Implementation of 3D Object Recognition Based on Correspondence Grouping Final Report
|
|
|
- Scott Melton
- 5 years ago
- Views:
Transcription
1 Implementation of 3D Object Recognition Based on Correspondence Grouping Final Report Jamison Miles, Kevin Sheng, Jeffrey Huang May 15, 2017 Instructor: Jivko Sinapov I. Abstract Currently, the Segbots in the BWI lab lack the capability of object recognition even with additional input from the user. The purpose of our project, therefore, is to implement 3D object recognition by working with point cloud data and correspondence grouping by giving the Segbot PCD files containing models of the objects we want recognized as input and having it return whether there was a match as a result of the point-to-point correspondences. In order to achieve this task, we developed an algorithm that utilized PCL functions to create keypoints found in the scene seen by the Segbot and compared them to keypoints on models that were also in the scene. In this paper, we outline the details of the 3D correspondence grouping algorithm, the associated tests and results, and our hopes for future development and research regarding it. II. Introduction and Problem Formulation The Segbots have a camera (a Kinect for some) that can be used for many purposes. These include self-localization on a map, detecting certain colors, and other functions. However, one of the biggest flaws of the current robot was the lack of ability for the robot to recognize objects. It saw them only as numbers that needed to be translated into an image. Thus, we attempted to 1
2 solve this problem with pre-rendered images of 3D objects and give the robot the ability to see and recognize the object. There are many applications to this project. It could also be used to teach people the names of certain objects. Someone who wants to learn English could use one of these robots to learn the names of certain objects from the robot. However, the most possible application of this program is that it provides a good starting ground for possible future robot developments. If the robot can recognize a basketball, it could show on screen the word basketball or just have the robot know it is a basketball and determine another action such as throw it. The task is to give the robot the ability to see a 3D object, have it search for it in its memory and actually return what the object is onscreen. For example, if we added a basketball 3D object in the robot s memory, the robot should have the ability to see, recognize the basketball, and show on-screen the basketball being displayed. III. Related Work We reviewed the literature on 3D object recognition to help us with our project. Some of them were helpful enough that we incorporated their concepts and some we used to get a better idea of the different ways this feat could be achieved. Many articles that we found interesting but did not incorporate into our final project included edge detection, which involved involved looking for a significant local change in the image intensity [1]. Edge detection had many issues such as false positives, where objects seemingly blended into the background, and inaccuracies at times, so this idea was scrapped. Some other ideas we got from scientific articles but never incorporated into the final version included the attempt to find objects via color. [2] Such an approach involves taking into account the RGB value, saturation, hue and lighting on the object for possible identification from a database of images. This approach contained errors with reading RGB values from the PCD files as shown by the colorless pictures below of the PointCloud2 data, so ultimately this approach was not implemented. Another concern with the color approach was a practicality. This approach could most likely identify basketballs quite well, as it only came in one form. It would not work well on objects such as hats that could come in multiple colors. It was obvious that if we took a color approach, we could not base objects based on color alone and also had to implement shape recognition. There was even more complex ideas such as local-scale invariant features. [3] An example might be a simple picture of an airplane in a background of a blue sky. By being able to pick out a very small portion of the 2
3 airplane such as the wings, the computer might be able to deduce the object. Due to a potential for a high margin of error with this approach, this idea was also scrapped. Thus, due to the flaws of the above, we decided to use PointCloud2 data and keypoint recognition as the basis of the project instead. Although it is not possible to have a 0% margin of error, this approached seemed to be the most likely path to reduce the margin of error. One article that we followed a bit more closely was the concept of pose clustering. [4] Pose clustering is selecting points based on what the camera reads and seeing if clustering them together could make a recognizable object. Although our method was not 100% pose clustering, it helped form the framework for our project for retrieving keypoints for object recognition. Our approach was different because we used PointCloud2 data and converted them to PCD files. Ultimately, we did use some of the ideas about pose clustering but with more of a correspondence grouping approach and used altogether a different method for 3D object recognition given by the PCL library, which also involved 3D models captured by either utilizing PCD files from online databases, such as the PCL website, or extracting our own Euclidean clusters. We felt this method had much more practical use outside of a controlled setting. IV. Technical Approach The first step to approaching this problem was to read and understand the documentation of the algorithm provided by the Point Cloud Library tutorials. In the beginning, we misread how to program the PCL functions and did not understand what a PCD file was, believing it to be like a 3D model render made in an program like Blender. It is nothing like that at all. A PCD is a point cloud data file that is made up of many keypoints. To utilize PCD files, we would need to develop an algorithm that would take in as input PCD files that consisted of the test models were looking for in the scene. Then, the algorithm had to be able to compare the robot s current vision to the keypoints in the PCD file stored on the robot. We needed to subscribe to one of the topics on the Kinect in order to retrieve the right form of data for our algorithm to take in. In order to integrate ROS with the PCL functions necessary for the algorithm to work, we realized that we would need a way to retrieve PointCloud data from the Kinect. By subscribing to /nav_kinect/depth_registered/points, we were able to retrieve the PointCloud2 data directly 3
4 from the Kinect, then store it as a PCD file for later. After we were able to retrieve the data, we had to make sure that the program was reading the keypoints properly. Using pcl_viewer, a visualization of the scene being recorded was shown and allowed us to verify that the scene was correct. [Figure 2] From there, we could add in PCD files containing the models we wanted to search for in the PCD file containing the scene. For the PCD models, we utilized some from online databases while also extracting our own Euclidean clusters to form our own PCD models, though each individual model tended to be separated into numerous PCD files that contained parts of the model s keypoints, but not all together. [Figure 3] As a result, we utilized PCD files more from online databases. In addition, the orientations of the test models was always the front of the objects due to the limitation of our PCD files, which were extracted from a single-point perspective (the Kinect), and therefore only had one view to see the models: the front. The 3D correspondence grouping algorithm had a number of functions that allowed it to process the PCD files it was given. First, the PCD models were placed in the catkin_pkg directory, and the command to rosrun the algorithm would be run from that directory to allow access to the models. With the PCD input models, normals of both that and the scene were computed using the PCL function NormalEstimationOMP, which estimated local surface properties at each 3D point. The PointCloud2 data retrieved from the PCDs of the model and scene was then downsampled through the PCL function UniformSampling (which forms a 3D grid over the PointCloud2 data) to find keypoints that would be given a 3D descriptor to allow for point-to-point correspondences through the PCL function SHOTEstimationOMP. To determine point-to-point correspondence, the PCL function KdTreeFLANN was used to compare keypoints in the scene to keypoints in the model in order to find the most similar keypoint based on Euclidian distance, and placed into a vector of correspondences. Clustering of correspondences was done with the PCL function Hough3DGrouping (which forced the algorithm to create its own local reference frames for each keypoint), though the PCL function GeometricConsistencyGrouping was used as an alternative from time to time. In addition, we created two thresholds to determine the status of a model in a scene; These two thresholds defined which models had correlation and which models had full model recognition. For correlation, the minimum correspondences necessary was set to 500 correspondences: this was due to the fact that the test objects we worked with had, on average, 1000 key points to work with. If half of those keypoints managed to be grouped, then there was proof that a version of the model did exist in the scene. On the other hand, full model recognition required nearly 4
5 one hundred percent exact keypoint to keypoint correspondence: this was to assure that the model recognized was without a shadow of a doubt the input model. V. Evaluation and Example Demonstration In order to evaluate the correctness of our algorithm, we focused on having the Segbot recognize three simple objects: a milk carton, a bike helmet, and a red plastic cup. The main test scene was the BWI lab room where we placed the test objects for easy access to the v2 Segbot without having to maneuver it to a different area. Among the first many tests we ran was the capturing of the scene, and then immediately using that captured PCD scene as a model to determine if the correspondence grouping algorithm was at least recording the scene successfully. That test was immediately successful: the scene itself was recognized as a full model recognition, which meant that the algorithm was certain that the input file was the model in the scene. Afterwards, the test objects were individually placed onto a table and their combined Euclidean clusters were sent in as a single PCD input file. Unfortunately, the results did not lead to full model recognitions. The combined models were only seen as correlated, meaning that the algorithm believed that there were enough correspondences to assume the model was there, but not enough to be considered as a full model recognition. The same results happened even after the models Euclidean clusters were separated into individual PCD models and sent in one after the other. Throughout all of this, the scene was constant: there were no changes to the orientations or positions of the test objects. The lighting did not seem to affect the algorithm: this was due to a bug that resulted in the algorithm being unable to take in RGB values. [Figure 1] To bypass this, the algorithm used geometric consistency for correspondence grouping. Ultimately, we came to a conclusion from our test results that although our 3D correspondence grouping algorithm was able to understand that input PCD models also in the scene were present, it failed to realize that the two models were one in the same nearly all of the time. 5
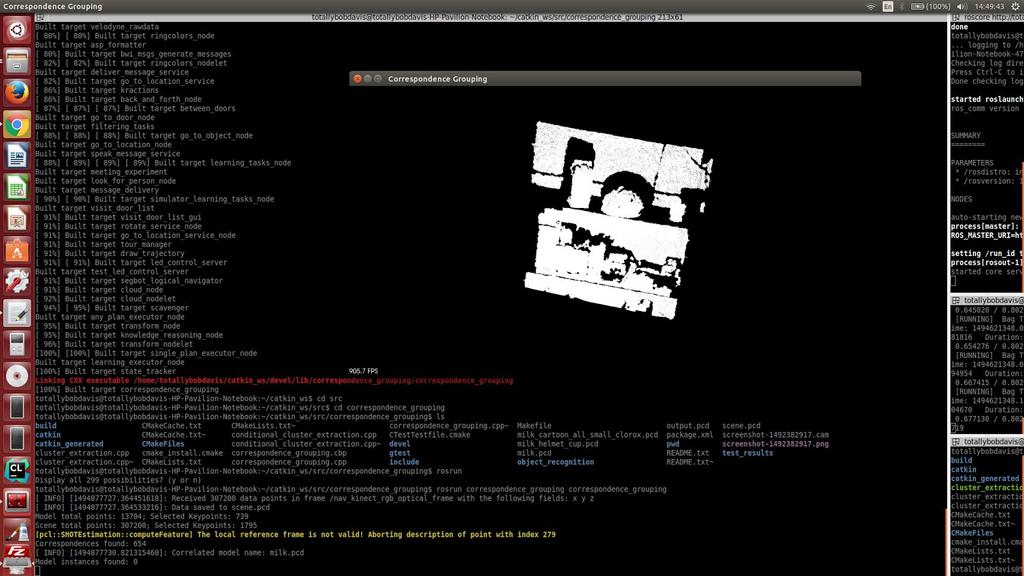
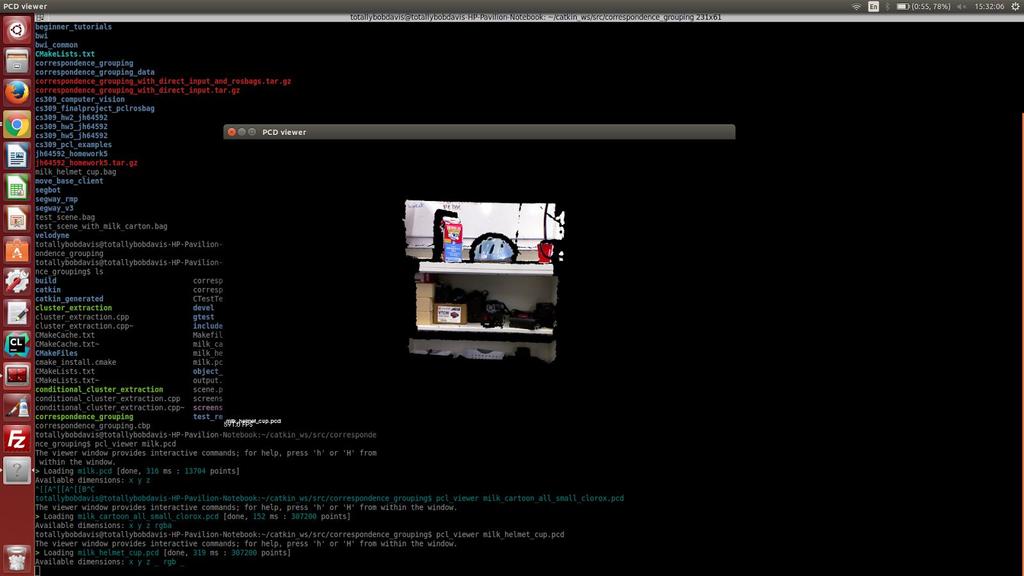



6 VI. Conclusion and Future Work 6


7 In conclusion, we were able to have the robot successfully identify the desired objects with high accuracy and consistency. The robot was able to identify a bike helmet, a red plastic cup, and a milk carton in a cluttered scene. However, there is much to be done in terms of future work. We seem to have a bug in which the program is not able to read-in RGB values. This does not affect the program at all, but is simply a portion of the program that could use some polishing. In addition, we will need to improve on the correspondence grouping as keypoints of one model may be mistaken for another model s, possibly resulting in misassociation. [Figure 4] There is also room for future improvement in terms of communicating that the object has been successfully identified. For now, there is only an output to the terminal that states that the object has been identified. It could be easier to communicate that the object has been discovered with flashing LEDs. Another possible improvement would be to make sure this program works with the V3 s. Currently our program subscribes to the Kinect, and we are not sure if the V3 s camera uses the same subscriber as the kinect does. If it does not, then we will have to improve our program by including the correct subscriber. Another improvement, and possibly the most important, would be to have our ROS node return the x, y, and z coordinates of the identified object. This would allow robots to know the exact location of the identified object. This way, if someone wanted a robot with an arm to pick up a specific object. Then the robot could pick up the object that it was specifically requested, and have the robot identify the object itself. Then it would pick it up with the returned coordinates after the identification. 7
8 VII. Works Cited [1] Ramadevi, Y., T. Sridevi, B. Poornima, and B. Kalyani. "Segmentation And Object Recognition Using Edge Detection Techniques." International Journal of Computer Science and Information Technology 2, no. 6 (2010): [2] Gevers, Theo, and Arnold W.m. Smeulders. "Color-based object recognition." Pattern Recognition 32, no. 3 (1999): [3] Lowe, D.g. "Object recognition from local scale-invariant features." Proceedings of the Seventh IEEE International Conference on Computer Vision, [4] Stockman, George. "Object recognition and localization via pose clustering." Computer Vision, Graphics, and Image Processing 39, no. 3 (1987):
3D object recognition used by team robotto
 3D object recognition used by team robotto Workshop Juliane Hoebel February 1, 2016 Faculty of Computer Science, Otto-von-Guericke University Magdeburg Content 1. Introduction 2. Depth sensor 3. 3D object
3D object recognition used by team robotto Workshop Juliane Hoebel February 1, 2016 Faculty of Computer Science, Otto-von-Guericke University Magdeburg Content 1. Introduction 2. Depth sensor 3. 3D object
Final Project Report: Mobile Pick and Place
 Final Project Report: Mobile Pick and Place Xiaoyang Liu (xiaoyan1) Juncheng Zhang (junchen1) Karthik Ramachandran (kramacha) Sumit Saxena (sumits1) Yihao Qian (yihaoq) Adviser: Dr Matthew Travers Carnegie
Final Project Report: Mobile Pick and Place Xiaoyang Liu (xiaoyan1) Juncheng Zhang (junchen1) Karthik Ramachandran (kramacha) Sumit Saxena (sumits1) Yihao Qian (yihaoq) Adviser: Dr Matthew Travers Carnegie
CS 378: Autonomous Intelligent Robotics. Instructor: Jivko Sinapov
 CS 378: Autonomous Intelligent Robotics Instructor: Jivko Sinapov http://www.cs.utexas.edu/~jsinapov/teaching/cs378/ Visual Registration and Recognition Announcements Homework 6 is out, due 4/5 4/7 Installing
CS 378: Autonomous Intelligent Robotics Instructor: Jivko Sinapov http://www.cs.utexas.edu/~jsinapov/teaching/cs378/ Visual Registration and Recognition Announcements Homework 6 is out, due 4/5 4/7 Installing
Generating and Learning from 3D Models of Objects through Interactions. by Kiana Alcala, Kathryn Baldauf, Aylish Wrench
 Generating and Learning from 3D Models of Objects through Interactions by Kiana Alcala, Kathryn Baldauf, Aylish Wrench Abstract For our project, we plan to implement code on the robotic arm that will allow
Generating and Learning from 3D Models of Objects through Interactions by Kiana Alcala, Kathryn Baldauf, Aylish Wrench Abstract For our project, we plan to implement code on the robotic arm that will allow
Automatic Colorization of Grayscale Images
 Automatic Colorization of Grayscale Images Austin Sousa Rasoul Kabirzadeh Patrick Blaes Department of Electrical Engineering, Stanford University 1 Introduction ere exists a wealth of photographic images,
Automatic Colorization of Grayscale Images Austin Sousa Rasoul Kabirzadeh Patrick Blaes Department of Electrical Engineering, Stanford University 1 Introduction ere exists a wealth of photographic images,
EE368 Project Report CD Cover Recognition Using Modified SIFT Algorithm
 EE368 Project Report CD Cover Recognition Using Modified SIFT Algorithm Group 1: Mina A. Makar Stanford University mamakar@stanford.edu Abstract In this report, we investigate the application of the Scale-Invariant
EE368 Project Report CD Cover Recognition Using Modified SIFT Algorithm Group 1: Mina A. Makar Stanford University mamakar@stanford.edu Abstract In this report, we investigate the application of the Scale-Invariant
Keywords: clustering, construction, machine vision
 CS4758: Robot Construction Worker Alycia Gailey, biomedical engineering, graduate student: asg47@cornell.edu Alex Slover, computer science, junior: ais46@cornell.edu Abstract: Progress has been made in
CS4758: Robot Construction Worker Alycia Gailey, biomedical engineering, graduate student: asg47@cornell.edu Alex Slover, computer science, junior: ais46@cornell.edu Abstract: Progress has been made in
A Novel Approach to Image Segmentation for Traffic Sign Recognition Jon Jay Hack and Sidd Jagadish
 A Novel Approach to Image Segmentation for Traffic Sign Recognition Jon Jay Hack and Sidd Jagadish Introduction/Motivation: As autonomous vehicles, such as Google s self-driving car, have recently become
A Novel Approach to Image Segmentation for Traffic Sign Recognition Jon Jay Hack and Sidd Jagadish Introduction/Motivation: As autonomous vehicles, such as Google s self-driving car, have recently become
A System of Image Matching and 3D Reconstruction
 A System of Image Matching and 3D Reconstruction CS231A Project Report 1. Introduction Xianfeng Rui Given thousands of unordered images of photos with a variety of scenes in your gallery, you will find
A System of Image Matching and 3D Reconstruction CS231A Project Report 1. Introduction Xianfeng Rui Given thousands of unordered images of photos with a variety of scenes in your gallery, you will find
Robotics Programming Laboratory
 Chair of Software Engineering Robotics Programming Laboratory Bertrand Meyer Jiwon Shin Lecture 8: Robot Perception Perception http://pascallin.ecs.soton.ac.uk/challenges/voc/databases.html#caltech car
Chair of Software Engineering Robotics Programming Laboratory Bertrand Meyer Jiwon Shin Lecture 8: Robot Perception Perception http://pascallin.ecs.soton.ac.uk/challenges/voc/databases.html#caltech car
CS 4758: Automated Semantic Mapping of Environment
 CS 4758: Automated Semantic Mapping of Environment Dongsu Lee, ECE, M.Eng., dl624@cornell.edu Aperahama Parangi, CS, 2013, alp75@cornell.edu Abstract The purpose of this project is to program an Erratic
CS 4758: Automated Semantic Mapping of Environment Dongsu Lee, ECE, M.Eng., dl624@cornell.edu Aperahama Parangi, CS, 2013, alp75@cornell.edu Abstract The purpose of this project is to program an Erratic
CSE 145/237D FINAL REPORT. 3D Reconstruction with Dynamic Fusion. Junyu Wang, Zeyangyi Wang
 CSE 145/237D FINAL REPORT 3D Reconstruction with Dynamic Fusion Junyu Wang, Zeyangyi Wang Contents Abstract... 2 Background... 2 Implementation... 4 Development setup... 4 Real time capturing... 5 Build
CSE 145/237D FINAL REPORT 3D Reconstruction with Dynamic Fusion Junyu Wang, Zeyangyi Wang Contents Abstract... 2 Background... 2 Implementation... 4 Development setup... 4 Real time capturing... 5 Build
Designing Applications that See Lecture 7: Object Recognition
 stanford hci group / cs377s Designing Applications that See Lecture 7: Object Recognition Dan Maynes-Aminzade 29 January 2008 Designing Applications that See http://cs377s.stanford.edu Reminders Pick up
stanford hci group / cs377s Designing Applications that See Lecture 7: Object Recognition Dan Maynes-Aminzade 29 January 2008 Designing Applications that See http://cs377s.stanford.edu Reminders Pick up
arxiv: v1 [cs.cv] 1 Jan 2019
![arxiv: v1 [cs.cv] 1 Jan 2019](/thumbs/93/112194933.jpg "arxiv: v1 [cs.cv] 1 Jan 2019") Mapping Areas using Computer Vision Algorithms and Drones Bashar Alhafni Saulo Fernando Guedes Lays Cavalcante Ribeiro Juhyun Park Jeongkyu Lee University of Bridgeport. Bridgeport, CT, 06606. United States
Mapping Areas using Computer Vision Algorithms and Drones Bashar Alhafni Saulo Fernando Guedes Lays Cavalcante Ribeiro Juhyun Park Jeongkyu Lee University of Bridgeport. Bridgeport, CT, 06606. United States
Set up and Foundation of the Husky
 Set up and Foundation of the Husky Marisa Warner, Jeremy Gottlieb, Gabriel Elkaim Worcester Polytechnic Institute University of California, Santa Cruz Abstract Clearpath s Husky A200 is an unmanned ground
Set up and Foundation of the Husky Marisa Warner, Jeremy Gottlieb, Gabriel Elkaim Worcester Polytechnic Institute University of California, Santa Cruz Abstract Clearpath s Husky A200 is an unmanned ground
Advanced Vision Guided Robotics. David Bruce Engineering Manager FANUC America Corporation
 Advanced Vision Guided Robotics David Bruce Engineering Manager FANUC America Corporation Traditional Vision vs. Vision based Robot Guidance Traditional Machine Vision Determine if a product passes or
Advanced Vision Guided Robotics David Bruce Engineering Manager FANUC America Corporation Traditional Vision vs. Vision based Robot Guidance Traditional Machine Vision Determine if a product passes or
Melvin Diaz and Timothy Campbell Advanced Computer Graphics Final Report: ICU Virtual Window OpenGL Cloud and Snow Simulation
 Melvin Diaz and Timothy Campbell Advanced Computer Graphics Final Report: ICU Virtual Window OpenGL Cloud and Snow Simulation Introduction This paper describes the implementation of OpenGL effects for
Melvin Diaz and Timothy Campbell Advanced Computer Graphics Final Report: ICU Virtual Window OpenGL Cloud and Snow Simulation Introduction This paper describes the implementation of OpenGL effects for
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
Arnold W.M Smeulders Theo Gevers. University of Amsterdam smeulders}
 Arnold W.M Smeulders Theo evers University of Amsterdam email: smeulders@wins.uva.nl http://carol.wins.uva.nl/~{gevers smeulders} 0 Prolem statement Query matching Query 0 Prolem statement Query classes
Arnold W.M Smeulders Theo evers University of Amsterdam email: smeulders@wins.uva.nl http://carol.wins.uva.nl/~{gevers smeulders} 0 Prolem statement Query matching Query 0 Prolem statement Query classes
Human detection solution for a retail store environment
 FACULDADE DE ENGENHARIA DA UNIVERSIDADE DO PORTO Human detection solution for a retail store environment Vítor Araújo PREPARATION OF THE MSC DISSERTATION Mestrado Integrado em Engenharia Eletrotécnica
FACULDADE DE ENGENHARIA DA UNIVERSIDADE DO PORTO Human detection solution for a retail store environment Vítor Araújo PREPARATION OF THE MSC DISSERTATION Mestrado Integrado em Engenharia Eletrotécnica
3D Reconstruction of a Hopkins Landmark
 3D Reconstruction of a Hopkins Landmark Ayushi Sinha (461), Hau Sze (461), Diane Duros (361) Abstract - This paper outlines a method for 3D reconstruction from two images. Our procedure is based on known
3D Reconstruction of a Hopkins Landmark Ayushi Sinha (461), Hau Sze (461), Diane Duros (361) Abstract - This paper outlines a method for 3D reconstruction from two images. Our procedure is based on known
To scope this project, we selected three top-tier biomedical journals that publish systematic reviews, hoping that they had a higher standard of
 1 Here we aim to answer the question: Does searching more databases add value to the systematic review. Especially when considering the time it takes for the ENTIRE process, the resources available like
1 Here we aim to answer the question: Does searching more databases add value to the systematic review. Especially when considering the time it takes for the ENTIRE process, the resources available like
Physically-Based Laser Simulation
 Physically-Based Laser Simulation Greg Reshko Carnegie Mellon University reshko@cs.cmu.edu Dave Mowatt Carnegie Mellon University dmowatt@andrew.cmu.edu Abstract In this paper, we describe our work on
Physically-Based Laser Simulation Greg Reshko Carnegie Mellon University reshko@cs.cmu.edu Dave Mowatt Carnegie Mellon University dmowatt@andrew.cmu.edu Abstract In this paper, we describe our work on
Depth Estimation Using Collection of Models
 Depth Estimation Using Collection of Models Karankumar Thakkar 1, Viral Borisagar 2 PG scholar 1, Assistant Professor 2 Computer Science & Engineering Department 1, 2 Government Engineering College, Sector
Depth Estimation Using Collection of Models Karankumar Thakkar 1, Viral Borisagar 2 PG scholar 1, Assistant Professor 2 Computer Science & Engineering Department 1, 2 Government Engineering College, Sector
Strawberry Ice Cream. Modeling the Ice Cream: Brennan Shacklett and Peter Do
 Strawberry Ice Cream Brennan Shacklett and Peter Do Modeling the Ice Cream: Our first approach was to simply attempt sculpting the ice cream from a sphere manually in blender, but we rapidly discovered
Strawberry Ice Cream Brennan Shacklett and Peter Do Modeling the Ice Cream: Our first approach was to simply attempt sculpting the ice cream from a sphere manually in blender, but we rapidly discovered
How to Tell a Human apart from a Computer. The Turing Test. (and Computer Literacy) Spring 2013 ITS B 1. Are Computers like Human Brains?
 Spring 2013 ITS B 1. Are Computers like Human Brains?") How to Tell a Human apart from a Computer The Turing Test (and Computer Literacy) Spring 2013 ITS102.23 - B 1 Are Computers like Human Brains? The impressive contributions of computers during World War
How to Tell a Human apart from a Computer The Turing Test (and Computer Literacy) Spring 2013 ITS102.23 - B 1 Are Computers like Human Brains? The impressive contributions of computers during World War
Freehand Voxel Carving Scanning on a Mobile Device
 Technion Institute of Technology Project in Image Processing and Analysis 234329 Freehand Voxel Carving Scanning on a Mobile Device Author: Student Number: 305950099 Supervisors: Aaron Wetzler, Yaron Honen,
Technion Institute of Technology Project in Image Processing and Analysis 234329 Freehand Voxel Carving Scanning on a Mobile Device Author: Student Number: 305950099 Supervisors: Aaron Wetzler, Yaron Honen,
E27 Computer Vision - Final Project: Creating Panoramas David Nahmias, Dan Spagnolo, Vincent Stigliani Professor Zucker Due 5/10/13
 E27 Computer Vision - Final Project: Creating Panoramas David Nahmias, Dan Spagnolo, Vincent Stigliani Professor Zucker Due 5/10/13 Sources Brown, M.; Lowe, D.G., "Recognising panoramas," Computer Vision,
E27 Computer Vision - Final Project: Creating Panoramas David Nahmias, Dan Spagnolo, Vincent Stigliani Professor Zucker Due 5/10/13 Sources Brown, M.; Lowe, D.G., "Recognising panoramas," Computer Vision,
Generating Object Candidates from RGB-D Images and Point Clouds
 Generating Object Candidates from RGB-D Images and Point Clouds Helge Wrede 11.05.2017 1 / 36 Outline Introduction Methods Overview The Data RGB-D Images Point Clouds Microsoft Kinect Generating Object
Generating Object Candidates from RGB-D Images and Point Clouds Helge Wrede 11.05.2017 1 / 36 Outline Introduction Methods Overview The Data RGB-D Images Point Clouds Microsoft Kinect Generating Object
Breaking it Down: The World as Legos Benjamin Savage, Eric Chu
 Breaking it Down: The World as Legos Benjamin Savage, Eric Chu To devise a general formalization for identifying objects via image processing, we suggest a two-pronged approach of identifying principal
Breaking it Down: The World as Legos Benjamin Savage, Eric Chu To devise a general formalization for identifying objects via image processing, we suggest a two-pronged approach of identifying principal
Efficient Surface and Feature Estimation in RGBD
 Efficient Surface and Feature Estimation in RGBD Zoltan-Csaba Marton, Dejan Pangercic, Michael Beetz Intelligent Autonomous Systems Group Technische Universität München RGB-D Workshop on 3D Perception
Efficient Surface and Feature Estimation in RGBD Zoltan-Csaba Marton, Dejan Pangercic, Michael Beetz Intelligent Autonomous Systems Group Technische Universität München RGB-D Workshop on 3D Perception
The Detection of Faces in Color Images: EE368 Project Report
 The Detection of Faces in Color Images: EE368 Project Report Angela Chau, Ezinne Oji, Jeff Walters Dept. of Electrical Engineering Stanford University Stanford, CA 9435 angichau,ezinne,jwalt@stanford.edu
The Detection of Faces in Color Images: EE368 Project Report Angela Chau, Ezinne Oji, Jeff Walters Dept. of Electrical Engineering Stanford University Stanford, CA 9435 angichau,ezinne,jwalt@stanford.edu
An Interactive Technique for Robot Control by Using Image Processing Method
 An Interactive Technique for Robot Control by Using Image Processing Method Mr. Raskar D. S 1., Prof. Mrs. Belagali P. P 2 1, E&TC Dept. Dr. JJMCOE., Jaysingpur. Maharashtra., India. 2 Associate Prof.
An Interactive Technique for Robot Control by Using Image Processing Method Mr. Raskar D. S 1., Prof. Mrs. Belagali P. P 2 1, E&TC Dept. Dr. JJMCOE., Jaysingpur. Maharashtra., India. 2 Associate Prof.
Generating and Learning from 3D Models of Objects through Interactions
 Generating and Learning from 3D Models of Objects through Interactions Kathryn Baldauf, Aylish Wrench, Kiana Alcala {kathrynbaldauf, aylish.wrench, kiana.alcala}@utexas.edu Abstract In this paper we implement
Generating and Learning from 3D Models of Objects through Interactions Kathryn Baldauf, Aylish Wrench, Kiana Alcala {kathrynbaldauf, aylish.wrench, kiana.alcala}@utexas.edu Abstract In this paper we implement
Modeling Body Motion Posture Recognition Using 2D-Skeleton Angle Feature
 2012 International Conference on Image, Vision and Computing (ICIVC 2012) IPCSIT vol. 50 (2012) (2012) IACSIT Press, Singapore DOI: 10.7763/IPCSIT.2012.V50.1 Modeling Body Motion Posture Recognition Using
2012 International Conference on Image, Vision and Computing (ICIVC 2012) IPCSIT vol. 50 (2012) (2012) IACSIT Press, Singapore DOI: 10.7763/IPCSIT.2012.V50.1 Modeling Body Motion Posture Recognition Using
Indoor Object Recognition of 3D Kinect Dataset with RNNs
 Indoor Object Recognition of 3D Kinect Dataset with RNNs Thiraphat Charoensripongsa, Yue Chen, Brian Cheng 1. Introduction Recent work at Stanford in the area of scene understanding has involved using
Indoor Object Recognition of 3D Kinect Dataset with RNNs Thiraphat Charoensripongsa, Yue Chen, Brian Cheng 1. Introduction Recent work at Stanford in the area of scene understanding has involved using
Fast Face Detection Assisted with Skin Color Detection
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 18, Issue 4, Ver. II (Jul.-Aug. 2016), PP 70-76 www.iosrjournals.org Fast Face Detection Assisted with Skin Color
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 18, Issue 4, Ver. II (Jul.-Aug. 2016), PP 70-76 www.iosrjournals.org Fast Face Detection Assisted with Skin Color
SUMMARY: DISTINCTIVE IMAGE FEATURES FROM SCALE- INVARIANT KEYPOINTS
 SUMMARY: DISTINCTIVE IMAGE FEATURES FROM SCALE- INVARIANT KEYPOINTS Cognitive Robotics Original: David G. Lowe, 004 Summary: Coen van Leeuwen, s1460919 Abstract: This article presents a method to extract
SUMMARY: DISTINCTIVE IMAGE FEATURES FROM SCALE- INVARIANT KEYPOINTS Cognitive Robotics Original: David G. Lowe, 004 Summary: Coen van Leeuwen, s1460919 Abstract: This article presents a method to extract
CS231A Course Project Final Report Sign Language Recognition with Unsupervised Feature Learning
 CS231A Course Project Final Report Sign Language Recognition with Unsupervised Feature Learning Justin Chen Stanford University justinkchen@stanford.edu Abstract This paper focuses on experimenting with
CS231A Course Project Final Report Sign Language Recognition with Unsupervised Feature Learning Justin Chen Stanford University justinkchen@stanford.edu Abstract This paper focuses on experimenting with
Character Recognition
 Character Recognition 5.1 INTRODUCTION Recognition is one of the important steps in image processing. There are different methods such as Histogram method, Hough transformation, Neural computing approaches
Character Recognition 5.1 INTRODUCTION Recognition is one of the important steps in image processing. There are different methods such as Histogram method, Hough transformation, Neural computing approaches
Panoramic Image Stitching
 Mcgill University Panoramic Image Stitching by Kai Wang Pengbo Li A report submitted in fulfillment for the COMP 558 Final project in the Faculty of Computer Science April 2013 Mcgill University Abstract
Mcgill University Panoramic Image Stitching by Kai Wang Pengbo Li A report submitted in fulfillment for the COMP 558 Final project in the Faculty of Computer Science April 2013 Mcgill University Abstract
An Implementation on Histogram of Oriented Gradients for Human Detection
 An Implementation on Histogram of Oriented Gradients for Human Detection Cansın Yıldız Dept. of Computer Engineering Bilkent University Ankara,Turkey cansin@cs.bilkent.edu.tr Abstract I implemented a Histogram
An Implementation on Histogram of Oriented Gradients for Human Detection Cansın Yıldız Dept. of Computer Engineering Bilkent University Ankara,Turkey cansin@cs.bilkent.edu.tr Abstract I implemented a Histogram
Study on road sign recognition in LabVIEW
 IOP Conference Series: Materials Science and Engineering PAPER OPEN ACCESS Study on road sign recognition in LabVIEW To cite this article: M Panoiu et al 2016 IOP Conf. Ser.: Mater. Sci. Eng. 106 012009
IOP Conference Series: Materials Science and Engineering PAPER OPEN ACCESS Study on road sign recognition in LabVIEW To cite this article: M Panoiu et al 2016 IOP Conf. Ser.: Mater. Sci. Eng. 106 012009
In this lesson, you ll learn how to:
 LESSON 5: ADVANCED DRAWING TECHNIQUES OBJECTIVES In this lesson, you ll learn how to: apply gradient fills modify graphics by smoothing, straightening, and optimizing understand the difference between
LESSON 5: ADVANCED DRAWING TECHNIQUES OBJECTIVES In this lesson, you ll learn how to: apply gradient fills modify graphics by smoothing, straightening, and optimizing understand the difference between
Data-driven Depth Inference from a Single Still Image
 Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Computer Vision Course Lecture 04. Template Matching Image Pyramids. Ceyhun Burak Akgül, PhD cba-research.com. Spring 2015 Last updated 11/03/2015
 Computer Vision Course Lecture 04 Template Matching Image Pyramids Ceyhun Burak Akgül, PhD cba-research.com Spring 2015 Last updated 11/03/2015 Photo credit: Olivier Teboul vision.mas.ecp.fr/personnel/teboul
Computer Vision Course Lecture 04 Template Matching Image Pyramids Ceyhun Burak Akgül, PhD cba-research.com Spring 2015 Last updated 11/03/2015 Photo credit: Olivier Teboul vision.mas.ecp.fr/personnel/teboul
Appendix 1: REVIEW OF TREATMENT OF SIGNIFICANT FIGURES
 Appendix 1: REVIEW OF TREATMENT OF SIGNIFICANT FIGURES PART I: HOW MANY DIGITS SHOULD YOU RECORD? When you measure an object with a ruler such as Ruler I shown in the figure below, you know for sure that
Appendix 1: REVIEW OF TREATMENT OF SIGNIFICANT FIGURES PART I: HOW MANY DIGITS SHOULD YOU RECORD? When you measure an object with a ruler such as Ruler I shown in the figure below, you know for sure that
IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues
 2016 International Conference on Computational Science and Computational Intelligence IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues Taylor Ripke Department of Computer Science
2016 International Conference on Computational Science and Computational Intelligence IDE-3D: Predicting Indoor Depth Utilizing Geometric and Monocular Cues Taylor Ripke Department of Computer Science
MATLAB Based Interactive Music Player using XBOX Kinect
 1 MATLAB Based Interactive Music Player using XBOX Kinect EN.600.461 Final Project MATLAB Based Interactive Music Player using XBOX Kinect Gowtham G. Piyush R. Ashish K. (ggarime1, proutra1, akumar34)@jhu.edu
1 MATLAB Based Interactive Music Player using XBOX Kinect EN.600.461 Final Project MATLAB Based Interactive Music Player using XBOX Kinect Gowtham G. Piyush R. Ashish K. (ggarime1, proutra1, akumar34)@jhu.edu
Robot localization method based on visual features and their geometric relationship
 , pp.46-50 http://dx.doi.org/10.14257/astl.2015.85.11 Robot localization method based on visual features and their geometric relationship Sangyun Lee 1, Changkyung Eem 2, and Hyunki Hong 3 1 Department
, pp.46-50 http://dx.doi.org/10.14257/astl.2015.85.11 Robot localization method based on visual features and their geometric relationship Sangyun Lee 1, Changkyung Eem 2, and Hyunki Hong 3 1 Department
Pedestrian Detection with Improved LBP and Hog Algorithm
 Open Access Library Journal 2018, Volume 5, e4573 ISSN Online: 2333-9721 ISSN Print: 2333-9705 Pedestrian Detection with Improved LBP and Hog Algorithm Wei Zhou, Suyun Luo Automotive Engineering College,
Open Access Library Journal 2018, Volume 5, e4573 ISSN Online: 2333-9721 ISSN Print: 2333-9705 Pedestrian Detection with Improved LBP and Hog Algorithm Wei Zhou, Suyun Luo Automotive Engineering College,
PRECEDING VEHICLE TRACKING IN STEREO IMAGES VIA 3D FEATURE MATCHING
 PRECEDING VEHICLE TRACKING IN STEREO IMAGES VIA 3D FEATURE MATCHING Daniel Weingerl, Wilfried Kubinger, Corinna Engelhardt-Nowitzki UAS Technikum Wien: Department for Advanced Engineering Technologies,
PRECEDING VEHICLE TRACKING IN STEREO IMAGES VIA 3D FEATURE MATCHING Daniel Weingerl, Wilfried Kubinger, Corinna Engelhardt-Nowitzki UAS Technikum Wien: Department for Advanced Engineering Technologies,
Rigid ICP registration with Kinect
 Rigid ICP registration with Kinect Students: Yoni Choukroun, Elie Semmel Advisor: Yonathan Aflalo 1 Overview.p.3 Development of the project..p.3 Papers p.4 Project algorithm..p.6 Result of the whole body.p.7
Rigid ICP registration with Kinect Students: Yoni Choukroun, Elie Semmel Advisor: Yonathan Aflalo 1 Overview.p.3 Development of the project..p.3 Papers p.4 Project algorithm..p.6 Result of the whole body.p.7
New approaches to pattern recognition and automated learning
 Z Y X New approaches to pattern recognition and automated learning Technology Forum 2015 Johannes Zuegner STEMMER IMAGING GmbH, Puchheim, Germany OUTLINE Introduction Description of the task What does
Z Y X New approaches to pattern recognition and automated learning Technology Forum 2015 Johannes Zuegner STEMMER IMAGING GmbH, Puchheim, Germany OUTLINE Introduction Description of the task What does
Aalborg Universitet. A new approach for detecting local features Nguyen, Phuong Giang; Andersen, Hans Jørgen
 Aalborg Universitet A new approach for detecting local features Nguyen, Phuong Giang; Andersen, Hans Jørgen Published in: International Conference on Computer Vision Theory and Applications Publication
Aalborg Universitet A new approach for detecting local features Nguyen, Phuong Giang; Andersen, Hans Jørgen Published in: International Conference on Computer Vision Theory and Applications Publication
Local Feature Detectors
 Local Feature Detectors Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr Slides adapted from Cordelia Schmid and David Lowe, CVPR 2003 Tutorial, Matthew Brown,
Local Feature Detectors Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr Slides adapted from Cordelia Schmid and David Lowe, CVPR 2003 Tutorial, Matthew Brown,
BSB663 Image Processing Pinar Duygulu. Slides are adapted from Selim Aksoy
 BSB663 Image Processing Pinar Duygulu Slides are adapted from Selim Aksoy Image matching Image matching is a fundamental aspect of many problems in computer vision. Object or scene recognition Solving
BSB663 Image Processing Pinar Duygulu Slides are adapted from Selim Aksoy Image matching Image matching is a fundamental aspect of many problems in computer vision. Object or scene recognition Solving
Group Name: Team Epsilon Max Hinson Jhon Faghih Nassiri
 Software Requirements Specification for UCSB 360 Version 1.2 Prepared by Group Name: Team Epsilon Max Hinson 4426771 maxwellhinson@gmail.com Jhon Faghih Nassiri 4111274 jfaghihnassiri@gmail.com Luke Buckland
Software Requirements Specification for UCSB 360 Version 1.2 Prepared by Group Name: Team Epsilon Max Hinson 4426771 maxwellhinson@gmail.com Jhon Faghih Nassiri 4111274 jfaghihnassiri@gmail.com Luke Buckland
CS4495/6495 Introduction to Computer Vision
 CS4495/6495 Introduction to Computer Vision 9C-L1 3D perception Some slides by Kelsey Hawkins Motivation Why do animals, people & robots need vision? To detect and recognize objects/landmarks Is that a
CS4495/6495 Introduction to Computer Vision 9C-L1 3D perception Some slides by Kelsey Hawkins Motivation Why do animals, people & robots need vision? To detect and recognize objects/landmarks Is that a
Locality through Modular Network Topology
 Locality through Modular Network Topology Oliver Lipton and Harry Huchra December 18, 2017 Abstract Our experiment concerns designing a robot to accomplish the task of locality grounding. Through a dataset
Locality through Modular Network Topology Oliver Lipton and Harry Huchra December 18, 2017 Abstract Our experiment concerns designing a robot to accomplish the task of locality grounding. Through a dataset
Texas Instruments Electronics Online Challenge. Discobots Team 1104A
 Texas Instruments Electronics Online Challenge Discobots Team 1104A Introduction: Final Report For the Texas Instruments Electronics Online Challenge, the electronic device we chose to deconstruct was
Texas Instruments Electronics Online Challenge Discobots Team 1104A Introduction: Final Report For the Texas Instruments Electronics Online Challenge, the electronic device we chose to deconstruct was
Filtering and mapping systems for underwater 3D imaging sonar
 Filtering and mapping systems for underwater 3D imaging sonar Tomohiro Koshikawa 1, a, Shin Kato 1,b, and Hitoshi Arisumi 1,c 1 Field Robotics Research Group, National Institute of Advanced Industrial
Filtering and mapping systems for underwater 3D imaging sonar Tomohiro Koshikawa 1, a, Shin Kato 1,b, and Hitoshi Arisumi 1,c 1 Field Robotics Research Group, National Institute of Advanced Industrial
COMS W4735: Visual Interfaces To Computers. Final Project (Finger Mouse) Submitted by: Tarandeep Singh Uni: ts2379
 Submitted by: Tarandeep Singh Uni: ts2379") COMS W4735: Visual Interfaces To Computers Final Project (Finger Mouse) Submitted by: Tarandeep Singh Uni: ts2379 FINGER MOUSE (Fingertip tracking to control mouse pointer) Abstract. This report discusses
COMS W4735: Visual Interfaces To Computers Final Project (Finger Mouse) Submitted by: Tarandeep Singh Uni: ts2379 FINGER MOUSE (Fingertip tracking to control mouse pointer) Abstract. This report discusses
Deep Learning in Image and Face Intrinsics
 Deep Learning in Image and Face Intrinsics Theo Gevers Professor in Computer Vision: University of Amsterdam Co-founder: Sightcorp 3DUniversum Scanm WIC, Eindhoven, February 24th, 2018 Amsterdam A.I. -
Deep Learning in Image and Face Intrinsics Theo Gevers Professor in Computer Vision: University of Amsterdam Co-founder: Sightcorp 3DUniversum Scanm WIC, Eindhoven, February 24th, 2018 Amsterdam A.I. -
ENGR3390: Robotics Fall 2009
 J. Gorasia Vision Lab ENGR339: Robotics ENGR339: Robotics Fall 29 Vision Lab Team Bravo J. Gorasia - 1/4/9 J. Gorasia Vision Lab ENGR339: Robotics Table of Contents 1.Theory and summary of background readings...4
J. Gorasia Vision Lab ENGR339: Robotics ENGR339: Robotics Fall 29 Vision Lab Team Bravo J. Gorasia - 1/4/9 J. Gorasia Vision Lab ENGR339: Robotics Table of Contents 1.Theory and summary of background readings...4
Parallel algorithms for stereo vision shape from stereo
 Parallel algorithms for stereo vision shape from stereo XINGJIE RUAN, XENOPHON Institute of Information & Mathematical Sciences Massey University at Albany, Auckland, New Zealand Xingjie.Ruan.1@uni.massey.ac.nz
Parallel algorithms for stereo vision shape from stereo XINGJIE RUAN, XENOPHON Institute of Information & Mathematical Sciences Massey University at Albany, Auckland, New Zealand Xingjie.Ruan.1@uni.massey.ac.nz
COMP 102: Computers and Computing
 COMP 102: Computers and Computing Lecture 23: Computer Vision Instructor: Kaleem Siddiqi (siddiqi@cim.mcgill.ca) Class web page: www.cim.mcgill.ca/~siddiqi/102.html What is computer vision? Broadly speaking,
COMP 102: Computers and Computing Lecture 23: Computer Vision Instructor: Kaleem Siddiqi (siddiqi@cim.mcgill.ca) Class web page: www.cim.mcgill.ca/~siddiqi/102.html What is computer vision? Broadly speaking,
A New Approach For 3D Image Reconstruction From Multiple Images
 International Journal of Electronics Engineering Research. ISSN 0975-6450 Volume 9, Number 4 (2017) pp. 569-574 Research India Publications http://www.ripublication.com A New Approach For 3D Image Reconstruction
International Journal of Electronics Engineering Research. ISSN 0975-6450 Volume 9, Number 4 (2017) pp. 569-574 Research India Publications http://www.ripublication.com A New Approach For 3D Image Reconstruction
Mesh Modeling Dice Boolean
 Course: 3D Design Title: Mesh Modeling Dice - Boolean Dropbox File: Dice.zip Blender: Version 2.41 Level: Beginning Author: Neal Hirsig (nhirsig@tufts.edu) Mesh Modeling Dice Boolean In this tutorial,
Course: 3D Design Title: Mesh Modeling Dice - Boolean Dropbox File: Dice.zip Blender: Version 2.41 Level: Beginning Author: Neal Hirsig (nhirsig@tufts.edu) Mesh Modeling Dice Boolean In this tutorial,
A Review: Content Base Image Mining Technique for Image Retrieval Using Hybrid Clustering
 A Review: Content Base Image Mining Technique for Image Retrieval Using Hybrid Clustering Gurpreet Kaur M-Tech Student, Department of Computer Engineering, Yadawindra College of Engineering, Talwandi Sabo,
A Review: Content Base Image Mining Technique for Image Retrieval Using Hybrid Clustering Gurpreet Kaur M-Tech Student, Department of Computer Engineering, Yadawindra College of Engineering, Talwandi Sabo,
Image Processing Pipeline for Facial Expression Recognition under Variable Lighting
 Image Processing Pipeline for Facial Expression Recognition under Variable Lighting Ralph Ma, Amr Mohamed ralphma@stanford.edu, amr1@stanford.edu Abstract Much research has been done in the field of automated
Image Processing Pipeline for Facial Expression Recognition under Variable Lighting Ralph Ma, Amr Mohamed ralphma@stanford.edu, amr1@stanford.edu Abstract Much research has been done in the field of automated
CSE 527: Intro. to Computer
 CSE 527: Intro. to Computer Vision CSE 527: Intro. to Computer Vision www.cs.sunysb.edu/~cse527 Instructor: Prof. M. Alex O. Vasilescu Email: maov@cs.sunysb.edu Phone: 631 632-8457 Office: 1421 Prerequisites:
CSE 527: Intro. to Computer Vision CSE 527: Intro. to Computer Vision www.cs.sunysb.edu/~cse527 Instructor: Prof. M. Alex O. Vasilescu Email: maov@cs.sunysb.edu Phone: 631 632-8457 Office: 1421 Prerequisites:
Visual Learning and Recognition of 3D Objects from Appearance
 Visual Learning and Recognition of 3D Objects from Appearance (H. Murase and S. Nayar, "Visual Learning and Recognition of 3D Objects from Appearance", International Journal of Computer Vision, vol. 14,
Visual Learning and Recognition of 3D Objects from Appearance (H. Murase and S. Nayar, "Visual Learning and Recognition of 3D Objects from Appearance", International Journal of Computer Vision, vol. 14,
HOW USEFUL ARE COLOUR INVARIANTS FOR IMAGE RETRIEVAL?
 HOW USEFUL ARE COLOUR INVARIANTS FOR IMAGE RETRIEVAL? Gerald Schaefer School of Computing and Technology Nottingham Trent University Nottingham, U.K. Gerald.Schaefer@ntu.ac.uk Abstract Keywords: The images
HOW USEFUL ARE COLOUR INVARIANTS FOR IMAGE RETRIEVAL? Gerald Schaefer School of Computing and Technology Nottingham Trent University Nottingham, U.K. Gerald.Schaefer@ntu.ac.uk Abstract Keywords: The images
The Kinect Sensor. Luís Carriço FCUL 2014/15
 Advanced Interaction Techniques The Kinect Sensor Luís Carriço FCUL 2014/15 Sources: MS Kinect for Xbox 360 John C. Tang. Using Kinect to explore NUI, Ms Research, From Stanford CS247 Shotton et al. Real-Time
Advanced Interaction Techniques The Kinect Sensor Luís Carriço FCUL 2014/15 Sources: MS Kinect for Xbox 360 John C. Tang. Using Kinect to explore NUI, Ms Research, From Stanford CS247 Shotton et al. Real-Time
Robo-Librarian: Sliding-Grasping Task
 Robo-Librarian: Sliding-Grasping Task Adao Henrique Ribeiro Justo Filho, Rei Suzuki Abstract Picking up objects from a flat surface is quite cumbersome task for a robot to perform. We explore a simple
Robo-Librarian: Sliding-Grasping Task Adao Henrique Ribeiro Justo Filho, Rei Suzuki Abstract Picking up objects from a flat surface is quite cumbersome task for a robot to perform. We explore a simple
Robot Autonomy Final Report : Team Husky
 Robot Autonomy Final Report : Team Husky 1 Amit Bansal Master student in Robotics Institute, CMU ab1@andrew.cmu.edu Akshay Hinduja Master student in Mechanical Engineering, CMU ahinduja@andrew.cmu.edu
Robot Autonomy Final Report : Team Husky 1 Amit Bansal Master student in Robotics Institute, CMU ab1@andrew.cmu.edu Akshay Hinduja Master student in Mechanical Engineering, CMU ahinduja@andrew.cmu.edu
BRYCE 5 Mini Tutorial
 BRYCE 5 Mini Tutorial Abstract Panoramics by David Brinnen March 2005 HTML Version by Hans-Rudolf Wernli Blotchy Splashes of Colour > If you have photographed a panorama with your camera once, you know
BRYCE 5 Mini Tutorial Abstract Panoramics by David Brinnen March 2005 HTML Version by Hans-Rudolf Wernli Blotchy Splashes of Colour > If you have photographed a panorama with your camera once, you know
Introduction to PCL: The Point Cloud Library
 Introduction to PCL: The Point Cloud Library Basic topics Alberto Pretto Thanks to Radu Bogdan Rusu, Bastian Steder and Jeff Delmerico for some of the slides! Point clouds: a definition A point cloud is
Introduction to PCL: The Point Cloud Library Basic topics Alberto Pretto Thanks to Radu Bogdan Rusu, Bastian Steder and Jeff Delmerico for some of the slides! Point clouds: a definition A point cloud is
Toward Part-based Document Image Decoding
 2012 10th IAPR International Workshop on Document Analysis Systems Toward Part-based Document Image Decoding Wang Song, Seiichi Uchida Kyushu University, Fukuoka, Japan wangsong@human.ait.kyushu-u.ac.jp,
2012 10th IAPR International Workshop on Document Analysis Systems Toward Part-based Document Image Decoding Wang Song, Seiichi Uchida Kyushu University, Fukuoka, Japan wangsong@human.ait.kyushu-u.ac.jp,
Motivation: why study sound? Motivation (2) Related Work. Our Study. Related Work (2)
 Related Work. Our Study. Related Work (2)") Motivation: why study sound? Interactive Learning of the Acoustic Properties of Objects by a Robot Sound Producing Event Jivko Sinapov Mark Wiemer Alexander Stoytchev {jsinapov banff alexs}@iastate.edu
Motivation: why study sound? Interactive Learning of the Acoustic Properties of Objects by a Robot Sound Producing Event Jivko Sinapov Mark Wiemer Alexander Stoytchev {jsinapov banff alexs}@iastate.edu
Ensemble of Bayesian Filters for Loop Closure Detection
 Ensemble of Bayesian Filters for Loop Closure Detection Mohammad Omar Salameh, Azizi Abdullah, Shahnorbanun Sahran Pattern Recognition Research Group Center for Artificial Intelligence Faculty of Information
Ensemble of Bayesian Filters for Loop Closure Detection Mohammad Omar Salameh, Azizi Abdullah, Shahnorbanun Sahran Pattern Recognition Research Group Center for Artificial Intelligence Faculty of Information
CS4670: Computer Vision
 CS4670: Computer Vision Noah Snavely Lecture 6: Feature matching and alignment Szeliski: Chapter 6.1 Reading Last time: Corners and blobs Scale-space blob detector: Example Feature descriptors We know
CS4670: Computer Vision Noah Snavely Lecture 6: Feature matching and alignment Szeliski: Chapter 6.1 Reading Last time: Corners and blobs Scale-space blob detector: Example Feature descriptors We know
Final Review CMSC 733 Fall 2014
 Final Review CMSC 733 Fall 2014 We have covered a lot of material in this course. One way to organize this material is around a set of key equations and algorithms. You should be familiar with all of these,
Final Review CMSC 733 Fall 2014 We have covered a lot of material in this course. One way to organize this material is around a set of key equations and algorithms. You should be familiar with all of these,
CS 395T Numerical Optimization for Graphics and AI (3D Vision) Qixing Huang August 29 th 2018
 Qixing Huang August 29 th 2018") CS 395T Numerical Optimization for Graphics and AI (3D Vision) Qixing Huang August 29 th 2018 3D Vision Understanding geometric relations between images and the 3D world between images Obtaining 3D information
CS 395T Numerical Optimization for Graphics and AI (3D Vision) Qixing Huang August 29 th 2018 3D Vision Understanding geometric relations between images and the 3D world between images Obtaining 3D information
Selective Search for Object Recognition
 Selective Search for Object Recognition Uijlings et al. Schuyler Smith Overview Introduction Object Recognition Selective Search Similarity Metrics Results Object Recognition Kitten Goal: Problem: Where
Selective Search for Object Recognition Uijlings et al. Schuyler Smith Overview Introduction Object Recognition Selective Search Similarity Metrics Results Object Recognition Kitten Goal: Problem: Where
Journal of Industrial Engineering Research
 IWNEST PUBLISHER Journal of Industrial Engineering Research (ISSN: 2077-4559) Journal home page: http://www.iwnest.com/aace/ Mammogram Image Segmentation Using voronoi Diagram Properties Dr. J. Subash
