Goal of the presentation is to give an introduction of NoSQL databases, why they are there.
|
|
|
- Cecil Gardner
- 6 years ago
- Views:
Transcription
1 1
2 Goal of the presentation is to give an introduction of NoSQL databases, why they are there. We want to present "Why?" first to explain the need of something like "NoSQL" and then in "What?" we go in detail. In addition there are lots and lots of NoSQL databases available, we have chosen some widely used databases in the industry. We think it's important that one should be aware of these databases and have the basic understanding of why they exist, and how they are different. 2
3 Justify their usage. Let's look at new trends in recent years. 3

4 1. Each year more and more data is created. Over two years we create more digital data than all the data created in history before that! 2. The rigidly defined, schema-based approach used by relational databases makes it impossible to quickly incorporate new types of data. 3. RDBMs are really good at transactions. perfected over the years. but huge amount of data today doesn't require transactional properties. 3. NoSQL provides a data model that maps better to these needs. 4
5 1. Data now has much more complex relations. It has evolved from hyptertext, RSS, blogs(have backlinks) to highly complex social graphs. 2. No more efficient to represent in strict tables. - We need different data models. Graph databases. 5

6 1. Relational databases are fundamentally centralized. 3-tier systems. Scale up system. 2. To scale the application you add more web servers. 3. To support more concurrent users and/or store more data, you need a bigger and bigger server with more CPUs, more memory, and more disk storage to keep all the tables. 4. Maintaining this single server becomes a headache both in terms of man power and cost. 6
7 Now we are moving towards distributed databases. We'll talk more about this later - ACID properties. Relational databases aims for consistency. In a distributed environment we need to make a choice because of CAP. 7

8 A survey done by couchbase.com shows that the major reason for choosing NoSQL databases are Flexibility and Scalability. 8
9 lots of traffic => buy bigger boxes. Lot of small boxes. SQL was designed to run on single box. 1. SQL databases are very reliable and mature technologies. People have tried to extend the scope by changing SQL databases to adapt to the new trends that we saw. Distributed caching - offload reads, in memory cached, using memcached over SQL server. (highly common, lot of big companies use it) Example: Zynga - roughly 600 memcached databases over 400 SQL databases. Massive software - difficult management. 9

10 Lot of vendors have tried to extend the scope but what's evident is that one solution is not enough. 10

11 11
12 Will spend a minute or two on ACID slides, basically a very quick review. 12
13 Single machines: partition tolerance is irrelevant. consistency and availability can be achieve on a single machine. Consistency: so you can read or write to/from any node and get the same data. 13
14 We will not spend much time on this, since there is a group that's presenting CAP in quite a detail. Only thing to take from this slide is that all three properties cannot be achieved at the same time. 14

15 An illustration to show where most of the NoSQL and Relational databases lie on the CAP spectrum. It is interesting to see that the databases following CA model are primarily relational databases, this is because, they are not built for partitioning and distributed structure. NoSQL databases either show CP model or AP model. We will discuss a single database from each as our case study. 15
16 Not just SQL 16
17 1. A paradigm shift from the traditional data model. SQL databases enforce a strict schema, whereas NoSQL databases has a week notion of schema. At the core all NoSQL databases are key/value systems, the difference is whether the database understands the value or not. Different type of NoSQL databases have different properties. We'll see four major data models in a minute. 2. As we are moving towards distributed databases and not all the data is transactional we need a separate set of guarantees. 17

18 1. Key/Value stores don't understand the data in value. To query a key/value database you must have the key. 2. Redis is a very popular database with support of special data structures where values are of special kind. It can perform common operations on the provided dataset. 3. Another database that deserves a mention here is membase. It's an in-memory only database. Disk-based, fill cache, ADD/Remove nodes on the fly. So you have datastores with different features like only in-memory, persistent, support for data structures -> this shows amount of diversity in NoSQL databases. 18
19 1. Key/Value stores don't understand the data in value. To query a key/value database you must have the key. 2. Redis is a very popular database with support of special data structures where values are of special kind. It can perform common operations on the provided dataset. So you have datastores with different features like only in-memory, persistent, support for data structures -> this shows amount of diversity in NoSQL databases. 3. Apache Dynamo is also one of them, which we will discuss in detail as a case study. 19

20 Instead of Value the database takes in a document which is semi structured data. Some use JSON, some XML and other BSON. 20
21 1. BSON - binary version of JSON objects. Higher performance on the wire and compact storage. 2. In couchbase you need to materialize views to make ad-hoc queries. Declare what your indexes will be, you can query. MongoDB doesn't require xanti declaration of indexes to query. Ad-hoc queries are queries that are created on the fly with a variable parameters. 21

22 Concept is still the same. Key -> Value Notion of column forms - i.e, instead of writing the whole document at a single physical location the document is now written split across these column forms/families. Say a document has 10 columns or 10 attributes: you could write subsets of columns at particular locations so that queries on those columns are answered faster. This works well for predefined schema - HP Vertica. Cassandra is a little different from this type of storage. Cassandra writes these to different family objects which by themselves are column dependent stores. This is driven not by the schema but by the queries that are expected to be answered. 22

23 BigTable coined the column oriented structure. Joins as in relational databases is not supported. Usually different column family objects are there in a keyspace, each supporting one or more queries. To achieve the effect of joins, some extent of denormalization is necessary. 23
24 1. HBase runs only on top of HDFS while Cassandra can run on various file systems 2. Both are modeled as per BigTable's model 3. CP : Handles Consistency, Partioning out of the three in CAP. 4. AP : Handles Availability, Partioning out of the three in CAP. Cassandra supports reads and writes in case of network partition and patches it up later thus resulting in eventual consistency whereas Couchbase prevents these network partitioned writes thus maintaining consistency at any time. 24

25 Concept is still the same. Key -> Value 25

26 When performing a write transaction on a slave each write operation will be synchronized with the master (locks will be acquired on both master and slave). When the transaction commits it will first be committed on the master and then, if successful, on the slave. To ensure consistency, a slave has to be up to date with the master before performing a write operation 26

27 Couchbase = Membase(front backend for HA)+ CouchDB (deeper backend to provide query functionality) BDB can be setup as a persistent database. Depends on the config. Mostly used as embedded database. BDB when compared to membase has much much lower concurrency rates supporting only in the lower tens. Also membase is memcached cluster compatible whereas there is no implemented notion of bdb cluster. 27
28 To address above problems lot of big companies developed their in-house solutions. Non-relational, cluster friendly, open-source, 28

29 29

30 30
31 Structured because data is stored in an indexed map. 3-dimensional structure because it is just a large map that is indexed by a row key, column key, and a timestamp, which act as the dimensions. Will be more clear in the next slide. Uninterpretated becuase Each value within the map is just an array of bytes that is eventually interpreted by the application. Consistency over Availability: BigTable will preserve the guarantees of its atomic reads and writes by refusing to respond to some requests. It may decide to shut down entirely (like the clients of a single-node data store), refuse writes (like Two- Phase Commit), or only respond to reads and writes for pieces of data whose master node is inside the partition component (like Membase).It responds only after having quorom of locks [Paxos] which is managed by Chubby. [not in current 31
32 scope] 31
.")
33 Sparse : The table is sparse, meaning that different rows in a table may use different columns, with many of the columns empty for a particular row. Distributed : BigTable's data is distributed among many independent machines. At Google, BigTable is built on top of GFS (Google File System). The Apache open source version of BigTable, HBase, is built on top of HDFS (Hadoop Distributed File System) or Amazon S3. The table is broken up among rows, with groups of adjacent rows managed by a server. A row itself is never distributed. Scalable : Without changing applications, more and more nodes can be added to the network to make the cluster more scalable. Sorted A key is hashed to a position in a table. BigTable sorts its data by keys. This helps keep related data close together, usually on the same machine assuming that one structures keys in such a way that sorting brings the data together. For example, if 32
34 domain names are used as keys in a BigTable, it makes sense to store them in reverse order to ensure that related domains are close together. map A map is an associative array; a data structure that allows one to look up a value to a corresponding key quickly. BigTable is a collection of (key, value) pairs where the key identifies a row and the value is the set of columns. 32

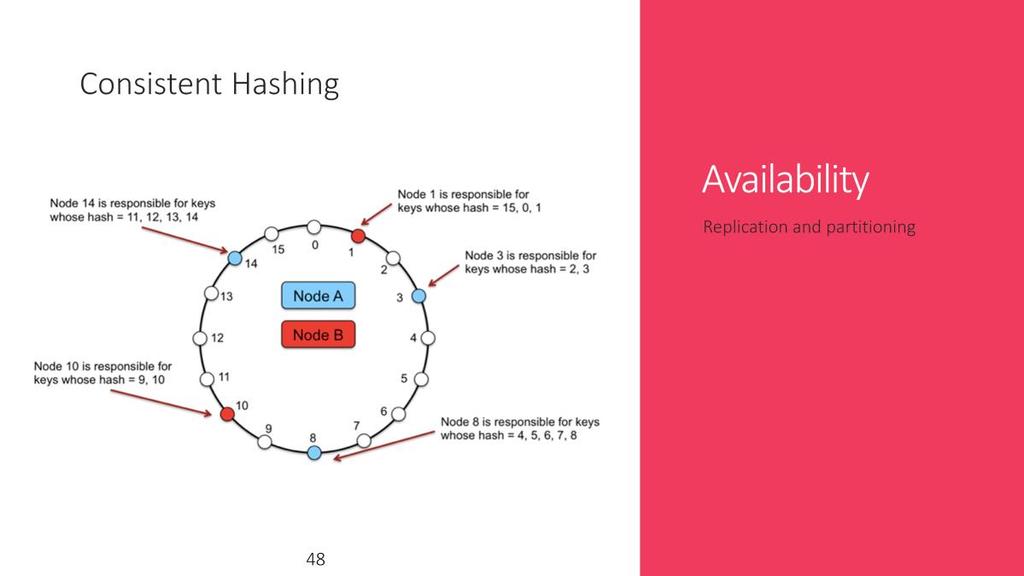
35 A table is indexed by rows. Each row contains one or more named column families. Column families are defined when the table is first created. Within a column family, one may have one or more named columns. All data within a column family is usually of the same type. The implementation of BigTable usually compresses all the columns within a column family together. Columns within a column family can be created on the fly. Rows, column families and columns provide a three-level naming hierarchy in identifying data. To get data from BigTable, you need to provide a fully-qualified name in the form column-family:column. 33
36 Chubby is a highly available and persistent distributed lock service that manages leases for resources and stores configuration information. In BigTable, Chubby is used to: ensure there is only one active master store the bootstrap location of BigTable data discover tablet servers Locating rows within a BigTable is managed in a three-level hierarchy. The root (toplevel) tablet stores the location of all Metadata tablets in a special Metadata tablet. Each Metadata table contains the location of user data tablets. This table is keyed by node IDs and each row identifies a tablet's table ID and end row. For efficiency, the client library caches tablet locations. 34

37 Need of Bloom Filters: Typically, a read operation has to read from the user tables that make up the state of a tablet. If these are not in memory, we may end up doing many disk accesses. We reduce the number of accesses by allowing clients to specify that Bloom filters should be created for these user tables. A Bloom filter allows us to ask whether an user table might contain any data for a specified row/column pair. Thus, a small amount of tablet server memory used for storing Bloom filters drastically reduces the number of disk seeks required for read operations. Interesting, isn't it! 35

38 To improve read performance, tablet servers use two levels of caching. The Scan Cache is a higher level cache that caches the key-value pairs returned by the user table interface to the tablet server code. It is most useful for applications that tend to read the same data repeatedly. The Block Cache is a lower-level cache that caches row blocks that were read from GFS. It is useful for applications that tend to read data that is close to the data they recently read (e.g., sequential reads, or random reads of different columns in the same locality group within a hot row) 36

39 37
40 DynamoDB is database from amazon that they designed to solve their availability issues. Lot of their services didn't need transactional capabilities, and they required simple key value access. They were ready to tolerate some inconsistency (for example, an item may appear in the shopping cart after you have deleted it), however you should always be able to add items to the shopping cart even in presence of failures. 38
41 low latency, SLA (service level agreement) of serving 99.9% of requests with response within 300ms at a max rate of 500req/sec 39
42 Key techniques that the dynamo chooses. 40
43 Dynamo uses consistent hashing to distribute content to nodes. Ring is the core of consistent hashing. In consistent hashing you map your data to points on ring. Ring is divided into regions and each region is then mapped to physical servers. However this approach may lead to load imbalance. allows you to have diverse set of machines by assigning diff. virtual nodes. Moreover it allows you add/remove nodes on the fly. 41
44 adding a node requires on an average 1/n+1 nodes to move. 42
45 Removing a node requires only content of removed node to be shifted. 43

46 Dynamo uses virtual nodes where multiple virtual nodes are assigned to physical nodes. This helps in balancing of load 44

47 Now we know how to distribute data. Consistent hashing also makes it easier to replicate data. Simply choose next two nodes in the cycle and replicate the data to those nodes. In the above figure N = 3. So the data is replicated to total 3 nodes. In the given example, if the hash maps to 3, then it lies in the region of A. We put the data in A, now we follow the cycle and replicate the data to two more available nodes. 45
48 "Sloppy quorums" choose the first N healthy nodes. This may lead to inconsistencies. Strict quorum systems become unavailable in case of simplest of failures, so sloppy quorums are used. 46
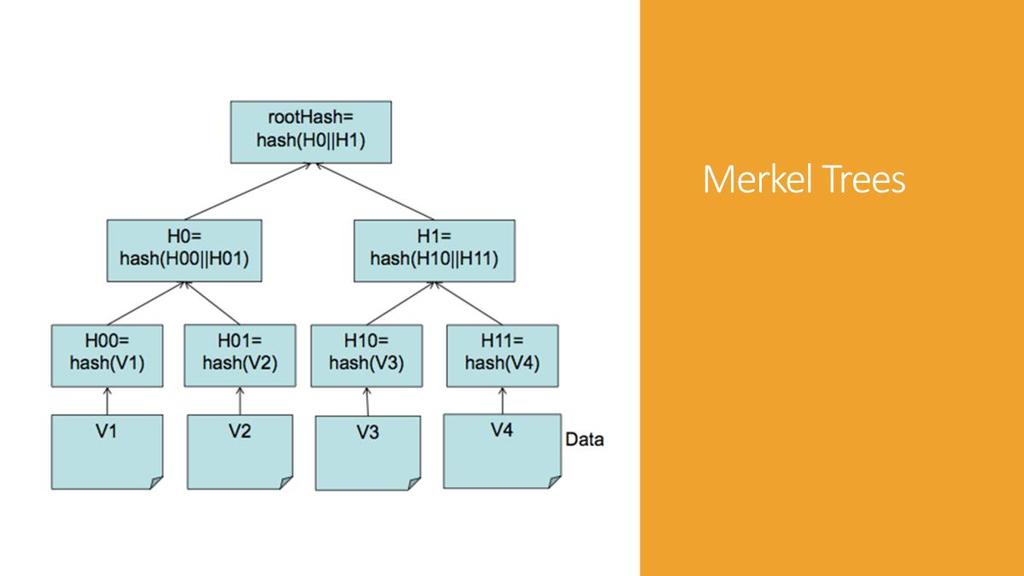
49 Key ranges because one tree per key range. Merkel tree used for synchronizing replicas. Each node keep route information to all other nodes. Routing can be done by load balancer or client library. Using client lib. it directly goes the node in the "preference list", however in case of load balancer - node routes the request to first node in list Also uses unreliable failure detection to identify failed nodes. Keeps checking in case of partitions also...built into the nodes and not a separate entities. 47
50 48

51 Hot topic in tech industry More and more companies handling a lot of data are adding NoSQL to their workflow 49
52 50
53 51
54 52

55 53
56 54

57 1. Social networks are often persisted in the form of trees and graphs. 2. Other NoSQL models resemble storing blobs against a key or even a complete XML documents against a key. 3. The main characterstic of these models are that they do not interact with each other unlike relations. Here model can be referred to the data structure used for the data storage in the database. By interacting, we mean that one data structure is independent in itself. It would never need to "join" with other data structure to get any other data. 55
58 56
59 57

60 Key techniques that the dynamo chooses. 58
61 59
 Track the version of data.")
62 Each write to a key K is associated with a vector clock VC(K) Track the version of data. 60

63 Key ranges because one tree per key range. Merkel tree used for synchronizing replicas. Each node keep route information to all other nodes. Routing can be done by load balancer or client library. Using client lib. it directly goes the node in the "preference list", however in case of load balancer - node routes the request to first node in list Also uses unreliable failure detection to identify failed nodes. Keeps checking in case of partitions also...built into the nodes and not a separate entities. 61
64 62
65 In an atomic transaction, a series of database operations either all occur, or nothing occurs. A guarantee of atomicity prevents updates to the database occurring only partially, which can cause greater problems than rejecting the whole series outright. Atomicity is said to be fulfilled in the example if either A and B both occur or neither of A or B occurs, i.e. all or none. 63
66 Consistency of the transaction in the above example requires that the total sum of A and B remain constant before and after the transaction. If after transactions, the total sum of A and B becomes a+b-10, then the database is not consistent. 64
67 Concurrency control comprises the underlying mechanisms in a DBMS which handles isolation and guarantees related correctness. It is heavily utilized by the database and storage engines both to guarantee the correct execution of concurrent transactions. (All discussed in detail in the class) 65

68 Durability is the ACID property which guarantees that transactions that have committed will survive permanently. For example, if a flight booking reports that a seat has successfully been booked, then the seat will remain booked even if the system crashes. 66

69 Sorted A key is hashed to a position in a table. BigTable sorts its data by keys. This helps keep related data close together, usually on the same machine assuming that one structures keys in such a way that sorting brings the data together. For example, if domain names are used as keys in a BigTable, it makes sense to store them in reverse order to ensure that related domains are close together. map A map is an associative array; a data structure that allows one to look up a value to a corresponding key quickly. BigTable is a collection of (key, value) pairs where the key identifies a row and the value is the set of columns. 67
70 According to CAP you can pick only two of the alternatives. BASE focuses on Availability and Partition tolerance whereas ACID focuses on Consistency and Availability. 68
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Cassandra, MongoDB, and HBase. Cassandra, MongoDB, and HBase. I have chosen these three due to their recent
 Tanton Jeppson CS 401R Lab 3 Cassandra, MongoDB, and HBase Introduction For my report I have chosen to take a deeper look at 3 NoSQL database systems: Cassandra, MongoDB, and HBase. I have chosen these
Tanton Jeppson CS 401R Lab 3 Cassandra, MongoDB, and HBase Introduction For my report I have chosen to take a deeper look at 3 NoSQL database systems: Cassandra, MongoDB, and HBase. I have chosen these
NoSQL systems. Lecture 21 (optional) Instructor: Sudeepa Roy. CompSci 516 Data Intensive Computing Systems
 Instructor: Sudeepa Roy. CompSci 516 Data Intensive Computing Systems") CompSci 516 Data Intensive Computing Systems Lecture 21 (optional) NoSQL systems Instructor: Sudeepa Roy Duke CS, Spring 2016 CompSci 516: Data Intensive Computing Systems 1 Key- Value Stores Duke CS,
CompSci 516 Data Intensive Computing Systems Lecture 21 (optional) NoSQL systems Instructor: Sudeepa Roy Duke CS, Spring 2016 CompSci 516: Data Intensive Computing Systems 1 Key- Value Stores Duke CS,
CA485 Ray Walshe NoSQL
 NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
Overview. * Some History. * What is NoSQL? * Why NoSQL? * RDBMS vs NoSQL. * NoSQL Taxonomy. *TowardsNewSQL
 * Some History * What is NoSQL? * Why NoSQL? * RDBMS vs NoSQL * NoSQL Taxonomy * Towards NewSQL Overview * Some History * What is NoSQL? * Why NoSQL? * RDBMS vs NoSQL * NoSQL Taxonomy *TowardsNewSQL NoSQL
* Some History * What is NoSQL? * Why NoSQL? * RDBMS vs NoSQL * NoSQL Taxonomy * Towards NewSQL Overview * Some History * What is NoSQL? * Why NoSQL? * RDBMS vs NoSQL * NoSQL Taxonomy *TowardsNewSQL NoSQL
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
Introduction to NoSQL Databases
 Introduction to NoSQL Databases Roman Kern KTI, TU Graz 2017-10-16 Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 1 / 31 Introduction Intro Why NoSQL? Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 2 / 31 Introduction
Introduction to NoSQL Databases Roman Kern KTI, TU Graz 2017-10-16 Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 1 / 31 Introduction Intro Why NoSQL? Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 2 / 31 Introduction
CSE 444: Database Internals. Lectures 26 NoSQL: Extensible Record Stores
 CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
References. What is Bigtable? Bigtable Data Model. Outline. Key Features. CSE 444: Database Internals
 References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
CSE 544 Principles of Database Management Systems. Magdalena Balazinska Winter 2015 Lecture 14 NoSQL
 CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2015 Lecture 14 NoSQL References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No.
CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2015 Lecture 14 NoSQL References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No.
BigTable: A Distributed Storage System for Structured Data
 BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
CS November 2018
 Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
BigTable. CSE-291 (Cloud Computing) Fall 2016
 Fall 2016") BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI Presented by Xiang Gao
 Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Introduction to Big Data. NoSQL Databases. Instituto Politécnico de Tomar. Ricardo Campos
 Instituto Politécnico de Tomar Introduction to Big Data NoSQL Databases Ricardo Campos Mestrado EI-IC Análise e Processamento de Grandes Volumes de Dados Tomar, Portugal, 2016 Part of the slides used in
Instituto Politécnico de Tomar Introduction to Big Data NoSQL Databases Ricardo Campos Mestrado EI-IC Análise e Processamento de Grandes Volumes de Dados Tomar, Portugal, 2016 Part of the slides used in
A Survey Paper on NoSQL Databases: Key-Value Data Stores and Document Stores
 A Survey Paper on NoSQL Databases: Key-Value Data Stores and Document Stores Nikhil Dasharath Karande 1 Department of CSE, Sanjay Ghodawat Institutes, Atigre nikhilkarande18@gmail.com Abstract- This paper
A Survey Paper on NoSQL Databases: Key-Value Data Stores and Document Stores Nikhil Dasharath Karande 1 Department of CSE, Sanjay Ghodawat Institutes, Atigre nikhilkarande18@gmail.com Abstract- This paper
Chapter 24 NOSQL Databases and Big Data Storage Systems
 Chapter 24 NOSQL Databases and Big Data Storage Systems - Large amounts of data such as social media, Web links, user profiles, marketing and sales, posts and tweets, road maps, spatial data, email - NOSQL
Chapter 24 NOSQL Databases and Big Data Storage Systems - Large amounts of data such as social media, Web links, user profiles, marketing and sales, posts and tweets, road maps, spatial data, email - NOSQL
DIVING IN: INSIDE THE DATA CENTER
 1 DIVING IN: INSIDE THE DATA CENTER Anwar Alhenshiri Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs it to
1 DIVING IN: INSIDE THE DATA CENTER Anwar Alhenshiri Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs it to
Introduction Aggregate data model Distribution Models Consistency Map-Reduce Types of NoSQL Databases
 Introduction Aggregate data model Distribution Models Consistency Map-Reduce Types of NoSQL Databases Key-Value Document Column Family Graph John Edgar 2 Relational databases are the prevalent solution
Introduction Aggregate data model Distribution Models Consistency Map-Reduce Types of NoSQL Databases Key-Value Document Column Family Graph John Edgar 2 Relational databases are the prevalent solution
Cassandra- A Distributed Database
 Cassandra- A Distributed Database Tulika Gupta Department of Information Technology Poornima Institute of Engineering and Technology Jaipur, Rajasthan, India Abstract- A relational database is a traditional
Cassandra- A Distributed Database Tulika Gupta Department of Information Technology Poornima Institute of Engineering and Technology Jaipur, Rajasthan, India Abstract- A relational database is a traditional
CS 655 Advanced Topics in Distributed Systems
 Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Extreme Computing. NoSQL.
 Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
Large-Scale Key-Value Stores Eventual Consistency Marco Serafini
 Large-Scale Key-Value Stores Eventual Consistency Marco Serafini COMPSCI 590S Lecture 13 Goals of Key-Value Stores Export simple API put(key, value) get(key) Simpler and faster than a DBMS Less complexity,
Large-Scale Key-Value Stores Eventual Consistency Marco Serafini COMPSCI 590S Lecture 13 Goals of Key-Value Stores Export simple API put(key, value) get(key) Simpler and faster than a DBMS Less complexity,
NoSQL Databases. Amir H. Payberah. Swedish Institute of Computer Science. April 10, 2014
 NoSQL Databases Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 10, 2014 Amir H. Payberah (SICS) NoSQL Databases April 10, 2014 1 / 67 Database and Database Management System
NoSQL Databases Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 10, 2014 Amir H. Payberah (SICS) NoSQL Databases April 10, 2014 1 / 67 Database and Database Management System
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Distributed Data Store
 Distributed Data Store Large-Scale Distributed le system Q: What if we have too much data to store in a single machine? Q: How can we create one big filesystem over a cluster of machines, whose data is
Distributed Data Store Large-Scale Distributed le system Q: What if we have too much data to store in a single machine? Q: How can we create one big filesystem over a cluster of machines, whose data is
big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures
 mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures") Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
Ghislain Fourny. Big Data 5. Wide column stores
 Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
A Study of NoSQL Database
 A Study of NoSQL Database International Journal of Engineering Research & Technology (IJERT) Biswajeet Sethi 1, Samaresh Mishra 2, Prasant ku. Patnaik 3 1,2,3 School of Computer Engineering, KIIT University
A Study of NoSQL Database International Journal of Engineering Research & Technology (IJERT) Biswajeet Sethi 1, Samaresh Mishra 2, Prasant ku. Patnaik 3 1,2,3 School of Computer Engineering, KIIT University
10. Replication. Motivation
 10. Replication Page 1 10. Replication Motivation Reliable and high-performance computation on a single instance of a data object is prone to failure. Replicate data to overcome single points of failure
10. Replication Page 1 10. Replication Motivation Reliable and high-performance computation on a single instance of a data object is prone to failure. Replicate data to overcome single points of failure
CS5412: DIVING IN: INSIDE THE DATA CENTER
 1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman We ve seen one cloud service 2 Inside a cloud, Dynamo is an example of a service used to make sure that cloud-hosted applications can scale
1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman We ve seen one cloud service 2 Inside a cloud, Dynamo is an example of a service used to make sure that cloud-hosted applications can scale
Introduction to Computer Science. William Hsu Department of Computer Science and Engineering National Taiwan Ocean University
 Introduction to Computer Science William Hsu Department of Computer Science and Engineering National Taiwan Ocean University Chapter 9: Database Systems supplementary - nosql You can have data without
Introduction to Computer Science William Hsu Department of Computer Science and Engineering National Taiwan Ocean University Chapter 9: Database Systems supplementary - nosql You can have data without
Bigtable. Presenter: Yijun Hou, Yixiao Peng
 Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Jargons, Concepts, Scope and Systems. Key Value Stores, Document Stores, Extensible Record Stores. Overview of different scalable relational systems
 Jargons, Concepts, Scope and Systems Key Value Stores, Document Stores, Extensible Record Stores Overview of different scalable relational systems Examples of different Data stores Predictions, Comparisons
Jargons, Concepts, Scope and Systems Key Value Stores, Document Stores, Extensible Record Stores Overview of different scalable relational systems Examples of different Data stores Predictions, Comparisons
CSE 530A. Non-Relational Databases. Washington University Fall 2013
 CSE 530A Non-Relational Databases Washington University Fall 2013 NoSQL "NoSQL" was originally the name of a specific RDBMS project that did not use a SQL interface Was co-opted years later to refer to
CSE 530A Non-Relational Databases Washington University Fall 2013 NoSQL "NoSQL" was originally the name of a specific RDBMS project that did not use a SQL interface Was co-opted years later to refer to
NOSQL EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY
 NOSQL EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY WHAT IS NOSQL? Stands for No-SQL or Not Only SQL. Class of non-relational data storage systems E.g.
NOSQL EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY WHAT IS NOSQL? Stands for No-SQL or Not Only SQL. Class of non-relational data storage systems E.g.
NoSQL Databases MongoDB vs Cassandra. Kenny Huynh, Andre Chik, Kevin Vu
 NoSQL Databases MongoDB vs Cassandra Kenny Huynh, Andre Chik, Kevin Vu Introduction - Relational database model - Concept developed in 1970 - Inefficient - NoSQL - Concept introduced in 1980 - Related
NoSQL Databases MongoDB vs Cassandra Kenny Huynh, Andre Chik, Kevin Vu Introduction - Relational database model - Concept developed in 1970 - Inefficient - NoSQL - Concept introduced in 1980 - Related
Database Evolution. DB NoSQL Linked Open Data. L. Vigliano
 Database Evolution DB NoSQL Linked Open Data Requirements and features Large volumes of data..increasing No regular data structure to manage Relatively homogeneous elements among them (no correlation between
Database Evolution DB NoSQL Linked Open Data Requirements and features Large volumes of data..increasing No regular data structure to manage Relatively homogeneous elements among them (no correlation between
FAQs Snapshots and locks Vector Clock
 //08 CS5 Introduction to Big - FALL 08 W.B.0.0 CS5 Introduction to Big //08 CS5 Introduction to Big - FALL 08 W.B. FAQs Snapshots and locks Vector Clock PART. LARGE SCALE DATA STORAGE SYSTEMS NO SQL DATA
//08 CS5 Introduction to Big - FALL 08 W.B.0.0 CS5 Introduction to Big //08 CS5 Introduction to Big - FALL 08 W.B. FAQs Snapshots and locks Vector Clock PART. LARGE SCALE DATA STORAGE SYSTEMS NO SQL DATA
Introduction to NoSQL
 Introduction to NoSQL Agenda History What is NoSQL Types of NoSQL The CAP theorem History - RDBMS Relational DataBase Management Systems were invented in the 1970s. E. F. Codd, "Relational Model of Data
Introduction to NoSQL Agenda History What is NoSQL Types of NoSQL The CAP theorem History - RDBMS Relational DataBase Management Systems were invented in the 1970s. E. F. Codd, "Relational Model of Data
Understanding NoSQL Database Implementations
 Understanding NoSQL Database Implementations Sadalage and Fowler, Chapters 7 11 Class 07: Understanding NoSQL Database Implementations 1 Foreword NoSQL is a broad and diverse collection of technologies.
Understanding NoSQL Database Implementations Sadalage and Fowler, Chapters 7 11 Class 07: Understanding NoSQL Database Implementations 1 Foreword NoSQL is a broad and diverse collection of technologies.
Dynamo: Amazon s Highly Available Key-value Store. ID2210-VT13 Slides by Tallat M. Shafaat
 Dynamo: Amazon s Highly Available Key-value Store ID2210-VT13 Slides by Tallat M. Shafaat Dynamo An infrastructure to host services Reliability and fault-tolerance at massive scale Availability providing
Dynamo: Amazon s Highly Available Key-value Store ID2210-VT13 Slides by Tallat M. Shafaat Dynamo An infrastructure to host services Reliability and fault-tolerance at massive scale Availability providing
Bigtable: A Distributed Storage System for Structured Data. Andrew Hon, Phyllis Lau, Justin Ng
 Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
Why NoSQL? Why Riak?
