IN11E: Architecture and Integration Testbed for Earth/Space Science Cyberinfrastructures
|
|
|
- Randall Bradley
- 6 years ago
- Views:
Transcription
University of Maryland Baltimore County, Computer Science, Baltimore, MD, United")
1 IN11E: Architecture and Integration Testbed for Earth/Space Science Cyberinfrastructures A Future Accelerated Cognitive Distributed Hybrid Testbed for Big Data Science Analytics Milton Halem 1, John Edward Dorband 1, Navid Golpayegani 2, Smriti Prathapan 1, Yin Huang 1, Timothy Blattner 3 and Kaushik Velusamy 1 (1)University of Maryland Baltimore County, Computer Science, Baltimore, MD, United States, (2)NASA Goddard Space Flight Center, Greenbelt, MD, United States, (3)National Institute of Standards and Technology Gaithersburg, Gaithersburg, MD, United States
2 What is Cognitive computing? Cognition is the process of acquiring knowledge and understanding through thought, experience, observations and use of other senses; It encompasses integrating reasoning, memory, language and tools for attaining knowledge from information. Cognitive computing is the simulation of the human learning processes by employing accelerated computerized component architectures that mimic the human brain. The components address problems that are characterized by ambiguity and uncertainty. Cognitive systems integrate diverse sources of massive information using machine learning algorithms to find patterns and then apply those patterns to respond to the needs. Cognitive applications such as machine learning to regress flux measurements from long records or to integrate a variety of sensor data, reanalysis model output along with propositional based rules to infer trends, issue warnings or recommendations to decision makers.

3 Basic general purpose compute cluster
4 THE IBM IDATAPLEX CLUSTER: BLUEWAVE The Bluewave Cluster Originally known at NASA Center for Climate Simulation(NCCS) as Discover Series Scalable Unit 8, was competitively awarded by NASA under the Congressional Stevenson- Wyndler Surplus System Act and came to CHMPR at UMBC in late The acquired NCCS system consisted of 6 racks with 512 nodes, of which 4 racks are employed by UMBC/CHMPR. Now called Bluewave, the system currently consists of 336 nodes which includes management nodes, storage nodes, and SLURM client compute nodes. Most nodes are running a Linux image based CentOS 6.5 system. Each node has 2 quad core Intel Nehalem processors (Xeon X5560) and 24GB RAM and 250GB of local storage Bluewave includes a 32 node Hadoop cloud sub-cluster with each node containing 1TB of local disk storage. In addition, 4 nodes with 2 oct core Intel Sandy bridge and 4 Intel Many Integrated Core (Phi) co-processors are currently being integrated into the system. The cluster is used both for research by graduate students and faculty for integrating and testing high performance specialized prototyping computing components for Big Data Analytics.
 with 2 Nvidia's NVLinks from the power 8+ to each pair of GPUs have been integrated into Bluewave.")
5 A State-of-the-Art A elerated Cognitive Test ed ACT for CHMPR Big Data science Acquired prototype of the next gen IBM 250 Petaflops summit processor, two IBM Minsky nodes each with dual Power 8+ processors with 10 cores at 3.0 GHz with 1TB ram and four Nvidia Tesla P100 GPUs (3584 cores) with 2 Nvidia's NVLinks from the power 8+ to each pair of GPUs have been integrated into Bluewave. In addition, an IBM Flash system A 900 with 30TB of flashram expandable to 40 TB are connected to the Minsky nodes with a Coherent Accelerator Processor Interface (CAPI). The flashram A900 system supports both nodes and partitioning of flash ram is programmable An additional 8TB of SSD through an NVME card is available as local storage.

 20 TB")
6 Acquired Two IBM Minsky Nodes Each Node contains: 2 Upgraded Power 8 processors, 10 cores and 8 threads/core 4 Nvida P100 GPUs with 2 Nvidia Links 1TB of DRAM 3.2 GHz Non Volatile Mem card 4 SSDs with 4 TBs each Memory bandwidth 115 GB/s Infiniband In addition: CAPI (Coherent Acelerator Processor Interface FPGA) 20 TB Flash Memory
7 Nvidia s First GPU-to-GPU and GPU-to-CPU High-Speed Interconnect Accelerated computing with increasing numbers of highly dense GPU server nodes has become the de-facto standard for attaining HPC ratings. Interconnect bandwidth between GPUs is the most significant bottleneck to application performance. NVLink is the first high-speed interconnect for NVIDIA GPUs to solve the interconnect problem. Four NVLink connections per GPU can deliver a total 160 GB/s bidirectional bandwidth for the Tesla P100. This is over 5X the bandwidth of PCI Express Gen3.
