MapReduce. Stony Brook University CSE545, Fall 2016
|
|
|
- Griffin Anderson
- 6 years ago
- Views:
Transcription
1 MapReduce Stony Brook University CSE545, Fall 2016
2 Classical Data Mining CPU Memory Disk
3 Classical Data Mining CPU Memory (64 GB) Disk
4 Classical Data Mining CPU Memory (64 GB) Disk
5 Classical Data Mining CPU Memory (64 GB) Disk

6 IO Bounded Reading a word from disk versus main memory: 10 5 slower! Reading many contiguously stored words is faster per word, but fast modern disks still only reach 150MB/s for sequential reads. IO Bound: biggest performance bottleneck is reading / writing to disk. (starts around 100 GBs; ~10 minutes just to read).
7 Classical Big Data Analysis CPU Memory Often focused on efficiently utilizing the disk. e.g. Apache Lucene / Solr Disk Still bounded when needing to process all of a large file.
8 IO Bound How to solve?
9 Distributed Architecture (Cluster) Switch ~10Gbps Rack 1 Switch ~1Gbps Rack 2 Switch ~1Gbps... CPU CPU CPU CPU CPU CPU Memory Memory... Memory Memory Memory... Memory Disk Disk Disk Disk Disk Disk
10 Distributed Architecture (Cluster) In reality, modern setups often have multiple cpus and disks per server, but we will model as if one machine per cpu-disk pair. Switch ~1Gbps CPU CPU Memory... CPU CPU CPU Memory... CPU... Disk Disk... Disk Disk Disk... Disk
11 Challenges for IO Cluster Computing 1. Nodes fail 1 in 1000 nodes fail a day 2. Network is a bottleneck Typically 1-10 Gb/s throughput 3. Traditional distributed programming is often ad-hoc and complicated
12 Challenges for IO Cluster Computing 1. Nodes fail 1 in 1000 nodes fail a day Duplicate Data 2. Network is a bottleneck Typically 1-10 Gb/s throughput Bring computation to nodes, rather than data to nodes. 3. Traditional distributed programming is often ad-hoc and complicated Stipulate a programming system that can easily be distributed
13 Challenges for IO Cluster Computing 1. Nodes fail 1 in 1000 nodes fail a day Duplicate Data 2. Network is a bottleneck Typically 1-10 Gb/s throughput Bring computation to nodes, rather than data to nodes. 3. Traditional distributed programming is often ad-hoc and complicated Stipulate a programming system that can easily be distributed MapReduce to the rescue!
14 Common Characteristics of Big Data Large files (i.e. >100 GB to TBs) No need to update in place (append preferred) Reads are most common (e.g. web logs, social media, product purchases)
15 Distributed File System (e.g. Apache HadoopDFS, GoogleFS) C, D: Two different files chunk server 1 chunk server 2 chunk server 3 chunk server n (Leskovec at al., 2014;
16 Distributed File System (e.g. Apache HadoopDFS, GoogleFS) C, D: Two different files chunk server 1 chunk server 2 chunk server 3 chunk server n (Leskovec at al., 2014;
 C, D: Two different files chunk server 1 chunk server 2 chunk")
17 Distributed File System (e.g. Apache HadoopDFS, GoogleFS) C, D: Two different files chunk server 1 chunk server 2 chunk server 3 chunk server n (Leskovec at al., 2014;
18 Components of a Distributed File System Chunk servers (on Data Nodes) File is split into contiguous chunks Typically each chunk is 16-64MB Each chunk replicated (usually 2x or 3x) Try to keep replicas in different racks Name node (aka master node) Stores metadata about where files are stored Might be replicated or distributed across data nodes. Client library for file access Talks to master to find chunk servers Connects directly to chunk servers to access data (Leskovec at al., 2014;

19 Challenges for IO Cluster Computing 1. Nodes fail 1 in 1000 nodes fail a day Duplicate Data (Distributed FS) 2. Network is a bottleneck Typically 1-10 Gb/s throughput Bring computation to nodes, rather than data to nodes. 3. Traditional distributed programming is often ad-hoc and complicated Stipulate a programming system that can easily be distributed
20 What is MapReduce? 1. A style of programming input chunks => map tasks group_by keys reduce tasks => output is the linux pipe symbol: passes stdout from first process to stdin of next. E.g. counting words: tokenize(document) sort uniq -C
21 What is MapReduce? 1. A style of programming input chunks => map tasks group_by keys reduce tasks => output is the linux pipe symbol: passes stdout from first process to stdin of next. E.g. counting words: tokenize(document) sort uniq -C 2. A system that distributes MapReduce style programs across a distributed file-system. (e.g. Google s internal MapReduce or apache.hadoop.mapreduce with hdfs)
