Cray Performance Tools Enhancements for Next Generation Systems Heidi Poxon
|
|
|
- Norma Gilbert
- 5 years ago
- Views:
Transcription

1 Cray Performance Tools Enhancements for Next Generation Systems Heidi Poxon
2 Agenda Cray Performance Tools Overview Recent Enhancements Support for Cray systems with KNL 2
3 Cray Performance Analysis Tools Overview Assist the user with application performance analysis and optimization Help user identify important and meaningful information from potentially massive data sets Help user identify problem areas instead of just reporting data Bring optimization knowledge to a wider set of users Focus on ease of use and intuitive user interfaces Automatic program instrumentation Automatic analysis Whole program analysis across many nodes 3
4 Two Modes of Use CrayPat-lite for novice users, or convenience CrayPat for in-depth performance investigation and tuning assistance Both offer: Whole program analysis across many nodes Indication of causes of problems Suggestions of modifications for performance improvement 4

 > make")
 > aprun a.out a.")

5 Lite Mode Load performance tools modules > module load perftools-lite Build program (no modification to makefile) > make Run program (no modification to batch script) > aprun a.out a.out (instrumented program) Condensed report to stdout a.out*.rpt (same as stdout) a.out*.ap2 files 5

 Avg Process Time: 64.38 secs High Memory: 1,563 MBytes 24.")
6 Example CrayPat-lite Output ################################################################# # # # CrayPat-lite Performance Statistics # # # ################################################################# CrayPat/X: Version Revision 56930ff 02/01/16 15:31:33 Experiment: lite lite/sample_profile Number of PEs (MPI ranks): 64 Numbers of PEs per Node: 32 PEs on each of 2 Nodes Numbers of Threads per PE: 1 Number of Cores per Socket: 16 Execution start time: Tue Feb 2 18:53: System name and speed: kay 2301 MHz (approx) Avg Process Time: secs High Memory: 1,563 MBytes MBytes per PE MFLOPS: Not supported (see observation below) I/O Read Rate: MBytes/sec I/O Write Rate: MBytes/sec Avg CPU Energy: 41,820 joules 20,910 joules per node Avg CPU Power: watts watts per node Table 1: Profile by Function Group and Function (top 10 functions shown) Samp% Samp Imb. Imb. Group Samp Samp% Function PE=HIDE 100.0% 6, Total % 4, USER % % mult_su3_mat_vec_sum_4dir 10.2% % mult_adj_su3_mat_4vec 6.1% % mult_su3_nn 5.9% % mult_su3_na 5.4% % scalar_mult_add_lathwvec_proj 3.8% % mult_su3_sitelink_lathwvec ============================================================== 25.3% 1, MPI % % MPI_Wait 6.7% % MPI_Isend 4.9% % MPI_Allreduce ============================================================== 5.9% % STRING % % memcpy ========================================================== 6

7 Guidance: How Can I Learn More? MPI utilization: The time spent processing MPI communications is relatively high. Functions and callsites responsible for consuming the most time can be found in the table generated by pat_report -O callers+src (within the MPI group). 7

8 Guidance: Reduce Shared Resource Contention Metric-Based Rank Order: When the use of a shared resource like memory bandwidth is unbalanced across nodes, total execution time may be reduced with a rank order that improves the balance. A file named MPICH_RANK_ORDER.USER_Time was generated along with this report and contains usage instructions and the custom rank order from the following table. Rank Node Reduction Maximum Average Order Metric in Max Value Value Imb. Value Current 15.46% 1.134e e+02 Custom 1.46% % 9.731e e+02 8









9 GPU Program Timeline CPU call stack: Bar represents CPU function or region: Hover over bar to get function name, start and end time Bar represents GPU stream event: Hover over bar to get event info Program histogram of wait, copy kernel time Program wallclock time line
10 Recent Enhancements through perftools/6.3.2
11 Highlights Since Last CUG New perftools-base and instrumentation modules (6.3.0) Sampling over time and gnuplots (6.2.3) Apprentice2 sampling over time plots with call stack (6.3.0) Apprentice2 MPI communication pattern in summary mode (6.3.0) Observation for helper threads in reports (6.3.0) Performance data comparison in Apprentice2 (6.3.1) 11

12 Evaluate Scaling with Cray Apprentice2 Add file for performance comparison here seconds seconds 12



13 Energy Consumption Over Time (XC Systems) Call stack: Bar represents function or region: Hover over bar to get function name, start and end time Plots of energy consumed by the socket and by the cores within a socket over time. Can also show memory high water mark, etc. 13

14 Support for Cray Systems with KNL Port Analyze
15 Overview of Support for KNL CrayPat and CrayPat-lite Identifies top time consuming routines, work load imbalance, MPI rank placement strategies, etc. Enhanced program memory high water mark Broken down into DDR and MCDRAM memory Report active allocations at samples or during tracing at the function level PAPI Cray Apprentice2 Helps identify load imbalance, excessive communication, network contention, excessive serialization Reveal support for adding OpenMP and allocating in MCDRAM 15
16 Functionality Coming in 2016 MCDRAM configuration information New trace groups for MemKind, HBW, CrayMem OpenCL Lustre API Parallel NetCDF Support for Charm++ 16
: 64 Numbers of PEs per Node: 1 PE on each of 64 Nodes Numbers of Threads per PE: 1.")
17 Example: MCDRAM Configuration Information CrayPat/X: Version 6.4.X Revision e82c848 04/29/16 14:13:55 Number of PEs (MPI ranks): 64 Numbers of PEs per Node: 1 PE on each of 64 Nodes Numbers of Threads per PE: 1... Execution start time: Mon May 2 15:54: Intel knl CPU... MCDRAM: 16 GiB available as snc2, cache (100% cache) for 16 PEs MCDRAM: 16 GiB available as snc2, flat ( 0% cache) for 16 PEs MCDRAM: 16 GiB available as snc4, flat ( 0% cache) for 1 PE MCDRAM: 16 GiB available as quad, flat ( 0% cache) for 15 PEs MCDRAM: 16 GiB available as quad, equal ( 50% cache) for 16 PEs 17



 Insert parallel directives")

18 Adding OpenMP with Reveal Navigate to relevant loops to parallelize Identify parallelization and scoping issues Get feedback on issues down the call chain (shared reductions, etc.) Insert parallel directives into source for performance portable code Validate scoping correctness on existing directives 18

