A Python extension for the massively parallel framework walberla
|
|
|
- Warren Goodwin
- 6 years ago
- Views:
Transcription

1 A Python extension for the massively parallel framework walberla PyHPC at SC 14, November 17 th 2014 Martin Bauer, Florian Schornbaum, Christian Godenschwager, Matthias Markl, Daniela Anderl, Harald Köstler and Ulrich Rüde Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen, Germany


2 Outline walberla Framework Data Structures Communication patterns Application Python interface: Motivation: Simulation Setup Data structure export for simulation evaluation/control Challenges of writing a C++/Python interface 2
3 The walberla Framework
 but other algorithms working on structured grid also possible:")
 around a sphere Microstructure simulation of ternary, eutectic solidification process (phase")
4 walberla Framework widely applicable Lattice-Boltzmann from Erlangen general HPC software framework, originally developed for CFD simulations with Lattice Boltzmann Method (LBM) but other algorithms working on structured grid also possible: phase field models, molecular dynamics with linked cell algorithm coupling with in-house rigid body physics engine pe Turbulent flow (Re=11000) around a sphere Microstructure simulation of ternary, eutectic solidification process (phase field method) 4



")






5 walberla Framework Written in C++ with Python extensions Hybridly parallelized (MPI + OpenMP) No data structures growing with number of processes involved Scales from laptop to recent petascale machines Parallel I/O Portable (Compiler/OS) Automated tests / CI servers Open Source release planned llvm/clang 5
 blocks are the basic unit of load")
6 Block Structured Grids structured grid domain is decomposed into blocks blocks are the container data structure for simulation data (lattice) blocks are the basic unit of load balancing 6
7 Block Structured Grids Complex geometry given by surface Add regular block partitioning Load balancing Discard empty blocks Allocate block data 7



8 Block Structured Grids Domain partitioning of coronary tree dataset One block per process 512 processes 458,752 processes 9
9 MLUP/s per core Weak scaling Weak scaling - TRT kernel (3.34 million cells per core) islands Cores Communication share (%) 16P 1T 4P 4T 2P 8T Comm 11
10 Modular Software Design walberla Library field mpi domain_decomposition cuda geometry communication lattice_boltzmann phasefield pde Main Goal: Modularity Decoupling: heavy use of template concepts 12
11 Python Extension Motivation: Simulation Setup
12 Simulation Setup Example Application: free surface LBM simulation Bubbly Flow through channel

13 Simulation Setup Example Application: free surface LBM simulation Bubbly Flow through channel
14 Simulation Workflow

15 Motivation: Configuration files walberla provides a hierarchic key-value pair configuration specified in a JSON-like syntax DomainSetup { dx 0.01; cells < 200,200,1000>; } Physics { LBM_Model { type SRT; relaxation_time 1.9; } } Geometry { free_surface { sphere { position < 100,100,500>; radius 10; } // } at_boundary { position west; type inflow; vel 0.01; } } Compute from dx,dt,viscosity? Use previous values? cells/2 Check valid range? Physical Units?
16 Motivation: Configuration files Special C++ modules were developed to enhance the config file unit conversion automatic calculation of missing parameters check for valid parameter combinations and ranges support for functions/macros? essentially we started to develop a custom scripting language Python was chosen because: popular in scientific community easy to use together with C/C++ boost::python


17 Library Stack walberla python_coupling module interface to expose walberla datatypes and call Python functions boost::python C++ Interface libpython C Interface
18 Callbacks Simulation (still) driven by C++ code, Callbacks to Python functions configuration provided in a Python dict import "config" ) def make_config( **kwargs ): return { 'DomainSetup' : { 'cells' : (200,200,1000), } 'Geometry' : { } } python_coupling::callback cb ( "config" ); cb(); // run python function auto config = convertdicttoconfig ( cb.returnvalue() )
19 Simulation "config" ) def config(): c = { 'Physical' : { 'viscosity' : 1e-6*m*m/s, 'surface_tension': 0.072*N/m 'dx' : 0.01*m, #... } 'Control' : { 'timesteps' : 10000, 'vtk_output_interval': 100, #... } } compute_derived_parameters(c) c['physical']['dt'] = find_optimal_dt(c) nondimensionalize(c) return c Units Library Computation and Optimization
20 Simulation Setup Further callbacks, for example for boundary setup: gas_bubbles = "domain_init" ) def geometry_and_boundary_setup( cell ): p_w = c['physics']['pressure_west'] if is_at_border( cell, 'W' ): boundary = [ 'pressure', p_w ] elif is_at_border( cell, 'E' ): boundary = [ 'pressure', 1.0 ] elif is_at_border( cell, 'NSTB'): boundary = [ 'noslip' ] else: boundary = [] return{'fill_level': 1-gas_bubbles.overlap(cell), 'boundary' : boundary }
21 Python Extension Simulation Evaluation

22 Simulation Workflow
23 Callbacks Next step: make C++ data structures available in Python functions Most of them straightforward, using boost::python wrappers import "at_end_of_timestep" ) def my_callback( blockstorage, **kwargs ): for block in blockstorage: # access and analyse simulation data velocity_field = block['velocity'] Callback cb ( "at_end_of_timestep" ); cb.exposeptr("blockstorage", blockstorage ); cb(); // run python function

24 Field access in Python Field is the central data structure in walberla ( stores all simulation data ) four dimensional array, that stores all simulation data easy switching between AoS and SoA memory layout distributed: field only represents the locally stored part of the lattice
25 Field access in Python Field is the central data structure in walberla ( stores all simulation data ) four dimensional array, that stores all simulation data easy switching between AoS and SoA memory layout distributed: field only represents the locally stored part of the lattice user friendly and efficient access from Python is essential no copying should behave like a numpy.array (indexing, slicing, etc. )
