Apache Spark Internals
|
|
|
- Rudolph Reeves
- 5 years ago
- Views:
Transcription
1 Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80
2 Acknowledgments & Sources Sources Research papers: Presentations: M. Zaharia, Introduction to Spark Internals, A. Davidson, A Deeper Understanding of Spark Internals, Blogs: Quang-Nhat Hoang-Xuan, Eurecom, Khoa Nguyen Trong, Eurecom, Pietro Michiardi (Eurecom) Apache Spark Internals 2 / 80
3 Anatomy of a Spark Application Anatomy of a Spark Application Pietro Michiardi (Eurecom) Apache Spark Internals 13 / 80
4 Anatomy of a Spark Application A Very Simple Application Example val sc = new SparkContext("spark://...", "MyJob", home, jars) val file = sc.textfile("hdfs://...") // This is an RDD val errors = file.filter(_.contains("error")) // This is an RDD errors.cache() errors.count() // This is an action Pietro Michiardi (Eurecom) Apache Spark Internals 14 / 80
 Apache Spark Internals 15 / 80")
5 Anatomy of a Spark Application Spark Applications: The Big Picture There are two ways to manipulate data in Spark Use the interactive shell, i.e., the REPL Write standalone applications, i.e., driver programs Pietro Michiardi (Eurecom) Apache Spark Internals 15 / 80
 Apache Spark Internals 16 /")
6 Anatomy of a Spark Application Spark Components: details Pietro Michiardi (Eurecom) Apache Spark Internals 16 / 80



 Apache")
7 Anatomy of a Spark Application The RDD graph: dataset vs. partition views Pietro Michiardi (Eurecom) Apache Spark Internals 17 / 80
8 Anatomy of a Spark Application Data Locality Data locality principle Same as for Hadoop MapReduce Avoid network I/O, workers should manage local data Data locality and caching First run: data not in cache, so use HadoopRDD s locality prefs (from HDFS) Second run: FilteredRDD is in cache, so use its locations If something falls out of cache, go back to HDFS Pietro Michiardi (Eurecom) Apache Spark Internals 18 / 80
.groupby(...).filter(.")

9 Anatomy of a Spark Application Lifetime of a Job in Spark RDD Objects DAG Scheduler Task Scheduler Worker Cluster( manager( Threads& Block& manager& rdd1.join(rdd2).groupby(...).filter(...) Split the DAG into stages of tasks Launch tasks via Master Retry failed and strag- Execute tasks Store and serve blocks Submit each stage and gler tasks Build the operator DAG its tasks as ready Pietro Michiardi (Eurecom) Apache Spark Internals 19 / 80
10 Application model for scheduling Application: Driver code that represents the DAG Job: Subset of application triggered for execution by an action in the DAG Stage: Job sub-divided into stages that have dependencies with each other Task: Unit of work in a stage that is scheduled on a worker
11 Anatomy of a Spark Application In Summary Our example Application: a jar file Creates a SparkContext, which is the core component of the driver Creates an input RDD, from a file in HDFS Manipulates the input RDD by applying a filter(f: T => Boolean) transformation Invokes the action count() on the transformed RDD The DAG Scheduler Gets: RDDs, functions to run on each partition and a listener for results Builds Stages of Tasks objects (code + preferred location) Submits Tasks to the Task Scheduler as ready Resubmits failed Stages The Task Scheduler Launches Tasks on executors Relaunches failed Tasks Reports to the DAG Scheduler Pietro Michiardi (Eurecom) Apache Spark Internals 20 / 80
12 Spark Deployments Spark Deployments Pietro Michiardi (Eurecom) Apache Spark Internals 21 / 80
 Apache Spark Internals 22 /")
13 Spark Deployments Spark Components: System-level View Pietro Michiardi (Eurecom) Apache Spark Internals 22 / 80
14 Spark Deployment Modes Spark Deployments The Spark Framework can adopt several cluster managers Local Mode Standalone mode Apache Mesos Hadoop YARN General workflow Spark application creates SparkContext, which initializes the DriverProgram Registers to the ClusterManager Ask resources to allocate Executors Schedule Task execution Pietro Michiardi (Eurecom) Apache Spark Internals 23 / 80
 Execute one or more task using threads in a ThreadPool Pietro Michiardi (Eurecom) Apache")
15 Spark Deployments Worker Nodes and Executors Worker nodes are machines that run executors Host one or multiple Workers One JVM (= 1 UNIX process) per Worker Each Worker can spawn one or more Executors Executors run tasks, used by 1 application, for whole lifetime Run in child JVM (= 1 UNIX process) Execute one or more task using threads in a ThreadPool Pietro Michiardi (Eurecom) Apache Spark Internals 24 / 80
16 Spark Deployments Comparison to Hadoop MapReduce Hadoop MapReduce One Task per UNIX process (JVM), more if JVM reuse MultiThreadedMapper, advanced feature to have threads in Map Tasks Short-lived Executor, with one large Task Spark Tasks run in one or more Threads, within a single UNIX process (JVM) Executor process statically allocated to worker, even with no threads Long-lived Executor, with many small Tasks Pietro Michiardi (Eurecom) Apache Spark Internals 25 / 80
17 Spark Deployments Benefits of the Spark Architecture Isolation Applications are completely isolated Task scheduling per application Low-overhead Task setup cost is that of spawning a thread, not a process times faster Small tasks mitigate effects of data skew Sharing data Applications cannot share data in memory natively Use an external storage service like Tachyon Resource allocation Static process provisioning for executors, even without active tasks Dynamic provisioning under development Pietro Michiardi (Eurecom) Apache Spark Internals 26 / 80

 Apache Spark")
18 Resilient Distributed Datasets RDD Partition Dependency Types Narrow dependencies Wide dependencies Pietro Michiardi (Eurecom) Apache Spark Internals 34 / 80
19 Dependency Types (2) Resilient Distributed Datasets Narrow dependencies Each partition of the parent RDD is used by at most one partition of the child RDD Task can be executed locally and we don t have to shuffle. (Eg: map, flatmap, filter, sample) Wide Dependencies Multiple child partitions may depend on one partition of the parent RDD This means we have to shuffle data unless the parents are hash-partitioned (Eg: sortbykey, reducebykey, groupbykey, cogroupbykey, join, cartesian) Pietro Michiardi (Eurecom) Apache Spark Internals 35 / 80
 Apache Spark Internals 36 /")
20 Resilient Distributed Datasets Dependency Types: Optimizations Benefits of Lazy evaluation The DAG Scheduler optimizes Stages and Tasks before submitting them to the Task Scheduler Piplining narrow dependencies within a Stage Join plan selection based on partitioning Cache reuse Pietro Michiardi (Eurecom) Apache Spark Internals 36 / 80
21 Spark Word Count Detailed Example: Word Count Pietro Michiardi (Eurecom) Apache Spark Internals 48 / 80
22 Spark Word Count Spark Word Count: the driver import org.apache.spark.sparkcontext import org.apache.spark.sparkcontext._ val sc = new SparkContext("spark://...", "MyJob", "spark home", "additional jars") Driver and SparkContext A SparkContext initializes the application driver, the latter then registers the application to the cluster manager, and gets a list of executors Then, the driver takes full control of the Spark job Pietro Michiardi (Eurecom) Apache Spark Internals 49 / 80
23 Spark Word Count Spark Word Count: the code val lines = sc.textfile("input") val words = lines.flatmap(_.split(" ")) val ones = words.map(_ -> 1) val counts = ones.reducebykey(_ + _) val result = counts.collectasmap() RDD lineage DAG is built on driver side with Data source RDD(s) Transformation RDD(s), which are created by transformations Job submission An action triggers the DAG scheduler to submit a job Pietro Michiardi (Eurecom) Apache Spark Internals 50 / 80
 Apache Spark Internals 51")
24 Spark Word Count Spark Word Count: the DAG Directed Acyclic Graph Built from the RDD lineage DAG scheduler Transforms the DAG into stages and turns each partition of a stage into a single task Decides what to run Pietro Michiardi (Eurecom) Apache Spark Internals 51 / 80
 Apache Spark Internals 52 /")
25 Spark Word Count Spark Word Count: the execution plan Spark Tasks Serialized RDD lineage DAG + closures of transformations Run by Spark executors Task scheduling The driver side task scheduler launches tasks on executors according to resource and locality constraints The task scheduler decides where to run tasks Pietro Michiardi (Eurecom) Apache Spark Internals 52 / 80
26 Spark Word Count Spark Word Count: the Shuffle phase val lines = sc.textfile("input") val words = lines.flatmap(_.split(" ")) val ones = words.map(_ -> 1) val counts = ones.reducebykey(_ + _) val result = counts.collectasmap() reducebykey transformation Induces the shuffle phase In particular, we have a wide dependency Like in Hadoop MapReduce, intermediate <key,value> pairs are stored on the local file system Automatic combiners! The reducebykey transformation implements map-side combiners to pre-aggregate data Pietro Michiardi (Eurecom) Apache Spark Internals 53 / 80
27 Resource Allocation Spark Schedulers Two main scheduler components, executed by the driver The DAG scheduler The Task scheduler Objectives Gain a broad understanding of how Spark submits Applications Understand how Stages and Tasks are built, and their optimization Understand interaction among various other Spark components Pietro Michiardi (Eurecom) Apache Spark Internals 62 / 80
 Apache Spark Internals 63")
28 Resource Allocation Submitting a Spark Application: A Walk Through Pietro Michiardi (Eurecom) Apache Spark Internals 63 / 80
29 Resource Allocation The DAG Scheduler Stage-oriented scheduling Computes a DAG of stages for each job in the application Keeps track of which RDD and stage output are materialized Determines an optimal schedule, minimizing stages Submit stages as sets of Tasks (TaskSets) to the Task scheduler Data locality principle Uses preferred location information (optionally) attached to each RDD Package this information into Tasks and send it to the Task scheduler Manages Stage failures Failure type: (intermediate) data loss of shuffle output files Failed stages will be resubmitted NOTE: Task failures are handled by the Task scheduler, which simply resubmit them if they can be computed with no dependency on previous output Pietro Michiardi (Eurecom) Apache Spark Internals 65 / 80
30 Resource Allocation More About Stages What is a DAG Directed acyclic graph of stages Stage boundaries determined by the shuffle phase Stages are run in topological order Definition of a Stage Set of independent tasks All tasks of a stage apply the same function All tasks of a stage have the same dependency type All tasks in a stage belong to a TaskSet Stage types Shuffle Map Stage: stage tasks results are inputs for another stage Result Stage: tasks compute the final action that initiated a job (e.g., count(), save(), etc.) Pietro Michiardi (Eurecom) Apache Spark Internals 68 / 80
31 Resource Allocation The Task Scheduler Task oriented scheduling Schedules tasks for a single SparkContext Submits tasks sets produced by the DAG Scheduler Retries failed tasks Takes care of stragglers with speculative execution Produces events for the DAG Scheduler Implementation details The Task scheduler creates a TaskSetManager to wrap the TaskSet from the DAG scheduler The TaskSetManager class operates as follows: Keeps track of each task status Retries failed tasks Imposes data locality using delayed scheduling Message passing implemented using Actors, and precisely using the Akka framework Pietro Michiardi (Eurecom) Apache Spark Internals 69 / 80
 Apache Spark Internals")
32 Resource Allocation Running Tasks on Executors Pietro Michiardi (Eurecom) Apache Spark Internals 70 / 80
33 Resource Allocation Running Tasks on Executors Executors run two kinds of tasks ResultTask: apply the action on the RDD, once it has been computed, alongside all its dependencies Line 19 ShuffleTask: use the Block Manager to store shuffle output using the ShuffleWriter Lines 23,24 The ShuffleRead component depends on the type of the RDD, which is determined by the compute function and the transformation applied to it Pietro Michiardi (Eurecom) Apache Spark Internals 71 / 80
34 Data Shuffling Data Shuffling Pietro Michiardi (Eurecom) Apache Spark Internals 72 / 80
35 Data Shuffling The Spark Shuffle Mechanism Same concept as for Hadoop MapReduce, involving: Storage of intermediate results on the local file-system Partitioning of intermediate data Serialization / De-serialization Pulling data over the network Transformations requiring a shuffle phase groupbykey(), reducebykey(), sortbykey(), distinct() Various types of Shuffle Hash Shuffle Consolidate Hash Shuffle Sort-based Shuffle Pietro Michiardi (Eurecom) Apache Spark Internals 73 / 80
 Apache Spark Internals 74 /")
36 Data Shuffling The Spark Shuffle Mechanism: an Illustration Data Aggregation Defined on ShuffleMapTask Two methods available: AppendOnlyMap: in-memory hash table combiner ExternalAppendOnlyMap: memory + disk hash table combiner Batching disk writes to increase throughput Pietro Michiardi (Eurecom) Apache Spark Internals 74 / 80

37 Data Shuffling The Hash Shuffle Mechanism Map Tasks write output to multiple files Assume: m map tasks and r reduce tasks Then: m r shuffle files as well as in-memory buffers (for batching writes) Be careful on storage space requirements! Buffer size must not be too big with many tasks Buffer size must not be too small, for otherwise throughput decreases Pietro Michiardi (Eurecom) Apache Spark Internals 76 / 80
 Apache Spark Internals 78 /")
38 Data Shuffling The Sort-based Shuffle Mechanism Implements the Hadoop Shuffle mechanism Single shuffle file, plus an index file to find buckets Very beneficial for write throughput, as more disk writes can be batched Sorting mechanism Pluggable external sorter Degenerates to Hash Shuffle if no sorting is required Pietro Michiardi (Eurecom) Apache Spark Internals 78 / 80
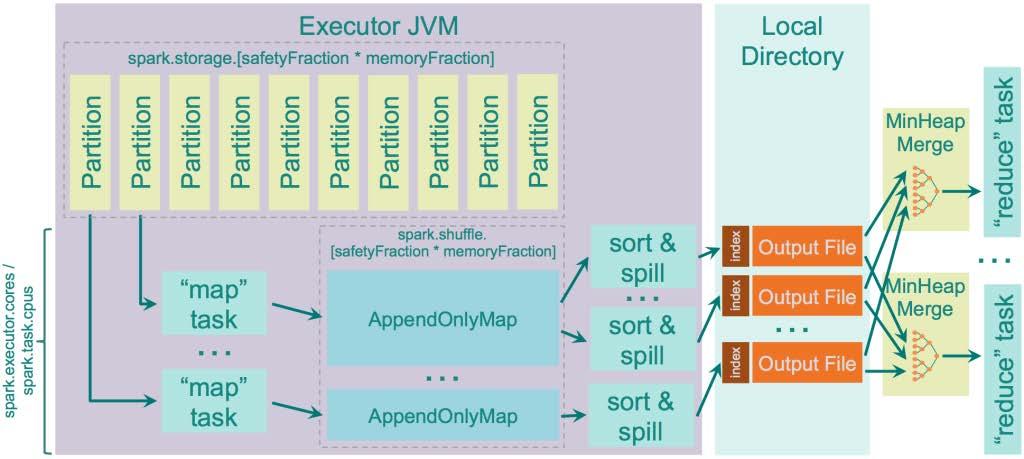
39
Data-intensive computing systems
 Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
CS435 Introduction to Big Data FALL 2018 Colorado State University. 10/24/2018 Week 10-B Sangmi Lee Pallickara
 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
An Introduction to Apache Spark
 An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
08/04/2018. RDDs. RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application contains
are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application contains
2/26/2017. RDDs. RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is used to run an application
are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is used to run an application
RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 1 RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application
1 RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
An Introduction to Big Data Analysis using Spark
 An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
Hadoop Map Reduce 10/17/2018 1
 Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
We consider the general additive objective function that we saw in previous lectures: n F (w; x i, y i ) i=1
 i=1") CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 13, 5/9/2016. Scribed by Alfredo Láinez, Luke de Oliveira.
CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 13, 5/9/2016. Scribed by Alfredo Láinez, Luke de Oliveira.
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Evolution From Shark To Spark SQL:
 Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
2/26/2017. For instance, consider running Word Count across 20 splits
 Based on the slides of prof. Pietro Michiardi Hadoop Internals https://github.com/michiard/disc-cloud-course/raw/master/hadoop/hadoop.pdf Job: execution of a MapReduce application across a data set Task:
Based on the slides of prof. Pietro Michiardi Hadoop Internals https://github.com/michiard/disc-cloud-course/raw/master/hadoop/hadoop.pdf Job: execution of a MapReduce application across a data set Task:
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
Data Engineering. How MapReduce Works. Shivnath Babu
 Data Engineering How MapReduce Works Shivnath Babu Lifecycle of a MapReduce Job Map function Reduce function Run this program as a MapReduce job Lifecycle of a MapReduce Job Map function Reduce function
Data Engineering How MapReduce Works Shivnath Babu Lifecycle of a MapReduce Job Map function Reduce function Run this program as a MapReduce job Lifecycle of a MapReduce Job Map function Reduce function
Big Data Analytics with Apache Spark. Nastaran Fatemi
 Big Data Analytics with Apache Spark Nastaran Fatemi Apache Spark Throughout this part of the course we will use the Apache Spark framework for distributed data-parallel programming. Spark implements a
Big Data Analytics with Apache Spark Nastaran Fatemi Apache Spark Throughout this part of the course we will use the Apache Spark framework for distributed data-parallel programming. Spark implements a
Spark: A Brief History. https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf
 Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
2/4/2019 Week 3- A Sangmi Lee Pallickara
 Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Introduction to Spark
 Introduction to Spark Outlines A brief history of Spark Programming with RDDs Transformations Actions A brief history Limitations of MapReduce MapReduce use cases showed two major limitations: Difficulty
Introduction to Spark Outlines A brief history of Spark Programming with RDDs Transformations Actions A brief history Limitations of MapReduce MapReduce use cases showed two major limitations: Difficulty
An Introduction to Apache Spark Big Data Madison: 29 July William Red Hat, Inc.
 An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
YARN: A Resource Manager for Analytic Platform Tsuyoshi Ozawa
 YARN: A Resource Manager for Analytic Platform Tsuyoshi Ozawa ozawa.tsuyoshi@lab.ntt.co.jp ozawa@apache.org About me Tsuyoshi Ozawa Research Engineer @ NTT Twitter: @oza_x86_64 Over 150 reviews in 2015
YARN: A Resource Manager for Analytic Platform Tsuyoshi Ozawa ozawa.tsuyoshi@lab.ntt.co.jp ozawa@apache.org About me Tsuyoshi Ozawa Research Engineer @ NTT Twitter: @oza_x86_64 Over 150 reviews in 2015
Introduction to Apache Spark. Patrick Wendell - Databricks
 Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
COSC 6339 Big Data Analytics. Introduction to Spark. Edgar Gabriel Fall What is SPARK?
 COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Beyond MapReduce: Apache Spark Antonino Virgillito
 Beyond MapReduce: Apache Spark Antonino Virgillito 1 Why Spark? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration
Beyond MapReduce: Apache Spark Antonino Virgillito 1 Why Spark? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration
Today s content. Resilient Distributed Datasets(RDDs) Spark and its data model
 Spark and its data model") Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Hadoop MapReduce Framework
 Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce
Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Apache Spark. CS240A T Yang. Some of them are based on P. Wendell s Spark slides
 Apache Spark CS240A T Yang Some of them are based on P. Wendell s Spark slides Parallel Processing using Spark+Hadoop Hadoop: Distributed file system that connects machines. Mapreduce: parallel programming
Apache Spark CS240A T Yang Some of them are based on P. Wendell s Spark slides Parallel Processing using Spark+Hadoop Hadoop: Distributed file system that connects machines. Mapreduce: parallel programming
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Distributed Systems. 22. Spark. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Lecture 4, 04/08/2015. Scribed by Eric Lax, Andreas Santucci, Charles Zheng.
 CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Databricks and Stanford. Lecture 4, 04/08/2015. Scribed by Eric Lax, Andreas Santucci,
CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Databricks and Stanford. Lecture 4, 04/08/2015. Scribed by Eric Lax, Andreas Santucci,
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Cloud, Big Data & Linear Algebra
 Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Spark and Spark SQL. Amir H. Payberah. SICS Swedish ICT. Amir H. Payberah (SICS) Spark and Spark SQL June 29, / 71
 Spark and Spark SQL June 29, / 71") Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
An Overview of Apache Spark
 An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
An Introduction to Apache Spark
 An Introduction to Apache Spark Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 1 / 67 Big Data small data big data Amir H. Payberah (SICS) Apache Spark
An Introduction to Apache Spark Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 1 / 67 Big Data small data big data Amir H. Payberah (SICS) Apache Spark
Introduction to Apache Spark
 Introduction to Apache Spark Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Introduction to Apache Spark Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Redesigning Apache Flink s Distributed Architecture. Till
 Redesigning Apache Flink s Distributed Architecture Till Rohrmann trohrmann@apache.org @stsffap 2 1001 Deployment Scenarios Many different deployment scenarios Yarn Mesos Docker/Kubernetes Standalone Etc.
