Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift. Amit Patel Sambit Pradhan
|
|
|
- Herbert Garrison
- 5 years ago
- Views:
Transcription

1 Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift Amit Patel Sambit Pradhan

2 Introduction Internal Covariate Shift Batch Normalization Computational Graph of Batch Normalization Real World Application Practical Demo Discussion

3 Introduction Batch Normalization
4 The story of Scaredy Cat
5 Baby kitten for Christmas! Yey! Young, Naïve, Innocent, Scared of everything = Not Trained
6 Task Train it to eat






7




8 First step in Training Scaredy Cat to Eat Train it to Recognize a Pizza Features Training Data Model Output
9 Every Day







10 One Special Day Features

11 Training Data with distribution of the features is different
12 The Pizza Super Duper Man
13 The Pizza Super Duper Man

14 The Pizza Super Duper Man - Normalizes Batch Normalization Layer





15 Happily Ever After


16 Internal Covariate Shift
17 Covariate Shift Covariate The Features of the Input Data Covariate Shift - Formally, is defined as a change in the distribution of a function s domain. Feature space of Target is drastically different than Source Training Data with distribution of the features is different. Informally, when input feature change, and algorithm can t deal with it, thus slowing the training. Let s say you have a goal to reach, which is easier, a fixed goal a goal that keeps moving about? It is clear that a static goal is much easier to reach than a dynamic goal.
18 Why Covariate Shift slows learning? IID Independent and identically distributed - Each random variable has the same probability distribution as the others and all are mutually independent. Between the source (S) and target (T) given the same observation X = x conditional distributions of Y is same in both domains. P s (Y X = x) = P t (Y X = x) x X In real world In the wild P s (Y X = x) P t (Y X = x)
19 Why Covariate Shift slows learning? To analyze the issue We consider a Parametric Model Family {P(Y X, θ)} θ Ɵ We select a model {P(Y X, θ*)}, which minimizes the expected classification error. If none of the models in the model family can exactly match the true relation between X and Y => there does not exist any θ Ɵ such that P(Y X = x, θ) = P(Y X = x) x X => We call this a misspecified model family. With a misspecified model family, the optimal model we select depends on P(X) and if Ps(X) Pt(X) then the optimal model for the target domain will differ from that for the source domain
20 Why Covariate Shift slows learning? The intuitive is that the optimal model performs better in dense regions of than in sparse regions of, because the dense regions dominate the average classification error, which is what we want to minimize. If the dense regions of are different in the source and target then the optimal model for the source domain domain will no longer be optimal for the target domain. We re-weigh the We therefore re-weight each training instance with
21 Why Covariate Shift slows learning? Improving predictive inference under covariate shift by weighting the log-likelihood function - Hidetoshi Shimodaira
22 Internal Covariate Shift Deep learning Is parameterized in a hierarchical fashion The first layere (Input Layer) looksa at the souce and the output of the first layer feeds the second layer, the second feeds the third, and so on. The distribution of the input is important - Because we are actually learning a MODEL from the training data and NOT the right model. Internal Covariate Shift - Small changes to the network get amplified down the network which leads to change in the input distribution to internal layers of the deep network.
23 Internal Covariate Shift Internal covariate shift refers to covariate shift occurring within a neural network, i.e. going from (say) layer 2 to layer 3. This happens because, as the network learns and the weights are updated, the distribution of outputs of a specific layer in the network changes. This forces the higher layers to adapt to that drift, which slows down learning. Small Change Gets Amplified Large Change
24 Internal Covariate Shift Internal Covariate Shift applied to its parts, such as a sub-network or a layer. Where F1 and F2 are arbitrary transformations, and the parameters Ɵ1, Ɵ2 are to be learned so as to minimize the loss l. Learning Ɵ2 can be viewed as if the inputs x = F1(u, Ɵ1) are fed into the sub-network (for batch size m and learning rate α) is exactly equivalent to that for a stand-alone network F2 with input x.

25 Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift

26 Batch Normalization Batch Normalization Is a process normalize each scalar feature independently, by making it have the mean of zero and the variance of 1 and then scale and shift the normalized value for each training mini-batch thus reducing internal covariate shift fixing the distribution of the layer inputs x as the training progresses. Using mini-batches of examples, as opposed to one example at a time, is helpful in several ways. First, the gradient of the loss over a mini-batch is an estimate of the gradient over the training set, whose quality improves as the batch size increases. Second, computation over a batch can be much more efficient than m computations for individual examples, due to the parallelism afforded by the modern computing platforms.
27 Batch Normalizing Transform To remedy internal covariate shift, the solution proposed in the paper is to normalize each batch by both mean and variance
28 Batch Normalizing Transform Let us say that the layer we want to normalize has d dimensions x = (x 1,... x d ). Then, we can normalize the k th dimension as follows: the parameters γ and β are to be learned, but it should be noted that the BN transform does not independently process the activation in each training example. Rather, BNγ,β(x) depends both on the training example and the other examples in the mini-batch. The scaled and shifted values y are passed to other network layers.
29 Batch Normalizing Transform During training we need to backpropagate the gradient of loss l through this transformation, as well as compute the gradients with respect to the parameters of the BN transform.

30 Batch Normalizing Transform To remedy internal covariate shift, the solution proposed in the paper is to normalize each batch by both mean and variance



