcome this difficulty, we suggest a more essential solution, i.e, training detectors only on occlusion-free images, but allowing the learned knowledge (e.g., the spatial relationship between semantic parts, etc.) to be transferred from nonocclusion images to occlusion images. This motivates us to design models that are inherently robust to occlusions. A related work is [5], which pointed out that proposal-based deep networks are less robust to occlusion, and instead proposed a voting mechanism that accumulates evidences from


.")

![This motivates us to see if the robustness shown in [5] can be incorporated into a deep network which enables](/docs-images/82/86364611/images/4-5.jpg "end-to-end training naturally.")


![were verified to be capable of detecting semantic parts [6].](/docs-images/82/86364611/images/4-8.jpg "This layer is followed by a ReLU activation [16], which sets a threshold for filtering the matched patterns, and a")
![dropout layer [], which allows part of evidences to be missing.](/docs-images/82/86364611/images/4-9.jpg "After that, the second convolution layer is added to perform a voting mechanism by utilizing the spatial relationship")






 DeepVoting enjoys much lower")
 DeepVoting provides the possibility to interpret the detection results via looking up the voting")

![19, 13, 9], etc.](/docs-images/82/86364611/images/4-21.jpg "For object detection, one of the most popular pipeline [7, 0] involved first extracting a number of regions named")
![object proposals [1, 4, 1, 0], and then determining if each of them belongs to the target class.](/docs-images/82/86364611/images/4-22.jpg "Bounding-box regression and non-maximum suppression were attached for post-processing.")

4 nosetip jet engine wheel seat wheel side body wheel side window wheel seat nosetip round nose v. stablizer side tail pedal headset headlight disp. screen headlight side mirror engine gas tank chimney smoke box airplane bicycle bus car motorbike Figure 1. Typical semantic parts on six types of rigid objects from the VehicleSemanticPart dataset [5]. Some semantic parts (e.g., wheel) can appear in different object classes, while some others (e.g., chimney) only appear in one class (train). train multiple local visual cues, and locate the semantic parts with the help of geometric constraints (i.e., the spatial relationship between the visual cues and the target semantic part). However, this manually-designed framework is broken down into several stages, and thus it is difficult to optimize it in an end-to-end manner. This motivates us to see if the robustness shown in [5] can be incorporated into a deep network which enables end-to-end training naturally. To this end, we propose DeepVoting, an end-to-end framework for semantic part detection under partial occlusion. Specifically, we add two convolutional layers after the intermediate features of a deep neural network, e.g., the neural responses at the pool-4 layer of VGGNet. The first convolutional layer performs template matching and outputs local visual cues named visual concepts, which were verified to be capable of detecting semantic parts [6]. This layer is followed by a ReLU activation [16], which sets a threshold for filtering the matched patterns, and a dropout layer [], which allows part of evidences to be missing. After that, the second convolution layer is added to perform a voting mechanism by utilizing the spatial relationship between visual cues and semantic parts. The spatial/geometric relations are stored as convolutional weights and visualized as spatial heatmaps. The visual concepts and spatial heatmaps can be learned either on foreground objects only or on whole image with context. We first follow [5] to train our model on foreground objects only by cropping the object bounding boxes. We further show that visual concepts and spatial heatmaps can also exploit context information by using the whole image to train our model, and we call this improved version DeepVoting+. We investigate both DeepVoting and DeepVoting+ in our experiments. The first version, in which contexts are excluded, significantly outperforms [5] with the same setting, arguably because the end-to-end training manner provides a stronger method for joint optimization. The second version, which allows contextual cues to be incorporated, fits the training data better and consequently produces higher detection accuracies. In comparison to the state-ofthe-art object detectors such as Faster-RCNN [0], Deep- Voting enjoys a consistent advantage, and the advantage becomes more significant as the occlusion level goes up. DeepVoting brings two additional benefits apart from being robust to occlusion: (i) DeepVoting enjoys much lower model complexity, i.e., the number of parameters is one order of magnitude smaller, and the average testing speed is.5 faster; and (ii) DeepVoting provides the possibility to interpret the detection results via looking up the voting cues.. Related Work Deep convolutional neural networks have been applied successfully to a wide range of computer vision problems, including image recognition [11, 1, 3, 9], semantic segmentation [14,, 30], object detection [7, 0, 19, 13, 9], etc. For object detection, one of the most popular pipeline [7, 0] involved first extracting a number of regions named object proposals [1, 4, 1, 0], and then determining if each of them belongs to the target class. Bounding-box regression and non-maximum suppression were attached for post-processing. This framework significantly outperforms the deformable part-based model [6] trained on top of a set of handcrafted features [4]. There are some works using semantic parts to assist object detection [3, 31]. Graphical model was used to assemble parts into an object. Also, parts can be used for finegrained object recognition [8, 7], be applied as auxiliary cues to understand classification [10], or be trained for action and attribute classification [8]. Besides, [17] investigated the transferability of semantic parts across a large target set of visually dissimilar classes in image understanding. Detecting semantic parts under occlusion is an important problem but was less studied before. [5] combined multiple visual concepts via the geometric constraints, i.e., the spatial distribution of the visual concepts related to the target semantic parts, to obtain a strong detector. Different from [5], DeepVoting implements visual concept extraction and the geometric relationships as two layers, and attach them directly to the intermediate outputs of a deep neural network to perform an end-to-end training. This yields much better performance compared to [5].