22 What is MapReduce?
23 What is MapReduce? extract what you care about. Map
24 What is MapReduce? extract what you care about. sort and shuffle Map
25 What is MapReduce? extract what you care about. Map sort and shuffle aggregate, summarize Reduce
26 What is MapReduce? (Leskovec at al., 2014;
27 The Map Step (Leskovec at al., 2014;
28 The Reduce Step (Leskovec at al., 2014;
29 What is MapReduce? Map: (k,v) -> (k, v )* (Written by programmer) Group by key: (k 1, v 1 ), (k 2, v 2 ),... -> (k 1, (v 1, v, ), (system handles) (k 2, (v 1, v, ), Reduce: (k, (v 1, v, )) -> (k, v )* (Written by programmer)
30 Example: Word Count tokenize(document) sort uniq -C
31 Example: Word Count tokenize(document) sort uniq -C Map: extract what you care about. sort and shuffle Reduce: aggregate, summarize
32 Example: Word Count (Leskovec at al., 2014;
33
34
35
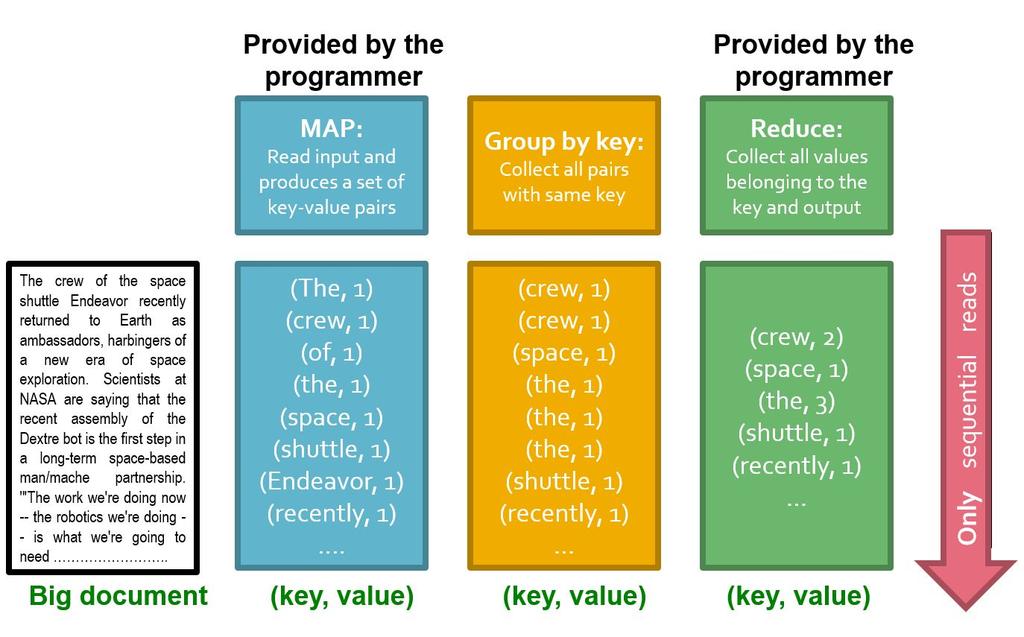
36 Chunks
37 Example: Word Count (version 1) def map(k, v): for w in tokenize(v): yield (w,1) def reduce(k, vs): return len(vs)
38 Example: Word Count (version 2) def map(k, v): counts = dict() for w in tokenize(v): try: counts[w] += 1 except KeyError: counts[w] = 1 for item in counts.iteritems() yield item counts each word within the chunk (try/except is faster than if w in counts ) def reduce(k, vs): return sum(vs) sum of counts from different chunks
39 Example: Relational Algebra Select Project Union, Intersection, Difference Natural Join Grouping
40 Example: Relational Algebra Select Project Union, Intersection, Difference Natural Join Grouping
41 Example: Relational Algebra Select R(A 1,A 2,A 3,...), Relation R, Attributes A * return only those attribute tuples where condition C is true
42 Example: Relational Algebra Select R(A 1,A 2,A 3,...), Relation R, Attributes A * return only those attribute tuples where condition C is true def map(k, v): #v is list of attribute tuples for t in v: if t satisfies C: yield (t, t) def reduce(k, vs): For each v in vs: yield (k, v)
43 Example: Relational Algebra Natural Join Given R 1 and R 2 return R join -- union of all pairs of tuples that match given attributes.
44 Example: Relational Algebra Natural Join Given R 1 and R 2 return R join -- union of all pairs of tuples that match given attributes. def map(k, v): #v is (R 1 =(A, B), R 2 =(B, C));B are matched attributes for (a, b) in R 1 : yield (b,(r 1, a)) for (b, c) in R 2 : yield (b,(r 2, c))
45 Example: Relational Algebra Natural Join Given R 1 and R 2 return R join -- union of all pairs of tuples that match given attributes. def map(k, v): #v is (R 1 =(A, B), R 2 =(B, C));B are matched attributes for (a, b) in R 1 : yield (b,(r 1, a)) def reduce(k, vs): for (b, c) in R 2 : r1, r2 = [], [] yield (b,(r 2, c)) for (S, x) in vs: #separate rs if S == r1: r1.append(x) else: r2.append(x) for a in r1: #join as tuple for each c in r2: yield (R join, (a, k, c)) #k is
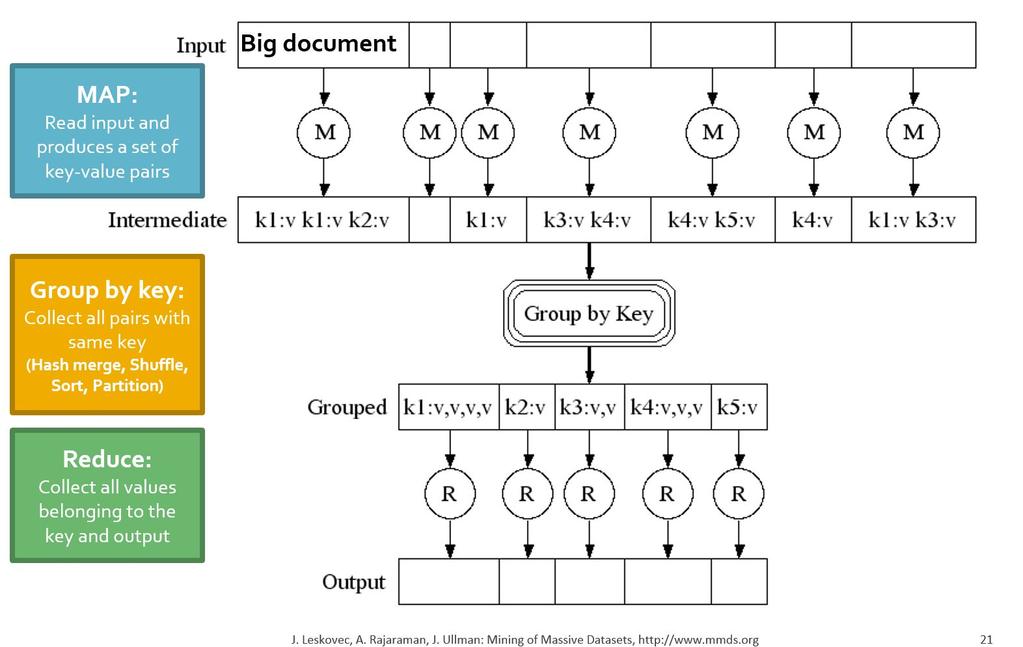
46 Data Flow
47 Data Flow: In Parallel hash (Leskovec at al., 2014;
48 Data Flow: In Parallel Programmed hash Programmed (Leskovec at al., 2014;
49 Data Flow DFS Map Map s Local FS Reduce DFS
50 Data Flow MapReduce system handles: Partitioning Scheduling map / reducer execution Group by key Restarts from node failures Inter-machine communication
51 Data Flow DFS MapReduce DFS Schedule map tasks near physical storage of chunk Intermediate results stored locally Master / Name Node coordinates
52 Data Flow DFS MapReduce DFS Schedule map tasks near physical storage of chunk Intermediate results stored locally Master / Name Node coordinates Task status: idle, in-progress, complete Receives location of intermediate results and schedules with reducer Checks nodes for failures and restarts when necessary All map tasks on nodes must be completely restarted Reduce tasks can pickup with reduce task failed
53 Data Flow DFS MapReduce DFS Schedule map tasks near physical storage of chunk Intermediate results stored locally Master / Name Node coordinates Task status: idle, in-progress, complete Receives location of intermediate results and schedules with reducer Checks nodes for failures and restarts when necessary All map tasks on nodes must be completely restarted Reduce tasks can pickup with reduce task failed DFS MapReduce DFS MapReduce DFS
54 Data Flow Skew: The degree to which certain tasks end up taking much longer than others. Handled with: More reducers than reduce tasks More reduce tasks than nodes
55 Data Flow Key Question: How many Map and Reduce jobs?
56 Data Flow Key Question: How many Map and Reduce jobs? M: map tasks, R: reducer tasks A: If possible, one chunk per map task. and M >> nodes R < M (better handling of node failures, better load balancing) (reduces number of files stored in DFS)
57 Communication Cost Model How to assess performance? (1) Computation: Map + Reduce + System Tasks (2) Communication: Moving key, value pairs
58 Communication Cost Model How to assess performance? (1) Computation: Map + Reduce + System Tasks (2) Communication: Moving key, value pairs Ultimate Goal: wall-clock Time.
59 Communication Cost Model How to assess performance? (1) Computation: Map + Reduce + System Tasks Mappers and reducers often single pass O(n) within node System: sort the keys is usually most expensive In any case, can add more nodes (2) Communication: Moving key, value pairs Ultimate Goal: wall-clock Time.
60 Communication Cost Model How to assess performance? (1) Computation: Map + Reduce + System Tasks (2) Communication: Moving key, value pairs Often dominates computation. Connection speeds: 1-10 gigabits per sec; HD read: gigabytes per sec Even reading from disk to memory typically takes longer than operating on the data. Ultimate Goal: wall-clock Time.
61 Communication Cost Model How to assess performance? (1) Communication Computation: Cost Map = input + Reduce size + + System Tasks (2) Communication: Moving key, value pairs Often dominates computation. Connection speeds: 1-10 gigabits per sec; HD read: gigabytes per sec Even reading from disk to memory typically takes longer than operating on the data. Ultimate Goal: wall-clock Time. (sum of size of all map-to-reducer files)
62 Communication Cost Model How to assess performance? (1) Communication Computation: Cost Map = input + Reduce size + + System Tasks (2) Communication: Moving key, value pairs Often dominates computation. Connection speeds: 1-10 gigabits per sec; HD read: gigabytes per sec Even reading from disk to memory typically takes longer than operating on the data. Output from reducer ignored because it s either small (finished summarizing data) or being passed to another mapreduce job. Ultimate Goal: wall-clock Time. (sum of size of all map-to-reducer files)
63 Example: Natural Join R 1, R 2 : Relations (Tables) Communication Cost = input size + (sum of size of all map-to-reducer files) = R + S + ( R + S ) = O( R + S )
64 Exercise: Calculate Communication Cost for Matrix Multiplication with One MapReduce Step (see MMDS section )
65 Last Notes Performance Refinements: Backup tasks (aka speculative tasks) Schedule multiple copies of tasks when close to the end to mitigate certain nodes running slow. Combiners (like word count version 2) Do some reducing from within map before passing to reduce Reduces communication cost Override partition hash function E.g. instead of hash(url) use hash(hostname(url))
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
Outline. Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins
 MapReduce 1 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins 2 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce
MapReduce 1 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins 2 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce
MapReduce: Recap. Juliana Freire & Cláudio Silva. Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec
 MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Introduction to MapReduce (cont.)
") Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Introduction to MapReduce
 732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Distributed Computations MapReduce. adapted from Jeff Dean s slides
 Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
Databases 2 (VU) ( )
 ( )") Databases 2 (VU) (707.030) Map-Reduce Denis Helic KMI, TU Graz Nov 4, 2013 Denis Helic (KMI, TU Graz) Map-Reduce Nov 4, 2013 1 / 90 Outline 1 Motivation 2 Large Scale Computation 3 Map-Reduce 4 Environment
Databases 2 (VU) (707.030) Map-Reduce Denis Helic KMI, TU Graz Nov 4, 2013 Denis Helic (KMI, TU Graz) Map-Reduce Nov 4, 2013 1 / 90 Outline 1 Motivation 2 Large Scale Computation 3 Map-Reduce 4 Environment
The MapReduce Abstraction
 The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
Announcements. Optional Reading. Distributed File System (DFS) MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm
 MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm") Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Dis Commodity Clusters Web data sets can be ery large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Dis Commodity Clusters Web data sets can be ery large Tens to hundreds of terabytes
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016
Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU
 Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU !2 MapReduce Overview! Sometimes a single computer cannot process data or takes too long traditional serial programming is not always
Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU !2 MapReduce Overview! Sometimes a single computer cannot process data or takes too long traditional serial programming is not always
Principles of Data Management. Lecture #16 (MapReduce & DFS for Big Data)
") Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
MapReduce and Friends
 MapReduce and Friends Craig C. Douglas University of Wyoming with thanks to Mookwon Seo Why was it invented? MapReduce is a mergesort for large distributed memory computers. It was the basis for a web
MapReduce and Friends Craig C. Douglas University of Wyoming with thanks to Mookwon Seo Why was it invented? MapReduce is a mergesort for large distributed memory computers. It was the basis for a web
Announcements. Parallel Data Processing in the 20 th Century. Parallel Join Illustration. Introduction to Database Systems CSE 414
 Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Database Applications (15-415)
") Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
INTRODUCTION TO DATA SCIENCE. MapReduce and the New Software Stacks(MMDS2)
") INTRODUCTION TO DATA SCIENCE MapReduce and the New Software Stacks(MMDS2) Big-Data Hardware Computer Clusters Computation: large number of computers/cpus Network: Ethernet switching Storage: Large collection
INTRODUCTION TO DATA SCIENCE MapReduce and the New Software Stacks(MMDS2) Big-Data Hardware Computer Clusters Computation: large number of computers/cpus Network: Ethernet switching Storage: Large collection
Big Data Analytics: What is Big Data? Stony Brook University CSE545, Fall 2016 the inaugural edition
 Big Data Analytics: What is Big Data? Stony Brook University CSE545, Fall 2016 the inaugural edition What s the BIG deal?! 2011 2011 2008 2010 2012 What s the BIG deal?! (Gartner Hype Cycle) What s the
Big Data Analytics: What is Big Data? Stony Brook University CSE545, Fall 2016 the inaugural edition What s the BIG deal?! 2011 2011 2008 2010 2012 What s the BIG deal?! (Gartner Hype Cycle) What s the
Parallel Nested Loops
 Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Partition-Based. Parallel Nested Loops. Median. More Join Thoughts. Parallel Office Tools 9/15/2011
 Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
FLAT DATACENTER STORAGE. Paper-3 Presenter-Pratik Bhatt fx6568
 FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
CSE 344 MAY 2 ND MAP/REDUCE
 CSE 344 MAY 2 ND MAP/REDUCE ADMINISTRIVIA HW5 Due Tonight Practice midterm Section tomorrow Exam review PERFORMANCE METRICS FOR PARALLEL DBMSS Nodes = processors, computers Speedup: More nodes, same data
CSE 344 MAY 2 ND MAP/REDUCE ADMINISTRIVIA HW5 Due Tonight Practice midterm Section tomorrow Exam review PERFORMANCE METRICS FOR PARALLEL DBMSS Nodes = processors, computers Speedup: More nodes, same data
PARALLEL & DISTRIBUTED DATABASES CS561-SPRING 2012 WPI, MOHAMED ELTABAKH
 PARALLEL & DISTRIBUTED DATABASES CS561-SPRING 2012 WPI, MOHAMED ELTABAKH 1 INTRODUCTION In centralized database: Data is located in one place (one server) All DBMS functionalities are done by that server
PARALLEL & DISTRIBUTED DATABASES CS561-SPRING 2012 WPI, MOHAMED ELTABAKH 1 INTRODUCTION In centralized database: Data is located in one place (one server) All DBMS functionalities are done by that server
MASSACHUSETTS INSTITUTE OF TECHNOLOGY Database Systems: Fall 2008 Quiz II
 Department of Electrical Engineering and Computer Science MASSACHUSETTS INSTITUTE OF TECHNOLOGY 6.830 Database Systems: Fall 2008 Quiz II There are 14 questions and 11 pages in this quiz booklet. To receive
Department of Electrical Engineering and Computer Science MASSACHUSETTS INSTITUTE OF TECHNOLOGY 6.830 Database Systems: Fall 2008 Quiz II There are 14 questions and 11 pages in this quiz booklet. To receive
The amount of data increases every day Some numbers ( 2012):
:") 1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
2/26/2017. The amount of data increases every day Some numbers ( 2012):
:") The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
Programming Models MapReduce
 Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
Cloud Computing CS
 Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Parallel Programming Concepts
 Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Streaming Algorithms. Stony Brook University CSE545, Fall 2016
 Streaming Algorithms Stony Brook University CSE545, Fall 2016 Big Data Analytics -- The Class We will learn: to analyze different types of data: high dimensional graphs infinite/never-ending labeled to
Streaming Algorithms Stony Brook University CSE545, Fall 2016 Big Data Analytics -- The Class We will learn: to analyze different types of data: high dimensional graphs infinite/never-ending labeled to
CSE Lecture 11: Map/Reduce 7 October Nate Nystrom UTA
 CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
MapReduce and Hadoop. Debapriyo Majumdar Indian Statistical Institute Kolkata
 MapReduce and Hadoop Debapriyo Majumdar Indian Statistical Institute Kolkata debapriyo@isical.ac.in Let s keep the intro short Modern data mining: process immense amount of data quickly Exploit parallelism
MapReduce and Hadoop Debapriyo Majumdar Indian Statistical Institute Kolkata debapriyo@isical.ac.in Let s keep the intro short Modern data mining: process immense amount of data quickly Exploit parallelism
Data Partitioning and MapReduce
 Data Partitioning and MapReduce Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies,
Data Partitioning and MapReduce Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies,
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Map-Reduce and Related Systems
 Map-Reduce and Related Systems Acknowledgement The slides used in this chapter are adapted from the following sources: CS246 Mining Massive Data-sets, by Jure Leskovec, Stanford University, http://www.mmds.org
Map-Reduce and Related Systems Acknowledgement The slides used in this chapter are adapted from the following sources: CS246 Mining Massive Data-sets, by Jure Leskovec, Stanford University, http://www.mmds.org
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CS / Cloud Computing. Recitation 3 September 9 th & 11 th, 2014
 CS15-319 / 15-619 Cloud Computing Recitation 3 September 9 th & 11 th, 2014 Overview Last Week s Reflection --Project 1.1, Quiz 1, Unit 1 This Week s Schedule --Unit2 (module 3 & 4), Project 1.2 Questions
CS15-319 / 15-619 Cloud Computing Recitation 3 September 9 th & 11 th, 2014 Overview Last Week s Reflection --Project 1.1, Quiz 1, Unit 1 This Week s Schedule --Unit2 (module 3 & 4), Project 1.2 Questions
Cloud Programming. Programming Environment Oct 29, 2015 Osamu Tatebe
 Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Flat Datacenter Storage. Edmund B. Nightingale, Jeremy Elson, et al. 6.S897
 Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
FLAT DATACENTER STORAGE CHANDNI MODI (FN8692)
") FLAT DATACENTER STORAGE CHANDNI MODI (FN8692) OUTLINE Flat datacenter storage Deterministic data placement in fds Metadata properties of fds Per-blob metadata in fds Dynamic Work Allocation in fds Replication
FLAT DATACENTER STORAGE CHANDNI MODI (FN8692) OUTLINE Flat datacenter storage Deterministic data placement in fds Metadata properties of fds Per-blob metadata in fds Dynamic Work Allocation in fds Replication
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
SQL, NoSQL, MongoDB. CSE-291 (Cloud Computing) Fall 2016 Gregory Kesden
 Fall 2016 Gregory Kesden") SQL, NoSQL, MongoDB CSE-291 (Cloud Computing) Fall 2016 Gregory Kesden SQL Databases Really better called Relational Databases Key construct is the Relation, a.k.a. the table Rows represent records Columns
SQL, NoSQL, MongoDB CSE-291 (Cloud Computing) Fall 2016 Gregory Kesden SQL Databases Really better called Relational Databases Key construct is the Relation, a.k.a. the table Rows represent records Columns
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기
 MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
Remote Procedure Call. Tom Anderson
 Remote Procedure Call Tom Anderson Why Are Distributed Systems Hard? Asynchrony Different nodes run at different speeds Messages can be unpredictably, arbitrarily delayed Failures (partial and ambiguous)
Remote Procedure Call Tom Anderson Why Are Distributed Systems Hard? Asynchrony Different nodes run at different speeds Messages can be unpredictably, arbitrarily delayed Failures (partial and ambiguous)
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Motivation. Map in Lisp (Scheme) Map/Reduce. MapReduce: Simplified Data Processing on Large Clusters
 Map/Reduce. MapReduce: Simplified Data Processing on Large Clusters") Motivation MapReduce: Simplified Data Processing on Large Clusters These are slides from Dan Weld s class at U. Washington (who in turn made his slides based on those by Jeff Dean, Sanjay Ghemawat, Google,
Motivation MapReduce: Simplified Data Processing on Large Clusters These are slides from Dan Weld s class at U. Washington (who in turn made his slides based on those by Jeff Dean, Sanjay Ghemawat, Google,
CS-2510 COMPUTER OPERATING SYSTEMS
 CS-2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application Functional
CS-2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application Functional
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Announcements. Database Systems CSE 414. Why compute in parallel? Big Data 10/11/2017. Two Kinds of Parallel Data Processing
 Announcements Database Systems CSE 414 HW4 is due tomorrow 11pm Lectures 18: Parallel Databases (Ch. 20.1) 1 2 Why compute in parallel? Multi-cores: Most processors have multiple cores This trend will
Announcements Database Systems CSE 414 HW4 is due tomorrow 11pm Lectures 18: Parallel Databases (Ch. 20.1) 1 2 Why compute in parallel? Multi-cores: Most processors have multiple cores This trend will
Page 1. Goals for Today" Background of Cloud Computing" Sources Driving Big Data" CS162 Operating Systems and Systems Programming Lecture 24
 Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
Introduction to Distributed Data Systems
 Introduction to Distributed Data Systems Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook January
Introduction to Distributed Data Systems Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook January
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Developing MapReduce Programs
 Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Database Architectures
 Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 11/15/12 Agenda Check-in Centralized and Client-Server Models Parallelism Distributed Databases Homework 6 Check-in
Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 11/15/12 Agenda Check-in Centralized and Client-Server Models Parallelism Distributed Databases Homework 6 Check-in
Parallel Processing - MapReduce and FlumeJava. Amir H. Payberah 14/09/2018
 Parallel Processing - MapReduce and FlumeJava Amir H. Payberah payberah@kth.se 14/09/2018 The Course Web Page https://id2221kth.github.io 1 / 83 Where Are We? 2 / 83 What do we do when there is too much
Parallel Processing - MapReduce and FlumeJava Amir H. Payberah payberah@kth.se 14/09/2018 The Course Web Page https://id2221kth.github.io 1 / 83 Where Are We? 2 / 83 What do we do when there is too much
MapReduce-style data processing
 MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Laarge-Scale Data Engineering
 Laarge-Scale Data Engineering The MapReduce Framework & Hadoop Key premise: divide and conquer work partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 result combine Parallelisation challenges How
Laarge-Scale Data Engineering The MapReduce Framework & Hadoop Key premise: divide and conquer work partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 result combine Parallelisation challenges How
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Parallel DBMS. Parallel Database Systems. PDBS vs Distributed DBS. Types of Parallelism. Goals and Metrics Speedup. Types of Parallelism
 Parallel DBMS Parallel Database Systems CS5225 Parallel DB 1 Uniprocessor technology has reached its limit Difficult to build machines powerful enough to meet the CPU and I/O demands of DBMS serving large
Parallel DBMS Parallel Database Systems CS5225 Parallel DB 1 Uniprocessor technology has reached its limit Difficult to build machines powerful enough to meet the CPU and I/O demands of DBMS serving large