Blocks, Grids, and Shared Memory
|
|
|
- Marvin Norris
- 5 years ago
- Views:
Transcription
1 Blocks, Grids, and Shared Memory GPU Course, Fall 2012
2 Last week: ax+b Homework
3 Threads, Blocks, Grids CUDA threads are organized into blocks Threads operate in SIMD(ish) manner -- each executing same instructions in lockstep. Only difference are thread ids Can have a grid of multiple blocks CUDA Thread Block of CUDA Threads Grid of CUDA Blocks
4 CUDA - H/W mapping Blocks are assigned to a particular SM Executed there one warp at a time (typically 32 threads) Multiple blocks may be on SM concurrently Good; latency hiding Bad - SM resources must be divided between blocks SM#1 SM#2 GPU If only use 1 Block - 1 SM
5 Multi-block y=ax+b Break input, output vectors into blocks Within each block, thread index specifies which item to work on Each thread does one update, puts results in y[i] } y[i] = a*x[i]+b } x y
6 Multi-block y=ax+b x } } y[i] = a*x[i]+b y block-saxpb.cu

7 More blocks more SMs more FLOPs On newer cards, where we can use 1024 threads/ block: Multiple calcs, so timing not dominated by memory copy GPU SM#1 SM#2
8 Multi-block y=ax+b x } } y[i] = a*x[i]+b y Index within block (0..blocksize-1)
9 Multi-block y=ax+b x } } y[i] = a*x[i]+b y Index of block (0..nblocks-1) Size of block (blocksize)
10 Multi-block y=ax+b Blocksize = 100 Block 2 x } } Thread 10 y i = *100 = 210 yd[210] = a*xd[210] + b
11 How many threads/ Should be integral multiple of warp (32) No more than max allowed by scheduling hardware Can get last number from hardware specs But what if will be needed on several machines? API can return it: block?
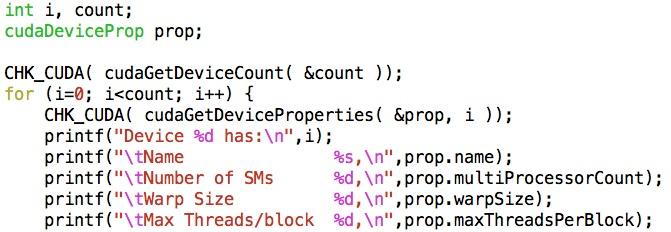
12 cudagetdeviceproperty querydevs.cu
13 cudagetdeviceproperty All CUDA calls return cudasuccess on successful completion. GPU hardware does not try very hard to catch errors/notify you; testing return codes important! Common to see simple automation like this wrapping all CUDA calls; bare minimum for sensible operation. Test early, fail often.
14 Why the.xs? For convenience, CUDA allows thread, block indicies to be multidimensional Thread blocks can be 3 dimensional (512,512,64) Grids of blocks can be 2 dimensional (64k, 64k, 1) These variables are of type dim3 or uint3 CUDA has int1, int2, int3, int4, float1, float2, float3, float4, etc.
15 Why the.xs? threadidx.{x,y,z} - thread index blockdim.{x,y,z} - size of block (# of threads in each dim) blockidx.{x,y,z} - block index griddim.{x,y,z} - size of grid (# of blocks in each dim) warpsize - size of warp (int)
16 Why the.xs? global - device code that can be seen (invoked) from host. host - default. Not usually interesting. device - device code. Can be called only from other device code. host device - compiled for both host and device.
17 Compilation process.cu file nvcc host obj code Intermediate, device-independent PTX code 2nd compilation stage device code Executable
18 Restrictions global functions can t recurse, neither can device on non-fermis No function pointers to device functions on non-fermis, can t take address of device function Can t have static variables in global, device functions Can t use varargs with device code
19 2-Dimensional Blocks Use of 2/3d thread blocks, or 2d grids, never strictly necessary... But can make code clearer, shorter. Matrix multiplication = * C i,j = X k A i,k B k,j
20 2-Dimensional Blocks = * C i,j = X k A i,k B k,j matmult.cu
21 2-Dimensional Blocks = * C i,j = X k A i,k B k,j
22 2-Dimensional Blocks = * C i,j = X k A i,k B k,j
23 Timings: Orig $./matmult --matsize=160 --nblocks=10 Matrix size = 160, Number of blocks = 10. CPU time = millisec. GPU time = millisec. CUDA and CPU results differ by Double Prec. sum $./matmult --matsize=160 --nblocks=10 Matrix size = 160, Number of blocks = 10. CPU time = millisec. GPU time = millisec. CUDA and CPU results differ by Faster, even with double precision sums - why?
24 CUDA Memories All HPC, but especially GPU, all about planning memory access to be fast Global mem is off the GPU chip (but on the card); ~100 cycle latency Thread-local variables get put into registers on each SM - fast (~1 cycle) but small Global Mem (On Card) Registers (On Chip) SM#1 SM#2
25 CUDA Memories Memory On Chip? Cached? R/W Scope Register On No R/W Thread Shared On No R/W Block Global Mem (On Card) Global Off No R/W Kernel, Host Constant Off Yes R Kernel, Host Registers (On Chip) SM#1 SM#2 Texture Off Yes R(W?) Kernel, Host Local * Off No R/W Thread * if you run out of registers, will put local mem in global.
26 Memory usage in SGEMM How can we exploit this? N 3 multiplies, adds 2N 2 data Regular access Opportunity for high memory re-use Need to find ways to bring data into shared memory (incurring global mem overhead once), use it several times = * C i,j = X k A i,k B k,j
27 Memory usage in SGEMM One nice thing about matrix multiplication - same as block multiplication, each subblock is a matrix mult Neighbouring threads within block all see nearby rows, columns Pull whole block in If b blocks in each dim, each data only pulled in 2b times, not 2n times = * C bi,bj = X k A bi,bk B bk,bj
28 Memory usage in SGEMM = * C bi,bj = X k A bi,bk B bk,bj
29 syncthreads() Computation must wait until all threads have brought in their data Not all memory accesses may take same length of time syncthreads() - waits until all threads in block are at same point. No equivalent between blocks Loop must similarly wait for computation
30 shared arrays If declared in device code, must be sized at compile time. No sharedmalloc (all threads in block would have to agree) Global Mem (On Card) Shared mem (On Chip) SM#1 SM#2 can use consts or #defines to size array, but we want to maintain flexibility
31 extern shared Optional 3rd argument - size (in bytes) of shared memory to allocate per block
32 extern shared Comes in as one array; can type, name it anything you like
33 extern shared If you want to use it for 2 things, you have to deal with that yourself.
34 Orig Timings (tpb2): $./matmult --matsize=160 --nblocks=10 Matrix size = 160, Number of blocks = 10. CPU time = millisec. GPU time = millisec. CUDA and CPU results differ by Double Prec. sum $./matmult --matsize=160 --nblocks=10 Matrix size = 160, Number of blocks = 10. CPU time = millisec. GPU time = millisec. CUDA and CPU results differ by Shared $/matmult Matrix size = 160, Number of blocks = 10. CPU time = millisec. GPU time = millisec. CUDA and CPU results differ by
35 Homework Using matmult.cu as a template, look at smoothimage.c in the code I ll send out; implements image convolution. Implement a CUDA version using shared memory, and make sure it gets same answer as CPU version. How does data reuse vary as a function of the halo size?
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
GPGPUGPGPU: Multi-GPU Programming
 GPGPUGPGPU: Multi-GPU Programming Fall 2012 HW4 global void cuda_transpose(const float *ad, const int n, float *atd) { } int i = threadidx.y + blockidx.y*blockdim.y; int j = threadidx.x + blockidx.x*blockdim.x;
GPGPUGPGPU: Multi-GPU Programming Fall 2012 HW4 global void cuda_transpose(const float *ad, const int n, float *atd) { } int i = threadidx.y + blockidx.y*blockdim.y; int j = threadidx.x + blockidx.x*blockdim.x;
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CUDA. Sathish Vadhiyar High Performance Computing
 CUDA Sathish Vadhiyar High Performance Computing Hierarchical Parallelism Parallel computations arranged as grids One grid executes after another Grid consists of blocks Blocks assigned to SM. A single
CUDA Sathish Vadhiyar High Performance Computing Hierarchical Parallelism Parallel computations arranged as grids One grid executes after another Grid consists of blocks Blocks assigned to SM. A single
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
GPU Programming. Performance Considerations. Miaoqing Huang University of Arkansas Fall / 60
 1 / 60 GPU Programming Performance Considerations Miaoqing Huang University of Arkansas Fall 2013 2 / 60 Outline Control Flow Divergence Memory Coalescing Shared Memory Bank Conflicts Occupancy Loop Unrolling
1 / 60 GPU Programming Performance Considerations Miaoqing Huang University of Arkansas Fall 2013 2 / 60 Outline Control Flow Divergence Memory Coalescing Shared Memory Bank Conflicts Occupancy Loop Unrolling
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Review Secret behind GPU performance: simple cores but a large number of them; even more threads can exist live on the hardware (10k 20k threads live). Important performance
CME 213 S PRING 2017 Eric Darve Review Secret behind GPU performance: simple cores but a large number of them; even more threads can exist live on the hardware (10k 20k threads live). Important performance
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
CUDA Programming. Week 1. Basic Programming Concepts Materials are copied from the reference list
 CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer
 CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
1/25/12. Administrative
 Administrative L3: Memory Hierarchy Optimization I, Locality and Data Placement Next assignment due Friday, 5 PM Use handin program on CADE machines handin CS6235 lab1 TA: Preethi Kotari - Email:
Administrative L3: Memory Hierarchy Optimization I, Locality and Data Placement Next assignment due Friday, 5 PM Use handin program on CADE machines handin CS6235 lab1 TA: Preethi Kotari - Email:
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
CSE 591: GPU Programming. Memories. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591: GPU Programming Memories Klaus Mueller Computer Science Department Stony Brook University Importance of Memory Access Efficiency Every loop iteration has two global memory accesses two floating
CSE 591: GPU Programming Memories Klaus Mueller Computer Science Department Stony Brook University Importance of Memory Access Efficiency Every loop iteration has two global memory accesses two floating
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
Hardware/Software Co-Design
 1 / 13 Hardware/Software Co-Design Review so far Miaoqing Huang University of Arkansas Fall 2011 2 / 13 Problem I A student mentioned that he was able to multiply two 1,024 1,024 matrices using a tiled
1 / 13 Hardware/Software Co-Design Review so far Miaoqing Huang University of Arkansas Fall 2011 2 / 13 Problem I A student mentioned that he was able to multiply two 1,024 1,024 matrices using a tiled
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
Matrix Multiplication in CUDA. A case study
 Matrix Multiplication in CUDA A case study 1 Matrix Multiplication: A Case Study Matrix multiplication illustrates many of the basic features of memory and thread management in CUDA Usage of thread/block
Matrix Multiplication in CUDA A case study 1 Matrix Multiplication: A Case Study Matrix multiplication illustrates many of the basic features of memory and thread management in CUDA Usage of thread/block
CUDA Performance Optimization. Patrick Legresley
 CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
High Performance Computing and GPU Programming
 High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
Introduction to CUDA (1 of n*)
") Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
Programming in CUDA. Malik M Khan
 Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Introduction to CUDA 5.0
 Introduction to CUDA 5.0 CUDA 5 In this article, I will introduce the reader to CUDA 5.0. I will briefly talk about the architecture of the Kepler GPU (Graphics Processing Unit) and I will show you how
Introduction to CUDA 5.0 CUDA 5 In this article, I will introduce the reader to CUDA 5.0. I will briefly talk about the architecture of the Kepler GPU (Graphics Processing Unit) and I will show you how
Introduction to GPU programming. Introduction to GPU programming p. 1/17
 Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
GPU Memory Memory issue for CUDA programming
 Memory issue for CUDA programming Variable declaration Memory Scope Lifetime device local int LocalVar; local thread thread device shared int SharedVar; shared block block device int GlobalVar; global
Memory issue for CUDA programming Variable declaration Memory Scope Lifetime device local int LocalVar; local thread thread device shared int SharedVar; shared block block device int GlobalVar; global
Lecture 11: GPU programming
 Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
GPU programming: CUDA basics. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
GPU Memory. GPU Memory. Memory issue for CUDA programming. Copyright 2013 Yong Cao, Referencing UIUC ECE498AL Course Notes
 Memory issue for CUDA programming CUDA Variable Type Qualifiers Variable declaration Memory Scope Lifetime device local int LocalVar; local thread thread device shared int SharedVar; shared block block
Memory issue for CUDA programming CUDA Variable Type Qualifiers Variable declaration Memory Scope Lifetime device local int LocalVar; local thread thread device shared int SharedVar; shared block block
Introduction to GPU programming with CUDA
 Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Optimizing CUDA for GPU Architecture. CSInParallel Project
 Optimizing CUDA for GPU Architecture CSInParallel Project August 13, 2014 CONTENTS 1 CUDA Architecture 2 1.1 Physical Architecture........................................... 2 1.2 Virtual Architecture...........................................
Optimizing CUDA for GPU Architecture CSInParallel Project August 13, 2014 CONTENTS 1 CUDA Architecture 2 1.1 Physical Architecture........................................... 2 1.2 Virtual Architecture...........................................
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
NVIDIA Fermi Architecture
 Administrivia NVIDIA Fermi Architecture Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Assignment 4 grades returned Project checkpoint on Monday Post an update on your blog beforehand Poster
Administrivia NVIDIA Fermi Architecture Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Assignment 4 grades returned Project checkpoint on Monday Post an update on your blog beforehand Poster
CUDA (Compute Unified Device Architecture)
") CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
Device Memories and Matrix Multiplication
 Device Memories and Matrix Multiplication 1 Device Memories global, constant, and shared memories CUDA variable type qualifiers 2 Matrix Multiplication an application of tiling runningmatrixmul in the
Device Memories and Matrix Multiplication 1 Device Memories global, constant, and shared memories CUDA variable type qualifiers 2 Matrix Multiplication an application of tiling runningmatrixmul in the
Programming with CUDA, WS09
 Programming with CUDA and Parallel Algorithms Waqar Saleem Jens Müller Lecture 3 Thursday, 29 Nov, 2009 Recap Motivational videos Example kernel Thread IDs Memory overhead CUDA hardware and programming
Programming with CUDA and Parallel Algorithms Waqar Saleem Jens Müller Lecture 3 Thursday, 29 Nov, 2009 Recap Motivational videos Example kernel Thread IDs Memory overhead CUDA hardware and programming
simcuda: A C++ based CUDA Simulation Framework
 Technical Report simcuda: A C++ based CUDA Simulation Framework Abhishek Das and Andreas Gerstlauer UT-CERC-16-01 May 20, 2016 Computer Engineering Research Center Department of Electrical & Computer Engineering
Technical Report simcuda: A C++ based CUDA Simulation Framework Abhishek Das and Andreas Gerstlauer UT-CERC-16-01 May 20, 2016 Computer Engineering Research Center Department of Electrical & Computer Engineering
B. Tech. Project Second Stage Report on
 B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Building CUDA apps under Visual Studio Accessing Newton CUDA Programming Model CUDA API February 03, 2011 Dan Negrut, 2011 ME964 UW-Madison
ME964 High Performance Computing for Engineering Applications Building CUDA apps under Visual Studio Accessing Newton CUDA Programming Model CUDA API February 03, 2011 Dan Negrut, 2011 ME964 UW-Madison
Code Optimizations for High Performance GPU Computing
 Code Optimizations for High Performance GPU Computing Yi Yang and Huiyang Zhou Department of Electrical and Computer Engineering North Carolina State University 1 Question to answer Given a task to accelerate
Code Optimizations for High Performance GPU Computing Yi Yang and Huiyang Zhou Department of Electrical and Computer Engineering North Carolina State University 1 Question to answer Given a task to accelerate
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Register file. A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks.
 is partitioned among the threads of the dispatched blocks.") Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
HPC COMPUTING WITH CUDA AND TESLA HARDWARE. Timothy Lanfear, NVIDIA
 HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
CUDA Lecture 2. Manfred Liebmann. Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17
 CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
Advanced CUDA Optimizations. Umar Arshad ArrayFire
 Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
CUDA Memory Model. Monday, 21 February Some material David Kirk, NVIDIA and Wen-mei W. Hwu, (used with permission)
") CUDA Memory Model Some material David Kirk, NVIDIA and Wen-mei W. Hwu, 2007-2009 (used with permission) 1 G80 Implementation of CUDA Memories Each thread can: Grid Read/write per-thread registers Read/write
CUDA Memory Model Some material David Kirk, NVIDIA and Wen-mei W. Hwu, 2007-2009 (used with permission) 1 G80 Implementation of CUDA Memories Each thread can: Grid Read/write per-thread registers Read/write
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
An Introduction to GPU Architecture and CUDA C/C++ Programming. Bin Chen April 4, 2018 Research Computing Center
 An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
Introduction to GPGPUs and to CUDA programming model
 Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
Data Parallel Execution Model
 CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
GPU Programming. Rupesh Nasre.
 GPU Programming Rupesh Nasre. http://www.cse.iitm.ac.in/~rupesh IIT Madras July 2017 Hello World. #include int main() { printf("hello World.\n"); return 0; Compile: nvcc hello.cu Run: a.out GPU
GPU Programming Rupesh Nasre. http://www.cse.iitm.ac.in/~rupesh IIT Madras July 2017 Hello World. #include int main() { printf("hello World.\n"); return 0; Compile: nvcc hello.cu Run: a.out GPU
CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012
 CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012 Overview 1. Memory Access Efficiency 2. CUDA Memory Types 3. Reducing Global Memory Traffic 4. Example: Matrix-Matrix
CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012 Overview 1. Memory Access Efficiency 2. CUDA Memory Types 3. Reducing Global Memory Traffic 4. Example: Matrix-Matrix
Fundamental Optimizations
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Introduction to GPU Computing. Design and Analysis of Parallel Algorithms
 Introduction to GPU Computing Design and Analysis of Parallel Algorithms Sources CUDA Programming Guide (3.2) CUDA Best Practices Guide (3.2) CUDA Toolkit Reference Manual (3.2) CUDA SDK Examples Part
Introduction to GPU Computing Design and Analysis of Parallel Algorithms Sources CUDA Programming Guide (3.2) CUDA Best Practices Guide (3.2) CUDA Toolkit Reference Manual (3.2) CUDA SDK Examples Part
Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
Unrolling parallel loops
 Unrolling parallel loops Vasily Volkov UC Berkeley November 14, 2011 1 Today Very simple optimization technique Closely resembles loop unrolling Widely used in high performance codes 2 Mapping to GPU:
Unrolling parallel loops Vasily Volkov UC Berkeley November 14, 2011 1 Today Very simple optimization technique Closely resembles loop unrolling Widely used in high performance codes 2 Mapping to GPU:
GPU CUDA Programming
 GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
CSE 591: GPU Programming. Programmer Interface. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591: GPU Programming Programmer Interface Klaus Mueller Computer Science Department Stony Brook University Compute Levels Encodes the hardware capability of a GPU card newer cards have higher compute
CSE 591: GPU Programming Programmer Interface Klaus Mueller Computer Science Department Stony Brook University Compute Levels Encodes the hardware capability of a GPU card newer cards have higher compute
Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow
 Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Supporting Data Parallelism in Matcloud: Final Report
 Supporting Data Parallelism in Matcloud: Final Report Yongpeng Zhang, Xing Wu 1 Overview Matcloud is an on-line service to run Matlab-like script on client s web browser. Internally it is accelerated by
Supporting Data Parallelism in Matcloud: Final Report Yongpeng Zhang, Xing Wu 1 Overview Matcloud is an on-line service to run Matlab-like script on client s web browser. Internally it is accelerated by
Stanford University. NVIDIA Tesla M2090. NVIDIA GeForce GTX 690
 Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Hands-on CUDA Optimization. CUDA Workshop
 Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
S WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS. Jakob Progsch, Mathias Wagner GTC 2018
 S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
Sparse Linear Algebra in CUDA
 Sparse Linear Algebra in CUDA HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 22 nd 2017 Table of Contents Homework - Worksheet 2
Sparse Linear Algebra in CUDA HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 22 nd 2017 Table of Contents Homework - Worksheet 2
OpenCL C. Matt Sellitto Dana Schaa Northeastern University NUCAR
 OpenCL C Matt Sellitto Dana Schaa Northeastern University NUCAR OpenCL C Is used to write kernels when working with OpenCL Used to code the part that runs on the device Based on C99 with some extensions
OpenCL C Matt Sellitto Dana Schaa Northeastern University NUCAR OpenCL C Is used to write kernels when working with OpenCL Used to code the part that runs on the device Based on C99 with some extensions
L3: Data Partitioning and Memory Organization, Synchronization
 Outline More on CUDA L3: Data Partitioning and Organization, Synchronization January 21, 2009 1 First assignment, due Jan. 30 (later in lecture) Error checking mechanisms Synchronization More on data partitioning
Outline More on CUDA L3: Data Partitioning and Organization, Synchronization January 21, 2009 1 First assignment, due Jan. 30 (later in lecture) Error checking mechanisms Synchronization More on data partitioning
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Lecture 10!! Introduction to CUDA!
 1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
Advanced CUDA Optimizations
 Advanced CUDA Optimizations General Audience Assumptions General working knowledge of CUDA Want kernels to perform better Profiling Before optimizing, make sure you are spending effort in correct location
Advanced CUDA Optimizations General Audience Assumptions General working knowledge of CUDA Want kernels to perform better Profiling Before optimizing, make sure you are spending effort in correct location
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CS 179: GPU Computing
 CS 179: GPU Computing LECTURE 2: INTRO TO THE SIMD LIFESTYLE AND GPU INTERNALS Recap Can use GPU to solve highly parallelizable problems Straightforward extension to C++ Separate CUDA code into.cu and.cuh
CS 179: GPU Computing LECTURE 2: INTRO TO THE SIMD LIFESTYLE AND GPU INTERNALS Recap Can use GPU to solve highly parallelizable problems Straightforward extension to C++ Separate CUDA code into.cu and.cuh
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA Memories. Introduction 5/4/11
 5/4/11 CUDA Memories James Gain, Michelle Kuttel, Sebastian Wyngaard, Simon Perkins and Jason Brownbridge { jgain mkuttel sperkins jbrownbr}@cs.uct.ac.za swyngaard@csir.co.za 3-6 May 2011 Introduction
5/4/11 CUDA Memories James Gain, Michelle Kuttel, Sebastian Wyngaard, Simon Perkins and Jason Brownbridge { jgain mkuttel sperkins jbrownbr}@cs.uct.ac.za swyngaard@csir.co.za 3-6 May 2011 Introduction
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
CS 179: GPU Computing. Recitation 2: Synchronization, Shared memory, Matrix Transpose
 CS 179: GPU Computing Recitation 2: Synchronization, Shared memory, Matrix Transpose Synchronization Ideal case for parallelism: no resources shared between threads no communication between threads Many
CS 179: GPU Computing Recitation 2: Synchronization, Shared memory, Matrix Transpose Synchronization Ideal case for parallelism: no resources shared between threads no communication between threads Many
CUDA Parallelism Model
 GPU Teaching Kit Accelerated Computing CUDA Parallelism Model Kernel-Based SPMD Parallel Programming Multidimensional Kernel Configuration Color-to-Grayscale Image Processing Example Image Blur Example
GPU Teaching Kit Accelerated Computing CUDA Parallelism Model Kernel-Based SPMD Parallel Programming Multidimensional Kernel Configuration Color-to-Grayscale Image Processing Example Image Blur Example
NVIDIA CUDA. Fermi Compatibility Guide for CUDA Applications. Version 1.1
 NVIDIA CUDA Fermi Compatibility Guide for CUDA Applications Version 1.1 4/19/2010 Table of Contents Software Requirements... 1 What Is This Document?... 1 1.1 Application Compatibility on Fermi... 1 1.2
NVIDIA CUDA Fermi Compatibility Guide for CUDA Applications Version 1.1 4/19/2010 Table of Contents Software Requirements... 1 What Is This Document?... 1 1.1 Application Compatibility on Fermi... 1 1.2
Practical Introduction to CUDA and GPU
 Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA Kenjiro Taura 1 / 36
 CUDA Kenjiro Taura 1 / 36 Contents 1 Overview 2 CUDA Basics 3 Kernels 4 Threads and thread blocks 5 Moving data between host and device 6 Data sharing among threads in the device 2 / 36 Contents 1 Overview
CUDA Kenjiro Taura 1 / 36 Contents 1 Overview 2 CUDA Basics 3 Kernels 4 Threads and thread blocks 5 Moving data between host and device 6 Data sharing among threads in the device 2 / 36 Contents 1 Overview
CS377P Programming for Performance GPU Programming - I
 CS377P Programming for Performance GPU Programming - I Sreepathi Pai UTCS November 9, 2015 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance Outline 1 Introduction to CUDA 2 Basic
CS377P Programming for Performance GPU Programming - I Sreepathi Pai UTCS November 9, 2015 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance Outline 1 Introduction to CUDA 2 Basic
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC.
 David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
Identifying Performance Limiters Paulius Micikevicius NVIDIA August 23, 2011
 Identifying Performance Limiters Paulius Micikevicius NVIDIA August 23, 2011 Performance Optimization Process Use appropriate performance metric for each kernel For example, Gflops/s don t make sense for
Identifying Performance Limiters Paulius Micikevicius NVIDIA August 23, 2011 Performance Optimization Process Use appropriate performance metric for each kernel For example, Gflops/s don t make sense for
Memory. Lecture 2: different memory and variable types. Memory Hierarchy. CPU Memory Hierarchy. Main memory
 Memory Lecture 2: different memory and variable types Prof. Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Key challenge in modern computer architecture
Memory Lecture 2: different memory and variable types Prof. Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Key challenge in modern computer architecture
Memory concept. Grid concept, Synchronization. GPU Programming. Szénási Sándor.
 Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip