Chase Wu New Jersey Institute of Technology
|
|
|
- Emmeline Palmer
- 5 years ago
- Views:
Transcription
1 CS 644: Introduction to Big Data Chapter 5. Big Data Computing and Processing Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia University 1
2 Remind -- Apache Hadoop The Apache Hadoop project develops open-source software for reliable, scalable, distributed computing. The project includes these modules: Hadoop Common: The common utilities that support the other Hadoop modules. Hadoop Distributed File System (HDFS ): A distributed file system that provides highthroughput access to application data. Hadoop YARN: A framework for job scheduling and cluster resource management. Hadoop MapReduce: A YARN-based system for parallel processing of large data sets. 2
3 Remind -- Hadoop-related Apache Projects Ambari : A web-based tool for provisioning, managing, and monitoring Hadoop clusters.it also provides a dashboard for viewing cluster health and ability to view MapReduce, Pig and Hive applications visually. Avro : A data serialization system. Cassandra : A scalable multi-master database with no single points of failure. Chukwa : A data collection system for managing large distributed systems. HBase : A scalable, distributed database that supports structured data storage for large tables. Hive : A data warehouse infrastructure that provides data summarization and ad hoc querying. Mahout : A Scalable machine learning and data mining library. Pig : A high-level data-flow language and execution framework for parallel computation. Spark : A fast and general compute engine for Hadoop data. Spark provides a simple and expressive programming model that supports a wide range of applications, including ETL, machine learning, stream processing, and graph computation. Tez : A generalized data-flow programming framework, built on Hadoop YARN, which provides a powerful and flexible engine to execute an arbitrary DAG of tasks to process data for both batch and interactive use-cases. ZooKeeper : A high-performance coordination service for distributed applications. 3
4 YARN YARN Yet Another Resource Negotiator: A Tool that enables the other processing frameworks to run on Hadoop. A general-purpose resource management facility that can schedule and assign CPU cycles and memory (and in the future, other resources, such as network bandwidth) from the Hadoop cluster to waiting applications. èyarn has converted Hadoop from simply a batch processing engine into a platform for many different modes of data processing, from traditional batch to interactive queries to streaming analysis. 4

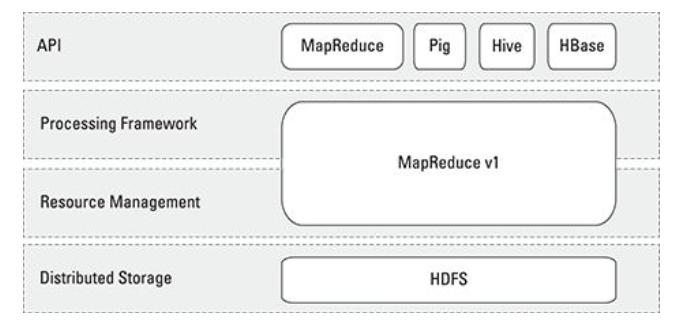
5 Four distinctive layers of Hadoop 5
6 Haoop 1 execution 1. The client application submits an application request to the JobTracker. 2. The JobTracker determines how many processing resources are needed to execute the entire application. 3. The JobTracker looks at the state of the slave nodes and queues all the map tasks and reduce tasks for execution. 4. As processing slots become available on the slave nodes, map tasks are deployed to the slave nodes. Map tasks are assigned to nodes where the same data is stored. 5. The TaskTracker monitors task progress. If failure, the task is restarted on the next available slot. 6. After the map tasks are finished, reduce tasks process the interim results sets from the map tasks. 7. The result set is returned to the client application. 6
7 Limitation of Hadoop 1 MapReduce is a successful batch-oriented programming model. A glass ceiling in terms of wider use: Exclusive tie to MapReduce, which means it could be used only for batch-style workloads and for general-purpose analysis. Triggered demands for additional processing modes: Stream data processing Message passing Graph Analysis è Demand is growing for real-time and ad-hoc analysis è Analysts ask many smaller questions against subsets of data and need a near-instant response. è Some analysts are more used to SQL & Relational databases YARN was created to move beyond the limitation of a Hadoop 1 / MapReduce world. 7

8 Hadoop 2 Data Processing Architecture 8

9 YARN s application execution Client submits an application to Resource Manager. Resource Manager asks a Node Manager to create an Application Master instance and starts up. Application Master initializes itself and register with the Resource Manager Application Master figures out how many resources are needed to execute the application. Application Master then requests the necessary resources from the Resource Manager. It sends heartbeat message to the Resource Manager throughout its lifetime. The Resource Manager accepts the request and queue up. As the requested resources become available on the slave nodes, the Resource Manager grants the Application Master leases for containers on specific slave nodes.. è only need to decide on how much memory tasks can have. 9

10 MapReduce example 10

11 MapReduce Data Flow 11
12 Spark Fast, Interactive, Language-Integrated Cluster Computing Download source release:
13 Project Goals Extend the MapReduce model to better support two common classes of analytics apps: Iterative algorithms (machine learning, graphs) Interactive data mining Enhance programmability: Integrate into Scala programming language Allow interactive use from Scala interpreter


14 Motivation Most current cluster programming models are based on acyclic data flow from stable storage to stable storage Map Reduce Input Map Output Map Reduce
15 Motivation Most current cluster programming models are based on acyclic data flow from stable storage to stable storage Map Reduce Benefits of data flow: runtime can decide where Input to run Map tasks and can automatically Output recover from failures Map Reduce
16 Motivation Acyclic data flow is inefficient for applications that repeatedly reuse a working set of data: Iterative algorithms (machine learning, graphs) Interactive data mining tools (R, Excel, Python) With current frameworks, apps reload data from stable storage on each query
17 Solution: Resilient Distributed Datasets (RDDs) Allow apps to keep working sets in memory for efficient reuse Retain the attractive properties of MapReduce Fault tolerance, data locality, scalability Support a wide range of applications
18 Programming Model Resilient distributed datasets (RDDs) Immutable, partitioned collections of objects Created through parallel transformations (map, filter, groupby, join, ) on data in stable storage Can be cached for efficient reuse Actions on RDDs Count, reduce, collect, save,

) messages = errors.map(_.")
 Base RDD Transformed RDD Driver results tasks Worker")


19 Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns lines = spark.textfile( hdfs://... ) errors = lines.filter(_.startswith( ERROR )) messages = errors.map(_.split( \t )(2)) cachedmsgs = messages.cache() Base RDD Transformed RDD Driver results tasks Worker Block 1 Cache 1 cachedmsgs.filter(_.contains( foo )).count cachedmsgs.filter(_.contains( bar )).count... Result: full-text search of Wikipedia in <1 sec (vs 20 sec (vs 170 sec for on-disk data) for on-disk data) Result: scaled to 1 TB data in 5-7 sec Action Cache 3 Worker Block 3 Worker Block 2 Cache 2
).map(_.split( \t )(2)) HDFS File Filtered RDD Mapped RDD filter (func = _.contains(...)) map (func = _.")
20 RDD Fault Tolerance RDDs maintain lineage information that can be used to reconstruct lost partitions Ex: messages = textfile(...).filter(_.startswith( ERROR )).map(_.split( \t )(2)) HDFS File Filtered RDD Mapped RDD filter (func = _.contains(...)) map (func = _.split(...))
21 Example: Logistic Regression Goal: find best line separating two sets of points random initial line target
22 Example: Logistic Regression val data = spark.textfile(...).map(readpoint).cache() var w = Vector.random(D) for (i <- 1 to ITERATIONS) { val gradient = data.map(p => (1 / (1 + exp(-p.y*(w dot p.x))) - 1) * p.y * p.x ).reduce(_ + _) w -= gradient } println("final w: " + w)


