NUMA-Aware Shared-Memory Collective Communication for MPI
|
|
|
- Sydney Gilbert
- 6 years ago
- Views:
Transcription
1 NUMA-Aware Shared-Memory Collective Communication for MPI Shigang Li Torsten Hoefler Marc Snir Presented By: Shafayat Rahman
2 Motivation Number of cores per node keeps increasing So it becomes important for MPI to leverage shared memory for intranode communication.
3 Introduction The paper investigates: The design and optimizations of MPI collectives For cluster of NUMA nodes Keywords: MPI, Multithreading, MPI_Allreduce, Collective Communication, NUMA
4 Some basic definitions MPI: a standardized and portable message passing system Collective Functions: functions involving communication among all processes within a process group. Example: MPI_Bcast call NUMA: Non Uniform Memory Access. A computer memory design used in multiprocessing where the memory access time depends on the memory location relative to the processor.
5 Contributions Developed performance model for collective communication using shared memory Developed several algorithm for various collectives. Conducted experiments on Xeon X5650 and Operton 6100 Infiniband clusters Compared their shared-memory allreduce algorithm with several traditional MPI implementations: Open MPI, MPICH2, and MVAPICH2
6 Findings Different algorithms dominate for short vectors and long vectors On a 16-node Xeon cluster and 8-node Operton cluster, their implementation achieves on average 2.5X and 2.3X sppedup over MPICH2.
7 Background Applications using MPI often run multiple MPI processes in each node. With increasing number or cores per node and non-uniform memory, performance of MPI collectives depend more and more on intranode communications.
8 Background Current implementations of MPI collectives take advantage of shared memory in two ways: Collectives are built using point-to-point message passing, which uses shared memory as a transport layer inside a node. (MPICH2) Collectives are implemented directly on top of shared memory. Data is copied from user space to shared memory space. (Open MPI and MVAPICH2). The second approach reduces the number of memory transfers but still requires extra data movement. Plus, shared memory is a limited system resource.
9 HMPI: Hybrid MPI Replacing the process-based rank design with a thread-based rank. All MPI ranks (threads) on a node are running within the same address space. Utilizes existing MPI infrastructure for internode communication A similar approach is to use a globally shared heap for all MPI processes on a node (XPMEM)

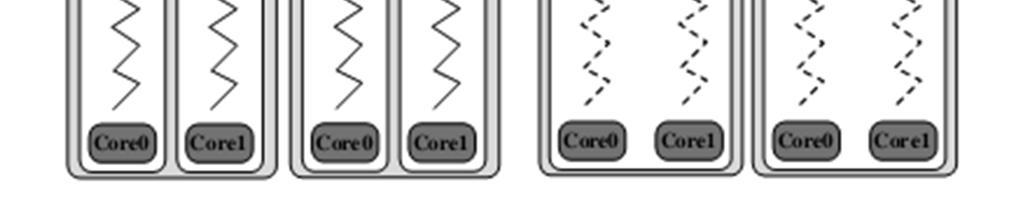
10 HMPI: Hybrid MPI
11 Contributions Designed NUMA-aware algorithms for thread-based HMPI_Allreduce on cluster of NUMA nodes Showed a set of motifs and techniques to optimize collective operations on multicore architecture Established performance models based on memory access latency and bandwidth to select the best algorithm for different vector sizes Performed a detailed benchmarking study to assess the benefits of using their algorithms over existing approaches
12 Contributions They specifically selected MPI_Allreduce to show the benefits of HMPI.
13 MPI_Allreduce A combination of MPI_Reduce and MPI_broadcast
14 Performance Model Ignored internode communication and focused on intranode communication. Each algorithm is designed and implemented hierarchically between intramodule (for cores sharing L2 cache), intrasocket (for cores sharing L3 cache), intersocket, and internode. Assumptions: Each core has a private L2 cache Each socket contains a shared L3 cache If there are s sockets and q threads running in each socket, then total thread per node is p = q * s
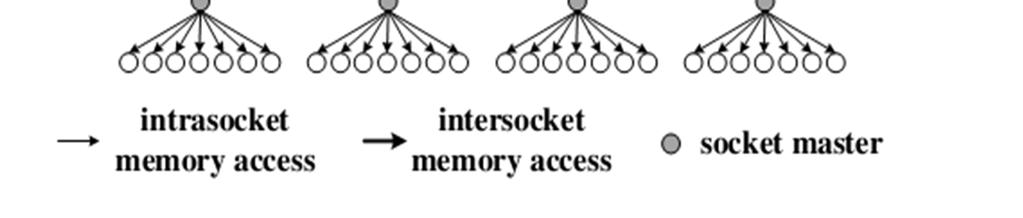
15 Algorithm 1: Reduce_Broadcast Uses a tree reduction, followed by a tree broadcast In reduction, each thread performs a reduction after it has synchronized with n-1 children and finished its previous step. The first child acts as a parent in next step.
16 Algorithm 1: Reduce_Broadcast In broadcast, one thread writes the vector, and n threads read the vector simultaneously. Communication involves cache, and no memory write back. Broadcast can be done in two ways: One stage, where all threads read the vector simultaneously Two-stage, where a "socket-master" at each socket reads the vector at first step, and then all threads within a socket, excluding the master, reads it simultaneously.
17 Algorithm 1: Reduce_Broadcast
18 Algorithm 2: Dissemination The dissemination algorithm achieves complete dissemination of information among p threads in log synchronized steps. The algorithm has fewer steps but more total communication than reduce-broadcast algorithm.
19 Algorithm 2: Dissemination
20 Algorithm 3: Tiled-Reduce Broadcast Since all threads can access all vectors, each thread compute a tile of final result and then broadcast it to all other threads. Works for long vectors and can be expected to have better performance than other algorithms for large vectors, because it can keep all the threads busy and make better use of bandwidth. Used only within sockets, tree reduction is better for intersocket because of limited intersocket bandwidth. For broadcasting, one or two stage broadcasting is used.

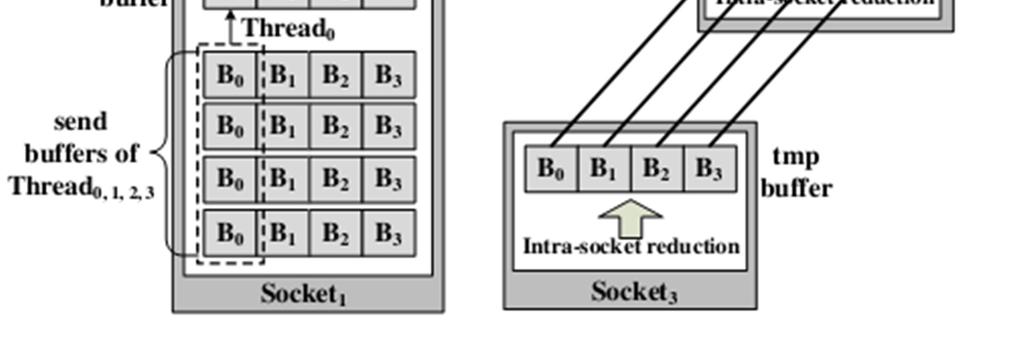
21 Algorithm 3: Tiled-Reduce Broadcast
22 Evaluation Intel Xeon X5650 (Westmere), 2 sockets, 12 cores AMD Operton 6100 (Magny-Cours), 4 sockets, 32 cores Performance of HMPI's allreduce against MPICH2, MVAPICH2, Open MPI

23 Performance Analysis: Reduce Broadcast One stage broadcast (where all threads read from the root thread) works better for 12- core Westmere. The reason is inclusive L3 cache exhibits affordable contention with all the threads accessing it simultaneously.
24 Performance Analysis: Reduce Broadcast Two stage broadcast works better for 32-core Magny- Cours. The reason is: more sockets and cores, so high contention overhead for onestep broadcast. For large vector sizes, flatter broadcast trees becomes advantageous. Reason? Data size is bigger than L3 cache, so more memory access needed, so reducing the numberof passes is important.
25 Performance Analysis: Tiled Reduce Naive tiled-reduce does the reduction in parallel, but without considering NUMA, so high contention. Cyclic tiled-reduce perform slightly better. Hierarchical tiled-reduce, that uses tile reduce inside nodes and tree reduction across sockets performs best
26 Performance Analysis: HMPI Allreducevs. Traditional MPI HMPI outperforms traditional MPIs Reasons: Direct memory access Low synchronization overhead Aggreesive NUMA
27 Performance Analysis: HMPI Allreducevs. Traditional MPI Dissimination is the worst algorithm in all platform, because of redundant computation. MPICH2 shows the worst performance, bacause it uses shared memory only as a transport layer. Proposed implementations gets 3.6X lower latency than Open MPI, 4.3X than MVAPICH2. Tree based algorithms gets the best performance if vector size < 16 KB Tiled-reduce followed by broadcast has best performance if vector size > 16 KB
28 Comparison with OpenMP OpenMP is another sharedmemory programming environment. Its reductions have been optimized for direct shared-memory access. HMPI reduce achieves on average 1.5X speedup over OpenMP for all vector sizes. Probably due to hierarchyaware HMPI reduce implementations on NUMA machines.
29 Performance on Distributed Memory On a 16-node Xeon cluster Dissemination works worst because of high internode communication overhead HMPI_Bcast and HMPI_Reduce get on avergae 1.8X and 1.4X speedup over MVAPICH2
30 Conclusion Multithreading has several advantages over multiprocessing on shared memory for collectives Using this principle, they improved MPI performance Proposed new algorithms for MPI_Allreduce Performed experiments and analyzed results
NUMA-Aware Shared-Memory Collective Communication for MPI
 NUMA-Aware Shared-Memory Collective Communication for MPI Shigang Li School of Computer and Communication Engineering University of Science and Technology Beijing shigangli.cs@gmail.com Torsten Hoefler
NUMA-Aware Shared-Memory Collective Communication for MPI Shigang Li School of Computer and Communication Engineering University of Science and Technology Beijing shigangli.cs@gmail.com Torsten Hoefler
Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures
 Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures M. Bayatpour, S. Chakraborty, H. Subramoni, X. Lu, and D. K. Panda Department of Computer Science and Engineering
Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures M. Bayatpour, S. Chakraborty, H. Subramoni, X. Lu, and D. K. Panda Department of Computer Science and Engineering
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters
 InfiniBand Clusters") Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
GPU-Aware Intranode MPI_Allreduce
 GPU-Aware Intranode MPI_Allreduce Iman Faraji ECE Dept, Queen s University Kingston, ON, Canada KL 3N6 ifaraji@queensuca Ahmad Afsahi ECE Dept, Queen s University Kingston, ON, Canada KL 3N6 ahmadafsahi@queensuca
GPU-Aware Intranode MPI_Allreduce Iman Faraji ECE Dept, Queen s University Kingston, ON, Canada KL 3N6 ifaraji@queensuca Ahmad Afsahi ECE Dept, Queen s University Kingston, ON, Canada KL 3N6 ahmadafsahi@queensuca
MPI Optimizations via MXM and FCA for Maximum Performance on LS-DYNA
 MPI Optimizations via MXM and FCA for Maximum Performance on LS-DYNA Gilad Shainer 1, Tong Liu 1, Pak Lui 1, Todd Wilde 1 1 Mellanox Technologies Abstract From concept to engineering, and from design to
MPI Optimizations via MXM and FCA for Maximum Performance on LS-DYNA Gilad Shainer 1, Tong Liu 1, Pak Lui 1, Todd Wilde 1 1 Mellanox Technologies Abstract From concept to engineering, and from design to
Designing Multi-Leader-Based Allgather Algorithms for Multi-Core Clusters *
 Designing Multi-Leader-Based Allgather Algorithms for Multi-Core Clusters * Krishna Kandalla, Hari Subramoni, Gopal Santhanaraman, Matthew Koop and Dhabaleswar K. Panda Department of Computer Science and
Designing Multi-Leader-Based Allgather Algorithms for Multi-Core Clusters * Krishna Kandalla, Hari Subramoni, Gopal Santhanaraman, Matthew Koop and Dhabaleswar K. Panda Department of Computer Science and
Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures Mohammadreza Bayatpour, Hari Subramoni, D. K.
 Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures Mohammadreza Bayatpour, Hari Subramoni, D. K. Panda Department of Computer Science and Engineering The Ohio
Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures Mohammadreza Bayatpour, Hari Subramoni, D. K. Panda Department of Computer Science and Engineering The Ohio
MPI Programming Techniques
 MPI Programming Techniques Copyright (c) 2012 Young W. Lim. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any
MPI Programming Techniques Copyright (c) 2012 Young W. Lim. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any
MPI Performance Analysis and Optimization on Tile64/Maestro
 MPI Performance Analysis and Optimization on Tile64/Maestro Mikyung Kang, Eunhui Park, Minkyoung Cho, Jinwoo Suh, Dong-In Kang, and Stephen P. Crago USC/ISI-East July 19~23, 2009 Overview Background MPI
MPI Performance Analysis and Optimization on Tile64/Maestro Mikyung Kang, Eunhui Park, Minkyoung Cho, Jinwoo Suh, Dong-In Kang, and Stephen P. Crago USC/ISI-East July 19~23, 2009 Overview Background MPI
Designing High-Performance MPI Collectives in MVAPICH2 for HPC and Deep Learning
 5th ANNUAL WORKSHOP 209 Designing High-Performance MPI Collectives in MVAPICH2 for HPC and Deep Learning Hari Subramoni Dhabaleswar K. (DK) Panda The Ohio State University The Ohio State University E-mail:
5th ANNUAL WORKSHOP 209 Designing High-Performance MPI Collectives in MVAPICH2 for HPC and Deep Learning Hari Subramoni Dhabaleswar K. (DK) Panda The Ohio State University The Ohio State University E-mail:
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
How to Boost the Performance of Your MPI and PGAS Applications with MVAPICH2 Libraries
 How to Boost the Performance of Your MPI and PGAS s with MVAPICH2 Libraries A Tutorial at the MVAPICH User Group (MUG) Meeting 18 by The MVAPICH Team The Ohio State University E-mail: panda@cse.ohio-state.edu
How to Boost the Performance of Your MPI and PGAS s with MVAPICH2 Libraries A Tutorial at the MVAPICH User Group (MUG) Meeting 18 by The MVAPICH Team The Ohio State University E-mail: panda@cse.ohio-state.edu
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
Designing High Performance Communication Middleware with Emerging Multi-core Architectures
 Designing High Performance Communication Middleware with Emerging Multi-core Architectures Dhabaleswar K. (DK) Panda Department of Computer Science and Engg. The Ohio State University E-mail: panda@cse.ohio-state.edu
Designing High Performance Communication Middleware with Emerging Multi-core Architectures Dhabaleswar K. (DK) Panda Department of Computer Science and Engg. The Ohio State University E-mail: panda@cse.ohio-state.edu
Towards Efficient MapReduce Using MPI
 Towards Efficient MapReduce Using MPI Torsten Hoefler¹, Andrew Lumsdaine¹, Jack Dongarra² ¹Open Systems Lab Indiana University Bloomington ²Dept. of Computer Science University of Tennessee Knoxville 09/09/09
Towards Efficient MapReduce Using MPI Torsten Hoefler¹, Andrew Lumsdaine¹, Jack Dongarra² ¹Open Systems Lab Indiana University Bloomington ²Dept. of Computer Science University of Tennessee Knoxville 09/09/09
Designing Shared Address Space MPI libraries in the Many-core Era
 Designing Shared Address Space MPI libraries in the Many-core Era Jahanzeb Hashmi hashmi.29@osu.edu (NBCL) The Ohio State University Outline Introduction and Motivation Background Shared-memory Communication
Designing Shared Address Space MPI libraries in the Many-core Era Jahanzeb Hashmi hashmi.29@osu.edu (NBCL) The Ohio State University Outline Introduction and Motivation Background Shared-memory Communication
Multi-Threaded UPC Runtime for GPU to GPU communication over InfiniBand
 Multi-Threaded UPC Runtime for GPU to GPU communication over InfiniBand Miao Luo, Hao Wang, & D. K. Panda Network- Based Compu2ng Laboratory Department of Computer Science and Engineering The Ohio State
Multi-Threaded UPC Runtime for GPU to GPU communication over InfiniBand Miao Luo, Hao Wang, & D. K. Panda Network- Based Compu2ng Laboratory Department of Computer Science and Engineering The Ohio State
Optimised all-to-all communication on multicore architectures applied to FFTs with pencil decomposition
 Optimised all-to-all communication on multicore architectures applied to FFTs with pencil decomposition CUG 2018, Stockholm Andreas Jocksch, Matthias Kraushaar (CSCS), David Daverio (University of Cambridge,
Optimised all-to-all communication on multicore architectures applied to FFTs with pencil decomposition CUG 2018, Stockholm Andreas Jocksch, Matthias Kraushaar (CSCS), David Daverio (University of Cambridge,
Case study: OpenMP-parallel sparse matrix-vector multiplication
 Case study: OpenMP-parallel sparse matrix-vector multiplication A simple (but sometimes not-so-simple) example for bandwidth-bound code and saturation effects in memory Sparse matrix-vector multiply (spmvm)
Case study: OpenMP-parallel sparse matrix-vector multiplication A simple (but sometimes not-so-simple) example for bandwidth-bound code and saturation effects in memory Sparse matrix-vector multiply (spmvm)
Binding Nested OpenMP Programs on Hierarchical Memory Architectures
 Binding Nested OpenMP Programs on Hierarchical Memory Architectures Dirk Schmidl, Christian Terboven, Dieter an Mey, and Martin Bücker {schmidl, terboven, anmey}@rz.rwth-aachen.de buecker@sc.rwth-aachen.de
Binding Nested OpenMP Programs on Hierarchical Memory Architectures Dirk Schmidl, Christian Terboven, Dieter an Mey, and Martin Bücker {schmidl, terboven, anmey}@rz.rwth-aachen.de buecker@sc.rwth-aachen.de
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
MPI - Today and Tomorrow
 MPI - Today and Tomorrow ScicomP 9 - Bologna, Italy Dick Treumann - MPI Development The material presented represents a mix of experimentation, prototyping and development. While topics discussed may appear
MPI - Today and Tomorrow ScicomP 9 - Bologna, Italy Dick Treumann - MPI Development The material presented represents a mix of experimentation, prototyping and development. While topics discussed may appear
DELIVERABLE D5.5 Report on ICARUS visualization cluster installation. John BIDDISCOMBE (CSCS) Jerome SOUMAGNE (CSCS)
 Jerome SOUMAGNE (CSCS)") DELIVERABLE D5.5 Report on ICARUS visualization cluster installation John BIDDISCOMBE (CSCS) Jerome SOUMAGNE (CSCS) 02 May 2011 NextMuSE 2 Next generation Multi-mechanics Simulation Environment Cluster
DELIVERABLE D5.5 Report on ICARUS visualization cluster installation John BIDDISCOMBE (CSCS) Jerome SOUMAGNE (CSCS) 02 May 2011 NextMuSE 2 Next generation Multi-mechanics Simulation Environment Cluster
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Optimizing MPI Communication Within Large Multicore Nodes with Kernel Assistance
