walberla: Developing a Massively Parallel HPC Framework
|
|
|
- James Sparks
- 6 years ago
- Views:
Transcription

1 walberla: Developing a Massively Parallel HPC Framework SIAM CS&E 2013, Boston February 26, 2013 Florian Schornbaum*, Christian Godenschwager*, Martin Bauer*, Matthias Markl, Ulrich Rüde* *Chair for System Simulation, Chair of Metals Science and Technology Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen, Germany
2 Outline Introduction Implementation From Polymorphism to Concepts Code Generation C++11 Tools & Maintenance CMake, CTest, and CDash git Fast, Distributed Source Code Management Results / Benchmarks Conclusion 2
3 Introduction What is walberla? What are its goals as a software framework?
4 Introduction walberla (widely applicable Lattice Boltzmann framework from Erlangen): originally developed for CFD simulations based on the Lattice Boltzmann method (LBM) general HPC software framework (still strong focus on LBM, but multigrid methods also possible) coupling with in-house rigid body physics engine pe written in C++ Lattice Boltzmann method: stream (neighbors) & collide (cell-local) different models & methods: D2Q9/D3Q19/D3Q27 & SRT/TRT/MRT 4
 around sphere (E.")
 blood flow through")
5 Examples turbulent flow (Re=11000) around sphere (E. Fattahi, D. Weingaertner) blood flow through coronary arteries (C. Godenschwager) 5

 ] POV-Ray")
6 Examples electron beam melting metal powder: 3D printing (R. Ammer, M. Markl) [ liquid: walberla (LBM) metal powder: pe (fully resolved rigid bodies) ] POV-Ray rendering of actual simulation 6
7 HPC Framework Goals High single node performance vectorized compute kernels (SIMD: SSE, AVX, QPX) performance modeling Scalability run with 10 0 to 10 6 cores/processes ( unlimited number of processes) only fully distributed data structures/algorithms and local, process-to-process (no all-to-one or all-to-all) communication 7
8 HPC Framework Goals Flexibility / Extensibility arbitrary number of different compute kernels interchangeable/configurable boundary handling, communication, and input/output mechanisms allow any arbitrary combination of functionality Support for many platforms/compilers laptops, desktops, supercomputers (Linux/Unix, Windows) compilers: GCC, Intel, Visual Studio, IBM parallelization: no MPI, pure MPI, pure OpenMP, MPI+OpenMP 8
9 Implementation Polymorphism, concepts, or code generation? Where to with C++?
10 Data Structures / Software Design Domain decomposition blocks containing uniform grids uniform block decomposition non-uniform, octree-like block decomposition Former software design mistake: non-uniform, octree-like block decomposition equal number of cells per block tight coupling between one particular domain decomposition and everything else (compute kernels, input, output, etc.) 10
11 Data Structures / Software Design Better design: make use of polymorphism similarities between different block decompositions introduce interfaces/base classes for block structures, blocks, and block IDs a lot of the framework functionality can already be implemented in these base classes many algorithms can be implemented using these interfaces much better maintainability high reusability of existing code (input, output, ) Performance? overhead of virtual function calls can be neglected for high-level framework functionality 11
12 Data Structures / Software Design Interchangeability / reusability of functionality in lowlevel, performance-critical parts of code? example: boundary handling (different boundary conditions) polymorphism: works, but too much overhead solution: combination of templates (compile time evaluation) solution: and concepts Concept: interface without polymorphism no language support (considered for C++11, removed from draft in 2009) [ ] is a description of supported operations on a type, including syntax and semantics [ ] related to abstract base classes but [ ] do not require a subtype relationship (Wikipedia) 12
13 Data Structures / Software Design Example: template< typename T > int foo( const T& t, const int bar ) { return t.baz(bar); } every type usable with function foo must have a public member function int baz( const int ) Concepts and boundary handling: boundary condition: must implement a specific concept boundary handling: receives an arbitrary number of boundary conditions as templates 13
14 Data Structures / Software Design Concepts and boundary handling (cond.): At compile time, an application-specific boundary handling is assembled from a list of boundary conditions. high performance (identical to hard-coded, problem-adapted function) highly customizable Conclusion: high-level framework functionality: polymorphism low-level, performance-critical code: concepts & templates 14
15 Data Structures / Software Design Interchangeability / reusability of functionality in lowlevel, performance-critical parts of code (cond.): example: The same data structures and the same algoexample: rithms can be used with different stencils. D2Q9: D2Q5: define concept stencil, use templates, write code once flexible, reusable, high performance. but: hard to keep consistent when concept stencil is changed ( maintenance overhead, prone to mistakes) However, all stencils are constructed using the same pattern! (different to boundary handling & boundary conditions) 15
16 Data Structures / Software Design Concept stencil (cond.): All stencils are constructed following the same pattern! use template metaprogramming to generate all required stencils at compile time? failed attempt messy, complex C++ template code C++03: no guarantees that certain specific values are evaluated at compile time (C++11: constexpr!) code generation via scripts: file template used to generate all stencils maintainability: no code duplication compile time evaluation (concepts & templates) high performance 16
17 C++11 / Software Design C++11: Embrace the full capabilities of your C++11: programming language! Bad news first: The common subset of features implemented by all major compilers (GCC, Intel, IBM, Visual Studio) is very small. Even if (many) language features are already implemented, often compiling the standard library (and/or boost) will fail when C++11 is fully activated. cannot use: variadic templates, constexpr, lambdas, 17
18 C++11 / Software Design C++11: Embrace the full capabilities of your C++11: programming language! The good news (features you can use): compile time checks (with full support by the language): static_assert( sizeof(t) >= 8, "some meaningful message" ); auto (much less typedefs/screen filling types): for( auto block = blockstorage.begin(); { } block!= blockstorage.end(); ++block ) const auto& aabb = block->getaabb(); [...] makes code a lot cleaner and faster to develop 18
19 Tools & Maintenance Can there be too much Kitware? Distribution trumps centralization?
, SuperMUC (Top6)) CMake allows walberla to be build anywhere from a MacBook Air to Blue Gene/Q supercomputers with just one CMake configuration/setup.")
20 Building and Testing walberla uses CMake: platform-/compiler-independent build system Makefile on Linux/Unix, project files for Visual Studio, compiler support: GCC, Intel, IBM, Visual Studio, available on supercomputers (JUQUEEN (Top5), SuperMUC (Top6)) CMake allows walberla to be build anywhere from a MacBook Air to Blue Gene/Q supercomputers with just one CMake configuration/setup. 20
21 Building and Testing Testing: CTest fully integrated into CMake ecosystem tests can be manually executed, but become particularly interesting when combined with our own fully automatic build and testing environment controlled by Python build scripts (rely on XML configuration files) triggered by every check-in in main repository several different combinations of compilers and build types: GCC or Intel, MPI or no MPI, Release or Debug, nightly builds: Windows & Visual Studio reports results to CDash 21


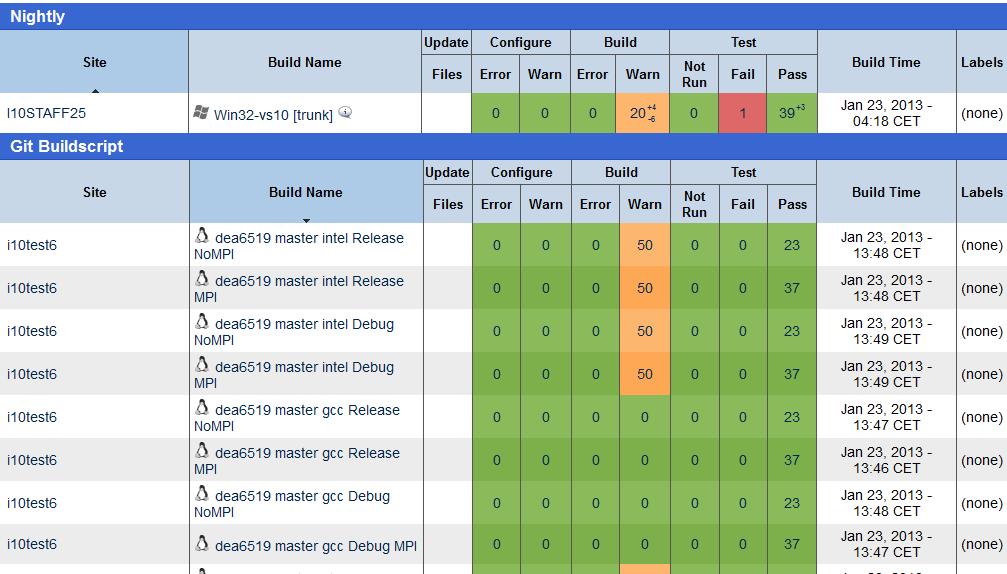
22 Building and Testing walberla uses 22
23 Revision Control walberla used to use Subversion (SVN) walberla now uses distributed revision control system git & supercomputers: available on all supercomputers we are currently using git just works: allows for pull/fetch and push operations Even if outgoing connections are blocked, you can still push (via ssh) your local commits to your repository on the cluster. unbelievably fast! 23
24 Results / Benchmarks Blue Gene/Q or Xeon? IBM vs. Intel!
25 Results / Benchmarks Testing environments: JUQUEEN (TOP500: 5), Blue Gene/Q, 459K cores, 1 GB/core IBM compiler 12.1, IBM MPI Green500: 5 (2, MFLOPS / Watt ) SuperMUC (TOP500: 6), Intel Xeon, 147K cores, 2 GB/core Benchmark: Intel compiler , IBM MPI worlds fastest x86-based supercomputer LBM fluid simulation (D3Q19) uniform grid (lid driven cavity, flow around object in channel) weak scaling (const. number of cells per core) MLUP/s: million/mega lattice cell updates per second 25
26 Results / Benchmarks SuperMUC single node (3.34 million cells per core) LBM compute kernel type 140 MLUP/s 120 SRT TRT cores 12 more complex, but also much more relevant for real 16 simulations! limited by memory bandwidth 26
27 Results / Benchmarks SuperMUC single node (3.34 million cells per core) MLUP/s SRT 100 TRT 80 SRT. 60 SRT already quite optimized! cores 12 limited by memory bandwidth 16 naïve, straightforward implementation 27
28 Results / Benchmarks JUQUEEN single node (1.73 million cells per core) MLUP/s 60 SRT 50 TRT 40 SRT. 30 SRT already quite optimized! cores limited by memory bandwidth 16 naïve, straightforward implementation 28
29 Results / Benchmarks JUQUEEN single node (1.73 million cells per core) MLUP/s SRT. 40 hybrid version (4 threads per core) TRT cores 16 limited by memory bandwidth 29
30 MLUP/s per core Results / Benchmarks SuperMUC TRT kernel (3.34 million cells per core) jobs are already in the queue, waiting to be executed cores #processes per node 16P 1T 4P 4T 2P 8T #threads per process 30
31 MLUP/s per core Results / Benchmarks JUQUEEN TRT kernel (1.73 million cells per core) 5 4,5 4 3,5 3 2,5 2 1,5 1 0, x cells updated per second! (19 values per cell) 0.33 PFlop/s (0.33 x Flop/s) cores #processes per node 64P 1T 16P 4T 8P 8T #threads per process 31

32 Summary & Conclusion So, what was it all about? What next?
33 Summary & Conclusion Usability of the framework & reusability of code: possible, even if main focus is on speed/performance Programming language of choice: C++ (C++11) Maintainability: An automatic build and testing system allows walberla to support a wide variety of platforms (Linux, Windows, laptops, desktops, supercomputers, MPI, no MPI, OpenMP, hybrid, ) and compilers (GCC, Intel, IBM, Visual Studio). future plan for walberla: go open source (current owner? which license? which parts of the code?) 33
34 THANK YOU FOR YOUR ATTENTION! QUESTIONS?
simulation framework for piecewise regular grids
 WALBERLA, an ultra-scalable multiphysics simulation framework for piecewise regular grids ParCo 2015, Edinburgh September 3rd, 2015 Christian Godenschwager, Florian Schornbaum, Martin Bauer, Harald Köstler
WALBERLA, an ultra-scalable multiphysics simulation framework for piecewise regular grids ParCo 2015, Edinburgh September 3rd, 2015 Christian Godenschwager, Florian Schornbaum, Martin Bauer, Harald Köstler
Computational Fluid Dynamics with the Lattice Boltzmann Method KTH SCI, Stockholm
 Computational Fluid Dynamics with the Lattice Boltzmann Method KTH SCI, Stockholm March 17 March 21, 2014 Florian Schornbaum, Martin Bauer, Simon Bogner Chair for System Simulation Friedrich-Alexander-Universität
Computational Fluid Dynamics with the Lattice Boltzmann Method KTH SCI, Stockholm March 17 March 21, 2014 Florian Schornbaum, Martin Bauer, Simon Bogner Chair for System Simulation Friedrich-Alexander-Universität
Peta-Scale Simulations with the HPC Software Framework walberla:
 Peta-Scale Simulations with the HPC Software Framework walberla: Massively Parallel AMR for the Lattice Boltzmann Method SIAM PP 2016, Paris April 15, 2016 Florian Schornbaum, Christian Godenschwager,
Peta-Scale Simulations with the HPC Software Framework walberla: Massively Parallel AMR for the Lattice Boltzmann Method SIAM PP 2016, Paris April 15, 2016 Florian Schornbaum, Christian Godenschwager,
Performance Optimization of a Massively Parallel Phase-Field Method Using the HPC Framework walberla
 Performance Optimization of a Massively Parallel Phase-Field Method Using the HPC Framework walberla SIAM PP 2016, April 13 th 2016 Martin Bauer, Florian Schornbaum, Christian Godenschwager, Johannes Hötzer,
Performance Optimization of a Massively Parallel Phase-Field Method Using the HPC Framework walberla SIAM PP 2016, April 13 th 2016 Martin Bauer, Florian Schornbaum, Christian Godenschwager, Johannes Hötzer,
Massively Parallel Phase Field Simulations using HPC Framework walberla
 Massively Parallel Phase Field Simulations using HPC Framework walberla SIAM CSE 2015, March 15 th 2015 Martin Bauer, Florian Schornbaum, Christian Godenschwager, Johannes Hötzer, Harald Köstler and Ulrich
Massively Parallel Phase Field Simulations using HPC Framework walberla SIAM CSE 2015, March 15 th 2015 Martin Bauer, Florian Schornbaum, Christian Godenschwager, Johannes Hötzer, Harald Köstler and Ulrich
The walberla Framework: Multi-physics Simulations on Heterogeneous Parallel Platforms
 The walberla Framework: Multi-physics Simulations on Heterogeneous Parallel Platforms Harald Köstler, Uli Rüde (LSS Erlangen, ruede@cs.fau.de) Lehrstuhl für Simulation Universität Erlangen-Nürnberg www10.informatik.uni-erlangen.de
The walberla Framework: Multi-physics Simulations on Heterogeneous Parallel Platforms Harald Köstler, Uli Rüde (LSS Erlangen, ruede@cs.fau.de) Lehrstuhl für Simulation Universität Erlangen-Nürnberg www10.informatik.uni-erlangen.de
A Python extension for the massively parallel framework walberla
 A Python extension for the massively parallel framework walberla PyHPC at SC 14, November 17 th 2014 Martin Bauer, Florian Schornbaum, Christian Godenschwager, Matthias Markl, Daniela Anderl, Harald Köstler
A Python extension for the massively parallel framework walberla PyHPC at SC 14, November 17 th 2014 Martin Bauer, Florian Schornbaum, Christian Godenschwager, Matthias Markl, Daniela Anderl, Harald Köstler
Lattice Boltzmann Methods on the way to exascale
 Lattice Boltzmann Methods on the way to exascale Ulrich Rüde (LSS Erlangen, ulrich.ruede@fau.de) Lehrstuhl für Simulation Universität Erlangen-Nürnberg www10.informatik.uni-erlangen.de HIGH PERFORMANCE
Lattice Boltzmann Methods on the way to exascale Ulrich Rüde (LSS Erlangen, ulrich.ruede@fau.de) Lehrstuhl für Simulation Universität Erlangen-Nürnberg www10.informatik.uni-erlangen.de HIGH PERFORMANCE
Introducing a Cache-Oblivious Blocking Approach for the Lattice Boltzmann Method
 Introducing a Cache-Oblivious Blocking Approach for the Lattice Boltzmann Method G. Wellein, T. Zeiser, G. Hager HPC Services Regional Computing Center A. Nitsure, K. Iglberger, U. Rüde Chair for System
Introducing a Cache-Oblivious Blocking Approach for the Lattice Boltzmann Method G. Wellein, T. Zeiser, G. Hager HPC Services Regional Computing Center A. Nitsure, K. Iglberger, U. Rüde Chair for System
Large scale Imaging on Current Many- Core Platforms
 Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Performance and Accuracy of Lattice-Boltzmann Kernels on Multi- and Manycore Architectures
 Performance and Accuracy of Lattice-Boltzmann Kernels on Multi- and Manycore Architectures Dirk Ribbrock, Markus Geveler, Dominik Göddeke, Stefan Turek Angewandte Mathematik, Technische Universität Dortmund
Performance and Accuracy of Lattice-Boltzmann Kernels on Multi- and Manycore Architectures Dirk Ribbrock, Markus Geveler, Dominik Göddeke, Stefan Turek Angewandte Mathematik, Technische Universität Dortmund
Software and Performance Engineering for numerical codes on GPU clusters
 Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
Reconstruction of Trees from Laser Scan Data and further Simulation Topics
 Reconstruction of Trees from Laser Scan Data and further Simulation Topics Helmholtz-Research Center, Munich Daniel Ritter http://www10.informatik.uni-erlangen.de Overview 1. Introduction of the Chair
Reconstruction of Trees from Laser Scan Data and further Simulation Topics Helmholtz-Research Center, Munich Daniel Ritter http://www10.informatik.uni-erlangen.de Overview 1. Introduction of the Chair
From Notebooks to Supercomputers: Tap the Full Potential of Your CUDA Resources with LibGeoDecomp
 From Notebooks to Supercomputers: Tap the Full Potential of Your CUDA Resources with andreas.schaefer@cs.fau.de Friedrich-Alexander-Universität Erlangen-Nürnberg GPU Technology Conference 2013, San José,
From Notebooks to Supercomputers: Tap the Full Potential of Your CUDA Resources with andreas.schaefer@cs.fau.de Friedrich-Alexander-Universität Erlangen-Nürnberg GPU Technology Conference 2013, San José,
Simulation of Liquid-Gas-Solid Flows with the Lattice Boltzmann Method
 Simulation of Liquid-Gas-Solid Flows with the Lattice Boltzmann Method June 21, 2011 Introduction Free Surface LBM Liquid-Gas-Solid Flows Parallel Computing Examples and More References Fig. Simulation
Simulation of Liquid-Gas-Solid Flows with the Lattice Boltzmann Method June 21, 2011 Introduction Free Surface LBM Liquid-Gas-Solid Flows Parallel Computing Examples and More References Fig. Simulation
Turbostream: A CFD solver for manycore
 Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Performance Analysis of the Lattice Boltzmann Method on x86-64 Architectures
 Performance Analysis of the Lattice Boltzmann Method on x86-64 Architectures Jan Treibig, Simon Hausmann, Ulrich Ruede Zusammenfassung The Lattice Boltzmann method (LBM) is a well established algorithm
Performance Analysis of the Lattice Boltzmann Method on x86-64 Architectures Jan Treibig, Simon Hausmann, Ulrich Ruede Zusammenfassung The Lattice Boltzmann method (LBM) is a well established algorithm
High Performance Computing Course Notes HPC Fundamentals
 High Performance Computing Course Notes 2008-2009 2009 HPC Fundamentals Introduction What is High Performance Computing (HPC)? Difficult to define - it s a moving target. Later 1980s, a supercomputer performs
High Performance Computing Course Notes 2008-2009 2009 HPC Fundamentals Introduction What is High Performance Computing (HPC)? Difficult to define - it s a moving target. Later 1980s, a supercomputer performs
Performance and Software-Engineering Considerations for Massively Parallel Simulations
 Performance and Software-Engineering Considerations for Massively Parallel Simulations Ulrich Rüde (ruede@cs.fau.de) Ben Bergen, Frank Hülsemann, Christoph Freundl Universität Erlangen-Nürnberg www10.informatik.uni-erlangen.de
Performance and Software-Engineering Considerations for Massively Parallel Simulations Ulrich Rüde (ruede@cs.fau.de) Ben Bergen, Frank Hülsemann, Christoph Freundl Universität Erlangen-Nürnberg www10.informatik.uni-erlangen.de
Lattice Boltzmann methods on the way to exascale
 Lattice Boltzmann methods on the way to exascale Ulrich Rüde LSS Erlangen and CERFACS Toulouse ulrich.ruede@fau.de Centre Européen de Recherche et de Formation Avancée en Calcul Scientifique www.cerfacs.fr
Lattice Boltzmann methods on the way to exascale Ulrich Rüde LSS Erlangen and CERFACS Toulouse ulrich.ruede@fau.de Centre Européen de Recherche et de Formation Avancée en Calcul Scientifique www.cerfacs.fr
Benchmark results on Knight Landing (KNL) architecture
 architecture") Benchmark results on Knight Landing (KNL) architecture Domenico Guida, CINECA SCAI (Bologna) Giorgio Amati, CINECA SCAI (Roma) Roma 23/10/2017 KNL, BDW, SKL A1 BDW A2 KNL A3 SKL cores per node 2 x 18 @2.3
Benchmark results on Knight Landing (KNL) architecture Domenico Guida, CINECA SCAI (Bologna) Giorgio Amati, CINECA SCAI (Roma) Roma 23/10/2017 KNL, BDW, SKL A1 BDW A2 KNL A3 SKL cores per node 2 x 18 @2.3
High Performance Computing Course Notes Course Administration
 High Performance Computing Course Notes 2009-2010 2010 Course Administration Contacts details Dr. Ligang He Home page: http://www.dcs.warwick.ac.uk/~liganghe Email: liganghe@dcs.warwick.ac.uk Office hours:
High Performance Computing Course Notes 2009-2010 2010 Course Administration Contacts details Dr. Ligang He Home page: http://www.dcs.warwick.ac.uk/~liganghe Email: liganghe@dcs.warwick.ac.uk Office hours:
Automatic Generation of Algorithms and Data Structures for Geometric Multigrid. Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014
 Automatic Generation of Algorithms and Data Structures for Geometric Multigrid Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014 Introduction Multigrid Goal: Solve a partial differential
Automatic Generation of Algorithms and Data Structures for Geometric Multigrid Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014 Introduction Multigrid Goal: Solve a partial differential
Two-Phase flows on massively parallel multi-gpu clusters
 Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Numerical Algorithms on Multi-GPU Architectures
 Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Performance Tools for Technical Computing
 Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
International Supercomputing Conference 2009
 International Supercomputing Conference 2009 Implementation of a Lattice-Boltzmann-Method for Numerical Fluid Mechanics Using the nvidia CUDA Technology E. Riegel, T. Indinger, N.A. Adams Technische Universität
International Supercomputing Conference 2009 Implementation of a Lattice-Boltzmann-Method for Numerical Fluid Mechanics Using the nvidia CUDA Technology E. Riegel, T. Indinger, N.A. Adams Technische Universität
High-Performance Scientific Computing
 High-Performance Scientific Computing Instructor: Randy LeVeque TA: Grady Lemoine Applied Mathematics 483/583, Spring 2011 http://www.amath.washington.edu/~rjl/am583 World s fastest computers http://top500.org
High-Performance Scientific Computing Instructor: Randy LeVeque TA: Grady Lemoine Applied Mathematics 483/583, Spring 2011 http://www.amath.washington.edu/~rjl/am583 World s fastest computers http://top500.org
IMPLEMENTATION OF THE. Alexander J. Yee University of Illinois Urbana-Champaign
 SINGLE-TRANSPOSE IMPLEMENTATION OF THE OUT-OF-ORDER 3D-FFT Alexander J. Yee University of Illinois Urbana-Champaign The Problem FFTs are extremely memory-intensive. Completely bound by memory access. Memory
SINGLE-TRANSPOSE IMPLEMENTATION OF THE OUT-OF-ORDER 3D-FFT Alexander J. Yee University of Illinois Urbana-Champaign The Problem FFTs are extremely memory-intensive. Completely bound by memory access. Memory
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Simulation of Dendritic Growth On Unstructured Grids
 Parallel Simulation of Dendritic Growth On Unstructured Grids, Julian Hammer, Dietmar Fey Friedrich-Alexander-Universität Erlangen-Nürnberg IA 3 Workshop @SC11, Nov. 13th, 2011 Outline 1 What and why?
Parallel Simulation of Dendritic Growth On Unstructured Grids, Julian Hammer, Dietmar Fey Friedrich-Alexander-Universität Erlangen-Nürnberg IA 3 Workshop @SC11, Nov. 13th, 2011 Outline 1 What and why?
High Performance Computing
 High Performance Computing ADVANCED SCIENTIFIC COMPUTING Dr. Ing. Morris Riedel Adjunct Associated Professor School of Engineering and Natural Sciences, University of Iceland Research Group Leader, Juelich
High Performance Computing ADVANCED SCIENTIFIC COMPUTING Dr. Ing. Morris Riedel Adjunct Associated Professor School of Engineering and Natural Sciences, University of Iceland Research Group Leader, Juelich
ICON for HD(CP) 2. High Definition Clouds and Precipitation for Advancing Climate Prediction
 2. High Definition Clouds and Precipitation for Advancing Climate Prediction") ICON for HD(CP) 2 High Definition Clouds and Precipitation for Advancing Climate Prediction High Definition Clouds and Precipitation for Advancing Climate Prediction ICON 2 years ago Parameterize shallow
ICON for HD(CP) 2 High Definition Clouds and Precipitation for Advancing Climate Prediction High Definition Clouds and Precipitation for Advancing Climate Prediction ICON 2 years ago Parameterize shallow
Monitoring the software quality in FairRoot. Gesellschaft für Schwerionenforschung, Plankstrasse 1, Darmstadt, Germany
 Gesellschaft für Schwerionenforschung, Plankstrasse 1, 64291 Darmstadt, Germany E-mail: f.uhlig@gsi.de Mohammad Al-Turany Gesellschaft für Schwerionenforschung, Plankstrasse 1, 64291 Darmstadt, Germany
Gesellschaft für Schwerionenforschung, Plankstrasse 1, 64291 Darmstadt, Germany E-mail: f.uhlig@gsi.de Mohammad Al-Turany Gesellschaft für Schwerionenforschung, Plankstrasse 1, 64291 Darmstadt, Germany
Intel C++ Compiler User's Guide With Support For The Streaming Simd Extensions 2
 Intel C++ Compiler User's Guide With Support For The Streaming Simd Extensions 2 This release of the Intel C++ Compiler 16.0 product is a Pre-Release, and as such is 64 architecture processor supporting
Intel C++ Compiler User's Guide With Support For The Streaming Simd Extensions 2 This release of the Intel C++ Compiler 16.0 product is a Pre-Release, and as such is 64 architecture processor supporting
What Could Deskside Supercomputers Do For The Power Grid?
 What Could Deskside Supercomputers Do For The Power Grid? Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com Joint work with Tao Cui and Cory Thoma
What Could Deskside Supercomputers Do For The Power Grid? Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com Joint work with Tao Cui and Cory Thoma
An Introduction to OpenACC
 An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
Simulation of moving Particles in 3D with the Lattice Boltzmann Method
 Simulation of moving Particles in 3D with the Lattice Boltzmann Method, Nils Thürey, Christian Feichtinger, Hans-Joachim Schmid Chair for System Simulation University Erlangen/Nuremberg Chair for Particle
Simulation of moving Particles in 3D with the Lattice Boltzmann Method, Nils Thürey, Christian Feichtinger, Hans-Joachim Schmid Chair for System Simulation University Erlangen/Nuremberg Chair for Particle
Outline. Motivation Parallel k-means Clustering Intel Computing Architectures Baseline Performance Performance Optimizations Future Trends
 Collaborators: Richard T. Mills, Argonne National Laboratory Sarat Sreepathi, Oak Ridge National Laboratory Forrest M. Hoffman, Oak Ridge National Laboratory Jitendra Kumar, Oak Ridge National Laboratory
Collaborators: Richard T. Mills, Argonne National Laboratory Sarat Sreepathi, Oak Ridge National Laboratory Forrest M. Hoffman, Oak Ridge National Laboratory Jitendra Kumar, Oak Ridge National Laboratory
The Eclipse Parallel Tools Platform
 May 1, 2012 Toward an Integrated Development Environment for Improved Software Engineering on Crays Agenda 1. What is the Eclipse Parallel Tools Platform (PTP) 2. Tour of features available in Eclipse/PTP
May 1, 2012 Toward an Integrated Development Environment for Improved Software Engineering on Crays Agenda 1. What is the Eclipse Parallel Tools Platform (PTP) 2. Tour of features available in Eclipse/PTP
ORAP Forum October 10, 2013
 Towards Petaflop simulations of core collapse supernovae ORAP Forum October 10, 2013 Andreas Marek 1 together with Markus Rampp 1, Florian Hanke 2, and Thomas Janka 2 1 Rechenzentrum der Max-Planck-Gesellschaft
Towards Petaflop simulations of core collapse supernovae ORAP Forum October 10, 2013 Andreas Marek 1 together with Markus Rampp 1, Florian Hanke 2, and Thomas Janka 2 1 Rechenzentrum der Max-Planck-Gesellschaft
Lattice Boltzmann with CUDA
 Lattice Boltzmann with CUDA Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Overview of LBM An usage of LBM Algorithm Implementation in CUDA and Optimization
Lattice Boltzmann with CUDA Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Overview of LBM An usage of LBM Algorithm Implementation in CUDA and Optimization
FFTSS Library Version 3.0 User s Guide
 Last Modified: 31/10/07 FFTSS Library Version 3.0 User s Guide Copyright (C) 2002-2007 The Scalable Software Infrastructure Project, is supported by the Development of Software Infrastructure for Large
Last Modified: 31/10/07 FFTSS Library Version 3.0 User s Guide Copyright (C) 2002-2007 The Scalable Software Infrastructure Project, is supported by the Development of Software Infrastructure for Large
Geometric Multigrid on Multicore Architectures: Performance-Optimized Complex Diffusion
 Geometric Multigrid on Multicore Architectures: Performance-Optimized Complex Diffusion M. Stürmer, H. Köstler, and U. Rüde Lehrstuhl für Systemsimulation Friedrich-Alexander-Universität Erlangen-Nürnberg
Geometric Multigrid on Multicore Architectures: Performance-Optimized Complex Diffusion M. Stürmer, H. Köstler, and U. Rüde Lehrstuhl für Systemsimulation Friedrich-Alexander-Universität Erlangen-Nürnberg
trisycl Open Source C++17 & OpenMP-based OpenCL SYCL prototype Ronan Keryell 05/12/2015 IWOCL 2015 SYCL Tutorial Khronos OpenCL SYCL committee
 trisycl Open Source C++17 & OpenMP-based OpenCL SYCL prototype Ronan Keryell Khronos OpenCL SYCL committee 05/12/2015 IWOCL 2015 SYCL Tutorial OpenCL SYCL committee work... Weekly telephone meeting Define
trisycl Open Source C++17 & OpenMP-based OpenCL SYCL prototype Ronan Keryell Khronos OpenCL SYCL committee 05/12/2015 IWOCL 2015 SYCL Tutorial OpenCL SYCL committee work... Weekly telephone meeting Define
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Experiences with using Python in Mercurial
 Experiences with using Python in Mercurial Martin Geisler mg@aragost.com Python Geek Night November 16th, 2010 About the Speaker Martin Geisler: core Mercurial developer: reviews patches from the community
Experiences with using Python in Mercurial Martin Geisler mg@aragost.com Python Geek Night November 16th, 2010 About the Speaker Martin Geisler: core Mercurial developer: reviews patches from the community
High Scalability of Lattice Boltzmann Simulations with Turbulence Models using Heterogeneous Clusters
 SIAM PP 2014 High Scalability of Lattice Boltzmann Simulations with Turbulence Models using Heterogeneous Clusters C. Riesinger, A. Bakhtiari, M. Schreiber Technische Universität München February 20, 2014
SIAM PP 2014 High Scalability of Lattice Boltzmann Simulations with Turbulence Models using Heterogeneous Clusters C. Riesinger, A. Bakhtiari, M. Schreiber Technische Universität München February 20, 2014
Performance of the hybrid MPI/OpenMP version of the HERACLES code on the Curie «Fat nodes» system
 Performance of the hybrid MPI/OpenMP version of the HERACLES code on the Curie «Fat nodes» system Edouard Audit, Matthias Gonzalez, Pierre Kestener and Pierre-François Lavallé The HERACLES code Fixed grid
Performance of the hybrid MPI/OpenMP version of the HERACLES code on the Curie «Fat nodes» system Edouard Audit, Matthias Gonzalez, Pierre Kestener and Pierre-François Lavallé The HERACLES code Fixed grid
Performance of the 3D-Combustion Simulation Code RECOM-AIOLOS on IBM POWER8 Architecture. Alexander Berreth. Markus Bühler, Benedikt Anlauf
 PADC Anual Workshop 20 Performance of the 3D-Combustion Simulation Code RECOM-AIOLOS on IBM POWER8 Architecture Alexander Berreth RECOM Services GmbH, Stuttgart Markus Bühler, Benedikt Anlauf IBM Deutschland
PADC Anual Workshop 20 Performance of the 3D-Combustion Simulation Code RECOM-AIOLOS on IBM POWER8 Architecture Alexander Berreth RECOM Services GmbH, Stuttgart Markus Bühler, Benedikt Anlauf IBM Deutschland
Multicore-aware parallelization strategies for efficient temporal blocking (BMBF project: SKALB)
") Multicore-aware parallelization strategies for efficient temporal blocking (BMBF project: SKALB) G. Wellein, G. Hager, M. Wittmann, J. Habich, J. Treibig Department für Informatik H Services, Regionales
Multicore-aware parallelization strategies for efficient temporal blocking (BMBF project: SKALB) G. Wellein, G. Hager, M. Wittmann, J. Habich, J. Treibig Department für Informatik H Services, Regionales
Fujitsu s Approach to Application Centric Petascale Computing
 Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010
 Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010 Windows HPC Server 2008 R2 Windows HPC Server 2008 R2 makes supercomputing
Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010 Windows HPC Server 2008 R2 Windows HPC Server 2008 R2 makes supercomputing
Progress Report on QDP-JIT
 Progress Report on QDP-JIT F. T. Winter Thomas Jefferson National Accelerator Facility USQCD Software Meeting 14 April 16-17, 14 at Jefferson Lab F. Winter (Jefferson Lab) QDP-JIT USQCD-Software 14 1 /
Progress Report on QDP-JIT F. T. Winter Thomas Jefferson National Accelerator Facility USQCD Software Meeting 14 April 16-17, 14 at Jefferson Lab F. Winter (Jefferson Lab) QDP-JIT USQCD-Software 14 1 /
Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC
 DLR.de Chart 1 Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC Melven Röhrig-Zöllner DLR, Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU)
DLR.de Chart 1 Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC Melven Röhrig-Zöllner DLR, Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU)
References. T. LeBlanc, Memory management for large-scale numa multiprocessors, Department of Computer Science: Technical report*311
 References [Ande 89] [Ande 92] [Ghos 93] [LeBl 89] [Rüde92] T. Anderson, E. Lazowska, H. Levy, The Performance Implication of Thread Management Alternatives for Shared-Memory Multiprocessors, ACM Trans.
References [Ande 89] [Ande 92] [Ghos 93] [LeBl 89] [Rüde92] T. Anderson, E. Lazowska, H. Levy, The Performance Implication of Thread Management Alternatives for Shared-Memory Multiprocessors, ACM Trans.
LLVM and Clang on the Most Powerful Supercomputer in the World
 LLVM and Clang on the Most Powerful Supercomputer in the World Hal Finkel November 7, 2012 The 2012 LLVM Developers Meeting Hal Finkel (Argonne National Laboratory) LLVM and Clang on the BG/Q November
LLVM and Clang on the Most Powerful Supercomputer in the World Hal Finkel November 7, 2012 The 2012 LLVM Developers Meeting Hal Finkel (Argonne National Laboratory) LLVM and Clang on the BG/Q November
Parallel Systems. Project topics
 Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
OpenACC programming for GPGPUs: Rotor wake simulation
 DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
Intel Parallel Studio XE 2015
 2015 Create faster code faster with this comprehensive parallel software development suite. Faster code: Boost applications performance that scales on today s and next-gen processors Create code faster:
2015 Create faster code faster with this comprehensive parallel software development suite. Faster code: Boost applications performance that scales on today s and next-gen processors Create code faster:
Cerebrospinal Fluid Flow Analysis in Subarachnoid Space
 Jh160055-NAHI Cerebrospinal Fluid Flow Analysis in Subarachnoid Space Ryusuke Egawa Cyberscience Center, Tohoku University Abstract A better understanding of the hydrodynamics of the cerebrospinal fluid
Jh160055-NAHI Cerebrospinal Fluid Flow Analysis in Subarachnoid Space Ryusuke Egawa Cyberscience Center, Tohoku University Abstract A better understanding of the hydrodynamics of the cerebrospinal fluid
Code optimization in a 3D diffusion model
 Code optimization in a 3D diffusion model Roger Philp Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 18 th 2016, Barcelona Agenda Background Diffusion
Code optimization in a 3D diffusion model Roger Philp Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 18 th 2016, Barcelona Agenda Background Diffusion
Benchmark results on Knight Landing architecture
 Benchmark results on Knight Landing architecture Domenico Guida, CINECA SCAI (Bologna) Giorgio Amati, CINECA SCAI (Roma) Milano, 21/04/2017 KNL vs BDW A1 BDW A2 KNL cores per node 2 x 18 @2.3 GHz 1 x 68
Benchmark results on Knight Landing architecture Domenico Guida, CINECA SCAI (Bologna) Giorgio Amati, CINECA SCAI (Roma) Milano, 21/04/2017 KNL vs BDW A1 BDW A2 KNL cores per node 2 x 18 @2.3 GHz 1 x 68
A Python Extension for the Massively Parallel Multiphysics Simulation Framework walberla
 A Python Extension for the Massively Parallel Multiphysics Simulation Framework walberla Martin Bauer, Florian Schornbaum, Christian Godenschwager, Matthias Markl, Daniela Anderl, Harald Köstler, and Ulrich
A Python Extension for the Massively Parallel Multiphysics Simulation Framework walberla Martin Bauer, Florian Schornbaum, Christian Godenschwager, Matthias Markl, Daniela Anderl, Harald Köstler, and Ulrich
Advanced Threading and Optimization
 Mikko Byckling, CSC Michael Klemm, Intel Advanced Threading and Optimization February 24-26, 2015 PRACE Advanced Training Centre CSC IT Center for Science Ltd, Finland!$omp parallel do collapse(3) do p4=1,p4d
Mikko Byckling, CSC Michael Klemm, Intel Advanced Threading and Optimization February 24-26, 2015 PRACE Advanced Training Centre CSC IT Center for Science Ltd, Finland!$omp parallel do collapse(3) do p4=1,p4d
Performance of deal.ii on a node
 Performance of deal.ii on a node Bruno Turcksin Texas A&M University, Dept. of Mathematics Bruno Turcksin Deal.II on a node 1/37 Outline 1 Introduction 2 Architecture 3 Paralution 4 Other Libraries 5 Conclusions
Performance of deal.ii on a node Bruno Turcksin Texas A&M University, Dept. of Mathematics Bruno Turcksin Deal.II on a node 1/37 Outline 1 Introduction 2 Architecture 3 Paralution 4 Other Libraries 5 Conclusions
(LSS Erlangen, Simon Bogner, Ulrich Rüde, Thomas Pohl, Nils Thürey in collaboration with many more
 Parallel Free-Surface Extension of the Lattice-Boltzmann Method A Lattice-Boltzmann Approach for Simulation of Two-Phase Flows Stefan Donath (LSS Erlangen, stefan.donath@informatik.uni-erlangen.de) Simon
Parallel Free-Surface Extension of the Lattice-Boltzmann Method A Lattice-Boltzmann Approach for Simulation of Two-Phase Flows Stefan Donath (LSS Erlangen, stefan.donath@informatik.uni-erlangen.de) Simon
AutoTuneTMP: Auto-Tuning in C++ With Runtime Template Metaprogramming
 AutoTuneTMP: Auto-Tuning in C++ With Runtime Template Metaprogramming David Pfander, Malte Brunn, Dirk Pflüger University of Stuttgart, Germany May 25, 2018 Vancouver, Canada, iwapt18 May 25, 2018 Vancouver,
AutoTuneTMP: Auto-Tuning in C++ With Runtime Template Metaprogramming David Pfander, Malte Brunn, Dirk Pflüger University of Stuttgart, Germany May 25, 2018 Vancouver, Canada, iwapt18 May 25, 2018 Vancouver,
Introduction to High-Performance Computing
 Introduction to High-Performance Computing Dr. Axel Kohlmeyer Associate Dean for Scientific Computing, CST Associate Director, Institute for Computational Science Assistant Vice President for High-Performance
Introduction to High-Performance Computing Dr. Axel Kohlmeyer Associate Dean for Scientific Computing, CST Associate Director, Institute for Computational Science Assistant Vice President for High-Performance
Towards Generating Solvers for the Simulation of non-newtonian Fluids. Harald Köstler, Sebastian Kuckuk FAU Erlangen-Nürnberg
 Towards Generating Solvers for the Simulation of non-newtonian Fluids Harald Köstler, Sebastian Kuckuk FAU Erlangen-Nürnberg 22.12.2015 Outline Outline Scope and Motivation Project ExaStencils The Application
Towards Generating Solvers for the Simulation of non-newtonian Fluids Harald Köstler, Sebastian Kuckuk FAU Erlangen-Nürnberg 22.12.2015 Outline Outline Scope and Motivation Project ExaStencils The Application
High-level Abstraction for Block Structured Applications: A lattice Boltzmann Exploration
 High-level Abstraction for Block Structured Applications: A lattice Boltzmann Exploration Jianping Meng, Xiao-Jun Gu, David R. Emerson, Gihan Mudalige, István Reguly and Mike B Giles Scientific Computing
High-level Abstraction for Block Structured Applications: A lattice Boltzmann Exploration Jianping Meng, Xiao-Jun Gu, David R. Emerson, Gihan Mudalige, István Reguly and Mike B Giles Scientific Computing
Blue Gene/Q. Hardware Overview Michael Stephan. Mitglied der Helmholtz-Gemeinschaft
 Blue Gene/Q Hardware Overview 02.02.2015 Michael Stephan Blue Gene/Q: Design goals System-on-Chip (SoC) design Processor comprises both processing cores and network Optimal performance / watt ratio Small
Blue Gene/Q Hardware Overview 02.02.2015 Michael Stephan Blue Gene/Q: Design goals System-on-Chip (SoC) design Processor comprises both processing cores and network Optimal performance / watt ratio Small
LATTICE-BOLTZMANN AND COMPUTATIONAL FLUID DYNAMICS
 LATTICE-BOLTZMANN AND COMPUTATIONAL FLUID DYNAMICS NAVIER-STOKES EQUATIONS u t + u u + 1 ρ p = Ԧg + ν u u=0 WHAT IS COMPUTATIONAL FLUID DYNAMICS? Branch of Fluid Dynamics which uses computer power to approximate
LATTICE-BOLTZMANN AND COMPUTATIONAL FLUID DYNAMICS NAVIER-STOKES EQUATIONS u t + u u + 1 ρ p = Ԧg + ν u u=0 WHAT IS COMPUTATIONAL FLUID DYNAMICS? Branch of Fluid Dynamics which uses computer power to approximate
Large-scale Gas Turbine Simulations on GPU clusters
 Large-scale Gas Turbine Simulations on GPU clusters Tobias Brandvik and Graham Pullan Whittle Laboratory University of Cambridge A large-scale simulation Overview PART I: Turbomachinery PART II: Stencil-based
Large-scale Gas Turbine Simulations on GPU clusters Tobias Brandvik and Graham Pullan Whittle Laboratory University of Cambridge A large-scale simulation Overview PART I: Turbomachinery PART II: Stencil-based
Altix Usage and Application Programming
 Center for Information Services and High Performance Computing (ZIH) Altix Usage and Application Programming Discussion And Important Information For Users Zellescher Weg 12 Willers-Bau A113 Tel. +49 351-463
Center for Information Services and High Performance Computing (ZIH) Altix Usage and Application Programming Discussion And Important Information For Users Zellescher Weg 12 Willers-Bau A113 Tel. +49 351-463
Clusters. Rob Kunz and Justin Watson. Penn State Applied Research Laboratory
 Clusters Rob Kunz and Justin Watson Penn State Applied Research Laboratory rfk102@psu.edu Contents Beowulf Cluster History Hardware Elements Networking Software Performance & Scalability Infrastructure
Clusters Rob Kunz and Justin Watson Penn State Applied Research Laboratory rfk102@psu.edu Contents Beowulf Cluster History Hardware Elements Networking Software Performance & Scalability Infrastructure
Making New Pseudo-Languages with C++
 Making New Pseudo-Languages with C++ Build You a C++ For Great Good ++ A 10,000 Metre Talk by David Williams-King Agenda 1/4 Introduction 2/4 Polymorphism & Multimethods 3/4 Changing the Behaviour of C++
Making New Pseudo-Languages with C++ Build You a C++ For Great Good ++ A 10,000 Metre Talk by David Williams-King Agenda 1/4 Introduction 2/4 Polymorphism & Multimethods 3/4 Changing the Behaviour of C++
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Deutscher Wetterdienst
 Accelerating Work at DWD Ulrich Schättler Deutscher Wetterdienst Roadmap Porting operational models: revisited Preparations for enabling practical work at DWD My first steps with the COSMO on a GPU First
Accelerating Work at DWD Ulrich Schättler Deutscher Wetterdienst Roadmap Porting operational models: revisited Preparations for enabling practical work at DWD My first steps with the COSMO on a GPU First
Parallel 3D Sweep Kernel with PaRSEC
 Parallel 3D Sweep Kernel with PaRSEC Salli Moustafa Mathieu Faverge Laurent Plagne Pierre Ramet 1 st International Workshop on HPC-CFD in Energy/Transport Domains August 22, 2014 Overview 1. Cartesian
Parallel 3D Sweep Kernel with PaRSEC Salli Moustafa Mathieu Faverge Laurent Plagne Pierre Ramet 1 st International Workshop on HPC-CFD in Energy/Transport Domains August 22, 2014 Overview 1. Cartesian
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit
 Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT
 TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
GRID Testing and Profiling. November 2017
 GRID Testing and Profiling November 2017 2 GRID C++ library for Lattice Quantum Chromodynamics (Lattice QCD) calculations Developed by Peter Boyle (U. of Edinburgh) et al. Hybrid MPI+OpenMP plus NUMA aware
GRID Testing and Profiling November 2017 2 GRID C++ library for Lattice Quantum Chromodynamics (Lattice QCD) calculations Developed by Peter Boyle (U. of Edinburgh) et al. Hybrid MPI+OpenMP plus NUMA aware
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
MULTI-CORE PROGRAMMING. Dongrui She December 9, 2010 ASSIGNMENT
 MULTI-CORE PROGRAMMING Dongrui She December 9, 2010 ASSIGNMENT Goal of the Assignment 1 The purpose of this assignment is to Have in-depth understanding of the architectures of real-world multi-core CPUs
MULTI-CORE PROGRAMMING Dongrui She December 9, 2010 ASSIGNMENT Goal of the Assignment 1 The purpose of this assignment is to Have in-depth understanding of the architectures of real-world multi-core CPUs
Software Ecosystem for Arm-based HPC
 Software Ecosystem for Arm-based HPC CUG 2018 - Stockholm Florent.Lebeau@arm.com Ecosystem for HPC List of components needed: Linux OS availability Compilers Libraries Job schedulers Debuggers Profilers
Software Ecosystem for Arm-based HPC CUG 2018 - Stockholm Florent.Lebeau@arm.com Ecosystem for HPC List of components needed: Linux OS availability Compilers Libraries Job schedulers Debuggers Profilers
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
Architecture Aware Multigrid
 Architecture Aware Multigrid U. Rüde (LSS Erlangen, ruede@cs.fau.de) joint work with D. Ritter, T. Gradl, M. Stürmer, H. Köstler, J. Treibig and many more students Lehrstuhl für Informatik 10 (Systemsimulation)
Architecture Aware Multigrid U. Rüde (LSS Erlangen, ruede@cs.fau.de) joint work with D. Ritter, T. Gradl, M. Stürmer, H. Köstler, J. Treibig and many more students Lehrstuhl für Informatik 10 (Systemsimulation)
Challenges in Fully Generating Multigrid Solvers for the Simulation of non-newtonian Fluids
 Challenges in Fully Generating Multigrid Solvers for the Simulation of non-newtonian Fluids Sebastian Kuckuk FAU Erlangen-Nürnberg 18.01.2016 HiStencils 2016, Prague, Czech Republic Outline Outline Scope
Challenges in Fully Generating Multigrid Solvers for the Simulation of non-newtonian Fluids Sebastian Kuckuk FAU Erlangen-Nürnberg 18.01.2016 HiStencils 2016, Prague, Czech Republic Outline Outline Scope
Experiences with ENZO on the Intel Many Integrated Core Architecture
 Experiences with ENZO on the Intel Many Integrated Core Architecture Dr. Robert Harkness National Institute for Computational Sciences April 10th, 2012 Overview ENZO applications at petascale ENZO and
Experiences with ENZO on the Intel Many Integrated Core Architecture Dr. Robert Harkness National Institute for Computational Sciences April 10th, 2012 Overview ENZO applications at petascale ENZO and
HPC on Windows. Visual Studio 2010 and ISV Software
 HPC on Windows Visual Studio 2010 and ISV Software Christian Terboven 19.03.2012 / Aachen, Germany Stand: 16.03.2012 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda
HPC on Windows Visual Studio 2010 and ISV Software Christian Terboven 19.03.2012 / Aachen, Germany Stand: 16.03.2012 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda
ASYNCHRONOUS COMPUTING IN C++
 http://stellar-goup.org ASYNCHRONOUS COMPUTING IN C++ Hartmut Kaiser (Hartmut.Kaiser@gmail.com) CppCon 2014 WHAT IS ASYNCHRONOUS COMPUTING? Spawning off some work without immediately waiting for the work
http://stellar-goup.org ASYNCHRONOUS COMPUTING IN C++ Hartmut Kaiser (Hartmut.Kaiser@gmail.com) CppCon 2014 WHAT IS ASYNCHRONOUS COMPUTING? Spawning off some work without immediately waiting for the work
Vaango Installation Guide
 Vaango Installation Guide Version Version 17.10 October 1, 2017 The Utah Vaango team and Biswajit Banerjee Copyright 2015-2017 Parresia Research Limited The contents of this manual can and will change
Vaango Installation Guide Version Version 17.10 October 1, 2017 The Utah Vaango team and Biswajit Banerjee Copyright 2015-2017 Parresia Research Limited The contents of this manual can and will change
Tools and Methodology for Ensuring HPC Programs Correctness and Performance. Beau Paisley
 Tools and Methodology for Ensuring HPC Programs Correctness and Performance Beau Paisley bpaisley@allinea.com About Allinea Over 15 years of business focused on parallel programming development tools Strong
Tools and Methodology for Ensuring HPC Programs Correctness and Performance Beau Paisley bpaisley@allinea.com About Allinea Over 15 years of business focused on parallel programming development tools Strong
Generation of Multigrid-based Numerical Solvers for FPGA Accelerators
 Generation of Multigrid-based Numerical Solvers for FPGA Accelerators Christian Schmitt, Moritz Schmid, Frank Hannig, Jürgen Teich, Sebastian Kuckuk, Harald Köstler Hardware/Software Co-Design, System
Generation of Multigrid-based Numerical Solvers for FPGA Accelerators Christian Schmitt, Moritz Schmid, Frank Hannig, Jürgen Teich, Sebastian Kuckuk, Harald Köstler Hardware/Software Co-Design, System
High Performance Computing. Leopold Grinberg T. J. Watson IBM Research Center, USA
 High Performance Computing Leopold Grinberg T. J. Watson IBM Research Center, USA High Performance Computing Why do we need HPC? High Performance Computing Amazon can ship products within hours would it
High Performance Computing Leopold Grinberg T. J. Watson IBM Research Center, USA High Performance Computing Why do we need HPC? High Performance Computing Amazon can ship products within hours would it
CFD Solvers on Many-core Processors
 CFD Solvers on Many-core Processors Tobias Brandvik Whittle Laboratory CFD Solvers on Many-core Processors p.1/36 CFD Backgroud CFD: Computational Fluid Dynamics Whittle Laboratory - Turbomachinery CFD
CFD Solvers on Many-core Processors Tobias Brandvik Whittle Laboratory CFD Solvers on Many-core Processors p.1/36 CFD Backgroud CFD: Computational Fluid Dynamics Whittle Laboratory - Turbomachinery CFD