COSC 6385 Computer Architecture - Thread Level Parallelism (III)
|
|
|
- Jordan Campbell
- 5 years ago
- Views:
Transcription
1 OS 6385 omputer Architecture - Thread Level Parallelism (III) Edgar Gabriel Spring 2018 Some slides are based on a lecture by David uller, University of alifornia, Berkley Larger Shared Memory Systems Typically Distributed Shared Memory Systems Local or remote memory access via memory controller Directory per cache that tracks state of every block in every cache Which caches have a copy of block, dirty vs. clean,... Info per memory block vs. per cache block? PLUS: In memory => simpler protocol (centralized/one location) MINUS: In memory => directory is ƒ(memory size) vs. ƒ(cache size) Prevent directory as bottleneck? distribute directory entries with memory, each keeping track of which procs have copies of their blocks 1
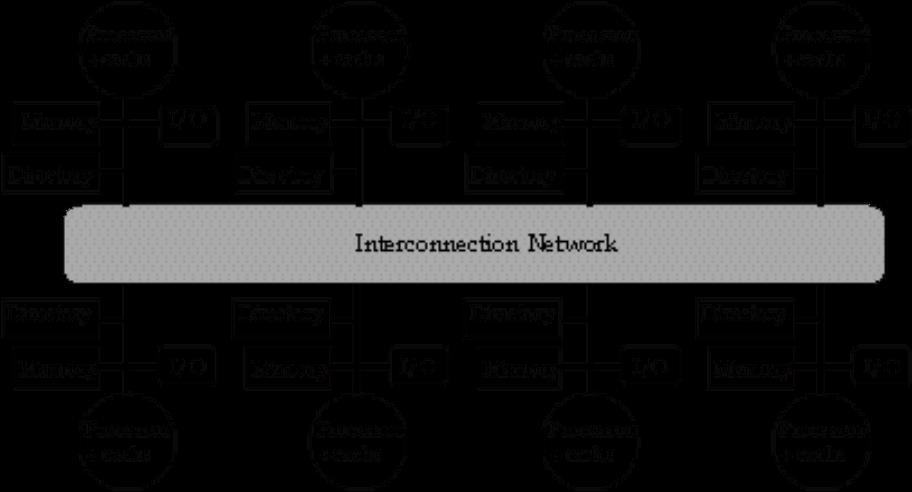
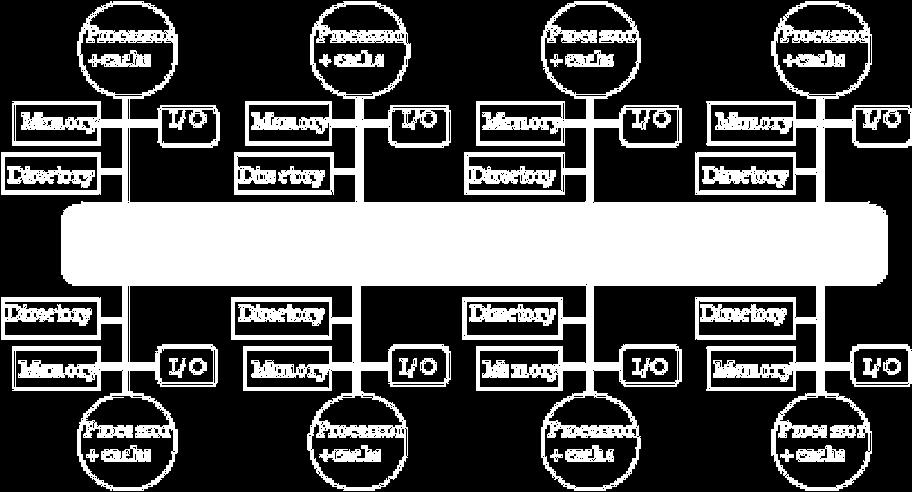

2 Distributed Directory MPs Distributed Shared Memory Systems 2
3 Memory Memory AMD 8350 quad-core Opteron Multi-processor configuration Distributed shared memory system 0 1 Socket 0 Socket 1 2 L3 3 HT HT HT 8 GB/s L3 7 HT HT HT Memory 8 GB/s 8 GB/s HT HT HT 8 9 L GB/s HT HT HT L Memory Socket 2 Socket 3 Programming distributed shared memory systems Programmers must use threads or processes Spread the workload across multiple cores Write parallel algorithms OS will map threads/processes to cores True concurrency, not just uni-processor time-slicing Pre-emptive context switching: context switch can happen at any time oncurrency bugs exposed much faster with multi-core Slide based on a lecture of Jernej Barbic, MIT, 3
4 Programming distributed shared memory systems Each thread/process has an affinity mask Specifies what cores the thread is allowed to run on Different threads can have different masks Affinities are inherited across fork() Example: 4-way multi-core, without SMT core 3 core 2 core 1 core 0 Process/thread is allowed to run on cores 0,2,3, but not on core 1 Slide based on a lecture of Jernej Barbic, MIT, Process migration is costly Default Affinities Default affinity mask is all 1s: all threads can run on all processors and cores OS scheduler decides which thread runs on which core OS scheduler detects skewed workloads, migrating threads to less busy processors Soft affinity: Tendency of a scheduler to try to keep processes on the same PU as long as possible Hard affinity: Affinity information has been explicitly set by application OS has to adhere to this setting 4
5 Linux Kernel scheduler API Retrieve the current affinity mask of a process #include <sys/types.h> #include <sched.h> #include <unistd.h> #include <errno.h> unsigned int len = sizeof(cpu_set_t); cpu_set_t mask; pid_t pid = getpid();/* get the process id of this app */ ret = sched_getaffinity (pid, len, &mask); if ( ret!= 0 ) printf( Error in getaffinity %d (%s)\n, errno, strerror(errno); for (i=0; i<numpus; i++) { if ( PU_ISSET(i, &mask) ) printf( Process could run on PU %d\n, i); } Linux Kernel scheduler API (II) Set the affinity mask of a process unsigned int len = sizeof(cpu_set_t); cpu_set_t mask; pid_t pid = getpid();/* get the process id of this app */ /* clear the mask */ PU_ZERO (&mask); /* set the mask such that the process is only allowed to execute on the desired PU */ PU_SET ( cpu_id, &mask); ret = sched_setaffinity (pid, len, &mask); if ( ret!= 0 ) { printf( Error in setaffinity %d (%s)\n, errno, strerror(errno); } 5
6 Linux Kernel scheduler API (III) Setting thread-related affinity information Use sched_setaffinity with a pid = 0 hanges the affinity settings for this thread only Use libnuma functionality numa_run_on_node(); numa_run_on_node_mask(); Modifying affinity information based on PU sockets, not on cores Use pthread functions on most linux systems #define USE_GNU pthread_setaffinity_np(thread_t t, len, mask); pthread_attr_setaffinity_np ( thread_attr_t a, len, mask); Directory based ache oherence Protocol Similar to Snoopy Protocol: Three states Shared: 1 processors have data, memory up-to-date Uncached (no processor has it; not valid in any cache) Exclusive: 1 processor (owner) has data; memory out-of-date In addition to cache state, must track which processors have data when in the shared state (usually bit vector, 1 if processor has copy) Assumptions: Writes to non-exclusive data => write miss Processor blocks until access completes Assume messages received and acted upon in order sent 6
7 Directory Protocol No bus and don t want to broadcast: interconnect no longer single arbitration point all messages have explicit responses Terms: typically 3 processors involved Local node where a request originates Home node where the memory location of an address resides Remote node has a copy of a cache block, whether exclusive or shared Example messages on next slide: P = processor number, A = address Loca node vs. Home node vs. Remote node Home node: Node that holds the data item in its main memory PU 0 ache PU 1 ache Remote node: Node that holds a copy of the data item in cache Memory Memory Local node: Posts a LOAD or STORE instruction on that data item Memory ache PU 2 Memory ache PU 3 7
8 Directory Protocol Messages Message type Source Destination Msg ontent Read miss Local cache Home directory P, A Processor P reads data at address A; make P a read sharer and arrange to send data back Write miss Local cache Home directory P, A Processor P writes data at address A; make P the exclusive owner and arrange to send data back Invalidate Home directory Remote caches A Invalidate a shared copy at address A. Fetch Home directory Remote cache A Fetch the block at address A and send it to its home directory Fetch/Invalidate Home directory Remote cache A Fetch the block at address A and send it to its home directory; invalidate the block in the cache Data value reply Home directory Local cache Data Return a data value from the home memory (read miss response) Data write-back Remote cache Home directory A, Data Write-back a data value for address A (invalidate response) State Transition Diagram for an Individual ache Block in a Directory Based System States identical to snoopy case; transactions very similar. Transitions caused by read misses, write misses, invalidates, data fetch requests Generates read miss & write miss msg to home directory. Write misses that were broadcast on the bus for snooping => explicit invalidate & data fetch requests. Note: on a write, a cache block is bigger, so need to read the full cache block 8