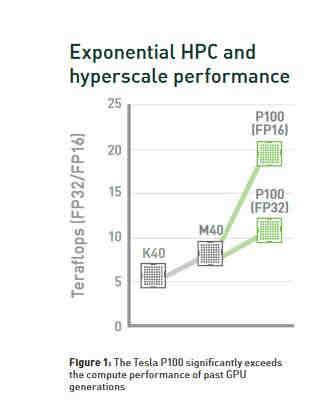
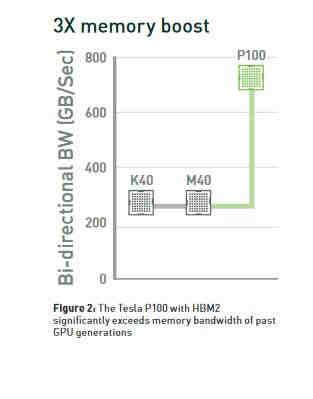
8 Nvidia

9 STANDARD DISK STORAGE TB The Network-Attached Storage (NAS) The NAS has 3 components. Store1 43 Terabytes Store2-21 Terabytes Store3-43 Terabytes Each node in the Bluewave can access the above 3 stores for external persistent storage The NAS component in the Blu

10 IBM Flashram Storage System 30TB
11 IBM Flashram as Cognitive Memory Did not use traditional SSDs off the shelf, but created their own flash modules. Flashram is 3x-4x faster than SSDs since it is directly tied to mother board similar to DRAM. Flash and SSDs are doing to hard drive arrays what hard drive arrays did to tape.
12 Flashram Storage as a Cognitive Memory IBM claims All-flash arrays are cognitive in design and operation, and include intelligent storage automation that enables data to move from flash to other storage media within an array. Moving data from tier-to-tier occurs by the storage management system which evaluates and learns data access usage patterns.

13 Seagate: Holy Grail of Active Storage Research Acquired object oriented key value Seagate kinetic disk system consisting of 2 chassis each with 12 disks. Each disk has 4TB and its own ethernet cable, IP address and local processor. Total storage 96TB. Harnessing processor to allow an object storage platform to delegate intelligent functionality to the drives. Could run their own virus scanning, content discovery, and compression functions. Developed Lightweight Virtual File System (LVFS) which separates data retrieval from metadata information Performed first ever satellite processing directly on Active Kinetic Disk using the MapReduce parallel programming model for gridding 2 years of global OCO-2 CO2 data. Interfacing active kinetic disks to IBM idataplex for Image Stitching, Deep belief Nets, Variable block size for out of core matrix multiplication.

14 REMOTE ACCESS TO THE D-WAVE 2X CHMPR has access to the D-Wave 2X at ARC at NASA. D-Wave 2X is the only commercially available quantum computer. We view the D-Wave not as a general purpose, but rather designed to be a hybrid quantum annealing coprocessor. D-Wave 2X consists of ~1152 qubits. 8 X 12 X 12 Qubit arrays and announced at SC16 the D-Wave 3X with ~ 2048 qubits to be delivered in 1 st quarter Plan to couple Bluewave to D-Wave 3X over Internet 2 as an accelerator for optimization.
15 PGI OpenACC and NIST HTGS S/W Installing Portland Group Inc (PGI) OpenACC software for implementing C, C++ and Fortran 90 onto GPUs. Implementing a Hybrid Task Graph Scheduler developed at NIST to improve programmer productivity by implementing and optimizing parallel algorithms to fully utilize the multicore CPUs and multiple GPUs, while managing dependencies, locality of data and overlapping data motion with computation.
16 Summary Presented an existing accelerated cognitive distributed hybrid testbed ready for Big Data Science Analytics. We wish to publicly acknowledge the following organizations for enabling the provisioning of this prototype cognitive architecture a UMBC for future Big Data Science: NASA/GSFC, IBM, Seagate, D-Wave, NASA/AIST, NSF/IUCRC.
17 Thank You 4/3/2017 Page 17 ICCE
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
IBM Power Advanced Compute (AC) AC922 Server
 AC922 Server") IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
IBM Power AC922 Server
 IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
LBRN - HPC systems : CCT, LSU
 LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Inspur AI Computing Platform
 Inspur Server Inspur AI Computing Platform 3 Server NF5280M4 (2CPU + 3 ) 4 Server NF5280M5 (2 CPU + 4 ) Node (2U 4 Only) 8 Server NF5288M5 (2 CPU + 8 ) 16 Server SR BOX (16 P40 Only) Server target market
Inspur Server Inspur AI Computing Platform 3 Server NF5280M4 (2CPU + 3 ) 4 Server NF5280M5 (2 CPU + 4 ) Node (2U 4 Only) 8 Server NF5288M5 (2 CPU + 8 ) 16 Server SR BOX (16 P40 Only) Server target market
Deep Learning mit PowerAI - Ein Überblick
 Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems
 S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems Khoa Huynh Senior Technical Staff Member (STSM), IBM Jonathan Samn Software Engineer, IBM Evolving from compute systems to
S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems Khoa Huynh Senior Technical Staff Member (STSM), IBM Jonathan Samn Software Engineer, IBM Evolving from compute systems to
Mapping MPI+X Applications to Multi-GPU Architectures
 Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Data Analytics and Storage System (DASS) Mixing POSIX and Hadoop Architectures. 13 November 2016
 Mixing POSIX and Hadoop Architectures. 13 November 2016") National Aeronautics and Space Administration Data Analytics and Storage System (DASS) Mixing POSIX and Hadoop Architectures 13 November 2016 Carrie Spear (carrie.e.spear@nasa.gov) HPC Architect/Contractor
National Aeronautics and Space Administration Data Analytics and Storage System (DASS) Mixing POSIX and Hadoop Architectures 13 November 2016 Carrie Spear (carrie.e.spear@nasa.gov) HPC Architect/Contractor
