Enabling Contiguous Node Scheduling on the Cray XT3
|
|
|
- Stella Newman
- 5 years ago
- Views:
Transcription
1 Enabling Contiguous Node Scheduling on the Cray XT3 Chad Vizino Pittsburgh Supercomputing Center Cray User Group Helsinki, Finland May 2008 With acknowledgements to Deborah Weisser, Jared Yanovich, Derek Simmel, Abhinav Bhatele, and Adam Liwo CUG 2008
2 Overview Introduction to machine Previous work System changes to help improve application performance for - Topologically unaware codes - Topologically aware codes Conclusion CUG
3 PSC S Cray XT3 CUG

4 Cray XT3 Arch. Overview SMW = System Mgmt Workstation CUG 2008 Full machine is 11x12x16 4 Illustration courtesy Cray, Inc.
5 Previous Work 2005, Batch Scheduling on the Cray XT3 - Batch system on harness system 2006, XT3 Operational Enhancements - Batch system with CPA - Graphical monitor CUG

6 CUG

7 CUG


8 CUG
9 Optimizing Job Placement 2006, Optimizing Job Placement on the XT3, Weisser et al. Quantified effects of job layout on communication intensive codes: App P Placed: Default Placed: Opt Prod Ave Prod Std Dev Opt vs. Prod Ave PTRANS gb/s gb/s gb/s 21.2 gb/s 11.7% DNSmsp s s s 9.2 s 4.7% DNSmsp s s s 23.5 s 10.3% NAMD s s s 13.1 s 9.8% NAMD s s s 12.2 s 9.4% CUG 2008 DNSmsp numerical sim. Code for analysis of turbulence; NAMD MD code 9
10 Outcome Jobs assigned in cubes or near-cubes will have lowest communication contention - Contiguous is good! Assign jobs to processors in directly connected cabinets - Assign down one row in X-major order Then down other row CUG
11 CUG

12 CUG

13 CUG


14 Cray XT3 Compute Cabinet VRM = Voltage Regulator Module SCM = Shelf Controller Module PDU = Power Distribution Unit CUG Illustration courtesy Cray, Inc.
15 CUG

16 CUG

17 CUG
18 CUG
19 CUG

20 2
21

22
23
24 Outcome Jobs assigned in cubes or near-cubes will have lowest communication contention - Contiguous is good! Assign jobs to processors in directly connected cabinets - Assign down one row in X-major order Then down other row CUG
25 System changes to benefit all jobs Code scheduler to assign free nodes according to predefined optimal order Order free list according to an optimal order mask - Doesn t slow down scheduler - Fragmentation Pass list to CPA via pbs_mom - CPA does not get to do node selection CUG
26 Optimal order mask [See for animation.] CUG

27 Optimized vs. Numeric Order [See for animation.] CUG
28 What if users know what they want? How do you give users a shape? - System issues Batch system Node ids How can they tell what they got? CUG
29 OpenAtom Improving parallel scaling performance using topology-aware task mapping on Cray XT3 and IBM Blue Gene/L, Bhatele, Bohm and Kale Molecular Dynamics code Benchmarks used to measure OpenAtom - WATER_32M_70Ry - WATER_256M_70Ry CUG
30 OpenAtom Results Performance of OpenAtom Using MD WATER benchmark - Single core per node - Times represent time per step in seconds Processors 32M_70Ry Default 32M_70Ry Topology % Speedup 256M_70Ry Default 256M_70R y Topology % Speedup CUG
31 OpenAtom Results Using WATER benchmark - Two cores per node - Times represent time per step in seconds Processors 32M_70Ry Default 32M_70Ry Topology % Speedup 256M_70Ry Default 256M_70Ry Default % Speedup CUG
32 OpenAtom Provide specific shapes: - 8x8x16=1024, 8x8x8=512, 8x8x4=256, 8x4x4=128 Provide node id/dimension mapping CUG
33 System issues First Pass Provide 4 shape reservations and transition as needed Problems - Time consuming - Admin in the loop while running CUG
34 System Issues Second Pass Provide 1 shape reservation - 8x8x16=1024 Provide nid shape lists to yod - Developed script to get shape for reservation From SDB - yod list `cat /usr/local/shapes/xxyxz.rl` CUG
35 Roadblocks Topology information scarce on XT3 - int rca_get_meshcoord(uint16_t nid, rca_mesh_coord_t *xyz); Nodes can be down so must pick around them or not run at all CUG

36 3
37
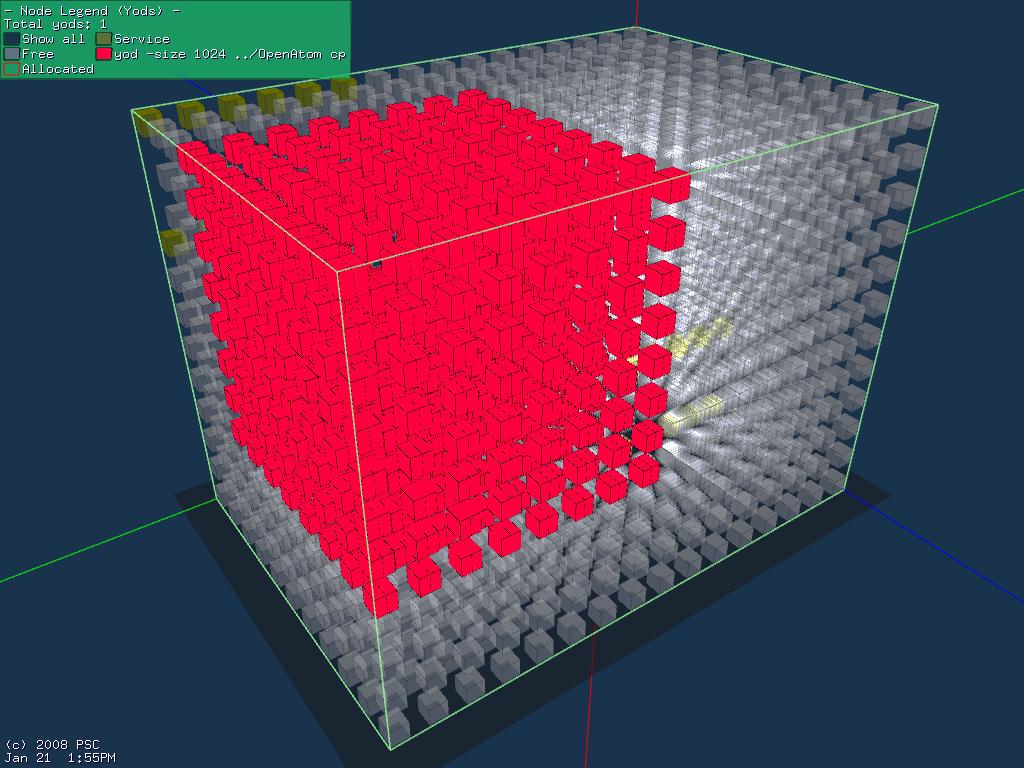

38
39


40

41

42

43
44 OpenAtom Conclusions 20% speedup for single core 38% speedup for dual core difficulties in obtaining topology information on XT3 project that topology-aware mapping should yield improvements proportional to torus size on larger XT3 or XT4 installations. CUG 2008
45 Another Topo-aware Case Adam Liwo, Czarek Czaplewski, Stan Oldziej, and Harold Scheraga Molecular dynamics force field simulator for predicting the structure and properties of proteins No reference to cite yet CUG
46 Molecular Dynamics Code Goal is to speed up simulations by running many in parallel Need to decompose code - Coarse-grain level - Infrequent communications - Fine-grain level - Frequent communications - Small number of cores CUG

47 4
48
49 Future Work Gather more statistics on nid ordering benefit Deal with fragmentation issues Work into production model - Allow users to specify shape reservations - Figure out how to make topology information more accessible Test under Compute Node Linux CUG
50 Conclusion Contiguous placement can influence code performance System changes have provided benefit to both regular and special needs jobs Cray provided way to get topology information would help our users CUG
Enabling Contiguous Node Scheduling on the Cray XT3
 Enabling Contiguous Node Scheduling on the Cray XT3 Chad Vizino vizino@psc.edu Pittsburgh Supercomputing Center ABSTRACT: The Pittsburgh Supercomputing Center has enabled contiguous node scheduling to
Enabling Contiguous Node Scheduling on the Cray XT3 Chad Vizino vizino@psc.edu Pittsburgh Supercomputing Center ABSTRACT: The Pittsburgh Supercomputing Center has enabled contiguous node scheduling to
A CASE STUDY OF COMMUNICATION OPTIMIZATIONS ON 3D MESH INTERCONNECTS
 A CASE STUDY OF COMMUNICATION OPTIMIZATIONS ON 3D MESH INTERCONNECTS Abhinav Bhatele, Eric Bohm, Laxmikant V. Kale Parallel Programming Laboratory Euro-Par 2009 University of Illinois at Urbana-Champaign
A CASE STUDY OF COMMUNICATION OPTIMIZATIONS ON 3D MESH INTERCONNECTS Abhinav Bhatele, Eric Bohm, Laxmikant V. Kale Parallel Programming Laboratory Euro-Par 2009 University of Illinois at Urbana-Champaign
IS TOPOLOGY IMPORTANT AGAIN? Effects of Contention on Message Latencies in Large Supercomputers
 IS TOPOLOGY IMPORTANT AGAIN? Effects of Contention on Message Latencies in Large Supercomputers Abhinav S Bhatele and Laxmikant V Kale ACM Research Competition, SC 08 Outline Why should we consider topology
IS TOPOLOGY IMPORTANT AGAIN? Effects of Contention on Message Latencies in Large Supercomputers Abhinav S Bhatele and Laxmikant V Kale ACM Research Competition, SC 08 Outline Why should we consider topology
Batch Scheduling on XT3
 Batch Scheduling on XT3 Chad Vizino Pittsburgh Supercomputing Center Overview Simon Scheduler Design Features XT3 Scheduling at PSC Past Present Future Back to the Future! Scheduler Design
Batch Scheduling on XT3 Chad Vizino Pittsburgh Supercomputing Center Overview Simon Scheduler Design Features XT3 Scheduling at PSC Past Present Future Back to the Future! Scheduler Design
Abhinav Bhatele, Laxmikant V. Kale University of Illinois at Urbana Champaign Sameer Kumar IBM T. J. Watson Research Center
 Abhinav Bhatele, Laxmikant V. Kale University of Illinois at Urbana Champaign Sameer Kumar IBM T. J. Watson Research Center Motivation: Contention Experiments Bhatele, A., Kale, L. V. 2008 An Evaluation
Abhinav Bhatele, Laxmikant V. Kale University of Illinois at Urbana Champaign Sameer Kumar IBM T. J. Watson Research Center Motivation: Contention Experiments Bhatele, A., Kale, L. V. 2008 An Evaluation
Charm++ for Productivity and Performance
 Charm++ for Productivity and Performance A Submission to the 2011 HPC Class II Challenge Laxmikant V. Kale Anshu Arya Abhinav Bhatele Abhishek Gupta Nikhil Jain Pritish Jetley Jonathan Lifflander Phil
Charm++ for Productivity and Performance A Submission to the 2011 HPC Class II Challenge Laxmikant V. Kale Anshu Arya Abhinav Bhatele Abhishek Gupta Nikhil Jain Pritish Jetley Jonathan Lifflander Phil
Scalable Topology Aware Object Mapping for Large Supercomputers
 Scalable Topology Aware Object Mapping for Large Supercomputers Abhinav Bhatele (bhatele@illinois.edu) Department of Computer Science, University of Illinois at Urbana-Champaign Advisor: Laxmikant V. Kale
Scalable Topology Aware Object Mapping for Large Supercomputers Abhinav Bhatele (bhatele@illinois.edu) Department of Computer Science, University of Illinois at Urbana-Champaign Advisor: Laxmikant V. Kale
Toward Runtime Power Management of Exascale Networks by On/Off Control of Links
 Toward Runtime Power Management of Exascale Networks by On/Off Control of Links, Nikhil Jain, Laxmikant Kale University of Illinois at Urbana-Champaign HPPAC May 20, 2013 1 Power challenge Power is a major
Toward Runtime Power Management of Exascale Networks by On/Off Control of Links, Nikhil Jain, Laxmikant Kale University of Illinois at Urbana-Champaign HPPAC May 20, 2013 1 Power challenge Power is a major
NAMD Serial and Parallel Performance
 NAMD Serial and Parallel Performance Jim Phillips Theoretical Biophysics Group Serial performance basics Main factors affecting serial performance: Molecular system size and composition. Cutoff distance
NAMD Serial and Parallel Performance Jim Phillips Theoretical Biophysics Group Serial performance basics Main factors affecting serial performance: Molecular system size and composition. Cutoff distance
Topology, Bandwidth and Performance: A New Approach in Linear Orderings for Application Placement in a 3D Torus
 Topology, Bandwidth and Performance: A New Approach in Linear Orderings for Application Placement in a 3D Torus Carl Albing Cray Inc., University of Reading; Norm Troullier, Stephen Whalen, Ryan Olson,
Topology, Bandwidth and Performance: A New Approach in Linear Orderings for Application Placement in a 3D Torus Carl Albing Cray Inc., University of Reading; Norm Troullier, Stephen Whalen, Ryan Olson,
A Case Study of Communication Optimizations on 3D Mesh Interconnects
 A Case Study of Communication Optimizations on 3D Mesh Interconnects Abhinav Bhatelé, Eric Bohm, and Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign, Urbana,
A Case Study of Communication Optimizations on 3D Mesh Interconnects Abhinav Bhatelé, Eric Bohm, and Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign, Urbana,
Tutorial: Application MPI Task Placement
 Tutorial: Application MPI Task Placement Juan Galvez Nikhil Jain Palash Sharma PPL, University of Illinois at Urbana-Champaign Tutorial Outline Why Task Mapping on Blue Waters? When to do mapping? How
Tutorial: Application MPI Task Placement Juan Galvez Nikhil Jain Palash Sharma PPL, University of Illinois at Urbana-Champaign Tutorial Outline Why Task Mapping on Blue Waters? When to do mapping? How
Blue Waters I/O Performance
 Blue Waters I/O Performance Mark Swan Performance Group Cray Inc. Saint Paul, Minnesota, USA mswan@cray.com Doug Petesch Performance Group Cray Inc. Saint Paul, Minnesota, USA dpetesch@cray.com Abstract
Blue Waters I/O Performance Mark Swan Performance Group Cray Inc. Saint Paul, Minnesota, USA mswan@cray.com Doug Petesch Performance Group Cray Inc. Saint Paul, Minnesota, USA dpetesch@cray.com Abstract
Optimizing communication for Charm++ applications by reducing network contention
 CONCURRENCY AND COMPUTATION: PRACTICE AND EXPERIENCE Concurrency Computat.: Pract. Exper. 2009; 00:1 7 [Version: 2002/09/19 v2.02] Optimizing communication for Charm++ applications by reducing network
CONCURRENCY AND COMPUTATION: PRACTICE AND EXPERIENCE Concurrency Computat.: Pract. Exper. 2009; 00:1 7 [Version: 2002/09/19 v2.02] Optimizing communication for Charm++ applications by reducing network
Update on Topology Aware Scheduling (aka TAS)
") Update on Topology Aware Scheduling (aka TAS) Work done in collaboration with J. Enos, G. Bauer, R. Brunner, S. Islam R. Fiedler Adaptive Computing 2 When things look good Image credit: Dave Semeraro 3
Update on Topology Aware Scheduling (aka TAS) Work done in collaboration with J. Enos, G. Bauer, R. Brunner, S. Islam R. Fiedler Adaptive Computing 2 When things look good Image credit: Dave Semeraro 3
PREDICTING COMMUNICATION PERFORMANCE
 PREDICTING COMMUNICATION PERFORMANCE Nikhil Jain CASC Seminar, LLNL This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract
PREDICTING COMMUNICATION PERFORMANCE Nikhil Jain CASC Seminar, LLNL This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract
TraceR: A Parallel Trace Replay Tool for Studying Interconnection Networks
 TraceR: A Parallel Trace Replay Tool for Studying Interconnection Networks Bilge Acun, PhD Candidate Department of Computer Science University of Illinois at Urbana- Champaign *Contributors: Nikhil Jain,
TraceR: A Parallel Trace Replay Tool for Studying Interconnection Networks Bilge Acun, PhD Candidate Department of Computer Science University of Illinois at Urbana- Champaign *Contributors: Nikhil Jain,
Automated Mapping of Regular Communication Graphs on Mesh Interconnects
 Automated Mapping of Regular Communication Graphs on Mesh Interconnects Abhinav Bhatele, Gagan Gupta, Laxmikant V. Kale and I-Hsin Chung Motivation Running a parallel application on a linear array of processors:
Automated Mapping of Regular Communication Graphs on Mesh Interconnects Abhinav Bhatele, Gagan Gupta, Laxmikant V. Kale and I-Hsin Chung Motivation Running a parallel application on a linear array of processors:
Porting SLURM to the Cray XT and XE. Neil Stringfellow and Gerrit Renker
 Porting SLURM to the Cray XT and XE Neil Stringfellow and Gerrit Renker Background Cray XT/XE basics Cray XT systems are among the largest in the world 9 out of the top 30 machines on the top500 list June
Porting SLURM to the Cray XT and XE Neil Stringfellow and Gerrit Renker Background Cray XT/XE basics Cray XT systems are among the largest in the world 9 out of the top 30 machines on the top500 list June
Executing dynamic heterogeneous workloads on Blue Waters with RADICAL-Pilot
 Executing dynamic heterogeneous workloads on Blue Waters with RADICAL-Pilot Research in Advanced DIstributed Cyberinfrastructure & Applications Laboratory (RADICAL) Rutgers University http://radical.rutgers.edu
Executing dynamic heterogeneous workloads on Blue Waters with RADICAL-Pilot Research in Advanced DIstributed Cyberinfrastructure & Applications Laboratory (RADICAL) Rutgers University http://radical.rutgers.edu
*University of Illinois at Urbana Champaign/NCSA Bell Labs
 Analysis of Gemini Interconnect Recovery Mechanisms: Methods and Observations Saurabh Jha*, Valerio Formicola*, Catello Di Martino, William Kramer*, Zbigniew Kalbarczyk*, Ravishankar K. Iyer* *University
Analysis of Gemini Interconnect Recovery Mechanisms: Methods and Observations Saurabh Jha*, Valerio Formicola*, Catello Di Martino, William Kramer*, Zbigniew Kalbarczyk*, Ravishankar K. Iyer* *University
SLURM Operation on Cray XT and XE
 SLURM Operation on Cray XT and XE Morris Jette jette@schedmd.com Contributors and Collaborators This work was supported by the Oak Ridge National Laboratory Extreme Scale Systems Center. Swiss National
SLURM Operation on Cray XT and XE Morris Jette jette@schedmd.com Contributors and Collaborators This work was supported by the Oak Ridge National Laboratory Extreme Scale Systems Center. Swiss National
Resource allocation and utilization in the Blue Gene/L supercomputer
 Resource allocation and utilization in the Blue Gene/L supercomputer Tamar Domany, Y Aridor, O Goldshmidt, Y Kliteynik, EShmueli, U Silbershtein IBM Labs in Haifa Agenda Blue Gene/L Background Blue Gene/L
Resource allocation and utilization in the Blue Gene/L supercomputer Tamar Domany, Y Aridor, O Goldshmidt, Y Kliteynik, EShmueli, U Silbershtein IBM Labs in Haifa Agenda Blue Gene/L Background Blue Gene/L
Introduction to Molecular Dynamics on ARCHER: Instructions for running parallel jobs on ARCHER
 Introduction to Molecular Dynamics on ARCHER: Instructions for running parallel jobs on ARCHER 1 Introduction This handout contains basic instructions for how to login in to ARCHER and submit jobs to the
Introduction to Molecular Dynamics on ARCHER: Instructions for running parallel jobs on ARCHER 1 Introduction This handout contains basic instructions for how to login in to ARCHER and submit jobs to the
QUANTIFYING NETWORK CONTENTION ON LARGE PARALLEL MACHINES
 Parallel Processing Letters c World Scientific Publishing Company QUANTIFYING NETWORK CONTENTION ON LARGE PARALLEL MACHINES Abhinav Bhatelé Department of Computer Science University of Illinois at Urbana-Champaign
Parallel Processing Letters c World Scientific Publishing Company QUANTIFYING NETWORK CONTENTION ON LARGE PARALLEL MACHINES Abhinav Bhatelé Department of Computer Science University of Illinois at Urbana-Champaign
Large Scale Visualization on the Cray XT3 Using ParaView
 Large Scale Visualization on the Cray XT3 Using ParaView Cray User s Group 2008 May 8, 2008 Kenneth Moreland David Rogers John Greenfield Sandia National Laboratories Alexander Neundorf Technical University
Large Scale Visualization on the Cray XT3 Using ParaView Cray User s Group 2008 May 8, 2008 Kenneth Moreland David Rogers John Greenfield Sandia National Laboratories Alexander Neundorf Technical University
Our Workshop Environment
 Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2015 Our Environment Today Your laptops or workstations: only used for portal access Blue Waters
Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2015 Our Environment Today Your laptops or workstations: only used for portal access Blue Waters
Laplace Exercise Solution Review
