Natural Language Processing with Deep Learning CS224N/Ling284. Christopher Manning Lecture 4: Backpropagation and computation graphs
|
|
|
- Nelson Homer Black
- 5 years ago
- Views:
Transcription

1 Natural Language Processing with Deep Learning CS4N/Ling84 Christopher Manning Lecture 4: Backpropagation and computation graphs
2 Lecture Plan Lecture 4: Backpropagation and computation graphs 1. Matrix gradients for our simple neural net and some tips [15 mins]. Computation graphs and backpropagation [40 mins] 3. Stuff you should know [15 mins] a. Regularization to prevent overfitting b. Vectorization c. Nonlinearities d. Initialization e. Optimizers f. Learning rates


3 1. Derivative wrt a weight matrix Let s look carefully at computing Using the chain rule again: ) = * + " " = $ % % = &! + ( 3! = [ x museums x in x Paris x are x amazing ]
4 Deriving gradients for backprop For this function (following on from last time):!"!# = %!&!# = %!!# #' + ) Let s consider the derivative of a single weight W ij W ij only contributes to z i For example: W 3 is only used to compute z not z 1 4!* + =! #!, +-!, +. ' + / + +- = , = 9-3 s u f(z 1 )= h 1 h =f(z ) W 3b x 1 x x 3 +1

5 Deriving gradients for backprop So for derivative of single W ij :!"!# $% = ' $ ( % Error signal from above Local gradient signal We want gradient for full W but each case is the same Overall answer: Outer product: 5
6 Deriving gradients: Tips Tip 1: Carefully define your variables and keep track of their dimensionality! Tip : Chain rule! If y = f(u) and u = g(x), i.e., y = f(g(x)), then:!"!# =!"!%!%!# Keep straight what variables feed into what computations Tip 3: For the top softmax part of a model: First consider the derivative wrt f c when c = y (the correct class), then consider derivative wrt f c when c ¹ y (all the incorrect classes) Tip 4: Work out element-wise partial derivatives if you re getting confused by matrix calculus! Tip 5: Use Shape Convention. Note: The error message & that arrives at a hidden layer has the same dimensionality as that hidden layer 6
7 Deriving gradients wrt words for window model The gradient that arrives at and updates the word vectors can simply be split up for each word vector: Let With x window = [ x museums x in x Paris x are x amazing ] We have 7
8 Updating word gradients in window model This will push word vectors around so that they will (in principle) be more helpful in determining named entities. For example, the model can learn that seeing x in as the word just before the center word is indicative for the center word to be a location 8

9 A pitfall when retraining word vectors Setting: We are training a logistic regression classification model for movie review sentiment using single words. In the training data we have TV and telly In the testing data we have television The pre-trained word vectors have all three similar: TV telly television Question: What happens when we update the word vectors? 9
10 A pitfall when retraining word vectors Question: What happens when we update the word vectors? Answer: Those words that are in the training data move around TV and telly Words not in the training data stay where they were television telly TV This can be bad! 10 television
11 So what should I do? Question: Should I use available pre-trained word vectors Answer: Almost always, yes! They are trained on a huge amount of data, and so they will know about words not in your training data and will know more about words that are in your training data Have 100s of millions of words of data? Okay to start random Question: Should I update ( fine tune ) my own word vectors? Answer: If you only have a small training data set, don t train the word vectors If you have have a large dataset, it probably will work better to train = update = fine-tune word vectors to the task 11
12 Backpropagation We ve almost shown you backpropagation It s taking derivatives and using the (generalized) chain rule Other trick: we re-use derivatives computed for higher layers in computing derivatives for lower layers so as to minimize computation 1
13 . Computation Graphs and Backpropagation We represent our neural net equations as a graph Source nodes: inputs Interior nodes: operations + 13
14 Computation Graphs and Backpropagation We represent our neural net equations as a graph Source nodes: inputs Interior nodes: operations Edges pass along result of the operation + 14
15 Computation Graphs and Backpropagation Representing our neural net equations as a graph Source nodes: inputs Forward Propagation Interior nodes: operations Edges pass along result of the operation + 15


16 Backpropagation Go backwards along edges Pass along gradients + 16
17 Backpropagation: Single Node Node receives an upstream gradient Goal is to pass on the correct downstream gradient 17 Downstream gradient Upstream gradient

18 Backpropagation: Single Node Each node has a local gradient The gradient of it s output with respect to it s input 18 Downstream gradient Local gradient Upstream gradient
19 Backpropagation: Single Node Each node has a local gradient The gradient of it s output with respect to it s input Chain rule! 19 Downstream gradient Local gradient Upstream gradient

20 Backpropagation: Single Node Each node has a local gradient The gradient of it s output with respect to it s input [downstream gradient] = [upstream gradient] x [local gradient] 0 Downstream gradient Local gradient Upstream gradient
21 Backpropagation: Single Node What about nodes with multiple inputs? * 1


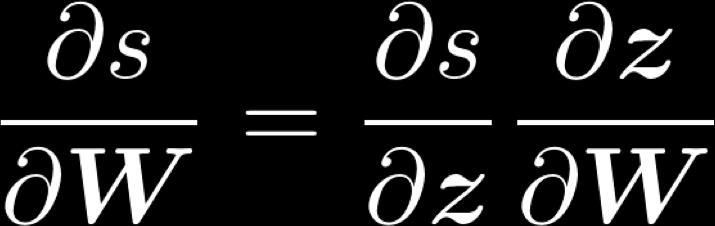

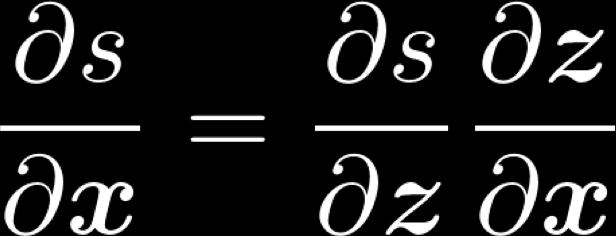
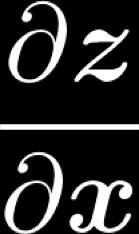
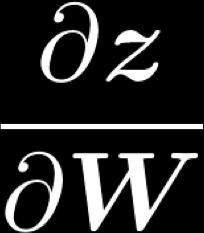
22 Backpropagation: Single Node Multiple inputs multiple local gradients * Downstream gradients Local gradients Upstream gradient
23 An Example 3
24 An Example Forward prop steps + max * 4
25 An Example Forward prop steps max 3 * 6 5
26 An Example Forward prop steps Local gradients max 3 * 6 6
27 An Example Forward prop steps Local gradients max 3 * 6 7
28 An Example Forward prop steps Local gradients max 3 * 6 8