Redesigning Apache Flink s Distributed Architecture Till Rohrmann trohrmann@apache.org @stsffap 2 1001 Deployment Scenarios Many different deployment scenarios Yarn Mesos Docker/Kubernetes Standalone Etc.
Pig on Spark project proposes to add Spark as an execution engine option for Pig, similar to current options of MapReduce and Tez.
 Pig on Spark Mohit Sabharwal and Xuefu Zhang, 06/30/2015 Objective The initial patch of Pig on Spark feature was delivered by Sigmoid Analytics in September 2014. Since then, there has been effort by a
Pig on Spark Mohit Sabharwal and Xuefu Zhang, 06/30/2015 Objective The initial patch of Pig on Spark feature was delivered by Sigmoid Analytics in September 2014. Since then, there has been effort by a
a Spark in the cloud iterative and interactive cluster computing
 a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
CS435 Introduction to Big Data FALL 2018 Colorado State University. 10/22/2018 Week 10-A Sangmi Lee Pallickara. FAQs.
 10/22/2018 - FALL 2018 W10.A.0.0 10/22/2018 - FALL 2018 W10.A.1 FAQs Term project: Proposal 5:00PM October 23, 2018 PART 1. LARGE SCALE DATA ANALYTICS IN-MEMORY CLUSTER COMPUTING Computer Science, Colorado
10/22/2018 - FALL 2018 W10.A.0.0 10/22/2018 - FALL 2018 W10.A.1 FAQs Term project: Proposal 5:00PM October 23, 2018 PART 1. LARGE SCALE DATA ANALYTICS IN-MEMORY CLUSTER COMPUTING Computer Science, Colorado
Reactive App using Actor model & Apache Spark. Rahul Kumar Software
 Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application
Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application
Introduction to Apache Spark
 1 Introduction to Apache Spark Thomas Ropars thomas.ropars@univ-grenoble-alpes.fr 2017 2 References The content of this lectures is inspired by: The lecture notes of Yann Vernaz. The lecture notes of Vincent
1 Introduction to Apache Spark Thomas Ropars thomas.ropars@univ-grenoble-alpes.fr 2017 2 References The content of this lectures is inspired by: The lecture notes of Yann Vernaz. The lecture notes of Vincent
CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University
![CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University](/thumbs/83/87457683.jpg "CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University") CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Return type for collect()? Can
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Return type for collect()? Can
Spark.jl: Resilient Distributed Datasets in Julia
 Spark.jl: Resilient Distributed Datasets in Julia Dennis Wilson, Martín Martínez Rivera, Nicole Power, Tim Mickel [dennisw, martinmr, npower, tmickel]@mit.edu INTRODUCTION 1 Julia is a new high level,
Spark.jl: Resilient Distributed Datasets in Julia Dennis Wilson, Martín Martínez Rivera, Nicole Power, Tim Mickel [dennisw, martinmr, npower, tmickel]@mit.edu INTRODUCTION 1 Julia is a new high level,
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Part II: Software Infrastructure in Data Centers: Distributed Execution Engines
 CSE 6350 File and Storage System Infrastructure in Data centers Supporting Internet-wide Services Part II: Software Infrastructure in Data Centers: Distributed Execution Engines 1 MapReduce: Simplified
CSE 6350 File and Storage System Infrastructure in Data centers Supporting Internet-wide Services Part II: Software Infrastructure in Data Centers: Distributed Execution Engines 1 MapReduce: Simplified
Accelerating Spark Workloads using GPUs
 Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Expert Lecture plan proposal Hadoop& itsapplication
 Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
15.1 Data flow vs. traditional network programming
 CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/83/87457744.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey If an RDD is read once, transformed will Spark
CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey If an RDD is read once, transformed will Spark
Spark. Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica.
 Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Programming Models MapReduce
 Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Outline. CS-562 Introduction to data analysis using Apache Spark
 Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
 About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION
 Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
In-Memory Processing with Apache Spark. Vincent Leroy
 In-Memory Processing with Apache Spark Vincent Leroy Sources Resilient Distributed Datasets, Henggang Cui Coursera IntroducBon to Apache Spark, University of California, Databricks Datacenter OrganizaBon
In-Memory Processing with Apache Spark Vincent Leroy Sources Resilient Distributed Datasets, Henggang Cui Coursera IntroducBon to Apache Spark, University of California, Databricks Datacenter OrganizaBon
L3: Spark & RDD. CDS Department of Computational and Data Sciences. Department of Computational and Data Sciences
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Big Data Analytics. C. Distributed Computing Environments / C.2. Resilient Distributed Datasets: Apache Spark. Lars Schmidt-Thieme
 Big Data Analytics C. Distributed Computing Environments / C.2. Resilient Distributed Datasets: Apache Spark Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute of Computer
Big Data Analytics C. Distributed Computing Environments / C.2. Resilient Distributed Datasets: Apache Spark Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute of Computer
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 21 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Streaming
Data processing in Apache Spark Pelle Jakovits 21 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Streaming
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
CS Spark. Slides from Matei Zaharia and Databricks
 CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Hadoop. Course Duration: 25 days (60 hours duration). Bigdata Fundamentals. Day1: (2hours)
. Bigdata Fundamentals. Day1: (2hours)") Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Techno Expert Solutions An institute for specialized studies!
 Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Applied Spark. From Concepts to Bitcoin Analytics. Andrew F.
 Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Lecture 30: Distributed Map-Reduce using Hadoop and Spark Frameworks
 COMP 322: Fundamentals of Parallel Programming Lecture 30: Distributed Map-Reduce using Hadoop and Spark Frameworks Mack Joyner and Zoran Budimlić {mjoyner, zoran}@rice.edu http://comp322.rice.edu COMP
COMP 322: Fundamentals of Parallel Programming Lecture 30: Distributed Map-Reduce using Hadoop and Spark Frameworks Mack Joyner and Zoran Budimlić {mjoyner, zoran}@rice.edu http://comp322.rice.edu COMP
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
The detailed Spark programming guide is available at:
 Aims This exercise aims to get you to: Analyze data using Spark shell Monitor Spark tasks using Web UI Write self-contained Spark applications using Scala in Eclipse Background Spark is already installed
Aims This exercise aims to get you to: Analyze data using Spark shell Monitor Spark tasks using Web UI Write self-contained Spark applications using Scala in Eclipse Background Spark is already installed
Announcements. Optional Reading. Distributed File System (DFS) MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm
 MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm") Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Improving the MapReduce Big Data Processing Framework
 Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
Parallel Processing Spark and Spark SQL
 Parallel Processing Spark and Spark SQL Amir H. Payberah amir@sics.se KTH Royal Institute of Technology Amir H. Payberah (KTH) Spark and Spark SQL 2016/09/16 1 / 82 Motivation (1/4) Most current cluster
Parallel Processing Spark and Spark SQL Amir H. Payberah amir@sics.se KTH Royal Institute of Technology Amir H. Payberah (KTH) Spark and Spark SQL 2016/09/16 1 / 82 Motivation (1/4) Most current cluster
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics
 Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Presented by: Dishant Mittal Authors: Juwei Shi, Yunjie Qiu, Umar Firooq Minhas, Lemei Jiao, Chen Wang, Berthold Reinwald and Fatma
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Presented by: Dishant Mittal Authors: Juwei Shi, Yunjie Qiu, Umar Firooq Minhas, Lemei Jiao, Chen Wang, Berthold Reinwald and Fatma
Fault Tolerant Distributed Main Memory Systems
 Fault Tolerant Distributed Main Memory Systems CompSci 590.04 Instructor: Ashwin Machanavajjhala Lecture 16 : 590.04 Fall 15 1 Recap: Map Reduce! map!!,!! list!!!!reduce!!, list(!! )!! Map Phase (per record
Fault Tolerant Distributed Main Memory Systems CompSci 590.04 Instructor: Ashwin Machanavajjhala Lecture 16 : 590.04 Fall 15 1 Recap: Map Reduce! map!!,!! list!!!!reduce!!, list(!! )!! Map Phase (per record
Experiences Running and Optimizing the Berkeley Data Analytics Stack on Cray Platforms
 Experiences Running and Optimizing the Berkeley Data Analytics Stack on Cray Platforms Kristyn J. Maschhoff and Michael F. Ringenburg Cray Inc. CUG 2015 Copyright 2015 Cray Inc Legal Disclaimer Information
Experiences Running and Optimizing the Berkeley Data Analytics Stack on Cray Platforms Kristyn J. Maschhoff and Michael F. Ringenburg Cray Inc. CUG 2015 Copyright 2015 Cray Inc Legal Disclaimer Information
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation