GPGPUGPGPU: Multi-GPU Programming
|
|
|
- Jacob Carpenter
- 6 years ago
- Views:
Transcription
1 GPGPUGPGPU: Multi-GPU Programming Fall 2012
2 HW4 global void cuda_transpose(const float *ad, const int n, float *atd) { } int i = threadidx.y + blockidx.y*blockdim.y; int j = threadidx.x + blockidx.x*blockdim.x; if (i<n && j<n) atd[i*n + j] = ad[j*n + i]; return;
3 HW4 global void cuda_transpose_shared(const float *ad, const int n, float *atd) { extern shared float atile[]; int loci = threadidx.y, locj = threadidx.x; int bi = blockidx.y, bj = blockidx.x; int blocksize = blockdim.x; int i = loci + bi*blocksize; int j = locj + bj*blocksize; /* read in shared data */ if (i<n && j<n) { atile[loci*blocksize + locj] = ad[i*n + j]; } syncthreads(); } if (i<n && j<n) { atd[(loci+bj*blocksize)*n + (locj+bi*blocksize)] = atile[locj*blocksize+loci]; } return;
4 HW4 global void cuda_transpose_shared(const float *ad Advantages: coallesced reads, writes (what is optimum blocksize for coallescing? Can get 100% memory efficiency) Downsides: syncthreads() } extern shared float atile[]; int loci = threadidx.y, locj = threadidx.x; int bi = blockidx.y, bj = blockidx.x; int blocksize = blockdim.x; int i = loci + bi*blocksize; int j = locj + bj*blocksize; /* read in shared data */ if (i<n && j<n) { atile[loci*blocksize + locj] = ad[i*n + j]; } syncthreads(); if (i<n && j<n) { atd[(loci+bj*blocksize)*n + (locj+bi*blocksiz } return;
5 HW4 32x32 blocks - perfect coallescing have to wait for 32 memory transactions to complete before proceed At least 132 cycles for scheduling Can get around with more blocks... But 4kB/block shared; past 12 blocks per SM (=168, 400^2 matrix) occupancy suffers.
6 HW4 What can we do? Want to either reduce blocks shared memory footprint, or more fewer waits before syncthreads() without impacting coallescing.
7 HW4 Narrower blocks?
8 HW4 Narrower blocks? Means outputting the transpose is inefficient
9 HW4 Multiple transactions per thread...
10 HW4 if (j<n) { for (int iter=0; iter<multi; iter++) { int inrow =multi*i+iter; int tilerow=multi*loci+iter; if ( inrow < n) { atile[tilerow*(blockdim.x+1) + locj] = ad[inrow*n + j]; } } } syncthreads(); for (int iter=0; iter<multi; iter++) { int outrow=blockdim.x*bj + loci/multi; int outcol=blockdim.y*bi*multi + (loci%multi)*blockdim.y + locj; if (outrow < n && outcol < n) { atd[outrow*n + outcol] = atile[(multi*locj+iter)*(blockdim.x+1)+loci]; } } return;
11 HW4 arc01-$./transpose --matsize=384 --nblocks=12 --multi=4 Matrix size = 384, Number of blocks = 12, Blocksize = 32. CPU time = millisec. GPU time = millisec (global mem). CUDA global mem and CPU results differ by GPU time = millisec (shared mem). CUDA shared mem and CPU results differ by GPU time = millisec (shared mem). CUDA shared mem - bank and CPU results differ by GPU time = millisec (multiple transactions). CUDA multiple transactions and CPU results differ by arc01-$./transpose --matsize= nblocks=32 --multi=4 Matrix size = 1024, Number of blocks = 32, Blocksize = 32. CPU time = millisec. GPU time = millisec (global mem). CUDA global mem and CPU results differ by GPU time = millisec (shared mem). CUDA shared mem and CPU results differ by GPU time = millisec (shared mem). CUDA shared mem - bank and CPU results differ by GPU time = millisec (multiple transactions).
12 Optimizizing around Tradeoffs Want memory accesses that are 32-floats wide Want many blocks (latency) Want few blocks (shared mem/node: occupancy) Not clear a priori what best choices are; have to experiment (and different hardware can shift balance.) For sticky problems, people have often already found good solutions: MatrixTranspose.pdf
13 Multiple GPUS Might want to use multiple GPUs in a node for: More cores (you have enough work; but occupancy!) More memory (~6GB/card isn t a tonne) More memory bandwidth between global + cores
14 Multiple GPUS If you have an existing parallel program, relatively easy Each thread/process drives its own GPU Communicate amongst themselves as before MPI programs lend themselves particularly well to this
15 Multiple GPUS Multi-GPU machines becoming more common Haven t talked about CPU parallelism in this class Will talk about driving multiple GPUs from a single CPU program
16 Very simple since CUDA 4.0 All you really need to know is: int ngpus; cudagetdevicecount( &ngpus ); and cudasetdevice(gpunum);
17 Very simple since CUDA 4.0 Consider our simple GPU C = A x B matrix multiply Note that we can recast this as a block-matrix multiply, with C and A both broken down by rows Each chunk of A, C can be assigned to a different GPU = * = *
18 matmult.cu
19 matmult.cu
20 Matmult-multi.cu
21 Matmult-multi.cu
22 Matmult-multi.cu
23 Matmult-multi.cu
24 matmult-multi.cu
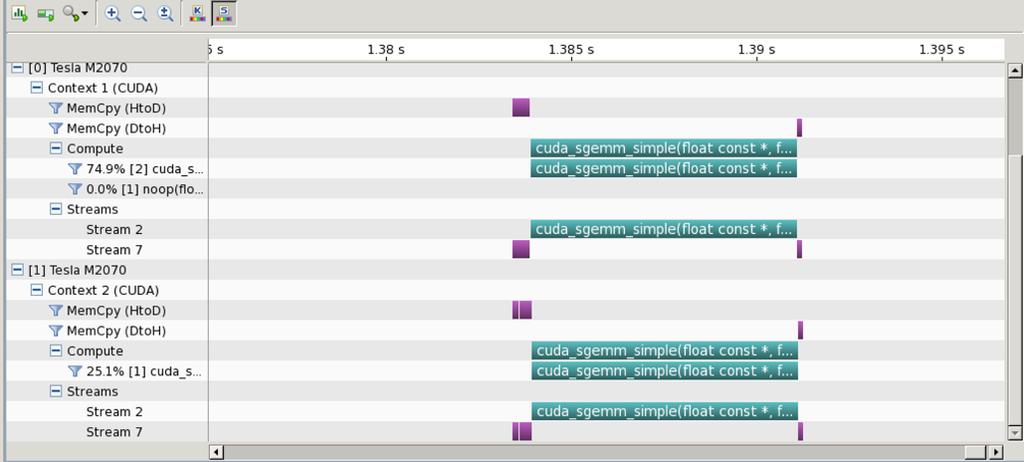
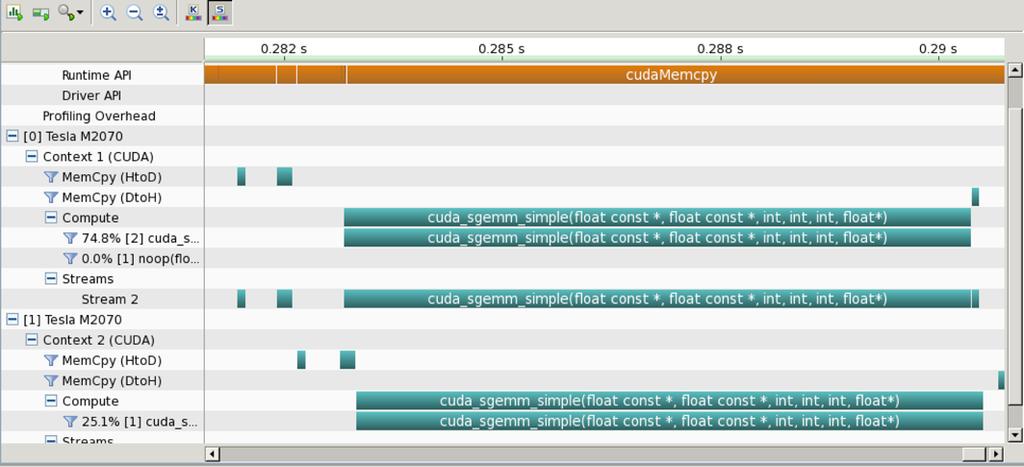
25 matmult-stream.cu
26 Blocking vs Async arc01-$./matmult-multi --matsize=512 --nblocks=32 Matrix size = 512, Number of blocks = 32. CPU time = millisec. GPU time = millisec (1 gpu). Single GPU and CPU results differ by GPU time = millisec (2 gpu). 2-GPU and CPU results differ by arc01-$./matmult-stream --matsize=512 --nblocks=32 Matrix size = 512, Number of blocks = 32. CPU a = millisec. GPU time = millisec (1 gpu). Single GPU and CPU results differ by GPU time = millisec (2 gpu). 2-GPU and CPU results differ by
27 Memory exchange In general, don t just fire off one kernel and then done Iterative methods, timesteps, etc. Dealing with multiple GPUs introduces more complex CPU/ GPU memory issues More bookeeping Efficiency (waiting for CPU to copy data out of one GPU, into another) CUDA 4,5 introduce nicer ways to deal with this
28 Memory exchange Options: Explicit CPU copying Zero-copy from host (bookkeeping, maybe lower efficiency) Peer-to-peer transfers Peer-to-peer memory access
 Access through slow PCIe bus Host/global like global/shared; fine if only going to access once, slow if you need to access")
29 Zero (explicit) copy GPU can see region of host memory As with async memory copy, and for same reasons, must be pinned memory, allocated with cudahostalloc (or registered) Access through slow PCIe bus Host/global like global/shared; fine if only going to access once, slow if you need to access it repeatedly.