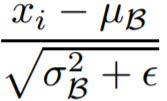
31 Computational Graph of Batch Normalization
32 Backpropagation
33 Chain Rule in Backpropagation
34 Computational Graph of Batch Normalization STEP 9
35 STEP 9 Summation gate
36 Computational Graph of Batch Normalization STEP 8 STEP 9
37 STEP 8 First Multiplication gate
38 Computational Graph of Batch Normalization STEP 7 STEP 8 STEP 9
39 STEP 7 Second Multiplication gate
40 Computational Graph of Batch Normalization STEP 7 STEP 8 STEP 9 STEP 6
41 STEP 6 Inverse gate
42 Computational Graph of Batch Normalization STEP 7 STEP 8 STEP 9 STEP 5 STEP 6
43 STEP 5 Square root gate
44 Computational Graph of Batch Normalization STEP 7 STEP 8 STEP 9 STEP 4 STEP 5 STEP 6
45 STEP 4 Mean gate
46 Computational Graph of Batch Normalization STEP 7 STEP 8 STEP 9 STEP 3 STEP 4 STEP 5 STEP 6
47 STEP 3 Square gate
48 Computational Graph of Batch Normalization STEP 2 STEP 7 STEP 8 STEP 9 STEP 3 STEP 4 STEP 5 STEP 6
49 STEP 2 Subtraction gate
50 Computational Graph of Batch Normalization STEP 2 STEP 7 STEP 8 STEP 9 STEP 3 STEP 4 STEP 5 STEP 6 STEP 1
51 STEP 1 Mean gate
52 Computational Graph of Batch Normalization STEP 0 STEP 2 STEP 7 STEP 8 STEP 9 STEP 3 STEP 4 STEP 5 STEP 6 STEP 1
53 STEP 0 Input

