Intel Advisor XE Future Release Threading Design & Prototyping Vectorization Assistant
|
|
|
- Neil Terry
- 5 years ago
- Views:
Transcription



1 Intel Advisor XE Future Release Threading Design & Prototyping Vectorization Assistant


2 Parallel is the Path Forward Intel Xeon and Intel Xeon Phi Product Families are both going parallel Intel Xeon processor 64-bit Intel Xeon processor 5100 series Intel Xeon processor 5500 series Intel Xeon processor 5600 series Intel Xeon processor code-named Sandy Bridge EP Intel Xeon processor code-named Ivy Bridge EP Intel Xeon processor code-named Haswell EP Intel Xeon Phi coprocessor Knights Corner Intel Xeon Phi processor & coprocessor Knights Landing 1 Core(s) Threads SIMD Width *Product specification for launched and shipped products available on ark.intel.com. 1. Not launched or in planning. More cores More Threads Wider vectors 2

3 Don t use a single Vector lane! To fully utilize the hardware you need to: Parallelize and Vectorize 3
4 Options Per Sec How much potential lies untapped today? Binomial Options SP (Higher is Better) 179x Parallelized Single Thread Vectorized Scalar Single Thread Scalar Intel Xeon Processor X5472 formerly codenamed Harpertown 2009 Intel Xeon Processor X5570 formerly codenamed Nehalem 2010 Intel Xeon Processor X5680 formerly codenamed Westmere 2012 Intel Xeon Processor E family formerly codenamed Sandy Bridge 2013 Intel Xeon Processor E v2 family formerly codenamed Ivy Bridge 2014 Intel Xeon Processor E v3 family formerly codenamed Haswell Configuration info on Configurations for Binomial Options SP slide at the end of this presentation Parallel + Vectorized is much faster than either one alone Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more information go to 4

5 Permission to design for all lanes Threading and Vectorization Intel Advisor XE: Today Threading Vectorization Future 5

6 Data Driven Threading Design Intel Advisor XE Thread Prototyping Have you: Tried threading an app, but seen little performance benefit? Hit a scalability barrier? Performance gains level off as you add cores? Delayed a release that adds threading because of synchronization errors? Breakthrough for threading design: Quickly prototype multiple options Project scaling on larger systems Find synchronization errors before implementing threading Separate design and implementation -Design without disrupting development Add Parallelism with Less Effort, Less Risk and More Impact Part of Intel Parallel Studio For Windows* and Linux* From $1,599 Intel Advisor XE has allowed us to quickly prototype ideas for parallelism, saving developer time and effort Simon Hammond Senior Technical Staff Sandia National Laboratories 6

7 Data Driven Vectorization Design Intel Advisor XE Vectorization Advisor (future release) Have you: Recompiled with AVX2, but seen little benefit? Wondered where to start adding vectorization? Recoded intrinsics for each new architecture? Struggled with cryptic compiler vectorization messages? In Beta soon. Sign-up! Breakthrough for vectorization design What vectorization will pay off the most? What is blocking vectorization and why? Are my loops vector friendly? Will reorganizing data increase performance? Is it safe to just use pragma simd? More Performance Fewer Machine Dependencies 7
8 Vectorization Advisor Providing the data you need for high impact vectorization Compiler diagnostics + Performance Data = All the data you need in one place Find hot un-vectorized or under vectorized loops. Convince the compiler to vectorize Recommendations How do I fix it? Correctness via dependency analysis Is it safe to vectorize? Data on specific variable causing the loop dependency Memory Access Patterns analysis Unit stride vs Non-unit stride access, Unaligned memory access, etc. 8

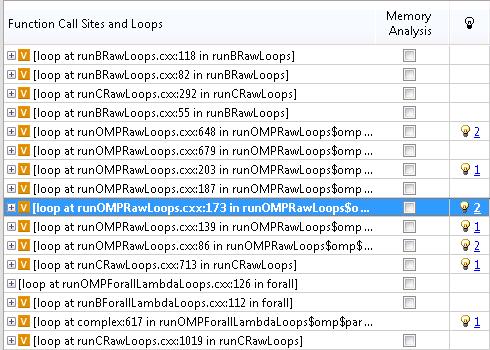
9 Vector Advisor Survey: all in one place Vector indicator (filter) Profile data (priority) Loop type (filter) Compiler data Static analysis Loop body/peel/reminder break-down and grouping Top-down functionloops tree Source tab Suggestions and OpenMP4 snippets 9
10 What Makes Vectorization Difficult? Non-contiguous memory access Potential to vectorize but may be inefficient Non-unit strided access to arrays for (i=0;i<n;i+=2) //Incrementing i by 2 is not unit-stride Indirect reference in a loop for (i=0;i<n;i++) Data dependencies A[B[i]] = C[i]*D[i]; //We have to decode B[i] to find out //which element of A to reference for (i=0;i<n;i++) A[i] = A[i-1]*С[i]; 10

11 Compiler diagnostics + Performance Data Find hot un-vectorized or under vectorized loops All of the information you require to vectorize available on one screen! 11


12 Gives estimated expected gain! Gain estimates Gives recommendations and the gain you can expect by using a different vector instruction or rewriting the control flow of your program. 12



13 Vector Advisor: All the data in one place Intel Compiler 15.x reports Integration Deep dive analysis 13

14 Convince the compiler to vectorize Unvectorized loops / under vectorized loops Assumed dependencies Control structures preventing vectorization. Rewrite loops to vectorize remove conditions, breaks and returns and many other techniques. 14


15 Deep source and assembly integration All the data you need in one place 15
16 16 Optimizing Recommendations How do I fix it? SIZE: 64B for Intel Xeon Phi, 32B for AVX1/2, 16B for SSE4.2 and below Alignment optimization A[i] A[i+ 1] Addr % SIZE == 0 A[i] A[i] A[i+ 2] A[i+ 3] Misaligned Unit-stride A[i+ 1] A[i+ 2] Addr % SIZE!= 0 A[i+ 3] Alignment Unknown Unit-stride A[i+ 1] A[i+ 2] Addr % SIZE ==??? A[i+ 3] Peel/remainder Typical vectorized loop consists of Optional peel part Needed to improve alignment Scalar or slower vector Main vector part Fastest among the three. remainder part Due to trip_count%vl!= 0 Scalar or slower vector. Larger vector register means more iterations in peel/remainder Align your data Block to fight remainders

17 Recommendations Mark-up interesting loops to move on 17
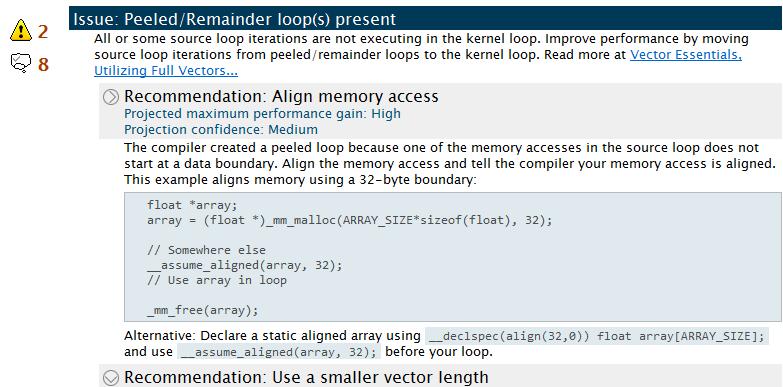
18 End-user recommendations, performance penalties 18

19 Correctness Is It Safe to Vectorize? Loop-carried dependencies analysis Detected dependencies Source lines with Read and Write accesses detected Got recommendations to enforce vectorization of the loop: 1. Mark-up the loop and check for the presence of REAL dependencies 2. Explore dependencies in more details with code snippets Are there dependencies in your loop preventing vectorization? (if you force the compiler to vectorize this could generate incorrect code) 19
20 20 Optimizing Memory Access Patterns Data Layout Is Key Vectorizing i-loop Private: v, c.q, a[j], a[j][k], a[b[j]] (j i, k i) v v v v Unit-stride: a[i], c.x[i], *(p++) A[i] A[2*i ] A[i+ 1] A[i+ 2] A[2*i+1] A[i+ 3] A[2*i+2] Non-unit-stride: a[2*i], c[i].x, a[i][j], a[i][0] F90 Arrays in most cases if not contiguous Gather/scatter: j = b[i]; a[j], a[b.x[i]] p = a[i]; *p Intel IMCI: especially slow A[B[i+2]] A[B[i]] A[B[i+1]] Private good Almost no alignment requirements Any addressing if Not depend on vectorizable loop index Unit-Stride Good with one exception. Subject to vector alignment Out-of-order cores won t store-forward masked (unit-stride) store. On Intel Xeon Phi correctness prevents efficient implementation of masked (unit-stride) store. Consider using opt-assume-safe-padding Strided, Gather/Scatter is less efficient Perf varies on micro-arch and the actual index patterns. Big latency is exposed if you have these on the critical path Better if done at outer loop level if loop nest is vectorized



21 Improve Vectorization Memory Access pattern analysis Mark-up loops for deeper analysis 21
22 Vectorization Advisor Providing the data you need for high impact vectorization Compiler diagnostics + Performance Data = All the data you need in one place Find hot un-vectorized or under vectorized loops. Convince the compiler to vectorize Recommendations How do I fix it? Correctness via dependency analysis Is it safe to vectorize? Data on specific variable causing the loop dependency Memory Access Patterns analysis Unit stride vs Non-unit stride access, Unaligned memory access, etc. 22



23 Summary: Vector Advisor Alpha 4 Analysis Features for Efficient Vectorization 1. Compiler diagnostics with Performance Data 2. Recommendations on how to improve vectorization 3. Correctness Dependency Analysis 4. Memory Access Patterns Analysis 23
24 Intel Advisor XE is part of Intel Parallel Studio XE Intel Parallel Studio XE 2015 Composer Edition Intel C++ Compiler Intel Fortran Compiler Intel Threading Building Blocks Intel Integrated Performance Primitives Intel Math Kernel Library Intel Cilk Plus Intel OpenMP* Intel Parallel Studio XE 2015 Professional Edition Intel C++ Compiler Intel Fortran Compiler Intel Threading Building Blocks Intel Integrated Performance Primitives Intel Math Kernel Library Intel Cilk Plus Intel OpenMP* Intel Advisor XE Intel Inspector XE Intel VTune Amplifier XE Intel Parallel Studio XE 2015 Cluster Edition Intel C++ Compiler Intel Fortran Compiler Intel Threading Building Blocks Intel Integrated Performance Primitives Intel Math Kernel Library Intel Cilk Plus Intel OpenMP* Intel Advisor XE Intel Inspector XE Intel VTune Amplifier XE Intel MPI Library Intel Trace Analyzer and Collector For more information: 24
25 Join the beta! Intel Advisor XE Vectorization Advisor Send to to participate in the Vectorization Advisor beta. Limited alpha access is available now under NDA Public beta is coming late Q1 or Q Sign-up now and we will contact you when we have more details. 25