23 Logistic Regression Performance 127 s / iteration first iteration 174 s further iterations 6 s
24 Spark Applications In-memory data mining on Hive data (Conviva) Predictive analytics (Quantifind) City traffic prediction (Mobile Millennium) Twitter spam classification (Monarch) Collaborative filtering via matrix factorization


25 Frameworks Built on Spark Pregel on Spark (Bagel) Google message passing model for graph computation 200 lines of code Hive on Spark (Shark) 3000 lines of code Compatible with Apache Hive ML operators in Scala
26 Implementation Runs on Apache Mesos to share resources with Hadoop & other apps Can read from any Hadoop input source (e.g. HDFS) No changes to Scala compiler Spark Hadoop MPI Mesos Node Node Node Node
27 Spark Scheduler Dryad-like DAGs Pipelines functions within a stage Cache-aware work reuse & locality Partitioning-aware to avoid shuffles A: B: Stage 1 groupby C: D: F: map E: join G: Stage 2 union Stage 3 = cached data partition
28 Interactive Spark Modified Scala interpreter to allow Spark to be used interactively from the command line Required two changes: Modified wrapper code generation so that each line typed has references to objects for its dependencies Distribute generated classes over the network
29 Spark Operations Transformations (define a new RDD) map filter sample groupbykey reducebykey sortbykey flatmap union join cogroup cross mapvalues Actions (return a result to driver program) collect reduce count save lookupkey

30 Apache Tez 30


31 Tez s characteristics Dataflow graph with vertices to express, model, and execute data processing logic Performance via Dynamic Graph Reconfiguration Flexible Input- Processor-Output task model Optimal Resource Management 31

32 Apache Storm Stream Processing -- On Hadoop, you run MapReduce jobs; On Storm, you run Topologies. -- Two kinds of nodes on a Storm cluster: -- the master node runs Nimbus -- the worker nodes called the Supervisor. 32
33 How Storm processes data? 33

34 Storm s Goals and Plans 34

35 Oozie Workflow Scheduler for Hadoop Oozie supports a wide range of job types, including Pig, Hive, and MapReduce, as well as jobs coming from Java programs and Shell scripts. Sample Oozie XML file 35
![Action and Control Nodes START Control Node MapReduc e ERROR KILL OK Action END <workflow-app name="foo-wf".. <start to="[node-name]"/> <map-reduce>.](/docs-images/92/108057279/images/36-1.jpg "..... </map-reduce> <kill name=\"[node-name]\"> <message>error occurred</message </kill> <end name=\"[node-name]\"/> </workflow-app> Control Flow start, end, kill")
 Oozie Coordination Engine can trigger workflows by Time (Periodically) Data Availability (Data appears in")
36 Action and Control Nodes START Control Node MapReduc e ERROR KILL OK Action END <workflow-app name="foo-wf".. <start to="[node-name]"/> <map-reduce> </map-reduce> <kill name="[node-name]"> <message>error occurred</message </kill> <end name="[node-name]"/> </workflow-app> Control Flow start, end, kill decision fork, join Actions map-reduce Java pig hive hdfs Workflows begin with START node Workflows succeed with END node Workflows fail with KILL node Several actions support JSP Expression Language (EL) Oozie Coordination Engine can trigger workflows by Time (Periodically) Data Availability (Data appears in a directory) 36
37 Schedule Workflow by Time 37
38 Schedule Workflow by Time and Data Availability 38
39 Install Oozie $ mkdir <OOZIE_HOME>/libext Download ExtJS and place under <OOZIE_HOME>/libext ext-2.2.zip Place Hadoop libs under libext $ cd <OOZIE_HOME> $ tar xvf oozie-hadooplibs cdh4.0.0.tar.gz $ cp oozie cdh4.0.0/hadooplibs/hadooplib cdh4.0.0/*.jar libext/ Configure Oozie with components under libext $ bin/oozie-setup.sh Create environment variable for default url export OOZIE_URL= This allows you to use $oozie command without providing url Update oozie-site.xml to point to Hadoop configuration <property> <name>oozie.service.hadoopaccessorservice.hadoop.configurations</name> <value>*=/home/hadoop/training/cdh4/hadoop cdh4.0.0/conf</value> </property> Setup Oozie database $./bin/ooziedb.sh create -sqlfile oozie.sql -run DB Connection. 39
40 Install Oozie Update core-site.xml to allow Oozie become hadoop and for that user to connect from any host <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> <description>allow the superuser oozie to impersonate any members of the group group1 and group2</description> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> <description>the superuser can connect only from host1 and host2 to impersonate a user</description> </property> 40


41 Start Oozie $ oozie-start.sh /home/hadoop/training/cdh4/oozie cdh4.0.0 Setting OOZIE_HOME: /home/hadoop/training/cdh4/oozie cdh4.0.0/conf Setting OOZIE_CONFIG: Sourcing: /home/hadoop/training/cdh4/oozie cdh4.0.0/conf/oozie-env.sh setting OOZIE_LOG=/home/hadoop/Training/logs/oozie setting CATALINA_PID=/home/hadoop/Training/hadoop_work/pids/oozie.pid Setting OOZIE_CONFIG_FILE: oozie-site.xml Setting OOZIE_DATA: /home/hadoop/training/cdh4/oozie cdh4.0.0/data Using OOZIE_LOG: /home/hadoop/training/logs/oozie Setting OOZIE_LOG4J_FILE: oozie-log4j.properties Setting OOZIE_LOG4J_RELOAD: 10 Setting OOZIE_HTTP_HOSTNAME: localhost Setting OOZIE_HTTP_PORT: Setting OOZIE_ADMIN_PORT: $ oozie admin -status System mode: NORMAL
42 Running Oozie Examples Extract examples packaged with Oozie $ cd $OOZIE_HOME $ tar xvf oozie-examples.tar.gz Copy examples to HDFS from user s home directory $ hdfs dfs -put examples examples Run an example $ oozie job -config examples/apps/map-reduce/job.properties - run Check Web Console 42


43 An example workflow START Count Each Letter MapReduce OK Find Max Letter MapReduce OK Clean Up ERROR KILL END Count Each Letter MapReduce END - Action Node - Control Flow Node - Control Node This source is in HadoopSamples project under /src/main/resources/mr/workflows 43
44 Workflow definition <workflow-app xmlns="uri:oozie:workflow:0.2" name="most-seen-letter"> <start to="count-each-letter"/> <action name="count-each-letter"> START Action Node <map-reduce> to count-each-letter <job-tracker>${jobtracker}</job-tracker> MapReduce action <name-node>${namenode}</name-node> <prepare> MapReduce have optional Prepare section... <delete path="${namenode}${outputdir}"/> <delete path="${namenode}${intermediatedir}"/> </prepare> <configuration> <property>... </map-reduce> <ok to="find-max-letter"/> <error to="fail"/> </action> Pass property that will be set on MapReduce job s Configuration object <name>mapreduce.job.map.class</name> <value>mr.wordcount.startswithcountmapper</value> </property>... </configuration> In case of success, go to the next job; in case of failure go to fail node 44
45 Package and Run Your Workflow 1. Create application directory structure with workflow definitions and resources Workflow.xml, jars, etc.. 2. Copy application directory to HDFS 3. Create application configuration file specify location of the application directory on HDFS specify location of the namenode and resource manager 4. Submit workflow to Oozie Utilize oozie command line 5. Monitor running workflow(s) Two options Command line ($oozie) Web Interface ( Oozie Application Directory Must comply to directory structure spec mostseenletter-oozieworkflow --lib/ --HadoopSamples.jar --workflow.xml Libraries should be placed under lib directory Workflow.xml defines workflow Application Workflow Root 45

46 How Hadoop Works 46
47 MapReduce Use Case Example flight data Data Source: Airline On-time Performance data set (flight data set). All the logs of domestic flights from the period of October 1987 to April Each record represents an individual flight where various details are captured: Time and date of arrival and departure Originating and destination airports Amount of time taken to taxi from the runway to the gate. Download it from Statistical Computing: 47
48 Other datasets available from Statistical Computing 48
49 Flight Data Schema 49
50 MapReduce Use Case Example flight data Count the number of flights for each carrier Serial way (not MapReduce): 50
51 MapReduce Use Case Example flight data Count the number of flights for each carrier Parallel way: 51


52 MapReduce application flow 52
53 MapReduce steps for flight data computation 53
54 FlightsByCarrier application Create FlightsByCarrier.java: 54
55 FlightsByCarrier application 55
56 FlightsByCarrier Mapper 56
57 FlightsByCarrier Reducer 57
58 Run the code 58
59 See Result 59

60 Using Pig Script E.g.: totalmiles.pig: calculates the total miles flown for all flights flown in one year Execute it: pig totalmiles.pig See result: hdfs dfs cat /user/root/totalmiles/part-r è

61 Pig 61
62 Pig example 62

63 Characteristics of Pig 63
64 Pig vs. SQL In comparison to SQL, Pig 1. uses lazy evaluation, 2. uses ETL (Extract-Transform-Load), 3. is able to store data at any point during a pipeline, 4. declares execution plans, 5. supports pipeline splits. On the other hand, it has been argued DBMSs are substantially faster than the MapReduce system once the data is loaded, but that loading the data takes considerably longer in the database systems. It has also been argued RDBMSs offer out of the box support for column-storage, working with compressed data, indexes for efficient random data access, and transaction-level fault tolerance. Pig Latin is procedural and fits very naturally in the pipeline paradigm while SQL is instead declarative. In SQL users can specify that data from two tables must be joined, but not what join implementation to use. Pig Latin allows users to specify an implementation or aspects of an implementation to be used in executing a script in several ways. Pig Latin programming is similar to specifying a query execution plan. 64

65 Pig Data Types and Syntax Atom: An atom is any single value, such as a string or number Tuple: A tuple is a record that consists of a sequence of fields. Each field can be of any type. Bag: A bag is a collection of non-unique tuples. Map: A map is a collection of key value pairs. 65
66 Pig Latin Operators 66

67 Pig Latin Expressions 67

68 Pig User-Defined Functions (UDFs) Command to run the script. The.java contains UPPER 68

69 Apache Hive 69
70 Using Hive to Create a Table 70

71 Another Hive Example 71
72 Exercises 1. Download Airline Data and one of your own selected datasets from Stat-Computing.org 3. Learn to use PIG. You can try the example in the reference 4. Use Oozie to schedule a few jobs 5. Try HBase. Use your own example 6. Try Hive. Use your own example 72
73 Questions? 73
Chase Wu New Jersey Institute of Technology
 CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
CS Spark. Slides from Matei Zaharia and Databricks
 CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
Fast, Interactive, Language-Integrated Cluster Computing
 Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark. Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica.
 Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
a Spark in the cloud iterative and interactive cluster computing
 a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Spark & Spark SQL. High- Speed In- Memory Analytics over Hadoop and Hive Data. Instructor: Duen Horng (Polo) Chau
 Chau") CSE 6242 / CX 4242 Data and Visual Analytics Georgia Tech Spark & Spark SQL High- Speed In- Memory Analytics over Hadoop and Hive Data Instructor: Duen Horng (Polo) Chau Slides adopted from Matei Zaharia
CSE 6242 / CX 4242 Data and Visual Analytics Georgia Tech Spark & Spark SQL High- Speed In- Memory Analytics over Hadoop and Hive Data Instructor: Duen Horng (Polo) Chau Slides adopted from Matei Zaharia
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Hadoop. Course Duration: 25 days (60 hours duration). Bigdata Fundamentals. Day1: (2hours)
. Bigdata Fundamentals. Day1: (2hours)") Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Spark: A Brief History. https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf
 Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
About 1. Chapter 1: Getting started with oozie 2. Remarks 2. Versions 2. Examples 2. Installation or Setup 2. Chapter 2: Oozie
 oozie #oozie Table of Contents About 1 Chapter 1: Getting started with oozie 2 Remarks 2 Versions 2 Examples 2 Installation or Setup 2 Chapter 2: Oozie 101 7 Examples 7 Oozie Architecture 7 Oozie Application
oozie #oozie Table of Contents About 1 Chapter 1: Getting started with oozie 2 Remarks 2 Versions 2 Examples 2 Installation or Setup 2 Chapter 2: Oozie 101 7 Examples 7 Oozie Architecture 7 Oozie Application
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Distributed Computing with Spark
 Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Data-intensive computing systems
 Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Hadoop. Introduction to BIGDATA and HADOOP
 Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Hadoop & Big Data Analytics Complete Practical & Real-time Training
 An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Hortonworks Data Platform
 Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Introduction into Big Data analytics Lecture 3 Hadoop ecosystem. Janusz Szwabiński
 Introduction into Big Data analytics Lecture 3 Hadoop ecosystem Janusz Szwabiński Outlook of today s talk Apache Hadoop Project Common use cases Getting started with Hadoop Single node cluster Further
Introduction into Big Data analytics Lecture 3 Hadoop ecosystem Janusz Szwabiński Outlook of today s talk Apache Hadoop Project Common use cases Getting started with Hadoop Single node cluster Further
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation)
 (Development, Administration & REAL TIME Projects Implementation)") HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
An Introduction to Big Data Analysis using Spark
 An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
Webinar Series TMIP VISION
 Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Today s content. Resilient Distributed Datasets(RDDs) Spark and its data model
 Spark and its data model") Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Fault Tolerant Distributed Main Memory Systems
 Fault Tolerant Distributed Main Memory Systems CompSci 590.04 Instructor: Ashwin Machanavajjhala Lecture 16 : 590.04 Fall 15 1 Recap: Map Reduce! map!!,!! list!!!!reduce!!, list(!! )!! Map Phase (per record
Fault Tolerant Distributed Main Memory Systems CompSci 590.04 Instructor: Ashwin Machanavajjhala Lecture 16 : 590.04 Fall 15 1 Recap: Map Reduce! map!!,!! list!!!!reduce!!, list(!! )!! Map Phase (per record
2/4/2019 Week 3- A Sangmi Lee Pallickara
 Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Hadoop course content
 course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
Practical Big Data Processing An Overview of Apache Flink
 Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Introduction to Apache Spark. Patrick Wendell - Databricks
 Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Apache Flink Big Data Stream Processing
 Apache Flink Big Data Stream Processing Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de XLDB 11.10.2017 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2017
Apache Flink Big Data Stream Processing Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de XLDB 11.10.2017 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2017
Techno Expert Solutions An institute for specialized studies!
 Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
Shark: SQL and Rich Analytics at Scale. Michael Xueyuan Han Ronny Hajoon Ko
 Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Exam Questions
 Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
An Introduction to Apache Spark Big Data Madison: 29 July William Red Hat, Inc.
 An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
COSC 6339 Big Data Analytics. Introduction to Spark. Edgar Gabriel Fall What is SPARK?
 COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Dell In-Memory Appliance for Cloudera Enterprise
 Dell In-Memory Appliance for Cloudera Enterprise Spark Technology Overview and Streaming Workload Use Cases Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
Dell In-Memory Appliance for Cloudera Enterprise Spark Technology Overview and Streaming Workload Use Cases Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
BIG DATA COURSE CONTENT
 BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
Apache Spark and Scala Certification Training
 About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Big Data Infrastructures & Technologies Hadoop Streaming Revisit.
 Big Data Infrastructures & Technologies Hadoop Streaming Revisit ENRON Mapper ENRON Mapper Output (Excerpt) acomnes@enron.com blake.walker@enron.com edward.snowden@cia.gov alex.berenson@nyt.com ENRON Reducer
Big Data Infrastructures & Technologies Hadoop Streaming Revisit ENRON Mapper ENRON Mapper Output (Excerpt) acomnes@enron.com blake.walker@enron.com edward.snowden@cia.gov alex.berenson@nyt.com ENRON Reducer
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Microsoft. Exam Questions Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo
 Version:Demo") Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 HOTSPOT You install the Microsoft Hive ODBC Driver on a computer that runs Windows
Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 HOTSPOT You install the Microsoft Hive ODBC Driver on a computer that runs Windows
Analyzing Flight Data
 IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Lambda Architecture with Apache Spark
 Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR
Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Apache Spark Internals
 Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
Introduction to the Hadoop Ecosystem - 1
 Hello and welcome to this online, self-paced course titled Administering and Managing the Oracle Big Data Appliance (BDA). This course contains several lessons. This lesson is titled Introduction to the
Hello and welcome to this online, self-paced course titled Administering and Managing the Oracle Big Data Appliance (BDA). This course contains several lessons. This lesson is titled Introduction to the
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
An Introduction to Apache Spark
 An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Lecture 30: Distributed Map-Reduce using Hadoop and Spark Frameworks
 COMP 322: Fundamentals of Parallel Programming Lecture 30: Distributed Map-Reduce using Hadoop and Spark Frameworks Mack Joyner and Zoran Budimlić {mjoyner, zoran}@rice.edu http://comp322.rice.edu COMP
COMP 322: Fundamentals of Parallel Programming Lecture 30: Distributed Map-Reduce using Hadoop and Spark Frameworks Mack Joyner and Zoran Budimlić {mjoyner, zoran}@rice.edu http://comp322.rice.edu COMP
exam. Microsoft Perform Data Engineering on Microsoft Azure HDInsight. Version 1.0
 70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
Shark: SQL and Rich Analytics at Scale. Reynold Xin UC Berkeley
 Shark: SQL and Rich Analytics at Scale Reynold Xin UC Berkeley Challenges in Modern Data Analysis Data volumes expanding. Faults and stragglers complicate parallel database design. Complexity of analysis:
Shark: SQL and Rich Analytics at Scale Reynold Xin UC Berkeley Challenges in Modern Data Analysis Data volumes expanding. Faults and stragglers complicate parallel database design. Complexity of analysis:
Hortonworks PR PowerCenter Data Integration 9.x Administrator Specialist.
 Hortonworks PR000007 PowerCenter Data Integration 9.x Administrator Specialist https://killexams.com/pass4sure/exam-detail/pr000007 QUESTION: 102 When can a reduce class also serve as a combiner without
Hortonworks PR000007 PowerCenter Data Integration 9.x Administrator Specialist https://killexams.com/pass4sure/exam-detail/pr000007 QUESTION: 102 When can a reduce class also serve as a combiner without
Hadoop Execution Environment
 Hadoop Execution Environment Hadoop Execution Environment Learn about execution environments in Hadoop. Limitations of classic MapReduce framework. New frameworks like YARN, Tez, Spark to compliment classic
Hadoop Execution Environment Hadoop Execution Environment Learn about execution environments in Hadoop. Limitations of classic MapReduce framework. New frameworks like YARN, Tez, Spark to compliment classic
Improving the MapReduce Big Data Processing Framework
 Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
We consider the general additive objective function that we saw in previous lectures: n F (w; x i, y i ) i=1
 i=1") CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 13, 5/9/2016. Scribed by Alfredo Láinez, Luke de Oliveira.
CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 13, 5/9/2016. Scribed by Alfredo Láinez, Luke de Oliveira.
Distributed Systems. 22. Spark. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to