54 Real World Applications
55 Advantages of Batch Normalization Increased learning rate Remove Dropout Increased accuracy Allow use of saturating nonlinearities
56 Disadvantages of Batch Normalization Difficult to estimate mean and standard deviation of input during testing Cannot use batch size of 1 during training Computational overhead during training
57 Practical Demo CIFAR-10 4 convolutional layers. ReLu activation function. Mini-batch size to be 32. Batch Normalization added before each activation. 50,000 train samples 10,00 test samples
58 Learning curve on CIFAR-10
59 Related Work Recurrent Batch Normalization - Batch-normalize the hidden-tohidden transition, thereby reducing internal covariate shift between time steps. Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks Normalization Propagation: A Parametric Technique for Removing Internal Covariate Shift in Deep Networks Layer Normalization
60 Citations
Deep neural networks II
 Deep neural networks II May 31 st, 2018 Yong Jae Lee UC Davis Many slides from Rob Fergus, Svetlana Lazebnik, Jia-Bin Huang, Derek Hoiem, Adriana Kovashka, Why (convolutional) neural networks? State of
Deep neural networks II May 31 st, 2018 Yong Jae Lee UC Davis Many slides from Rob Fergus, Svetlana Lazebnik, Jia-Bin Huang, Derek Hoiem, Adriana Kovashka, Why (convolutional) neural networks? State of
Lecture 21 : A Hybrid: Deep Learning and Graphical Models
 10-708: Probabilistic Graphical Models, Spring 2018 Lecture 21 : A Hybrid: Deep Learning and Graphical Models Lecturer: Kayhan Batmanghelich Scribes: Paul Liang, Anirudha Rayasam 1 Introduction and Motivation
10-708: Probabilistic Graphical Models, Spring 2018 Lecture 21 : A Hybrid: Deep Learning and Graphical Models Lecturer: Kayhan Batmanghelich Scribes: Paul Liang, Anirudha Rayasam 1 Introduction and Motivation
COMP9444 Neural Networks and Deep Learning 7. Image Processing. COMP9444 c Alan Blair, 2017
 COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
DEEP LEARNING IN PYTHON. The need for optimization
 DEEP LEARNING IN PYTHON The need for optimization A baseline neural network Input 2 Hidden Layer 5 2 Output - 9-3 Actual Value of Target: 3 Error: Actual - Predicted = 4 A baseline neural network Input
DEEP LEARNING IN PYTHON The need for optimization A baseline neural network Input 2 Hidden Layer 5 2 Output - 9-3 Actual Value of Target: 3 Error: Actual - Predicted = 4 A baseline neural network Input
Deep Learning Cook Book
 Deep Learning Cook Book Robert Haschke (CITEC) Overview Input Representation Output Layer + Cost Function Hidden Layer Units Initialization Regularization Input representation Choose an input representation
Deep Learning Cook Book Robert Haschke (CITEC) Overview Input Representation Output Layer + Cost Function Hidden Layer Units Initialization Regularization Input representation Choose an input representation
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Image Data: Classification via Neural Networks Instructor: Yizhou Sun yzsun@ccs.neu.edu November 19, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining
CS6220: DATA MINING TECHNIQUES Image Data: Classification via Neural Networks Instructor: Yizhou Sun yzsun@ccs.neu.edu November 19, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining
Machine Learning 13. week
 Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
CS489/698: Intro to ML
 CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
Convolutional Neural Networks
 NPFL114, Lecture 4 Convolutional Neural Networks Milan Straka March 25, 2019 Charles University in Prague Faculty of Mathematics and Physics Institute of Formal and Applied Linguistics unless otherwise
NPFL114, Lecture 4 Convolutional Neural Networks Milan Straka March 25, 2019 Charles University in Prague Faculty of Mathematics and Physics Institute of Formal and Applied Linguistics unless otherwise
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
Ensemble methods in machine learning. Example. Neural networks. Neural networks
 Ensemble methods in machine learning Bootstrap aggregating (bagging) train an ensemble of models based on randomly resampled versions of the training set, then take a majority vote Example What if you
Ensemble methods in machine learning Bootstrap aggregating (bagging) train an ensemble of models based on randomly resampled versions of the training set, then take a majority vote Example What if you
Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Index. Springer Nature Switzerland AG 2019 B. Moons et al., Embedded Deep Learning,
 Index A Algorithmic noise tolerance (ANT), 93 94 Application specific instruction set processors (ASIPs), 115 116 Approximate computing application level, 95 circuits-levels, 93 94 DAS and DVAS, 107 110
Index A Algorithmic noise tolerance (ANT), 93 94 Application specific instruction set processors (ASIPs), 115 116 Approximate computing application level, 95 circuits-levels, 93 94 DAS and DVAS, 107 110
Deep Learning with Tensorflow AlexNet
 Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 10, 2017
 INF 5860 Machine learning for image classification Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 0, 207 Mandatory exercise Available tonight,
INF 5860 Machine learning for image classification Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 0, 207 Mandatory exercise Available tonight,
Natural Language Processing with Deep Learning CS224N/Ling284. Christopher Manning Lecture 4: Backpropagation and computation graphs
 Natural Language Processing with Deep Learning CS4N/Ling84 Christopher Manning Lecture 4: Backpropagation and computation graphs Lecture Plan Lecture 4: Backpropagation and computation graphs 1. Matrix
Natural Language Processing with Deep Learning CS4N/Ling84 Christopher Manning Lecture 4: Backpropagation and computation graphs Lecture Plan Lecture 4: Backpropagation and computation graphs 1. Matrix
27: Hybrid Graphical Models and Neural Networks
 10-708: Probabilistic Graphical Models 10-708 Spring 2016 27: Hybrid Graphical Models and Neural Networks Lecturer: Matt Gormley Scribes: Jakob Bauer Otilia Stretcu Rohan Varma 1 Motivation We first look
10-708: Probabilistic Graphical Models 10-708 Spring 2016 27: Hybrid Graphical Models and Neural Networks Lecturer: Matt Gormley Scribes: Jakob Bauer Otilia Stretcu Rohan Varma 1 Motivation We first look
SEMANTIC COMPUTING. Lecture 8: Introduction to Deep Learning. TU Dresden, 7 December Dagmar Gromann International Center For Computational Logic
 SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
CPSC 340: Machine Learning and Data Mining. Deep Learning Fall 2016
 CPSC 340: Machine Learning and Data Mining Deep Learning Fall 2016 Assignment 5: Due Friday. Assignment 6: Due next Friday. Final: Admin December 12 (8:30am HEBB 100) Covers Assignments 1-6. Final from
CPSC 340: Machine Learning and Data Mining Deep Learning Fall 2016 Assignment 5: Due Friday. Assignment 6: Due next Friday. Final: Admin December 12 (8:30am HEBB 100) Covers Assignments 1-6. Final from
CS 6501: Deep Learning for Computer Graphics. Training Neural Networks II. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Training Neural Networks II Connelly Barnes Overview Preprocessing Initialization Vanishing/exploding gradients problem Batch normalization Dropout Additional
CS 6501: Deep Learning for Computer Graphics Training Neural Networks II Connelly Barnes Overview Preprocessing Initialization Vanishing/exploding gradients problem Batch normalization Dropout Additional
Lecture 20: Neural Networks for NLP. Zubin Pahuja
 Lecture 20: Neural Networks for NLP Zubin Pahuja zpahuja2@illinois.edu courses.engr.illinois.edu/cs447 CS447: Natural Language Processing 1 Today s Lecture Feed-forward neural networks as classifiers simple
Lecture 20: Neural Networks for NLP Zubin Pahuja zpahuja2@illinois.edu courses.engr.illinois.edu/cs447 CS447: Natural Language Processing 1 Today s Lecture Feed-forward neural networks as classifiers simple
Supervised Learning in Neural Networks (Part 2)
") Supervised Learning in Neural Networks (Part 2) Multilayer neural networks (back-propagation training algorithm) The input signals are propagated in a forward direction on a layer-bylayer basis. Learning
Supervised Learning in Neural Networks (Part 2) Multilayer neural networks (back-propagation training algorithm) The input signals are propagated in a forward direction on a layer-bylayer basis. Learning
Deep Learning for Computer Vision II
 IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
Deep Generative Models Variational Autoencoders
 Deep Generative Models Variational Autoencoders Sudeshna Sarkar 5 April 2017 Generative Nets Generative models that represent probability distributions over multiple variables in some way. Directed Generative
Deep Generative Models Variational Autoencoders Sudeshna Sarkar 5 April 2017 Generative Nets Generative models that represent probability distributions over multiple variables in some way. Directed Generative
Deep Neural Networks Optimization
 Deep Neural Networks Optimization Creative Commons (cc) by Akritasa http://arxiv.org/pdf/1406.2572.pdf Slides from Geoffrey Hinton CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy
Deep Neural Networks Optimization Creative Commons (cc) by Akritasa http://arxiv.org/pdf/1406.2572.pdf Slides from Geoffrey Hinton CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy
Perceptron: This is convolution!
 Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
COMP 551 Applied Machine Learning Lecture 16: Deep Learning
 COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
RNNs as Directed Graphical Models
 RNNs as Directed Graphical Models Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 10. Topics in Sequence Modeling Overview
RNNs as Directed Graphical Models Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 10. Topics in Sequence Modeling Overview
Neural Network Optimization and Tuning / Spring 2018 / Recitation 3
 Neural Network Optimization and Tuning 11-785 / Spring 2018 / Recitation 3 1 Logistics You will work through a Jupyter notebook that contains sample and starter code with explanations and comments throughout.
Neural Network Optimization and Tuning 11-785 / Spring 2018 / Recitation 3 1 Logistics You will work through a Jupyter notebook that contains sample and starter code with explanations and comments throughout.
Dropout. Sargur N. Srihari This is part of lecture slides on Deep Learning:
 Dropout Sargur N. srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Regularization Strategies 1. Parameter Norm Penalties 2. Norm Penalties
Dropout Sargur N. srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Regularization Strategies 1. Parameter Norm Penalties 2. Norm Penalties
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
Recurrent Convolutional Neural Networks for Scene Labeling
 Recurrent Convolutional Neural Networks for Scene Labeling Pedro O. Pinheiro, Ronan Collobert Reviewed by Yizhe Zhang August 14, 2015 Scene labeling task Scene labeling: assign a class label to each pixel
Recurrent Convolutional Neural Networks for Scene Labeling Pedro O. Pinheiro, Ronan Collobert Reviewed by Yizhe Zhang August 14, 2015 Scene labeling task Scene labeling: assign a class label to each pixel
Residual Networks And Attention Models. cs273b Recitation 11/11/2016. Anna Shcherbina
 Residual Networks And Attention Models cs273b Recitation 11/11/2016 Anna Shcherbina Introduction to ResNets Introduced in 2015 by Microsoft Research Deep Residual Learning for Image Recognition (He, Zhang,
Residual Networks And Attention Models cs273b Recitation 11/11/2016 Anna Shcherbina Introduction to ResNets Introduced in 2015 by Microsoft Research Deep Residual Learning for Image Recognition (He, Zhang,
Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization. Presented by: Karen Lucknavalai and Alexandr Kuznetsov
 Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization Presented by: Karen Lucknavalai and Alexandr Kuznetsov Example Style Content Result Motivation Transforming content of an image
Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization Presented by: Karen Lucknavalai and Alexandr Kuznetsov Example Style Content Result Motivation Transforming content of an image
The Mathematics Behind Neural Networks
 The Mathematics Behind Neural Networks Pattern Recognition and Machine Learning by Christopher M. Bishop Student: Shivam Agrawal Mentor: Nathaniel Monson Courtesy of xkcd.com The Black Box Training the
The Mathematics Behind Neural Networks Pattern Recognition and Machine Learning by Christopher M. Bishop Student: Shivam Agrawal Mentor: Nathaniel Monson Courtesy of xkcd.com The Black Box Training the
Machine Learning. Deep Learning. Eric Xing (and Pengtao Xie) , Fall Lecture 8, October 6, Eric CMU,
 , Fall Lecture 8, October 6, Eric CMU,") Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Machine Learning. The Breadth of ML Neural Networks & Deep Learning. Marc Toussaint. Duy Nguyen-Tuong. University of Stuttgart
 Machine Learning The Breadth of ML Neural Networks & Deep Learning Marc Toussaint University of Stuttgart Duy Nguyen-Tuong Bosch Center for Artificial Intelligence Summer 2017 Neural Networks Consider
Machine Learning The Breadth of ML Neural Networks & Deep Learning Marc Toussaint University of Stuttgart Duy Nguyen-Tuong Bosch Center for Artificial Intelligence Summer 2017 Neural Networks Consider
Hidden Units. Sargur N. Srihari
 Hidden Units Sargur N. srihari@cedar.buffalo.edu 1 Topics in Deep Feedforward Networks Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation
Hidden Units Sargur N. srihari@cedar.buffalo.edu 1 Topics in Deep Feedforward Networks Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation
Unrolling Inference: The Recurrent Inference Machine
 Unrolling Inference: The Recurrent Inference Machine Max Welling University of Amsterdam / Qualcomm Canadian Institute for Advanced Research ML @ UvA (2 fte) (12fte) Machine Learning in Amsterdam (3fte)
Unrolling Inference: The Recurrent Inference Machine Max Welling University of Amsterdam / Qualcomm Canadian Institute for Advanced Research ML @ UvA (2 fte) (12fte) Machine Learning in Amsterdam (3fte)
In-Place Activated BatchNorm for Memory- Optimized Training of DNNs
 In-Place Activated BatchNorm for Memory- Optimized Training of DNNs Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder Mapillary Research Paper: https://arxiv.org/abs/1712.02616 Code: https://github.com/mapillary/inplace_abn
In-Place Activated BatchNorm for Memory- Optimized Training of DNNs Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder Mapillary Research Paper: https://arxiv.org/abs/1712.02616 Code: https://github.com/mapillary/inplace_abn
Deep Boltzmann Machines
 Deep Boltzmann Machines Sargur N. Srihari srihari@cedar.buffalo.edu Topics 1. Boltzmann machines 2. Restricted Boltzmann machines 3. Deep Belief Networks 4. Deep Boltzmann machines 5. Boltzmann machines
Deep Boltzmann Machines Sargur N. Srihari srihari@cedar.buffalo.edu Topics 1. Boltzmann machines 2. Restricted Boltzmann machines 3. Deep Belief Networks 4. Deep Boltzmann machines 5. Boltzmann machines
Opening the black box of Deep Neural Networks via Information (Ravid Shwartz-Ziv and Naftali Tishby) An overview by Philip Amortila and Nicolas Gagné
 An overview by Philip Amortila and Nicolas Gagné") Opening the black box of Deep Neural Networks via Information (Ravid Shwartz-Ziv and Naftali Tishby) An overview by Philip Amortila and Nicolas Gagné 1 Problem: The usual "black box" story: "Despite their
Opening the black box of Deep Neural Networks via Information (Ravid Shwartz-Ziv and Naftali Tishby) An overview by Philip Amortila and Nicolas Gagné 1 Problem: The usual "black box" story: "Despite their
Recurrent Neural Network (RNN) Industrial AI Lab.
 Industrial AI Lab.") Recurrent Neural Network (RNN) Industrial AI Lab. For example (Deterministic) Time Series Data Closed- form Linear difference equation (LDE) and initial condition High order LDEs 2 (Stochastic) Time Series
Recurrent Neural Network (RNN) Industrial AI Lab. For example (Deterministic) Time Series Data Closed- form Linear difference equation (LDE) and initial condition High order LDEs 2 (Stochastic) Time Series
Deep Learning. Architecture Design for. Sargur N. Srihari
 Architecture Design for Deep Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation
Architecture Design for Deep Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation
CSC 578 Neural Networks and Deep Learning
 CSC 578 Neural Networks and Deep Learning Fall 2018/19 7. Recurrent Neural Networks (Some figures adapted from NNDL book) 1 Recurrent Neural Networks 1. Recurrent Neural Networks (RNNs) 2. RNN Training
CSC 578 Neural Networks and Deep Learning Fall 2018/19 7. Recurrent Neural Networks (Some figures adapted from NNDL book) 1 Recurrent Neural Networks 1. Recurrent Neural Networks (RNNs) 2. RNN Training
CENG 783. Special topics in. Deep Learning. AlchemyAPI. Week 11. Sinan Kalkan
 CENG 783 Special topics in Deep Learning AlchemyAPI Week 11 Sinan Kalkan TRAINING A CNN Fig: http://www.robots.ox.ac.uk/~vgg/practicals/cnn/ Feed-forward pass Note that this is written in terms of the
CENG 783 Special topics in Deep Learning AlchemyAPI Week 11 Sinan Kalkan TRAINING A CNN Fig: http://www.robots.ox.ac.uk/~vgg/practicals/cnn/ Feed-forward pass Note that this is written in terms of the
Deep Learning. Practical introduction with Keras JORDI TORRES 27/05/2018. Chapter 3 JORDI TORRES
 Deep Learning Practical introduction with Keras Chapter 3 27/05/2018 Neuron A neural network is formed by neurons connected to each other; in turn, each connection of one neural network is associated
Deep Learning Practical introduction with Keras Chapter 3 27/05/2018 Neuron A neural network is formed by neurons connected to each other; in turn, each connection of one neural network is associated
CS 1674: Intro to Computer Vision. Neural Networks. Prof. Adriana Kovashka University of Pittsburgh November 16, 2016
 CS 1674: Intro to Computer Vision Neural Networks Prof. Adriana Kovashka University of Pittsburgh November 16, 2016 Announcements Please watch the videos I sent you, if you haven t yet (that s your reading)
CS 1674: Intro to Computer Vision Neural Networks Prof. Adriana Kovashka University of Pittsburgh November 16, 2016 Announcements Please watch the videos I sent you, if you haven t yet (that s your reading)
Machine Learning With Python. Bin Chen Nov. 7, 2017 Research Computing Center
 Machine Learning With Python Bin Chen Nov. 7, 2017 Research Computing Center Outline Introduction to Machine Learning (ML) Introduction to Neural Network (NN) Introduction to Deep Learning NN Introduction
Machine Learning With Python Bin Chen Nov. 7, 2017 Research Computing Center Outline Introduction to Machine Learning (ML) Introduction to Neural Network (NN) Introduction to Deep Learning NN Introduction
Inception Network Overview. David White CS793
 Inception Network Overview David White CS793 So, Leonardo DiCaprio dreams about dreaming... https://m.media-amazon.com/images/m/mv5bmjaxmzy3njcxnf5bml5banbnxkftztcwnti5otm0mw@@._v1_sy1000_cr0,0,675,1 000_AL_.jpg
Inception Network Overview David White CS793 So, Leonardo DiCaprio dreams about dreaming... https://m.media-amazon.com/images/m/mv5bmjaxmzy3njcxnf5bml5banbnxkftztcwnti5otm0mw@@._v1_sy1000_cr0,0,675,1 000_AL_.jpg
A Quick Guide on Training a neural network using Keras.
 A Quick Guide on Training a neural network using Keras. TensorFlow and Keras Keras Open source High level, less flexible Easy to learn Perfect for quick implementations Starts by François Chollet from
A Quick Guide on Training a neural network using Keras. TensorFlow and Keras Keras Open source High level, less flexible Easy to learn Perfect for quick implementations Starts by François Chollet from
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Report: Privacy-Preserving Classification on Deep Neural Network
 Report: Privacy-Preserving Classification on Deep Neural Network Janno Veeorg Supervised by Helger Lipmaa and Raul Vicente Zafra May 25, 2017 1 Introduction In this report we consider following task: how
Report: Privacy-Preserving Classification on Deep Neural Network Janno Veeorg Supervised by Helger Lipmaa and Raul Vicente Zafra May 25, 2017 1 Introduction In this report we consider following task: how
MoonRiver: Deep Neural Network in C++
 MoonRiver: Deep Neural Network in C++ Chung-Yi Weng Computer Science & Engineering University of Washington chungyi@cs.washington.edu Abstract Artificial intelligence resurges with its dramatic improvement