26
27 Legal Disclaimer & INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. INTEL ASSUMES NO LIABILITY WHATSOEVER AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO THIS INFORMATION INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. Copyright 2014, Intel Corporation. All rights reserved. Intel, Pentium, Xeon, Xeon Phi, Core, VTune, Cilk, and the Intel logo are trademarks of Intel Corporation in the U.S. and other countries. Intel s compilers may or may not optimize to the same degree for non-intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Notice revision #
Kevin O Leary, Intel Technical Consulting Engineer
 Kevin O Leary, Intel Technical Consulting Engineer Moore s Law Is Going Strong Hardware performance continues to grow exponentially We think we can continue Moore's Law for at least another 10 years."
Kevin O Leary, Intel Technical Consulting Engineer Moore s Law Is Going Strong Hardware performance continues to grow exponentially We think we can continue Moore's Law for at least another 10 years."
Intel Advisor XE. Vectorization Optimization. Optimization Notice
 Intel Advisor XE Vectorization Optimization 1 Performance is a Proven Game Changer It is driving disruptive change in multiple industries Protecting buildings from extreme events Sophisticated mechanics
Intel Advisor XE Vectorization Optimization 1 Performance is a Proven Game Changer It is driving disruptive change in multiple industries Protecting buildings from extreme events Sophisticated mechanics
What s New August 2015
 What s New August 2015 Significant New Features New Directory Structure OpenMP* 4.1 Extensions C11 Standard Support More C++14 Standard Support Fortran 2008 Submodules and IMPURE ELEMENTAL Further C Interoperability
What s New August 2015 Significant New Features New Directory Structure OpenMP* 4.1 Extensions C11 Standard Support More C++14 Standard Support Fortran 2008 Submodules and IMPURE ELEMENTAL Further C Interoperability
Compiling for Scalable Computing Systems the Merit of SIMD. Ayal Zaks Intel Corporation Acknowledgements: too many to list
 Compiling for Scalable Computing Systems the Merit of SIMD Ayal Zaks Intel Corporation Acknowledgements: too many to list Takeaways 1. SIMD is mainstream and ubiquitous in HW 2. Compiler support for SIMD
Compiling for Scalable Computing Systems the Merit of SIMD Ayal Zaks Intel Corporation Acknowledgements: too many to list Takeaways 1. SIMD is mainstream and ubiquitous in HW 2. Compiler support for SIMD
Code modernization and optimization for improved performance using the OpenMP* programming model for threading and SIMD parallelism.
 Code modernization and optimization for improved performance using the OpenMP* programming model for threading and SIMD parallelism. Parallel + SIMD is the Path Forward Intel Xeon and Intel Xeon Phi Product
Code modernization and optimization for improved performance using the OpenMP* programming model for threading and SIMD parallelism. Parallel + SIMD is the Path Forward Intel Xeon and Intel Xeon Phi Product
Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature
 Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature Intel Software Developer Conference Frankfurt, 2017 Klaus-Dieter Oertel, Intel Agenda Intel Advisor for vectorization
Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature Intel Software Developer Conference Frankfurt, 2017 Klaus-Dieter Oertel, Intel Agenda Intel Advisor for vectorization
Memory & Thread Debugger
 Memory & Thread Debugger Here is What Will Be Covered Overview Memory/Thread analysis New Features Deep dive into debugger integrations Demo Call to action Intel Confidential 2 Analysis Tools for Diagnosis
Memory & Thread Debugger Here is What Will Be Covered Overview Memory/Thread analysis New Features Deep dive into debugger integrations Demo Call to action Intel Confidential 2 Analysis Tools for Diagnosis
Vectorization Advisor: getting started
 Vectorization Advisor: getting started Before you analyze Run GUI or Command Line Set-up environment Linux: source /advixe-vars.sh Windows: \advixe-vars.bat Run GUI or Command
Vectorization Advisor: getting started Before you analyze Run GUI or Command Line Set-up environment Linux: source /advixe-vars.sh Windows: \advixe-vars.bat Run GUI or Command
Agenda. Optimization Notice Copyright 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
 Agenda VTune Amplifier XE OpenMP* Analysis: answering on customers questions about performance in the same language a program was written in Concepts, metrics and technology inside VTune Amplifier XE OpenMP
Agenda VTune Amplifier XE OpenMP* Analysis: answering on customers questions about performance in the same language a program was written in Concepts, metrics and technology inside VTune Amplifier XE OpenMP
Jackson Marusarz Software Technical Consulting Engineer
 Jackson Marusarz Software Technical Consulting Engineer What Will Be Covered Overview Memory/Thread analysis New Features Deep dive into debugger integrations Demo Call to action 2 Analysis Tools for Diagnosis
Jackson Marusarz Software Technical Consulting Engineer What Will Be Covered Overview Memory/Thread analysis New Features Deep dive into debugger integrations Demo Call to action 2 Analysis Tools for Diagnosis
Intel Software Development Products Licensing & Programs Channel EMEA
 Intel Software Development Products Licensing & Programs Channel EMEA Intel Software Development Products Advanced Performance Distributed Performance Intel Software Development Products Foundation of
Intel Software Development Products Licensing & Programs Channel EMEA Intel Software Development Products Advanced Performance Distributed Performance Intel Software Development Products Foundation of
Intel Xeon Phi Coprocessor. Technical Resources. Intel Xeon Phi Coprocessor Workshop Pawsey Centre & CSIRO, Aug Intel Xeon Phi Coprocessor
 Technical Resources Legal Disclaimer INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPETY RIGHTS
Technical Resources Legal Disclaimer INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPETY RIGHTS
OpenMP * 4 Support in Clang * / LLVM * Andrey Bokhanko, Intel
 OpenMP * 4 Support in Clang * / LLVM * Andrey Bokhanko, Intel Clang * : An Excellent C++ Compiler LLVM * : Collection of modular and reusable compiler and toolchain technologies Created by Chris Lattner
OpenMP * 4 Support in Clang * / LLVM * Andrey Bokhanko, Intel Clang * : An Excellent C++ Compiler LLVM * : Collection of modular and reusable compiler and toolchain technologies Created by Chris Lattner
Bei Wang, Dmitry Prohorov and Carlos Rosales
 Bei Wang, Dmitry Prohorov and Carlos Rosales Aspects of Application Performance What are the Aspects of Performance Intel Hardware Features Omni-Path Architecture MCDRAM 3D XPoint Many-core Xeon Phi AVX-512
Bei Wang, Dmitry Prohorov and Carlos Rosales Aspects of Application Performance What are the Aspects of Performance Intel Hardware Features Omni-Path Architecture MCDRAM 3D XPoint Many-core Xeon Phi AVX-512
IXPUG 16. Dmitry Durnov, Intel MPI team
 IXPUG 16 Dmitry Durnov, Intel MPI team Agenda - Intel MPI 2017 Beta U1 product availability - New features overview - Competitive results - Useful links - Q/A 2 Intel MPI 2017 Beta U1 is available! Key
IXPUG 16 Dmitry Durnov, Intel MPI team Agenda - Intel MPI 2017 Beta U1 product availability - New features overview - Competitive results - Useful links - Q/A 2 Intel MPI 2017 Beta U1 is available! Key
Growth in Cores - A well rehearsed story
 Intel CPUs Growth in Cores - A well rehearsed story 2 1. Multicore is just a fad! Copyright 2012, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
Intel CPUs Growth in Cores - A well rehearsed story 2 1. Multicore is just a fad! Copyright 2012, Intel Corporation. All rights reserved. *Other brands and names are the property of their respective owners.
Graphics Performance Analyzer for Android
 Graphics Performance Analyzer for Android 1 What you will learn from this slide deck Detailed optimization workflow of Graphics Performance Analyzer Android* System Analysis Only Please see subsequent
Graphics Performance Analyzer for Android 1 What you will learn from this slide deck Detailed optimization workflow of Graphics Performance Analyzer Android* System Analysis Only Please see subsequent
Using Intel VTune Amplifier XE for High Performance Computing
 Using Intel VTune Amplifier XE for High Performance Computing Vladimir Tsymbal Performance, Analysis and Threading Lab 1 The Majority of all HPC-Systems are Clusters Interconnect I/O I/O... I/O I/O Message
Using Intel VTune Amplifier XE for High Performance Computing Vladimir Tsymbal Performance, Analysis and Threading Lab 1 The Majority of all HPC-Systems are Clusters Interconnect I/O I/O... I/O I/O Message
Achieving High Performance. Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013
 Achieving High Performance Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013 Does Instruction Set Matter? We find that ARM and x86 processors are simply engineering design points optimized
Achieving High Performance Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013 Does Instruction Set Matter? We find that ARM and x86 processors are simply engineering design points optimized
Becca Paren Cluster Systems Engineer Software and Services Group. May 2017
 Becca Paren Cluster Systems Engineer Software and Services Group May 2017 Clusters are complex systems! Challenge is to reduce this complexity barrier for: Cluster architects System administrators Application
Becca Paren Cluster Systems Engineer Software and Services Group May 2017 Clusters are complex systems! Challenge is to reduce this complexity barrier for: Cluster architects System administrators Application
Guy Blank Intel Corporation, Israel March 27-28, 2017 European LLVM Developers Meeting Saarland Informatics Campus, Saarbrücken, Germany
 Guy Blank Intel Corporation, Israel March 27-28, 2017 European LLVM Developers Meeting Saarland Informatics Campus, Saarbrücken, Germany Motivation C AVX2 AVX512 New instructions utilized! Scalar performance
Guy Blank Intel Corporation, Israel March 27-28, 2017 European LLVM Developers Meeting Saarland Informatics Campus, Saarbrücken, Germany Motivation C AVX2 AVX512 New instructions utilized! Scalar performance
Tuning Python Applications Can Dramatically Increase Performance
 Tuning Python Applications Can Dramatically Increase Performance Vasilij Litvinov Software Engineer, Intel Legal Disclaimer & 2 INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS OR IMPLIED,
Tuning Python Applications Can Dramatically Increase Performance Vasilij Litvinov Software Engineer, Intel Legal Disclaimer & 2 INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS OR IMPLIED,
Compiling for Scalable Computing Systems the Merit of SIMD. Ayal Zaks Intel Corporation Acknowledgements: too many to list
 Compiling for Scalable Computing Systems the Merit of SIMD Ayal Zaks Intel Corporation Acknowledgements: too many to list Lo F IRST, Thanks for the Technion For Inspiration and Recognition of Science and
Compiling for Scalable Computing Systems the Merit of SIMD Ayal Zaks Intel Corporation Acknowledgements: too many to list Lo F IRST, Thanks for the Technion For Inspiration and Recognition of Science and
Expressing and Analyzing Dependencies in your C++ Application
 Expressing and Analyzing Dependencies in your C++ Application Pablo Reble, Software Engineer Developer Products Division Software and Services Group, Intel Agenda TBB and Flow Graph extensions Composable
Expressing and Analyzing Dependencies in your C++ Application Pablo Reble, Software Engineer Developer Products Division Software and Services Group, Intel Agenda TBB and Flow Graph extensions Composable
H.J. Lu, Sunil K Pandey. Intel. November, 2018
 H.J. Lu, Sunil K Pandey Intel November, 2018 Issues with Run-time Library on IA Memory, string and math functions in today s glibc are optimized for today s Intel processors: AVX/AVX2/AVX512 FMA It takes
H.J. Lu, Sunil K Pandey Intel November, 2018 Issues with Run-time Library on IA Memory, string and math functions in today s glibc are optimized for today s Intel processors: AVX/AVX2/AVX512 FMA It takes
LIBXSMM Library for small matrix multiplications. Intel High Performance and Throughput Computing (EMEA) Hans Pabst, March 12 th 2015
 Hans Pabst, March 12 th 2015") LIBXSMM Library for small matrix multiplications. Intel High Performance and Throughput Computing (EMEA) Hans Pabst, March 12 th 2015 Abstract Library for small matrix-matrix multiplications targeting
LIBXSMM Library for small matrix multiplications. Intel High Performance and Throughput Computing (EMEA) Hans Pabst, March 12 th 2015 Abstract Library for small matrix-matrix multiplications targeting
Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature. Intel Software Developer Conference London, 2017
 Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature Intel Software Developer Conference London, 2017 Agenda Vectorization is becoming more and more important What is
Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature Intel Software Developer Conference London, 2017 Agenda Vectorization is becoming more and more important What is
Installation Guide and Release Notes
 Intel C++ Studio XE 2013 for Windows* Installation Guide and Release Notes Document number: 323805-003US 26 June 2013 Table of Contents 1 Introduction... 1 1.1 What s New... 2 1.1.1 Changes since Intel
Intel C++ Studio XE 2013 for Windows* Installation Guide and Release Notes Document number: 323805-003US 26 June 2013 Table of Contents 1 Introduction... 1 1.1 What s New... 2 1.1.1 Changes since Intel
Achieving Peak Performance on Intel Hardware. Intel Software Developer Conference London, 2017
 Achieving Peak Performance on Intel Hardware Intel Software Developer Conference London, 2017 Welcome Aims for the day You understand some of the critical features of Intel processors and other hardware
Achieving Peak Performance on Intel Hardware Intel Software Developer Conference London, 2017 Welcome Aims for the day You understand some of the critical features of Intel processors and other hardware
A Simple Path to Parallelism with Intel Cilk Plus
 Introduction This introductory tutorial describes how to use Intel Cilk Plus to simplify making taking advantage of vectorization and threading parallelism in your code. It provides a brief description
Introduction This introductory tutorial describes how to use Intel Cilk Plus to simplify making taking advantage of vectorization and threading parallelism in your code. It provides a brief description
Contributors: Surabhi Jain, Gengbin Zheng, Maria Garzaran, Jim Cownie, Taru Doodi, and Terry L. Wilmarth
 Presenter: Surabhi Jain Contributors: Surabhi Jain, Gengbin Zheng, Maria Garzaran, Jim Cownie, Taru Doodi, and Terry L. Wilmarth May 25, 2018 ROME workshop (in conjunction with IPDPS 2018), Vancouver,
Presenter: Surabhi Jain Contributors: Surabhi Jain, Gengbin Zheng, Maria Garzaran, Jim Cownie, Taru Doodi, and Terry L. Wilmarth May 25, 2018 ROME workshop (in conjunction with IPDPS 2018), Vancouver,
Performance Profiler. Klaus-Dieter Oertel Intel-SSG-DPD IT4I HPC Workshop, Ostrava,
 Performance Profiler Klaus-Dieter Oertel Intel-SSG-DPD IT4I HPC Workshop, Ostrava, 08-09-2016 Faster, Scalable Code, Faster Intel VTune Amplifier Performance Profiler Get Faster Code Faster With Accurate
Performance Profiler Klaus-Dieter Oertel Intel-SSG-DPD IT4I HPC Workshop, Ostrava, 08-09-2016 Faster, Scalable Code, Faster Intel VTune Amplifier Performance Profiler Get Faster Code Faster With Accurate
Getting Started with Intel SDK for OpenCL Applications
 Getting Started with Intel SDK for OpenCL Applications Webinar #1 in the Three-part OpenCL Webinar Series July 11, 2012 Register Now for All Webinars in the Series Welcome to Getting Started with Intel
Getting Started with Intel SDK for OpenCL Applications Webinar #1 in the Three-part OpenCL Webinar Series July 11, 2012 Register Now for All Webinars in the Series Welcome to Getting Started with Intel
Intel tools for High Performance Python 데이터분석및기타기능을위한고성능 Python
 Intel tools for High Performance Python 데이터분석및기타기능을위한고성능 Python Python Landscape Adoption of Python continues to grow among domain specialists and developers for its productivity benefits Challenge#1:
Intel tools for High Performance Python 데이터분석및기타기능을위한고성능 Python Python Landscape Adoption of Python continues to grow among domain specialists and developers for its productivity benefits Challenge#1:
This guide will show you how to use Intel Inspector XE to identify and fix resource leak errors in your programs before they start causing problems.
 Introduction A resource leak refers to a type of resource consumption in which the program cannot release resources it has acquired. Typically the result of a bug, common resource issues, such as memory
Introduction A resource leak refers to a type of resource consumption in which the program cannot release resources it has acquired. Typically the result of a bug, common resource issues, such as memory
More performance options
 More performance options OpenCL, streaming media, and native coding options with INDE April 8, 2014 2014, Intel Corporation. All rights reserved. Intel, the Intel logo, Intel Inside, Intel Xeon, and Intel
More performance options OpenCL, streaming media, and native coding options with INDE April 8, 2014 2014, Intel Corporation. All rights reserved. Intel, the Intel logo, Intel Inside, Intel Xeon, and Intel
Intel Cluster Checker 3.0 webinar
 Intel Cluster Checker 3.0 webinar June 3, 2015 Christopher Heller Technical Consulting Engineer Q2, 2015 1 Introduction Intel Cluster Checker 3.0 is a systems tool for Linux high performance compute clusters
Intel Cluster Checker 3.0 webinar June 3, 2015 Christopher Heller Technical Consulting Engineer Q2, 2015 1 Introduction Intel Cluster Checker 3.0 is a systems tool for Linux high performance compute clusters
Intel Parallel Studio XE 2015
 2015 Create faster code faster with this comprehensive parallel software development suite. Faster code: Boost applications performance that scales on today s and next-gen processors Create code faster:
2015 Create faster code faster with this comprehensive parallel software development suite. Faster code: Boost applications performance that scales on today s and next-gen processors Create code faster:
Real World Development examples of systems / iot
 Real World Development examples of systems / iot Intel Software Developer Conference Seoul 2017 Jon Kim Software Consulting Engineer Contents IOT end-to-end Scalability with Intel x86 Architect Real World
Real World Development examples of systems / iot Intel Software Developer Conference Seoul 2017 Jon Kim Software Consulting Engineer Contents IOT end-to-end Scalability with Intel x86 Architect Real World
Intel Many Integrated Core (MIC) Architecture
 Architecture") Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Installation Guide and Release Notes
 Intel Parallel Studio XE 2013 for Linux* Installation Guide and Release Notes Document number: 323804-003US 10 March 2013 Table of Contents 1 Introduction... 1 1.1 What s New... 1 1.1.1 Changes since Intel
Intel Parallel Studio XE 2013 for Linux* Installation Guide and Release Notes Document number: 323804-003US 10 March 2013 Table of Contents 1 Introduction... 1 1.1 What s New... 1 1.1.1 Changes since Intel
Intel Parallel Studio XE 2011 for Windows* Installation Guide and Release Notes
 Intel Parallel Studio XE 2011 for Windows* Installation Guide and Release Notes Document number: 323803-001US 4 May 2011 Table of Contents 1 Introduction... 1 1.1 What s New... 2 1.2 Product Contents...
Intel Parallel Studio XE 2011 for Windows* Installation Guide and Release Notes Document number: 323803-001US 4 May 2011 Table of Contents 1 Introduction... 1 1.1 What s New... 2 1.2 Product Contents...
Diego Caballero and Vectorizer Team, Intel Corporation. April 16 th, 2018 Euro LLVM Developers Meeting. Bristol, UK.
 Diego Caballero and Vectorizer Team, Intel Corporation. April 16 th, 2018 Euro LLVM Developers Meeting. Bristol, UK. Legal Disclaimer & Software and workloads used in performance tests may have been optimized
Diego Caballero and Vectorizer Team, Intel Corporation. April 16 th, 2018 Euro LLVM Developers Meeting. Bristol, UK. Legal Disclaimer & Software and workloads used in performance tests may have been optimized
Mikhail Dvorskiy, Jim Cownie, Alexey Kukanov
 Mikhail Dvorskiy, Jim Cownie, Alexey Kukanov What is the Parallel STL? C++17 C++ Next An extension of the C++ Standard Template Library algorithms with the execution policy argument Support for parallel
Mikhail Dvorskiy, Jim Cownie, Alexey Kukanov What is the Parallel STL? C++17 C++ Next An extension of the C++ Standard Template Library algorithms with the execution policy argument Support for parallel
High Performance Computing The Essential Tool for a Knowledge Economy
 High Performance Computing The Essential Tool for a Knowledge Economy Rajeeb Hazra Vice President & General Manager Technical Computing Group Datacenter & Connected Systems Group July 22 nd 2013 1 What
High Performance Computing The Essential Tool for a Knowledge Economy Rajeeb Hazra Vice President & General Manager Technical Computing Group Datacenter & Connected Systems Group July 22 nd 2013 1 What
Intel VTune Amplifier XE
 Intel VTune Amplifier XE Vladimir Tsymbal Performance, Analysis and Threading Lab 1 Agenda Intel VTune Amplifier XE Overview Features Data collectors Analysis types Key Concepts Collecting performance
Intel VTune Amplifier XE Vladimir Tsymbal Performance, Analysis and Threading Lab 1 Agenda Intel VTune Amplifier XE Overview Features Data collectors Analysis types Key Concepts Collecting performance
Klaus-Dieter Oertel, May 28 th 2013 Software and Services Group Intel Corporation
 S c i c o m P 2 0 1 3 T u t o r i a l Intel Xeon Phi Product Family Programming Tools Klaus-Dieter Oertel, May 28 th 2013 Software and Services Group Intel Corporation Agenda Intel Parallel Studio XE 2013
S c i c o m P 2 0 1 3 T u t o r i a l Intel Xeon Phi Product Family Programming Tools Klaus-Dieter Oertel, May 28 th 2013 Software and Services Group Intel Corporation Agenda Intel Parallel Studio XE 2013
Using Intel VTune Amplifier XE and Inspector XE in.net environment
 Using Intel VTune Amplifier XE and Inspector XE in.net environment Levent Akyil Technical Computing, Analyzers and Runtime Software and Services group 1 Refresher - Intel VTune Amplifier XE Intel Inspector
Using Intel VTune Amplifier XE and Inspector XE in.net environment Levent Akyil Technical Computing, Analyzers and Runtime Software and Services group 1 Refresher - Intel VTune Amplifier XE Intel Inspector
What s P. Thierry
 What s new@intel P. Thierry Principal Engineer, Intel Corp philippe.thierry@intel.com CPU trend Memory update Software Characterization in 30 mn 10 000 feet view CPU : Range of few TF/s and
What s new@intel P. Thierry Principal Engineer, Intel Corp philippe.thierry@intel.com CPU trend Memory update Software Characterization in 30 mn 10 000 feet view CPU : Range of few TF/s and
Efficiently Introduce Threading using Intel TBB
 Introduction This guide will illustrate how to efficiently introduce threading using Intel Threading Building Blocks (Intel TBB), part of Intel Parallel Studio XE. It is a widely used, award-winning C++
Introduction This guide will illustrate how to efficiently introduce threading using Intel Threading Building Blocks (Intel TBB), part of Intel Parallel Studio XE. It is a widely used, award-winning C++
Sarah Knepper. Intel Math Kernel Library (Intel MKL) 25 May 2018, iwapt 2018
 25 May 2018, iwapt 2018") Sarah Knepper Intel Math Kernel Library (Intel MKL) 25 May 2018, iwapt 2018 Outline Motivation Problem statement and solutions Simple example Performance comparison 2 Motivation Partial differential equations
Sarah Knepper Intel Math Kernel Library (Intel MKL) 25 May 2018, iwapt 2018 Outline Motivation Problem statement and solutions Simple example Performance comparison 2 Motivation Partial differential equations
Eliminate Threading Errors to Improve Program Stability
 Introduction This guide will illustrate how the thread checking capabilities in Intel Parallel Studio XE can be used to find crucial threading defects early in the development cycle. It provides detailed
Introduction This guide will illustrate how the thread checking capabilities in Intel Parallel Studio XE can be used to find crucial threading defects early in the development cycle. It provides detailed
Jackson Marusarz Intel
 Jackson Marusarz Intel Agenda Motivation Threading Advisor Threading Advisor Workflow Advisor Interface Survey Report Annotations Suitability Analysis Dependencies Analysis Vectorization Advisor & Roofline
Jackson Marusarz Intel Agenda Motivation Threading Advisor Threading Advisor Workflow Advisor Interface Survey Report Annotations Suitability Analysis Dependencies Analysis Vectorization Advisor & Roofline
Obtaining the Last Values of Conditionally Assigned Privates
 Obtaining the Last Values of Conditionally Assigned Privates Hideki Saito, Serge Preis*, Aleksei Cherkasov, Xinmin Tian Intel Corporation (* at submission time) 2016/10/04 OpenMPCon2016 Legal Disclaimer
Obtaining the Last Values of Conditionally Assigned Privates Hideki Saito, Serge Preis*, Aleksei Cherkasov, Xinmin Tian Intel Corporation (* at submission time) 2016/10/04 OpenMPCon2016 Legal Disclaimer
Sample for OpenCL* and DirectX* Video Acceleration Surface Sharing
 Sample for OpenCL* and DirectX* Video Acceleration Surface Sharing User s Guide Intel SDK for OpenCL* Applications Sample Documentation Copyright 2010 2013 Intel Corporation All Rights Reserved Document
Sample for OpenCL* and DirectX* Video Acceleration Surface Sharing User s Guide Intel SDK for OpenCL* Applications Sample Documentation Copyright 2010 2013 Intel Corporation All Rights Reserved Document
Intel Math Kernel Library (Intel MKL) BLAS. Victor Kostin Intel MKL Dense Solvers team manager
 BLAS. Victor Kostin Intel MKL Dense Solvers team manager") Intel Math Kernel Library (Intel MKL) BLAS Victor Kostin Intel MKL Dense Solvers team manager Intel MKL BLAS/Sparse BLAS Original ( dense ) BLAS available from www.netlib.org Additionally Intel MKL provides
Intel Math Kernel Library (Intel MKL) BLAS Victor Kostin Intel MKL Dense Solvers team manager Intel MKL BLAS/Sparse BLAS Original ( dense ) BLAS available from www.netlib.org Additionally Intel MKL provides
Parallel Programming Features in the Fortran Standard. Steve Lionel 12/4/2012
 Parallel Programming Features in the Fortran Standard Steve Lionel 12/4/2012 Agenda Overview of popular parallelism methodologies FORALL a look back DO CONCURRENT Coarrays Fortran 2015 Q+A 12/5/2012 2
Parallel Programming Features in the Fortran Standard Steve Lionel 12/4/2012 Agenda Overview of popular parallelism methodologies FORALL a look back DO CONCURRENT Coarrays Fortran 2015 Q+A 12/5/2012 2
Intel Xeon Phi Coprocessor Performance Analysis
 Intel Xeon Phi Coprocessor Performance Analysis Legal Disclaimer INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO
Intel Xeon Phi Coprocessor Performance Analysis Legal Disclaimer INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO
Eliminate Threading Errors to Improve Program Stability
 Eliminate Threading Errors to Improve Program Stability This guide will illustrate how the thread checking capabilities in Parallel Studio can be used to find crucial threading defects early in the development
Eliminate Threading Errors to Improve Program Stability This guide will illustrate how the thread checking capabilities in Parallel Studio can be used to find crucial threading defects early in the development
Munara Tolubaeva Technical Consulting Engineer. 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries.
 Munara Tolubaeva Technical Consulting Engineer 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries. notices and disclaimers Intel technologies features and benefits depend
Munara Tolubaeva Technical Consulting Engineer 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries. notices and disclaimers Intel technologies features and benefits depend
Intel Software Development Products for High Performance Computing and Parallel Programming
 Intel Software Development Products for High Performance Computing and Parallel Programming Multicore development tools with extensions to many-core Notices INFORMATION IN THIS DOCUMENT IS PROVIDED IN
Intel Software Development Products for High Performance Computing and Parallel Programming Multicore development tools with extensions to many-core Notices INFORMATION IN THIS DOCUMENT IS PROVIDED IN
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Intel Xeon Processor E7 v2 Family-Based Platforms
 Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
HPC code modernization with Intel development tools
 HPC code modernization with Intel development tools Bayncore, Ltd. Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 17 th 2016, Barcelona Microprocessor
HPC code modernization with Intel development tools Bayncore, Ltd. Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 17 th 2016, Barcelona Microprocessor
OpenCL* and Microsoft DirectX* Video Acceleration Surface Sharing
 OpenCL* and Microsoft DirectX* Video Acceleration Surface Sharing Intel SDK for OpenCL* Applications Sample Documentation Copyright 2010 2012 Intel Corporation All Rights Reserved Document Number: 327281-001US
OpenCL* and Microsoft DirectX* Video Acceleration Surface Sharing Intel SDK for OpenCL* Applications Sample Documentation Copyright 2010 2012 Intel Corporation All Rights Reserved Document Number: 327281-001US
The Intel Xeon Phi Coprocessor. Dr-Ing. Michael Klemm Software and Services Group Intel Corporation
 The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
Sergey Maidanov. Software Engineering Manager for Intel Distribution for Python*
 Sergey Maidanov Software Engineering Manager for Intel Distribution for Python* Introduction Python is among the most popular programming languages Especially for prototyping But very limited use in production
Sergey Maidanov Software Engineering Manager for Intel Distribution for Python* Introduction Python is among the most popular programming languages Especially for prototyping But very limited use in production
Crosstalk between VMs. Alexander Komarov, Application Engineer Software and Services Group Developer Relations Division EMEA
 Crosstalk between VMs Alexander Komarov, Application Engineer Software and Services Group Developer Relations Division EMEA 2 September 2015 Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT
Crosstalk between VMs Alexander Komarov, Application Engineer Software and Services Group Developer Relations Division EMEA 2 September 2015 Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT
Jim Cownie, Johnny Peyton with help from Nitya Hariharan and Doug Jacobsen
 Jim Cownie, Johnny Peyton with help from Nitya Hariharan and Doug Jacobsen Features We Discuss Synchronization (lock) hints The nonmonotonic:dynamic schedule Both Were new in OpenMP 4.5 May have slipped
Jim Cownie, Johnny Peyton with help from Nitya Hariharan and Doug Jacobsen Features We Discuss Synchronization (lock) hints The nonmonotonic:dynamic schedule Both Were new in OpenMP 4.5 May have slipped
Alexei Katranov. IWOCL '16, April 21, 2016, Vienna, Austria
 Alexei Katranov IWOCL '16, April 21, 2016, Vienna, Austria Hardware: customization, integration, heterogeneity Intel Processor Graphics CPU CPU CPU CPU Multicore CPU + integrated units for graphics, media
Alexei Katranov IWOCL '16, April 21, 2016, Vienna, Austria Hardware: customization, integration, heterogeneity Intel Processor Graphics CPU CPU CPU CPU Multicore CPU + integrated units for graphics, media
MICHAL MROZEK ZBIGNIEW ZDANOWICZ
 MICHAL MROZEK ZBIGNIEW ZDANOWICZ Legal Notices and Disclaimers INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY
MICHAL MROZEK ZBIGNIEW ZDANOWICZ Legal Notices and Disclaimers INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY
Gil Rapaport and Ayal Zaks. Intel Corporation, Israel Development Center. March 27-28, 2017 European LLVM Developers Meeting
 Gil Rapaport and Ayal Zaks Intel Corporation, Israel Development Center March 27-28, 2017 European LLVM Developers Meeting Saarland Informatics Campus, Saarbrücken, Germany Legal Disclaimer & INFORMATION
Gil Rapaport and Ayal Zaks Intel Corporation, Israel Development Center March 27-28, 2017 European LLVM Developers Meeting Saarland Informatics Campus, Saarbrücken, Germany Legal Disclaimer & INFORMATION
Intel Math Kernel Library (Intel MKL) Team - Presenter: Murat Efe Guney Workshop on Batched, Reproducible, and Reduced Precision BLAS Georgia Tech,
 Team - Presenter: Murat Efe Guney Workshop on Batched, Reproducible, and Reduced Precision BLAS Georgia Tech,") Intel Math Kernel Library (Intel MKL) Team - Presenter: Murat Efe Guney Workshop on Batched, Reproducible, and Reduced Precision BLAS Georgia Tech, Atlanta February 24, 2017 Acknowledgements Benoit Jacob
Intel Math Kernel Library (Intel MKL) Team - Presenter: Murat Efe Guney Workshop on Batched, Reproducible, and Reduced Precision BLAS Georgia Tech, Atlanta February 24, 2017 Acknowledgements Benoit Jacob
Intel Architecture for Software Developers
 Intel Architecture for Software Developers 1 Agenda Introduction Processor Architecture Basics Intel Architecture Intel Core and Intel Xeon Intel Atom Intel Xeon Phi Coprocessor Use Cases for Software
Intel Architecture for Software Developers 1 Agenda Introduction Processor Architecture Basics Intel Architecture Intel Core and Intel Xeon Intel Atom Intel Xeon Phi Coprocessor Use Cases for Software
IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor
 IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor D.Sc. Mikko Byckling 17th Workshop on High Performance Computing in Meteorology October 24 th 2016, Reading, UK Legal Disclaimer & Optimization
IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor D.Sc. Mikko Byckling 17th Workshop on High Performance Computing in Meteorology October 24 th 2016, Reading, UK Legal Disclaimer & Optimization
Eliminate Memory Errors to Improve Program Stability
 Introduction INTEL PARALLEL STUDIO XE EVALUATION GUIDE This guide will illustrate how Intel Parallel Studio XE memory checking capabilities can find crucial memory defects early in the development cycle.
Introduction INTEL PARALLEL STUDIO XE EVALUATION GUIDE This guide will illustrate how Intel Parallel Studio XE memory checking capabilities can find crucial memory defects early in the development cycle.
Bitonic Sorting Intel OpenCL SDK Sample Documentation
 Intel OpenCL SDK Sample Documentation Document Number: 325262-002US Legal Information INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL
Intel OpenCL SDK Sample Documentation Document Number: 325262-002US Legal Information INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL
Повышение энергоэффективности мобильных приложений путем их распараллеливания. Примеры. Владимир Полин
 Повышение энергоэффективности мобильных приложений путем их распараллеливания. Примеры. Владимир Полин Legal Notices This presentation is for informational purposes only. INTEL MAKES NO WARRANTIES, EXPRESS
Повышение энергоэффективности мобильных приложений путем их распараллеливания. Примеры. Владимир Полин Legal Notices This presentation is for informational purposes only. INTEL MAKES NO WARRANTIES, EXPRESS
Intel Xeon Phi Coprocessor
 Intel Xeon Phi Coprocessor http://tinyurl.com/inteljames twitter @jamesreinders James Reinders it s all about parallel programming Source Multicore CPU Compilers Libraries, Parallel Models Multicore CPU
Intel Xeon Phi Coprocessor http://tinyurl.com/inteljames twitter @jamesreinders James Reinders it s all about parallel programming Source Multicore CPU Compilers Libraries, Parallel Models Multicore CPU
Bitonic Sorting. Intel SDK for OpenCL* Applications Sample Documentation. Copyright Intel Corporation. All Rights Reserved
 Intel SDK for OpenCL* Applications Sample Documentation Copyright 2010 2012 Intel Corporation All Rights Reserved Document Number: 325262-002US Revision: 1.3 World Wide Web: http://www.intel.com Document
Intel SDK for OpenCL* Applications Sample Documentation Copyright 2010 2012 Intel Corporation All Rights Reserved Document Number: 325262-002US Revision: 1.3 World Wide Web: http://www.intel.com Document
INTEL MKL Vectorized Compact routines
 INTEL MKL Vectorized Compact routines Mesut Meterelliyoz, Peter Caday, Timothy B. Costa, Kazushige Goto, Louise Huot, Sarah Knepper, Arthur Araujo Mitrano, Shane Story 2018 BLIS RETREAT 09/17/2018 OUTLINE
INTEL MKL Vectorized Compact routines Mesut Meterelliyoz, Peter Caday, Timothy B. Costa, Kazushige Goto, Louise Huot, Sarah Knepper, Arthur Araujo Mitrano, Shane Story 2018 BLIS RETREAT 09/17/2018 OUTLINE
Intel Parallel Studio XE 2015 Composer Edition for Linux* Installation Guide and Release Notes
 Intel Parallel Studio XE 2015 Composer Edition for Linux* Installation Guide and Release Notes 23 October 2014 Table of Contents 1 Introduction... 1 1.1 Product Contents... 2 1.2 Intel Debugger (IDB) is
Intel Parallel Studio XE 2015 Composer Edition for Linux* Installation Guide and Release Notes 23 October 2014 Table of Contents 1 Introduction... 1 1.1 Product Contents... 2 1.2 Intel Debugger (IDB) is
Intel VTune Amplifier XE for Tuning of HPC Applications Intel Software Developer Conference Frankfurt, 2017 Klaus-Dieter Oertel, Intel
 Intel VTune Amplifier XE for Tuning of HPC Applications Intel Software Developer Conference Frankfurt, 2017 Klaus-Dieter Oertel, Intel Agenda Which performance analysis tool should I use first? Intel Application
Intel VTune Amplifier XE for Tuning of HPC Applications Intel Software Developer Conference Frankfurt, 2017 Klaus-Dieter Oertel, Intel Agenda Which performance analysis tool should I use first? Intel Application
Ayal Zaks and Gil Rapaport, Vectorization Team, Intel Corporation. October 18 th, 2017 US LLVM Developers Meeting, San Jose, CA
 Ayal Zaks and Gil Rapaport, Vectorization Team, Intel Corporation October 18 th, 2017 US LLVM Developers Meeting, San Jose, CA Legal Disclaimer & INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE,
Ayal Zaks and Gil Rapaport, Vectorization Team, Intel Corporation October 18 th, 2017 US LLVM Developers Meeting, San Jose, CA Legal Disclaimer & INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE,
Revealing the performance aspects in your code
 Revealing the performance aspects in your code 1 Three corner stones of HPC The parallelism can be exploited at three levels: message passing, fork/join, SIMD Hyperthreading is not quite threading A popular
Revealing the performance aspects in your code 1 Three corner stones of HPC The parallelism can be exploited at three levels: message passing, fork/join, SIMD Hyperthreading is not quite threading A popular
HPCG on Intel Xeon Phi 2 nd Generation, Knights Landing. Alexander Kleymenov and Jongsoo Park Intel Corporation SC16, HPCG BoF
 HPCG on Intel Xeon Phi 2 nd Generation, Knights Landing Alexander Kleymenov and Jongsoo Park Intel Corporation SC16, HPCG BoF 1 Outline KNL results Our other work related to HPCG 2 ~47 GF/s per KNL ~10
HPCG on Intel Xeon Phi 2 nd Generation, Knights Landing Alexander Kleymenov and Jongsoo Park Intel Corporation SC16, HPCG BoF 1 Outline KNL results Our other work related to HPCG 2 ~47 GF/s per KNL ~10
Simplified and Effective Serial and Parallel Performance Optimization
 HPC Code Modernization Workshop at LRZ Simplified and Effective Serial and Parallel Performance Optimization Performance tuning Using Intel VTune Performance Profiler Performance Tuning Methodology Goal:
HPC Code Modernization Workshop at LRZ Simplified and Effective Serial and Parallel Performance Optimization Performance tuning Using Intel VTune Performance Profiler Performance Tuning Methodology Goal:
Intel VTune Amplifier XE. Dr. Michael Klemm Software and Services Group Developer Relations Division
 Intel VTune Amplifier XE Dr. Michael Klemm Software and Services Group Developer Relations Division Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS
Intel VTune Amplifier XE Dr. Michael Klemm Software and Services Group Developer Relations Division Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS
Intel Xeon Phi coprocessor (codename Knights Corner) George Chrysos Senior Principal Engineer Hot Chips, August 28, 2012
 George Chrysos Senior Principal Engineer Hot Chips, August 28, 2012") Intel Xeon Phi coprocessor (codename Knights Corner) George Chrysos Senior Principal Engineer Hot Chips, August 28, 2012 Legal Disclaimers INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL
Intel Xeon Phi coprocessor (codename Knights Corner) George Chrysos Senior Principal Engineer Hot Chips, August 28, 2012 Legal Disclaimers INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL
Intel Parallel Studio XE 2011 SP1 for Linux* Installation Guide and Release Notes
 Intel Parallel Studio XE 2011 SP1 for Linux* Installation Guide and Release Notes Document number: 323804-002US 21 June 2012 Table of Contents 1 Introduction... 1 1.1 What s New... 1 1.2 Product Contents...
Intel Parallel Studio XE 2011 SP1 for Linux* Installation Guide and Release Notes Document number: 323804-002US 21 June 2012 Table of Contents 1 Introduction... 1 1.1 What s New... 1 1.2 Product Contents...
Sayantan Sur, Intel. ExaComm Workshop held in conjunction with ISC 2018
 Sayantan Sur, Intel ExaComm Workshop held in conjunction with ISC 2018 Legal Disclaimer & Optimization Notice Software and workloads used in performance tests may have been optimized for performance only
Sayantan Sur, Intel ExaComm Workshop held in conjunction with ISC 2018 Legal Disclaimer & Optimization Notice Software and workloads used in performance tests may have been optimized for performance only
Achieving Peak Performance on Intel Hardware. Jim Cownie: Intel Software Developer Conference Frankfurt, December 2017
 Achieving Peak Performance on Intel Hardware Jim Cownie: Intel Software Developer Conference Frankfurt, December 2017 Welcome Aims for the day You understand some of the critical features of Intel processors
Achieving Peak Performance on Intel Hardware Jim Cownie: Intel Software Developer Conference Frankfurt, December 2017 Welcome Aims for the day You understand some of the critical features of Intel processors
Programming for the Intel Many Integrated Core Architecture By James Reinders. The Architecture for Discovery. PowerPoint Title
 Programming for the Intel Many Integrated Core Architecture By James Reinders The Architecture for Discovery PowerPoint Title Intel Xeon Phi coprocessor 1. Designed for Highly Parallel workloads 2. and
Programming for the Intel Many Integrated Core Architecture By James Reinders The Architecture for Discovery PowerPoint Title Intel Xeon Phi coprocessor 1. Designed for Highly Parallel workloads 2. and
Fastest and most used math library for Intel -based systems 1
 Fastest and most used math library for Intel -based systems 1 Speaker: Alexander Kalinkin Contributing authors: Peter Caday, Kazushige Goto, Louise Huot, Sarah Knepper, Mesut Meterelliyoz, Arthur Araujo
Fastest and most used math library for Intel -based systems 1 Speaker: Alexander Kalinkin Contributing authors: Peter Caday, Kazushige Goto, Louise Huot, Sarah Knepper, Mesut Meterelliyoz, Arthur Araujo
Software Optimization Case Study. Yu-Ping Zhao
 Software Optimization Case Study Yu-Ping Zhao Yuping.zhao@intel.com Agenda RELION Background RELION ITAC and VTUE Analyze RELION Auto-Refine Workload Optimization RELION 2D Classification Workload Optimization
Software Optimization Case Study Yu-Ping Zhao Yuping.zhao@intel.com Agenda RELION Background RELION ITAC and VTUE Analyze RELION Auto-Refine Workload Optimization RELION 2D Classification Workload Optimization
Sayantan Sur, Intel. SEA Symposium on Overlapping Computation and Communication. April 4 th, 2018
 Sayantan Sur, Intel SEA Symposium on Overlapping Computation and Communication April 4 th, 2018 Legal Disclaimer & Benchmark results were obtained prior to implementation of recent software patches and
Sayantan Sur, Intel SEA Symposium on Overlapping Computation and Communication April 4 th, 2018 Legal Disclaimer & Benchmark results were obtained prior to implementation of recent software patches and
Using Intel Inspector XE 2011 with Fortran Applications
 Using Intel Inspector XE 2011 with Fortran Applications Jackson Marusarz Intel Corporation Legal Disclaimer INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS
Using Intel Inspector XE 2011 with Fortran Applications Jackson Marusarz Intel Corporation Legal Disclaimer INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS
Intel Math Kernel Library (Intel MKL) Latest Features
 Latest Features") Intel Math Kernel Library (Intel MKL) Latest Features Sridevi Allam Technical Consulting Engineer Sridevi.allam@intel.com 1 Agenda - Introduction to Support on Intel Xeon Phi Coprocessors - Performance
Intel Math Kernel Library (Intel MKL) Latest Features Sridevi Allam Technical Consulting Engineer Sridevi.allam@intel.com 1 Agenda - Introduction to Support on Intel Xeon Phi Coprocessors - Performance
Embree Ray Tracing Kernels: Overview and New Features
 Embree Ray Tracing Kernels: Overview and New Features Attila Áfra, Ingo Wald, Carsten Benthin, Sven Woop Intel Corporation Intel, the Intel logo, Intel Xeon Phi, Intel Xeon Processor are trademarks of
Embree Ray Tracing Kernels: Overview and New Features Attila Áfra, Ingo Wald, Carsten Benthin, Sven Woop Intel Corporation Intel, the Intel logo, Intel Xeon Phi, Intel Xeon Processor are trademarks of
Intel SDK for OpenCL* - Sample for OpenCL* and Intel Media SDK Interoperability
 Intel SDK for OpenCL* - Sample for OpenCL* and Intel Media SDK Interoperability User s Guide Copyright 2010 2012 Intel Corporation All Rights Reserved Document Number: 327283-001US Revision: 1.0 World
Intel SDK for OpenCL* - Sample for OpenCL* and Intel Media SDK Interoperability User s Guide Copyright 2010 2012 Intel Corporation All Rights Reserved Document Number: 327283-001US Revision: 1.0 World
VLPL-S Optimization on Knights Landing
 VLPL-S Optimization on Knights Landing 英特尔软件与服务事业部 周姗 2016.5 Agenda VLPL-S 性能分析 VLPL-S 性能优化 总结 2 VLPL-S Workload Descriptions VLPL-S is the in-house code from SJTU, paralleled with MPI and written in C++.
VLPL-S Optimization on Knights Landing 英特尔软件与服务事业部 周姗 2016.5 Agenda VLPL-S 性能分析 VLPL-S 性能优化 总结 2 VLPL-S Workload Descriptions VLPL-S is the in-house code from SJTU, paralleled with MPI and written in C++.