19 More Information for C/C++ Programs 19
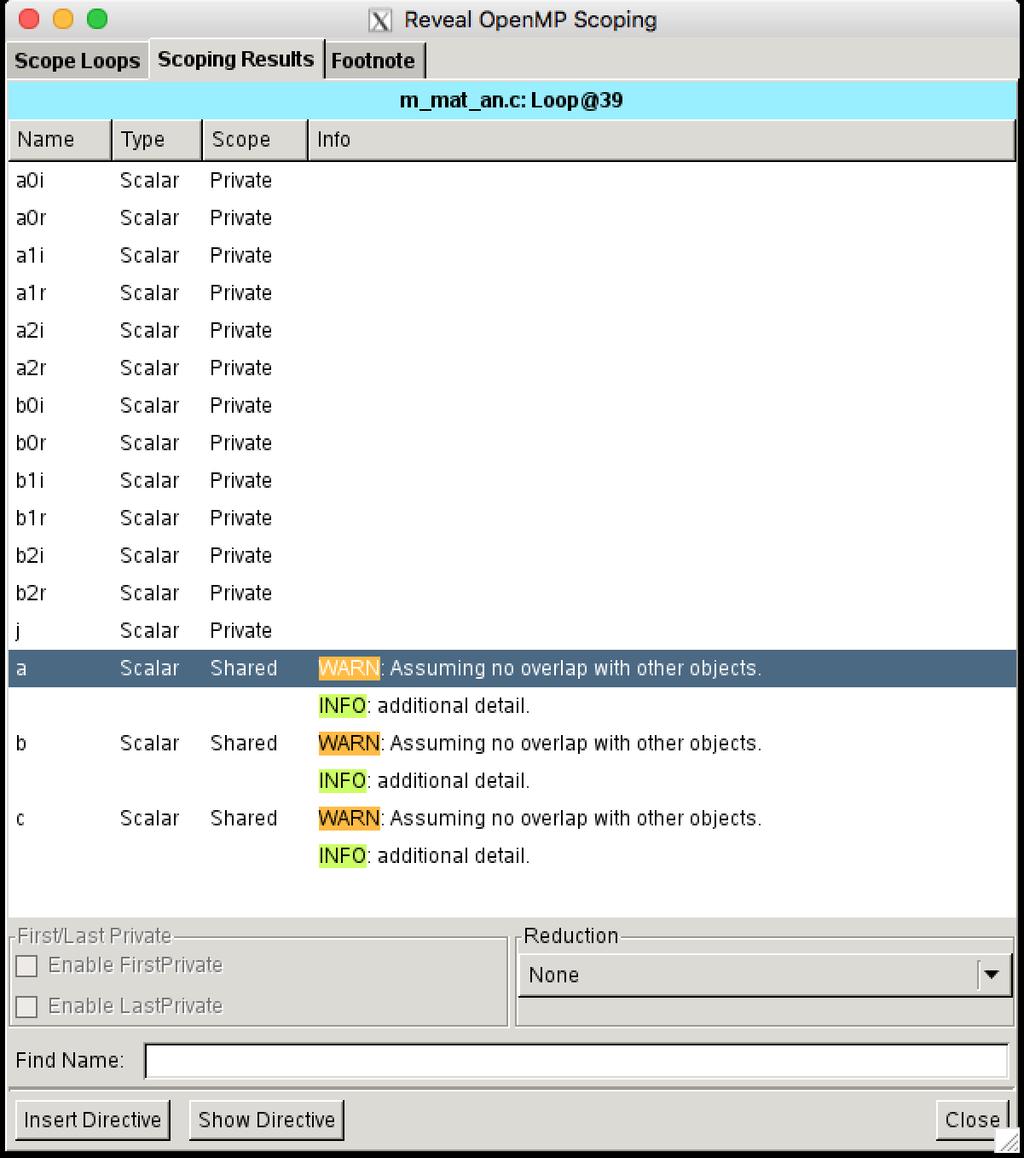

20 More Information for C/C++ Programs (2) 20


21 Reveal Auto-Parallelization Build an experimental binary that includes automatic runtime-assisted parallelization No source code changes required to see if high level loops that contain calls can be automatically parallelized Result includes parallelization of serial loops via traditional OpenMP as well as more extensive loop optimizations User Workflow: 1. Obtain loop work estimates using CCE 8.5 and perftools-liteloops from perftools/ Use Reveal and CCE s program library to parallelize loops and create experimental binary 3. Run experimental binary and compare performance against baseline 4. If auto-parallelization is successful, use Reveal to insert parallel directives into source Trigger dependence analysis scope loops above given threshold create new binary 21


22 Examples of Reveal Analysis Feedback 22
23 Reveal Auto-Parallelization Recap Minimal user time investment includes time to set up and run optimization experiment Collect loop work estimates Build program library Click button in Reveal Run experimental binary and compare against original program Even if experiment does not yield a performance improvement, Reveal will provide insight into parallelization issues Targeted for KNL, where a pure MPI solution cannot utilize all cores on a node Can be used on existing hardware (AMD Interlagos, Intel Haswell, etc.) Infrastructure will allow different optimization experiments in the future 23
24 Coming Soon Identifying Objects for Allocation in KNL MCDRAM
25 FLOPS vs Data Movement / Data Locality Next generation memory systems will be more complicated Multi-tier hierarchies NUMA domains Complicated caches Data movement through the memory hierarchy is critical to performance Compared to the price of data movement, flops are free Monitoring and minimizing data movement within node and across nodes is key 25
26 Identifying Objects for Allocation in MCDRAM Is application predominantly memory intensive? Does application data all fit within MCDRAM? What data contributes most to memory bandwidth? Where is data allocated within program? 26

