PlaFRIM. Technical presentation of the platform
|
|
|
- Brianne Wheeler
- 5 years ago
- Views:
Transcription
1 PlaFRIM Technical presentation of the platform 1-11/12/2018
2 Contents 2-11/12/ Overview Nodes description Networks Storage Evolutions How to acces PlaFRIM? Need Help?
3 mardi 11 décembre 2018 Overview
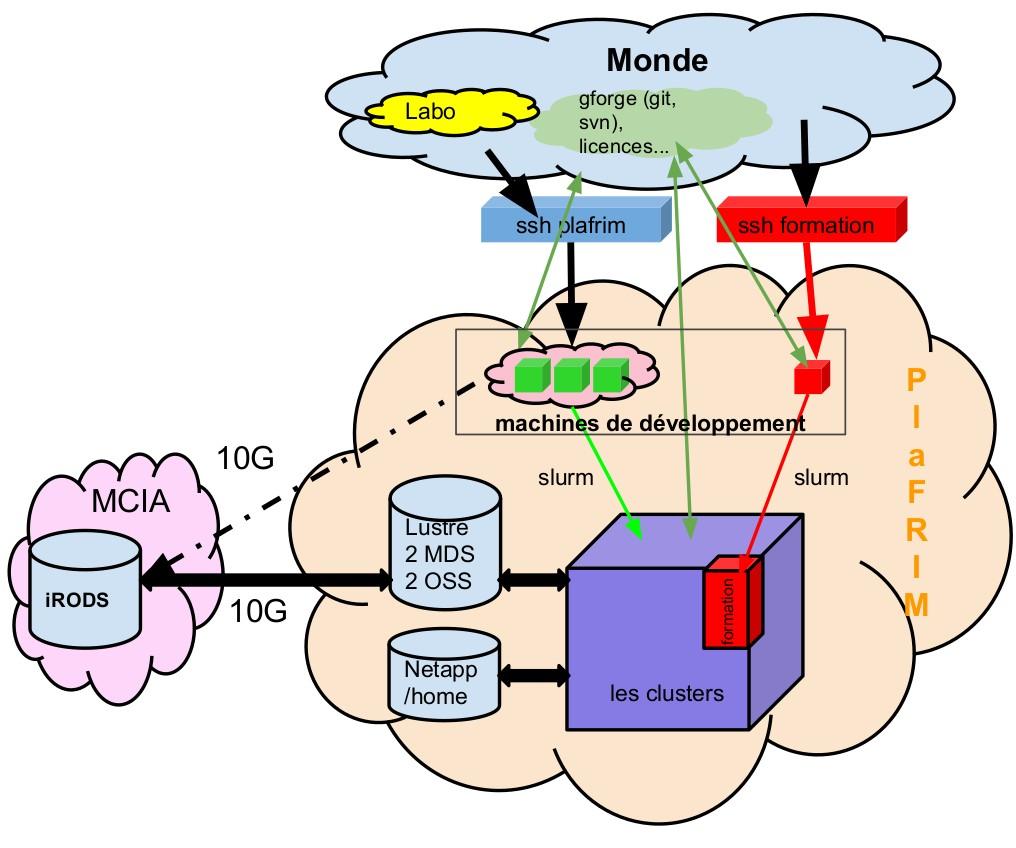
4 Overview 4-11/12/2018
5 Overview 2 platforms (1 research and 1 formation) More than 100 nodes and 3000 cores More than 35 GPUs accelerators More than 350 users Heterogeneous cluster Nodes for modelization (equivalent nodes of mesocentres or computer center of GENCI) Miriel Cluster (88 nodes) Souris node (1 SGI UV cores and 3TB memory) Nodes for experimentation (more innovative nodes) Mistral cluster (18 nodes with 2 x Xeon Phi accelerator) Sirocco cluster (13 nodes with Nvidia GPU accelerator) Kona cluster (4 nodes with KNL) Brise node (1 node with 96 cores and 1TB memory) 5-11/12/2018
6 Overview The hidden side a security audit has been carried out from which certain security rules have been applied (access with SSH key pair, isolated network between formation and research cluster, internet filtering,...) 1 master node which provides : Name resolution (DNS), IP attribution (DHCP), SLURM server, Server TFTP, deployement node tool (Bright Cluster Manager), internet gateway, and more... 2 hypervisors (ovirt nodes) to provide infrastructure virtual servers : 2 LDAP in master/master mode and 1 LDAP for the formation cluster to 2 server GUIX (formation and research clusters) 1 supervision based on zabbix 1 HIDS (intrusion detection system) 1 NFS for the formation cluster Bastion SSH (ssh.plafrim.fr, formation.plafrim.fr, ) And more /12/2018
7 Overview The hidden side Storage : Luster Parallel File System : 2 MDS servers (in manual failover mode with only 1 MDT ) 2 OSS servers (in manual failover mode with 2 OST mounted on each) 2 NetApp which serves NFS for /home, /projets and modules. 1 located at Inria and 1 at IMB Network : Compute network : 4 switchs 10Gbit/s Ethernet Management network : 5 switchs 1Gbit/s Ethernet Omnipath Network : 4 switchs 100Gbit/s Infiniband : 7 switchs 40Gbit/s 7-11/12/2018
8 02 Nodes description /12/2018
![Nodes description miriel[001-088] : 88 standards computational nodes 2 x 12 cores Haswell Intel Xeon E5-2680 v3 @ 2,5 GHz 128GB RAM (2133](/docs-images/92/109151427/images/9-0.jpg "MHz) Infiniband QDR TrueScale: 40Gbit/s for miriel[001-088] Omnipath 100Gbit/s for miriel[001-043] Ethernet : 10Gbit/s /tmp : ~300GB")
9 Nodes description miriel[ ] : 88 standards computational nodes 2 x 12 cores Haswell Intel Xeon E ,5 GHz 128GB RAM (2133 MHz) Infiniband QDR TrueScale: 40Gbit/s for miriel[ ] Omnipath 100Gbit/s for miriel[ ] Ethernet : 10Gbit/s /tmp : ~300GB 9-11/12/2018

10 Nodes description brise : 96 cores node 4 x 24 cores Broadwell Intel(R) Xeon(R) CPU E GHz 1TB RAM (1600 MHz) Ethernet : 10Gbit/s /tmp : ~400GB 1-11/12/2018 0
 CPU E5-4620 v2 @ 2.")
11 Nodes description souris : 96 cores node 12 x 8(16HT) cores Ivy Bridge Intel(R) Xeon(R) CPU E GHz 3TB RAM (1333 MHz) Ethernet : 10Gbit/s 1-11/12/2018 1
12 Nodes description kona[01-04] : 4 KNL nodes 1 x 64 cores Knights Landing Intel(R) Xeon Phi(TM) CPU 1.30GHz 96GB RAM (2400 MHz) + 16 Go MCDRAM (7200 MHz) OmniPath : 100Gbit/s Ethernet : 1Gbit/s /tmp : ~600GB 1-11/12/ Node Memory mode Cluster mode kona01 flat quadrant kona02 cache quadrant kona03 flat snc-4 kona04 cache snc-4
13 Nodes description sirocco[01-13] : Nvidia GPU accelerator nodes Node CPU sirocco[01-05] 2 x 12 cores Haswell Intel(R) Xeon(R) CPU E GHz sirocco06 2 x 10 cores Ivy Bridge Intel(R) Xeon(R) CPU E GHz sirocco[07-13] 2 x 16 cores Broadwell Intel(R) Xeon(R) CPU E GHz 1-11/12/ Memory GPU Network 4x Nvidia Tesla K40m Infiniband QDR Mellanox 10Gbit/s Ethernet 128GB RAM (1866 MHz) 2x Nvidia Tesla K40m Infiniband QDR Mellanox 10Gbit/s Ethernet 256 GB RAM (2133 MHz) 2x Nvidia Tesla P100 Omnipath 10Gbit/s Ethernet 128GB RAM (2133 MHz)
14 Nodes description visu01 : visualization node 2 x 10 cores Haswell Intel(R) Xeon(R) CPU E GHz 128GB RAM (2133 MHz) 2 x Nvidia Quadro K4000 Ethernet : 1OGbit/s /tmp : ~1,8TB /12/2018 4
15 /12/ Networks
16 Networks Multiples networks Omnipath 100Gbit/s network Infiniband QDR 40Gbit/s network : Qlogic and Mellanox Ethernet 10Gbit/s network 1-11/12/2018 6

17 Networks Omnipath Network 1-11/12/2018 7
18 Networks Infiniband Network 1-11/12/2018 8
19 04 Storage /12/2018 9
20 Storage Storage available Name Max size Deletion /home 20GB / user never ON /projets 200GB / user never /lustre 1TB / user files / user /tmp Variable 2-11/12/ Hardware Backup Protection Use How to obtain ON individual automatic ON ON group On demand If needed ON OFF individual automatic At reboot and if needed OFF OFF individual automatic
21 /12/ Evolutions
22 Evolutions Before the end of 2018 : 1 ARM node with 2 x 28 cores Cavium ThunderX2(R) CPU CN GHz and 256GB memory. 4 nodes with 2 x 16 cores Skylake Intel Xeon Gold ,6 GHz, 2x Nvidia V100 GPU and NVMe and 384GB memory 1 nodes with 2 x 20 cores Skylake Intel Xeon Gold ,4 GHz, 2x Nvidia V100 GPU and 1TB memory Second half of 2019 : Renewal of computational nodes cluster 2-11/12/2018 2
23 06 How to access PlaFRIM? /12/2018 3

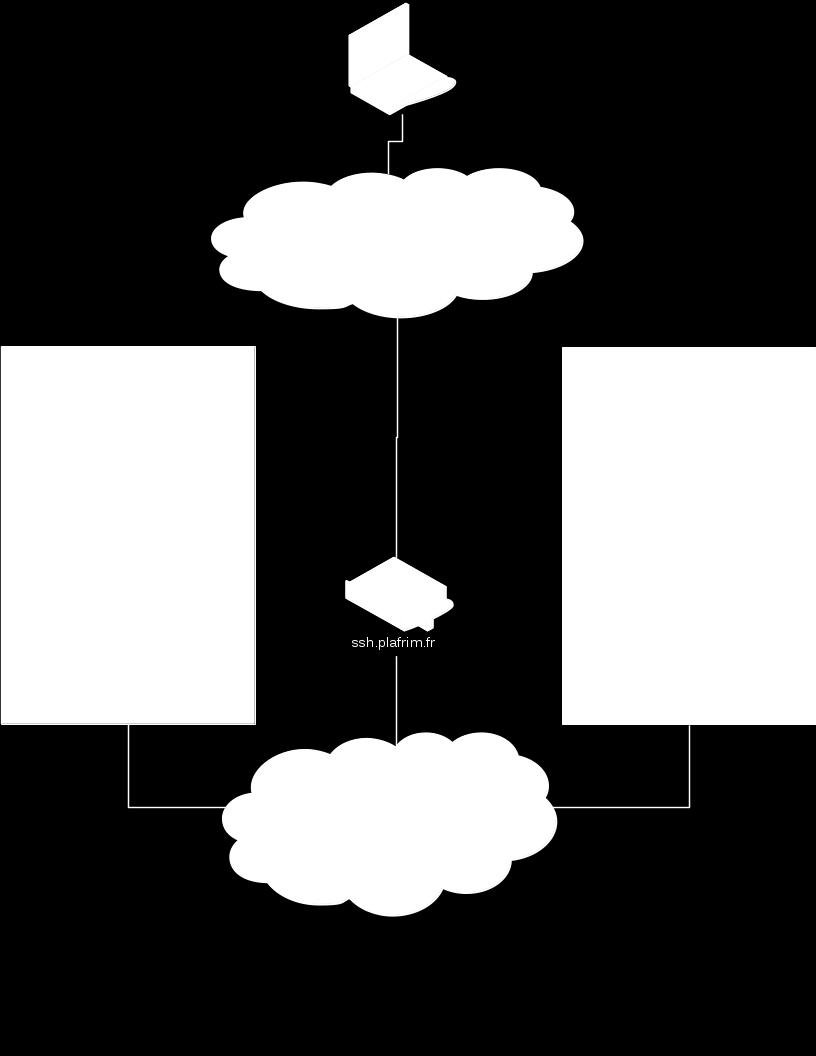
24 How to access PlaFRIM? 2-11/12/2018 4
25 How to access PlaFRIM? 1. if you don t have one yet, create your ssh key pair with ssh-keygen 2. ask your account on : 3. Your ssh client must use a "ProxyCommand" to reach the target server Sample configuration of.ssh/config to reach plafrim on port 22 : (replace LOGIN_PLAFRIM with your actual login) Host plafrim User LOGIN_PLAFRIM ForwardAgent yes ForwardX11 yes ProxyCommand ssh -A -l LOGIN_PLAFRIM ssh.plafrim.fr -W plafrim:22 Check that your private key is loaded with ssh-add -l. If not, load it with ssh-add ~/.ssh/ private_key Then use ssh LOGIN_PLAFRIM@plafrim 2 - Dec
26 /12/ Need Help?
27 Need Help? If you need Help 1. The FAQ : 2. PlaFRIM support : plafrim-support@inria.fr For technical problems (access, account, administration, modules ) 3. Users community : plafrim-users@inria.fr If you need help about more specific use or want to share with others users platform : contact plafrim-users@inria.fr or view archives here /12/2018 7


28 Need Help? Some tools Performance monitoring : Jobs monitoring : /12/2018 8
29 Need Help? Some tools GUIX to easy install your packages ( the last presentation of the day by L. Courtès) Modules to modify your environment and load/unload programs ( next presentation by F. Rué) SLURM to submit jobs on the cluster ( next presentation by F. Rué) 2-11/12/2018 9
30 11/12/ Thank you! Follow us on -
LBRN - HPC systems : CCT, LSU
 LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
HPC Innovation Lab Update. Dell EMC HPC Community Meeting 3/28/2017
 HPC Innovation Lab Update Dell EMC HPC Community Meeting 3/28/2017 Dell EMC HPC Innovation Lab charter Design, develop and integrate Heading HPC systems Lorem ipsum Flexible reference dolor sit amet, architectures
HPC Innovation Lab Update Dell EMC HPC Community Meeting 3/28/2017 Dell EMC HPC Innovation Lab charter Design, develop and integrate Heading HPC systems Lorem ipsum Flexible reference dolor sit amet, architectures
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0)
") PRACE 16th Call Technical Guidelines for Applicants V1: published on 26/09/17 TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0) The contributing sites and the corresponding computer systems
PRACE 16th Call Technical Guidelines for Applicants V1: published on 26/09/17 TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0) The contributing sites and the corresponding computer systems
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
PRACE Project Access Technical Guidelines - 19 th Call for Proposals
 PRACE Project Access Technical Guidelines - 19 th Call for Proposals Peer-Review Office Version 5 06/03/2019 The contributing sites and the corresponding computer systems for this call are: System Architecture
PRACE Project Access Technical Guidelines - 19 th Call for Proposals Peer-Review Office Version 5 06/03/2019 The contributing sites and the corresponding computer systems for this call are: System Architecture
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 14 th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 14 th CALL (T ier0) Contributing sites and the corresponding computer systems for this call are: GENCI CEA, France Bull Bullx cluster GCS HLRS, Germany Cray
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 14 th CALL (T ier0) Contributing sites and the corresponding computer systems for this call are: GENCI CEA, France Bull Bullx cluster GCS HLRS, Germany Cray
HPC-CINECA infrastructure: The New Marconi System. HPC methods for Computational Fluid Dynamics and Astrophysics Giorgio Amati,
 HPC-CINECA infrastructure: The New Marconi System HPC methods for Computational Fluid Dynamics and Astrophysics Giorgio Amati, g.amati@cineca.it Agenda 1. New Marconi system Roadmap Some performance info
HPC-CINECA infrastructure: The New Marconi System HPC methods for Computational Fluid Dynamics and Astrophysics Giorgio Amati, g.amati@cineca.it Agenda 1. New Marconi system Roadmap Some performance info
HPC and AI Solution Overview. Garima Kochhar HPC and AI Innovation Lab
 HPC and AI Solution Overview Garima Kochhar HPC and AI Innovation Lab 1 Dell EMC HPC and DL team charter Design, develop and integrate HPC and DL Heading systems Lorem ipsum dolor sit amet, consectetur
HPC and AI Solution Overview Garima Kochhar HPC and AI Innovation Lab 1 Dell EMC HPC and DL team charter Design, develop and integrate HPC and DL Heading systems Lorem ipsum dolor sit amet, consectetur
HMEM and Lemaitre2: First bricks of the CÉCI s infrastructure
 HMEM and Lemaitre2: First bricks of the CÉCI s infrastructure - CÉCI: What we want - Cluster HMEM - Cluster Lemaitre2 - Comparison - What next? - Support and training - Conclusions CÉCI: What we want CÉCI:
HMEM and Lemaitre2: First bricks of the CÉCI s infrastructure - CÉCI: What we want - Cluster HMEM - Cluster Lemaitre2 - Comparison - What next? - Support and training - Conclusions CÉCI: What we want CÉCI:
Lustre HSM at Cambridge. Early user experience using Intel Lemur HSM agent
 Lustre HSM at Cambridge Early user experience using Intel Lemur HSM agent Matt Rásó-Barnett Wojciech Turek Research Computing Services @ Cambridge University-wide service with broad remit to provide research
Lustre HSM at Cambridge Early user experience using Intel Lemur HSM agent Matt Rásó-Barnett Wojciech Turek Research Computing Services @ Cambridge University-wide service with broad remit to provide research
HPC Cineca Infrastructure: State of the art and towards the exascale
 HPC Cineca Infrastructure: State of the art and towards the exascale HPC Methods for CFD and Astrophysics 13 Nov. 2017, Casalecchio di Reno, Bologna Ivan Spisso, i.spisso@cineca.it Contents CINECA in a
HPC Cineca Infrastructure: State of the art and towards the exascale HPC Methods for CFD and Astrophysics 13 Nov. 2017, Casalecchio di Reno, Bologna Ivan Spisso, i.spisso@cineca.it Contents CINECA in a
Feedback on BeeGFS. A Parallel File System for High Performance Computing
 Feedback on BeeGFS A Parallel File System for High Performance Computing Philippe Dos Santos et Georges Raseev FR 2764 Fédération de Recherche LUmière MATière December 13 2016 LOGO CNRS LOGO IO December
Feedback on BeeGFS A Parallel File System for High Performance Computing Philippe Dos Santos et Georges Raseev FR 2764 Fédération de Recherche LUmière MATière December 13 2016 LOGO CNRS LOGO IO December
Emerging Technologies for HPC Storage
 Emerging Technologies for HPC Storage Dr. Wolfgang Mertz CTO EMEA Unstructured Data Solutions June 2018 The very definition of HPC is expanding Blazing Fast Speed Accessibility and flexibility 2 Traditional
Emerging Technologies for HPC Storage Dr. Wolfgang Mertz CTO EMEA Unstructured Data Solutions June 2018 The very definition of HPC is expanding Blazing Fast Speed Accessibility and flexibility 2 Traditional
Outline. Motivation Parallel k-means Clustering Intel Computing Architectures Baseline Performance Performance Optimizations Future Trends
 Collaborators: Richard T. Mills, Argonne National Laboratory Sarat Sreepathi, Oak Ridge National Laboratory Forrest M. Hoffman, Oak Ridge National Laboratory Jitendra Kumar, Oak Ridge National Laboratory
Collaborators: Richard T. Mills, Argonne National Laboratory Sarat Sreepathi, Oak Ridge National Laboratory Forrest M. Hoffman, Oak Ridge National Laboratory Jitendra Kumar, Oak Ridge National Laboratory
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
JÜLICH SUPERCOMPUTING CENTRE Site Introduction Michael Stephan Forschungszentrum Jülich
 JÜLICH SUPERCOMPUTING CENTRE Site Introduction 09.04.2018 Michael Stephan JSC @ Forschungszentrum Jülich FORSCHUNGSZENTRUM JÜLICH Research Centre Jülich One of the 15 Helmholtz Research Centers in Germany
JÜLICH SUPERCOMPUTING CENTRE Site Introduction 09.04.2018 Michael Stephan JSC @ Forschungszentrum Jülich FORSCHUNGSZENTRUM JÜLICH Research Centre Jülich One of the 15 Helmholtz Research Centers in Germany
1. ALMA Pipeline Cluster specification. 2. Compute processing node specification: $26K
 1. ALMA Pipeline Cluster specification The following document describes the recommended hardware for the Chilean based cluster for the ALMA pipeline and local post processing to support early science and
1. ALMA Pipeline Cluster specification The following document describes the recommended hardware for the Chilean based cluster for the ALMA pipeline and local post processing to support early science and
Submitting and running jobs on PlaFRIM2 Redouane Bouchouirbat
 Submitting and running jobs on PlaFRIM2 Redouane Bouchouirbat Summary 1. Submitting Jobs: Batch mode - Interactive mode 2. Partition 3. Jobs: Serial, Parallel 4. Using generic resources Gres : GPUs, MICs.