9 PU -ache State Machine PU Read hit State machine for each cache block Invalid state if in memory Fetch/Invalidate send Data Write Back message to home directory PU read hit PU write hit Invalid Exclusive (read/writ) Invalidate PU Read Send Read Miss message PU Write: Send Write Miss msg to h.d. Shared (read/only) PU Write:Send Write Miss message to home directory Fetch: send Data Write Back message to home directory PU read miss: send Data Write Back message and read miss to home directory PU write miss: send Data Write Back message and Write Miss to home directory State Transition Diagram for the Directory Same states & structure as the transition diagram for an individual cache 2 actions: update of directory state & send msgs to satisfy requests Tracks all copies of memory block. Also indicates an action that updates the sharing set, Sharers, as well as sending a message. 9
10 State machine for Directory requests for each memory block Uncached state if in memory Directory State Machine Data Write Back: Sharers = {} (Write back block) Write Miss: Sharers = {P}; send Fetch/Invalidate; send Data Value Reply msg to remote cache Uncached Exclusive (read/writ) Read miss: Sharers = {P} send Data Value Reply Write Miss: Sharers = {P}; send Data Value Reply msg Shared (read only) Read miss: Sharers += {P}; send Fetch; send Data Value Reply msg to remote cache (Write back block) Write Miss: send Invalidate to Sharers; then Sharers = {P}; send Data Value Reply msg Example Directory Protocol Message sent to directory causes two actions: Update the directory More messages to satisfy request Block is in Uncached state: the copy in memory is the current value; only possible requests for that block are: Read miss: requesting processor sent data from memory &requestor made only sharing node; state of block made Shared. Write miss: requesting processor is sent the value & becomes the Sharing node. The block is made Exclusive to indicate that the only valid copy is cached. Sharers indicates the identity of the owner. Block is Shared => the memory value is up-to-date: Read miss: requesting processor is sent back the data from memory & requesting processor is added to the sharing set. Write miss: requesting processor is sent the value. All processors in the set Sharers are sent invalidate messages, & Sharers is set to identity of requesting processor. The state of the block is made Exclusive. 10
11 Example Directory Protocol Block is Exclusive: current value of the block is held in the cache of the processor identified by the set Sharers (the owner) => three possible directory requests: Read miss: owner processor sent data fetch message, causing state of block in owner s cache to transition to Shared and causes owner to send data to directory, where it is written to memory & sent back to requesting processor. Identity of requesting processor is added to set Sharers, which still contains the identity of the processor that was the owner (since it still has a readable copy). State is shared. Data write-back: owner processor is replacing the block and hence must write it back, making memory copy up-to-date (the home directory essentially becomes the owner), the block is now Uncached, and the Sharer set is empty. Write miss: block has a new owner. A message is sent to old owner causing the cache to send the value of the block to the directory from which it is sent to the requesting processor, which becomes the new owner. Sharers is set to identity of new owner, and state of block is made Exclusive. Example Processor 1 Processor 2 Interconnect Directory Memory step P1: Write 10 to A1 P1 P2 Bus Directory Memory State Addr Value State Addr Value Action Proc. Addr Value Addr State {Procs} Value P1: Read A1 P2: Read A1 P2: Write 20 to A1 P2: Write 40 to A2 A1 and A2 map to the same cache block 11
12 Example Processor 1 Processor 2 Interconnect Directory Memory P1 P2 Bus Directory Memory step State Addr Value State Addr Value Action Proc. Addr Value Addr State {Procs} Value P1: Write 10 to A1 WrMs P1 A1 A1 Ex {P1} Excl. A1 10 DaRp P1 A1 0 P1: Read A1 P2: Read A1 P2: Write 20 to A1 P2: Write 40 to A2 A1 and A2 map to the same cache block Example Processor 1 Processor 2 Interconnect Directory Memory P1 P2 Bus Directory Memory step State Addr Value State Addr Value Action Proc. Addr Value Addr State {Procs} Value P1: Write 10 to A1 WrMs P1 A1 A1 Ex {P1} Excl. A1 10 DaRp P1 A1 0 P1: Read A1 Excl. A1 10 P2: Read A1 P2: Write 20 to A1 P2: Write 40 to A2 A1 and A2 map to the same cache block 12
13 Example Processor 1 Processor 2 Interconnect Directory Memory P1 P2 Bus Directory Memory step State Addr Value State Addr Value Action Proc. Addr Value Addr State {Procs} Value P1: Write 10 to A1 WrMs P1 A1 A1 Ex {P1} Excl. A1 10 DaRp P1 A1 0 P1: Read A1 Excl. A1 10 P2: Read A1 Shar. A1 RdMs P2 A1 Shar. A1 10 Ftch P1 A Shar. A1 10 DaRp P2 A1 10 A1 Shar. P1,P2} 10 P2: Write 20 to A P2: Write 40 to A2 10 Write Back A1 and A2 map to the same cache block Example Processor 1 Processor 2 Interconnect Directory Memory P1 P2 Bus Directory Memory step State Addr Value State Addr Value Action Proc. Addr Value Addr State {Procs} Value P1: Write 10 to A1 WrMs P1 A1 A1 Ex {P1} Excl. A1 10 DaRp P1 A1 0 P1: Read A1 Excl. A1 10 P2: Read A1 Shar. A1 RdMs P2 A1 Shar. A1 10 Ftch P1 A Shar. A1 10 DaRp P2 A1 10 A1 Shar. P1,P2} 10 P2: Write 20 to A1 Excl. A1 20 WrMs P2 A1 10 Inv. Inval. P1 A1 A1 Excl. {P2} 10 P2: Write 40 to A2 10 A1 and A2 map to the same cache block 13
14 Example Processor 1 Processor 2 Interconnect Directory Memory P1 P2 Bus Directory Memory step State Addr Value State Addr Value Action Proc. Addr Value Addr State {Procs} Value P1: Write 10 to A1 WrMs P1 A1 A1 Ex {P1} Excl. A1 10 DaRp P1 A1 0 P1: Read A1 Excl. A1 10 P2: Read A1 Shar. A1 RdMs P2 A1 Shar. A1 10 Ftch P1 A1 10 A1 10 Shar. A1 10 DaRp P2 A1 10 A1 Shar. P1,P2} 10 P2: Write 20 to A1 Excl. A1 20 WrMs P2 A1 10 Inv. Inval. P1 A1 A1 Excl. {P2} 10 P2: Write 40 to A2 WrMs P2 A2 A2 Excl. {P2} 0 WrBk P2 A1 20 A1 Unca. {} 20 Excl. A2 40 DaRp P2 A2 0 A2 Excl. {P2} 0 A1 and A2 map to the same cache block Implementing a Directory We assume operations atomic, but they are not; reality is much harder; must avoid deadlock when run out of buffers in network Optimizations: read miss or write miss in Exclusive: send data directly to requestor from owner vs. 1st to memory and then from memory to requestor 14
COSC 6385 Computer Architecture. - Thread Level Parallelism (III)
") OS 6385 omputer Architecture - Thread Level Parallelism (III) Spring 2013 Some slides are based on a lecture by David uller, University of alifornia, Berkley http://www.eecs.berkeley.edu/~culler/courses/cs252-s05
OS 6385 omputer Architecture - Thread Level Parallelism (III) Spring 2013 Some slides are based on a lecture by David uller, University of alifornia, Berkley http://www.eecs.berkeley.edu/~culler/courses/cs252-s05
Lecture 24: Thread Level Parallelism -- Distributed Shared Memory and Directory-based Coherence Protocol
 Lecture 24: Thread Level Parallelism -- Distributed Shared Memory and Directory-based Coherence Protocol CSE 564 Computer Architecture Fall 2016 Department of Computer Science and Engineering Yonghong
Lecture 24: Thread Level Parallelism -- Distributed Shared Memory and Directory-based Coherence Protocol CSE 564 Computer Architecture Fall 2016 Department of Computer Science and Engineering Yonghong
COSC 6385 Computer Architecture. - Multi-Processors (IV) Simultaneous multi-threading and multi-core processors
 Simultaneous multi-threading and multi-core processors") OS 6385 omputer Architecture - Multi-Processors (IV) Simultaneous multi-threading and multi-core processors Spring 2012 Long-term trend on the number of transistor per integrated circuit Number of transistors
OS 6385 omputer Architecture - Multi-Processors (IV) Simultaneous multi-threading and multi-core processors Spring 2012 Long-term trend on the number of transistor per integrated circuit Number of transistors
Shared Memory SMP and Cache Coherence (cont) Adapted from UCB CS252 S01, Copyright 2001 USB
 Adapted from UCB CS252 S01, Copyright 2001 USB") Shared SMP and Cache Coherence (cont) Adapted from UCB CS252 S01, Copyright 2001 USB 1 Review: Snoopy Cache Protocol Write Invalidate Protocol: Multiple readers, single writer Write to shared data: an
Shared SMP and Cache Coherence (cont) Adapted from UCB CS252 S01, Copyright 2001 USB 1 Review: Snoopy Cache Protocol Write Invalidate Protocol: Multiple readers, single writer Write to shared data: an
CMSC 611: Advanced. Distributed & Shared Memory
 CMSC 611: Advanced Computer Architecture Distributed & Shared Memory Centralized Shared Memory MIMD Processors share a single centralized memory through a bus interconnect Feasible for small processor
CMSC 611: Advanced Computer Architecture Distributed & Shared Memory Centralized Shared Memory MIMD Processors share a single centralized memory through a bus interconnect Feasible for small processor
Review: Multiprocessor. CPE 631 Session 21: Multiprocessors (Part 2) Potential HW Coherency Solutions. Bus Snooping Topology
 Potential HW Coherency Solutions. Bus Snooping Topology") Review: Multiprocessor CPE 631 Session 21: Multiprocessors (Part 2) Department of Electrical and Computer Engineering University of Alabama in Huntsville Basic issues and terminology Communication: share
Review: Multiprocessor CPE 631 Session 21: Multiprocessors (Part 2) Department of Electrical and Computer Engineering University of Alabama in Huntsville Basic issues and terminology Communication: share
CMSC 611: Advanced Computer Architecture
 CMSC 611: Advanced Computer Architecture Shared Memory Most slides adapted from David Patterson. Some from Mohomed Younis Interconnection Networks Massively processor networks (MPP) Thousands of nodes
CMSC 611: Advanced Computer Architecture Shared Memory Most slides adapted from David Patterson. Some from Mohomed Younis Interconnection Networks Massively processor networks (MPP) Thousands of nodes
COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence
 1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
Page 1. Lecture 12: Multiprocessor 2: Snooping Protocol, Directory Protocol, Synchronization, Consistency. Bus Snooping Topology
 CS252 Graduate Computer Architecture Lecture 12: Multiprocessor 2: Snooping Protocol, Directory Protocol, Synchronization, Consistency Review: Multiprocessor Basic issues and terminology Communication:
CS252 Graduate Computer Architecture Lecture 12: Multiprocessor 2: Snooping Protocol, Directory Protocol, Synchronization, Consistency Review: Multiprocessor Basic issues and terminology Communication:
Aleksandar Milenkovic, Electrical and Computer Engineering University of Alabama in Huntsville. Review: Small-Scale Shared Memory
 Lecture 20: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Review: Small-Scale Shared Memory Caches serve to: Increase
Lecture 20: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Review: Small-Scale Shared Memory Caches serve to: Increase
CPE 631 Lecture 21: Multiprocessors
 Lecture 2: Multiprocessors Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Review: Small-Scale Shared Memory Caches serve to: Increase
Lecture 2: Multiprocessors Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Review: Small-Scale Shared Memory Caches serve to: Increase
ECSE 425 Lecture 30: Directory Coherence
 ECSE 425 Lecture 30: Directory Coherence H&P Chapter 4 Last Time Snoopy Coherence Symmetric SMP Performance 2 Today Directory- based Coherence 3 A Scalable Approach: Directories One directory entry for
ECSE 425 Lecture 30: Directory Coherence H&P Chapter 4 Last Time Snoopy Coherence Symmetric SMP Performance 2 Today Directory- based Coherence 3 A Scalable Approach: Directories One directory entry for
CMSC 411 Computer Systems Architecture Lecture 21 Multiprocessors 3
 MS 411 omputer Systems rchitecture Lecture 21 Multiprocessors 3 Outline Review oherence Write onsistency dministrivia Snooping Building Blocks Snooping protocols and examples oherence traffic and performance
MS 411 omputer Systems rchitecture Lecture 21 Multiprocessors 3 Outline Review oherence Write onsistency dministrivia Snooping Building Blocks Snooping protocols and examples oherence traffic and performance
Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano
 Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano Outline The problem of cache coherence Snooping protocols Directory-based protocols Prof. Cristina Silvano, Politecnico
Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano Outline The problem of cache coherence Snooping protocols Directory-based protocols Prof. Cristina Silvano, Politecnico
Aleksandar Milenkovich 1
 Parallel Computers Lecture 8: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection
Parallel Computers Lecture 8: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection
Aleksandar Milenkovic, Electrical and Computer Engineering University of Alabama in Huntsville
 Lecture 18: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Parallel Computers Definition: A parallel computer is a collection
Lecture 18: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Parallel Computers Definition: A parallel computer is a collection
CS654 Advanced Computer Architecture Lec 14 Directory Based Multiprocessors
 CS654 Advanced Computer Architecture Lec 14 Directory Based Multiprocessors Peter Kemper Adapted from the slides of EECS 252 by Prof. David Patterson Electrical Engineering and Computer Sciences University
CS654 Advanced Computer Architecture Lec 14 Directory Based Multiprocessors Peter Kemper Adapted from the slides of EECS 252 by Prof. David Patterson Electrical Engineering and Computer Sciences University
5008: Computer Architecture
 5008: Computer Architecture Chapter 4 Multiprocessors and Thread-Level Parallelism --II CA Lecture08 - multiprocessors and TLP (cwliu@twins.ee.nctu.edu.tw) 09-1 Review Caches contain all information on
5008: Computer Architecture Chapter 4 Multiprocessors and Thread-Level Parallelism --II CA Lecture08 - multiprocessors and TLP (cwliu@twins.ee.nctu.edu.tw) 09-1 Review Caches contain all information on
Computer Architecture. A Quantitative Approach, Fifth Edition. Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Directory Implementation. A High-end MP
 ectory Implementation Distributed memory each processor (or cluster of processors) has its own memory processor-memory pairs are connected via a multi-path interconnection network snooping with broadcasting
ectory Implementation Distributed memory each processor (or cluster of processors) has its own memory processor-memory pairs are connected via a multi-path interconnection network snooping with broadcasting
Computer Architecture Lecture 10: Thread Level Parallelism II (Chapter 5) Chih Wei Liu 劉志尉 National Chiao Tung University
 Chih Wei Liu 劉志尉 National Chiao Tung University") Computer Architecture Lecture 10: Thread Level Parallelism II (Chapter 5) Chih Wei Liu 劉志尉 National Chiao Tung University cwliu@twins.ee.nctu.edu.tw Review Caches contain all information on state of cached
Computer Architecture Lecture 10: Thread Level Parallelism II (Chapter 5) Chih Wei Liu 劉志尉 National Chiao Tung University cwliu@twins.ee.nctu.edu.tw Review Caches contain all information on state of cached
Lecture 17: Multiprocessors: Size, Consitency. Review: Networking Summary
 Lecture 17: Multiprocessors: Size, Consitency Professor David A. Patterson Computer Science 252 Spring 1998 DAP Spr. 98 UCB 1 Review: Networking Summary Protocols allow hetereogeneous networking Protocols
Lecture 17: Multiprocessors: Size, Consitency Professor David A. Patterson Computer Science 252 Spring 1998 DAP Spr. 98 UCB 1 Review: Networking Summary Protocols allow hetereogeneous networking Protocols
Thread- Level Parallelism. ECE 154B Dmitri Strukov
 Thread- Level Parallelism ECE 154B Dmitri Strukov Introduc?on Thread- Level parallelism Have mul?ple program counters and resources Uses MIMD model Targeted for?ghtly- coupled shared- memory mul?processors
Thread- Level Parallelism ECE 154B Dmitri Strukov Introduc?on Thread- Level parallelism Have mul?ple program counters and resources Uses MIMD model Targeted for?ghtly- coupled shared- memory mul?processors
CISC 662 Graduate Computer Architecture Lectures 15 and 16 - Multiprocessors and Thread-Level Parallelism
 CISC 662 Graduate Computer Architecture Lectures 15 and 16 - Multiprocessors and Thread-Level Parallelism Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from
CISC 662 Graduate Computer Architecture Lectures 15 and 16 - Multiprocessors and Thread-Level Parallelism Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu Outline Parallel computing? Multi-core architectures Memory hierarchy Vs. SMT Cache coherence What is parallel computing? Using multiple processors in parallel to
Multi-core Architectures Dr. Yingwu Zhu Outline Parallel computing? Multi-core architectures Memory hierarchy Vs. SMT Cache coherence What is parallel computing? Using multiple processors in parallel to
ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols CA SMP and cache coherence
 Computer Architecture ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols 1 Shared Memory Multiprocessor Memory Bus P 1 Snoopy Cache Physical Memory P 2 Snoopy
Computer Architecture ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols 1 Shared Memory Multiprocessor Memory Bus P 1 Snoopy Cache Physical Memory P 2 Snoopy
CSE 502 Graduate Computer Architecture Lec 19 Directory-Based Shared-Memory Multiprocessors & MP Synchronization
 CSE 502 Graduate Computer Architecture Lec 19 Directory-Based Shared-Memory Multiprocessors & MP Synchronization Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and
CSE 502 Graduate Computer Architecture Lec 19 Directory-Based Shared-Memory Multiprocessors & MP Synchronization Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and
Multiprocessor Cache Coherence. Chapter 5. Memory System is Coherent If... From ILP to TLP. Enforcing Cache Coherence. Multiprocessor Types
 Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Lecture 30: Multiprocessors Flynn Categories, Large vs. Small Scale, Cache Coherency Professor Randy H. Katz Computer Science 252 Spring 1996
 Lecture 30: Multiprocessors Flynn Categories, Large vs. Small Scale, Cache Coherency Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Flynn Categories SISD (Single Instruction Single
Lecture 30: Multiprocessors Flynn Categories, Large vs. Small Scale, Cache Coherency Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Flynn Categories SISD (Single Instruction Single
Page 1. Instruction-Level Parallelism (ILP) CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism
 CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism") CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism Michela Taufer Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism Michela Taufer Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Chapter 6: Multiprocessors and Thread-Level Parallelism
 Chapter 6: Multiprocessors and Thread-Level Parallelism 1 Parallel Architectures 2 Flynn s Four Categories SISD (Single Instruction Single Data) Uniprocessors MISD (Multiple Instruction Single Data)???;
Chapter 6: Multiprocessors and Thread-Level Parallelism 1 Parallel Architectures 2 Flynn s Four Categories SISD (Single Instruction Single Data) Uniprocessors MISD (Multiple Instruction Single Data)???;
Parallel Computers. CPE 631 Session 20: Multiprocessors. Flynn s Tahonomy (1972) Why Multiprocessors?
 Why Multiprocessors?") Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Multiprocessors: Basics, Cache coherence, Synchronization, and Memory consistency
 Multiprocessors: Basics, Cache coherence, Synchronization, and Memory consistency Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475
Multiprocessors: Basics, Cache coherence, Synchronization, and Memory consistency Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475
EC 513 Computer Architecture
 EC 513 Computer Architecture Cache Coherence - Directory Cache Coherence Prof. Michel A. Kinsy Shared Memory Multiprocessor Processor Cores Local Memories Memory Bus P 1 Snoopy Cache Physical Memory P
EC 513 Computer Architecture Cache Coherence - Directory Cache Coherence Prof. Michel A. Kinsy Shared Memory Multiprocessor Processor Cores Local Memories Memory Bus P 1 Snoopy Cache Physical Memory P
Review. EECS 252 Graduate Computer Architecture. Lec 13 Snooping Cache and Directory Based Multiprocessors. Outline. Challenges of Parallel Processing
 EEC 252 Graduate Computer Architecture Lec 13 nooping Cache and Directory Based Multiprocessors David atterson Electrical Engineering and Computer ciences University of California, Berkeley http://www.eecs.berkeley.edu/~pattrsn
EEC 252 Graduate Computer Architecture Lec 13 nooping Cache and Directory Based Multiprocessors David atterson Electrical Engineering and Computer ciences University of California, Berkeley http://www.eecs.berkeley.edu/~pattrsn
Flynn s Classification
 Flynn s Classification SISD (Single Instruction Single Data) Uniprocessors MISD (Multiple Instruction Single Data) No machine is built yet for this type SIMD (Single Instruction Multiple Data) Examples:
Flynn s Classification SISD (Single Instruction Single Data) Uniprocessors MISD (Multiple Instruction Single Data) No machine is built yet for this type SIMD (Single Instruction Multiple Data) Examples:
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Parallel Computer Architecture Spring Distributed Shared Memory Architectures & Directory-Based Memory Coherence
 Parallel Computer Architecture Spring 2018 Distributed Shared Memory Architectures & Directory-Based Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly
Parallel Computer Architecture Spring 2018 Distributed Shared Memory Architectures & Directory-Based Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly
Lecture 8: Snooping and Directory Protocols. Topics: split-transaction implementation details, directory implementations (memory- and cache-based)
") Lecture 8: Snooping and Directory Protocols Topics: split-transaction implementation details, directory implementations (memory- and cache-based) 1 Split Transaction Bus So far, we have assumed that a
Lecture 8: Snooping and Directory Protocols Topics: split-transaction implementation details, directory implementations (memory- and cache-based) 1 Split Transaction Bus So far, we have assumed that a
??%/year. ! All microprocessor companies switch to MP (2X CPUs / 2 yrs) " Procrastination penalized: 2X sequential perf. / 5 yrs
 Procrastination penalized: 2X sequential perf. / 5 yrs") Outline EEL 5764 Graduate Computer Architecture Chapter 4 - Multiprocessors and TLP Ann Gordon-oss Electrical and Computer Engineering University of Florida MP Motivation ID v. IMD v. MIMD Centralized
Outline EEL 5764 Graduate Computer Architecture Chapter 4 - Multiprocessors and TLP Ann Gordon-oss Electrical and Computer Engineering University of Florida MP Motivation ID v. IMD v. MIMD Centralized
Lecture 5: Directory Protocols. Topics: directory-based cache coherence implementations
 Lecture 5: Directory Protocols Topics: directory-based cache coherence implementations 1 Flat Memory-Based Directories Block size = 128 B Memory in each node = 1 GB Cache in each node = 1 MB For 64 nodes
Lecture 5: Directory Protocols Topics: directory-based cache coherence implementations 1 Flat Memory-Based Directories Block size = 128 B Memory in each node = 1 GB Cache in each node = 1 MB For 64 nodes
Lecture 25: Multiprocessors. Today s topics: Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization
 Lecture 25: Multiprocessors Today s topics: Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization 1 Snooping-Based Protocols Three states for a block: invalid,
Lecture 25: Multiprocessors Today s topics: Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization 1 Snooping-Based Protocols Three states for a block: invalid,
Multiprocessor Cache Coherency. What is Cache Coherence?
 Multiprocessor Cache Coherency CS448 1 What is Cache Coherence? Two processors can have two different values for the same memory location 2 1 Terminology Coherence Defines what values can be returned by
Multiprocessor Cache Coherency CS448 1 What is Cache Coherence? Two processors can have two different values for the same memory location 2 1 Terminology Coherence Defines what values can be returned by
Multiprocessor Systems
 Multiprocessor ystems 55:132/22C:160 pring2011 1 (vs. VAX-11/780) erformance 10000 1000 100 10 1 Uniprocessor erformance (ECint) From Hennessy and atterson, Computer Architecture: A Quantitative Approach,
Multiprocessor ystems 55:132/22C:160 pring2011 1 (vs. VAX-11/780) erformance 10000 1000 100 10 1 Uniprocessor erformance (ECint) From Hennessy and atterson, Computer Architecture: A Quantitative Approach,
Lecture 2: Snooping and Directory Protocols. Topics: Snooping wrap-up and directory implementations
 Lecture 2: Snooping and Directory Protocols Topics: Snooping wrap-up and directory implementations 1 Split Transaction Bus So far, we have assumed that a coherence operation (request, snoops, responses,
Lecture 2: Snooping and Directory Protocols Topics: Snooping wrap-up and directory implementations 1 Split Transaction Bus So far, we have assumed that a coherence operation (request, snoops, responses,
Lecture 23: Thread Level Parallelism -- Introduction, SMP and Snooping Cache Coherence Protocol
 Lecture 23: Thread Level Parallelism -- Introduction, SMP and Snooping Cache Coherence Protocol CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu
Lecture 23: Thread Level Parallelism -- Introduction, SMP and Snooping Cache Coherence Protocol CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu
CSE 392/CS 378: High-performance Computing - Principles and Practice
 CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
COMP Parallel Computing. CC-NUMA (1) CC-NUMA implementation
 CC-NUMA implementation") COP 633 - Parallel Computing Lecture 10 September 27, 2018 CC-NUA (1) CC-NUA implementation Reading for next time emory consistency models tutorial (sections 1-6, pp 1-17) COP 633 - Prins CC-NUA (1) Topics
COP 633 - Parallel Computing Lecture 10 September 27, 2018 CC-NUA (1) CC-NUA implementation Reading for next time emory consistency models tutorial (sections 1-6, pp 1-17) COP 633 - Prins CC-NUA (1) Topics
Scalable Cache Coherence
 Scalable Cache Coherence [ 8.1] All of the cache-coherent systems we have talked about until now have had a bus. Not only does the bus guarantee serialization of transactions; it also serves as convenient
Scalable Cache Coherence [ 8.1] All of the cache-coherent systems we have talked about until now have had a bus. Not only does the bus guarantee serialization of transactions; it also serves as convenient
Computer Architecture
 Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 83 Part III Multi-Core
Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 83 Part III Multi-Core
Lecture 18: Coherence and Synchronization. Topics: directory-based coherence protocols, synchronization primitives (Sections
 Lecture 18: Coherence and Synchronization Topics: directory-based coherence protocols, synchronization primitives (Sections 5.1-5.5) 1 Cache Coherence Protocols Directory-based: A single location (directory)
Lecture 18: Coherence and Synchronization Topics: directory-based coherence protocols, synchronization primitives (Sections 5.1-5.5) 1 Cache Coherence Protocols Directory-based: A single location (directory)
Thread-Level Parallelism
 Advanced Computer Architecture Thread-Level Parallelism Some slides are from the instructors resources which accompany the 6 th and previous editions. Some slides are from David Patterson, David Culler
Advanced Computer Architecture Thread-Level Parallelism Some slides are from the instructors resources which accompany the 6 th and previous editions. Some slides are from David Patterson, David Culler
Lecture 25: Multiprocessors
 Lecture 25: Multiprocessors Today s topics: Virtual memory wrap-up Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization 1 TLB and Cache Is the cache indexed
Lecture 25: Multiprocessors Today s topics: Virtual memory wrap-up Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization 1 TLB and Cache Is the cache indexed
Cache Coherence. Bryan Mills, PhD. Slides provided by Rami Melhem
 Cache Coherence Bryan Mills, PhD Slides provided by Rami Melhem Cache coherence Programmers have no control over caches and when they get updated. x = 2; /* initially */ y0 eventually ends up = 2 y1 eventually
Cache Coherence Bryan Mills, PhD Slides provided by Rami Melhem Cache coherence Programmers have no control over caches and when they get updated. x = 2; /* initially */ y0 eventually ends up = 2 y1 eventually
A Scalable SAS Machine
 arallel omputer Organization and Design : Lecture 8 er Stenström. 2008, Sally. ckee 2009 Scalable ache oherence Design principles of scalable cache protocols Overview of design space (8.1) Basic operation
arallel omputer Organization and Design : Lecture 8 er Stenström. 2008, Sally. ckee 2009 Scalable ache oherence Design principles of scalable cache protocols Overview of design space (8.1) Basic operation
CS 152 Computer Architecture and Engineering. Lecture 19: Directory-Based Cache Protocols
 CS 152 Computer Architecture and Engineering Lecture 19: Directory-Based Cache Protocols Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 19: Directory-Based Cache Protocols Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
3/13/2008 Csci 211 Lecture %/year. Manufacturer/Year. Processors/chip Threads/Processor. Threads/chip 3/13/2008 Csci 211 Lecture 8 4
 Outline CSCI Computer System Architecture Lec 8 Multiprocessor Introduction Xiuzhen Cheng Department of Computer Sciences The George Washington University MP Motivation SISD v. SIMD v. MIMD Centralized
Outline CSCI Computer System Architecture Lec 8 Multiprocessor Introduction Xiuzhen Cheng Department of Computer Sciences The George Washington University MP Motivation SISD v. SIMD v. MIMD Centralized
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 18: Directory-Based Cache Protocols John Wawrzynek EECS, University of California at Berkeley http://inst.eecs.berkeley.edu/~cs152 Administrivia 2 Recap:
CS 152 Computer Architecture and Engineering Lecture 18: Directory-Based Cache Protocols John Wawrzynek EECS, University of California at Berkeley http://inst.eecs.berkeley.edu/~cs152 Administrivia 2 Recap:
Parallel Architecture. Hwansoo Han
 Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley
 Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley Avinash Kodi Department of Electrical Engineering & Computer
Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley Avinash Kodi Department of Electrical Engineering & Computer
Lecture 3: Snooping Protocols. Topics: snooping-based cache coherence implementations
 Lecture 3: Snooping Protocols Topics: snooping-based cache coherence implementations 1 Design Issues, Optimizations When does memory get updated? demotion from modified to shared? move from modified in
Lecture 3: Snooping Protocols Topics: snooping-based cache coherence implementations 1 Design Issues, Optimizations When does memory get updated? demotion from modified to shared? move from modified in
Cache Coherence. CMU : Parallel Computer Architecture and Programming (Spring 2012)
") Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
Application Note 228
 Application Note 228 Implementing DMA on ARM SMP Systems Document number: ARM DAI 0228 A Issued: 1 st August 2009 Copyright ARM Limited 2009 Copyright 2006 ARM Limited. All rights reserved. Application
Application Note 228 Implementing DMA on ARM SMP Systems Document number: ARM DAI 0228 A Issued: 1 st August 2009 Copyright ARM Limited 2009 Copyright 2006 ARM Limited. All rights reserved. Application
Lecture 3: Directory Protocol Implementations. Topics: coherence vs. msg-passing, corner cases in directory protocols
 Lecture 3: Directory Protocol Implementations Topics: coherence vs. msg-passing, corner cases in directory protocols 1 Future Scalable Designs Intel s Single Cloud Computer (SCC): an example prototype
Lecture 3: Directory Protocol Implementations Topics: coherence vs. msg-passing, corner cases in directory protocols 1 Future Scalable Designs Intel s Single Cloud Computer (SCC): an example prototype
Lecture 18: Coherence Protocols. Topics: coherence protocols for symmetric and distributed shared-memory multiprocessors (Sections
 Lecture 18: Coherence Protocols Topics: coherence protocols for symmetric and distributed shared-memory multiprocessors (Sections 4.2-4.4) 1 SMP/UMA/Centralized Memory Multiprocessor Main Memory I/O System
Lecture 18: Coherence Protocols Topics: coherence protocols for symmetric and distributed shared-memory multiprocessors (Sections 4.2-4.4) 1 SMP/UMA/Centralized Memory Multiprocessor Main Memory I/O System
Multiprocessors and Thread Level Parallelism CS 282 KAUST Spring 2010 Muhamed Mudawar
 Multiprocessors and Thread Level Parallelism CS 282 KAUST Spring 2010 Muhamed Mudawar Original slides created by: David Patterson Uniprocessor Performance (SPECint) 80) Performance (vs. VAX-11/78 10000
Multiprocessors and Thread Level Parallelism CS 282 KAUST Spring 2010 Muhamed Mudawar Original slides created by: David Patterson Uniprocessor Performance (SPECint) 80) Performance (vs. VAX-11/78 10000
CS 152 Computer Architecture and Engineering. Lecture 19: Directory-Based Cache Protocols
 CS 152 Computer Architecture and Engineering Lecture 19: Directory-Based Protocols Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory http://inst.eecs.berkeley.edu/~cs152
CS 152 Computer Architecture and Engineering Lecture 19: Directory-Based Protocols Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory http://inst.eecs.berkeley.edu/~cs152
Lecture 10: Cache Coherence: Part I. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
Module 9: Addendum to Module 6: Shared Memory Multiprocessors Lecture 17: Multiprocessor Organizations and Cache Coherence. The Lecture Contains:
 The Lecture Contains: Shared Memory Multiprocessors Shared Cache Private Cache/Dancehall Distributed Shared Memory Shared vs. Private in CMPs Cache Coherence Cache Coherence: Example What Went Wrong? Implementations
The Lecture Contains: Shared Memory Multiprocessors Shared Cache Private Cache/Dancehall Distributed Shared Memory Shared vs. Private in CMPs Cache Coherence Cache Coherence: Example What Went Wrong? Implementations
Cache Coherence in Scalable Machines
 ache oherence in Scalable Machines SE 661 arallel and Vector Architectures rof. Muhamed Mudawar omputer Engineering Department King Fahd University of etroleum and Minerals Generic Scalable Multiprocessor
ache oherence in Scalable Machines SE 661 arallel and Vector Architectures rof. Muhamed Mudawar omputer Engineering Department King Fahd University of etroleum and Minerals Generic Scalable Multiprocessor
Lecture 26: Multiprocessors. Today s topics: Directory-based coherence Synchronization Consistency Shared memory vs message-passing
 Lecture 26: Multiprocessors Today s topics: Directory-based coherence Synchronization Consistency Shared memory vs message-passing 1 Cache Coherence Protocols Directory-based: A single location (directory)
Lecture 26: Multiprocessors Today s topics: Directory-based coherence Synchronization Consistency Shared memory vs message-passing 1 Cache Coherence Protocols Directory-based: A single location (directory)
Shared Memory Multiprocessors. Symmetric Shared Memory Architecture (SMP) Cache Coherence. Cache Coherence Mechanism. Interconnection Network
 Cache Coherence. Cache Coherence Mechanism. Interconnection Network") Shared Memory Multis Processor Processor Processor i Processor n Symmetric Shared Memory Architecture (SMP) cache cache cache cache Interconnection Network Main Memory I/O System Cache Coherence Cache
Shared Memory Multis Processor Processor Processor i Processor n Symmetric Shared Memory Architecture (SMP) cache cache cache cache Interconnection Network Main Memory I/O System Cache Coherence Cache
Scalable Multiprocessors
 Scalable Multiprocessors [ 11.1] scalable system is one in which resources can be added to the system without reaching a hard limit. Of course, there may still be economic limits. s the size of the system
Scalable Multiprocessors [ 11.1] scalable system is one in which resources can be added to the system without reaching a hard limit. Of course, there may still be economic limits. s the size of the system
Chapter-4 Multiprocessors and Thread-Level Parallelism
 Chapter-4 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing returns
Chapter-4 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing returns
CS 152 Computer Architecture and Engineering. Lecture 19: Directory-Based Cache Protocols
 CS 152 Computer Architecture and Engineering Lecture 19: Directory-Based Cache Protocols Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 19: Directory-Based Cache Protocols Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
Limitations of parallel processing
 Your professor du jour: Steve Gribble gribble@cs.washington.edu 323B Sieg Hall all material in this lecture in Henessey and Patterson, Chapter 8 635-640 645, 646 654-665 11/8/00 CSE 471 Multiprocessors
Your professor du jour: Steve Gribble gribble@cs.washington.edu 323B Sieg Hall all material in this lecture in Henessey and Patterson, Chapter 8 635-640 645, 646 654-665 11/8/00 CSE 471 Multiprocessors
Lecture 10: Cache Coherence: Part I. Parallel Computer Architecture and Programming CMU /15-618, Spring 2015
 Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Marble House The Knife (Silent Shout) Before starting The Knife, we were working
Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Marble House The Knife (Silent Shout) Before starting The Knife, we were working
COSC4201 Multiprocessors
 COSC4201 Multiprocessors Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Multiprocessing We are dedicating all of our future product development to multicore
COSC4201 Multiprocessors Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Multiprocessing We are dedicating all of our future product development to multicore
Lecture 1: Introduction
 Lecture 1: Introduction ourse organization: 4 lectures on cache coherence and consistency 2 lectures on transactional memory 2 lectures on interconnection networks 4 lectures on caches 4 lectures on memory
Lecture 1: Introduction ourse organization: 4 lectures on cache coherence and consistency 2 lectures on transactional memory 2 lectures on interconnection networks 4 lectures on caches 4 lectures on memory
Foundations of Computer Systems
 18-600 Foundations of Computer Systems Lecture 21: Multicore Cache Coherence John P. Shen & Zhiyi Yu November 14, 2016 Prevalence of multicore processors: 2006: 75% for desktops, 85% for servers 2007:
18-600 Foundations of Computer Systems Lecture 21: Multicore Cache Coherence John P. Shen & Zhiyi Yu November 14, 2016 Prevalence of multicore processors: 2006: 75% for desktops, 85% for servers 2007:
CSC 631: High-Performance Computer Architecture
 CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 10: Memory Part II CSC 631: High-Performance Computer Architecture 1 Two predictable properties of memory references: Temporal Locality:
CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 10: Memory Part II CSC 631: High-Performance Computer Architecture 1 Two predictable properties of memory references: Temporal Locality:
Introduction. Coherency vs Consistency. Lec-11. Multi-Threading Concepts: Coherency, Consistency, and Synchronization
 Lec-11 Multi-Threading Concepts: Coherency, Consistency, and Synchronization Coherency vs Consistency Memory coherency and consistency are major concerns in the design of shared-memory systems. Consistency
Lec-11 Multi-Threading Concepts: Coherency, Consistency, and Synchronization Coherency vs Consistency Memory coherency and consistency are major concerns in the design of shared-memory systems. Consistency
Computer Architecture
 18-447 Computer Architecture CSCI-564 Advanced Computer Architecture Lecture 29: Consistency & Coherence Lecture 20: Consistency and Coherence Bo Wu Prof. Onur Mutlu Colorado Carnegie School Mellon University
18-447 Computer Architecture CSCI-564 Advanced Computer Architecture Lecture 29: Consistency & Coherence Lecture 20: Consistency and Coherence Bo Wu Prof. Onur Mutlu Colorado Carnegie School Mellon University
CS252 Spring 2017 Graduate Computer Architecture. Lecture 12: Cache Coherence
 CS252 Spring 2017 Graduate Computer Architecture Lecture 12: Cache Coherence Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time in Lecture 11 Memory Systems DRAM
CS252 Spring 2017 Graduate Computer Architecture Lecture 12: Cache Coherence Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time in Lecture 11 Memory Systems DRAM
Overview: Shared Memory Hardware. Shared Address Space Systems. Shared Address Space and Shared Memory Computers. Shared Memory Hardware
 Overview: Shared Memory Hardware Shared Address Space Systems overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and
Overview: Shared Memory Hardware Shared Address Space Systems overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and
Overview: Shared Memory Hardware
 Overview: Shared Memory Hardware overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and update protocols false sharing
Overview: Shared Memory Hardware overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and update protocols false sharing
Incoherent each cache copy behaves as an individual copy, instead of as the same memory location.
 Cache Coherence This lesson discusses the problems and solutions for coherence. Different coherence protocols are discussed, including: MSI, MOSI, MOESI, and Directory. Each has advantages and disadvantages
Cache Coherence This lesson discusses the problems and solutions for coherence. Different coherence protocols are discussed, including: MSI, MOSI, MOESI, and Directory. Each has advantages and disadvantages
Page 1. SMP Review. Multiprocessors. Bus Based Coherence. Bus Based Coherence. Characteristics. Cache coherence. Cache coherence
 SMP Review Multiprocessors Today s topics: SMP cache coherence general cache coherence issues snooping protocols Improved interaction lots of questions warning I m going to wait for answers granted it
SMP Review Multiprocessors Today s topics: SMP cache coherence general cache coherence issues snooping protocols Improved interaction lots of questions warning I m going to wait for answers granted it
1. Memory technology & Hierarchy
 1. Memory technology & Hierarchy Back to caching... Advances in Computer Architecture Andy D. Pimentel Caches in a multi-processor context Dealing with concurrent updates Multiprocessor architecture In
1. Memory technology & Hierarchy Back to caching... Advances in Computer Architecture Andy D. Pimentel Caches in a multi-processor context Dealing with concurrent updates Multiprocessor architecture In
Outline. EEL 5764 Graduate Computer Architecture. Chapter 4 - Multiprocessors and TLP. Déjà vu all over again?
 Outline EEL 5764 Graduate Computer Architecture Chapter 4 - Multiprocessors and TLP Ann Gordon-Ross Electrical and Computer Engineering University of Florida MP Motivation ID v. IMD v. MIMD Centralized
Outline EEL 5764 Graduate Computer Architecture Chapter 4 - Multiprocessors and TLP Ann Gordon-Ross Electrical and Computer Engineering University of Florida MP Motivation ID v. IMD v. MIMD Centralized
Module 9: "Introduction to Shared Memory Multiprocessors" Lecture 16: "Multiprocessor Organizations and Cache Coherence" Shared Memory Multiprocessors
 Shared Memory Multiprocessors Shared memory multiprocessors Shared cache Private cache/dancehall Distributed shared memory Shared vs. private in CMPs Cache coherence Cache coherence: Example What went
Shared Memory Multiprocessors Shared memory multiprocessors Shared cache Private cache/dancehall Distributed shared memory Shared vs. private in CMPs Cache coherence Cache coherence: Example What went
Cache Coherence. Introduction to High Performance Computing Systems (CS1645) Esteban Meneses. Spring, 2014
 Esteban Meneses. Spring, 2014") Cache Coherence Introduction to High Performance Computing Systems (CS1645) Esteban Meneses Spring, 2014 Supercomputer Galore Starting around 1983, the number of companies building supercomputers exploded:
Cache Coherence Introduction to High Performance Computing Systems (CS1645) Esteban Meneses Spring, 2014 Supercomputer Galore Starting around 1983, the number of companies building supercomputers exploded:
CPU Scheduling (Part II)
") CPU Scheduling (Part II) Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) CPU Scheduling 1393/7/28 1 / 58 Motivation Amir H. Payberah
CPU Scheduling (Part II) Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) CPU Scheduling 1393/7/28 1 / 58 Motivation Amir H. Payberah
Cache Coherence. (Architectural Supports for Efficient Shared Memory) Mainak Chaudhuri
 Mainak Chaudhuri") Cache Coherence (Architectural Supports for Efficient Shared Memory) Mainak Chaudhuri mainakc@cse.iitk.ac.in 1 Setting Agenda Software: shared address space Hardware: shared memory multiprocessors Cache
Cache Coherence (Architectural Supports for Efficient Shared Memory) Mainak Chaudhuri mainakc@cse.iitk.ac.in 1 Setting Agenda Software: shared address space Hardware: shared memory multiprocessors Cache
Chapter 5. Thread-Level Parallelism
 Chapter 5 Thread-Level Parallelism Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors saturated
Chapter 5 Thread-Level Parallelism Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors saturated
Chapter 6. Parallel Processors from Client to Cloud Part 2 COMPUTER ORGANIZATION AND DESIGN. Homogeneous & Heterogeneous Multicore Architectures
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Part 2 Homogeneous & Heterogeneous Multicore Architectures Intel XEON 22nm
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Part 2 Homogeneous & Heterogeneous Multicore Architectures Intel XEON 22nm
Scalable Cache Coherent Systems Scalable distributed shared memory machines Assumptions:
 Scalable ache oherent Systems Scalable distributed shared memory machines ssumptions: rocessor-ache-memory nodes connected by scalable network. Distributed shared physical address space. ommunication assist
Scalable ache oherent Systems Scalable distributed shared memory machines ssumptions: rocessor-ache-memory nodes connected by scalable network. Distributed shared physical address space. ommunication assist