29 An Example Forward prop steps Local gradients max 3 * 6 9
30 An Example Forward prop steps Local gradients max 3 1* = 1*3 = 3 * 6 1 upstream * local = downstream
31 An Example Forward prop steps Local gradients *1 = 3 0 3*0 = 0 + max 3 3 * 6 1 upstream * local = downstream
32 An Example Forward prop steps Local gradients 3 1 *1 = *1 = max 3 3 * 6 1 upstream * local = downstream

33 An Example Forward prop steps Local gradients max 3 3 * 6 1
34 Gradients sum at outward branches + 34


35 Gradients sum at outward branches + 35
36 Node Intuitions + distributes the upstream gradient max 3 *
37 Node Intuitions + distributes the upstream gradient to each summand max routes the upstream gradient max 3 3 * 6 1
38 Node Intuitions + distributes the upstream gradient max routes the upstream gradient * switches the upstream gradient max 3 3 *
39 Efficiency: compute all gradients at once Incorrect way of doing backprop: First compute * + 39

40 Efficiency: compute all gradients at once Incorrect way of doing backprop: First compute Then independently compute Duplicated computation! * + 40
41 Efficiency: compute all gradients at once Correct way: Compute all the gradients at once Analogous to using! when we computed gradients by hand * + 41

 complexity of fprop and bprop is the same In")
42 Back-Prop in General Computation Graph Single scalar output 1. Fprop: visit nodes in topological sort order - Compute value of node given predecessors. Bprop: - initialize output gradient = 1 - visit nodes in reverse order: Compute gradient wrt each node using gradient wrt successors = successors of 4 Done correctly, big O() complexity of fprop and bprop is the same In general our nets have regular layer-structure and so we can use matrices and Jacobians
43 Automatic Differentiation The gradient computation can be automatically inferred from the symbolic expression of the fprop Each node type needs to know how to compute its output and how to compute the gradient wrt its inputs given the gradient wrt its output Modern DL frameworks (Tensorflow, PyTorch, etc.) do backpropagation for you but mainly leave layer/node writer to hand-calculate the local derivative 43
44 Backprop Implementations 44
45 Implementation: forward/backward API 45
46 Implementation: forward/backward API 46

47 Gradient checking: Numeric Gradient For small h ( 1e-4), Easy to implement correctly But approximate and very slow: Have to recompute f for every parameter of our model Useful for checking your implementation In the old days when we hand-wrote everything, it was key to do this everywhere. 47 Now much less needed, when throwing together layers
48 Summary We ve mastered the core technology of neural nets!!! Backpropagation: recursively apply the chain rule along computation graph [downstream gradient] = [upstream gradient] x [local gradient] Forward pass: compute results of operations and save intermediate values Backward pass: apply chain rule to compute gradients 48
49 Why learn all these details about gradients? Modern deep learning frameworks compute gradients for you But why take a class on compilers or systems when they are implemented for you? Understanding what is going on under the hood is useful! Backpropagation doesn t always work perfectly. 49 Understanding why is crucial for debugging and improving models See Karpathy article (in syllabus): Example in future lecture: exploding and vanishing gradients

50 3. We have models with many params! Regularization! Really a full loss function in practice includes regularization over all parameters!, e.g., L regularization: Regularization (largely) prevents overfitting when we have a lot of features (or later a very powerful/deep model, ++) Test error overfitting Training error 50 model power
51 Vectorization E.g., looping over word vectors versus concatenating them all into one large matrix and then multiplying the softmax weights with that matrix 1000 loops, best of 3: 639 µs per loop loops, best of 3: 53.8 µs per loop 51
52 Vectorization The (10x) faster method is using a C x N matrix Always try to use vectors and matrices rather than for loops! You should speed-test your code a lot too!! tl;dr: Matrices are awesome!!! 5
53 Non-linearities: The starting points logistic ( sigmoid ) tanh hard tanh tanh is just a rescaled and shifted sigmoid ( as steep, [ 1,1]): tanh(z) = logistic(z) 1 Both logistic and tanh are still used in particular uses, but are no longer the defaults for making deep networks