IBM Deep Learning Solutions
 IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
Infrastructure Matters: POWER8 vs. Xeon x86
 Advisory Infrastructure Matters: POWER8 vs. Xeon x86 Executive Summary This report compares IBM s new POWER8-based scale-out Power System to Intel E5 v2 x86- based scale-out systems. A follow-on report
Advisory Infrastructure Matters: POWER8 vs. Xeon x86 Executive Summary This report compares IBM s new POWER8-based scale-out Power System to Intel E5 v2 x86- based scale-out systems. A follow-on report
MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE
 MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE LEVERAGE OUR EXPERTISE sales@microway.com http://microway.com/tesla NUMBERSMASHER TESLA 4-GPU SERVER/WORKSTATION Flexible form factor 4 PCI-E GPUs + 3 additional
MICROWAY S NVIDIA TESLA V100 GPU SOLUTIONS GUIDE LEVERAGE OUR EXPERTISE sales@microway.com http://microway.com/tesla NUMBERSMASHER TESLA 4-GPU SERVER/WORKSTATION Flexible form factor 4 PCI-E GPUs + 3 additional
ADVANCED IN-MEMORY COMPUTING USING SUPERMICRO MEMX SOLUTION
 TABLE OF CONTENTS 2 WHAT IS IN-MEMORY COMPUTING (IMC) Benefits of IMC Concerns with In-Memory Processing Advanced In-Memory Computing using Supermicro MemX 1 3 MEMX ARCHITECTURE MemX Functionality and
TABLE OF CONTENTS 2 WHAT IS IN-MEMORY COMPUTING (IMC) Benefits of IMC Concerns with In-Memory Processing Advanced In-Memory Computing using Supermicro MemX 1 3 MEMX ARCHITECTURE MemX Functionality and
IBM Spectrum Scale IO performance
 IBM Spectrum Scale 5.0.0 IO performance Silverton Consulting, Inc. StorInt Briefing 2 Introduction High-performance computing (HPC) and scientific computing are in a constant state of transition. Artificial
IBM Spectrum Scale 5.0.0 IO performance Silverton Consulting, Inc. StorInt Briefing 2 Introduction High-performance computing (HPC) and scientific computing are in a constant state of transition. Artificial
University at Buffalo Center for Computational Research
 University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
Optimizing Out-of-Core Nearest Neighbor Problems on Multi-GPU Systems Using NVLink
 Optimizing Out-of-Core Nearest Neighbor Problems on Multi-GPU Systems Using NVLink Rajesh Bordawekar IBM T. J. Watson Research Center bordaw@us.ibm.com Pidad D Souza IBM Systems pidsouza@in.ibm.com 1 Outline
Optimizing Out-of-Core Nearest Neighbor Problems on Multi-GPU Systems Using NVLink Rajesh Bordawekar IBM T. J. Watson Research Center bordaw@us.ibm.com Pidad D Souza IBM Systems pidsouza@in.ibm.com 1 Outline
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Big Data Systems on Future Hardware. Bingsheng He NUS Computing
 Big Data Systems on Future Hardware Bingsheng He NUS Computing http://www.comp.nus.edu.sg/~hebs/ 1 Outline Challenges for Big Data Systems Why Hardware Matters? Open Challenges Summary 2 3 ANYs in Big
Big Data Systems on Future Hardware Bingsheng He NUS Computing http://www.comp.nus.edu.sg/~hebs/ 1 Outline Challenges for Big Data Systems Why Hardware Matters? Open Challenges Summary 2 3 ANYs in Big
Real Parallel Computers
 Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
How Might Recently Formed System Interconnect Consortia Affect PM? Doug Voigt, SNIA TC
 How Might Recently Formed System Interconnect Consortia Affect PM? Doug Voigt, SNIA TC Three Consortia Formed in Oct 2016 Gen-Z Open CAPI CCIX complex to rack scale memory fabric Cache coherent accelerator
How Might Recently Formed System Interconnect Consortia Affect PM? Doug Voigt, SNIA TC Three Consortia Formed in Oct 2016 Gen-Z Open CAPI CCIX complex to rack scale memory fabric Cache coherent accelerator
Tiny GPU Cluster for Big Spatial Data: A Preliminary Performance Evaluation
 Tiny GPU Cluster for Big Spatial Data: A Preliminary Performance Evaluation Jianting Zhang 1,2 Simin You 2, Le Gruenwald 3 1 Depart of Computer Science, CUNY City College (CCNY) 2 Department of Computer
Tiny GPU Cluster for Big Spatial Data: A Preliminary Performance Evaluation Jianting Zhang 1,2 Simin You 2, Le Gruenwald 3 1 Depart of Computer Science, CUNY City College (CCNY) 2 Department of Computer
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
BlueDBM: An Appliance for Big Data Analytics*
 BlueDBM: An Appliance for Big Data Analytics* Arvind *[ISCA, 2015] Sang-Woo Jun, Ming Liu, Sungjin Lee, Shuotao Xu, Arvind (MIT) and Jamey Hicks, John Ankcorn, Myron King(Quanta) BigData@CSAIL Annual Meeting
BlueDBM: An Appliance for Big Data Analytics* Arvind *[ISCA, 2015] Sang-Woo Jun, Ming Liu, Sungjin Lee, Shuotao Xu, Arvind (MIT) and Jamey Hicks, John Ankcorn, Myron King(Quanta) BigData@CSAIL Annual Meeting
Pedraforca: a First ARM + GPU Cluster for HPC
 www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
HPC Hardware Overview
 HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
Advanced Research Compu2ng Informa2on Technology Virginia Tech
 Advanced Research Compu2ng Informa2on Technology Virginia Tech www.arc.vt.edu Personnel Associate VP for Research Compu6ng: Terry Herdman (herd88@vt.edu) Director, HPC: Vijay Agarwala (vijaykag@vt.edu)
Advanced Research Compu2ng Informa2on Technology Virginia Tech www.arc.vt.edu Personnel Associate VP for Research Compu6ng: Terry Herdman (herd88@vt.edu) Director, HPC: Vijay Agarwala (vijaykag@vt.edu)
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010
 Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010 Windows HPC Server 2008 R2 Windows HPC Server 2008 R2 makes supercomputing
Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010 Windows HPC Server 2008 R2 Windows HPC Server 2008 R2 makes supercomputing
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
Interconnect Your Future Enabling the Best Datacenter Return on Investment. TOP500 Supercomputers, November 2017
 Interconnect Your Future Enabling the Best Datacenter Return on Investment TOP500 Supercomputers, November 2017 InfiniBand Accelerates Majority of New Systems on TOP500 InfiniBand connects 77% of new HPC
Interconnect Your Future Enabling the Best Datacenter Return on Investment TOP500 Supercomputers, November 2017 InfiniBand Accelerates Majority of New Systems on TOP500 InfiniBand connects 77% of new HPC
Fast Hardware For AI
 Fast Hardware For AI Karl Freund karl@moorinsightsstrategy.com Sr. Analyst, AI and HPC Moor Insights & Strategy Follow my blogs covering Machine Learning Hardware on Forbes: http://www.forbes.com/sites/moorinsights
Fast Hardware For AI Karl Freund karl@moorinsightsstrategy.com Sr. Analyst, AI and HPC Moor Insights & Strategy Follow my blogs covering Machine Learning Hardware on Forbes: http://www.forbes.com/sites/moorinsights
SUPERMICRO, VEXATA AND INTEL ENABLING NEW LEVELS PERFORMANCE AND EFFICIENCY FOR REAL-TIME DATA ANALYTICS FOR SQL DATA WAREHOUSE DEPLOYMENTS
 TABLE OF CONTENTS 2 THE AGE OF INFORMATION ACCELERATION Vexata Provides the Missing Piece in The Information Acceleration Puzzle The Vexata - Supermicro Partnership 4 CREATING ULTRA HIGH-PERFORMANCE DATA
TABLE OF CONTENTS 2 THE AGE OF INFORMATION ACCELERATION Vexata Provides the Missing Piece in The Information Acceleration Puzzle The Vexata - Supermicro Partnership 4 CREATING ULTRA HIGH-PERFORMANCE DATA
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Power Systems AC922 Overview. Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017
 Power Systems AC922 Overview Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017 IBM POWER HPC Platform Strategy High-performance computer and high-performance
Power Systems AC922 Overview Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017 IBM POWER HPC Platform Strategy High-performance computer and high-performance
Oracle Exadata X7. Uwe Kirchhoff Oracle ACS - Delivery Senior Principal Service Delivery Engineer
 Oracle Exadata X7 Uwe Kirchhoff Oracle ACS - Delivery Senior Principal Service Delivery Engineer 05.12.2017 Oracle Engineered Systems ZFS Backup Appliance Zero Data Loss Recovery Appliance Exadata Database
Oracle Exadata X7 Uwe Kirchhoff Oracle ACS - Delivery Senior Principal Service Delivery Engineer 05.12.2017 Oracle Engineered Systems ZFS Backup Appliance Zero Data Loss Recovery Appliance Exadata Database
Building an Exotic HPC Ecosystem at The University of Tulsa
 Building an Exotic HPC Ecosystem at The University of Tulsa John Hale Peter Hawrylak Andrew Kongs Changing Our CS Culture Platforms Desktop, workstations, mobile Programming Java, python Serial Changing
Building an Exotic HPC Ecosystem at The University of Tulsa John Hale Peter Hawrylak Andrew Kongs Changing Our CS Culture Platforms Desktop, workstations, mobile Programming Java, python Serial Changing
Distributed File Systems Part IV. Hierarchical Mass Storage Systems
 Distributed File Systems Part IV Daniel A. Menascé Hierarchical Mass Storage Systems On-line data requirements Mass Storage Systems Concepts Mass storage system architectures Example systems Performance
Distributed File Systems Part IV Daniel A. Menascé Hierarchical Mass Storage Systems On-line data requirements Mass Storage Systems Concepts Mass storage system architectures Example systems Performance
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System X idataplex CINECA, Italy The site selection
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System X idataplex CINECA, Italy The site selection
Gen-Z Memory-Driven Computing
 Gen-Z Memory-Driven Computing Our vision for the future of computing Patrick Demichel Distinguished Technologist Explosive growth of data More Data Need answers FAST! Value of Analyzed Data 2005 0.1ZB
Gen-Z Memory-Driven Computing Our vision for the future of computing Patrick Demichel Distinguished Technologist Explosive growth of data More Data Need answers FAST! Value of Analyzed Data 2005 0.1ZB
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
Storage for HPC, HPDA and Machine Learning (ML)
") for HPC, HPDA and Machine Learning (ML) Frank Kraemer, IBM Systems Architect mailto:kraemerf@de.ibm.com IBM Data Management for Autonomous Driving (AD) significantly increase development efficiency by
for HPC, HPDA and Machine Learning (ML) Frank Kraemer, IBM Systems Architect mailto:kraemerf@de.ibm.com IBM Data Management for Autonomous Driving (AD) significantly increase development efficiency by
Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive. Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center
 Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center 3/17/2015 2014 IBM Corporation Outline IBM OpenPower Platform Accelerating
Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center 3/17/2015 2014 IBM Corporation Outline IBM OpenPower Platform Accelerating
Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments
 Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments Torben Kling-Petersen, PhD Presenter s Name Principle Field Title andengineer Division HPC &Cloud LoB SunComputing Microsystems
Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments Torben Kling-Petersen, PhD Presenter s Name Principle Field Title andengineer Division HPC &Cloud LoB SunComputing Microsystems
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
High performance Computing and O&G Challenges
 High performance Computing and O&G Challenges 2 Seismic exploration challenges High Performance Computing and O&G challenges Worldwide Context Seismic,sub-surface imaging Computing Power needs Accelerating
High performance Computing and O&G Challenges 2 Seismic exploration challenges High Performance Computing and O&G challenges Worldwide Context Seismic,sub-surface imaging Computing Power needs Accelerating
IBM Power Systems HPC Cluster
 IBM Power Systems HPC Cluster Highlights Complete and fully Integrated HPC cluster for demanding workloads Modular and Extensible: match components & configurations to meet demands Integrated: racked &
IBM Power Systems HPC Cluster Highlights Complete and fully Integrated HPC cluster for demanding workloads Modular and Extensible: match components & configurations to meet demands Integrated: racked &
ACCELERATED COMPUTING: THE PATH FORWARD. Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015
 ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Xcellis Technical Overview: A deep dive into the latest hardware designed for StorNext 5
 TECHNOLOGY BRIEF Xcellis Technical Overview: A deep dive into the latest hardware designed for StorNext 5 ABSTRACT Xcellis represents the culmination of over 15 years of file system and data management
TECHNOLOGY BRIEF Xcellis Technical Overview: A deep dive into the latest hardware designed for StorNext 5 ABSTRACT Xcellis represents the culmination of over 15 years of file system and data management
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment. TOP500 Supercomputers, June 2014
 InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0)
") PRACE 16th Call Technical Guidelines for Applicants V1: published on 26/09/17 TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0) The contributing sites and the corresponding computer systems
PRACE 16th Call Technical Guidelines for Applicants V1: published on 26/09/17 TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0) The contributing sites and the corresponding computer systems
Diamond Networks/Computing. Nick Rees January 2011
 Diamond Networks/Computing Nick Rees January 2011 2008 computing requirements Diamond originally had no provision for central science computing. Started to develop in 2007-2008, with a major development
Diamond Networks/Computing Nick Rees January 2011 2008 computing requirements Diamond originally had no provision for central science computing. Started to develop in 2007-2008, with a major development
The Stampede is Coming Welcome to Stampede Introductory Training. Dan Stanzione Texas Advanced Computing Center
 The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
IBM s Data Warehouse Appliance Offerings
 IBM s Data Warehouse Appliance Offerings RChaitanya IBM India Software Labs Agenda 1 IBM Smart Analytics System (D5600) System Overview Technical Architecture Software / Hardware stack details 2 Netezza
IBM s Data Warehouse Appliance Offerings RChaitanya IBM India Software Labs Agenda 1 IBM Smart Analytics System (D5600) System Overview Technical Architecture Software / Hardware stack details 2 Netezza
HPC Saudi Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences. Presented to: March 14, 2017
 Creating an Exascale Ecosystem for Science Presented to: HPC Saudi 2017 Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences March 14, 2017 ORNL is managed by UT-Battelle
Creating an Exascale Ecosystem for Science Presented to: HPC Saudi 2017 Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences March 14, 2017 ORNL is managed by UT-Battelle
New HPE 3PAR StoreServ 8000 and series Optimized for Flash
 New HPE 3PAR StoreServ 8000 and 20000 series Optimized for Flash AGENDA HPE 3PAR StoreServ architecture fundamentals HPE 3PAR Flash optimizations HPE 3PAR portfolio overview HPE 3PAR Flash example from
New HPE 3PAR StoreServ 8000 and 20000 series Optimized for Flash AGENDA HPE 3PAR StoreServ architecture fundamentals HPE 3PAR Flash optimizations HPE 3PAR portfolio overview HPE 3PAR Flash example from
Organizational Update: December 2015
 Organizational Update: December 2015 David Hudak Doug Johnson Alan Chalker www.osc.edu Slide 1 OSC Organizational Update Leadership changes State of OSC Roadmap Web app demonstration (if time) Slide 2
Organizational Update: December 2015 David Hudak Doug Johnson Alan Chalker www.osc.edu Slide 1 OSC Organizational Update Leadership changes State of OSC Roadmap Web app demonstration (if time) Slide 2
HPC Storage Use Cases & Future Trends
 Oct, 2014 HPC Storage Use Cases & Future Trends Massively-Scalable Platforms and Solutions Engineered for the Big Data and Cloud Era Atul Vidwansa Email: atul@ DDN About Us DDN is a Leader in Massively
Oct, 2014 HPC Storage Use Cases & Future Trends Massively-Scalable Platforms and Solutions Engineered for the Big Data and Cloud Era Atul Vidwansa Email: atul@ DDN About Us DDN is a Leader in Massively
Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete
 Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete 1 DDN Who We Are 2 We Design, Deploy and Optimize Storage Systems Which Solve HPC, Big Data and Cloud Business
Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete 1 DDN Who We Are 2 We Design, Deploy and Optimize Storage Systems Which Solve HPC, Big Data and Cloud Business
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit
 Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
A U G U S T 8, S A N T A C L A R A, C A
 A U G U S T 8, 2 0 1 8 S A N T A C L A R A, C A Data-Centric Innovation Summit LISA SPELMAN VICE PRESIDENT & GENERAL MANAGER INTEL XEON PRODUCTS AND DATA CENTER MARKETING Increased integration and optimization
A U G U S T 8, 2 0 1 8 S A N T A C L A R A, C A Data-Centric Innovation Summit LISA SPELMAN VICE PRESIDENT & GENERAL MANAGER INTEL XEON PRODUCTS AND DATA CENTER MARKETING Increased integration and optimization
PracticeTorrent. Latest study torrent with verified answers will facilitate your actual test
 PracticeTorrent http://www.practicetorrent.com Latest study torrent with verified answers will facilitate your actual test Exam : C9020-668 Title : IBM Storage Technical V1 Vendor : IBM Version : DEMO
PracticeTorrent http://www.practicetorrent.com Latest study torrent with verified answers will facilitate your actual test Exam : C9020-668 Title : IBM Storage Technical V1 Vendor : IBM Version : DEMO
Interconnect Your Future
 Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Recent Innovations in Data Storage Technologies Dr Roger MacNicol Software Architect
 Recent Innovations in Data Storage Technologies Dr Roger MacNicol Software Architect Copyright 2017, Oracle and/or its affiliates. All rights reserved. Safe Harbor Statement The following is intended to
Recent Innovations in Data Storage Technologies Dr Roger MacNicol Software Architect Copyright 2017, Oracle and/or its affiliates. All rights reserved. Safe Harbor Statement The following is intended to
Dr. Jean-Laurent PHILIPPE, PhD EMEA HPC Technical Sales Specialist. With Dell Amsterdam, October 27, 2016
 Dr. Jean-Laurent PHILIPPE, PhD EMEA HPC Technical Sales Specialist With Dell Amsterdam, October 27, 2016 Legal Disclaimers Intel technologies features and benefits depend on system configuration and may
Dr. Jean-Laurent PHILIPPE, PhD EMEA HPC Technical Sales Specialist With Dell Amsterdam, October 27, 2016 Legal Disclaimers Intel technologies features and benefits depend on system configuration and may
Parallel Applications on Distributed Memory Systems. Le Yan HPC User LSU
 Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Our Workshop Environment
 Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Our Environment Today Your laptops or workstations: only used for portal access Bridges
Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Our Environment Today Your laptops or workstations: only used for portal access Bridges
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Broadberry. Artificial Intelligence Server for Fraud. Date: Q Application: Artificial Intelligence
 TM Artificial Intelligence Server for Fraud Date: Q2 2017 Application: Artificial Intelligence Tags: Artificial intelligence, GPU, GTX 1080 TI HM Revenue & Customs The UK s tax, payments and customs authority
TM Artificial Intelligence Server for Fraud Date: Q2 2017 Application: Artificial Intelligence Tags: Artificial intelligence, GPU, GTX 1080 TI HM Revenue & Customs The UK s tax, payments and customs authority
Storage Class Memory in Scalable Cognitive Systems
 Storage Class Memory in Scalable Cognitive Systems Balint Fleischer Chief Research Officer The impact of NVM on the Application/Data architecture Accelerated demanding applications OLTP, Big Data, Etc.
Storage Class Memory in Scalable Cognitive Systems Balint Fleischer Chief Research Officer The impact of NVM on the Application/Data architecture Accelerated demanding applications OLTP, Big Data, Etc.
Exascale: challenges and opportunities in a power constrained world
 Exascale: challenges and opportunities in a power constrained world Carlo Cavazzoni c.cavazzoni@cineca.it SuperComputing Applications and Innovation Department CINECA CINECA non profit Consortium, made
Exascale: challenges and opportunities in a power constrained world Carlo Cavazzoni c.cavazzoni@cineca.it SuperComputing Applications and Innovation Department CINECA CINECA non profit Consortium, made
OpenPOWER Performance
 OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
SGI Overview. HPC User Forum Dearborn, Michigan September 17 th, 2012
 SGI Overview HPC User Forum Dearborn, Michigan September 17 th, 2012 SGI Market Strategy HPC Commercial Scientific Modeling & Simulation Big Data Hadoop In-memory Analytics Archive Cloud Public Private
SGI Overview HPC User Forum Dearborn, Michigan September 17 th, 2012 SGI Market Strategy HPC Commercial Scientific Modeling & Simulation Big Data Hadoop In-memory Analytics Archive Cloud Public Private
19. prosince 2018 CIIRC Praha. Milan Král, IBM Radek Špimr
 19. prosince 2018 CIIRC Praha Milan Král, IBM Radek Špimr CORAL CORAL 2 CORAL Installation at ORNL CORAL Installation at LLNL Order of Magnitude Leap in Computational Power Real, Accelerated Science ACME
19. prosince 2018 CIIRC Praha Milan Král, IBM Radek Špimr CORAL CORAL 2 CORAL Installation at ORNL CORAL Installation at LLNL Order of Magnitude Leap in Computational Power Real, Accelerated Science ACME
OpenPOWER Innovations for HPC. IBM Research. IWOPH workshop, ISC, Germany June 21, Christoph Hagleitner,
 IWOPH workshop, ISC, Germany June 21, 2017 OpenPOWER Innovations for HPC IBM Research Christoph Hagleitner, hle@zurich.ibm.com IBM Research - Zurich Lab IBM Research - Zurich Established in 1956 45+ different
IWOPH workshop, ISC, Germany June 21, 2017 OpenPOWER Innovations for HPC IBM Research Christoph Hagleitner, hle@zurich.ibm.com IBM Research - Zurich Lab IBM Research - Zurich Established in 1956 45+ different
IBM Leading High Performance Computing and Deep Learning Technologies
 IBM Leading High Performance Computing and Deep Learning Technologies Yubo Li ( 李玉博 ) Chief Architect, on Cloud IBM Research -- China email: liyubobj@cn.ibm.com QQ: 395238640 GTC China 2016 Sept. 13, 2016
IBM Leading High Performance Computing and Deep Learning Technologies Yubo Li ( 李玉博 ) Chief Architect, on Cloud IBM Research -- China email: liyubobj@cn.ibm.com QQ: 395238640 GTC China 2016 Sept. 13, 2016
Cisco UCS M5 Blade and Rack Servers
 F Cisco UCS M5 Blade and Rack Servers General What is Cisco announcing? Cisco is announcing the Cisco Unified Computing System (Cisco UCS ) M5 blade and rack servers, our fifth generation of x86 servers
F Cisco UCS M5 Blade and Rack Servers General What is Cisco announcing? Cisco is announcing the Cisco Unified Computing System (Cisco UCS ) M5 blade and rack servers, our fifth generation of x86 servers
Machine Learning In A Snap. Thomas Parnell Research Staff Member IBM Research - Zurich
 Machine Learning In A Snap Thomas Parnell Research Staff Member IBM Research - Zurich What are GLMs? Ridge Regression Support Vector Machines Regression Generalized Linear Models Classification Lasso Regression
Machine Learning In A Snap Thomas Parnell Research Staff Member IBM Research - Zurich What are GLMs? Ridge Regression Support Vector Machines Regression Generalized Linear Models Classification Lasso Regression
Oak Ridge National Laboratory Computing and Computational Sciences
 Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
ACCELERATE YOUR ANALYTICS GAME WITH ORACLE SOLUTIONS ON PURE STORAGE
 ACCELERATE YOUR ANALYTICS GAME WITH ORACLE SOLUTIONS ON PURE STORAGE An innovative storage solution from Pure Storage can help you get the most business value from all of your data THE SINGLE MOST IMPORTANT
ACCELERATE YOUR ANALYTICS GAME WITH ORACLE SOLUTIONS ON PURE STORAGE An innovative storage solution from Pure Storage can help you get the most business value from all of your data THE SINGLE MOST IMPORTANT
WVU RESEARCH COMPUTING INTRODUCTION. Introduction to WVU s Research Computing Services
 WVU RESEARCH COMPUTING INTRODUCTION Introduction to WVU s Research Computing Services WHO ARE WE? Division of Information Technology Services Funded through WVU Research Corporation Provide centralized
WVU RESEARCH COMPUTING INTRODUCTION Introduction to WVU s Research Computing Services WHO ARE WE? Division of Information Technology Services Funded through WVU Research Corporation Provide centralized
Introduction to IBM System Storage SVC 2145-DH8 and IBM Storwize V7000 model 524
 Introduction to IBM System Storage SVC 2145-DH8 and IBM Storwize V7000 model 524 Guide v1.0 Bhushan Gavankar, Sarvesh S. Patel IBM Systems and Technology Group June 2014 Copyright IBM Corporation, 2014
Introduction to IBM System Storage SVC 2145-DH8 and IBM Storwize V7000 model 524 Guide v1.0 Bhushan Gavankar, Sarvesh S. Patel IBM Systems and Technology Group June 2014 Copyright IBM Corporation, 2014
Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE
 Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE Hitoshi Sato *1, Shuichi Ihara *2, Satoshi Matsuoka *1 *1 Tokyo Institute
Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE Hitoshi Sato *1, Shuichi Ihara *2, Satoshi Matsuoka *1 *1 Tokyo Institute
HPC Cloud at SURFsara
 HPC Cloud at SURFsara Offering cloud as a service SURF Research Boot Camp 21st April 2016 Ander Astudillo Markus van Dijk What is cloud computing?
