RECAP. B649 Parallel Architectures and Programming
|
|
|
- Ethelbert Bridges
- 5 years ago
- Views:
Transcription
1 RECAP B649 Parallel Architectures and Programming
2 RECAP 2
3 Recap ILP Exploiting ILP Dynamic scheduling Thread-level Parallelism Memory Hierarchy Other topics through student presentations Virtual Machines 3
4 ILP: Pipelining 4
5 Pipelining: Adding Latches 5
6 Pipelining: Adding Forwarding 6

7 Pipelining: Adding Branch Delay Slots 7
8 Extending the Basic Pipeline 8
9 Extending the Basic Pipeline 8

10 Extending the Basic Pipeline 8
11 Exploiting ILP Through Compiler Techniques Loop unrolling Making use of branch delayed slots Static branch prediction Loop fusion Unroll and jam... 9

12 Dynamic Branch Prediction Address bits bits to index BPB Branch Prediction Buffer 10

13 Two-bit Branch Predictor 11
 Use Branch Target Buffers (BTBs) for caching branch targets")
14 General n-bit Correlating Branch Predictors Address bits bits to index BPB n bits Branch Prediction Buffer global shift register (m bits) Use Branch Target Buffers (BTBs) for caching branch targets 12
15 Dynamic Scheduling: Tomasulo s Approach 13
16 Tomasulo s Approach: Observations RAW hazards handled by waiting for operands WAR and WAW hazards handled by register renaming only WAR and WAW hazards between instructions currently in the pipeline are handled; is this a problem? larger number of hidden names reduces name dependences CDB implements forwarding 14

17 Fields in ROB 1. Instruction type 2. Destination 3. Value 4. Ready Tomasulo s Approach + Speculation 15
18 Observations on Speculation Speculation enables precise exception handling defer exception handling until instruction ready to commit Branches are critical to performance prediction accuracy latency of misprediction detection misprediction recovery time Must avoid hazards through memory WAR and WAW already taken care of (how?) for RAW don t allow load to proceed if an active ROB entry has Destination field matching with A field of load maintain program order for effective address computation (why?) 16
19 Multiple Issue Processor Types 17
20 Dyn. Scheduling+Multiple Issue+Speculation Design parameters two-way issue (two instruction issues per cycle) pipelined and separate integer and FP functional units dynamic scheduling, but not out-of-order issue speculative execution Task per issue: assign reservation station and update pipeline control tables (i.e., control signals) Two possible techniques do the task in half a clock cycle build wider logic to issue any pair of instructions together Modern processors use both (4 or more way superscalar) 18
21 Shared-Memory Multiprocessors 19

22 Distributed-Memory Multiprocessors 20

23 Other Ways to Categorize Parallel Programming threads vs producer-consumer client-sever vs p-to-p / master-slave vs symm. course vs fine grained SPMD vs MPMD tightly vs loosely coupled Parallel Programs recursive vs iterative shared mem vs msg passing data vs task parallel synch. vs asynch. 21
24 Write Invalidate Cache Coherence Protocol for Write-Back Caches 22
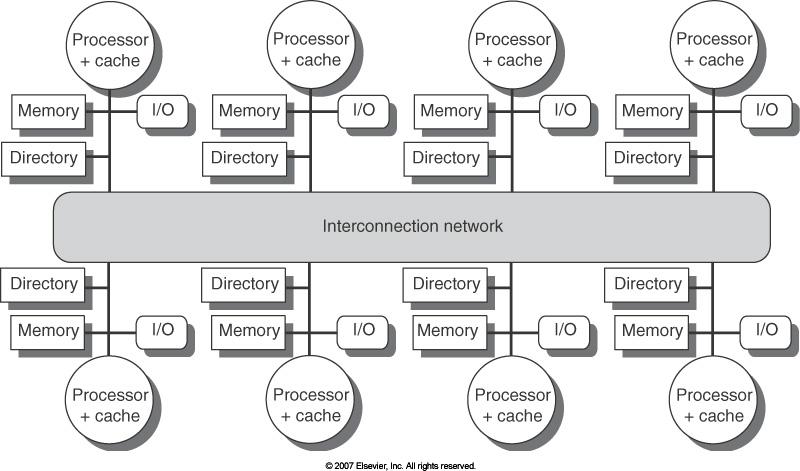
25 Distributed Memory+Directories 23

26 Directory-Based Cache Coherence 24
27 Other Topics x86 assembly programming VLIW / EPIC Vector processors Embedded systems Scientific applications GPUs and GPGPUs CUDA and OpenCL Interconnection networks Virtualization 25
28 WHAT S NEXT? 26
29 Future Continued importance of parallel programming challenge: how to program multiprocessors role of programming languages and compilers Convergence or specialization? standardization of general purpose architecture migration of special-purpose CPUs for general use 27

30 Landscape of Parallel Computing Research: A View from Berkeley 28
CMSC411 Fall 2013 Midterm 2 Solutions
 CMSC411 Fall 2013 Midterm 2 Solutions 1. (12 pts) Memory hierarchy a. (6 pts) Suppose we have a virtual memory of size 64 GB, or 2 36 bytes, where pages are 16 KB (2 14 bytes) each, and the machine has
CMSC411 Fall 2013 Midterm 2 Solutions 1. (12 pts) Memory hierarchy a. (6 pts) Suppose we have a virtual memory of size 64 GB, or 2 36 bytes, where pages are 16 KB (2 14 bytes) each, and the machine has
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 3. Instruction-Level Parallelism and Its Exploitation
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
ILP: Instruction Level Parallelism
 ILP: Instruction Level Parallelism Tassadaq Hussain Riphah International University Barcelona Supercomputing Center Universitat Politècnica de Catalunya Introduction Introduction Pipelining become universal
ILP: Instruction Level Parallelism Tassadaq Hussain Riphah International University Barcelona Supercomputing Center Universitat Politècnica de Catalunya Introduction Introduction Pipelining become universal
Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.
 Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.") Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Instruction Level Parallelism (ILP)
") 1 / 26 Instruction Level Parallelism (ILP) ILP: The simultaneous execution of multiple instructions from a program. While pipelining is a form of ILP, the general application of ILP goes much further into
1 / 26 Instruction Level Parallelism (ILP) ILP: The simultaneous execution of multiple instructions from a program. While pipelining is a form of ILP, the general application of ILP goes much further into
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Final Review Shuai Wang Department of Computer Science and Technology Nanjing University Computer Architecture Computer architecture, like other architecture, is the art
Computer Architecture Spring 2016 Final Review Shuai Wang Department of Computer Science and Technology Nanjing University Computer Architecture Computer architecture, like other architecture, is the art
DYNAMIC AND SPECULATIVE INSTRUCTION SCHEDULING
 DYNAMIC AND SPECULATIVE INSTRUCTION SCHEDULING Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 3, John L. Hennessy and David A. Patterson,
DYNAMIC AND SPECULATIVE INSTRUCTION SCHEDULING Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 3, John L. Hennessy and David A. Patterson,
Instruction-Level Parallelism and Its Exploitation
 Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)
 Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)") Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Dynamic Scheduling. CSE471 Susan Eggers 1
 Dynamic Scheduling Why go out of style? expensive hardware for the time (actually, still is, relatively) register files grew so less register pressure early RISCs had lower CPIs Why come back? higher chip
Dynamic Scheduling Why go out of style? expensive hardware for the time (actually, still is, relatively) register files grew so less register pressure early RISCs had lower CPIs Why come back? higher chip
Getting CPI under 1: Outline
 CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
Performance of Computer Systems. CSE 586 Computer Architecture. Review. ISA s (RISC, CISC, EPIC) Basic Pipeline Model.
 Basic Pipeline Model.") Performance of Computer Systems CSE 586 Computer Architecture Review Jean-Loup Baer http://www.cs.washington.edu/education/courses/586/00sp Performance metrics Use (weighted) arithmetic means for execution
Performance of Computer Systems CSE 586 Computer Architecture Review Jean-Loup Baer http://www.cs.washington.edu/education/courses/586/00sp Performance metrics Use (weighted) arithmetic means for execution
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1)
") Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Chapter 06: Instruction Pipelining and Parallel Processing
 Chapter 06: Instruction Pipelining and Parallel Processing Lesson 09: Superscalar Processors and Parallel Computer Systems Objective To understand parallel pipelines and multiple execution units Instruction
Chapter 06: Instruction Pipelining and Parallel Processing Lesson 09: Superscalar Processors and Parallel Computer Systems Objective To understand parallel pipelines and multiple execution units Instruction
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism. In-Cheol Park Dept. of EE, KAIST
 Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
5008: Computer Architecture
 5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
Website for Students VTU NOTES QUESTION PAPERS NEWS RESULTS
 Advanced Computer Architecture- 06CS81 Hardware Based Speculation Tomasulu algorithm and Reorder Buffer Tomasulu idea: 1. Have reservation stations where register renaming is possible 2. Results are directly
Advanced Computer Architecture- 06CS81 Hardware Based Speculation Tomasulu algorithm and Reorder Buffer Tomasulu idea: 1. Have reservation stations where register renaming is possible 2. Results are directly
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects
 Announcements UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects Inf3 Computer Architecture - 2017-2018 1 Last time: Tomasulo s Algorithm Inf3 Computer
Announcements UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects Inf3 Computer Architecture - 2017-2018 1 Last time: Tomasulo s Algorithm Inf3 Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1
 CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Exploitation of instruction level parallelism
 Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions
 CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis6627 Powerpoint Lecture Notes from John Hennessy
CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis6627 Powerpoint Lecture Notes from John Hennessy
Four Steps of Speculative Tomasulo cycle 0
 HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
Metodologie di Progettazione Hardware-Software
 Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
Course on Advanced Computer Architectures
 Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, July 9, 2018 Course on Advanced Computer Architectures Prof. D. Sciuto, Prof. C. Silvano EX1 EX2 EX3 Q1
Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, July 9, 2018 Course on Advanced Computer Architectures Prof. D. Sciuto, Prof. C. Silvano EX1 EX2 EX3 Q1
Adapted from David Patterson s slides on graduate computer architecture
 Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
CS 654 Computer Architecture Summary. Peter Kemper
 CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Instruction Level Parallelism
 Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Lecture 8: Branch Prediction, Dynamic ILP. Topics: static speculation and branch prediction (Sections )
") Lecture 8: Branch Prediction, Dynamic ILP Topics: static speculation and branch prediction (Sections 2.3-2.6) 1 Correlating Predictors Basic branch prediction: maintain a 2-bit saturating counter for each
Lecture 8: Branch Prediction, Dynamic ILP Topics: static speculation and branch prediction (Sections 2.3-2.6) 1 Correlating Predictors Basic branch prediction: maintain a 2-bit saturating counter for each
Multiple Instruction Issue and Hardware Based Speculation
 Multiple Instruction Issue and Hardware Based Speculation Soner Önder Michigan Technological University, Houghton MI www.cs.mtu.edu/~soner Hardware Based Speculation Exploiting more ILP requires that we
Multiple Instruction Issue and Hardware Based Speculation Soner Önder Michigan Technological University, Houghton MI www.cs.mtu.edu/~soner Hardware Based Speculation Exploiting more ILP requires that we
Multiple Issue and Static Scheduling. Multiple Issue. MSc Informatics Eng. Beyond Instruction-Level Parallelism
 Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Computer Systems Architecture
 Computer Systems Architecture Lecture 12 Mahadevan Gomathisankaran March 4, 2010 03/04/2010 Lecture 12 CSCE 4610/5610 1 Discussion: Assignment 2 03/04/2010 Lecture 12 CSCE 4610/5610 2 Increasing Fetch
Computer Systems Architecture Lecture 12 Mahadevan Gomathisankaran March 4, 2010 03/04/2010 Lecture 12 CSCE 4610/5610 1 Discussion: Assignment 2 03/04/2010 Lecture 12 CSCE 4610/5610 2 Increasing Fetch
EECC551 Exam Review 4 questions out of 6 questions
 EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
S = 32 2 d kb (1) L = 32 2 D B (2) A = 2 2 m mod 4 (3) W = 16 2 y mod 4 b (4)
 L = 32 2 D B (2) A = 2 2 m mod 4 (3) W = 16 2 y mod 4 b (4)") 1 Cache Design You have already written your civic registration number (personnummer) on the cover page in the format YyMmDd-XXXX. Use the following formulas to calculate the parameters of your caches:
1 Cache Design You have already written your civic registration number (personnummer) on the cover page in the format YyMmDd-XXXX. Use the following formulas to calculate the parameters of your caches:
CPE 631 Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Lecture 9: More ILP. Today: limits of ILP, case studies, boosting ILP (Sections )
") Lecture 9: More ILP Today: limits of ILP, case studies, boosting ILP (Sections 3.8-3.14) 1 ILP Limits The perfect processor: Infinite registers (no WAW or WAR hazards) Perfect branch direction and target
Lecture 9: More ILP Today: limits of ILP, case studies, boosting ILP (Sections 3.8-3.14) 1 ILP Limits The perfect processor: Infinite registers (no WAW or WAR hazards) Perfect branch direction and target
LIMITS OF ILP. B649 Parallel Architectures and Programming
 LIMITS OF ILP B649 Parallel Architectures and Programming A Perfect Processor Register renaming infinite number of registers hence, avoids all WAW and WAR hazards Branch prediction perfect prediction Jump
LIMITS OF ILP B649 Parallel Architectures and Programming A Perfect Processor Register renaming infinite number of registers hence, avoids all WAW and WAR hazards Branch prediction perfect prediction Jump
Static vs. Dynamic Scheduling
 Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
CS433 Midterm. Prof Josep Torrellas. October 19, Time: 1 hour + 15 minutes
 CS433 Midterm Prof Josep Torrellas October 19, 2017 Time: 1 hour + 15 minutes Name: Instructions: 1. This is a closed-book, closed-notes examination. 2. The Exam has 4 Questions. Please budget your time.
CS433 Midterm Prof Josep Torrellas October 19, 2017 Time: 1 hour + 15 minutes Name: Instructions: 1. This is a closed-book, closed-notes examination. 2. The Exam has 4 Questions. Please budget your time.
CS Mid-Term Examination - Fall Solutions. Section A.
 CS 211 - Mid-Term Examination - Fall 2008. Solutions Section A. Ques.1: 10 points For each of the questions, underline or circle the most suitable answer(s). The performance of a pipeline processor is
CS 211 - Mid-Term Examination - Fall 2008. Solutions Section A. Ques.1: 10 points For each of the questions, underline or circle the most suitable answer(s). The performance of a pipeline processor is
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
CPI IPC. 1 - One At Best 1 - One At best. Multiple issue processors: VLIW (Very Long Instruction Word) Speculative Tomasulo Processor
 Speculative Tomasulo Processor") Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Load1 no Load2 no Add1 Y Sub Reg[F2] Reg[F6] Add2 Y Add Reg[F2] Add1 Add3 no Mult1 Y Mul Reg[F2] Reg[F4] Mult2 Y Div Reg[F6] Mult1
![Load1 no Load2 no Add1 Y Sub Reg[F2] Reg[F6] Add2 Y Add Reg[F2] Add1 Add3 no Mult1 Y Mul Reg[F2] Reg[F4] Mult2 Y Div Reg[F6] Mult1](/thumbs/92/108067849.jpg "Load1 no Load2 no Add1 Y Sub Reg[F2] Reg[F6] Add2 Y Add Reg[F2] Add1 Add3 no Mult1 Y Mul Reg[F2] Reg[F4] Mult2 Y Div Reg[F6] Mult1") Instruction Issue Execute Write result L.D F6, 34(R2) L.D F2, 45(R3) MUL.D F0, F2, F4 SUB.D F8, F2, F6 DIV.D F10, F0, F6 ADD.D F6, F8, F2 Name Busy Op Vj Vk Qj Qk A Load1 no Load2 no Add1 Y Sub Reg[F2]
Instruction Issue Execute Write result L.D F6, 34(R2) L.D F2, 45(R3) MUL.D F0, F2, F4 SUB.D F8, F2, F6 DIV.D F10, F0, F6 ADD.D F6, F8, F2 Name Busy Op Vj Vk Qj Qk A Load1 no Load2 no Add1 Y Sub Reg[F2]
Instruction Level Parallelism
 Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
CPI < 1? How? What if dynamic branch prediction is wrong? Multiple issue processors: Speculative Tomasulo Processor
 1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
Page # CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Michela Taufer
 Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW. Computer Architectures S
 Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW Computer Architectures 521480S Dynamic Branch Prediction Performance = ƒ(accuracy, cost of misprediction) Branch History Table (BHT) is simplest
Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW Computer Architectures 521480S Dynamic Branch Prediction Performance = ƒ(accuracy, cost of misprediction) Branch History Table (BHT) is simplest
Tutorial 11. Final Exam Review
 Tutorial 11 Final Exam Review Introduction Instruction Set Architecture: contract between programmer and designers (e.g.: IA-32, IA-64, X86-64) Computer organization: describe the functional units, cache
Tutorial 11 Final Exam Review Introduction Instruction Set Architecture: contract between programmer and designers (e.g.: IA-32, IA-64, X86-64) Computer organization: describe the functional units, cache
Chapter 3 (CONT II) Instructor: Josep Torrellas CS433. Copyright J. Torrellas 1999,2001,2002,2007,
 Instructor: Josep Torrellas CS433. Copyright J. Torrellas 1999,2001,2002,2007,") Chapter 3 (CONT II) Instructor: Josep Torrellas CS433 Copyright J. Torrellas 1999,2001,2002,2007, 2013 1 Hardware-Based Speculation (Section 3.6) In multiple issue processors, stalls due to branches would
Chapter 3 (CONT II) Instructor: Josep Torrellas CS433 Copyright J. Torrellas 1999,2001,2002,2007, 2013 1 Hardware-Based Speculation (Section 3.6) In multiple issue processors, stalls due to branches would
CPE 631 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
Reorder Buffer Implementation (Pentium Pro) Reorder Buffer Implementation (Pentium Pro)
 Reorder Buffer Implementation (Pentium Pro)") Reorder Buffer Implementation (Pentium Pro) Hardware data structures retirement register file (RRF) (~ IBM 360/91 physical registers) physical register file that is the same size as the architectural registers
Reorder Buffer Implementation (Pentium Pro) Hardware data structures retirement register file (RRF) (~ IBM 360/91 physical registers) physical register file that is the same size as the architectural registers
In embedded systems there is a trade off between performance and power consumption. Using ILP saves power and leads to DECREASING clock frequency.
 Lesson 1 Course Notes Review of Computer Architecture Embedded Systems ideal: low power, low cost, high performance Overview of VLIW and ILP What is ILP? It can be seen in: Superscalar In Order Processors
Lesson 1 Course Notes Review of Computer Architecture Embedded Systems ideal: low power, low cost, high performance Overview of VLIW and ILP What is ILP? It can be seen in: Superscalar In Order Processors
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EITF20: Computer Architecture Part3.2.1: Pipeline - 3
 EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
Donn Morrison Department of Computer Science. TDT4255 ILP and speculation
 TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
Outline EEL 5764 Graduate Computer Architecture. Chapter 3 Limits to ILP and Simultaneous Multithreading. Overcoming Limits - What do we need??
 Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
EECC551 - Shaaban. 1 GHz? to???? GHz CPI > (?)
") Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Page 1. CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Pipeline CPI (II) Michela Taufer
 Pipeline CPI (II) Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING UNIT-1
 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by:
 Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by: Result forwarding (register bypassing) to reduce or eliminate stalls needed
Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by: Result forwarding (register bypassing) to reduce or eliminate stalls needed
EE382A Lecture 7: Dynamic Scheduling. Department of Electrical Engineering Stanford University
 EE382A Lecture 7: Dynamic Scheduling Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 7-1 Announcements Project proposal due on Wed 10/14 2-3 pages submitted
EE382A Lecture 7: Dynamic Scheduling Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 7-1 Announcements Project proposal due on Wed 10/14 2-3 pages submitted
Chapter 3: Instruction Level Parallelism (ILP) and its exploitation. Types of dependences
 and its exploitation. Types of dependences") Chapter 3: Instruction Level Parallelism (ILP) and its exploitation Pipeline CPI = Ideal pipeline CPI + stalls due to hazards invisible to programmer (unlike process level parallelism) ILP: overlap execution
Chapter 3: Instruction Level Parallelism (ILP) and its exploitation Pipeline CPI = Ideal pipeline CPI + stalls due to hazards invisible to programmer (unlike process level parallelism) ILP: overlap execution
CISC 662 Graduate Computer Architecture. Lecture 10 - ILP 3
 CISC 662 Graduate Computer Architecture Lecture 10 - ILP 3 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 10 - ILP 3 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CSE 502 Graduate Computer Architecture
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 CSE 502 Graduate Computer Architecture Lec 15-19 Inst. Lvl. Parallelism Instruction-Level Parallelism and Its Exploitation Larry Wittie
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 CSE 502 Graduate Computer Architecture Lec 15-19 Inst. Lvl. Parallelism Instruction-Level Parallelism and Its Exploitation Larry Wittie
Lecture 9: Dynamic ILP. Topics: out-of-order processors (Sections )
") Lecture 9: Dynamic ILP Topics: out-of-order processors (Sections 2.3-2.6) 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB) Branch prediction and instr fetch R1 R1+R2 R2 R1+R3 BEQZ R2 R3
Lecture 9: Dynamic ILP Topics: out-of-order processors (Sections 2.3-2.6) 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB) Branch prediction and instr fetch R1 R1+R2 R2 R1+R3 BEQZ R2 R3
Hardware-based Speculation
 Hardware-based Speculation M. Sonza Reorda Politecnico di Torino Dipartimento di Automatica e Informatica 1 Introduction Hardware-based speculation is a technique for reducing the effects of control dependences
Hardware-based Speculation M. Sonza Reorda Politecnico di Torino Dipartimento di Automatica e Informatica 1 Introduction Hardware-based speculation is a technique for reducing the effects of control dependences
ארכי טק טורת יחיד ת עיבוד מרכזי ת
 ארכי טק טורת יחיד ת עיבוד מרכזי ת (36113741) תשס"ג סמסטר א' March, 2007 Hugo Guterman (hugo@ee.bgu.ac.il) Web site: http://www.ee.bgu.ac.il/~cpuarch Arch. CPU L5 Pipeline II 1 Outline More pipelining Control
ארכי טק טורת יחיד ת עיבוד מרכזי ת (36113741) תשס"ג סמסטר א' March, 2007 Hugo Guterman (hugo@ee.bgu.ac.il) Web site: http://www.ee.bgu.ac.il/~cpuarch Arch. CPU L5 Pipeline II 1 Outline More pipelining Control
ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING
 ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING 16 MARKS CS 2354 ADVANCE COMPUTER ARCHITECTURE 1. Explain the concepts and challenges of Instruction-Level Parallelism. Define
ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING 16 MARKS CS 2354 ADVANCE COMPUTER ARCHITECTURE 1. Explain the concepts and challenges of Instruction-Level Parallelism. Define
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
COSC4201 Instruction Level Parallelism Dynamic Scheduling
 COSC4201 Instruction Level Parallelism Dynamic Scheduling Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Outline Data dependence and hazards Exposing parallelism
COSC4201 Instruction Level Parallelism Dynamic Scheduling Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Outline Data dependence and hazards Exposing parallelism
Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar, VLIW. CPE 631 Session 19 Exploiting ILP with SW Approaches
 Session xploiting ILP with SW Approaches lectrical and Computer ngineering University of Alabama in Huntsville Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar,
Session xploiting ILP with SW Approaches lectrical and Computer ngineering University of Alabama in Huntsville Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar,
Processor: Superscalars Dynamic Scheduling
 Processor: Superscalars Dynamic Scheduling Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475 03, Peh/ELE475 (Princeton),
Processor: Superscalars Dynamic Scheduling Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475 03, Peh/ELE475 (Princeton),
Page 1. Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
TDT 4260 lecture 7 spring semester 2015
 1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
CS 2410 Mid term (fall 2015) Indicate which of the following statements is true and which is false.
 Indicate which of the following statements is true and which is false.") CS 2410 Mid term (fall 2015) Name: Question 1 (10 points) Indicate which of the following statements is true and which is false. (1) SMT architectures reduces the thread context switch time by saving in
CS 2410 Mid term (fall 2015) Name: Question 1 (10 points) Indicate which of the following statements is true and which is false. (1) SMT architectures reduces the thread context switch time by saving in
Chapter 4 The Processor 1. Chapter 4D. The Processor
 Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
ECE 505 Computer Architecture
 ECE 505 Computer Architecture Pipelining 2 Berk Sunar and Thomas Eisenbarth Review 5 stages of RISC IF ID EX MEM WB Ideal speedup of pipelining = Pipeline depth (N) Practically Implementation problems
ECE 505 Computer Architecture Pipelining 2 Berk Sunar and Thomas Eisenbarth Review 5 stages of RISC IF ID EX MEM WB Ideal speedup of pipelining = Pipeline depth (N) Practically Implementation problems
Super Scalar. Kalyan Basu March 21,
 Super Scalar Kalyan Basu basu@cse.uta.edu March 21, 2007 1 Super scalar Pipelines A pipeline that can complete more than 1 instruction per cycle is called a super scalar pipeline. We know how to build
Super Scalar Kalyan Basu basu@cse.uta.edu March 21, 2007 1 Super scalar Pipelines A pipeline that can complete more than 1 instruction per cycle is called a super scalar pipeline. We know how to build
E0-243: Computer Architecture
 E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
UNIT I (Two Marks Questions & Answers)
") UNIT I (Two Marks Questions & Answers) Discuss the different ways how instruction set architecture can be classified? Stack Architecture,Accumulator Architecture, Register-Memory Architecture,Register-
UNIT I (Two Marks Questions & Answers) Discuss the different ways how instruction set architecture can be classified? Stack Architecture,Accumulator Architecture, Register-Memory Architecture,Register-
CMSC411 Epic Cheat Sheet Draft Summer 2014
 CMSC411 Epic Cheat Sheet Draft Summer 2014 Table of Contents (Locations in 5thEd) ISAs and MIPS, Appendix B Classifications B.2 Encodings B.3 MIPS B.9 Quantitative CPU Analysis Ch. 1.8 1.9 Amdahl's Law
CMSC411 Epic Cheat Sheet Draft Summer 2014 Table of Contents (Locations in 5thEd) ISAs and MIPS, Appendix B Classifications B.2 Encodings B.3 MIPS B.9 Quantitative CPU Analysis Ch. 1.8 1.9 Amdahl's Law
Chapter 3 & Appendix C Part B: ILP and Its Exploitation
 CS359: Computer Architecture Chapter 3 & Appendix C Part B: ILP and Its Exploitation Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 3.1 Concepts and
CS359: Computer Architecture Chapter 3 & Appendix C Part B: ILP and Its Exploitation Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 3.1 Concepts and
Chapter 03. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 03 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 3.3 Comparison of 2-bit predictors. A noncorrelating predictor for 4096 bits is first, followed
Chapter 03 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 3.3 Comparison of 2-bit predictors. A noncorrelating predictor for 4096 bits is first, followed
Keywords and Review Questions
 Keywords and Review Questions lec1: Keywords: ISA, Moore s Law Q1. Who are the people credited for inventing transistor? Q2. In which year IC was invented and who was the inventor? Q3. What is ISA? Explain
Keywords and Review Questions lec1: Keywords: ISA, Moore s Law Q1. Who are the people credited for inventing transistor? Q2. In which year IC was invented and who was the inventor? Q3. What is ISA? Explain
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CSE 490/590 Computer Architecture Homework 2
 CSE 490/590 Computer Architecture Homework 2 1. Suppose that you have the following out-of-order datapath with 1-cycle ALU, 2-cycle Mem, 3-cycle Fadd, 5-cycle Fmul, no branch prediction, and in-order fetch
CSE 490/590 Computer Architecture Homework 2 1. Suppose that you have the following out-of-order datapath with 1-cycle ALU, 2-cycle Mem, 3-cycle Fadd, 5-cycle Fmul, no branch prediction, and in-order fetch
Dynamic Control Hazard Avoidance
 Dynamic Control Hazard Avoidance Consider Effects of Increasing the ILP Control dependencies rapidly become the limiting factor they tend to not get optimized by the compiler more instructions/sec ==>
Dynamic Control Hazard Avoidance Consider Effects of Increasing the ILP Control dependencies rapidly become the limiting factor they tend to not get optimized by the compiler more instructions/sec ==>
Advanced issues in pipelining
 Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
CS 152, Spring 2011 Section 8
 CS 152, Spring 2011 Section 8 Christopher Celio University of California, Berkeley Agenda Grades Upcoming Quiz 3 What it covers OOO processors VLIW Branch Prediction Intel Core 2 Duo (Penryn) Vs. NVidia
CS 152, Spring 2011 Section 8 Christopher Celio University of California, Berkeley Agenda Grades Upcoming Quiz 3 What it covers OOO processors VLIW Branch Prediction Intel Core 2 Duo (Penryn) Vs. NVidia
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
Last lecture. Some misc. stuff An older real processor Class review/overview.
 Last lecture Some misc. stuff An older real processor Class review/overview. HW5 Misc. Status issues Answers posted Returned on Wednesday (next week) Project presentation signup at http://tinyurl.com/470w14talks
Last lecture Some misc. stuff An older real processor Class review/overview. HW5 Misc. Status issues Answers posted Returned on Wednesday (next week) Project presentation signup at http://tinyurl.com/470w14talks