LITE Kernel RDMA. Support for Datacenter Applications. Shin-Yeh Tsai, Yiying Zhang
|
|
|
- Bernice James
- 6 years ago
- Views:
Transcription


1 LITE Kernel RDMA Support for Datacenter Applications Shin-Yeh Tsai, Yiying Zhang
2 Time 2
3 Berkeley Socket Userspace Kernel Hardware Time
4 Berkeley Socket TCP Offload engine Arrakis & mtcp IX Userspace Kernel Hardware Time s 2014? U-Net RDMA in HPC RDMA in Datacenters 2
5 RDMA (Remote Direct Memory Access) CPU User Kernel Memory RDMA Directly read/write remote memory Bypassing kernel Memory zero copy Benefits Low latency High throughput Low CPU utilization 3
6 Things have worked well in HPC Special hardware Few applications Cheaper developer 4
7 RDMA-Based Datacenter Applications 5
8 RDMA-Based Datacenter Applications Pilaf [ATC 13] HERD-RPC [ATC 16] Cell [ATC 16] FaRM [NSDI 14] Wukong [OSDI 16] FaSST [OSDI 16] HERD [SIGCOMM 14] Hotpot [SoCC 17] NAM-DB [VLDB 17] RSI [VLDB 16] DrTM [SOSP 15] APUS [SoCC 17] Octopus [ATC 17] DrTM+R [EuroSys 16] FaRM+Xact Mojim [SOSP 15] [ASPLOS 15] 5
9 Things have worked well in HPC Special hardware Few applications Cheaper developer What about datacenters? Commodity, cheaper hardware Many (changing) applications Resource sharing and isolation 6
10 Userspace Native RDMA Hardware User Space Conn Mgmt User-Level RDMA App send recv Connections Queues Keys node, lkey, rkey addr Mem Mgmt Memory space Kernel Space OS Library Hardware RNIC Permission check Address mapping Cached PTEs lkey 1 lkey n rkey 1 rkey n 7
11 Userspace Native RDMA Hardware User Space Conn Mgmt User-Level RDMA App send recv Connections Queues Keys node, lkey, rkey addr Mem Mgmt Memory space Library Kernel Space OS Kernel Bypassing Hardware RNIC Permission check Address mapping Cached PTEs lkey 1 lkey n rkey 1 rkey n 7
12 Userspace Native RDMA Hardware User Space Conn Mgmt User-Level RDMA App send recv Connections Queues Keys node, lkey, rkey addr Mem Mgmt Memory space Library Kernel Space OS Kernel Bypassing Hardware RNIC Permission check Address mapping Cached PTEs lkey 1 lkey n rkey 1 rkey n 7
13 Userspace Hardware Low-level Difficult to use High-level Easy to use 8
14 Userspace Hardware Low-level Difficult to use Developers want High-level Easy to use 8
15 Userspace Hardware Low-level Difficult to use Developers want High-level Easy to use Socket 8
16 Userspace Hardware Low-level Difficult to use RDMA Developers want High-level Easy to use Socket 8
17 Userspace Hardware Low-level Difficult to use Difficult to share RDMA Socket Developers want High-level Easy to use Resource share Isolation 8
18 Userspace Hardware Low-level Difficult to use Difficult to share RDMA Socket Developers want High-level Easy to use Resource share Isolation Abstraction Mismatch 8
19 Userspace Fat applications No resource sharing Hardware Low-level Difficult to use Difficult to share RDMA Socket Developers want High-level Easy to use Resource share Isolation Abstraction Mismatch 8
20 Things have worked well in HPC Special hardware Few applications Cheaper developer What about datacenters? Commodity, cheaper hardware Many (changing) applications Resource sharing and isolation 9
21 Things have worked well in HPC Special hardware Few applications Cheaper developer What about datacenters? Commodity, cheaper hardware Many (changing) applications Resource sharing and isolation 9
22 Things have worked well in HPC Special hardware Few applications Cheaper developer What about datacenters? Commodity, cheaper hardware Many (changing) applications Resource sharing and isolation 9
23 Userspace Native RDMA Hardware User Space Conn Mgmt User-Level RDMA App send recv Connections Queues Keys node, lkey, rkey addr Mem Mgmt Memory space Library Kernel Space OS Kernel Bypassing Hardware RNIC Permission check Address mapping Cached PTEs lkey 1 lkey n rkey 1 rkey n 10
24 Userspace Hardware 11
25 Userspace On-NIC SRAM 1. Fetches and caches page table entries 2. Stores secret keys for every consecutive memory region Hardware 11
26 Userspace Hardware On-NIC SRAM 1. Fetches and caches page table entries 2. Stores secret keys for every consecutive memory region Requests /us Write-64B Write-1K Total Size (MB) 11
27 Userspace Hardware Requests /us Expensive, unscalable On-NIC SRAM 1. Fetches and caches page table entries 2. Stores secret keys for every consecutive memory region Total Size (MB) Write-64B Write-1K hardware 11
28 Things have been good in HPC Special hardware Few applications Cheaper developer What about datacenters? Commodity, cheaper hardware Many (changing) applications Resource sharing and isolation 12
29 Things have been good in HPC Special hardware Few applications Cheaper developer What about datacenters? Commodity, cheaper hardware Many (changing) applications Resource sharing and isolation 12
30 Things have been good in HPC Special hardware Few applications Cheaper developer What about datacenters? Commodity, cheaper hardware Many (changing) applications Resource sharing and isolation 12
31 13
32 Fat applications No resource sharing Expensive, unscalable hardware 13

33 Fat applications No resource sharing Expensive, unscalable hardware Are we removing too much from kernel? 13
34 Outline Introduction and motivation Overall design and abstraction LITE internals LITE applications Conclusion 14
35 Without Kernel High-level abstraction Resource sharing Protection Performance isolation 15
36 Without Kernel High-level abstraction Resource sharing Protection Performance isolation 15
37 Without Kernel High-level abstraction Resource sharing Protection Performance isolation 15
38 Without Kernel High-level abstraction Resource sharing Protection Performance isolation 15
39 Without Kernel High-level abstraction Resource sharing Protection Performance isolation 15

40 LITE - Local Indirection TiEr High-level High-level abstraction abstraction Resource Resource sharing sharing Protection Performance isolation Performance isolation Protection 15
41 All problems in computer science can be solved by another level of indirection Butler Lampson 16
42 User Space Conn Mgmt User-Level RDMA App send recv Connections Queues Keys node, lkey, rkey addr Mem Mgmt Memory space Library Hardware RNIC Permission check Address mapping Cached PTEs lkey 1 lkey n rkey 1 rkey n 17
43 User-Level RDMA App User Space Conn Mgmt send recv node, lkey, rkey addr LITE APIs Memory APIs RPC/Msg APIs Sync APIs Mem Mgmt Kernel Space LITE Connections Queues Keys Memory space Hardware RNIC Permission check Address mapping Cached PTEs lkey 1 lkey n rkey 1 rkey n 18
44 Simpler applications User-Level RDMA App User Space Conn Mgmt send recv node, lkey, rkey addr LITE APIs Memory APIs RPC/Msg APIs Sync APIs Mem Mgmt Kernel Space LITE Connections Queues Keys Memory space Hardware RNIC Permission check Address mapping Cached PTEs lkey 1 lkey n rkey 1 rkey n 18
45 Simpler applications User-Level RDMA App User Space Conn Mgmt send recv node, lkey, rkey addr Mem Mgmt LITE APIs Memory APIs RPC/Msg APIs Sync APIs Kernel Space LITE Connections Queues Keys Permission check Address mapping Global lkey Memory space Global rkey Hardware RNIC Global lkey Global rkey Cheaper hardware Scalable performance 19
46 Simpler applications User-Level RDMA App User Space Conn Mgmt send recv node, lkey, rkey addr LITE APIs Memory APIs RPC/Msg APIs Sync APIs Mem Mgmt Kernel Space LITE Connections Queues Keys Permission check Address mapping RDMA Verbs Global lkey Memory space Global rkey Hardware RNIC Global lkey Global rkey Cheaper hardware Scalable performance 19
47 User Space Simpler applications Conn Mgmt User-Level RDMA App send recv node, lkey, rkey addr Mem Mgmt LITE APIs Memory APIs RPC/Msg APIs Sync APIs Kernel Space LITE Connections Queues Keys Permission check Address mapping RDMA Verbs Global lkey Memory space Global rkey Hardware RNIC Global lkey Global rkey Cheaper hardware Scalable performance 19
48 Implementing Remote memset Native RDMA 20
49 Implementing Remote memset Native RDMA LITE 20
50 Implementing Remote memset Native RDMA LITE 20
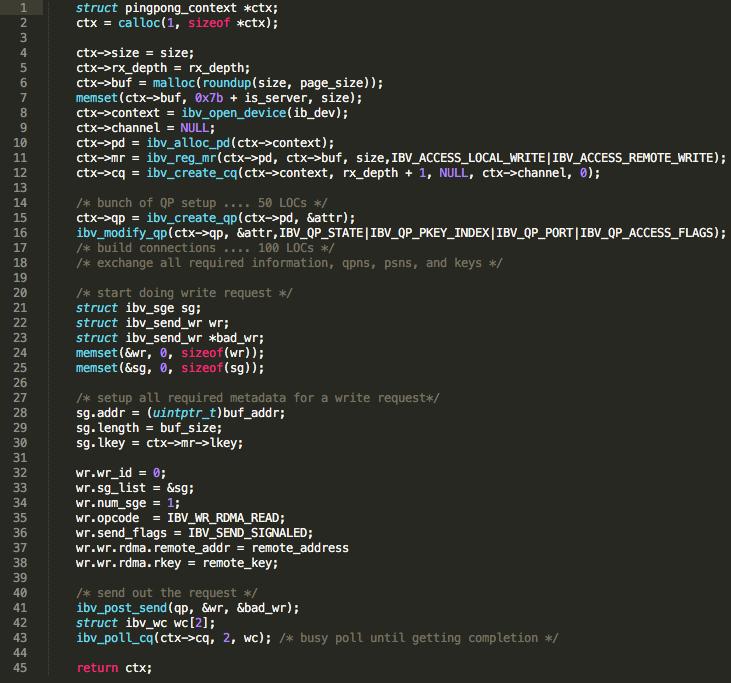

51 Implementing Remote memset Native RDMA LITE 20
52 All problems in computer science can be solved by another level of indirection Butler Lampson 21
53 All problems in computer science can be solved by another level of indirection Butler Lampson David Wheeler 21


54 All problems in computer science can be solved by another level of indirection Butler Lampson David Wheeler except for the problem of too many layers of indirection David Wheeler 21
55 Main Challenge: How to preserve the performance benefit of RDMA? 22
56 Design Principles 1.Indirection only at local for one-sided RDMA CPU User Memory Kernel Berkeley Socket CPU User Kernel Memory RDMA Userspace Kernel Hardware 23
57 Design Principles 1.Indirection only at local for one-sided RDMA CPU User Memory Kernel CPU User Memory Kernel CPU User Memory Kernel Berkeley Socket RDMA LITE Userspace Kernel Hardware 23
58 Design Principles 1.Indirection only at local for one-sided RDMA 2.Avoid hardware indirection Kernel Space LITE Hardware RNIC Address mapping Permission check 24
59 Design Principles 1.Indirection only at local for one-sided RDMA 2.Avoid hardware indirection Kernel Space LITE Address mapping Permission check Hardware RNIC Address mapping Permission check 24
60 Design Principles 1.Indirection only at local for one-sided RDMA 2.Avoid hardware indirection Kernel Space LITE Address mapping Permission check Hardware RNIC No redundant indirection Scalable performance 24
61 Design Principles 1.Indirection only at local for one-sided RDMA 2.Avoid hardware indirection 3.Hide kernel cost 25
62 Design Principles 1.Indirection only at local for one-sided RDMA 2.Avoid hardware indirection 3.Hide kernel cost except for the problem of too many layers of indirection David Wheeler 25
63 Design Principles 1.Indirection only at local for one-sided RDMA 2.Avoid hardware indirection 3.Hide kernel cost except for the problem of too many layers of indirection David Wheeler Great Performance and Scalability 25
64 Outline Introduction and motivation Overall design and abstraction LITE internals LITE applications Conclusion 26
65 LITE - Architecture Mgmt User-Level App User-Level App User-Level RPC Function LITE Abstraction OS Kernel App Verbs Abstraction RNIC Driver RNIC global lkey global rkey 27
66 LITE - Architecture Mgmt User-Level App User-Level App User-Level RPC Function LITE Abstraction OS Kernel App Verbs Abstraction LITE 1-Side RDMA global lkey global rkey RNIC Driver lh1 lh2 Permission check Address mapping addr1 addr2 RNIC global lkey global rkey 27
67 LITE - Architecture Mgmt User-Level App User-Level App User-Level RPC Function LITE Abstraction OS Kernel App Verbs Abstraction LITE 1-Side RDMA global lkey global rkey RNIC Driver lh1 lh2 Permission check Address mapping addr1 addr2 LITE RPC RDMA Buffer Mgmt send RPC Client RPC Server Connections Queues poll recv RNIC global lkey global rkey 27
68 LITE - Architecture Mgmt User-Level App User-Level App User-Level RPC Function LITE Abstraction OS LITE APIs Kernel App mgmt mem synch msging RPC Verbs Abstraction LITE 1-Side RDMA global lkey global rkey RNIC Driver lh1 lh2 Permission check Address mapping addr1 addr2 LITE RPC RDMA Buffer Mgmt send RPC Client RPC Server Connections Queues poll recv RNIC global lkey global rkey 27
69 LITE - Architecture Mgmt User-Level App User-Level App User-Level RPC Function LITE Abstraction Verbs Abstraction OS LITE 1-Side RDMA LITE APIs global lkey global rkey RNIC Driver lh1 Kernel App lh2 mgmt mem synch msging RPC Permission check Address mapping LITE RPC addr1 addr2 RDMA Buffer Mgmt send RPC Client RPC Server Connections Queues poll recv RNIC global lkey global rkey 27
70 Onload Costly Operations LITE Connections Queues Keys Memory space OS RNIC Permission check Address mapping 28
71 Onload Costly Operations LITE OS Connections Queues Keys Permission check Address mapping Memory space RNIC Perform address mapping and protection in kernel 28
72 Avoid Hardware Indirection LITE OS Connections Queues Keys Permission check Address mapping Memory space RNIC lkey 1 lkey n rkey 1 rkey n Cached PTEs Challenge: How to eliminate hardware indirection without changing hardware? 29
73 Avoid Hardware Indirection LITE OS Connections Queues Keys Permission check Address mapping Memory space RNIC lkey 1 lkey n rkey 1 rkey n Cached PTEs Challenge: How to eliminate hardware indirection without changing hardware? Register with physical address no need for any PTEs 29
74 Avoid Hardware Indirection LITE OS Connections Queues Keys Permission check Address mapping Memory space RNIC lkey 1 lkey n rkey 1 rkey n Challenge: How to eliminate hardware indirection without changing hardware? Register with physical address no need for any PTEs 29
75 Avoid Hardware Indirection LITE OS Connections Queues Keys Permission check Address mapping Memory space RNIC lkey 1 lkey n rkey 1 rkey n Challenge: How to eliminate hardware indirection without changing hardware? Register with physical address no need for any PTEs Register whole memory at once one global key 29
76 Avoid Hardware Indirection LITE OS Connections Queues Keys Permission check Address mapping Global lkey Memory space Global rkey RNIC Global lkey Global rkey Challenge: How to eliminate hardware indirection without changing hardware? Register with physical address no need for any PTEs Register whole memory at once one global key 29
77 LITE LMR and RDMA Userspace application LITE in Kernel Network Remote nodes 30
78 LITE LMR and RDMA LMR Userspace application LITE in Kernel Network Remote nodes 30
79 LITE LMR and RDMA LMR Node Phy Addr 1 0x45 4 0x27 Userspace application LITE in Kernel Network Remote nodes 30
80 LITE LMR and RDMA LMR Node Phy Addr 1 0x45 Node 1 0x45 4 0x27 Node 4 Userspace application LITE in Kernel Network 0x27 Remote nodes 30
81 LITE LMR and RDMA lh LMR Node Phy Addr 1 0x45 Node 1 0x45 4 0x27 Node 4 Userspace application LITE in Kernel Network 0x27 Remote nodes 30
82 LITE LMR and RDMA lh LITE_read(lh, offset, size) LMR Node Phy Addr 1 0x45 Node 1 0x45 4 0x27 Node 4 Userspace application LITE in Kernel Network 0x27 Remote nodes 30
83 LITE LMR and RDMA lh LITE_read(lh, offset, size) LMR Node Phy Addr 1 0x45 Node 1 Permission check QoS 4 0x27 Node 4 0x45 Userspace application LITE in Kernel Network 0x27 Remote nodes 30
84 LITE LMR and RDMA lh LITE_read(lh, offset, size) LMR Node Phy Addr 1 0x45 Node 1 Permission check Userspace application QoS Offset 4 0x27 LITE in Kernel Network Node 4 0x27 Remote nodes 0x45 30
85 LITE LMR and RDMA lh LITE_read(lh, offset, size) LMR Node Phy Addr 1 0x45 Node 1 Permission check QoS 4 0x27 Node 4 0x45 Userspace application LITE in Kernel Network 0x27 Remote nodes 30
 LMR Node Phy Addr 1 0x45 Node 1")

86 LITE LMR and RDMA lh LITE_read(lh, offset, size) LMR Node Phy Addr 1 0x45 Node 1 Permission check QoS 4 0x27 Node 4 0x45 Userspace application LITE in Kernel Network 0x27 Remote nodes 30
87 LITE RDMA:Size of MR Scalability Requests /us Write-64B LITE_write-64B Write-1K LITE_write-1K Total Size (MB) 31
88 LITE RDMA:Size of MR Scalability Requests /us Write-64B LITE_write-64B Write-1K LITE_write-1K Total Size (MB) 31
89 LITE RDMA:Size of MR Scalability Requests /us Write-64B LITE_write-64B Write-1K LITE_write-1K 0 LITE 1 scales 4 much 16 better 64 than 256 native 1024 RDMA wrt MR Total size Size (MB) and numbers 31
90 LITE-RDMA Latency 60 Latency (us) user space kernel space K 32K Request Size (B) 32
91 LITE-RDMA Latency 60 Latency (us) user space kernel space K 32K Request Size (B) 32
92 LITE-RDMA Latency 60 Latency (us) user space kernel space K 32K Request Size (B) 32
93 LITE-RDMA Latency 60 Latency (us) user space kernel space K 32K Request Size (B) 32
94 LITE-RDMA Latency 60 Latency (us) user space kernel space LITE 15only adds a very slight overhead even when native RDMA doesn t have 0 scalability issues K 32K Request Size (B) 32
95 LITE RPC RPC communication using two RDMA-write-imm One global busy poll thread Separate LMRs at server for different RPC clients Hide syscall cost behind performance critical path Benefits Low latency Low memory utilization Low CPU utilization 33
96 Outline Introduction and motivation Overall design and abstraction LITE internals LITE applications Conclusion 34
97 LITE Application Effort Application LOC LOC using LITE Student Days LITE-Log LITE-MapReduce 600* 49 4 LITE-Graph LITE-Kernel-DSM LITE-Graph-DSM Simple to use Needs no expert knowledge Flexible, powerful abstraction Easy to achieve optimized performance * LITE-MapReduce ports from the 3000-LOC Phoenix with 600 lines of change or addition 35
98 MapReduce Results LITE-MapReduce adapted from Phoenix [1] Runtime (sec) Hadoop Phoenix LITE 2 0 Phoenix 2-node 4-node 8-node [1]: Ranger etal., Evaluating MapReduce for Multi-core and Multiprocessor Systems. (HPCA 07) 36
99 MapReduce Results LITE-MapReduce adapted from Phoenix [1] Runtime (sec) Hadoop Phoenix LITE LITE-MapReduce 2 outperforms Hadoop by 4.3x to 5.3x 0 Phoenix 2-node 4-node 8-node [1]: Ranger etal., Evaluating MapReduce for Multi-core and Multiprocessor Systems. (HPCA 07) 36
100 Graph Results LITE-Graph built directly on LITE using PowerGraph design Grappa and PowerGraph 10 Runtime (sec) LITE-Graph Grappa PowerGraph 0 4 nodes x 4threads 7x4 4 nodes x 4 threads 7 nodes x 4 threads 37
101 Graph Results LITE-Graph built directly on LITE using PowerGraph design Grappa and PowerGraph 10 Runtime (sec) LITE-Graph Grappa PowerGraph LITE-Graph 2 outperforms PowerGraph 0 by 3.5x to 5.6x 4 nodes x 4threads 7x4 4 nodes x 4 threads 7 nodes x 4 threads 37
102 Conclusion LITE virtualizes RDMA into flexible abstraction LITE preserves RDMA s performance benefits Indirection not always degrade performance! 38
103 Conclusion LITE virtualizes RDMA into flexible abstraction LITE preserves RDMA s performance benefits Indirection not always degrade performance! Division across user space, kernel, and hardware 38



104 Thank you Questions? Get LITE at: wuklab.io
Farewell to Servers: Hardware, Software, and Network Approaches towards Datacenter Resource Disaggregation
 Farewell to Servers: Hardware, Software, and Network Approaches towards Datacenter Resource Disaggregation Yiying Zhang Datacenter 3 Monolithic Computer OS / Hypervisor 4 Can monolithic Application Hardware
Farewell to Servers: Hardware, Software, and Network Approaches towards Datacenter Resource Disaggregation Yiying Zhang Datacenter 3 Monolithic Computer OS / Hypervisor 4 Can monolithic Application Hardware
Farewell to Servers: Resource Disaggregation
 Farewell to Servers: Hardware, Software, and Network Approaches towards Datacenter Resource Disaggregation Yiying Zhang 2 Monolithic Computer OS / Hypervisor 3 Can monolithic Application Hardware servers
Farewell to Servers: Hardware, Software, and Network Approaches towards Datacenter Resource Disaggregation Yiying Zhang 2 Monolithic Computer OS / Hypervisor 3 Can monolithic Application Hardware servers
IsoStack Highly Efficient Network Processing on Dedicated Cores
 IsoStack Highly Efficient Network Processing on Dedicated Cores Leah Shalev Eran Borovik, Julian Satran, Muli Ben-Yehuda Outline Motivation IsoStack architecture Prototype TCP/IP over 10GE on a single
IsoStack Highly Efficient Network Processing on Dedicated Cores Leah Shalev Eran Borovik, Julian Satran, Muli Ben-Yehuda Outline Motivation IsoStack architecture Prototype TCP/IP over 10GE on a single
Distributed Shared Persistent Memory
 Distributed Shared Persistent Memory (SoCC 17) Yizhou Shan, Yiying Zhang Persistent Memory (PM/NVM) Byte Addressable Persistent CPU Cache Low Latency Capacity Cost effective PM DRAM 2 Many PM Work, but
Distributed Shared Persistent Memory (SoCC 17) Yizhou Shan, Yiying Zhang Persistent Memory (PM/NVM) Byte Addressable Persistent CPU Cache Low Latency Capacity Cost effective PM DRAM 2 Many PM Work, but
Deconstructing RDMA-enabled Distributed Transaction Processing: Hybrid is Better!
 Deconstructing RDMA-enabled Distributed Transaction Processing: Hybrid is Better! Xingda Wei, Zhiyuan Dong, Rong Chen, Haibo Chen Institute of Parallel and Distributed Systems (IPADS) Shanghai Jiao Tong
Deconstructing RDMA-enabled Distributed Transaction Processing: Hybrid is Better! Xingda Wei, Zhiyuan Dong, Rong Chen, Haibo Chen Institute of Parallel and Distributed Systems (IPADS) Shanghai Jiao Tong
FaSST: Fast, Scalable, and Simple Distributed Transactions with Two-Sided (RDMA) Datagram RPCs
 Datagram RPCs") FaSST: Fast, Scalable, and Simple Distributed Transactions with Two-Sided (RDMA) Datagram RPCs Anuj Kalia (CMU), Michael Kaminsky (Intel Labs), David Andersen (CMU) RDMA RDMA is a network feature that
FaSST: Fast, Scalable, and Simple Distributed Transactions with Two-Sided (RDMA) Datagram RPCs Anuj Kalia (CMU), Michael Kaminsky (Intel Labs), David Andersen (CMU) RDMA RDMA is a network feature that
SoftRDMA: Rekindling High Performance Software RDMA over Commodity Ethernet
 SoftRDMA: Rekindling High Performance Software RDMA over Commodity Ethernet Mao Miao, Fengyuan Ren, Xiaohui Luo, Jing Xie, Qingkai Meng, Wenxue Cheng Dept. of Computer Science and Technology, Tsinghua
SoftRDMA: Rekindling High Performance Software RDMA over Commodity Ethernet Mao Miao, Fengyuan Ren, Xiaohui Luo, Jing Xie, Qingkai Meng, Wenxue Cheng Dept. of Computer Science and Technology, Tsinghua
FaRM: Fast Remote Memory
 FaRM: Fast Remote Memory Problem Context DRAM prices have decreased significantly Cost effective to build commodity servers w/hundreds of GBs E.g. - cluster with 100 machines can hold tens of TBs of main
FaRM: Fast Remote Memory Problem Context DRAM prices have decreased significantly Cost effective to build commodity servers w/hundreds of GBs E.g. - cluster with 100 machines can hold tens of TBs of main
Tailwind: Fast and Atomic RDMA-based Replication. Yacine Taleb, Ryan Stutsman, Gabriel Antoniu, Toni Cortes
 Tailwind: Fast and Atomic RDMA-based Replication Yacine Taleb, Ryan Stutsman, Gabriel Antoniu, Toni Cortes In-Memory Key-Value Stores General purpose in-memory key-value stores are widely used nowadays
Tailwind: Fast and Atomic RDMA-based Replication Yacine Taleb, Ryan Stutsman, Gabriel Antoniu, Toni Cortes In-Memory Key-Value Stores General purpose in-memory key-value stores are widely used nowadays
Memory Management Strategies for Data Serving with RDMA
 Memory Management Strategies for Data Serving with RDMA Dennis Dalessandro and Pete Wyckoff (presenting) Ohio Supercomputer Center {dennis,pw}@osc.edu HotI'07 23 August 2007 Motivation Increasing demands
Memory Management Strategies for Data Serving with RDMA Dennis Dalessandro and Pete Wyckoff (presenting) Ohio Supercomputer Center {dennis,pw}@osc.edu HotI'07 23 August 2007 Motivation Increasing demands
Infiniswap. Efficient Memory Disaggregation. Mosharaf Chowdhury. with Juncheng Gu, Youngmoon Lee, Yiwen Zhang, and Kang G. Shin
 Infiniswap Efficient Memory Disaggregation Mosharaf Chowdhury with Juncheng Gu, Youngmoon Lee, Yiwen Zhang, and Kang G. Shin Rack-Scale Computing Datacenter-Scale Computing Geo-Distributed Computing Coflow
Infiniswap Efficient Memory Disaggregation Mosharaf Chowdhury with Juncheng Gu, Youngmoon Lee, Yiwen Zhang, and Kang G. Shin Rack-Scale Computing Datacenter-Scale Computing Geo-Distributed Computing Coflow
IX: A Protected Dataplane Operating System for High Throughput and Low Latency
 IX: A Protected Dataplane Operating System for High Throughput and Low Latency Adam Belay et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Presented by Han Zhang & Zaina Hamid Challenges
IX: A Protected Dataplane Operating System for High Throughput and Low Latency Adam Belay et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Presented by Han Zhang & Zaina Hamid Challenges
2017 Storage Developer Conference. Mellanox Technologies. All Rights Reserved.
 Ethernet Storage Fabrics Using RDMA with Fast NVMe-oF Storage to Reduce Latency and Improve Efficiency Kevin Deierling & Idan Burstein Mellanox Technologies 1 Storage Media Technology Storage Media Access
Ethernet Storage Fabrics Using RDMA with Fast NVMe-oF Storage to Reduce Latency and Improve Efficiency Kevin Deierling & Idan Burstein Mellanox Technologies 1 Storage Media Technology Storage Media Access
A Distributed Hash Table for Shared Memory
 A Distributed Hash Table for Shared Memory Wytse Oortwijn Formal Methods and Tools, University of Twente August 31, 2015 Wytse Oortwijn (Formal Methods and Tools, AUniversity Distributed of Twente) Hash
A Distributed Hash Table for Shared Memory Wytse Oortwijn Formal Methods and Tools, University of Twente August 31, 2015 Wytse Oortwijn (Formal Methods and Tools, AUniversity Distributed of Twente) Hash
Multifunction Networking Adapters
 Ethernet s Extreme Makeover: Multifunction Networking Adapters Chuck Hudson Manager, ProLiant Networking Technology Hewlett-Packard 2004 Hewlett-Packard Development Company, L.P. The information contained
Ethernet s Extreme Makeover: Multifunction Networking Adapters Chuck Hudson Manager, ProLiant Networking Technology Hewlett-Packard 2004 Hewlett-Packard Development Company, L.P. The information contained
Efficient Memory Disaggregation with Infiniswap. Juncheng Gu, Youngmoon Lee, Yiwen Zhang, MosharafChowdhury, Kang G. Shin
 Efficient Memory Disaggregation with Juncheng Gu, Youngmoon Lee, Yiwen Zhang, MosharafChowdhury, Kang G. Shin Agenda Motivation and related work Design and system overview Implementation and evaluation
Efficient Memory Disaggregation with Juncheng Gu, Youngmoon Lee, Yiwen Zhang, MosharafChowdhury, Kang G. Shin Agenda Motivation and related work Design and system overview Implementation and evaluation
RoGUE: RDMA over Generic Unconverged Ethernet
 RoGUE: RDMA over Generic Unconverged Ethernet Yanfang Le with Brent Stephens, Arjun Singhvi, Aditya Akella, Mike Swift RDMA Overview RDMA USER KERNEL Zero Copy Application Application Buffer Buffer HARWARE
RoGUE: RDMA over Generic Unconverged Ethernet Yanfang Le with Brent Stephens, Arjun Singhvi, Aditya Akella, Mike Swift RDMA Overview RDMA USER KERNEL Zero Copy Application Application Buffer Buffer HARWARE
Advanced Computer Networks. End Host Optimization
 Oriana Riva, Department of Computer Science ETH Zürich 263 3501 00 End Host Optimization Patrick Stuedi Spring Semester 2017 1 Today End-host optimizations: NUMA-aware networking Kernel-bypass Remote Direct
Oriana Riva, Department of Computer Science ETH Zürich 263 3501 00 End Host Optimization Patrick Stuedi Spring Semester 2017 1 Today End-host optimizations: NUMA-aware networking Kernel-bypass Remote Direct
HIGH-PERFORMANCE NETWORKING :: USER-LEVEL NETWORKING :: REMOTE DIRECT MEMORY ACCESS
 HIGH-PERFORMANCE NETWORKING :: USER-LEVEL NETWORKING :: REMOTE DIRECT MEMORY ACCESS CS6410 Moontae Lee (Nov 20, 2014) Part 1 Overview 00 Background User-level Networking (U-Net) Remote Direct Memory Access
HIGH-PERFORMANCE NETWORKING :: USER-LEVEL NETWORKING :: REMOTE DIRECT MEMORY ACCESS CS6410 Moontae Lee (Nov 20, 2014) Part 1 Overview 00 Background User-level Networking (U-Net) Remote Direct Memory Access
libvnf: building VNFs made easy
 libvnf: building VNFs made easy Priyanka Naik, Akash Kanase, Trishal Patel, Mythili Vutukuru Dept. of Computer Science and Engineering Indian Institute of Technology, Bombay SoCC 18 11 th October, 2018
libvnf: building VNFs made easy Priyanka Naik, Akash Kanase, Trishal Patel, Mythili Vutukuru Dept. of Computer Science and Engineering Indian Institute of Technology, Bombay SoCC 18 11 th October, 2018
Near- Data Computa.on: It s Not (Just) About Performance
 About Performance") Near- Data Computa.on: It s Not (Just) About Performance Steven Swanson Non- Vola0le Systems Laboratory Computer Science and Engineering University of California, San Diego 1 Solid State Memories NAND
Near- Data Computa.on: It s Not (Just) About Performance Steven Swanson Non- Vola0le Systems Laboratory Computer Science and Engineering University of California, San Diego 1 Solid State Memories NAND
08:End-host Optimizations. Advanced Computer Networks
 08:End-host Optimizations 1 What today is about We've seen lots of datacenter networking Topologies Routing algorithms Transport What about end-systems? Transfers between CPU registers/cache/ram Focus
08:End-host Optimizations 1 What today is about We've seen lots of datacenter networking Topologies Routing algorithms Transport What about end-systems? Transfers between CPU registers/cache/ram Focus
A Disseminated Distributed OS for Hardware Resource Disaggregation Yizhou Shan
 LegoOS A Disseminated Distributed OS for Hardware Resource Disaggregation Yizhou Shan, Yutong Huang, Yilun Chen, and Yiying Zhang Y 4 1 2 Monolithic Server OS / Hypervisor 3 Problems? 4 cpu mem Resource
LegoOS A Disseminated Distributed OS for Hardware Resource Disaggregation Yizhou Shan, Yutong Huang, Yilun Chen, and Yiying Zhang Y 4 1 2 Monolithic Server OS / Hypervisor 3 Problems? 4 cpu mem Resource
PASTE: A Network Programming Interface for Non-Volatile Main Memory
 PASTE: A Network Programming Interface for Non-Volatile Main Memory Michio Honda (NEC Laboratories Europe) Giuseppe Lettieri (Università di Pisa) Lars Eggert and Douglas Santry (NetApp) USENIX NSDI 2018
PASTE: A Network Programming Interface for Non-Volatile Main Memory Michio Honda (NEC Laboratories Europe) Giuseppe Lettieri (Università di Pisa) Lars Eggert and Douglas Santry (NetApp) USENIX NSDI 2018
Eleos: Exit-Less OS Services for SGX Enclaves
 Eleos: Exit-Less OS Services for SGX Enclaves Meni Orenbach Marina Minkin Pavel Lifshits Mark Silberstein Accelerated Computing Systems Lab Haifa, Israel What do we do? Improve performance: I/O intensive
Eleos: Exit-Less OS Services for SGX Enclaves Meni Orenbach Marina Minkin Pavel Lifshits Mark Silberstein Accelerated Computing Systems Lab Haifa, Israel What do we do? Improve performance: I/O intensive
RDMA and Hardware Support
 RDMA and Hardware Support SIGCOMM Topic Preview 2018 Yibo Zhu Microsoft Research 1 The (Traditional) Journey of Data How app developers see the network Under the hood This architecture had been working
RDMA and Hardware Support SIGCOMM Topic Preview 2018 Yibo Zhu Microsoft Research 1 The (Traditional) Journey of Data How app developers see the network Under the hood This architecture had been working
PASTE: A Networking API for Non-Volatile Main Memory
 PASTE: A Networking API for Non-Volatile Main Memory Michio Honda (NEC Laboratories Europe) Lars Eggert (NetApp) Douglas Santry (NetApp) TSVAREA@IETF 99, Prague May 22th 2017 More details at our HotNets
PASTE: A Networking API for Non-Volatile Main Memory Michio Honda (NEC Laboratories Europe) Lars Eggert (NetApp) Douglas Santry (NetApp) TSVAREA@IETF 99, Prague May 22th 2017 More details at our HotNets
An O/S perspective on networks: Active Messages and U-Net
 An O/S perspective on networks: Active Messages and U-Net Theo Jepsen Cornell University 17 October 2013 Theo Jepsen (Cornell University) CS 6410: Advanced Systems 17 October 2013 1 / 30 Brief History
An O/S perspective on networks: Active Messages and U-Net Theo Jepsen Cornell University 17 October 2013 Theo Jepsen (Cornell University) CS 6410: Advanced Systems 17 October 2013 1 / 30 Brief History
IX: A Protected Dataplane Operating System for High Throughput and Low Latency
 IX: A Protected Dataplane Operating System for High Throughput and Low Latency Belay, A. et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Reviewed by Chun-Yu and Xinghao Li Summary In this
IX: A Protected Dataplane Operating System for High Throughput and Low Latency Belay, A. et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Reviewed by Chun-Yu and Xinghao Li Summary In this
Pocket: Elastic Ephemeral Storage for Serverless Analytics
 Pocket: Elastic Ephemeral Storage for Serverless Analytics Ana Klimovic*, Yawen Wang*, Patrick Stuedi +, Animesh Trivedi +, Jonas Pfefferle +, Christos Kozyrakis* *Stanford University, + IBM Research 1
Pocket: Elastic Ephemeral Storage for Serverless Analytics Ana Klimovic*, Yawen Wang*, Patrick Stuedi +, Animesh Trivedi +, Jonas Pfefferle +, Christos Kozyrakis* *Stanford University, + IBM Research 1
PARAVIRTUAL RDMA DEVICE
 12th ANNUAL WORKSHOP 2016 PARAVIRTUAL RDMA DEVICE Aditya Sarwade, Adit Ranadive, Jorgen Hansen, Bhavesh Davda, George Zhang, Shelley Gong VMware, Inc. [ April 5th, 2016 ] MOTIVATION User Kernel Socket
12th ANNUAL WORKSHOP 2016 PARAVIRTUAL RDMA DEVICE Aditya Sarwade, Adit Ranadive, Jorgen Hansen, Bhavesh Davda, George Zhang, Shelley Gong VMware, Inc. [ April 5th, 2016 ] MOTIVATION User Kernel Socket
Optimized Distributed Data Sharing Substrate in Multi-Core Commodity Clusters: A Comprehensive Study with Applications
 Optimized Distributed Data Sharing Substrate in Multi-Core Commodity Clusters: A Comprehensive Study with Applications K. Vaidyanathan, P. Lai, S. Narravula and D. K. Panda Network Based Computing Laboratory
Optimized Distributed Data Sharing Substrate in Multi-Core Commodity Clusters: A Comprehensive Study with Applications K. Vaidyanathan, P. Lai, S. Narravula and D. K. Panda Network Based Computing Laboratory
Why AI Frameworks Need (not only) RDMA?
 RDMA?") Why AI Frameworks Need (not only) RDMA? With Design and Implementation Experience of Networking Support on TensorFlow GDR, Apache MXNet, WeChat Amber, and Tencent Angel Bairen Yi (byi@connect.ust.hk) Jingrong
Why AI Frameworks Need (not only) RDMA? With Design and Implementation Experience of Networking Support on TensorFlow GDR, Apache MXNet, WeChat Amber, and Tencent Angel Bairen Yi (byi@connect.ust.hk) Jingrong
Generic RDMA Enablement in Linux
 Generic RDMA Enablement in Linux (Why do we need it, and how) Krishna Kumar Linux Technology Center, IBM February 28, 2006 AGENDA RDMA : Definition Why RDMA, and how does it work OpenRDMA history Architectural
Generic RDMA Enablement in Linux (Why do we need it, and how) Krishna Kumar Linux Technology Center, IBM February 28, 2006 AGENDA RDMA : Definition Why RDMA, and how does it work OpenRDMA history Architectural
GPUnet: networking abstractions for GPU programs
 net: networking abstractions for programs Mark Silberstein Technion Israel Institute of Technology Sangman Kim, Seonggu Huh, Xinya Zhang Yige Hu, Emmett Witchel University of Texas at Austin Amir Wated
net: networking abstractions for programs Mark Silberstein Technion Israel Institute of Technology Sangman Kim, Seonggu Huh, Xinya Zhang Yige Hu, Emmett Witchel University of Texas at Austin Amir Wated
Designing Next-Generation Data- Centers with Advanced Communication Protocols and Systems Services. Presented by: Jitong Chen
 Designing Next-Generation Data- Centers with Advanced Communication Protocols and Systems Services Presented by: Jitong Chen Outline Architecture of Web-based Data Center Three-Stage framework to benefit
Designing Next-Generation Data- Centers with Advanced Communication Protocols and Systems Services Presented by: Jitong Chen Outline Architecture of Web-based Data Center Three-Stage framework to benefit
GPUnet: Networking Abstractions for GPU Programs. Author: Andrzej Jackowski
 Author: Andrzej Jackowski 1 Author: Andrzej Jackowski 2 GPU programming problem 3 GPU distributed application flow 1. recv req Network 4. send repl 2. exec on GPU CPU & Memory 3. get results GPU & Memory
Author: Andrzej Jackowski 1 Author: Andrzej Jackowski 2 GPU programming problem 3 GPU distributed application flow 1. recv req Network 4. send repl 2. exec on GPU CPU & Memory 3. get results GPU & Memory
Data Processing at the Speed of 100 Gbps using Apache Crail. Patrick Stuedi IBM Research
 Data Processing at the Speed of 100 Gbps using Apache Crail Patrick Stuedi IBM Research The CRAIL Project: Overview Data Processing Framework (e.g., Spark, TensorFlow, λ Compute) Spark-IO Albis Pocket
Data Processing at the Speed of 100 Gbps using Apache Crail Patrick Stuedi IBM Research The CRAIL Project: Overview Data Processing Framework (e.g., Spark, TensorFlow, λ Compute) Spark-IO Albis Pocket
Solros: A Data-Centric Operating System Architecture for Heterogeneous Computing
 Solros: A Data-Centric Operating System Architecture for Heterogeneous Computing Changwoo Min, Woonhak Kang, Mohan Kumar, Sanidhya Kashyap, Steffen Maass, Heeseung Jo, Taesoo Kim Virginia Tech, ebay, Georgia
Solros: A Data-Centric Operating System Architecture for Heterogeneous Computing Changwoo Min, Woonhak Kang, Mohan Kumar, Sanidhya Kashyap, Steffen Maass, Heeseung Jo, Taesoo Kim Virginia Tech, ebay, Georgia
Containing RDMA and High Performance Computing
 Containing RDMA and High Performance Computing Liran Liss ContainerCon 2015 Agenda High Performance Computing (HPC) networking RDMA 101 Containing RDMA Challenges Solution approach RDMA network namespace
Containing RDMA and High Performance Computing Liran Liss ContainerCon 2015 Agenda High Performance Computing (HPC) networking RDMA 101 Containing RDMA Challenges Solution approach RDMA network namespace
Euro-Par Pisa - Italy
 Euro-Par 2004 - Pisa - Italy Accelerating farms through ad- distributed scalable object repository Marco Aldinucci, ISTI-CNR, Pisa, Italy Massimo Torquati, CS dept. Uni. Pisa, Italy Outline (Herd of Object
Euro-Par 2004 - Pisa - Italy Accelerating farms through ad- distributed scalable object repository Marco Aldinucci, ISTI-CNR, Pisa, Italy Massimo Torquati, CS dept. Uni. Pisa, Italy Outline (Herd of Object
Advanced Computer Networks. RDMA, Network Virtualization
 Advanced Computer Networks 263 3501 00 RDMA, Network Virtualization Patrick Stuedi Spring Semester 2013 Oriana Riva, Department of Computer Science ETH Zürich Last Week Scaling Layer 2 Portland VL2 TCP
Advanced Computer Networks 263 3501 00 RDMA, Network Virtualization Patrick Stuedi Spring Semester 2013 Oriana Riva, Department of Computer Science ETH Zürich Last Week Scaling Layer 2 Portland VL2 TCP
Latency-Tolerant Software Distributed Shared Memory
 Latency-Tolerant Software Distributed Shared Memory Jacob Nelson, Brandon Holt, Brandon Myers, Preston Briggs, Luis Ceze, Simon Kahan, Mark Oskin University of Washington USENIX ATC 2015 July 9, 2015 25
Latency-Tolerant Software Distributed Shared Memory Jacob Nelson, Brandon Holt, Brandon Myers, Preston Briggs, Luis Ceze, Simon Kahan, Mark Oskin University of Washington USENIX ATC 2015 July 9, 2015 25
SafeBricks: Shielding Network Functions in the Cloud
 SafeBricks: Shielding Network Functions in the Cloud Rishabh Poddar, Chang Lan, Raluca Ada Popa, Sylvia Ratnasamy UC Berkeley Network Functions (NFs) in the cloud Clients 2 Enterprise Destination Network
SafeBricks: Shielding Network Functions in the Cloud Rishabh Poddar, Chang Lan, Raluca Ada Popa, Sylvia Ratnasamy UC Berkeley Network Functions (NFs) in the cloud Clients 2 Enterprise Destination Network
Kernel Bypass. Sujay Jayakar (dsj36) 11/17/2016
 11/17/2016") Kernel Bypass Sujay Jayakar (dsj36) 11/17/2016 Kernel Bypass Background Why networking? Status quo: Linux Papers Arrakis: The Operating System is the Control Plane. Simon Peter, Jialin Li, Irene Zhang,
Kernel Bypass Sujay Jayakar (dsj36) 11/17/2016 Kernel Bypass Background Why networking? Status quo: Linux Papers Arrakis: The Operating System is the Control Plane. Simon Peter, Jialin Li, Irene Zhang,
ZBD: Using Transparent Compression at the Block Level to Increase Storage Space Efficiency
 ZBD: Using Transparent Compression at the Block Level to Increase Storage Space Efficiency Thanos Makatos, Yannis Klonatos, Manolis Marazakis, Michail D. Flouris, and Angelos Bilas {mcatos,klonatos,maraz,flouris,bilas}@ics.forth.gr
ZBD: Using Transparent Compression at the Block Level to Increase Storage Space Efficiency Thanos Makatos, Yannis Klonatos, Manolis Marazakis, Michail D. Flouris, and Angelos Bilas {mcatos,klonatos,maraz,flouris,bilas}@ics.forth.gr
OFED Storage Protocols
 OFED Storage Protocols R. Pearson System Fabric Works, Inc. Agenda Why OFED Storage Introduction to OFED Storage Protocols OFED Storage Protocol Update 2 Why OFED Storage 3 Goals of I/O Consolidation Cluster
OFED Storage Protocols R. Pearson System Fabric Works, Inc. Agenda Why OFED Storage Introduction to OFED Storage Protocols OFED Storage Protocol Update 2 Why OFED Storage 3 Goals of I/O Consolidation Cluster
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay Mellanox Technologies
 Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
Flexible Architecture Research Machine (FARM)
") Flexible Architecture Research Machine (FARM) RAMP Retreat June 25, 2009 Jared Casper, Tayo Oguntebi, Sungpack Hong, Nathan Bronson Christos Kozyrakis, Kunle Olukotun Motivation Why CPUs + FPGAs make sense
Flexible Architecture Research Machine (FARM) RAMP Retreat June 25, 2009 Jared Casper, Tayo Oguntebi, Sungpack Hong, Nathan Bronson Christos Kozyrakis, Kunle Olukotun Motivation Why CPUs + FPGAs make sense
Research Statement. 1 Thesis research: Efficient networked systems for datacenters with RPCs. Anuj Kalia
 Research Statement Anuj Kalia With the seeming end of Moore s law, software does not automatically get faster every year: per-core CPU performance has stagnated, and core count increases slowly. My goal
Research Statement Anuj Kalia With the seeming end of Moore s law, software does not automatically get faster every year: per-core CPU performance has stagnated, and core count increases slowly. My goal
Fast and Concurrent RDF Queries with RDMA-Based Distributed Graph Exploration
 Fast and Concurrent RDF Queries with RDMA-Based Distributed Graph Exploration JIAXIN SHI, YOUYANG YAO, RONG CHEN, HAIBO CHEN, FEIFEI LI PRESENTED BY ANDREW XIA APRIL 25, 2018 Wukong Overview of Wukong
Fast and Concurrent RDF Queries with RDMA-Based Distributed Graph Exploration JIAXIN SHI, YOUYANG YAO, RONG CHEN, HAIBO CHEN, FEIFEI LI PRESENTED BY ANDREW XIA APRIL 25, 2018 Wukong Overview of Wukong
Distributed Shared Persistent Memory
 Yizhou Shan Purdue University shan13@purdue.edu Shin-Yeh Tsai Purdue University tsai46@purdue.edu Yiying Zhang Purdue University yiying@purdue.edu ABSTRACT Next-generation non-volatile memories (NVMs)
Yizhou Shan Purdue University shan13@purdue.edu Shin-Yeh Tsai Purdue University tsai46@purdue.edu Yiying Zhang Purdue University yiying@purdue.edu ABSTRACT Next-generation non-volatile memories (NVMs)
Background: I/O Concurrency
 Background: I/O Concurrency Brad Karp UCL Computer Science CS GZ03 / M030 5 th October 2011 Outline Worse Is Better and Distributed Systems Problem: Naïve single-process server leaves system resources
Background: I/O Concurrency Brad Karp UCL Computer Science CS GZ03 / M030 5 th October 2011 Outline Worse Is Better and Distributed Systems Problem: Naïve single-process server leaves system resources
EXTENDING AN ASYNCHRONOUS MESSAGING LIBRARY USING AN RDMA-ENABLED INTERCONNECT. Konstantinos Alexopoulos ECE NTUA CSLab
 EXTENDING AN ASYNCHRONOUS MESSAGING LIBRARY USING AN RDMA-ENABLED INTERCONNECT Konstantinos Alexopoulos ECE NTUA CSLab MOTIVATION HPC, Multi-node & Heterogeneous Systems Communication with low latency
EXTENDING AN ASYNCHRONOUS MESSAGING LIBRARY USING AN RDMA-ENABLED INTERCONNECT Konstantinos Alexopoulos ECE NTUA CSLab MOTIVATION HPC, Multi-node & Heterogeneous Systems Communication with low latency
Arrakis: The Operating System is the Control Plane
 Arrakis: The Operating System is the Control Plane Simon Peter, Jialin Li, Irene Zhang, Dan Ports, Doug Woos, Arvind Krishnamurthy, Tom Anderson University of Washington Timothy Roscoe ETH Zurich Building
Arrakis: The Operating System is the Control Plane Simon Peter, Jialin Li, Irene Zhang, Dan Ports, Doug Woos, Arvind Krishnamurthy, Tom Anderson University of Washington Timothy Roscoe ETH Zurich Building
Virtual Memory. CS 3410 Computer System Organization & Programming
 Virtual Memory CS 3410 Computer System Organization & Programming These slides are the product of many rounds of teaching CS 3410 by Professors Weatherspoon, Bala, Bracy, and Sirer. Where are we now and
Virtual Memory CS 3410 Computer System Organization & Programming These slides are the product of many rounds of teaching CS 3410 by Professors Weatherspoon, Bala, Bracy, and Sirer. Where are we now and
I/O Buffering and Streaming
 I/O Buffering and Streaming I/O Buffering and Caching I/O accesses are reads or writes (e.g., to files) Application access is arbitary (offset, len) Convert accesses to read/write of fixed-size blocks
I/O Buffering and Streaming I/O Buffering and Caching I/O accesses are reads or writes (e.g., to files) Application access is arbitary (offset, len) Convert accesses to read/write of fixed-size blocks
Virtual Memory. Reading. Sections 5.4, 5.5, 5.6, 5.8, 5.10 (2) Lecture notes from MKP and S. Yalamanchili
 Lecture notes from MKP and S. Yalamanchili") Virtual Memory Lecture notes from MKP and S. Yalamanchili Sections 5.4, 5.5, 5.6, 5.8, 5.10 Reading (2) 1 The Memory Hierarchy ALU registers Cache Memory Memory Memory Managed by the compiler Memory Managed
Virtual Memory Lecture notes from MKP and S. Yalamanchili Sections 5.4, 5.5, 5.6, 5.8, 5.10 Reading (2) 1 The Memory Hierarchy ALU registers Cache Memory Memory Memory Managed by the compiler Memory Managed
14 May 2012 Virtual Memory. Definition: A process is an instance of a running program
 Virtual Memory (VM) Overview and motivation VM as tool for caching VM as tool for memory management VM as tool for memory protection Address translation 4 May 22 Virtual Memory Processes Definition: A
Virtual Memory (VM) Overview and motivation VM as tool for caching VM as tool for memory management VM as tool for memory protection Address translation 4 May 22 Virtual Memory Processes Definition: A
Application Acceleration Beyond Flash Storage
 Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
Live Migration: Even faster, now with a dedicated thread!
 Live Migration: Even faster, now with a dedicated thread! Juan Quintela Orit Wasserman Vinod Chegu KVM Forum 2012 Agenda Introduction Migration
Live Migration: Even faster, now with a dedicated thread! Juan Quintela Orit Wasserman Vinod Chegu KVM Forum 2012 Agenda Introduction Migration
Portland State University ECE 587/687. Virtual Memory and Virtualization
 Portland State University ECE 587/687 Virtual Memory and Virtualization Copyright by Alaa Alameldeen and Zeshan Chishti, 2015 Virtual Memory A layer of abstraction between applications and hardware Programs
Portland State University ECE 587/687 Virtual Memory and Virtualization Copyright by Alaa Alameldeen and Zeshan Chishti, 2015 Virtual Memory A layer of abstraction between applications and hardware Programs
IO virtualization. Michael Kagan Mellanox Technologies
 IO virtualization Michael Kagan Mellanox Technologies IO Virtualization Mission non-stop s to consumers Flexibility assign IO resources to consumer as needed Agility assignment of IO resources to consumer
IO virtualization Michael Kagan Mellanox Technologies IO Virtualization Mission non-stop s to consumers Flexibility assign IO resources to consumer as needed Agility assignment of IO resources to consumer
RiceNIC. A Reconfigurable Network Interface for Experimental Research and Education. Jeffrey Shafer Scott Rixner
 RiceNIC A Reconfigurable Network Interface for Experimental Research and Education Jeffrey Shafer Scott Rixner Introduction Networking is critical to modern computer systems Role of the network interface
RiceNIC A Reconfigurable Network Interface for Experimental Research and Education Jeffrey Shafer Scott Rixner Introduction Networking is critical to modern computer systems Role of the network interface
Much Faster Networking
 Much Faster Networking David Riddoch driddoch@solarflare.com Copyright 2016 Solarflare Communications, Inc. All rights reserved. What is kernel bypass? The standard receive path The standard receive path
Much Faster Networking David Riddoch driddoch@solarflare.com Copyright 2016 Solarflare Communications, Inc. All rights reserved. What is kernel bypass? The standard receive path The standard receive path
OpenFabrics Interface WG A brief introduction. Paul Grun co chair OFI WG Cray, Inc.
 OpenFabrics Interface WG A brief introduction Paul Grun co chair OFI WG Cray, Inc. OFI WG a brief overview and status report 1. Keep everybody on the same page, and 2. An example of a possible model for
OpenFabrics Interface WG A brief introduction Paul Grun co chair OFI WG Cray, Inc. OFI WG a brief overview and status report 1. Keep everybody on the same page, and 2. An example of a possible model for
A Userspace Packet Switch for Virtual Machines
 SHRINKING THE HYPERVISOR ONE SUBSYSTEM AT A TIME A Userspace Packet Switch for Virtual Machines Julian Stecklina OS Group, TU Dresden jsteckli@os.inf.tu-dresden.de VEE 2014, Salt Lake City 1 Motivation
SHRINKING THE HYPERVISOR ONE SUBSYSTEM AT A TIME A Userspace Packet Switch for Virtual Machines Julian Stecklina OS Group, TU Dresden jsteckli@os.inf.tu-dresden.de VEE 2014, Salt Lake City 1 Motivation
Data Processing at the Speed of 100 Gbps using Apache Crail. Patrick Stuedi IBM Research
 Data Processing at the Speed of 100 Gbps using Apache Crail Patrick Stuedi IBM Research The CRAIL Project: Overview Data Processing Framework (e.g., Spark, TensorFlow, λ Compute) Spark-IO FS Albis Streaming
Data Processing at the Speed of 100 Gbps using Apache Crail Patrick Stuedi IBM Research The CRAIL Project: Overview Data Processing Framework (e.g., Spark, TensorFlow, λ Compute) Spark-IO FS Albis Streaming
Virtual Memory 3. Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University. P & H Chapter 5.4
 Virtual Memory 3 Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University P & H Chapter 5.4 Project3 available now Administrivia Design Doc due next week, Monday, April 16 th Schedule
Virtual Memory 3 Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University P & H Chapter 5.4 Project3 available now Administrivia Design Doc due next week, Monday, April 16 th Schedule
CSC501 Operating Systems Principles. OS Structure
 CSC501 Operating Systems Principles OS Structure 1 Announcements q TA s office hour has changed Q Thursday 1:30pm 3:00pm, MRC-409C Q Or email: awang@ncsu.edu q From department: No audit allowed 2 Last
CSC501 Operating Systems Principles OS Structure 1 Announcements q TA s office hour has changed Q Thursday 1:30pm 3:00pm, MRC-409C Q Or email: awang@ncsu.edu q From department: No audit allowed 2 Last
Using RDMA for Lock Management
 Using RDMA for Lock Management Yeounoh Chung Erfan Zamanian {yeounoh, erfanz}@cs.brown.edu Supervised by: John Meehan Stan Zdonik {john, sbz}@cs.brown.edu Abstract arxiv:1507.03274v2 [cs.dc] 20 Jul 2015
Using RDMA for Lock Management Yeounoh Chung Erfan Zamanian {yeounoh, erfanz}@cs.brown.edu Supervised by: John Meehan Stan Zdonik {john, sbz}@cs.brown.edu Abstract arxiv:1507.03274v2 [cs.dc] 20 Jul 2015
DON T CRY OVER SPILLED RECORDS Memory elasticity of data-parallel applications and its application to cluster scheduling
 DON T CRY OVER SPILLED RECORDS Memory elasticity of data-parallel applications and its application to cluster scheduling Călin Iorgulescu (EPFL), Florin Dinu (EPFL), Aunn Raza (NUST Pakistan), Wajih Ul
DON T CRY OVER SPILLED RECORDS Memory elasticity of data-parallel applications and its application to cluster scheduling Călin Iorgulescu (EPFL), Florin Dinu (EPFL), Aunn Raza (NUST Pakistan), Wajih Ul
Software Routers: NetMap
 Software Routers: NetMap Hakim Weatherspoon Assistant Professor, Dept of Computer Science CS 5413: High Performance Systems and Networking October 8, 2014 Slides from the NetMap: A Novel Framework for
Software Routers: NetMap Hakim Weatherspoon Assistant Professor, Dept of Computer Science CS 5413: High Performance Systems and Networking October 8, 2014 Slides from the NetMap: A Novel Framework for
Accelerating Web Protocols Using RDMA
 Accelerating Web Protocols Using RDMA Dennis Dalessandro Ohio Supercomputer Center NCA 2007 Who's Responsible for this? Dennis Dalessandro Ohio Supercomputer Center - Springfield dennis@osc.edu Pete Wyckoff
Accelerating Web Protocols Using RDMA Dennis Dalessandro Ohio Supercomputer Center NCA 2007 Who's Responsible for this? Dennis Dalessandro Ohio Supercomputer Center - Springfield dennis@osc.edu Pete Wyckoff
Designing a True Direct-Access File System with DevFS
 Designing a True Direct-Access File System with DevFS Sudarsun Kannan, Andrea Arpaci-Dusseau, Remzi Arpaci-Dusseau University of Wisconsin-Madison Yuangang Wang, Jun Xu, Gopinath Palani Huawei Technologies
Designing a True Direct-Access File System with DevFS Sudarsun Kannan, Andrea Arpaci-Dusseau, Remzi Arpaci-Dusseau University of Wisconsin-Madison Yuangang Wang, Jun Xu, Gopinath Palani Huawei Technologies
Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference
 The 2017 IEEE International Symposium on Workload Characterization Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference Shin-Ying Lee
The 2017 IEEE International Symposium on Workload Characterization Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference Shin-Ying Lee
CSE 451: Operating Systems. Section 10 Project 3 wrap-up, final exam review
 CSE 451: Operating Systems Section 10 Project 3 wrap-up, final exam review Final exam review Goal of this section: key concepts you should understand Not just a summary of lectures Slides coverage and
CSE 451: Operating Systems Section 10 Project 3 wrap-up, final exam review Final exam review Goal of this section: key concepts you should understand Not just a summary of lectures Slides coverage and
OpenOnload. Dave Parry VP of Engineering Steve Pope CTO Dave Riddoch Chief Software Architect
 OpenOnload Dave Parry VP of Engineering Steve Pope CTO Dave Riddoch Chief Software Architect Copyright 2012 Solarflare Communications, Inc. All Rights Reserved. OpenOnload Acceleration Software Accelerated
OpenOnload Dave Parry VP of Engineering Steve Pope CTO Dave Riddoch Chief Software Architect Copyright 2012 Solarflare Communications, Inc. All Rights Reserved. OpenOnload Acceleration Software Accelerated
NTRDMA v0.1. An Open Source Driver for PCIe NTB and DMA. Allen Hubbe at Linux Piter 2015 NTRDMA. Messaging App. IB Verbs. dmaengine.h ntb.
 Messaging App IB Verbs NTRDMA dmaengine.h ntb.h DMA DMA DMA NTRDMA v0.1 An Open Source Driver for PCIe and DMA Allen Hubbe at Linux Piter 2015 1 INTRODUCTION Allen Hubbe Senior Software Engineer EMC Corporation
Messaging App IB Verbs NTRDMA dmaengine.h ntb.h DMA DMA DMA NTRDMA v0.1 An Open Source Driver for PCIe and DMA Allen Hubbe at Linux Piter 2015 1 INTRODUCTION Allen Hubbe Senior Software Engineer EMC Corporation
High Speed Asynchronous Data Transfers on the Cray XT3
 High Speed Asynchronous Data Transfers on the Cray XT3 Ciprian Docan, Manish Parashar and Scott Klasky The Applied Software System Laboratory Rutgers, The State University of New Jersey CUG 2007, Seattle,
High Speed Asynchronous Data Transfers on the Cray XT3 Ciprian Docan, Manish Parashar and Scott Klasky The Applied Software System Laboratory Rutgers, The State University of New Jersey CUG 2007, Seattle,
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to
virtual memory Page 1 CSE 361S Disk Disk
 CSE 36S Motivations for Use DRAM a for the Address space of a process can exceed physical memory size Sum of address spaces of multiple processes can exceed physical memory Simplify Management 2 Multiple
CSE 36S Motivations for Use DRAM a for the Address space of a process can exceed physical memory size Sum of address spaces of multiple processes can exceed physical memory Simplify Management 2 Multiple
REMOTE PERSISTENT MEMORY ACCESS WORKLOAD SCENARIOS AND RDMA SEMANTICS
 13th ANNUAL WORKSHOP 2017 REMOTE PERSISTENT MEMORY ACCESS WORKLOAD SCENARIOS AND RDMA SEMANTICS Tom Talpey Microsoft [ March 31, 2017 ] OUTLINE Windows Persistent Memory Support A brief summary, for better
13th ANNUAL WORKSHOP 2017 REMOTE PERSISTENT MEMORY ACCESS WORKLOAD SCENARIOS AND RDMA SEMANTICS Tom Talpey Microsoft [ March 31, 2017 ] OUTLINE Windows Persistent Memory Support A brief summary, for better
QuartzV: Bringing Quality of Time to Virtual Machines
 QuartzV: Bringing Quality of Time to Virtual Machines Sandeep D souza and Raj Rajkumar Carnegie Mellon University IEEE RTAS @ CPS Week 2018 1 A Shared Notion of Time Coordinated Actions Ordering of Events
QuartzV: Bringing Quality of Time to Virtual Machines Sandeep D souza and Raj Rajkumar Carnegie Mellon University IEEE RTAS @ CPS Week 2018 1 A Shared Notion of Time Coordinated Actions Ordering of Events
Accelerator-centric operating systems
 Accelerator-centric operating systems Rethinking the role of s in modern computers Mark Silberstein EE, Technion System design challenge: Programmability and Performance 2 System design challenge: Programmability
Accelerator-centric operating systems Rethinking the role of s in modern computers Mark Silberstein EE, Technion System design challenge: Programmability and Performance 2 System design challenge: Programmability
SEDA: An Architecture for Well-Conditioned, Scalable Internet Services
 SEDA: An Architecture for Well-Conditioned, Scalable Internet Services Matt Welsh, David Culler, and Eric Brewer Computer Science Division University of California, Berkeley Operating Systems Principles
SEDA: An Architecture for Well-Conditioned, Scalable Internet Services Matt Welsh, David Culler, and Eric Brewer Computer Science Division University of California, Berkeley Operating Systems Principles
Speeding up Linux TCP/IP with a Fast Packet I/O Framework
 Speeding up Linux TCP/IP with a Fast Packet I/O Framework Michio Honda Advanced Technology Group, NetApp michio@netapp.com With acknowledge to Kenichi Yasukata, Douglas Santry and Lars Eggert 1 Motivation
Speeding up Linux TCP/IP with a Fast Packet I/O Framework Michio Honda Advanced Technology Group, NetApp michio@netapp.com With acknowledge to Kenichi Yasukata, Douglas Santry and Lars Eggert 1 Motivation
Virtual Memory. Kevin Webb Swarthmore College March 8, 2018
 irtual Memory Kevin Webb Swarthmore College March 8, 2018 Today s Goals Describe the mechanisms behind address translation. Analyze the performance of address translation alternatives. Explore page replacement
irtual Memory Kevin Webb Swarthmore College March 8, 2018 Today s Goals Describe the mechanisms behind address translation. Analyze the performance of address translation alternatives. Explore page replacement
Containers Do Not Need Network Stacks
 s Do Not Need Network Stacks Ryo Nakamura iijlab seminar 2018/10/16 Based on Ryo Nakamura, Yuji Sekiya, and Hajime Tazaki. 2018. Grafting Sockets for Fast Networking. In ANCS 18: Symposium on Architectures
s Do Not Need Network Stacks Ryo Nakamura iijlab seminar 2018/10/16 Based on Ryo Nakamura, Yuji Sekiya, and Hajime Tazaki. 2018. Grafting Sockets for Fast Networking. In ANCS 18: Symposium on Architectures
Virtual Memory. Physical Addressing. Problem 2: Capacity. Problem 1: Memory Management 11/20/15
 Memory Addressing Motivation: why not direct physical memory access? Address translation with pages Optimizing translation: translation lookaside buffer Extra benefits: sharing and protection Memory as
Memory Addressing Motivation: why not direct physical memory access? Address translation with pages Optimizing translation: translation lookaside buffer Extra benefits: sharing and protection Memory as
jverbs: Java/OFED Integration for the Cloud
 jverbs: Java/OFED Integration for the Cloud Authors: Bernard Metzler, Patrick Stuedi, Animesh Trivedi. IBM Research Zurich Date: 03/27/12 www.openfabrics.org 1 Motivation The commodity Cloud is Flexible
jverbs: Java/OFED Integration for the Cloud Authors: Bernard Metzler, Patrick Stuedi, Animesh Trivedi. IBM Research Zurich Date: 03/27/12 www.openfabrics.org 1 Motivation The commodity Cloud is Flexible
CS 350 Winter 2011 Current Topics: Virtual Machines + Solid State Drives
 CS 350 Winter 2011 Current Topics: Virtual Machines + Solid State Drives Virtual Machines Resource Virtualization Separating the abstract view of computing resources from the implementation of these resources
CS 350 Winter 2011 Current Topics: Virtual Machines + Solid State Drives Virtual Machines Resource Virtualization Separating the abstract view of computing resources from the implementation of these resources
Dynamic Translator-Based Virtualization
 Dynamic Translator-Based Virtualization Yuki Kinebuchi 1,HidenariKoshimae 1,ShuichiOikawa 2, and Tatsuo Nakajima 1 1 Department of Computer Science, Waseda University {yukikine, hide, tatsuo}@dcl.info.waseda.ac.jp
Dynamic Translator-Based Virtualization Yuki Kinebuchi 1,HidenariKoshimae 1,ShuichiOikawa 2, and Tatsuo Nakajima 1 1 Department of Computer Science, Waseda University {yukikine, hide, tatsuo}@dcl.info.waseda.ac.jp
RiceNIC. Prototyping Network Interfaces. Jeffrey Shafer Scott Rixner
 RiceNIC Prototyping Network Interfaces Jeffrey Shafer Scott Rixner RiceNIC Overview Gigabit Ethernet Network Interface Card RiceNIC - Prototyping Network Interfaces 2 RiceNIC Overview Reconfigurable and
RiceNIC Prototyping Network Interfaces Jeffrey Shafer Scott Rixner RiceNIC Overview Gigabit Ethernet Network Interface Card RiceNIC - Prototyping Network Interfaces 2 RiceNIC Overview Reconfigurable and
Designing Next Generation Data-Centers with Advanced Communication Protocols and Systems Services
 Designing Next Generation Data-Centers with Advanced Communication Protocols and Systems Services P. Balaji, K. Vaidyanathan, S. Narravula, H. W. Jin and D. K. Panda Network Based Computing Laboratory
Designing Next Generation Data-Centers with Advanced Communication Protocols and Systems Services P. Balaji, K. Vaidyanathan, S. Narravula, H. W. Jin and D. K. Panda Network Based Computing Laboratory
Deconstructing RDMA-enabled Distributed Transactions: Hybrid is Better!
 Deconstructing RDMA-enabled Distributed Transactions: Hybrid is Better! Xingda Wei, Zhiyuan Dong, Rong Chen, Haibo Chen Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University Contacts:
Deconstructing RDMA-enabled Distributed Transactions: Hybrid is Better! Xingda Wei, Zhiyuan Dong, Rong Chen, Haibo Chen Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University Contacts:
@2010 Badri Computer Architecture Assembly II. Virtual Memory. Topics (Chapter 9) Motivations for VM Address translation
 Motivations for VM Address translation") Virtual Memory Topics (Chapter 9) Motivations for VM Address translation 1 Motivations for Virtual Memory Use Physical DRAM as a Cache for the Disk Address space of a process can exceed physical memory
Virtual Memory Topics (Chapter 9) Motivations for VM Address translation 1 Motivations for Virtual Memory Use Physical DRAM as a Cache for the Disk Address space of a process can exceed physical memory
In the multi-core age, How do larger, faster and cheaper and more responsive memory sub-systems affect data management? Dhabaleswar K.
 In the multi-core age, How do larger, faster and cheaper and more responsive sub-systems affect data management? Panel at ADMS 211 Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory Department
In the multi-core age, How do larger, faster and cheaper and more responsive sub-systems affect data management? Panel at ADMS 211 Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory Department
SSS: An Implementation of Key-value Store based MapReduce Framework. Hirotaka Ogawa (AIST, Japan) Hidemoto Nakada Ryousei Takano Tomohiro Kudoh
 Hidemoto Nakada Ryousei Takano Tomohiro Kudoh") SSS: An Implementation of Key-value Store based MapReduce Framework Hirotaka Ogawa (AIST, Japan) Hidemoto Nakada Ryousei Takano Tomohiro Kudoh MapReduce A promising programming tool for implementing largescale
SSS: An Implementation of Key-value Store based MapReduce Framework Hirotaka Ogawa (AIST, Japan) Hidemoto Nakada Ryousei Takano Tomohiro Kudoh MapReduce A promising programming tool for implementing largescale
Virtual Memory Oct. 29, 2002
 5-23 The course that gives CMU its Zip! Virtual Memory Oct. 29, 22 Topics Motivations for VM Address translation Accelerating translation with TLBs class9.ppt Motivations for Virtual Memory Use Physical
5-23 The course that gives CMU its Zip! Virtual Memory Oct. 29, 22 Topics Motivations for VM Address translation Accelerating translation with TLBs class9.ppt Motivations for Virtual Memory Use Physical