EECS 598: Integrating Emerging Technologies with Computer Architecture. Lecture 12: On-Chip Interconnects
|
|
|
- Beryl Boone
- 5 years ago
- Views:
Transcription


1 1 EECS 598: Integrating Emerging Technologies with Computer Architecture Lecture 12: On-Chip Interconnects Instructor: Ron Dreslinski Winter
2 Announcements Upcoming lecture schedule Today: On-chip Interconnects (Circuits and Photonics) 2/25: Off-chip Interconnects 3/1 & 3/3: Spring Break 3/8: Midterm Review, Structure for rest of lectures, Project Specification Midterm Exam: In-Class March 1 th, closed notes 2 Reading Assignments: For this week: "Swizzle-Switch Networks for Many-Core Systems," Korey Sewell et al. JETCAS IEEE Journal on Emerging and Selected Topics in Circuits and Systems, June 212 "Corona: System implications of emerging nanophotonic technology." Dana Vantrease et al. ISCA
3 Outline Swizzle Switch Circuit & Microarchitecture Overview Arbitration Prototype Swizzle Switch Cache Coherent Manycore Interconnect Motivation & Existing Interconnects Swizzle Switch Interconnect Evaluation 3 3 3




4 Swizzle Switch 4 Conventional Matrix Crossbar Swizzle Switch Embeds arbitration within crossbar single cycle arbitration Re-use input/output data buses for arbitration SRAM-like layout with priority bits at cross-points Low-power optimizations Excellent scalability 4 4
5 Data Routing Source IP Source IP Pre-charge 1 Multicast & Broadcast Bitlines discharged if Data = 1 Crosspoint = 1 5 Source IP 1 Read Buffers 128 Dest. IP Dest. IP Dest. IP 5 5
6 Swizzle Switch Architecture 6 Output bus used as prioritybus Source IP Source IP Pre-charge 1 Req k Rel k Req l Rel l vector Source IP vectors 1 Req m Rel m Dest. IP Read Buffers Dest. IP Dest. IP Sense Amp + Latch Req n Rel n 1 1 Data routing, arbitration, And priority update control embedded within crosspoints 6 6
7 Outline Swizzle Switch Circuit & Microarchitecture Overview Arbitration Prototype Swizzle Switch Cache Coherent Manycore Interconnect Motivation & Existing Interconnects Swizzle Switch Interconnect Evaluation 7 7 7
8 Inhibit Based Arbitration Req l Req m Sense Amp + Latch Req n Output bus used as priority bus x y z line l x < y line m 1 z > y 1 1 line n This diagram is a single column in the Swizzle-Switch (output), each output arbitrates/transfers data independently Each Crosspoint has a sense amp/ latch to indicate connectivity. Each input samples a unique bit of the output bus to determine if it has been granted the channel vectors are stored and when a request is issued they discharge bits along the output columns to INHIBIT lower priority requests Finally, the priority vectors are updated when the data transfer completes
9 Least Recently Granted(LRG) Output bus used as priority bus 9 Req l x line l x < y line n LOWEST Discharges NO Lines Req m Sense Amp + Latch Req n y z line m 1 z > y 1 1 INTERMEDIATE Discharges SOME Lines HIGHEST Discharges ALL Lines 9 9
10 Least Recently Granted(LRG) Output bus used as priority bus 1 Req l Req m Sense Amp + Latch Req n x 1 y z line l x < y line m 1 z > y 1 1 line n Example Arbitration: (1) Req l and Req m Request the bus (red lines) (2) Req m discharges line l, priority lines m and n remain charged (green lines) (3) Req l senses line l and is inhibited (not granted), Req m senses line m and is not inhibited (4) The crosspoint records the connectivity at input m 1 1
11 Least Recently Granted(LRG) Output bus used as priority bus 11 Example Update: Req l Rel l x SET Input m signals it is done with data transfer by asserting Rel m Req m Rel m 1 y 1 RESET Req n Rel n z
12 Least Recently Granted(LRG) Output bus used as priority bus 12 Req l Rel l x INTERMEDIATE Discharges SOME Lines Req m Rel m LOWEST Discharges NO Lines Req n Rel n z 1 1 HIGHEST Discharges ALL Lines 12 12
13 Least Recently Granted(LRG) Output bus used as priority bus 13 Req l Rel l Req m Rel m x Increasing x y 62 z LRG Algorithm l m 62 n m m releases channel l m-1 62 n Least priority upgraded unchanged Req n Rel n z
14 Outline Swizzle Switch Circuit & Microarchitecture Overview Arbitration Prototype Swizzle Switch Cache Coherent Manycore Interconnect Motivation & Existing Interconnects Swizzle Switch Interconnect Evaluation

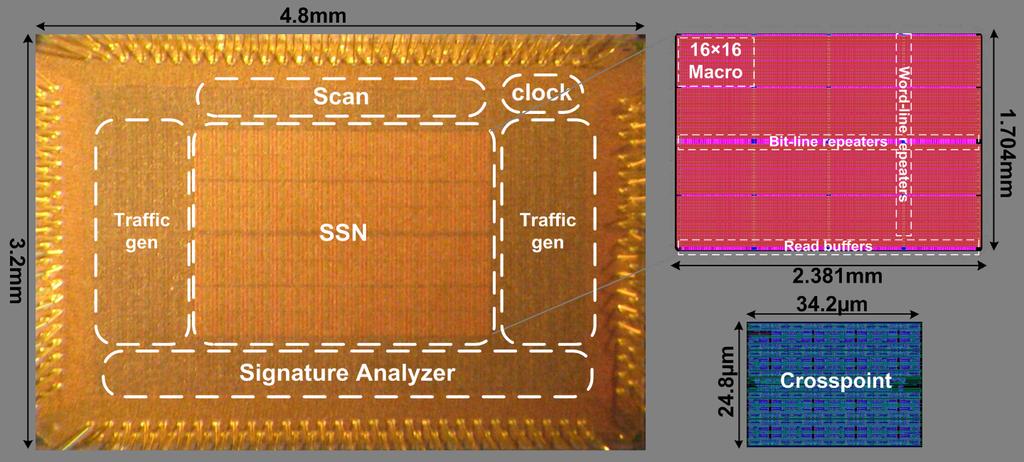
15 64x64 Prototype
16 Measurement Results
17 Measurement Results
18 Outline Swizzle Switch Circuit & Microarchitecture Overview Arbitration Prototype Swizzle Switch Cache Coherent Manycore Interconnect Motivation & Existing Interconnects Swizzle Switch Interconnect Evaluation
19 Scaling Interconnect for Many-Cores 19 Existing interconnects Buses, Crossbars, Rings Limited to ~16 cores Other s Interconnect proposals for Many-Cores Packet-switched, multi-hop, network-on-chip (NoC) Grid of routers meshes, tori and flattened butterfly Our Proposal Swizzle Switch Networks Flat single-stage, one-hop, crossbar++ interconnect 19 19


20 Mesh Network-on-Chip 2 Memory Controller Memory Controller Memory Controller Memory Controller Memory Controller Memory Controller 13.8 mm 32 kb ICache 1.73 mm ARM Cortex A5 256 kb L2 Cache Bank 32 kb DCache R 1.73 mm Memory Controller Memory Controller Area = 3. mm mm Area = 19 mm 2 (a) Router R 2 2
21 Flattened Butterfly Network-on-Chip 21 Memory Controller Memory Controller Memory Controller Memory Controller Router Router Router Router Router Router Router Router Router Router Router Router Router Router Router Router Memory Controller Memory Controller 13.8 mm Memory Controller Memory Controller 13.8 mm Area = 19 mm
22 Motivating Swizzle Switch Networks 22 Uniform access latency Ease of programming, data placement, thread placement,... Low Power Simplicity Packet-switched NoCs need routing, congestion management, flow control, wormhole switching,


















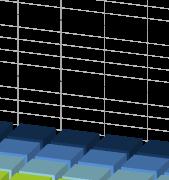


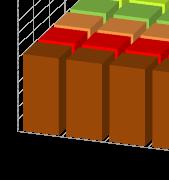



23 Motivating Swizzle Switch Networks 23 Mesh SSN Average'='.17'flits/node/sec' Unfairness'='42.2''' Average'='.13'flits/node/sec' Unfairness'='1.8''' accepted throughput [flits/node/cycle] node index (X) node index (Y) node index (X) node index (Y) Unfairness = Node highest_throughput / Node lowest_throughput Hotspot Traffic = All nodes sending data to node 8,8 Under Hotspot traffic, the Crossbar has a slightly less throughput than the Mesh but is 4x more fair










24 Motivating Swizzle Switch Networks 24 Mesh Average'='.36'flits/node/sec' Unfairness'='1.89''' SSN Average'='.47'flits/node/sec' Unfairness'='1.2''' node index (X) node index (Y) node index (X) node index (Y) In the Mesh, nodes closest to the center receive the highest throughput Under Uniform Random traffic, the Crossbar has more throughput than the Mesh and is 87% more fair

25 Motivating Swizzle Switch Networks
26 Outline Swizzle Switch Circuit & Microarchitecture Overview Arbitration Prototype Swizzle Switch Cache Coherent Manycore Interconnect Motivation & Existing Interconnects Swizzle Switch Interconnect Evaluation
27 Top-Level Floorplan 27 Memory Controller Memory Controller Memory Controller Memory Controller NW WN WS SW Swizzle Switch x 3 NE EN ES SE Memory Controller Memory Controller 14.3 mm 3.27 mm 512 kb L2 cache L2 Area = 4.5 mm 2 32 kb Icache.86 mm Arm Cortex A5 32 kb Dcache.86 mm 1.38 mm Memory Controller 14.3 mm Total Area = 24 mm 2 Memory Controller Core + L1 Area =.74 mm
28 Outline Swizzle Switch Circuit & Microarchitecture Overview Arbitration Prototype Swizzle Switch Cache Coherent Manycore Interconnect Motivation & Existing Interconnects Swizzle Switch Interconnect Evaluation
29 Evaluation 29 Simulation Parameters Feature NoC (Mesh/FBFly) SSN Processors L1 Cache 64 in-order cores, 1 IPC, 1.5 GHz 32kB I/D Caches, 4-way associative, 64-byte line size, 1 cycle latency L2 Cache Shared L2, 16 MB, 64-way banked, 8- way associative, 64-byte line size, 1 cycle latency Interconnect Main Memory 3. GHz, 128-bit, 4-stage Routers, 3 virt. networks w/ 3 virt. channels 496MB, 5 cycle latency Shared L2, 16MB, 32-way banked, 16-way associative, 64-byte line size, 11 cycle latency 1.5 GHz, 64x32x128bit Swizzle Switch Network Benchmarks SPLASH 2 : Scientific parallel application suite 29 29
30 Results Performance & QoS 3 Normalized Execution Time 1% 9% 8% 7% 6% 5% 4% 3% 2% 1% % Mesh FBFly SSN Mesh FBFly SSN Mesh FBFly SSN Mesh FBFly SSN Synchronization Stall Core Active Memory Stall Mesh FBFly SSN Mesh FBFly SSN Mesh FBFly SSN Mesh FBFly SSN Mesh FBFly SSN Mesh FBFly SSN Mesh FBFly SSN Mesh FBFly SSN Barnes. Cholesky. FFT. FMM. Lu Contig. Lu NonContig. Ocean Contig. Ocean NonContig. Radix. Raytrace. Water NSquared. Water Spatial Overall Performance Quality-of-Service 3 3
31 Results Power 31 Interconnect Power (mw)! 7,! 6,! 5,! 4,! 3,! 2,! 1,!! Wire Dynamic! SSN/Router Dynamic! SSN/Router Leakage! Clock! Buffer! Barnes!.! Cholesky!.! FFT!.! FMM!.! Lu Contig!.! Lu NonContig!.! Ocean Contig!.! Ocean NonContig!.! Radix!.! Raytrace!.! Water NSquared!.! Water Spatial!.! Weighted Average! On average the SSN uses 28% less power in the interconnect compared to a flattened butterfly Total Benchmark Energy! (pj/inst)! 9! 8! 7! 6! 5! 4! 3! 2! 1!! Interconnect! L2 Dynamic! L2 Leakage! Core/L1 Dynamic! Core/L1 Leakage! Barnes!.! Cholesky!.! FFT!.! FMM!.! LuContig!.! Lu NonContig!.! Ocean Contig!.! Ocean NonContig!.! Radix!.! Raytrace!.! Water NSquared! Which results in an average reduction in total system energy to complete the task of 11%.! Water Spatial!.! Average! 31 31
32 Summary Swizzle Switch Prototype (45nm) 64x64 Crossbar with 128-bit busses Embedded LRG priority arbitration Achieved 4.4 ~6MHz consuming only 1.3W of power 32 Swizzle Switch Network Evaluation Improved performance by 21% Reduced power by 28% Reduced latency variability by 3x 32 32
33 33 Additional Detailed Slides 33 33
34 Arbitration Mechanism (Matrix View) 34 Pre-charge 128 Source IP Req Rel Source IP Req Rel Inhibits (X) Source IP Req Rel 128 Dest. IP Read Buffers Dest. IP Dest. IP Requests (R) X X 1 X 2 X 3 X 4 R X 1 1 R 1 X R X 2 R X 1 4 R X

35 Least Recently Granted (LRG) 35 S et Reset X X 1 X 2 X 3 X 4 In X 1 1 In 1 X In X 2 In X 1 4 In X 3 X X 1 X 2 X 3 X 4 In X In 1 X 1 1 In X 1 3 In X 1 4 In 4 X 35 35
36 Round Robin Arbitration Output bus used as priority bus 36 Req l Rel l x SET Req m Rel m y 1 Req n Rel n z 1 1 RESET 36 36
37 Round Robin Arbitration Output bus used as priority bus 37 Req l Rel l Req m Rel m x + 1 y Increasing Round Robin Algorithm x y 62 z l m 62 n m l m-1 62 n Least priority upgraded Req n Rel n 37 37


38 QoS Arbitration 38 Increasing QoS Arbitration QoS values LRG Arbitration Highest QoS Winner

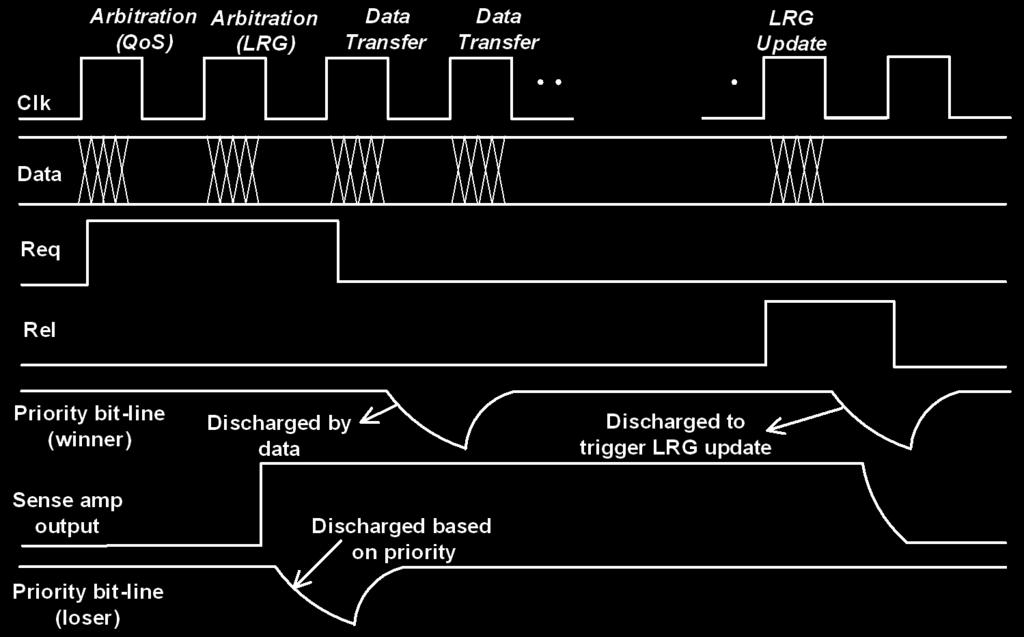
39 Timing Diagram
40 Crosspoint Circuit 4 wl out<> out<64> clock_b Crosspoint(x,y) Rel_b in<> in<64> wl -line bit clock Sense_ amp out<y> Reset_b Rel in<y> out<y> (priority_line) Rel Req wl Ack in<x+64> clock_b in<x> used to index Req/Rel out<y> sampled for Arbitration in<x+64> used for sending ack out<y> discharged for LRG update in<63> Rel_b wl out<63> out<127> in<127> 4 4

41 Regenerative Bit-line Repeater Macro clock_b clock_b Bit-line Repeaters Bitline_R SSN Bitline_L clock Regeneration and Decoupling improves speed Bitline_L Bitline_R 41 41
42 Simulated bit-line delay improvement 42 Technology : 45nm Supply : 1.1V Temperature : 25 C 42 42
43 SSN Scaling: Simulation Technology : 45nm Supply : 1.1V Temperature : 25 C 43 wo Repeater 256 bit Bus with Repeater 128 bit Bus with Repeater Regenerative repeaters improve SSN scalability 43 43
44 Swizzle Switch Network-on-Chip 44 (1%)*%3, (1%)!%-./ ('%)!%-./ ('%)*%+, (1%)!%+, (1%)*%-./ ('%)*%-./ ('%)!%+, Memory Controller Memory Controller $ # 4 $ # $ $ 4 Memory Controller Memory Controller NW WN WS SW Swizzle Switch x 3 Memory Controller L mm NE EN ES SE Memory Controller Destination L2 Memory Controller Memory Controller 14.3 mm 1(%)*%-./ 1(%)!%-./ 1(%)*%+, 1%)*%+, 1%)!%-./ 1(%)!%+, 1%)!%+, 1%)*%-./ $ 4 $ $ # 4 # $ $!"#$%&$!'# ()*+'*"', -./12$ -./ '%)!%-./ 1%)!%-./ 1%)*%3, 4 # $ 4!"#$%&$!"- ()*()*"', -./12 -./345 "6"88 9!"$:;*!'#$%&$!"# +'*()*"', -./12$-./ $ $ # '%)!%+, $ # $ # 4 $ $ 4 '(%)*%+,% '(%)!%-./% '(%)*%-./!"#$%&& '(%)!%+, '%)!%+, '%)*%+, '%)*%-./ '%)!%-./ Source L1 L2 Shared Data Data Forwarding Responses Invalidations Requests Writebacks '%)*%-./ 1%)*%-./ 1%2!%+, '%)*%+,!"#$%&& (b) 44 44
45 Results 64-core with A9 O3 cores
Swizzle Switch: A Self-Arbitrating High-Radix Crossbar for NoC Systems
 1 Swizzle Switch: A Self-Arbitrating High-Radix Crossbar for NoC Systems Ronald Dreslinski, Korey Sewell, Thomas Manville, Sudhir Satpathy, Nathaniel Pinckney, Geoff Blake, Michael Cieslak, Reetuparna
1 Swizzle Switch: A Self-Arbitrating High-Radix Crossbar for NoC Systems Ronald Dreslinski, Korey Sewell, Thomas Manville, Sudhir Satpathy, Nathaniel Pinckney, Geoff Blake, Michael Cieslak, Reetuparna
Swizzle-Switch Networks for Many-Core Systems
 278 IEEE JOURNAL ON EMERGING AND SELECTED TOPICS IN CIRCUITS AND SYSTEMS, VOL. 2, NO. 2, JUNE 2012 Swizzle-Switch Networks for Many-Core Systems Korey Sewell, Ronald G. Dreslinski, Thomas Manville, Sudhir
278 IEEE JOURNAL ON EMERGING AND SELECTED TOPICS IN CIRCUITS AND SYSTEMS, VOL. 2, NO. 2, JUNE 2012 Swizzle-Switch Networks for Many-Core Systems Korey Sewell, Ronald G. Dreslinski, Thomas Manville, Sudhir
EECS 598: Integrating Emerging Technologies with Computer Architecture. Lecture 14: Photonic Interconnect
 1 EECS 598: Integrating Emerging Technologies with Computer Architecture Lecture 14: Photonic Interconnect Instructor: Ron Dreslinski Winter 2016 1 1 Announcements 2 Remaining lecture schedule 3/15: Photonics
1 EECS 598: Integrating Emerging Technologies with Computer Architecture Lecture 14: Photonic Interconnect Instructor: Ron Dreslinski Winter 2016 1 1 Announcements 2 Remaining lecture schedule 3/15: Photonics
Quality-of-Service for a High-Radix Switch
 Quality-of-Service for a High-Radix Switch Nilmini Abeyratne, Supreet Jeloka, Yiping Kang, David Blaauw, Ronald G. Dreslinski, Reetuparna Das, and Trevor Mudge University of Michigan 51 st DAC 06/05/2014
Quality-of-Service for a High-Radix Switch Nilmini Abeyratne, Supreet Jeloka, Yiping Kang, David Blaauw, Ronald G. Dreslinski, Reetuparna Das, and Trevor Mudge University of Michigan 51 st DAC 06/05/2014
Phastlane: A Rapid Transit Optical Routing Network
 Phastlane: A Rapid Transit Optical Routing Network Mark Cianchetti, Joseph Kerekes, and David Albonesi Computer Systems Laboratory Cornell University The Interconnect Bottleneck Future processors: tens
Phastlane: A Rapid Transit Optical Routing Network Mark Cianchetti, Joseph Kerekes, and David Albonesi Computer Systems Laboratory Cornell University The Interconnect Bottleneck Future processors: tens
Interconnection Networks: Topology. Prof. Natalie Enright Jerger
 Interconnection Networks: Topology Prof. Natalie Enright Jerger Topology Overview Definition: determines arrangement of channels and nodes in network Analogous to road map Often first step in network design
Interconnection Networks: Topology Prof. Natalie Enright Jerger Topology Overview Definition: determines arrangement of channels and nodes in network Analogous to road map Often first step in network design
Shared Memory Multiprocessors. Symmetric Shared Memory Architecture (SMP) Cache Coherence. Cache Coherence Mechanism. Interconnection Network
 Cache Coherence. Cache Coherence Mechanism. Interconnection Network") Shared Memory Multis Processor Processor Processor i Processor n Symmetric Shared Memory Architecture (SMP) cache cache cache cache Interconnection Network Main Memory I/O System Cache Coherence Cache
Shared Memory Multis Processor Processor Processor i Processor n Symmetric Shared Memory Architecture (SMP) cache cache cache cache Interconnection Network Main Memory I/O System Cache Coherence Cache
Achieving Lightweight Multicast in Asynchronous Networks-on-Chip Using Local Speculation
 Achieving Lightweight Multicast in Asynchronous Networks-on-Chip Using Local Speculation Kshitij Bhardwaj Dept. of Computer Science Columbia University Steven M. Nowick 2016 ACM/IEEE Design Automation
Achieving Lightweight Multicast in Asynchronous Networks-on-Chip Using Local Speculation Kshitij Bhardwaj Dept. of Computer Science Columbia University Steven M. Nowick 2016 ACM/IEEE Design Automation
Lecture 3: Flow-Control
 High-Performance On-Chip Interconnects for Emerging SoCs http://tusharkrishna.ece.gatech.edu/teaching/nocs_acaces17/ ACACES Summer School 2017 Lecture 3: Flow-Control Tushar Krishna Assistant Professor
High-Performance On-Chip Interconnects for Emerging SoCs http://tusharkrishna.ece.gatech.edu/teaching/nocs_acaces17/ ACACES Summer School 2017 Lecture 3: Flow-Control Tushar Krishna Assistant Professor
TDT Appendix E Interconnection Networks
 TDT 4260 Appendix E Interconnection Networks Review Advantages of a snooping coherency protocol? Disadvantages of a snooping coherency protocol? Advantages of a directory coherency protocol? Disadvantages
TDT 4260 Appendix E Interconnection Networks Review Advantages of a snooping coherency protocol? Disadvantages of a snooping coherency protocol? Advantages of a directory coherency protocol? Disadvantages
Lecture 2: Topology - I
 ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 2: Topology - I Tushar Krishna Assistant Professor School of Electrical and
ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 2: Topology - I Tushar Krishna Assistant Professor School of Electrical and
Interconnection Networks
 Lecture 18: Interconnection Networks Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Credit: many of these slides were created by Michael Papamichael This lecture is partially
Lecture 18: Interconnection Networks Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Credit: many of these slides were created by Michael Papamichael This lecture is partially
Low-Power Interconnection Networks
 Low-Power Interconnection Networks Li-Shiuan Peh Associate Professor EECS, CSAIL & MTL MIT 1 Moore s Law: Double the number of transistors on chip every 2 years 1970: Clock speed: 108kHz No. transistors:
Low-Power Interconnection Networks Li-Shiuan Peh Associate Professor EECS, CSAIL & MTL MIT 1 Moore s Law: Double the number of transistors on chip every 2 years 1970: Clock speed: 108kHz No. transistors:
Overlaid Mesh Topology Design and Deadlock Free Routing in Wireless Network-on-Chip. Danella Zhao and Ruizhe Wu Presented by Zhonghai Lu, KTH
 Overlaid Mesh Topology Design and Deadlock Free Routing in Wireless Network-on-Chip Danella Zhao and Ruizhe Wu Presented by Zhonghai Lu, KTH Outline Introduction Overview of WiNoC system architecture Overlaid
Overlaid Mesh Topology Design and Deadlock Free Routing in Wireless Network-on-Chip Danella Zhao and Ruizhe Wu Presented by Zhonghai Lu, KTH Outline Introduction Overview of WiNoC system architecture Overlaid
CHAPTER 6 FPGA IMPLEMENTATION OF ARBITERS ALGORITHM FOR NETWORK-ON-CHIP
 133 CHAPTER 6 FPGA IMPLEMENTATION OF ARBITERS ALGORITHM FOR NETWORK-ON-CHIP 6.1 INTRODUCTION As the era of a billion transistors on a one chip approaches, a lot of Processing Elements (PEs) could be located
133 CHAPTER 6 FPGA IMPLEMENTATION OF ARBITERS ALGORITHM FOR NETWORK-ON-CHIP 6.1 INTRODUCTION As the era of a billion transistors on a one chip approaches, a lot of Processing Elements (PEs) could be located
Lecture 18: Communication Models and Architectures: Interconnection Networks
 Design & Co-design of Embedded Systems Lecture 18: Communication Models and Architectures: Interconnection Networks Sharif University of Technology Computer Engineering g Dept. Winter-Spring 2008 Mehdi
Design & Co-design of Embedded Systems Lecture 18: Communication Models and Architectures: Interconnection Networks Sharif University of Technology Computer Engineering g Dept. Winter-Spring 2008 Mehdi
A Reconfigurable Crossbar Switch with Adaptive Bandwidth Control for Networks-on
 A Reconfigurable Crossbar Switch with Adaptive Bandwidth Control for Networks-on on-chip Donghyun Kim, Kangmin Lee, Se-joong Lee and Hoi-Jun Yoo Semiconductor System Laboratory, Dept. of EECS, Korea Advanced
A Reconfigurable Crossbar Switch with Adaptive Bandwidth Control for Networks-on on-chip Donghyun Kim, Kangmin Lee, Se-joong Lee and Hoi-Jun Yoo Semiconductor System Laboratory, Dept. of EECS, Korea Advanced
OASIS Network-on-Chip Prototyping on FPGA
 Master thesis of the University of Aizu, Feb. 20, 2012 OASIS Network-on-Chip Prototyping on FPGA m5141120, Kenichi Mori Supervised by Prof. Ben Abdallah Abderazek Adaptive Systems Laboratory, Master of
Master thesis of the University of Aizu, Feb. 20, 2012 OASIS Network-on-Chip Prototyping on FPGA m5141120, Kenichi Mori Supervised by Prof. Ben Abdallah Abderazek Adaptive Systems Laboratory, Master of
4. Networks. in parallel computers. Advances in Computer Architecture
 4. Networks in parallel computers Advances in Computer Architecture System architectures for parallel computers Control organization Single Instruction stream Multiple Data stream (SIMD) All processors
4. Networks in parallel computers Advances in Computer Architecture System architectures for parallel computers Control organization Single Instruction stream Multiple Data stream (SIMD) All processors
CS252 Graduate Computer Architecture Lecture 14. Multiprocessor Networks March 9 th, 2011
 CS252 Graduate Computer Architecture Lecture 14 Multiprocessor Networks March 9 th, 2011 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~kubitron/cs252
CS252 Graduate Computer Architecture Lecture 14 Multiprocessor Networks March 9 th, 2011 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~kubitron/cs252
Chapter 9 Multiprocessors
 ECE200 Computer Organization Chapter 9 Multiprocessors David H. lbonesi and the University of Rochester Henk Corporaal, TU Eindhoven, Netherlands Jari Nurmi, Tampere University of Technology, Finland University
ECE200 Computer Organization Chapter 9 Multiprocessors David H. lbonesi and the University of Rochester Henk Corporaal, TU Eindhoven, Netherlands Jari Nurmi, Tampere University of Technology, Finland University
Design and Simulation of Router Using WWF Arbiter and Crossbar
 Design and Simulation of Router Using WWF Arbiter and Crossbar M.Saravana Kumar, K.Rajasekar Electronics and Communication Engineering PSG College of Technology, Coimbatore, India Abstract - Packet scheduling
Design and Simulation of Router Using WWF Arbiter and Crossbar M.Saravana Kumar, K.Rajasekar Electronics and Communication Engineering PSG College of Technology, Coimbatore, India Abstract - Packet scheduling
Embedded Systems: Hardware Components (part II) Todor Stefanov
 Todor Stefanov") Embedded Systems: Hardware Components (part II) Todor Stefanov Leiden Embedded Research Center, Leiden Institute of Advanced Computer Science Leiden University, The Netherlands Outline Generic Embedded
Embedded Systems: Hardware Components (part II) Todor Stefanov Leiden Embedded Research Center, Leiden Institute of Advanced Computer Science Leiden University, The Netherlands Outline Generic Embedded
Lecture 26: Interconnects. James C. Hoe Department of ECE Carnegie Mellon University
 18 447 Lecture 26: Interconnects James C. Hoe Department of ECE Carnegie Mellon University 18 447 S18 L26 S1, James C. Hoe, CMU/ECE/CALCM, 2018 Housekeeping Your goal today get an overview of parallel
18 447 Lecture 26: Interconnects James C. Hoe Department of ECE Carnegie Mellon University 18 447 S18 L26 S1, James C. Hoe, CMU/ECE/CALCM, 2018 Housekeeping Your goal today get an overview of parallel
OpenSMART: Single-cycle Multi-hop NoC Generator in BSV and Chisel
 OpenSMART: Single-cycle Multi-hop NoC Generator in BSV and Chisel Hyoukjun Kwon and Tushar Krishna Georgia Institute of Technology Synergy Lab (http://synergy.ece.gatech.edu) hyoukjun@gatech.edu April
OpenSMART: Single-cycle Multi-hop NoC Generator in BSV and Chisel Hyoukjun Kwon and Tushar Krishna Georgia Institute of Technology Synergy Lab (http://synergy.ece.gatech.edu) hyoukjun@gatech.edu April
Pseudo-Circuit: Accelerating Communication for On-Chip Interconnection Networks
 Department of Computer Science and Engineering, Texas A&M University Technical eport #2010-3-1 seudo-circuit: Accelerating Communication for On-Chip Interconnection Networks Minseon Ahn, Eun Jung Kim Department
Department of Computer Science and Engineering, Texas A&M University Technical eport #2010-3-1 seudo-circuit: Accelerating Communication for On-Chip Interconnection Networks Minseon Ahn, Eun Jung Kim Department
CCNoC: Specializing On-Chip Interconnects for Energy Efficiency in Cache-Coherent Servers
 CCNoC: Specializing On-Chip Interconnects for Energy Efficiency in Cache-Coherent Servers Stavros Volos, Ciprian Seiculescu, Boris Grot, Naser Khosro Pour, Babak Falsafi, and Giovanni De Micheli Toward
CCNoC: Specializing On-Chip Interconnects for Energy Efficiency in Cache-Coherent Servers Stavros Volos, Ciprian Seiculescu, Boris Grot, Naser Khosro Pour, Babak Falsafi, and Giovanni De Micheli Toward
Interconnection Networks
 Lecture 15: Interconnection Networks Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2016 Credit: some slides created by Michael Papamichael, others based on slides from Onur Mutlu
Lecture 15: Interconnection Networks Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2016 Credit: some slides created by Michael Papamichael, others based on slides from Onur Mutlu
Meet in the Middle: Leveraging Optical Interconnection Opportunities in Chip Multi Processors
 Meet in the Middle: Leveraging Optical Interconnection Opportunities in Chip Multi Processors Sandro Bartolini* Department of Information Engineering, University of Siena, Italy bartolini@dii.unisi.it
Meet in the Middle: Leveraging Optical Interconnection Opportunities in Chip Multi Processors Sandro Bartolini* Department of Information Engineering, University of Siena, Italy bartolini@dii.unisi.it
Cache Performance, System Performance, and Off-Chip Bandwidth... Pick any Two
 Cache Performance, System Performance, and Off-Chip Bandwidth... Pick any Two Bushra Ahsan and Mohamed Zahran Dept. of Electrical Engineering City University of New York ahsan bushra@yahoo.com mzahran@ccny.cuny.edu
Cache Performance, System Performance, and Off-Chip Bandwidth... Pick any Two Bushra Ahsan and Mohamed Zahran Dept. of Electrical Engineering City University of New York ahsan bushra@yahoo.com mzahran@ccny.cuny.edu
Lecture 7: Flow Control - I
 ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 7: Flow Control - I Tushar Krishna Assistant Professor School of Electrical
ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 7: Flow Control - I Tushar Krishna Assistant Professor School of Electrical
Snoop-Based Multiprocessor Design III: Case Studies
 Snoop-Based Multiprocessor Design III: Case Studies Todd C. Mowry CS 41 March, Case Studies of Bus-based Machines SGI Challenge, with Powerpath SUN Enterprise, with Gigaplane Take very different positions
Snoop-Based Multiprocessor Design III: Case Studies Todd C. Mowry CS 41 March, Case Studies of Bus-based Machines SGI Challenge, with Powerpath SUN Enterprise, with Gigaplane Take very different positions
Lecture: Interconnection Networks
 Lecture: Interconnection Networks Topics: Router microarchitecture, topologies Final exam next Tuesday: same rules as the first midterm 1 Packets/Flits A message is broken into multiple packets (each packet
Lecture: Interconnection Networks Topics: Router microarchitecture, topologies Final exam next Tuesday: same rules as the first midterm 1 Packets/Flits A message is broken into multiple packets (each packet
NetSpeed ORION: A New Approach to Design On-chip Interconnects. August 26 th, 2013
 NetSpeed ORION: A New Approach to Design On-chip Interconnects August 26 th, 2013 INTERCONNECTS BECOMING INCREASINGLY IMPORTANT Growing number of IP cores Average SoCs today have 100+ IPs Mixing and matching
NetSpeed ORION: A New Approach to Design On-chip Interconnects August 26 th, 2013 INTERCONNECTS BECOMING INCREASINGLY IMPORTANT Growing number of IP cores Average SoCs today have 100+ IPs Mixing and matching
Quality-of-Service for a High-Radix Switch
 Quality-of-Service for a High-Radix Switch Nilmini Abeyratne, Supreet Jeloka, Yiping Kang, David Blaauw, Ronald G. Dreslinski, Reetuparna Das and Trevor Mudge University of Michigan, Ann Arbor, MI 4819
Quality-of-Service for a High-Radix Switch Nilmini Abeyratne, Supreet Jeloka, Yiping Kang, David Blaauw, Ronald G. Dreslinski, Reetuparna Das and Trevor Mudge University of Michigan, Ann Arbor, MI 4819
ECE 551 System on Chip Design
 ECE 551 System on Chip Design Introducing Bus Communications Garrett S. Rose Fall 2018 Emerging Applications Requirements Data Flow vs. Processing µp µp Mem Bus DRAMC Core 2 Core N Main Bus µp Core 1 SoCs
ECE 551 System on Chip Design Introducing Bus Communications Garrett S. Rose Fall 2018 Emerging Applications Requirements Data Flow vs. Processing µp µp Mem Bus DRAMC Core 2 Core N Main Bus µp Core 1 SoCs
Future of Interconnect Fabric A Contrarian View. Shekhar Borkar June 13, 2010 Intel Corp. 1
 Future of Interconnect Fabric A ontrarian View Shekhar Borkar June 13, 2010 Intel orp. 1 Outline Evolution of interconnect fabric On die network challenges Some simple contrarian proposals Evaluation and
Future of Interconnect Fabric A ontrarian View Shekhar Borkar June 13, 2010 Intel orp. 1 Outline Evolution of interconnect fabric On die network challenges Some simple contrarian proposals Evaluation and
Lecture 12: Interconnection Networks. Topics: communication latency, centralized and decentralized switches, routing, deadlocks (Appendix E)
") Lecture 12: Interconnection Networks Topics: communication latency, centralized and decentralized switches, routing, deadlocks (Appendix E) 1 Topologies Internet topologies are not very regular they grew
Lecture 12: Interconnection Networks Topics: communication latency, centralized and decentralized switches, routing, deadlocks (Appendix E) 1 Topologies Internet topologies are not very regular they grew
Lecture 16: On-Chip Networks. Topics: Cache networks, NoC basics
 Lecture 16: On-Chip Networks Topics: Cache networks, NoC basics 1 Traditional Networks Huh et al. ICS 05, Beckmann MICRO 04 Example designs for contiguous L2 cache regions 2 Explorations for Optimality
Lecture 16: On-Chip Networks Topics: Cache networks, NoC basics 1 Traditional Networks Huh et al. ICS 05, Beckmann MICRO 04 Example designs for contiguous L2 cache regions 2 Explorations for Optimality
Lecture 3: Topology - II
 ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 3: Topology - II Tushar Krishna Assistant Professor School of Electrical and
ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 3: Topology - II Tushar Krishna Assistant Professor School of Electrical and
SIGNET: NETWORK-ON-CHIP FILTERING FOR COARSE VECTOR DIRECTORIES. Natalie Enright Jerger University of Toronto
 SIGNET: NETWORK-ON-CHIP FILTERING FOR COARSE VECTOR DIRECTORIES University of Toronto Interaction of Coherence and Network 2 Cache coherence protocol drives network-on-chip traffic Scalable coherence protocols
SIGNET: NETWORK-ON-CHIP FILTERING FOR COARSE VECTOR DIRECTORIES University of Toronto Interaction of Coherence and Network 2 Cache coherence protocol drives network-on-chip traffic Scalable coherence protocols
18-447: Computer Architecture Lecture 25: Main Memory. Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/3/2013
 18-447: Computer Architecture Lecture 25: Main Memory Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/3/2013 Reminder: Homework 5 (Today) Due April 3 (Wednesday!) Topics: Vector processing,
18-447: Computer Architecture Lecture 25: Main Memory Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/3/2013 Reminder: Homework 5 (Today) Due April 3 (Wednesday!) Topics: Vector processing,
Portland State University ECE 588/688. Directory-Based Cache Coherence Protocols
 Portland State University ECE 588/688 Directory-Based Cache Coherence Protocols Copyright by Alaa Alameldeen and Haitham Akkary 2018 Why Directory Protocols? Snooping-based protocols may not scale All
Portland State University ECE 588/688 Directory-Based Cache Coherence Protocols Copyright by Alaa Alameldeen and Haitham Akkary 2018 Why Directory Protocols? Snooping-based protocols may not scale All
Networks for Multi-core Chips A A Contrarian View. Shekhar Borkar Aug 27, 2007 Intel Corp.
 Networks for Multi-core hips A A ontrarian View Shekhar Borkar Aug 27, 2007 Intel orp. 1 Outline Multi-core system outlook On die network challenges A simple contrarian proposal Benefits Summary 2 A Sample
Networks for Multi-core hips A A ontrarian View Shekhar Borkar Aug 27, 2007 Intel orp. 1 Outline Multi-core system outlook On die network challenges A simple contrarian proposal Benefits Summary 2 A Sample
Design and Implementation of Multistage Interconnection Networks for SoC Networks
 International Journal of Computer Science, Engineering and Information Technology (IJCSEIT), Vol.2, No.5, October 212 Design and Implementation of Multistage Interconnection Networks for SoC Networks Mahsa
International Journal of Computer Science, Engineering and Information Technology (IJCSEIT), Vol.2, No.5, October 212 Design and Implementation of Multistage Interconnection Networks for SoC Networks Mahsa
Network on Chip Architecture: An Overview
 Network on Chip Architecture: An Overview Md Shahriar Shamim & Naseef Mansoor 12/5/2014 1 Overview Introduction Multi core chip Challenges Network on Chip Architecture Regular Topology Irregular Topology
Network on Chip Architecture: An Overview Md Shahriar Shamim & Naseef Mansoor 12/5/2014 1 Overview Introduction Multi core chip Challenges Network on Chip Architecture Regular Topology Irregular Topology
Design of Adaptive Communication Channel Buffers for Low-Power Area- Efficient Network-on. on-chip Architecture
 Design of Adaptive Communication Channel Buffers for Low-Power Area- Efficient Network-on on-chip Architecture Avinash Kodi, Ashwini Sarathy * and Ahmed Louri * Department of Electrical Engineering and
Design of Adaptive Communication Channel Buffers for Low-Power Area- Efficient Network-on on-chip Architecture Avinash Kodi, Ashwini Sarathy * and Ahmed Louri * Department of Electrical Engineering and
Challenges for Future Interconnection Networks Hot Interconnects Panel August 24, Dennis Abts Sr. Principal Engineer
 Challenges for Future Interconnection Networks Hot Interconnects Panel August 24, 2006 Sr. Principal Engineer Panel Questions How do we build scalable networks that balance power, reliability and performance
Challenges for Future Interconnection Networks Hot Interconnects Panel August 24, 2006 Sr. Principal Engineer Panel Questions How do we build scalable networks that balance power, reliability and performance
Interconnection Networks
 Lecture 17: Interconnection Networks Parallel Computer Architecture and Programming A comment on web site comments It is okay to make a comment on a slide/topic that has already been commented on. In fact
Lecture 17: Interconnection Networks Parallel Computer Architecture and Programming A comment on web site comments It is okay to make a comment on a slide/topic that has already been commented on. In fact
OASIS NoC Architecture Design in Verilog HDL Technical Report: TR OASIS
 OASIS NoC Architecture Design in Verilog HDL Technical Report: TR-062010-OASIS Written by Kenichi Mori ASL-Ben Abdallah Group Graduate School of Computer Science and Engineering The University of Aizu
OASIS NoC Architecture Design in Verilog HDL Technical Report: TR-062010-OASIS Written by Kenichi Mori ASL-Ben Abdallah Group Graduate School of Computer Science and Engineering The University of Aizu
Lect. 6: Directory Coherence Protocol
 Lect. 6: Directory Coherence Protocol Snooping coherence Global state of a memory line is the collection of its state in all caches, and there is no summary state anywhere All cache controllers monitor
Lect. 6: Directory Coherence Protocol Snooping coherence Global state of a memory line is the collection of its state in all caches, and there is no summary state anywhere All cache controllers monitor
Lecture 3: Snooping Protocols. Topics: snooping-based cache coherence implementations
 Lecture 3: Snooping Protocols Topics: snooping-based cache coherence implementations 1 Design Issues, Optimizations When does memory get updated? demotion from modified to shared? move from modified in
Lecture 3: Snooping Protocols Topics: snooping-based cache coherence implementations 1 Design Issues, Optimizations When does memory get updated? demotion from modified to shared? move from modified in
Brief Background in Fiber Optics
 The Future of Photonics in Upcoming Processors ECE 4750 Fall 08 Brief Background in Fiber Optics Light can travel down an optical fiber if it is completely confined Determined by Snells Law Various modes
The Future of Photonics in Upcoming Processors ECE 4750 Fall 08 Brief Background in Fiber Optics Light can travel down an optical fiber if it is completely confined Determined by Snells Law Various modes
FCUDA-NoC: A Scalable and Efficient Network-on-Chip Implementation for the CUDA-to-FPGA Flow
 FCUDA-NoC: A Scalable and Efficient Network-on-Chip Implementation for the CUDA-to-FPGA Flow Abstract: High-level synthesis (HLS) of data-parallel input languages, such as the Compute Unified Device Architecture
FCUDA-NoC: A Scalable and Efficient Network-on-Chip Implementation for the CUDA-to-FPGA Flow Abstract: High-level synthesis (HLS) of data-parallel input languages, such as the Compute Unified Device Architecture
Lecture 12: SMART NoC
 ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 12: SMART NoC Tushar Krishna Assistant Professor School of Electrical and Computer
ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 12: SMART NoC Tushar Krishna Assistant Professor School of Electrical and Computer
A Closer Look at the Epiphany IV 28nm 64 core Coprocessor. Andreas Olofsson PEGPUM 2013
 A Closer Look at the Epiphany IV 28nm 64 core Coprocessor Andreas Olofsson PEGPUM 2013 1 Adapteva Achieves 3 World Firsts 1. First processor company to reach 50 GFLOPS/W 3. First semiconductor company
A Closer Look at the Epiphany IV 28nm 64 core Coprocessor Andreas Olofsson PEGPUM 2013 1 Adapteva Achieves 3 World Firsts 1. First processor company to reach 50 GFLOPS/W 3. First semiconductor company
Lecture 11: Large Cache Design
 Lecture 11: Large Cache Design Topics: large cache basics and An Adaptive, Non-Uniform Cache Structure for Wire-Dominated On-Chip Caches, Kim et al., ASPLOS 02 Distance Associativity for High-Performance
Lecture 11: Large Cache Design Topics: large cache basics and An Adaptive, Non-Uniform Cache Structure for Wire-Dominated On-Chip Caches, Kim et al., ASPLOS 02 Distance Associativity for High-Performance
Thomas Moscibroda Microsoft Research. Onur Mutlu CMU
 Thomas Moscibroda Microsoft Research Onur Mutlu CMU CPU+L1 CPU+L1 CPU+L1 CPU+L1 Multi-core Chip Cache -Bank Cache -Bank Cache -Bank Cache -Bank CPU+L1 CPU+L1 CPU+L1 CPU+L1 Accelerator, etc Cache -Bank
Thomas Moscibroda Microsoft Research Onur Mutlu CMU CPU+L1 CPU+L1 CPU+L1 CPU+L1 Multi-core Chip Cache -Bank Cache -Bank Cache -Bank Cache -Bank CPU+L1 CPU+L1 CPU+L1 CPU+L1 Accelerator, etc Cache -Bank
ECE 571 Advanced Microprocessor-Based Design Lecture 10
 ECE 571 Advanced Microprocessor-Based Design Lecture 10 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 22 February 2018 Announcements HW#5 will be posted, caches Midterm: Thursday
ECE 571 Advanced Microprocessor-Based Design Lecture 10 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 22 February 2018 Announcements HW#5 will be posted, caches Midterm: Thursday
Lecture 13: Interconnection Networks. Topics: lots of background, recent innovations for power and performance
 Lecture 13: Interconnection Networks Topics: lots of background, recent innovations for power and performance 1 Interconnection Networks Recall: fully connected network, arrays/rings, meshes/tori, trees,
Lecture 13: Interconnection Networks Topics: lots of background, recent innovations for power and performance 1 Interconnection Networks Recall: fully connected network, arrays/rings, meshes/tori, trees,
Power and Performance Efficient Partial Circuits in Packet-Switched Networks-on-Chip
 2013 21st Euromicro International Conference on Parallel, Distributed, and Network-Based Processing Power and Performance Efficient Partial Circuits in Packet-Switched Networks-on-Chip Nasibeh Teimouri
2013 21st Euromicro International Conference on Parallel, Distributed, and Network-Based Processing Power and Performance Efficient Partial Circuits in Packet-Switched Networks-on-Chip Nasibeh Teimouri
SCORPIO: 36-Core Shared Memory Processor
 : 36- Shared Memory Processor Demonstrating Snoopy Coherence on a Mesh Interconnect Chia-Hsin Owen Chen Collaborators: Sunghyun Park, Suvinay Subramanian, Tushar Krishna, Bhavya Daya, Woo Cheol Kwon, Brett
: 36- Shared Memory Processor Demonstrating Snoopy Coherence on a Mesh Interconnect Chia-Hsin Owen Chen Collaborators: Sunghyun Park, Suvinay Subramanian, Tushar Krishna, Bhavya Daya, Woo Cheol Kwon, Brett
15-740/ Computer Architecture Lecture 19: Main Memory. Prof. Onur Mutlu Carnegie Mellon University
 15-740/18-740 Computer Architecture Lecture 19: Main Memory Prof. Onur Mutlu Carnegie Mellon University Last Time Multi-core issues in caching OS-based cache partitioning (using page coloring) Handling
15-740/18-740 Computer Architecture Lecture 19: Main Memory Prof. Onur Mutlu Carnegie Mellon University Last Time Multi-core issues in caching OS-based cache partitioning (using page coloring) Handling
On-chip Monitoring Infrastructures and Strategies for Many-core Systems
 On-chip Monitoring Infrastructures and Strategies for Many-core Systems ussell Tessier, Jia Zhao, Justin Lu, Sailaja Madduri, and Wayne Burleson esearch supported by the Semiconductor esearch Corporation
On-chip Monitoring Infrastructures and Strategies for Many-core Systems ussell Tessier, Jia Zhao, Justin Lu, Sailaja Madduri, and Wayne Burleson esearch supported by the Semiconductor esearch Corporation
Performance of coherence protocols
 Performance of coherence protocols Cache misses have traditionally been classified into four categories: Cold misses (or compulsory misses ) occur the first time that a block is referenced. Conflict misses
Performance of coherence protocols Cache misses have traditionally been classified into four categories: Cold misses (or compulsory misses ) occur the first time that a block is referenced. Conflict misses
ECE/CS 757: Advanced Computer Architecture II Interconnects
 ECE/CS 757: Advanced Computer Architecture II Interconnects Instructor:Mikko H Lipasti Spring 2017 University of Wisconsin-Madison Lecture notes created by Natalie Enright Jerger Lecture Outline Introduction
ECE/CS 757: Advanced Computer Architecture II Interconnects Instructor:Mikko H Lipasti Spring 2017 University of Wisconsin-Madison Lecture notes created by Natalie Enright Jerger Lecture Outline Introduction
Scalable Cache Coherence
 arallel Computing Scalable Cache Coherence Hwansoo Han Hierarchical Cache Coherence Hierarchies in cache organization Multiple levels of caches on a processor Large scale multiprocessors with hierarchy
arallel Computing Scalable Cache Coherence Hwansoo Han Hierarchical Cache Coherence Hierarchies in cache organization Multiple levels of caches on a processor Large scale multiprocessors with hierarchy
STLAC: A Spatial and Temporal Locality-Aware Cache and Networkon-Chip
 STLAC: A Spatial and Temporal Locality-Aware Cache and Networkon-Chip Codesign for Tiled Manycore Systems Mingyu Wang and Zhaolin Li Institute of Microelectronics, Tsinghua University, Beijing 100084,
STLAC: A Spatial and Temporal Locality-Aware Cache and Networkon-Chip Codesign for Tiled Manycore Systems Mingyu Wang and Zhaolin Li Institute of Microelectronics, Tsinghua University, Beijing 100084,
Lecture 25: Multiprocessors. Today s topics: Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization
 Lecture 25: Multiprocessors Today s topics: Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization 1 Snooping-Based Protocols Three states for a block: invalid,
Lecture 25: Multiprocessors Today s topics: Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization 1 Snooping-Based Protocols Three states for a block: invalid,
FUTURE high-performance computers (HPCs) and data. Runtime Management of Laser Power in Silicon-Photonic Multibus NoC Architecture
 and data. Runtime Management of Laser Power in Silicon-Photonic Multibus NoC Architecture") Runtime Management of Laser Power in Silicon-Photonic Multibus NoC Architecture Chao Chen, Student Member, IEEE, and Ajay Joshi, Member, IEEE (Invited Paper) Abstract Silicon-photonic links have been proposed
Runtime Management of Laser Power in Silicon-Photonic Multibus NoC Architecture Chao Chen, Student Member, IEEE, and Ajay Joshi, Member, IEEE (Invited Paper) Abstract Silicon-photonic links have been proposed
Module 17: "Interconnection Networks" Lecture 37: "Introduction to Routers" Interconnection Networks. Fundamentals. Latency and bandwidth
 Interconnection Networks Fundamentals Latency and bandwidth Router architecture Coherence protocol and routing [From Chapter 10 of Culler, Singh, Gupta] file:///e /parallel_com_arch/lecture37/37_1.htm[6/13/2012
Interconnection Networks Fundamentals Latency and bandwidth Router architecture Coherence protocol and routing [From Chapter 10 of Culler, Singh, Gupta] file:///e /parallel_com_arch/lecture37/37_1.htm[6/13/2012
Cache Coherence. CMU : Parallel Computer Architecture and Programming (Spring 2012)
") Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
SEMICON Solutions. Bus Structure. Created by: Duong Dang Date: 20 th Oct,2010
 SEMICON Solutions Bus Structure Created by: Duong Dang Date: 20 th Oct,2010 Introduction Buses are the simplest and most widely used interconnection networks A number of modules is connected via a single
SEMICON Solutions Bus Structure Created by: Duong Dang Date: 20 th Oct,2010 Introduction Buses are the simplest and most widely used interconnection networks A number of modules is connected via a single
A VERIOG-HDL IMPLEMENTATION OF VIRTUAL CHANNELS IN A NETWORK-ON-CHIP ROUTER. A Thesis SUNGHO PARK
 A VERIOG-HDL IMPLEMENTATION OF VIRTUAL CHANNELS IN A NETWORK-ON-CHIP ROUTER A Thesis by SUNGHO PARK Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements
A VERIOG-HDL IMPLEMENTATION OF VIRTUAL CHANNELS IN A NETWORK-ON-CHIP ROUTER A Thesis by SUNGHO PARK Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements
EE/CSCI 451: Parallel and Distributed Computation
 EE/CSCI 451: Parallel and Distributed Computation Lecture #8 2/7/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline From last class
EE/CSCI 451: Parallel and Distributed Computation Lecture #8 2/7/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline From last class
Efficient Throughput-Guarantees for Latency-Sensitive Networks-On-Chip
 ASP-DAC 2010 20 Jan 2010 Session 6C Efficient Throughput-Guarantees for Latency-Sensitive Networks-On-Chip Jonas Diemer, Rolf Ernst TU Braunschweig, Germany diemer@ida.ing.tu-bs.de Michael Kauschke Intel,
ASP-DAC 2010 20 Jan 2010 Session 6C Efficient Throughput-Guarantees for Latency-Sensitive Networks-On-Chip Jonas Diemer, Rolf Ernst TU Braunschweig, Germany diemer@ida.ing.tu-bs.de Michael Kauschke Intel,
International Journal of Research and Innovation in Applied Science (IJRIAS) Volume I, Issue IX, December 2016 ISSN
 Volume I, Issue IX, December 2016 ISSN") Comparative Analysis of Latency, Throughput and Network Power for West First, North Last and West First North Last Routing For 2D 4 X 4 Mesh Topology NoC Architecture Bhupendra Kumar Soni 1, Dr. Girish
Comparative Analysis of Latency, Throughput and Network Power for West First, North Last and West First North Last Routing For 2D 4 X 4 Mesh Topology NoC Architecture Bhupendra Kumar Soni 1, Dr. Girish
EE382 Processor Design. Illinois
 EE382 Processor Design Winter 1998 Chapter 8 Lectures Multiprocessors Part II EE 382 Processor Design Winter 98/99 Michael Flynn 1 Illinois EE 382 Processor Design Winter 98/99 Michael Flynn 2 1 Write-invalidate
EE382 Processor Design Winter 1998 Chapter 8 Lectures Multiprocessors Part II EE 382 Processor Design Winter 98/99 Michael Flynn 1 Illinois EE 382 Processor Design Winter 98/99 Michael Flynn 2 1 Write-invalidate
Lecture 22: Router Design
 Lecture 22: Router Design Papers: Power-Driven Design of Router Microarchitectures in On-Chip Networks, MICRO 03, Princeton A Gracefully Degrading and Energy-Efficient Modular Router Architecture for On-Chip
Lecture 22: Router Design Papers: Power-Driven Design of Router Microarchitectures in On-Chip Networks, MICRO 03, Princeton A Gracefully Degrading and Energy-Efficient Modular Router Architecture for On-Chip
High Performance and Low Power On-Die Interconnect Fabrics
 High Performance and Low Power On-Die Interconnect Fabrics by Sudhir Kumar Satpathy A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Electrical
High Performance and Low Power On-Die Interconnect Fabrics by Sudhir Kumar Satpathy A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Electrical
Buses. Maurizio Palesi. Maurizio Palesi 1
 Buses Maurizio Palesi Maurizio Palesi 1 Introduction Buses are the simplest and most widely used interconnection networks A number of modules is connected via a single shared channel Microcontroller Microcontroller
Buses Maurizio Palesi Maurizio Palesi 1 Introduction Buses are the simplest and most widely used interconnection networks A number of modules is connected via a single shared channel Microcontroller Microcontroller
EECS 570 Final Exam - SOLUTIONS Winter 2015
 EECS 570 Final Exam - SOLUTIONS Winter 2015 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points 1 / 21 2 / 32
EECS 570 Final Exam - SOLUTIONS Winter 2015 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points 1 / 21 2 / 32
ECE 669 Parallel Computer Architecture
 ECE 669 Parallel Computer Architecture Lecture 21 Routing Outline Routing Switch Design Flow Control Case Studies Routing Routing algorithm determines which of the possible paths are used as routes how
ECE 669 Parallel Computer Architecture Lecture 21 Routing Outline Routing Switch Design Flow Control Case Studies Routing Routing algorithm determines which of the possible paths are used as routes how
1. NoCs: What s the point?
 1. Nos: What s the point? What is the role of networks-on-chip in future many-core systems? What topologies are most promising for performance? What about for energy scaling? How heavily utilized are Nos
1. Nos: What s the point? What is the role of networks-on-chip in future many-core systems? What topologies are most promising for performance? What about for energy scaling? How heavily utilized are Nos
Packet Switch Architecture
 Packet Switch Architecture 3. Output Queueing Architectures 4. Input Queueing Architectures 5. Switching Fabrics 6. Flow and Congestion Control in Sw. Fabrics 7. Output Scheduling for QoS Guarantees 8.
Packet Switch Architecture 3. Output Queueing Architectures 4. Input Queueing Architectures 5. Switching Fabrics 6. Flow and Congestion Control in Sw. Fabrics 7. Output Scheduling for QoS Guarantees 8.
Packet Switch Architecture
 Packet Switch Architecture 3. Output Queueing Architectures 4. Input Queueing Architectures 5. Switching Fabrics 6. Flow and Congestion Control in Sw. Fabrics 7. Output Scheduling for QoS Guarantees 8.
Packet Switch Architecture 3. Output Queueing Architectures 4. Input Queueing Architectures 5. Switching Fabrics 6. Flow and Congestion Control in Sw. Fabrics 7. Output Scheduling for QoS Guarantees 8.
Network-on-Chip Architecture
 Multiple Processor Systems(CMPE-655) Network-on-Chip Architecture Performance aspect and Firefly network architecture By Siva Shankar Chandrasekaran and SreeGowri Shankar Agenda (Enhancing performance)
Multiple Processor Systems(CMPE-655) Network-on-Chip Architecture Performance aspect and Firefly network architecture By Siva Shankar Chandrasekaran and SreeGowri Shankar Agenda (Enhancing performance)
A More Sophisticated Snooping-Based Multi-Processor
 Lecture 16: A More Sophisticated Snooping-Based Multi-Processor Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2014 Tunes The Projects Handsome Boy Modeling School (So... How
Lecture 16: A More Sophisticated Snooping-Based Multi-Processor Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2014 Tunes The Projects Handsome Boy Modeling School (So... How
Implementing Flexible Interconnect Topologies for Machine Learning Acceleration
 Implementing Flexible Interconnect for Machine Learning Acceleration A R M T E C H S Y M P O S I A O C T 2 0 1 8 WILLIAM TSENG Mem Controller 20 mm Mem Controller Machine Learning / AI SoC New Challenges
Implementing Flexible Interconnect for Machine Learning Acceleration A R M T E C H S Y M P O S I A O C T 2 0 1 8 WILLIAM TSENG Mem Controller 20 mm Mem Controller Machine Learning / AI SoC New Challenges
Lecture 11: SMT and Caching Basics. Today: SMT, cache access basics (Sections 3.5, 5.1)
") Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
Lecture: Transactional Memory, Networks. Topics: TM implementations, on-chip networks
 Lecture: Transactional Memory, Networks Topics: TM implementations, on-chip networks 1 Summary of TM Benefits As easy to program as coarse-grain locks Performance similar to fine-grain locks Avoids deadlock
Lecture: Transactional Memory, Networks Topics: TM implementations, on-chip networks 1 Summary of TM Benefits As easy to program as coarse-grain locks Performance similar to fine-grain locks Avoids deadlock
Design of a high-throughput distributed shared-buffer NoC router
 Design of a high-throughput distributed shared-buffer NoC router The MIT Faculty has made this article openly available Please share how this access benefits you Your story matters Citation As Published
Design of a high-throughput distributed shared-buffer NoC router The MIT Faculty has made this article openly available Please share how this access benefits you Your story matters Citation As Published
CMPE 150/L : Introduction to Computer Networks. Chen Qian Computer Engineering UCSC Baskin Engineering Lecture 11
 CMPE 150/L : Introduction to Computer Networks Chen Qian Computer Engineering UCSC Baskin Engineering Lecture 11 1 Midterm exam Midterm this Thursday Close book but one-side 8.5"x11" note is allowed (must
CMPE 150/L : Introduction to Computer Networks Chen Qian Computer Engineering UCSC Baskin Engineering Lecture 11 1 Midterm exam Midterm this Thursday Close book but one-side 8.5"x11" note is allowed (must
Recall: The Routing problem: Local decisions. Recall: Multidimensional Meshes and Tori. Properties of Routing Algorithms
 CS252 Graduate Computer Architecture Lecture 16 Multiprocessor Networks (con t) March 14 th, 212 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~kubitron/cs252
CS252 Graduate Computer Architecture Lecture 16 Multiprocessor Networks (con t) March 14 th, 212 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~kubitron/cs252
Lecture 24: Interconnection Networks. Topics: topologies, routing, deadlocks, flow control
 Lecture 24: Interconnection Networks Topics: topologies, routing, deadlocks, flow control 1 Topology Examples Grid Torus Hypercube Criteria Bus Ring 2Dtorus 6-cube Fully connected Performance Bisection
Lecture 24: Interconnection Networks Topics: topologies, routing, deadlocks, flow control 1 Topology Examples Grid Torus Hypercube Criteria Bus Ring 2Dtorus 6-cube Fully connected Performance Bisection
Buses. Disks PCI RDRAM RDRAM LAN. Some slides adapted from lecture by David Culler. Pentium 4 Processor. Memory Controller Hub.
 es > 100 MB/sec Pentium 4 Processor L1 and L2 caches Some slides adapted from lecture by David Culler 3.2 GB/sec Display Memory Controller Hub RDRAM RDRAM Dual Ultra ATA/100 24 Mbit/sec Disks LAN I/O Controller
es > 100 MB/sec Pentium 4 Processor L1 and L2 caches Some slides adapted from lecture by David Culler 3.2 GB/sec Display Memory Controller Hub RDRAM RDRAM Dual Ultra ATA/100 24 Mbit/sec Disks LAN I/O Controller
EE108B Lecture 17 I/O Buses and Interfacing to CPU. Christos Kozyrakis Stanford University
 EE108B Lecture 17 I/O Buses and Interfacing to CPU Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee108b 1 Announcements Remaining deliverables PA2.2. today HW4 on 3/13 Lab4 on 3/19
EE108B Lecture 17 I/O Buses and Interfacing to CPU Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee108b 1 Announcements Remaining deliverables PA2.2. today HW4 on 3/13 Lab4 on 3/19
Lecture 15: NoC Innovations. Today: power and performance innovations for NoCs
 Lecture 15: NoC Innovations Today: power and performance innovations for NoCs 1 Network Power Power-Driven Design of Router Microarchitectures in On-Chip Networks, MICRO 03, Princeton Energy for a flit
Lecture 15: NoC Innovations Today: power and performance innovations for NoCs 1 Network Power Power-Driven Design of Router Microarchitectures in On-Chip Networks, MICRO 03, Princeton Energy for a flit
Hardware Design, Synthesis, and Verification of a Multicore Communications API
 Hardware Design, Synthesis, and Verification of a Multicore Communications API Benjamin Meakin Ganesh Gopalakrishnan University of Utah School of Computing {meakin, ganesh}@cs.utah.edu Abstract Modern
Hardware Design, Synthesis, and Verification of a Multicore Communications API Benjamin Meakin Ganesh Gopalakrishnan University of Utah School of Computing {meakin, ganesh}@cs.utah.edu Abstract Modern
IV. PACKET SWITCH ARCHITECTURES
 IV. PACKET SWITCH ARCHITECTURES (a) General Concept - as packet arrives at switch, destination (and possibly source) field in packet header is used as index into routing tables specifying next switch in
IV. PACKET SWITCH ARCHITECTURES (a) General Concept - as packet arrives at switch, destination (and possibly source) field in packet header is used as index into routing tables specifying next switch in