MoonRiver: Deep Neural Network in C++ Chung-Yi Weng Computer Science & Engineering University of Washington chungyi@cs.washington.edu Abstract Artificial intelligence resurges with its dramatic improvement
Neural Networks. Theory And Practice. Marco Del Vecchio 19/07/2017. Warwick Manufacturing Group University of Warwick
 Neural Networks Theory And Practice Marco Del Vecchio marco@delvecchiomarco.com Warwick Manufacturing Group University of Warwick 19/07/2017 Outline I 1 Introduction 2 Linear Regression Models 3 Linear
Neural Networks Theory And Practice Marco Del Vecchio marco@delvecchiomarco.com Warwick Manufacturing Group University of Warwick 19/07/2017 Outline I 1 Introduction 2 Linear Regression Models 3 Linear
Machine Learning. Sourangshu Bhattacharya
 Machine Learning Sourangshu Bhattacharya Bayesian Networks Directed Acyclic Graph (DAG) Bayesian Networks General Factorization Curve Fitting Re-visited Maximum Likelihood Determine by minimizing sum-of-squares
Machine Learning Sourangshu Bhattacharya Bayesian Networks Directed Acyclic Graph (DAG) Bayesian Networks General Factorization Curve Fitting Re-visited Maximum Likelihood Determine by minimizing sum-of-squares
Asynchronous Parallel Learning for Neural Networks and Structured Models with Dense Features
 Asynchronous Parallel Learning for Neural Networks and Structured Models with Dense Features Xu SUN ( 孙栩 ) Peking University xusun@pku.edu.cn Motivation Neural networks -> Good Performance CNN, RNN, LSTM
Asynchronous Parallel Learning for Neural Networks and Structured Models with Dense Features Xu SUN ( 孙栩 ) Peking University xusun@pku.edu.cn Motivation Neural networks -> Good Performance CNN, RNN, LSTM
DECISION TREES & RANDOM FORESTS X CONVOLUTIONAL NEURAL NETWORKS
 DECISION TREES & RANDOM FORESTS X CONVOLUTIONAL NEURAL NETWORKS Deep Neural Decision Forests Microsoft Research Cambridge UK, ICCV 2015 Decision Forests, Convolutional Networks and the Models in-between
DECISION TREES & RANDOM FORESTS X CONVOLUTIONAL NEURAL NETWORKS Deep Neural Decision Forests Microsoft Research Cambridge UK, ICCV 2015 Decision Forests, Convolutional Networks and the Models in-between
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Example Learning Problem Example Learning Problem Celebrity Faces in the Wild Machine Learning Pipeline Raw data Feature extract. Feature computation Inference: prediction,
Neural Networks and Deep Learning Example Learning Problem Example Learning Problem Celebrity Faces in the Wild Machine Learning Pipeline Raw data Feature extract. Feature computation Inference: prediction,
Deep Learning Basic Lecture - Complex Systems & Artificial Intelligence 2017/18 (VO) Asan Agibetov, PhD.
 Asan Agibetov, PhD.") Deep Learning 861.061 Basic Lecture - Complex Systems & Artificial Intelligence 2017/18 (VO) Asan Agibetov, PhD asan.agibetov@meduniwien.ac.at Medical University of Vienna Center for Medical Statistics,
Deep Learning 861.061 Basic Lecture - Complex Systems & Artificial Intelligence 2017/18 (VO) Asan Agibetov, PhD asan.agibetov@meduniwien.ac.at Medical University of Vienna Center for Medical Statistics,
Lecture : Training a neural net part I Initialization, activations, normalizations and other practical details Anne Solberg February 28, 2018
 INF 5860 Machine learning for image classification Lecture : Training a neural net part I Initialization, activations, normalizations and other practical details Anne Solberg February 28, 2018 Reading
INF 5860 Machine learning for image classification Lecture : Training a neural net part I Initialization, activations, normalizations and other practical details Anne Solberg February 28, 2018 Reading
Modeling Sequences Conditioned on Context with RNNs
 Modeling Sequences Conditioned on Context with RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 10. Topics in Sequence
Modeling Sequences Conditioned on Context with RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 10. Topics in Sequence
Unsupervised Learning
 Deep Learning for Graphics Unsupervised Learning Niloy Mitra Iasonas Kokkinos Paul Guerrero Vladimir Kim Kostas Rematas Tobias Ritschel UCL UCL/Facebook UCL Adobe Research U Washington UCL Timetable Niloy
Deep Learning for Graphics Unsupervised Learning Niloy Mitra Iasonas Kokkinos Paul Guerrero Vladimir Kim Kostas Rematas Tobias Ritschel UCL UCL/Facebook UCL Adobe Research U Washington UCL Timetable Niloy
Generative Modeling with Convolutional Neural Networks. Denis Dus Data Scientist at InData Labs
 Generative Modeling with Convolutional Neural Networks Denis Dus Data Scientist at InData Labs What we will discuss 1. 2. 3. 4. Discriminative vs Generative modeling Convolutional Neural Networks How to
Generative Modeling with Convolutional Neural Networks Denis Dus Data Scientist at InData Labs What we will discuss 1. 2. 3. 4. Discriminative vs Generative modeling Convolutional Neural Networks How to
IMPROVEMENTS TO THE BACKPROPAGATION ALGORITHM
 Annals of the University of Petroşani, Economics, 12(4), 2012, 185-192 185 IMPROVEMENTS TO THE BACKPROPAGATION ALGORITHM MIRCEA PETRINI * ABSTACT: This paper presents some simple techniques to improve
Annals of the University of Petroşani, Economics, 12(4), 2012, 185-192 185 IMPROVEMENTS TO THE BACKPROPAGATION ALGORITHM MIRCEA PETRINI * ABSTACT: This paper presents some simple techniques to improve
Old Image De-noising and Auto-Colorization Using Linear Regression, Multilayer Perceptron and Convolutional Nearual Network
 Old Image De-noising and Auto-Colorization Using Linear Regression, Multilayer Perceptron and Convolutional Nearual Network Junkyo Suh (006035729), Koosha Nassiri Nazif (005950924), and Aravindh Kumar
Old Image De-noising and Auto-Colorization Using Linear Regression, Multilayer Perceptron and Convolutional Nearual Network Junkyo Suh (006035729), Koosha Nassiri Nazif (005950924), and Aravindh Kumar
Lecture 2 Notes. Outline. Neural Networks. The Big Idea. Architecture. Instructors: Parth Shah, Riju Pahwa
 Instructors: Parth Shah, Riju Pahwa Lecture 2 Notes Outline 1. Neural Networks The Big Idea Architecture SGD and Backpropagation 2. Convolutional Neural Networks Intuition Architecture 3. Recurrent Neural
Instructors: Parth Shah, Riju Pahwa Lecture 2 Notes Outline 1. Neural Networks The Big Idea Architecture SGD and Backpropagation 2. Convolutional Neural Networks Intuition Architecture 3. Recurrent Neural
Dynamic Routing Between Capsules
 Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Neural Networks. CE-725: Statistical Pattern Recognition Sharif University of Technology Spring Soleymani
 Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
Bayesian model ensembling using meta-trained recurrent neural networks