IWNEST PUBLISHER Journal of Industrial Engineering Research (ISSN: 2077-4559) Journal home page: http://www.iwnest.com/aace/ Mammogram Image Segmentation Using voronoi Diagram Properties Dr. J. Subash
Introduction to PCL: The Point Cloud Library
 Introduction to PCL: The Point Cloud Library 1 - basic topics Alberto Pretto Thanks to Radu Bogdan Rusu, Bastian Steder and Jeff Delmerico for some of the slides! Contact Alberto Pretto, PhD Assistant
Introduction to PCL: The Point Cloud Library 1 - basic topics Alberto Pretto Thanks to Radu Bogdan Rusu, Bastian Steder and Jeff Delmerico for some of the slides! Contact Alberto Pretto, PhD Assistant
3D Perception. CS 4495 Computer Vision K. Hawkins. CS 4495 Computer Vision. 3D Perception. Kelsey Hawkins Robotics
 CS 4495 Computer Vision Kelsey Hawkins Robotics Motivation What do animals, people, and robots want to do with vision? Detect and recognize objects/landmarks Find location of objects with respect to themselves
CS 4495 Computer Vision Kelsey Hawkins Robotics Motivation What do animals, people, and robots want to do with vision? Detect and recognize objects/landmarks Find location of objects with respect to themselves
INTELLIGENT AUTONOMOUS SYSTEMS LAB
 Matteo Munaro 1,3, Alex Horn 2, Randy Illum 2, Jeff Burke 2, and Radu Bogdan Rusu 3 1 IAS-Lab at Department of Information Engineering, University of Padova 2 Center for Research in Engineering, Media
Matteo Munaro 1,3, Alex Horn 2, Randy Illum 2, Jeff Burke 2, and Radu Bogdan Rusu 3 1 IAS-Lab at Department of Information Engineering, University of Padova 2 Center for Research in Engineering, Media
A Statistical Approach to Culture Colors Distribution in Video Sensors Angela D Angelo, Jean-Luc Dugelay
 A Statistical Approach to Culture Colors Distribution in Video Sensors Angela D Angelo, Jean-Luc Dugelay VPQM 2010, Scottsdale, Arizona, U.S.A, January 13-15 Outline Introduction Proposed approach Colors
A Statistical Approach to Culture Colors Distribution in Video Sensors Angela D Angelo, Jean-Luc Dugelay VPQM 2010, Scottsdale, Arizona, U.S.A, January 13-15 Outline Introduction Proposed approach Colors
MATRIX BASED INDEXING TECHNIQUE FOR VIDEO DATA
 Journal of Computer Science, 9 (5): 534-542, 2013 ISSN 1549-3636 2013 doi:10.3844/jcssp.2013.534.542 Published Online 9 (5) 2013 (http://www.thescipub.com/jcs.toc) MATRIX BASED INDEXING TECHNIQUE FOR VIDEO
Journal of Computer Science, 9 (5): 534-542, 2013 ISSN 1549-3636 2013 doi:10.3844/jcssp.2013.534.542 Published Online 9 (5) 2013 (http://www.thescipub.com/jcs.toc) MATRIX BASED INDEXING TECHNIQUE FOR VIDEO
Object Classification Using Tripod Operators
 Object Classification Using Tripod Operators David Bonanno, Frank Pipitone, G. Charmaine Gilbreath, Kristen Nock, Carlos A. Font, and Chadwick T. Hawley US Naval Research Laboratory, 4555 Overlook Ave.
Object Classification Using Tripod Operators David Bonanno, Frank Pipitone, G. Charmaine Gilbreath, Kristen Nock, Carlos A. Font, and Chadwick T. Hawley US Naval Research Laboratory, 4555 Overlook Ave.
Abstract. 1 Introduction
 Human Pose Estimation using Google Tango Victor Vahram Shahbazian Assisted: Sam Gbolahan Adesoye Co-assistant: Sam Song March 17, 2017 CMPS 161 Introduction to Data Visualization Professor Alex Pang Abstract
Human Pose Estimation using Google Tango Victor Vahram Shahbazian Assisted: Sam Gbolahan Adesoye Co-assistant: Sam Song March 17, 2017 CMPS 161 Introduction to Data Visualization Professor Alex Pang Abstract
Content-based Image Retrieval (CBIR)
") Content-based Image Retrieval (CBIR) Content-based Image Retrieval (CBIR) Searching a large database for images that match a query: What kinds of databases? What kinds of queries? What constitutes a match?
Content-based Image Retrieval (CBIR) Content-based Image Retrieval (CBIR) Searching a large database for images that match a query: What kinds of databases? What kinds of queries? What constitutes a match?
UNIK 4690 Maskinsyn Introduction
 UNIK 4690 Maskinsyn Introduction 18.01.2018 Trym Vegard Haavardsholm (trym.haavardsholm@its.uio.no) Idar Dyrdal (idar.dyrdal@its.uio.no) Thomas Opsahl (thomasoo@its.uio.no) Ragnar Smestad (ragnar.smestad@ffi.no)
UNIK 4690 Maskinsyn Introduction 18.01.2018 Trym Vegard Haavardsholm (trym.haavardsholm@its.uio.no) Idar Dyrdal (idar.dyrdal@its.uio.no) Thomas Opsahl (thomasoo@its.uio.no) Ragnar Smestad (ragnar.smestad@ffi.no)
Image Features: Local Descriptors. Sanja Fidler CSC420: Intro to Image Understanding 1/ 58
 Image Features: Local Descriptors Sanja Fidler CSC420: Intro to Image Understanding 1/ 58 [Source: K. Grauman] Sanja Fidler CSC420: Intro to Image Understanding 2/ 58 Local Features Detection: Identify
Image Features: Local Descriptors Sanja Fidler CSC420: Intro to Image Understanding 1/ 58 [Source: K. Grauman] Sanja Fidler CSC420: Intro to Image Understanding 2/ 58 Local Features Detection: Identify
Sea Turtle Identification by Matching Their Scale Patterns
 Sea Turtle Identification by Matching Their Scale Patterns Technical Report Rajmadhan Ekambaram and Rangachar Kasturi Department of Computer Science and Engineering, University of South Florida Abstract
Sea Turtle Identification by Matching Their Scale Patterns Technical Report Rajmadhan Ekambaram and Rangachar Kasturi Department of Computer Science and Engineering, University of South Florida Abstract
ROS-Industrial Basic Developer s Training Class
 ROS-Industrial Basic Developer s Training Class Southwest Research Institute 1 Session 4: More Advanced Topics (Descartes and Perception) Southwest Research Institute 2 MOVEIT! CONTINUED 3 Motion Planning
ROS-Industrial Basic Developer s Training Class Southwest Research Institute 1 Session 4: More Advanced Topics (Descartes and Perception) Southwest Research Institute 2 MOVEIT! CONTINUED 3 Motion Planning
Cell Clustering Using Shape and Cell Context. Descriptor
 Cell Clustering Using Shape and Cell Context Descriptor Allison Mok: 55596627 F. Park E. Esser UC Irvine August 11, 2011 Abstract Given a set of boundary points from a 2-D image, the shape context captures
Cell Clustering Using Shape and Cell Context Descriptor Allison Mok: 55596627 F. Park E. Esser UC Irvine August 11, 2011 Abstract Given a set of boundary points from a 2-D image, the shape context captures