Lightweight Streaming-based Runtime for Cloud Computing. Shrideep Pallickara. Community Grids Lab, Indiana University
|
|
|
- Amy Heath
- 5 years ago
- Views:
Transcription

1 Lightweight Streaming-based Runtime for Cloud Computing granules Shrideep Pallickara Community Grids Lab, Indiana University
2 A unique confluence of factors have driven the need for cloud computing DEMAND PULLS: Process and store large data volumes Y02 22-EB : Y EB : Y EB ~ I ZB TECHNOLOGY PUSHES: Falling hardware costs & better networks RESULT: Aggregation to scale 2
3 Since the cloud is not monolithic it is easier to cope with flux and evolve Replacement and upgrades are two sides of the same coin Desktop: 4 GB RAM, 400 GB Disk, 50 GFLOPS & 4 cores 250 x Desktop = 1 TB RAM, 100 TB Disk, 6.25TFLOP and 1000 cores 3
4 Cloud and traditional HPC systems have some fundamental differences One job at a time = Underutilization Execution pipelines IO Bound activities An application is the sum of its parts Cloud strategy is to interleave 1000s of tasks on the same resource 4

5 Projects utilizing NaradaBrokering QuakeSim 5
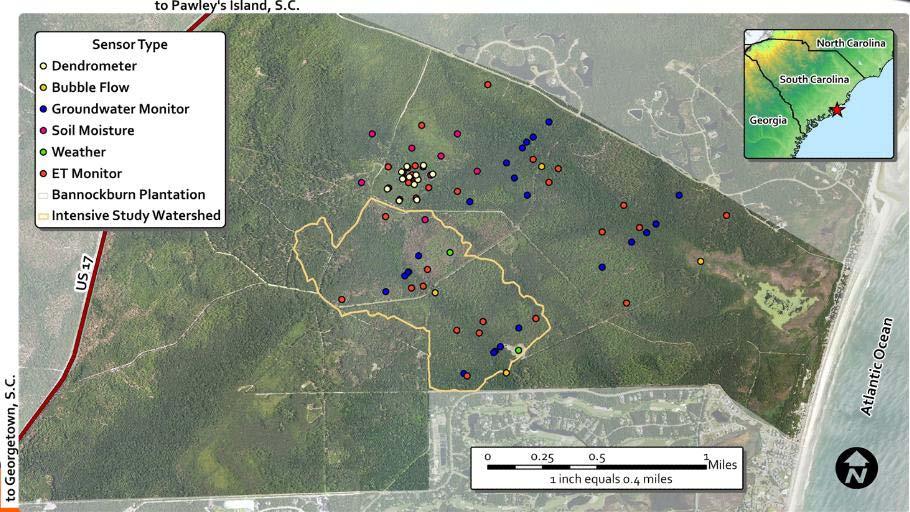

6 Ecological Monitoring: PISCES 6

7 Projects utilizing NaradaBrokering Sensor Grids RFID Tag RFID Reader GPS Sensor Nokia N800 7
8 Lessons learned from multi-disciplinary settings Framework for processing streaming data Compute demands will outpace availability Manage computational load transparently 8
9 Big Picture Simulations & Services Networked Devices {Sensors, Instruments} Experimental Models Burgeoning data volumes 9
10 Fueled the need for a new type of computational task Operate on dynamic and voluminous data. Comparably smaller CPU-bound times Milliseconds to minutes BUT concurrently interleave 1000s of these long running tasks Granules provisions this 10




11 Granules is dispersed over, and permeates, distributed components A A C A C G G Content Distribution Network G G G R 1 R 2 R N Discovery Services Concurrent Execution Queue Lifecycle Management Deployment Manager Diagnostics Dataset Initializer 11
12 An application is the sum of its computational tasks that are Agnostic about the resources that they execute on Responsible for processing a subset of the data Fragment of a stream Subset of files Portions of a database 12
13 Granules does most of the work for the applications except for 1. Processing Functionality 2. Specifying the Datasets 3. Scheduling strategy for constituent tasks 13
14 Granules processing functionality 1 is domain specific Implement just one method: execute() Processing 1 TB of data over 100 machines is done in 150 lines of Java code. 14
15 Computational tasks often need to cope with multiple datasets 2 TYPES: Streams, Files, Databases & URIs INITIALIZE: Configuration & allocations ACCESS: Permissions and authorizations DISPOSE: Reclaim allocated resources 15
16 Computational tasks specify their lifetime and scheduling 3 strategy Data availability Permute on any of these dimensions Change during execution Assert completion Number of times Periodicity 16
17 Granules discovers resources to deploy computational tasks Deploy computation instance on multiple resources Instantiate computational tasks & execute in Sandbox Initialize task s STATE and DATASETS Interleave multiple computations on a given machine 17



18 Deploying computational tasks C G Content Distribution Network G R N G G R 2 R 1 18
19 Granules manages the state transitions for computational tasks Transition Triggers: Data Availability Periodicity Termination conditions External Requests Dormant Initialize Terminate Activated 19
20 Activation and processing of computational tasks Dispose Execute Dormant D 1 P P D P D 20



21 MAP-REDUCE enables concurrent processing of large datasets d 1 Map 1 Reduce 1 Dataset d 2 Map 2 o 1 Reduce K d N Map N o K 21
22 Substantial benefits can be accrued in a streaming version of MAP-REDUCE File-based = Disk IO Expensive Streaming is much faster Allows access to intermediate results Enables time bound responses Granules Map-Reduce based on streams 22
23 In Granules MAP and REDUCE are two roles of a computational task Linking of MAP-REDUCE roles is easy M1.addReduce(R1) or R1.addMap(M1) Unlinking is easy too: remove Maps generate result streams, which are consumed by reducers Reducers can track outputs from Maps 23
24 In Granules MAP-REDUCE roles are interchangeable M1 M2 R1 RM M3 M4 R2 RM.addReduce(M1) RM.addReduce(M2) RM.addReduce(M3) RM.addReduce(M4) 24
25 Scientific applications can harness MAP-REDUCE variants in Granules ITERATIVE: Fixed number of times RECURSIVE: Till termination condition PERIODIC DATA AVAILABILITY DRIVEN 25
26 Complex computational pipelines can be set up using Granules STAGE 1 STAGE 2 STAGE 3 Iterative, Periodic, Recursive & Data driven Each stage could comprise computations dispersed on multiple machines 26
27 Granules manages pipeline communications complexity No arduous management of fan-ins Facilities to track outputs Confirm receipt from all preceding stages
28 Granules allows computational tasks to be cloned M1 M1 M2 M2 M3 M4 R1 R1 R2 Fine tune redundancies Double-check results Discard duplicates from clones 28
29 Related work HADOOP: File-based, Java, HDFS DRYAD: Dataflow graphs, C#, LinQ, MSD DISCO: File-based, Erlang PHEONIX: Multicore GOOGLE CLOUD: GFS 29
30 Granules outperforms Hadoop & Dryad in a traditional IR benchmark Overhead for histogramming words (Seconds) Hadoop DRYAD Granules Total size of dataset (GB) 30
31 Clustering data points using K-means Overhead (Seconds) Hadoop Granules MPI Number of 2D data points (millions) 31
32 Computing the product of two 16Kx16 K matrices using streaming datasets Computing overhead in Seconds Each Granules instance deals with at least 18K streams Number of Machines 32
33 Maximizing core utilizations when assembling mrna sequences Computing overhead in Seconds Computing Overhead Speedup Number of Cores Program aims to reconstruct full-length mrna sequences for each expressed gene Speed-up 33
34 Preserving scheduling periodicity for 10 4 concurrent computational tasks Time task scheduled at (Seconds) Computational Tasks 34
35 The streaming substrate provides consistent high performance throughput Mean transit delay (Milliseconds) Delay Standard Deviation Streaming overheads for different payload sizes (100B - 100KB) Content Payload Size (Bytes) Standard Deviation (Milliseconds) 35
36 The streaming substrate provides consistent high performance throughput Mean transit delay (Milliseconds) Delay Standard Deviation Streaming overheads for different payload sizes (100B - 1MB) e Content Payload Size (Bytes) Standard Deviation (Milliseconds) 36
37 Cautionary Tale: Gains when Disk-IO cannot keep pace with processing Processing overhead (Seconds) Histogramming words in a 500 GB dataset 1600 Files & 100 Map Functions 95% 72% 41% 65% Number of Processors 42% 37
38 Key innovations within Granules Easy to develop applications Support for real-time streaming datasets Rich lifecycle and scheduling support for computational tasks. Enforces semantics of complex, distributed computational graphs Seamless cloning at finer & coarser levels 38
39 Future Work Probabilistic guarantees within the cloud Efficient generation of compute streams Throttling and steering of computations Staging datasets to maximize throughput Support policies with global & local scope 39
40 Conclusions Pressing need to cloud-enable network data intensive systems Complexity should be managed BY the runtime, and NOT by domain specialists Autonomy of Granules instances allows it to cope well with resource pool expansion Provisioning lifecycle metrics for the parts makes it easier to do so for the sum 40
MOHA: Many-Task Computing Framework on Hadoop
 Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
HPC learning using Cloud infrastructure
 HPC learning using Cloud infrastructure Florin MANAILA IT Architect florin.manaila@ro.ibm.com Cluj-Napoca 16 March, 2010 Agenda 1. Leveraging Cloud model 2. HPC on Cloud 3. Recent projects - FutureGRID
HPC learning using Cloud infrastructure Florin MANAILA IT Architect florin.manaila@ro.ibm.com Cluj-Napoca 16 March, 2010 Agenda 1. Leveraging Cloud model 2. HPC on Cloud 3. Recent projects - FutureGRID
HiTune. Dataflow-Based Performance Analysis for Big Data Cloud
 HiTune Dataflow-Based Performance Analysis for Big Data Cloud Jinquan (Jason) Dai, Jie Huang, Shengsheng Huang, Bo Huang, Yan Liu Intel Asia-Pacific Research and Development Ltd Shanghai, China, 200241
HiTune Dataflow-Based Performance Analysis for Big Data Cloud Jinquan (Jason) Dai, Jie Huang, Shengsheng Huang, Bo Huang, Yan Liu Intel Asia-Pacific Research and Development Ltd Shanghai, China, 200241
Nowcasting. D B M G Data Base and Data Mining Group of Politecnico di Torino. Big Data: Hype or Hallelujah? Big data hype?
 Big data hype? Big Data: Hype or Hallelujah? Data Base and Data Mining Group of 2 Google Flu trends On the Internet February 2010 detected flu outbreak two weeks ahead of CDC data Nowcasting http://www.internetlivestats.com/
Big data hype? Big Data: Hype or Hallelujah? Data Base and Data Mining Group of 2 Google Flu trends On the Internet February 2010 detected flu outbreak two weeks ahead of CDC data Nowcasting http://www.internetlivestats.com/
The Future of Virtualization Desktop to the Datacentre. Raghu Raghuram Vice President Product and Solutions VMware
 The Future of Virtualization Desktop to the Datacentre Raghu Raghuram Vice President Product and Solutions VMware Virtualization- Desktop to the Datacentre VDC- vcloud vclient With our partners, we are
The Future of Virtualization Desktop to the Datacentre Raghu Raghuram Vice President Product and Solutions VMware Virtualization- Desktop to the Datacentre VDC- vcloud vclient With our partners, we are
Triton file systems - an introduction. slide 1 of 28
 Triton file systems - an introduction slide 1 of 28 File systems Motivation & basic concepts Storage locations Basic flow of IO Do's and Don'ts Exercises slide 2 of 28 File systems: Motivation Case #1:
Triton file systems - an introduction slide 1 of 28 File systems Motivation & basic concepts Storage locations Basic flow of IO Do's and Don'ts Exercises slide 2 of 28 File systems: Motivation Case #1:
Job sample: SCOPE (VLDBJ, 2012)
") Apollo High level SQL-Like language The job query plan is represented as a DAG Tasks are the basic unit of computation Tasks are grouped in Stages Execution is driven by a scheduler Job sample: SCOPE (VLDBJ,
Apollo High level SQL-Like language The job query plan is represented as a DAG Tasks are the basic unit of computation Tasks are grouped in Stages Execution is driven by a scheduler Job sample: SCOPE (VLDBJ,
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
The Future of Virtualization. Jeff Jennings Global Vice President Products & Solutions VMware
 The Future of Virtualization Jeff Jennings Global Vice President Products & Solutions VMware From Virtual Infrastructure to VDC- Windows Linux Future Future Future lication Availability Security Scalability
The Future of Virtualization Jeff Jennings Global Vice President Products & Solutions VMware From Virtual Infrastructure to VDC- Windows Linux Future Future Future lication Availability Security Scalability
Cloud Programming. Programming Environment Oct 29, 2015 Osamu Tatebe
 Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
MapReduce for Data Intensive Scientific Analyses
 apreduce for Data Intensive Scientific Analyses Jaliya Ekanayake Shrideep Pallickara Geoffrey Fox Department of Computer Science Indiana University Bloomington, IN, 47405 5/11/2009 Jaliya Ekanayake 1 Presentation
apreduce for Data Intensive Scientific Analyses Jaliya Ekanayake Shrideep Pallickara Geoffrey Fox Department of Computer Science Indiana University Bloomington, IN, 47405 5/11/2009 Jaliya Ekanayake 1 Presentation
Analyzing Electroencephalograms Using Cloud Computing Techniques
 Analyzing Electroencephalograms Using Cloud Computing Techniques Kathleen Ericson Shrideep Pallickara Charles W. Anderson Colorado State University December 1, 2010 Outline Background 1 Background BCI
Analyzing Electroencephalograms Using Cloud Computing Techniques Kathleen Ericson Shrideep Pallickara Charles W. Anderson Colorado State University December 1, 2010 Outline Background 1 Background BCI
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
The ATLAS EventIndex: Full chain deployment and first operation
 The ATLAS EventIndex: Full chain deployment and first operation Álvaro Fernández Casaní Instituto de Física Corpuscular () Universitat de València CSIC On behalf of the ATLAS Collaboration 1 Outline ATLAS
The ATLAS EventIndex: Full chain deployment and first operation Álvaro Fernández Casaní Instituto de Física Corpuscular () Universitat de València CSIC On behalf of the ATLAS Collaboration 1 Outline ATLAS
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Harp-DAAL for High Performance Big Data Computing
 Harp-DAAL for High Performance Big Data Computing Large-scale data analytics is revolutionizing many business and scientific domains. Easy-touse scalable parallel techniques are necessary to process big
Harp-DAAL for High Performance Big Data Computing Large-scale data analytics is revolutionizing many business and scientific domains. Easy-touse scalable parallel techniques are necessary to process big
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay Mellanox Technologies
 Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
GFS: The Google File System
 GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
Milestone Solution Partner IT Infrastructure Components Certification Report
 Milestone Solution Partner IT Infrastructure Components Certification Report Dell MD3860i Storage Array Multi-Server 1050 Camera Test Case 4-2-2016 Table of Contents Executive Summary:... 3 Abstract...
Milestone Solution Partner IT Infrastructure Components Certification Report Dell MD3860i Storage Array Multi-Server 1050 Camera Test Case 4-2-2016 Table of Contents Executive Summary:... 3 Abstract...
Voldemort. Smruti R. Sarangi. Department of Computer Science Indian Institute of Technology New Delhi, India. Overview Design Evaluation
 Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
SoftNAS Cloud Performance Evaluation on AWS
 SoftNAS Cloud Performance Evaluation on AWS October 25, 2016 Contents SoftNAS Cloud Overview... 3 Introduction... 3 Executive Summary... 4 Key Findings for AWS:... 5 Test Methodology... 6 Performance Summary
SoftNAS Cloud Performance Evaluation on AWS October 25, 2016 Contents SoftNAS Cloud Overview... 3 Introduction... 3 Executive Summary... 4 Key Findings for AWS:... 5 Test Methodology... 6 Performance Summary
The Fusion Distributed File System
 Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
MapReduce: A Programming Model for Large-Scale Distributed Computation
 CSC 258/458 MapReduce: A Programming Model for Large-Scale Distributed Computation University of Rochester Department of Computer Science Shantonu Hossain April 18, 2011 Outline Motivation MapReduce Overview
CSC 258/458 MapReduce: A Programming Model for Large-Scale Distributed Computation University of Rochester Department of Computer Science Shantonu Hossain April 18, 2011 Outline Motivation MapReduce Overview
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Cisco Tetration Analytics Platform: A Dive into Blazing Fast Deep Storage
 White Paper Cisco Tetration Analytics Platform: A Dive into Blazing Fast Deep Storage What You Will Learn A Cisco Tetration Analytics appliance bundles computing, networking, and storage resources in one
White Paper Cisco Tetration Analytics Platform: A Dive into Blazing Fast Deep Storage What You Will Learn A Cisco Tetration Analytics appliance bundles computing, networking, and storage resources in one
<Insert Picture Here> Managing Oracle Exadata Database Machine with Oracle Enterprise Manager 11g
 Managing Oracle Exadata Database Machine with Oracle Enterprise Manager 11g Exadata Overview Oracle Exadata Database Machine Extreme ROI Platform Fast Predictable Performance Monitor
Managing Oracle Exadata Database Machine with Oracle Enterprise Manager 11g Exadata Overview Oracle Exadata Database Machine Extreme ROI Platform Fast Predictable Performance Monitor
StreamSets Control Hub Installation Guide
 StreamSets Control Hub Installation Guide Version 3.2.1 2018, StreamSets, Inc. All rights reserved. Table of Contents 2 Table of Contents Chapter 1: What's New...1 What's New in 3.2.1... 2 What's New in
StreamSets Control Hub Installation Guide Version 3.2.1 2018, StreamSets, Inc. All rights reserved. Table of Contents 2 Table of Contents Chapter 1: What's New...1 What's New in 3.2.1... 2 What's New in
Cloud Computing CS
 Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Embedded Technosolutions
 Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed?
 Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
SQL Azure as a Self- Managing Database Service: Lessons Learned and Challenges Ahead
 SQL Azure as a Self- Managing Database Service: Lessons Learned and Challenges Ahead 1 Introduction Key features: -Shared nothing architecture -Log based replication -Support for full ACID properties -Consistency
SQL Azure as a Self- Managing Database Service: Lessons Learned and Challenges Ahead 1 Introduction Key features: -Shared nothing architecture -Log based replication -Support for full ACID properties -Consistency
Tuning Intelligent Data Lake Performance
 Tuning Intelligent Data Lake Performance 2016 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or otherwise) without
Tuning Intelligent Data Lake Performance 2016 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or otherwise) without
CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University
![CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University](/thumbs/77/76273701.jpg "CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University") CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [NETWORKING] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Why not spawn processes
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [NETWORKING] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Why not spawn processes
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning
 Extreme Application Acceleration & Highly Efficient I/O Provisioning") IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
PUBLIC SAP Vora Sizing Guide
 SAP Vora 2.0 Document Version: 1.1 2017-11-14 PUBLIC Content 1 Introduction to SAP Vora....3 1.1 System Architecture....5 2 Factors That Influence Performance....6 3 Sizing Fundamentals and Terminology....7
SAP Vora 2.0 Document Version: 1.1 2017-11-14 PUBLIC Content 1 Introduction to SAP Vora....3 1.1 System Architecture....5 2 Factors That Influence Performance....6 3 Sizing Fundamentals and Terminology....7
EsgynDB Enterprise 2.0 Platform Reference Architecture
 EsgynDB Enterprise 2.0 Platform Reference Architecture This document outlines a Platform Reference Architecture for EsgynDB Enterprise, built on Apache Trafodion (Incubating) implementation with licensed
EsgynDB Enterprise 2.0 Platform Reference Architecture This document outlines a Platform Reference Architecture for EsgynDB Enterprise, built on Apache Trafodion (Incubating) implementation with licensed
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
On the Creation & Discovery of Topics in Distributed Publish/Subscribe systems
 On the Creation & Discovery of Topics in Distributed Publish/Subscribe systems Shrideep Pallickara, Geoffrey Fox & Harshawardhan Gadgil Community Grids Lab, Indiana University 1 Messaging Systems Messaging
On the Creation & Discovery of Topics in Distributed Publish/Subscribe systems Shrideep Pallickara, Geoffrey Fox & Harshawardhan Gadgil Community Grids Lab, Indiana University 1 Messaging Systems Messaging
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Key aspects of cloud computing. Towards fuller utilization. Two main sources of resource demand. Cluster Scheduling
 Key aspects of cloud computing Cluster Scheduling 1. Illusion of infinite computing resources available on demand, eliminating need for up-front provisioning. The elimination of an up-front commitment
Key aspects of cloud computing Cluster Scheduling 1. Illusion of infinite computing resources available on demand, eliminating need for up-front provisioning. The elimination of an up-front commitment
Evolution of the ATLAS PanDA Workload Management System for Exascale Computational Science
 Evolution of the ATLAS PanDA Workload Management System for Exascale Computational Science T. Maeno, K. De, A. Klimentov, P. Nilsson, D. Oleynik, S. Panitkin, A. Petrosyan, J. Schovancova, A. Vaniachine,
Evolution of the ATLAS PanDA Workload Management System for Exascale Computational Science T. Maeno, K. De, A. Klimentov, P. Nilsson, D. Oleynik, S. Panitkin, A. Petrosyan, J. Schovancova, A. Vaniachine,
Grid Computing with Voyager
 Grid Computing with Voyager By Saikumar Dubugunta Recursion Software, Inc. September 28, 2005 TABLE OF CONTENTS Introduction... 1 Using Voyager for Grid Computing... 2 Voyager Core Components... 3 Code
Grid Computing with Voyager By Saikumar Dubugunta Recursion Software, Inc. September 28, 2005 TABLE OF CONTENTS Introduction... 1 Using Voyager for Grid Computing... 2 Voyager Core Components... 3 Code
webmethods Task Engine 9.9 on Red Hat Operating System
 webmethods Task Engine 9.9 on Red Hat Operating System Performance Technical Report 1 2015 Software AG. All rights reserved. Table of Contents INTRODUCTION 3 1.0 Benchmark Goals 4 2.0 Hardware and Software
webmethods Task Engine 9.9 on Red Hat Operating System Performance Technical Report 1 2015 Software AG. All rights reserved. Table of Contents INTRODUCTION 3 1.0 Benchmark Goals 4 2.0 Hardware and Software
Enterprise print management in VMware Horizon
 Enterprise print management in VMware Horizon Introduction: Embracing and Extending VMware Horizon Tricerat Simplify Printing enhances the capabilities of VMware Horizon environments by enabling reliable
Enterprise print management in VMware Horizon Introduction: Embracing and Extending VMware Horizon Tricerat Simplify Printing enhances the capabilities of VMware Horizon environments by enabling reliable
Sizing Guidelines and Performance Tuning for Intelligent Streaming
 Sizing Guidelines and Performance Tuning for Intelligent Streaming Copyright Informatica LLC 2017. Informatica and the Informatica logo are trademarks or registered trademarks of Informatica LLC in the
Sizing Guidelines and Performance Tuning for Intelligent Streaming Copyright Informatica LLC 2017. Informatica and the Informatica logo are trademarks or registered trademarks of Informatica LLC in the
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
GFS: The Google File System. Dr. Yingwu Zhu
 GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
Improving Hadoop MapReduce Performance on Supercomputers with JVM Reuse
 Thanh-Chung Dao 1 Improving Hadoop MapReduce Performance on Supercomputers with JVM Reuse Thanh-Chung Dao and Shigeru Chiba The University of Tokyo Thanh-Chung Dao 2 Supercomputers Expensive clusters Multi-core
Thanh-Chung Dao 1 Improving Hadoop MapReduce Performance on Supercomputers with JVM Reuse Thanh-Chung Dao and Shigeru Chiba The University of Tokyo Thanh-Chung Dao 2 Supercomputers Expensive clusters Multi-core
Operating Systems: Internals and Design Principles. Chapter 2 Operating System Overview Seventh Edition By William Stallings
 Operating Systems: Internals and Design Principles Chapter 2 Operating System Overview Seventh Edition By William Stallings Operating Systems: Internals and Design Principles Operating systems are those
Operating Systems: Internals and Design Principles Chapter 2 Operating System Overview Seventh Edition By William Stallings Operating Systems: Internals and Design Principles Operating systems are those
20762B: DEVELOPING SQL DATABASES
 ABOUT THIS COURSE This five day instructor-led course provides students with the knowledge and skills to develop a Microsoft SQL Server 2016 database. The course focuses on teaching individuals how to
ABOUT THIS COURSE This five day instructor-led course provides students with the knowledge and skills to develop a Microsoft SQL Server 2016 database. The course focuses on teaching individuals how to
Nimble Storage Adaptive Flash
 Nimble Storage Adaptive Flash Read more Nimble solutions Contact Us 800-544-8877 solutions@microage.com MicroAge.com TECHNOLOGY OVERVIEW Nimble Storage Adaptive Flash Nimble Storage s Adaptive Flash platform
Nimble Storage Adaptive Flash Read more Nimble solutions Contact Us 800-544-8877 solutions@microage.com MicroAge.com TECHNOLOGY OVERVIEW Nimble Storage Adaptive Flash Nimble Storage s Adaptive Flash platform
Resource and Performance Distribution Prediction for Large Scale Analytics Queries
 Resource and Performance Distribution Prediction for Large Scale Analytics Queries Prof. Rajiv Ranjan, SMIEEE School of Computing Science, Newcastle University, UK Visiting Scientist, Data61, CSIRO, Australia
Resource and Performance Distribution Prediction for Large Scale Analytics Queries Prof. Rajiv Ranjan, SMIEEE School of Computing Science, Newcastle University, UK Visiting Scientist, Data61, CSIRO, Australia
<Insert Picture Here> Enterprise Data Management using Grid Technology
 Enterprise Data using Grid Technology Kriangsak Tiawsirisup Sales Consulting Manager Oracle Corporation (Thailand) 3 Related Data Centre Trends. Service Oriented Architecture Flexibility
Enterprise Data using Grid Technology Kriangsak Tiawsirisup Sales Consulting Manager Oracle Corporation (Thailand) 3 Related Data Centre Trends. Service Oriented Architecture Flexibility
Table of Contents HOL SLN
 Table of Contents Lab Overview - - Modernizing Your Data Center with VMware Cloud Foundation... 3 Lab Guidance... 4 Module 1 - Deploying VMware Cloud Foundation (15 Minutes)... 7 Introduction... 8 Hands-on
Table of Contents Lab Overview - - Modernizing Your Data Center with VMware Cloud Foundation... 3 Lab Guidance... 4 Module 1 - Deploying VMware Cloud Foundation (15 Minutes)... 7 Introduction... 8 Hands-on
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT
 TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
Integrate MATLAB Analytics into Enterprise Applications
 Integrate Analytics into Enterprise Applications Aurélie Urbain MathWorks Consulting Services 2015 The MathWorks, Inc. 1 Data Analytics Workflow Data Acquisition Data Analytics Analytics Integration Business
Integrate Analytics into Enterprise Applications Aurélie Urbain MathWorks Consulting Services 2015 The MathWorks, Inc. 1 Data Analytics Workflow Data Acquisition Data Analytics Analytics Integration Business
ELASTIC DATA PLATFORM
 SERVICE OVERVIEW ELASTIC DATA PLATFORM A scalable and efficient approach to provisioning analytics sandboxes with a data lake ESSENTIALS Powerful: provide read-only data to anyone in the enterprise while
SERVICE OVERVIEW ELASTIC DATA PLATFORM A scalable and efficient approach to provisioning analytics sandboxes with a data lake ESSENTIALS Powerful: provide read-only data to anyone in the enterprise while
Welcome to the New Era of Cloud Computing
 Welcome to the New Era of Cloud Computing Aaron Kimball The web is replacing the desktop 1 SDKs & toolkits are there What about the backend? Image: Wikipedia user Calyponte 2 Two key concepts Processing
Welcome to the New Era of Cloud Computing Aaron Kimball The web is replacing the desktop 1 SDKs & toolkits are there What about the backend? Image: Wikipedia user Calyponte 2 Two key concepts Processing
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [THREAD SAFETY & MAPREDUCE] Are you set on reinventing the wheel? Shunning libraries and frameworks, are you, despite the peril? Emerge scathed, from arduous
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [THREAD SAFETY & MAPREDUCE] Are you set on reinventing the wheel? Shunning libraries and frameworks, are you, despite the peril? Emerge scathed, from arduous
Frequently asked questions from the previous class survey
 CS 370: OPERATING SYSTEMS [THREADS] Shrideep Pallickara Computer Science Colorado State University L7.1 Frequently asked questions from the previous class survey When a process is waiting, does it get
CS 370: OPERATING SYSTEMS [THREADS] Shrideep Pallickara Computer Science Colorado State University L7.1 Frequently asked questions from the previous class survey When a process is waiting, does it get
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
FLAT DATACENTER STORAGE. Paper-3 Presenter-Pratik Bhatt fx6568
 FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
Milestone Solution Partner IT Infrastructure Components Certification Report
 Milestone Solution Partner IT Infrastructure Components Certification Report Dell Storage PS6610, Dell EqualLogic PS6210, Dell EqualLogic FS7610 July 2015 Revisions Date July 2015 Description Initial release
Milestone Solution Partner IT Infrastructure Components Certification Report Dell Storage PS6610, Dell EqualLogic PS6210, Dell EqualLogic FS7610 July 2015 Revisions Date July 2015 Description Initial release
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Machine Learning at the Limit
 Machine Learning at the Limit John Canny*^ * Computer Science Division University of California, Berkeley ^ Yahoo Research Labs @GTC, March, 2015 My Other Job(s) Yahoo [Chen, Pavlov, Canny, KDD 2009]*
Machine Learning at the Limit John Canny*^ * Computer Science Division University of California, Berkeley ^ Yahoo Research Labs @GTC, March, 2015 My Other Job(s) Yahoo [Chen, Pavlov, Canny, KDD 2009]*
Building a Data-Friendly Platform for a Data- Driven Future
 Building a Data-Friendly Platform for a Data- Driven Future Benjamin Hindman - @benh 2016 Mesosphere, Inc. All Rights Reserved. INTRO $ whoami BENJAMIN HINDMAN Co-founder and Chief Architect of Mesosphere,
Building a Data-Friendly Platform for a Data- Driven Future Benjamin Hindman - @benh 2016 Mesosphere, Inc. All Rights Reserved. INTRO $ whoami BENJAMIN HINDMAN Co-founder and Chief Architect of Mesosphere,
Evolving To The Big Data Warehouse
 Evolving To The Big Data Warehouse Kevin Lancaster 1 Copyright Director, 2012, Oracle and/or its Engineered affiliates. All rights Insert Systems, Information Protection Policy Oracle Classification from
Evolving To The Big Data Warehouse Kevin Lancaster 1 Copyright Director, 2012, Oracle and/or its Engineered affiliates. All rights Insert Systems, Information Protection Policy Oracle Classification from
Google File System. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google fall DIP Heerak lim, Donghun Koo
 Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Preemptive, Low Latency Datacenter Scheduling via Lightweight Virtualization
 Preemptive, Low Latency Datacenter Scheduling via Lightweight Virtualization Wei Chen, Jia Rao*, and Xiaobo Zhou University of Colorado, Colorado Springs * University of Texas at Arlington Data Center
Preemptive, Low Latency Datacenter Scheduling via Lightweight Virtualization Wei Chen, Jia Rao*, and Xiaobo Zhou University of Colorado, Colorado Springs * University of Texas at Arlington Data Center
Altair OptiStruct 13.0 Performance Benchmark and Profiling. May 2015
 Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
Large Scale Computing Infrastructures
 GC3: Grid Computing Competence Center Large Scale Computing Infrastructures Lecture 2: Cloud technologies Sergio Maffioletti GC3: Grid Computing Competence Center, University
GC3: Grid Computing Competence Center Large Scale Computing Infrastructures Lecture 2: Cloud technologies Sergio Maffioletti GC3: Grid Computing Competence Center, University
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Certified Reference Design for VMware Cloud Providers
 VMware vcloud Architecture Toolkit for Service Providers Certified Reference Design for VMware Cloud Providers Version 2.5 August 2018 2018 VMware, Inc. All rights reserved. This product is protected by
VMware vcloud Architecture Toolkit for Service Providers Certified Reference Design for VMware Cloud Providers Version 2.5 August 2018 2018 VMware, Inc. All rights reserved. This product is protected by
NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC
 Segregated storage and compute NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC Co-located storage and compute HDFS, GFS Data
Segregated storage and compute NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC Co-located storage and compute HDFS, GFS Data
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
Improved MapReduce k-means Clustering Algorithm with Combiner
 2014 UKSim-AMSS 16th International Conference on Computer Modelling and Simulation Improved MapReduce k-means Clustering Algorithm with Combiner Prajesh P Anchalia Department Of Computer Science and Engineering
2014 UKSim-AMSS 16th International Conference on Computer Modelling and Simulation Improved MapReduce k-means Clustering Algorithm with Combiner Prajesh P Anchalia Department Of Computer Science and Engineering
Data Platforms and Pattern Mining
 Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09. Presented by: Daniel Isaacs
 Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09 Presented by: Daniel Isaacs It all starts with cluster computing. MapReduce Why
Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09 Presented by: Daniel Isaacs It all starts with cluster computing. MapReduce Why
Survey Paper on Traditional Hadoop and Pipelined Map Reduce
 International Journal of Computational Engineering Research Vol, 03 Issue, 12 Survey Paper on Traditional Hadoop and Pipelined Map Reduce Dhole Poonam B 1, Gunjal Baisa L 2 1 M.E.ComputerAVCOE, Sangamner,
International Journal of Computational Engineering Research Vol, 03 Issue, 12 Survey Paper on Traditional Hadoop and Pipelined Map Reduce Dhole Poonam B 1, Gunjal Baisa L 2 1 M.E.ComputerAVCOE, Sangamner,
High Performance Computing on MapReduce Programming Framework
 International Journal of Private Cloud Computing Environment and Management Vol. 2, No. 1, (2015), pp. 27-32 http://dx.doi.org/10.21742/ijpccem.2015.2.1.04 High Performance Computing on MapReduce Programming
International Journal of Private Cloud Computing Environment and Management Vol. 2, No. 1, (2015), pp. 27-32 http://dx.doi.org/10.21742/ijpccem.2015.2.1.04 High Performance Computing on MapReduce Programming
Tuning I/O Performance for Data Intensive Computing. Nicholas J. Wright. lbl.gov
 Tuning I/O Performance for Data Intensive Computing. Nicholas J. Wright njwright @ lbl.gov NERSC- National Energy Research Scientific Computing Center Mission: Accelerate the pace of scientific discovery
Tuning I/O Performance for Data Intensive Computing. Nicholas J. Wright njwright @ lbl.gov NERSC- National Energy Research Scientific Computing Center Mission: Accelerate the pace of scientific discovery
DRYADLINQ CTP EVALUATION
 DRYADLINQ CTP EVALUATION Performance of Key Features and Interfaces in DryadLINQ CTP Hui Li, Yang Ruan, Yuduo Zhou, Judy Qiu December 13, 2011 SALSA Group, Pervasive Technology Institute, Indiana University
DRYADLINQ CTP EVALUATION Performance of Key Features and Interfaces in DryadLINQ CTP Hui Li, Yang Ruan, Yuduo Zhou, Judy Qiu December 13, 2011 SALSA Group, Pervasive Technology Institute, Indiana University
CS435 Introduction to Big Data FALL 2018 Colorado State University. 11/7/2018 Week 12-B Sangmi Lee Pallickara. FAQs
 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.0.0 CS435 Introduction to Big Data 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.1 FAQs Deadline of the Programming Assignment 3
11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.0.0 CS435 Introduction to Big Data 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.1 FAQs Deadline of the Programming Assignment 3
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/90/104368640.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
The Evolution of a Data Project
 The Evolution of a Data Project The Evolution of a Data Project Python script The Evolution of a Data Project Python script SQL on live DB The Evolution of a Data Project Python script SQL on live DB SQL
The Evolution of a Data Project The Evolution of a Data Project Python script The Evolution of a Data Project Python script SQL on live DB The Evolution of a Data Project Python script SQL on live DB SQL
Data Intensive Scalable Computing
 Data Intensive Scalable Computing Randal E. Bryant Carnegie Mellon University http://www.cs.cmu.edu/~bryant Examples of Big Data Sources Wal-Mart 267 million items/day, sold at 6,000 stores HP built them
Data Intensive Scalable Computing Randal E. Bryant Carnegie Mellon University http://www.cs.cmu.edu/~bryant Examples of Big Data Sources Wal-Mart 267 million items/day, sold at 6,000 stores HP built them
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
A Parallel R Framework
 A Parallel R Framework for Processing Large Dataset on Distributed Systems Nov. 17, 2013 This work is initiated and supported by Huawei Technologies Rise of Data-Intensive Analytics Data Sources Personal
A Parallel R Framework for Processing Large Dataset on Distributed Systems Nov. 17, 2013 This work is initiated and supported by Huawei Technologies Rise of Data-Intensive Analytics Data Sources Personal
Information Brokerage
 Information Brokerage Sensing Networking Leonidas Guibas Stanford University Computation CS321 Information Brokerage Services in Dynamic Environments Information Brokerage Information providers (sources,
Information Brokerage Sensing Networking Leonidas Guibas Stanford University Computation CS321 Information Brokerage Services in Dynamic Environments Information Brokerage Information providers (sources,
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Design Tradeoffs for Data Deduplication Performance in Backup Workloads
 Design Tradeoffs for Data Deduplication Performance in Backup Workloads Min Fu,DanFeng,YuHua,XubinHe, Zuoning Chen *, Wen Xia,YuchengZhang,YujuanTan Huazhong University of Science and Technology Virginia
Design Tradeoffs for Data Deduplication Performance in Backup Workloads Min Fu,DanFeng,YuHua,XubinHe, Zuoning Chen *, Wen Xia,YuchengZhang,YujuanTan Huazhong University of Science and Technology Virginia
Analysis in the Big Data Era
 Analysis in the Big Data Era Massive Data Data Analysis Insight Key to Success = Timely and Cost-Effective Analysis 2 Hadoop MapReduce Ecosystem Popular solution to Big Data Analytics Java / C++ / R /
Analysis in the Big Data Era Massive Data Data Analysis Insight Key to Success = Timely and Cost-Effective Analysis 2 Hadoop MapReduce Ecosystem Popular solution to Big Data Analytics Java / C++ / R /
Five Common Myths About Scaling MySQL
 WHITE PAPER Five Common Myths About Scaling MySQL Five Common Myths About Scaling MySQL In this age of data driven applications, the ability to rapidly store, retrieve and process data is incredibly important.
WHITE PAPER Five Common Myths About Scaling MySQL Five Common Myths About Scaling MySQL In this age of data driven applications, the ability to rapidly store, retrieve and process data is incredibly important.