CME 213 S PRING Eric Darve
|
|
|
- Anna Rogers
- 5 years ago
- Views:
Transcription
1 CME 213 S PRING 2017 Eric Darve
2 Review Secret behind GPU performance: simple cores but a large number of them; even more threads can exist live on the hardware (10k 20k threads live). Important performance bottleneck: data traffic between memory and register files Programming on a GPU: Warp = 32 threads Block = group of threads running on one SM SM runs an integer number of thread blocks Grid = set of blocks representing the entire data set
3 Code overview
4 Function to execute Input variables Number of threads to use
5 Device kernels
6 global host device What are these mysterious keywords? global kernel will be Executed on the device Callable from the host host kernel will be Executed on the host Callable from the host device kernel will be Executed on the device Callable from the device only Compiled for host Compiled for device

7 Fails at 1025! Blocks and grid required for real runs.

8
9
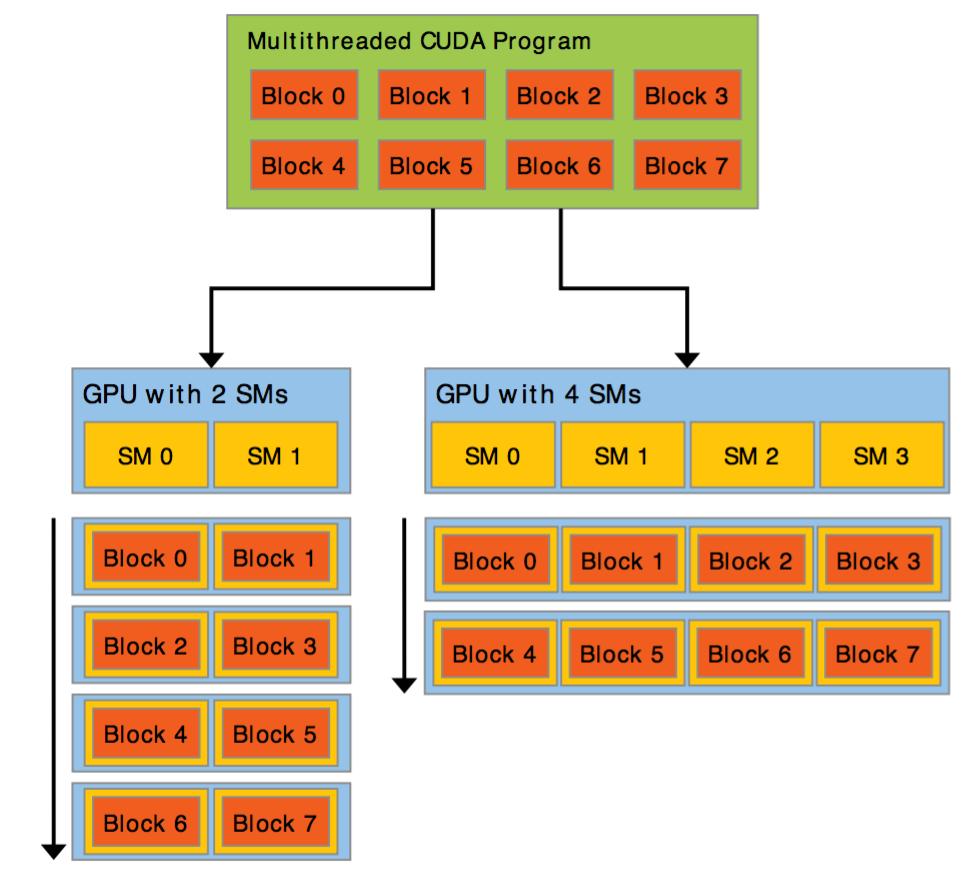
10 Thread hierarchy Two levels of hierarchy: Thread block: a block is loaded entirely on an SM. This means that a block of threads cannot require more resources than available, for example to store register variables. Grid of blocks: for large problems, we can use multiple blocks. A very large number of blocks can be allocated so that we can execute a kernel over a very large data set.
11 Problem decomposition Decompose your problem into: Small blocks so that data can fit in SM. Typically the number of threads per block is around Create a grid of blocks so that you can process the entire data. Hardware limitations for GPUs on Certainty: Maximum threads per block: 1024 Maximum dimension 0 of block: 1024 Maximum dimension 1 of block: 1024 Maximum dimension 2 of block: 64 Maximum dimension 0 of grid: Maximum dimension 1 of grid: Maximum dimension 2 of grid: 65535
12
13 Block execution The device will start by loading data on each SM to execute the blocks. At least one block must fit on an SM, e.g., there should be enough memory for register variables. The SM will load up as many blocks as possible until it runs out of resources. Then it will start executing the blocks, that is all threads will execute the kernel. Once all threads in a block are done with the kernel, another block gets loaded in the SM. And so on until the device runs out of blocks to execute.
14 Dimensions Blocks and grids can be 1D, 2D or 3D. Their dimensions is declared using: dim3 threadsperblock(nx); dim3 numblocks(mx); dim3 threadsperblock(nx, Ny); dim3 numblocks(mx, My); dim3 threadsperblock(nx, Ny, Nz); dim3 numblocks(mx, My, Mz); Block size Thread index example: int col = blockidx.x * blockdim.x + threadidx.x; int row = blockidx.y * blockdim.y + threadidx.y; Block ID Thread ID in block

15 addmatrices.cu
16

17
18 Compiler options and other tricks -g debug on the host -G debug on the device (see documentation, CUDA-gdb, Nsight Eclipse Edition) -pg profiling info for use with gprof -Xcompiler (options for underlying gcc compiler) More on profiling: nvprof
19 Profiling The visual profiler (nvvp) is the simplest way to profile your code. You get a graphical interface that helps navigate the information. You can also use a command line tool: nvprof. This can also be used to collect information on a cluster to be visualized using nvvp on your local computer. Run nvprof./addmatrices -n 4000
20
21 cuda-memcheck Several tools available to verify your code. 4 tools accessible with cuda-memcheck command: memcheck: Memory access checking initcheck: Global memory initialization checking racecheck: Shared memory hazard checking synccheck: Synchronization checking; syncthreads(), not on SM 2.x Usage example: cuda-memcheck./memcheck_demo cuda-memcheck --leak-check full./memcheck_demo

22 GPU Optimization!
23 Top factors to consider Memory: data movement! Occupancy and concurrency: hide latency through concurrency Control flow: branching
24 Memory The number one bottleneck in scientific applications are not flops! Flops are plentiful and abundant. The problem is data starvation. Computing units are idle because they are waiting on data coming from / going to memory.
25 Memory access Similar to a regular processor but with some important differences. Caches are used to optimize memory accesses: L1 and L2 caches. Cache behavior is complicated and depends on the compute capability of the card (that is the type of GPU you are using). Generations (compute capability): 2.x, 3.x, 5.x, and 6.x (no 4.x). For this class, we have access to 2.0 hardware. We will focus on this for our discussion.
26 Cache There are two main levels of cache: L1 and L2. L2 is shared across SMs. Each L1 is assigned to only one SM. When reading data from global memory, the device can only read entire cache lines. There is no such thing as reading a single float from memory. To read a single float, you read the entire cache line and throw out the data you don t need.
27 Cache lines L1: 128-byte lines = 32 floats. L2: 32-byte segments = 8 floats. Commit these fundamental numbers to memory now!
28 How is data read from memory then? Remember how the hardware works. All threads in a warp execute the same instruction at the same time. Take 32 threads in a warp. Each thread is going to request a memory location. Hardware groups these requests into a number of cache line requests. Then data is read from memory. At the end of the day, what matters is not how much data threads are requesting from memory, it s how many memory transactions (cache lines) are performed!
29 Example offset = 0 This is the best case. All memory accesses are coalesced into a single memory transaction.
30 One memory transaction
31 Misaligned by 1 offset = 1

32 Strided access Stride is 2. Effective bandwidth of application reduced by 2.
33 Efficiency of reads Perfectly coalesced access: one memory transaction. Bandwidth = Peak Bandwidth Misaligned: two memory transactions. Bandwidth = Peak Bandwidth / 2 Strided access Bandwidth = Peak Bandwidth / s for a stride of s Random access Bandwidth = Peak Bandwidth / 32
34 Data type size The previous discussion covered the most common case where threads read a 4-byte float or int. char: 1 byte. float: 4 bytes. double: 8 bytes. CUDA has many built-in data types that are shorter/longer: char1-4, uchar1-4 short1-4, ushort1-4 int1-4, uint1-4 long1-4, ulong1-4 longlong1-2, ulonglong1-2 float1-4 double1-2 Example: char1, int2, long4, double2
35
36 How to calculate the warp ID How do you know if 2 threads are in the same warp? Answer: look at the thread ID. Divide by 32: you get the warp ID. Thread ID is computed from the 1D, 2d or 3D thread index using: x + yd x + zd x D y
37 Matrix transpose Let s put all these concepts into play through a specific example: a matrix transpose. It s all about bandwidth! Even for such a simple calculation, there are many optimizations.
38 simpletranspose


39 Memory access pattern Coalesced reads Strided writes
CUDA Lecture 2. Manfred Liebmann. Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17
 CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
Hands-on CUDA Optimization. CUDA Workshop
 Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Lab 1 Part 1: Introduction to CUDA
 Lab 1 Part 1: Introduction to CUDA Code tarball: lab1.tgz In this hands-on lab, you will learn to use CUDA to program a GPU. The lab can be conducted on the SSSU Fermi Blade (M2050) or NCSA Forge using
Lab 1 Part 1: Introduction to CUDA Code tarball: lab1.tgz In this hands-on lab, you will learn to use CUDA to program a GPU. The lab can be conducted on the SSSU Fermi Blade (M2050) or NCSA Forge using
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
CS 179: GPU Computing. Recitation 2: Synchronization, Shared memory, Matrix Transpose
 CS 179: GPU Computing Recitation 2: Synchronization, Shared memory, Matrix Transpose Synchronization Ideal case for parallelism: no resources shared between threads no communication between threads Many
CS 179: GPU Computing Recitation 2: Synchronization, Shared memory, Matrix Transpose Synchronization Ideal case for parallelism: no resources shared between threads no communication between threads Many
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
NVIDIA GPU CODING & COMPUTING
 NVIDIA GPU CODING & COMPUTING WHY GPU S? ARCHITECTURE & PROGRAM MODEL CPU v. GPU Multiprocessor Model Memory Model Memory Model: Thread Level Programing Model: Logical Mapping of Threads Programing Model:
NVIDIA GPU CODING & COMPUTING WHY GPU S? ARCHITECTURE & PROGRAM MODEL CPU v. GPU Multiprocessor Model Memory Model Memory Model: Thread Level Programing Model: Logical Mapping of Threads Programing Model:
Dense Linear Algebra. HPC - Algorithms and Applications
 Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
Module Memory and Data Locality
 GPU Teaching Kit Accelerated Computing Module 4.4 - Memory and Data Locality Tiled Matrix Multiplication Kernel Objective To learn to write a tiled matrix-multiplication kernel Loading and using tiles
GPU Teaching Kit Accelerated Computing Module 4.4 - Memory and Data Locality Tiled Matrix Multiplication Kernel Objective To learn to write a tiled matrix-multiplication kernel Loading and using tiles
CUDA Tools for Debugging and Profiling
 CUDA Tools for Debugging and Profiling CUDA Course, Jülich Supercomputing Centre Andreas Herten, Forschungszentrum Jülich, 3 August 2016 Overview What you will learn in this session Use cuda-memcheck to
CUDA Tools for Debugging and Profiling CUDA Course, Jülich Supercomputing Centre Andreas Herten, Forschungszentrum Jülich, 3 August 2016 Overview What you will learn in this session Use cuda-memcheck to
CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012
 CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012 Overview 1. Memory Access Efficiency 2. CUDA Memory Types 3. Reducing Global Memory Traffic 4. Example: Matrix-Matrix
CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012 Overview 1. Memory Access Efficiency 2. CUDA Memory Types 3. Reducing Global Memory Traffic 4. Example: Matrix-Matrix
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
Hardware/Software Co-Design
 1 / 13 Hardware/Software Co-Design Review so far Miaoqing Huang University of Arkansas Fall 2011 2 / 13 Problem I A student mentioned that he was able to multiply two 1,024 1,024 matrices using a tiled
1 / 13 Hardware/Software Co-Design Review so far Miaoqing Huang University of Arkansas Fall 2011 2 / 13 Problem I A student mentioned that he was able to multiply two 1,024 1,024 matrices using a tiled
GPU Performance Nuggets
 GPU Performance Nuggets Simon Garcia de Gonzalo & Carl Pearson PhD Students, IMPACT Research Group Advised by Professor Wen-mei Hwu Jun. 15, 2016 grcdgnz2@illinois.edu pearson@illinois.edu GPU Performance
GPU Performance Nuggets Simon Garcia de Gonzalo & Carl Pearson PhD Students, IMPACT Research Group Advised by Professor Wen-mei Hwu Jun. 15, 2016 grcdgnz2@illinois.edu pearson@illinois.edu GPU Performance
Shared Memory. Table of Contents. Shared Memory Learning CUDA to Solve Scientific Problems. Objectives. Technical Issues Shared Memory.
 Table of Contents Shared Memory Learning CUDA to Solve Scientific Problems. 1 Objectives Miguel Cárdenas Montes Centro de Investigaciones Energéticas Medioambientales y Tecnológicas, Madrid, Spain miguel.cardenas@ciemat.es
Table of Contents Shared Memory Learning CUDA to Solve Scientific Problems. 1 Objectives Miguel Cárdenas Montes Centro de Investigaciones Energéticas Medioambientales y Tecnológicas, Madrid, Spain miguel.cardenas@ciemat.es
Introduction to CUDA (2 of 2)
") Announcements Introduction to CUDA (2 of 2) Patrick Cozzi University of Pennsylvania CIS 565 - Fall 2012 Open pull request for Project 0 Project 1 released. Due Sunday 09/30 Not due Tuesday, 09/25 Code
Announcements Introduction to CUDA (2 of 2) Patrick Cozzi University of Pennsylvania CIS 565 - Fall 2012 Open pull request for Project 0 Project 1 released. Due Sunday 09/30 Not due Tuesday, 09/25 Code
GPU Programming. Performance Considerations. Miaoqing Huang University of Arkansas Fall / 60
 1 / 60 GPU Programming Performance Considerations Miaoqing Huang University of Arkansas Fall 2013 2 / 60 Outline Control Flow Divergence Memory Coalescing Shared Memory Bank Conflicts Occupancy Loop Unrolling
1 / 60 GPU Programming Performance Considerations Miaoqing Huang University of Arkansas Fall 2013 2 / 60 Outline Control Flow Divergence Memory Coalescing Shared Memory Bank Conflicts Occupancy Loop Unrolling
Advanced CUDA Optimizations
 Advanced CUDA Optimizations General Audience Assumptions General working knowledge of CUDA Want kernels to perform better Profiling Before optimizing, make sure you are spending effort in correct location
Advanced CUDA Optimizations General Audience Assumptions General working knowledge of CUDA Want kernels to perform better Profiling Before optimizing, make sure you are spending effort in correct location
Information Coding / Computer Graphics, ISY, LiTH. CUDA memory! ! Coalescing!! Constant memory!! Texture memory!! Pinned memory 26(86)
") 26(86) Information Coding / Computer Graphics, ISY, LiTH CUDA memory Coalescing Constant memory Texture memory Pinned memory 26(86) CUDA memory We already know... Global memory is slow. Shared memory is
26(86) Information Coding / Computer Graphics, ISY, LiTH CUDA memory Coalescing Constant memory Texture memory Pinned memory 26(86) CUDA memory We already know... Global memory is slow. Shared memory is
Learn CUDA in an Afternoon. Alan Gray EPCC The University of Edinburgh
 Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
High Performance Computing and GPU Programming
 High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
Programming with CUDA, WS09
 Programming with CUDA and Parallel Algorithms Waqar Saleem Jens Müller Lecture 3 Thursday, 29 Nov, 2009 Recap Motivational videos Example kernel Thread IDs Memory overhead CUDA hardware and programming
Programming with CUDA and Parallel Algorithms Waqar Saleem Jens Müller Lecture 3 Thursday, 29 Nov, 2009 Recap Motivational videos Example kernel Thread IDs Memory overhead CUDA hardware and programming
CUDA Memory Model. Monday, 21 February Some material David Kirk, NVIDIA and Wen-mei W. Hwu, (used with permission)
") CUDA Memory Model Some material David Kirk, NVIDIA and Wen-mei W. Hwu, 2007-2009 (used with permission) 1 G80 Implementation of CUDA Memories Each thread can: Grid Read/write per-thread registers Read/write
CUDA Memory Model Some material David Kirk, NVIDIA and Wen-mei W. Hwu, 2007-2009 (used with permission) 1 G80 Implementation of CUDA Memories Each thread can: Grid Read/write per-thread registers Read/write
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
Tiled Matrix Multiplication
 Tiled Matrix Multiplication Basic Matrix Multiplication Kernel global void MatrixMulKernel(int m, m, int n, n, int k, k, float* A, A, float* B, B, float* C) C) { int Row = blockidx.y*blockdim.y+threadidx.y;
Tiled Matrix Multiplication Basic Matrix Multiplication Kernel global void MatrixMulKernel(int m, m, int n, n, int k, k, float* A, A, float* B, B, float* C) C) { int Row = blockidx.y*blockdim.y+threadidx.y;
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CS516 Programming Languages and Compilers II
 CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 29 GPU Programming II Rutgers University Review: Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing
CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 29 GPU Programming II Rutgers University Review: Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing
E6895 Advanced Big Data Analytics Lecture 8: GPU Examples and GPU on ios devices
 E6895 Advanced Big Data Analytics Lecture 8: GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist, Graph
E6895 Advanced Big Data Analytics Lecture 8: GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist, Graph
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION
 CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION WHAT YOU WILL LEARN An iterative method to optimize your GPU code Some common bottlenecks to look out for Performance diagnostics with NVIDIA Nsight
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION WHAT YOU WILL LEARN An iterative method to optimize your GPU code Some common bottlenecks to look out for Performance diagnostics with NVIDIA Nsight
Practical Introduction to CUDA and GPU
 Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose Joe Stam Optimization GPUs are very fast BUT Poor programming can lead to disappointing performance Squeaking out the most speed
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose Joe Stam Optimization GPUs are very fast BUT Poor programming can lead to disappointing performance Squeaking out the most speed
GPU Memory Memory issue for CUDA programming
 Memory issue for CUDA programming Variable declaration Memory Scope Lifetime device local int LocalVar; local thread thread device shared int SharedVar; shared block block device int GlobalVar; global
Memory issue for CUDA programming Variable declaration Memory Scope Lifetime device local int LocalVar; local thread thread device shared int SharedVar; shared block block device int GlobalVar; global
Reductions and Low-Level Performance Considerations CME343 / ME May David Tarjan NVIDIA Research
 Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
Register file. A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks.
 is partitioned among the threads of the dispatched blocks.") Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Introduction to GPU programming. Introduction to GPU programming p. 1/17
 Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
CSE 591: GPU Programming. Memories. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591: GPU Programming Memories Klaus Mueller Computer Science Department Stony Brook University Importance of Memory Access Efficiency Every loop iteration has two global memory accesses two floating
CSE 591: GPU Programming Memories Klaus Mueller Computer Science Department Stony Brook University Importance of Memory Access Efficiency Every loop iteration has two global memory accesses two floating
ECE 408 / CS 483 Final Exam, Fall 2014
 ECE 408 / CS 483 Final Exam, Fall 2014 Thursday 18 December 2014 8:00 to 11:00 Central Standard Time You may use any notes, books, papers, or other reference materials. In the interest of fair access across
ECE 408 / CS 483 Final Exam, Fall 2014 Thursday 18 December 2014 8:00 to 11:00 Central Standard Time You may use any notes, books, papers, or other reference materials. In the interest of fair access across
Advanced CUDA Optimizations. Umar Arshad ArrayFire
 Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
Optimizing Parallel Reduction in CUDA
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology http://developer.download.nvidia.com/assets/cuda/files/reduction.pdf Parallel Reduction Tree-based approach used within each
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology http://developer.download.nvidia.com/assets/cuda/files/reduction.pdf Parallel Reduction Tree-based approach used within each
Example 1: Color-to-Grayscale Image Processing
 GPU Teaching Kit Accelerated Computing Lecture 16: CUDA Parallelism Model Examples Example 1: Color-to-Grayscale Image Processing RGB Color Image Representation Each pixel in an image is an RGB value The
GPU Teaching Kit Accelerated Computing Lecture 16: CUDA Parallelism Model Examples Example 1: Color-to-Grayscale Image Processing RGB Color Image Representation Each pixel in an image is an RGB value The
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Introduction to GPGPUs and to CUDA programming model
 Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
Optimizing Parallel Reduction in CUDA. Mark Harris NVIDIA Developer Technology
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
CUDA Parallelism Model
 GPU Teaching Kit Accelerated Computing CUDA Parallelism Model Kernel-Based SPMD Parallel Programming Multidimensional Kernel Configuration Color-to-Grayscale Image Processing Example Image Blur Example
GPU Teaching Kit Accelerated Computing CUDA Parallelism Model Kernel-Based SPMD Parallel Programming Multidimensional Kernel Configuration Color-to-Grayscale Image Processing Example Image Blur Example
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
CUDA Tools for Debugging and Profiling. Jiri Kraus (NVIDIA)
") Mitglied der Helmholtz-Gemeinschaft CUDA Tools for Debugging and Profiling Jiri Kraus (NVIDIA) GPU Programming with CUDA@Jülich Supercomputing Centre Jülich 25-27 April 2016 What you will learn How to
Mitglied der Helmholtz-Gemeinschaft CUDA Tools for Debugging and Profiling Jiri Kraus (NVIDIA) GPU Programming with CUDA@Jülich Supercomputing Centre Jülich 25-27 April 2016 What you will learn How to
Matrix Multiplication in CUDA. A case study
 Matrix Multiplication in CUDA A case study 1 Matrix Multiplication: A Case Study Matrix multiplication illustrates many of the basic features of memory and thread management in CUDA Usage of thread/block
Matrix Multiplication in CUDA A case study 1 Matrix Multiplication: A Case Study Matrix multiplication illustrates many of the basic features of memory and thread management in CUDA Usage of thread/block
Programming in CUDA. Malik M Khan
 Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Introduction to GPU Computing. Design and Analysis of Parallel Algorithms
 Introduction to GPU Computing Design and Analysis of Parallel Algorithms Sources CUDA Programming Guide (3.2) CUDA Best Practices Guide (3.2) CUDA Toolkit Reference Manual (3.2) CUDA SDK Examples Part
Introduction to GPU Computing Design and Analysis of Parallel Algorithms Sources CUDA Programming Guide (3.2) CUDA Best Practices Guide (3.2) CUDA Toolkit Reference Manual (3.2) CUDA SDK Examples Part
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Optimizing Parallel Reduction in CUDA. Mark Harris NVIDIA Developer Technology
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
CS/EE 217 Midterm. Question Possible Points Points Scored Total 100
 CS/EE 217 Midterm ANSWER ALL QUESTIONS TIME ALLOWED 60 MINUTES Question Possible Points Points Scored 1 24 2 32 3 20 4 24 Total 100 Question 1] [24 Points] Given a GPGPU with 14 streaming multiprocessor
CS/EE 217 Midterm ANSWER ALL QUESTIONS TIME ALLOWED 60 MINUTES Question Possible Points Points Scored 1 24 2 32 3 20 4 24 Total 100 Question 1] [24 Points] Given a GPGPU with 14 streaming multiprocessor
S WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS. Jakob Progsch, Mathias Wagner GTC 2018
 S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION. Julien Demouth, NVIDIA Cliff Woolley, NVIDIA
 CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION Julien Demouth, NVIDIA Cliff Woolley, NVIDIA WHAT WILL YOU LEARN? An iterative method to optimize your GPU code A way to conduct that method with NVIDIA
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION Julien Demouth, NVIDIA Cliff Woolley, NVIDIA WHAT WILL YOU LEARN? An iterative method to optimize your GPU code A way to conduct that method with NVIDIA
GPU Programming. Alan Gray, James Perry EPCC The University of Edinburgh
 GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
Advanced CUDA Programming. Dr. Timo Stich
 Advanced CUDA Programming Dr. Timo Stich (tstich@nvidia.com) Outline SIMT Architecture, Warps Kernel optimizations Global memory throughput Launch configuration Shared memory access Instruction throughput
Advanced CUDA Programming Dr. Timo Stich (tstich@nvidia.com) Outline SIMT Architecture, Warps Kernel optimizations Global memory throughput Launch configuration Shared memory access Instruction throughput
Analysis Report. Number of Multiprocessors 3 Multiprocessor Clock Rate Concurrent Kernel Max IPC 6 Threads per Warp 32 Global Memory Bandwidth
 Analysis Report v3 Duration 932.612 µs Grid Size [ 1024,1,1 ] Block Size [ 1024,1,1 ] Registers/Thread 32 Shared Memory/Block 28 KiB Shared Memory Requested 64 KiB Shared Memory Executed 64 KiB Shared
Analysis Report v3 Duration 932.612 µs Grid Size [ 1024,1,1 ] Block Size [ 1024,1,1 ] Registers/Thread 32 Shared Memory/Block 28 KiB Shared Memory Requested 64 KiB Shared Memory Executed 64 KiB Shared
Lecture 7. Using Shared Memory Performance programming and the memory hierarchy
 Lecture 7 Using Shared Memory Performance programming and the memory hierarchy Announcements Scott B. Baden /CSE 260/ Winter 2014 2 Assignment #1 Blocking for cache will boost performance but a lot more
Lecture 7 Using Shared Memory Performance programming and the memory hierarchy Announcements Scott B. Baden /CSE 260/ Winter 2014 2 Assignment #1 Blocking for cache will boost performance but a lot more
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
GPU Memory. GPU Memory. Memory issue for CUDA programming. Copyright 2013 Yong Cao, Referencing UIUC ECE498AL Course Notes
 Memory issue for CUDA programming CUDA Variable Type Qualifiers Variable declaration Memory Scope Lifetime device local int LocalVar; local thread thread device shared int SharedVar; shared block block
Memory issue for CUDA programming CUDA Variable Type Qualifiers Variable declaration Memory Scope Lifetime device local int LocalVar; local thread thread device shared int SharedVar; shared block block
Memory concept. Grid concept, Synchronization. GPU Programming. Szénási Sándor.
 Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
GPGPU LAB. Case study: Finite-Difference Time- Domain Method on CUDA
 GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
GPU programming basics. Prof. Marco Bertini
 GPU programming basics Prof. Marco Bertini CUDA: atomic operations, privatization, algorithms Atomic operations The basics atomic operation in hardware is something like a read-modify-write operation performed
GPU programming basics Prof. Marco Bertini CUDA: atomic operations, privatization, algorithms Atomic operations The basics atomic operation in hardware is something like a read-modify-write operation performed
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
CUDA Performance Optimization. Patrick Legresley
 CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Introduction to GPGPU and GPU-architectures
 Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Image convolution with CUDA
 Image convolution with CUDA Lecture Alexey Abramov abramov _at_ physik3.gwdg.de Georg-August University, Bernstein Center for Computational Neuroscience, III Physikalisches Institut, Göttingen, Germany
Image convolution with CUDA Lecture Alexey Abramov abramov _at_ physik3.gwdg.de Georg-August University, Bernstein Center for Computational Neuroscience, III Physikalisches Institut, Göttingen, Germany
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Sparse Linear Algebra in CUDA
 Sparse Linear Algebra in CUDA HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 22 nd 2017 Table of Contents Homework - Worksheet 2
Sparse Linear Algebra in CUDA HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 22 nd 2017 Table of Contents Homework - Worksheet 2
2/2/11. Administrative. L6: Memory Hierarchy Optimization IV, Bandwidth Optimization. Project Proposal (due 3/9) Faculty Project Suggestions
 Faculty Project Suggestions") Administrative L6: Memory Hierarchy Optimization IV, Bandwidth Optimization Next assignment available Goals of assignment: simple memory hierarchy management block-thread decomposition tradeoff Due Tuesday,
Administrative L6: Memory Hierarchy Optimization IV, Bandwidth Optimization Next assignment available Goals of assignment: simple memory hierarchy management block-thread decomposition tradeoff Due Tuesday,
Lecture 5. Performance Programming with CUDA
 Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
Implementation of Adaptive Coarsening Algorithm on GPU using CUDA
 Implementation of Adaptive Coarsening Algorithm on GPU using CUDA 1. Introduction , In scientific computing today, the high-performance computers grow
Implementation of Adaptive Coarsening Algorithm on GPU using CUDA 1. Introduction , In scientific computing today, the high-performance computers grow
CUDA Workshop. High Performance GPU computing EXEBIT Karthikeyan
 CUDA Workshop High Performance GPU computing EXEBIT- 2014 Karthikeyan CPU vs GPU CPU Very fast, serial, Low Latency GPU Slow, massively parallel, High Throughput Play Demonstration Compute Unified Device
CUDA Workshop High Performance GPU computing EXEBIT- 2014 Karthikeyan CPU vs GPU CPU Very fast, serial, Low Latency GPU Slow, massively parallel, High Throughput Play Demonstration Compute Unified Device
Blocks, Grids, and Shared Memory
 Blocks, Grids, and Shared Memory GPU Course, Fall 2012 Last week: ax+b Homework Threads, Blocks, Grids CUDA threads are organized into blocks Threads operate in SIMD(ish) manner -- each executing same
Blocks, Grids, and Shared Memory GPU Course, Fall 2012 Last week: ax+b Homework Threads, Blocks, Grids CUDA threads are organized into blocks Threads operate in SIMD(ish) manner -- each executing same
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Profiling & Tuning Applications. CUDA Course István Reguly
 Profiling & Tuning Applications CUDA Course István Reguly Introduction Why is my application running slow? Work it out on paper Instrument code Profile it NVIDIA Visual Profiler Works with CUDA, needs
Profiling & Tuning Applications CUDA Course István Reguly Introduction Why is my application running slow? Work it out on paper Instrument code Profile it NVIDIA Visual Profiler Works with CUDA, needs
Performance optimization with CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Performance optimization with CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide
Performance optimization with CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide
G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G
 Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
More CUDA. Advanced programming
 More CUDA 1 Advanced programming Synchronization and atomics Warps and Occupancy Memory coalescing Shared Memory Streams and Asynchronous Execution Bank conflicts Other features 2 Synchronization and Atomics
More CUDA 1 Advanced programming Synchronization and atomics Warps and Occupancy Memory coalescing Shared Memory Streams and Asynchronous Execution Bank conflicts Other features 2 Synchronization and Atomics
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
GPU Profiling and Optimization. Scott Grauer-Gray
 GPU Profiling and Optimization Scott Grauer-Gray Benefits of GPU Programming "Free" speedup with new architectures More cores in new architecture Improved features such as L1 and L2 cache Increased shared/local
GPU Profiling and Optimization Scott Grauer-Gray Benefits of GPU Programming "Free" speedup with new architectures More cores in new architecture Improved features such as L1 and L2 cache Increased shared/local
Parallel Computing. Lecture 19: CUDA - I
 CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
2/17/10. Administrative. L7: Memory Hierarchy Optimization IV, Bandwidth Optimization and Case Studies. Administrative, cont.
 Administrative L7: Memory Hierarchy Optimization IV, Bandwidth Optimization and Case Studies Next assignment on the website Description at end of class Due Wednesday, Feb. 17, 5PM Use handin program on
Administrative L7: Memory Hierarchy Optimization IV, Bandwidth Optimization and Case Studies Next assignment on the website Description at end of class Due Wednesday, Feb. 17, 5PM Use handin program on
Module 3: CUDA Execution Model -I. Objective
 ECE 8823A GPU Architectures odule 3: CUDA Execution odel -I 1 Objective A more detailed look at kernel execution Data to thread assignment To understand the organization and scheduling of threads Resource
ECE 8823A GPU Architectures odule 3: CUDA Execution odel -I 1 Objective A more detailed look at kernel execution Data to thread assignment To understand the organization and scheduling of threads Resource
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
Computer Architecture
 Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
CS179 GPU Programming Recitation 4: CUDA Particles
 Recitation 4: CUDA Particles Lab 4 CUDA Particle systems Two parts Simple repeat of Lab 3 Interacting Flocking simulation 2 Setup Two folders given particles_simple, particles_interact Must install NVIDIA_CUDA_SDK
Recitation 4: CUDA Particles Lab 4 CUDA Particle systems Two parts Simple repeat of Lab 3 Interacting Flocking simulation 2 Setup Two folders given particles_simple, particles_interact Must install NVIDIA_CUDA_SDK
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
Profiling and Parallelizing with the OpenACC Toolkit OpenACC Course: Lecture 2 October 15, 2015
 Profiling and Parallelizing with the OpenACC Toolkit OpenACC Course: Lecture 2 October 15, 2015 Oct 1: Introduction to OpenACC Oct 6: Office Hours Oct 15: Profiling and Parallelizing with the OpenACC Toolkit
Profiling and Parallelizing with the OpenACC Toolkit OpenACC Course: Lecture 2 October 15, 2015 Oct 1: Introduction to OpenACC Oct 6: Office Hours Oct 15: Profiling and Parallelizing with the OpenACC Toolkit
Data Parallel Execution Model
 CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
April 4-7, 2016 Silicon Valley. CUDA DEBUGGING TOOLS IN CUDA8 Vyas Venkataraman, Kudbudeen Jalaludeen, April 6, 2016
 April 4-7, 2016 Silicon Valley CUDA DEBUGGING TOOLS IN CUDA8 Vyas Venkataraman, Kudbudeen Jalaludeen, April 6, 2016 AGENDA General debugging approaches Cuda-gdb Demo 2 CUDA API CHECKING CUDA calls are
April 4-7, 2016 Silicon Valley CUDA DEBUGGING TOOLS IN CUDA8 Vyas Venkataraman, Kudbudeen Jalaludeen, April 6, 2016 AGENDA General debugging approaches Cuda-gdb Demo 2 CUDA API CHECKING CUDA calls are
Lecture 10!! Introduction to CUDA!
 1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.