High performance Computing and O&G Challenges
|
|
|
- Nickolas Powell
- 5 years ago
- Views:
Transcription

1 High performance Computing and O&G Challenges

2 2 Seismic exploration challenges
3 High Performance Computing and O&G challenges Worldwide Context Seismic,sub-surface imaging Computing Power needs Accelerating technology status and perspectives in TOTAL
 200 Production discoveries 150 100 50 50 0 0 1920 1930 1940 1950 1960 1970 1980 1990 2000 Gboe 60 50 Industrie : Réserves des nouvelles")
4 Worldwide context Worldwide O&G consumption/year approx. 50 Gboe Average size of new Oil field discovery ~ 50 Mboe since the last 25 years Oil Discoveries vs. Oil Production Gboe Hydrocarbons (Liquids & Gas) 200 Production discoveries Gboe Industrie : Réserves des nouvelles découvertes Source: IHS-Edin (avril 2008) RR_Gas (Gboe) 52.9 Gaz (Liquids & Gas) RR_Liquids Liquides (Gb)
 Image resolution: few mm.")
5 Principle: Ultrasound Seismic imaging Medical imaging 7000km² 10 KM Signal frequency: between 6 and 90 Hz Image resolution: some tens of m. Heterogeneous media (spatial Signal frequency: 1 MHz variability of density and signal velocity) Image resolution: few mm. Approximately homogeneous media. 5


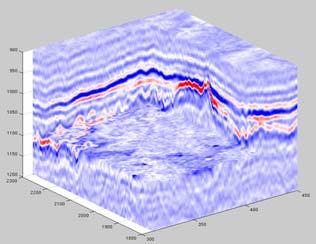

6 Seismic imaging in a nutshell Data acquisition? Interprétation Depth imaging loop 6






=")




7 Wave Equation the basic tool Seismic modeling Velocity model update 1 2 c 2 t 2 2 x y z 2 P ( x, y, z, t)= 0. Depth Imaging asymptotic approximation Depth Imaging Paraxial/full approximation



8 Seismic acquisition breakthrough and modeling $/km² 70x100 m Acquisition modeling is routinely applied to optimize survey acquisition design and reduce overall cost. 10,000 modeled shots - 4 weeks - 100TF $/km² 7000 m 10x100 m m $/km² 7000 m Source 7000 m 4x100 m 400 m 5000 m 100 s GB disk storage 10 s TB Migration section and illumination maps computed from modeled seismic acquistion provide useful information to geophysicist 8 Progress in acquisition seismic gives access to high seismic data quality but increase dramatically the size of storage and overall cost



9 Codes and computing effort some figures 3-55 Hz flops Algorithm complexity 9.5 PF Visco elastic FWI petro-elastic inversion 3-35 Hz 900 TF 10 elastic FWI visco elastic modeling 1 isotropic/anisotropic FWI elastic modeling/rtm 3-18 Hz 56 TF 0,5 isotropic/anisotropic RTM isotropic/anisotropic modeling RTM 0,1 Paraxial isotropic/anisotropic imaging Asymptotic approximation imaging Computing ressource evolution when only one parameter is changed while using the same algorithm: In this case we request the processing to be performed in 8 days 9 Algorithmic complexity and corresponding computing power
10 HPC: the necessary link 2 «Improved» Seismic data Off shore On shore HPC (Petaflops) 3 More realistic Modeling / Simulations 1 More efficient Imaging algorithm 10





11 450 HPC Evolution in TOTAL TeraFlops From SMP cluster to MPP and Hybrid computing SGI ICE+ MPP (16384 Intel X GPUS ) SGI ICE+ MPP (10240 Intel X86-64 ) IBM SMP cluster ( 2048 P5) 11 SGI Altix SMP cluster ( 1024 intel ia64)

12 Why MPP? Seismic depth is massively Parallel: Embarrassingly over the shots: ex shots can be solved in one iteration on a cpus machine Explicit data distribution and data parallel model programming when processing one shot Reliability and performances on very large configurations Impact on footprint and power dissipation SGI ICE+ Hypercube topology interconnect: Scalable single system Easy to manage Taking advantage of Scalable interconnect Leads to very efficient algorithm implementation (3D Wave Equation Finite difference solver)



13 Trends: multiply the number of cores Why hybrid Computing? Our codes can take advantage of many core technology GPUs can be seen as large multicore processors and can offer tremendous speed up. GPUS first step to the massive multicore technology? 4 cores Intel processor 80 cores Intel processor (prototype) Nvidia GPU 240 cores ~ 1TF single precision core 4 cores 8 cores 1 GPU (speed up) 3D Wave Equation solver speed up comparison Having access to different technologies through the same interconnect can offer new perspectives in terms of model programming and application development To reach the performances needed for solving our problems, we have no choice but combining high scalable interconnect an massive multicore technology.
14 Accelerating technology actual status and perspectives in TOTAL Starting in 2007 with the following questions 1. Is it possible to take advantage of GPU for seismic depth imaging 2. What programming model and what programming language? 3. What about communication between host and GPU, best configuration? 4. Can we extrapolate the performances obtained on a single GPU to a full system: Cluster? 5. What about building industrial applications ( Modeling, RTM ) on a GPU cluster based system? 14



15 1. Is it possible to take advantage of GPU? 15 - Références, date, lieu
16 Taking advantage of GPUS: actual status 2 main applications implemented on GPU cluster: Seismic modeling Reverse time Migration Seismic modeling motivation: accelerate survey acquisition modeling Wave Equation solver is the basic kernel for seismic depth imaging algorithm Explore different implementations on GPUS: (single GPU, multi GPUs) Explore model programming and programming language RTM Motivation Most accurate depth imaging method: the most expensive Take advantage of progress made on Seismic modeling ( same kernel) Explore communication load balancing between host and device
17 Seismic modeling Based on the solution of the Wave Equation Explicit Time-space finite difference

 8 cores (8 MPI) 16 cores (16 MPI) 32 cores")
18 Implementation 2 passes: Seismic modeling 1. compute partial derivative along z axis 2. 2D tile sliding window Padding to ensure global memory coalescing Partial transfer and page locked host memory Example Model size 512x512x time step SGI ICE+, Harpertown 3GHZ Test : 1 GPU 4 cores (4 MPI) 8 cores (8 MPI) 16 cores (16 MPI) 32 cores (32 MPI):

 200 150 100 50 54 number of shots computed in 24H 0 Rack CPU")
19 Seismic modeling Example Model size 560x557x905, time steps SGI ICE+, 512 harpertown 3GHZ SGI ICE+, 16 blades harpertown 3 GHZ, 8 Teslas 8 cores per shot (64 shots in parallel) 2 GPUs per shot ( 16 shots in parallel) number of shots computed in 24H 0 Rack CPU Rack GPU
20 Reverse Time Migration Based on the solution of similar kernel used for seismic modeling RTM is solved in 2 Steps involving: 1. Seismic modeling and wavefield storage 2. Seismic modeling, wavefield reload and imaging condition For efficiency reasons Seismic modeling must recover wavefield store/load

21 CPU-GPU Data transfer optimization Take advantage of asynchronous communications to overlap data transfer First implementation: 75% of elapsed time spent on PCIe communications Take advantage of : PCIe Gen2 bandwidth DMA accessible pinned memory Asynchronous communications FWD BWD % synch asynch Execution 25 Data transfers Execution time
22 2/ Programming model and programming language Model programming: Take advantage of data parallelism Mainly based on efficiently using memory hierarchy, with different approaches: Increase the data locality and re-use Use simple 3D cache blocking, Replace by a 2D cache, sliding on the 3 rd dimension Number of read accesses per data point RTM 2D 4,25 RTM 3D with texture 29 RTM 3D with 3D shared memory accesses 7,5 RTM 3D with sliding 2D shared memory 4
23 2/ Programming model and programming language Programming language: CUDA: progess rapidely, new features such as partial copy, asynchronous communications, pined memory data access HMPP: Express parallelism and communications in C, Fortran source code: Direct integration into Fortran Code through the use of directives à la OpenMP HMPP handles CPU-GPU communications and kernel launch. HMPP manage automatically HW device. Systematically used in TOTAL for developing accelerated kernel. Work in close relation with CAPS on the automatic code generation. Some delays between new features in CUDA and HMPP support should be anticipated: CUDA pre-released to CAPS? OpenCL: Standard (wait and see), will be addressed through HMPP
24 3/ Host Device configuration
25 4/ Single GPU to multi GPU : Cluster
26 Computation needs for seismic processing is nearly not bounded! Algorithm improvement taking advantage Of high frequency seismic ( impact the size of computational grid) Seismic acquisition parameters (Azimuth width, distance between receivers, ) Implement more complete solution of the imaging solver to solve new challenges: foothills, Heavy Oil. Need a pro-active R&D strategy Algorithms (Full Waveform Inversion, new Solvers, reservoir simulation, EM ) New Hardware architectures and programming models Impact of new technology on processing: Several Teraflops in a WorkStation? Conclusion HPC containers: On site processing, embedded processing 26 Accelerating solution: good progress in understanding the use of GPUs we have a clear strategy : model programming and application development GPUs: first step before many core technology? We do not exclude hybrid technology: (many core + GPUS ) Still need to work in close relation with industrial partners to improve Hardware and tools.
Addressing Heterogeneity in Manycore Applications
 Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS
 ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit
 Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
The determination of the correct
 SPECIAL High-performance SECTION: H i gh-performance computing computing MARK NOBLE, Mines ParisTech PHILIPPE THIERRY, Intel CEDRIC TAILLANDIER, CGGVeritas (formerly Mines ParisTech) HENRI CALANDRA, Total
SPECIAL High-performance SECTION: H i gh-performance computing computing MARK NOBLE, Mines ParisTech PHILIPPE THIERRY, Intel CEDRIC TAILLANDIER, CGGVeritas (formerly Mines ParisTech) HENRI CALANDRA, Total
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Speedup Altair RADIOSS Solvers Using NVIDIA GPU
 Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
HPC and IT Issues Session Agenda. Deployment of Simulation (Trends and Issues Impacting IT) Mapping HPC to Performance (Scaling, Technology Advances)
 Mapping HPC to Performance (Scaling, Technology Advances)") HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
designing a GPU Computing Solution
 designing a GPU Computing Solution Patrick Van Reeth EMEA HPC Competency Center - GPU Computing Solutions Saturday, May the 29th, 2010 1 2010 Hewlett-Packard Development Company, L.P. The information contained
designing a GPU Computing Solution Patrick Van Reeth EMEA HPC Competency Center - GPU Computing Solutions Saturday, May the 29th, 2010 1 2010 Hewlett-Packard Development Company, L.P. The information contained
ANSYS HPC. Technology Leadership. Barbara Hutchings ANSYS, Inc. September 20, 2011
 ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
Exploration seismology and the return of the supercomputer
 Exploration seismology and the return of the supercomputer Exploring scalability for speed in development and delivery Sverre Brandsberg-Dahl Chief Geophysicist, Imaging and Engineering Marine seismic
Exploration seismology and the return of the supercomputer Exploring scalability for speed in development and delivery Sverre Brandsberg-Dahl Chief Geophysicist, Imaging and Engineering Marine seismic
GPU implementation of minimal dispersion recursive operators for reverse time migration
 GPU implementation of minimal dispersion recursive operators for reverse time migration Allon Bartana*, Dan Kosloff, Brandon Warnell, Chris Connor, Jeff Codd and David Kessler, SeismicCity Inc. Paulius
GPU implementation of minimal dispersion recursive operators for reverse time migration Allon Bartana*, Dan Kosloff, Brandon Warnell, Chris Connor, Jeff Codd and David Kessler, SeismicCity Inc. Paulius
ANSYS HPC Technology Leadership
 ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation
 Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
IBM Power AC922 Server
 IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
Real Parallel Computers
 Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Current Trends in Computer Graphics Hardware
 Current Trends in Computer Graphics Hardware Dirk Reiners University of Louisiana Lafayette, LA Quick Introduction Assistant Professor in Computer Science at University of Louisiana, Lafayette (since 2006)
Current Trends in Computer Graphics Hardware Dirk Reiners University of Louisiana Lafayette, LA Quick Introduction Assistant Professor in Computer Science at University of Louisiana, Lafayette (since 2006)
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
Software and Performance Engineering for numerical codes on GPU clusters
 Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Large scale Imaging on Current Many- Core Platforms
 Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
Hybrid programming with MPI and OpenMP On the way to exascale
 Institut du Développement et des Ressources en Informatique Scientifique www.idris.fr Hybrid programming with MPI and OpenMP On the way to exascale 1 Trends of hardware evolution Main problematic : how
Institut du Développement et des Ressources en Informatique Scientifique www.idris.fr Hybrid programming with MPI and OpenMP On the way to exascale 1 Trends of hardware evolution Main problematic : how
High Performance Ocean Modeling using CUDA
 using CUDA Chris Lupo Computer Science Cal Poly Slide 1 Acknowledgements Dr. Paul Choboter Jason Mak Ian Panzer Spencer Lines Sagiv Sheelo Jake Gardner Slide 2 Background Joint research with Dr. Paul Choboter
using CUDA Chris Lupo Computer Science Cal Poly Slide 1 Acknowledgements Dr. Paul Choboter Jason Mak Ian Panzer Spencer Lines Sagiv Sheelo Jake Gardner Slide 2 Background Joint research with Dr. Paul Choboter
Optimization of finite-difference kernels on multi-core architectures for seismic applications
 Optimization of finite-difference kernels on multi-core architectures for seismic applications V. Etienne 1, T. Tonellot 1, K. Akbudak 2, H. Ltaief 2, S. Kortas 3, T. Malas 4, P. Thierry 4, D. Keyes 2
Optimization of finite-difference kernels on multi-core architectures for seismic applications V. Etienne 1, T. Tonellot 1, K. Akbudak 2, H. Ltaief 2, S. Kortas 3, T. Malas 4, P. Thierry 4, D. Keyes 2
Optimizing Out-of-Core Nearest Neighbor Problems on Multi-GPU Systems Using NVLink
 Optimizing Out-of-Core Nearest Neighbor Problems on Multi-GPU Systems Using NVLink Rajesh Bordawekar IBM T. J. Watson Research Center bordaw@us.ibm.com Pidad D Souza IBM Systems pidsouza@in.ibm.com 1 Outline
Optimizing Out-of-Core Nearest Neighbor Problems on Multi-GPU Systems Using NVLink Rajesh Bordawekar IBM T. J. Watson Research Center bordaw@us.ibm.com Pidad D Souza IBM Systems pidsouza@in.ibm.com 1 Outline
Accelerating Implicit LS-DYNA with GPU
 Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Pedraforca: a First ARM + GPU Cluster for HPC
 www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Real Parallel Computers
 Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions
 Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions Ziming Zhong Vladimir Rychkov Alexey Lastovetsky Heterogeneous Computing
Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions Ziming Zhong Vladimir Rychkov Alexey Lastovetsky Heterogeneous Computing
Two-Phase flows on massively parallel multi-gpu clusters
 Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Solving Large Complex Problems. Efficient and Smart Solutions for Large Models
 Solving Large Complex Problems Efficient and Smart Solutions for Large Models 1 ANSYS Structural Mechanics Solutions offers several techniques 2 Current trends in simulation show an increased need for
Solving Large Complex Problems Efficient and Smart Solutions for Large Models 1 ANSYS Structural Mechanics Solutions offers several techniques 2 Current trends in simulation show an increased need for
Parallel Applications on Distributed Memory Systems. Le Yan HPC User LSU
 Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
What does Heterogeneity bring?
 What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
Adapting Numerical Weather Prediction codes to heterogeneous architectures: porting the COSMO model to GPUs
 Adapting Numerical Weather Prediction codes to heterogeneous architectures: porting the COSMO model to GPUs O. Fuhrer, T. Gysi, X. Lapillonne, C. Osuna, T. Dimanti, T. Schultess and the HP2C team Eidgenössisches
Adapting Numerical Weather Prediction codes to heterogeneous architectures: porting the COSMO model to GPUs O. Fuhrer, T. Gysi, X. Lapillonne, C. Osuna, T. Dimanti, T. Schultess and the HP2C team Eidgenössisches
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
High Performance Compute Platform Based on multi-core DSP for Seismic Modeling and Imaging
 High Performance Compute Platform Based on multi-core DSP for Seismic Modeling and Imaging Presenter: Murtaza Ali, Texas Instruments Contributors: Murtaza Ali, Eric Stotzer, Xiaohui Li, Texas Instruments
High Performance Compute Platform Based on multi-core DSP for Seismic Modeling and Imaging Presenter: Murtaza Ali, Texas Instruments Contributors: Murtaza Ali, Eric Stotzer, Xiaohui Li, Texas Instruments
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs
 High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
Numerical Algorithms on Multi-GPU Architectures
 Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Intel Xeon Processor E7 v2 Family-Based Platforms
 Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
Designed for Maximum Accelerator Performance
 Designed for Maximum Accelerator Performance A dense, GPU-accelerated cluster supercomputer that delivers up to 329 double-precision GPU teraflops in one rack. This power- and spaceefficient system can
Designed for Maximum Accelerator Performance A dense, GPU-accelerated cluster supercomputer that delivers up to 329 double-precision GPU teraflops in one rack. This power- and spaceefficient system can
HPC with GPU and its applications from Inspur. Haibo Xie, Ph.D
 HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
Creating High Performance Clusters for Embedded Use
 Creating High Performance Clusters for Embedded Use 1 The Hype.. The Internet of Things has the capacity to create huge amounts of data Gartner forecasts 35ZB of data from things by 2020 etc Intel Putting
Creating High Performance Clusters for Embedded Use 1 The Hype.. The Internet of Things has the capacity to create huge amounts of data Gartner forecasts 35ZB of data from things by 2020 etc Intel Putting
Hybrid Implementation of 3D Kirchhoff Migration
 Hybrid Implementation of 3D Kirchhoff Migration Max Grossman, Mauricio Araya-Polo, Gladys Gonzalez GTC, San Jose March 19, 2013 Agenda 1. Motivation 2. The Problem at Hand 3. Solution Strategy 4. GPU Implementation
Hybrid Implementation of 3D Kirchhoff Migration Max Grossman, Mauricio Araya-Polo, Gladys Gonzalez GTC, San Jose March 19, 2013 Agenda 1. Motivation 2. The Problem at Hand 3. Solution Strategy 4. GPU Implementation
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
14MMFD-34 Parallel Efficiency and Algorithmic Optimality in Reservoir Simulation on GPUs
 14MMFD-34 Parallel Efficiency and Algorithmic Optimality in Reservoir Simulation on GPUs K. Esler, D. Dembeck, K. Mukundakrishnan, V. Natoli, J. Shumway and Y. Zhang Stone Ridge Technology, Bel Air, MD
14MMFD-34 Parallel Efficiency and Algorithmic Optimality in Reservoir Simulation on GPUs K. Esler, D. Dembeck, K. Mukundakrishnan, V. Natoli, J. Shumway and Y. Zhang Stone Ridge Technology, Bel Air, MD
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Outline. Distributed Shared Memory. Shared Memory. ECE574 Cluster Computing. Dichotomy of Parallel Computing Platforms (Continued)
") Cluster Computing Dichotomy of Parallel Computing Platforms (Continued) Lecturer: Dr Yifeng Zhu Class Review Interconnections Crossbar» Example: myrinet Multistage» Example: Omega network Outline Flynn
Cluster Computing Dichotomy of Parallel Computing Platforms (Continued) Lecturer: Dr Yifeng Zhu Class Review Interconnections Crossbar» Example: myrinet Multistage» Example: Omega network Outline Flynn
Accelerating computation with FPGAs
 Accelerating computation with FPGAs Michael J. Flynn Maxeler Technologies and Stanford University M. J. Flynn Maxeler Technologies 1 Based on work done by my colleagues at Maxeler, especially Oskar Mencer,
Accelerating computation with FPGAs Michael J. Flynn Maxeler Technologies and Stanford University M. J. Flynn Maxeler Technologies 1 Based on work done by my colleagues at Maxeler, especially Oskar Mencer,
Modelling Multi-GPU Systems 1
 Modelling Multi-GPU Systems 1 Daniele G. SPAMPINATO a, Anne C. ELSTER a and Thorvald NATVIG a a Norwegian University of Science and Technology (NTNU), Trondheim, Norway Abstract. Due to the power and frequency
Modelling Multi-GPU Systems 1 Daniele G. SPAMPINATO a, Anne C. ELSTER a and Thorvald NATVIG a a Norwegian University of Science and Technology (NTNU), Trondheim, Norway Abstract. Due to the power and frequency
BlueGene/L. Computer Science, University of Warwick. Source: IBM
 BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
Carlo Cavazzoni, HPC department, CINECA
 Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
An Innovative Massively Parallelized Molecular Dynamic Software
 Renewable energies Eco-friendly production Innovative transport Eco-efficient processes Sustainable resources An Innovative Massively Parallelized Molecular Dynamic Software Mohamed Hacene, Ani Anciaux,
Renewable energies Eco-friendly production Innovative transport Eco-efficient processes Sustainable resources An Innovative Massively Parallelized Molecular Dynamic Software Mohamed Hacene, Ani Anciaux,
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
The Stampede is Coming Welcome to Stampede Introductory Training. Dan Stanzione Texas Advanced Computing Center
 The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
Progress on GPU Parallelization of the NIM Prototype Numerical Weather Prediction Dynamical Core
 Progress on GPU Parallelization of the NIM Prototype Numerical Weather Prediction Dynamical Core Tom Henderson NOAA/OAR/ESRL/GSD/ACE Thomas.B.Henderson@noaa.gov Mark Govett, Jacques Middlecoff Paul Madden,
Progress on GPU Parallelization of the NIM Prototype Numerical Weather Prediction Dynamical Core Tom Henderson NOAA/OAR/ESRL/GSD/ACE Thomas.B.Henderson@noaa.gov Mark Govett, Jacques Middlecoff Paul Madden,
The next generation supercomputer. Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency
 The next generation supercomputer and NWP system of JMA Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency Contents JMA supercomputer systems Current system (Mar
The next generation supercomputer and NWP system of JMA Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency Contents JMA supercomputer systems Current system (Mar
H003 Deriving 3D Q Models from Surface Seismic Data Using Attenuated Traveltime Tomography
 H003 Deriving 3D Q Models from Surface Seismic Data Using Attenuated Traveltime Tomography M. Cavalca* (Schlumberger - Westerngeco) & R.P. Fletcher (Schlumberger - Westerngeco) SUMMARY Estimation of the
H003 Deriving 3D Q Models from Surface Seismic Data Using Attenuated Traveltime Tomography M. Cavalca* (Schlumberger - Westerngeco) & R.P. Fletcher (Schlumberger - Westerngeco) SUMMARY Estimation of the
Parallel Hybrid Computing F. Bodin, CAPS Entreprise
 Parallel Hybrid Computing F. Bodin, CAPS Entreprise Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous
Parallel Hybrid Computing F. Bodin, CAPS Entreprise Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous
3D Finite Difference Time-Domain Modeling of Acoustic Wave Propagation based on Domain Decomposition
 3D Finite Difference Time-Domain Modeling of Acoustic Wave Propagation based on Domain Decomposition UMR Géosciences Azur CNRS-IRD-UNSA-OCA Villefranche-sur-mer Supervised by: Dr. Stéphane Operto Jade
3D Finite Difference Time-Domain Modeling of Acoustic Wave Propagation based on Domain Decomposition UMR Géosciences Azur CNRS-IRD-UNSA-OCA Villefranche-sur-mer Supervised by: Dr. Stéphane Operto Jade
A Comprehensive Study on the Performance of Implicit LS-DYNA
 12 th International LS-DYNA Users Conference Computing Technologies(4) A Comprehensive Study on the Performance of Implicit LS-DYNA Yih-Yih Lin Hewlett-Packard Company Abstract This work addresses four
12 th International LS-DYNA Users Conference Computing Technologies(4) A Comprehensive Study on the Performance of Implicit LS-DYNA Yih-Yih Lin Hewlett-Packard Company Abstract This work addresses four
Lecture 1. Introduction Course Overview
 Lecture 1 Introduction Course Overview Welcome to CSE 260! Your instructor is Scott Baden baden@ucsd.edu Office: room 3244 in EBU3B Office hours Week 1: Today (after class), Tuesday (after class) Remainder
Lecture 1 Introduction Course Overview Welcome to CSE 260! Your instructor is Scott Baden baden@ucsd.edu Office: room 3244 in EBU3B Office hours Week 1: Today (after class), Tuesday (after class) Remainder
IBM Power Advanced Compute (AC) AC922 Server
 AC922 Server") IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
Optimisation Myths and Facts as Seen in Statistical Physics
 Optimisation Myths and Facts as Seen in Statistical Physics Massimo Bernaschi Institute for Applied Computing National Research Council & Computer Science Department University La Sapienza Rome - ITALY
Optimisation Myths and Facts as Seen in Statistical Physics Massimo Bernaschi Institute for Applied Computing National Research Council & Computer Science Department University La Sapienza Rome - ITALY
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management
 X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
MAGMA. Matrix Algebra on GPU and Multicore Architectures
 MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
Particleworks: Particle-based CAE Software fully ported to GPU
 Particleworks: Particle-based CAE Software fully ported to GPU Introduction PrometechVideo_v3.2.3.wmv 3.5 min. Particleworks Why the particle method? Existing methods FEM, FVM, FLIP, Fluid calculation
Particleworks: Particle-based CAE Software fully ported to GPU Introduction PrometechVideo_v3.2.3.wmv 3.5 min. Particleworks Why the particle method? Existing methods FEM, FVM, FLIP, Fluid calculation
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
The IBM Blue Gene/Q: Application performance, scalability and optimisation
 The IBM Blue Gene/Q: Application performance, scalability and optimisation Mike Ashworth, Andrew Porter Scientific Computing Department & STFC Hartree Centre Manish Modani IBM STFC Daresbury Laboratory,
The IBM Blue Gene/Q: Application performance, scalability and optimisation Mike Ashworth, Andrew Porter Scientific Computing Department & STFC Hartree Centre Manish Modani IBM STFC Daresbury Laboratory,
Automated Geophysical Feature Detection with Deep Learning
 Automated Geophysical Feature Detection with Deep Learning Chiyuan Zhang, Charlie Frogner and Tomaso Poggio, MIT. Mauricio Araya-Polo, Jan Limbeck and Detlef Hohl, Shell International Exploration & Production
Automated Geophysical Feature Detection with Deep Learning Chiyuan Zhang, Charlie Frogner and Tomaso Poggio, MIT. Mauricio Araya-Polo, Jan Limbeck and Detlef Hohl, Shell International Exploration & Production
IBM Power Systems HPC Cluster
 IBM Power Systems HPC Cluster Highlights Complete and fully Integrated HPC cluster for demanding workloads Modular and Extensible: match components & configurations to meet demands Integrated: racked &
IBM Power Systems HPC Cluster Highlights Complete and fully Integrated HPC cluster for demanding workloads Modular and Extensible: match components & configurations to meet demands Integrated: racked &
The Omega Seismic Processing System. Seismic analysis at your fingertips
 The Omega Seismic Processing System Seismic analysis at your fingertips Omega is a flexible, scalable system that allows for processing and imaging on a single workstation up to massive compute clusters,
The Omega Seismic Processing System Seismic analysis at your fingertips Omega is a flexible, scalable system that allows for processing and imaging on a single workstation up to massive compute clusters,
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
Outline. Single GPU Implementation. Multi-GPU Implementation. 2-pass and 1-pass approaches Performance evaluation. Scalability on clusters
 Implementing 3D Finite Difference Codes on the GPU Paulius Micikevicius NVIDIA Outline Single GPU Implementation 2-pass and 1-pass approaches Performance evaluation Multi-GPU Implementation Scalability
Implementing 3D Finite Difference Codes on the GPU Paulius Micikevicius NVIDIA Outline Single GPU Implementation 2-pass and 1-pass approaches Performance evaluation Multi-GPU Implementation Scalability
Turbostream: A CFD solver for manycore
 Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems.
 Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
FUJITSU Server PRIMERGY CX400 M4 Workload-specific power in a modular form factor. 0 Copyright 2018 FUJITSU LIMITED
 FUJITSU Server PRIMERGY CX400 M4 Workload-specific power in a modular form factor 0 Copyright 2018 FUJITSU LIMITED FUJITSU Server PRIMERGY CX400 M4 Workload-specific power in a compact and modular form
FUJITSU Server PRIMERGY CX400 M4 Workload-specific power in a modular form factor 0 Copyright 2018 FUJITSU LIMITED FUJITSU Server PRIMERGY CX400 M4 Workload-specific power in a compact and modular form
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Exploring XMP programming model applied to Seismic Imaging application. Laurence BEAUDE
 Exploring XMP programming model applied to Seismic Imaging application Introduction Total at a glance: 96 000 employees in more than 130 countries Upstream operations (oil and gas exploration, development
Exploring XMP programming model applied to Seismic Imaging application Introduction Total at a glance: 96 000 employees in more than 130 countries Upstream operations (oil and gas exploration, development
TESLA P100 PERFORMANCE GUIDE. Deep Learning and HPC Applications
 TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
Performance Benefits of NVIDIA GPUs for LS-DYNA
 Performance Benefits of NVIDIA GPUs for LS-DYNA Mr. Stan Posey and Dr. Srinivas Kodiyalam NVIDIA Corporation, Santa Clara, CA, USA Summary: This work examines the performance characteristics of LS-DYNA
Performance Benefits of NVIDIA GPUs for LS-DYNA Mr. Stan Posey and Dr. Srinivas Kodiyalam NVIDIA Corporation, Santa Clara, CA, USA Summary: This work examines the performance characteristics of LS-DYNA
High-Performance Reservoir Simulations on Modern CPU-GPU Computational Platforms Abstract Introduction
 High-Performance Reservoir Simulations on Modern CPU-GPU Computational Platforms K. Bogachev 1, S. Milyutin 1, A. Telishev 1, V. Nazarov 1, V. Shelkov 1, D. Eydinov 1, O. Malinur 2, S. Hinneh 2 ; 1. Rock
High-Performance Reservoir Simulations on Modern CPU-GPU Computational Platforms K. Bogachev 1, S. Milyutin 1, A. Telishev 1, V. Nazarov 1, V. Shelkov 1, D. Eydinov 1, O. Malinur 2, S. Hinneh 2 ; 1. Rock