Rama Malladi. Application Engineer. Software & Services Group. PDF created with pdffactory Pro trial version
|
|
|
- Austen Thomas
- 5 years ago
- Views:
Transcription

1 Threaded Programming Methodology Rama Malladi Application Engineer Software & Services Group
2 Objectives After completion of this module you will Learn how to use Intel Software Development Products for multi-core programming and optimizations Be able to rapidly prototype and estimate the effort required to thread time consuming regions 2
3 Agenda A Generic Development Cycle Case Study: Prime Number Generation Common Performance Issues 3
4 What is Parallelism? Two or more processes or threads execute at the same time Parallelism for threading architectures Multiple processes Communication through Inter-Process Communication (IPC) Single process, multiple threads Communication through shared memory 4
5 Amdahl s Law Describes the upper bound of parallel execution speedup n = T serial (1-P) P (1-P) P/2 P/ T parallel = {(1-P) + P/n} T serial n = number of processors Speedup = T serial / T parallel 1.0/ /0.5 = = Serial code limits speedup 5
6 Processes and Threads Stack thread Stack thread main() Stack thread Code segment Data segment Modern operating systems load programs as processes Resource holder Execution A process starts executing at its entry point as a thread Threads can create other threads within the process Each thread gets its own stack All threads within a process share code & data segments 6
7 Threads Benefits & Risks Benefits Increased performance and better resource utilization Even on single processor systems - for hiding latency and increasing throughput IPC through shared memory is more efficient Risks Increases complexity of the application Difficult to debug (data races, deadlocks, etc.) 7
8 Commonly Encountered Questions with Threading Applications Where to thread? How long would it take to thread? How much re-design/effort is required? Is it worth threading a selected region? What should the expected speedup be? Will the performance meet expectations? Will it scale as more threads/data are added? Which threading model to use? 8
(sqrtf((float)val)+0.")
9 Prime Number Generation i factor bool TestForPrime(int val) { // let s start checking from 2 int limit, factor = 2; limit = (long)(sqrtf((float)val)+0.5f); while( (factor <= limit) && (val % factor) ) factor ++; } return (factor > limit); void FindPrimes(int start, int end) { int range = end - start + 1; for( int i = start; i <= end; i += 2 ) { if( TestForPrime(i) ) globalprimes[gprimesfound++] = i; ShowProgress(i, range); } } 9
10 Development Methodology Analysis Find computationally intense code Design (Introduce Threads) Determine how to implement threading solution Debug for correctness Detect any problems resulting from using threads Tune for performance Achieve best parallel performance 10
11 Development Cycle Analysis VTune Performance Analyzer Design (Introduce Threads) Intel Performance libraries: IPP and MKL OpenMP* (Intel Compiler) Explicit threading (Pthreads*, Win32*) Debug for correctness Intel Thread Checker Intel Debugger Tune for performance Thread Profiler VTune Performance Analyzer 11
(sqrtf((float)val)+0.5f); while( (factor <= limit) && (val % factor)) factor ++; return (factor > limit); PrimeSingle <start> <end> } Usage:.")
12 Analysis - Sampling Use VTune Sampling to find hotspots in application Let s use the project PrimeSingle for analysis bool TestForPrime(int val) { // let s start checking from 3 int limit, factor = 3; limit = (long)(sqrtf((float)val)+0.5f); while( (factor <= limit) && (val % factor)) factor ++; return (factor > limit); PrimeSingle <start> <end> } Usage:./PrimeSingle void 1 FindPrimes(int start, int end) { // start is always odd int range = end - start + 1; for( int i = start; i <= end; i+= 2 ){ if( TestForPrime(i) ) globalprimes[gprimesfound++] = i; ShowProgress(i, range); } } Identifies the time consuming regions 12

13 Analysis - Call Graph This is the level in the call tree where we need to thread Used to find proper level in the call-tree to thread 13

14 Analysis Where to thread? FindPrimes() Is it worth threading a selected region? Appears to have minimal dependencies Appears to be data-parallel Consumes over 95% of the run time Baseline measurement 14
15 Foster s Design Methodology From Designing and Building Parallel Programs by Ian Foster Four Steps: Partitioning Dividing computation and data Communication Sharing data between computations Agglomeration Grouping tasks to improve performance Mapping Assigning tasks to processors/threads 15
16 Designing Threaded Programs Partition Divide problem into tasks Communicate Determine amount and pattern of communication Agglomerate Combine tasks Map Assign agglomerated tasks to created threads The Problem Communication Initial tasks Combined Tasks 16 Final Program
17 Parallel Programming Models Functional Decomposition Task parallelism Divide the computation, then associate the data Independent tasks of the same problem Data Decomposition Same operation performed on different data Divide data into pieces, then associate computation 17

18 Decomposition Methods Functional Decomposition Focusing on computations can reveal structure in a problem Atmosphere Model Hydrology Model Ocean Model Grid reprinted with permission of Dr. Phu V. Luong, Coastal and Hydraulics Laboratory, ERDC Land Surface Model Domain Decomposition Focus on largest or most frequently accessed data structure Data Parallelism Same operation applied to all data 18
19 Pipelined Decomposition Computation done in independent stages Functional decomposition Threads are assigned stage to compute Automobile assembly line Data decomposition Thread processes all stages of single instance One worker builds an entire car 19
20 LAME Encoder Example LAME MP3 encoder Open source project Educational tool used for learning The goal of project is To improve the psychoacoustics quality To improve the speed of MP3 encoding 20
21 LAME Pipeline Strategy Prelude Acoustics Encoding Other Fetch next frame Frame characterization Set encode parameters Time T 1 Prelude N Psycho Analysis FFT long/short Filter assemblage Prelude N+1 Hierarchical Barrier Frame Prelude N+2 Apply filtering Noise Shaping Quantize & Count bits Prelude N+3 Add frame header Check correctness Write to disk T 2 Acoustics N Acoustics N+1 Acoustics N+2 T 3 Encoding N Encoding N+1 T 4 Other N Other N+1 21 Frame N Frame N + 1
22 Prime Number Generation Design What is the expected benefit? Speedup(2P) = 100/(97/2+3) = ~1.94X How do you determine this with the least effort? Rapid prototyping with OpenMP How long would it take to thread? How much re-design/effort is required? 22
23 OpenMP Fork-join parallelism: Master thread spawns a team of threads as needed Parallelism is added incrementally sequential program evolves into a parallel program Master Thread Parallel Regions 23
24 Design #pragma omp parallel for for( int i = start; i <= end; i+= 2 ){ OpenMP i; } if( TestForPrime(i) ) globalprimes[gprimesfound++] = Create threads here for this parallel region ShowProgress(i, range); Divide iterations of the for loop 24
25 Design What is the expected benefit? How do you determine this with the least effort? Speedup of 1.12X (less than 1.94X) How long would it take to thread? How much re-design/effort is required? Is this the best scaling possible? 25

26 Debugging for Correctness Is this threaded implementation right? No! The answers are different each time 26

27 Debugging for Correctness Intel Thread Checker pinpoints notorious threading bugs like data races, stalls and deadlocks Primes.c Compiler -openmp -tcheck Source Instrumentation Primes.exe VTune Performance Analyzer Intel Thread Checker Binary Instrumentation Runtime Data Collector Primes.exe (Instrumented) +.so s (Instrumented) 27 threadchecker.thr (result file)
28 Debugging for Correctness If application has source instrumentation, it can be run from command prompt Primes.c threadchecker.thr (result file) Compiler Source Instrumentation Primes.exe 28


29 Threaded Programming Methodology for Linux 29
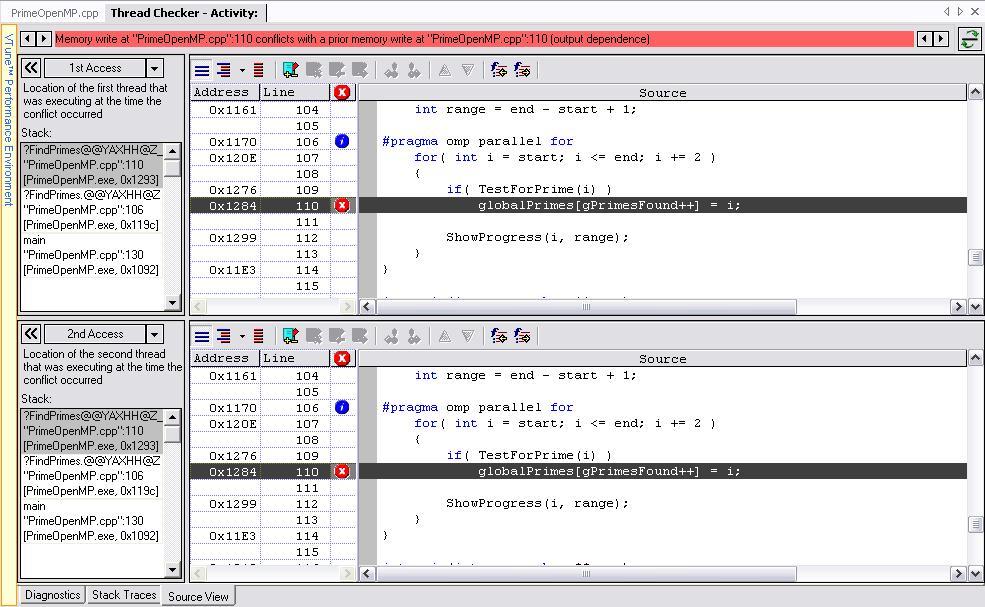
30 Debugging for Correctness How much re-design/effort is required? Thread Checker reported only 2 dependencies, so effort required should be low How long would it take to thread? 30
31 Debugging for Correctness #pragma omp parallel for for( int i = start; i <= end; i+= 2 ){ if( TestForPrime(i) ) #pragma omp critical globalprimes[gprimesfound++] = i; ShowProgress(i, range); } Will create a critical section for this reference #pragma omp critical { } gprogress++; percentdone = (int)(gprogress/range *200.0f+0.5f) Will create a critical section for both these references 31
32 Correctness Correct answer, but performance has slipped to ~1.03X! Is this the best we can expect from this algorithm? No! From Amdahl s Law, we expect scaling close to 1.9X 32
33 Common Performance Issues Parallel Overhead Due to thread creation, scheduling Synchronization Excessive use of global data, contention for the same synchronization object Load Imbalance Improper distribution of parallel work Granularity No sufficient parallel work 33
34 Tuning for Performance Thread Profiler pinpoints performance bottlenecks in threaded applications Primes.c Compiler -openmp_profile Source Instrumentation Primes.exe VTune Performance Analyzer Thread Profiler Binary Instrumentation Runtime Data Collector Primes.exe (Instrumented) +.so s (Instrumented) 34 Bistro.tp/guide.gvs (result file)
35 Tuning for Performance If application has source instrumentation, it can be run from command prompt Primes.c Bistro.tp/guide.gvs (result file) Compiler Source Instrumentation Primes.exe 35

36 Thread Profiler for OpenMP 36
37 Thread Profiler for OpenMP Speedup Graph Estimates threading speedup and potential speedup Based on Amdahl s Law computation Gives upper and lower bound estimates 37

38 Thread Profiler for OpenMP serial parallel serial 38
39 Thread Profiler for OpenMP Thread 0 Thread 1 Thread 2 Thread 3 39
40 Thread Profiler for OpenMP Thread factors to test Thread factors to test Thread factors to test Thread factors to test

41 Thread Profiler for OpenMP Thread factors to test Thread factors to test Thread factors to test Thread factors to test
 for( int i = start; i <= end; i += 2 ) { if( TestForPrime(i) ) #pragma omp critical globalprimes[gprimesfound++] = i; } ShowProgress(i, range); } Scaling achieved")
42 Fixing the Load Imbalance Distribute the work more evenly void FindPrimes(int start, int end) { // start is always odd int range = end - start + 1; #pragma omp parallel for schedule(static, 8) for( int i = start; i <= end; i += 2 ) { if( TestForPrime(i) ) #pragma omp critical globalprimes[gprimesfound++] = i; } ShowProgress(i, range); } Scaling achieved is 1.02X 42

43 Back to Thread Profiler Too much time in locks and synchronization? If no sync, would only achieve 1.17X 43 Why are we not getting any speedup?

44 Is it Possible to do Better? Using top we see Serial code runs at 100% Threaded code runs poorly but has flashes of good performance 44
45 Other Causes to Consider Problems Cache Thrashing False Sharing Excessive context switching I/O Tools VTune Performance Analyzer Thread Profiler (explicit threads) Linux tools vmstat and sar Disk i/o, all CPUs, context switches, network traffic, interrupts 45

46 Linux sar Output Acceptable context switching Less than 5000 context switches per second should be acceptable Little paging activity Memory doesn t seem a problem 46
47 Performance This implementation has implicit synchronization calls Thread-safe libraries may have hidden synchronization to protect shared resources Will serialize access to resources I/O libraries share file pointers Limits number of operations in parallel Physical limits 47
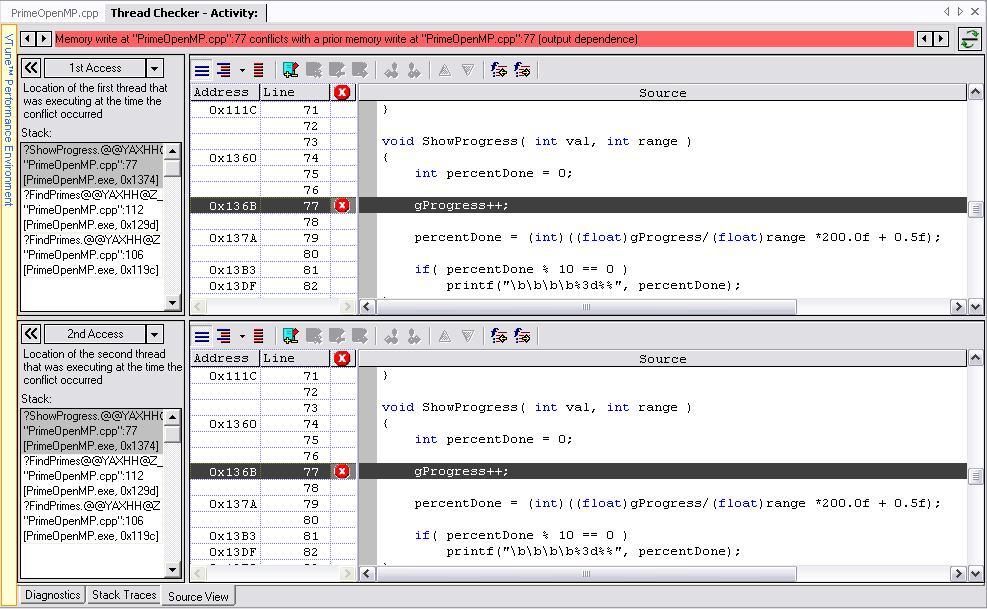
48 Performance How many times is printf() executed? void ShowProgress( int val, int range ) void ShowProgress( int val, int range ) { { int percentdone; int percentdone; static int lastpercentdone = 0; #pragma omp critical #pragma omp critical { { gprogress++; gprogress++; percentdone = (int)((float)gprogress/(float)range*200.0f+0.5f); percentdone = (int)((float)gprogress/(float)range*200.0f+0.5f); } } if( percentdone % 10 == 0 ) if( percentdone % 10 == 0 && lastpercentdone < percentdone / 10){ printf("\b\b\b\b%3d%%", percentdone); printf("\b\b\b\b%3d%%", percentdone); } lastpercentdone++; Hypothesis: } The algorithm has many more updates than the 10 needed for showing } progress. Why? This change should fix the contention issue 48
49 Design Eliminate the contention due to implicit synchronization Speedup is 17.87X! Can that be right? 49

50 Performance Our original baseline measurement had the flawed progress update algorithm Is this the best we can expect from this algorithm? Speedup achieved is 1.49X (<1.9X) 50
51 Performance Re-visited Let s use Thread Profiler again 70% of time spent in synchronization and overhead 51
52 OpenMP Critical Regions #pragma omp parallel for for( int i = start; i <= end; i+= 2 ){ if( TestForPrime(i) ) #pragma omp critical (one) } globalprimes[gprimesfound++] = i; ShowProgress(i, range); #pragma omp critical (two) { } gprogress++; Naming regions will create a different critical section for code regions percentdone = (int)(gprogress/range *200.0f+0.5f) 52


53 Performance Re-visited Any better? 53
54 Reducing Critical Region Size #pragma omp parallel for for( int i = start; i <= end; i+= 2 ){ if( TestForPrime(i) ) #pragma omp critical (one) } #pragma omp critical (two) Two operations (read & write) Only gprimesfound update needs protection Use globalprimes[gprimesfound++] local variables for = i; read access ShowProgress(i, outside range); critical region Write and read are separate { gprogress++; percentdone = (int)(gprogress/range *200.0f+0.5f) } 54
55 Reducing Critical Region Size #pragma omp parallel for for( int i = start; i <= end; i+= 2 ){ if( TestForPrime(i) ) { #pragma omp critical (one) lprimesfound = gprimesfound++; globalprimes[lprimesfound] = i; } ShowProgress(i, range); } #pragma omp critical (two) lprogress = gprogress++; Speedup is up to 1.89X percentdone = (int)(lprogress/range *200.0f+0.5f) 55

56 Scaling Performance 1.96X 1.97X 56
57 Summary Threading applications require multiple iterations of designing, debugging and performance tuning steps Use tools to improve productivity Unleash the power of dual-core and multi-core processors with multithreaded applications 57
58 Threaded Programming Methodology for Linux 58
59 Threading for Performance -Other Threading Issues
60 Synchronization is an expensive, but necessary evil Ways to minimize impact Heap contention Allocation from heap causes implicit synchronization Use local variable for partial results, update global after local computations Allocate space on thread stack (alloca) Use thread-local storage API (TlsAlloc) Atomic updates versus Critical Sections Some global data updates can use atomic operations (Interlocked family) Use atomic updates whenever possible Critical Sections versus Mutual Exclusion Critical Section objects reside in user space Introduces lesser overhead 60
61 False Sharing is a common problem when using data parallel threading False sharing can occur when 2 threads access distinct or independent data that fall into the same cache line Care should be taken to duplicate private buffers and counter variables be thread local Split dataset in such a manner as to avoid cache conflicts 61
62 False sharing Example Two threads divide the work by every other 3-component vertex Thread 1 Thread 2 P 0 P 1. P 2 P 3 P 4 P 5 P 6 P 7 P 8 P 9 Two threads update the contiguous vertices, v[k] and P v[k+1], which fall on the k P same cache k+1 line (common case). X k Y k Z k X k+1 12 bytes k+1 12 bytes Cache line 64 bytes Y k+1 Z k+1. 62
63 False sharing Example: Problem Fixed Let each thread handle half of the vertices by dividing the data into equal halves Thread 1 P 0 P 1 P 2 P N/2 Thread 2 P N/2+1 P N/2+2 P N/2+3 P N-1 63
64 Granularity of data decomposition is important to dynamically scale for the system Finding the right sized chunks can be challenging Too large can lead to load imbalance Too small can lead to synchronization overhead What is the optimal # of concurrent threads? Depends on Total size of working set Thread synchronization overhead Adjust dynamically to help keep the balance right and reduce synchronization GetSystemInfo(&lpSystemInfo); N = lpsysteminfo->dwnumberofprocessors; 64
65 Threading with OpenMP Simple, portable, scalable SMP Specification Compiler directives Library routines Quick and Easy #pragma omp parallel for Thread scheduling, synchronization, sections, and more OpenMP is supported in Visual Studio 2005 Fork / Join programming Model Pool of Sleeping threads Single threaded until a Fork is reached 65
66 Intel Threading Building Blocks A Parallel Programming Model for C++ Generic Parallel Algorithms ParallelFor ParallelWhile ParallelReduce Pipeline ParallelSort ParallelScan Concurrent Containers ConcurrentHashTable ConcurrentQueue ConcurrentVector TaskScheduler 66 Low-Level Level Synchronization Primitives SpinMutex QueuingMutex ReaderWriterMutex Mutex Optimizing Performance of Parallel 66 Programs on Emerging
67 Native Win32 Threads is the most commonly used currently _beginthread() / _endthread() Basic thread creation function Lacks configurability with potential for errors CreateThread() / ExitThread() Provides more flexibility during thread creation No automatic TLS (Thread Local Storage) created _beginthreadex() / _endthreadex() Best native thread creation function to use Automatically creates TLS to correctly execute multi-threaded C Runtime libraries 67
68 Atomic Updates Use Win32 Interlocked* intrinsics in place of synchronization object static long counter; // Fast InterlockedIncrement (&counter); // Slower EnterCriticalSection (&cs); counter++; LeaveCriticalSection (&cs); 68
69 Lock free algorithms See Game Programming Gems 6 and other recent literature Compare and Swap: implemented by InterlockedCompareAndExchange Atomically implemented in hardware in x86 CPUs 69
70 Parallel Overhead Thread Creation overhead Overhead increases rapidly as the number of active threads increases Solution Use of re-usable threads and thread pools Amortizes the cost of thread creation Keeps number of active threads relatively constant 70
71 Synchronization Heap contention Allocation from heap causes implicit synchronization Allocate on stack or use thread local storage Atomic updates versus critical sections Some global data updates can use atomic operations (Interlocked family) Use atomic updates whenever possible 71
72 Load Imbalance Unequal work loads lead to idle threads and wasted time Time Busy Idle 72
73 Granularity Loosely defined as the ratio of computation to synchronization Be sure there is enough work to merit parallel computation Example: Two farmers divide a field. How many more farmers can be added? 73
From Serial to Parallel. Stephen Blair-Chappell Intel Compiler Labs
 Stephen Blair-Chappell Intel Compiler Labs www.intel.com Agenda Why Parallel? Optimising Applications Steps to move from Serial to Parallel 2 Intel Software Development Products Overview Copyright 2007,
Stephen Blair-Chappell Intel Compiler Labs www.intel.com Agenda Why Parallel? Optimising Applications Steps to move from Serial to Parallel 2 Intel Software Development Products Overview Copyright 2007,
Intel Threading Tools
 Intel Threading Tools Paul Petersen, Intel -1- INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS,
Intel Threading Tools Paul Petersen, Intel -1- INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS,
David R. Mackay, Ph.D. Libraries play an important role in threading software to run faster on Intel multi-core platforms.
 Whitepaper Introduction A Library Based Approach to Threading for Performance David R. Mackay, Ph.D. Libraries play an important role in threading software to run faster on Intel multi-core platforms.
Whitepaper Introduction A Library Based Approach to Threading for Performance David R. Mackay, Ph.D. Libraries play an important role in threading software to run faster on Intel multi-core platforms.
Threading Methodology: Principles and Practices. Version 2.0
 Threading Methodology: Principles and Practices Version 2.0 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY
Threading Methodology: Principles and Practices Version 2.0 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY
1 of 6 Lecture 7: March 4. CISC 879 Software Support for Multicore Architectures Spring Lecture 7: March 4, 2008
 1 of 6 Lecture 7: March 4 CISC 879 Software Support for Multicore Architectures Spring 2008 Lecture 7: March 4, 2008 Lecturer: Lori Pollock Scribe: Navreet Virk Open MP Programming Topics covered 1. Introduction
1 of 6 Lecture 7: March 4 CISC 879 Software Support for Multicore Architectures Spring 2008 Lecture 7: March 4, 2008 Lecturer: Lori Pollock Scribe: Navreet Virk Open MP Programming Topics covered 1. Introduction
Parallel Programming Principle and Practice. Lecture 7 Threads programming with TBB. Jin, Hai
 Parallel Programming Principle and Practice Lecture 7 Threads programming with TBB Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Outline Intel Threading
Parallel Programming Principle and Practice Lecture 7 Threads programming with TBB Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Outline Intel Threading
Introduction to OpenMP.
 Introduction to OpenMP www.openmp.org Motivation Parallelize the following code using threads: for (i=0; i
Introduction to OpenMP www.openmp.org Motivation Parallelize the following code using threads: for (i=0; i
Martin Kruliš, v
 Martin Kruliš 1 Optimizations in General Code And Compilation Memory Considerations Parallelism Profiling And Optimization Examples 2 Premature optimization is the root of all evil. -- D. Knuth Our goal
Martin Kruliš 1 Optimizations in General Code And Compilation Memory Considerations Parallelism Profiling And Optimization Examples 2 Premature optimization is the root of all evil. -- D. Knuth Our goal
A common scenario... Most of us have probably been here. Where did my performance go? It disappeared into overheads...
 OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
Concurrency, Thread. Dongkun Shin, SKKU
 Concurrency, Thread 1 Thread Classic view a single point of execution within a program a single PC where instructions are being fetched from and executed), Multi-threaded program Has more than one point
Concurrency, Thread 1 Thread Classic view a single point of execution within a program a single PC where instructions are being fetched from and executed), Multi-threaded program Has more than one point
A common scenario... Most of us have probably been here. Where did my performance go? It disappeared into overheads...
 OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing
 Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing NTNU, IMF February 16. 2018 1 Recap: Distributed memory programming model Parallelism with MPI. An MPI execution is started
Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing NTNU, IMF February 16. 2018 1 Recap: Distributed memory programming model Parallelism with MPI. An MPI execution is started
Module 10: Open Multi-Processing Lecture 19: What is Parallelization? The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program
 The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program Amdahl's Law About Data What is Data Race? Overview to OpenMP Components of OpenMP OpenMP Programming Model OpenMP Directives
The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program Amdahl's Law About Data What is Data Race? Overview to OpenMP Components of OpenMP OpenMP Programming Model OpenMP Directives
Acknowledgments. Amdahl s Law. Contents. Programming with MPI Parallel programming. 1 speedup = (1 P )+ P N. Type to enter text
+ P N. Type to enter text") Acknowledgments Programming with MPI Parallel ming Jan Thorbecke Type to enter text This course is partly based on the MPI courses developed by Rolf Rabenseifner at the High-Performance Computing-Center
Acknowledgments Programming with MPI Parallel ming Jan Thorbecke Type to enter text This course is partly based on the MPI courses developed by Rolf Rabenseifner at the High-Performance Computing-Center
SHARCNET Workshop on Parallel Computing. Hugh Merz Laurentian University May 2008
 SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
Multithreading in C with OpenMP
 Multithreading in C with OpenMP ICS432 - Spring 2017 Concurrent and High-Performance Programming Henri Casanova (henric@hawaii.edu) Pthreads are good and bad! Multi-threaded programming in C with Pthreads
Multithreading in C with OpenMP ICS432 - Spring 2017 Concurrent and High-Performance Programming Henri Casanova (henric@hawaii.edu) Pthreads are good and bad! Multi-threaded programming in C with Pthreads
CMSC 714 Lecture 4 OpenMP and UPC. Chau-Wen Tseng (from A. Sussman)
") CMSC 714 Lecture 4 OpenMP and UPC Chau-Wen Tseng (from A. Sussman) Programming Model Overview Message passing (MPI, PVM) Separate address spaces Explicit messages to access shared data Send / receive (MPI
CMSC 714 Lecture 4 OpenMP and UPC Chau-Wen Tseng (from A. Sussman) Programming Model Overview Message passing (MPI, PVM) Separate address spaces Explicit messages to access shared data Send / receive (MPI
Barbara Chapman, Gabriele Jost, Ruud van der Pas
 Using OpenMP Portable Shared Memory Parallel Programming Barbara Chapman, Gabriele Jost, Ruud van der Pas The MIT Press Cambridge, Massachusetts London, England c 2008 Massachusetts Institute of Technology
Using OpenMP Portable Shared Memory Parallel Programming Barbara Chapman, Gabriele Jost, Ruud van der Pas The MIT Press Cambridge, Massachusetts London, England c 2008 Massachusetts Institute of Technology
Allows program to be incrementally parallelized
 Basic OpenMP What is OpenMP An open standard for shared memory programming in C/C+ + and Fortran supported by Intel, Gnu, Microsoft, Apple, IBM, HP and others Compiler directives and library support OpenMP
Basic OpenMP What is OpenMP An open standard for shared memory programming in C/C+ + and Fortran supported by Intel, Gnu, Microsoft, Apple, IBM, HP and others Compiler directives and library support OpenMP
A brief introduction to OpenMP
 A brief introduction to OpenMP Alejandro Duran Barcelona Supercomputing Center Outline 1 Introduction 2 Writing OpenMP programs 3 Data-sharing attributes 4 Synchronization 5 Worksharings 6 Task parallelism
A brief introduction to OpenMP Alejandro Duran Barcelona Supercomputing Center Outline 1 Introduction 2 Writing OpenMP programs 3 Data-sharing attributes 4 Synchronization 5 Worksharings 6 Task parallelism
Chapter 4: Multi-Threaded Programming
 Chapter 4: Multi-Threaded Programming Chapter 4: Threads 4.1 Overview 4.2 Multicore Programming 4.3 Multithreading Models 4.4 Thread Libraries Pthreads Win32 Threads Java Threads 4.5 Implicit Threading
Chapter 4: Multi-Threaded Programming Chapter 4: Threads 4.1 Overview 4.2 Multicore Programming 4.3 Multithreading Models 4.4 Thread Libraries Pthreads Win32 Threads Java Threads 4.5 Implicit Threading
Visualization Mathematica Graphics
 Table of Contents 304 Motivation & Trends in HPC R&D Projects @ PP Mathematical Modeling Numerical Methods used in HPSC Systems of Differential Equations: ODEs & PDEs Automatic Differentiation Solving
Table of Contents 304 Motivation & Trends in HPC R&D Projects @ PP Mathematical Modeling Numerical Methods used in HPSC Systems of Differential Equations: ODEs & PDEs Automatic Differentiation Solving
CS 5523 Operating Systems: Midterm II - reivew Instructor: Dr. Tongping Liu Department Computer Science The University of Texas at San Antonio
 CS 5523 Operating Systems: Midterm II - reivew Instructor: Dr. Tongping Liu Department Computer Science The University of Texas at San Antonio Fall 2017 1 Outline Inter-Process Communication (20) Threads
CS 5523 Operating Systems: Midterm II - reivew Instructor: Dr. Tongping Liu Department Computer Science The University of Texas at San Antonio Fall 2017 1 Outline Inter-Process Communication (20) Threads
CS420: Operating Systems
 Threads James Moscola Department of Physical Sciences York College of Pennsylvania Based on Operating System Concepts, 9th Edition by Silberschatz, Galvin, Gagne Threads A thread is a basic unit of processing
Threads James Moscola Department of Physical Sciences York College of Pennsylvania Based on Operating System Concepts, 9th Edition by Silberschatz, Galvin, Gagne Threads A thread is a basic unit of processing
Lecture 16: Recapitulations. Lecture 16: Recapitulations p. 1
 Lecture 16: Recapitulations Lecture 16: Recapitulations p. 1 Parallel computing and programming in general Parallel computing a form of parallel processing by utilizing multiple computing units concurrently
Lecture 16: Recapitulations Lecture 16: Recapitulations p. 1 Parallel computing and programming in general Parallel computing a form of parallel processing by utilizing multiple computing units concurrently
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
CS 261 Fall Mike Lam, Professor. Threads
 CS 261 Fall 2017 Mike Lam, Professor Threads Parallel computing Goal: concurrent or parallel computing Take advantage of multiple hardware units to solve multiple problems simultaneously Motivations: Maintain
CS 261 Fall 2017 Mike Lam, Professor Threads Parallel computing Goal: concurrent or parallel computing Take advantage of multiple hardware units to solve multiple problems simultaneously Motivations: Maintain
Efficiently Introduce Threading using Intel TBB
 Introduction This guide will illustrate how to efficiently introduce threading using Intel Threading Building Blocks (Intel TBB), part of Intel Parallel Studio XE. It is a widely used, award-winning C++
Introduction This guide will illustrate how to efficiently introduce threading using Intel Threading Building Blocks (Intel TBB), part of Intel Parallel Studio XE. It is a widely used, award-winning C++
Computer Systems A Programmer s Perspective 1 (Beta Draft)
") Computer Systems A Programmer s Perspective 1 (Beta Draft) Randal E. Bryant David R. O Hallaron August 1, 2001 1 Copyright c 2001, R. E. Bryant, D. R. O Hallaron. All rights reserved. 2 Contents Preface
Computer Systems A Programmer s Perspective 1 (Beta Draft) Randal E. Bryant David R. O Hallaron August 1, 2001 1 Copyright c 2001, R. E. Bryant, D. R. O Hallaron. All rights reserved. 2 Contents Preface
Multi-core Architecture and Programming
 Multi-core Architecture and Programming Yang Quansheng( 杨全胜 ) http://www.njyangqs.com School of Computer Science & Engineering 1 http://www.njyangqs.com Programming with OpenMP Content What is PpenMP Parallel
Multi-core Architecture and Programming Yang Quansheng( 杨全胜 ) http://www.njyangqs.com School of Computer Science & Engineering 1 http://www.njyangqs.com Programming with OpenMP Content What is PpenMP Parallel
CS 333 Introduction to Operating Systems. Class 3 Threads & Concurrency. Jonathan Walpole Computer Science Portland State University
 CS 333 Introduction to Operating Systems Class 3 Threads & Concurrency Jonathan Walpole Computer Science Portland State University 1 Process creation in UNIX All processes have a unique process id getpid(),
CS 333 Introduction to Operating Systems Class 3 Threads & Concurrency Jonathan Walpole Computer Science Portland State University 1 Process creation in UNIX All processes have a unique process id getpid(),
CS 333 Introduction to Operating Systems. Class 3 Threads & Concurrency. Jonathan Walpole Computer Science Portland State University
 CS 333 Introduction to Operating Systems Class 3 Threads & Concurrency Jonathan Walpole Computer Science Portland State University 1 The Process Concept 2 The Process Concept Process a program in execution
CS 333 Introduction to Operating Systems Class 3 Threads & Concurrency Jonathan Walpole Computer Science Portland State University 1 The Process Concept 2 The Process Concept Process a program in execution
Effective Performance Measurement and Analysis of Multithreaded Applications
 Effective Performance Measurement and Analysis of Multithreaded Applications Nathan Tallent John Mellor-Crummey Rice University CSCaDS hpctoolkit.org Wanted: Multicore Programming Models Simple well-defined
Effective Performance Measurement and Analysis of Multithreaded Applications Nathan Tallent John Mellor-Crummey Rice University CSCaDS hpctoolkit.org Wanted: Multicore Programming Models Simple well-defined
Multiprocessor Systems. Chapter 8, 8.1
 Multiprocessor Systems Chapter 8, 8.1 1 Learning Outcomes An understanding of the structure and limits of multiprocessor hardware. An appreciation of approaches to operating system support for multiprocessor
Multiprocessor Systems Chapter 8, 8.1 1 Learning Outcomes An understanding of the structure and limits of multiprocessor hardware. An appreciation of approaches to operating system support for multiprocessor
Multi-core Architecture and Programming
 Multi-core Architecture and Programming Yang Quansheng( 杨全胜 ) http://www.njyangqs.com School of Computer Science & Engineering 1 http://www.njyangqs.com Process, threads and Parallel Programming Content
Multi-core Architecture and Programming Yang Quansheng( 杨全胜 ) http://www.njyangqs.com School of Computer Science & Engineering 1 http://www.njyangqs.com Process, threads and Parallel Programming Content
Parallel Programming using OpenMP
 1 Parallel Programming using OpenMP Mike Bailey mjb@cs.oregonstate.edu openmp.pptx OpenMP Multithreaded Programming 2 OpenMP stands for Open Multi-Processing OpenMP is a multi-vendor (see next page) standard
1 Parallel Programming using OpenMP Mike Bailey mjb@cs.oregonstate.edu openmp.pptx OpenMP Multithreaded Programming 2 OpenMP stands for Open Multi-Processing OpenMP is a multi-vendor (see next page) standard
Parallel Programming using OpenMP
 1 OpenMP Multithreaded Programming 2 Parallel Programming using OpenMP OpenMP stands for Open Multi-Processing OpenMP is a multi-vendor (see next page) standard to perform shared-memory multithreading
1 OpenMP Multithreaded Programming 2 Parallel Programming using OpenMP OpenMP stands for Open Multi-Processing OpenMP is a multi-vendor (see next page) standard to perform shared-memory multithreading
Optimize an Existing Program by Introducing Parallelism
 Optimize an Existing Program by Introducing Parallelism 1 Introduction This guide will help you add parallelism to your application using Intel Parallel Studio. You will get hands-on experience with our
Optimize an Existing Program by Introducing Parallelism 1 Introduction This guide will help you add parallelism to your application using Intel Parallel Studio. You will get hands-on experience with our
Overview: The OpenMP Programming Model
 Overview: The OpenMP Programming Model motivation and overview the parallel directive: clauses, equivalent pthread code, examples the for directive and scheduling of loop iterations Pi example in OpenMP
Overview: The OpenMP Programming Model motivation and overview the parallel directive: clauses, equivalent pthread code, examples the for directive and scheduling of loop iterations Pi example in OpenMP
Agenda Process Concept Process Scheduling Operations on Processes Interprocess Communication 3.2
 Lecture 3: Processes Agenda Process Concept Process Scheduling Operations on Processes Interprocess Communication 3.2 Process in General 3.3 Process Concept Process is an active program in execution; process
Lecture 3: Processes Agenda Process Concept Process Scheduling Operations on Processes Interprocess Communication 3.2 Process in General 3.3 Process Concept Process is an active program in execution; process
Application Programming
 Multicore Application Programming For Windows, Linux, and Oracle Solaris Darryl Gove AAddison-Wesley Upper Saddle River, NJ Boston Indianapolis San Francisco New York Toronto Montreal London Munich Paris
Multicore Application Programming For Windows, Linux, and Oracle Solaris Darryl Gove AAddison-Wesley Upper Saddle River, NJ Boston Indianapolis San Francisco New York Toronto Montreal London Munich Paris
COSC 462. Parallel Algorithms. The Design Basics. Piotr Luszczek
 COSC 462 Parallel Algorithms The Design Basics Piotr Luszczek September 18, 2017 1/16 Levels of Abstraction 2/16 Concepts Tools Algorithms: partitioning, communication, agglomeration, mapping Domain, channel,
COSC 462 Parallel Algorithms The Design Basics Piotr Luszczek September 18, 2017 1/16 Levels of Abstraction 2/16 Concepts Tools Algorithms: partitioning, communication, agglomeration, mapping Domain, channel,
The University of Texas at Arlington
 The University of Texas at Arlington Lecture 10: Threading and Parallel Programming Constraints CSE 5343/4342 Embedded d Systems II Objectives: Lab 3: Windows Threads (win32 threading API) Convert serial
The University of Texas at Arlington Lecture 10: Threading and Parallel Programming Constraints CSE 5343/4342 Embedded d Systems II Objectives: Lab 3: Windows Threads (win32 threading API) Convert serial
Cluster Computing. Performance and Debugging Issues in OpenMP. Topics. Factors impacting performance. Scalable Speedup
 Topics Scalable Speedup and Data Locality Parallelizing Sequential Programs Breaking data dependencies Avoiding synchronization overheads Performance and Debugging Issues in OpenMP Achieving Cache and
Topics Scalable Speedup and Data Locality Parallelizing Sequential Programs Breaking data dependencies Avoiding synchronization overheads Performance and Debugging Issues in OpenMP Achieving Cache and
Main Points of the Computer Organization and System Software Module
 Main Points of the Computer Organization and System Software Module You can find below the topics we have covered during the COSS module. Reading the relevant parts of the textbooks is essential for a
Main Points of the Computer Organization and System Software Module You can find below the topics we have covered during the COSS module. Reading the relevant parts of the textbooks is essential for a
Introduction to Parallel Computing
 Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Chapter 4: Threads. Chapter 4: Threads
 Chapter 4: Threads Silberschatz, Galvin and Gagne 2013 Chapter 4: Threads Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading Issues Operating System Examples
Chapter 4: Threads Silberschatz, Galvin and Gagne 2013 Chapter 4: Threads Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading Issues Operating System Examples
Shared-Memory Programming
 Shared-Memory Programming 1. Threads 2. Mutual Exclusion 3. Thread Scheduling 4. Thread Interfaces 4.1. POSIX Threads 4.2. C++ Threads 4.3. OpenMP 4.4. Threading Building Blocks 5. Side Effects of Hardware
Shared-Memory Programming 1. Threads 2. Mutual Exclusion 3. Thread Scheduling 4. Thread Interfaces 4.1. POSIX Threads 4.2. C++ Threads 4.3. OpenMP 4.4. Threading Building Blocks 5. Side Effects of Hardware
MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016
 Ion Stoica, UC Berkeley November 19, 2016") MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016 Message passing vs. Shared memory Client Client Client Client send(msg) recv(msg) send(msg) recv(msg) MSG MSG MSG IPC Shared
MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016 Message passing vs. Shared memory Client Client Client Client send(msg) recv(msg) send(msg) recv(msg) MSG MSG MSG IPC Shared
Concurrent Programming with OpenMP
 Concurrent Programming with OpenMP Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico October 11, 2012 CPD (DEI / IST) Parallel and Distributed
Concurrent Programming with OpenMP Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico October 11, 2012 CPD (DEI / IST) Parallel and Distributed
Chapter 4: Threads. Overview Multithreading Models Thread Libraries Threading Issues Operating System Examples Windows XP Threads Linux Threads
 Chapter 4: Threads Overview Multithreading Models Thread Libraries Threading Issues Operating System Examples Windows XP Threads Linux Threads Chapter 4: Threads Objectives To introduce the notion of a
Chapter 4: Threads Overview Multithreading Models Thread Libraries Threading Issues Operating System Examples Windows XP Threads Linux Threads Chapter 4: Threads Objectives To introduce the notion of a
OpenMP Programming. Prof. Thomas Sterling. High Performance Computing: Concepts, Methods & Means
 High Performance Computing: Concepts, Methods & Means OpenMP Programming Prof. Thomas Sterling Department of Computer Science Louisiana State University February 8 th, 2007 Topics Introduction Overview
High Performance Computing: Concepts, Methods & Means OpenMP Programming Prof. Thomas Sterling Department of Computer Science Louisiana State University February 8 th, 2007 Topics Introduction Overview
A Study of High Performance Computing and the Cray SV1 Supercomputer. Michael Sullivan TJHSST Class of 2004
 A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
EI 338: Computer Systems Engineering (Operating Systems & Computer Architecture)
") EI 338: Computer Systems Engineering (Operating Systems & Computer Architecture) Dept. of Computer Science & Engineering Chentao Wu wuct@cs.sjtu.edu.cn Download lectures ftp://public.sjtu.edu.cn User:
EI 338: Computer Systems Engineering (Operating Systems & Computer Architecture) Dept. of Computer Science & Engineering Chentao Wu wuct@cs.sjtu.edu.cn Download lectures ftp://public.sjtu.edu.cn User:
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
High Performance Computing. Introduction to Parallel Computing
 High Performance Computing Introduction to Parallel Computing Acknowledgements Content of the following presentation is borrowed from The Lawrence Livermore National Laboratory https://hpc.llnl.gov/training/tutorials
High Performance Computing Introduction to Parallel Computing Acknowledgements Content of the following presentation is borrowed from The Lawrence Livermore National Laboratory https://hpc.llnl.gov/training/tutorials
Introduction to Multicore Programming
 Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Synchronization 3 Automatic Parallelization and OpenMP 4 GPGPU 5 Q& A 2 Multithreaded
Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Synchronization 3 Automatic Parallelization and OpenMP 4 GPGPU 5 Q& A 2 Multithreaded
Intel Parallel Studio
 Intel Parallel Studio Product Brief Intel Parallel Studio Parallelism for your Development Lifecycle Intel Parallel Studio brings comprehensive parallelism to C/C++ Microsoft Visual Studio* application
Intel Parallel Studio Product Brief Intel Parallel Studio Parallelism for your Development Lifecycle Intel Parallel Studio brings comprehensive parallelism to C/C++ Microsoft Visual Studio* application
Parallel Programming with OpenMP. CS240A, T. Yang
 Parallel Programming with OpenMP CS240A, T. Yang 1 A Programmer s View of OpenMP What is OpenMP? Open specification for Multi-Processing Standard API for defining multi-threaded shared-memory programs
Parallel Programming with OpenMP CS240A, T. Yang 1 A Programmer s View of OpenMP What is OpenMP? Open specification for Multi-Processing Standard API for defining multi-threaded shared-memory programs
Parallel Programming. OpenMP Parallel programming for multiprocessors for loops
 Parallel Programming OpenMP Parallel programming for multiprocessors for loops OpenMP OpenMP An application programming interface (API) for parallel programming on multiprocessors Assumes shared memory
Parallel Programming OpenMP Parallel programming for multiprocessors for loops OpenMP OpenMP An application programming interface (API) for parallel programming on multiprocessors Assumes shared memory
An Introduction to Parallel Programming
 An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
Parallel Programming
 Parallel Programming OpenMP Nils Moschüring PhD Student (LMU) Nils Moschüring PhD Student (LMU), OpenMP 1 1 Overview What is parallel software development Why do we need parallel computation? Problems
Parallel Programming OpenMP Nils Moschüring PhD Student (LMU) Nils Moschüring PhD Student (LMU), OpenMP 1 1 Overview What is parallel software development Why do we need parallel computation? Problems
Introduction to OpenMP
 Introduction to OpenMP Lecture 9: Performance tuning Sources of overhead There are 6 main causes of poor performance in shared memory parallel programs: sequential code communication load imbalance synchronisation
Introduction to OpenMP Lecture 9: Performance tuning Sources of overhead There are 6 main causes of poor performance in shared memory parallel programs: sequential code communication load imbalance synchronisation
OPERATING SYSTEM. Chapter 4: Threads
 OPERATING SYSTEM Chapter 4: Threads Chapter 4: Threads Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading Issues Operating System Examples Objectives To
OPERATING SYSTEM Chapter 4: Threads Chapter 4: Threads Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading Issues Operating System Examples Objectives To
Chapter 4: Multithreaded Programming
 Chapter 4: Multithreaded Programming Silberschatz, Galvin and Gagne 2013 Chapter 4: Multithreaded Programming Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading
Chapter 4: Multithreaded Programming Silberschatz, Galvin and Gagne 2013 Chapter 4: Multithreaded Programming Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading
Parallel Computing Using OpenMP/MPI. Presented by - Jyotsna 29/01/2008
 Parallel Computing Using OpenMP/MPI Presented by - Jyotsna 29/01/2008 Serial Computing Serially solving a problem Parallel Computing Parallelly solving a problem Parallel Computer Memory Architecture Shared
Parallel Computing Using OpenMP/MPI Presented by - Jyotsna 29/01/2008 Serial Computing Serially solving a problem Parallel Computing Parallelly solving a problem Parallel Computer Memory Architecture Shared
Jukka Julku Multicore programming: Low-level libraries. Outline. Processes and threads TBB MPI UPC. Examples
 Multicore Jukka Julku 19.2.2009 1 2 3 4 5 6 Disclaimer There are several low-level, languages and directive based approaches But no silver bullets This presentation only covers some examples of them is
Multicore Jukka Julku 19.2.2009 1 2 3 4 5 6 Disclaimer There are several low-level, languages and directive based approaches But no silver bullets This presentation only covers some examples of them is
Parallel Computing. Prof. Marco Bertini
 Parallel Computing Prof. Marco Bertini Shared memory: OpenMP Implicit threads: motivations Implicit threading frameworks and libraries take care of much of the minutiae needed to create, manage, and (to
Parallel Computing Prof. Marco Bertini Shared memory: OpenMP Implicit threads: motivations Implicit threading frameworks and libraries take care of much of the minutiae needed to create, manage, and (to
Lecture 10 Midterm review
 Lecture 10 Midterm review Announcements The midterm is on Tue Feb 9 th in class 4Bring photo ID 4You may bring a single sheet of notebook sized paper 8x10 inches with notes on both sides (A4 OK) 4You may
Lecture 10 Midterm review Announcements The midterm is on Tue Feb 9 th in class 4Bring photo ID 4You may bring a single sheet of notebook sized paper 8x10 inches with notes on both sides (A4 OK) 4You may
Agenda. Highlight issues with multi threaded programming Introduce thread synchronization primitives Introduce thread safe collections
 Thread Safety Agenda Highlight issues with multi threaded programming Introduce thread synchronization primitives Introduce thread safe collections 2 2 Need for Synchronization Creating threads is easy
Thread Safety Agenda Highlight issues with multi threaded programming Introduce thread synchronization primitives Introduce thread safe collections 2 2 Need for Synchronization Creating threads is easy
Parallel Programming. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Parallel Programming Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Challenges Difficult to write parallel programs Most programmers think sequentially
Parallel Programming Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Challenges Difficult to write parallel programs Most programmers think sequentially
Parallelization and Synchronization. CS165 Section 8
 Parallelization and Synchronization CS165 Section 8 Multiprocessing & the Multicore Era Single-core performance stagnates (breakdown of Dennard scaling) Moore s law continues use additional transistors
Parallelization and Synchronization CS165 Section 8 Multiprocessing & the Multicore Era Single-core performance stagnates (breakdown of Dennard scaling) Moore s law continues use additional transistors
CPSC/ECE 3220 Fall 2017 Exam Give the definition (note: not the roles) for an operating system as stated in the textbook. (2 pts.
 for an operating system as stated in the textbook. (2 pts.") CPSC/ECE 3220 Fall 2017 Exam 1 Name: 1. Give the definition (note: not the roles) for an operating system as stated in the textbook. (2 pts.) Referee / Illusionist / Glue. Circle only one of R, I, or G.
CPSC/ECE 3220 Fall 2017 Exam 1 Name: 1. Give the definition (note: not the roles) for an operating system as stated in the textbook. (2 pts.) Referee / Illusionist / Glue. Circle only one of R, I, or G.
CS4961 Parallel Programming. Lecture 5: More OpenMP, Introduction to Data Parallel Algorithms 9/5/12. Administrative. Mary Hall September 4, 2012
 CS4961 Parallel Programming Lecture 5: More OpenMP, Introduction to Data Parallel Algorithms Administrative Mailing list set up, everyone should be on it - You should have received a test mail last night
CS4961 Parallel Programming Lecture 5: More OpenMP, Introduction to Data Parallel Algorithms Administrative Mailing list set up, everyone should be on it - You should have received a test mail last night
Introduction to Multicore Programming
 Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Automatic Parallelization and OpenMP 3 GPGPU 2 Multithreaded Programming
Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Automatic Parallelization and OpenMP 3 GPGPU 2 Multithreaded Programming
Shared Memory Programming Model
 Shared Memory Programming Model Ahmed El-Mahdy and Waleed Lotfy What is a shared memory system? Activity! Consider the board as a shared memory Consider a sheet of paper in front of you as a local cache
Shared Memory Programming Model Ahmed El-Mahdy and Waleed Lotfy What is a shared memory system? Activity! Consider the board as a shared memory Consider a sheet of paper in front of you as a local cache
15-418, Spring 2008 OpenMP: A Short Introduction
 15-418, Spring 2008 OpenMP: A Short Introduction This is a short introduction to OpenMP, an API (Application Program Interface) that supports multithreaded, shared address space (aka shared memory) parallelism.
15-418, Spring 2008 OpenMP: A Short Introduction This is a short introduction to OpenMP, an API (Application Program Interface) that supports multithreaded, shared address space (aka shared memory) parallelism.
Chapter 4: Threads. Chapter 4: Threads. Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading Issues
 Chapter 4: Threads Silberschatz, Galvin and Gagne 2013 Chapter 4: Threads Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading Issues 4.2 Silberschatz, Galvin
Chapter 4: Threads Silberschatz, Galvin and Gagne 2013 Chapter 4: Threads Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading Issues 4.2 Silberschatz, Galvin
Parallel Programming with OpenMP. CS240A, T. Yang, 2013 Modified from Demmel/Yelick s and Mary Hall s Slides
 Parallel Programming with OpenMP CS240A, T. Yang, 203 Modified from Demmel/Yelick s and Mary Hall s Slides Introduction to OpenMP What is OpenMP? Open specification for Multi-Processing Standard API for
Parallel Programming with OpenMP CS240A, T. Yang, 203 Modified from Demmel/Yelick s and Mary Hall s Slides Introduction to OpenMP What is OpenMP? Open specification for Multi-Processing Standard API for
"Charting the Course to Your Success!" MOC A Developing High-performance Applications using Microsoft Windows HPC Server 2008
 Description Course Summary This course provides students with the knowledge and skills to develop high-performance computing (HPC) applications for Microsoft. Students learn about the product Microsoft,
Description Course Summary This course provides students with the knowledge and skills to develop high-performance computing (HPC) applications for Microsoft. Students learn about the product Microsoft,
Parallel Programming. Exploring local computational resources OpenMP Parallel programming for multiprocessors for loops
 Parallel Programming Exploring local computational resources OpenMP Parallel programming for multiprocessors for loops Single computers nowadays Several CPUs (cores) 4 to 8 cores on a single chip Hyper-threading
Parallel Programming Exploring local computational resources OpenMP Parallel programming for multiprocessors for loops Single computers nowadays Several CPUs (cores) 4 to 8 cores on a single chip Hyper-threading
The University of Texas at Arlington
 The University of Texas at Arlington Lecture 6: Threading and Parallel Programming Constraints CSE 5343/4342 Embedded Systems II Based heavily on slides by Dr. Roger Walker More Task Decomposition: Dependence
The University of Texas at Arlington Lecture 6: Threading and Parallel Programming Constraints CSE 5343/4342 Embedded Systems II Based heavily on slides by Dr. Roger Walker More Task Decomposition: Dependence
EE/CSCI 451: Parallel and Distributed Computation
 EE/CSCI 451: Parallel and Distributed Computation Lecture #7 2/5/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline From last class
EE/CSCI 451: Parallel and Distributed Computation Lecture #7 2/5/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline From last class
COMP4510 Introduction to Parallel Computation. Shared Memory and OpenMP. Outline (cont d) Shared Memory and OpenMP
 Shared Memory and OpenMP") COMP4510 Introduction to Parallel Computation Shared Memory and OpenMP Thanks to Jon Aronsson (UofM HPC consultant) for some of the material in these notes. Outline (cont d) Shared Memory and OpenMP Including
COMP4510 Introduction to Parallel Computation Shared Memory and OpenMP Thanks to Jon Aronsson (UofM HPC consultant) for some of the material in these notes. Outline (cont d) Shared Memory and OpenMP Including
CS 470 Spring Mike Lam, Professor. Advanced OpenMP
 CS 470 Spring 2017 Mike Lam, Professor Advanced OpenMP Atomics OpenMP provides access to highly-efficient hardware synchronization mechanisms Use the atomic pragma to annotate a single statement Statement
CS 470 Spring 2017 Mike Lam, Professor Advanced OpenMP Atomics OpenMP provides access to highly-efficient hardware synchronization mechanisms Use the atomic pragma to annotate a single statement Statement
Simplified and Effective Serial and Parallel Performance Optimization
 HPC Code Modernization Workshop at LRZ Simplified and Effective Serial and Parallel Performance Optimization Performance tuning Using Intel VTune Performance Profiler Performance Tuning Methodology Goal:
HPC Code Modernization Workshop at LRZ Simplified and Effective Serial and Parallel Performance Optimization Performance tuning Using Intel VTune Performance Profiler Performance Tuning Methodology Goal:
CS5460: Operating Systems
 CS5460: Operating Systems Lecture 9: Implementing Synchronization (Chapter 6) Multiprocessor Memory Models Uniprocessor memory is simple Every load from a location retrieves the last value stored to that
CS5460: Operating Systems Lecture 9: Implementing Synchronization (Chapter 6) Multiprocessor Memory Models Uniprocessor memory is simple Every load from a location retrieves the last value stored to that
Overview. CMSC 330: Organization of Programming Languages. Concurrency. Multiprocessors. Processes vs. Threads. Computation Abstractions
 CMSC 330: Organization of Programming Languages Multithreaded Programming Patterns in Java CMSC 330 2 Multiprocessors Description Multiple processing units (multiprocessor) From single microprocessor to
CMSC 330: Organization of Programming Languages Multithreaded Programming Patterns in Java CMSC 330 2 Multiprocessors Description Multiple processing units (multiprocessor) From single microprocessor to
Exploiting the Power of the Intel Compiler Suite. Dr. Mario Deilmann Intel Compiler and Languages Lab Software Solutions Group
 Exploiting the Power of the Intel Compiler Suite Dr. Mario Deilmann Intel Compiler and Languages Lab Software Solutions Group Agenda Compiler Overview Intel C++ Compiler High level optimization IPO, PGO
Exploiting the Power of the Intel Compiler Suite Dr. Mario Deilmann Intel Compiler and Languages Lab Software Solutions Group Agenda Compiler Overview Intel C++ Compiler High level optimization IPO, PGO
Performance Tools for Technical Computing
 Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Multiprocessor System. Multiprocessor Systems. Bus Based UMA. Types of Multiprocessors (MPs) Cache Consistency. Bus Based UMA. Chapter 8, 8.
 Cache Consistency. Bus Based UMA. Chapter 8, 8.") Multiprocessor System Multiprocessor Systems Chapter 8, 8.1 We will look at shared-memory multiprocessors More than one processor sharing the same memory A single CPU can only go so fast Use more than
Multiprocessor System Multiprocessor Systems Chapter 8, 8.1 We will look at shared-memory multiprocessors More than one processor sharing the same memory A single CPU can only go so fast Use more than
Lecture 4: OpenMP Open Multi-Processing
 CS 4230: Parallel Programming Lecture 4: OpenMP Open Multi-Processing January 23, 2017 01/23/2017 CS4230 1 Outline OpenMP another approach for thread parallel programming Fork-Join execution model OpenMP
CS 4230: Parallel Programming Lecture 4: OpenMP Open Multi-Processing January 23, 2017 01/23/2017 CS4230 1 Outline OpenMP another approach for thread parallel programming Fork-Join execution model OpenMP
OpenMP Overview. in 30 Minutes. Christian Terboven / Aachen, Germany Stand: Version 2.
 OpenMP Overview in 30 Minutes Christian Terboven 06.12.2010 / Aachen, Germany Stand: 03.12.2010 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda OpenMP: Parallel Regions,
OpenMP Overview in 30 Minutes Christian Terboven 06.12.2010 / Aachen, Germany Stand: 03.12.2010 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda OpenMP: Parallel Regions,
Designing Parallel Programs. This review was developed from Introduction to Parallel Computing
 Designing Parallel Programs This review was developed from Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory references: https://computing.llnl.gov/tutorials/parallel_comp/#whatis
Designing Parallel Programs This review was developed from Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory references: https://computing.llnl.gov/tutorials/parallel_comp/#whatis
Introduction to Parallel Performance Engineering
 Introduction to Parallel Performance Engineering Markus Geimer, Brian Wylie Jülich Supercomputing Centre (with content used with permission from tutorials by Bernd Mohr/JSC and Luiz DeRose/Cray) Performance:
Introduction to Parallel Performance Engineering Markus Geimer, Brian Wylie Jülich Supercomputing Centre (with content used with permission from tutorials by Bernd Mohr/JSC and Luiz DeRose/Cray) Performance:
Introduction to OpenMP. OpenMP basics OpenMP directives, clauses, and library routines
 Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
Copyright 2010, Elsevier Inc. All rights Reserved
 An Introduction to Parallel Programming Peter Pacheco Chapter 6 Parallel Program Development 1 Roadmap Solving non-trivial problems. The n-body problem. The traveling salesman problem. Applying Foster
An Introduction to Parallel Programming Peter Pacheco Chapter 6 Parallel Program Development 1 Roadmap Solving non-trivial problems. The n-body problem. The traveling salesman problem. Applying Foster
Intel VTune Amplifier XE
 Intel VTune Amplifier XE Vladimir Tsymbal Performance, Analysis and Threading Lab 1 Agenda Intel VTune Amplifier XE Overview Features Data collectors Analysis types Key Concepts Collecting performance
Intel VTune Amplifier XE Vladimir Tsymbal Performance, Analysis and Threading Lab 1 Agenda Intel VTune Amplifier XE Overview Features Data collectors Analysis types Key Concepts Collecting performance
Contents. Preface xvii Acknowledgments. CHAPTER 1 Introduction to Parallel Computing 1. CHAPTER 2 Parallel Programming Platforms 11
 Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
Multiprocessor Systems. COMP s1
 Multiprocessor Systems 1 Multiprocessor System We will look at shared-memory multiprocessors More than one processor sharing the same memory A single CPU can only go so fast Use more than one CPU to improve
Multiprocessor Systems 1 Multiprocessor System We will look at shared-memory multiprocessors More than one processor sharing the same memory A single CPU can only go so fast Use more than one CPU to improve