Why AI Frameworks Need (not only) RDMA?
|
|
|
- Clinton Casey
- 5 years ago
- Views:
Transcription
1 Why AI Frameworks Need (not only) RDMA? With Design and Implementation Experience of Networking Support on TensorFlow GDR, Apache MXNet, WeChat Amber, and Tencent Angel Bairen Yi Jingrong Chen, Junxue Zhang, Jiacheng Xia, Li Chen, and Kai Chen SING Group, WHAT Lab, Big Data Institute Hong Kong University of Science & Technology 1
2 A Perspective from (non-hpc) System and Networking Community Prof. Kai Chen and System & Networking HKUST Research interests include networked systems design and implementation, data center networks, data centric networking, and cloud & big data systems 5 papers in NSDI 15-18, 4 papers in SIGCOMM Collaborations with industrial partners including Tencent & Huawei on real-world systems in AI, Big Data, and Cloud 2
3 Industrial Experience from an Academic Lab? Worked on real-world AI & Big Data systems, like CoDA with Huawei (2015), Tencent Angel (2016), WeChat Amber (2017) Contributed network optimisation patches to several open source projects, including TensorFlow & Apache MXNet A recently funded startup in Beijing, providing commodity & high performance data center networking solutions to AI teams of data scientists, developers, and operations 3
4 Agenda A glance to commodity data center networking Convergence of networking in cloud data centers Anti-patterns with high performance networks End-to-end design principles for AI frameworks 4

5 The Rise of Cloud Computing 40 Azure Regions across the World 5

6 Data Centers What does data center network look like? 6

7 7
8 What Modern Data Center Networks Offer High throughput: single connection at line rate Low latency: 99.9% tail latency within 200 μs* Scalability: >100,000 nodes in routable IP network Commodity: <$100($500) 25(100) GbE per port *RDMA over Commodity Ethernet at Scale, SIGCOMM 16 8
9 Convergence of Data Center Networking Technologies InfiniBand, OmniPath, Fibre Channel, and PLX (PCIe Switch) Replacing 4 networks (and switches) with a single Ethernet Convergence of networking applications to IP as well: computation, storage, messaging, and remote management (Routable) RDMA over Converged Ethernet (RoCEv2) 9
10 Evolution of Network I/O Latency dropped from ~10 ms to ~10 μs From kernel to user space (VMA, DPDK, Onload) From software to hardware (RoCE, iwarp) Reduced CPU load for better performance 10
11 Software Anti-Patterns High performance networking costs and we can only afford commodity Ethernet (a.k.a. AWS VPC) Network communication hurts performance and we need to avoid communication as much as possible Either high-level APIs with poor performance or lowlevel APIs with high performance; not both 11
12 Networking APIs Revisited Messaging libraries: socket, 0MQ, Netty, Akka RPC libraries: grpc, Thrift, Dubbo, brpc Encoding libraries: protobuf, thrift, kryo, flatbuffers Compression libraries: zlib, snappy, lz4 12

13 ~100 MB/s encoding throughput Lesson Learnt: Do not encode your data when your network >100 Gbps Taken from: 13

14 ~850 MB/s compression throughput Lesson Learnt: Do not compress your data when your network >100 Gbps Taken from: 14
15 How about Memory Copy? 15

16 Throughput (MB/s) Cached Cache-bypass Buffer Size (KB) Cached Writes: 37.7 GB/s at 16 KB, 3.0 GB/s >L3 cache Cache Bypassed Writes: 3.0 GB/s at all buffer sizes 16 Taken from:
17 AI Applications are Bottlenecked by its Anti-Patterns The performance of Spark 1.4 increases only 2% by medium even if the network is infinitely fast*! Encoding, compression, serialisation, and memory copying take the most CPU cycles, not networking (nor disk I/O; about 20% better if it s infinitely fast) Software architecture makes CPU its bottleneck *Making Sense of Performance in Data Analytics Frameworks, NSDI 15 17



18 Network Device RDMA??? Networking Protocol Stack Memory Copy Compression Performance Gain eaten by Software Forwarding of Data Computation Job Scheduler Serialization Storage File System CUDA??? NVMe??? Computation Device 18 Storage Device

19 Yahoo s TensorFlow RDMA * Removing Ser/Des gives 1.5 GB/s throughput 19
20 0-Copy Dataflow The end-to-end offloaded dataflow pipeline: NVMe storage, RDMA networks, and GPU accelerators Lesson learnt from network switches: we need to separate control plane and data plane CPU/software for flexible control plane, hardware offloading for high performance data plane 20



21 Disaggregated Architecture CPU/Software Control Plane High Performance Data Plane Offloaded Computation/Networking/Storage Computation Device Network Device Storage Device Lean Data Structures P2P Switching 21
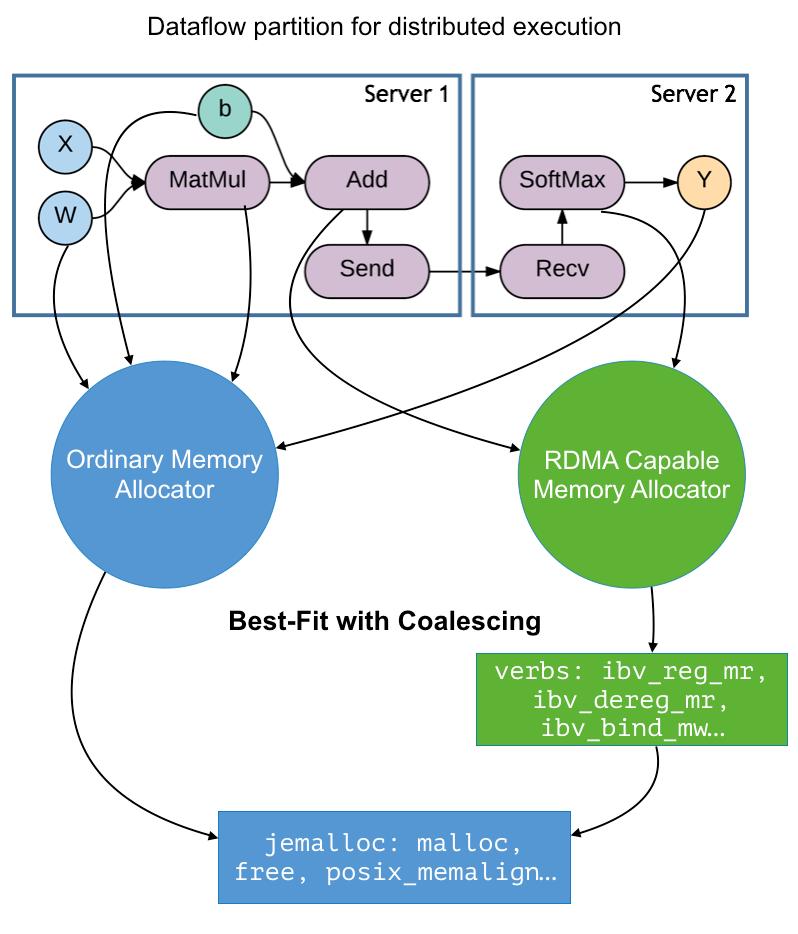
22 22
23 TensorFlow GDR 23
24 TensorFlow GDR We kept 100% grpc calls without introducing significant overhead compared to pure RDMA Easy to fallback to grpc with mixed deployment Less code changes compared to verbs with even more features (<1,000 lines of C++, mostly on GPU Direct RDMA and RDMA memory management) 24
25 WeChat s Amber w/ RDMA Taken from: 25

26 WeChat s Amber w/ RDMA Scalability Ratio (0MQ for TCP) Ego Network Deep Conversation Object Recognition Taken from: 26
27 To Copy or Not To Copy RDMA messages need to be registered (pinned) through ibv_reg_mr before send/recv Pinning memory pages through get_user_pages in kernel is costly, e.s.p. frequently for small buffers Typically we introduce transmitting/receiving side ring buffers w/ huge pages for RDMA buffer reuse Buffer bloat and extra latency introduced in copy 27
28 Looking Forward Unified Virtual Memory (UVM) in CUDA 6 On Demand Paging (ODP) in OFED 4 MSG_ZEROCOPY by Google in Linux 4.14 Heterogeneous Memory Management (HMM) for universal coherent host+device memory space 28
29 Conclusion Embrace end-to-end principle designing AI frameworks for data intensive applications Revisit old operating system concepts and learn how to write low level programs for your hardware Combining high-level APIs with efficient offloading actually works (as long as hardware does all the heavy lifting and software only in the control plane) 29
30 Questions? 30
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Meltdown and Spectre Interconnect Performance Evaluation Jan Mellanox Technologies
 Meltdown and Spectre Interconnect Evaluation Jan 2018 1 Meltdown and Spectre - Background Most modern processors perform speculative execution This speculation can be measured, disclosing information about
Meltdown and Spectre Interconnect Evaluation Jan 2018 1 Meltdown and Spectre - Background Most modern processors perform speculative execution This speculation can be measured, disclosing information about
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Data Processing at the Speed of 100 Gbps using Apache Crail. Patrick Stuedi IBM Research
 Data Processing at the Speed of 100 Gbps using Apache Crail Patrick Stuedi IBM Research The CRAIL Project: Overview Data Processing Framework (e.g., Spark, TensorFlow, λ Compute) Spark-IO FS Albis Streaming
Data Processing at the Speed of 100 Gbps using Apache Crail Patrick Stuedi IBM Research The CRAIL Project: Overview Data Processing Framework (e.g., Spark, TensorFlow, λ Compute) Spark-IO FS Albis Streaming
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay Mellanox Technologies
 Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
The Future of High Performance Interconnects
 The Future of High Performance Interconnects Ashrut Ambastha HPC Advisory Council Perth, Australia :: August 2017 When Algorithms Go Rogue 2017 Mellanox Technologies 2 When Algorithms Go Rogue 2017 Mellanox
The Future of High Performance Interconnects Ashrut Ambastha HPC Advisory Council Perth, Australia :: August 2017 When Algorithms Go Rogue 2017 Mellanox Technologies 2 When Algorithms Go Rogue 2017 Mellanox
Data Processing at the Speed of 100 Gbps using Apache Crail. Patrick Stuedi IBM Research
 Data Processing at the Speed of 100 Gbps using Apache Crail Patrick Stuedi IBM Research The CRAIL Project: Overview Data Processing Framework (e.g., Spark, TensorFlow, λ Compute) Spark-IO Albis Pocket
Data Processing at the Speed of 100 Gbps using Apache Crail Patrick Stuedi IBM Research The CRAIL Project: Overview Data Processing Framework (e.g., Spark, TensorFlow, λ Compute) Spark-IO Albis Pocket
Towards Converged SmartNIC Architecture for Bare Metal & Public Clouds. Layong (Larry) Luo, Tencent TEG August 8, 2018
 Luo, Tencent TEG August 8, 2018") Towards Converged Smart Architecture for Bare Metal & Public Clouds Layong (Larry) Luo, Tencent TEG August 8, 2018 Agenda 1 Smart in Bare Metal Cloud 2 Smart in Public Cloud 3 Converged Smart Architecture
Towards Converged Smart Architecture for Bare Metal & Public Clouds Layong (Larry) Luo, Tencent TEG August 8, 2018 Agenda 1 Smart in Bare Metal Cloud 2 Smart in Public Cloud 3 Converged Smart Architecture
Deep Learning Frameworks with Spark and GPUs
 Deep Learning Frameworks with Spark and GPUs Abstract Spark is a powerful, scalable, real-time data analytics engine that is fast becoming the de facto hub for data science and big data. However, in parallel,
Deep Learning Frameworks with Spark and GPUs Abstract Spark is a powerful, scalable, real-time data analytics engine that is fast becoming the de facto hub for data science and big data. However, in parallel,
RDMA and Hardware Support
 RDMA and Hardware Support SIGCOMM Topic Preview 2018 Yibo Zhu Microsoft Research 1 The (Traditional) Journey of Data How app developers see the network Under the hood This architecture had been working
RDMA and Hardware Support SIGCOMM Topic Preview 2018 Yibo Zhu Microsoft Research 1 The (Traditional) Journey of Data How app developers see the network Under the hood This architecture had been working
SoftRDMA: Rekindling High Performance Software RDMA over Commodity Ethernet
 SoftRDMA: Rekindling High Performance Software RDMA over Commodity Ethernet Mao Miao, Fengyuan Ren, Xiaohui Luo, Jing Xie, Qingkai Meng, Wenxue Cheng Dept. of Computer Science and Technology, Tsinghua
SoftRDMA: Rekindling High Performance Software RDMA over Commodity Ethernet Mao Miao, Fengyuan Ren, Xiaohui Luo, Jing Xie, Qingkai Meng, Wenxue Cheng Dept. of Computer Science and Technology, Tsinghua
Bare Metal Library. Abstractions for modern hardware Cyprien Noel
 Bare Metal Library Abstractions for modern hardware Cyprien Noel Plan 1. 2. 3. Modern Hardware? New challenges & opportunities Three use cases Current solutions Leveraging hardware Simple abstraction Myself
Bare Metal Library Abstractions for modern hardware Cyprien Noel Plan 1. 2. 3. Modern Hardware? New challenges & opportunities Three use cases Current solutions Leveraging hardware Simple abstraction Myself
NFS/RDMA over 40Gbps iwarp Wael Noureddine Chelsio Communications
 NFS/RDMA over 40Gbps iwarp Wael Noureddine Chelsio Communications Outline RDMA Motivating trends iwarp NFS over RDMA Overview Chelsio T5 support Performance results 2 Adoption Rate of 40GbE Source: Crehan
NFS/RDMA over 40Gbps iwarp Wael Noureddine Chelsio Communications Outline RDMA Motivating trends iwarp NFS over RDMA Overview Chelsio T5 support Performance results 2 Adoption Rate of 40GbE Source: Crehan
RoCE vs. iwarp A Great Storage Debate. Live Webcast August 22, :00 am PT
 RoCE vs. iwarp A Great Storage Debate Live Webcast August 22, 2018 10:00 am PT Today s Presenters John Kim SNIA ESF Chair Mellanox Tim Lustig Mellanox Fred Zhang Intel 2 SNIA-At-A-Glance 3 SNIA Legal Notice
RoCE vs. iwarp A Great Storage Debate Live Webcast August 22, 2018 10:00 am PT Today s Presenters John Kim SNIA ESF Chair Mellanox Tim Lustig Mellanox Fred Zhang Intel 2 SNIA-At-A-Glance 3 SNIA Legal Notice
NVMe over Universal RDMA Fabrics
 NVMe over Universal RDMA Fabrics Build a Flexible Scale-Out NVMe Fabric with Concurrent RoCE and iwarp Acceleration Broad spectrum Ethernet connectivity Universal RDMA NVMe Direct End-to-end solutions
NVMe over Universal RDMA Fabrics Build a Flexible Scale-Out NVMe Fabric with Concurrent RoCE and iwarp Acceleration Broad spectrum Ethernet connectivity Universal RDMA NVMe Direct End-to-end solutions
Low-Overhead Flash Disaggregation via NVMe-over-Fabrics Vijay Balakrishnan Memory Solutions Lab. Samsung Semiconductor, Inc.
 Low-Overhead Flash Disaggregation via NVMe-over-Fabrics Vijay Balakrishnan Memory Solutions Lab. Samsung Semiconductor, Inc. 1 DISCLAIMER This presentation and/or accompanying oral statements by Samsung
Low-Overhead Flash Disaggregation via NVMe-over-Fabrics Vijay Balakrishnan Memory Solutions Lab. Samsung Semiconductor, Inc. 1 DISCLAIMER This presentation and/or accompanying oral statements by Samsung
Memory Management Strategies for Data Serving with RDMA
 Memory Management Strategies for Data Serving with RDMA Dennis Dalessandro and Pete Wyckoff (presenting) Ohio Supercomputer Center {dennis,pw}@osc.edu HotI'07 23 August 2007 Motivation Increasing demands
Memory Management Strategies for Data Serving with RDMA Dennis Dalessandro and Pete Wyckoff (presenting) Ohio Supercomputer Center {dennis,pw}@osc.edu HotI'07 23 August 2007 Motivation Increasing demands
Storage Protocol Offload for Virtualized Environments Session 301-F
 Storage Protocol Offload for Virtualized Environments Session 301-F Dennis Martin, President August 2016 1 Agenda About Demartek Offloads I/O Virtualization Concepts RDMA Concepts Overlay Networks and
Storage Protocol Offload for Virtualized Environments Session 301-F Dennis Martin, President August 2016 1 Agenda About Demartek Offloads I/O Virtualization Concepts RDMA Concepts Overlay Networks and
The NE010 iwarp Adapter
 The NE010 iwarp Adapter Gary Montry Senior Scientist +1-512-493-3241 GMontry@NetEffect.com Today s Data Center Users Applications networking adapter LAN Ethernet NAS block storage clustering adapter adapter
The NE010 iwarp Adapter Gary Montry Senior Scientist +1-512-493-3241 GMontry@NetEffect.com Today s Data Center Users Applications networking adapter LAN Ethernet NAS block storage clustering adapter adapter
ReFlex: Remote Flash Local Flash
 ReFlex: Remote Flash Local Flash Ana Klimovic Heiner Litz Christos Kozyrakis NVMW 18 Memorable Paper Award Finalist 1 Flash in Datacenters Flash provides 1000 higher throughput and 100 lower latency than
ReFlex: Remote Flash Local Flash Ana Klimovic Heiner Litz Christos Kozyrakis NVMW 18 Memorable Paper Award Finalist 1 Flash in Datacenters Flash provides 1000 higher throughput and 100 lower latency than
Low-Overhead Flash Disaggregation via NVMe-over-Fabrics
 Low-Overhead Flash Disaggregation via NVMe-over-Fabrics Vijay Balakrishnan Memory Solutions Lab. Samsung Semiconductor, Inc. August 2017 1 DISCLAIMER This presentation and/or accompanying oral statements
Low-Overhead Flash Disaggregation via NVMe-over-Fabrics Vijay Balakrishnan Memory Solutions Lab. Samsung Semiconductor, Inc. August 2017 1 DISCLAIMER This presentation and/or accompanying oral statements
Sharing High-Performance Devices Across Multiple Virtual Machines
 Sharing High-Performance Devices Across Multiple Virtual Machines Preamble What does sharing devices across multiple virtual machines in our title mean? How is it different from virtual networking / NSX,
Sharing High-Performance Devices Across Multiple Virtual Machines Preamble What does sharing devices across multiple virtual machines in our title mean? How is it different from virtual networking / NSX,
Learn Your Alphabet - SRIOV, NPIV, RoCE, iwarp to Pump Up Virtual Infrastructure Performance
 Learn Your Alphabet - SRIOV, NPIV, RoCE, iwarp to Pump Up Virtual Infrastructure Performance TechTarget Dennis Martin 1 Agenda About Demartek I/O Virtualization Concepts RDMA Concepts Examples Demartek
Learn Your Alphabet - SRIOV, NPIV, RoCE, iwarp to Pump Up Virtual Infrastructure Performance TechTarget Dennis Martin 1 Agenda About Demartek I/O Virtualization Concepts RDMA Concepts Examples Demartek
An Approach for Implementing NVMeOF based Solutions
 An Approach for Implementing OF based olutions anjeev Kumar oftware Product Engineering, HiTech, Tata Consultancy ervices 25 May 2018 1 DC India 2018 Copyright 2018 Tata Consultancy ervices Limited Agenda
An Approach for Implementing OF based olutions anjeev Kumar oftware Product Engineering, HiTech, Tata Consultancy ervices 25 May 2018 1 DC India 2018 Copyright 2018 Tata Consultancy ervices Limited Agenda
Advanced Computer Networks. End Host Optimization
 Oriana Riva, Department of Computer Science ETH Zürich 263 3501 00 End Host Optimization Patrick Stuedi Spring Semester 2017 1 Today End-host optimizations: NUMA-aware networking Kernel-bypass Remote Direct
Oriana Riva, Department of Computer Science ETH Zürich 263 3501 00 End Host Optimization Patrick Stuedi Spring Semester 2017 1 Today End-host optimizations: NUMA-aware networking Kernel-bypass Remote Direct
iscsi or iser? Asgeir Eiriksson CTO Chelsio Communications Inc
 iscsi or iser? Asgeir Eiriksson CTO Chelsio Communications Inc Introduction iscsi is compatible with 15 years of deployment on all OSes and preserves software investment iser and iscsi are layered on top
iscsi or iser? Asgeir Eiriksson CTO Chelsio Communications Inc Introduction iscsi is compatible with 15 years of deployment on all OSes and preserves software investment iser and iscsi are layered on top
Application Acceleration Beyond Flash Storage
 Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
Fast packet processing in the cloud. Dániel Géhberger Ericsson Research
 Fast packet processing in the cloud Dániel Géhberger Ericsson Research Outline Motivation Service chains Hardware related topics, acceleration Virtualization basics Software performance and acceleration
Fast packet processing in the cloud Dániel Géhberger Ericsson Research Outline Motivation Service chains Hardware related topics, acceleration Virtualization basics Software performance and acceleration
Chelsio Communications. Meeting Today s Datacenter Challenges. Produced by Tabor Custom Publishing in conjunction with: CUSTOM PUBLISHING
 Meeting Today s Datacenter Challenges Produced by Tabor Custom Publishing in conjunction with: 1 Introduction In this era of Big Data, today s HPC systems are faced with unprecedented growth in the complexity
Meeting Today s Datacenter Challenges Produced by Tabor Custom Publishing in conjunction with: 1 Introduction In this era of Big Data, today s HPC systems are faced with unprecedented growth in the complexity
SOFTWARE-DEFINED BLOCK STORAGE FOR HYPERSCALE APPLICATIONS
 SOFTWARE-DEFINED BLOCK STORAGE FOR HYPERSCALE APPLICATIONS SCALE-OUT SERVER SAN WITH DISTRIBUTED NVME, POWERED BY HIGH-PERFORMANCE NETWORK TECHNOLOGY INTRODUCTION The evolution in data-centric applications,
SOFTWARE-DEFINED BLOCK STORAGE FOR HYPERSCALE APPLICATIONS SCALE-OUT SERVER SAN WITH DISTRIBUTED NVME, POWERED BY HIGH-PERFORMANCE NETWORK TECHNOLOGY INTRODUCTION The evolution in data-centric applications,
Big Data Meets HPC: Exploiting HPC Technologies for Accelerating Big Data Processing and Management
 Big Data Meets HPC: Exploiting HPC Technologies for Accelerating Big Data Processing and Management SigHPC BigData BoF (SC 17) by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu
Big Data Meets HPC: Exploiting HPC Technologies for Accelerating Big Data Processing and Management SigHPC BigData BoF (SC 17) by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu
Networking at the Speed of Light
 Networking at the Speed of Light Dror Goldenberg VP Software Architecture MaRS Workshop April 2017 Cloud The Software Defined Data Center Resource virtualization Efficient services VM, Containers uservices
Networking at the Speed of Light Dror Goldenberg VP Software Architecture MaRS Workshop April 2017 Cloud The Software Defined Data Center Resource virtualization Efficient services VM, Containers uservices
N V M e o v e r F a b r i c s -
 N V M e o v e r F a b r i c s - H i g h p e r f o r m a n c e S S D s n e t w o r k e d f o r c o m p o s a b l e i n f r a s t r u c t u r e Rob Davis, VP Storage Technology, Mellanox OCP Evolution Server
N V M e o v e r F a b r i c s - H i g h p e r f o r m a n c e S S D s n e t w o r k e d f o r c o m p o s a b l e i n f r a s t r u c t u r e Rob Davis, VP Storage Technology, Mellanox OCP Evolution Server
InfiniBand Networked Flash Storage
 InfiniBand Networked Flash Storage Superior Performance, Efficiency and Scalability Motti Beck Director Enterprise Market Development, Mellanox Technologies Flash Memory Summit 2016 Santa Clara, CA 1 17PB
InfiniBand Networked Flash Storage Superior Performance, Efficiency and Scalability Motti Beck Director Enterprise Market Development, Mellanox Technologies Flash Memory Summit 2016 Santa Clara, CA 1 17PB
SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience
 SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience Jithin Jose, Mingzhe Li, Xiaoyi Lu, Krishna Kandalla, Mark Arnold and Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory
SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience Jithin Jose, Mingzhe Li, Xiaoyi Lu, Krishna Kandalla, Mark Arnold and Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory
2017 Storage Developer Conference. Mellanox Technologies. All Rights Reserved.
 Ethernet Storage Fabrics Using RDMA with Fast NVMe-oF Storage to Reduce Latency and Improve Efficiency Kevin Deierling & Idan Burstein Mellanox Technologies 1 Storage Media Technology Storage Media Access
Ethernet Storage Fabrics Using RDMA with Fast NVMe-oF Storage to Reduce Latency and Improve Efficiency Kevin Deierling & Idan Burstein Mellanox Technologies 1 Storage Media Technology Storage Media Access
Audience This paper is targeted for IT managers and architects. It showcases how to utilize your network efficiently and gain higher performance using
 White paper Benefits of Remote Direct Memory Access Over Routed Fabrics Introduction An enormous impact on data center design and operations is happening because of the rapid evolution of enterprise IT.
White paper Benefits of Remote Direct Memory Access Over Routed Fabrics Introduction An enormous impact on data center design and operations is happening because of the rapid evolution of enterprise IT.
SNIA Developers Conference - Growth of the iscsi RDMA (iser) Ecosystem
 Ecosystem") SNIA Developers Conference - Growth of the iscsi RDMA (iser) Ecosystem Rob Davis Mellanox Technologies robd@mellanox.com The FASTEST Storage Protocol: iser The FASTEST Storage: Flash What it is: iscsi
SNIA Developers Conference - Growth of the iscsi RDMA (iser) Ecosystem Rob Davis Mellanox Technologies robd@mellanox.com The FASTEST Storage Protocol: iser The FASTEST Storage: Flash What it is: iscsi
The rcuda middleware and applications
 The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
Improving Altibase Performance with Solarflare 10GbE Server Adapters and OpenOnload
 Improving Altibase Performance with Solarflare 10GbE Server Adapters and OpenOnload Summary As today s corporations process more and more data, the business ramifications of faster and more resilient database
Improving Altibase Performance with Solarflare 10GbE Server Adapters and OpenOnload Summary As today s corporations process more and more data, the business ramifications of faster and more resilient database
SoftFlash: Programmable Storage in Future Data Centers Jae Do Researcher, Microsoft Research
 SoftFlash: Programmable Storage in Future Data Centers Jae Do Researcher, Microsoft Research 1 The world s most valuable resource Data is everywhere! May. 2017 Values from Data! Need infrastructures for
SoftFlash: Programmable Storage in Future Data Centers Jae Do Researcher, Microsoft Research 1 The world s most valuable resource Data is everywhere! May. 2017 Values from Data! Need infrastructures for
LegUp: Accelerating Memcached on Cloud FPGAs
 0 LegUp: Accelerating Memcached on Cloud FPGAs Xilinx Developer Forum December 10, 2018 Andrew Canis & Ruolong Lian LegUp Computing Inc. 1 COMPUTE IS BECOMING SPECIALIZED 1 GPU Nvidia graphics cards are
0 LegUp: Accelerating Memcached on Cloud FPGAs Xilinx Developer Forum December 10, 2018 Andrew Canis & Ruolong Lian LegUp Computing Inc. 1 COMPUTE IS BECOMING SPECIALIZED 1 GPU Nvidia graphics cards are
Kaminario and K2 All Flash Array At A Glance 275+ Employees Boston HQ Locations in Israel, London, Paris, Beijing & Seoul 200+ Channel Partners K2 All
 STO1013BES Dynamically Composable NVMe-oF Storage for Cloud Applications Tom O Neill & Mike Uzan Chief Technology Office #VMworld #STO1013BES Kaminario and K2 All Flash Array At A Glance 275+ Employees
STO1013BES Dynamically Composable NVMe-oF Storage for Cloud Applications Tom O Neill & Mike Uzan Chief Technology Office #VMworld #STO1013BES Kaminario and K2 All Flash Array At A Glance 275+ Employees
Low latency, high bandwidth communication. Infiniband and RDMA programming. Bandwidth vs latency. Knut Omang Ifi/Oracle 2 Nov, 2015
 Low latency, high bandwidth communication. Infiniband and RDMA programming Knut Omang Ifi/Oracle 2 Nov, 2015 1 Bandwidth vs latency There is an old network saying: Bandwidth problems can be cured with
Low latency, high bandwidth communication. Infiniband and RDMA programming Knut Omang Ifi/Oracle 2 Nov, 2015 1 Bandwidth vs latency There is an old network saying: Bandwidth problems can be cured with
Beyond the Hype of NVMe & NVMeoF:
 Beyond the Hype of NVMe & NVMeoF: Introducing Kaminario K2.N and Flex, the industry's first composable storage vision In-Booth Presentation at 2:45 PM Eyal David Chief Technology Officer Kaminario and
Beyond the Hype of NVMe & NVMeoF: Introducing Kaminario K2.N and Flex, the industry's first composable storage vision In-Booth Presentation at 2:45 PM Eyal David Chief Technology Officer Kaminario and
High-Performance Training for Deep Learning and Computer Vision HPC
 High-Performance Training for Deep Learning and Computer Vision HPC Panel at CVPR-ECV 18 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
High-Performance Training for Deep Learning and Computer Vision HPC Panel at CVPR-ECV 18 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Accessing NVM Locally and over RDMA Challenges and Opportunities
 Accessing NVM Locally and over RDMA Challenges and Opportunities Wendy Elsasser Megan Grodowitz William Wang MSST - May 2018 Emerging NVM A wide variety of technologies with varied characteristics Address
Accessing NVM Locally and over RDMA Challenges and Opportunities Wendy Elsasser Megan Grodowitz William Wang MSST - May 2018 Emerging NVM A wide variety of technologies with varied characteristics Address
How to Network Flash Storage Efficiently at Hyperscale. Flash Memory Summit 2017 Santa Clara, CA 1
 How to Network Flash Storage Efficiently at Hyperscale Manoj Wadekar Michael Kagan Flash Memory Summit 2017 Santa Clara, CA 1 ebay Hyper scale Infrastructure Search Front-End & Product Hadoop Object Store
How to Network Flash Storage Efficiently at Hyperscale Manoj Wadekar Michael Kagan Flash Memory Summit 2017 Santa Clara, CA 1 ebay Hyper scale Infrastructure Search Front-End & Product Hadoop Object Store
Oracle Exadata: Strategy and Roadmap
 Oracle Exadata: Strategy and Roadmap - New Technologies, Cloud, and On-Premises Juan Loaiza Senior Vice President, Database Systems Technologies, Oracle Safe Harbor Statement The following is intended
Oracle Exadata: Strategy and Roadmap - New Technologies, Cloud, and On-Premises Juan Loaiza Senior Vice President, Database Systems Technologies, Oracle Safe Harbor Statement The following is intended
iser as accelerator for Software Defined Storage Rahul Fiske, Subhojit Roy IBM (India)
") iser as accelerator for Software Defined Storage Rahul Fiske, Subhojit Roy IBM (India) Agenda Network storage virtualization Current state of Fiber Channel iscsi seeing significant adoption Emergence of
iser as accelerator for Software Defined Storage Rahul Fiske, Subhojit Roy IBM (India) Agenda Network storage virtualization Current state of Fiber Channel iscsi seeing significant adoption Emergence of
Farewell to Servers: Hardware, Software, and Network Approaches towards Datacenter Resource Disaggregation
 Farewell to Servers: Hardware, Software, and Network Approaches towards Datacenter Resource Disaggregation Yiying Zhang Datacenter 3 Monolithic Computer OS / Hypervisor 4 Can monolithic Application Hardware
Farewell to Servers: Hardware, Software, and Network Approaches towards Datacenter Resource Disaggregation Yiying Zhang Datacenter 3 Monolithic Computer OS / Hypervisor 4 Can monolithic Application Hardware
Baidu s Best Practice with Low Latency Networks
 Baidu s Best Practice with Low Latency Networks Feng Gao IEEE 802 IC NEND Orlando, FL November 2017 Presented by Huawei Low Latency Network Solutions 01 1. Background Introduction 2. Network Latency Analysis
Baidu s Best Practice with Low Latency Networks Feng Gao IEEE 802 IC NEND Orlando, FL November 2017 Presented by Huawei Low Latency Network Solutions 01 1. Background Introduction 2. Network Latency Analysis
Intra-MIC MPI Communication using MVAPICH2: Early Experience
 Intra-MIC MPI Communication using MVAPICH: Early Experience Sreeram Potluri, Karen Tomko, Devendar Bureddy, and Dhabaleswar K. Panda Department of Computer Science and Engineering Ohio State University
Intra-MIC MPI Communication using MVAPICH: Early Experience Sreeram Potluri, Karen Tomko, Devendar Bureddy, and Dhabaleswar K. Panda Department of Computer Science and Engineering Ohio State University
Infiniswap. Efficient Memory Disaggregation. Mosharaf Chowdhury. with Juncheng Gu, Youngmoon Lee, Yiwen Zhang, and Kang G. Shin
 Infiniswap Efficient Memory Disaggregation Mosharaf Chowdhury with Juncheng Gu, Youngmoon Lee, Yiwen Zhang, and Kang G. Shin Rack-Scale Computing Datacenter-Scale Computing Geo-Distributed Computing Coflow
Infiniswap Efficient Memory Disaggregation Mosharaf Chowdhury with Juncheng Gu, Youngmoon Lee, Yiwen Zhang, and Kang G. Shin Rack-Scale Computing Datacenter-Scale Computing Geo-Distributed Computing Coflow
NTRDMA v0.1. An Open Source Driver for PCIe NTB and DMA. Allen Hubbe at Linux Piter 2015 NTRDMA. Messaging App. IB Verbs. dmaengine.h ntb.
 Messaging App IB Verbs NTRDMA dmaengine.h ntb.h DMA DMA DMA NTRDMA v0.1 An Open Source Driver for PCIe and DMA Allen Hubbe at Linux Piter 2015 1 INTRODUCTION Allen Hubbe Senior Software Engineer EMC Corporation
Messaging App IB Verbs NTRDMA dmaengine.h ntb.h DMA DMA DMA NTRDMA v0.1 An Open Source Driver for PCIe and DMA Allen Hubbe at Linux Piter 2015 1 INTRODUCTION Allen Hubbe Senior Software Engineer EMC Corporation
Interconnect Your Future Enabling the Best Datacenter Return on Investment. TOP500 Supercomputers, November 2017
 Interconnect Your Future Enabling the Best Datacenter Return on Investment TOP500 Supercomputers, November 2017 InfiniBand Accelerates Majority of New Systems on TOP500 InfiniBand connects 77% of new HPC
Interconnect Your Future Enabling the Best Datacenter Return on Investment TOP500 Supercomputers, November 2017 InfiniBand Accelerates Majority of New Systems on TOP500 InfiniBand connects 77% of new HPC
Exploiting InfiniBand and GPUDirect Technology for High Performance Collectives on GPU Clusters
 Exploiting InfiniBand and Direct Technology for High Performance Collectives on Clusters Ching-Hsiang Chu chu.368@osu.edu Department of Computer Science and Engineering The Ohio State University OSU Booth
Exploiting InfiniBand and Direct Technology for High Performance Collectives on Clusters Ching-Hsiang Chu chu.368@osu.edu Department of Computer Science and Engineering The Ohio State University OSU Booth
PARAVIRTUAL RDMA DEVICE
 12th ANNUAL WORKSHOP 2016 PARAVIRTUAL RDMA DEVICE Aditya Sarwade, Adit Ranadive, Jorgen Hansen, Bhavesh Davda, George Zhang, Shelley Gong VMware, Inc. [ April 5th, 2016 ] MOTIVATION User Kernel Socket
12th ANNUAL WORKSHOP 2016 PARAVIRTUAL RDMA DEVICE Aditya Sarwade, Adit Ranadive, Jorgen Hansen, Bhavesh Davda, George Zhang, Shelley Gong VMware, Inc. [ April 5th, 2016 ] MOTIVATION User Kernel Socket
Chelsio 10G Ethernet Open MPI OFED iwarp with Arista Switch
 PERFORMANCE BENCHMARKS Chelsio 10G Ethernet Open MPI OFED iwarp with Arista Switch Chelsio Communications www.chelsio.com sales@chelsio.com +1-408-962-3600 Executive Summary Ethernet provides a reliable
PERFORMANCE BENCHMARKS Chelsio 10G Ethernet Open MPI OFED iwarp with Arista Switch Chelsio Communications www.chelsio.com sales@chelsio.com +1-408-962-3600 Executive Summary Ethernet provides a reliable
A Disseminated Distributed OS for Hardware Resource Disaggregation Yizhou Shan
 LegoOS A Disseminated Distributed OS for Hardware Resource Disaggregation Yizhou Shan, Yutong Huang, Yilun Chen, and Yiying Zhang Y 4 1 2 Monolithic Server OS / Hypervisor 3 Problems? 4 cpu mem Resource
LegoOS A Disseminated Distributed OS for Hardware Resource Disaggregation Yizhou Shan, Yutong Huang, Yilun Chen, and Yiying Zhang Y 4 1 2 Monolithic Server OS / Hypervisor 3 Problems? 4 cpu mem Resource
GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS
 CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU
CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU
Characterizing and Benchmarking Deep Learning Systems on Modern Data Center Architectures
 Characterizing and Benchmarking Deep Learning Systems on Modern Data Center Architectures Talk at Bench 2018 by Xiaoyi Lu The Ohio State University E-mail: luxi@cse.ohio-state.edu http://www.cse.ohio-state.edu/~luxi
Characterizing and Benchmarking Deep Learning Systems on Modern Data Center Architectures Talk at Bench 2018 by Xiaoyi Lu The Ohio State University E-mail: luxi@cse.ohio-state.edu http://www.cse.ohio-state.edu/~luxi
Universal RDMA: A Unique Approach for Heterogeneous Data-Center Acceleration
 Universal RDMA: A Unique Approach for Heterogeneous Data-Center Acceleration By Bob Wheeler Principal Analyst June 2017 www.linleygroup.com Universal RDMA: A Unique Approach for Heterogeneous Data-Center
Universal RDMA: A Unique Approach for Heterogeneous Data-Center Acceleration By Bob Wheeler Principal Analyst June 2017 www.linleygroup.com Universal RDMA: A Unique Approach for Heterogeneous Data-Center
RDMA in Embedded Fabrics
 RDMA in Embedded Fabrics Ken Cain, kcain@mc.com Mercury Computer Systems 06 April 2011 www.openfabrics.org 2011 Mercury Computer Systems, Inc. www.mc.com Uncontrolled for Export Purposes 1 Outline Embedded
RDMA in Embedded Fabrics Ken Cain, kcain@mc.com Mercury Computer Systems 06 April 2011 www.openfabrics.org 2011 Mercury Computer Systems, Inc. www.mc.com Uncontrolled for Export Purposes 1 Outline Embedded
Mark Falco Oracle Coherence Development
 Achieving the performance benefits of Infiniband in Java Mark Falco Oracle Coherence Development 1 Copyright 2011, Oracle and/or its affiliates. All rights reserved. Insert Information Protection Policy
Achieving the performance benefits of Infiniband in Java Mark Falco Oracle Coherence Development 1 Copyright 2011, Oracle and/or its affiliates. All rights reserved. Insert Information Protection Policy
The Road to ExaScale. Advances in High-Performance Interconnect Infrastructure. September 2011
 The Road to ExaScale Advances in High-Performance Interconnect Infrastructure September 2011 diego@mellanox.com ExaScale Computing Ambitious Challenges Foster Progress Demand Research Institutes, Universities
The Road to ExaScale Advances in High-Performance Interconnect Infrastructure September 2011 diego@mellanox.com ExaScale Computing Ambitious Challenges Foster Progress Demand Research Institutes, Universities
Application Advantages of NVMe over Fabrics RDMA and Fibre Channel
 Application Advantages of NVMe over Fabrics RDMA and Fibre Channel Brandon Hoff Broadcom Limited Tuesday, June 14 2016 10:55 11:35 a.m. Agenda r Applications that have a need for speed r The Benefits of
Application Advantages of NVMe over Fabrics RDMA and Fibre Channel Brandon Hoff Broadcom Limited Tuesday, June 14 2016 10:55 11:35 a.m. Agenda r Applications that have a need for speed r The Benefits of
NVMf based Integration of Non-volatile Memory in a Distributed System - Lessons learned
 14th ANNUAL WORKSHOP 2018 NVMf based Integration of Non-volatile Memory in a Distributed System - Lessons learned Jonas Pfefferle, Bernard Metzler, Patrick Stuedi, Animesh Trivedi and Adrian Schuepbach
14th ANNUAL WORKSHOP 2018 NVMf based Integration of Non-volatile Memory in a Distributed System - Lessons learned Jonas Pfefferle, Bernard Metzler, Patrick Stuedi, Animesh Trivedi and Adrian Schuepbach
THE STORAGE PERFORMANCE DEVELOPMENT KIT AND NVME-OF
 14th ANNUAL WORKSHOP 2018 THE STORAGE PERFORMANCE DEVELOPMENT KIT AND NVME-OF Paul Luse Intel Corporation Apr 2018 AGENDA Storage Performance Development Kit What is SPDK? The SPDK Community Why are so
14th ANNUAL WORKSHOP 2018 THE STORAGE PERFORMANCE DEVELOPMENT KIT AND NVME-OF Paul Luse Intel Corporation Apr 2018 AGENDA Storage Performance Development Kit What is SPDK? The SPDK Community Why are so
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구
 MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand
 Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Democratizing Machine Learning on Kubernetes
 Democratizing Machine Learning on Kubernetes Joy Qiao, Senior Solution Architect - AI and Research Group, Microsoft Lachlan Evenson - Principal Program Manager AKS/ACS, Microsoft Who are we? The Data Scientist
Democratizing Machine Learning on Kubernetes Joy Qiao, Senior Solution Architect - AI and Research Group, Microsoft Lachlan Evenson - Principal Program Manager AKS/ACS, Microsoft Who are we? The Data Scientist
Disclaimer This presentation may contain product features that are currently under development. This overview of new technology represents no commitme
 SER1740BU RDMA: The World Of Possibilities Sudhanshu (Suds) Jain # SER1740BU #VMworld2017 Disclaimer This presentation may contain product features that are currently under development. This overview of
SER1740BU RDMA: The World Of Possibilities Sudhanshu (Suds) Jain # SER1740BU #VMworld2017 Disclaimer This presentation may contain product features that are currently under development. This overview of
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
High Performance Packet Processing with FlexNIC
 High Performance Packet Processing with FlexNIC Antoine Kaufmann, Naveen Kr. Sharma Thomas Anderson, Arvind Krishnamurthy University of Washington Simon Peter The University of Texas at Austin Ethernet
High Performance Packet Processing with FlexNIC Antoine Kaufmann, Naveen Kr. Sharma Thomas Anderson, Arvind Krishnamurthy University of Washington Simon Peter The University of Texas at Austin Ethernet
QuickSpecs. Overview. HPE Ethernet 10Gb 2-port 535 Adapter. HPE Ethernet 10Gb 2-port 535 Adapter. 1. Product description. 2.
 Overview 1. Product description 2. Product features 1. Product description HPE Ethernet 10Gb 2-port 535FLR-T adapter 1 HPE Ethernet 10Gb 2-port 535T adapter The HPE Ethernet 10GBase-T 2-port 535 adapters
Overview 1. Product description 2. Product features 1. Product description HPE Ethernet 10Gb 2-port 535FLR-T adapter 1 HPE Ethernet 10Gb 2-port 535T adapter The HPE Ethernet 10GBase-T 2-port 535 adapters
EC-Bench: Benchmarking Onload and Offload Erasure Coders on Modern Hardware Architectures
 EC-Bench: Benchmarking Onload and Offload Erasure Coders on Modern Hardware Architectures Haiyang Shi, Xiaoyi Lu, and Dhabaleswar K. (DK) Panda {shi.876, lu.932, panda.2}@osu.edu The Ohio State University
EC-Bench: Benchmarking Onload and Offload Erasure Coders on Modern Hardware Architectures Haiyang Shi, Xiaoyi Lu, and Dhabaleswar K. (DK) Panda {shi.876, lu.932, panda.2}@osu.edu The Ohio State University
Solutions for Scalable HPC
 Solutions for Scalable HPC Scot Schultz, Director HPC/Technical Computing HPC Advisory Council Stanford Conference Feb 2014 Leading Supplier of End-to-End Interconnect Solutions Comprehensive End-to-End
Solutions for Scalable HPC Scot Schultz, Director HPC/Technical Computing HPC Advisory Council Stanford Conference Feb 2014 Leading Supplier of End-to-End Interconnect Solutions Comprehensive End-to-End
A 101 Guide to Heterogeneous, Accelerated, Data Centric Computing Architectures
 A 101 Guide to Heterogeneous, Accelerated, Centric Computing Architectures Allan Cantle President & Founder, Nallatech Join the Conversation #OpenPOWERSummit 2016 OpenPOWER Foundation Buzzword & Acronym
A 101 Guide to Heterogeneous, Accelerated, Centric Computing Architectures Allan Cantle President & Founder, Nallatech Join the Conversation #OpenPOWERSummit 2016 OpenPOWER Foundation Buzzword & Acronym
Industry Collaboration and Innovation
 Industry Collaboration and Innovation Open Coherent Accelerator Processor Interface OpenCAPI TM - A New Standard for High Performance Memory, Acceleration and Networks Jeff Stuecheli April 10, 2017 What
Industry Collaboration and Innovation Open Coherent Accelerator Processor Interface OpenCAPI TM - A New Standard for High Performance Memory, Acceleration and Networks Jeff Stuecheli April 10, 2017 What
LITE Kernel RDMA. Support for Datacenter Applications. Shin-Yeh Tsai, Yiying Zhang
 LITE Kernel RDMA Support for Datacenter Applications Shin-Yeh Tsai, Yiying Zhang Time 2 Berkeley Socket Userspace Kernel Hardware Time 1983 2 Berkeley Socket TCP Offload engine Arrakis & mtcp IX Userspace
LITE Kernel RDMA Support for Datacenter Applications Shin-Yeh Tsai, Yiying Zhang Time 2 Berkeley Socket Userspace Kernel Hardware Time 1983 2 Berkeley Socket TCP Offload engine Arrakis & mtcp IX Userspace
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries
 Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
Revisiting Network Support for RDMA
 Revisiting Network Support for RDMA Radhika Mittal 1, Alex Shpiner 3, Aurojit Panda 1, Eitan Zahavi 3, Arvind Krishnamurthy 2, Sylvia Ratnasamy 1, Scott Shenker 1 (1: UC Berkeley, 2: Univ. of Washington,
Revisiting Network Support for RDMA Radhika Mittal 1, Alex Shpiner 3, Aurojit Panda 1, Eitan Zahavi 3, Arvind Krishnamurthy 2, Sylvia Ratnasamy 1, Scott Shenker 1 (1: UC Berkeley, 2: Univ. of Washington,
Big Data Systems on Future Hardware. Bingsheng He NUS Computing
 Big Data Systems on Future Hardware Bingsheng He NUS Computing http://www.comp.nus.edu.sg/~hebs/ 1 Outline Challenges for Big Data Systems Why Hardware Matters? Open Challenges Summary 2 3 ANYs in Big
Big Data Systems on Future Hardware Bingsheng He NUS Computing http://www.comp.nus.edu.sg/~hebs/ 1 Outline Challenges for Big Data Systems Why Hardware Matters? Open Challenges Summary 2 3 ANYs in Big
Deep Learning mit PowerAI - Ein Überblick
 Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
Scaling Internet TV Content Delivery ALEX GUTARIN DIRECTOR OF ENGINEERING, NETFLIX
 Scaling Internet TV Content Delivery ALEX GUTARIN DIRECTOR OF ENGINEERING, NETFLIX Inventing Internet TV Available in more than 190 countries 104+ million subscribers Lots of Streaming == Lots of Traffic
Scaling Internet TV Content Delivery ALEX GUTARIN DIRECTOR OF ENGINEERING, NETFLIX Inventing Internet TV Available in more than 190 countries 104+ million subscribers Lots of Streaming == Lots of Traffic
The Common Communication Interface (CCI)
") The Common Communication Interface (CCI) Presented by: Galen Shipman Technology Integration Lead Oak Ridge National Laboratory Collaborators: Scott Atchley, George Bosilca, Peter Braam, David Dillow, Patrick
The Common Communication Interface (CCI) Presented by: Galen Shipman Technology Integration Lead Oak Ridge National Laboratory Collaborators: Scott Atchley, George Bosilca, Peter Braam, David Dillow, Patrick
Farewell to Servers: Resource Disaggregation
 Farewell to Servers: Hardware, Software, and Network Approaches towards Datacenter Resource Disaggregation Yiying Zhang 2 Monolithic Computer OS / Hypervisor 3 Can monolithic Application Hardware servers
Farewell to Servers: Hardware, Software, and Network Approaches towards Datacenter Resource Disaggregation Yiying Zhang 2 Monolithic Computer OS / Hypervisor 3 Can monolithic Application Hardware servers
A Plugin-based Approach to Exploit RDMA Benefits for Apache and Enterprise HDFS
 A Plugin-based Approach to Exploit RDMA Benefits for Apache and Enterprise HDFS Adithya Bhat, Nusrat Islam, Xiaoyi Lu, Md. Wasi- ur- Rahman, Dip: Shankar, and Dhabaleswar K. (DK) Panda Network- Based Compu2ng
A Plugin-based Approach to Exploit RDMA Benefits for Apache and Enterprise HDFS Adithya Bhat, Nusrat Islam, Xiaoyi Lu, Md. Wasi- ur- Rahman, Dip: Shankar, and Dhabaleswar K. (DK) Panda Network- Based Compu2ng
RoCE vs. iwarp Competitive Analysis
 WHITE PAPER February 217 RoCE vs. iwarp Competitive Analysis Executive Summary...1 RoCE s Advantages over iwarp...1 Performance and Benchmark Examples...3 Best Performance for Virtualization...5 Summary...6
WHITE PAPER February 217 RoCE vs. iwarp Competitive Analysis Executive Summary...1 RoCE s Advantages over iwarp...1 Performance and Benchmark Examples...3 Best Performance for Virtualization...5 Summary...6
Deconstructing RDMA-enabled Distributed Transaction Processing: Hybrid is Better!
 Deconstructing RDMA-enabled Distributed Transaction Processing: Hybrid is Better! Xingda Wei, Zhiyuan Dong, Rong Chen, Haibo Chen Institute of Parallel and Distributed Systems (IPADS) Shanghai Jiao Tong
Deconstructing RDMA-enabled Distributed Transaction Processing: Hybrid is Better! Xingda Wei, Zhiyuan Dong, Rong Chen, Haibo Chen Institute of Parallel and Distributed Systems (IPADS) Shanghai Jiao Tong
Support for GPUs with GPUDirect RDMA in MVAPICH2 SC 13 NVIDIA Booth
 Support for GPUs with GPUDirect RDMA in MVAPICH2 SC 13 NVIDIA Booth by D.K. Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda Outline Overview of MVAPICH2-GPU
Support for GPUs with GPUDirect RDMA in MVAPICH2 SC 13 NVIDIA Booth by D.K. Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda Outline Overview of MVAPICH2-GPU
SMB Direct Update. Tom Talpey and Greg Kramer Microsoft Storage Developer Conference. Microsoft Corporation. All Rights Reserved.
 SMB Direct Update Tom Talpey and Greg Kramer Microsoft 1 Outline Part I Ecosystem status and updates SMB 3.02 status SMB Direct applications RDMA protocols and networks Part II SMB Direct details Protocol
SMB Direct Update Tom Talpey and Greg Kramer Microsoft 1 Outline Part I Ecosystem status and updates SMB 3.02 status SMB Direct applications RDMA protocols and networks Part II SMB Direct details Protocol
Can Parallel Replication Benefit Hadoop Distributed File System for High Performance Interconnects?
 Can Parallel Replication Benefit Hadoop Distributed File System for High Performance Interconnects? N. S. Islam, X. Lu, M. W. Rahman, and D. K. Panda Network- Based Compu2ng Laboratory Department of Computer
Can Parallel Replication Benefit Hadoop Distributed File System for High Performance Interconnects? N. S. Islam, X. Lu, M. W. Rahman, and D. K. Panda Network- Based Compu2ng Laboratory Department of Computer
QuickSpecs. HP Z 10GbE Dual Port Module. Models
 Overview Models Part Number: 1Ql49AA Introduction The is a 10GBASE-T adapter utilizing the Intel X722 MAC and X557-AT2 PHY pairing to deliver full line-rate performance, utilizing CAT 6A UTP cabling (or
Overview Models Part Number: 1Ql49AA Introduction The is a 10GBASE-T adapter utilizing the Intel X722 MAC and X557-AT2 PHY pairing to deliver full line-rate performance, utilizing CAT 6A UTP cabling (or
Accelerating Web Protocols Using RDMA
 Accelerating Web Protocols Using RDMA Dennis Dalessandro Ohio Supercomputer Center NCA 2007 Who's Responsible for this? Dennis Dalessandro Ohio Supercomputer Center - Springfield dennis@osc.edu Pete Wyckoff
Accelerating Web Protocols Using RDMA Dennis Dalessandro Ohio Supercomputer Center NCA 2007 Who's Responsible for this? Dennis Dalessandro Ohio Supercomputer Center - Springfield dennis@osc.edu Pete Wyckoff
IX: A Protected Dataplane Operating System for High Throughput and Low Latency
 IX: A Protected Dataplane Operating System for High Throughput and Low Latency Adam Belay et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Presented by Han Zhang & Zaina Hamid Challenges
IX: A Protected Dataplane Operating System for High Throughput and Low Latency Adam Belay et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Presented by Han Zhang & Zaina Hamid Challenges
Maximum Performance. How to get it and how to avoid pitfalls. Christoph Lameter, PhD
 Maximum Performance How to get it and how to avoid pitfalls Christoph Lameter, PhD cl@linux.com Performance Just push a button? Systems are optimized by default for good general performance in all areas.
Maximum Performance How to get it and how to avoid pitfalls Christoph Lameter, PhD cl@linux.com Performance Just push a button? Systems are optimized by default for good general performance in all areas.
Interconnect Your Future
 Interconnect Your Future Paving the Path to Exascale November 2017 Mellanox Accelerates Leading HPC and AI Systems Summit CORAL System Sierra CORAL System Fastest Supercomputer in Japan Fastest Supercomputer
Interconnect Your Future Paving the Path to Exascale November 2017 Mellanox Accelerates Leading HPC and AI Systems Summit CORAL System Sierra CORAL System Fastest Supercomputer in Japan Fastest Supercomputer
Concurrent Support of NVMe over RDMA Fabrics and Established Networked Block and File Storage
 Concurrent Support of NVMe over RDMA Fabrics and Established Networked Block and File Storage Ásgeir Eiriksson CTO Chelsio Communications Inc. August 2016 1 Introduction API are evolving for optimal use
Concurrent Support of NVMe over RDMA Fabrics and Established Networked Block and File Storage Ásgeir Eiriksson CTO Chelsio Communications Inc. August 2016 1 Introduction API are evolving for optimal use