5 3. The DeepVoting Framework 3.1. Motivation We aim at detecting the semantic parts of an object under occlusion. First of all, we argue that only occlusion-free images should be used in the training phase. This is because the appearance and position of the occluders can be arbitrary, thus it is almost impossible to cover all of them by a limited training set. It is our goal to design a framework which can transfer the learned knowledge from the occlusion-free domain to the occlusion domain. One possible solution is to adapt the state-of-the-art object detection methods, such as Faster-RCNN [0], to detect semantic parts. Specifically, the adapted methods first extract a number of proposals for semantic parts and then compute the classification scores for each of them. But, we point out that this strategy may miss some partially or fully occluded semantic parts because of two important factors: (1) occlusion may distract the proposal generation network from extracting good proposals for semantic parts; () even with correct proposals, the classifier may still go wrong since the appearance of the occluded semantic parts can be totally different. We verify that these factors indeed downgrade the performance of Faster-RCNN in Section 4.3. The voting mechanism [5] suggests an alternative strategy, which accumulates mid-level visual cues to detect high-level semantic parts. These mid-level cues are called visual concepts [6], i.e., a set of intermediate CNN states which are closely related to semantic parts. A semantic part is supported by multiple visual concepts via the geometric constraints between them. Even if the evidences from some visual concepts are missing due to occlusion, it is still possible to infer the presence of the semantic part via the evidences from the remaining ones. However, it involves too many hyper-parameters and thus is hard to be optimized. In this paper, we propose DeepVoting which incorporates the robustness shown by [5] into a deep network. Following [6], the visual concepts are learned when the objects appear at a fixed scale since each neuron on the intermediate layer, e.g., the pool-4 layer, has a fixed receptive field size [1]. Therefore, we assume that the object scale is approximately the same in both training and testing stages. In the training stage, we used the ground-truth bounding box to resize the object for the DeepVoting, and compute the object-to-image ratio to train a standalone network, ScaleNet [18], for scale prediction (see Section 3.4 for details). In the testing stage, the trained ScaleNet was used to predict the resizing ratio, and then we resize the testing image according to the predicted ratio. 3.. Formulation Let I denote an image with a size of W H. Following [5], we feed this image into a 16-layer VGGNet [1], and extract the pool-4 features as a set of intermediate neural outputs. Denote the output of the pool-4 layer as X, or a W H D cube, where W and H are the down-sampled scales of W and H, and D is 51 for VGGNet. These features can be considered as W H high-dimensional vectors, and each of them represents the appearance of a local region. Denote each D-dimensional feature vector as x i where i is an index at the W H grid. These feature vectors are l -normalized so that x i = Visual Concept Extraction In [5], a set of visual concepts V = {v 1,..., v K } are obtained via K-means clustering, and each visual concept is considered intuitively as a template to capture the mid-level semantics from these intermediate outputs. Specifically, the response of the visual concept v k at the pool-4 feature vector x i is measured by the l -distance, i.e., v k x i. We note that x i has unit length, and so v k 1 as it is averaged over a set of neighboring x i s, so we have v k x i v k, x i where, is the dot product operator. Then the log-likelihood ratio tests are applied to eliminate negative responses. This is driven by the idea that the presence of a visual concept can provide positive cues for the existence of a semantic part, but the absence of a visual concept shall not give the opposite information. Different from [5], DeepVoting implements this module as a convolutional layer, namely visual concept layer, and attaches it directly after the normalized intermediate outputs of a deep neural network. The kernel size of this convolutional layer is set to be 1 1, i.e., each x i is considered individually. The ReLU activation [16] follows to set the negative responses as 0 s and thus avoids them from providing negative cues. We append a dropout layer [] with a drop ratio 0.5, so that a random subset of the visual concept responses are discarded in the training process. This strategy facilitates the model to perform detection robustly using incomplete information and, consequently, improves the testing accuracy when occlusion is present. The output of visual concept layer is a map Y of size W H V, where V is the set of visual concepts. We set V = 56, though a larger set may lead to slightly better performance. Although these visual concepts are trained from scratch rather than obtained from clustering [6], we show in Section 4.4 that they are also capable of capturing repeatable visual patterns and semantically meaningful. 3.. Semantic Part Detection via the Voting Layer After the previous stage, we can find some fired visual concepts, i.e., those positions with positive response values. In [5], the fired visual concepts are determined via loglikelihood ratio tests. These fired visual concepts are then
.")
6 Input Image pool-4 Features Visual Concept Map Semantic Part Map VGGNet VC layer Voting layer W H 3 W H 51 W H K W H S Figure. The overall framework of DeepVoting (best viewed in color). A car image with two wheels (marked by red frames, one of them is occluded) is fed into VGGNet [1], and the intermediate outputs are passed through a visual concept extraction layer and a voting layer. We aggregate local cues from the visual concept map (darker blue indicates more significant cues), consider their spatial relationship to the target semantic part via voting, and obtain a low-resolution map of semantic parts (darker red or a larger number indicates higher confidence). Based on this map, we perform bounding box regression followed by non-maximum suppression to obtain the final results. accumulated together for semantic part detection by considering the spatial constraints between each pair of visual concept and semantic part. It is motivated by the nature that a visual concept can, at least weakly, suggest the existence of a semantic part. For example, as shown in Figure, in a car image, finding a headlight implies that there is a wheel nearby, and the distance and direction from the headlight to the wheel are approximately the same under a fixed scale. Different from [5], DeepVoting implements the spatial constraints between visual concepts and the semantic parts as another convolutional layer, named the voting layer, in which we set the receptive field of each convolutional kernel to be large, e.g., 15 15, so that a visual concept can vote for the presence of a semantic part at a relatively long distance. This strategy helps particularly when the object is partially occluded, as effective visual cues often emerge outside the occluder and may be far from the target. Though the spatial constraints are learned from scratch and only semantic part level supervision is imposed during training, they can still represent the frequency that visual concepts appear at different relative positions. We refer to each learned convolutional kernel at this layer as a spatial heatmap, and some of them are visualized in Section 4.4. Denote the output of the voting layer, i.e., the semantic part map, as Z. It is a W H S cube where S is the set of semantic parts. Each local maximum at the semantic part map corresponds to a region on the image lattice according to their receptive filed. To generate a bounding box for semantic part detection, we first set an anchor box, sized and centered at this region, and then learn the spatial rescaling and translation to regress the anchor box (following the same regression procedure in [7]) from the training data. The anchor size is the average semantic part scale over the entire training dataset [5] Training and Testing We train the network on an occlusion-free image corpus. This helps us obtain clear relationship between the visual concepts and the semantic parts. We discard the background region by cropping the object according to the ground-truth bounding box, to be consistent with [5]. Then, we rescale the cropped image so that the object short edge has 4 pixels, which is motivated by [6] to capture the visual concepts at a fixed scale. The image is fed into the 16-layer VGGNet, and we get the feature vectors at the pool-4 layer. These feature vectors are normalized and passed through two layers for visual concept extraction and voting. We compare the output semantic part map Z with the groundtruth annotation L by computing dice coefficient between prediction and ground-truth [15]. To generate the groundtruth, we find the nearest grid point at the W H grid (down-sampled from the original image by the factor of 16) based on the center pixel of each annotated semantic part, and set the labels of these positions as 1 and others as 0. Then we apply Gaussian filtering on the binary ground-truth annotation, to generate the smoothed ground-truth annotation L. The label cube L is also of size W H S. The similarity between Z and L is defined as: D(Z, L) = 1 S W,H w=1,h=1 z w,h,s l w,h,s S W ( ), (1),H s=1 w=1,h=1 zw,h,s + l w,h,s It is straightforward to compute the gradients based on the loss function L(Z, L) = 1 D(Z, L). On the testing stage, we first use ScaleNet (see Section 3.4) to obtain the object scale. Then, we rescale the image so that the short edge of the object roughly contains 4 pixels. We do not crop the object because we do not know its location. Then, the image is passed through the VGGNet followed by both visual concept extraction and voting layers, and finally we apply the spatial rescaling and translation to the anchor box ( ) towards more accurate localization. A standard non-maximum suppression is performed to finalize the detection results. DeepVoting is trained on the images cropped with respect to the object bounding boxes to be consistent with [5]. Moreover, visual concepts and spatial heatmaps can also exploit context outside object bounding boxes. To
 are from VehicleOcclusion dataset. There are, 3 and 4 occluders, and the occluded ratio of object, computed by pixels, is 0. 0.4, 0.4 0.6 and 0.")


7 Figure 3. Examples of images in VehicleSemanticPart dataset and VehicleOcclusion dataset. The first is the original occlusion-free image from VehicleSemanticPart dataset. The second, third and forth image (in row-major order) are from VehicleOcclusion dataset. There are, 3 and 4 occluders, and the occluded ratio of object, computed by pixels, is , and , respectively. verify this, we train an improved version, named DeepVoting+, without cropping the bounding boxes. We also resize the image so that the object short edge contains 4 pixels in the training stage, and the testing stage is the same as DeepVoting. Experiments show that DeepVoting+ achieves better performance than DeepVoting The Scale Prediction Network The above framework is based on an important assumption, that the objects appear in approximately the same scale. This is due to two reasons. First, as shown in [6], the visual concepts emerge when the object is rescaled to the same scale, i.e., the short edge of the object bounding box contains 4 pixels. Second, we expect the voting layer to learn fixed spatial offsets which relate a visual concept to a semantic part. As an example, the heatmap delivers the knowledge that in the side view of a car, the headlight often appears at the upperleft direction of a wheel, and the spatial offset on x and y axes are about 64 and 48 pixels (4 and 3 at the pool-4 grid), respectively. Such information is not scale-invariant. To deal with these issues, we introduce an individual network, namely the ScaleNet [18], to predict the object scale in each image. The main idea is to feed an input image to a 16-layer VGGNet for a regression task (the fc-8 layer is replaced by a 1-dimensional output), and the label is the ground-truth object size. Each input image is rescaled, so that the long edge contains 4 pixels. It is placed at the center of an 4 4 square and the remaining pixels are filled up with the averaged intensity. During the training, we consider the short edge of the object, and ask the deep network to predict the ratio of the object short edge to the image long edge (4 pixels). In the test phase, an image is prepared and fed into the network in the same flowchart, and the predicted ratio is used to normalize the object to the desired size, i.e., its short edge contains 4 pixels. We show in Section 4..1 that this method works very well Discussions and Relationship to Other Works The overall framework of DeepVoting is quite different from the conventional proposal-based detection methods, such as Faster-RCNN [0]. This is mainly due to the problem setting, i.e., when the occlusion is present, the accuracy of both proposal and classification networks becomes lower. However, DeepVoting is able to infer the occluded semantic parts via accumulating those non-occluded visual cues. We show more comparative experiments in Section 4.3. We decompose semantic part detection into two steps, i.e., central pixel detection and bounding box regression. The first step is performed like semantic segmentation [14] in a very low-resolution setting (down-sampled from the original image by the factor of 16). We also borrow the idea from segmentation [15], which uses a loss function related to the dice coefficient in optimization. As the semantic part is often much smaller compared to the entire image, this strategy alleviates the bias of data imbalance, i.e., the model is more likely to predict each pixel as background as it appears dominantly in the training data. 4. Experiments 4.1. Dataset and Baseline We use the VehicleSemanticPart dataset and the VehicleOcclusion dataset [5] for evaluation. The VehicleSemanticPart dataset contains 4549 training images and 4507 testing images covering six types of vehicles, i.e., airplane, bicycle, bus, car, motorbike and train. In total, 133 semantic parts are annotated. For each test image in Vehicle- SemanticPart dataset, some randomly-positioned occluders (irrelevant to the target object) are placed onto the target object, and make sure that the occlusion ratio of the target object is constrained. Figure 3 shows several examples with different occlusion levels. We train six models, one for each object class. All the models are trained on an occlusion-free dataset, but evaluated on either non-occluded images, or the images with different levels of occlusions added. In the later case, we vary the difficulty level by occluding different fractions of the object. We evaluate all the competitors following a popular criterion [5], which computes the mean average precision (map) based on the list of detected semantic parts. A detected box is considered to be true-positive if and only if its IoU rate with a ground-truth box is not lower than 0.5. Each semantic part is evaluated individually, and the map of each
8 No Occlusions L1 L L3 Category KVC DVC VT FR DV DV+ VT FR DV DV+ VT FR DV DV+ VT FR DV DV+ airplane bicycle bus car motorbike train mean Table 1. Left 6 columns: Comparison of detection accuracy (mean AP, %) of KVC, DVC, VT, FR, DV and DV+ without occlusion. Right 1 columns: Comparison of detection accuracy (mean AP, %) of VT, FR, DV and DV+ when the object is occluded at three different levels. Note that DV+ is DeepVoting trained with context outside object bounding boxes. See the texts for details. object class is the average map over all the semantic parts. DeepVoting and DeepVoting+ (denoted by DV and DV+, respectively, Section 3.3) are compared with four baselines: KVC: These visual concepts are clustered from a set of pool-4 features using K-Means [6]. The ScaleNet (detailed in Section 3.4) is used to tackle scale issue and the extracted visual concepts are directly used to detect the semantic parts. DVC: These visual concepts are obtained from Deep- Voting, i.e., the weights of the visual concept extraction layer. The ScaleNet (detailed in Section 3.4) is used to tackle scale issue and the extracted visual concepts are directly used to detect the semantic parts. VT: The voting method first finds fired visual concepts via log-likelihood ratio tests, and then utilizes spatial constraints to combine these local visual cues. FR: We train models for each category independently. Each semantic part of a category is considered as a separate class during training, i.e., for each category, we train a model with S + 1 classes, corresponding to S semantic parts and the background. Different from other baselines, Faster-RCNN here is trained on full images, i.e., object cropping is not required. This enables Faster-RCNN to use context for semantic parts detection and handle scale issue naturally since semantic parts with various scales are used in training. 4.. Semantic Part Detection without Occlusion As a simplified task, we evaluate our algorithm in detecting semantic parts on non-occluded objects. This is also a baseline for later comparison. In the left six columns of Table 1, we list the detection accuracy produced by different methods. The average detection accuracies by both voting and DeepVoting are significantly higher than using single visual concept for detection, regardless whether the visual concepts are obtained from K-Means clustering or DeepVoting. This indicates the advantage of the approaches Figure 4. The distribution of the ratio of the predicted scale to the actual scale. which aggregates multiple visual cues for detection. Meanwhile, DeepVoting is much better than voting due to the better scale prediction and the end-to-end training manner. Even the right scale is provided for voting (oracle scale results in [5]), DeepVoting still beat it by more than 0% in terms of averaged map over 6 objects, which indicates the benefit brought by the joint optimization of both weights for visual concept extraction layer and voting layer. On the other hand, DeepVoting produces slightly lower detection accuracy compared to Faster-RCNN. We argue that Faster-RCNN benefits from the context outside object bounding boxes, as we can see, if we improve DeepVoting by adding context during the training (i.e. DeepVoting+), Faster-RCNN will be less competitive compared with our method. Meanwhile, DeepVoting enjoys lower computational overheads, i.e., it runs.5 faster Scale Prediction Accuracy We investigate the accuracy of ScaleNet, which is essential for scale normalization. For each testing image, we compute the ratio of the predicted object scale to the actual scale, and plot the contribution of this ratio over the entire testing set in Figure 4. One can see that in more than
9 Recall at Different Levels map w/ Addt l Prop. map by DeepVoting+ Category L0 L1 L L3 L1 L L3 L1 L L3 airplane bicycle bus car motorbike train mean Table. Left 4 columns: the recall rates (%) of the proposal network at different occlusion levels. Middle 3 and right 3 columns: detection maps (%) of Faster-RCNN (ground-truth bounding boxes are added as additional proposals) and DeepVoting+ at different occlusion levels. 75% cases, the relative error of the predicted scale does not exceed 10%. Actually, these prediction results are accurate enough for DeepVoting. Even if ground-truth scale is provided and we rescale the images accordingly, the detection accuracy is slightly improved from 7.0% to 74.5% Semantic Part Detection under Occlusion We further detect semantic parts when the object is occluded in three different levels. Since the baselines KVC and DVC perform much worse than other methods even when occlusion is not present, we ignore these two methods when performing semantic part detection under occlusion. In the first level (i.e. L1), we place occluders on each object, and the occluded ratio r of the object, computed by pixels, satisfying 0. r < 0.4. For L and L3, we have 3 and 4 occluders, and 0.4 r < 0.6 and 0.6 r < 0.8, respectively (see Figure 3 for examples). The original occlusionfree testing set is denoted as L0. The detection results are summarized in Table 1. One can see that DeepVoting outperforms the voting and the Faster-RCNN significantly in these cases. For the Faster-RCNN, the accuracy gain increases as the occlusion level goes up, suggesting the advantage of DeepVoting in detecting occluded semantic parts. As a side evidence, we investigate the impact of the size of spatial heatmap (the kernel of the voting layer). At the heaviest occlusion level, when we shrink the default to 11 11, the mean detection accuracy drops from 31.6% to 30.6%, suggesting the usefulness of long-distance voting in detecting occluded semantic parts. When the kernel size is increased to 19 19, the accuracy is slightly improved to 31.8%. Therefore, we keep the kernel size to be for a lower model complexity. To verify our motivation that Faster-RCNN suffers downgraded performance in both the proposal network and the classifier, we investigate both the recall of the proposals and the accuracy of the classifier. Results are summarized in Table. First, we can see that the recall of the proposals goes down significantly as the occlusion level goes up, since the objectness of the semantic part region may become weaker due to the randomly placed occluders. Thus the second stage, i.e., classification, has to start with a relatively low-quality set of candidates. In the second part, we add the ground-truth bounding boxes to the existing proposals so that the recall is 100%, feed these candidates to the classifier, and evaluate its performance on the occluded images. Even with such benefits, Faster-RCNN still produces unsatisfying detection accuracy. For example, in detecting the semantic parts of a bicycle at the highest occlusion level (L3), making use of the additional proposals from ground-truth bounding boxes merely improves the detection accuracy from 41.1% to 44.7%, which is still much lower than the number 6.5% produced by DeepVoting+. This implies that the classifier may be confused since the occluder changes the appearance of the proposals Visualizing Visual Concepts and Heatmaps In Figure 5, we show some typical examples of the learned visual concepts and spatial heatmaps. The visualization of visual concepts follows the approach used in [6], which finds 10 most significant responses on each convolutional filter, i.e., the matching template, traces back to the original image lattice, and crops the region corresponding to the neuron at the pool-4 layer. To show different spatial heatmaps, we randomly choose some relevant pairs of visual concept and semantic part, and plot the convolutional weights of the voting layer for comparison. We see that the learned visual concepts and spatial heatmaps are semantically meaningful, even though there is only semantic part level supervision during training Explaining the Detection Results Finally, we show an intriguing benefit of our approach, which allows us to explain the detection results. In Figure 6, we display three examples, in which the target semantic parts are not occluded, partially occluded and fully occluded, respectively. DeepVoting can infer the occluded semantic parts, and is also capable of looking up the voting (supporting) visual concepts for diagnosis, to dig into errors and understand the working mechanism of our approach.










 often appears")
")
.")









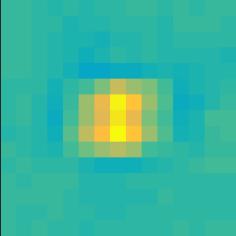


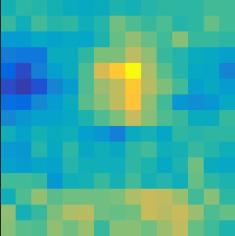




























10 Object class: car SP #0: license plate SP #3: rear window Object class: car SP #1: car wheel SP #1: side window VC #07: license plate VC #09: car wheel, left side VC #073: windshield, right side VC #170: car side Figure 5. Visualization of visual concepts and spatial heatmaps (best viewed in color). For each visual concept, we show 10 patches with the highest responses. Each spatial heatmap illustrates the cues to detect a semantic part, in which yellow, cyan and dark blue indicate positive, zero and negative cues, respectively. For example, VC #073 (windshield) often appears above SP #0 (license plate), and VC #170 (car side bottom) often appears below SP #1 (side window). Object: car; SP #17: headlight Object: car; SP #13: side window Object: car; SP #0: licence plate VC #160 VC #076 VC # List of voted VC s: 1. #160: score = x, y = 0,0. #45: score = x, y = +5, #091: score = x, y = +6, +3 VC #45 VC # List of voted VC s: 1. #076: score = 0.03 x, y = +1, +. #038: score = x, y = +3, 3. #101: score = x, y = +3, +6 VC #038 VC # List of voted VC s: 1. #073: score = 0.00 x, y = 0, 6. #35: score = 0.01 x, y = 0, #3: score = x, y = 5, 3 Figure 6. DeepVoting allows us to explain the detection results. In the example of heavy occlusion (the third column), the target semantic part, i.e., the licence plate on a car, is fully occluded by a bird. With the help of some visual concepts (blue dots), especially the 73-rd VC (also displayed in Figure 5), we can infer the position of the occluded semantic part (marked in red). Note that we only plot the 3 VC s with the highest scores, regardless the number of voting VC s can be much larger. VC #35 VC #3 5. Conclusions In this paper, we propose a robust and explainable deep network, named DeepVoting, for semantic part detection under partial occlusion. The intermediate visual representations, named visual concepts, are extracted and used to vote for semantic parts via two convolutional layers. The spatial relationship between visual concepts and semantic parts is learned from a occlusion-free dataset and then transferred to the occluded testing images. DeepVoting is evaluated on both the VehicleSemanticPart dataset and the VehicleOcclusion dataset, and shows comparable performance to Faster-RCNN in the non-occlusion scenario, and superior performance in the occlusion scenario. If context is utilized, i.e., DeepVoting+, this framework outperforms both Deep- Voting and Faster-RCNN significantly under all scenarios. Moreover, our approach enjoys the advantage of being explainable, which allows us to diagnose the semantic parts detection results by checking the contribution of each voting visual concepts. In the future, we plan to extend DeepVoting to detect semantic parts of non-rigid and articulated objects like animals. Also, we plan to perform object-level detection under occlusion by combining these semantic cues. Acknowledgements This research was supported by ONR grant N , and also by the Center for Brains, Minds, and Machines (CBMM), funded by NSF STC award CCF We thank Chenxi Liu, Zhuotun Zhu, Jun Zhu, Siyuan Qiao, Yuyin Zhou and Wei Shen for instructive discussions.
11 References [1] B. Alexe, T. Deselaers, and V. Ferrari. Measuring the objectness of image windows. IEEE Transactions on Pattern Analysis and Machine Intelligence, 34(11):189 0, 01. [] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 017. [3] X. Chen, R. Mottaghi, X. Liu, S. Fidler, R. Urtasun, and A. Yuille. Detect what you can: Detecting and representing objects using holistic models and body parts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 014. [4] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In Computer Vision and Pattern Recognition. IEEE, 005. [5] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge. International Journal of Computer Vision, 88(): , [6] P. F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained partbased models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 3(9): , 010. [7] R. Girshick. Fast r-cnn. In International Conference on Computer Vision. IEEE, ,, 4 [8] G. Gkioxari, R. Girshick, and J. Malik. Actions and attributes from wholes and parts. In International Conference on Computer Vision. IEEE, 015. [9] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Computer Vision and Pattern Recognition. IEEE, 016. [10] S. Huang, Z. Xu, D. Tao, and Y. Zhang. Part-stacked cnn for fine-grained visual categorization. In Computer Vision and Pattern Recognition. IEEE, 016. [11] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems, 01. [1] W. Kuo, B. Hariharan, and J. Malik. Deepbox: Learning objectness with convolutional networks. In International Conference on Computer Vision. IEEE, 015. [13] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg. Ssd: Single shot multibox detector. In European conference on computer vision. Springer, , [14] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In Computer Vision and Pattern Recognition. IEEE, 015., 5 [15] F. Milletari, N. Navab, and S.-A. Ahmadi. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In International Conference on 3D Vision. IEEE, , 5 [16] V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In International Conference on Machine Learning, 010., 3 [17] D. Novotný, D. Larlus, and A. Vedaldi. I have seen enough: Transferring parts across categories. In British Machine Vision Conference, 016. [18] S. Qiao, W. Shen, W. Qiu, C. Liu, and A. Yuille. Scalenet: Guiding object proposal generation in supermarkets and beyond. arxiv preprint arxiv: , , 5 [19] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. In Computer Vision and Pattern Recognition. IEEE, , [0] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems, ,, 3, 5 [1] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In International Conference on Learning Representations, 015., 3, 4 [] N. Srivastava, G. E. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 15(1): , 014., 3 [3] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In Computer Vision and Pattern Recognition. IEEE, 015. [4] J. R. Uijlings, K. E. Van De Sande, T. Gevers, and A. W. Smeulders. Selective search for object recognition. International Journal of Computer Vision, 104(): , 013. [5] J. Wang, C. Xie, Z. Zhang, J. Zhu, L. Xie, and A. Yuille. Detecting semantic parts on partially occluded objects. In British Machine Vision Conference, ,, 3, 4, 5, 6 [6] J. Wang, Z. Zhang, C. Xie, Y. Zhou, V. Premachandran, J. Zhu, X. Lingxi, and A. Yuille. Visual concepts and compositional voting. Annals of Mathematical Sciences and Applications, 018., 3, 4, 5, 6, 7 [7] H. Zhang, T. Xu, M. Elhoseiny, X. Huang, S. Zhang, A. Elgammal, and D. Metaxas. Spda-cnn: Unifying semantic part detection and abstraction for fine-grained recognition. In Computer Vision and Pattern Recognition. IEEE, 016. [8] N. Zhang, J. Donahue, R. Girshick, and T. Darrell. Partbased r-cnns for fine-grained category detection. In European Conference on Computer Vision. Springer, 014. [9] Z. Zhang, S. Qiao, C. Xie, W. Shen, B. Wang, and A. L. Yuille. Single-shot object detection with enriched semantics. arxiv preprint arxiv: , , [30] S. Zheng, S. Jayasumana, B. Romera-Paredes, V. Vineet, Z. Su, D. Du, C. Huang, and P. H. Torr. Conditional random fields as recurrent neural networks. In International Conference on Computer Vision. IEEE, 015. [31] J. Zhu, X. Chen, and A. L. Yuille. Deepm: A deep partbased model for object detection and semantic part localization. arxiv preprint arxiv: , 015.
Detecting Semantic Parts on Partially Occluded Objects
 WANG ET.AL.: DETECTING SEMANTIC PARTS ON PARTIALLY OCCLUDED OBJECTS 1 Detecting Semantic Parts on Partially Occluded Objects Jianyu Wang* 1 wjyouch@gmail.com Cihang Xie* 2 cihangxie306@gmail.com Zhishuai
WANG ET.AL.: DETECTING SEMANTIC PARTS ON PARTIALLY OCCLUDED OBJECTS 1 Detecting Semantic Parts on Partially Occluded Objects Jianyu Wang* 1 wjyouch@gmail.com Cihang Xie* 2 cihangxie306@gmail.com Zhishuai
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Unified, real-time object detection
 Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
Feature-Fused SSD: Fast Detection for Small Objects
 Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION
 HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION Chien-Yao Wang, Jyun-Hong Li, Seksan Mathulaprangsan, Chin-Chin Chiang, and Jia-Ching Wang Department of Computer Science and Information
HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION Chien-Yao Wang, Jyun-Hong Li, Seksan Mathulaprangsan, Chin-Chin Chiang, and Jia-Ching Wang Department of Computer Science and Information
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK. Wenjie Guan, YueXian Zou*, Xiaoqun Zhou
 MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
Efficient Segmentation-Aided Text Detection For Intelligent Robots
 Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Traffic Multiple Target Detection on YOLOv2
 Traffic Multiple Target Detection on YOLOv2 Junhong Li, Huibin Ge, Ziyang Zhang, Weiqin Wang, Yi Yang Taiyuan University of Technology, Shanxi, 030600, China wangweiqin1609@link.tyut.edu.cn Abstract Background
Traffic Multiple Target Detection on YOLOv2 Junhong Li, Huibin Ge, Ziyang Zhang, Weiqin Wang, Yi Yang Taiyuan University of Technology, Shanxi, 030600, China wangweiqin1609@link.tyut.edu.cn Abstract Background
arxiv: v2 [cs.cv] 8 Apr 2018
![arxiv: v2 [cs.cv] 8 Apr 2018](/thumbs/86/94330536.jpg "arxiv: v2 [cs.cv] 8 Apr 2018") Single-Shot Object Detection with Enriched Semantics Zhishuai Zhang 1 Siyuan Qiao 1 Cihang Xie 1 Wei Shen 1,2 Bo Wang 3 Alan L. Yuille 1 Johns Hopkins University 1 Shanghai University 2 Hikvision Research
Single-Shot Object Detection with Enriched Semantics Zhishuai Zhang 1 Siyuan Qiao 1 Cihang Xie 1 Wei Shen 1,2 Bo Wang 3 Alan L. Yuille 1 Johns Hopkins University 1 Shanghai University 2 Hikvision Research
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network
 Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Yiqi Yan. May 10, 2017
 Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors
![[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors](/thumbs/89/97941029.jpg "[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors") [Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
Towards Real-Time Automatic Number Plate. Detection: Dots in the Search Space
 Towards Real-Time Automatic Number Plate Detection: Dots in the Search Space Chi Zhang Department of Computer Science and Technology, Zhejiang University wellyzhangc@zju.edu.cn Abstract Automatic Number
Towards Real-Time Automatic Number Plate Detection: Dots in the Search Space Chi Zhang Department of Computer Science and Technology, Zhejiang University wellyzhangc@zju.edu.cn Abstract Automatic Number
YOLO9000: Better, Faster, Stronger
 YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
Detecting and Parsing of Visual Objects: Humans and Animals. Alan Yuille (UCLA)
") Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
arxiv: v1 [cs.cv] 26 Jun 2017
![arxiv: v1 [cs.cv] 26 Jun 2017](/thumbs/80/82184026.jpg "arxiv: v1 [cs.cv] 26 Jun 2017") Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
Gradient of the lower bound
 Weakly Supervised with Latent PhD advisor: Dr. Ambedkar Dukkipati Department of Computer Science and Automation gaurav.pandey@csa.iisc.ernet.in Objective Given a training set that comprises image and image-level
Weakly Supervised with Latent PhD advisor: Dr. Ambedkar Dukkipati Department of Computer Science and Automation gaurav.pandey@csa.iisc.ernet.in Objective Given a training set that comprises image and image-level
Pedestrian Detection based on Deep Fusion Network using Feature Correlation
 Pedestrian Detection based on Deep Fusion Network using Feature Correlation Yongwoo Lee, Toan Duc Bui and Jitae Shin School of Electronic and Electrical Engineering, Sungkyunkwan University, Suwon, South
Pedestrian Detection based on Deep Fusion Network using Feature Correlation Yongwoo Lee, Toan Duc Bui and Jitae Shin School of Electronic and Electrical Engineering, Sungkyunkwan University, Suwon, South
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
arxiv: v4 [cs.cv] 6 Jul 2016
![arxiv: v4 [cs.cv] 6 Jul 2016](/thumbs/93/112985717.jpg "arxiv: v4 [cs.cv] 6 Jul 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task
 Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Classification of objects from Video Data (Group 30)
") Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Deconvolutions in Convolutional Neural Networks
 Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Detection III: Analyzing and Debugging Detection Methods
 CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
arxiv: v4 [cs.cv] 21 Jun 2017
![arxiv: v4 [cs.cv] 21 Jun 2017](/thumbs/89/100750447.jpg "arxiv: v4 [cs.cv] 21 Jun 2017") A Fixed-Point Model for Pancreas Segmentation in Abdominal CT Scans Yuyin Zhou 1, Lingxi Xie 2( ), Wei Shen 3, Yan Wang 4, Elliot K. Fishman 5, Alan L. Yuille 6 arxiv:1612.08230v4 [cs.cv] 21 Jun 2017 1,2,3,4,6
A Fixed-Point Model for Pancreas Segmentation in Abdominal CT Scans Yuyin Zhou 1, Lingxi Xie 2( ), Wei Shen 3, Yan Wang 4, Elliot K. Fishman 5, Alan L. Yuille 6 arxiv:1612.08230v4 [cs.cv] 21 Jun 2017 1,2,3,4,6
arxiv: v1 [cs.cv] 5 Oct 2015
![arxiv: v1 [cs.cv] 5 Oct 2015](/thumbs/71/66021937.jpg "arxiv: v1 [cs.cv] 5 Oct 2015") Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Supplementary Material: Unconstrained Salient Object Detection via Proposal Subset Optimization
 Supplementary Material: Unconstrained Salient Object via Proposal Subset Optimization 1. Proof of the Submodularity According to Eqns. 10-12 in our paper, the objective function of the proposed optimization
Supplementary Material: Unconstrained Salient Object via Proposal Subset Optimization 1. Proof of the Submodularity According to Eqns. 10-12 in our paper, the objective function of the proposed optimization
arxiv: v2 [cs.cv] 18 Jul 2017
![arxiv: v2 [cs.cv] 18 Jul 2017](/thumbs/72/67294650.jpg "arxiv: v2 [cs.cv] 18 Jul 2017") PHAM, ITO, KOZAKAYA: BISEG 1 arxiv:1706.02135v2 [cs.cv] 18 Jul 2017 BiSeg: Simultaneous Instance Segmentation and Semantic Segmentation with Fully Convolutional Networks Viet-Quoc Pham quocviet.pham@toshiba.co.jp
PHAM, ITO, KOZAKAYA: BISEG 1 arxiv:1706.02135v2 [cs.cv] 18 Jul 2017 BiSeg: Simultaneous Instance Segmentation and Semantic Segmentation with Fully Convolutional Networks Viet-Quoc Pham quocviet.pham@toshiba.co.jp
Pixel Offset Regression (POR) for Single-shot Instance Segmentation
 for Single-shot Instance Segmentation") Pixel Offset Regression (POR) for Single-shot Instance Segmentation Yuezun Li 1, Xiao Bian 2, Ming-ching Chang 1, Longyin Wen 2 and Siwei Lyu 1 1 University at Albany, State University of New York, NY,
Pixel Offset Regression (POR) for Single-shot Instance Segmentation Yuezun Li 1, Xiao Bian 2, Ming-ching Chang 1, Longyin Wen 2 and Siwei Lyu 1 1 University at Albany, State University of New York, NY,
3 Object Detection. BVM 2018 Tutorial: Advanced Deep Learning Methods. Paul F. Jaeger, Division of Medical Image Computing
 3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
Object Detection. TA : Young-geun Kim. Biostatistics Lab., Seoul National University. March-June, 2018
 Object Detection TA : Young-geun Kim Biostatistics Lab., Seoul National University March-June, 2018 Seoul National University Deep Learning March-June, 2018 1 / 57 Index 1 Introduction 2 R-CNN 3 YOLO 4
Object Detection TA : Young-geun Kim Biostatistics Lab., Seoul National University March-June, 2018 Seoul National University Deep Learning March-June, 2018 1 / 57 Index 1 Introduction 2 R-CNN 3 YOLO 4
Kaggle Data Science Bowl 2017 Technical Report
 Kaggle Data Science Bowl 2017 Technical Report qfpxfd Team May 11, 2017 1 Team Members Table 1: Team members Name E-Mail University Jia Ding dingjia@pku.edu.cn Peking University, Beijing, China Aoxue Li
Kaggle Data Science Bowl 2017 Technical Report qfpxfd Team May 11, 2017 1 Team Members Table 1: Team members Name E-Mail University Jia Ding dingjia@pku.edu.cn Peking University, Beijing, China Aoxue Li
Object Detection. CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR
 Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
arxiv: v1 [cs.cv] 5 Dec 2017
![arxiv: v1 [cs.cv] 5 Dec 2017](/thumbs/87/95895504.jpg "arxiv: v1 [cs.cv] 5 Dec 2017") R-FCN-3000 at 30fps: Decoupling Detection and Classification Bharat Singh*1 Hengduo Li*2 Abhishek Sharma3 Larry S. Davis1 University of Maryland, College Park 1 Fudan University2 Gobasco AI Labs3 arxiv:1712.01802v1
R-FCN-3000 at 30fps: Decoupling Detection and Classification Bharat Singh*1 Hengduo Li*2 Abhishek Sharma3 Larry S. Davis1 University of Maryland, College Park 1 Fudan University2 Gobasco AI Labs3 arxiv:1712.01802v1
Robust Object detection for tiny and dense targets in VHR Aerial Images
 Robust Object detection for tiny and dense targets in VHR Aerial Images Haining Xie 1,Tian Wang 1,Meina Qiao 1,Mengyi Zhang 2,Guangcun Shan 1,Hichem Snoussi 3 1 School of Automation Science and Electrical
Robust Object detection for tiny and dense targets in VHR Aerial Images Haining Xie 1,Tian Wang 1,Meina Qiao 1,Mengyi Zhang 2,Guangcun Shan 1,Hichem Snoussi 3 1 School of Automation Science and Electrical
Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model
 Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model Johnson Hsieh (johnsonhsieh@gmail.com), Alexander Chia (alexchia@stanford.edu) Abstract -- Object occlusion presents a major
Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model Johnson Hsieh (johnsonhsieh@gmail.com), Alexander Chia (alexchia@stanford.edu) Abstract -- Object occlusion presents a major
Object Recognition II
 Object Recognition II Linda Shapiro EE/CSE 576 with CNN slides from Ross Girshick 1 Outline Object detection the task, evaluation, datasets Convolutional Neural Networks (CNNs) overview and history Region-based
Object Recognition II Linda Shapiro EE/CSE 576 with CNN slides from Ross Girshick 1 Outline Object detection the task, evaluation, datasets Convolutional Neural Networks (CNNs) overview and history Region-based
Object detection using Region Proposals (RCNN) Ernest Cheung COMP Presentation
 Ernest Cheung COMP Presentation") Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Actions and Attributes from Wholes and Parts
 Actions and Attributes from Wholes and Parts Georgia Gkioxari UC Berkeley gkioxari@berkeley.edu Ross Girshick Microsoft Research rbg@microsoft.com Jitendra Malik UC Berkeley malik@berkeley.edu Abstract
Actions and Attributes from Wholes and Parts Georgia Gkioxari UC Berkeley gkioxari@berkeley.edu Ross Girshick Microsoft Research rbg@microsoft.com Jitendra Malik UC Berkeley malik@berkeley.edu Abstract
Regionlet Object Detector with Hand-crafted and CNN Feature
 Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
arxiv: v1 [cs.cv] 15 Oct 2018
![arxiv: v1 [cs.cv] 15 Oct 2018](/thumbs/89/99052786.jpg "arxiv: v1 [cs.cv] 15 Oct 2018") Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Supplementary material for Analyzing Filters Toward Efficient ConvNet
 Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Finding Tiny Faces Supplementary Materials
 Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
A Novel Representation and Pipeline for Object Detection
 A Novel Representation and Pipeline for Object Detection Vishakh Hegde Stanford University vishakh@stanford.edu Manik Dhar Stanford University dmanik@stanford.edu Abstract Object detection is an important
A Novel Representation and Pipeline for Object Detection Vishakh Hegde Stanford University vishakh@stanford.edu Manik Dhar Stanford University dmanik@stanford.edu Abstract Object detection is an important
Mimicking Very Efficient Network for Object Detection
 Mimicking Very Efficient Network for Object Detection Quanquan Li 1, Shengying Jin 2, Junjie Yan 1 1 SenseTime 2 Beihang University liquanquan@sensetime.com, jsychffy@gmail.com, yanjunjie@outlook.com Abstract
Mimicking Very Efficient Network for Object Detection Quanquan Li 1, Shengying Jin 2, Junjie Yan 1 1 SenseTime 2 Beihang University liquanquan@sensetime.com, jsychffy@gmail.com, yanjunjie@outlook.com Abstract
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
arxiv: v1 [cs.cv] 24 May 2016
![arxiv: v1 [cs.cv] 24 May 2016](/thumbs/80/80473828.jpg "arxiv: v1 [cs.cv] 24 May 2016") Dense CNN Learning with Equivalent Mappings arxiv:1605.07251v1 [cs.cv] 24 May 2016 Jianxin Wu Chen-Wei Xie Jian-Hao Luo National Key Laboratory for Novel Software Technology, Nanjing University 163 Xianlin
Dense CNN Learning with Equivalent Mappings arxiv:1605.07251v1 [cs.cv] 24 May 2016 Jianxin Wu Chen-Wei Xie Jian-Hao Luo National Key Laboratory for Novel Software Technology, Nanjing University 163 Xianlin
CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm
 CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm Instructions This is an individual assignment. Individual means each student must hand in their
CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm Instructions This is an individual assignment. Individual means each student must hand in their
Hand Detection For Grab-and-Go Groceries
 Hand Detection For Grab-and-Go Groceries Xianlei Qiu Stanford University xianlei@stanford.edu Shuying Zhang Stanford University shuyingz@stanford.edu Abstract Hands detection system is a very critical
Hand Detection For Grab-and-Go Groceries Xianlei Qiu Stanford University xianlei@stanford.edu Shuying Zhang Stanford University shuyingz@stanford.edu Abstract Hands detection system is a very critical
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
R-FCN-3000 at 30fps: Decoupling Detection and Classification
 R-FCN-3000 at 30fps: Decoupling Detection and Classification Bharat Singh* 1 Hengduo Li* 2 Abhishek Sharma 3 Larry S. Davis 1 University of Maryland, College Park 1 Fudan University 2 Gobasco AI Labs 3
R-FCN-3000 at 30fps: Decoupling Detection and Classification Bharat Singh* 1 Hengduo Li* 2 Abhishek Sharma 3 Larry S. Davis 1 University of Maryland, College Park 1 Fudan University 2 Gobasco AI Labs 3
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
SSD: Single Shot MultiBox Detector. Author: Wei Liu et al. Presenter: Siyu Jiang
 SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Part Localization by Exploiting Deep Convolutional Networks
 Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Dense Image Labeling Using Deep Convolutional Neural Networks
 Dense Image Labeling Using Deep Convolutional Neural Networks Md Amirul Islam, Neil Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, MB {amirul, bruce, ywang}@cs.umanitoba.ca
Dense Image Labeling Using Deep Convolutional Neural Networks Md Amirul Islam, Neil Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, MB {amirul, bruce, ywang}@cs.umanitoba.ca
Learning From Weakly Supervised Data by The Expectation Loss SVM (e-svm) algorithm
 algorithm") Learning From Weakly Supervised Data by The Expectation Loss SVM (e-svm) algorithm Jun Zhu Department of Statistics University of California, Los Angeles jzh@ucla.edu Junhua Mao Department of Statistics
Learning From Weakly Supervised Data by The Expectation Loss SVM (e-svm) algorithm Jun Zhu Department of Statistics University of California, Los Angeles jzh@ucla.edu Junhua Mao Department of Statistics
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
Gated Bi-directional CNN for Object Detection
 Gated Bi-directional CNN for Object Detection Xingyu Zeng,, Wanli Ouyang, Bin Yang, Junjie Yan, Xiaogang Wang The Chinese University of Hong Kong, Sensetime Group Limited {xyzeng,wlouyang}@ee.cuhk.edu.hk,
Gated Bi-directional CNN for Object Detection Xingyu Zeng,, Wanli Ouyang, Bin Yang, Junjie Yan, Xiaogang Wang The Chinese University of Hong Kong, Sensetime Group Limited {xyzeng,wlouyang}@ee.cuhk.edu.hk,
Ryerson University CP8208. Soft Computing and Machine Intelligence. Naive Road-Detection using CNNS. Authors: Sarah Asiri - Domenic Curro
 Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Segmenting Objects in Weakly Labeled Videos
 Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Object Detection with YOLO on Artwork Dataset
 Object Detection with YOLO on Artwork Dataset Yihui He Computer Science Department, Xi an Jiaotong University heyihui@stu.xjtu.edu.cn Abstract Person: 0.64 Horse: 0.28 I design a small object detection
Object Detection with YOLO on Artwork Dataset Yihui He Computer Science Department, Xi an Jiaotong University heyihui@stu.xjtu.edu.cn Abstract Person: 0.64 Horse: 0.28 I design a small object detection
Learning to Segment Object Candidates
 Learning to Segment Object Candidates Pedro O. Pinheiro Ronan Collobert Piotr Dollár pedro@opinheiro.com locronan@fb.com pdollar@fb.com Facebook AI Research Abstract Recent object detection systems rely
Learning to Segment Object Candidates Pedro O. Pinheiro Ronan Collobert Piotr Dollár pedro@opinheiro.com locronan@fb.com pdollar@fb.com Facebook AI Research Abstract Recent object detection systems rely
An Object Detection Algorithm based on Deformable Part Models with Bing Features Chunwei Li1, a and Youjun Bu1, b
 5th International Conference on Advanced Materials and Computer Science (ICAMCS 2016) An Object Detection Algorithm based on Deformable Part Models with Bing Features Chunwei Li1, a and Youjun Bu1, b 1
5th International Conference on Advanced Materials and Computer Science (ICAMCS 2016) An Object Detection Algorithm based on Deformable Part Models with Bing Features Chunwei Li1, a and Youjun Bu1, b 1
arxiv: v1 [cs.cv] 30 Apr 2018
![arxiv: v1 [cs.cv] 30 Apr 2018](/thumbs/89/98495424.jpg "arxiv: v1 [cs.cv] 30 Apr 2018") An Anti-fraud System for Car Insurance Claim Based on Visual Evidence Pei Li Univeristy of Notre Dame BingYu Shen University of Notre dame Weishan Dong IBM Research China arxiv:184.1127v1 [cs.cv] 3 Apr
An Anti-fraud System for Car Insurance Claim Based on Visual Evidence Pei Li Univeristy of Notre Dame BingYu Shen University of Notre dame Weishan Dong IBM Research China arxiv:184.1127v1 [cs.cv] 3 Apr
Final Report: Smart Trash Net: Waste Localization and Classification
 Final Report: Smart Trash Net: Waste Localization and Classification Oluwasanya Awe oawe@stanford.edu Robel Mengistu robel@stanford.edu December 15, 2017 Vikram Sreedhar vsreed@stanford.edu Abstract Given
Final Report: Smart Trash Net: Waste Localization and Classification Oluwasanya Awe oawe@stanford.edu Robel Mengistu robel@stanford.edu December 15, 2017 Vikram Sreedhar vsreed@stanford.edu Abstract Given
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network
 Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
Conditional Random Fields as Recurrent Neural Networks
 BIL722 - Deep Learning for Computer Vision Conditional Random Fields as Recurrent Neural Networks S. Zheng, S. Jayasumana, B. Romera-Paredes V. Vineet, Z. Su, D. Du, C. Huang, P.H.S. Torr Introduction
BIL722 - Deep Learning for Computer Vision Conditional Random Fields as Recurrent Neural Networks S. Zheng, S. Jayasumana, B. Romera-Paredes V. Vineet, Z. Su, D. Du, C. Huang, P.H.S. Torr Introduction
Rich feature hierarchies for accurate object detection and semantic segmentation
 Rich feature hierarchies for accurate object detection and semantic segmentation BY; ROSS GIRSHICK, JEFF DONAHUE, TREVOR DARRELL AND JITENDRA MALIK PRESENTER; MUHAMMAD OSAMA Object detection vs. classification
Rich feature hierarchies for accurate object detection and semantic segmentation BY; ROSS GIRSHICK, JEFF DONAHUE, TREVOR DARRELL AND JITENDRA MALIK PRESENTER; MUHAMMAD OSAMA Object detection vs. classification
Study of Residual Networks for Image Recognition
 Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Object Detection and Its Implementation on Android Devices
 Object Detection and Its Implementation on Android Devices Zhongjie Li Stanford University 450 Serra Mall, Stanford, CA 94305 jay2015@stanford.edu Rao Zhang Stanford University 450 Serra Mall, Stanford,
Object Detection and Its Implementation on Android Devices Zhongjie Li Stanford University 450 Serra Mall, Stanford, CA 94305 jay2015@stanford.edu Rao Zhang Stanford University 450 Serra Mall, Stanford,
Object Detection on Self-Driving Cars in China. Lingyun Li
 Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
PT-NET: IMPROVE OBJECT AND FACE DETECTION VIA A PRE-TRAINED CNN MODEL
 PT-NET: IMPROVE OBJECT AND FACE DETECTION VIA A PRE-TRAINED CNN MODEL Yingxin Lou 1, Guangtao Fu 2, Zhuqing Jiang 1, Aidong Men 1, and Yun Zhou 2 1 Beijing University of Posts and Telecommunications, Beijing,
PT-NET: IMPROVE OBJECT AND FACE DETECTION VIA A PRE-TRAINED CNN MODEL Yingxin Lou 1, Guangtao Fu 2, Zhuqing Jiang 1, Aidong Men 1, and Yun Zhou 2 1 Beijing University of Posts and Telecommunications, Beijing,
An Exploration of Computer Vision Techniques for Bird Species Classification
 An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren Kaiming He Ross Girshick Jian Sun Present by: Yixin Yang Mingdong Wang 1 Object Detection 2 1 Applications Basic
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren Kaiming He Ross Girshick Jian Sun Present by: Yixin Yang Mingdong Wang 1 Object Detection 2 1 Applications Basic
Vehicle Classification on Low-resolution and Occluded images: A low-cost labeled dataset for augmentation
 Vehicle Classification on Low-resolution and Occluded images: A low-cost labeled dataset for augmentation Anonymous Author(s) Affiliation Address email Abstract 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Video image
Vehicle Classification on Low-resolution and Occluded images: A low-cost labeled dataset for augmentation Anonymous Author(s) Affiliation Address email Abstract 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Video image
Elastic Neural Networks for Classification
 Elastic Neural Networks for Classification Yi Zhou 1, Yue Bai 1, Shuvra S. Bhattacharyya 1, 2 and Heikki Huttunen 1 1 Tampere University of Technology, Finland, 2 University of Maryland, USA arxiv:1810.00589v3
Elastic Neural Networks for Classification Yi Zhou 1, Yue Bai 1, Shuvra S. Bhattacharyya 1, 2 and Heikki Huttunen 1 1 Tampere University of Technology, Finland, 2 University of Maryland, USA arxiv:1810.00589v3
When Big Datasets are Not Enough: The need for visual virtual worlds.
 When Big Datasets are Not Enough: The need for visual virtual worlds. Alan Yuille Bloomberg Distinguished Professor Departments of Cognitive Science and Computer Science Johns Hopkins University Computational
When Big Datasets are Not Enough: The need for visual virtual worlds. Alan Yuille Bloomberg Distinguished Professor Departments of Cognitive Science and Computer Science Johns Hopkins University Computational
Adversarial Examples for Semantic Segmentation and Object Detection
 Adversarial Examples for Semantic Segmentation and Object Detection Cihang Xie 1, Jianyu Wang 2, Zhishuai Zhang 1, Yuyin Zhou 1, Lingxi Xie 1( ), Alan Yuille 1 1 Department of Computer Science, The Johns
Adversarial Examples for Semantic Segmentation and Object Detection Cihang Xie 1, Jianyu Wang 2, Zhishuai Zhang 1, Yuyin Zhou 1, Lingxi Xie 1( ), Alan Yuille 1 1 Department of Computer Science, The Johns
Classifying a specific image region using convolutional nets with an ROI mask as input
 Classifying a specific image region using convolutional nets with an ROI mask as input 1 Sagi Eppel Abstract Convolutional neural nets (CNN) are the leading computer vision method for classifying images.
Classifying a specific image region using convolutional nets with an ROI mask as input 1 Sagi Eppel Abstract Convolutional neural nets (CNN) are the leading computer vision method for classifying images.