Chapter 6: Multiprocessors and Thread-Level Parallelism
|
|
|
- Charla Andrews
- 5 years ago
- Views:
Transcription
1 Chapter 6: Multiprocessors and Thread-Level Parallelism 1
2 Parallel Architectures 2
3 Flynn s Four Categories SISD (Single Instruction Single Data) Uniprocessors MISD (Multiple Instruction Single Data)???; multiple processors on a single data stream SIMD (Single Instruction Multiple Data) Examples: Illiac-IV, CM-2 Simple programming model Low overhead Flexibility All custom integrated circuits (Phrase reused by Intel marketing for media instructions ~ vector) MIMD (Multiple Instruction Multiple Data) Examples: Sun Enterprise 5000, Cray T3D, SGI Origin Flexible Use off-the-shelf micros MIMD current winner: Concentrate on major design emphasis <= 128 processor MIMD machines 3
4 MIMD In order to take advantage of an MIMD multiprocessor with n processors, we must have at least n threads or processes to execute. Thread-level parallelism 4
5 Major MIMD Styles 1. Centralized shared memory architectures ("Uniform Memory Access" or "Shared Memory Processor") For multiprocessors with small processor count, it is possible to share a single centralized memory and to interconnect the processors and memory by a bus. 2. Decentralized memory (memory module with CPU) get more memory bandwidth, lower memory latency Drawback: Longer communication latency Drawback: Software model more complex Shared memory model Message passing model 5
6 What is a Multiprocessor? A collection of communicating processors Goals: balance load, reduce inherent communication and extra work A multi-cache, multi-memory system Role of these components essential regardless of programming model Prog. model and comm. abstr. affect specific performance tradeoffs... P P P... P P P 6
7 Natural Extensions of Memory System P 1 Switch P n Scale (Interleaved) First-level $ P 1 P n (Interleaved) Main memory $ Interconnection network $ Shared Cache Mem Mem Centralized Memory Dance Hall, UMA P 1 P n Mem $ Mem $ Interconnection network Distributed Memory (NUMA) 7
8 Decentralized Memory versions 1. Shared Memory with "Non Uniform Memory Access" time (NUMA) 2. Message passing "multicomputer" with separate address space per processor Can invoke software with Remote Procedue Call (RPC) Often via library, such as MPI: Message Passing Interface Also called "Synchronous communication" since communication causes synchronization between 2 processes 8
9 Parallel Architecture Parallel Architecture extends traditional computer architecture with a communication architecture abstractions (HW/SW interface) organizational structure to realize abstraction efficiently 9
10 Parallel Framework Layers: Programming Model: Multiprogramming : lots of jobs, no communication Shared address space: communicate via memory Message passing: send and receive messages Data Parallel: several agents operate on several data sets simultaneously and then exchange information globally and simultaneously (shared or message passing) Communication Abstraction: Shared address space: e.g., load, store, atomic swap Message passing: e.g., send, receive library calls Debate over this topic (ease of programming, scaling) => many hardware designs 1:1 programming model 10
11 Shared address space model 11
12 Shared Address Model Summary Each processor can name every physical location in the machine Each process can name all data it shares with other processes Data transfer via load and store Data size: byte, word,... or cache blocks Uses virtual memory to map virtual to local or remote physical Memory hierarchy model applies: now communication moves data to local processor cache (as load moves data from memory to cache) Latency, BW, scalability when communicate? 12
13 Message passing model 13
14 Message Passing Model Whole computers (CPU, memory, I/O devices) communicate as explicit I/O operations Essentially NUMA but integrated at I/O devices vs. memory system Send specifies local buffer + receiving process on remote computer Receive specifies sending process on remote computer + local buffer to place data Usually send includes process tag and receive has rule on tag: match 1, match any Sync: when send completes, when buffer free, when request accepted, receive wait for send Send+receive => memory-memory copy, where each supplies local address, AND does pairwise sychronization! 14
15 Performance Metrics: Latency and Bandwidth 1. Bandwidth Need high bandwidth in communication Match limits in network, memory, and processor Challenge is link speed of network interface vs. bisection bandwidth of network 2. Latency Affects performance, since processor may have to wait Affects ease of programming, since requires more thought to overlap communication and computation Overhead to communicate is a problem in many machines 3. Latency Hiding How can a mechanism help hide latency? Increases programming system burden Examples: overlap message send with computation, prefetch data, switch to other tasks 15
16 Data parallel model 16
17 Data Parallel Model Operations can be performed in parallel on each element of a large regular data structure, such as an array 1 Control Processor broadcast to many PEs When computers were large, could amortize the control portion of many replicated PEs Condition flag per PE so that can skip Data distributed in each memory Early 1980s VLSI => SIMD rebirth: 32 1-bit PEs + memory on a chip was the PE Data parallel programming languages lay out data to processor 17
18 Data Parallel Model Vector processors have similar ISAs, but no data placement restriction SIMD led to Data Parallel Programming languages (High Performance Fortran and friends) Advancing VLSI led to single chip FPUs and whole fast µprocs (SIMD less attractive) SIMD programming model led to Single Program Multiple Data (SPMD) model All processors execute identical program Data parallel programming languages still useful, do communication all at once: Bulk Synchronous phases in which all communicate after a global barrier 18
19 Comparing models of parallelism 19
20 Advantages shared-memory communication model Compatibility with SMP hardware Ease of programming when communication patterns are complex or vary dynamically during execution Ability to develop apps using familiar SMP model, attention only on performance critical accesses Lower communication overhead, better use of BW for small items, due to implicit communication and memory mapping to implement protection in hardware, rather than through I/O system HW-controlled caching to reduce remote comm. by caching of all data, both shared and private. 20
21 Advantages message-passing communication model The hardware can be simpler (esp. vs. NUMA) Communication explicit => simpler to understand; in shared memory it can be hard to know when communicating and when not, and how costly it is Explicit communication focuses attention on costly aspect of parallel computation, sometimes leading to improved structure in multiprocessor program Synchronization is naturally associated with sending messages, reducing the possibility for errors introduced by incorrect synchronization Easier to use sender-initiated communication, which may have some advantages in performance 21
22 Review: Communication Models Shared Memory Processors communicate with shared address space Easy on small-scale machines Advantages: Model of choice for uniprocessors, small-scale MPs Ease of programming Lower latency Easier to use hardware controlled caching Message passing Processors have private memories, communicate via messages Advantages: Less hardware, easier to design Focuses attention on costly non-local operations Can support either SW model on either HW base 22
23 Amdahl s Law and Parallel Computers Amdahl s Law (FracX: original % to be speed up) Speedup = 1 / [(FracX/SpeedupX + (1-FracX)] A portion is sequential => limits parallel speedup Speedup <= 1/ (1-FracX) Ex. What fraction sequential to get 80X speedup from 100 processors? Assume either 1 processor or 100 fully used 80 = 1 / [(FracX/100 + (1-FracX)] 0.8*FracX + 80*(1-FracX) = *FracX = 1 FracX = (80-1)/79.2 = Only 0.25% sequential! 23
24 6.3 Symmetric Shared-Memory Architectures 24
25 Bus-Based Symmetric Shared Memory P1 Pn $ $ Bus Mem I/O devices Dominate the server market Building blocks for larger systems; arriving to desktop Attractive as throughput servers and for parallel programs Fine-grain resource sharing Uniform access via loads/stores Automatic data movement and coherent replication in caches Cheap and powerful extension Normal uniprocessor mechanisms to access data Key is extension of memory hierarchy to support multiple processors Now Chip Multiprocessors 25
26 Symmetric Multi-Processors The large, multilevel caches reduce the memory demand of a processor This allows for more than one processor to share the bus to the memory Different organizations: Processor and cache on an extension board Integrated on the mainboard (most popular) Integrated on the same chip The new problem: cache coherence 26
27 Cache coherence 27
28 Caches are Critical for Performance Reduce average latency automatic replication closer to processor Reduce average bandwidth Data is logically transferred from producer to consumer to memory store reg --> mem load reg <-- mem Many processors can shared data efficiently What happens when store & load are executed on different processors? P P P 28
29 Example Cache Coherence Problem u :5 P 1 P 2 P 3 u =? u =? 4 $ $ 5 $ u :5 3 u= 7 1 u:5 2 I/O devices Memory Processors see different values for u after event 3 With write-back caches, value written back to memory depends on happenstance of which cache flushes or writes back value when Processes accessing main memory may see very stale value Unacceptable to programs, and frequent! 29
30 Caches and Cache Coherence Caches play key role in all cases Reduce average data access time Reduce bandwidth demands placed on shared interconnect Private processor caches create a problem Copies of a variable can be present in multiple caches A write by one processor may not become visible to others They ll keep accessing stale value in their caches Cache coherence problem What do we do about it? Organize the mem hierarchy to make it go away Detect and take actions to eliminate the problem 30
31 Cache Coherence 31
32 Small-Scale Shared Memory Caches serve to: Increase bandwidth versus bus/memory Reduce latency of access Valuable for both private data and shared data What about cache consistency? Time Event $ A $ B X (memo ory) CPU A reads X 2 CPU B reads X 3 CPU A stores 0 into X
33 Example 33
34 What Does Coherency Mean? Informally: Any read must return the most recent write Too strict and too difficult to implement Better: Any write must eventually be seen by a read All writes are seen in proper order ( serialization ) Two rules to ensure this: If P writes x and P1 reads it, P s write will be seen by P1 if the read and write are sufficiently far apart Writes to a single location are serialized: seen in one order Latest write will be seen Otherwise could see writes in illogical order (could see older value after a newer value) 34
35 Potential HW Coherency Solutions Snooping Solution (Snoopy Bus): Send all requests for data to all processors Processors snoop to see if they have a copy and respond accordingly Requires broadcast, since caching information is at processors Works well with bus (natural broadcast medium) Dominates for small scale machines (most of the market) Directory-Based Schemes (discuss later) Keep track of what is being shared in 1 centralized place (logically) Distributed memory => distributed directory for scalability (avoids bottlenecks) Send point-to-point requests to processors via network Scales better than Snooping Actually existed BEFORE Snooping-based schemes 35
36 Snooping Protocols- Write Invalidate Invalidate other copies on a write All other cached copies of the item are invalidated. 36
37 Snooping Protocols- Write Update Update all the cached copies of a data item when that item is written. 37
38 Snoopy Cache-Coherence Protocols State Address Data P 1 $ Bus snoop P n $ Mem I/O devices Cache-memory transaction Bus is a broadcast medium & Caches know what they have Cache Controller snoops all transactions on the shared bus relevant transaction if for a block it contains take action to ensure coherence invalidate, update, or supply value depends on state of the block and the protocol 38
39 Example: Write-thru Invalidate P 1 P 2 P 3 u =? u =? 3 4 $ $ 5 $ u :5 u :5 u= 7 1 u:5 u = 7 2 I/O devices Memory 39
40 Design Choices Controller updates state of blocks in response to processor and snoop events and generates bus transactions Snoopy protocol set of states state-transition diagram actions Basic Choices Write-through vs Write-back Invalidate vs. Update Snoop Processor Ld/St Cache Controller State Tag Data 40
41 Write-through Invalidate Protocol Two states per block in each cache as in uniprocessor state of a block is a p-vector of states Hardware state bits associated with blocks that are in the cache other blocks can be seen as being in invalid (not-present) state in that cache Writes invalidate all other caches can have multiple simultaneous readers of block,but write invalidates them PrRd / BusRd State Tag Data P1 Mem V I PrRd/ -- PrWr / BusWr BusWr / - PrWr / BusWr State Tag Data Pn $ $ Bus I/O devices 41
42 Write-Invalidate Example 42
43 Write-Update Example 43
44 Write-through vs. Write-back Write-through protocol is simple every write is observable Every write goes on the bus => Only one write can take place at a time in any processor Uses a lot of bandwidth! Example: 200 MHz dual issue, CPI = 1, 15% stores of 8 bytes => 30 M stores per second per processor => 240 MB/s per processor 1GB/s bus can support only about 4 processors without saturating 44
45 Invalidate vs. Update Basic question of program behavior: Is a block written by one processor later read by others before it is overwritten? Invalidate. yes: readers will take a miss no: multiple writes without addition traffic also clears out copies that will never be used again Update. yes: avoids misses on later references no: multiple useless updates even to pack rats => Need to look at program reference patterns and hardware complexity but first - correctness 45
46 Invalidate vs. Update Protocols 46
47 Basic Snoopy Protocols Write Invalidate Protocol: Multiple readers, single writer Write to shared data: an invalidate is sent to all caches which snoop and invalidate any copies Read Miss: Write-through: memory is always up-to-date Write-back: snoop in caches to find most recent copy Write Broadcast Protocol (typically write through): Write to shared data: broadcast on bus, processors snoop, and update any copies Read miss: memory is always up-to-date Write serialization: bus serializes requests! Bus is single point of arbitration 47
48 Basic Snoopy Protocols Write Invalidate versus Broadcast: Invalidate requires one transaction per write-run Invalidate uses spatial locality: one transaction per block Broadcast has lower latency between write and read 48
49 Snooping Cache Variations Basic Protocol Exclusive Shared Invalid Berkeley Protocol Owned Exclusive Owned Shared Shared Invalid Illinois Protocol Private Dirty Private Clean Shared Invalid MESI Protocol Modfied (private,!=memory) exclusive (private,=memory) Shared (shared,=memory) Invalid Owner can update via bus invalidate operation Owner must write back when replaced in cache If read sourced from memory, then Private Clean if read sourced from other cache, then Shared Can write in cache if held private clean or dirty 49
50 An Example Snoopy Protocol Invalidation protocol, write-back cache Each block of memory is in one state: Clean in all caches and up-to-date in memory (Shared) OR Dirty in exactly one cache (Exclusive) OR Not in any caches Each cache block is in one state (track these): Shared : block can be read OR Exclusive : cache has only copy, its writeable, and dirty OR Invalid : block contains no data Read misses: cause all caches to snoop bus Writes to clean line are treated as misses 50
51 Snoopy-Cache State Machine-I State machine for CPU requests for each cache block Invalid CPU Read Place read miss on bus CPU Read hit Shared (read/only) CPU Write Place Write Miss on bus CPU read miss Write back block, Place read miss on bus CPU Read miss Place read miss on bus Cache Block State CPU read hit CPU write hit Exclusive (read/write) CPU Write Place Write Miss on Bus CPU Write Miss Write back cache block Place write miss on bus 51
52 Snoopy-Cache State Machine-II State machine for bus requests for each cache block Appendix E? gives details of bus requests Write miss for this block Invalid Write Back Block; (abort memory access) Exclusive (read/write) Write miss for this block Read miss for this block Write Back Block; (abort memory access) Shared (read/only) 52
53 Snoopy-Cache State Machine-III State machine for CPU requests for each cache block and for bus requests for each cache block Cache Block State Write miss for this block Write Back Block; (abort memory access) CPU read hit CPU write hit Write miss for this block Invalid CPU Read Place read miss CPU Write on bus Place Write Miss on bus Exclusive (read/write) CPU read miss Write back block, Place read miss on bus CPU Write CPU Read hit Shared (read/only) CPU Read miss Place read miss on bus Place Write Miss on Bus Read miss for this block Write Back Block; (abort memory access) CPU Write Miss Write back cache block Place write miss on bus 53
54 Example P1 P2 Bus Memory step State Addr ValueState Addr ValueActionProc.Addr ValueAddrValu P1: Write 10 to A1 P1: P1: Read ReadA1 A1 P2: Read A1 P2: Write 20 to A1 P2: Write 40 to A2 Assumes A1 and A2 map to same cache block, initial cache state is invalid 54
55 Example P1 P2 Bus Memory step State Addr Value State Addr ValueAction Proc. Addr ValueAddrValu P1: Write W 10 to A1 Excl. A1 10 WrMs P1 A1 P1: P1: Read A1 A1 P2: Read A1 P2: Write 20 to A1 P2: Write 40 to A2 Assumes A1 and A2 map to same cache block 55
56 Example P1 P2 Bus Memory step State Addr Value State Addr ValueAction Proc. Addr ValueAddrValu P1: Write W 10 to A1 Excl. A1 10 WrMs P1 A1 P1: P1: Read A1 A1 Excl. A1 10 P2: Read A1 P2: Write 20 to A1 P2: Write 40 to A2 Assumes A1 and A2 map to same cache block 56
57 Example P1 P2 Bus Memory step State Addr Value State Addr ValueAction Proc. Addr ValueAddrValu P1: Write W 10 to A1 Excl. A1 10 WrMs P1 A1 P1: P1: Read A1 A1 Excl. A1 10 P2: Read A1 Shar. A1 RdMs P2 A1 Shar. A1 10 WrBk P1 A1 10 A1 10 Shar. A1 10 RdDa P2 A1 10 A1 10 P2: Write 20 to A1 P2: Write 40 to A2 Assumes A1 and A2 map to same cache block 57
58 Example P1 P2 Bus Memory step State Addr Value State Addr ValueAction Proc. Addr ValueAddrValu P1: Write W 10 to A1 Excl. A1 10 WrMs P1 A1 P1: P1: Read A1 A1 Excl. A1 10 P2: Read A1 Shar. A1 RdMs P2 A1 Shar. A1 10 WrBk P1 A1 10 A1 10 Shar. A1 10 RdDa P2 A1 10 A1 10 P2: Write W 20 to A1 Inv. Excl. A1 20 WrMs P2 A1 A1 10 P2: Write 40 to A2 Assumes A1 and A2 map to same cache block 58
59 Example P1 P2 Bus Memory step State Addr Value State Addr ValueAction Proc. Addr ValueAddrValu P1: Write W 10 to A1 Excl. A1 10 WrMs P1 A1 P1: P1: Read A1 A1 Excl. A1 10 P2: Read A1 Shar. A1 RdMs P2 A1 Shar. A1 10 WrBk P1 A1 10 A1 10 Shar. A1 10 RdDa P2 A1 10 A1 10 P2: Write W 20 to A1 Inv. Excl. A1 20 WrMs P2 A1 A1 10 P2: Write W 40 to A2 WrMs P2 A2 A1 10 Excl. A2 40 WrBk P2 A1 20 A1 20 Assumes A1 and A2 map to same cache block, but A1!= A2 59
60 Implementation Complications Write Races: Cannot update cache until bus is obtained Otherwise, another processor may get bus first, and then write the same cache block! Two step process: Arbitrate for bus Place miss on bus and complete operation If miss occurs to block while waiting for bus, handle miss (invalidate may be needed) and then restart. Split transaction bus: Bus transaction is not atomic: can have multiple outstanding transactions for a block Multiple misses can interleave, allowing two caches to grab block in the Exclusive state Must track and prevent multiple misses for one block Must support interventions and invalidations 60
61 Implementing Snooping Caches Multiple processors must be on bus, access to both addresses and data Add a few new commands to perform coherency, in addition to read and write Processors continuously snoop on address bus If address matches tag, either invalidate or update Since every bus transaction checks cache tags, could interfere with CPU just to check: solution 1: duplicate set of tags for L1 caches just to allow checks in parallel with CPU solution 2: L2 cache already duplicate, provided L2 obeys inclusion with L1 cache block size, associativity of L2 affects L1 61
62 Implementing Snooping Caches Bus serializes writes, getting bus ensures no one else can perform memory operation On a miss in a write back cache, may have the desired copy and its dirty, so must reply Add extra state bit to cache to determine shared or not 62
63 6.5 Distributed Shared-Memory Architectures 63
64 Larger MPs Separate Memory per Processor Local or Remote access via memory controller 1 Cache Coherency solution: non-cached pages Alternative: directory per cache that tracks state of every block in every cache Which caches have a copies of block, dirty vs. clean,... Info per memory block vs. per cache block? PLUS: In memory => simpler protocol (centralized/one location) MINUS: In memory => directory is ƒ(memory size) vs. ƒ(cache size) Prevent directory as bottleneck? distribute directory entries with memory, each keeping track of which Procs have copies of their blocks 64

65 Distributed Directory MPs 65
66 Directory Protocol Similar to Snoopy Protocol: Three states Shared: 1 processors have data, memory up-to-date Uncached (no processor has it; not valid in any cache) Exclusive: 1 processor (owner) has data; memory out-of-date In addition to cache state, must track which processors have data when in the shared state (usually bit vector, 1 if processor has copy) Keep it simple(r): Writes to non-exclusive data => write miss Processor blocks until access completes Assume messages received and acted upon in order sent 66
67 Directory Protocol No bus and don t want to broadcast: interconnect no longer single arbitration point all messages have explicit responses Terms: typically 3 processors involved Local node where a request originates Home node where the memory location of an address resides Remote node has a copy of a cache block, whether exclusive or shared Example messages on next slide: P = processor number, A = address 67
68 Directory Protocol Messages Message type Source Destination Msg Content Read miss Local cache Home directory P, A Processor P reads data at address A; make P a read sharer and arrange to send data back Write miss Local cache Home directory P, A Processor P writes data at address A; make P the exclusive owner and arrange to send data back Invalidate Home directory Remote caches A Invalidate a shared copy at address A. Fetch Home directory Remote cache A Fetch the block at address A and send it to its home directory Fetch/Invalidate Home directory Remote cache A Fetch the block at address A and send it to its home directory; invalidate the block in the cache Data value reply Home directory Local cache Data Return a data value from the home memory (read miss response) Data write-back Remote cache Home directory A, Data Write-back a data value for address A (invalidate response) 68
69 State Transition Diagram for an Individual Cache Block in a Directory Based System States identical to snoopy case; transactions very similar. Transitions caused by read misses, write misses, invalidates, data fetch requests Generates read miss & write miss msg to home directory. Write misses that were broadcast on the bus for snooping => explicit invalidate & data fetch requests. Note: on a write, a cache block is bigger, so need to read the full cache block 69
70 CPU -Cache State Machine CPU Read hit State machine for CPU requests for each memory block Invalid state if in memory Fetch/Invalidate send Data Write Back message to home directory Invalid Exclusive (read/writ) Invalidate CPU Read CPU Write: Send Write Miss msg to h.d. Send Read Miss message Shared (read/only) CPU Write:Send Write Miss message to home directory Fetch: send Data Write Back message to home directory CPU read miss: send Data Write Back message and read miss to home directory CPU read miss: Send Read Miss CPU read hit CPU write hit CPU write miss: send Data Write Back message and Write Miss to home directory 70
71 State Transition Diagram for the Directory Same states & structure as the transition diagram for an individual cache 2 actions: update of directory state & send msgs to statisfy requests Tracks all copies of memory block. Also indicates an action that updates the sharing set, Sharers, as well as sending a message. 71
72 Directory State Machine State machine for Directory requests for each memory block Uncached state if in memory Data Write Back: Sharers = {} (Write back block) Write Miss: Sharers = {P}; send Fetch/Invalidate; send Data Value Reply msg to remote cache Uncached Exclusive (read/writ) Read miss: Sharers = {P} send Data Value Reply Write Miss: Sharers = {P}; send Data Value Reply msg Shared (read only) Read miss: Sharers += {P}; send Fetch; send Data Value Reply msg to remote cache (Write back block) Read miss: Sharers += {P}; send Data Value Reply Write Miss: send Invalidate to Sharers; then Sharers = {P}; send Data Value Reply msg 72
73 Example Directory Protocol Message sent to directory causes two actions: Update the directory More messages to satisfy request Block is in Uncached state: the copy in memory is the current value; only possible requests for that block are: Read miss: requesting processor sent data from memory &requestor made only sharing node; state of block made Shared. Write miss: requesting processor is sent the value & becomes the Sharing node. The block is made Exclusive to indicate that the only valid copy is cached. Sharers indicates the identity of the owner. Block is Shared => the memory value is up-to-date: Read miss: requesting processor is sent back the data from memory & requesting processor is added to the sharing set. Write miss: requesting processor is sent the value. All processors in the set Sharers are sent invalidate messages, & Sharers is set to identity of requesting processor. The state of the block is made Exclusive. 73
74 Example Directory Protocol Block is Exclusive: current value of the block is held in the cache of the processor identified by the set Sharers (the owner) => three possible directory requests: Read miss: owner processor sent data fetch message, causing state of block in owner s cache to transition to Shared and causes owner to send data to directory, where it is written to memory & sent back to requesting processor. Identity of requesting processor is added to set Sharers, which still contains the identity of the processor that was the owner (since it still has a readable copy). State is shared. Data write-back: owner processor is replacing the block and hence must write it back, making memory copy up-to-date (the home directory essentially becomes the owner), the block is now Uncached, and the Sharer set is empty. Write miss: block has a new owner. A message is sent to old owner causing the cache to send the value of the block to the directory from which it is sent to the requesting processor, which becomes the new owner. Sharers is set to identity of new owner, and state of block is made Exclusive. 74
75 Implementing a Directory We assume operations atomic, but they are not; reality is much harder; must avoid deadlock when run out of buffers in network Optimizations: read miss or write miss in Exclusive: send data directly to requestor from owner vs. 1st to memory and then from memory to requestor 75
76 6.7 Synchronization 76
77 Synchronization Why Synchronize? Need to know when it is safe for different processes to use shared data Issues for Synchronization: Uninterruptible instruction to fetch and update memory (atomic operation); User level synchronization operation using this primitive; For large scale MPs, synchronization can be a bottleneck; techniques to reduce contention and latency of synchronization 77
78 Uninterruptible Instruction to Fetch and Update Memory Atomic exchange: interchange a value in a register for a value in memory 0 => synchronization variable is free 1 => synchronization variable is locked and unavailable Set register to 1 & swap New value in register determines success in getting lock 0 if you succeeded in setting the lock (you were first) 1 if other processor had already claimed access Key is that exchange operation is indivisible Test-and-set: tests a value and sets it if the value passes the test Fetch-and-increment: it returns the value of a memory location and atomically increments it 0 => synchronization variable is free 78
79 Uninterruptible Instruction to Fetch and Update Memory Hard to have read & write in 1 instruction: use 2 instead Load linked (or load locked) + store conditional Load linked returns the initial value Store conditional returns 1 if it succeeds (no other store to same memory location since preceeding load) and 0 otherwise Example doing atomic swap with LL & SC: try: mov R3,R4 ; mov exchange value ll R2,0(R1) ; load linked sc R3,0(R1) ; store conditional beqz R3,try ; branch store fails (R3 = 0) mov R4,R2 ; put load value in R4 Example doing fetch & increment with LL & SC: try: ll R2,0(R1) ; load linked addi R2,R2,#1 ; increment (OK if reg reg) sc R2,0(R1) ; store conditional beqz R2,try ; branch store fails (R2 = 0) 79
80 User Level Synchronization Operation Using this Primitive Spin locks: processor continuously tries to acquire, spinning around a loop trying to get the lock li R2,#1 lockit: exch R2,0(R1) ;atomic exchange bnez R2,lockit ;already locked? What about MP with cache coherency? Want to spin on cache copy to avoid full memory latency Likely to get cache hits for such variables Problem: exchange includes a write, which invalidates all other copies; this generates considerable bus traffic Solution: start by simply repeatedly reading the variable; when it changes, then try exchange ( test and test&set ): try: li R2,#1 lockit: lw R3,0(R1) ;load var bnez R3,lockit ;not free=>spin exch R2,0(R1) ;atomic exchange bnez R2,try ;already locked? 80
81 6.8 Models of Memory Consistency 81
82 Another MP Issue: Memory Consistency Models What is consistency? When must a processor see the new value? e.g., seems that P1: A = 0; P2: B = 0; A = 1; B = 1; L1: if (B == 0)... L2: if (A == 0)... Impossible for both if statements L1 & L2 to be true? What if write invalidate is delayed & processor continues? Memory consistency models: what are the rules for such cases? Sequential consistency: result of any execution is the same as if the accesses of each processor were kept in order and the accesses among different processors were interleaved => assignments before ifs above SC: delay all memory accesses until all invalidates done 82
83 6.9 Multithreading 83
84 Data Access Latency Cache misses (L1, L2) Concept Memory latency (remote, local) Often unpredictable Multithreading (MT) Tolerate or mask long and often unpredictable latency operations by switching to another context, which is able to do useful work. 84
85 Why Multithreading Today? ILP is exhausted, TLP is in. Large performance gap bet. MEM and PROC. Too many transistors on chip More existing MT applications Today. Multiprocessors on a single chip. Long network latency, too. 85
86 Requirements of Multithreading Storage need to hold multiple context s PC, registers, status word, etc. Coordination to match an event with a saved context A way to switch contexts Long latency operations must use resources not in use 86
87 Processor Utilization vs. Latency R = the run length to a long latency event L = the amount of latency 87
88 How do the processors communicate? Shared Memory Potential long latency on every load Cache coherency becomes an issue Examples include NYU s Ultracomputer, IBM s RP3, BBN s Butterfly, MIT s Alewife, and later Stanford s Dash. Synchronization occurs through share variables, locks, flags, and semaphores. Message Passing Programmer deals with latency. This enables them to minimize the number of messages, while maximizing the size, and this scheme allows for delay minimization by sending a message so that it reaches the receiver at the time it expects it. Examples include Intel s PSC and Paragon, Caltech s Cosmic Cube, and Thinking Machines CM-5 Synchronization occurs through send and receive 88
89 Improving Single Thread Performance Do more operations per instruction (VLIW) Allow multiple instructions to issue into pipeline from each context. This could lead to pipeline hazards, so other safe instructions could be interleaved into the execution. For Horizon & Tera, the compiler detects such data dependencies and the hardware enforces it by switching to another context if detected. Switch on load Switch on miss Switching on load or miss will increase the context switch time. 89
90 Simultaneous Multithreading (SMT) Tullsen, et. al. (U. of Washington), ISCA 95 A way to utilize pipeline with increased parallelism from multiple threads. 90
91 Simultaneous Multithreading 91
92 SMT Architecture Straightforward extension to conventional superscalar design. multiple program counters and some mechanism by which the fetch unit selects one each cycle, a separate return stack for each thread for predicting subroutine return destinations, per-thread instruction retirement, instruction queue flush, and trap mechanisms, a thread id with each branch target buffer entry to avoid predicting phantom branches, and a larger register file, to support logical registers for all threads plus additional registers for register renaming. The size of the register file affects the pipeline and the scheduling of loaddependent instructions. 92
93 Commercial Machines w/ MT Support Intel Hyperthreding (HT) Dual threads Pentium 4, XEON Sun CoolThreads UltraSPARC T1 4-threads per core IBM POWER5 93
94 IBM Power5 94
95 IBM Power5 95
96 Pros: SMT Summary Increased throughput w/o adding much cost Fast response for multitasking environment Cons: Slower single processor performance 96
97 Multicore Multiple processor cores on a chip Chip multiprocessor (CMP) Sun s Chip Multithreading (CMT) UltraSPARC T1 (Niagara) Intel s Pentium D AMD dual-core Opteron Also a way to utilize TLP, but 2 cores 2X costs No good for single thread performacne Can be used together with SMT 97
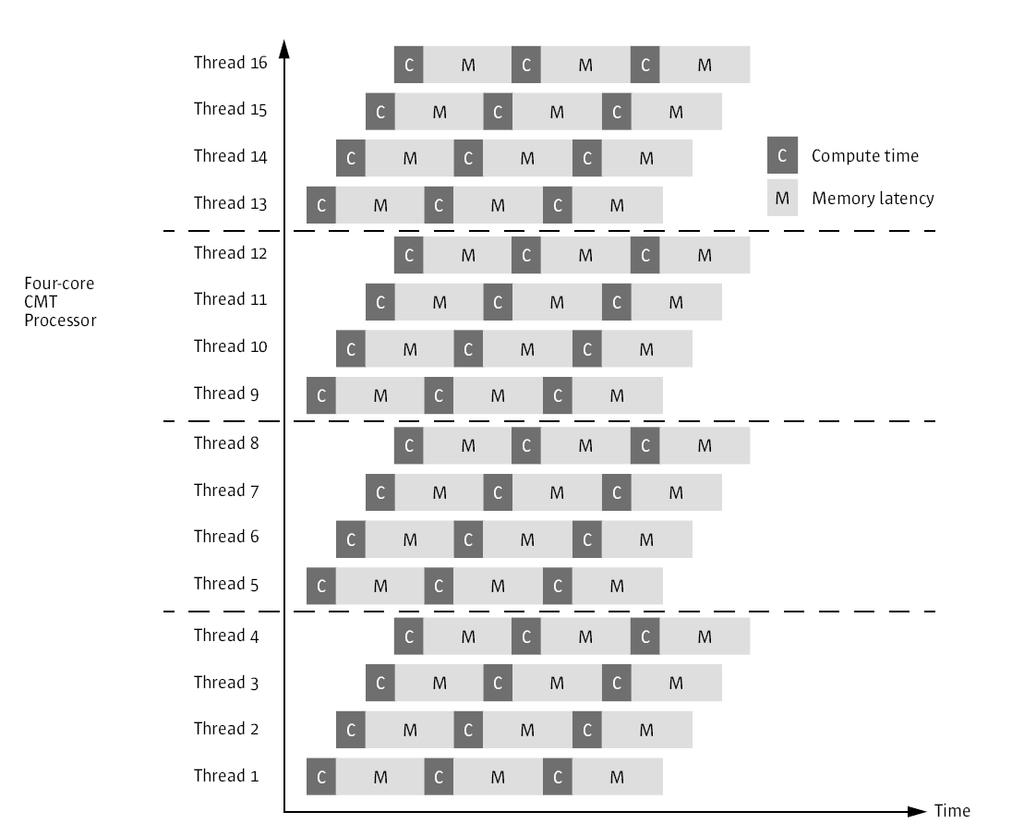
98 Chip Multithreading (CMT) 98

99 Sun UltraSPARC T1 Processor 99
100 8 Cores vs 2 Cores Is 8-cores too aggressive? Good for server applications, given Lots of threads Scalable operating environment Large memory space (64bit) Good for power efficiency Simple pipeline design for each core Good for availability Not intended for PCs, gaming, etc 100
101 SPECWeb 2005 IBM X346: 3Ghz Xeon T2000: 8 core 1.0GHz T1 Processor 101

102 Sun Fire T2000 Server 102
103 Server Pricing UltraSPARC Sun Fire T1000 Server 6 core 1.0GHz T1 Processor 2GB memory, 1x 80GB disk List price: $5,745 X86 Sun Fire X2100 Server Dual core AMD Opteron 175 2GB memory, 1x80GB disk List price: $2,295 Sun Fire T2000 Server 8 core 1.0GHz T1 Processor 8GB DDR2 memory, 2 X 73GB disk List price: $13,395 Sun Fire X4200 Server 2x Dual core AMD Opteron 275 4GB memory, 2x 73GB disk List price: $7,
104 Multiprocessor Conclusion Some optimism about future Parallel processing beginning to be understood in some domains More performance than that achieved with a single-chip microprocessor MPs are highly effective for multiprogrammed workloads MPs proved effective for intensive commercial workloads, such as OLTP (assuming enough I/O to be CPU-limited), DSS applications (where query optimization is critical), and large-scale, web searching applications On-chip MPs appears to be growing 1) embedded market where natural parallelism often exists an obvious alternative to faster less silicon efficient, CPU. 2) diminishing returns in high-end microprocessor encourage designers to pursue on-chip multiprocessing 104
Parallel Computers. CPE 631 Session 20: Multiprocessors. Flynn s Tahonomy (1972) Why Multiprocessors?
 Why Multiprocessors?") Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Review: Multiprocessor. CPE 631 Session 21: Multiprocessors (Part 2) Potential HW Coherency Solutions. Bus Snooping Topology
 Potential HW Coherency Solutions. Bus Snooping Topology") Review: Multiprocessor CPE 631 Session 21: Multiprocessors (Part 2) Department of Electrical and Computer Engineering University of Alabama in Huntsville Basic issues and terminology Communication: share
Review: Multiprocessor CPE 631 Session 21: Multiprocessors (Part 2) Department of Electrical and Computer Engineering University of Alabama in Huntsville Basic issues and terminology Communication: share
Aleksandar Milenkovich 1
 Parallel Computers Lecture 8: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection
Parallel Computers Lecture 8: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection
Aleksandar Milenkovic, Electrical and Computer Engineering University of Alabama in Huntsville
 Lecture 18: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Parallel Computers Definition: A parallel computer is a collection
Lecture 18: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Parallel Computers Definition: A parallel computer is a collection
Page 1. Lecture 12: Multiprocessor 2: Snooping Protocol, Directory Protocol, Synchronization, Consistency. Bus Snooping Topology
 CS252 Graduate Computer Architecture Lecture 12: Multiprocessor 2: Snooping Protocol, Directory Protocol, Synchronization, Consistency Review: Multiprocessor Basic issues and terminology Communication:
CS252 Graduate Computer Architecture Lecture 12: Multiprocessor 2: Snooping Protocol, Directory Protocol, Synchronization, Consistency Review: Multiprocessor Basic issues and terminology Communication:
Computer Architecture. A Quantitative Approach, Fifth Edition. Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Lecture 30: Multiprocessors Flynn Categories, Large vs. Small Scale, Cache Coherency Professor Randy H. Katz Computer Science 252 Spring 1996
 Lecture 30: Multiprocessors Flynn Categories, Large vs. Small Scale, Cache Coherency Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Flynn Categories SISD (Single Instruction Single
Lecture 30: Multiprocessors Flynn Categories, Large vs. Small Scale, Cache Coherency Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Flynn Categories SISD (Single Instruction Single
Lecture 17: Multiprocessors: Size, Consitency. Review: Networking Summary
 Lecture 17: Multiprocessors: Size, Consitency Professor David A. Patterson Computer Science 252 Spring 1998 DAP Spr. 98 UCB 1 Review: Networking Summary Protocols allow hetereogeneous networking Protocols
Lecture 17: Multiprocessors: Size, Consitency Professor David A. Patterson Computer Science 252 Spring 1998 DAP Spr. 98 UCB 1 Review: Networking Summary Protocols allow hetereogeneous networking Protocols
Chapter-4 Multiprocessors and Thread-Level Parallelism
 Chapter-4 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing returns
Chapter-4 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing returns
COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence
 1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
Aleksandar Milenkovic, Electrical and Computer Engineering University of Alabama in Huntsville. Review: Small-Scale Shared Memory
 Lecture 20: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Review: Small-Scale Shared Memory Caches serve to: Increase
Lecture 20: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Review: Small-Scale Shared Memory Caches serve to: Increase
Multiprocessor Cache Coherence. Chapter 5. Memory System is Coherent If... From ILP to TLP. Enforcing Cache Coherence. Multiprocessor Types
 Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
CMSC 611: Advanced. Distributed & Shared Memory
 CMSC 611: Advanced Computer Architecture Distributed & Shared Memory Centralized Shared Memory MIMD Processors share a single centralized memory through a bus interconnect Feasible for small processor
CMSC 611: Advanced Computer Architecture Distributed & Shared Memory Centralized Shared Memory MIMD Processors share a single centralized memory through a bus interconnect Feasible for small processor
ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols CA SMP and cache coherence
 Computer Architecture ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols 1 Shared Memory Multiprocessor Memory Bus P 1 Snoopy Cache Physical Memory P 2 Snoopy
Computer Architecture ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols 1 Shared Memory Multiprocessor Memory Bus P 1 Snoopy Cache Physical Memory P 2 Snoopy
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Parallel Architecture. Hwansoo Han
 Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
CPE 631 Lecture 21: Multiprocessors
 Lecture 2: Multiprocessors Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Review: Small-Scale Shared Memory Caches serve to: Increase
Lecture 2: Multiprocessors Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Review: Small-Scale Shared Memory Caches serve to: Increase
Multiprocessor Synchronization
 Multiprocessor Synchronization Material in this lecture in Henessey and Patterson, Chapter 8 pgs. 694-708 Some material from David Patterson s slides for CS 252 at Berkeley 1 Multiprogramming and Multiprocessing
Multiprocessor Synchronization Material in this lecture in Henessey and Patterson, Chapter 8 pgs. 694-708 Some material from David Patterson s slides for CS 252 at Berkeley 1 Multiprogramming and Multiprocessing
CS654 Advanced Computer Architecture Lec 14 Directory Based Multiprocessors
 CS654 Advanced Computer Architecture Lec 14 Directory Based Multiprocessors Peter Kemper Adapted from the slides of EECS 252 by Prof. David Patterson Electrical Engineering and Computer Sciences University
CS654 Advanced Computer Architecture Lec 14 Directory Based Multiprocessors Peter Kemper Adapted from the slides of EECS 252 by Prof. David Patterson Electrical Engineering and Computer Sciences University
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Chap. 4 Multiprocessors and Thread-Level Parallelism
 Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
5008: Computer Architecture
 5008: Computer Architecture Chapter 4 Multiprocessors and Thread-Level Parallelism --II CA Lecture08 - multiprocessors and TLP (cwliu@twins.ee.nctu.edu.tw) 09-1 Review Caches contain all information on
5008: Computer Architecture Chapter 4 Multiprocessors and Thread-Level Parallelism --II CA Lecture08 - multiprocessors and TLP (cwliu@twins.ee.nctu.edu.tw) 09-1 Review Caches contain all information on
Shared Memory SMP and Cache Coherence (cont) Adapted from UCB CS252 S01, Copyright 2001 USB
 Adapted from UCB CS252 S01, Copyright 2001 USB") Shared SMP and Cache Coherence (cont) Adapted from UCB CS252 S01, Copyright 2001 USB 1 Review: Snoopy Cache Protocol Write Invalidate Protocol: Multiple readers, single writer Write to shared data: an
Shared SMP and Cache Coherence (cont) Adapted from UCB CS252 S01, Copyright 2001 USB 1 Review: Snoopy Cache Protocol Write Invalidate Protocol: Multiple readers, single writer Write to shared data: an
Chapter 5 Thread-Level Parallelism. Abdullah Muzahid
 Chapter 5 Thread-Level Parallelism Abdullah Muzahid 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors is saturating + Modern multiple issue processors are becoming very complex
Chapter 5 Thread-Level Parallelism Abdullah Muzahid 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors is saturating + Modern multiple issue processors are becoming very complex
Chapter 5. Thread-Level Parallelism
 Chapter 5 Thread-Level Parallelism Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors saturated
Chapter 5 Thread-Level Parallelism Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors saturated
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Thread- Level Parallelism. ECE 154B Dmitri Strukov
 Thread- Level Parallelism ECE 154B Dmitri Strukov Introduc?on Thread- Level parallelism Have mul?ple program counters and resources Uses MIMD model Targeted for?ghtly- coupled shared- memory mul?processors
Thread- Level Parallelism ECE 154B Dmitri Strukov Introduc?on Thread- Level parallelism Have mul?ple program counters and resources Uses MIMD model Targeted for?ghtly- coupled shared- memory mul?processors
Handout 3 Multiprocessor and thread level parallelism
 Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Lecture 23: Thread Level Parallelism -- Introduction, SMP and Snooping Cache Coherence Protocol
 Lecture 23: Thread Level Parallelism -- Introduction, SMP and Snooping Cache Coherence Protocol CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu
Lecture 23: Thread Level Parallelism -- Introduction, SMP and Snooping Cache Coherence Protocol CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu
CMSC 611: Advanced Computer Architecture
 CMSC 611: Advanced Computer Architecture Shared Memory Most slides adapted from David Patterson. Some from Mohomed Younis Interconnection Networks Massively processor networks (MPP) Thousands of nodes
CMSC 611: Advanced Computer Architecture Shared Memory Most slides adapted from David Patterson. Some from Mohomed Younis Interconnection Networks Massively processor networks (MPP) Thousands of nodes
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Chapter 8. Multiprocessors. In-Cheol Park Dept. of EE, KAIST
 Chapter 8. Multiprocessors In-Cheol Park Dept. of EE, KAIST Can the rapid rate of uniprocessor performance growth be sustained indefinitely? If the pace does slow down, multiprocessor architectures will
Chapter 8. Multiprocessors In-Cheol Park Dept. of EE, KAIST Can the rapid rate of uniprocessor performance growth be sustained indefinitely? If the pace does slow down, multiprocessor architectures will
Flynn s Classification
 Flynn s Classification SISD (Single Instruction Single Data) Uniprocessors MISD (Multiple Instruction Single Data) No machine is built yet for this type SIMD (Single Instruction Multiple Data) Examples:
Flynn s Classification SISD (Single Instruction Single Data) Uniprocessors MISD (Multiple Instruction Single Data) No machine is built yet for this type SIMD (Single Instruction Multiple Data) Examples:
Multiprocessors: Basics, Cache coherence, Synchronization, and Memory consistency
 Multiprocessors: Basics, Cache coherence, Synchronization, and Memory consistency Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475
Multiprocessors: Basics, Cache coherence, Synchronization, and Memory consistency Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475
Multiprocessors 1. Outline
 Multiprocessors 1 Outline Multiprocessing Coherence Write Consistency Snooping Building Blocks Snooping protocols and examples Coherence traffic and performance on MP Directory-based protocols and examples
Multiprocessors 1 Outline Multiprocessing Coherence Write Consistency Snooping Building Blocks Snooping protocols and examples Coherence traffic and performance on MP Directory-based protocols and examples
Computer Architecture Lecture 10: Thread Level Parallelism II (Chapter 5) Chih Wei Liu 劉志尉 National Chiao Tung University
 Chih Wei Liu 劉志尉 National Chiao Tung University") Computer Architecture Lecture 10: Thread Level Parallelism II (Chapter 5) Chih Wei Liu 劉志尉 National Chiao Tung University cwliu@twins.ee.nctu.edu.tw Review Caches contain all information on state of cached
Computer Architecture Lecture 10: Thread Level Parallelism II (Chapter 5) Chih Wei Liu 劉志尉 National Chiao Tung University cwliu@twins.ee.nctu.edu.tw Review Caches contain all information on state of cached
Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano
 Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano Outline The problem of cache coherence Snooping protocols Directory-based protocols Prof. Cristina Silvano, Politecnico
Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano Outline The problem of cache coherence Snooping protocols Directory-based protocols Prof. Cristina Silvano, Politecnico
Chapter 9 Multiprocessors
 ECE200 Computer Organization Chapter 9 Multiprocessors David H. lbonesi and the University of Rochester Henk Corporaal, TU Eindhoven, Netherlands Jari Nurmi, Tampere University of Technology, Finland University
ECE200 Computer Organization Chapter 9 Multiprocessors David H. lbonesi and the University of Rochester Henk Corporaal, TU Eindhoven, Netherlands Jari Nurmi, Tampere University of Technology, Finland University
Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley
 Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley Avinash Kodi Department of Electrical Engineering & Computer
Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley Avinash Kodi Department of Electrical Engineering & Computer
3/13/2008 Csci 211 Lecture %/year. Manufacturer/Year. Processors/chip Threads/Processor. Threads/chip 3/13/2008 Csci 211 Lecture 8 4
 Outline CSCI Computer System Architecture Lec 8 Multiprocessor Introduction Xiuzhen Cheng Department of Computer Sciences The George Washington University MP Motivation SISD v. SIMD v. MIMD Centralized
Outline CSCI Computer System Architecture Lec 8 Multiprocessor Introduction Xiuzhen Cheng Department of Computer Sciences The George Washington University MP Motivation SISD v. SIMD v. MIMD Centralized
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Lecture 24: Thread Level Parallelism -- Distributed Shared Memory and Directory-based Coherence Protocol
 Lecture 24: Thread Level Parallelism -- Distributed Shared Memory and Directory-based Coherence Protocol CSE 564 Computer Architecture Fall 2016 Department of Computer Science and Engineering Yonghong
Lecture 24: Thread Level Parallelism -- Distributed Shared Memory and Directory-based Coherence Protocol CSE 564 Computer Architecture Fall 2016 Department of Computer Science and Engineering Yonghong
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Multiprocessors. Flynn Taxonomy. Classifying Multiprocessors. why would you want a multiprocessor? more is better? Cache Cache Cache.
 Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Multiprocessors and Thread-Level Parallelism. Department of Electrical & Electronics Engineering, Amrita School of Engineering
 Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
CISC 662 Graduate Computer Architecture Lectures 15 and 16 - Multiprocessors and Thread-Level Parallelism
 CISC 662 Graduate Computer Architecture Lectures 15 and 16 - Multiprocessors and Thread-Level Parallelism Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from
CISC 662 Graduate Computer Architecture Lectures 15 and 16 - Multiprocessors and Thread-Level Parallelism Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from
Computer Science 146. Computer Architecture
 Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Computer Systems Architecture
 Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
MULTIPROCESSORS AND THREAD LEVEL PARALLELISM
 UNIT III MULTIPROCESSORS AND THREAD LEVEL PARALLELISM 1. Symmetric Shared Memory Architectures: The Symmetric Shared Memory Architecture consists of several processors with a single physical memory shared
UNIT III MULTIPROCESSORS AND THREAD LEVEL PARALLELISM 1. Symmetric Shared Memory Architectures: The Symmetric Shared Memory Architecture consists of several processors with a single physical memory shared
COSC 6385 Computer Architecture. - Thread Level Parallelism (III)
") OS 6385 omputer Architecture - Thread Level Parallelism (III) Spring 2013 Some slides are based on a lecture by David uller, University of alifornia, Berkley http://www.eecs.berkeley.edu/~culler/courses/cs252-s05
OS 6385 omputer Architecture - Thread Level Parallelism (III) Spring 2013 Some slides are based on a lecture by David uller, University of alifornia, Berkley http://www.eecs.berkeley.edu/~culler/courses/cs252-s05
EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University
 EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University Material from: Parallel Computer Organization and Design by Debois,
EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University Material from: Parallel Computer Organization and Design by Debois,
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Page 1. Instruction-Level Parallelism (ILP) CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism
 CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism") CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism Michela Taufer Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism Michela Taufer Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
COSC4201 Multiprocessors
 COSC4201 Multiprocessors Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Multiprocessing We are dedicating all of our future product development to multicore
COSC4201 Multiprocessors Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Multiprocessing We are dedicating all of our future product development to multicore
EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy
 EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University Material from: Parallel Computer Organization and Design by Debois,
EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University Material from: Parallel Computer Organization and Design by Debois,
Chapter Seven. Idea: create powerful computers by connecting many smaller ones
 Chapter Seven Multiprocessors Idea: create powerful computers by connecting many smaller ones good news: works for timesharing (better than supercomputer) vector processing may be coming back bad news:
Chapter Seven Multiprocessors Idea: create powerful computers by connecting many smaller ones good news: works for timesharing (better than supercomputer) vector processing may be coming back bad news:
CS252 Spring 2017 Graduate Computer Architecture. Lecture 12: Cache Coherence
 CS252 Spring 2017 Graduate Computer Architecture Lecture 12: Cache Coherence Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time in Lecture 11 Memory Systems DRAM
CS252 Spring 2017 Graduate Computer Architecture Lecture 12: Cache Coherence Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time in Lecture 11 Memory Systems DRAM
CSE 502 Graduate Computer Architecture Lec 19 Directory-Based Shared-Memory Multiprocessors & MP Synchronization
 CSE 502 Graduate Computer Architecture Lec 19 Directory-Based Shared-Memory Multiprocessors & MP Synchronization Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and
CSE 502 Graduate Computer Architecture Lec 19 Directory-Based Shared-Memory Multiprocessors & MP Synchronization Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and
Lecture 33: Multiprocessors Synchronization and Consistency Professor Randy H. Katz Computer Science 252 Spring 1996
 Lecture 33: Multiprocessors Synchronization and Consistency Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Review: Miss Rates for Snooping Protocol 4th C: Coherency Misses More processors:
Lecture 33: Multiprocessors Synchronization and Consistency Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Review: Miss Rates for Snooping Protocol 4th C: Coherency Misses More processors:
10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems
 1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
Computer Architecture
 18-447 Computer Architecture CSCI-564 Advanced Computer Architecture Lecture 29: Consistency & Coherence Lecture 20: Consistency and Coherence Bo Wu Prof. Onur Mutlu Colorado Carnegie School Mellon University
18-447 Computer Architecture CSCI-564 Advanced Computer Architecture Lecture 29: Consistency & Coherence Lecture 20: Consistency and Coherence Bo Wu Prof. Onur Mutlu Colorado Carnegie School Mellon University
Page 1. Lecture 11: Multiprocessor 1: Reasons, Classifications, Performance Metrics, Applications. Parallel Processors Religion. Parallel Computers
 CS252 Graduate Computer Architecture Lecture 11: Multiprocessor 1: Reasons, Classifications, Performance Metrics, Applications February 23, 2001 Prof. David A. Patterson Computer Science 252 Spring 2001
CS252 Graduate Computer Architecture Lecture 11: Multiprocessor 1: Reasons, Classifications, Performance Metrics, Applications February 23, 2001 Prof. David A. Patterson Computer Science 252 Spring 2001
Cache Coherence. CMU : Parallel Computer Architecture and Programming (Spring 2012)
") Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
COSC 6385 Computer Architecture - Thread Level Parallelism (III)
") OS 6385 omputer Architecture - Thread Level Parallelism (III) Edgar Gabriel Spring 2018 Some slides are based on a lecture by David uller, University of alifornia, Berkley http://www.eecs.berkeley.edu/~culler/courses/cs252-s05
OS 6385 omputer Architecture - Thread Level Parallelism (III) Edgar Gabriel Spring 2018 Some slides are based on a lecture by David uller, University of alifornia, Berkley http://www.eecs.berkeley.edu/~culler/courses/cs252-s05
Computer Architecture
 Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 83 Part III Multi-Core
Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 83 Part III Multi-Core
Multiple Issue and Static Scheduling. Multiple Issue. MSc Informatics Eng. Beyond Instruction-Level Parallelism
 Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
EITF20: Computer Architecture Part 5.2.1: IO and MultiProcessor
 EITF20: Computer Architecture Part 5.2.1: IO and MultiProcessor Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration I/O MultiProcessor Summary 2 Virtual memory benifits Using physical memory efficiently
EITF20: Computer Architecture Part 5.2.1: IO and MultiProcessor Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration I/O MultiProcessor Summary 2 Virtual memory benifits Using physical memory efficiently
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano
 Prof. Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Lecture 10: Cache Coherence: Part I. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
Parallel Computer Architecture Spring Shared Memory Multiprocessors Memory Coherence
 Parallel Computer Architecture Spring 2018 Shared Memory Multiprocessors Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly Parallel Computer Architecture
Parallel Computer Architecture Spring 2018 Shared Memory Multiprocessors Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly Parallel Computer Architecture
CS252 Lecture Notes Multithreaded Architectures
 CS252 Lecture Notes Multithreaded Architectures Concept Tolerate or mask long and often unpredictable latency operations by switching to another context, which is able to do useful work. Situation Today
CS252 Lecture Notes Multithreaded Architectures Concept Tolerate or mask long and often unpredictable latency operations by switching to another context, which is able to do useful work. Situation Today
Cache Coherence in Bus-Based Shared Memory Multiprocessors
 Cache Coherence in Bus-Based Shared Memory Multiprocessors Shared Memory Multiprocessors Variations Cache Coherence in Shared Memory Multiprocessors A Coherent Memory System: Intuition Formal Definition
Cache Coherence in Bus-Based Shared Memory Multiprocessors Shared Memory Multiprocessors Variations Cache Coherence in Shared Memory Multiprocessors A Coherent Memory System: Intuition Formal Definition
Chapter 6. Parallel Processors from Client to Cloud Part 2 COMPUTER ORGANIZATION AND DESIGN. Homogeneous & Heterogeneous Multicore Architectures
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Part 2 Homogeneous & Heterogeneous Multicore Architectures Intel XEON 22nm
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Part 2 Homogeneous & Heterogeneous Multicore Architectures Intel XEON 22nm
Multiprocessors - Flynn s Taxonomy (1966)
") Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Lecture 10: Cache Coherence: Part I. Parallel Computer Architecture and Programming CMU /15-618, Spring 2015
 Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Marble House The Knife (Silent Shout) Before starting The Knife, we were working
Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Marble House The Knife (Silent Shout) Before starting The Knife, we were working
Chapter - 5 Multiprocessors and Thread-Level Parallelism
 Chapter - 5 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing
Chapter - 5 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing
Thread-Level Parallelism
 Advanced Computer Architecture Thread-Level Parallelism Some slides are from the instructors resources which accompany the 6 th and previous editions. Some slides are from David Patterson, David Culler
Advanced Computer Architecture Thread-Level Parallelism Some slides are from the instructors resources which accompany the 6 th and previous editions. Some slides are from David Patterson, David Culler
Parallel Computer Architecture Spring Distributed Shared Memory Architectures & Directory-Based Memory Coherence
 Parallel Computer Architecture Spring 2018 Distributed Shared Memory Architectures & Directory-Based Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly
Parallel Computer Architecture Spring 2018 Distributed Shared Memory Architectures & Directory-Based Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly
Lecture 24: Multiprocessing Computer Architecture and Systems Programming ( )
") Systems Group Department of Computer Science ETH Zürich Lecture 24: Multiprocessing Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Most of the rest of this
Systems Group Department of Computer Science ETH Zürich Lecture 24: Multiprocessing Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Most of the rest of this
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Symmetric Multiprocessors Part 1 (Chapter 5)
 Symmetric Multiprocessors Part 1 (Chapter 5)") CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Symmetric Multiprocessors Part 1 (Chapter 5) Copyright 2001 Mark D. Hill University of Wisconsin-Madison Slides are derived
CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Symmetric Multiprocessors Part 1 (Chapter 5) Copyright 2001 Mark D. Hill University of Wisconsin-Madison Slides are derived
Introduction. Coherency vs Consistency. Lec-11. Multi-Threading Concepts: Coherency, Consistency, and Synchronization
 Lec-11 Multi-Threading Concepts: Coherency, Consistency, and Synchronization Coherency vs Consistency Memory coherency and consistency are major concerns in the design of shared-memory systems. Consistency
Lec-11 Multi-Threading Concepts: Coherency, Consistency, and Synchronization Coherency vs Consistency Memory coherency and consistency are major concerns in the design of shared-memory systems. Consistency
COSC4201. Multiprocessors and Thread Level Parallelism. Prof. Mokhtar Aboelaze York University
 COSC4201 Multiprocessors and Thread Level Parallelism Prof. Mokhtar Aboelaze York University COSC 4201 1 Introduction Why multiprocessor The turning away from the conventional organization came in the
COSC4201 Multiprocessors and Thread Level Parallelism Prof. Mokhtar Aboelaze York University COSC 4201 1 Introduction Why multiprocessor The turning away from the conventional organization came in the
Module 5 Introduction to Parallel Processing Systems
 Module 5 Introduction to Parallel Processing Systems 1. What is the difference between pipelining and parallelism? In general, parallelism is simply multiple operations being done at the same time.this
Module 5 Introduction to Parallel Processing Systems 1. What is the difference between pipelining and parallelism? In general, parallelism is simply multiple operations being done at the same time.this
Shared Memory Architectures. Approaches to Building Parallel Machines
 Shared Memory Architectures Arvind Krishnamurthy Fall 2004 Approaches to Building Parallel Machines P 1 Switch/Bus P n Scale (Interleaved) First-level $ P 1 P n $ $ (Interleaved) Main memory Shared Cache
Shared Memory Architectures Arvind Krishnamurthy Fall 2004 Approaches to Building Parallel Machines P 1 Switch/Bus P n Scale (Interleaved) First-level $ P 1 P n $ $ (Interleaved) Main memory Shared Cache
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
Multiprocessing and Scalability. A.R. Hurson Computer Science and Engineering The Pennsylvania State University
 A.R. Hurson Computer Science and Engineering The Pennsylvania State University 1 Large-scale multiprocessor systems have long held the promise of substantially higher performance than traditional uniprocessor
A.R. Hurson Computer Science and Engineering The Pennsylvania State University 1 Large-scale multiprocessor systems have long held the promise of substantially higher performance than traditional uniprocessor
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448. The Greed for Speed
 Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Processor Architecture and Interconnect
 Processor Architecture and Interconnect What is Parallelism? Parallel processing is a term used to denote simultaneous computation in CPU for the purpose of measuring its computation speeds. Parallel Processing
Processor Architecture and Interconnect What is Parallelism? Parallel processing is a term used to denote simultaneous computation in CPU for the purpose of measuring its computation speeds. Parallel Processing
UNIT I (Two Marks Questions & Answers)
") UNIT I (Two Marks Questions & Answers) Discuss the different ways how instruction set architecture can be classified? Stack Architecture,Accumulator Architecture, Register-Memory Architecture,Register-
UNIT I (Two Marks Questions & Answers) Discuss the different ways how instruction set architecture can be classified? Stack Architecture,Accumulator Architecture, Register-Memory Architecture,Register-
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
NOW Handout Page 1. Recap: Performance Trade-offs. Shared Memory Multiprocessors. Uniprocessor View. Recap (cont) What is a Multiprocessor?
 What is a Multiprocessor?") ecap: erformance Trade-offs Shared ory Multiprocessors CS 258, Spring 99 David E. Culler Computer Science Division U.C. Berkeley rogrammer s View of erformance Speedup < Sequential Work Max (Work + Synch
ecap: erformance Trade-offs Shared ory Multiprocessors CS 258, Spring 99 David E. Culler Computer Science Division U.C. Berkeley rogrammer s View of erformance Speedup < Sequential Work Max (Work + Synch
Multiprocessors and Thread Level Parallelism CS 282 KAUST Spring 2010 Muhamed Mudawar
 Multiprocessors and Thread Level Parallelism CS 282 KAUST Spring 2010 Muhamed Mudawar Original slides created by: David Patterson Uniprocessor Performance (SPECint) 80) Performance (vs. VAX-11/78 10000
Multiprocessors and Thread Level Parallelism CS 282 KAUST Spring 2010 Muhamed Mudawar Original slides created by: David Patterson Uniprocessor Performance (SPECint) 80) Performance (vs. VAX-11/78 10000
EEC 581 Computer Architecture. Lec 11 Synchronization and Memory Consistency Models (4.5 & 4.6)
") EEC 581 Computer rchitecture Lec 11 Synchronization and Memory Consistency Models (4.5 & 4.6) Chansu Yu Electrical and Computer Engineering Cleveland State University cknowledgement Part of class notes
EEC 581 Computer rchitecture Lec 11 Synchronization and Memory Consistency Models (4.5 & 4.6) Chansu Yu Electrical and Computer Engineering Cleveland State University cknowledgement Part of class notes
EC 513 Computer Architecture
 EC 513 Computer Architecture Cache Coherence - Directory Cache Coherence Prof. Michel A. Kinsy Shared Memory Multiprocessor Processor Cores Local Memories Memory Bus P 1 Snoopy Cache Physical Memory P
EC 513 Computer Architecture Cache Coherence - Directory Cache Coherence Prof. Michel A. Kinsy Shared Memory Multiprocessor Processor Cores Local Memories Memory Bus P 1 Snoopy Cache Physical Memory P
CMSC 611: Advanced. Parallel Systems
 CMSC 611: Advanced Computer Architecture Parallel Systems Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems
CMSC 611: Advanced Computer Architecture Parallel Systems Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems
CMSC 411 Computer Systems Architecture Lecture 21 Multiprocessors 3
 MS 411 omputer Systems rchitecture Lecture 21 Multiprocessors 3 Outline Review oherence Write onsistency dministrivia Snooping Building Blocks Snooping protocols and examples oherence traffic and performance
MS 411 omputer Systems rchitecture Lecture 21 Multiprocessors 3 Outline Review oherence Write onsistency dministrivia Snooping Building Blocks Snooping protocols and examples oherence traffic and performance
Page 1. SMP Review. Multiprocessors. Bus Based Coherence. Bus Based Coherence. Characteristics. Cache coherence. Cache coherence
 SMP Review Multiprocessors Today s topics: SMP cache coherence general cache coherence issues snooping protocols Improved interaction lots of questions warning I m going to wait for answers granted it
SMP Review Multiprocessors Today s topics: SMP cache coherence general cache coherence issues snooping protocols Improved interaction lots of questions warning I m going to wait for answers granted it
Multiprocessors II: CC-NUMA DSM. CC-NUMA for Large Systems
 Multiprocessors II: CC-NUMA DSM DSM cache coherence the hardware stuff Today s topics: what happens when we lose snooping new issues: global vs. local cache line state enter the directory issues of increasing
Multiprocessors II: CC-NUMA DSM DSM cache coherence the hardware stuff Today s topics: what happens when we lose snooping new issues: global vs. local cache line state enter the directory issues of increasing
Convergence of Parallel Architecture
 Parallel Computing Convergence of Parallel Architecture Hwansoo Han History Parallel architectures tied closely to programming models Divergent architectures, with no predictable pattern of growth Uncertainty
Parallel Computing Convergence of Parallel Architecture Hwansoo Han History Parallel architectures tied closely to programming models Divergent architectures, with no predictable pattern of growth Uncertainty