 Why NoSQL? Why Riak? Justin Sheehy justin@basho.com 1 What's all of this NoSQL nonsense? Riak Voldemort HBase MongoDB Neo4j Cassandra CouchDB Membase Redis (and the list goes on...) 2 What went wrong with
Why NoSQL? Why Riak? Justin Sheehy justin@basho.com 1 What's all of this NoSQL nonsense? Riak Voldemort HBase MongoDB Neo4j Cassandra CouchDB Membase Redis (and the list goes on...) 2 What went wrong with
Big Table. Google s Storage Choice for Structured Data. Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla
 Big Table Google s Storage Choice for Structured Data Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla Bigtable: Introduction Resembles a database. Does not support
Big Table Google s Storage Choice for Structured Data Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla Bigtable: Introduction Resembles a database. Does not support
BigTable. Chubby. BigTable. Chubby. Why Chubby? How to do consensus as a service
 BigTable BigTable Doug Woos and Tom Anderson In the early 2000s, Google had way more than anybody else did Traditional bases couldn t scale Want something better than a filesystem () BigTable optimized
BigTable BigTable Doug Woos and Tom Anderson In the early 2000s, Google had way more than anybody else did Traditional bases couldn t scale Want something better than a filesystem () BigTable optimized
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
CSE-E5430 Scalable Cloud Computing Lecture 9
 CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
CS Amazon Dynamo
 CS 5450 Amazon Dynamo Amazon s Architecture Dynamo The platform for Amazon's e-commerce services: shopping chart, best seller list, produce catalog, promotional items etc. A highly available, distributed
CS 5450 Amazon Dynamo Amazon s Architecture Dynamo The platform for Amazon's e-commerce services: shopping chart, best seller list, produce catalog, promotional items etc. A highly available, distributed
CS5412: OTHER DATA CENTER SERVICES
 1 CS5412: OTHER DATA CENTER SERVICES Lecture V Ken Birman Tier two and Inner Tiers 2 If tier one faces the user and constructs responses, what lives in tier two? Caching services are very common (many
1 CS5412: OTHER DATA CENTER SERVICES Lecture V Ken Birman Tier two and Inner Tiers 2 If tier one faces the user and constructs responses, what lives in tier two? Caching services are very common (many
Study of NoSQL Database Along With Security Comparison
 Study of NoSQL Database Along With Security Comparison Ankita A. Mall [1], Jwalant B. Baria [2] [1] Student, Computer Engineering Department, Government Engineering College, Modasa, Gujarat, India ank.fetr@gmail.com
Study of NoSQL Database Along With Security Comparison Ankita A. Mall [1], Jwalant B. Baria [2] [1] Student, Computer Engineering Department, Government Engineering College, Modasa, Gujarat, India ank.fetr@gmail.com
CIB Session 12th NoSQL Databases Structures
 CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
10 Million Smart Meter Data with Apache HBase
 10 Million Smart Meter Data with Apache HBase 5/31/2017 OSS Solution Center Hitachi, Ltd. Masahiro Ito OSS Summit Japan 2017 Who am I? Masahiro Ito ( 伊藤雅博 ) Software Engineer at Hitachi, Ltd. Focus on
10 Million Smart Meter Data with Apache HBase 5/31/2017 OSS Solution Center Hitachi, Ltd. Masahiro Ito OSS Summit Japan 2017 Who am I? Masahiro Ito ( 伊藤雅博 ) Software Engineer at Hitachi, Ltd. Focus on
Introduction to Distributed Data Systems
 Introduction to Distributed Data Systems Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook January
Introduction to Distributed Data Systems Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook January
Transactions and ACID
 Transactions and ACID Kevin Swingler Contents Recap of ACID transactions in RDBMSs Transactions and ACID in MongoDB 1 Concurrency Databases are almost always accessed by multiple users concurrently A user
Transactions and ACID Kevin Swingler Contents Recap of ACID transactions in RDBMSs Transactions and ACID in MongoDB 1 Concurrency Databases are almost always accessed by multiple users concurrently A user
Database Architectures
 Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 4/15/15 Agenda Check-in Parallelism and Distributed Databases Technology Research Project Introduction to NoSQL
Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 4/15/15 Agenda Check-in Parallelism and Distributed Databases Technology Research Project Introduction to NoSQL
Big Data Analytics. Rasoul Karimi
 Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Outline
Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Outline
Database Availability and Integrity in NoSQL. Fahri Firdausillah [M ]
![Database Availability and Integrity in NoSQL. Fahri Firdausillah [M ]](/thumbs/83/88388270.jpg "Database Availability and Integrity in NoSQL. Fahri Firdausillah [M ]") Database Availability and Integrity in NoSQL Fahri Firdausillah [M031010012] What is NoSQL Stands for Not Only SQL Mostly addressing some of the points: nonrelational, distributed, horizontal scalable,
Database Availability and Integrity in NoSQL Fahri Firdausillah [M031010012] What is NoSQL Stands for Not Only SQL Mostly addressing some of the points: nonrelational, distributed, horizontal scalable,
Sources. P. J. Sadalage, M Fowler, NoSQL Distilled, Addison Wesley
 Big Data and NoSQL Sources P. J. Sadalage, M Fowler, NoSQL Distilled, Addison Wesley Very short history of DBMSs The seventies: IMS end of the sixties, built for the Apollo program (today: Version 15)
Big Data and NoSQL Sources P. J. Sadalage, M Fowler, NoSQL Distilled, Addison Wesley Very short history of DBMSs The seventies: IMS end of the sixties, built for the Apollo program (today: Version 15)
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612
 Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
CISC 7610 Lecture 5 Distributed multimedia databases. Topics: Scaling up vs out Replication Partitioning CAP Theorem NoSQL NewSQL
 CISC 7610 Lecture 5 Distributed multimedia databases Topics: Scaling up vs out Replication Partitioning CAP Theorem NoSQL NewSQL Motivation YouTube receives 400 hours of video per minute That is 200M hours
CISC 7610 Lecture 5 Distributed multimedia databases Topics: Scaling up vs out Replication Partitioning CAP Theorem NoSQL NewSQL Motivation YouTube receives 400 hours of video per minute That is 200M hours
CompSci 516 Database Systems
 CompSci 516 Database Systems Lecture 20 NoSQL and Column Store Instructor: Sudeepa Roy Duke CS, Fall 2018 CompSci 516: Database Systems 1 Reading Material NOSQL: Scalable SQL and NoSQL Data Stores Rick
CompSci 516 Database Systems Lecture 20 NoSQL and Column Store Instructor: Sudeepa Roy Duke CS, Fall 2018 CompSci 516: Database Systems 1 Reading Material NOSQL: Scalable SQL and NoSQL Data Stores Rick
CMU SCS CMU SCS Who: What: When: Where: Why: CMU SCS
 Carnegie Mellon Univ. Dept. of Computer Science 15-415/615 - DB s C. Faloutsos A. Pavlo Lecture#23: Distributed Database Systems (R&G ch. 22) Administrivia Final Exam Who: You What: R&G Chapters 15-22
Carnegie Mellon Univ. Dept. of Computer Science 15-415/615 - DB s C. Faloutsos A. Pavlo Lecture#23: Distributed Database Systems (R&G ch. 22) Administrivia Final Exam Who: You What: R&G Chapters 15-22
Recap. CSE 486/586 Distributed Systems Case Study: Amazon Dynamo. Amazon Dynamo. Amazon Dynamo. Necessary Pieces? Overview of Key Design Techniques
 Recap CSE 486/586 Distributed Systems Case Study: Amazon Dynamo Steve Ko Computer Sciences and Engineering University at Buffalo CAP Theorem? Consistency, Availability, Partition Tolerance P then C? A?
Recap CSE 486/586 Distributed Systems Case Study: Amazon Dynamo Steve Ko Computer Sciences and Engineering University at Buffalo CAP Theorem? Consistency, Availability, Partition Tolerance P then C? A?
COSC 416 NoSQL Databases. NoSQL Databases Overview. Dr. Ramon Lawrence University of British Columbia Okanagan
 COSC 416 NoSQL Databases NoSQL Databases Overview Dr. Ramon Lawrence University of British Columbia Okanagan ramon.lawrence@ubc.ca Databases Brought Back to Life!!! Image copyright: www.dragoart.com Image
COSC 416 NoSQL Databases NoSQL Databases Overview Dr. Ramon Lawrence University of British Columbia Okanagan ramon.lawrence@ubc.ca Databases Brought Back to Life!!! Image copyright: www.dragoart.com Image
Big Data Processing Technologies. Chentao Wu Associate Professor Dept. of Computer Science and Engineering
 Big Data Processing Technologies Chentao Wu Associate Professor Dept. of Computer Science and Engineering wuct@cs.sjtu.edu.cn Schedule (1) Storage system part (first eight weeks) lec1: Introduction on
Big Data Processing Technologies Chentao Wu Associate Professor Dept. of Computer Science and Engineering wuct@cs.sjtu.edu.cn Schedule (1) Storage system part (first eight weeks) lec1: Introduction on
6.830 Lecture Spark 11/15/2017
 6.830 Lecture 19 -- Spark 11/15/2017 Recap / finish dynamo Sloppy Quorum (healthy N) Dynamo authors don't think quorums are sufficient, for 2 reasons: - Decreased durability (want to write all data at
6.830 Lecture 19 -- Spark 11/15/2017 Recap / finish dynamo Sloppy Quorum (healthy N) Dynamo authors don't think quorums are sufficient, for 2 reasons: - Decreased durability (want to write all data at
Advanced Data Management Technologies
 ADMT 2017/18 Unit 15 J. Gamper 1/44 Advanced Data Management Technologies Unit 15 Introduction to NoSQL J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE ADMT 2017/18 Unit 15
ADMT 2017/18 Unit 15 J. Gamper 1/44 Advanced Data Management Technologies Unit 15 Introduction to NoSQL J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE ADMT 2017/18 Unit 15
The NoSQL Landscape. Frank Weigel VP, Field Technical Opera;ons
 The NoSQL Landscape Frank Weigel VP, Field Technical Opera;ons What we ll talk about Why RDBMS are not enough? What are the different NoSQL taxonomies? Which NoSQL is right for me? Macro Trends Driving
The NoSQL Landscape Frank Weigel VP, Field Technical Opera;ons What we ll talk about Why RDBMS are not enough? What are the different NoSQL taxonomies? Which NoSQL is right for me? Macro Trends Driving
Apache Cassandra - A Decentralized Structured Storage System
 Apache Cassandra - A Decentralized Structured Storage System Avinash Lakshman Prashant Malik from Facebook Presented by: Oded Naor Acknowledgments Some slides are based on material from: Idit Keidar, Topics
Apache Cassandra - A Decentralized Structured Storage System Avinash Lakshman Prashant Malik from Facebook Presented by: Oded Naor Acknowledgments Some slides are based on material from: Idit Keidar, Topics
NoSQL systems: sharding, replication and consistency. Riccardo Torlone Università Roma Tre
 NoSQL systems: sharding, replication and consistency Riccardo Torlone Università Roma Tre Data distribution NoSQL systems: data distributed over large clusters Aggregate is a natural unit to use for data
NoSQL systems: sharding, replication and consistency Riccardo Torlone Università Roma Tre Data distribution NoSQL systems: data distributed over large clusters Aggregate is a natural unit to use for data
CS5412: DIVING IN: INSIDE THE DATA CENTER
 1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs
1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs
The NoSQL movement. CouchDB as an example
 The NoSQL movement CouchDB as an example About me sleepnova - I'm a freelancer Interests: emerging technology, digital art web, embedded system, javascript, programming language Some of my works: Chrome
The NoSQL movement CouchDB as an example About me sleepnova - I'm a freelancer Interests: emerging technology, digital art web, embedded system, javascript, programming language Some of my works: Chrome
Cassandra Design Patterns
 Cassandra Design Patterns Sanjay Sharma Chapter No. 1 "An Overview of Architecture and Data Modeling in Cassandra" In this package, you will find: A Biography of the author of the book A preview chapter
Cassandra Design Patterns Sanjay Sharma Chapter No. 1 "An Overview of Architecture and Data Modeling in Cassandra" In this package, you will find: A Biography of the author of the book A preview chapter
Integrity in Distributed Databases
 Integrity in Distributed Databases Andreas Farella Free University of Bozen-Bolzano Table of Contents 1 Introduction................................................... 3 2 Different aspects of integrity.....................................
Integrity in Distributed Databases Andreas Farella Free University of Bozen-Bolzano Table of Contents 1 Introduction................................................... 3 2 Different aspects of integrity.....................................
Relational databases
 COSC 6397 Big Data Analytics NoSQL databases Edgar Gabriel Spring 2017 Relational databases Long lasting industry standard to store data persistently Key points concurrency control, transactions, standard
COSC 6397 Big Data Analytics NoSQL databases Edgar Gabriel Spring 2017 Relational databases Long lasting industry standard to store data persistently Key points concurrency control, transactions, standard
10/18/2017. Announcements. NoSQL Motivation. NoSQL. Serverless Architecture. What is the Problem? Database Systems CSE 414
 Announcements Database Systems CSE 414 Lecture 11: NoSQL & JSON (mostly not in textbook only Ch 11.1) HW5 will be posted on Friday and due on Nov. 14, 11pm [No Web Quiz 5] Today s lecture: NoSQL & JSON
Announcements Database Systems CSE 414 Lecture 11: NoSQL & JSON (mostly not in textbook only Ch 11.1) HW5 will be posted on Friday and due on Nov. 14, 11pm [No Web Quiz 5] Today s lecture: NoSQL & JSON
Bigtable. A Distributed Storage System for Structured Data. Presenter: Yunming Zhang Conglong Li. Saturday, September 21, 13
 Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
CS 138: Dynamo. CS 138 XXIV 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 138: Dynamo CS 138 XXIV 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Dynamo Highly available and scalable distributed data store Manages state of services that have high reliability and
CS 138: Dynamo CS 138 XXIV 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Dynamo Highly available and scalable distributed data store Manages state of services that have high reliability and
Performance and Forgiveness. June 23, 2008 Margo Seltzer Harvard University School of Engineering and Applied Sciences
 Performance and Forgiveness June 23, 2008 Margo Seltzer Harvard University School of Engineering and Applied Sciences Margo Seltzer Architect Outline A consistency primer Techniques and costs of consistency
Performance and Forgiveness June 23, 2008 Margo Seltzer Harvard University School of Engineering and Applied Sciences Margo Seltzer Architect Outline A consistency primer Techniques and costs of consistency
Non-Relational Databases. Pelle Jakovits
 Non-Relational Databases Pelle Jakovits 25 October 2017 Outline Background Relational model Database scaling The NoSQL Movement CAP Theorem Non-relational data models Key-value Document-oriented Column
Non-Relational Databases Pelle Jakovits 25 October 2017 Outline Background Relational model Database scaling The NoSQL Movement CAP Theorem Non-relational data models Key-value Document-oriented Column
Ghislain Fourny. Big Data 5. Column stores
 Ghislain Fourny Big Data 5. Column stores 1 Introduction 2 Relational model 3 Relational model Schema 4 Issues with relational databases (RDBMS) Small scale Single machine 5 Can we fix a RDBMS? Scale up
Ghislain Fourny Big Data 5. Column stores 1 Introduction 2 Relational model 3 Relational model Schema 4 Issues with relational databases (RDBMS) Small scale Single machine 5 Can we fix a RDBMS? Scale up
Spotify. Scaling storage to million of users world wide. Jimmy Mårdell October 14, 2014
 Cassandra @ Spotify Scaling storage to million of users world wide! Jimmy Mårdell October 14, 2014 2 About me Jimmy Mårdell Tech Product Owner in the Cassandra team 4 years at Spotify
Cassandra @ Spotify Scaling storage to million of users world wide! Jimmy Mårdell October 14, 2014 2 About me Jimmy Mårdell Tech Product Owner in the Cassandra team 4 years at Spotify
Recap. CSE 486/586 Distributed Systems Case Study: Amazon Dynamo. Amazon Dynamo. Amazon Dynamo. Necessary Pieces? Overview of Key Design Techniques
 Recap Distributed Systems Case Study: Amazon Dynamo CAP Theorem? Consistency, Availability, Partition Tolerance P then C? A? Eventual consistency? Availability and partition tolerance over consistency
Recap Distributed Systems Case Study: Amazon Dynamo CAP Theorem? Consistency, Availability, Partition Tolerance P then C? A? Eventual consistency? Availability and partition tolerance over consistency
CAP Theorem, BASE & DynamoDB
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत DS256:Jan18 (3:1) Department of Computational and Data Sciences CAP Theorem, BASE & DynamoDB Yogesh Simmhan Yogesh Simmhan
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत DS256:Jan18 (3:1) Department of Computational and Data Sciences CAP Theorem, BASE & DynamoDB Yogesh Simmhan Yogesh Simmhan
DYNAMO: AMAZON S HIGHLY AVAILABLE KEY-VALUE STORE. Presented by Byungjin Jun
 DYNAMO: AMAZON S HIGHLY AVAILABLE KEY-VALUE STORE Presented by Byungjin Jun 1 What is Dynamo for? Highly available key-value storages system Simple primary-key only interface Scalable and Reliable Tradeoff:
DYNAMO: AMAZON S HIGHLY AVAILABLE KEY-VALUE STORE Presented by Byungjin Jun 1 What is Dynamo for? Highly available key-value storages system Simple primary-key only interface Scalable and Reliable Tradeoff:
Module - 17 Lecture - 23 SQL and NoSQL systems. (Refer Slide Time: 00:04)
") Introduction to Morden Application Development Dr. Gaurav Raina Prof. Tanmai Gopal Department of Computer Science and Engineering Indian Institute of Technology, Madras Module - 17 Lecture - 23 SQL and
Introduction to Morden Application Development Dr. Gaurav Raina Prof. Tanmai Gopal Department of Computer Science and Engineering Indian Institute of Technology, Madras Module - 17 Lecture - 23 SQL and
CSE 344 JULY 9 TH NOSQL
 CSE 344 JULY 9 TH NOSQL ADMINISTRATIVE MINUTIAE HW3 due Wednesday tests released actual_time should have 0s not NULLs upload new data file or use UPDATE to change 0 ~> NULL Extra OOs on Mondays 5-7pm in
CSE 344 JULY 9 TH NOSQL ADMINISTRATIVE MINUTIAE HW3 due Wednesday tests released actual_time should have 0s not NULLs upload new data file or use UPDATE to change 0 ~> NULL Extra OOs on Mondays 5-7pm in
Google big data techniques (2)
") Google big data techniques (2) Lecturer: Jiaheng Lu Fall 2016 10.12.2016 1 Outline Google File System and HDFS Relational DB V.S. Big data system Google Bigtable and NoSQL databases 2016/12/10 3 The Google
Google big data techniques (2) Lecturer: Jiaheng Lu Fall 2016 10.12.2016 1 Outline Google File System and HDFS Relational DB V.S. Big data system Google Bigtable and NoSQL databases 2016/12/10 3 The Google
Scalability of web applications
 Scalability of web applications CSCI 470: Web Science Keith Vertanen Copyright 2014 Scalability questions Overview What's important in order to build scalable web sites? High availability vs. load balancing
Scalability of web applications CSCI 470: Web Science Keith Vertanen Copyright 2014 Scalability questions Overview What's important in order to build scalable web sites? High availability vs. load balancing
Final Exam Logistics. CS 133: Databases. Goals for Today. Some References Used. Final exam take-home. Same resources as midterm
 Final Exam Logistics CS 133: Databases Fall 2018 Lec 25 12/06 NoSQL Final exam take-home Available: Friday December 14 th, 4:00pm in Olin Due: Monday December 17 th, 5:15pm Same resources as midterm Except
Final Exam Logistics CS 133: Databases Fall 2018 Lec 25 12/06 NoSQL Final exam take-home Available: Friday December 14 th, 4:00pm in Olin Due: Monday December 17 th, 5:15pm Same resources as midterm Except
Column-Family Databases Cassandra and HBase
 Column-Family Databases Cassandra and HBase Kevin Swingler Google Big Table Google invented BigTableto store the massive amounts of semi-structured data it was generating Basic model stores items indexed
Column-Family Databases Cassandra and HBase Kevin Swingler Google Big Table Google invented BigTableto store the massive amounts of semi-structured data it was generating Basic model stores items indexed
CS-580K/480K Advanced Topics in Cloud Computing. NoSQL Database
 CS-580K/480K dvanced Topics in Cloud Computing NoSQL Database 1 1 Where are we? Cloud latforms 2 VM1 VM2 VM3 3 Operating System 4 1 2 3 Operating System 4 1 2 Virtualization Layer 3 Operating System 4
CS-580K/480K dvanced Topics in Cloud Computing NoSQL Database 1 1 Where are we? Cloud latforms 2 VM1 VM2 VM3 3 Operating System 4 1 2 3 Operating System 4 1 2 Virtualization Layer 3 Operating System 4
Using space-filling curves for multidimensional
 Using space-filling curves for multidimensional indexing Dr. Bisztray Dénes Senior Research Engineer 1 Nokia Solutions and Networks 2014 In medias res Performance problems with RDBMS Switch to NoSQL store
Using space-filling curves for multidimensional indexing Dr. Bisztray Dénes Senior Research Engineer 1 Nokia Solutions and Networks 2014 In medias res Performance problems with RDBMS Switch to NoSQL store
EECS 498 Introduction to Distributed Systems
 EECS 498 Introduction to Distributed Systems Fall 2017 Harsha V. Madhyastha Dynamo Recap Consistent hashing 1-hop DHT enabled by gossip Execution of reads and writes Coordinated by first available successor
EECS 498 Introduction to Distributed Systems Fall 2017 Harsha V. Madhyastha Dynamo Recap Consistent hashing 1-hop DHT enabled by gossip Execution of reads and writes Coordinated by first available successor
W b b 2.0. = = Data Ex E pl p o l s o io i n
 Hypertable Doug Judd Zvents, Inc. Background Web 2.0 = Data Explosion Web 2.0 Mt. Web 2.0 Traditional Tools Don t Scale Well Designed for a single machine Typical scaling solutions ad-hoc manual/static
Hypertable Doug Judd Zvents, Inc. Background Web 2.0 = Data Explosion Web 2.0 Mt. Web 2.0 Traditional Tools Don t Scale Well Designed for a single machine Typical scaling solutions ad-hoc manual/static
Advances in Data Management - NoSQL, NewSQL and Big Data A.Poulovassilis
 Advances in Data Management - NoSQL, NewSQL and Big Data A.Poulovassilis 1 NoSQL So-called NoSQL systems offer reduced functionalities compared to traditional Relational DBMSs, with the aim of achieving
Advances in Data Management - NoSQL, NewSQL and Big Data A.Poulovassilis 1 NoSQL So-called NoSQL systems offer reduced functionalities compared to traditional Relational DBMSs, with the aim of achieving