*src(i,j,k,n) 393 end do 394 end do c.")
27 Reveal Data Allocation Assistance Use combination of CrayPat and Reveal to identify data most relevant for allocation in MCDRAM subroutine sweep (it,jt, kt, nm, isct, mm,mmo,mmi, mk, myid, 1 hi, hj, hk, di, dj, dk, Phi, Phii, 2 Src, Flux, Sigt, 3 w,mu,eta,tsi, wmu,weta,wtsi, pn, 387 do i = 1, it 388 phi(i) = src(i,j,k,1) 389 end do 390 do n = 2, nm 391 do i = 1, it 392 phi(i) = phi(i) + pn(m,n,iq)*src(i,j,k,n) 393 end do 394 end do c...automatic ARRAYS double precision Src(it,jt,kt,nm) double precision pn(mm,nm,8) double precision Phi(it) 27
28 Example Workflow Enable data collection for memory analysis experiment and build program with CCE s program library feature Run program to collect data Pass program library and memory traffic data to Reveal Reveal shows best candidates for allocation in MCDRAM and identifies points of allocation Reveal helps insert allocation directives into source 28
29 Summary Users continue to need tools to help find critical performance bottlenecks within a program Cray performance tools offer functionality that reduces the time investment associated with porting and tuning applications on new and existing Cray systems 29
30 Q&A Heidi Poxon 30
31 Legal Disclaimer Information in this document is provided in connection with Cray Inc. products. No license, express or implied, to any intellectual property rights is granted by this document. Cray Inc. may make changes to specifications and product descriptions at any time, without notice. All products, dates and figures specified are preliminary based on current expectations, and are subject to change without notice. Cray hardware and software products may contain design defects or errors known as errata, which may cause the product to deviate from published specifications. Current characterized errata are available on request. Cray uses codenames internally to identify products that are in development and not yet publically announced for release. Customers and other third parties are not authorized by Cray Inc. to use codenames in advertising, promotion or marketing and any use of Cray Inc. internal codenames is at the sole risk of the user. Performance tests and ratings are measured using specific systems and/or components and reflect the approximate performance of Cray Inc. products as measured by those tests. Any difference in system hardware or software design or configuration may affect actual performance. The following are trademarks of Cray Inc. and are registered in the United States and other countries: CRAY and design, SONEXION, and URIKA. The following are trademarks of Cray Inc.: APPRENTICE2, CHAPEL, CLUSTER CONNECT, CRAYPAT, CRAYPORT, ECOPHLEX, LIBSCI, NODEKARE, THREADSTORM. The following system family marks, and associated model number marks, are trademarks of Cray Inc.: CS, CX, XC, XE, XK, XMT, and XT. The registered trademark LINUX is used pursuant to a sublicense from LMI, the exclusive licensee of Linus Torvalds, owner of the mark on a worldwide basis. Other trademarks used in this document are the property of their respective owners. 31
Reveal. Dr. Stephen Sachs
 Reveal Dr. Stephen Sachs Agenda Reveal Overview Loop work estimates Creating program library with CCE Using Reveal to add OpenMP 2 Cray Compiler Optimization Feedback OpenMP Assistance MCDRAM Allocation
Reveal Dr. Stephen Sachs Agenda Reveal Overview Loop work estimates Creating program library with CCE Using Reveal to add OpenMP 2 Cray Compiler Optimization Feedback OpenMP Assistance MCDRAM Allocation
Reveal Heidi Poxon Sr. Principal Engineer Cray Programming Environment
 Reveal Heidi Poxon Sr. Principal Engineer Cray Programming Environment Legal Disclaimer Information in this document is provided in connection with Cray Inc. products. No license, express or implied, to
Reveal Heidi Poxon Sr. Principal Engineer Cray Programming Environment Legal Disclaimer Information in this document is provided in connection with Cray Inc. products. No license, express or implied, to
Hands-On II: Ray Tracing (data parallelism) COMPUTE STORE ANALYZE
 COMPUTE STORE ANALYZE") Hands-On II: Ray Tracing (data parallelism) Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking statements may include
Hands-On II: Ray Tracing (data parallelism) Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking statements may include
OpenFOAM Scaling on Cray Supercomputers Dr. Stephen Sachs GOFUN 2017
 OpenFOAM Scaling on Cray Supercomputers Dr. Stephen Sachs GOFUN 2017 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking
OpenFOAM Scaling on Cray Supercomputers Dr. Stephen Sachs GOFUN 2017 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking
Sonexion GridRAID Characteristics
 Sonexion GridRAID Characteristics CUG 2014 Mark Swan, Cray Inc. 1 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking
Sonexion GridRAID Characteristics CUG 2014 Mark Swan, Cray Inc. 1 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking
An Exploration into Object Storage for Exascale Supercomputers. Raghu Chandrasekar
 An Exploration into Object Storage for Exascale Supercomputers Raghu Chandrasekar Agenda Introduction Trends and Challenges Design and Implementation of SAROJA Preliminary evaluations Summary and Conclusion
An Exploration into Object Storage for Exascale Supercomputers Raghu Chandrasekar Agenda Introduction Trends and Challenges Design and Implementation of SAROJA Preliminary evaluations Summary and Conclusion
XC System Management Usability BOF Joel Landsteiner & Harold Longley, Cray Inc. Copyright 2017 Cray Inc.
 XC System Management Usability BOF Joel Landsteiner & Harold Longley, Cray Inc. 1 BOF Survey https://www.surveymonkey.com/r/kmg657s Aggregate Ideas at scale! Take a moment to fill out quick feedback form
XC System Management Usability BOF Joel Landsteiner & Harold Longley, Cray Inc. 1 BOF Survey https://www.surveymonkey.com/r/kmg657s Aggregate Ideas at scale! Take a moment to fill out quick feedback form
Array, Domain, & Domain Map Improvements Chapel Team, Cray Inc. Chapel version 1.17 April 5, 2018
 Array, Domain, & Domain Map Improvements Chapel Team, Cray Inc. Chapel version 1.17 April 5, 2018 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current
Array, Domain, & Domain Map Improvements Chapel Team, Cray Inc. Chapel version 1.17 April 5, 2018 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current
Lustre Lockahead: Early Experience and Performance using Optimized Locking. Michael Moore
 Lustre Lockahead: Early Experience and Performance using Optimized Locking Michael Moore Agenda Purpose Investigate performance of a new Lustre and MPI-IO feature called Lustre Lockahead (LLA) Discuss
Lustre Lockahead: Early Experience and Performance using Optimized Locking Michael Moore Agenda Purpose Investigate performance of a new Lustre and MPI-IO feature called Lustre Lockahead (LLA) Discuss
Memory Leaks Chapel Team, Cray Inc. Chapel version 1.14 October 6, 2016
 Memory Leaks Chapel Team, Cray Inc. Chapel version 1.14 October 6, 2016 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward
Memory Leaks Chapel Team, Cray Inc. Chapel version 1.14 October 6, 2016 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward
Intel Xeon PhiTM Knights Landing (KNL) System Software Clark Snyder, Peter Hill, John Sygulla
 System Software Clark Snyder, Peter Hill, John Sygulla") Intel Xeon PhiTM Knights Landing (KNL) System Software Clark Snyder, Peter Hill, John Sygulla Motivation The Intel Xeon Phi TM Knights Landing (KNL) has 20 different configurations 5 NUMA modes X 4 memory
Intel Xeon PhiTM Knights Landing (KNL) System Software Clark Snyder, Peter Hill, John Sygulla Motivation The Intel Xeon Phi TM Knights Landing (KNL) has 20 different configurations 5 NUMA modes X 4 memory
MPI for Cray XE/XK Systems & Recent Enhancements
 MPI for Cray XE/XK Systems & Recent Enhancements Heidi Poxon Technical Lead Programming Environment Cray Inc. Legal Disclaimer Information in this document is provided in connection with Cray Inc. products.
MPI for Cray XE/XK Systems & Recent Enhancements Heidi Poxon Technical Lead Programming Environment Cray Inc. Legal Disclaimer Information in this document is provided in connection with Cray Inc. products.
Productive Programming in Chapel: A Computation-Driven Introduction Chapel Team, Cray Inc. SC16, Salt Lake City, UT November 13, 2016
 Productive Programming in Chapel: A Computation-Driven Introduction Chapel Team, Cray Inc. SC16, Salt Lake City, UT November 13, 2016 Safe Harbor Statement This presentation may contain forward-looking
Productive Programming in Chapel: A Computation-Driven Introduction Chapel Team, Cray Inc. SC16, Salt Lake City, UT November 13, 2016 Safe Harbor Statement This presentation may contain forward-looking
The Use and I: Transitivity of Module Uses and its Impact
 The Use and I: Transitivity of Module Uses and its Impact Lydia Duncan, Cray Inc. CHIUW 2016 May 27 th, 2016 Safe Harbor Statement This presentation may contain forward-looking statements that are based
The Use and I: Transitivity of Module Uses and its Impact Lydia Duncan, Cray Inc. CHIUW 2016 May 27 th, 2016 Safe Harbor Statement This presentation may contain forward-looking statements that are based
Q & A, Project Status, and Wrap-up COMPUTE STORE ANALYZE
 Q & A, Project Status, and Wrap-up Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking statements may include statements
Q & A, Project Status, and Wrap-up Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking statements may include statements
Project Caribou; Streaming metrics for Sonexion Craig Flaskerud
 Project Caribou; Streaming metrics for Sonexion Craig Flaskerud Legal Disclaimer Information in this document is provided in connection with Cray Inc. products. No license, express or implied, to any intellectual
Project Caribou; Streaming metrics for Sonexion Craig Flaskerud Legal Disclaimer Information in this document is provided in connection with Cray Inc. products. No license, express or implied, to any intellectual
Locality/Affinity Features COMPUTE STORE ANALYZE
 Locality/Affinity Features Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking statements may include statements about
Locality/Affinity Features Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking statements may include statements about
Cray XC System Node Diagnosability. Jeffrey J. Schutkoske Platform Services Group (PSG)
") Cray XC System Node Diagnosability Jeffrey J. Schutkoske Platform Services Group (PSG) jjs@cray.com Safe Harbor Statement This presentation may contain forward-looking statements that are based on our
Cray XC System Node Diagnosability Jeffrey J. Schutkoske Platform Services Group (PSG) jjs@cray.com Safe Harbor Statement This presentation may contain forward-looking statements that are based on our
Data-Centric Locality in Chapel
 Data-Centric Locality in Chapel Ben Harshbarger Cray Inc. CHIUW 2015 1 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward
Data-Centric Locality in Chapel Ben Harshbarger Cray Inc. CHIUW 2015 1 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward
Compiler Improvements Chapel Team, Cray Inc. Chapel version 1.13 April 7, 2016
 Compiler Improvements Chapel Team, Cray Inc. Chapel version 1.13 April 7, 2016 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations.
Compiler Improvements Chapel Team, Cray Inc. Chapel version 1.13 April 7, 2016 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations.
Porting the parallel Nek5000 application to GPU accelerators with OpenMP4.5. Alistair Hart (Cray UK Ltd.)
") Porting the parallel Nek5000 application to GPU accelerators with OpenMP4.5 Alistair Hart (Cray UK Ltd.) Safe Harbor Statement This presentation may contain forward-looking statements that are based on
Porting the parallel Nek5000 application to GPU accelerators with OpenMP4.5 Alistair Hart (Cray UK Ltd.) Safe Harbor Statement This presentation may contain forward-looking statements that are based on
Adding Lifetime Checking to Chapel Michael Ferguson, Cray Inc. CHIUW 2018 May 25, 2018
 Adding Lifetime Checking to Chapel Michael Ferguson, Cray Inc. CHIUW 2018 May 25, 2018 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations.
Adding Lifetime Checking to Chapel Michael Ferguson, Cray Inc. CHIUW 2018 May 25, 2018 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations.
Compiler / Tools Chapel Team, Cray Inc. Chapel version 1.17 April 5, 2018
 Compiler / Tools Chapel Team, Cray Inc. Chapel version 1.17 April 5, 2018 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward
Compiler / Tools Chapel Team, Cray Inc. Chapel version 1.17 April 5, 2018 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward
Transferring User Defined Types in
 Transferring User Defined Types in OpenACC James Beyer, Ph.D () 1 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking
Transferring User Defined Types in OpenACC James Beyer, Ph.D () 1 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking
Grab-Bag Topics / Demo COMPUTE STORE ANALYZE
 Grab-Bag Topics / Demo Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking statements may include statements about
Grab-Bag Topics / Demo Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking statements may include statements about
Caching Puts and Gets in a PGAS Language Runtime
 Caching Puts and Gets in a PGAS Language Runtime Michael Ferguson Cray Inc. Daniel Buettner Laboratory for Telecommunication Sciences September 17, 2015 C O M P U T E S T O R E A N A L Y Z E Safe Harbor
Caching Puts and Gets in a PGAS Language Runtime Michael Ferguson Cray Inc. Daniel Buettner Laboratory for Telecommunication Sciences September 17, 2015 C O M P U T E S T O R E A N A L Y Z E Safe Harbor
How-to write a xtpmd_plugin for your Cray XC system Steven J. Martin
 How-to write a xtpmd_plugin for your Cray XC system Steven J. Martin (stevem@cray.com) Cray XC Telemetry Plugin Introduction Enabling sites to get telemetry data off the Cray Plugin interface enables site
How-to write a xtpmd_plugin for your Cray XC system Steven J. Martin (stevem@cray.com) Cray XC Telemetry Plugin Introduction Enabling sites to get telemetry data off the Cray Plugin interface enables site
Data Parallelism COMPUTE STORE ANALYZE
 Data Parallelism Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking statements may include statements about our financial
Data Parallelism Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking statements may include statements about our financial
Hybrid Warm Water Direct Cooling Solution Implementation in CS300-LC
 Hybrid Warm Water Direct Cooling Solution Implementation in CS300-LC Roger Smith Mississippi State University Giridhar Chukkapalli Cray, Inc. C O M P U T E S T O R E A N A L Y Z E 1 Safe Harbor Statement
Hybrid Warm Water Direct Cooling Solution Implementation in CS300-LC Roger Smith Mississippi State University Giridhar Chukkapalli Cray, Inc. C O M P U T E S T O R E A N A L Y Z E 1 Safe Harbor Statement
Redfish APIs on Next Generation Cray Hardware CUG 2018 Steven J. Martin, Cray Inc.
 Redfish APIs on Next Generation Cray Hardware Steven J. Martin, Cray Inc. Modernizing Cray Systems Management Use of Redfish APIs on Next Generation Cray Hardware Steven Martin, David Rush, Kevin Hughes,
Redfish APIs on Next Generation Cray Hardware Steven J. Martin, Cray Inc. Modernizing Cray Systems Management Use of Redfish APIs on Next Generation Cray Hardware Steven Martin, David Rush, Kevin Hughes,
Monitoring Power CrayPat-lite
 Monitoring Power CrayPat-lite (Courtesy of Heidi Poxon) Monitoring Power on Intel Feedback to the user on performance and power consumption will be key to understanding the behavior of an applications
Monitoring Power CrayPat-lite (Courtesy of Heidi Poxon) Monitoring Power on Intel Feedback to the user on performance and power consumption will be key to understanding the behavior of an applications
Enhancing scalability of the gyrokinetic code GS2 by using MPI Shared Memory for FFTs
 Enhancing scalability of the gyrokinetic code GS2 by using MPI Shared Memory for FFTs Lucian Anton 1, Ferdinand van Wyk 2,4, Edmund Highcock 2, Colin Roach 3, Joseph T. Parker 5 1 Cray UK, 2 University
Enhancing scalability of the gyrokinetic code GS2 by using MPI Shared Memory for FFTs Lucian Anton 1, Ferdinand van Wyk 2,4, Edmund Highcock 2, Colin Roach 3, Joseph T. Parker 5 1 Cray UK, 2 University
Chapel s New Adventures in Data Locality Brad Chamberlain Chapel Team, Cray Inc. August 2, 2017
 Chapel s New Adventures in Data Locality Brad Chamberlain Chapel Team, Cray Inc. August 2, 2017 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current
Chapel s New Adventures in Data Locality Brad Chamberlain Chapel Team, Cray Inc. August 2, 2017 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current
New Tools and Tool Improvements Chapel Team, Cray Inc. Chapel version 1.16 October 5, 2017
 New Tools and Tool Improvements Chapel Team, Cray Inc. Chapel version 1.16 October 5, 2017 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations.
New Tools and Tool Improvements Chapel Team, Cray Inc. Chapel version 1.16 October 5, 2017 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations.
Tutorial: Analyzing MPI Applications. Intel Trace Analyzer and Collector Intel VTune Amplifier XE
 Tutorial: Analyzing MPI Applications Intel Trace Analyzer and Collector Intel VTune Amplifier XE Contents Legal Information... 3 1. Overview... 4 1.1. Prerequisites... 5 1.1.1. Required Software... 5 1.1.2.
Tutorial: Analyzing MPI Applications Intel Trace Analyzer and Collector Intel VTune Amplifier XE Contents Legal Information... 3 1. Overview... 4 1.1. Prerequisites... 5 1.1.1. Required Software... 5 1.1.2.
Lustre Networking at Cray. Chris Horn
 Lustre Networking at Cray Chris Horn hornc@cray.com Agenda Lustre Networking at Cray LNet Basics Flat vs. Fine-Grained Routing Cost Effectiveness - Bandwidth Matching Connection Reliability Dealing with
Lustre Networking at Cray Chris Horn hornc@cray.com Agenda Lustre Networking at Cray LNet Basics Flat vs. Fine-Grained Routing Cost Effectiveness - Bandwidth Matching Connection Reliability Dealing with
Evaluating Shifter for HPC Applications Don Bahls Cray Inc.
 Evaluating Shifter for HPC Applications Don Bahls Cray Inc. Agenda Motivation Shifter User Defined Images (UDIs) provide a mechanism to access a wider array of software in the HPC environment without enduring
Evaluating Shifter for HPC Applications Don Bahls Cray Inc. Agenda Motivation Shifter User Defined Images (UDIs) provide a mechanism to access a wider array of software in the HPC environment without enduring
First experiences porting a parallel application to a hybrid supercomputer with OpenMP 4.0 device constructs. Alistair Hart (Cray UK Ltd.
 First experiences porting a parallel application to a hybrid supercomputer with OpenMP 4.0 device constructs Alistair Hart (Cray UK Ltd.) Safe Harbor Statement This presentation may contain forward-looking
First experiences porting a parallel application to a hybrid supercomputer with OpenMP 4.0 device constructs Alistair Hart (Cray UK Ltd.) Safe Harbor Statement This presentation may contain forward-looking
Experiences Running and Optimizing the Berkeley Data Analytics Stack on Cray Platforms
 Experiences Running and Optimizing the Berkeley Data Analytics Stack on Cray Platforms Kristyn J. Maschhoff and Michael F. Ringenburg Cray Inc. CUG 2015 Copyright 2015 Cray Inc Legal Disclaimer Information
Experiences Running and Optimizing the Berkeley Data Analytics Stack on Cray Platforms Kristyn J. Maschhoff and Michael F. Ringenburg Cray Inc. CUG 2015 Copyright 2015 Cray Inc Legal Disclaimer Information
Heidi Poxon Cray Inc.
 Heidi Poxon Topics GPU support in the Cray performance tools CUDA proxy MPI support for GPUs (GPU-to-GPU) 2 3 Programming Models Supported for the GPU Goal is to provide whole program analysis for programs
Heidi Poxon Topics GPU support in the Cray performance tools CUDA proxy MPI support for GPUs (GPU-to-GPU) 2 3 Programming Models Supported for the GPU Goal is to provide whole program analysis for programs
Vectorization of Chapel Code Elliot Ronaghan, Cray Inc. June 13, 2015
 Vectorization of Chapel Code Elliot Ronaghan, Cray Inc. CHIUW @PLDI June 13, 2015 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations.
Vectorization of Chapel Code Elliot Ronaghan, Cray Inc. CHIUW @PLDI June 13, 2015 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations.
Chapel Hierarchical Locales
 Chapel Hierarchical Locales Greg Titus, Chapel Team, Cray Inc. SC14 Emerging Technologies November 18 th, 2014 Safe Harbor Statement This presentation may contain forward-looking statements that are based
Chapel Hierarchical Locales Greg Titus, Chapel Team, Cray Inc. SC14 Emerging Technologies November 18 th, 2014 Safe Harbor Statement This presentation may contain forward-looking statements that are based
Addressing Performance and Programmability Challenges in Current and Future Supercomputers
 Addressing Performance and Programmability Challenges in Current and Future Supercomputers Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. VI-HPS - SC'13 Luiz DeRose 2013
Addressing Performance and Programmability Challenges in Current and Future Supercomputers Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. VI-HPS - SC'13 Luiz DeRose 2013
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
ARCHER Single Node Optimisation
 ARCHER Single Node Optimisation Profiling Slides contributed by Cray and EPCC What is profiling? Analysing your code to find out the proportion of execution time spent in different routines. Essential
ARCHER Single Node Optimisation Profiling Slides contributed by Cray and EPCC What is profiling? Analysing your code to find out the proportion of execution time spent in different routines. Essential
XC Series Shifter User Guide (CLE 6.0.UP02) S-2571
 S-2571") XC Series Shifter User Guide (CLE 6.0.UP02) S-2571 Contents Contents 1 About the XC Series Shifter User Guide...3 2 Shifter System Introduction...6 3 Download and Convert the Docker Image...7 4 Submit
XC Series Shifter User Guide (CLE 6.0.UP02) S-2571 Contents Contents 1 About the XC Series Shifter User Guide...3 2 Shifter System Introduction...6 3 Download and Convert the Docker Image...7 4 Submit
IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor
 IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor D.Sc. Mikko Byckling 17th Workshop on High Performance Computing in Meteorology October 24 th 2016, Reading, UK Legal Disclaimer & Optimization
IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor D.Sc. Mikko Byckling 17th Workshop on High Performance Computing in Meteorology October 24 th 2016, Reading, UK Legal Disclaimer & Optimization
Using CrayPAT and Apprentice2: A Stepby-step
 Using CrayPAT and Apprentice2: A Stepby-step guide Cray Inc. (2014) Abstract This tutorial introduces Cray XC30 users to the Cray Performance Analysis Tool and its Graphical User Interface, Apprentice2.
Using CrayPAT and Apprentice2: A Stepby-step guide Cray Inc. (2014) Abstract This tutorial introduces Cray XC30 users to the Cray Performance Analysis Tool and its Graphical User Interface, Apprentice2.
Productive Programming in Chapel:
 Productive Programming in Chapel: A Computation-Driven Introduction Base Language with n-body Michael Ferguson and Lydia Duncan Cray Inc, SC15 November 15th, 2015 C O M P U T E S T O R E A N A L Y Z E
Productive Programming in Chapel: A Computation-Driven Introduction Base Language with n-body Michael Ferguson and Lydia Duncan Cray Inc, SC15 November 15th, 2015 C O M P U T E S T O R E A N A L Y Z E
ISTeC Cray High-Performance Computing System. Richard Casey, PhD RMRCE CSU Center for Bioinformatics
 ISTeC Cray High-Performance Computing System Richard Casey, PhD RMRCE CSU Center for Bioinformatics Compute Node Status Check whether interactive and batch compute nodes are up or down: xtprocadmin NID
ISTeC Cray High-Performance Computing System Richard Casey, PhD RMRCE CSU Center for Bioinformatics Compute Node Status Check whether interactive and batch compute nodes are up or down: xtprocadmin NID
Munara Tolubaeva Technical Consulting Engineer. 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries.
 Munara Tolubaeva Technical Consulting Engineer 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries. notices and disclaimers Intel technologies features and benefits depend
Munara Tolubaeva Technical Consulting Engineer 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries. notices and disclaimers Intel technologies features and benefits depend
The Cray Programming Environment. An Introduction
 The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
Performance Measurement and Analysis Tools Installation Guide S
 Performance Measurement and Analysis Tools Installation Guide S-2474-63 Contents About Cray Performance Measurement and Analysis Tools...3 Install Performance Measurement and Analysis Tools on Cray Systems...4
Performance Measurement and Analysis Tools Installation Guide S-2474-63 Contents About Cray Performance Measurement and Analysis Tools...3 Install Performance Measurement and Analysis Tools on Cray Systems...4
Performance Analysis of Parallel Scientific Applications In Eclipse
 Performance Analysis of Parallel Scientific Applications In Eclipse EclipseCon 2015 Wyatt Spear, University of Oregon wspear@cs.uoregon.edu Supercomputing Big systems solving big problems Performance gains
Performance Analysis of Parallel Scientific Applications In Eclipse EclipseCon 2015 Wyatt Spear, University of Oregon wspear@cs.uoregon.edu Supercomputing Big systems solving big problems Performance gains
Steps to create a hybrid code
 Steps to create a hybrid code Alistair Hart Cray Exascale Research Initiative Europe 29-30.Aug.12 PRACE training course, Edinburgh 1 Contents This lecture is all about finding as much parallelism as you
Steps to create a hybrid code Alistair Hart Cray Exascale Research Initiative Europe 29-30.Aug.12 PRACE training course, Edinburgh 1 Contents This lecture is all about finding as much parallelism as you
Agenda. Optimization Notice Copyright 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
 Agenda VTune Amplifier XE OpenMP* Analysis: answering on customers questions about performance in the same language a program was written in Concepts, metrics and technology inside VTune Amplifier XE OpenMP
Agenda VTune Amplifier XE OpenMP* Analysis: answering on customers questions about performance in the same language a program was written in Concepts, metrics and technology inside VTune Amplifier XE OpenMP
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Bei Wang, Dmitry Prohorov and Carlos Rosales
 Bei Wang, Dmitry Prohorov and Carlos Rosales Aspects of Application Performance What are the Aspects of Performance Intel Hardware Features Omni-Path Architecture MCDRAM 3D XPoint Many-core Xeon Phi AVX-512
Bei Wang, Dmitry Prohorov and Carlos Rosales Aspects of Application Performance What are the Aspects of Performance Intel Hardware Features Omni-Path Architecture MCDRAM 3D XPoint Many-core Xeon Phi AVX-512
Compiling applications for the Cray XC
 Compiling applications for the Cray XC Compiler Driver Wrappers (1) All applications that will run in parallel on the Cray XC should be compiled with the standard language wrappers. The compiler drivers
Compiling applications for the Cray XC Compiler Driver Wrappers (1) All applications that will run in parallel on the Cray XC should be compiled with the standard language wrappers. The compiler drivers
OP2 FOR MANY-CORE ARCHITECTURES
 OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
Intel VTune Amplifier XE
 Intel VTune Amplifier XE Vladimir Tsymbal Performance, Analysis and Threading Lab 1 Agenda Intel VTune Amplifier XE Overview Features Data collectors Analysis types Key Concepts Collecting performance
Intel VTune Amplifier XE Vladimir Tsymbal Performance, Analysis and Threading Lab 1 Agenda Intel VTune Amplifier XE Overview Features Data collectors Analysis types Key Concepts Collecting performance
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools
 Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Portable and Productive Performance with OpenACC Compilers and Tools. Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Porting and Optimisation of UM on ARCHER. Karthee Sivalingam, NCAS-CMS. HPC Workshop ECMWF JWCRP
 Porting and Optimisation of UM on ARCHER Karthee Sivalingam, NCAS-CMS HPC Workshop ECMWF JWCRP Acknowledgements! NCAS-CMS Bryan Lawrence Jeffrey Cole Rosalyn Hatcher Andrew Heaps David Hassell Grenville
Porting and Optimisation of UM on ARCHER Karthee Sivalingam, NCAS-CMS HPC Workshop ECMWF JWCRP Acknowledgements! NCAS-CMS Bryan Lawrence Jeffrey Cole Rosalyn Hatcher Andrew Heaps David Hassell Grenville
IXPUG 16. Dmitry Durnov, Intel MPI team
 IXPUG 16 Dmitry Durnov, Intel MPI team Agenda - Intel MPI 2017 Beta U1 product availability - New features overview - Competitive results - Useful links - Q/A 2 Intel MPI 2017 Beta U1 is available! Key
IXPUG 16 Dmitry Durnov, Intel MPI team Agenda - Intel MPI 2017 Beta U1 product availability - New features overview - Competitive results - Useful links - Q/A 2 Intel MPI 2017 Beta U1 is available! Key
Performance Optimizations Chapel Team, Cray Inc. Chapel version 1.14 October 6, 2016
 Performance Optimizations Chapel Team, Cray Inc. Chapel version 1.14 October 6, 2016 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations.
Performance Optimizations Chapel Team, Cray Inc. Chapel version 1.14 October 6, 2016 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations.
Toward Automated Application Profiling on Cray Systems
 Toward Automated Application Profiling on Cray Systems Charlene Yang, Brian Friesen, Thorsten Kurth, Brandon Cook NERSC at LBNL Samuel Williams CRD at LBNL I have a dream.. M.L.K. Collect performance data:
Toward Automated Application Profiling on Cray Systems Charlene Yang, Brian Friesen, Thorsten Kurth, Brandon Cook NERSC at LBNL Samuel Williams CRD at LBNL I have a dream.. M.L.K. Collect performance data:
Advanced Job Launching. mapping applications to hardware
 Advanced Job Launching mapping applications to hardware A Quick Recap - Glossary of terms Hardware This terminology is used to cover hardware from multiple vendors Socket The hardware you can touch and
Advanced Job Launching mapping applications to hardware A Quick Recap - Glossary of terms Hardware This terminology is used to cover hardware from multiple vendors Socket The hardware you can touch and
User Training Cray XC40 IITM, Pune
 User Training Cray XC40 IITM, Pune Sudhakar Yerneni, Raviteja K, Nachiket Manapragada, etc. 1 Cray XC40 Architecture & Packaging 3 Cray XC Series Building Blocks XC40 System Compute Blade 4 Compute Nodes
User Training Cray XC40 IITM, Pune Sudhakar Yerneni, Raviteja K, Nachiket Manapragada, etc. 1 Cray XC40 Architecture & Packaging 3 Cray XC Series Building Blocks XC40 System Compute Blade 4 Compute Nodes
Intel VTune Amplifier XE for Tuning of HPC Applications Intel Software Developer Conference Frankfurt, 2017 Klaus-Dieter Oertel, Intel
 Intel VTune Amplifier XE for Tuning of HPC Applications Intel Software Developer Conference Frankfurt, 2017 Klaus-Dieter Oertel, Intel Agenda Which performance analysis tool should I use first? Intel Application
Intel VTune Amplifier XE for Tuning of HPC Applications Intel Software Developer Conference Frankfurt, 2017 Klaus-Dieter Oertel, Intel Agenda Which performance analysis tool should I use first? Intel Application
Tutorial: Finding Hotspots with Intel VTune Amplifier - Linux* Intel VTune Amplifier Legal Information
 Tutorial: Finding Hotspots with Intel VTune Amplifier - Linux* Intel VTune Amplifier Legal Information Tutorial: Finding Hotspots with Intel VTune Amplifier - Linux* Contents Legal Information... 3 Chapter
Tutorial: Finding Hotspots with Intel VTune Amplifier - Linux* Intel VTune Amplifier Legal Information Tutorial: Finding Hotspots with Intel VTune Amplifier - Linux* Contents Legal Information... 3 Chapter
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA
 EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
Chapel: Productive Parallel Programming from the Pacific Northwest
 Chapel: Productive Parallel Programming from the Pacific Northwest Brad Chamberlain, Cray Inc. / UW CS&E Pacific Northwest Prog. Languages and Software Eng. Meeting March 15 th, 2016 Safe Harbor Statement
Chapel: Productive Parallel Programming from the Pacific Northwest Brad Chamberlain, Cray Inc. / UW CS&E Pacific Northwest Prog. Languages and Software Eng. Meeting March 15 th, 2016 Safe Harbor Statement
Performance Profiler. Klaus-Dieter Oertel Intel-SSG-DPD IT4I HPC Workshop, Ostrava,
 Performance Profiler Klaus-Dieter Oertel Intel-SSG-DPD IT4I HPC Workshop, Ostrava, 08-09-2016 Faster, Scalable Code, Faster Intel VTune Amplifier Performance Profiler Get Faster Code Faster With Accurate
Performance Profiler Klaus-Dieter Oertel Intel-SSG-DPD IT4I HPC Workshop, Ostrava, 08-09-2016 Faster, Scalable Code, Faster Intel VTune Amplifier Performance Profiler Get Faster Code Faster With Accurate
NERSC Site Update. National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory. Richard Gerber
 NERSC Site Update National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory Richard Gerber NERSC Senior Science Advisor High Performance Computing Department Head Cori
NERSC Site Update National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory Richard Gerber NERSC Senior Science Advisor High Performance Computing Department Head Cori
Running Docker* Containers on Intel Xeon Phi Processors
 Running Docker* Containers on Intel Xeon Phi Processors White Paper March 2017 Revision 001 Document Number: 335644-001US Notice: This document contains information on products in the design phase of development.
Running Docker* Containers on Intel Xeon Phi Processors White Paper March 2017 Revision 001 Document Number: 335644-001US Notice: This document contains information on products in the design phase of development.
Using Intel VTune Amplifier XE and Inspector XE in.net environment
 Using Intel VTune Amplifier XE and Inspector XE in.net environment Levent Akyil Technical Computing, Analyzers and Runtime Software and Services group 1 Refresher - Intel VTune Amplifier XE Intel Inspector
Using Intel VTune Amplifier XE and Inspector XE in.net environment Levent Akyil Technical Computing, Analyzers and Runtime Software and Services group 1 Refresher - Intel VTune Amplifier XE Intel Inspector
Intel Xeon Phi Coprocessor Performance Analysis
 Intel Xeon Phi Coprocessor Performance Analysis Legal Disclaimer INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO
Intel Xeon Phi Coprocessor Performance Analysis Legal Disclaimer INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO
Performance and Energy Usage of Workloads on KNL and Haswell Architectures
 Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
The Cray Programming Environment. An Introduction
 The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
Outline. Motivation Parallel k-means Clustering Intel Computing Architectures Baseline Performance Performance Optimizations Future Trends
 Collaborators: Richard T. Mills, Argonne National Laboratory Sarat Sreepathi, Oak Ridge National Laboratory Forrest M. Hoffman, Oak Ridge National Laboratory Jitendra Kumar, Oak Ridge National Laboratory
Collaborators: Richard T. Mills, Argonne National Laboratory Sarat Sreepathi, Oak Ridge National Laboratory Forrest M. Hoffman, Oak Ridge National Laboratory Jitendra Kumar, Oak Ridge National Laboratory
Intel VTune Amplifier XE. Dr. Michael Klemm Software and Services Group Developer Relations Division
 Intel VTune Amplifier XE Dr. Michael Klemm Software and Services Group Developer Relations Division Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS
Intel VTune Amplifier XE Dr. Michael Klemm Software and Services Group Developer Relations Division Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS
Cray Programming Environment User's Guide S
 R Cray Programming Environment User's Guide S 2529 116 2004 2014 Cray Inc. All Rights Reserved. This document or parts thereof may not be reproduced in any form unless permitted by contract or by written
R Cray Programming Environment User's Guide S 2529 116 2004 2014 Cray Inc. All Rights Reserved. This document or parts thereof may not be reproduced in any form unless permitted by contract or by written
Performance Evaluation of NWChem Ab-Initio Molecular Dynamics (AIMD) Simulations on the Intel Xeon Phi Processor
 Simulations on the Intel Xeon Phi Processor") * Some names and brands may be claimed as the property of others. Performance Evaluation of NWChem Ab-Initio Molecular Dynamics (AIMD) Simulations on the Intel Xeon Phi Processor E.J. Bylaska 1, M. Jacquelin
* Some names and brands may be claimed as the property of others. Performance Evaluation of NWChem Ab-Initio Molecular Dynamics (AIMD) Simulations on the Intel Xeon Phi Processor E.J. Bylaska 1, M. Jacquelin
Performance of Variant Memory Configurations for Cray XT Systems
 Performance of Variant Memory Configurations for Cray XT Systems Wayne Joubert, Oak Ridge National Laboratory ABSTRACT: In late 29 NICS will upgrade its 832 socket Cray XT from Barcelona (4 cores/socket)
Performance of Variant Memory Configurations for Cray XT Systems Wayne Joubert, Oak Ridge National Laboratory ABSTRACT: In late 29 NICS will upgrade its 832 socket Cray XT from Barcelona (4 cores/socket)
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Intel Xeon Processor E7 v2 Family-Based Platforms
 Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Intel Xeon Phi Coprocessor. Technical Resources. Intel Xeon Phi Coprocessor Workshop Pawsey Centre & CSIRO, Aug Intel Xeon Phi Coprocessor
 Technical Resources Legal Disclaimer INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPETY RIGHTS
Technical Resources Legal Disclaimer INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPETY RIGHTS
Graphics Performance Analyzer for Android
 Graphics Performance Analyzer for Android 1 What you will learn from this slide deck Detailed optimization workflow of Graphics Performance Analyzer Android* System Analysis Only Please see subsequent
Graphics Performance Analyzer for Android 1 What you will learn from this slide deck Detailed optimization workflow of Graphics Performance Analyzer Android* System Analysis Only Please see subsequent
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit
 Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
KNL tools. Dr. Fabio Baruffa
 KNL tools Dr. Fabio Baruffa fabio.baruffa@lrz.de 2 Which tool do I use? A roadmap to optimization We will focus on tools developed by Intel, available to users of the LRZ systems. Again, we will skip the
KNL tools Dr. Fabio Baruffa fabio.baruffa@lrz.de 2 Which tool do I use? A roadmap to optimization We will focus on tools developed by Intel, available to users of the LRZ systems. Again, we will skip the
Scalasca support for Intel Xeon Phi. Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany
 Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Cray Operating System Plans and Status. Charlie Carroll May 2012
 Cray Operating System Plans and Status Charlie Carroll May 2012 Cray Operating Systems and I/O Compute Node Linux NVIDIA GPU driver Compute node Service node OS File systems: Lustre Networking HSN: Gemini
Cray Operating System Plans and Status Charlie Carroll May 2012 Cray Operating Systems and I/O Compute Node Linux NVIDIA GPU driver Compute node Service node OS File systems: Lustre Networking HSN: Gemini
Analyzing I/O Performance on a NEXTGenIO Class System
 Analyzing I/O Performance on a NEXTGenIO Class System holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden LUG17, Indiana University, June 2 nd 2017 NEXTGenIO Fact Sheet Project Research & Innovation
Analyzing I/O Performance on a NEXTGenIO Class System holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden LUG17, Indiana University, June 2 nd 2017 NEXTGenIO Fact Sheet Project Research & Innovation
Performance analysis tools: Intel VTuneTM Amplifier and Advisor. Dr. Luigi Iapichino
 Performance analysis tools: Intel VTuneTM Amplifier and Advisor Dr. Luigi Iapichino luigi.iapichino@lrz.de Which tool do I use in my project? A roadmap to optimisation After having considered the MPI layer,
Performance analysis tools: Intel VTuneTM Amplifier and Advisor Dr. Luigi Iapichino luigi.iapichino@lrz.de Which tool do I use in my project? A roadmap to optimisation After having considered the MPI layer,
Standard Library and Interoperability Improvements Chapel Team, Cray Inc. Chapel version 1.11 April 2, 2015
 Standard Library and Interoperability Improvements Chapel Team, Cray Inc. Chapel version 1.11 April 2, 2015 Safe Harbor Statement This presentation may contain forward-looking statements that are based
Standard Library and Interoperability Improvements Chapel Team, Cray Inc. Chapel version 1.11 April 2, 2015 Safe Harbor Statement This presentation may contain forward-looking statements that are based
Eliminate Threading Errors to Improve Program Stability
 Introduction This guide will illustrate how the thread checking capabilities in Intel Parallel Studio XE can be used to find crucial threading defects early in the development cycle. It provides detailed
Introduction This guide will illustrate how the thread checking capabilities in Intel Parallel Studio XE can be used to find crucial threading defects early in the development cycle. It provides detailed
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
Accelerating HPC. (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing
 Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing") Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Mobility: Innovation Unleashed!
 Mobility: Innovation Unleashed! Mooly Eden Corporate Vice President General Manager, Mobile Platforms Group Intel Corporation Legal Notices INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL
Mobility: Innovation Unleashed! Mooly Eden Corporate Vice President General Manager, Mobile Platforms Group Intel Corporation Legal Notices INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL
MPI Performance Snapshot
 User's Guide 2014-2015 Intel Corporation Legal Information No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. Intel disclaims all
User's Guide 2014-2015 Intel Corporation Legal Information No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. Intel disclaims all