Modeling and Optimization of Resource Allocation in Cloud
|
|
|
- Meredith Barber
- 5 years ago
- Views:
Transcription
1 PhD Thesis Progress First Report Thesis Advisor: Asst. Prof. Dr. Tolga Ovatman Istanbul Technical University Department of Computer Engineering January 8, 2015
2 Outline 1 Introduction 2 Studies Time Plan 3 4 5
3 Summary Optimization on 3 related phases of the cloud software life cycle 1 Map Reduce Configuration 2 Resource Selection and Assignment 3 Work Distribution and Load Balancing Graph based modeling of the cloud environment and RA problem Inclusion of cloud computing aspects to the RA problem Cloud providers will benefit since they will be able to use their resources more efficiently and will be able to serve more customers without violating the SLAs. Cloud users will also benefit in terms of shorter application execution time and less infrastructure requirement (lower cost).
4 Life Cycle of Cloud Software Development of Distributed Software MapReduce Configuration Phase 2 Resource Allocation Resource Selection and Optimization Phase 1 Load Balancing Distribution of Work to Resources Phase 3
5 MapReduce Configuration Motivation The cost of using 1000 machines for 1 hour, is the same as using 1 machine for 1000 hours in the cloud paradigm (Cost associativity). Aim Maximizing the utilization of all nodes for a Hadoop job by calculating the optimum parameters i.e. number of mappers and reducers Optimum parameters depend on the resource consumption of the SW. Design model of the software will be statically analyzed in order to guess resource consumption pattern and bottleneck resources.
6 Resource Selection and Optimization Motivation In distributed computing environments, up to 85 percent of computing capacity remains idle mainly due to poor optimization of placement. Aim Optimally assigning interconnected virtual nodes to substrate network with constraints VN requests and DC network will be represented as weighted graphs. Graph similarity subgraph matching algorithms will be employed. There are several possible constraints to consider / optimize.
7 Work Distribution to Resources Motivation Data flows between nodes only in the shuffle step of the MapReduce job, and tuning it can have a big impact on job execution time. Aim Analysis of the shuffle and scheduling algorithms of Apache Hadoop framework Selection of node roles is critical to reduce network traffic. Dynamic re-distribution of work during execution results in better load balancing and better performance. Cost based analysis of the existing schedulers will be performed.
8 Studies Time Plan We decided to use a real-world cloud datacenter topology for the experiments. Performed tasks include: Finding candidate topologies by examining similar studies Choosing the most appropriate topology Converting the topology into a machine-readable format
9 Studies Time Plan CloudSim Framework is chosen to simulate the cloud infrastructure. A general purpose tool which allows: DC and VM creation DC topologies Load generation Simple scheduling and logging Improvements and extensions: Interrelated VMs an VM topologies Delayed and continuous load generation Automated topology creation Visualization of resource allocation
10 Studies Time Plan Experimental Setup 9 baseline methods (6 of them are implemented) for resource selection and VM placement 16 metrics (10 of them are implemented) to evaluate the performance of these methods Analysis and hierarchical categorization of the metrics Analysis of the baseline methods and their expected effects on the metrics
11 Studies Time Plan Validation of the baseline methods Comparison of the baseline methods and the initial version of the suggested algorithm Validation and improvement of the suggested algorithm Evaluation of different configurations on each method s performance
12 Studies Time Plan Gannt Chart Experimental Setup Documentation
13 Other Approaches Randomly generated DC topology [Ilyashenko,2008] and [Ghazar, 2013] Proprietary data [Agarwal et al., 2010] DC topology generated based on cities, their populations and locations [Larumbe and Sanso, 2013] GÉANT network map A European research and education network that interconnects National Research and Education Networks
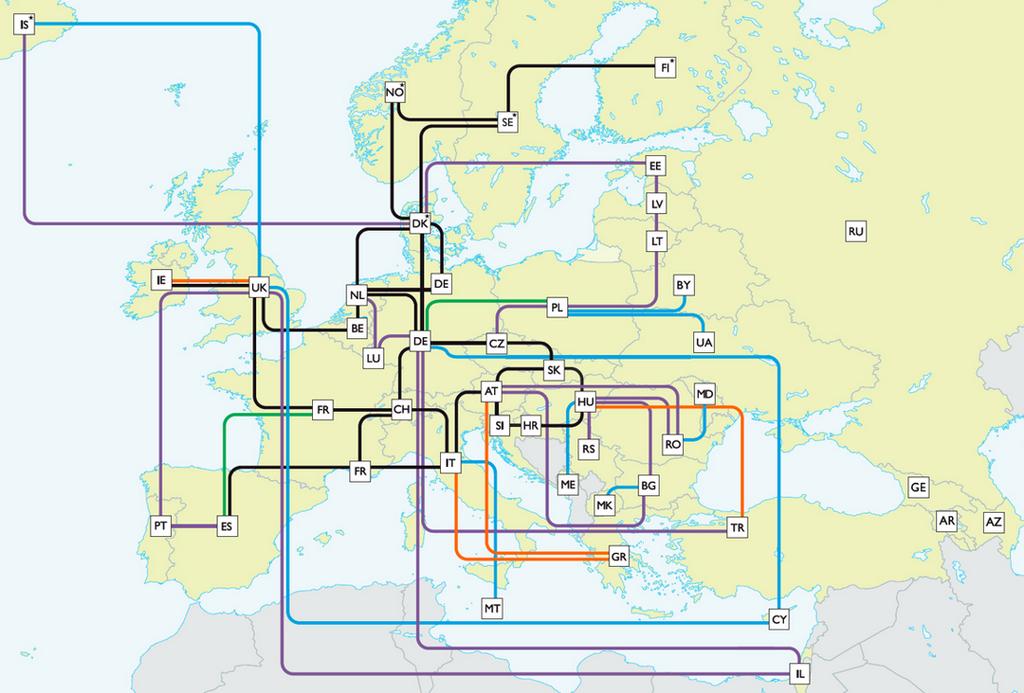
14 GÉANT
15 FEDERICA
16 FEDERICA FP-7 Project completed in 2010 Hosts experimental activities on new Internet architectures and protocols Available data: 4 core and 10 non-core Point of Presences Dedicated 1 Gbps channels Core PoPs contain 2+ virtualization nodes (servers) with VMware Non-core PoPs contain 1 virtualization nodes (servers) with VMware Node and link specifications
17 BRITE Format Output format of the Boston University Representative Topology Generator
18 CloudSim A framework for modeling and simulation of cloud computing infrastructures and services [Calheiros et al., 2011]
19 CloudSim Features Benefited from Cloud entity classes: Datacenter, Host, Vm, Cloudlet Message passing mechanism for the communication among cloud entities Datacenter network topology Simulation
20 Design Decisions DC A host represents the aggregation of all computing capacity at a particular DC. Hosts are mapped one-to-one to DCs. Allows abstraction of host allocation within DCs A cloudlet represents the aggregation of all the load for a particular VM. Cloudlets are mapped one-to-one to VMs. Allows abstraction of cloudlet allocation within VMs Broker Host VM Cloudlet
21 New CloudSim Features Implemented Automatic creation of datacenters and brokers at each location
22 New CloudSim Features Implemented Interrelated VMs VM topology generation (Complete, Linear, Circular, Star, Custom) Directed undirected dependencies Delay for communication VM Life-cycle Deferred initialization for related VMs Destruction after the completion of cloudlets Statistics logging

23 New CloudSim Features Implemented Visualization of the topology and allocation
24 Categorization Quality of Service Temporal Volumetrical Distributional Other Latency Duration AUL MUL ADL MDL HPC JRT JCT WTT SLA UTR TRP CPR DSF LDB RJR FRN PSP
25 Average User Latency (AUL) This criterion is the average time (in ms) it takes for cloud users to access their VMs. Here, average value is calculated both for the users and for their VMs. It should be measured with equal load of VM requests to compare two methods. A high value of user latency means the input and output transfer between user and the processing units is slow.
26 Maximum User Latency (MUL) Even if the average user latency is low in a system, one of the users may be starving to access one of its VMs. To reveal such problems, we suggest the maximum user latency metric. Here, high values indicate starvation.
27 Average Inter-DC Latency (ADL) If two VMs are adjacent in the topology requested by the user, then these VMs need to transfer data or communication signals to each other. Average inter-dc latency is the time it takes to complete transfer between such nodes on average. It is critical to keep inter-dc latency low for the performance of the cloud software. Inter-DC latency is minimum when all VMs of a user are placed to the same DC.
28 Maximum Inter-DC Latency (MDL) Similar to maximum user latency, maximum inter-dc latency is used to detect outlier cases where it takes too much time to transfer data or communication signals between two VMs.
29 Hop Count (HPC) Hop count is the average number of hops per dependencies between VMs. Minimum values of this criterion (which is 0) is achieved when all dependent VMs in the request are placed to the same DC.
30 Job Run Time (JRT) This criterion is the average time it takes to complete the jobs divided by their size (in million instructions - MI). Since a host has a finite number of CPU cores and a CPU core can be used by a single VM at a time, time-sharing is used when number of VMs in a host is greater than the number of CPU cores in that hosts. In such cases, running time of the job is longer because it can be executed only part-time and is paused at other times. For this criterion, we ignore the time spent in data transfer between user and VM since it is measured in latency criteria. Additionally, we consider each VM individually since the communication with other VMs also depends on latency.
31 Job Completion Time (JCT) Job completion time includes both latency and running times. It is an average value for all users but is not normalized by job size. It indicates the promptness in responding user requests.
32 Waiting Time (WTT) Apart from latency, some VM requests will be delayed due to lack of available capacity. Waiting time criteria measures the time it takes until a job restarts after it is postponed.
33 SLA Violations (SLA) Service level agreements (SLAs) usually define a deadline for job completion time and a penalty is issued if it is not respected. This criterion is the cumulative number of SLA violations due to tardiness.
34 Utilization Rate (UTR) Utilization rate is the percentage of the resources in a given DC topology that are assigned to VMs. It is measured after the first time the placement algorithm fails to assign a VM topology to any DC (resources achieve saturation). A different utilization rate exists for each type of resource e.g. memory utilization, bandwidth utilization etc. A high utilization rate indicates that the resources are assigned efficiently so that a great number of VM requests are responded successfully.
35 Throughput (TRP) We measure throughput as the millions instructions processed in the whole system per second (MIPS). Indeed, it is equal to the total CPU utilization of all DCs. High throughput means a better placement of VMs and less wasted resources.
36 Cumulative Profit (CPR) This criterion aims to represent the profit of the cloud provider in a fixed duration given prices for each resource type. Cumulative profit is directly proportional to throughput.
37 Distribution Factor (DSF) Distribution factor is the extent that the VMs of a user are placed to separate DCs. We define distribution factor in Equation 1 where U is the set of users whose VM requests are responded, VM(u) is the VMs requested by the user u, DC(u) is the DCs to which these VMs are placed. Range of the DF is (0, 1]. DF = u U DC(u) VM(u) U Higher values of distribution factor indicates that the VMs are highly distributed to separate DCs. Benefits of high distribution are high parallelization and low failure cost. (1)
38 Load Balance (LDB) This criterion is the evenness of load assigned to all DCs in terms of utilization rate. We use standard deviation to measure the amount of variation from the average utilization.
39 Rejection Rate (RJR) This is the percentage of VM requests that are failed to responded immediately and postponed until completion of other requests make enough room in DCs.
40 Fairness (FRN) Fairness is used to determine whether users are receiving a fair share of available resources. Since not all users require the same amount of resources, fair share does not mean equality in our case.
41 Path Splitting (PSP) Path Splitting is the average number of inter-dc flows utilized to respond a inter-vm link request. This criterion is valid only if flow bifurcation is allowed. Otherwise, output is always 1.
42 Remarks Strategy design pattern is used for the DC selection policy. It is possible to decide and use a different policy for each VM group in the runtime. It is also possible to use different policies single VMs and VM groups. Each broker has a list of available DCs in an arbitrary order.
43 Random Choice (RAN) Arbitrary First-fit (AFF) Arbitrary Next-fit (ANF) Latency based First-fit (LFF) Latency based Next-fit (LNF) Capacity based Best-fit (CBF) Load Balancing (LBG) Minimum Span (MSP) Shortest Path (SP) vs. Multicommodity Flow (MF)
44 Topology based Best-fit (TBF) Related VMs are considered as a group rather than independent individuals. It tries to find a subgraph of the DC topology that is isomorphic to the requested VM topology. Among the candidate subgraphs, VMs are assigned on the subgraph which has the lowest average latency from the broker. Rejected VMs are assigned to the next DC that has the lowest latency from the accepted VMs DCs on average.
45 Metric Expectations of the AFF ANF LFF LNF CBF TBF LBG MSP AUL MUL ADL MDL HPC JRT JCT WTT SLA UTR TRP CPR DSF LDB RJR FRN PSP
46 Configuration DC MIPS: 1538 MIPS DC RAM: 16 GB DC Storage: 1 TB DC BW: 1 Gbps VM MIPS: 50 MIPS VM RAM: 1 GB to 8 GB VM Size: 10 GB VM BW: 10 Mbps Cloudlet Length: 150 MI Cloudlet Input : 15 MB Cloudlet Output: 15 MB Group Count: 2 Group Size: 3 and 2 Group Topology: Both Linear
47 AUL (ms) Introduction MUL (ms) Results VM RAM (MB) AFF ANF LBG LFF RAN TBF VM RAM (MB) AFF ANF LBG LFF RAN TBF
48 ADL (ms) Introduction MDL (ms) Results VM RAM (MB) AFF ANF LBG LFF RAN TBF VM RAM (MB) AFF ANF LBG LFF RAN TBF
49 JRT (s) Introduction JCT (s) Results VM RAM (MB) AFF ANF LBG LFF RAN TBF VM RAM (MB) AFF ANF LBG LFF RAN TBF
50 TRP (MIPS) Introduction RJR (%) Results VM RAM (MB) AFF ANF LBG LFF RAN TBF VM RAM (MB) AFF ANF LBG LFF RAN TBF
51 DSF Introduction LDB Results VM RAM (MB) AFF ANF LBG LFF RAN TBF VM RAM (MB) AFF ANF LBG LFF RAN TBF
52 Changes to the Proposal Resource Selection Research Modeling Development Documentation MapReduce Configuration Research Modeling Development Documentation Work Distribution Research Modeling Development Documentation Today
53 Possible Directions MapReduce Configuration Resource Selection More evaluation Comparison against more advanced methods in the literature A probability distribution for the cloudlet load Time-sharing of the CPU Vertical scaling Focus on bandwidth allocation Homeomorphism Multi-objective optimization Hybrid methods and Meta-heuristics
54 Thank you for your time.

55 Appendix MapReduce MapReduce Definition A programming model for processing large data sets with a parallel, distributed algorithm on a cluster.
56 Appendix MapReduce MapReduce Entities DataNode: Stores blocks of data in distributed filesystem (HDFS). NameNode: Holds metadata (i.e. location information) of the files in HDFS. Jobtracker: Coordinates the MapReduce job. Tasktracker: Runs the tasks that the MapReduce job split into.
Network-Aware Resource Allocation in Distributed Clouds
 Dissertation Research Summary Thesis Advisor: Asst. Prof. Dr. Tolga Ovatman Istanbul Technical University Department of Computer Engineering E-mail: aralat@itu.edu.tr April 4, 2016 Short Bio Research and
Dissertation Research Summary Thesis Advisor: Asst. Prof. Dr. Tolga Ovatman Istanbul Technical University Department of Computer Engineering E-mail: aralat@itu.edu.tr April 4, 2016 Short Bio Research and
Hadoop Virtualization Extensions on VMware vsphere 5 T E C H N I C A L W H I T E P A P E R
 Hadoop Virtualization Extensions on VMware vsphere 5 T E C H N I C A L W H I T E P A P E R Table of Contents Introduction... 3 Topology Awareness in Hadoop... 3 Virtual Hadoop... 4 HVE Solution... 5 Architecture...
Hadoop Virtualization Extensions on VMware vsphere 5 T E C H N I C A L W H I T E P A P E R Table of Contents Introduction... 3 Topology Awareness in Hadoop... 3 Virtual Hadoop... 4 HVE Solution... 5 Architecture...
Mixing and matching virtual and physical HPC clusters. Paolo Anedda
 Mixing and matching virtual and physical HPC clusters Paolo Anedda paolo.anedda@crs4.it HPC 2010 - Cetraro 22/06/2010 1 Outline Introduction Scalability Issues System architecture Conclusions & Future
Mixing and matching virtual and physical HPC clusters Paolo Anedda paolo.anedda@crs4.it HPC 2010 - Cetraro 22/06/2010 1 Outline Introduction Scalability Issues System architecture Conclusions & Future
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Big Data 7. Resource Management
 Ghislain Fourny Big Data 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage
Ghislain Fourny Big Data 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage
Big Data for Engineers Spring Resource Management
 Ghislain Fourny Big Data for Engineers Spring 2018 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models
Ghislain Fourny Big Data for Engineers Spring 2018 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
CHAPTER 6 ENERGY AWARE SCHEDULING ALGORITHMS IN CLOUD ENVIRONMENT
 CHAPTER 6 ENERGY AWARE SCHEDULING ALGORITHMS IN CLOUD ENVIRONMENT This chapter discusses software based scheduling and testing. DVFS (Dynamic Voltage and Frequency Scaling) [42] based experiments have
CHAPTER 6 ENERGY AWARE SCHEDULING ALGORITHMS IN CLOUD ENVIRONMENT This chapter discusses software based scheduling and testing. DVFS (Dynamic Voltage and Frequency Scaling) [42] based experiments have
Simulation of Cloud Computing Environments with CloudSim
 Simulation of Cloud Computing Environments with CloudSim Print ISSN: 1312-2622; Online ISSN: 2367-5357 DOI: 10.1515/itc-2016-0001 Key Words: Cloud computing; datacenter; simulation; resource management.
Simulation of Cloud Computing Environments with CloudSim Print ISSN: 1312-2622; Online ISSN: 2367-5357 DOI: 10.1515/itc-2016-0001 Key Words: Cloud computing; datacenter; simulation; resource management.
Considering Resource Demand Misalignments To Reduce Resource Over-Provisioning in Cloud Datacenters
 Considering Resource Demand Misalignments To Reduce Resource Over-Provisioning in Cloud Datacenters Liuhua Chen Dept. of Electrical and Computer Eng. Clemson University, USA Haiying Shen Dept. of Computer
Considering Resource Demand Misalignments To Reduce Resource Over-Provisioning in Cloud Datacenters Liuhua Chen Dept. of Electrical and Computer Eng. Clemson University, USA Haiying Shen Dept. of Computer
A Network-aware Scheduler in Data-parallel Clusters for High Performance
 A Network-aware Scheduler in Data-parallel Clusters for High Performance Zhuozhao Li, Haiying Shen and Ankur Sarker Department of Computer Science University of Virginia May, 2018 1/61 Data-parallel clusters
A Network-aware Scheduler in Data-parallel Clusters for High Performance Zhuozhao Li, Haiying Shen and Ankur Sarker Department of Computer Science University of Virginia May, 2018 1/61 Data-parallel clusters
EN2910A: Advanced Computer Architecture Topic 06: Supercomputers & Data Centers Prof. Sherief Reda School of Engineering Brown University
 EN2910A: Advanced Computer Architecture Topic 06: Supercomputers & Data Centers Prof. Sherief Reda School of Engineering Brown University Material from: The Datacenter as a Computer: An Introduction to
EN2910A: Advanced Computer Architecture Topic 06: Supercomputers & Data Centers Prof. Sherief Reda School of Engineering Brown University Material from: The Datacenter as a Computer: An Introduction to
Chapter 5. Minimization of Average Completion Time and Waiting Time in Cloud Computing Environment
 Chapter 5 Minimization of Average Completion Time and Waiting Time in Cloud Computing Cloud computing is the use of the Internet for the tasks the users performing on their computer. Cloud computing, also
Chapter 5 Minimization of Average Completion Time and Waiting Time in Cloud Computing Cloud computing is the use of the Internet for the tasks the users performing on their computer. Cloud computing, also
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 10.1 A real SDN implementation: the Google B4 case. Antonio Cianfrani DIET Department Networking Group netlab.uniroma1.it
 Lecture 10.1 A real SDN implementation: the Google B4 case Antonio Cianfrani DIET Department Networking Group netlab.uniroma1.it WAN WAN = Wide Area Network WAN features: Very expensive (specialized high-end
Lecture 10.1 A real SDN implementation: the Google B4 case Antonio Cianfrani DIET Department Networking Group netlab.uniroma1.it WAN WAN = Wide Area Network WAN features: Very expensive (specialized high-end
Chapter 3 Virtualization Model for Cloud Computing Environment
 Chapter 3 Virtualization Model for Cloud Computing Environment This chapter introduces the concept of virtualization in Cloud Computing Environment along with need of virtualization, components and characteristics
Chapter 3 Virtualization Model for Cloud Computing Environment This chapter introduces the concept of virtualization in Cloud Computing Environment along with need of virtualization, components and characteristics
Consolidating Complementary VMs with Spatial/Temporalawareness
 Consolidating Complementary VMs with Spatial/Temporalawareness in Cloud Datacenters Liuhua Chen and Haiying Shen Dept. of Electrical and Computer Engineering Clemson University, SC, USA 1 Outline Introduction
Consolidating Complementary VMs with Spatial/Temporalawareness in Cloud Datacenters Liuhua Chen and Haiying Shen Dept. of Electrical and Computer Engineering Clemson University, SC, USA 1 Outline Introduction
CQNCR: Optimal VM Migration Planning in Cloud Data Centers
 CQNCR: Optimal VM Migration Planning in Cloud Data Centers Presented By Md. Faizul Bari PhD Candidate David R. Cheriton School of Computer science University of Waterloo Joint work with Mohamed Faten Zhani,
CQNCR: Optimal VM Migration Planning in Cloud Data Centers Presented By Md. Faizul Bari PhD Candidate David R. Cheriton School of Computer science University of Waterloo Joint work with Mohamed Faten Zhani,
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Double Threshold Based Load Balancing Approach by Using VM Migration for the Cloud Computing Environment
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume 4 Issue 1 January 2015, Page No. 9966-9970 Double Threshold Based Load Balancing Approach by Using VM Migration
www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume 4 Issue 1 January 2015, Page No. 9966-9970 Double Threshold Based Load Balancing Approach by Using VM Migration
Empirical Evaluation of Latency-Sensitive Application Performance in the Cloud
 Empirical Evaluation of Latency-Sensitive Application Performance in the Cloud Sean Barker and Prashant Shenoy University of Massachusetts Amherst Department of Computer Science Cloud Computing! Cloud
Empirical Evaluation of Latency-Sensitive Application Performance in the Cloud Sean Barker and Prashant Shenoy University of Massachusetts Amherst Department of Computer Science Cloud Computing! Cloud
CCA-410. Cloudera. Cloudera Certified Administrator for Apache Hadoop (CCAH)
") Cloudera CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Download Full Version : http://killexams.com/pass4sure/exam-detail/cca-410 Reference: CONFIGURATION PARAMETERS DFS.BLOCK.SIZE
Cloudera CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Download Full Version : http://killexams.com/pass4sure/exam-detail/cca-410 Reference: CONFIGURATION PARAMETERS DFS.BLOCK.SIZE
Research on Load Balancing in Task Allocation Process in Heterogeneous Hadoop Cluster
 2017 2 nd International Conference on Artificial Intelligence and Engineering Applications (AIEA 2017) ISBN: 978-1-60595-485-1 Research on Load Balancing in Task Allocation Process in Heterogeneous Hadoop
2017 2 nd International Conference on Artificial Intelligence and Engineering Applications (AIEA 2017) ISBN: 978-1-60595-485-1 Research on Load Balancing in Task Allocation Process in Heterogeneous Hadoop
Online Optimization of VM Deployment in IaaS Cloud
 Online Optimization of VM Deployment in IaaS Cloud Pei Fan, Zhenbang Chen, Ji Wang School of Computer Science National University of Defense Technology Changsha, 4173, P.R.China {peifan,zbchen}@nudt.edu.cn,
Online Optimization of VM Deployment in IaaS Cloud Pei Fan, Zhenbang Chen, Ji Wang School of Computer Science National University of Defense Technology Changsha, 4173, P.R.China {peifan,zbchen}@nudt.edu.cn,
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Traffic-aware Virtual Machine Placement without Power Consumption Increment in Cloud Data Center
 , pp.350-355 http://dx.doi.org/10.14257/astl.2013.29.74 Traffic-aware Virtual Machine Placement without Power Consumption Increment in Cloud Data Center Hieu Trong Vu 1,2, Soonwook Hwang 1* 1 National
, pp.350-355 http://dx.doi.org/10.14257/astl.2013.29.74 Traffic-aware Virtual Machine Placement without Power Consumption Increment in Cloud Data Center Hieu Trong Vu 1,2, Soonwook Hwang 1* 1 National
MapReduce. Stony Brook University CSE545, Fall 2016
 MapReduce Stony Brook University CSE545, Fall 2016 Classical Data Mining CPU Memory Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining
MapReduce Stony Brook University CSE545, Fall 2016 Classical Data Mining CPU Memory Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining
Application-Aware SDN Routing for Big-Data Processing
 Application-Aware SDN Routing for Big-Data Processing Evaluation by EstiNet OpenFlow Network Emulator Director/Prof. Shie-Yuan Wang Institute of Network Engineering National ChiaoTung University Taiwan
Application-Aware SDN Routing for Big-Data Processing Evaluation by EstiNet OpenFlow Network Emulator Director/Prof. Shie-Yuan Wang Institute of Network Engineering National ChiaoTung University Taiwan
Quantifying Load Imbalance on Virtualized Enterprise Servers
 Quantifying Load Imbalance on Virtualized Enterprise Servers Emmanuel Arzuaga and David Kaeli Department of Electrical and Computer Engineering Northeastern University Boston MA 1 Traditional Data Centers
Quantifying Load Imbalance on Virtualized Enterprise Servers Emmanuel Arzuaga and David Kaeli Department of Electrical and Computer Engineering Northeastern University Boston MA 1 Traditional Data Centers
CloudSim: A Toolkit for Modeling and Simulation of Cloud Computing Environments
 CloudSim: A Toolkit for Modeling and Simulation of Cloud Computing Environments Presented by: Dr. Faramarz Safi Islamic Azad University, Najafabad Branch, Esfahan, Iran. and with special thanks to Mrs.
CloudSim: A Toolkit for Modeling and Simulation of Cloud Computing Environments Presented by: Dr. Faramarz Safi Islamic Azad University, Najafabad Branch, Esfahan, Iran. and with special thanks to Mrs.
Efficient Task Scheduling Algorithms for Cloud Computing Environment
 Efficient Task Scheduling Algorithms for Cloud Computing Environment S. Sindhu 1 and Saswati Mukherjee 2 1 Research Scholar, Department of Information Science and Technology sindhu.nss@gmail.com 2 Professor
Efficient Task Scheduling Algorithms for Cloud Computing Environment S. Sindhu 1 and Saswati Mukherjee 2 1 Research Scholar, Department of Information Science and Technology sindhu.nss@gmail.com 2 Professor
CHAPTER 6 STATISTICAL MODELING OF REAL WORLD CLOUD ENVIRONMENT FOR RELIABILITY AND ITS EFFECT ON ENERGY AND PERFORMANCE
 143 CHAPTER 6 STATISTICAL MODELING OF REAL WORLD CLOUD ENVIRONMENT FOR RELIABILITY AND ITS EFFECT ON ENERGY AND PERFORMANCE 6.1 INTRODUCTION This chapter mainly focuses on how to handle the inherent unreliability
143 CHAPTER 6 STATISTICAL MODELING OF REAL WORLD CLOUD ENVIRONMENT FOR RELIABILITY AND ITS EFFECT ON ENERGY AND PERFORMANCE 6.1 INTRODUCTION This chapter mainly focuses on how to handle the inherent unreliability
Modeling Service Applications for Optimal Parallel Embedding
 Modeling Service Applications for Optimal Parallel Embedding Changcheng Huang Department of Systems and Computer Engineering Carleton University Ottawa, Canada huang@sce.carleton.ca Jiafeng Zhu Huawei
Modeling Service Applications for Optimal Parallel Embedding Changcheng Huang Department of Systems and Computer Engineering Carleton University Ottawa, Canada huang@sce.carleton.ca Jiafeng Zhu Huawei
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
3. Monitoring Scenarios
 3. Monitoring Scenarios This section describes the following: Navigation Alerts Interval Rules Navigation Ambari SCOM Use the Ambari SCOM main navigation tree to browse cluster, HDFS and MapReduce performance
3. Monitoring Scenarios This section describes the following: Navigation Alerts Interval Rules Navigation Ambari SCOM Use the Ambari SCOM main navigation tree to browse cluster, HDFS and MapReduce performance
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Data Center Services and Optimization. Sobir Bazarbayev Chris Cai CS538 October
 Data Center Services and Optimization Sobir Bazarbayev Chris Cai CS538 October 18 2011 Outline Background Volley: Automated Data Placement for Geo-Distributed Cloud Services, by Sharad Agarwal, John Dunagan,
Data Center Services and Optimization Sobir Bazarbayev Chris Cai CS538 October 18 2011 Outline Background Volley: Automated Data Placement for Geo-Distributed Cloud Services, by Sharad Agarwal, John Dunagan,
Multimedia Systems 2011/2012
 Multimedia Systems 2011/2012 System Architecture Prof. Dr. Paul Müller University of Kaiserslautern Department of Computer Science Integrated Communication Systems ICSY http://www.icsy.de Sitemap 2 Hardware
Multimedia Systems 2011/2012 System Architecture Prof. Dr. Paul Müller University of Kaiserslautern Department of Computer Science Integrated Communication Systems ICSY http://www.icsy.de Sitemap 2 Hardware
Deadline Guaranteed Service for Multi- Tenant Cloud Storage Guoxin Liu and Haiying Shen
 Deadline Guaranteed Service for Multi- Tenant Cloud Storage Guoxin Liu and Haiying Shen Presenter: Haiying Shen Associate professor *Department of Electrical and Computer Engineering, Clemson University,
Deadline Guaranteed Service for Multi- Tenant Cloud Storage Guoxin Liu and Haiying Shen Presenter: Haiying Shen Associate professor *Department of Electrical and Computer Engineering, Clemson University,
Parallel Genetic Algorithm to Solve Traveling Salesman Problem on MapReduce Framework using Hadoop Cluster
 Parallel Genetic Algorithm to Solve Traveling Salesman Problem on MapReduce Framework using Hadoop Cluster Abstract- Traveling Salesman Problem (TSP) is one of the most common studied problems in combinatorial
Parallel Genetic Algorithm to Solve Traveling Salesman Problem on MapReduce Framework using Hadoop Cluster Abstract- Traveling Salesman Problem (TSP) is one of the most common studied problems in combinatorial
Storage CloudSim A Simulation Environment for Cloud Object Storage Infrastructures
 Storage CloudSim A Simulation Environment for Cloud Object Storage Infrastructures Tobias Sturm, Foued Jrad and Achim Streit Steinbuch Centre for Computing (SCC) Department of Informatics, Karlsruhe Institute
Storage CloudSim A Simulation Environment for Cloud Object Storage Infrastructures Tobias Sturm, Foued Jrad and Achim Streit Steinbuch Centre for Computing (SCC) Department of Informatics, Karlsruhe Institute
ENERGY EFFICIENT VIRTUAL MACHINE INTEGRATION IN CLOUD COMPUTING
 ENERGY EFFICIENT VIRTUAL MACHINE INTEGRATION IN CLOUD COMPUTING Mrs. Shweta Agarwal Assistant Professor, Dept. of MCA St. Aloysius Institute of Technology, Jabalpur(India) ABSTRACT In the present study,
ENERGY EFFICIENT VIRTUAL MACHINE INTEGRATION IN CLOUD COMPUTING Mrs. Shweta Agarwal Assistant Professor, Dept. of MCA St. Aloysius Institute of Technology, Jabalpur(India) ABSTRACT In the present study,
Coflow. Big Data. Data-Parallel Applications. Big Datacenters for Massive Parallelism. Recent Advances and What s Next?
 Big Data Coflow The volume of data businesses want to make sense of is increasing Increasing variety of sources Recent Advances and What s Next? Web, mobile, wearables, vehicles, scientific, Cheaper disks,
Big Data Coflow The volume of data businesses want to make sense of is increasing Increasing variety of sources Recent Advances and What s Next? Web, mobile, wearables, vehicles, scientific, Cheaper disks,
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
2013 AWS Worldwide Public Sector Summit Washington, D.C.
 2013 AWS Worldwide Public Sector Summit Washington, D.C. EMR for Fun and for Profit Ben Butler Sr. Manager, Big Data butlerb@amazon.com @bensbutler Overview 1. What is big data? 2. What is AWS Elastic
2013 AWS Worldwide Public Sector Summit Washington, D.C. EMR for Fun and for Profit Ben Butler Sr. Manager, Big Data butlerb@amazon.com @bensbutler Overview 1. What is big data? 2. What is AWS Elastic
Next-Generation Cloud Platform
 Next-Generation Cloud Platform Jangwoo Kim Jun 24, 2013 E-mail: jangwoo@postech.ac.kr High Performance Computing Lab Department of Computer Science & Engineering Pohang University of Science and Technology
Next-Generation Cloud Platform Jangwoo Kim Jun 24, 2013 E-mail: jangwoo@postech.ac.kr High Performance Computing Lab Department of Computer Science & Engineering Pohang University of Science and Technology
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
PowerVault MD3 SSD Cache Overview
 PowerVault MD3 SSD Cache Overview A Dell Technical White Paper Dell Storage Engineering October 2015 A Dell Technical White Paper TECHNICAL INACCURACIES. THE CONTENT IS PROVIDED AS IS, WITHOUT EXPRESS
PowerVault MD3 SSD Cache Overview A Dell Technical White Paper Dell Storage Engineering October 2015 A Dell Technical White Paper TECHNICAL INACCURACIES. THE CONTENT IS PROVIDED AS IS, WITHOUT EXPRESS
HPC in Cloud. Presenter: Naresh K. Sehgal Contributors: Billy Cox, John M. Acken, Sohum Sohoni
 HPC in Cloud Presenter: Naresh K. Sehgal Contributors: Billy Cox, John M. Acken, Sohum Sohoni 2 Agenda What is HPC? Problem Statement(s) Cloud Workload Characterization Translation from High Level Issues
HPC in Cloud Presenter: Naresh K. Sehgal Contributors: Billy Cox, John M. Acken, Sohum Sohoni 2 Agenda What is HPC? Problem Statement(s) Cloud Workload Characterization Translation from High Level Issues
Distributed Face Recognition Using Hadoop
 Distributed Face Recognition Using Hadoop A. Thorat, V. Malhotra, S. Narvekar and A. Joshi Dept. of Computer Engineering and IT College of Engineering, Pune {abhishekthorat02@gmail.com, vinayak.malhotra20@gmail.com,
Distributed Face Recognition Using Hadoop A. Thorat, V. Malhotra, S. Narvekar and A. Joshi Dept. of Computer Engineering and IT College of Engineering, Pune {abhishekthorat02@gmail.com, vinayak.malhotra20@gmail.com,
MOHA: Many-Task Computing Framework on Hadoop
 Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
International Journal of Research In Science & Engineering e-issn: Special Issue: Techno-Xtreme 16 p-issn:
 Cloudlet Scheduling To Optimize Cloud Computing With Wireless Sensor Network Miss. P.P.Ingale, Prof. R. N. Khobragade, Dr. V. M. Thakare Dept. CS & IT, SGBAU, Amravati, India. ingalepragati@gmail.com Dept.
Cloudlet Scheduling To Optimize Cloud Computing With Wireless Sensor Network Miss. P.P.Ingale, Prof. R. N. Khobragade, Dr. V. M. Thakare Dept. CS & IT, SGBAU, Amravati, India. ingalepragati@gmail.com Dept.
Select Use Cases for VirtualWisdom Applied Analytics
 WHITEPAPER Select Use Cases for VirtualWisdom Applied Analytics April 7, 2017 CONTRIBUTORS Andrew Sebastian Roberta Sorbello Mark Samuelson Ricardo Negrete Ryan Perkowski Jim Bahn Introduction... 2 #1:
WHITEPAPER Select Use Cases for VirtualWisdom Applied Analytics April 7, 2017 CONTRIBUTORS Andrew Sebastian Roberta Sorbello Mark Samuelson Ricardo Negrete Ryan Perkowski Jim Bahn Introduction... 2 #1:
Sinbad. Leveraging Endpoint Flexibility in Data-Intensive Clusters. Mosharaf Chowdhury, Srikanth Kandula, Ion Stoica. UC Berkeley
 Sinbad Leveraging Endpoint Flexibility in Data-Intensive Clusters Mosharaf Chowdhury, Srikanth Kandula, Ion Stoica UC Berkeley Communication is Crucial for Analytics at Scale Performance Facebook analytics
Sinbad Leveraging Endpoint Flexibility in Data-Intensive Clusters Mosharaf Chowdhury, Srikanth Kandula, Ion Stoica UC Berkeley Communication is Crucial for Analytics at Scale Performance Facebook analytics
Network Design Considerations for Grid Computing
 Network Design Considerations for Grid Computing Engineering Systems How Bandwidth, Latency, and Packet Size Impact Grid Job Performance by Erik Burrows, Engineering Systems Analyst, Principal, Broadcom
Network Design Considerations for Grid Computing Engineering Systems How Bandwidth, Latency, and Packet Size Impact Grid Job Performance by Erik Burrows, Engineering Systems Analyst, Principal, Broadcom
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
MixApart: Decoupled Analytics for Shared Storage Systems. Madalin Mihailescu, Gokul Soundararajan, Cristiana Amza University of Toronto and NetApp
 MixApart: Decoupled Analytics for Shared Storage Systems Madalin Mihailescu, Gokul Soundararajan, Cristiana Amza University of Toronto and NetApp Hadoop Pig, Hive Hadoop + Enterprise storage?! Shared storage
MixApart: Decoupled Analytics for Shared Storage Systems Madalin Mihailescu, Gokul Soundararajan, Cristiana Amza University of Toronto and NetApp Hadoop Pig, Hive Hadoop + Enterprise storage?! Shared storage
Mochi: Visual Log-Analysis Based Tools for Debugging Hadoop
 Mochi: Visual Log-Analysis Based Tools for Debugging Hadoop Jiaqi Tan Xinghao Pan, Soila Kavulya, Rajeev Gandhi, Priya Narasimhan PARALLEL DATA LABORATORY Carnegie Mellon University Motivation Debugging
Mochi: Visual Log-Analysis Based Tools for Debugging Hadoop Jiaqi Tan Xinghao Pan, Soila Kavulya, Rajeev Gandhi, Priya Narasimhan PARALLEL DATA LABORATORY Carnegie Mellon University Motivation Debugging
itpass4sure Helps you pass the actual test with valid and latest training material.
 itpass4sure http://www.itpass4sure.com/ Helps you pass the actual test with valid and latest training material. Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Vendor : Cloudera
itpass4sure http://www.itpass4sure.com/ Helps you pass the actual test with valid and latest training material. Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Vendor : Cloudera
An Exploration of Designing a Hybrid Scale-Up/Out Hadoop Architecture Based on Performance Measurements
 This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI.9/TPDS.6.7, IEEE
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI.9/TPDS.6.7, IEEE
Public Cloud Leverage For IT/Business Alignment Business Goals Agility to speed time to market, adapt to market demands Elasticity to meet demand whil
 LHC2386BU True Costs Savings Modeling and Costing A Migration to VMware Cloud on AWS Chris Grossmeier chrisg@cloudphysics.com John Blumenthal john@cloudphysics.com #VMworld Public Cloud Leverage For IT/Business
LHC2386BU True Costs Savings Modeling and Costing A Migration to VMware Cloud on AWS Chris Grossmeier chrisg@cloudphysics.com John Blumenthal john@cloudphysics.com #VMworld Public Cloud Leverage For IT/Business
LOAD BALANCING ALGORITHM TO IMPROVE RESPONSE TIME ON CLOUD COMPUTING
 LOAD BALANCING ALGORITHM TO IMPROVE RESPONSE TIME ON CLOUD COMPUTING Nguyen Xuan Phi 1 and Tran Cong Hung 2 1,2 Posts and Telecommunications Institute of Technology, Ho Chi Minh, Vietnam. ABSTRACT Load
LOAD BALANCING ALGORITHM TO IMPROVE RESPONSE TIME ON CLOUD COMPUTING Nguyen Xuan Phi 1 and Tran Cong Hung 2 1,2 Posts and Telecommunications Institute of Technology, Ho Chi Minh, Vietnam. ABSTRACT Load
Ali Ghodsi, Matei Zaharia, Benjamin Hindman, Andy Konwinski, Scott Shenker, Ion Stoica. University of California, Berkeley nsdi 11
 Dominant Resource Fairness: Fair Allocation of Multiple Resource Types Ali Ghodsi, Matei Zaharia, Benjamin Hindman, Andy Konwinski, Scott Shenker, Ion Stoica University of California, Berkeley nsdi 11
Dominant Resource Fairness: Fair Allocation of Multiple Resource Types Ali Ghodsi, Matei Zaharia, Benjamin Hindman, Andy Konwinski, Scott Shenker, Ion Stoica University of California, Berkeley nsdi 11
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian ZHENG 1, Mingjiang LI 1, Jinpeng YUAN 1
 International Conference on Intelligent Systems Research and Mechatronics Engineering (ISRME 2015) The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian
International Conference on Intelligent Systems Research and Mechatronics Engineering (ISRME 2015) The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
Database Applications (15-415)
") Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
CS / Cloud Computing. Recitation 3 September 9 th & 11 th, 2014
 CS15-319 / 15-619 Cloud Computing Recitation 3 September 9 th & 11 th, 2014 Overview Last Week s Reflection --Project 1.1, Quiz 1, Unit 1 This Week s Schedule --Unit2 (module 3 & 4), Project 1.2 Questions
CS15-319 / 15-619 Cloud Computing Recitation 3 September 9 th & 11 th, 2014 Overview Last Week s Reflection --Project 1.1, Quiz 1, Unit 1 This Week s Schedule --Unit2 (module 3 & 4), Project 1.2 Questions
A priority based dynamic bandwidth scheduling in SDN networks 1
 Acta Technica 62 No. 2A/2017, 445 454 c 2017 Institute of Thermomechanics CAS, v.v.i. A priority based dynamic bandwidth scheduling in SDN networks 1 Zun Wang 2 Abstract. In order to solve the problems
Acta Technica 62 No. 2A/2017, 445 454 c 2017 Institute of Thermomechanics CAS, v.v.i. A priority based dynamic bandwidth scheduling in SDN networks 1 Zun Wang 2 Abstract. In order to solve the problems
Dynamic Data Placement Strategy in MapReduce-styled Data Processing Platform Hua-Ci WANG 1,a,*, Cai CHEN 2,b,*, Yi LIANG 3,c
 2016 Joint International Conference on Service Science, Management and Engineering (SSME 2016) and International Conference on Information Science and Technology (IST 2016) ISBN: 978-1-60595-379-3 Dynamic
2016 Joint International Conference on Service Science, Management and Engineering (SSME 2016) and International Conference on Information Science and Technology (IST 2016) ISBN: 978-1-60595-379-3 Dynamic
Advanced Computer Networks. Flow Control
 Advanced Computer Networks 263 3501 00 Flow Control Patrick Stuedi Spring Semester 2017 1 Oriana Riva, Department of Computer Science ETH Zürich Last week TCP in Datacenters Avoid incast problem - Reduce
Advanced Computer Networks 263 3501 00 Flow Control Patrick Stuedi Spring Semester 2017 1 Oriana Riva, Department of Computer Science ETH Zürich Last week TCP in Datacenters Avoid incast problem - Reduce
A Solution for Geographic Regions Load Balancing in Cloud Computing Environment
 Chapter 5 A Solution for Geographic Regions Load Balancing in Cloud Computing Environment 5.1 INTRODUCTION Cloud computing is one of the most interesting way of distributing the data as well as to get
Chapter 5 A Solution for Geographic Regions Load Balancing in Cloud Computing Environment 5.1 INTRODUCTION Cloud computing is one of the most interesting way of distributing the data as well as to get
Camdoop Exploiting In-network Aggregation for Big Data Applications Paolo Costa
 Camdoop Exploiting In-network Aggregation for Big Data Applications costa@imperial.ac.uk joint work with Austin Donnelly, Antony Rowstron, and Greg O Shea (MSR Cambridge) MapReduce Overview Input file
Camdoop Exploiting In-network Aggregation for Big Data Applications costa@imperial.ac.uk joint work with Austin Donnelly, Antony Rowstron, and Greg O Shea (MSR Cambridge) MapReduce Overview Input file
Test Methodology We conducted tests by adding load and measuring the performance of the environment components:
 Scalability Considerations for Using the XenApp and XenDesktop Service Local Host Cache Feature with Citrix Cloud Connector Author: Jahed Iqbal Overview The local host cache feature in the XenApp and XenDesktop
Scalability Considerations for Using the XenApp and XenDesktop Service Local Host Cache Feature with Citrix Cloud Connector Author: Jahed Iqbal Overview The local host cache feature in the XenApp and XenDesktop
Improved Task Scheduling Algorithm in Cloud Environment
 Improved Task Scheduling Algorithm in Cloud Environment Sumit Arora M.Tech Student Lovely Professional University Phagwara, India Sami Anand Assistant Professor Lovely Professional University Phagwara,
Improved Task Scheduling Algorithm in Cloud Environment Sumit Arora M.Tech Student Lovely Professional University Phagwara, India Sami Anand Assistant Professor Lovely Professional University Phagwara,
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
GSJ: VOLUME 6, ISSUE 6, August ISSN
 GSJ: VOLUME 6, ISSUE 6, August 2018 211 Cloud Computing Simulation Using CloudSim Toolkits Md. Nadimul Islam Rajshahi University Of Engineering Technology,RUET-6204 Email: nadimruet09@gmail.com Abstract
GSJ: VOLUME 6, ISSUE 6, August 2018 211 Cloud Computing Simulation Using CloudSim Toolkits Md. Nadimul Islam Rajshahi University Of Engineering Technology,RUET-6204 Email: nadimruet09@gmail.com Abstract
Energy-Aware Dynamic Load Balancing of Virtual Machines (VMs) in Cloud Data Center with Adaptive Threshold (AT) based Migration
 in Cloud Data Center with Adaptive Threshold (AT) based Migration") Khushbu Maurya et al, International Journal of Computer Science and Mobile Computing, Vol.4 Issue.12, December- 215, pg. 1-7 Available Online at www.ijcsmc.com International Journal of Computer Science
Khushbu Maurya et al, International Journal of Computer Science and Mobile Computing, Vol.4 Issue.12, December- 215, pg. 1-7 Available Online at www.ijcsmc.com International Journal of Computer Science
Elastic Resource Provisioning for Cloud Data Center
 Elastic Resource Provisioning for Cloud Data Center Thant Zin Tun, and Thandar Thein Abstract Cloud data centers promises flexible, scalable, powerful and cost-effective executing environment to users.
Elastic Resource Provisioning for Cloud Data Center Thant Zin Tun, and Thandar Thein Abstract Cloud data centers promises flexible, scalable, powerful and cost-effective executing environment to users.
Hadoop MapReduce Framework
 Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce
Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce
Lies, Damn Lies and Performance Metrics. PRESENTATION TITLE GOES HERE Barry Cooks Virtual Instruments
 Lies, Damn Lies and Performance Metrics PRESENTATION TITLE GOES HERE Barry Cooks Virtual Instruments Goal for This Talk Take away a sense of how to make the move from: Improving your mean time to innocence
Lies, Damn Lies and Performance Metrics PRESENTATION TITLE GOES HERE Barry Cooks Virtual Instruments Goal for This Talk Take away a sense of how to make the move from: Improving your mean time to innocence
Solace Message Routers and Cisco Ethernet Switches: Unified Infrastructure for Financial Services Middleware
 Solace Message Routers and Cisco Ethernet Switches: Unified Infrastructure for Financial Services Middleware What You Will Learn The goal of zero latency in financial services has caused the creation of
Solace Message Routers and Cisco Ethernet Switches: Unified Infrastructure for Financial Services Middleware What You Will Learn The goal of zero latency in financial services has caused the creation of
Adaptive Cluster Computing using JavaSpaces
 Adaptive Cluster Computing using JavaSpaces Jyoti Batheja and Manish Parashar The Applied Software Systems Lab. ECE Department, Rutgers University Outline Background Introduction Related Work Summary of
Adaptive Cluster Computing using JavaSpaces Jyoti Batheja and Manish Parashar The Applied Software Systems Lab. ECE Department, Rutgers University Outline Background Introduction Related Work Summary of
PARDA: Proportional Allocation of Resources for Distributed Storage Access
 PARDA: Proportional Allocation of Resources for Distributed Storage Access Ajay Gulati, Irfan Ahmad, Carl Waldspurger Resource Management Team VMware Inc. USENIX FAST 09 Conference February 26, 2009 The
PARDA: Proportional Allocation of Resources for Distributed Storage Access Ajay Gulati, Irfan Ahmad, Carl Waldspurger Resource Management Team VMware Inc. USENIX FAST 09 Conference February 26, 2009 The
CAVA: Exploring Memory Locality for Big Data Analytics in Virtualized Clusters
 2018 18th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing : Exploring Memory Locality for Big Data Analytics in Virtualized Clusters Eunji Hwang, Hyungoo Kim, Beomseok Nam and Young-ri
2018 18th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing : Exploring Memory Locality for Big Data Analytics in Virtualized Clusters Eunji Hwang, Hyungoo Kim, Beomseok Nam and Young-ri
Data Sharing Made Easier through Programmable Metadata. University of Wisconsin-Madison
 Data Sharing Made Easier through Programmable Metadata Zhe Zhang IBM Research! Remzi Arpaci-Dusseau University of Wisconsin-Madison How do applications share data today? Syncing data between storage systems:
Data Sharing Made Easier through Programmable Metadata Zhe Zhang IBM Research! Remzi Arpaci-Dusseau University of Wisconsin-Madison How do applications share data today? Syncing data between storage systems:
MAPREDUCE FOR BIG DATA PROCESSING BASED ON NETWORK TRAFFIC PERFORMANCE Rajeshwari Adrakatti
 International Journal of Computer Engineering and Applications, ICCSTAR-2016, Special Issue, May.16 MAPREDUCE FOR BIG DATA PROCESSING BASED ON NETWORK TRAFFIC PERFORMANCE Rajeshwari Adrakatti 1 Department
International Journal of Computer Engineering and Applications, ICCSTAR-2016, Special Issue, May.16 MAPREDUCE FOR BIG DATA PROCESSING BASED ON NETWORK TRAFFIC PERFORMANCE Rajeshwari Adrakatti 1 Department
Multi-Criteria Strategy for Job Scheduling and Resource Load Balancing in Cloud Computing Environment
 Indian Journal of Science and Technology, Vol 8(30), DOI: 0.7485/ijst/205/v8i30/85923, November 205 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Multi-Criteria Strategy for Job Scheduling and Resource
Indian Journal of Science and Technology, Vol 8(30), DOI: 0.7485/ijst/205/v8i30/85923, November 205 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Multi-Criteria Strategy for Job Scheduling and Resource
High-performance aspects in virtualized infrastructures
 SVM 21 High-performance aspects in virtualized infrastructures Vitalian Danciu, Nils gentschen Felde, Dieter Kranzlmüller, Tobias Lindinger SVM 21 - HPC aspects in virtualized infrastructures 1/29/21 Niagara
SVM 21 High-performance aspects in virtualized infrastructures Vitalian Danciu, Nils gentschen Felde, Dieter Kranzlmüller, Tobias Lindinger SVM 21 - HPC aspects in virtualized infrastructures 1/29/21 Niagara
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Utilizing Datacenter Networks: Centralized or Distributed Solutions?
 Utilizing Datacenter Networks: Centralized or Distributed Solutions? Costin Raiciu Department of Computer Science University Politehnica of Bucharest We ve gotten used to great applications Enabling Such
Utilizing Datacenter Networks: Centralized or Distributed Solutions? Costin Raiciu Department of Computer Science University Politehnica of Bucharest We ve gotten used to great applications Enabling Such
Distributed Systems CS6421
 Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
ibench: Quantifying Interference in Datacenter Applications
 ibench: Quantifying Interference in Datacenter Applications Christina Delimitrou and Christos Kozyrakis Stanford University IISWC September 23 th 2013 Executive Summary Problem: Increasing utilization
ibench: Quantifying Interference in Datacenter Applications Christina Delimitrou and Christos Kozyrakis Stanford University IISWC September 23 th 2013 Executive Summary Problem: Increasing utilization
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
CLIENT DATA NODE NAME NODE
 Volume 6, Issue 12, December 2016 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Efficiency
Volume 6, Issue 12, December 2016 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Efficiency
What s New in Apache HTrace by Colin P. McCabe
 What s New in Apache HTrace by Colin P. McCabe About Me I work on HDFS and related storage technologies at Cloudera Committer on the Hadoop and HTrace projects. Previously worked on the Ceph distributed
What s New in Apache HTrace by Colin P. McCabe About Me I work on HDFS and related storage technologies at Cloudera Committer on the Hadoop and HTrace projects. Previously worked on the Ceph distributed
Risk-Aware Rapid Data Evacuation for Large- Scale Disasters in Optical Cloud Networks
 Risk-Aware Rapid Data Evacuation for Large- Scale Disasters in Optical Cloud Networks Presenter: Yongcheng (Jeremy) Li PhD student, School of Electronic and Information Engineering, Soochow University,
Risk-Aware Rapid Data Evacuation for Large- Scale Disasters in Optical Cloud Networks Presenter: Yongcheng (Jeremy) Li PhD student, School of Electronic and Information Engineering, Soochow University,
Ambry: LinkedIn s Scalable Geo- Distributed Object Store
 Ambry: LinkedIn s Scalable Geo- Distributed Object Store Shadi A. Noghabi *, Sriram Subramanian +, Priyesh Narayanan +, Sivabalan Narayanan +, Gopalakrishna Holla +, Mammad Zadeh +, Tianwei Li +, Indranil
Ambry: LinkedIn s Scalable Geo- Distributed Object Store Shadi A. Noghabi *, Sriram Subramanian +, Priyesh Narayanan +, Sivabalan Narayanan +, Gopalakrishna Holla +, Mammad Zadeh +, Tianwei Li +, Indranil
2/26/2017. For instance, consider running Word Count across 20 splits
 Based on the slides of prof. Pietro Michiardi Hadoop Internals https://github.com/michiard/disc-cloud-course/raw/master/hadoop/hadoop.pdf Job: execution of a MapReduce application across a data set Task:
Based on the slides of prof. Pietro Michiardi Hadoop Internals https://github.com/michiard/disc-cloud-course/raw/master/hadoop/hadoop.pdf Job: execution of a MapReduce application across a data set Task:
Milestone Solution Partner IT Infrastructure Components Certification Report
 Milestone Solution Partner IT Infrastructure Components Certification Report Dell MD3860i Storage Array Multi-Server 1050 Camera Test Case 4-2-2016 Table of Contents Executive Summary:... 3 Abstract...
Milestone Solution Partner IT Infrastructure Components Certification Report Dell MD3860i Storage Array Multi-Server 1050 Camera Test Case 4-2-2016 Table of Contents Executive Summary:... 3 Abstract...