54 Non-linearities: The new world order ReLU (rectified Leaky ReLU Parametric ReLU linear unit) hard tanh rect(z) = max(z, 0) For building a feed-forward deep network, the first thing you should try is ReLU it trains quickly and performs well due to good gradient backflow
55 Parameter Initialization You normally must initialize weights to small random values To avoid symmetries that prevent learning/specialization Initialize hidden layer biases to 0 and output (or reconstruction) biases to optimal value if weights were 0 (e.g., mean target or inverse sigmoid of mean target) Initialize all other weights ~ Uniform( r, r), with r chosen so numbers get neither too big or too small Xavier initialization has variance inversely proportional to fan-in n in (previous layer size) and fan-out n out (next layer size):
56 Optimizers Usually, plain SGD will work just fine However, getting good results will often require hand-tuning the learning rate (next slide) For more complex nets and situations, or just to avoid worry, you often do better with one of a family of more sophisticated adaptive optimizers that scale the parameter adjustment by an accumulated gradient. These models give per-parameter learning rates Adagrad RMSprop Adam ß A fairly good, safe place to begin in many cases SparseAdam
57 Learning Rates You can just use a constant learning rate. Start around lr = 0.001? It must be order of magnitude right try powers of 10 Too big: model may diverge or not converge Too small: your model may not have trained by the deadline Better results can generally be obtained by allowing learning rates to decrease as you train By hand: halve the learning rate every k epochs An epoch = a pass through the data (shuffled or sampled) By a formula:!" =!" $ % &'(, for epoch t There are fancier methods like cyclic learning rates (q.v.) Fancier optimizers still use a learning rate but it may be an initial rate that the optimizer shrinks so may be able to start high
Natural Language Processing with Deep Learning. CS224N/Ling284. Lecture 5: Backpropagation Kevin Clark
 Natural Language Processing with Deep Learning CS4N/Ling84 Lecture 5: Backpropagation Kevin Clark Announcements Assignment 1 due Thursday, 11:59 You can use up to 3 late days (making it due Sunday at midnight)
Natural Language Processing with Deep Learning CS4N/Ling84 Lecture 5: Backpropagation Kevin Clark Announcements Assignment 1 due Thursday, 11:59 You can use up to 3 late days (making it due Sunday at midnight)
Deep Learning. Practical introduction with Keras JORDI TORRES 27/05/2018. Chapter 3 JORDI TORRES
 Deep Learning Practical introduction with Keras Chapter 3 27/05/2018 Neuron A neural network is formed by neurons connected to each other; in turn, each connection of one neural network is associated
Deep Learning Practical introduction with Keras Chapter 3 27/05/2018 Neuron A neural network is formed by neurons connected to each other; in turn, each connection of one neural network is associated
Administrative. Assignment 1 due Wednesday April 18, 11:59pm
 Lecture 4-1 Administrative Assignment 1 due Wednesday April 18, 11:59pm Lecture 4-2 Administrative All office hours this week will use queuestatus Lecture 4-3 Where we are... scores function SVM loss data
Lecture 4-1 Administrative Assignment 1 due Wednesday April 18, 11:59pm Lecture 4-2 Administrative All office hours this week will use queuestatus Lecture 4-3 Where we are... scores function SVM loss data
EE 511 Neural Networks
 Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Andrei Karpathy EE 511 Neural Networks Instructor: Hanna Hajishirzi hannaneh@washington.edu Computational
Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Andrei Karpathy EE 511 Neural Networks Instructor: Hanna Hajishirzi hannaneh@washington.edu Computational
Natural Language Processing CS 6320 Lecture 6 Neural Language Models. Instructor: Sanda Harabagiu
 Natural Language Processing CS 6320 Lecture 6 Neural Language Models Instructor: Sanda Harabagiu In this lecture We shall cover: Deep Neural Models for Natural Language Processing Introduce Feed Forward
Natural Language Processing CS 6320 Lecture 6 Neural Language Models Instructor: Sanda Harabagiu In this lecture We shall cover: Deep Neural Models for Natural Language Processing Introduce Feed Forward
Backpropagation and Neural Networks. Lecture 4-1
 Lecture 4: Backpropagation and Neural Networks Lecture 4-1 Administrative Assignment 1 due Thursday April 20, 11:59pm on Canvas Lecture 4-2 Administrative Project: TA specialities and some project ideas
Lecture 4: Backpropagation and Neural Networks Lecture 4-1 Administrative Assignment 1 due Thursday April 20, 11:59pm on Canvas Lecture 4-2 Administrative Project: TA specialities and some project ideas
CS 6501: Deep Learning for Computer Graphics. Training Neural Networks II. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Training Neural Networks II Connelly Barnes Overview Preprocessing Initialization Vanishing/exploding gradients problem Batch normalization Dropout Additional
CS 6501: Deep Learning for Computer Graphics Training Neural Networks II Connelly Barnes Overview Preprocessing Initialization Vanishing/exploding gradients problem Batch normalization Dropout Additional
Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 10, 2017
 INF 5860 Machine learning for image classification Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 0, 207 Mandatory exercise Available tonight,
INF 5860 Machine learning for image classification Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 0, 207 Mandatory exercise Available tonight,
Natural Language Processing with Deep Learning CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 8: Recurrent Neural Networks Christopher Manning and Richard Socher Organization Extra project office hour today after lecture Overview
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 8: Recurrent Neural Networks Christopher Manning and Richard Socher Organization Extra project office hour today after lecture Overview
CPSC 340: Machine Learning and Data Mining. Deep Learning Fall 2016
 CPSC 340: Machine Learning and Data Mining Deep Learning Fall 2016 Assignment 5: Due Friday. Assignment 6: Due next Friday. Final: Admin December 12 (8:30am HEBB 100) Covers Assignments 1-6. Final from
CPSC 340: Machine Learning and Data Mining Deep Learning Fall 2016 Assignment 5: Due Friday. Assignment 6: Due next Friday. Final: Admin December 12 (8:30am HEBB 100) Covers Assignments 1-6. Final from
Lecture 20: Neural Networks for NLP. Zubin Pahuja
 Lecture 20: Neural Networks for NLP Zubin Pahuja zpahuja2@illinois.edu courses.engr.illinois.edu/cs447 CS447: Natural Language Processing 1 Today s Lecture Feed-forward neural networks as classifiers simple
Lecture 20: Neural Networks for NLP Zubin Pahuja zpahuja2@illinois.edu courses.engr.illinois.edu/cs447 CS447: Natural Language Processing 1 Today s Lecture Feed-forward neural networks as classifiers simple
Lecture : Training a neural net part I Initialization, activations, normalizations and other practical details Anne Solberg February 28, 2018
 INF 5860 Machine learning for image classification Lecture : Training a neural net part I Initialization, activations, normalizations and other practical details Anne Solberg February 28, 2018 Reading
INF 5860 Machine learning for image classification Lecture : Training a neural net part I Initialization, activations, normalizations and other practical details Anne Solberg February 28, 2018 Reading
Deep Neural Networks Optimization
 Deep Neural Networks Optimization Creative Commons (cc) by Akritasa http://arxiv.org/pdf/1406.2572.pdf Slides from Geoffrey Hinton CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy
Deep Neural Networks Optimization Creative Commons (cc) by Akritasa http://arxiv.org/pdf/1406.2572.pdf Slides from Geoffrey Hinton CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy
Neural Network Optimization and Tuning / Spring 2018 / Recitation 3
 Neural Network Optimization and Tuning 11-785 / Spring 2018 / Recitation 3 1 Logistics You will work through a Jupyter notebook that contains sample and starter code with explanations and comments throughout.
Neural Network Optimization and Tuning 11-785 / Spring 2018 / Recitation 3 1 Logistics You will work through a Jupyter notebook that contains sample and starter code with explanations and comments throughout.
A Quick Guide on Training a neural network using Keras.
 A Quick Guide on Training a neural network using Keras. TensorFlow and Keras Keras Open source High level, less flexible Easy to learn Perfect for quick implementations Starts by François Chollet from
A Quick Guide on Training a neural network using Keras. TensorFlow and Keras Keras Open source High level, less flexible Easy to learn Perfect for quick implementations Starts by François Chollet from
Deep Learning for Computer Vision II
 IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
Back Propagation and Other Differentiation Algorithms. Sargur N. Srihari
 Back Propagation and Other Differentiation Algorithms Sargur N. srihari@cedar.buffalo.edu 1 Topics (Deep Feedforward Networks) Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units
Back Propagation and Other Differentiation Algorithms Sargur N. srihari@cedar.buffalo.edu 1 Topics (Deep Feedforward Networks) Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units
CS489/698: Intro to ML
 CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
Backpropagation + Deep Learning
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation + Deep Learning Matt Gormley Lecture 13 Mar 1, 2018 1 Reminders
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation + Deep Learning Matt Gormley Lecture 13 Mar 1, 2018 1 Reminders
Sequence Modeling: Recurrent and Recursive Nets. By Pyry Takala 14 Oct 2015
 Sequence Modeling: Recurrent and Recursive Nets By Pyry Takala 14 Oct 2015 Agenda Why Recurrent neural networks? Anatomy and basic training of an RNN (10.2, 10.2.1) Properties of RNNs (10.2.2, 8.2.6) Using
Sequence Modeling: Recurrent and Recursive Nets By Pyry Takala 14 Oct 2015 Agenda Why Recurrent neural networks? Anatomy and basic training of an RNN (10.2, 10.2.1) Properties of RNNs (10.2.2, 8.2.6) Using
Deep neural networks II
 Deep neural networks II May 31 st, 2018 Yong Jae Lee UC Davis Many slides from Rob Fergus, Svetlana Lazebnik, Jia-Bin Huang, Derek Hoiem, Adriana Kovashka, Why (convolutional) neural networks? State of
Deep neural networks II May 31 st, 2018 Yong Jae Lee UC Davis Many slides from Rob Fergus, Svetlana Lazebnik, Jia-Bin Huang, Derek Hoiem, Adriana Kovashka, Why (convolutional) neural networks? State of
CMU Lecture 18: Deep learning and Vision: Convolutional neural networks. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 18: Deep learning and Vision: Convolutional neural networks Teacher: Gianni A. Di Caro DEEP, SHALLOW, CONNECTED, SPARSE? Fully connected multi-layer feed-forward perceptrons: More powerful
CMU 15-781 Lecture 18: Deep learning and Vision: Convolutional neural networks Teacher: Gianni A. Di Caro DEEP, SHALLOW, CONNECTED, SPARSE? Fully connected multi-layer feed-forward perceptrons: More powerful
Efficient Deep Learning Optimization Methods
 11-785/ Spring 2019/ Recitation 3 Efficient Deep Learning Optimization Methods Josh Moavenzadeh, Kai Hu, and Cody Smith Outline 1 Review of optimization 2 Optimization practice 3 Training tips in PyTorch
11-785/ Spring 2019/ Recitation 3 Efficient Deep Learning Optimization Methods Josh Moavenzadeh, Kai Hu, and Cody Smith Outline 1 Review of optimization 2 Optimization practice 3 Training tips in PyTorch
Lecture 2 Notes. Outline. Neural Networks. The Big Idea. Architecture. Instructors: Parth Shah, Riju Pahwa
 Instructors: Parth Shah, Riju Pahwa Lecture 2 Notes Outline 1. Neural Networks The Big Idea Architecture SGD and Backpropagation 2. Convolutional Neural Networks Intuition Architecture 3. Recurrent Neural
Instructors: Parth Shah, Riju Pahwa Lecture 2 Notes Outline 1. Neural Networks The Big Idea Architecture SGD and Backpropagation 2. Convolutional Neural Networks Intuition Architecture 3. Recurrent Neural
Machine Learning. Deep Learning. Eric Xing (and Pengtao Xie) , Fall Lecture 8, October 6, Eric CMU,
 , Fall Lecture 8, October 6, Eric CMU,") Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Training Deep Neural Networks (in parallel)
") Lecture 9: Training Deep Neural Networks (in parallel) Visual Computing Systems How would you describe this professor? Easy? Mean? Boring? Nerdy? Professor classification task Classifies professors as
Lecture 9: Training Deep Neural Networks (in parallel) Visual Computing Systems How would you describe this professor? Easy? Mean? Boring? Nerdy? Professor classification task Classifies professors as
Gradient Descent Optimization Algorithms for Deep Learning Batch gradient descent Stochastic gradient descent Mini-batch gradient descent
 Gradient Descent Optimization Algorithms for Deep Learning Batch gradient descent Stochastic gradient descent Mini-batch gradient descent Slide credit: http://sebastianruder.com/optimizing-gradient-descent/index.html#batchgradientdescent
Gradient Descent Optimization Algorithms for Deep Learning Batch gradient descent Stochastic gradient descent Mini-batch gradient descent Slide credit: http://sebastianruder.com/optimizing-gradient-descent/index.html#batchgradientdescent
Multinomial Regression and the Softmax Activation Function. Gary Cottrell!
 Multinomial Regression and the Softmax Activation Function Gary Cottrell Notation reminder We have N data points, or patterns, in the training set, with the pattern number as a superscript: {(x 1,t 1 ),
Multinomial Regression and the Softmax Activation Function Gary Cottrell Notation reminder We have N data points, or patterns, in the training set, with the pattern number as a superscript: {(x 1,t 1 ),
Machine Learning With Python. Bin Chen Nov. 7, 2017 Research Computing Center
 Machine Learning With Python Bin Chen Nov. 7, 2017 Research Computing Center Outline Introduction to Machine Learning (ML) Introduction to Neural Network (NN) Introduction to Deep Learning NN Introduction
Machine Learning With Python Bin Chen Nov. 7, 2017 Research Computing Center Outline Introduction to Machine Learning (ML) Introduction to Neural Network (NN) Introduction to Deep Learning NN Introduction
Machine learning for vision. It s the features, stupid! cathedral. high-rise. Winter Roland Memisevic. Lecture 2, January 26, 2016
 Winter 2016 Lecture 2, Januar 26, 2016 f2? cathedral high-rise f1 A common computer vision pipeline before 2012 1. 2. 3. 4. Find interest points. Crop patches around them. Represent each patch with a sparse
Winter 2016 Lecture 2, Januar 26, 2016 f2? cathedral high-rise f1 A common computer vision pipeline before 2012 1. 2. 3. 4. Find interest points. Crop patches around them. Represent each patch with a sparse
CS281 Section 3: Practical Optimization
 CS281 Section 3: Practical Optimization David Duvenaud and Dougal Maclaurin Most parameter estimation problems in machine learning cannot be solved in closed form, so we often have to resort to numerical
CS281 Section 3: Practical Optimization David Duvenaud and Dougal Maclaurin Most parameter estimation problems in machine learning cannot be solved in closed form, so we often have to resort to numerical
COMP9444 Neural Networks and Deep Learning 5. Geometry of Hidden Units
 COMP9 8s Geometry of Hidden Units COMP9 Neural Networks and Deep Learning 5. Geometry of Hidden Units Outline Geometry of Hidden Unit Activations Limitations of -layer networks Alternative transfer functions
COMP9 8s Geometry of Hidden Units COMP9 Neural Networks and Deep Learning 5. Geometry of Hidden Units Outline Geometry of Hidden Unit Activations Limitations of -layer networks Alternative transfer functions
Machine Learning. MGS Lecture 3: Deep Learning
 Dr Michel F. Valstar http://cs.nott.ac.uk/~mfv/ Machine Learning MGS Lecture 3: Deep Learning Dr Michel F. Valstar http://cs.nott.ac.uk/~mfv/ WHAT IS DEEP LEARNING? Shallow network: Only one hidden layer
Dr Michel F. Valstar http://cs.nott.ac.uk/~mfv/ Machine Learning MGS Lecture 3: Deep Learning Dr Michel F. Valstar http://cs.nott.ac.uk/~mfv/ WHAT IS DEEP LEARNING? Shallow network: Only one hidden layer
Deep Learning for Computer Vision
 Deep Learning for Computer Vision Lecture 7: Universal Approximation Theorem, More Hidden Units, Multi-Class Classifiers, Softmax, and Regularization Peter Belhumeur Computer Science Columbia University
Deep Learning for Computer Vision Lecture 7: Universal Approximation Theorem, More Hidden Units, Multi-Class Classifiers, Softmax, and Regularization Peter Belhumeur Computer Science Columbia University
SEMANTIC COMPUTING. Lecture 8: Introduction to Deep Learning. TU Dresden, 7 December Dagmar Gromann International Center For Computational Logic
 SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
Neural Networks for Machine Learning. Lecture 15a From Principal Components Analysis to Autoencoders
 Neural Networks for Machine Learning Lecture 15a From Principal Components Analysis to Autoencoders Geoffrey Hinton Nitish Srivastava, Kevin Swersky Tijmen Tieleman Abdel-rahman Mohamed Principal Components
Neural Networks for Machine Learning Lecture 15a From Principal Components Analysis to Autoencoders Geoffrey Hinton Nitish Srivastava, Kevin Swersky Tijmen Tieleman Abdel-rahman Mohamed Principal Components
LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS
 LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Neural Networks Classifier Introduction INPUT: classification data, i.e. it contains an classification (class) attribute. WE also say that the class
LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Neural Networks Classifier Introduction INPUT: classification data, i.e. it contains an classification (class) attribute. WE also say that the class
ECE 6504: Deep Learning for Perception
 ECE 6504: Deep Learning for Perception Topics: (Finish) Backprop Convolutional Neural Nets Dhruv Batra Virginia Tech Administrativia Presentation Assignments https://docs.google.com/spreadsheets/d/ 1m76E4mC0wfRjc4HRBWFdAlXKPIzlEwfw1-u7rBw9TJ8/
ECE 6504: Deep Learning for Perception Topics: (Finish) Backprop Convolutional Neural Nets Dhruv Batra Virginia Tech Administrativia Presentation Assignments https://docs.google.com/spreadsheets/d/ 1m76E4mC0wfRjc4HRBWFdAlXKPIzlEwfw1-u7rBw9TJ8/
Index. Umberto Michelucci 2018 U. Michelucci, Applied Deep Learning,
 A Acquisition function, 298, 301 Adam optimizer, 175 178 Anaconda navigator conda command, 3 Create button, 5 download and install, 1 installing packages, 8 Jupyter Notebook, 11 13 left navigation pane,
A Acquisition function, 298, 301 Adam optimizer, 175 178 Anaconda navigator conda command, 3 Create button, 5 download and install, 1 installing packages, 8 Jupyter Notebook, 11 13 left navigation pane,
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /10/2017
 3/0/207 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/0/207 Perceptron as a neural
3/0/207 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/0/207 Perceptron as a neural
MIXED PRECISION TRAINING: THEORY AND PRACTICE Paulius Micikevicius
 MIXED PRECISION TRAINING: THEORY AND PRACTICE Paulius Micikevicius What is Mixed Precision Training? Reduced precision tensor math with FP32 accumulation, FP16 storage Successfully used to train a variety
MIXED PRECISION TRAINING: THEORY AND PRACTICE Paulius Micikevicius What is Mixed Precision Training? Reduced precision tensor math with FP32 accumulation, FP16 storage Successfully used to train a variety
CSC321 Lecture 10: Automatic Differentiation
 CSC321 Lecture 10: Automatic Differentiation Roger Grosse Roger Grosse CSC321 Lecture 10: Automatic Differentiation 1 / 23 Overview Implementing backprop by hand is like programming in assembly language.
CSC321 Lecture 10: Automatic Differentiation Roger Grosse Roger Grosse CSC321 Lecture 10: Automatic Differentiation 1 / 23 Overview Implementing backprop by hand is like programming in assembly language.
Parallel Deep Network Training
 Lecture 26: Parallel Deep Network Training Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2016 Tunes Speech Debelle Finish This Album (Speech Therapy) Eat your veggies and study
Lecture 26: Parallel Deep Network Training Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2016 Tunes Speech Debelle Finish This Album (Speech Therapy) Eat your veggies and study
Practical Tips for using Backpropagation
 Practical Tips for using Backpropagation Keith L. Downing August 31, 2017 1 Introduction In practice, backpropagation is as much an art as a science. The user typically needs to try many combinations of
Practical Tips for using Backpropagation Keith L. Downing August 31, 2017 1 Introduction In practice, backpropagation is as much an art as a science. The user typically needs to try many combinations of
INTRODUCTION TO DEEP LEARNING
 INTRODUCTION TO DEEP LEARNING CONTENTS Introduction to deep learning Contents 1. Examples 2. Machine learning 3. Neural networks 4. Deep learning 5. Convolutional neural networks 6. Conclusion 7. Additional
INTRODUCTION TO DEEP LEARNING CONTENTS Introduction to deep learning Contents 1. Examples 2. Machine learning 3. Neural networks 4. Deep learning 5. Convolutional neural networks 6. Conclusion 7. Additional
COMP6237 Data Mining Data Mining & Machine Learning with Big Data. Jonathon Hare
 COMP6237 Data Mining Data Mining & Machine Learning with Big Data Jonathon Hare jsh2@ecs.soton.ac.uk Contents Going to look at two case-studies looking at how we can make machine-learning algorithms work
COMP6237 Data Mining Data Mining & Machine Learning with Big Data Jonathon Hare jsh2@ecs.soton.ac.uk Contents Going to look at two case-studies looking at how we can make machine-learning algorithms work
Homework 5. Due: April 20, 2018 at 7:00PM
 Homework 5 Due: April 20, 2018 at 7:00PM Written Questions Problem 1 (25 points) Recall that linear regression considers hypotheses that are linear functions of their inputs, h w (x) = w, x. In lecture,
Homework 5 Due: April 20, 2018 at 7:00PM Written Questions Problem 1 (25 points) Recall that linear regression considers hypotheses that are linear functions of their inputs, h w (x) = w, x. In lecture,
SEMANTIC COMPUTING. Lecture 9: Deep Learning: Recurrent Neural Networks (RNNs) TU Dresden, 21 December 2018
 TU Dresden, 21 December 2018") SEMANTIC COMPUTING Lecture 9: Deep Learning: Recurrent Neural Networks (RNNs) Dagmar Gromann International Center For Computational Logic TU Dresden, 21 December 2018 Overview Handling Overfitting Recurrent
SEMANTIC COMPUTING Lecture 9: Deep Learning: Recurrent Neural Networks (RNNs) Dagmar Gromann International Center For Computational Logic TU Dresden, 21 December 2018 Overview Handling Overfitting Recurrent
COMP 551 Applied Machine Learning Lecture 16: Deep Learning
 COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
Gradient Descent. Wed Sept 20th, James McInenrey Adapted from slides by Francisco J. R. Ruiz
 Gradient Descent Wed Sept 20th, 2017 James McInenrey Adapted from slides by Francisco J. R. Ruiz Housekeeping A few clarifications of and adjustments to the course schedule: No more breaks at the midpoint
Gradient Descent Wed Sept 20th, 2017 James McInenrey Adapted from slides by Francisco J. R. Ruiz Housekeeping A few clarifications of and adjustments to the course schedule: No more breaks at the midpoint
Neural Network Neurons
 Neural Networks Neural Network Neurons 1 Receives n inputs (plus a bias term) Multiplies each input by its weight Applies activation function to the sum of results Outputs result Activation Functions Given
Neural Networks Neural Network Neurons 1 Receives n inputs (plus a bias term) Multiplies each input by its weight Applies activation function to the sum of results Outputs result Activation Functions Given
Deep Learning with Tensorflow AlexNet
 Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Parallel Deep Network Training
 Lecture 19: Parallel Deep Network Training Parallel Computer Architecture and Programming How would you describe this professor? Easy? Mean? Boring? Nerdy? Professor classification task Classifies professors
Lecture 19: Parallel Deep Network Training Parallel Computer Architecture and Programming How would you describe this professor? Easy? Mean? Boring? Nerdy? Professor classification task Classifies professors
Introduction to SNNS
 Introduction to SNNS Caren Marzban http://www.nhn.ou.edu/ marzban Introduction In this lecture we will learn about a Neural Net (NN) program that I know a little about - the Stuttgart Neural Network Simulator
Introduction to SNNS Caren Marzban http://www.nhn.ou.edu/ marzban Introduction In this lecture we will learn about a Neural Net (NN) program that I know a little about - the Stuttgart Neural Network Simulator
Machine Learning 13. week
 Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Lecture 5: Training Neural Networks, Part I
 Lecture 5: Training Neural Networks, Part I Thursday February 2, 2017 comp150dl 1 Announcements! - HW1 due today! - Because of website typo, will accept homework 1 until Saturday with no late penalty.
Lecture 5: Training Neural Networks, Part I Thursday February 2, 2017 comp150dl 1 Announcements! - HW1 due today! - Because of website typo, will accept homework 1 until Saturday with no late penalty.
Knowledge Discovery and Data Mining. Neural Nets. A simple NN as a Mathematical Formula. Notes. Lecture 13 - Neural Nets. Tom Kelsey.
 Knowledge Discovery and Data Mining Lecture 13 - Neural Nets Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-13-NN
Knowledge Discovery and Data Mining Lecture 13 - Neural Nets Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-13-NN
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Lecture 13 - Neural Nets Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-13-NN
Knowledge Discovery and Data Mining Lecture 13 - Neural Nets Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-13-NN
Deep Learning Applications
 October 20, 2017 Overview Supervised Learning Feedforward neural network Convolution neural network Recurrent neural network Recursive neural network (Recursive neural tensor network) Unsupervised Learning
October 20, 2017 Overview Supervised Learning Feedforward neural network Convolution neural network Recurrent neural network Recursive neural network (Recursive neural tensor network) Unsupervised Learning
DEEP LEARNING IN PYTHON. The need for optimization
 DEEP LEARNING IN PYTHON The need for optimization A baseline neural network Input 2 Hidden Layer 5 2 Output - 9-3 Actual Value of Target: 3 Error: Actual - Predicted = 4 A baseline neural network Input
DEEP LEARNING IN PYTHON The need for optimization A baseline neural network Input 2 Hidden Layer 5 2 Output - 9-3 Actual Value of Target: 3 Error: Actual - Predicted = 4 A baseline neural network Input
Multi-layer Perceptron Forward Pass Backpropagation. Lecture 11: Aykut Erdem November 2016 Hacettepe University
 Multi-layer Perceptron Forward Pass Backpropagation Lecture 11: Aykut Erdem November 2016 Hacettepe University Administrative Assignment 2 due Nov. 10, 2016! Midterm exam on Monday, Nov. 14, 2016 You are
Multi-layer Perceptron Forward Pass Backpropagation Lecture 11: Aykut Erdem November 2016 Hacettepe University Administrative Assignment 2 due Nov. 10, 2016! Midterm exam on Monday, Nov. 14, 2016 You are
A Brief Look at Optimization
 A Brief Look at Optimization CSC 412/2506 Tutorial David Madras January 18, 2018 Slides adapted from last year s version Overview Introduction Classes of optimization problems Linear programming Steepest
A Brief Look at Optimization CSC 412/2506 Tutorial David Madras January 18, 2018 Slides adapted from last year s version Overview Introduction Classes of optimization problems Linear programming Steepest
All You Want To Know About CNNs. Yukun Zhu
 All You Want To Know About CNNs Yukun Zhu Deep Learning Deep Learning Image from http://imgur.com/ Deep Learning Image from http://imgur.com/ Deep Learning Image from http://imgur.com/ Deep Learning Image
All You Want To Know About CNNs Yukun Zhu Deep Learning Deep Learning Image from http://imgur.com/ Deep Learning Image from http://imgur.com/ Deep Learning Image from http://imgur.com/ Deep Learning Image
EECS 496 Statistical Language Models. Winter 2018
 EECS 496 Statistical Language Models Winter 2018 Introductions Professor: Doug Downey Course web site: www.cs.northwestern.edu/~ddowney/courses/496_winter2018 (linked off prof. home page) Logistics Grading
EECS 496 Statistical Language Models Winter 2018 Introductions Professor: Doug Downey Course web site: www.cs.northwestern.edu/~ddowney/courses/496_winter2018 (linked off prof. home page) Logistics Grading
Deep Learning. Volker Tresp Summer 2014
 Deep Learning Volker Tresp Summer 2014 1 Neural Network Winter and Revival While Machine Learning was flourishing, there was a Neural Network winter (late 1990 s until late 2000 s) Around 2010 there
Deep Learning Volker Tresp Summer 2014 1 Neural Network Winter and Revival While Machine Learning was flourishing, there was a Neural Network winter (late 1990 s until late 2000 s) Around 2010 there
Residual Networks And Attention Models. cs273b Recitation 11/11/2016. Anna Shcherbina
 Residual Networks And Attention Models cs273b Recitation 11/11/2016 Anna Shcherbina Introduction to ResNets Introduced in 2015 by Microsoft Research Deep Residual Learning for Image Recognition (He, Zhang,
Residual Networks And Attention Models cs273b Recitation 11/11/2016 Anna Shcherbina Introduction to ResNets Introduced in 2015 by Microsoft Research Deep Residual Learning for Image Recognition (He, Zhang,
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Image Data: Classification via Neural Networks Instructor: Yizhou Sun yzsun@ccs.neu.edu November 19, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining
CS6220: DATA MINING TECHNIQUES Image Data: Classification via Neural Networks Instructor: Yizhou Sun yzsun@ccs.neu.edu November 19, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining
ImageNet Classification with Deep Convolutional Neural Networks
 ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky Ilya Sutskever Geoffrey Hinton University of Toronto Canada Paper with same name to appear in NIPS 2012 Main idea Architecture
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky Ilya Sutskever Geoffrey Hinton University of Toronto Canada Paper with same name to appear in NIPS 2012 Main idea Architecture
INF 5860 Machine learning for image classification. Lecture 11: Visualization Anne Solberg April 4, 2018
 INF 5860 Machine learning for image classification Lecture 11: Visualization Anne Solberg April 4, 2018 Reading material The lecture is based on papers: Deep Dream: https://research.googleblog.com/2015/06/inceptionism-goingdeeper-into-neural.html
INF 5860 Machine learning for image classification Lecture 11: Visualization Anne Solberg April 4, 2018 Reading material The lecture is based on papers: Deep Dream: https://research.googleblog.com/2015/06/inceptionism-goingdeeper-into-neural.html
Deep Learning. Architecture Design for. Sargur N. Srihari
 Architecture Design for Deep Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation
Architecture Design for Deep Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics Overview 1. Example: Learning XOR 2. Gradient-Based Learning 3. Hidden Units 4. Architecture Design 5. Backpropagation
11. Neural Network Regularization
 11. Neural Network Regularization CS 519 Deep Learning, Winter 2016 Fuxin Li With materials from Andrej Karpathy, Zsolt Kira Preventing overfitting Approach 1: Get more data! Always best if possible! If
11. Neural Network Regularization CS 519 Deep Learning, Winter 2016 Fuxin Li With materials from Andrej Karpathy, Zsolt Kira Preventing overfitting Approach 1: Get more data! Always best if possible! If
Automatic Differentiation for R
 Automatic Differentiation for R Radford M. Neal, University of Toronto Dept. of Statistical Sciences and Dept. of Computer Science Vector Institute Affiliate http://www.cs.utoronto.ca/ radford http://radfordneal.wordpress.com
Automatic Differentiation for R Radford M. Neal, University of Toronto Dept. of Statistical Sciences and Dept. of Computer Science Vector Institute Affiliate http://www.cs.utoronto.ca/ radford http://radfordneal.wordpress.com
Artificial Neural Networks Lecture Notes Part 5. Stephen Lucci, PhD. Part 5
 Artificial Neural Networks Lecture Notes Part 5 About this file: If you have trouble reading the contents of this file, or in case of transcription errors, email gi0062@bcmail.brooklyn.cuny.edu Acknowledgments:
Artificial Neural Networks Lecture Notes Part 5 About this file: If you have trouble reading the contents of this file, or in case of transcription errors, email gi0062@bcmail.brooklyn.cuny.edu Acknowledgments:
CNN Basics. Chongruo Wu
 CNN Basics Chongruo Wu Overview 1. 2. 3. Forward: compute the output of each layer Back propagation: compute gradient Updating: update the parameters with computed gradient Agenda 1. Forward Conv, Fully
CNN Basics Chongruo Wu Overview 1. 2. 3. Forward: compute the output of each layer Back propagation: compute gradient Updating: update the parameters with computed gradient Agenda 1. Forward Conv, Fully
Neural Networks. Robot Image Credit: Viktoriya Sukhanova 123RF.com
 Neural Networks These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these slides
Neural Networks These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these slides
An Introduction to NNs using Keras
 An Introduction to NNs using Keras Michela Paganini michela.paganini@cern.ch Yale University 1 Keras Modular, powerful and intuitive Deep Learning python library built on Theano and TensorFlow Minimalist,
An Introduction to NNs using Keras Michela Paganini michela.paganini@cern.ch Yale University 1 Keras Modular, powerful and intuitive Deep Learning python library built on Theano and TensorFlow Minimalist,
Usable while performant: the challenges building. Soumith Chintala
 Usable while performant: the challenges building Soumith Chintala Problem Statement Deep Learning Workloads Problem Statement Deep Learning Workloads for epoch in range(max_epochs): for data, target in
Usable while performant: the challenges building Soumith Chintala Problem Statement Deep Learning Workloads Problem Statement Deep Learning Workloads for epoch in range(max_epochs): for data, target in
CS 4510/9010 Applied Machine Learning. Neural Nets. Paula Matuszek Fall copyright Paula Matuszek 2016
 CS 4510/9010 Applied Machine Learning 1 Neural Nets Paula Matuszek Fall 2016 Neural Nets, the very short version 2 A neural net consists of layers of nodes, or neurons, each of which has an activation
CS 4510/9010 Applied Machine Learning 1 Neural Nets Paula Matuszek Fall 2016 Neural Nets, the very short version 2 A neural net consists of layers of nodes, or neurons, each of which has an activation
Week 3: Perceptron and Multi-layer Perceptron
 Week 3: Perceptron and Multi-layer Perceptron Phong Le, Willem Zuidema November 12, 2013 Last week we studied two famous biological neuron models, Fitzhugh-Nagumo model and Izhikevich model. This week,
Week 3: Perceptron and Multi-layer Perceptron Phong Le, Willem Zuidema November 12, 2013 Last week we studied two famous biological neuron models, Fitzhugh-Nagumo model and Izhikevich model. This week,
CS 1674: Intro to Computer Vision. Neural Networks. Prof. Adriana Kovashka University of Pittsburgh November 16, 2016
 CS 1674: Intro to Computer Vision Neural Networks Prof. Adriana Kovashka University of Pittsburgh November 16, 2016 Announcements Please watch the videos I sent you, if you haven t yet (that s your reading)
CS 1674: Intro to Computer Vision Neural Networks Prof. Adriana Kovashka University of Pittsburgh November 16, 2016 Announcements Please watch the videos I sent you, if you haven t yet (that s your reading)
Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah
 Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah Reference Most of the slides are taken from the third chapter of the online book by Michael Nielson: neuralnetworksanddeeplearning.com
Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah Reference Most of the slides are taken from the third chapter of the online book by Michael Nielson: neuralnetworksanddeeplearning.com
Perceptron: This is convolution!
 Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Encoding RNNs, 48 End of sentence (EOS) token, 207 Exploding gradient, 131 Exponential function, 42 Exponential Linear Unit (ELU), 44
 token, 207 Exploding gradient, 131 Exponential function, 42 Exponential Linear Unit (ELU), 44") A Activation potential, 40 Annotated corpus add padding, 162 check versions, 158 create checkpoints, 164, 166 create input, 160 create train and validation datasets, 163 dropout, 163 DRUG-AE.rel file,
A Activation potential, 40 Annotated corpus add padding, 162 check versions, 158 create checkpoints, 164, 166 create input, 160 create train and validation datasets, 163 dropout, 163 DRUG-AE.rel file,
Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift. Amit Patel Sambit Pradhan
 Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift Amit Patel Sambit Pradhan Introduction Internal Covariate Shift Batch Normalization Computational Graph of Batch
Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift Amit Patel Sambit Pradhan Introduction Internal Covariate Shift Batch Normalization Computational Graph of Batch
DEEP LEARNING REVIEW. Yann LeCun, Yoshua Bengio & Geoffrey Hinton Nature Presented by Divya Chitimalla
 DEEP LEARNING REVIEW Yann LeCun, Yoshua Bengio & Geoffrey Hinton Nature 2015 -Presented by Divya Chitimalla What is deep learning Deep learning allows computational models that are composed of multiple
DEEP LEARNING REVIEW Yann LeCun, Yoshua Bengio & Geoffrey Hinton Nature 2015 -Presented by Divya Chitimalla What is deep learning Deep learning allows computational models that are composed of multiple
Logistic Regression and Gradient Ascent
 Logistic Regression and Gradient Ascent CS 349-02 (Machine Learning) April 0, 207 The perceptron algorithm has a couple of issues: () the predictions have no probabilistic interpretation or confidence
Logistic Regression and Gradient Ascent CS 349-02 (Machine Learning) April 0, 207 The perceptron algorithm has a couple of issues: () the predictions have no probabilistic interpretation or confidence
Simple Model Selection Cross Validation Regularization Neural Networks
 Neural Nets: Many possible refs e.g., Mitchell Chapter 4 Simple Model Selection Cross Validation Regularization Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February
Neural Nets: Many possible refs e.g., Mitchell Chapter 4 Simple Model Selection Cross Validation Regularization Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February
CS 2750: Machine Learning. Neural Networks. Prof. Adriana Kovashka University of Pittsburgh April 13, 2016
 CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
Deep Learning Cook Book
 Deep Learning Cook Book Robert Haschke (CITEC) Overview Input Representation Output Layer + Cost Function Hidden Layer Units Initialization Regularization Input representation Choose an input representation
Deep Learning Cook Book Robert Haschke (CITEC) Overview Input Representation Output Layer + Cost Function Hidden Layer Units Initialization Regularization Input representation Choose an input representation
Deep Convolutional Neural Networks. Nov. 20th, 2015 Bruce Draper
 Deep Convolutional Neural Networks Nov. 20th, 2015 Bruce Draper Background: Fully-connected single layer neural networks Feed-forward classification Trained through back-propagation Example Computer Vision
Deep Convolutional Neural Networks Nov. 20th, 2015 Bruce Draper Background: Fully-connected single layer neural networks Feed-forward classification Trained through back-propagation Example Computer Vision
Advanced Video Analysis & Imaging
 Advanced Video Analysis & Imaging (5LSH0), Module 09B Machine Learning with Convolutional Neural Networks (CNNs) - Workout Farhad G. Zanjani, Clint Sebastian, Egor Bondarev, Peter H.N. de With ( p.h.n.de.with@tue.nl
Advanced Video Analysis & Imaging (5LSH0), Module 09B Machine Learning with Convolutional Neural Networks (CNNs) - Workout Farhad G. Zanjani, Clint Sebastian, Egor Bondarev, Peter H.N. de With ( p.h.n.de.with@tue.nl
Adversarial Examples and Adversarial Training. Ian Goodfellow, Staff Research Scientist, Google Brain CS 231n, Stanford University,
 Adversarial Examples and Adversarial Training Ian Goodfellow, Staff Research Scientist, Google Brain CS 231n, Stanford University, 2017-05-30 Overview What are adversarial examples? Why do they happen?
Adversarial Examples and Adversarial Training Ian Goodfellow, Staff Research Scientist, Google Brain CS 231n, Stanford University, 2017-05-30 Overview What are adversarial examples? Why do they happen?
DEEP LEARNING IN PYTHON. Introduction to deep learning
 DEEP LEARNING IN PYTHON Introduction to deep learning Imagine you work for a bank You need to predict how many transactions each customer will make next year Example as seen by linear regression Age Bank
DEEP LEARNING IN PYTHON Introduction to deep learning Imagine you work for a bank You need to predict how many transactions each customer will make next year Example as seen by linear regression Age Bank
Capsule Networks. Eric Mintun
 Capsule Networks Eric Mintun Motivation An improvement* to regular Convolutional Neural Networks. Two goals: Replace max-pooling operation with something more intuitive. Keep more info about an activated
Capsule Networks Eric Mintun Motivation An improvement* to regular Convolutional Neural Networks. Two goals: Replace max-pooling operation with something more intuitive. Keep more info about an activated
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 15
 Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 15 Slides adapted from Jordan Boyd-Graber Machine Learning: Chenhao Tan Boulder 1 of 21 Logistics HW3 available on Github, due on October
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 15 Slides adapted from Jordan Boyd-Graber Machine Learning: Chenhao Tan Boulder 1 of 21 Logistics HW3 available on Github, due on October
Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class
 Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class Guidelines Submission. Submit a hardcopy of the report containing all the figures and printouts of code in class. For readability
Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class Guidelines Submission. Submit a hardcopy of the report containing all the figures and printouts of code in class. For readability
COMP9444 Neural Networks and Deep Learning 7. Image Processing. COMP9444 c Alan Blair, 2017
 COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
Linear Regression & Gradient Descent
 Linear Regression & Gradient Descent These slides were assembled by Byron Boots, with grateful acknowledgement to Eric Eaton and the many others who made their course materials freely available online.
Linear Regression & Gradient Descent These slides were assembled by Byron Boots, with grateful acknowledgement to Eric Eaton and the many others who made their course materials freely available online.
PLT: Inception (cuz there are so many layers)
") PLT: Inception (cuz there are so many layers) By: Andrew Aday, (aza2112) Amol Kapoor (ajk2227), Jonathan Zhang (jz2814) Proposal Abstract Overview of domain Purpose Language Outline Types Operators Syntax
PLT: Inception (cuz there are so many layers) By: Andrew Aday, (aza2112) Amol Kapoor (ajk2227), Jonathan Zhang (jz2814) Proposal Abstract Overview of domain Purpose Language Outline Types Operators Syntax