 Optimizing MPI Communication Within Large Multicore Nodes with Kernel Assistance S. Moreaud, B. Goglin, D. Goodell, R. Namyst University of Bordeaux RUNTIME team, LaBRI INRIA, France Argonne National Laboratory
Optimizing MPI Communication Within Large Multicore Nodes with Kernel Assistance S. Moreaud, B. Goglin, D. Goodell, R. Namyst University of Bordeaux RUNTIME team, LaBRI INRIA, France Argonne National Laboratory
Improving Virtual Machine Scheduling in NUMA Multicore Systems
 Improving Virtual Machine Scheduling in NUMA Multicore Systems Jia Rao, Xiaobo Zhou University of Colorado, Colorado Springs Kun Wang, Cheng-Zhong Xu Wayne State University http://cs.uccs.edu/~jrao/ Multicore
Improving Virtual Machine Scheduling in NUMA Multicore Systems Jia Rao, Xiaobo Zhou University of Colorado, Colorado Springs Kun Wang, Cheng-Zhong Xu Wayne State University http://cs.uccs.edu/~jrao/ Multicore
IBM HPC Development MPI update
 IBM HPC Development MPI update Chulho Kim Scicomp 2007 Enhancements in PE 4.3.0 & 4.3.1 MPI 1-sided improvements (October 2006) Selective collective enhancements (October 2006) AIX IB US enablement (July
IBM HPC Development MPI update Chulho Kim Scicomp 2007 Enhancements in PE 4.3.0 & 4.3.1 MPI 1-sided improvements (October 2006) Selective collective enhancements (October 2006) AIX IB US enablement (July
HierKNEM: An Adaptive Framework for Kernel-Assisted and Topology-Aware Collective Communications on Many-core Clusters
 : An Adaptive Framework for Kernel-Assisted and Topology-Aware Collective Communications on Many-core Clusters Teng Ma, George Bosilca, Aurelien Bouteiller, Jack J. Dongarra EECS, University of Tennessee
: An Adaptive Framework for Kernel-Assisted and Topology-Aware Collective Communications on Many-core Clusters Teng Ma, George Bosilca, Aurelien Bouteiller, Jack J. Dongarra EECS, University of Tennessee
Hybrid MPI - A Case Study on the Xeon Phi Platform
 Hybrid MPI - A Case Study on the Xeon Phi Platform Udayanga Wickramasinghe Center for Research on Extreme Scale Technologies (CREST) Indiana University Greg Bronevetsky Lawrence Livermore National Laboratory
Hybrid MPI - A Case Study on the Xeon Phi Platform Udayanga Wickramasinghe Center for Research on Extreme Scale Technologies (CREST) Indiana University Greg Bronevetsky Lawrence Livermore National Laboratory
Exploiting InfiniBand and GPUDirect Technology for High Performance Collectives on GPU Clusters
 Exploiting InfiniBand and Direct Technology for High Performance Collectives on Clusters Ching-Hsiang Chu chu.368@osu.edu Department of Computer Science and Engineering The Ohio State University OSU Booth
Exploiting InfiniBand and Direct Technology for High Performance Collectives on Clusters Ching-Hsiang Chu chu.368@osu.edu Department of Computer Science and Engineering The Ohio State University OSU Booth
Comparing Ethernet & Soft RoCE over 1 Gigabit Ethernet
 Comparing Ethernet & Soft RoCE over 1 Gigabit Ethernet Gurkirat Kaur, Manoj Kumar 1, Manju Bala 2 1 Department of Computer Science & Engineering, CTIEMT Jalandhar, Punjab, India 2 Department of Electronics
Comparing Ethernet & Soft RoCE over 1 Gigabit Ethernet Gurkirat Kaur, Manoj Kumar 1, Manju Bala 2 1 Department of Computer Science & Engineering, CTIEMT Jalandhar, Punjab, India 2 Department of Electronics
Parallel Applications on Distributed Memory Systems. Le Yan HPC User LSU
 Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures
 Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures Rolf Rabenseifner rabenseifner@hlrs.de Gerhard Wellein gerhard.wellein@rrze.uni-erlangen.de University of Stuttgart
Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures Rolf Rabenseifner rabenseifner@hlrs.de Gerhard Wellein gerhard.wellein@rrze.uni-erlangen.de University of Stuttgart
Research on the Implementation of MPI on Multicore Architectures
 Research on the Implementation of MPI on Multicore Architectures Pengqi Cheng Department of Computer Science & Technology, Tshinghua University, Beijing, China chengpq@gmail.com Yan Gu Department of Computer
Research on the Implementation of MPI on Multicore Architectures Pengqi Cheng Department of Computer Science & Technology, Tshinghua University, Beijing, China chengpq@gmail.com Yan Gu Department of Computer
Mapping MPI+X Applications to Multi-GPU Architectures
 Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit
 Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Non-Blocking Collectives for MPI
 Non-Blocking Collectives for MPI overlap at the highest level Torsten Höfler Open Systems Lab Indiana University Bloomington, IN, USA Institut für Wissenschaftliches Rechnen Technische Universität Dresden
Non-Blocking Collectives for MPI overlap at the highest level Torsten Höfler Open Systems Lab Indiana University Bloomington, IN, USA Institut für Wissenschaftliches Rechnen Technische Universität Dresden
Gerald Schubert 1, Georg Hager 2, Holger Fehske 1, Gerhard Wellein 2,3 1
 Parallel lsparse matrix-vector ti t multiplication li as a test case for hybrid MPI+OpenMP programming Gerald Schubert 1, Georg Hager 2, Holger Fehske 1, Gerhard Wellein 2,3 1 Institute of Physics, University
Parallel lsparse matrix-vector ti t multiplication li as a test case for hybrid MPI+OpenMP programming Gerald Schubert 1, Georg Hager 2, Holger Fehske 1, Gerhard Wellein 2,3 1 Institute of Physics, University
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Advanced Message-Passing Interface (MPI)
") Outline of the workshop 2 Advanced Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Morning: Advanced MPI Revision More on Collectives More on Point-to-Point
Outline of the workshop 2 Advanced Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Morning: Advanced MPI Revision More on Collectives More on Point-to-Point
CUDA GPGPU Workshop 2012
 CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
Evaluation of sparse LU factorization and triangular solution on multicore architectures. X. Sherry Li
 Evaluation of sparse LU factorization and triangular solution on multicore architectures X. Sherry Li Lawrence Berkeley National Laboratory ParLab, April 29, 28 Acknowledgement: John Shalf, LBNL Rich Vuduc,
Evaluation of sparse LU factorization and triangular solution on multicore architectures X. Sherry Li Lawrence Berkeley National Laboratory ParLab, April 29, 28 Acknowledgement: John Shalf, LBNL Rich Vuduc,
Load Balancing for Parallel Multi-core Machines with Non-Uniform Communication Costs
 Load Balancing for Parallel Multi-core Machines with Non-Uniform Communication Costs Laércio Lima Pilla llpilla@inf.ufrgs.br LIG Laboratory INRIA Grenoble University Grenoble, France Institute of Informatics
Load Balancing for Parallel Multi-core Machines with Non-Uniform Communication Costs Laércio Lima Pilla llpilla@inf.ufrgs.br LIG Laboratory INRIA Grenoble University Grenoble, France Institute of Informatics
OPEN MPI WITH RDMA SUPPORT AND CUDA. Rolf vandevaart, NVIDIA
 OPEN MPI WITH RDMA SUPPORT AND CUDA Rolf vandevaart, NVIDIA OVERVIEW What is CUDA-aware History of CUDA-aware support in Open MPI GPU Direct RDMA support Tuning parameters Application example Future work
OPEN MPI WITH RDMA SUPPORT AND CUDA Rolf vandevaart, NVIDIA OVERVIEW What is CUDA-aware History of CUDA-aware support in Open MPI GPU Direct RDMA support Tuning parameters Application example Future work
Challenges of Scaling Algebraic Multigrid Across Modern Multicore Architectures. Allison H. Baker, Todd Gamblin, Martin Schulz, and Ulrike Meier Yang
 Challenges of Scaling Algebraic Multigrid Across Modern Multicore Architectures. Allison H. Baker, Todd Gamblin, Martin Schulz, and Ulrike Meier Yang Multigrid Solvers Method of solving linear equation
Challenges of Scaling Algebraic Multigrid Across Modern Multicore Architectures. Allison H. Baker, Todd Gamblin, Martin Schulz, and Ulrike Meier Yang Multigrid Solvers Method of solving linear equation
SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience
 SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience Jithin Jose, Mingzhe Li, Xiaoyi Lu, Krishna Kandalla, Mark Arnold and Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory
SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience Jithin Jose, Mingzhe Li, Xiaoyi Lu, Krishna Kandalla, Mark Arnold and Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory
LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance
 11 th International LS-DYNA Users Conference Computing Technology LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton
11 th International LS-DYNA Users Conference Computing Technology LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton
Non-blocking Collective Operations for MPI
 Non-blocking Collective Operations for MPI - Towards Coordinated Optimization of Computation and Communication in Parallel Applications - Torsten Hoefler Open Systems Lab Indiana University Bloomington,
Non-blocking Collective Operations for MPI - Towards Coordinated Optimization of Computation and Communication in Parallel Applications - Torsten Hoefler Open Systems Lab Indiana University Bloomington,
Bei Wang, Dmitry Prohorov and Carlos Rosales
 Bei Wang, Dmitry Prohorov and Carlos Rosales Aspects of Application Performance What are the Aspects of Performance Intel Hardware Features Omni-Path Architecture MCDRAM 3D XPoint Many-core Xeon Phi AVX-512
Bei Wang, Dmitry Prohorov and Carlos Rosales Aspects of Application Performance What are the Aspects of Performance Intel Hardware Features Omni-Path Architecture MCDRAM 3D XPoint Many-core Xeon Phi AVX-512
Runtime Algorithm Selection of Collective Communication with RMA-based Monitoring Mechanism
 1 Runtime Algorithm Selection of Collective Communication with RMA-based Monitoring Mechanism Takeshi Nanri (Kyushu Univ. and JST CREST, Japan) 16 Aug, 2016 4th Annual MVAPICH Users Group Meeting 2 Background
1 Runtime Algorithm Selection of Collective Communication with RMA-based Monitoring Mechanism Takeshi Nanri (Kyushu Univ. and JST CREST, Japan) 16 Aug, 2016 4th Annual MVAPICH Users Group Meeting 2 Background
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
Lecture 14: Mixed MPI-OpenMP programming. Lecture 14: Mixed MPI-OpenMP programming p. 1
 Lecture 14: Mixed MPI-OpenMP programming Lecture 14: Mixed MPI-OpenMP programming p. 1 Overview Motivations for mixed MPI-OpenMP programming Advantages and disadvantages The example of the Jacobi method
Lecture 14: Mixed MPI-OpenMP programming Lecture 14: Mixed MPI-OpenMP programming p. 1 Overview Motivations for mixed MPI-OpenMP programming Advantages and disadvantages The example of the Jacobi method
Shared Memory and Distributed Multiprocessing. Bhanu Kapoor, Ph.D. The Saylor Foundation
 Shared Memory and Distributed Multiprocessing Bhanu Kapoor, Ph.D. The Saylor Foundation 1 Issue with Parallelism Parallel software is the problem Need to get significant performance improvement Otherwise,
Shared Memory and Distributed Multiprocessing Bhanu Kapoor, Ph.D. The Saylor Foundation 1 Issue with Parallelism Parallel software is the problem Need to get significant performance improvement Otherwise,
542 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 29, NO. 3, MARCH 2018
 542 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 29, NO. 3, MARCH 2018 Cache-Oblivious MPI All-to-All Communications Based on Morton Order Shigang Li, Member, IEEE, Yunquan Zhang, Member,
542 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 29, NO. 3, MARCH 2018 Cache-Oblivious MPI All-to-All Communications Based on Morton Order Shigang Li, Member, IEEE, Yunquan Zhang, Member,
Parallel Computing Using OpenMP/MPI. Presented by - Jyotsna 29/01/2008
 Parallel Computing Using OpenMP/MPI Presented by - Jyotsna 29/01/2008 Serial Computing Serially solving a problem Parallel Computing Parallelly solving a problem Parallel Computer Memory Architecture Shared
Parallel Computing Using OpenMP/MPI Presented by - Jyotsna 29/01/2008 Serial Computing Serially solving a problem Parallel Computing Parallelly solving a problem Parallel Computer Memory Architecture Shared
Op#miza#on and Tuning Collec#ves in MVAPICH2
 Op#miza#on and Tuning Collec#ves in MVAPICH2 MVAPICH2 User Group (MUG) Mee#ng by Hari Subramoni The Ohio State University E- mail: subramon@cse.ohio- state.edu h
Op#miza#on and Tuning Collec#ves in MVAPICH2 MVAPICH2 User Group (MUG) Mee#ng by Hari Subramoni The Ohio State University E- mail: subramon@cse.ohio- state.edu h
KNEM: a Generic and Scalable Kernel-Assisted Intra-node MPI Communication Framework
 KNEM: a Generic and Scalable Kernel-Assisted Intra-node MPI Communication Framework Brice Goglin, Stéphanie Moreaud To cite this version: Brice Goglin, Stéphanie Moreaud. KNEM: a Generic and Scalable Kernel-Assisted
KNEM: a Generic and Scalable Kernel-Assisted Intra-node MPI Communication Framework Brice Goglin, Stéphanie Moreaud To cite this version: Brice Goglin, Stéphanie Moreaud. KNEM: a Generic and Scalable Kernel-Assisted
Assessment of LS-DYNA Scalability Performance on Cray XD1
 5 th European LS-DYNA Users Conference Computing Technology (2) Assessment of LS-DYNA Scalability Performance on Cray Author: Ting-Ting Zhu, Cray Inc. Correspondence: Telephone: 651-65-987 Fax: 651-65-9123
5 th European LS-DYNA Users Conference Computing Technology (2) Assessment of LS-DYNA Scalability Performance on Cray Author: Ting-Ting Zhu, Cray Inc. Correspondence: Telephone: 651-65-987 Fax: 651-65-9123
Why you should care about hardware locality and how.
 Why you should care about hardware locality and how. Brice Goglin TADaaM team Inria Bordeaux Sud-Ouest Agenda Quick example as an introduction Bind your processes What's the actual problem? Convenient
Why you should care about hardware locality and how. Brice Goglin TADaaM team Inria Bordeaux Sud-Ouest Agenda Quick example as an introduction Bind your processes What's the actual problem? Convenient
LS-DYNA Productivity and Power-aware Simulations in Cluster Environments
 LS-DYNA Productivity and Power-aware Simulations in Cluster Environments Gilad Shainer 1, Tong Liu 1, Jacob Liberman 2, Jeff Layton 2 Onur Celebioglu 2, Scot A. Schultz 3, Joshua Mora 3, David Cownie 3,
LS-DYNA Productivity and Power-aware Simulations in Cluster Environments Gilad Shainer 1, Tong Liu 1, Jacob Liberman 2, Jeff Layton 2 Onur Celebioglu 2, Scot A. Schultz 3, Joshua Mora 3, David Cownie 3,
Communication Models for Resource Constrained Hierarchical Ethernet Networks
 Communication Models for Resource Constrained Hierarchical Ethernet Networks Speaker: Konstantinos Katrinis # Jun Zhu +, Alexey Lastovetsky *, Shoukat Ali #, Rolf Riesen # + Technical University of Eindhoven,
Communication Models for Resource Constrained Hierarchical Ethernet Networks Speaker: Konstantinos Katrinis # Jun Zhu +, Alexey Lastovetsky *, Shoukat Ali #, Rolf Riesen # + Technical University of Eindhoven,
Scalasca performance properties The metrics tour
 Scalasca performance properties The metrics tour Markus Geimer m.geimer@fz-juelich.de Scalasca analysis result Generic metrics Generic metrics Time Total CPU allocation time Execution Overhead Visits Hardware
Scalasca performance properties The metrics tour Markus Geimer m.geimer@fz-juelich.de Scalasca analysis result Generic metrics Generic metrics Time Total CPU allocation time Execution Overhead Visits Hardware
Barbara Chapman, Gabriele Jost, Ruud van der Pas
 Using OpenMP Portable Shared Memory Parallel Programming Barbara Chapman, Gabriele Jost, Ruud van der Pas The MIT Press Cambridge, Massachusetts London, England c 2008 Massachusetts Institute of Technology
Using OpenMP Portable Shared Memory Parallel Programming Barbara Chapman, Gabriele Jost, Ruud van der Pas The MIT Press Cambridge, Massachusetts London, England c 2008 Massachusetts Institute of Technology
Dmitry Durnov 15 February 2017
 Cовременные тенденции разработки высокопроизводительных приложений Dmitry Durnov 15 February 2017 Agenda Modern cluster architecture Node level Cluster level Programming models Tools 2/20/2017 2 Modern
Cовременные тенденции разработки высокопроизводительных приложений Dmitry Durnov 15 February 2017 Agenda Modern cluster architecture Node level Cluster level Programming models Tools 2/20/2017 2 Modern
A Case for High Performance Computing with Virtual Machines
 A Case for High Performance Computing with Virtual Machines Wei Huang*, Jiuxing Liu +, Bulent Abali +, and Dhabaleswar K. Panda* *The Ohio State University +IBM T. J. Waston Research Center Presentation
A Case for High Performance Computing with Virtual Machines Wei Huang*, Jiuxing Liu +, Bulent Abali +, and Dhabaleswar K. Panda* *The Ohio State University +IBM T. J. Waston Research Center Presentation
CANDY: Enabling Coherent DRAM Caches for Multi-Node Systems
 CANDY: Enabling Coherent DRAM Caches for Multi-Node Systems Chiachen Chou Aamer Jaleel Moinuddin K. Qureshi School of Electrical and Computer Engineering Georgia Institute of Technology {cc.chou, moin}@ece.gatech.edu
CANDY: Enabling Coherent DRAM Caches for Multi-Node Systems Chiachen Chou Aamer Jaleel Moinuddin K. Qureshi School of Electrical and Computer Engineering Georgia Institute of Technology {cc.chou, moin}@ece.gatech.edu
Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory
 Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory Roshan Dathathri Thejas Ramashekar Chandan Reddy Uday Bondhugula Department of Computer Science and Automation
Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory Roshan Dathathri Thejas Ramashekar Chandan Reddy Uday Bondhugula Department of Computer Science and Automation
LS-DYNA Scalability Analysis on Cray Supercomputers
 13 th International LS-DYNA Users Conference Session: Computing Technology LS-DYNA Scalability Analysis on Cray Supercomputers Ting-Ting Zhu Cray Inc. Jason Wang LSTC Abstract For the automotive industry,
13 th International LS-DYNA Users Conference Session: Computing Technology LS-DYNA Scalability Analysis on Cray Supercomputers Ting-Ting Zhu Cray Inc. Jason Wang LSTC Abstract For the automotive industry,
Efficient SMP-Aware MPI-Level Broadcast over InfiniBand s Hardware Multicast
 Efficient SMP-Aware MPI-Level Broadcast over InfiniBand s Hardware Multicast Amith R. Mamidala Lei Chai Hyun-Wook Jin Dhabaleswar K. Panda Department of Computer Science and Engineering The Ohio State
Efficient SMP-Aware MPI-Level Broadcast over InfiniBand s Hardware Multicast Amith R. Mamidala Lei Chai Hyun-Wook Jin Dhabaleswar K. Panda Department of Computer Science and Engineering The Ohio State
Topology-Aware Rank Reordering for MPI Collectives
 Topology-Aware Rank Reordering for MPI Collectives Seyed H. Mirsadeghi and Ahmad Afsahi ECE Department, Queen s University, Kingston, ON, Canada, K7L 3N6 Email: {s.mirsadeghi, ahmad.afsahi}@queensu.ca
Topology-Aware Rank Reordering for MPI Collectives Seyed H. Mirsadeghi and Ahmad Afsahi ECE Department, Queen s University, Kingston, ON, Canada, K7L 3N6 Email: {s.mirsadeghi, ahmad.afsahi}@queensu.ca
HYCOM Performance Benchmark and Profiling
 HYCOM Performance Benchmark and Profiling Jan 2011 Acknowledgment: - The DoD High Performance Computing Modernization Program Note The following research was performed under the HPC Advisory Council activities
HYCOM Performance Benchmark and Profiling Jan 2011 Acknowledgment: - The DoD High Performance Computing Modernization Program Note The following research was performed under the HPC Advisory Council activities
MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016
 Ion Stoica, UC Berkeley November 19, 2016") MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016 Message passing vs. Shared memory Client Client Client Client send(msg) recv(msg) send(msg) recv(msg) MSG MSG MSG IPC Shared
MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016 Message passing vs. Shared memory Client Client Client Client send(msg) recv(msg) send(msg) recv(msg) MSG MSG MSG IPC Shared
Parallel Processors. The dream of computer architects since 1950s: replicate processors to add performance vs. design a faster processor
 Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
NUMA-aware OpenMP Programming
 NUMA-aware OpenMP Programming Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group schmidl@itc.rwth-aachen.de Christian Terboven IT Center, RWTH Aachen University Deputy lead of the HPC
NUMA-aware OpenMP Programming Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group schmidl@itc.rwth-aachen.de Christian Terboven IT Center, RWTH Aachen University Deputy lead of the HPC
What communication library can do with a little hint from programmers? Takeshi Nanri (Kyushu Univ. and JST CREST, Japan)
") 1 What communication library can do with a little hint from programmers? Takeshi Nanri (Kyushu Univ. and JST CREST, Japan) 2 Background Various tuning opportunities in communication libraries:. Protocol?
1 What communication library can do with a little hint from programmers? Takeshi Nanri (Kyushu Univ. and JST CREST, Japan) 2 Background Various tuning opportunities in communication libraries:. Protocol?
Designing An Efficient Kernel-level and User-level Hybrid Approach for MPI Intra-node Communication on Multi-core Systems
 Designing An Efficient Kernel-level and User-level Hybrid Approach for MPI Intra-node Communication on Multi-core Systems Lei Chai Ping Lai Hyun-Wook Jin Dhabaleswar K. Panda Department of Computer Science
Designing An Efficient Kernel-level and User-level Hybrid Approach for MPI Intra-node Communication on Multi-core Systems Lei Chai Ping Lai Hyun-Wook Jin Dhabaleswar K. Panda Department of Computer Science
CRFS: A Lightweight User-Level Filesystem for Generic Checkpoint/Restart
 CRFS: A Lightweight User-Level Filesystem for Generic Checkpoint/Restart Xiangyong Ouyang, Raghunath Rajachandrasekar, Xavier Besseron, Hao Wang, Jian Huang, Dhabaleswar K. Panda Department of Computer
CRFS: A Lightweight User-Level Filesystem for Generic Checkpoint/Restart Xiangyong Ouyang, Raghunath Rajachandrasekar, Xavier Besseron, Hao Wang, Jian Huang, Dhabaleswar K. Panda Department of Computer
High Performance Computing: Tools and Applications
 High Performance Computing: Tools and Applications Edmond Chow School of Computational Science and Engineering Georgia Institute of Technology Lecture 20 Shared memory computers and clusters On a shared
High Performance Computing: Tools and Applications Edmond Chow School of Computational Science and Engineering Georgia Institute of Technology Lecture 20 Shared memory computers and clusters On a shared
Single-Points of Performance
 Single-Points of Performance Mellanox Technologies Inc. 29 Stender Way, Santa Clara, CA 9554 Tel: 48-97-34 Fax: 48-97-343 http://www.mellanox.com High-performance computations are rapidly becoming a critical
Single-Points of Performance Mellanox Technologies Inc. 29 Stender Way, Santa Clara, CA 9554 Tel: 48-97-34 Fax: 48-97-343 http://www.mellanox.com High-performance computations are rapidly becoming a critical
OCTOPUS Performance Benchmark and Profiling. June 2015
 OCTOPUS Performance Benchmark and Profiling June 2015 2 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the
OCTOPUS Performance Benchmark and Profiling June 2015 2 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Experiences in Tuning Performance of Hybrid MPI/OpenMP Applications on Quad-core Systems
 Experiences in Tuning Performance of Hybrid MPI/OpenMP Applications on Quad-core Systems Ashay Rane and Dan Stanzione Ph.D. {ashay.rane, dstanzi}@asu.edu Fulton High Performance Computing Initiative, Arizona
Experiences in Tuning Performance of Hybrid MPI/OpenMP Applications on Quad-core Systems Ashay Rane and Dan Stanzione Ph.D. {ashay.rane, dstanzi}@asu.edu Fulton High Performance Computing Initiative, Arizona
CUDA Kernel based Collective Reduction Operations on Large-scale GPU Clusters
 CUDA Kernel based Collective Reduction Operations on Large-scale GPU Clusters Ching-Hsiang Chu, Khaled Hamidouche, Akshay Venkatesh, Ammar Ahmad Awan and Dhabaleswar K. (DK) Panda Speaker: Sourav Chakraborty
CUDA Kernel based Collective Reduction Operations on Large-scale GPU Clusters Ching-Hsiang Chu, Khaled Hamidouche, Akshay Venkatesh, Ammar Ahmad Awan and Dhabaleswar K. (DK) Panda Speaker: Sourav Chakraborty
NUMA effects on multicore, multi socket systems
 NUMA effects on multicore, multi socket systems Iakovos Panourgias 9/9/2011 MSc in High Performance Computing The University of Edinburgh Year of Presentation: 2011 Abstract Modern multicore/multi socket
NUMA effects on multicore, multi socket systems Iakovos Panourgias 9/9/2011 MSc in High Performance Computing The University of Edinburgh Year of Presentation: 2011 Abstract Modern multicore/multi socket
Multi-threaded Queries. Intra-Query Parallelism in LLVM
 Multi-threaded Queries Intra-Query Parallelism in LLVM Multithreaded Queries Intra-Query Parallelism in LLVM Yang Liu Tianqi Wu Hao Li Interpreted vs Compiled (LLVM) Interpreted vs Compiled (LLVM) Interpreted
Multi-threaded Queries Intra-Query Parallelism in LLVM Multithreaded Queries Intra-Query Parallelism in LLVM Yang Liu Tianqi Wu Hao Li Interpreted vs Compiled (LLVM) Interpreted vs Compiled (LLVM) Interpreted
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
In the multi-core age, How do larger, faster and cheaper and more responsive memory sub-systems affect data management? Dhabaleswar K.
 In the multi-core age, How do larger, faster and cheaper and more responsive sub-systems affect data management? Panel at ADMS 211 Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory Department
In the multi-core age, How do larger, faster and cheaper and more responsive sub-systems affect data management? Panel at ADMS 211 Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory Department
Victor Malyshkin (Ed.) Malyshkin (Ed.) 13th International Conference, PaCT 2015 Petrozavodsk, Russia, August 31 September 4, 2015 Proceedings
 Malyshkin (Ed.) 13th International Conference, PaCT 2015 Petrozavodsk, Russia, August 31 September 4, 2015 Proceedings") Victor Malyshkin (Ed.) Lecture Notes in Computer Science The LNCS series reports state-of-the-art results in computer science re search, development, and education, at a high level and in both printed
Victor Malyshkin (Ed.) Lecture Notes in Computer Science The LNCS series reports state-of-the-art results in computer science re search, development, and education, at a high level and in both printed
CS 470 Spring Mike Lam, Professor. Distributed Programming & MPI
 CS 470 Spring 2017 Mike Lam, Professor Distributed Programming & MPI MPI paradigm Single program, multiple data (SPMD) One program, multiple processes (ranks) Processes communicate via messages An MPI
CS 470 Spring 2017 Mike Lam, Professor Distributed Programming & MPI MPI paradigm Single program, multiple data (SPMD) One program, multiple processes (ranks) Processes communicate via messages An MPI
UNDERSTANDING THE IMPACT OF MULTI-CORE ARCHITECTURE IN CLUSTER COMPUTING: A CASE STUDY WITH INTEL DUAL-CORE SYSTEM
 UNDERSTANDING THE IMPACT OF MULTI-CORE ARCHITECTURE IN CLUSTER COMPUTING: A CASE STUDY WITH INTEL DUAL-CORE SYSTEM Sweety Sen, Sonali Samanta B.Tech, Information Technology, Dronacharya College of Engineering,
UNDERSTANDING THE IMPACT OF MULTI-CORE ARCHITECTURE IN CLUSTER COMPUTING: A CASE STUDY WITH INTEL DUAL-CORE SYSTEM Sweety Sen, Sonali Samanta B.Tech, Information Technology, Dronacharya College of Engineering,
A Characterization of Shared Data Access Patterns in UPC Programs
 IBM T.J. Watson Research Center A Characterization of Shared Data Access Patterns in UPC Programs Christopher Barton, Calin Cascaval, Jose Nelson Amaral LCPC `06 November 2, 2006 Outline Motivation Overview
IBM T.J. Watson Research Center A Characterization of Shared Data Access Patterns in UPC Programs Christopher Barton, Calin Cascaval, Jose Nelson Amaral LCPC `06 November 2, 2006 Outline Motivation Overview
Leveraging MPI s One-Sided Communication Interface for Shared-Memory Programming
 Leveraging MPI s One-Sided Communication Interface for Shared-Memory Programming Torsten Hoefler, 1,2 James Dinan, 3 Darius Buntinas, 3 Pavan Balaji, 3 Brian Barrett, 4 Ron Brightwell, 4 William Gropp,
Leveraging MPI s One-Sided Communication Interface for Shared-Memory Programming Torsten Hoefler, 1,2 James Dinan, 3 Darius Buntinas, 3 Pavan Balaji, 3 Brian Barrett, 4 Ron Brightwell, 4 William Gropp,
NUMA Support for Charm++
 NUMA Support for Charm++ Christiane Pousa Ribeiro (INRIA) Filippo Gioachin (UIUC) Chao Mei (UIUC) Jean-François Méhaut (INRIA) Gengbin Zheng(UIUC) Laxmikant Kalé (UIUC) Outline Introduction Motivation
NUMA Support for Charm++ Christiane Pousa Ribeiro (INRIA) Filippo Gioachin (UIUC) Chao Mei (UIUC) Jean-François Méhaut (INRIA) Gengbin Zheng(UIUC) Laxmikant Kalé (UIUC) Outline Introduction Motivation
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
ad-heap: an Efficient Heap Data Structure for Asymmetric Multicore Processors
 ad-heap: an Efficient Heap Data Structure for Asymmetric Multicore Processors Weifeng Liu and Brian Vinter Niels Bohr Institute University of Copenhagen Denmark {weifeng, vinter}@nbi.dk March 1, 2014 Weifeng
ad-heap: an Efficient Heap Data Structure for Asymmetric Multicore Processors Weifeng Liu and Brian Vinter Niels Bohr Institute University of Copenhagen Denmark {weifeng, vinter}@nbi.dk March 1, 2014 Weifeng
OP2 FOR MANY-CORE ARCHITECTURES
 OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
Software Distributed Shared Memory with High Bandwidth Network: Production and Evaluation
 ,,.,, InfiniBand PCI Express,,,. Software Distributed Shared Memory with High Bandwidth Network: Production and Evaluation Akira Nishida, The recent development of commodity hardware technologies makes
,,.,, InfiniBand PCI Express,,,. Software Distributed Shared Memory with High Bandwidth Network: Production and Evaluation Akira Nishida, The recent development of commodity hardware technologies makes