 Bayesian model ensembling using meta-trained recurrent neural networks Luca Ambrogioni l.ambrogioni@donders.ru.nl Umut Güçlü u.guclu@donders.ru.nl Yağmur Güçlütürk y.gucluturk@donders.ru.nl Julia Berezutskaya
Bayesian model ensembling using meta-trained recurrent neural networks Luca Ambrogioni l.ambrogioni@donders.ru.nl Umut Güçlü u.guclu@donders.ru.nl Yağmur Güçlütürk y.gucluturk@donders.ru.nl Julia Berezutskaya
COMPUTATIONAL INTELLIGENCE
 COMPUTATIONAL INTELLIGENCE Radial Basis Function Networks Adrian Horzyk Preface Radial Basis Function Networks (RBFN) are a kind of artificial neural networks that use radial basis functions (RBF) as activation
COMPUTATIONAL INTELLIGENCE Radial Basis Function Networks Adrian Horzyk Preface Radial Basis Function Networks (RBFN) are a kind of artificial neural networks that use radial basis functions (RBF) as activation
Sequence Modeling: Recurrent and Recursive Nets. By Pyry Takala 14 Oct 2015
 Sequence Modeling: Recurrent and Recursive Nets By Pyry Takala 14 Oct 2015 Agenda Why Recurrent neural networks? Anatomy and basic training of an RNN (10.2, 10.2.1) Properties of RNNs (10.2.2, 8.2.6) Using
Sequence Modeling: Recurrent and Recursive Nets By Pyry Takala 14 Oct 2015 Agenda Why Recurrent neural networks? Anatomy and basic training of an RNN (10.2, 10.2.1) Properties of RNNs (10.2.2, 8.2.6) Using
Inception and Residual Networks. Hantao Zhang. Deep Learning with Python.
 Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
Convolutional Neural Networks and Supervised Learning
 Convolutional Neural Networks and Supervised Learning Eilif Solberg August 30, 2018 Outline Convolutional Architectures Convolutional neural networks Training Loss Optimization Regularization Hyperparameter
Convolutional Neural Networks and Supervised Learning Eilif Solberg August 30, 2018 Outline Convolutional Architectures Convolutional neural networks Training Loss Optimization Regularization Hyperparameter
A Brief Introduction to Reinforcement Learning
 A Brief Introduction to Reinforcement Learning Minlie Huang ( ) Dept. of Computer Science, Tsinghua University aihuang@tsinghua.edu.cn 1 http://coai.cs.tsinghua.edu.cn/hml Reinforcement Learning Agent
A Brief Introduction to Reinforcement Learning Minlie Huang ( ) Dept. of Computer Science, Tsinghua University aihuang@tsinghua.edu.cn 1 http://coai.cs.tsinghua.edu.cn/hml Reinforcement Learning Agent
Motivation: Shortcomings of Hidden Markov Model. Ko, Youngjoong. Solution: Maximum Entropy Markov Model (MEMM)
") Motivation: Shortcomings of Hidden Markov Model Maximum Entropy Markov Models and Conditional Random Fields Ko, Youngjoong Dept. of Computer Engineering, Dong-A University Intelligent System Laboratory,
Motivation: Shortcomings of Hidden Markov Model Maximum Entropy Markov Models and Conditional Random Fields Ko, Youngjoong Dept. of Computer Engineering, Dong-A University Intelligent System Laboratory,
Keras: Handwritten Digit Recognition using MNIST Dataset
 Keras: Handwritten Digit Recognition using MNIST Dataset IIT PATNA January 31, 2018 1 / 30 OUTLINE 1 Keras: Introduction 2 Installing Keras 3 Keras: Building, Testing, Improving A Simple Network 2 / 30
Keras: Handwritten Digit Recognition using MNIST Dataset IIT PATNA January 31, 2018 1 / 30 OUTLINE 1 Keras: Introduction 2 Installing Keras 3 Keras: Building, Testing, Improving A Simple Network 2 / 30
Artificial Neural Networks. Introduction to Computational Neuroscience Ardi Tampuu
 Artificial Neural Networks Introduction to Computational Neuroscience Ardi Tampuu 7.0.206 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Artificial Neural Networks Introduction to Computational Neuroscience Ardi Tampuu 7.0.206 Artificial neural network NB! Inspired by biology, not based on biology! Applications Automatic speech recognition
Machine Learning. Chao Lan
 Machine Learning Chao Lan Machine Learning Prediction Models Regression Model - linear regression (least square, ridge regression, Lasso) Classification Model - naive Bayes, logistic regression, Gaussian
Machine Learning Chao Lan Machine Learning Prediction Models Regression Model - linear regression (least square, ridge regression, Lasso) Classification Model - naive Bayes, logistic regression, Gaussian
10703 Deep Reinforcement Learning and Control
 10703 Deep Reinforcement Learning and Control Russ Salakhutdinov Machine Learning Department rsalakhu@cs.cmu.edu Policy Gradient I Used Materials Disclaimer: Much of the material and slides for this lecture
10703 Deep Reinforcement Learning and Control Russ Salakhutdinov Machine Learning Department rsalakhu@cs.cmu.edu Policy Gradient I Used Materials Disclaimer: Much of the material and slides for this lecture
Deep Learning and Its Applications
 Convolutional Neural Network and Its Application in Image Recognition Oct 28, 2016 Outline 1 A Motivating Example 2 The Convolutional Neural Network (CNN) Model 3 Training the CNN Model 4 Issues and Recent
Convolutional Neural Network and Its Application in Image Recognition Oct 28, 2016 Outline 1 A Motivating Example 2 The Convolutional Neural Network (CNN) Model 3 Training the CNN Model 4 Issues and Recent
Machine Learning Classifiers and Boosting
 Machine Learning Classifiers and Boosting Reading Ch 18.6-18.12, 20.1-20.3.2 Outline Different types of learning problems Different types of learning algorithms Supervised learning Decision trees Naïve
Machine Learning Classifiers and Boosting Reading Ch 18.6-18.12, 20.1-20.3.2 Outline Different types of learning problems Different types of learning algorithms Supervised learning Decision trees Naïve
EE 511 Neural Networks
 Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Andrei Karpathy EE 511 Neural Networks Instructor: Hanna Hajishirzi hannaneh@washington.edu Computational
Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Andrei Karpathy EE 511 Neural Networks Instructor: Hanna Hajishirzi hannaneh@washington.edu Computational
Artificial Intelligence
 Artificial Intelligence AI & Machine Learning & Neural Nets Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: Neural networks became a central topic for Machine Learning and AI. But in
Artificial Intelligence AI & Machine Learning & Neural Nets Marc Toussaint University of Stuttgart Winter 2018/19 Motivation: Neural networks became a central topic for Machine Learning and AI. But in
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
 PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Sikai Zhong February 14, 2018 COMPUTER SCIENCE Table of contents 1. PointNet 2. PointNet++ 3. Experiments 1 PointNet Property
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Sikai Zhong February 14, 2018 COMPUTER SCIENCE Table of contents 1. PointNet 2. PointNet++ 3. Experiments 1 PointNet Property
DEEP LEARNING REVIEW. Yann LeCun, Yoshua Bengio & Geoffrey Hinton Nature Presented by Divya Chitimalla
 DEEP LEARNING REVIEW Yann LeCun, Yoshua Bengio & Geoffrey Hinton Nature 2015 -Presented by Divya Chitimalla What is deep learning Deep learning allows computational models that are composed of multiple
DEEP LEARNING REVIEW Yann LeCun, Yoshua Bengio & Geoffrey Hinton Nature 2015 -Presented by Divya Chitimalla What is deep learning Deep learning allows computational models that are composed of multiple
ImageNet Classification with Deep Convolutional Neural Networks
 ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky Ilya Sutskever Geoffrey Hinton University of Toronto Canada Paper with same name to appear in NIPS 2012 Main idea Architecture
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky Ilya Sutskever Geoffrey Hinton University of Toronto Canada Paper with same name to appear in NIPS 2012 Main idea Architecture
An Introduction to NNs using Keras
 An Introduction to NNs using Keras Michela Paganini michela.paganini@cern.ch Yale University 1 Keras Modular, powerful and intuitive Deep Learning python library built on Theano and TensorFlow Minimalist,
An Introduction to NNs using Keras Michela Paganini michela.paganini@cern.ch Yale University 1 Keras Modular, powerful and intuitive Deep Learning python library built on Theano and TensorFlow Minimalist,
Alternatives to Direct Supervision
 CreativeAI: Deep Learning for Graphics Alternatives to Direct Supervision Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TUM UCL Timetable Theory and Basics State of
CreativeAI: Deep Learning for Graphics Alternatives to Direct Supervision Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TUM UCL Timetable Theory and Basics State of
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Clustering and EM Barnabás Póczos & Aarti Singh Contents Clustering K-means Mixture of Gaussians Expectation Maximization Variational Methods 2 Clustering 3 K-
Introduction to Machine Learning CMU-10701 Clustering and EM Barnabás Póczos & Aarti Singh Contents Clustering K-means Mixture of Gaussians Expectation Maximization Variational Methods 2 Clustering 3 K-
COMP9444 Neural Networks and Deep Learning 5. Geometry of Hidden Units
 COMP9 8s Geometry of Hidden Units COMP9 Neural Networks and Deep Learning 5. Geometry of Hidden Units Outline Geometry of Hidden Unit Activations Limitations of -layer networks Alternative transfer functions
COMP9 8s Geometry of Hidden Units COMP9 Neural Networks and Deep Learning 5. Geometry of Hidden Units Outline Geometry of Hidden Unit Activations Limitations of -layer networks Alternative transfer functions
Bottom Line. Data Science: From System Identification to (Deep) Learning and Big Data. Data Science? The core
 Learning and Big Data. Data Science? The core") ................ Bottom Line : From System Identification to (Deep) Learning and Big Data Reglerteknik, ISY, Linköpings Universitet Many Buzzwords:, Machine Learning, Deep Learning, Big Data... One well-defined
................ Bottom Line : From System Identification to (Deep) Learning and Big Data Reglerteknik, ISY, Linköpings Universitet Many Buzzwords:, Machine Learning, Deep Learning, Big Data... One well-defined
Partitioning Data. IRDS: Evaluation, Debugging, and Diagnostics. Cross-Validation. Cross-Validation for parameter tuning
 Partitioning Data IRDS: Evaluation, Debugging, and Diagnostics Charles Sutton University of Edinburgh Training Validation Test Training : Running learning algorithms Validation : Tuning parameters of learning
Partitioning Data IRDS: Evaluation, Debugging, and Diagnostics Charles Sutton University of Edinburgh Training Validation Test Training : Running learning algorithms Validation : Tuning parameters of learning
Multiview Feature Learning
 Multiview Feature Learning Roland Memisevic Frankfurt, Montreal Tutorial at IPAM 2012 Roland Memisevic (Frankfurt, Montreal) Multiview Feature Learning Tutorial at IPAM 2012 1 / 163 Outline 1 Introduction
Multiview Feature Learning Roland Memisevic Frankfurt, Montreal Tutorial at IPAM 2012 Roland Memisevic (Frankfurt, Montreal) Multiview Feature Learning Tutorial at IPAM 2012 1 / 163 Outline 1 Introduction
Knowledge Transfer for Deep Reinforcement Learning with Hierarchical Experience Replay
 Knowledge Transfer for Deep Reinforcement Learning with Hierarchical Experience Replay Haiyan (Helena) Yin, Sinno Jialin Pan School of Computer Science and Engineering Nanyang Technological University
Knowledge Transfer for Deep Reinforcement Learning with Hierarchical Experience Replay Haiyan (Helena) Yin, Sinno Jialin Pan School of Computer Science and Engineering Nanyang Technological University
Large-Scale Lasso and Elastic-Net Regularized Generalized Linear Models
 Large-Scale Lasso and Elastic-Net Regularized Generalized Linear Models DB Tsai Steven Hillion Outline Introduction Linear / Nonlinear Classification Feature Engineering - Polynomial Expansion Big-data
Large-Scale Lasso and Elastic-Net Regularized Generalized Linear Models DB Tsai Steven Hillion Outline Introduction Linear / Nonlinear Classification Feature Engineering - Polynomial Expansion Big-data
CMU Lecture 18: Deep learning and Vision: Convolutional neural networks. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 18: Deep learning and Vision: Convolutional neural networks Teacher: Gianni A. Di Caro DEEP, SHALLOW, CONNECTED, SPARSE? Fully connected multi-layer feed-forward perceptrons: More powerful
CMU 15-781 Lecture 18: Deep learning and Vision: Convolutional neural networks Teacher: Gianni A. Di Caro DEEP, SHALLOW, CONNECTED, SPARSE? Fully connected multi-layer feed-forward perceptrons: More powerful
Deep Feedforward Networks
 Chapter 6 Deep Feedforward Networks Deep feedforward networks, also often called feedforward neural networks, or multilayer perceptrons (MLPs), are the quintessential deep learning models. The goal of
Chapter 6 Deep Feedforward Networks Deep feedforward networks, also often called feedforward neural networks, or multilayer perceptrons (MLPs), are the quintessential deep learning models. The goal of
LSTM: An Image Classification Model Based on Fashion-MNIST Dataset
 LSTM: An Image Classification Model Based on Fashion-MNIST Dataset Kexin Zhang, Research School of Computer Science, Australian National University Kexin Zhang, U6342657@anu.edu.au Abstract. The application
LSTM: An Image Classification Model Based on Fashion-MNIST Dataset Kexin Zhang, Research School of Computer Science, Australian National University Kexin Zhang, U6342657@anu.edu.au Abstract. The application
Back propagation Algorithm:
 Network Neural: A neural network is a class of computing system. They are created from very simple processing nodes formed into a network. They are inspired by the way that biological systems such as the
Network Neural: A neural network is a class of computing system. They are created from very simple processing nodes formed into a network. They are inspired by the way that biological systems such as the