26 Field access in Python Solution: Buffer Protocol raw memory is the interface: pointer to beginning together with strides for each dimension not wrapped in boost::python -> directly use C interface import walberla def to_numpy( f ): return np.asarray( f.buffer() "at_end_of_timestep" ) def my_callback( blockstorage, **kwargs ): for block in blockstorage: # access and analyse simulation data velocity_field = to_numpy( block['velocity'] )
27 Exporting template code heavy use of template code due to performance reasons all templates have to instantiated which combinations to instantiate? namespace field { // field module template<typename T> class Field; template<typename T> class FlagField; } namespace lbm { // lbm module template<typename FieldType> class VelocityAdaptor; } namespace vtk { // vtk module template<typename FieldType> void write( const FieldType & f ); } namespace postprocessing { // postprocessing module template<typename FieldType> void generateisosurface( const FieldType & f ); }

28 Exporting template code using boost::mpl::vector; namespace field { // field module template<typename T> class; template<typename T> class FFieldlagField; walberla Library typedef vector< Field<double>, Field<int>, FlagField<unsigned char> > FieldTypes; } namespace lbm { // lbm module template<typename FieldType> class VelocityAdaptor; typedef boost::mpl::vector<velocityadaptor< double > FieldTypes; } typedef boost::mpl::joint_view< field::fieldtypes, lbm::fieldtypes > MyFieldTypes; Application vtk:: python::fieldfunctionexport<myfieldtypes>; postprocessing::python::fieldfunctionexport<myfieldtypes>;
29 Evaluation Example: determine maximal velocity in channel two stage process, due to distributed storage of lattice import numpy as "at_end_of_timestep" ) def evaluation(blockstorage, bubbles): # Distributed evaluation x_vel_max = 0 for block in blockstorage: vel_field = to_numpy(block['velocity']) x_vel_max = max(vel_field[:,:,:,0].max(), x_vel_max) x_vel_max = mpi.reduce( x_vel_max, mpi.max ) if x_vel_max: #valid on root only log.result("max X Vel", x_vel_max)
30 Evaluation for smaller simulations: simpler (non-distributed) version import numpy as "at_end_of_timestep" ) def evaluation(blockstorage, bubbles): # Gather and evaluate locally size = blockstorage.numberofcells() vel_profile_z = gather_slice(x=size[0]/2, y=size[1]/2,coarsen=4) if vel_profile_z: #valid on root only eval_vel_profile(vel_profile_z)
31 Evaluation Python ecosystem for evaluation scipy: FFT to get vertex shedding frequency sqlite3: store results of parameter studies matplotlib: instantly plot results for singlenode, debugging runs Simulation Control: use results of evaluation during simulation Example: when velocity does not change in channel a steady flow developed and simulation can be stopped All scenario related code (setup, analysis, control) in a single file
32 Summary
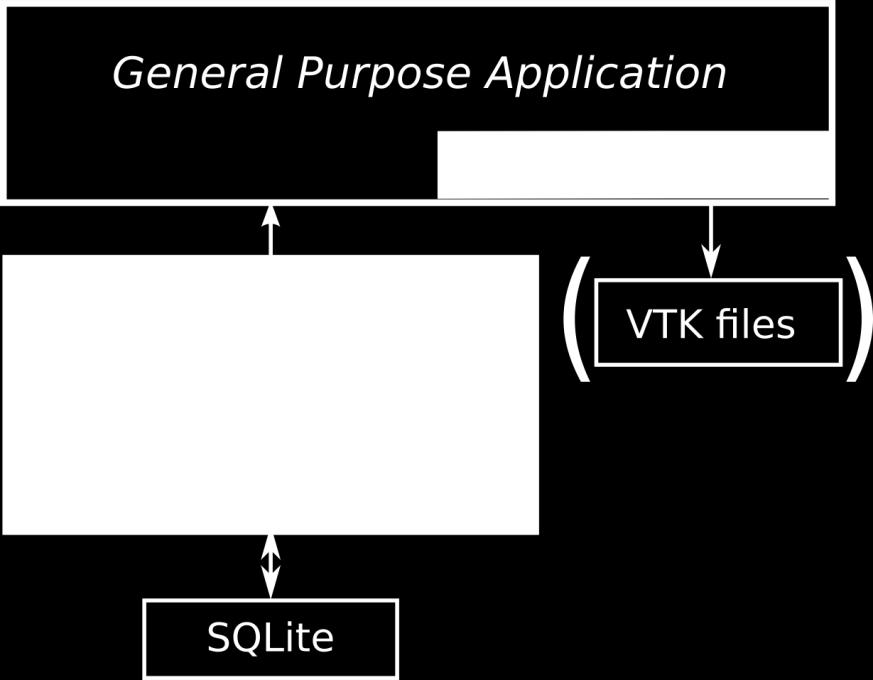
33 Summary
34 Summary / Outlook Summary Python simplifies all stages of the simulation workflow setup: nondimensionalization, geometry setup evaluation: simulation data accessible as numpy array, storage to database, plotting control: definition of stopping criteria, output control all scenario dependent code in one file, no custom C++ application necessary any more Outlook add possibility to drive simulation from Python (export all required data structures)




35 Thank you!
Performance Optimization of a Massively Parallel Phase-Field Method Using the HPC Framework walberla
 Performance Optimization of a Massively Parallel Phase-Field Method Using the HPC Framework walberla SIAM PP 2016, April 13 th 2016 Martin Bauer, Florian Schornbaum, Christian Godenschwager, Johannes Hötzer,
Performance Optimization of a Massively Parallel Phase-Field Method Using the HPC Framework walberla SIAM PP 2016, April 13 th 2016 Martin Bauer, Florian Schornbaum, Christian Godenschwager, Johannes Hötzer,
simulation framework for piecewise regular grids
 WALBERLA, an ultra-scalable multiphysics simulation framework for piecewise regular grids ParCo 2015, Edinburgh September 3rd, 2015 Christian Godenschwager, Florian Schornbaum, Martin Bauer, Harald Köstler
WALBERLA, an ultra-scalable multiphysics simulation framework for piecewise regular grids ParCo 2015, Edinburgh September 3rd, 2015 Christian Godenschwager, Florian Schornbaum, Martin Bauer, Harald Köstler
walberla: Developing a Massively Parallel HPC Framework
 walberla: Developing a Massively Parallel HPC Framework SIAM CS&E 2013, Boston February 26, 2013 Florian Schornbaum*, Christian Godenschwager*, Martin Bauer*, Matthias Markl, Ulrich Rüde* *Chair for System
walberla: Developing a Massively Parallel HPC Framework SIAM CS&E 2013, Boston February 26, 2013 Florian Schornbaum*, Christian Godenschwager*, Martin Bauer*, Matthias Markl, Ulrich Rüde* *Chair for System
Massively Parallel Phase Field Simulations using HPC Framework walberla
 Massively Parallel Phase Field Simulations using HPC Framework walberla SIAM CSE 2015, March 15 th 2015 Martin Bauer, Florian Schornbaum, Christian Godenschwager, Johannes Hötzer, Harald Köstler and Ulrich
Massively Parallel Phase Field Simulations using HPC Framework walberla SIAM CSE 2015, March 15 th 2015 Martin Bauer, Florian Schornbaum, Christian Godenschwager, Johannes Hötzer, Harald Köstler and Ulrich
Computational Fluid Dynamics with the Lattice Boltzmann Method KTH SCI, Stockholm
 Computational Fluid Dynamics with the Lattice Boltzmann Method KTH SCI, Stockholm March 17 March 21, 2014 Florian Schornbaum, Martin Bauer, Simon Bogner Chair for System Simulation Friedrich-Alexander-Universität
Computational Fluid Dynamics with the Lattice Boltzmann Method KTH SCI, Stockholm March 17 March 21, 2014 Florian Schornbaum, Martin Bauer, Simon Bogner Chair for System Simulation Friedrich-Alexander-Universität
Peta-Scale Simulations with the HPC Software Framework walberla:
 Peta-Scale Simulations with the HPC Software Framework walberla: Massively Parallel AMR for the Lattice Boltzmann Method SIAM PP 2016, Paris April 15, 2016 Florian Schornbaum, Christian Godenschwager,
Peta-Scale Simulations with the HPC Software Framework walberla: Massively Parallel AMR for the Lattice Boltzmann Method SIAM PP 2016, Paris April 15, 2016 Florian Schornbaum, Christian Godenschwager,
The walberla Framework: Multi-physics Simulations on Heterogeneous Parallel Platforms
 The walberla Framework: Multi-physics Simulations on Heterogeneous Parallel Platforms Harald Köstler, Uli Rüde (LSS Erlangen, ruede@cs.fau.de) Lehrstuhl für Simulation Universität Erlangen-Nürnberg www10.informatik.uni-erlangen.de
The walberla Framework: Multi-physics Simulations on Heterogeneous Parallel Platforms Harald Köstler, Uli Rüde (LSS Erlangen, ruede@cs.fau.de) Lehrstuhl für Simulation Universität Erlangen-Nürnberg www10.informatik.uni-erlangen.de
A Python Extension for the Massively Parallel Multiphysics Simulation Framework walberla
 A Python Extension for the Massively Parallel Multiphysics Simulation Framework walberla Martin Bauer, Florian Schornbaum, Christian Godenschwager, Matthias Markl, Daniela Anderl, Harald Köstler, and Ulrich
A Python Extension for the Massively Parallel Multiphysics Simulation Framework walberla Martin Bauer, Florian Schornbaum, Christian Godenschwager, Matthias Markl, Daniela Anderl, Harald Köstler, and Ulrich
From Notebooks to Supercomputers: Tap the Full Potential of Your CUDA Resources with LibGeoDecomp
 From Notebooks to Supercomputers: Tap the Full Potential of Your CUDA Resources with andreas.schaefer@cs.fau.de Friedrich-Alexander-Universität Erlangen-Nürnberg GPU Technology Conference 2013, San José,
From Notebooks to Supercomputers: Tap the Full Potential of Your CUDA Resources with andreas.schaefer@cs.fau.de Friedrich-Alexander-Universität Erlangen-Nürnberg GPU Technology Conference 2013, San José,
Lattice Boltzmann Methods on the way to exascale
 Lattice Boltzmann Methods on the way to exascale Ulrich Rüde (LSS Erlangen, ulrich.ruede@fau.de) Lehrstuhl für Simulation Universität Erlangen-Nürnberg www10.informatik.uni-erlangen.de HIGH PERFORMANCE
Lattice Boltzmann Methods on the way to exascale Ulrich Rüde (LSS Erlangen, ulrich.ruede@fau.de) Lehrstuhl für Simulation Universität Erlangen-Nürnberg www10.informatik.uni-erlangen.de HIGH PERFORMANCE
Python VSIP API: A first draft
 Python VSIP API: A first draft Stefan Seefeld HPEC WG meeting, December 9, 2014 Goals Use cases: Promote VSIP standard to a wider audience (SciPy users) Add more hardware acceleration to SciPy Allow VSIP
Python VSIP API: A first draft Stefan Seefeld HPEC WG meeting, December 9, 2014 Goals Use cases: Promote VSIP standard to a wider audience (SciPy users) Add more hardware acceleration to SciPy Allow VSIP
Simulation of Liquid-Gas-Solid Flows with the Lattice Boltzmann Method
 Simulation of Liquid-Gas-Solid Flows with the Lattice Boltzmann Method June 21, 2011 Introduction Free Surface LBM Liquid-Gas-Solid Flows Parallel Computing Examples and More References Fig. Simulation
Simulation of Liquid-Gas-Solid Flows with the Lattice Boltzmann Method June 21, 2011 Introduction Free Surface LBM Liquid-Gas-Solid Flows Parallel Computing Examples and More References Fig. Simulation
(LSS Erlangen, Simon Bogner, Ulrich Rüde, Thomas Pohl, Nils Thürey in collaboration with many more
 Parallel Free-Surface Extension of the Lattice-Boltzmann Method A Lattice-Boltzmann Approach for Simulation of Two-Phase Flows Stefan Donath (LSS Erlangen, stefan.donath@informatik.uni-erlangen.de) Simon
Parallel Free-Surface Extension of the Lattice-Boltzmann Method A Lattice-Boltzmann Approach for Simulation of Two-Phase Flows Stefan Donath (LSS Erlangen, stefan.donath@informatik.uni-erlangen.de) Simon
Software and Performance Engineering for numerical codes on GPU clusters
 Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
Simulation of moving Particles in 3D with the Lattice Boltzmann Method
 Simulation of moving Particles in 3D with the Lattice Boltzmann Method, Nils Thürey, Christian Feichtinger, Hans-Joachim Schmid Chair for System Simulation University Erlangen/Nuremberg Chair for Particle
Simulation of moving Particles in 3D with the Lattice Boltzmann Method, Nils Thürey, Christian Feichtinger, Hans-Joachim Schmid Chair for System Simulation University Erlangen/Nuremberg Chair for Particle
Introducing a Cache-Oblivious Blocking Approach for the Lattice Boltzmann Method
 Introducing a Cache-Oblivious Blocking Approach for the Lattice Boltzmann Method G. Wellein, T. Zeiser, G. Hager HPC Services Regional Computing Center A. Nitsure, K. Iglberger, U. Rüde Chair for System
Introducing a Cache-Oblivious Blocking Approach for the Lattice Boltzmann Method G. Wellein, T. Zeiser, G. Hager HPC Services Regional Computing Center A. Nitsure, K. Iglberger, U. Rüde Chair for System
International Supercomputing Conference 2009
 International Supercomputing Conference 2009 Implementation of a Lattice-Boltzmann-Method for Numerical Fluid Mechanics Using the nvidia CUDA Technology E. Riegel, T. Indinger, N.A. Adams Technische Universität
International Supercomputing Conference 2009 Implementation of a Lattice-Boltzmann-Method for Numerical Fluid Mechanics Using the nvidia CUDA Technology E. Riegel, T. Indinger, N.A. Adams Technische Universität
Two-Phase flows on massively parallel multi-gpu clusters
 Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
VisIt Libsim. An in-situ visualisation library
 VisIt Libsim. An in-situ visualisation library December 2017 Jean M. Favre, CSCS Outline Motivations In-situ visualization In-situ processing strategies VisIt s libsim library Enable visualization in a
VisIt Libsim. An in-situ visualisation library December 2017 Jean M. Favre, CSCS Outline Motivations In-situ visualization In-situ processing strategies VisIt s libsim library Enable visualization in a
Reconstruction of Trees from Laser Scan Data and further Simulation Topics
 Reconstruction of Trees from Laser Scan Data and further Simulation Topics Helmholtz-Research Center, Munich Daniel Ritter http://www10.informatik.uni-erlangen.de Overview 1. Introduction of the Chair
Reconstruction of Trees from Laser Scan Data and further Simulation Topics Helmholtz-Research Center, Munich Daniel Ritter http://www10.informatik.uni-erlangen.de Overview 1. Introduction of the Chair
Large scale Imaging on Current Many- Core Platforms
 Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Parallel Simulation of Dendritic Growth On Unstructured Grids
 Parallel Simulation of Dendritic Growth On Unstructured Grids, Julian Hammer, Dietmar Fey Friedrich-Alexander-Universität Erlangen-Nürnberg IA 3 Workshop @SC11, Nov. 13th, 2011 Outline 1 What and why?
Parallel Simulation of Dendritic Growth On Unstructured Grids, Julian Hammer, Dietmar Fey Friedrich-Alexander-Universität Erlangen-Nürnberg IA 3 Workshop @SC11, Nov. 13th, 2011 Outline 1 What and why?
FRIEDRICH-ALEXANDER-UNIVERSITÄT ERLANGEN-NÜRNBERG. Lehrstuhl für Informatik 10 (Systemsimulation)
") FRIEDRICH-ALEXANDER-UNIVERSITÄT ERLANGEN-NÜRNBERG INSTITUT FÜR INFORMATIK (MATHEMATISCHE MASCHINEN UND DATENVERARBEITUNG) Lehrstuhl für Informatik 10 (Systemsimulation) walberla: Visualization of Fluid
FRIEDRICH-ALEXANDER-UNIVERSITÄT ERLANGEN-NÜRNBERG INSTITUT FÜR INFORMATIK (MATHEMATISCHE MASCHINEN UND DATENVERARBEITUNG) Lehrstuhl für Informatik 10 (Systemsimulation) walberla: Visualization of Fluid
High Performance Computing
 High Performance Computing ADVANCED SCIENTIFIC COMPUTING Dr. Ing. Morris Riedel Adjunct Associated Professor School of Engineering and Natural Sciences, University of Iceland Research Group Leader, Juelich
High Performance Computing ADVANCED SCIENTIFIC COMPUTING Dr. Ing. Morris Riedel Adjunct Associated Professor School of Engineering and Natural Sciences, University of Iceland Research Group Leader, Juelich
Numerical Algorithms on Multi-GPU Architectures
 Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Challenges in Fully Generating Multigrid Solvers for the Simulation of non-newtonian Fluids
 Challenges in Fully Generating Multigrid Solvers for the Simulation of non-newtonian Fluids Sebastian Kuckuk FAU Erlangen-Nürnberg 18.01.2016 HiStencils 2016, Prague, Czech Republic Outline Outline Scope
Challenges in Fully Generating Multigrid Solvers for the Simulation of non-newtonian Fluids Sebastian Kuckuk FAU Erlangen-Nürnberg 18.01.2016 HiStencils 2016, Prague, Czech Republic Outline Outline Scope
Ikra-Cpp: A C++/CUDA DSL for Object-oriented Programming with Structure-of-Arrays Layout
 Ikra-Cpp: A C++/CUDA DSL for Object-oriented Programming with Structure-of-Arrays Layout Matthias Springer, Hidehiko Masuhara Tokyo Institute of Technology WPMVP 2018 Outline 1. Introduction 2. Ikra-Cpp
Ikra-Cpp: A C++/CUDA DSL for Object-oriented Programming with Structure-of-Arrays Layout Matthias Springer, Hidehiko Masuhara Tokyo Institute of Technology WPMVP 2018 Outline 1. Introduction 2. Ikra-Cpp
Automatic Generation of Algorithms and Data Structures for Geometric Multigrid. Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014
 Automatic Generation of Algorithms and Data Structures for Geometric Multigrid Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014 Introduction Multigrid Goal: Solve a partial differential
Automatic Generation of Algorithms and Data Structures for Geometric Multigrid Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014 Introduction Multigrid Goal: Solve a partial differential
Recent Updates to the CFD General Notation System (CGNS)
") Recent Updates to the CFD General Notation System (CGNS) C. L. Rumsey NASA Langley Research Center B. Wedan Computational Engineering Solutions T. Hauser University of Colorado M. Poinot ONERA AIAA-2012-1264,
Recent Updates to the CFD General Notation System (CGNS) C. L. Rumsey NASA Langley Research Center B. Wedan Computational Engineering Solutions T. Hauser University of Colorado M. Poinot ONERA AIAA-2012-1264,
Performance Analysis of the Lattice Boltzmann Method on x86-64 Architectures
 Performance Analysis of the Lattice Boltzmann Method on x86-64 Architectures Jan Treibig, Simon Hausmann, Ulrich Ruede Zusammenfassung The Lattice Boltzmann method (LBM) is a well established algorithm
Performance Analysis of the Lattice Boltzmann Method on x86-64 Architectures Jan Treibig, Simon Hausmann, Ulrich Ruede Zusammenfassung The Lattice Boltzmann method (LBM) is a well established algorithm
Generation of Multigrid-based Numerical Solvers for FPGA Accelerators
 Generation of Multigrid-based Numerical Solvers for FPGA Accelerators Christian Schmitt, Moritz Schmid, Frank Hannig, Jürgen Teich, Sebastian Kuckuk, Harald Köstler Hardware/Software Co-Design, System
Generation of Multigrid-based Numerical Solvers for FPGA Accelerators Christian Schmitt, Moritz Schmid, Frank Hannig, Jürgen Teich, Sebastian Kuckuk, Harald Köstler Hardware/Software Co-Design, System
LARGE-SCALE FREE-SURFACE FLOW SIMULATION USING LATTICE BOLTZMANN METHOD ON MULTI-GPU CLUSTERS
 ECCOMAS Congress 2016 VII European Congress on Computational Methods in Applied Sciences and Engineering M. Papadrakakis, V. Papadopoulos, G. Stefanou, V. Plevris (eds.) Crete Island, Greece, 5 10 June
ECCOMAS Congress 2016 VII European Congress on Computational Methods in Applied Sciences and Engineering M. Papadrakakis, V. Papadopoulos, G. Stefanou, V. Plevris (eds.) Crete Island, Greece, 5 10 June
AutoWIG Documentation
 AutoWIG Documentation Release 0.1 P. Fernique, C. Pradal Oct 30, 2018 Contents 1 Citation 3 2 Installation 5 2.1 Installation from binaries......................................... 5 2.2 Installation
AutoWIG Documentation Release 0.1 P. Fernique, C. Pradal Oct 30, 2018 Contents 1 Citation 3 2 Installation 5 2.1 Installation from binaries......................................... 5 2.2 Installation
Towards Generating Solvers for the Simulation of non-newtonian Fluids. Harald Köstler, Sebastian Kuckuk FAU Erlangen-Nürnberg
 Towards Generating Solvers for the Simulation of non-newtonian Fluids Harald Köstler, Sebastian Kuckuk FAU Erlangen-Nürnberg 22.12.2015 Outline Outline Scope and Motivation Project ExaStencils The Application
Towards Generating Solvers for the Simulation of non-newtonian Fluids Harald Köstler, Sebastian Kuckuk FAU Erlangen-Nürnberg 22.12.2015 Outline Outline Scope and Motivation Project ExaStencils The Application
Massively Parallel Phase-Field Simulations for Ternary Eutectic Directional Solidification
 Massively Parallel Phase-Field Simulations for Ternary Eutectic Directional Solidification Martin Bauer 1 *, Johannes Hötzer 2,3, Philipp Steinmetz 2, Marcus Jainta 2,3, Marco Berghoff 2, Florian Schornbaum
Massively Parallel Phase-Field Simulations for Ternary Eutectic Directional Solidification Martin Bauer 1 *, Johannes Hötzer 2,3, Philipp Steinmetz 2, Marcus Jainta 2,3, Marco Berghoff 2, Florian Schornbaum
Accelerating CFD with Graphics Hardware
 Accelerating CFD with Graphics Hardware Graham Pullan (Whittle Laboratory, Cambridge University) 16 March 2009 Today Motivation CPUs and GPUs Programming NVIDIA GPUs with CUDA Application to turbomachinery
Accelerating CFD with Graphics Hardware Graham Pullan (Whittle Laboratory, Cambridge University) 16 March 2009 Today Motivation CPUs and GPUs Programming NVIDIA GPUs with CUDA Application to turbomachinery
Sailfish: Lattice Boltzmann Fluid Simulations with GPUs and Python
 Sailfish: Lattice Boltzmann Fluid Simulations with GPUs and Python Micha l Januszewski Institute of Physics University of Silesia in Katowice, Poland Google GTC 2012 M. Januszewski (IoP, US) Sailfish:
Sailfish: Lattice Boltzmann Fluid Simulations with GPUs and Python Micha l Januszewski Institute of Physics University of Silesia in Katowice, Poland Google GTC 2012 M. Januszewski (IoP, US) Sailfish:
Scientific computing platforms at PGI / JCNS
 Member of the Helmholtz Association Scientific computing platforms at PGI / JCNS PGI-1 / IAS-1 Scientific Visualization Workshop Josef Heinen Outline Introduction Python distributions The SciPy stack Julia
Member of the Helmholtz Association Scientific computing platforms at PGI / JCNS PGI-1 / IAS-1 Scientific Visualization Workshop Josef Heinen Outline Introduction Python distributions The SciPy stack Julia
multiprocessing and mpi4py
 multiprocessing and mpi4py 02-03 May 2012 ARPA PIEMONTE m.cestari@cineca.it Bibliography multiprocessing http://docs.python.org/library/multiprocessing.html http://www.doughellmann.com/pymotw/multiprocessi
multiprocessing and mpi4py 02-03 May 2012 ARPA PIEMONTE m.cestari@cineca.it Bibliography multiprocessing http://docs.python.org/library/multiprocessing.html http://www.doughellmann.com/pymotw/multiprocessi
In-Situ Data Analysis and Visualization: ParaView, Calalyst and VTK-m
 In-Situ Data Analysis and Visualization: ParaView, Calalyst and VTK-m GTC, San Jose, CA March, 2015 Robert Maynard Marcus D. Hanwell 1 Agenda Introduction to ParaView Catalyst Run example Catalyst Script
In-Situ Data Analysis and Visualization: ParaView, Calalyst and VTK-m GTC, San Jose, CA March, 2015 Robert Maynard Marcus D. Hanwell 1 Agenda Introduction to ParaView Catalyst Run example Catalyst Script
Aerodynamic optimization of low pressure axial fans with OpenFOAM
 Aerodynamic optimization of low pressure axial fans with OpenFOAM 1, Max Hasenzahl 1, Prof. Dr.-Ing. Jens Friedrichs 2 1 Volkswagen AG (Cooling Development) 2 Institute of Jet Propulsion and Turbomachinery,
Aerodynamic optimization of low pressure axial fans with OpenFOAM 1, Max Hasenzahl 1, Prof. Dr.-Ing. Jens Friedrichs 2 1 Volkswagen AG (Cooling Development) 2 Institute of Jet Propulsion and Turbomachinery,
Python where we can, C ++ where we must
 Python where we can, C ++ where we must Source: http://xkcd.com/353/ Guy K. Kloss Python where we can,c++ where we must 1/28 Python where we can, C ++ where we must Guy K. Kloss BarCamp Auckland 2007 15
Python where we can, C ++ where we must Source: http://xkcd.com/353/ Guy K. Kloss Python where we can,c++ where we must 1/28 Python where we can, C ++ where we must Guy K. Kloss BarCamp Auckland 2007 15
A Multi-layered Domain-specific Language for Stencil Computations
 A Multi-layered Domain-specific Language for Stencil Computations Christian Schmitt Hardware/Software Co-Design, University of Erlangen-Nuremberg SPPEXA-Kolloquium, Erlangen, Germany; July 09, 2014 Challenges
A Multi-layered Domain-specific Language for Stencil Computations Christian Schmitt Hardware/Software Co-Design, University of Erlangen-Nuremberg SPPEXA-Kolloquium, Erlangen, Germany; July 09, 2014 Challenges
Performance and Software-Engineering Considerations for Massively Parallel Simulations
 Performance and Software-Engineering Considerations for Massively Parallel Simulations Ulrich Rüde (ruede@cs.fau.de) Ben Bergen, Frank Hülsemann, Christoph Freundl Universität Erlangen-Nürnberg www10.informatik.uni-erlangen.de
Performance and Software-Engineering Considerations for Massively Parallel Simulations Ulrich Rüde (ruede@cs.fau.de) Ben Bergen, Frank Hülsemann, Christoph Freundl Universität Erlangen-Nürnberg www10.informatik.uni-erlangen.de
Parallel I/O Libraries and Techniques
 Parallel I/O Libraries and Techniques Mark Howison User Services & Support I/O for scientifc data I/O is commonly used by scientific applications to: Store numerical output from simulations Load initial
Parallel I/O Libraries and Techniques Mark Howison User Services & Support I/O for scientifc data I/O is commonly used by scientific applications to: Store numerical output from simulations Load initial
PyCUDA. An Introduction
 PyCUDA An Introduction Scripting GPUs with PyCUDA Why do Scripting for GPUs? GPUs are everything that scripting languages are not: Highly parallel Very architecture-sensitive Built for maximum FP/memory
PyCUDA An Introduction Scripting GPUs with PyCUDA Why do Scripting for GPUs? GPUs are everything that scripting languages are not: Highly parallel Very architecture-sensitive Built for maximum FP/memory
MPI: the Message Passing Interface
 15 Parallel Programming with MPI Lab Objective: In the world of parallel computing, MPI is the most widespread and standardized message passing library. As such, it is used in the majority of parallel
15 Parallel Programming with MPI Lab Objective: In the world of parallel computing, MPI is the most widespread and standardized message passing library. As such, it is used in the majority of parallel
 A Contact Angle Model for the Parallel Free Surface Lattice Boltzmann Method in walberla Stefan Donath (stefan.donath@informatik.uni-erlangen.de) Computer Science 10 (System Simulation) University of Erlangen-Nuremberg
A Contact Angle Model for the Parallel Free Surface Lattice Boltzmann Method in walberla Stefan Donath (stefan.donath@informatik.uni-erlangen.de) Computer Science 10 (System Simulation) University of Erlangen-Nuremberg
High Scalability of Lattice Boltzmann Simulations with Turbulence Models using Heterogeneous Clusters
 SIAM PP 2014 High Scalability of Lattice Boltzmann Simulations with Turbulence Models using Heterogeneous Clusters C. Riesinger, A. Bakhtiari, M. Schreiber Technische Universität München February 20, 2014
SIAM PP 2014 High Scalability of Lattice Boltzmann Simulations with Turbulence Models using Heterogeneous Clusters C. Riesinger, A. Bakhtiari, M. Schreiber Technische Universität München February 20, 2014
The MoDeNa multi-scale simulation software framework
 The MoDeNa multi-scale simulation software framework Henrik Rusche h.rusche@wikki.co.uk Wikki Ltd. Jyväskylä, 28/05/2015 p. 1 MoDeNa project MOdelling of morphology DEvelopment of micro- and NAnostructures
The MoDeNa multi-scale simulation software framework Henrik Rusche h.rusche@wikki.co.uk Wikki Ltd. Jyväskylä, 28/05/2015 p. 1 MoDeNa project MOdelling of morphology DEvelopment of micro- and NAnostructures
Performance and Accuracy of Lattice-Boltzmann Kernels on Multi- and Manycore Architectures
 Performance and Accuracy of Lattice-Boltzmann Kernels on Multi- and Manycore Architectures Dirk Ribbrock, Markus Geveler, Dominik Göddeke, Stefan Turek Angewandte Mathematik, Technische Universität Dortmund
Performance and Accuracy of Lattice-Boltzmann Kernels on Multi- and Manycore Architectures Dirk Ribbrock, Markus Geveler, Dominik Göddeke, Stefan Turek Angewandte Mathematik, Technische Universität Dortmund
Mixed language programming with NumPy arrays
 Mixed language programming with NumPy arrays Simon Funke 1,2 Ola Skavhaug 3 Joakim Sundnes 1,2 Hans Petter Langtangen 1,2 Center for Biomedical Computing, Simula Research Laboratory 1 Dept. of Informatics,
Mixed language programming with NumPy arrays Simon Funke 1,2 Ola Skavhaug 3 Joakim Sundnes 1,2 Hans Petter Langtangen 1,2 Center for Biomedical Computing, Simula Research Laboratory 1 Dept. of Informatics,
Designing and Optimizing LQCD code using OpenACC
 Designing and Optimizing LQCD code using OpenACC E Calore, S F Schifano, R Tripiccione Enrico Calore University of Ferrara and INFN-Ferrara, Italy GPU Computing in High Energy Physics Pisa, Sep. 10 th,
Designing and Optimizing LQCD code using OpenACC E Calore, S F Schifano, R Tripiccione Enrico Calore University of Ferrara and INFN-Ferrara, Italy GPU Computing in High Energy Physics Pisa, Sep. 10 th,
ANSYS AIM 16.0 Overview. AIM Program Management
 1 2015 ANSYS, Inc. September 27, 2015 ANSYS AIM 16.0 Overview AIM Program Management 2 2015 ANSYS, Inc. September 27, 2015 Today s Simulation Challenges Leveraging simulation across engineering organizations
1 2015 ANSYS, Inc. September 27, 2015 ANSYS AIM 16.0 Overview AIM Program Management 2 2015 ANSYS, Inc. September 27, 2015 Today s Simulation Challenges Leveraging simulation across engineering organizations
The Icosahedral Nonhydrostatic (ICON) Model
 Model") The Icosahedral Nonhydrostatic (ICON) Model Scalability on Massively Parallel Computer Architectures Florian Prill, DWD + the ICON team 15th ECMWF Workshop on HPC in Meteorology October 2, 2012 ICON =
The Icosahedral Nonhydrostatic (ICON) Model Scalability on Massively Parallel Computer Architectures Florian Prill, DWD + the ICON team 15th ECMWF Workshop on HPC in Meteorology October 2, 2012 ICON =
Caching and Buffering in HDF5
 Caching and Buffering in HDF5 September 9, 2008 SPEEDUP Workshop - HDF5 Tutorial 1 Software stack Life cycle: What happens to data when it is transferred from application buffer to HDF5 file and from HDF5
Caching and Buffering in HDF5 September 9, 2008 SPEEDUP Workshop - HDF5 Tutorial 1 Software stack Life cycle: What happens to data when it is transferred from application buffer to HDF5 file and from HDF5
Python Scripting for Computational Science
 Hans Petter Langtangen Python Scripting for Computational Science Third Edition With 62 Figures 43 Springer Table of Contents 1 Introduction... 1 1.1 Scripting versus Traditional Programming... 1 1.1.1
Hans Petter Langtangen Python Scripting for Computational Science Third Edition With 62 Figures 43 Springer Table of Contents 1 Introduction... 1 1.1 Scripting versus Traditional Programming... 1 1.1.1
Foster s Methodology: Application Examples
 Foster s Methodology: Application Examples Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico October 19, 2011 CPD (DEI / IST) Parallel and
Foster s Methodology: Application Examples Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico October 19, 2011 CPD (DEI / IST) Parallel and
Architecture Aware Multigrid
 Architecture Aware Multigrid U. Rüde (LSS Erlangen, ruede@cs.fau.de) joint work with D. Ritter, T. Gradl, M. Stürmer, H. Köstler, J. Treibig and many more students Lehrstuhl für Informatik 10 (Systemsimulation)
Architecture Aware Multigrid U. Rüde (LSS Erlangen, ruede@cs.fau.de) joint work with D. Ritter, T. Gradl, M. Stürmer, H. Köstler, J. Treibig and many more students Lehrstuhl für Informatik 10 (Systemsimulation)
Speed and Accuracy of CFD: Achieving Both Successfully ANSYS UK S.A.Silvester
 Speed and Accuracy of CFD: Achieving Both Successfully ANSYS UK S.A.Silvester 2010 ANSYS, Inc. All rights reserved. 1 ANSYS, Inc. Proprietary Content ANSYS CFD Introduction ANSYS, the company Simulation
Speed and Accuracy of CFD: Achieving Both Successfully ANSYS UK S.A.Silvester 2010 ANSYS, Inc. All rights reserved. 1 ANSYS, Inc. Proprietary Content ANSYS CFD Introduction ANSYS, the company Simulation
3D ADI Method for Fluid Simulation on Multiple GPUs. Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA
 3D ADI Method for Fluid Simulation on Multiple GPUs Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA Introduction Fluid simulation using direct numerical methods Gives the most accurate result Requires
3D ADI Method for Fluid Simulation on Multiple GPUs Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA Introduction Fluid simulation using direct numerical methods Gives the most accurate result Requires
Simulation of nasal. flow...
 ...... Simulation of nasal flow Development of a process for estimating the pressure drop W.Liu, U.Janoske Lehrstuhl Strömungsmechanik, Bergische Universität Wuppertal B.Schmalenbeck, S.Langenberg, KWG
...... Simulation of nasal flow Development of a process for estimating the pressure drop W.Liu, U.Janoske Lehrstuhl Strömungsmechanik, Bergische Universität Wuppertal B.Schmalenbeck, S.Langenberg, KWG
Introduction to Scientific Computing with Python, part two.
 Introduction to Scientific Computing with Python, part two. M. Emmett Department of Mathematics University of North Carolina at Chapel Hill June 20 2012 The Zen of Python zen of python... fire up python
Introduction to Scientific Computing with Python, part two. M. Emmett Department of Mathematics University of North Carolina at Chapel Hill June 20 2012 The Zen of Python zen of python... fire up python
cobra-headtail ICE Meeting 6. November 2013, CERN
 cobra-headtail ICE Meeting 6. November 2013, CERN, Adrian Oeftiger, Giovanni Rumolo Overview Motivation Model Design Benchmark Demo Conclusions Motivation 3/68 What is cobra-headtail? A little success
cobra-headtail ICE Meeting 6. November 2013, CERN, Adrian Oeftiger, Giovanni Rumolo Overview Motivation Model Design Benchmark Demo Conclusions Motivation 3/68 What is cobra-headtail? A little success
Python Scripting for Computational Science
 Hans Petter Langtangen Python Scripting for Computational Science Third Edition With 62 Figures Sprin ger Table of Contents 1 Introduction 1 1.1 Scripting versus Traditional Programming 1 1.1.1 Why Scripting
Hans Petter Langtangen Python Scripting for Computational Science Third Edition With 62 Figures Sprin ger Table of Contents 1 Introduction 1 1.1 Scripting versus Traditional Programming 1 1.1.1 Why Scripting
Brook Spec v0.2. Ian Buck. May 20, What is Brook? 0.2 Streams
 Brook Spec v0.2 Ian Buck May 20, 2003 0.1 What is Brook? Brook is an extension of standard ANSI C which is designed to incorporate the ideas of data parallel computing and arithmetic intensity into a familiar,
Brook Spec v0.2 Ian Buck May 20, 2003 0.1 What is Brook? Brook is an extension of standard ANSI C which is designed to incorporate the ideas of data parallel computing and arithmetic intensity into a familiar,
Plotting data in a GPU with Histogrammar
 Plotting data in a GPU with Histogrammar Jim Pivarski Princeton DIANA September 30, 2016 1 / 20 Practical introduction Problem: You re developing a numerical algorithm for GPUs (tracking). If you were
Plotting data in a GPU with Histogrammar Jim Pivarski Princeton DIANA September 30, 2016 1 / 20 Practical introduction Problem: You re developing a numerical algorithm for GPUs (tracking). If you were
Message Passing Interface
 MPSoC Architectures MPI Alberto Bosio, Associate Professor UM Microelectronic Departement bosio@lirmm.fr Message Passing Interface API for distributed-memory programming parallel code that runs across
MPSoC Architectures MPI Alberto Bosio, Associate Professor UM Microelectronic Departement bosio@lirmm.fr Message Passing Interface API for distributed-memory programming parallel code that runs across
Using jupyter notebooks on Blue Waters. Roland Haas (NCSA / University of Illinois)
") Using jupyter notebooks on Blue Waters https://goo.gl/4eb7qw Roland Haas (NCSA / University of Illinois) Email: rhaas@ncsa.illinois.edu Jupyter notebooks 2/18 interactive, browser based interface to Python
Using jupyter notebooks on Blue Waters https://goo.gl/4eb7qw Roland Haas (NCSA / University of Illinois) Email: rhaas@ncsa.illinois.edu Jupyter notebooks 2/18 interactive, browser based interface to Python
Summer 2016 Internship: Mapping with MetPy
 Summer 2016 Internship: Mapping with MetPy Alex Haberlie 7/29/2016 MetPy refresher Collection of tools in Python for reading, visualizing and performing calculations with weather data. The space MetPy
Summer 2016 Internship: Mapping with MetPy Alex Haberlie 7/29/2016 MetPy refresher Collection of tools in Python for reading, visualizing and performing calculations with weather data. The space MetPy
An Evaluation of Domain-Specific Language Technologies for Code Generation
 An Evaluation of Domain-Specific Language Technologies for Code Generation Christian Schmitt, Sebastian Kuckuk, Harald Köstler, Frank Hannig, Jürgen Teich Hardware/Software Co-Design, System Simulation,
An Evaluation of Domain-Specific Language Technologies for Code Generation Christian Schmitt, Sebastian Kuckuk, Harald Köstler, Frank Hannig, Jürgen Teich Hardware/Software Co-Design, System Simulation,
OP2 C++ User s Manual
 OP2 C++ User s Manual Mike Giles, Gihan R. Mudalige, István Reguly December 2013 1 Contents 1 Introduction 4 2 Overview 5 3 OP2 C++ API 8 3.1 Initialisation and termination routines..........................
OP2 C++ User s Manual Mike Giles, Gihan R. Mudalige, István Reguly December 2013 1 Contents 1 Introduction 4 2 Overview 5 3 OP2 C++ API 8 3.1 Initialisation and termination routines..........................
The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy.! Thomas C.
 The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy! Thomas C. Schulthess ENES HPC Workshop, Hamburg, March 17, 2014 T. Schulthess!1
The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy! Thomas C. Schulthess ENES HPC Workshop, Hamburg, March 17, 2014 T. Schulthess!1
CD-adapco STAR Global Conference, Orlando, 2013, March 18-20
 Transient Radial Blower Simulation as Part of the Development Process W. Kühnel, M. Weinmann, G. Apostolopoulos, S. Larpent Behr GmbH & Co. KG, Germany CD-adapco STAR Global Conference, Orlando, 2013,
Transient Radial Blower Simulation as Part of the Development Process W. Kühnel, M. Weinmann, G. Apostolopoulos, S. Larpent Behr GmbH & Co. KG, Germany CD-adapco STAR Global Conference, Orlando, 2013,
STCE. An (more) effective Discrete Adjoint Model for OpenFOAM
 effective Discrete Adjoint Model for OpenFOAM") An (more) effective Discrete Adjoint Model for OpenFOAM Markus Towara, Uwe Naumann Software and Tools for Computational Engineering Science RWTH Aachen University EuroAD 2013, Oxford, 10. December 2013
An (more) effective Discrete Adjoint Model for OpenFOAM Markus Towara, Uwe Naumann Software and Tools for Computational Engineering Science RWTH Aachen University EuroAD 2013, Oxford, 10. December 2013
A performance portable implementation of HOMME via the Kokkos programming model
 E x c e p t i o n a l s e r v i c e i n t h e n a t i o n a l i n t e re s t A performance portable implementation of HOMME via the Kokkos programming model L.Bertagna, M.Deakin, O.Guba, D.Sunderland,
E x c e p t i o n a l s e r v i c e i n t h e n a t i o n a l i n t e re s t A performance portable implementation of HOMME via the Kokkos programming model L.Bertagna, M.Deakin, O.Guba, D.Sunderland,
An introduction to scientific programming with. Session 5: Extreme Python
 An introduction to scientific programming with Session 5: Extreme Python PyTables For creating, storing and analysing datasets from simple, small tables to complex, huge datasets standard HDF5 file format
An introduction to scientific programming with Session 5: Extreme Python PyTables For creating, storing and analysing datasets from simple, small tables to complex, huge datasets standard HDF5 file format
The Cut and Thrust of CUDA
 The Cut and Thrust of CUDA Luke Hodkinson Center for Astrophysics and Supercomputing Swinburne University of Technology Melbourne, Hawthorn 32000, Australia May 16, 2013 Luke Hodkinson The Cut and Thrust
The Cut and Thrust of CUDA Luke Hodkinson Center for Astrophysics and Supercomputing Swinburne University of Technology Melbourne, Hawthorn 32000, Australia May 16, 2013 Luke Hodkinson The Cut and Thrust
Data Intensive processing with irods and the middleware CiGri for the Whisper project Xavier Briand
 and the middleware CiGri for the Whisper project Use Case of Data-Intensive processing with irods Collaboration between: IT part of Whisper: Sofware development, computation () Platform Ciment: IT infrastructure
and the middleware CiGri for the Whisper project Use Case of Data-Intensive processing with irods Collaboration between: IT part of Whisper: Sofware development, computation () Platform Ciment: IT infrastructure
References. T. LeBlanc, Memory management for large-scale numa multiprocessors, Department of Computer Science: Technical report*311
 References [Ande 89] [Ande 92] [Ghos 93] [LeBl 89] [Rüde92] T. Anderson, E. Lazowska, H. Levy, The Performance Implication of Thread Management Alternatives for Shared-Memory Multiprocessors, ACM Trans.
References [Ande 89] [Ande 92] [Ghos 93] [LeBl 89] [Rüde92] T. Anderson, E. Lazowska, H. Levy, The Performance Implication of Thread Management Alternatives for Shared-Memory Multiprocessors, ACM Trans.
STAR-CCM+: Ventilation SPRING Notes on the software 2. Assigned exercise (submission via Blackboard; deadline: Thursday Week 9, 11 pm)
") STAR-CCM+: Ventilation SPRING 208. Notes on the software 2. Assigned exercise (submission via Blackboard; deadline: Thursday Week 9, pm). Features of the Exercise Natural ventilation driven by localised
STAR-CCM+: Ventilation SPRING 208. Notes on the software 2. Assigned exercise (submission via Blackboard; deadline: Thursday Week 9, pm). Features of the Exercise Natural ventilation driven by localised
Fast Dynamic Load Balancing for Extreme Scale Systems
 Fast Dynamic Load Balancing for Extreme Scale Systems Cameron W. Smith, Gerrett Diamond, M.S. Shephard Computation Research Center (SCOREC) Rensselaer Polytechnic Institute Outline: n Some comments on
Fast Dynamic Load Balancing for Extreme Scale Systems Cameron W. Smith, Gerrett Diamond, M.S. Shephard Computation Research Center (SCOREC) Rensselaer Polytechnic Institute Outline: n Some comments on
LATTICE-BOLTZMANN METHOD FOR THE SIMULATION OF LAMINAR MIXERS
 14 th European Conference on Mixing Warszawa, 10-13 September 2012 LATTICE-BOLTZMANN METHOD FOR THE SIMULATION OF LAMINAR MIXERS Felix Muggli a, Laurent Chatagny a, Jonas Lätt b a Sulzer Markets & Technology
14 th European Conference on Mixing Warszawa, 10-13 September 2012 LATTICE-BOLTZMANN METHOD FOR THE SIMULATION OF LAMINAR MIXERS Felix Muggli a, Laurent Chatagny a, Jonas Lätt b a Sulzer Markets & Technology
High-level Abstraction for Block Structured Applications: A lattice Boltzmann Exploration
 High-level Abstraction for Block Structured Applications: A lattice Boltzmann Exploration Jianping Meng, Xiao-Jun Gu, David R. Emerson, Gihan Mudalige, István Reguly and Mike B Giles Scientific Computing
High-level Abstraction for Block Structured Applications: A lattice Boltzmann Exploration Jianping Meng, Xiao-Jun Gu, David R. Emerson, Gihan Mudalige, István Reguly and Mike B Giles Scientific Computing
First Time Experiences Using SciPy for Computer Vision Research
 First Time Experiences Using SciPy for Computer Vision Research Damian Eads and Edward Rosten ISR Division Los Alamos National Laboratory Los Alamos, New Mexico {eads,edrosten}@lanl.gov Find the cars Research
First Time Experiences Using SciPy for Computer Vision Research Damian Eads and Edward Rosten ISR Division Los Alamos National Laboratory Los Alamos, New Mexico {eads,edrosten}@lanl.gov Find the cars Research
Comparison of PGAS Languages on a Linked Cell Algorithm
 Comparison of PGAS Languages on a Linked Cell Algorithm Martin Bauer, Christian Kuschel, Daniel Ritter, Klaus Sembritzki Lehrstuhl für Systemsimulation Friedrich-Alexander-Universität Erlangen-Nürnberg
Comparison of PGAS Languages on a Linked Cell Algorithm Martin Bauer, Christian Kuschel, Daniel Ritter, Klaus Sembritzki Lehrstuhl für Systemsimulation Friedrich-Alexander-Universität Erlangen-Nürnberg
Charm++ for Productivity and Performance
 Charm++ for Productivity and Performance A Submission to the 2011 HPC Class II Challenge Laxmikant V. Kale Anshu Arya Abhinav Bhatele Abhishek Gupta Nikhil Jain Pritish Jetley Jonathan Lifflander Phil
Charm++ for Productivity and Performance A Submission to the 2011 HPC Class II Challenge Laxmikant V. Kale Anshu Arya Abhinav Bhatele Abhishek Gupta Nikhil Jain Pritish Jetley Jonathan Lifflander Phil
Domain Decomposition for Colloid Clusters. Pedro Fernando Gómez Fernández
 Domain Decomposition for Colloid Clusters Pedro Fernando Gómez Fernández MSc in High Performance Computing The University of Edinburgh Year of Presentation: 2004 Authorship declaration I, Pedro Fernando
Domain Decomposition for Colloid Clusters Pedro Fernando Gómez Fernández MSc in High Performance Computing The University of Edinburgh Year of Presentation: 2004 Authorship declaration I, Pedro Fernando
Parallelization of Scientific Applications (II)
") Parallelization of Scientific Applications (II) Parallelization of Particle Based Methods Russian-German School on High Performance Computer Systems, June, 27 th until July, 6 th 2005, Novosibirsk 4. Day,
Parallelization of Scientific Applications (II) Parallelization of Particle Based Methods Russian-German School on High Performance Computer Systems, June, 27 th until July, 6 th 2005, Novosibirsk 4. Day,
MASSIVELY-PARALLEL MULTI-GPU SIMULATIONS FOR FAST AND ACCURATE AUTOMOTIVE AERODYNAMICS
 6th European Conference on Computational Mechanics (ECCM 6) 7th European Conference on Computational Fluid Dynamics (ECFD 7) -5 June 28, Glasgow, UK MASSIVELY-PARALLEL MULTI-GPU SIMULATIONS FOR FAST AND
6th European Conference on Computational Mechanics (ECCM 6) 7th European Conference on Computational Fluid Dynamics (ECFD 7) -5 June 28, Glasgow, UK MASSIVELY-PARALLEL MULTI-GPU SIMULATIONS FOR FAST AND
Introduction to High-Performance Computing
 Introduction to High-Performance Computing Dr. Axel Kohlmeyer Associate Dean for Scientific Computing, CST Associate Director, Institute for Computational Science Assistant Vice President for High-Performance
Introduction to High-Performance Computing Dr. Axel Kohlmeyer Associate Dean for Scientific Computing, CST Associate Director, Institute for Computational Science Assistant Vice President for High-Performance
Generic Refinement and Block Partitioning enabling efficient GPU CFD on Unstructured Grids
 Generic Refinement and Block Partitioning enabling efficient GPU CFD on Unstructured Grids Matthieu Lefebvre 1, Jean-Marie Le Gouez 2 1 PhD at Onera, now post-doc at Princeton, department of Geosciences,
Generic Refinement and Block Partitioning enabling efficient GPU CFD on Unstructured Grids Matthieu Lefebvre 1, Jean-Marie Le Gouez 2 1 PhD at Onera, now post-doc at Princeton, department of Geosciences,
6.S096 Lecture 10 Course Recap, Interviews, Advanced Topics
 6.S096 Lecture 10 Course Recap, Interviews, Advanced Topics Grab Bag & Perspective January 31, 2014 6.S096 Lecture 10 Course Recap, Interviews, Advanced Topics January 31, 2014 1 / 19 Outline 1 Perspective
6.S096 Lecture 10 Course Recap, Interviews, Advanced Topics Grab Bag & Perspective January 31, 2014 6.S096 Lecture 10 Course Recap, Interviews, Advanced Topics January 31, 2014 1 / 19 Outline 1 Perspective
CS4961 Parallel Programming. Lecture 16: Introduction to Message Passing 11/3/11. Administrative. Mary Hall November 3, 2011.
 CS4961 Parallel Programming Lecture 16: Introduction to Message Passing Administrative Next programming assignment due on Monday, Nov. 7 at midnight Need to define teams and have initial conversation with
CS4961 Parallel Programming Lecture 16: Introduction to Message Passing Administrative Next programming assignment due on Monday, Nov. 7 at midnight Need to define teams and have initial conversation with
Contribution of Python to LMGC90 platform
 Contribution of Python to LMGC90 platform Bagneris M., Dubois F., Iceta D., Martin A. and Mozul R. Laboratoire de Mécanique et Génie Civil Université Montpellier 2 - Centre National de la Recherche Scientifique
Contribution of Python to LMGC90 platform Bagneris M., Dubois F., Iceta D., Martin A. and Mozul R. Laboratoire de Mécanique et Génie Civil Université Montpellier 2 - Centre National de la Recherche Scientifique
PyROOT Automatic Python bindings for ROOT. Enric Tejedor, Stefan Wunsch, Guilherme Amadio for the ROOT team ROOT. Data Analysis Framework
 PyROOT Automatic Python bindings for ROOT Enric Tejedor, Stefan Wunsch, Guilherme Amadio for the ROOT team PyHEP 2018 Sofia, Bulgaria ROOT Data Analysis Framework https://root.cern Outline Introduction:
PyROOT Automatic Python bindings for ROOT Enric Tejedor, Stefan Wunsch, Guilherme Amadio for the ROOT team PyHEP 2018 Sofia, Bulgaria ROOT Data Analysis Framework https://root.cern Outline Introduction:
Post-processing utilities in Elmer
 Post-processing utilities in Elmer Peter Råback ElmerTeam CSC IT Center for Science PATC course on parallel workflows Stockholm, 4-6.12.2013 Alternative postprocessors for Elmer Open source ElmerPost Postprocessor
Post-processing utilities in Elmer Peter Råback ElmerTeam CSC IT Center for Science PATC course on parallel workflows Stockholm, 4-6.12.2013 Alternative postprocessors for Elmer Open source ElmerPost Postprocessor
How to Optimize Geometric Multigrid Methods on GPUs
 How to Optimize Geometric Multigrid Methods on GPUs Markus Stürmer, Harald Köstler, Ulrich Rüde System Simulation Group University Erlangen March 31st 2011 at Copper Schedule motivation imaging in gradient
How to Optimize Geometric Multigrid Methods on GPUs Markus Stürmer, Harald Köstler, Ulrich Rüde System Simulation Group University Erlangen March 31st 2011 at Copper Schedule motivation imaging in gradient
CAF versus MPI Applicability of Coarray Fortran to a Flow Solver
 CAF versus MPI Applicability of Coarray Fortran to a Flow Solver Manuel Hasert, Harald Klimach, Sabine Roller m.hasert@grs-sim.de Applied Supercomputing in Engineering Motivation We develop several CFD
CAF versus MPI Applicability of Coarray Fortran to a Flow Solver Manuel Hasert, Harald Klimach, Sabine Roller m.hasert@grs-sim.de Applied Supercomputing in Engineering Motivation We develop several CFD
CSCI 171 Chapter Outlines
 Contents CSCI 171 Chapter 1 Overview... 2 CSCI 171 Chapter 2 Programming Components... 3 CSCI 171 Chapter 3 (Sections 1 4) Selection Structures... 5 CSCI 171 Chapter 3 (Sections 5 & 6) Iteration Structures
Contents CSCI 171 Chapter 1 Overview... 2 CSCI 171 Chapter 2 Programming Components... 3 CSCI 171 Chapter 3 (Sections 1 4) Selection Structures... 5 CSCI 171 Chapter 3 (Sections 5 & 6) Iteration Structures