HPC Cloud at SURFsara Offering cloud as a service SURF Research Boot Camp 21st April 2016 Ander Astudillo Markus van Dijk What is cloud computing?
A Comprehensive Study on the Performance of Implicit LS-DYNA
 12 th International LS-DYNA Users Conference Computing Technologies(4) A Comprehensive Study on the Performance of Implicit LS-DYNA Yih-Yih Lin Hewlett-Packard Company Abstract This work addresses four
12 th International LS-DYNA Users Conference Computing Technologies(4) A Comprehensive Study on the Performance of Implicit LS-DYNA Yih-Yih Lin Hewlett-Packard Company Abstract This work addresses four
DDN About Us Solving Large Enterprise and Web Scale Challenges
 1 DDN About Us Solving Large Enterprise and Web Scale Challenges History Founded in 98 World s Largest Private Storage Company Growing, Profitable, Self Funded Headquarters: Santa Clara and Chatsworth,
1 DDN About Us Solving Large Enterprise and Web Scale Challenges History Founded in 98 World s Largest Private Storage Company Growing, Profitable, Self Funded Headquarters: Santa Clara and Chatsworth,
Looking ahead with IBM i. 10+ year roadmap
 Looking ahead with IBM i 10+ year roadmap 1 Enterprises Trust IBM Power 80 of Fortune 100 have IBM Power Systems The top 10 banking firms have IBM Power Systems 9 of top 10 insurance companies have IBM
Looking ahead with IBM i 10+ year roadmap 1 Enterprises Trust IBM Power 80 of Fortune 100 have IBM Power Systems The top 10 banking firms have IBM Power Systems 9 of top 10 insurance companies have IBM
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing
 TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
Description of Power8 Nodes Available on Mio (ppc[ ])
![Description of Power8 Nodes Available on Mio (ppc[ ])](/thumbs/93/112992376.jpg "Description of Power8 Nodes Available on Mio (ppc[ ])") Description of Power8 Nodes Available on Mio (ppc[001-002]) Introduction: HPC@Mines has released two brand-new IBM Power8 nodes (identified as ppc001 and ppc002) to production, as part of our Mio cluster.
Description of Power8 Nodes Available on Mio (ppc[001-002]) Introduction: HPC@Mines has released two brand-new IBM Power8 nodes (identified as ppc001 and ppc002) to production, as part of our Mio cluster.
Realizing the Next Generation of Exabyte-scale Persistent Memory-Centric Architectures and Memory Fabrics
 Realizing the Next Generation of Exabyte-scale Persistent Memory-Centric Architectures and Memory Fabrics Zvonimir Z. Bandic, Sr. Director, Next Generation Platform Technologies Western Digital Corporation
Realizing the Next Generation of Exabyte-scale Persistent Memory-Centric Architectures and Memory Fabrics Zvonimir Z. Bandic, Sr. Director, Next Generation Platform Technologies Western Digital Corporation
Mellanox InfiniBand Solutions Accelerate Oracle s Data Center and Cloud Solutions
 Mellanox InfiniBand Solutions Accelerate Oracle s Data Center and Cloud Solutions Providing Superior Server and Storage Performance, Efficiency and Return on Investment As Announced and Demonstrated at
Mellanox InfiniBand Solutions Accelerate Oracle s Data Center and Cloud Solutions Providing Superior Server and Storage Performance, Efficiency and Return on Investment As Announced and Demonstrated at
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
Lessons from Post-processing Climate Data on Modern Flash-based HPC Systems
 Lessons from Post-processing Climate Data on Modern Flash-based HPC Systems Adnan Haider 1, Sheri Mickelson 2, John Dennis 2 1 Illinois Institute of Technology, USA; 2 National Center of Atmospheric Research,
Lessons from Post-processing Climate Data on Modern Flash-based HPC Systems Adnan Haider 1, Sheri Mickelson 2, John Dennis 2 1 Illinois Institute of Technology, USA; 2 National Center of Atmospheric Research,
Accelerating Enterprise Search with Fusion iomemory PCIe Application Accelerators
 WHITE PAPER Accelerating Enterprise Search with Fusion iomemory PCIe Application Accelerators Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents
WHITE PAPER Accelerating Enterprise Search with Fusion iomemory PCIe Application Accelerators Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents