Multicore Architecture and Hybrid Programming
|
|
|
- Erick Sparks
- 5 years ago
- Views:
Transcription


1 Multicore Architecture and Hybrid Programming Rebecca Hartman-Baker Oak Ridge National Laboratory Rebecca Hartman-Baker. Reproduction permitted for non-commercial, educational use only.
2 Outline I. Computer Architecture II. Hybrid Programming 2

3 I. COMPUTER ARCHITECTURE Mare Nostrum, installed in Chapel Torre Girona, Barcelona Supercomputing Center. By courtesy of Barcelona Supercomputing Center



4 I. Computer Architecture 101 Source: (author unknown) 4
5 Computer Architecture 101 Processors Memory Memory Hierarchy TLB Interconnects Glossary 5

6 Computer Architecture 101: Processors CPU performs 4 basic operations: Fetch Decode Execute Writeback Source: 6
7 CPU Operations Fetch Retrieve instruction from program memory Location in memory tracked by program counter (PC) Instruction retrieval sped up by caching and pipelining Decode Interpret instruction by breaking into meaningful parts, e.g., opcode, operands Execute Connect to portions of CPU to perform operation, e.g., connect to arithmetic logic unit (ALU) to perform addition Writeback Write result of execution to memory 7
8 Computer Architecture 101: Memory Hierarchy of memory Fast-access memory: small (expensive) Slower-access memory: large (less expensive) Cache: fast-access memory where frequently used data stored Reduces average access time Works because typically, applications have locality of reference Cache in XT4/5 also hierarchical TLB: Translation lookaside buffer Used by memory management hardware to improve speed of virtual address translation 8
9 Cache Associativity Where to look in cache memory for copy of main memory location? Direct-Mapped/ 1-way Associative: only one location in cache for each main memory location Fully Associative: can be stored anywhere in cache 2-way Associative: two possible locations in cache N-way Associative: N possible locations in cache Doubling associativity ( 1 2, 2 4) has same effect on hit rate as doubling cache size Increasing beyond 4 does not substantially improve hit rate; higher associativity done for other reasons 9
10 Cache Associativity: Illustration Main Memory Main Memory Cache Memory Cache Memory Direct-Mapped Cache 2-Way Associative Cache 10
11 Computer Architecture 101: Interconnects Connect nodes of machine to one another Methods of interconnecting Fiber + switches and routers Directly connecting Topology 11 Torus Hypercube Butterfly Tree 2-D Torus Hypercube
12 Computer Architecture 101: Glossary SSE (Streaming SIMD Extensions): instruction set extension to x86 architecture, allowing CPU to work on multiple instructions in single clock cycle DDR2 (Double Data Rate 2): synchronous dynamic random access memory, operates twice as fast as DDR1 DDR2-xyz: performs xyz million data transfers/second Dcache: cache devoted to data storage Icache: cache devoted to instruction storage STREAM: data flow 12
13 Facts and Figures Kraken (Cray XT5) Athena (Cray XT4) Compute Nodes 16, Node Memory 2.6 GHz AMD Istanbul Dual Six- Core 16 GB/node DDR2-800 Network Cray SeaStar 2, 3- D torus 2.3 GHz AMD Opteron Quad Core 8 GB/node DDR2-667/ DDR2-800 Cray SeaStar 2, 3- D torus Ranger (Sun Constella:on) 2.3 GHz AMD Opteron Quad Core x 4 32 GB/node DDR2-667 Peak 1.03 PF 166 TF 579 TF Infiniband switch, fat tree 13
14 XT4/5 Architecture Hardware Processors Memory Memory Hierarchy TLB System architecture Interconnects Software Operating System Integration CNL vs Linux 14

15 15 Quad-Core Architecture
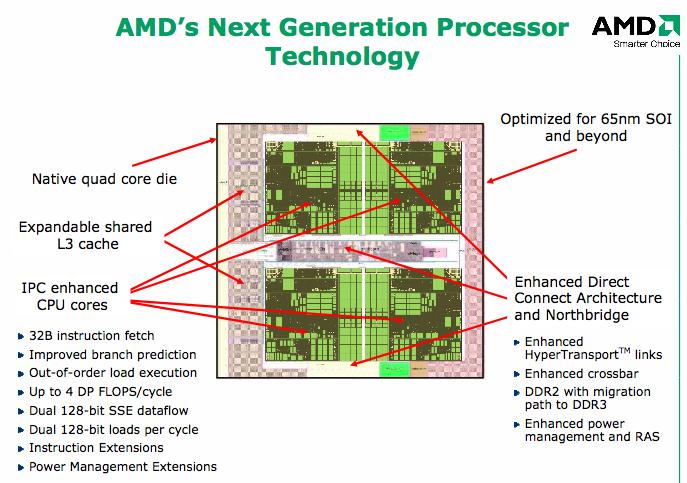
16 16
17 Quad Core Cache Hierarchy Core 1 Core 2 Core 3 Core 4 Cache Control Cache Control Cache Control Cache Control 64 KB 64 KB 64 KB 64 KB 512 KB 512 KB 512 KB 512 KB 2 MB 17
18 L1 Cache Core 1 Core 2 C Dedicated 2-way associativity 8 banks Cache Control Cache Control C 2 x 128-bit loads/cycle 64 KB 64 KB 512 KB 512 KB 18 2 MB
19 L2 Cache Core 1 Core 2 C Dedicated 16-way associativity Cache Control Cache Control C 64 KB 64 KB 512 KB 512 KB 19 2 MB
20 L3 Cache Core 1 Shared Sharing-aware replacement policy Cache Control 2 MB 20


21 Cray XT4 Architecture XT4 is 4 th generation Cray MPP Service nodes run full Linux Compute nodes run Compute Node Linux (CNL) 21


22 Cray XT4 Architecture 2- or 4-way SMP > 35 Gflops/node Up to 8 GB/node OpenMP Support within Socket 22

 Blade")
23 Cray SeaStar2 Architecture Router connects to 6 neighbors in 3-D torus Peak bidirectional BW 7.6 GB/s; sustained 6 GB/s Reliable link protocol with error correction and retransmission Communications Engine: DMA Engine + PPC 440 Together, perform messaging tasks so AMD processor can focus on computing 6-Port Router DMA Engine HyperTransport Interface Memory DMA Engine and OS together minimize latency with path directly from app to communication hardware (without traps and interrupts) Blade Control Processor Interface PowerPC 440 Processor 23

24 Cray XT5 Architecture 8-way SMP > 70 Gflops/node Up to 32 GB shared memory/node OpenMP support 24

25 Software Architecture CLE microkernel on compute nodes Full-featured Linux on service nodes Software architecture eliminates jitter and enables reproducible runtimes Even large machines can reboot in < 30 mins, including filesystem 25
26 Software Architecture Compute PE (processing element): used for computation only; users cannot directly access compute nodes Service PEs: run full Linux Login: users access these nodes to develop code and submit jobs, function like normal Linux box Network: provide high-speed connectivity with other systems System: run global system services such as system database I/O: provide connectivity to GPFS (global parallel file system) 26
27 CLE vs Linux CLE (Cray Linux Environment) contains subset of Linux features Minimizes system overhead because little between application and bare hardware 27
28 Resources: Computer Architecture 101 Wikipedia articles on computer architecture: Heath, Michael T. (2007) Notes for CS 554, Parallel Numerical Algorithms, 28
29 Resources: Cray XT4 Architecture NCCS machines Jaguar: Eugene: Jaguarpf: AMD architecture Waldecker, Brian (2008) Quad Core AMD Opteron Processor Overview, available at amd_craywkshp_apr2008.pdf Larkin, Jeff (2008) Optimizations for the AMD Core, available at XT4 Architecture Hartman-Baker, Rebecca (2008) XT4 Architecture and Software, available at using-xt pdf 29

30 II. HYBRID PROGRAMMING Hybrid Car. Source: 30
31 II. Hybrid Programming Motivation Considerations MPI threading support Designing hybrid algorithms Examples 31
32 Motivation Multicore architectures are here to stay Macro scale: distributed memory architecture, suitable for MPI Micro scale: each node contains multiple cores and shared memory, suitable for OpenMP Obvious solution: use MPI between nodes, and OpenMP within nodes Hybrid programming model 32
33 Considerations Sounds great, Rebecca, but is hybrid programming always better? No, not always Especially if poorly programmed Depends also on suitability of architecture Think of accelerator model in omp parallel region, use power of multicores; in serial region, use only 1 processor If your code can exploit threaded parallelism a lot, then try hybrid programming 33
34 Considerations: Scalability As number of MPI processes increases, Amdahl s Law hurts more and more Serial portion of code limits scalability A 0.1% serial code cannot have more than 1000x speedup, no matter the number of processes May not matter on small process counts, but 1000x speedup vs. serial on 224,256-core Jaguar? No! Hybrid programming can delay the inevitable On Jaguar, see speedup gains on up to 12,000 vs cores (not so embarrassing) 34
35 Considerations: Changing to Hybrid Model MPI Hybrid Lots of fine-grained parallelism intrinsic in problem Data that could be shared rather than reproduced on each process (e.g., constants, ghost cells) OpenMP Hybrid Want scalability to larger numbers of processors Coarse-grained tasks that could be distributed across machine 35
36 Considerations: Developing Hybrid Algorithms Hybrid parallel programming model Are communication and computation discrete phases of algorithm? Can/do communication and computation overlap? Communication between threads Communicate only outside of parallel regions Assign a manager thread responsible for inter-process communication Let some threads perform inter-process communication Let all threads communicate with other processes 36
37 MPI Threading Support MPI-2 standard defines four threading support levels (0) MPI_THREAD_SINGLE only one thread allowed (1) MPI_THREAD_FUNNELED master thread is only thread permitted to make MPI calls (2) MPI_THREAD_SERIALIZED all threads can make MPI calls, but only one at a time (3) MPI_THREAD_MULTIPLE no restrictions (0.5) MPI calls not permitted inside parallel regions (returns MPI_THREAD_SINGLE) this is MPI-1 37
38 What Threading Model Does My Machine Support? #include <mpi.h> #include <stdio.h> int main(int *argc, char **argv) { MPI_Init_thread(&argc, &argv, MPI_THREAD_MULTIPLE, &provided); printf("supports level %d of %d %d %d %d\n", provided, MPI_THREAD_SINGLE, MPI_THREAD_FUNNELED, MPI_THREAD_SERIALIZED, MPI_THREAD_MULTIPLE); MPI_Finalize(); return 0; } 38
39 MPI_Init_Thread MPI_Init_thread(int required, int *supported) Use this instead of MPI_Init( ) required: the level of thread support you want supported: the level of thread support provided by implementation (hopefully = required, but if not available, returns lowest level > required; failing that, largest level < required) Using MPI_Init( ) is equivalent to required = MPI_THREAD_SINGLE MPI_Finalize() should be called by same thread that called MPI_Init_thread( ) 39
40 Other Useful MPI Functions MPI_Is_thread_main(int *flag) Thread calls this to determine whether it is main thread MPI_Query_thread(int *provided) Thread calls to query level of thread support 40
41 Supported Threading Models: Single Use single pragma #pragma omp parallel { #pragma omp barrier #pragma omp single { MPI_Xyz( ) } #pragma omp barrier } 41
42 Supported Threading Models: Funneling Cray XT4/5 supports funneling (probably Ranger too?) Use master pragma #pragma omp parallel { #pragma omp barrier #pragma omp master { MPI_Xyz( ) } #pragma omp barrier } 42
43 What Threading Model Should I Use? Depends on the application! Model Advantages Disadvantages Single Portable: every MPI implementaxon supports this Limited flexibility Funneled Simpler to program Manager thread could get overloaded Serialized Freedom to communicate Risk of too much cross- communicaxon MulXple Completely thread safe Limited availability 43
44 Designing Hybrid Algorithms Just because you can communicate thread-to-thread, doesn t mean you should Tradeoff between lumping messages together and sending individual messages Lumping messages together: one big message, one overhead Sending individual messages: less wait time (?) Programmability: performance will be great, when you finally get it working! 44
45 Example: All-to-All Communication 4 quad-core nodes, 16 MPI processes 16 (# procs) x 15 (# msgs/ proc) = 240 individual messages to be sent Communication volume: 16 x 15 x 1 = quad-core nodes, 4 MPI processes with 4 threads each 4 (# procs) x 3 (#msgs/ proc) = 12 agglomerated messages (4 x original length) to be sent Communication volume: 4 x 3 x 4 = 48 bandwidth 45


46 Example: All-to-All Communication 4 quad-core nodes communicating 1 KB updates 16 MPI Processes 4 MPI Processes + 4 OpenMP threads per MPI Process # Messages 16 procs x 15 msgs/proc = 240 messages Message size (KB) Bandwidth required procs x 3 msgs/proc = 12 messages 240 messages x 1 size = 240 KB 12 messages x 4 size = 48 KB Factor of 5 difference! Factor of 5 difference! 46
47 Example: Mesh Partitioning Regular mesh of finite elements When we partition mesh, need to communicate information about (domain) adjacent cells to (computationally) remote neighbors 47


48 48 Example: Mesh Partitioning
49 Example: Mesh Partitioning Communication Patterns Processor Processor Processor
50 Bibliography/Resources von Alfthan, Sebastian, Introduction to Hybrid Programming, PRACE Summer School 2008, URL: Ye, Helen and Chris Ding, Hybrid OpenMP and MPI Programming and Tuning, Lawrence Berkeley National Laboratory, Jun04/NUG2004_yhe_hybrid.ppt Zollweg, John, Hybrid Programming with OpenMP and MPI, Cornell University Center for Advanced Computing, Hybrid pdf MPI-2.0 Standard, Section 8.7, MPI and Threads, node162.htm#node162 50
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Performance of Variant Memory Configurations for Cray XT Systems
 Performance of Variant Memory Configurations for Cray XT Systems Wayne Joubert, Oak Ridge National Laboratory ABSTRACT: In late 29 NICS will upgrade its 832 socket Cray XT from Barcelona (4 cores/socket)
Performance of Variant Memory Configurations for Cray XT Systems Wayne Joubert, Oak Ridge National Laboratory ABSTRACT: In late 29 NICS will upgrade its 832 socket Cray XT from Barcelona (4 cores/socket)
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Hybrid MPI/OpenMP parallelization. Recall: MPI uses processes for parallelism. Each process has its own, separate address space.
 Hybrid MPI/OpenMP parallelization Recall: MPI uses processes for parallelism. Each process has its own, separate address space. Thread parallelism (such as OpenMP or Pthreads) can provide additional parallelism
Hybrid MPI/OpenMP parallelization Recall: MPI uses processes for parallelism. Each process has its own, separate address space. Thread parallelism (such as OpenMP or Pthreads) can provide additional parallelism
MPI & OpenMP Mixed Hybrid Programming
 MPI & OpenMP Mixed Hybrid Programming Berk ONAT İTÜ Bilişim Enstitüsü 22 Haziran 2012 Outline Introduc/on Share & Distributed Memory Programming MPI & OpenMP Advantages/Disadvantages MPI vs. OpenMP Why
MPI & OpenMP Mixed Hybrid Programming Berk ONAT İTÜ Bilişim Enstitüsü 22 Haziran 2012 Outline Introduc/on Share & Distributed Memory Programming MPI & OpenMP Advantages/Disadvantages MPI vs. OpenMP Why
OpenMP and MPI. Parallel and Distributed Computing. Department of Computer Science and Engineering (DEI) Instituto Superior Técnico.
 Instituto Superior Técnico.") OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 16, 2011 CPD (DEI / IST) Parallel and Distributed Computing 18
OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 16, 2011 CPD (DEI / IST) Parallel and Distributed Computing 18
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
XT Node Architecture
 XT Node Architecture Let s Review: Dual Core v. Quad Core Core Dual Core 2.6Ghz clock frequency SSE SIMD FPU (2flops/cycle = 5.2GF peak) Cache Hierarchy L1 Dcache/Icache: 64k/core L2 D/I cache: 1M/core
XT Node Architecture Let s Review: Dual Core v. Quad Core Core Dual Core 2.6Ghz clock frequency SSE SIMD FPU (2flops/cycle = 5.2GF peak) Cache Hierarchy L1 Dcache/Icache: 64k/core L2 D/I cache: 1M/core
OpenMP and MPI. Parallel and Distributed Computing. Department of Computer Science and Engineering (DEI) Instituto Superior Técnico.
 Instituto Superior Técnico.") OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 15, 2010 José Monteiro (DEI / IST) Parallel and Distributed Computing
OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 15, 2010 José Monteiro (DEI / IST) Parallel and Distributed Computing
SHARCNET Workshop on Parallel Computing. Hugh Merz Laurentian University May 2008
 SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
General introduction: GPUs and the realm of parallel architectures
 General introduction: GPUs and the realm of parallel architectures GPU Computing Training August 17-19 th 2015 Jan Lemeire (jan.lemeire@vub.ac.be) Graduated as Engineer in 1994 at VUB Worked for 4 years
General introduction: GPUs and the realm of parallel architectures GPU Computing Training August 17-19 th 2015 Jan Lemeire (jan.lemeire@vub.ac.be) Graduated as Engineer in 1994 at VUB Worked for 4 years
Carlo Cavazzoni, HPC department, CINECA
 Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Lecture 36: MPI, Hybrid Programming, and Shared Memory. William Gropp
 Lecture 36: MPI, Hybrid Programming, and Shared Memory William Gropp www.cs.illinois.edu/~wgropp Thanks to This material based on the SC14 Tutorial presented by Pavan Balaji William Gropp Torsten Hoefler
Lecture 36: MPI, Hybrid Programming, and Shared Memory William Gropp www.cs.illinois.edu/~wgropp Thanks to This material based on the SC14 Tutorial presented by Pavan Balaji William Gropp Torsten Hoefler
Performance of Variant Memory Configurations for Cray XT Systems
 Performance of Variant Memory Configurations for Cray XT Systems presented by Wayne Joubert Motivation Design trends are leading to non-power of 2 core counts for multicore processors, due to layout constraints
Performance of Variant Memory Configurations for Cray XT Systems presented by Wayne Joubert Motivation Design trends are leading to non-power of 2 core counts for multicore processors, due to layout constraints
MPI and OpenMP. Mark Bull EPCC, University of Edinburgh
 1 MPI and OpenMP Mark Bull EPCC, University of Edinburgh markb@epcc.ed.ac.uk 2 Overview Motivation Potential advantages of MPI + OpenMP Problems with MPI + OpenMP Styles of MPI + OpenMP programming MPI
1 MPI and OpenMP Mark Bull EPCC, University of Edinburgh markb@epcc.ed.ac.uk 2 Overview Motivation Potential advantages of MPI + OpenMP Problems with MPI + OpenMP Styles of MPI + OpenMP programming MPI
Performance Characteristics of Hybrid MPI/OpenMP Implementations of NAS Parallel Benchmarks SP and BT on Large-scale Multicore Clusters
 Performance Characteristics of Hybrid MPI/OpenMP Implementations of NAS Parallel Benchmarks SP and BT on Large-scale Multicore Clusters Xingfu Wu and Valerie Taylor Department of Computer Science and Engineering
Performance Characteristics of Hybrid MPI/OpenMP Implementations of NAS Parallel Benchmarks SP and BT on Large-scale Multicore Clusters Xingfu Wu and Valerie Taylor Department of Computer Science and Engineering
Overlapping Computation and Communication for Advection on Hybrid Parallel Computers
 Overlapping Computation and Communication for Advection on Hybrid Parallel Computers James B White III (Trey) trey@ucar.edu National Center for Atmospheric Research Jack Dongarra dongarra@eecs.utk.edu
Overlapping Computation and Communication for Advection on Hybrid Parallel Computers James B White III (Trey) trey@ucar.edu National Center for Atmospheric Research Jack Dongarra dongarra@eecs.utk.edu
PC I/O. May 7, Howard Huang 1
 PC I/O Today wraps up the I/O material with a little bit about PC I/O systems. Internal buses like PCI and ISA are critical. External buses like USB and Firewire are becoming more important. Today also
PC I/O Today wraps up the I/O material with a little bit about PC I/O systems. Internal buses like PCI and ISA are critical. External buses like USB and Firewire are becoming more important. Today also
Parallel Computing. November 20, W.Homberg
 Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Lecture 14: Mixed MPI-OpenMP programming. Lecture 14: Mixed MPI-OpenMP programming p. 1
 Lecture 14: Mixed MPI-OpenMP programming Lecture 14: Mixed MPI-OpenMP programming p. 1 Overview Motivations for mixed MPI-OpenMP programming Advantages and disadvantages The example of the Jacobi method
Lecture 14: Mixed MPI-OpenMP programming Lecture 14: Mixed MPI-OpenMP programming p. 1 Overview Motivations for mixed MPI-OpenMP programming Advantages and disadvantages The example of the Jacobi method
Our new HPC-Cluster An overview
 Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
Final Lecture. A few minutes to wrap up and add some perspective
 Final Lecture A few minutes to wrap up and add some perspective 1 2 Instant replay The quarter was split into roughly three parts and a coda. The 1st part covered instruction set architectures the connection
Final Lecture A few minutes to wrap up and add some perspective 1 2 Instant replay The quarter was split into roughly three parts and a coda. The 1st part covered instruction set architectures the connection
Hybrid Computing. Lars Koesterke. University of Porto, Portugal May 28-29, 2009
 Hybrid Computing Lars Koesterke University of Porto, Portugal May 28-29, 29 Why Hybrid? Eliminates domain decomposition at node Automatic coherency at node Lower memory latency and data movement within
Hybrid Computing Lars Koesterke University of Porto, Portugal May 28-29, 29 Why Hybrid? Eliminates domain decomposition at node Automatic coherency at node Lower memory latency and data movement within
Chapter 18 - Multicore Computers
 Chapter 18 - Multicore Computers Luis Tarrataca luis.tarrataca@gmail.com CEFET-RJ Luis Tarrataca Chapter 18 - Multicore Computers 1 / 28 Table of Contents I 1 2 Where to focus your study Luis Tarrataca
Chapter 18 - Multicore Computers Luis Tarrataca luis.tarrataca@gmail.com CEFET-RJ Luis Tarrataca Chapter 18 - Multicore Computers 1 / 28 Table of Contents I 1 2 Where to focus your study Luis Tarrataca
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
Challenges of Scaling Algebraic Multigrid Across Modern Multicore Architectures. Allison H. Baker, Todd Gamblin, Martin Schulz, and Ulrike Meier Yang
 Challenges of Scaling Algebraic Multigrid Across Modern Multicore Architectures. Allison H. Baker, Todd Gamblin, Martin Schulz, and Ulrike Meier Yang Multigrid Solvers Method of solving linear equation
Challenges of Scaling Algebraic Multigrid Across Modern Multicore Architectures. Allison H. Baker, Todd Gamblin, Martin Schulz, and Ulrike Meier Yang Multigrid Solvers Method of solving linear equation
Introduction to Parallel Computing
 Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
What does Heterogeneity bring?
 What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
EE/CSCI 451: Parallel and Distributed Computation
 EE/CSCI 451: Parallel and Distributed Computation Lecture #11 2/21/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline Midterm 1:
EE/CSCI 451: Parallel and Distributed Computation Lecture #11 2/21/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline Midterm 1:
COSC 6374 Parallel Computation. Parallel Computer Architectures
 OS 6374 Parallel omputation Parallel omputer Architectures Some slides on network topologies based on a similar presentation by Michael Resch, University of Stuttgart Spring 2010 Flynn s Taxonomy SISD:
OS 6374 Parallel omputation Parallel omputer Architectures Some slides on network topologies based on a similar presentation by Michael Resch, University of Stuttgart Spring 2010 Flynn s Taxonomy SISD:
CS4230 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/28/12. Homework 1: Parallel Programming Basics
 CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
Flexible Architecture Research Machine (FARM)
") Flexible Architecture Research Machine (FARM) RAMP Retreat June 25, 2009 Jared Casper, Tayo Oguntebi, Sungpack Hong, Nathan Bronson Christos Kozyrakis, Kunle Olukotun Motivation Why CPUs + FPGAs make sense
Flexible Architecture Research Machine (FARM) RAMP Retreat June 25, 2009 Jared Casper, Tayo Oguntebi, Sungpack Hong, Nathan Bronson Christos Kozyrakis, Kunle Olukotun Motivation Why CPUs + FPGAs make sense
Hybrid programming with MPI and OpenMP On the way to exascale
 Institut du Développement et des Ressources en Informatique Scientifique www.idris.fr Hybrid programming with MPI and OpenMP On the way to exascale 1 Trends of hardware evolution Main problematic : how
Institut du Développement et des Ressources en Informatique Scientifique www.idris.fr Hybrid programming with MPI and OpenMP On the way to exascale 1 Trends of hardware evolution Main problematic : how
Simultaneous Multithreading on Pentium 4
 Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
COSC 6374 Parallel Computation. Parallel Computer Architectures
 OS 6374 Parallel omputation Parallel omputer Architectures Some slides on network topologies based on a similar presentation by Michael Resch, University of Stuttgart Edgar Gabriel Fall 2015 Flynn s Taxonomy
OS 6374 Parallel omputation Parallel omputer Architectures Some slides on network topologies based on a similar presentation by Michael Resch, University of Stuttgart Edgar Gabriel Fall 2015 Flynn s Taxonomy
Performance Considerations: Hardware Architecture
 Performance Considerations: Hardware Architecture John Zollweg Parallel Optimization and Scientific Visualization for Ranger March 13, 29 based on material developed by Kent Milfeld, TACC www.cac.cornell.edu
Performance Considerations: Hardware Architecture John Zollweg Parallel Optimization and Scientific Visualization for Ranger March 13, 29 based on material developed by Kent Milfeld, TACC www.cac.cornell.edu
Compute Node Linux (CNL) The Evolution of a Compute OS
 The Evolution of a Compute OS") Compute Node Linux (CNL) The Evolution of a Compute OS Overview CNL The original scheme plan, goals, requirements Status of CNL Plans Features and directions Futures May 08 Cray Inc. Proprietary Slide
Compute Node Linux (CNL) The Evolution of a Compute OS Overview CNL The original scheme plan, goals, requirements Status of CNL Plans Features and directions Futures May 08 Cray Inc. Proprietary Slide
Introducing the Cray XMT. Petr Konecny May 4 th 2007
 Introducing the Cray XMT Petr Konecny May 4 th 2007 Agenda Origins of the Cray XMT Cray XMT system architecture Cray XT infrastructure Cray Threadstorm processor Shared memory programming model Benefits/drawbacks/solutions
Introducing the Cray XMT Petr Konecny May 4 th 2007 Agenda Origins of the Cray XMT Cray XMT system architecture Cray XT infrastructure Cray Threadstorm processor Shared memory programming model Benefits/drawbacks/solutions
Tools and techniques for optimization and debugging. Fabio Affinito October 2015
 Tools and techniques for optimization and debugging Fabio Affinito October 2015 Fundamentals of computer architecture Serial architectures Introducing the CPU It s a complex, modular object, made of different
Tools and techniques for optimization and debugging Fabio Affinito October 2015 Fundamentals of computer architecture Serial architectures Introducing the CPU It s a complex, modular object, made of different
The Red Storm System: Architecture, System Update and Performance Analysis
 The Red Storm System: Architecture, System Update and Performance Analysis Douglas Doerfler, Jim Tomkins Sandia National Laboratories Center for Computation, Computers, Information and Mathematics LACSI
The Red Storm System: Architecture, System Update and Performance Analysis Douglas Doerfler, Jim Tomkins Sandia National Laboratories Center for Computation, Computers, Information and Mathematics LACSI
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
LS-DYNA Scalability Analysis on Cray Supercomputers
 13 th International LS-DYNA Users Conference Session: Computing Technology LS-DYNA Scalability Analysis on Cray Supercomputers Ting-Ting Zhu Cray Inc. Jason Wang LSTC Abstract For the automotive industry,
13 th International LS-DYNA Users Conference Session: Computing Technology LS-DYNA Scalability Analysis on Cray Supercomputers Ting-Ting Zhu Cray Inc. Jason Wang LSTC Abstract For the automotive industry,
CellSs Making it easier to program the Cell Broadband Engine processor
 Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Message Passing with MPI
 Message Passing with MPI PPCES 2016 Hristo Iliev IT Center / JARA-HPC IT Center der RWTH Aachen University Agenda Motivation Part 1 Concepts Point-to-point communication Non-blocking operations Part 2
Message Passing with MPI PPCES 2016 Hristo Iliev IT Center / JARA-HPC IT Center der RWTH Aachen University Agenda Motivation Part 1 Concepts Point-to-point communication Non-blocking operations Part 2
Tools and techniques for optimization and debugging. Andrew Emerson, Fabio Affinito November 2017
 Tools and techniques for optimization and debugging Andrew Emerson, Fabio Affinito November 2017 Fundamentals of computer architecture Serial architectures Introducing the CPU It s a complex, modular object,
Tools and techniques for optimization and debugging Andrew Emerson, Fabio Affinito November 2017 Fundamentals of computer architecture Serial architectures Introducing the CPU It s a complex, modular object,
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA
 EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems.
 Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Lecture 2 Parallel Programming Platforms
 Lecture 2 Parallel Programming Platforms Flynn s Taxonomy In 1966, Michael Flynn classified systems according to numbers of instruction streams and the number of data stream. Data stream Single Multiple
Lecture 2 Parallel Programming Platforms Flynn s Taxonomy In 1966, Michael Flynn classified systems according to numbers of instruction streams and the number of data stream. Data stream Single Multiple
CS 475: Parallel Programming Introduction
 CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
Dynamic Fine Grain Scheduling of Pipeline Parallelism. Presented by: Ram Manohar Oruganti and Michael TeWinkle
 Dynamic Fine Grain Scheduling of Pipeline Parallelism Presented by: Ram Manohar Oruganti and Michael TeWinkle Overview Introduction Motivation Scheduling Approaches GRAMPS scheduling method Evaluation
Dynamic Fine Grain Scheduling of Pipeline Parallelism Presented by: Ram Manohar Oruganti and Michael TeWinkle Overview Introduction Motivation Scheduling Approaches GRAMPS scheduling method Evaluation
MIMD Overview. Intel Paragon XP/S Overview. XP/S Usage. XP/S Nodes and Interconnection. ! Distributed-memory MIMD multicomputer
 MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
Design Principles for End-to-End Multicore Schedulers
 c Systems Group Department of Computer Science ETH Zürich HotPar 10 Design Principles for End-to-End Multicore Schedulers Simon Peter Adrian Schüpbach Paul Barham Andrew Baumann Rebecca Isaacs Tim Harris
c Systems Group Department of Computer Science ETH Zürich HotPar 10 Design Principles for End-to-End Multicore Schedulers Simon Peter Adrian Schüpbach Paul Barham Andrew Baumann Rebecca Isaacs Tim Harris
The Use of Cloud Computing Resources in an HPC Environment
 The Use of Cloud Computing Resources in an HPC Environment Bill, Labate, UCLA Office of Information Technology Prakashan Korambath, UCLA Institute for Digital Research & Education Cloud computing becomes
The Use of Cloud Computing Resources in an HPC Environment Bill, Labate, UCLA Office of Information Technology Prakashan Korambath, UCLA Institute for Digital Research & Education Cloud computing becomes
CSE 392/CS 378: High-performance Computing - Principles and Practice
 CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
Cray XE6 Performance Workshop
 Cray XE6 erformance Workshop odern HC Architectures David Henty d.henty@epcc.ed.ac.uk ECC, University of Edinburgh Overview Components History Flynn s Taxonomy SID ID Classification via emory Distributed
Cray XE6 erformance Workshop odern HC Architectures David Henty d.henty@epcc.ed.ac.uk ECC, University of Edinburgh Overview Components History Flynn s Taxonomy SID ID Classification via emory Distributed
Lecture 7: Distributed memory
 Lecture 7: Distributed memory David Bindel 15 Feb 2010 Logistics HW 1 due Wednesday: See wiki for notes on: Bottom-up strategy and debugging Matrix allocation issues Using SSE and alignment comments Timing
Lecture 7: Distributed memory David Bindel 15 Feb 2010 Logistics HW 1 due Wednesday: See wiki for notes on: Bottom-up strategy and debugging Matrix allocation issues Using SSE and alignment comments Timing
BlueGene/L. Computer Science, University of Warwick. Source: IBM
 BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit
 Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Blue Gene/Q. Hardware Overview Michael Stephan. Mitglied der Helmholtz-Gemeinschaft
 Blue Gene/Q Hardware Overview 02.02.2015 Michael Stephan Blue Gene/Q: Design goals System-on-Chip (SoC) design Processor comprises both processing cores and network Optimal performance / watt ratio Small
Blue Gene/Q Hardware Overview 02.02.2015 Michael Stephan Blue Gene/Q: Design goals System-on-Chip (SoC) design Processor comprises both processing cores and network Optimal performance / watt ratio Small
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448. The Greed for Speed
 Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Chapter 5B. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
Advanced Crash Course in Supercomputing: Programming Project
 Advanced Crash Course in Supercomputing: Programming Project Rebecca Hartman-Baker Oak Ridge National Laboratory hartmanbakrj@ornl.gov 2004-2009 Rebecca Hartman-Baker. Reproduction permitted for non-commercial,
Advanced Crash Course in Supercomputing: Programming Project Rebecca Hartman-Baker Oak Ridge National Laboratory hartmanbakrj@ornl.gov 2004-2009 Rebecca Hartman-Baker. Reproduction permitted for non-commercial,
Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow.
 Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow. Big problems and Very Big problems in Science How do we live Protein
Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow. Big problems and Very Big problems in Science How do we live Protein
Parallel Architectures
 Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
ABySS Performance Benchmark and Profiling. May 2010
 ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Scalable Computing at Work
 CRAY XT4 DATASHEET Scalable Computing at Work Cray XT4 Supercomputer Introducing the latest generation massively parallel processor (MPP) system from Cray the Cray XT4 supercomputer. Building on the success
CRAY XT4 DATASHEET Scalable Computing at Work Cray XT4 Supercomputer Introducing the latest generation massively parallel processor (MPP) system from Cray the Cray XT4 supercomputer. Building on the success
Introduction. CSCI 4850/5850 High-Performance Computing Spring 2018
 Introduction CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University What is Parallel
Introduction CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University What is Parallel
Memory. From Chapter 3 of High Performance Computing. c R. Leduc
 Memory From Chapter 3 of High Performance Computing c 2002-2004 R. Leduc Memory Even if CPU is infinitely fast, still need to read/write data to memory. Speed of memory increasing much slower than processor
Memory From Chapter 3 of High Performance Computing c 2002-2004 R. Leduc Memory Even if CPU is infinitely fast, still need to read/write data to memory. Speed of memory increasing much slower than processor
What is Parallel Computing?
 What is Parallel Computing? Parallel Computing is several processing elements working simultaneously to solve a problem faster. 1/33 What is Parallel Computing? Parallel Computing is several processing
What is Parallel Computing? Parallel Computing is several processing elements working simultaneously to solve a problem faster. 1/33 What is Parallel Computing? Parallel Computing is several processing
Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures
 Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures Rolf Rabenseifner rabenseifner@hlrs.de Gerhard Wellein gerhard.wellein@rrze.uni-erlangen.de University of Stuttgart
Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures Rolf Rabenseifner rabenseifner@hlrs.de Gerhard Wellein gerhard.wellein@rrze.uni-erlangen.de University of Stuttgart
Introduction to Parallel Programming
 Introduction to Parallel Programming Linda Woodard CAC 19 May 2010 Introduction to Parallel Computing on Ranger 5/18/2010 www.cac.cornell.edu 1 y What is Parallel Programming? Using more than one processor
Introduction to Parallel Programming Linda Woodard CAC 19 May 2010 Introduction to Parallel Computing on Ranger 5/18/2010 www.cac.cornell.edu 1 y What is Parallel Programming? Using more than one processor
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Processor Architecture and Interconnect
 Processor Architecture and Interconnect What is Parallelism? Parallel processing is a term used to denote simultaneous computation in CPU for the purpose of measuring its computation speeds. Parallel Processing
Processor Architecture and Interconnect What is Parallelism? Parallel processing is a term used to denote simultaneous computation in CPU for the purpose of measuring its computation speeds. Parallel Processing
Parallel Numerics, WT 2013/ Introduction
 Parallel Numerics, WT 2013/2014 1 Introduction page 1 of 122 Scope Revise standard numerical methods considering parallel computations! Required knowledge Numerics Parallel Programming Graphs Literature
Parallel Numerics, WT 2013/2014 1 Introduction page 1 of 122 Scope Revise standard numerical methods considering parallel computations! Required knowledge Numerics Parallel Programming Graphs Literature
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
A Study of High Performance Computing and the Cray SV1 Supercomputer. Michael Sullivan TJHSST Class of 2004
 A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
How to Write Fast Code , spring th Lecture, Mar. 31 st
 How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Kaisen Lin and Michael Conley
 Kaisen Lin and Michael Conley Simultaneous Multithreading Instructions from multiple threads run simultaneously on superscalar processor More instruction fetching and register state Commercialized! DEC
Kaisen Lin and Michael Conley Simultaneous Multithreading Instructions from multiple threads run simultaneously on superscalar processor More instruction fetching and register state Commercialized! DEC
Hybrid MPI + OpenMP Approach to Improve the Scalability of a Phase-Field-Crystal Code
 Hybrid MPI + OpenMP Approach to Improve the Scalability of a Phase-Field-Crystal Code Reuben D. Budiardja reubendb@utk.edu ECSS Symposium March 19 th, 2013 Project Background Project Team (University of
Hybrid MPI + OpenMP Approach to Improve the Scalability of a Phase-Field-Crystal Code Reuben D. Budiardja reubendb@utk.edu ECSS Symposium March 19 th, 2013 Project Background Project Team (University of
Memory Hierarchies && The New Bottleneck == Cache Conscious Data Access. Martin Grund
 Memory Hierarchies && The New Bottleneck == Cache Conscious Data Access Martin Grund Agenda Key Question: What is the memory hierarchy and how to exploit it? What to take home How is computer memory organized.
Memory Hierarchies && The New Bottleneck == Cache Conscious Data Access Martin Grund Agenda Key Question: What is the memory hierarchy and how to exploit it? What to take home How is computer memory organized.
What are Clusters? Why Clusters? - a Short History
 What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
CS4961 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/30/11. Administrative UPDATE. Mary Hall August 30, 2011
 CS4961 Parallel Programming Lecture 3: Introduction to Parallel Architectures Administrative UPDATE Nikhil office hours: - Monday, 2-3 PM, MEB 3115 Desk #12 - Lab hours on Tuesday afternoons during programming
CS4961 Parallel Programming Lecture 3: Introduction to Parallel Architectures Administrative UPDATE Nikhil office hours: - Monday, 2-3 PM, MEB 3115 Desk #12 - Lab hours on Tuesday afternoons during programming
Martin Kruliš, v
 Martin Kruliš 1 Optimizations in General Code And Compilation Memory Considerations Parallelism Profiling And Optimization Examples 2 Premature optimization is the root of all evil. -- D. Knuth Our goal
Martin Kruliš 1 Optimizations in General Code And Compilation Memory Considerations Parallelism Profiling And Optimization Examples 2 Premature optimization is the root of all evil. -- D. Knuth Our goal
COMP528: Multi-core and Multi-Processor Computing
 COMP528: Multi-core and Multi-Processor Computing Dr Michael K Bane, G14, Computer Science, University of Liverpool m.k.bane@liverpool.ac.uk https://cgi.csc.liv.ac.uk/~mkbane/comp528 2X So far Why and
COMP528: Multi-core and Multi-Processor Computing Dr Michael K Bane, G14, Computer Science, University of Liverpool m.k.bane@liverpool.ac.uk https://cgi.csc.liv.ac.uk/~mkbane/comp528 2X So far Why and
Oak Ridge National Laboratory Computing and Computational Sciences
 Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
High Performance Computing (HPC) Introduction
 Introduction") High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
Tile Processor (TILEPro64)
") Tile Processor Case Study of Contemporary Multicore Fall 2010 Agarwal 6.173 1 Tile Processor (TILEPro64) Performance # of cores On-chip cache (MB) Cache coherency Operations (16/32-bit BOPS) On chip bandwidth
Tile Processor Case Study of Contemporary Multicore Fall 2010 Agarwal 6.173 1 Tile Processor (TILEPro64) Performance # of cores On-chip cache (MB) Cache coherency Operations (16/32-bit BOPS) On chip bandwidth
Issues in Developing a Thread-Safe MPI Implementation. William Gropp Rajeev Thakur
 Issues in Developing a Thread-Safe MPI Implementation William Gropp Rajeev Thakur Why MPI and Threads Applications need more computing power than any one processor can provide Parallel computing (proof
Issues in Developing a Thread-Safe MPI Implementation William Gropp Rajeev Thakur Why MPI and Threads Applications need more computing power than any one processor can provide Parallel computing (proof
Introduction to Parallel Computing. CPS 5401 Fall 2014 Shirley Moore, Instructor October 13, 2014
 Introduction to Parallel Computing CPS 5401 Fall 2014 Shirley Moore, Instructor October 13, 2014 1 Definition of Parallel Computing Simultaneous use of multiple compute resources to solve a computational
Introduction to Parallel Computing CPS 5401 Fall 2014 Shirley Moore, Instructor October 13, 2014 1 Definition of Parallel Computing Simultaneous use of multiple compute resources to solve a computational
Creating a Scalable Microprocessor:
 Creating a Scalable Microprocessor: A 16-issue Multiple-Program-Counter Microprocessor With Point-to-Point Scalar Operand Network Michael Bedford Taylor J. Kim, J. Miller, D. Wentzlaff, F. Ghodrat, B.
Creating a Scalable Microprocessor: A 16-issue Multiple-Program-Counter Microprocessor With Point-to-Point Scalar Operand Network Michael Bedford Taylor J. Kim, J. Miller, D. Wentzlaff, F. Ghodrat, B.
Introduction Hybrid Programming. Sebastian von Alfthan 13/8/2008 CSC the Finnish IT Center for Science PRACE summer school 2008
 Introduction Hybrid Programming Sebastian von Alfthan 13/8/2008 CSC the Finnish IT Center for Science PRACE summer school 2008 Contents Introduction OpenMP in detail OpenMP programming models & performance
Introduction Hybrid Programming Sebastian von Alfthan 13/8/2008 CSC the Finnish IT Center for Science PRACE summer school 2008 Contents Introduction OpenMP in detail OpenMP programming models & performance
30 Nov Dec Advanced School in High Performance and GRID Computing Concepts and Applications, ICTP, Trieste, Italy
 Advanced School in High Performance and GRID Computing Concepts and Applications, ICTP, Trieste, Italy Why serial is not enough Computing architectures Parallel paradigms Message Passing Interface How
Advanced School in High Performance and GRID Computing Concepts and Applications, ICTP, Trieste, Italy Why serial is not enough Computing architectures Parallel paradigms Message Passing Interface How