30 Zero Copy Let s use this for (say) B... cudahostalloc(&a, n*n*sizeof(float), cudahostallocdefault); cudahostalloc(&b, n*n*sizeof(float), cudahostallocmapped cudahostallocportable ); cudahostalloc(&c, n*n*sizeof(float), cudahostallocdefault); cudahostalloc(&ccuda, n*n*sizeof(float), cudahostallocdefault); for (int dev=0; dev<ngpus; dev++) { cudasetdevice(dev);... CHK_CUDA( cudamalloc(&(multi_ad[dev]), locnrows*n*sizeof(float)) ); CHK_CUDA( cudahostgetdevicepointer(&(multi_bd[dev]), b, 0) ); CHK_CUDA( cudamalloc(&(multi_cd[dev]), locnrows*n*sizeof(float)) ); }... cuda_sgemm_simple<<<gridsize, blocksize>>>(multi_ad[dev], multi_bd[dev], locnrows, n, n, multi_cd[dev]);
31 Zero Copy Slower, but less explicit copying, memory usage on GPU arc01-$./matmult-zero --matsize=512 --nblocks=128 Matrix size = 512, Number of blocks = 128. CPU time = millisec. GPU time = millisec (1 gpu). Single GPU and CPU results differ by GPU time = millisec (2 gpu). 2-GPU and CPU results differ by
32 Unified Virtual Adressing Tesla Fermis and later CUDA 4.0 and later From programmer s point of view, one global memory space Can just use cudamemcpy for everything Mainly convenience
33 Direct Peer Copes With UVA, can enable copies directly from GPU to GPUfirst enable peer access for each peer pair: cudadeviceenablepeeraccess(int peerdevice, unsigned int flags ) flags always zero (for now) Give appropriate device ptr
34 Homework Goal: repeatedly smooth the large image from previous homework (models a PDE calculation) on multiple GPUs. Starting from smoothimage HW, just using global memory for image, loop over the memcopy/kernel/ memcopy with 1 gpu Then split over multiple gpus, as with simple matmult Then enable peer copying, and have kernels start with copy from neighbour. How to synchronize?
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Hardware/Software Co-Design
 1 / 13 Hardware/Software Co-Design Review so far Miaoqing Huang University of Arkansas Fall 2011 2 / 13 Problem I A student mentioned that he was able to multiply two 1,024 1,024 matrices using a tiled
1 / 13 Hardware/Software Co-Design Review so far Miaoqing Huang University of Arkansas Fall 2011 2 / 13 Problem I A student mentioned that he was able to multiply two 1,024 1,024 matrices using a tiled
Blocks, Grids, and Shared Memory
 Blocks, Grids, and Shared Memory GPU Course, Fall 2012 Last week: ax+b Homework Threads, Blocks, Grids CUDA threads are organized into blocks Threads operate in SIMD(ish) manner -- each executing same
Blocks, Grids, and Shared Memory GPU Course, Fall 2012 Last week: ax+b Homework Threads, Blocks, Grids CUDA threads are organized into blocks Threads operate in SIMD(ish) manner -- each executing same
Information Coding / Computer Graphics, ISY, LiTH. CUDA memory! ! Coalescing!! Constant memory!! Texture memory!! Pinned memory 26(86)
") 26(86) Information Coding / Computer Graphics, ISY, LiTH CUDA memory Coalescing Constant memory Texture memory Pinned memory 26(86) CUDA memory We already know... Global memory is slow. Shared memory is
26(86) Information Coding / Computer Graphics, ISY, LiTH CUDA memory Coalescing Constant memory Texture memory Pinned memory 26(86) CUDA memory We already know... Global memory is slow. Shared memory is
CUDA OPTIMIZATION TIPS, TRICKS AND TECHNIQUES. Stephen Jones, GTC 2017
 CUDA OPTIMIZATION TIPS, TRICKS AND TECHNIQUES Stephen Jones, GTC 2017 The art of doing more with less 2 Performance RULE #1: DON T TRY TOO HARD Peak Performance Time 3 Unrealistic Effort/Reward Performance
CUDA OPTIMIZATION TIPS, TRICKS AND TECHNIQUES Stephen Jones, GTC 2017 The art of doing more with less 2 Performance RULE #1: DON T TRY TOO HARD Peak Performance Time 3 Unrealistic Effort/Reward Performance
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Lab 1 Part 1: Introduction to CUDA
 Lab 1 Part 1: Introduction to CUDA Code tarball: lab1.tgz In this hands-on lab, you will learn to use CUDA to program a GPU. The lab can be conducted on the SSSU Fermi Blade (M2050) or NCSA Forge using
Lab 1 Part 1: Introduction to CUDA Code tarball: lab1.tgz In this hands-on lab, you will learn to use CUDA to program a GPU. The lab can be conducted on the SSSU Fermi Blade (M2050) or NCSA Forge using
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Learn CUDA in an Afternoon. Alan Gray EPCC The University of Edinburgh
 Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Introduction to GPU programming. Introduction to GPU programming p. 1/17
 Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Advanced CUDA Optimizations. Umar Arshad ArrayFire
 Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
Advanced CUDA Programming. Dr. Timo Stich
 Advanced CUDA Programming Dr. Timo Stich (tstich@nvidia.com) Outline SIMT Architecture, Warps Kernel optimizations Global memory throughput Launch configuration Shared memory access Instruction throughput
Advanced CUDA Programming Dr. Timo Stich (tstich@nvidia.com) Outline SIMT Architecture, Warps Kernel optimizations Global memory throughput Launch configuration Shared memory access Instruction throughput
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Module Memory and Data Locality
 GPU Teaching Kit Accelerated Computing Module 4.4 - Memory and Data Locality Tiled Matrix Multiplication Kernel Objective To learn to write a tiled matrix-multiplication kernel Loading and using tiles
GPU Teaching Kit Accelerated Computing Module 4.4 - Memory and Data Locality Tiled Matrix Multiplication Kernel Objective To learn to write a tiled matrix-multiplication kernel Loading and using tiles
GPU & High Performance Computing (by NVIDIA) CUDA. Compute Unified Device Architecture Florian Schornbaum
 CUDA. Compute Unified Device Architecture Florian Schornbaum") GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
CS 314 Principles of Programming Languages
 CS 314 Principles of Programming Languages Zheng Zhang Fall 2016 Dec 14 GPU Programming Rutgers University Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing computations
CS 314 Principles of Programming Languages Zheng Zhang Fall 2016 Dec 14 GPU Programming Rutgers University Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing computations
Lecture 7. Using Shared Memory Performance programming and the memory hierarchy
 Lecture 7 Using Shared Memory Performance programming and the memory hierarchy Announcements Scott B. Baden /CSE 260/ Winter 2014 2 Assignment #1 Blocking for cache will boost performance but a lot more
Lecture 7 Using Shared Memory Performance programming and the memory hierarchy Announcements Scott B. Baden /CSE 260/ Winter 2014 2 Assignment #1 Blocking for cache will boost performance but a lot more
COSC 6374 Parallel Computations Introduction to CUDA
 COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
GPU Programming. Performance Considerations. Miaoqing Huang University of Arkansas Fall / 60
 1 / 60 GPU Programming Performance Considerations Miaoqing Huang University of Arkansas Fall 2013 2 / 60 Outline Control Flow Divergence Memory Coalescing Shared Memory Bank Conflicts Occupancy Loop Unrolling
1 / 60 GPU Programming Performance Considerations Miaoqing Huang University of Arkansas Fall 2013 2 / 60 Outline Control Flow Divergence Memory Coalescing Shared Memory Bank Conflicts Occupancy Loop Unrolling
Example 1: Color-to-Grayscale Image Processing
 GPU Teaching Kit Accelerated Computing Lecture 16: CUDA Parallelism Model Examples Example 1: Color-to-Grayscale Image Processing RGB Color Image Representation Each pixel in an image is an RGB value The
GPU Teaching Kit Accelerated Computing Lecture 16: CUDA Parallelism Model Examples Example 1: Color-to-Grayscale Image Processing RGB Color Image Representation Each pixel in an image is an RGB value The
CS 179: GPU Computing. Recitation 2: Synchronization, Shared memory, Matrix Transpose
 CS 179: GPU Computing Recitation 2: Synchronization, Shared memory, Matrix Transpose Synchronization Ideal case for parallelism: no resources shared between threads no communication between threads Many
CS 179: GPU Computing Recitation 2: Synchronization, Shared memory, Matrix Transpose Synchronization Ideal case for parallelism: no resources shared between threads no communication between threads Many
ECE 408 / CS 483 Final Exam, Fall 2014
 ECE 408 / CS 483 Final Exam, Fall 2014 Thursday 18 December 2014 8:00 to 11:00 Central Standard Time You may use any notes, books, papers, or other reference materials. In the interest of fair access across
ECE 408 / CS 483 Final Exam, Fall 2014 Thursday 18 December 2014 8:00 to 11:00 Central Standard Time You may use any notes, books, papers, or other reference materials. In the interest of fair access across
Register file. A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks.
 is partitioned among the threads of the dispatched blocks.") Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Unrolling parallel loops
 Unrolling parallel loops Vasily Volkov UC Berkeley November 14, 2011 1 Today Very simple optimization technique Closely resembles loop unrolling Widely used in high performance codes 2 Mapping to GPU:
Unrolling parallel loops Vasily Volkov UC Berkeley November 14, 2011 1 Today Very simple optimization technique Closely resembles loop unrolling Widely used in high performance codes 2 Mapping to GPU:
1/25/12. Administrative
 Administrative L3: Memory Hierarchy Optimization I, Locality and Data Placement Next assignment due Friday, 5 PM Use handin program on CADE machines handin CS6235 lab1 TA: Preethi Kotari - Email:
Administrative L3: Memory Hierarchy Optimization I, Locality and Data Placement Next assignment due Friday, 5 PM Use handin program on CADE machines handin CS6235 lab1 TA: Preethi Kotari - Email:
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012
 CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012 Overview 1. Memory Access Efficiency 2. CUDA Memory Types 3. Reducing Global Memory Traffic 4. Example: Matrix-Matrix
CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012 Overview 1. Memory Access Efficiency 2. CUDA Memory Types 3. Reducing Global Memory Traffic 4. Example: Matrix-Matrix
Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow
 Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Tiled Matrix Multiplication
 Tiled Matrix Multiplication Basic Matrix Multiplication Kernel global void MatrixMulKernel(int m, m, int n, n, int k, k, float* A, A, float* B, B, float* C) C) { int Row = blockidx.y*blockdim.y+threadidx.y;
Tiled Matrix Multiplication Basic Matrix Multiplication Kernel global void MatrixMulKernel(int m, m, int n, n, int k, k, float* A, A, float* B, B, float* C) C) { int Row = blockidx.y*blockdim.y+threadidx.y;
GPU Programming Using CUDA. Samuli Laine NVIDIA Research
 GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
Fundamental Optimizations
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
CUDA Parallelism Model
 GPU Teaching Kit Accelerated Computing CUDA Parallelism Model Kernel-Based SPMD Parallel Programming Multidimensional Kernel Configuration Color-to-Grayscale Image Processing Example Image Blur Example
GPU Teaching Kit Accelerated Computing CUDA Parallelism Model Kernel-Based SPMD Parallel Programming Multidimensional Kernel Configuration Color-to-Grayscale Image Processing Example Image Blur Example
Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
CUDA Performance Considerations (2 of 2) Varun Sampath Original Slides by Patrick Cozzi University of Pennsylvania CIS Spring 2012
 Varun Sampath Original Slides by Patrick Cozzi University of Pennsylvania CIS Spring 2012") CUDA Performance Considerations (2 of 2) Varun Sampath Original Slides by Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2012 Agenda Instruction Optimizations Mixed Instruction Types Loop Unrolling
CUDA Performance Considerations (2 of 2) Varun Sampath Original Slides by Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2012 Agenda Instruction Optimizations Mixed Instruction Types Loop Unrolling
Zero-copy. Table of Contents. Multi-GPU Learning CUDA to Solve Scientific Problems. Objectives. Technical Issues Zero-copy. Multigpu.
 Table of Contents Multi-GPU Learning CUDA to Solve Scientific Problems. 1 Objectives Miguel Cárdenas Montes 2 Zero-copy Centro de Investigaciones Energéticas Medioambientales y Tecnológicas, Madrid, Spain
Table of Contents Multi-GPU Learning CUDA to Solve Scientific Problems. 1 Objectives Miguel Cárdenas Montes 2 Zero-copy Centro de Investigaciones Energéticas Medioambientales y Tecnológicas, Madrid, Spain
Dense Linear Algebra. HPC - Algorithms and Applications
 Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Review Secret behind GPU performance: simple cores but a large number of them; even more threads can exist live on the hardware (10k 20k threads live). Important performance
CME 213 S PRING 2017 Eric Darve Review Secret behind GPU performance: simple cores but a large number of them; even more threads can exist live on the hardware (10k 20k threads live). Important performance
Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory
 Institute of Computational Science Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory Juraj Kardoš (University of Lugano) July 9, 2014 Juraj Kardoš Efficient GPU data transfers July 9, 2014
Institute of Computational Science Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory Juraj Kardoš (University of Lugano) July 9, 2014 Juraj Kardoš Efficient GPU data transfers July 9, 2014
Optimizing Parallel Reduction in CUDA. Mark Harris NVIDIA Developer Technology
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Programming in CUDA. Malik M Khan
 Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Reductions and Low-Level Performance Considerations CME343 / ME May David Tarjan NVIDIA Research
 Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
GPU Computing Workshop CSU Getting Started. Garland Durham Quantos Analytics
 1 GPU Computing Workshop CSU 2013 Getting Started Garland Durham Quantos Analytics nvidia-smi 2 At command line, run command nvidia-smi to get/set GPU properties. nvidia-smi Options: -q query -L list attached
1 GPU Computing Workshop CSU 2013 Getting Started Garland Durham Quantos Analytics nvidia-smi 2 At command line, run command nvidia-smi to get/set GPU properties. nvidia-smi Options: -q query -L list attached
CUDA Advanced Techniques 2 Mohamed Zahran (aka Z)
") CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming CUDA Advanced Techniques 2 Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Alignment Memory Alignment Memory
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming CUDA Advanced Techniques 2 Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Alignment Memory Alignment Memory
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose Joe Stam Optimization GPUs are very fast BUT Poor programming can lead to disappointing performance Squeaking out the most speed
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose Joe Stam Optimization GPUs are very fast BUT Poor programming can lead to disappointing performance Squeaking out the most speed
Massively Parallel Architectures
 Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
Profiling & Tuning Applications. CUDA Course István Reguly
 Profiling & Tuning Applications CUDA Course István Reguly Introduction Why is my application running slow? Work it out on paper Instrument code Profile it NVIDIA Visual Profiler Works with CUDA, needs
Profiling & Tuning Applications CUDA Course István Reguly Introduction Why is my application running slow? Work it out on paper Instrument code Profile it NVIDIA Visual Profiler Works with CUDA, needs
Lecture 7. Overlap Using Shared Memory Performance programming the memory hierarchy
 Lecture 7 Overlap Using Shared Memory Performance programming the memory hierarchy Announcements Mac Mini lab (APM 2402) Starts Tuesday Every Tues and Fri for the next 2 weeks Project proposals due on
Lecture 7 Overlap Using Shared Memory Performance programming the memory hierarchy Announcements Mac Mini lab (APM 2402) Starts Tuesday Every Tues and Fri for the next 2 weeks Project proposals due on
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
2/2/11. Administrative. L6: Memory Hierarchy Optimization IV, Bandwidth Optimization. Project Proposal (due 3/9) Faculty Project Suggestions
 Faculty Project Suggestions") Administrative L6: Memory Hierarchy Optimization IV, Bandwidth Optimization Next assignment available Goals of assignment: simple memory hierarchy management block-thread decomposition tradeoff Due Tuesday,
Administrative L6: Memory Hierarchy Optimization IV, Bandwidth Optimization Next assignment available Goals of assignment: simple memory hierarchy management block-thread decomposition tradeoff Due Tuesday,
Memory concept. Grid concept, Synchronization. GPU Programming. Szénási Sándor.
 Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Memory. Lecture 2: different memory and variable types. Memory Hierarchy. CPU Memory Hierarchy. Main memory
 Memory Lecture 2: different memory and variable types Prof. Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Key challenge in modern computer architecture
Memory Lecture 2: different memory and variable types Prof. Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Key challenge in modern computer architecture
GPU Programming. Alan Gray, James Perry EPCC The University of Edinburgh
 GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
CUDA Programming. Week 1. Basic Programming Concepts Materials are copied from the reference list
 CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
Advanced CUDA Optimizations
 Advanced CUDA Optimizations General Audience Assumptions General working knowledge of CUDA Want kernels to perform better Profiling Before optimizing, make sure you are spending effort in correct location
Advanced CUDA Optimizations General Audience Assumptions General working knowledge of CUDA Want kernels to perform better Profiling Before optimizing, make sure you are spending effort in correct location
CUDA GPGPU Workshop CUDA/GPGPU Arch&Prog
 CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
Optimizing Parallel Reduction in CUDA
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology http://developer.download.nvidia.com/assets/cuda/files/reduction.pdf Parallel Reduction Tree-based approach used within each
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology http://developer.download.nvidia.com/assets/cuda/files/reduction.pdf Parallel Reduction Tree-based approach used within each
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
Optimizing Parallel Reduction in CUDA. Mark Harris NVIDIA Developer Technology
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Sparse Linear Algebra in CUDA
 Sparse Linear Algebra in CUDA HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 22 nd 2017 Table of Contents Homework - Worksheet 2
Sparse Linear Algebra in CUDA HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 22 nd 2017 Table of Contents Homework - Worksheet 2
Introduction to GPU Computing. Design and Analysis of Parallel Algorithms
 Introduction to GPU Computing Design and Analysis of Parallel Algorithms Sources CUDA Programming Guide (3.2) CUDA Best Practices Guide (3.2) CUDA Toolkit Reference Manual (3.2) CUDA SDK Examples Part
Introduction to GPU Computing Design and Analysis of Parallel Algorithms Sources CUDA Programming Guide (3.2) CUDA Best Practices Guide (3.2) CUDA Toolkit Reference Manual (3.2) CUDA SDK Examples Part
Image Processing Optimization C# on GPU with Hybridizer
 Image Processing Optimization C# on GPU with Hybridizer regis.portalez@altimesh.com Median Filter Denoising Noisy image (lena 1960x1960) Denoised image window = 3 2 Median Filter Denoising window Output[i,j]=
Image Processing Optimization C# on GPU with Hybridizer regis.portalez@altimesh.com Median Filter Denoising Noisy image (lena 1960x1960) Denoised image window = 3 2 Median Filter Denoising window Output[i,j]=
CS671 Parallel Programming in the Many-Core Era
 CS671 Parallel Programming in the Many-Core Era Lecture 3: GPU Programming - Reduce, Scan & Sort Zheng Zhang Rutgers University Review: Programming with CUDA An Example in C Add vector A and vector B to
CS671 Parallel Programming in the Many-Core Era Lecture 3: GPU Programming - Reduce, Scan & Sort Zheng Zhang Rutgers University Review: Programming with CUDA An Example in C Add vector A and vector B to
GPU programming basics. Prof. Marco Bertini
 GPU programming basics Prof. Marco Bertini CUDA: atomic operations, privatization, algorithms Atomic operations The basics atomic operation in hardware is something like a read-modify-write operation performed
GPU programming basics Prof. Marco Bertini CUDA: atomic operations, privatization, algorithms Atomic operations The basics atomic operation in hardware is something like a read-modify-write operation performed
Lecture 9. Outline. CUDA : a General-Purpose Parallel Computing Architecture. CUDA Device and Threads CUDA. CUDA Architecture CUDA (I)
") Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Lecture 5. Performance Programming with CUDA
 Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
GPU Accelerated Application Performance Tuning. Delivered by John Ashley, Slides by Cliff Woolley, NVIDIA Developer Technology Group
 GPU Accelerated Application Performance Tuning Delivered by John Ashley, Slides by Cliff Woolley, NVIDIA Developer Technology Group Main Requirements for GPU Performance Expose sufficient parallelism Use
GPU Accelerated Application Performance Tuning Delivered by John Ashley, Slides by Cliff Woolley, NVIDIA Developer Technology Group Main Requirements for GPU Performance Expose sufficient parallelism Use
CUDA C Programming Mark Harris NVIDIA Corporation
 CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CS/EE 217 Midterm. Question Possible Points Points Scored Total 100
 CS/EE 217 Midterm ANSWER ALL QUESTIONS TIME ALLOWED 60 MINUTES Question Possible Points Points Scored 1 24 2 32 3 20 4 24 Total 100 Question 1] [24 Points] Given a GPGPU with 14 streaming multiprocessor
CS/EE 217 Midterm ANSWER ALL QUESTIONS TIME ALLOWED 60 MINUTES Question Possible Points Points Scored 1 24 2 32 3 20 4 24 Total 100 Question 1] [24 Points] Given a GPGPU with 14 streaming multiprocessor
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Lecture 10!! Introduction to CUDA!
 1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA
 CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA Sreepathi Pai October 18, 2017 URCS Outline Background Memory Code Execution Model Outline Background Memory Code Execution Model
CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA Sreepathi Pai October 18, 2017 URCS Outline Background Memory Code Execution Model Outline Background Memory Code Execution Model
Introduction to GPGPU and GPU-architectures
 Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
High Performance Computing and GPU Programming
 High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU Programming Using CUDA. Samuli Laine NVIDIA Research
 GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
Matrix Multiplication in CUDA. A case study
 Matrix Multiplication in CUDA A case study 1 Matrix Multiplication: A Case Study Matrix multiplication illustrates many of the basic features of memory and thread management in CUDA Usage of thread/block
Matrix Multiplication in CUDA A case study 1 Matrix Multiplication: A Case Study Matrix multiplication illustrates many of the basic features of memory and thread management in CUDA Usage of thread/block
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
Code Optimizations for High Performance GPU Computing
 Code Optimizations for High Performance GPU Computing Yi Yang and Huiyang Zhou Department of Electrical and Computer Engineering North Carolina State University 1 Question to answer Given a task to accelerate
Code Optimizations for High Performance GPU Computing Yi Yang and Huiyang Zhou Department of Electrical and Computer Engineering North Carolina State University 1 Question to answer Given a task to accelerate
Lecture 2: different memory and variable types
 Lecture 2: different memory and variable types Prof. Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 2 p. 1 Memory Key challenge in modern
Lecture 2: different memory and variable types Prof. Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 2 p. 1 Memory Key challenge in modern
Scientific discovery, analysis and prediction made possible through high performance computing.
 Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Atomic Operations. Atomic operations, fast reduction. GPU Programming. Szénási Sándor.
 Atomic Operations Atomic operations, fast reduction GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University ATOMIC OPERATIONS
Atomic Operations Atomic operations, fast reduction GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University ATOMIC OPERATIONS
GPU Performance Nuggets
 GPU Performance Nuggets Simon Garcia de Gonzalo & Carl Pearson PhD Students, IMPACT Research Group Advised by Professor Wen-mei Hwu Jun. 15, 2016 grcdgnz2@illinois.edu pearson@illinois.edu GPU Performance
GPU Performance Nuggets Simon Garcia de Gonzalo & Carl Pearson PhD Students, IMPACT Research Group Advised by Professor Wen-mei Hwu Jun. 15, 2016 grcdgnz2@illinois.edu pearson@illinois.edu GPU Performance
CS 193G. Lecture 4: CUDA Memories
 CS 193G Lecture 4: CUDA Memories Hardware Implementation of CUDA Memories Grid! Each thread can:! Read/write per-thread registers! Read/write per-thread local memory Block (0, 0) Shared Memory Registers
CS 193G Lecture 4: CUDA Memories Hardware Implementation of CUDA Memories Grid! Each thread can:! Read/write per-thread registers! Read/write per-thread local memory Block (0, 0) Shared Memory Registers
CUDA. Sathish Vadhiyar High Performance Computing
 CUDA Sathish Vadhiyar High Performance Computing Hierarchical Parallelism Parallel computations arranged as grids One grid executes after another Grid consists of blocks Blocks assigned to SM. A single
CUDA Sathish Vadhiyar High Performance Computing Hierarchical Parallelism Parallel computations arranged as grids One grid executes after another Grid consists of blocks Blocks assigned to SM. A single
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Programmable Graphics Hardware (GPU) A Primer
 A Primer") Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
GPU Programming Using CUDA
 GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
Zero Copy Memory and Multiple GPUs
 Zero Copy Memory and Multiple GPUs Goals Zero Copy Memory Pinned and mapped memory on the host can be read and written to from the GPU program (if the device permits this) This may result in performance
Zero Copy Memory and Multiple GPUs Goals Zero Copy Memory Pinned and mapped memory on the host can be read and written to from the GPU program (if the device permits this) This may result in performance