 Laplace Exercise Solution Review John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Finished? If you have finished, we can review a few principles that you have inevitably
Laplace Exercise Solution Review John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Finished? If you have finished, we can review a few principles that you have inevitably
The Red Storm System: Architecture, System Update and Performance Analysis
 The Red Storm System: Architecture, System Update and Performance Analysis Douglas Doerfler, Jim Tomkins Sandia National Laboratories Center for Computation, Computers, Information and Mathematics LACSI
The Red Storm System: Architecture, System Update and Performance Analysis Douglas Doerfler, Jim Tomkins Sandia National Laboratories Center for Computation, Computers, Information and Mathematics LACSI
NAMD at Extreme Scale. Presented by: Eric Bohm Team: Eric Bohm, Chao Mei, Osman Sarood, David Kunzman, Yanhua, Sun, Jim Phillips, John Stone, LV Kale
 NAMD at Extreme Scale Presented by: Eric Bohm Team: Eric Bohm, Chao Mei, Osman Sarood, David Kunzman, Yanhua, Sun, Jim Phillips, John Stone, LV Kale Overview NAMD description Power7 Tuning Support for
NAMD at Extreme Scale Presented by: Eric Bohm Team: Eric Bohm, Chao Mei, Osman Sarood, David Kunzman, Yanhua, Sun, Jim Phillips, John Stone, LV Kale Overview NAMD description Power7 Tuning Support for
Moab Workload Manager on Cray XT3
 Moab Workload Manager on Cray XT3 presented by Don Maxwell (ORNL) Michael Jackson (Cluster Resources, Inc.) MOAB Workload Manager on Cray XT3 Why MOAB? Requirements Features Support/Futures 2 Why Moab?
Moab Workload Manager on Cray XT3 presented by Don Maxwell (ORNL) Michael Jackson (Cluster Resources, Inc.) MOAB Workload Manager on Cray XT3 Why MOAB? Requirements Features Support/Futures 2 Why Moab?
Jai Menon and the rest of the team IBM Research Autonomic Storage Systems April 11, 2002
 Jai Menon and the rest of the team IBM Research Autonomic Storage Systems April 11, 2002 Copyright IBM Corporation 2000. All rights reserved. Presentation File Name Why do we need Autonomic Storage? Storage
Jai Menon and the rest of the team IBM Research Autonomic Storage Systems April 11, 2002 Copyright IBM Corporation 2000. All rights reserved. Presentation File Name Why do we need Autonomic Storage? Storage
Mass Storage at the PSC
 Phil Andrews Manager, Data Intensive Systems Mass Storage at the PSC Pittsburgh Supercomputing Center, 4400 Fifth Ave, Pittsburgh Pa 15213, USA EMail:andrews@psc.edu Last modified: Mon May 12 18:03:43
Phil Andrews Manager, Data Intensive Systems Mass Storage at the PSC Pittsburgh Supercomputing Center, 4400 Fifth Ave, Pittsburgh Pa 15213, USA EMail:andrews@psc.edu Last modified: Mon May 12 18:03:43
Heuristic-based techniques for mapping irregular communication graphs to mesh topologies
 Heuristic-based techniques for mapping irregular communication graphs to mesh topologies Abhinav Bhatele and Laxmikant V. Kale University of Illinois at Urbana-Champaign LLNL-PRES-495871, P. O. Box 808,
Heuristic-based techniques for mapping irregular communication graphs to mesh topologies Abhinav Bhatele and Laxmikant V. Kale University of Illinois at Urbana-Champaign LLNL-PRES-495871, P. O. Box 808,
Real Parallel Computers
 Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
High-Performance Remote File I/O for the XT3 Nathan Stone Pittsburgh Supercomputing Center a.k.a. PITTSC
 High-Performance Remote File I/O for the XT3 Nathan Stone Pittsburgh Supercomputing Center a.k.a. PITTSC Nathan Stone - Portals Direct I/O - CUG'06 Explicit User Demand (!) The Woodward collaboration (umn.edu)
High-Performance Remote File I/O for the XT3 Nathan Stone Pittsburgh Supercomputing Center a.k.a. PITTSC Nathan Stone - Portals Direct I/O - CUG'06 Explicit User Demand (!) The Woodward collaboration (umn.edu)
The MOSIX Algorithms for Managing Cluster, Multi-Clusters, GPU Clusters and Clouds
 The MOSIX Algorithms for Managing Cluster, Multi-Clusters, GPU Clusters and Clouds Prof. Amnon Barak Department of Computer Science The Hebrew University of Jerusalem http:// www. MOSIX. Org 1 Background
The MOSIX Algorithms for Managing Cluster, Multi-Clusters, GPU Clusters and Clouds Prof. Amnon Barak Department of Computer Science The Hebrew University of Jerusalem http:// www. MOSIX. Org 1 Background
The Spider Center-Wide File System
 The Spider Center-Wide File System Presented by Feiyi Wang (Ph.D.) Technology Integration Group National Center of Computational Sciences Galen Shipman (Group Lead) Dave Dillow, Sarp Oral, James Simmons,
The Spider Center-Wide File System Presented by Feiyi Wang (Ph.D.) Technology Integration Group National Center of Computational Sciences Galen Shipman (Group Lead) Dave Dillow, Sarp Oral, James Simmons,
Running Jobs on Blue Waters. Greg Bauer
 Running Jobs on Blue Waters Greg Bauer Policies and Practices Placement Checkpointing Monitoring a job Getting a nodelist Viewing the torus 2 Resource and Job Scheduling Policies Runtime limits expected
Running Jobs on Blue Waters Greg Bauer Policies and Practices Placement Checkpointing Monitoring a job Getting a nodelist Viewing the torus 2 Resource and Job Scheduling Policies Runtime limits expected
The STREAM Benchmark. John D. McCalpin, Ph.D. IBM eserver Performance ^ Performance
 The STREAM Benchmark John D. McCalpin, Ph.D. IBM eserver Performance 2005-01-27 History Scientific computing was largely based on the vector paradigm from the late 1970 s through the 1980 s E.g., the classic
The STREAM Benchmark John D. McCalpin, Ph.D. IBM eserver Performance 2005-01-27 History Scientific computing was largely based on the vector paradigm from the late 1970 s through the 1980 s E.g., the classic
Implementing a Hierarchical Storage Management system in a large-scale Lustre and HPSS environment
 Implementing a Hierarchical Storage Management system in a large-scale Lustre and HPSS environment Brett Bode, Michelle Butler, Sean Stevens, Jim Glasgow National Center for Supercomputing Applications/University
Implementing a Hierarchical Storage Management system in a large-scale Lustre and HPSS environment Brett Bode, Michelle Butler, Sean Stevens, Jim Glasgow National Center for Supercomputing Applications/University
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Dr. Gengbin Zheng and Ehsan Totoni. Parallel Programming Laboratory University of Illinois at Urbana-Champaign
 Dr. Gengbin Zheng and Ehsan Totoni Parallel Programming Laboratory University of Illinois at Urbana-Champaign April 18, 2011 A function level simulator for parallel applications on peta scale machine An
Dr. Gengbin Zheng and Ehsan Totoni Parallel Programming Laboratory University of Illinois at Urbana-Champaign April 18, 2011 A function level simulator for parallel applications on peta scale machine An
Challenges in large-scale graph processing on HPC platforms and the Graph500 benchmark. by Nkemdirim Dockery
 Challenges in large-scale graph processing on HPC platforms and the Graph500 benchmark by Nkemdirim Dockery High Performance Computing Workloads Core-memory sized Floating point intensive Well-structured
Challenges in large-scale graph processing on HPC platforms and the Graph500 benchmark by Nkemdirim Dockery High Performance Computing Workloads Core-memory sized Floating point intensive Well-structured
Technical Computing Suite supporting the hybrid system
 Technical Computing Suite supporting the hybrid system Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster Hybrid System Configuration Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster 6D mesh/torus Interconnect
Technical Computing Suite supporting the hybrid system Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster Hybrid System Configuration Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster 6D mesh/torus Interconnect
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance
 Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance Jonathan Lifflander*, Esteban Meneses, Harshitha Menon*, Phil Miller*, Sriram Krishnamoorthy, Laxmikant V. Kale* jliffl2@illinois.edu,
Scalable Replay with Partial-Order Dependencies for Message-Logging Fault Tolerance Jonathan Lifflander*, Esteban Meneses, Harshitha Menon*, Phil Miller*, Sriram Krishnamoorthy, Laxmikant V. Kale* jliffl2@illinois.edu,
LOAD BALANCING DISTRIBUTED OPERATING SYSTEMS, SCALABILITY, SS Hermann Härtig
 LOAD BALANCING DISTRIBUTED OPERATING SYSTEMS, SCALABILITY, SS 2016 Hermann Härtig LECTURE OBJECTIVES starting points independent Unix processes and block synchronous execution which component (point in
LOAD BALANCING DISTRIBUTED OPERATING SYSTEMS, SCALABILITY, SS 2016 Hermann Härtig LECTURE OBJECTIVES starting points independent Unix processes and block synchronous execution which component (point in
Real Parallel Computers
 Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Operating Systems (2INC0) 2017/18
 2017/18") Operating Systems (2INC0) 2017/18 Memory Management (09) Dr. Courtesy of Dr. I. Radovanovic, Dr. R. Mak (figures from Bic & Shaw) System Architecture and Networking Group Agenda Reminder: OS & resources
Operating Systems (2INC0) 2017/18 Memory Management (09) Dr. Courtesy of Dr. I. Radovanovic, Dr. R. Mak (figures from Bic & Shaw) System Architecture and Networking Group Agenda Reminder: OS & resources
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Toward portable I/O performance by leveraging system abstractions of deep memory and interconnect hierarchies
 Toward portable I/O performance by leveraging system abstractions of deep memory and interconnect hierarchies François Tessier, Venkatram Vishwanath, Paul Gressier Argonne National Laboratory, USA Wednesday
Toward portable I/O performance by leveraging system abstractions of deep memory and interconnect hierarchies François Tessier, Venkatram Vishwanath, Paul Gressier Argonne National Laboratory, USA Wednesday
The MOSIX Algorithms for Managing Cluster, Multi-Clusters, GPU Clusters and Clouds
 The MOSIX Algorithms for Managing Cluster, Multi-Clusters, GPU Clusters and Clouds Prof. Amnon Barak Department of Computer Science The Hebrew University of Jerusalem http:// www. MOSIX. Org 1 Background
The MOSIX Algorithms for Managing Cluster, Multi-Clusters, GPU Clusters and Clouds Prof. Amnon Barak Department of Computer Science The Hebrew University of Jerusalem http:// www. MOSIX. Org 1 Background
Our Workshop Environment
 Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Our Environment This Week Your laptops or workstations: only used for portal access Bridges
Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Our Environment This Week Your laptops or workstations: only used for portal access Bridges
OPERATING SYSTEM. PREPARED BY : DHAVAL R. PATEL Page 1. Q.1 Explain Memory
 Q.1 Explain Memory Data Storage in storage device like CD, HDD, DVD, Pen drive etc, is called memory. The device which storage data is called storage device. E.g. hard disk, floppy etc. There are two types
Q.1 Explain Memory Data Storage in storage device like CD, HDD, DVD, Pen drive etc, is called memory. The device which storage data is called storage device. E.g. hard disk, floppy etc. There are two types
Short Talk: System abstractions to facilitate data movement in supercomputers with deep memory and interconnect hierarchy
 Short Talk: System abstractions to facilitate data movement in supercomputers with deep memory and interconnect hierarchy François Tessier, Venkatram Vishwanath Argonne National Laboratory, USA July 19,
Short Talk: System abstractions to facilitate data movement in supercomputers with deep memory and interconnect hierarchy François Tessier, Venkatram Vishwanath Argonne National Laboratory, USA July 19,
Cray XT Series System Overview S
 Cray XT Series System Overview S 2423 20 2004 2007 Cray Inc. All Rights Reserved. This manual or parts thereof may not be reproduced in any form unless permitted by contract or by written permission of
Cray XT Series System Overview S 2423 20 2004 2007 Cray Inc. All Rights Reserved. This manual or parts thereof may not be reproduced in any form unless permitted by contract or by written permission of
Exercises: April 11. Hermann Härtig, TU Dresden, Distributed OS, Load Balancing
 Exercises: April 11 1 PARTITIONING IN MPI COMMUNICATION AND NOISE AS HPC BOTTLENECK LOAD BALANCING DISTRIBUTED OPERATING SYSTEMS, SCALABILITY, SS 2017 Hermann Härtig THIS LECTURE Partitioning: bulk synchronous
Exercises: April 11 1 PARTITIONING IN MPI COMMUNICATION AND NOISE AS HPC BOTTLENECK LOAD BALANCING DISTRIBUTED OPERATING SYSTEMS, SCALABILITY, SS 2017 Hermann Härtig THIS LECTURE Partitioning: bulk synchronous
Understanding Aprun Use Patterns
 Understanding Aprun Use Patterns Hwa-Chun Wendy Lin, NERSC ABSTRACT: On the Cray XT, aprun is the command to launch an application to a set of compute nodes reserved through the Application Level Placement
Understanding Aprun Use Patterns Hwa-Chun Wendy Lin, NERSC ABSTRACT: On the Cray XT, aprun is the command to launch an application to a set of compute nodes reserved through the Application Level Placement
Eldorado. Outline. John Feo. Cray Inc. Why multithreaded architectures. The Cray Eldorado. Programming environment.
 Eldorado John Feo Cray Inc Outline Why multithreaded architectures The Cray Eldorado Programming environment Program examples 2 1 Overview Eldorado is a peak in the North Cascades. Internal Cray project
Eldorado John Feo Cray Inc Outline Why multithreaded architectures The Cray Eldorado Programming environment Program examples 2 1 Overview Eldorado is a peak in the North Cascades. Internal Cray project
Early Evaluation of the Cray XD1
 Early Evaluation of the Cray XD1 (FPGAs not covered here) Mark R. Fahey Sadaf Alam, Thomas Dunigan, Jeffrey Vetter, Patrick Worley Oak Ridge National Laboratory Cray User Group May 16-19, 2005 Albuquerque,
Early Evaluation of the Cray XD1 (FPGAs not covered here) Mark R. Fahey Sadaf Alam, Thomas Dunigan, Jeffrey Vetter, Patrick Worley Oak Ridge National Laboratory Cray User Group May 16-19, 2005 Albuquerque,
Reducing Communication Costs Associated with Parallel Algebraic Multigrid
 Reducing Communication Costs Associated with Parallel Algebraic Multigrid Amanda Bienz, Luke Olson (Advisor) University of Illinois at Urbana-Champaign Urbana, IL 11 I. PROBLEM AND MOTIVATION Algebraic
Reducing Communication Costs Associated with Parallel Algebraic Multigrid Amanda Bienz, Luke Olson (Advisor) University of Illinois at Urbana-Champaign Urbana, IL 11 I. PROBLEM AND MOTIVATION Algebraic
Parallel Computer Architecture II
 Parallel Computer Architecture II Stefan Lang Interdisciplinary Center for Scientific Computing (IWR) University of Heidelberg INF 368, Room 532 D-692 Heidelberg phone: 622/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
Parallel Computer Architecture II Stefan Lang Interdisciplinary Center for Scientific Computing (IWR) University of Heidelberg INF 368, Room 532 D-692 Heidelberg phone: 622/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
Algorithm Performance. (the Big-O)
") Algorithm Performance (the Big-O) Lecture 6 Today: Worst-case Behaviour Counting Operations Performance Considerations Time measurements Order Notation (the Big-O) Pessimistic Performance Measure Often
Algorithm Performance (the Big-O) Lecture 6 Today: Worst-case Behaviour Counting Operations Performance Considerations Time measurements Order Notation (the Big-O) Pessimistic Performance Measure Often
15-740/ Computer Architecture Lecture 20: Main Memory II. Prof. Onur Mutlu Carnegie Mellon University
 15-740/18-740 Computer Architecture Lecture 20: Main Memory II Prof. Onur Mutlu Carnegie Mellon University Today SRAM vs. DRAM Interleaving/Banking DRAM Microarchitecture Memory controller Memory buses
15-740/18-740 Computer Architecture Lecture 20: Main Memory II Prof. Onur Mutlu Carnegie Mellon University Today SRAM vs. DRAM Interleaving/Banking DRAM Microarchitecture Memory controller Memory buses
Philip C. Roth. Computer Science and Mathematics Division Oak Ridge National Laboratory
 Philip C. Roth Computer Science and Mathematics Division Oak Ridge National Laboratory A Tree-Based Overlay Network (TBON) like MRNet provides scalable infrastructure for tools and applications MRNet's
Philip C. Roth Computer Science and Mathematics Division Oak Ridge National Laboratory A Tree-Based Overlay Network (TBON) like MRNet provides scalable infrastructure for tools and applications MRNet's
Understanding application performance via micro-benchmarks on three large supercomputers: Intrepid, Ranger and Jaguar
 Understanding application performance via micro-benchmarks on three large supercomputers: Intrepid, and Jaguar Abhinav Bhatelé, Lukasz Wesolowski, Eric Bohm, Edgar Solomonik and Laxmikant V. Kalé Department
Understanding application performance via micro-benchmarks on three large supercomputers: Intrepid, and Jaguar Abhinav Bhatelé, Lukasz Wesolowski, Eric Bohm, Edgar Solomonik and Laxmikant V. Kalé Department
Our Workshop Environment
 Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Our Environment This Week Your laptops or workstations: only used for portal access Bridges
Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Our Environment This Week Your laptops or workstations: only used for portal access Bridges
Ehsan Totoni Babak Behzad Swapnil Ghike Josep Torrellas
 Ehsan Totoni Babak Behzad Swapnil Ghike Josep Torrellas 2 Increasing number of transistors on chip Power and energy limited Single- thread performance limited => parallelism Many opeons: heavy mulecore,
Ehsan Totoni Babak Behzad Swapnil Ghike Josep Torrellas 2 Increasing number of transistors on chip Power and energy limited Single- thread performance limited => parallelism Many opeons: heavy mulecore,
Topology-Aware Job Scheduling Strategies for Torus Networks
 Topology-Aware Job Scheduling Strategies for Torus Networks J. Enos, G. Bauer, R. Brunner, S. Islam NCSA, Blue Waters Project University of Illinois Urbana, IL USA e-mail: jenos@illinois.edu R. Fiedler
Topology-Aware Job Scheduling Strategies for Torus Networks J. Enos, G. Bauer, R. Brunner, S. Islam NCSA, Blue Waters Project University of Illinois Urbana, IL USA e-mail: jenos@illinois.edu R. Fiedler
Topology and affinity aware hierarchical and distributed load-balancing in Charm++
 Topology and affinity aware hierarchical and distributed load-balancing in Charm++ Emmanuel Jeannot, Guillaume Mercier, François Tessier Inria - IPB - LaBRI - University of Bordeaux - Argonne National
Topology and affinity aware hierarchical and distributed load-balancing in Charm++ Emmanuel Jeannot, Guillaume Mercier, François Tessier Inria - IPB - LaBRI - University of Bordeaux - Argonne National
Making System z the Center of Enterprise Computing
 8471 - Making System z the Center of Enterprise Computing Presented By: Mark Neft Accenture Application Modernization & Optimization Strategy Lead Mark.neft@accenture.com March 2, 2011 Session 8471 Presentation
8471 - Making System z the Center of Enterprise Computing Presented By: Mark Neft Accenture Application Modernization & Optimization Strategy Lead Mark.neft@accenture.com March 2, 2011 Session 8471 Presentation
Laplace Exercise Solution Review
 Laplace Exercise Solution Review John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Finished? If you have finished, we can review a few principles that you have inevitably
Laplace Exercise Solution Review John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Finished? If you have finished, we can review a few principles that you have inevitably
NAMD: A Portable and Highly Scalable Program for Biomolecular Simulations
 NAMD: A Portable and Highly Scalable Program for Biomolecular Simulations Abhinav Bhatele 1, Sameer Kumar 3, Chao Mei 1, James C. Phillips 2, Gengbin Zheng 1, Laxmikant V. Kalé 1 1 Department of Computer
NAMD: A Portable and Highly Scalable Program for Biomolecular Simulations Abhinav Bhatele 1, Sameer Kumar 3, Chao Mei 1, James C. Phillips 2, Gengbin Zheng 1, Laxmikant V. Kalé 1 1 Department of Computer
HANDLING LOAD IMBALANCE IN DISTRIBUTED & SHARED MEMORY
 HANDLING LOAD IMBALANCE IN DISTRIBUTED & SHARED MEMORY Presenters: Harshitha Menon, Seonmyeong Bak PPL Group Phil Miller, Sam White, Nitin Bhat, Tom Quinn, Jim Phillips, Laxmikant Kale MOTIVATION INTEGRATED
HANDLING LOAD IMBALANCE IN DISTRIBUTED & SHARED MEMORY Presenters: Harshitha Menon, Seonmyeong Bak PPL Group Phil Miller, Sam White, Nitin Bhat, Tom Quinn, Jim Phillips, Laxmikant Kale MOTIVATION INTEGRATED
Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18
 Accelerating PageRank using Partition-Centric Processing Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18 Outline Introduction Partition-centric Processing Methodology Analytical Evaluation
Accelerating PageRank using Partition-Centric Processing Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18 Outline Introduction Partition-centric Processing Methodology Analytical Evaluation
Mapping to Irregular Torus Topologies and Other Techniques for Petascale Biomolecular Simulation
 SC14: International Conference for High Performance Computing, Networking, Storage and Analysis Mapping to Irregular Torus Topologies and Other Techniques for Petascale Biomolecular Simulation James C.
SC14: International Conference for High Performance Computing, Networking, Storage and Analysis Mapping to Irregular Torus Topologies and Other Techniques for Petascale Biomolecular Simulation James C.
Scalable Fault Tolerance Schemes using Adaptive Runtime Support
 Scalable Fault Tolerance Schemes using Adaptive Runtime Support Laxmikant (Sanjay) Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at
Scalable Fault Tolerance Schemes using Adaptive Runtime Support Laxmikant (Sanjay) Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at
Optimization of the Hop-Byte Metric for Effective Topology Aware Mapping
 Optimization of the Hop-Byte Metric for Effective Topology Aware Mapping C. D. Sudheer Department of Mathematics and Computer Science Sri Sathya Sai Institute of Higher Learning, India Email: cdsudheerkumar@sssihl.edu.in
Optimization of the Hop-Byte Metric for Effective Topology Aware Mapping C. D. Sudheer Department of Mathematics and Computer Science Sri Sathya Sai Institute of Higher Learning, India Email: cdsudheerkumar@sssihl.edu.in
Using Graph Partitioning and Coloring for Flexible Coarse-Grained Shared-Memory Parallel Mesh Adaptation
 Available online at www.sciencedirect.com Procedia Engineering 00 (2017) 000 000 www.elsevier.com/locate/procedia 26th International Meshing Roundtable, IMR26, 18-21 September 2017, Barcelona, Spain Using
Available online at www.sciencedirect.com Procedia Engineering 00 (2017) 000 000 www.elsevier.com/locate/procedia 26th International Meshing Roundtable, IMR26, 18-21 September 2017, Barcelona, Spain Using
ECE 574 Cluster Computing Lecture 13
 ECE 574 Cluster Computing Lecture 13 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 21 March 2017 Announcements HW#5 Finally Graded Had right idea, but often result not an *exact*
ECE 574 Cluster Computing Lecture 13 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 21 March 2017 Announcements HW#5 Finally Graded Had right idea, but often result not an *exact*
The Road to ExaScale. Advances in High-Performance Interconnect Infrastructure. September 2011
 The Road to ExaScale Advances in High-Performance Interconnect Infrastructure September 2011 diego@mellanox.com ExaScale Computing Ambitious Challenges Foster Progress Demand Research Institutes, Universities
The Road to ExaScale Advances in High-Performance Interconnect Infrastructure September 2011 diego@mellanox.com ExaScale Computing Ambitious Challenges Foster Progress Demand Research Institutes, Universities
ZEST Snapshot Service. A Highly Parallel Production File System by the PSC Advanced Systems Group Pittsburgh Supercomputing Center 1
 ZEST Snapshot Service A Highly Parallel Production File System by the PSC Advanced Systems Group Pittsburgh Supercomputing Center 1 Design Motivation To optimize science utilization of the machine Maximize
ZEST Snapshot Service A Highly Parallel Production File System by the PSC Advanced Systems Group Pittsburgh Supercomputing Center 1 Design Motivation To optimize science utilization of the machine Maximize
Memory Allocation. Copyright : University of Illinois CS 241 Staff 1
 Memory Allocation Copyright : University of Illinois CS 241 Staff 1 Allocation of Page Frames Scenario Several physical pages allocated to processes A, B, and C. Process B page faults. Which page should
Memory Allocation Copyright : University of Illinois CS 241 Staff 1 Allocation of Page Frames Scenario Several physical pages allocated to processes A, B, and C. Process B page faults. Which page should
The Effect of Page Size and TLB Entries on Application Performance
 The Effect of Page Size and TLB Entries on Application Performance Neil Stringfellow CSCS Swiss National Supercomputing Centre June 5, 2006 Abstract The AMD Opteron processor allows for two page sizes
The Effect of Page Size and TLB Entries on Application Performance Neil Stringfellow CSCS Swiss National Supercomputing Centre June 5, 2006 Abstract The AMD Opteron processor allows for two page sizes
Managing Performance Variance of Applications Using Storage I/O Control
 Performance Study Managing Performance Variance of Applications Using Storage I/O Control VMware vsphere 4.1 Application performance can be impacted when servers contend for I/O resources in a shared storage
Performance Study Managing Performance Variance of Applications Using Storage I/O Control VMware vsphere 4.1 Application performance can be impacted when servers contend for I/O resources in a shared storage
Harnessing GPU speed to accelerate LAMMPS particle simulations
 Harnessing GPU speed to accelerate LAMMPS particle simulations Paul S. Crozier, W. Michael Brown, Peng Wang pscrozi@sandia.gov, wmbrown@sandia.gov, penwang@nvidia.com SC09, Portland, Oregon November 18,
Harnessing GPU speed to accelerate LAMMPS particle simulations Paul S. Crozier, W. Michael Brown, Peng Wang pscrozi@sandia.gov, wmbrown@sandia.gov, penwang@nvidia.com SC09, Portland, Oregon November 18,
Scaling Applications on Blue Waters
 May 23, 2013 New User BW Workshop May 22-23, 2013 NWChem NWChem is ab initio Quantum Chemistry package Compute electronic structure of molecular systems PNNL home: http://www.nwchem-sw.org 2 Coupled Cluster
May 23, 2013 New User BW Workshop May 22-23, 2013 NWChem NWChem is ab initio Quantum Chemistry package Compute electronic structure of molecular systems PNNL home: http://www.nwchem-sw.org 2 Coupled Cluster
Memory - Paging. Copyright : University of Illinois CS 241 Staff 1
 Memory - Paging Copyright : University of Illinois CS 241 Staff 1 Physical Frame Allocation How do we allocate physical memory across multiple processes? What if Process A needs to evict a page from Process
Memory - Paging Copyright : University of Illinois CS 241 Staff 1 Physical Frame Allocation How do we allocate physical memory across multiple processes? What if Process A needs to evict a page from Process
The Center for Computational Research & Grid Computing
 The Center for Computational Research & Grid Computing Russ Miller Center for Computational Research Computer Science & Engineering SUNY-Buffalo Hauptman-Woodward Medical Inst NSF, NIH, DOE NIMA, NYS,
The Center for Computational Research & Grid Computing Russ Miller Center for Computational Research Computer Science & Engineering SUNY-Buffalo Hauptman-Woodward Medical Inst NSF, NIH, DOE NIMA, NYS,
Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010
 Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010 Windows HPC Server 2008 R2 Windows HPC Server 2008 R2 makes supercomputing
Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010 Windows HPC Server 2008 R2 Windows HPC Server 2008 R2 makes supercomputing
Our Workshop Environment
 Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2016 Our Environment This Week Your laptops or workstations: only used for portal access Bridges
Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2016 Our Environment This Week Your laptops or workstations: only used for portal access Bridges
Strong Scaling for Molecular Dynamics Applications
 Strong Scaling for Molecular Dynamics Applications Scaling and Molecular Dynamics Strong Scaling How does solution time vary with the number of processors for a fixed problem size Classical Molecular Dynamics
Strong Scaling for Molecular Dynamics Applications Scaling and Molecular Dynamics Strong Scaling How does solution time vary with the number of processors for a fixed problem size Classical Molecular Dynamics
Automatic Identification of Application I/O Signatures from Noisy Server-Side Traces. Yang Liu Raghul Gunasekaran Xiaosong Ma Sudharshan S.
 Automatic Identification of Application I/O Signatures from Noisy Server-Side Traces Yang Liu Raghul Gunasekaran Xiaosong Ma Sudharshan S. Vazhkudai Instance of Large-Scale HPC Systems ORNL s TITAN (World
Automatic Identification of Application I/O Signatures from Noisy Server-Side Traces Yang Liu Raghul Gunasekaran Xiaosong Ma Sudharshan S. Vazhkudai Instance of Large-Scale HPC Systems ORNL s TITAN (World
Maximizing Throughput on a Dragonfly Network
 Maximizing Throughput on a Dragonfly Network Nikhil Jain, Abhinav Bhatele, Xiang Ni, Nicholas J. Wright, Laxmikant V. Kale Department of Computer Science, University of Illinois at Urbana-Champaign, Urbana,
Maximizing Throughput on a Dragonfly Network Nikhil Jain, Abhinav Bhatele, Xiang Ni, Nicholas J. Wright, Laxmikant V. Kale Department of Computer Science, University of Illinois at Urbana-Champaign, Urbana,
Composite Metrics for System Throughput in HPC
 Composite Metrics for System Throughput in HPC John D. McCalpin, Ph.D. IBM Corporation Austin, TX SuperComputing 2003 Phoenix, AZ November 18, 2003 Overview The HPC Challenge Benchmark was announced last
Composite Metrics for System Throughput in HPC John D. McCalpin, Ph.D. IBM Corporation Austin, TX SuperComputing 2003 Phoenix, AZ November 18, 2003 Overview The HPC Challenge Benchmark was announced last
HECToR. UK National Supercomputing Service. Andy Turner & Chris Johnson
 HECToR UK National Supercomputing Service Andy Turner & Chris Johnson Outline EPCC HECToR Introduction HECToR Phase 3 Introduction to AMD Bulldozer Architecture Performance Application placement the hardware
HECToR UK National Supercomputing Service Andy Turner & Chris Johnson Outline EPCC HECToR Introduction HECToR Phase 3 Introduction to AMD Bulldozer Architecture Performance Application placement the hardware
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning
 Extreme Application Acceleration & Highly Efficient I/O Provisioning") IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
Regression Testing on Petaflop Computational Resources. CUG 2010, Edinburgh Mike McCarty Software Developer May 27, 2010
 Regression Testing on Petaflop Computational Resources CUG 2010, Edinburgh Mike McCarty Software Developer May 27, 2010 Additional Authors Troy Baer (NICS) Lonnie Crosby (NICS) Outline What is NICS and
Regression Testing on Petaflop Computational Resources CUG 2010, Edinburgh Mike McCarty Software Developer May 27, 2010 Additional Authors Troy Baer (NICS) Lonnie Crosby (NICS) Outline What is NICS and
ARCHER/RDF Overview. How do they fit together? Andy Turner, EPCC
 ARCHER/RDF Overview How do they fit together? Andy Turner, EPCC a.turner@epcc.ed.ac.uk www.epcc.ed.ac.uk www.archer.ac.uk Outline ARCHER/RDF Layout Available file systems Compute resources ARCHER Compute
ARCHER/RDF Overview How do they fit together? Andy Turner, EPCC a.turner@epcc.ed.ac.uk www.epcc.ed.ac.uk www.archer.ac.uk Outline ARCHER/RDF Layout Available file systems Compute resources ARCHER Compute
Game-changing Extreme GPU computing with The Dell PowerEdge C4130
 Game-changing Extreme GPU computing with The Dell PowerEdge C4130 A Dell Technical White Paper This white paper describes the system architecture and performance characterization of the PowerEdge C4130.
Game-changing Extreme GPU computing with The Dell PowerEdge C4130 A Dell Technical White Paper This white paper describes the system architecture and performance characterization of the PowerEdge C4130.