Submitting and running jobs on PlaFRIM2 Redouane Bouchouirbat Summary 1. Submitting Jobs: Batch mode - Interactive mode 2. Partition 3. Jobs: Serial, Parallel 4. Using generic resources Gres : GPUs, MICs.
LS-DYNA Performance Benchmark and Profiling. October 2017
 LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments
 Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments Torben Kling-Petersen, PhD Presenter s Name Principle Field Title andengineer Division HPC &Cloud LoB SunComputing Microsystems
Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments Torben Kling-Petersen, PhD Presenter s Name Principle Field Title andengineer Division HPC &Cloud LoB SunComputing Microsystems
Umeå University
 HPC2N @ Umeå University Introduction to HPC2N and Kebnekaise Jerry Eriksson, Pedro Ojeda-May, and Birgitte Brydsö Outline Short presentation of HPC2N HPC at a glance. HPC2N Abisko, Kebnekaise HPC Programming
HPC2N @ Umeå University Introduction to HPC2N and Kebnekaise Jerry Eriksson, Pedro Ojeda-May, and Birgitte Brydsö Outline Short presentation of HPC2N HPC at a glance. HPC2N Abisko, Kebnekaise HPC Programming
Umeå University
 HPC2N: Introduction to HPC2N and Kebnekaise, 2017-09-12 HPC2N @ Umeå University Introduction to HPC2N and Kebnekaise Jerry Eriksson, Pedro Ojeda-May, and Birgitte Brydsö Outline Short presentation of HPC2N
HPC2N: Introduction to HPC2N and Kebnekaise, 2017-09-12 HPC2N @ Umeå University Introduction to HPC2N and Kebnekaise Jerry Eriksson, Pedro Ojeda-May, and Birgitte Brydsö Outline Short presentation of HPC2N
Frequently Asked Questions
 Frequently Asked Questions Fabien Archambault Aix-Marseille Université 2012 F. Archambault (AMU) Rheticus: F.A.Q. 2012 1 / 13 1 Rheticus configuration 2 Front-end connection 3 Modules 4 OAR submission
Frequently Asked Questions Fabien Archambault Aix-Marseille Université 2012 F. Archambault (AMU) Rheticus: F.A.Q. 2012 1 / 13 1 Rheticus configuration 2 Front-end connection 3 Modules 4 OAR submission
Before We Start. Sign in hpcxx account slips Windows Users: Download PuTTY. Google PuTTY First result Save putty.exe to Desktop
 Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
Comet Virtualization Code & Design Sprint
 Comet Virtualization Code & Design Sprint SDSC September 23-24 Rick Wagner San Diego Supercomputer Center Meeting Goals Build personal connections between the IU and SDSC members of the Comet team working
Comet Virtualization Code & Design Sprint SDSC September 23-24 Rick Wagner San Diego Supercomputer Center Meeting Goals Build personal connections between the IU and SDSC members of the Comet team working
HPC Hardware Overview
 HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
The rcuda middleware and applications
 The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
Multi-Rail LNet for Lustre
 Multi-Rail LNet for Lustre Rob Mollard September 2016 The SGI logos and SGI product names used or referenced herein are either registered trademarks or trademarks of Silicon Graphics International Corp.
Multi-Rail LNet for Lustre Rob Mollard September 2016 The SGI logos and SGI product names used or referenced herein are either registered trademarks or trademarks of Silicon Graphics International Corp.
Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science
 Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science ECSS Symposium, 12/16/14 M. L. Norman, R. L. Moore, D. Baxter, G. Fox (Indiana U), A Majumdar, P Papadopoulos, W Pfeiffer, R. S.
Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science ECSS Symposium, 12/16/14 M. L. Norman, R. L. Moore, D. Baxter, G. Fox (Indiana U), A Majumdar, P Papadopoulos, W Pfeiffer, R. S.
DATARMOR: Comment s'y préparer? Tina Odaka
 DATARMOR: Comment s'y préparer? Tina Odaka 30.09.2016 PLAN DATARMOR: Detailed explanation on hard ware What can you do today to be ready for DATARMOR DATARMOR : convention de nommage ClusterHPC REF SCRATCH
DATARMOR: Comment s'y préparer? Tina Odaka 30.09.2016 PLAN DATARMOR: Detailed explanation on hard ware What can you do today to be ready for DATARMOR DATARMOR : convention de nommage ClusterHPC REF SCRATCH
Demonstration Milestone for Parallel Directory Operations
 Demonstration Milestone for Parallel Directory Operations This milestone was submitted to the PAC for review on 2012-03-23. This document was signed off on 2012-04-06. Overview This document describes
Demonstration Milestone for Parallel Directory Operations This milestone was submitted to the PAC for review on 2012-03-23. This document was signed off on 2012-04-06. Overview This document describes
A performance comparison of Deep Learning frameworks on KNL
 A performance comparison of Deep Learning frameworks on KNL R. Zanella, G. Fiameni, M. Rorro Middleware, Data Management - SCAI - CINECA IXPUG Bologna, March 5, 2018 Table of Contents 1. Problem description
A performance comparison of Deep Learning frameworks on KNL R. Zanella, G. Fiameni, M. Rorro Middleware, Data Management - SCAI - CINECA IXPUG Bologna, March 5, 2018 Table of Contents 1. Problem description
GPU Computing with Fornax. Dr. Christopher Harris
 GPU Computing with Fornax Dr. Christopher Harris ivec@uwa CAASTRO GPU Training Workshop 8-9 October 2012 Introducing the Historical GPU Graphics Processing Unit (GPU) n : A specialised electronic circuit
GPU Computing with Fornax Dr. Christopher Harris ivec@uwa CAASTRO GPU Training Workshop 8-9 October 2012 Introducing the Historical GPU Graphics Processing Unit (GPU) n : A specialised electronic circuit
FUJITSU PHI Turnkey Solution
 FUJITSU PHI Turnkey Solution Integrated ready to use XEON-PHI based platform Dr. Pierre Lagier ISC2014 - Leipzig PHI Turnkey Solution challenges System performance challenges Parallel IO best architecture
FUJITSU PHI Turnkey Solution Integrated ready to use XEON-PHI based platform Dr. Pierre Lagier ISC2014 - Leipzig PHI Turnkey Solution challenges System performance challenges Parallel IO best architecture
Block Lanczos-Montgomery Method over Large Prime Fields with GPU Accelerated Dense Operations
 Block Lanczos-Montgomery Method over Large Prime Fields with GPU Accelerated Dense Operations D. Zheltkov, N. Zamarashkin INM RAS September 24, 2018 Scalability of Lanczos method Notations Matrix order
Block Lanczos-Montgomery Method over Large Prime Fields with GPU Accelerated Dense Operations D. Zheltkov, N. Zamarashkin INM RAS September 24, 2018 Scalability of Lanczos method Notations Matrix order
Extraordinary HPC file system solutions at KIT
 Extraordinary HPC file system solutions at KIT Roland Laifer STEINBUCH CENTRE FOR COMPUTING - SCC KIT University of the State Roland of Baden-Württemberg Laifer Lustre and tools for ldiskfs investigation
Extraordinary HPC file system solutions at KIT Roland Laifer STEINBUCH CENTRE FOR COMPUTING - SCC KIT University of the State Roland of Baden-Württemberg Laifer Lustre and tools for ldiskfs investigation
Habanero Operating Committee. January
 Habanero Operating Committee January 25 2017 Habanero Overview 1. Execute Nodes 2. Head Nodes 3. Storage 4. Network Execute Nodes Type Quantity Standard 176 High Memory 32 GPU* 14 Total 222 Execute Nodes
Habanero Operating Committee January 25 2017 Habanero Overview 1. Execute Nodes 2. Head Nodes 3. Storage 4. Network Execute Nodes Type Quantity Standard 176 High Memory 32 GPU* 14 Total 222 Execute Nodes
PowerServe HPC/AI Servers
 Product Data Sheet PowerServe HPC/AI Servers Realize the power of cutting-edge technology HPC, Machine Learning and AI enterprise servers hand crafted for maximum performance. With 25+ years experience
Product Data Sheet PowerServe HPC/AI Servers Realize the power of cutting-edge technology HPC, Machine Learning and AI enterprise servers hand crafted for maximum performance. With 25+ years experience
Übung zur Vorlesung Architektur paralleler Rechnersysteme
 Übung zur Vorlesung Architektur paralleler Rechnersysteme SoSe 17 L.079.05814 www.uni-paderborn.de/pc2 Architecture of Parallel Computer Systems SoSe 17 J.Simon 1 Overview Computer Systems Test Cluster
Übung zur Vorlesung Architektur paralleler Rechnersysteme SoSe 17 L.079.05814 www.uni-paderborn.de/pc2 Architecture of Parallel Computer Systems SoSe 17 J.Simon 1 Overview Computer Systems Test Cluster
Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance
 Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for Simulia
Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for Simulia
Genius Quick Start Guide
 Genius Quick Start Guide Overview of the system Genius consists of a total of 116 nodes with 2 Skylake Xeon Gold 6140 processors. Each with 18 cores, at least 192GB of memory and 800 GB of local SSD disk.
Genius Quick Start Guide Overview of the system Genius consists of a total of 116 nodes with 2 Skylake Xeon Gold 6140 processors. Each with 18 cores, at least 192GB of memory and 800 GB of local SSD disk.
PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE SHEET) Supply and installation of High Performance Computing System
 (TECHNICAL SPECIFICATIONS & COMPLIANCE SHEET) Supply and installation of High Performance Computing System") INSTITUTE FOR PLASMA RESEARCH (An Autonomous Institute of Department of Atomic Energy, Government of India) Near Indira Bridge; Bhat; Gandhinagar-382428; India PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE
INSTITUTE FOR PLASMA RESEARCH (An Autonomous Institute of Department of Atomic Energy, Government of India) Near Indira Bridge; Bhat; Gandhinagar-382428; India PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE
Users and utilization of CERIT-SC infrastructure
 Users and utilization of CERIT-SC infrastructure Equipment CERIT-SC is an integral part of the national e-infrastructure operated by CESNET, and it leverages many of its services (e.g. management of user
Users and utilization of CERIT-SC infrastructure Equipment CERIT-SC is an integral part of the national e-infrastructure operated by CESNET, and it leverages many of its services (e.g. management of user
Our Workshop Environment
 Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Our Environment Today Your laptops or workstations: only used for portal access Bridges
Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Our Environment Today Your laptops or workstations: only used for portal access Bridges
Installing and Configuring Oracle VM on Oracle Cloud Infrastructure ORACLE WHITE PAPER NOVEMBER 2017
 Installing and Configuring Oracle VM on Oracle Cloud Infrastructure ORACLE WHITE PAPER NOVEMBER 2017 Disclaimer The following is intended to outline our general product direction. It is intended for information
Installing and Configuring Oracle VM on Oracle Cloud Infrastructure ORACLE WHITE PAPER NOVEMBER 2017 Disclaimer The following is intended to outline our general product direction. It is intended for information
Performance and Energy Usage of Workloads on KNL and Haswell Architectures
 Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
Meltdown and Spectre Interconnect Performance Evaluation Jan Mellanox Technologies
 Meltdown and Spectre Interconnect Evaluation Jan 2018 1 Meltdown and Spectre - Background Most modern processors perform speculative execution This speculation can be measured, disclosing information about
Meltdown and Spectre Interconnect Evaluation Jan 2018 1 Meltdown and Spectre - Background Most modern processors perform speculative execution This speculation can be measured, disclosing information about
SuperMike-II Launch Workshop. System Overview and Allocations
 : System Overview and Allocations Dr Jim Lupo CCT Computational Enablement jalupo@cct.lsu.edu SuperMike-II: Serious Heterogeneous Computing Power System Hardware SuperMike provides 442 nodes, 221TB of
: System Overview and Allocations Dr Jim Lupo CCT Computational Enablement jalupo@cct.lsu.edu SuperMike-II: Serious Heterogeneous Computing Power System Hardware SuperMike provides 442 nodes, 221TB of
(Reaccredited with A Grade by the NAAC) RE-TENDER NOTICE. Advt. No. PU/R/RUSA Fund/Equipment Purchase-1/ Date:
 RE-TENDER NOTICE. Advt. No. PU/R/RUSA Fund/Equipment Purchase-1/ Date:") Phone: 0427-2345766 Fax: 0427-2345124 PERIYAR UNIVERSITY (Reaccredited with A Grade by the NAAC) PERIYAR PALKALAI NAGAR SALEM 636 011. RE-TENDER NOTICE Advt. No. PU/R/RUSA Fund/Equipment Purchase-1/139-2018
Phone: 0427-2345766 Fax: 0427-2345124 PERIYAR UNIVERSITY (Reaccredited with A Grade by the NAAC) PERIYAR PALKALAI NAGAR SALEM 636 011. RE-TENDER NOTICE Advt. No. PU/R/RUSA Fund/Equipment Purchase-1/139-2018
MAHA. - Supercomputing System for Bioinformatics
 MAHA - Supercomputing System for Bioinformatics - 2013.01.29 Outline 1. MAHA HW 2. MAHA SW 3. MAHA Storage System 2 ETRI HPC R&D Area - Overview Research area Computing HW MAHA System HW - Rpeak : 0.3
MAHA - Supercomputing System for Bioinformatics - 2013.01.29 Outline 1. MAHA HW 2. MAHA SW 3. MAHA Storage System 2 ETRI HPC R&D Area - Overview Research area Computing HW MAHA System HW - Rpeak : 0.3
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment. TOP500 Supercomputers, June 2014
 InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Installing and Configuring Oracle VM on Oracle Cloud Infrastructure O R A C L E W H I T E P A P E R D E C E M B E R
 Installing and Configuring Oracle VM on Oracle Cloud Infrastructure O R A C L E W H I T E P A P E R D E C E M B E R 2 0 1 7 Disclaimer The following is intended to outline our general product direction.
Installing and Configuring Oracle VM on Oracle Cloud Infrastructure O R A C L E W H I T E P A P E R D E C E M B E R 2 0 1 7 Disclaimer The following is intended to outline our general product direction.
University at Buffalo Center for Computational Research
 University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
J O U R N É E D E R E N C O N T R E D E S U T I L I S A T E U R S D U P Ô L E D E C A L C U L I N T E N S I F P O U R L A M E R P I E R R E C O T T Y
 J O U R N É E D E R E N C O N T R E D E S U T I L I S A T E U R S D U P Ô L E D E C A L C U L I N T E N S I F P O U R L A M E R P I E R R E C O T T Y Le programme de la journée 9 h 40-12 h 10 DATARMOR:
J O U R N É E D E R E N C O N T R E D E S U T I L I S A T E U R S D U P Ô L E D E C A L C U L I N T E N S I F P O U R L A M E R P I E R R E C O T T Y Le programme de la journée 9 h 40-12 h 10 DATARMOR:
Introduc)on to Hyades
on to Hyades") Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
Chelsio Communications. Meeting Today s Datacenter Challenges. Produced by Tabor Custom Publishing in conjunction with: CUSTOM PUBLISHING
 Meeting Today s Datacenter Challenges Produced by Tabor Custom Publishing in conjunction with: 1 Introduction In this era of Big Data, today s HPC systems are faced with unprecedented growth in the complexity
Meeting Today s Datacenter Challenges Produced by Tabor Custom Publishing in conjunction with: 1 Introduction In this era of Big Data, today s HPC systems are faced with unprecedented growth in the complexity
Erkenntnisse aus aktuellen Performance- Messungen mit LS-DYNA
 14. LS-DYNA Forum, Oktober 2016, Bamberg Erkenntnisse aus aktuellen Performance- Messungen mit LS-DYNA Eric Schnepf 1, Dr. Eckardt Kehl 1, Chih-Song Kuo 2, Dymitrios Kyranas 2 1 Fujitsu Technology Solutions
14. LS-DYNA Forum, Oktober 2016, Bamberg Erkenntnisse aus aktuellen Performance- Messungen mit LS-DYNA Eric Schnepf 1, Dr. Eckardt Kehl 1, Chih-Song Kuo 2, Dymitrios Kyranas 2 1 Fujitsu Technology Solutions
Architecting High Performance Computing Systems for Fault Tolerance and Reliability
 Architecting High Performance Computing Systems for Fault Tolerance and Reliability Blake T. Gonzales HPC Computer Scientist Dell Advanced Systems Group blake_gonzales@dell.com Agenda HPC Fault Tolerance
Architecting High Performance Computing Systems for Fault Tolerance and Reliability Blake T. Gonzales HPC Computer Scientist Dell Advanced Systems Group blake_gonzales@dell.com Agenda HPC Fault Tolerance
RHRK-Seminar. High Performance Computing with the Cluster Elwetritsch - II. Course instructor : Dr. Josef Schüle, RHRK
 RHRK-Seminar High Performance Computing with the Cluster Elwetritsch - II Course instructor : Dr. Josef Schüle, RHRK Overview Course I Login to cluster SSH RDP / NX Desktop Environments GNOME (default)
RHRK-Seminar High Performance Computing with the Cluster Elwetritsch - II Course instructor : Dr. Josef Schüle, RHRK Overview Course I Login to cluster SSH RDP / NX Desktop Environments GNOME (default)
CYFRONET SITE REPORT IMPROVING SLURM USABILITY AND MONITORING. M. Pawlik, J. Budzowski, L. Flis, P. Lasoń, M. Magryś
 CYFRONET SITE REPORT IMPROVING SLURM USABILITY AND MONITORING M. Pawlik, J. Budzowski, L. Flis, P. Lasoń, M. Magryś Presentation plan 2 Cyfronet introduction System description SLURM modifications Job
CYFRONET SITE REPORT IMPROVING SLURM USABILITY AND MONITORING M. Pawlik, J. Budzowski, L. Flis, P. Lasoń, M. Magryś Presentation plan 2 Cyfronet introduction System description SLURM modifications Job
Advanced Topics in High Performance Scientific Computing [MA5327] Exercise 1
![Advanced Topics in High Performance Scientific Computing [MA5327] Exercise 1](/thumbs/87/95383144.jpg "Advanced Topics in High Performance Scientific Computing [MA5327] Exercise 1") Advanced Topics in High Performance Scientific Computing [MA5327] Exercise 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de
Advanced Topics in High Performance Scientific Computing [MA5327] Exercise 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de
Analytics of Wide-Area Lustre Throughput Using LNet Routers
 Analytics of Wide-Area Throughput Using LNet Routers Nagi Rao, Neena Imam, Jesse Hanley, Sarp Oral Oak Ridge National Laboratory User Group Conference LUG 2018 April 24-26, 2018 Argonne National Laboratory
Analytics of Wide-Area Throughput Using LNet Routers Nagi Rao, Neena Imam, Jesse Hanley, Sarp Oral Oak Ridge National Laboratory User Group Conference LUG 2018 April 24-26, 2018 Argonne National Laboratory
The Stampede is Coming Welcome to Stampede Introductory Training. Dan Stanzione Texas Advanced Computing Center
 The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures
 Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures Dr. Fabio Baruffa Dr. Luigi Iapichino Leibniz Supercomputing Centre fabio.baruffa@lrz.de Outline of the talk
Performance Optimization of Smoothed Particle Hydrodynamics for Multi/Many-Core Architectures Dr. Fabio Baruffa Dr. Luigi Iapichino Leibniz Supercomputing Centre fabio.baruffa@lrz.de Outline of the talk
The Cray CX1 puts massive power and flexibility right where you need it in your workgroup
 The Cray CX1 puts massive power and flexibility right where you need it in your workgroup Up to 96 cores of Intel 5600 compute power 3D visualization Up to 32TB of storage GPU acceleration Small footprint
The Cray CX1 puts massive power and flexibility right where you need it in your workgroup Up to 96 cores of Intel 5600 compute power 3D visualization Up to 32TB of storage GPU acceleration Small footprint
Memory Footprint of Locality Information On Many-Core Platforms Brice Goglin Inria Bordeaux Sud-Ouest France 2018/05/25
 ROME Workshop @ IPDPS Vancouver Memory Footprint of Locality Information On Many- Platforms Brice Goglin Inria Bordeaux Sud-Ouest France 2018/05/25 Locality Matters to HPC Applications Locality Matters
ROME Workshop @ IPDPS Vancouver Memory Footprint of Locality Information On Many- Platforms Brice Goglin Inria Bordeaux Sud-Ouest France 2018/05/25 Locality Matters to HPC Applications Locality Matters
(software agnostic) Computational Considerations
 Computational Considerations") (software agnostic) Computational Considerations The Issues CPU GPU Emerging - FPGA, Phi, Nervana Storage Networking CPU 2 Threads core core Processor/Chip Processor/Chip Computer CPU Threads vs. Cores
(software agnostic) Computational Considerations The Issues CPU GPU Emerging - FPGA, Phi, Nervana Storage Networking CPU 2 Threads core core Processor/Chip Processor/Chip Computer CPU Threads vs. Cores
Intel Architecture for HPC
 Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Mission-Critical Lustre at Santos. Adam Fox, Lustre User Group 2016
 Mission-Critical Lustre at Santos Adam Fox, Lustre User Group 2016 About Santos One of the leading oil and gas producers in APAC Founded in 1954 South Australia Northern Territory Oil Search Cooper Basin
Mission-Critical Lustre at Santos Adam Fox, Lustre User Group 2016 About Santos One of the leading oil and gas producers in APAC Founded in 1954 South Australia Northern Territory Oil Search Cooper Basin
Purchasing Services SVC East Fowler Avenue Tampa, Florida (813)
") Purchasing Services SVC 1073 4202 East Fowler Avenue Tampa, Florida 33620 (813) 974-2481 Web Address: http://www.usf.edu/business-finance/purchasing/staff-procedures/index.aspx April 25, 2018 Invitation
Purchasing Services SVC 1073 4202 East Fowler Avenue Tampa, Florida 33620 (813) 974-2481 Web Address: http://www.usf.edu/business-finance/purchasing/staff-procedures/index.aspx April 25, 2018 Invitation
LUG 2012 From Lustre 2.1 to Lustre HSM IFERC (Rokkasho, Japan)
") LUG 2012 From Lustre 2.1 to Lustre HSM Lustre @ IFERC (Rokkasho, Japan) Diego.Moreno@bull.net From Lustre-2.1 to Lustre-HSM - Outline About Bull HELIOS @ IFERC (Rokkasho, Japan) Lustre-HSM - Basis of Lustre-HSM
LUG 2012 From Lustre 2.1 to Lustre HSM Lustre @ IFERC (Rokkasho, Japan) Diego.Moreno@bull.net From Lustre-2.1 to Lustre-HSM - Outline About Bull HELIOS @ IFERC (Rokkasho, Japan) Lustre-HSM - Basis of Lustre-HSM
Low-Overhead Flash Disaggregation via NVMe-over-Fabrics Vijay Balakrishnan Memory Solutions Lab. Samsung Semiconductor, Inc.
 Low-Overhead Flash Disaggregation via NVMe-over-Fabrics Vijay Balakrishnan Memory Solutions Lab. Samsung Semiconductor, Inc. 1 DISCLAIMER This presentation and/or accompanying oral statements by Samsung
Low-Overhead Flash Disaggregation via NVMe-over-Fabrics Vijay Balakrishnan Memory Solutions Lab. Samsung Semiconductor, Inc. 1 DISCLAIMER This presentation and/or accompanying oral statements by Samsung
Datura The new HPC-Plant at Albert Einstein Institute
 Datura The new HPC-Plant at Albert Einstein Institute Nico Budewitz Max Planck Institue for Gravitational Physics, Germany Cluster Day, 2011 Outline 1 History HPC-Plants at AEI -2009 Peyote, Lagavulin,
Datura The new HPC-Plant at Albert Einstein Institute Nico Budewitz Max Planck Institue for Gravitational Physics, Germany Cluster Day, 2011 Outline 1 History HPC-Plants at AEI -2009 Peyote, Lagavulin,
My operating system is old but I don't care : I'm using NIX! B.Bzeznik BUX meeting, Vilnius 22/03/2016
 My operating system is old but I don't care : I'm using NIX! B.Bzeznik BUX meeting, Vilnius 22/03/2016 CIMENT is the computing center of the University of Grenoble CIMENT computing platforms 132Tflops
My operating system is old but I don't care : I'm using NIX! B.Bzeznik BUX meeting, Vilnius 22/03/2016 CIMENT is the computing center of the University of Grenoble CIMENT computing platforms 132Tflops
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE
 MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE LEVERAGE OUR EXPERTISE sales@microway.com http://microway.com/tesla NUMBERSMASHER TESLA 4-GPU SERVER/WORKSTATION Flexible form factor 4 PCI-E GPUs + 3 additional
MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE LEVERAGE OUR EXPERTISE sales@microway.com http://microway.com/tesla NUMBERSMASHER TESLA 4-GPU SERVER/WORKSTATION Flexible form factor 4 PCI-E GPUs + 3 additional
Low-Overhead Flash Disaggregation via NVMe-over-Fabrics
 Low-Overhead Flash Disaggregation via NVMe-over-Fabrics Vijay Balakrishnan Memory Solutions Lab. Samsung Semiconductor, Inc. August 2017 1 DISCLAIMER This presentation and/or accompanying oral statements
Low-Overhead Flash Disaggregation via NVMe-over-Fabrics Vijay Balakrishnan Memory Solutions Lab. Samsung Semiconductor, Inc. August 2017 1 DISCLAIMER This presentation and/or accompanying oral statements
I/O at the Center for Information Services and High Performance Computing
 Mich ael Kluge, ZIH I/O at the Center for Information Services and High Performance Computing HPC-I/O in the Data Center Workshop @ ISC 2015 Zellescher Weg 12 Willers-Bau A 208 Tel. +49 351-463 34217 Michael
Mich ael Kluge, ZIH I/O at the Center for Information Services and High Performance Computing HPC-I/O in the Data Center Workshop @ ISC 2015 Zellescher Weg 12 Willers-Bau A 208 Tel. +49 351-463 34217 Michael
Scalability Testing of DNE2 in Lustre 2.7 and Metadata Performance using Virtual Machines Tom Crowe, Nathan Lavender, Stephen Simms
 Scalability Testing of DNE2 in Lustre 2.7 and Metadata Performance using Virtual Machines Tom Crowe, Nathan Lavender, Stephen Simms Research Technologies High Performance File Systems hpfs-admin@iu.edu
Scalability Testing of DNE2 in Lustre 2.7 and Metadata Performance using Virtual Machines Tom Crowe, Nathan Lavender, Stephen Simms Research Technologies High Performance File Systems hpfs-admin@iu.edu
HPC Capabilities at Research Intensive Universities
 HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
LS-DYNA Performance Benchmark and Profiling. October 2017
 LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
Cori (2016) and Beyond Ensuring NERSC Users Stay Productive
 and Beyond Ensuring NERSC Users Stay Productive") Cori (2016) and Beyond Ensuring NERSC Users Stay Productive Nicholas J. Wright! Advanced Technologies Group Lead! Heterogeneous Mul-- Core 4 Workshop 17 September 2014-1 - NERSC Systems Today Edison: 2.39PF,
Cori (2016) and Beyond Ensuring NERSC Users Stay Productive Nicholas J. Wright! Advanced Technologies Group Lead! Heterogeneous Mul-- Core 4 Workshop 17 September 2014-1 - NERSC Systems Today Edison: 2.39PF,
INTRODUCTION TO THE CLUSTER
 INTRODUCTION TO THE CLUSTER WHAT IS A CLUSTER? A computer cluster consists of a group of interconnected servers (nodes) that work together to form a single logical system. COMPUTE NODES GATEWAYS SCHEDULER
INTRODUCTION TO THE CLUSTER WHAT IS A CLUSTER? A computer cluster consists of a group of interconnected servers (nodes) that work together to form a single logical system. COMPUTE NODES GATEWAYS SCHEDULER
Configuration Maximums VMware vsphere 5.0
 Topic VMware vsphere 5.0 When you select and configure your virtual and physical equipment, you must stay at or below the maximums supported by vsphere 5.0. The limits presented in the following tables
Topic VMware vsphere 5.0 When you select and configure your virtual and physical equipment, you must stay at or below the maximums supported by vsphere 5.0. The limits presented in the following tables
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA
 Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
ARCHER/RDF Overview. How do they fit together? Andy Turner, EPCC
 ARCHER/RDF Overview How do they fit together? Andy Turner, EPCC a.turner@epcc.ed.ac.uk www.epcc.ed.ac.uk www.archer.ac.uk Outline ARCHER/RDF Layout Available file systems Compute resources ARCHER Compute
ARCHER/RDF Overview How do they fit together? Andy Turner, EPCC a.turner@epcc.ed.ac.uk www.epcc.ed.ac.uk www.archer.ac.uk Outline ARCHER/RDF Layout Available file systems Compute resources ARCHER Compute
Illinois Proposal Considerations Greg Bauer
 - 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
- 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
InfiniBand Networked Flash Storage
 InfiniBand Networked Flash Storage Superior Performance, Efficiency and Scalability Motti Beck Director Enterprise Market Development, Mellanox Technologies Flash Memory Summit 2016 Santa Clara, CA 1 17PB
InfiniBand Networked Flash Storage Superior Performance, Efficiency and Scalability Motti Beck Director Enterprise Market Development, Mellanox Technologies Flash Memory Summit 2016 Santa Clara, CA 1 17PB
Lustre usages and experiences
 Lustre usages and experiences at German Climate Computing Centre in Hamburg Carsten Beyer High Performance Computing Center Exclusively for the German Climate Research Limited Company, non-profit Staff:
Lustre usages and experiences at German Climate Computing Centre in Hamburg Carsten Beyer High Performance Computing Center Exclusively for the German Climate Research Limited Company, non-profit Staff:
Integration Path for Intel Omni-Path Fabric attached Intel Enterprise Edition for Lustre (IEEL) LNET
 LNET") Integration Path for Intel Omni-Path Fabric attached Intel Enterprise Edition for Lustre (IEEL) LNET Table of Contents Introduction 3 Architecture for LNET 4 Integration 5 Proof of Concept routing for
Integration Path for Intel Omni-Path Fabric attached Intel Enterprise Edition for Lustre (IEEL) LNET Table of Contents Introduction 3 Architecture for LNET 4 Integration 5 Proof of Concept routing for
The Future of High Performance Interconnects
 The Future of High Performance Interconnects Ashrut Ambastha HPC Advisory Council Perth, Australia :: August 2017 When Algorithms Go Rogue 2017 Mellanox Technologies 2 When Algorithms Go Rogue 2017 Mellanox
The Future of High Performance Interconnects Ashrut Ambastha HPC Advisory Council Perth, Australia :: August 2017 When Algorithms Go Rogue 2017 Mellanox Technologies 2 When Algorithms Go Rogue 2017 Mellanox
In partnership with. VelocityAI REFERENCE ARCHITECTURE WHITE PAPER
 In partnership with VelocityAI REFERENCE JULY // 2018 Contents Introduction 01 Challenges with Existing AI/ML/DL Solutions 01 Accelerate AI/ML/DL Workloads with Vexata VelocityAI 02 VelocityAI Reference
In partnership with VelocityAI REFERENCE JULY // 2018 Contents Introduction 01 Challenges with Existing AI/ML/DL Solutions 01 Accelerate AI/ML/DL Workloads with Vexata VelocityAI 02 VelocityAI Reference
IHK/McKernel: A Lightweight Multi-kernel Operating System for Extreme-Scale Supercomputing
 : A Lightweight Multi-kernel Operating System for Extreme-Scale Supercomputing Balazs Gerofi Exascale System Software Team, RIKEN Center for Computational Science 218/Nov/15 SC 18 Intel Extreme Computing
: A Lightweight Multi-kernel Operating System for Extreme-Scale Supercomputing Balazs Gerofi Exascale System Software Team, RIKEN Center for Computational Science 218/Nov/15 SC 18 Intel Extreme Computing
in Action Fujitsu High Performance Computing Ecosystem Human Centric Innovation Innovation Flexibility Simplicity
 Fujitsu High Performance Computing Ecosystem Human Centric Innovation in Action Dr. Pierre Lagier Chief Technology Officer Fujitsu Systems Europe Innovation Flexibility Simplicity INTERNAL USE ONLY 0 Copyright
Fujitsu High Performance Computing Ecosystem Human Centric Innovation in Action Dr. Pierre Lagier Chief Technology Officer Fujitsu Systems Europe Innovation Flexibility Simplicity INTERNAL USE ONLY 0 Copyright
Page 1 of 20 David Pimm Avid Technology 10 December 2013 Rev - D
 Avid Configuration Guidelines Lenovo ThinkStation C30 Dual 6-Core, Dual 8-Core, Dual 12-core CPU Workstation Media Composer 6.5.x, Symphony 6.5.x, NewsCutter 10.5.X and later Page 1 of 20 David Pimm Avid
Avid Configuration Guidelines Lenovo ThinkStation C30 Dual 6-Core, Dual 8-Core, Dual 12-core CPU Workstation Media Composer 6.5.x, Symphony 6.5.x, NewsCutter 10.5.X and later Page 1 of 20 David Pimm Avid
HPC Technology Update Challenges or Chances?
 HPC Technology Update Challenges or Chances? Swiss Distributed Computing Day Thomas Schoenemeyer, Technology Integration, CSCS 1 Move in Feb-April 2012 1500m2 16 MW Lake-water cooling PUE 1.2 New Datacenter
HPC Technology Update Challenges or Chances? Swiss Distributed Computing Day Thomas Schoenemeyer, Technology Integration, CSCS 1 Move in Feb-April 2012 1500m2 16 MW Lake-water cooling PUE 1.2 New Datacenter
NEMO Performance Benchmark and Profiling. May 2011
 NEMO Performance Benchmark and Profiling May 2011 Note The following research was performed under the HPC Advisory Council HPC works working group activities Participating vendors: HP, Intel, Mellanox
NEMO Performance Benchmark and Profiling May 2011 Note The following research was performed under the HPC Advisory Council HPC works working group activities Participating vendors: HP, Intel, Mellanox