Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI Presented by Xiang Gao
|
|
|
- Milton Randall
- 6 years ago
- Views:
Transcription
1 Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao
2 Outline Motivation Data Model APIs Building Blocks Implementation Refinement Evaluation
3 Outline Motivation Data Model APIs Building Blocks Implementation Refinement Evaluation
4 Google s Motivation Lots of data Web contents, satellite data, user data, , etc. Different projects/applications Billions of users Many incoming requests Storage for structured data No commercial system big enough Low-level storage optimization help performance significantly
5 Bigtable Distributed multi-level map Fault-tolerant, persistent Scalable Thousands of servers Terabytes of in-memory data Petabyte of disk-based data Millions of reads/writes per second, efficient scans Self-managing Servers can be added/removed dynamically Servers adjust to load imbalance
6 Outline Motivation Data Model APIs Building Blocks Implementation Refinement Evaluation
7 Data Model A sparse, distributed persistent multi-dimensional sorted map The map is indexed by a row key, a column key, and a timestamp; each value in the map is an uninterpreted array of bytes. (row, column, timestamp) -> cell contents
8 Data Model Rows Arbitrary string Access to data in a row is atomic Ordered lexicographically Row
9 Data Model Column Two-level name structure: family: qualifier Column Family is the unit of access control Column family
10 Data Model Timestamps Store different versions of data in a cell Lookup options Return most recent n versions Return new enough versions timestamps
11 Data Model The row range for a table is dynamically partitioned Each row range is called a tablet Tablet is the unit for distribution and load balancing
12 Outline Motivation Data Model APIs Building Blocks Implementation Refinement Evaluation
13 APIs Metadata operations Create/delete tables, column families, etc. Writes Set(): write cells in a row DeleteCells(): delete cells in a row DeleteRow(): delete all cells in a row Reads Scanner: read arbitrary cells in a bigtable Each row read is atomic Can restrict returned rows to a particular range Can ask for just data from 1 row, all rows, etc. Can ask for all columns, just certain column families, or specific columns
14 Outline Motivation Data Model APIs Building Blocks Implementation Refinement Evaluation
15 Building Blocks Bigtable uses the distributed Google File System (GFS) to store log and data files The Google SSTable file format is used internally to store Bigtable data An SSTable provides a persistent, ordered immutable map from keys to values Each SSTable contains a sequence of blocks A block index (stored at the end of SSTable) is used to locate blocks The index is loaded into memory when the SSTable is open

16 Tablet and SSTables SSTable 64KB 64KB 64KB Block Block Block
17 GFS write flow
18 Outline Motivation Data Model APIs Building Blocks Implementation Refinement Evaluation
19 Implementation Single-master distributed system Three major components Library that linked into every client One master server Assigning tablets to tablet servers Detecting addition and expiration of tablet servers Balancing tablet-server load Garbage collection Metadata Operations Many tablet servers Tablet servers handle read and write requests to its table Splits tablets that have grown too large
20 Implementation BigTable Client BigTable Master Performs metadata ops load balancing Metadata ops BigTable Client Library Read/Write BigTable Tablet Server Serves data BigTable Tablet Server Serves data Open Cluster scheduling system GFS Chubby Handles failover, monitoring, scheduling Holds tablet data, logs Holds metadata, handles master election
21 Master Operation Upon start up the master needs to discover the current tablet assignment. Obtains unique master lock in Chubby Prevents concurrent master instantiations Scans servers directory in Chubby for live servers Communicates with every live tablet server Discover all tablets Scans METADATA table to learn the set of tablets Unassigned tablets are marked for assignment
22 Master Operation Detect tablet server failures/resumption Master periodically asks each tablet server for the status of its lock Tablet server lost its lock or master cannot contact tablet server: Master attempts to acquire exclusive lock on the server s file in the servers directory If master acquires the lock then the tablets assigned to the tablet server are assigned to others If master loses its Chubby session then it kills itself Election will be triggered
23 Implementation Each Tablets is assigned to one tablet server. Tablet holds contiguous range of rows Clients can often choose row keys to achieve locality Aim for 100MB to 200MB of data per tablet Automatically split tablets that have grown too large Tablet server is responsible for tablets Clients communicate directly with tablet servers

24 Given a row, how do clients find the location of the tablet whose row range covers the target row? METADATA: Key: table id + end row, Data: location
25 Tablet Locating A 3-level hierarchy analogous to that of a B+ tree to store tablet location information : A file stored in chubby contains location of the root tablet Root tablet contains location of Metadata tablets The root tablet never splits Each meta-data tablet contains the locations of a set of user tablets Client library aggressively caches tablet locations
26 Tablet Server When a tablet server starts, it creates and acquires exclusive lock on, a uniquely-named file in a specific Chubby directory Call this servers directory A tablet server stops serving its tablets if it loses its exclusive lock This may happen if there is a network connection failure that causes the tablet server to lose its Chubby session
27 Tablet Server A tablet server will attempt to reacquire an exclusive lock on its file as long as the file still exists If the file no longer exists then the tablet server will never be able to serve again Kills itself At some point it can restart; it goes to a pool of unassigned tablet servers
28 Tablet Server Failover Master Chubby Server Master Chubby Server X Message sent to tablet server by master Tablet server X Tablet X server X X Tablet server (other tablet servers drafted to serve other abandoned tablets) Logical view: Tablet Tablet Tablet Tablet Tablet Tablet Logical view: Tablet Tablet Tablet Tablet GFS Chunkserver GFS Chunkserver GFS Chunkserver Backup copy of tablet made primary Physical layout: SSTable SSTable SSTable SSTable SSTable SSTable Physical layout: SSTable SSTable SSTable (replica) SSTable (replica) SSTable (replica) SSTable Extra replica of tablet created automatically by GFS Image source:
29 Tablet Server Commit log stores the updates that are made to the data Recent updates are stored in memtable (sorted buffer) Older updates are stored in SStable files Memtable Read Op Memory GFS Tablet Log SST SST SST Write Op SSTable Files
30 Compactions Minor compaction At the threshold Reduce memory usage Reduce log traffic on restart Merging compaction Periodically Reduce number of SSTables Good place to apply policy keep only N versions Major compaction Results in only one SSTable No deletion records, only live data
31 Refinements Locality groups Clients can group multiple column families together into a locality group. Compression Compression applied to each SSTable block separately Uses Bentley and McIlroy's scheme and fast compression algorithm Caching for read performance Scan Cache and Block Cache Bloom filters Reduce the number of disk accesses
32 Outline Motivation Data Model APIs Building Blocks Implementation Refinement Evaluation
33 Evaluation N tablet servers (N=1,50,250,500) Round-trip time less than 1ms R row-keys ~ 1GB data per tablet server 1000-byte values one time 6 operations
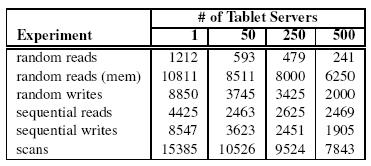
34 Evaluation
35 Performance - Scaling As the number of tablet servers is increased by a factor of 500: Performance of random reads from memory increases by a factor of 300. Performance of scans increases by a factor of 260. Not Linear! WHY?
36 Comments The authors claim a very low failure rate, whereas they also mentioned the vulnerability in lessons due to many types of failures. Extend in this direction. The API does not support standard SQL query, it could be obstacle for applications, such as secondary index.

37 Thanks!
Big Table. Google s Storage Choice for Structured Data. Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla
 Big Table Google s Storage Choice for Structured Data Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla Bigtable: Introduction Resembles a database. Does not support
Big Table Google s Storage Choice for Structured Data Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla Bigtable: Introduction Resembles a database. Does not support
CSE 444: Database Internals. Lectures 26 NoSQL: Extensible Record Stores
 CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
Bigtable. A Distributed Storage System for Structured Data. Presenter: Yunming Zhang Conglong Li. Saturday, September 21, 13
 Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable: A Distributed Storage System for Structured Data. Andrew Hon, Phyllis Lau, Justin Ng
 Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
Bigtable. Presenter: Yijun Hou, Yixiao Peng
 Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis
 Slides adapted by Tyler Davis") BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis Motivation Lots of (semi-)structured data at Google URLs: Contents, crawl metadata, links, anchors, pagerank,
BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis Motivation Lots of (semi-)structured data at Google URLs: Contents, crawl metadata, links, anchors, pagerank,
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612
 Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
References. What is Bigtable? Bigtable Data Model. Outline. Key Features. CSE 444: Database Internals
 References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
Introduction Data Model API Building Blocks SSTable Implementation Tablet Location Tablet Assingment Tablet Serving Compactions Refinements
 Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. M. Burak ÖZTÜRK 1 Introduction Data Model API Building
Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. M. Burak ÖZTÜRK 1 Introduction Data Model API Building
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
BigTable: A Distributed Storage System for Structured Data
 BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
Distributed Systems [Fall 2012]
![Distributed Systems [Fall 2012]](/thumbs/75/71557798.jpg "Distributed Systems [Fall 2012]") Distributed Systems [Fall 2012] Lec 20: Bigtable (cont ed) Slide acks: Mohsen Taheriyan (http://www-scf.usc.edu/~csci572/2011spring/presentations/taheriyan.pptx) 1 Chubby (Reminder) Lock service with a
Distributed Systems [Fall 2012] Lec 20: Bigtable (cont ed) Slide acks: Mohsen Taheriyan (http://www-scf.usc.edu/~csci572/2011spring/presentations/taheriyan.pptx) 1 Chubby (Reminder) Lock service with a
BigTable. CSE-291 (Cloud Computing) Fall 2016
 Fall 2016") BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
Structured Big Data 1: Google Bigtable & HBase Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC
 CSIE, NDHU, Taiwan, ROC") Structured Big Data 1: Google Bigtable & HBase Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC Lecture material is mostly home-grown, partly taken with permission and courtesy from Professor Shih-Wei Liao
Structured Big Data 1: Google Bigtable & HBase Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC Lecture material is mostly home-grown, partly taken with permission and courtesy from Professor Shih-Wei Liao
CS November 2018
 Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
BigTable. Chubby. BigTable. Chubby. Why Chubby? How to do consensus as a service
 BigTable BigTable Doug Woos and Tom Anderson In the early 2000s, Google had way more than anybody else did Traditional bases couldn t scale Want something better than a filesystem () BigTable optimized
BigTable BigTable Doug Woos and Tom Anderson In the early 2000s, Google had way more than anybody else did Traditional bases couldn t scale Want something better than a filesystem () BigTable optimized
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
7680: Distributed Systems
 Cristina Nita-Rotaru 7680: Distributed Systems BigTable. Hbase.Spanner. 1: BigTable Acknowledgement } Slides based on material from course at UMichigan, U Washington, and the authors of BigTable and Spanner.
Cristina Nita-Rotaru 7680: Distributed Systems BigTable. Hbase.Spanner. 1: BigTable Acknowledgement } Slides based on material from course at UMichigan, U Washington, and the authors of BigTable and Spanner.
BigTable A System for Distributed Structured Storage
 BigTable A System for Distributed Structured Storage Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber Adapted
BigTable A System for Distributed Structured Storage Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber Adapted
BigTable: A System for Distributed Structured Storage
 BigTable: A System for Distributed Structured Storage Jeff Dean Joint work with: Mike Burrows, Tushar Chandra, Fay Chang, Mike Epstein, Andrew Fikes, Sanjay Ghemawat, Robert Griesemer, Bob Gruber, Wilson
BigTable: A System for Distributed Structured Storage Jeff Dean Joint work with: Mike Burrows, Tushar Chandra, Fay Chang, Mike Epstein, Andrew Fikes, Sanjay Ghemawat, Robert Griesemer, Bob Gruber, Wilson
CSE 544 Principles of Database Management Systems. Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable
 CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable References Bigtable: A Distributed Storage System for Structured Data. Fay Chang et. al. OSDI
CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable References Bigtable: A Distributed Storage System for Structured Data. Fay Chang et. al. OSDI
Distributed Database Case Study on Google s Big Tables
 Distributed Database Case Study on Google s Big Tables Anjali diwakar dwivedi 1, Usha sadanand patil 2 and Vinayak D.Shinde 3 1,2,3 Computer Engineering, Shree l.r.tiwari college of engineering Abstract-
Distributed Database Case Study on Google s Big Tables Anjali diwakar dwivedi 1, Usha sadanand patil 2 and Vinayak D.Shinde 3 1,2,3 Computer Engineering, Shree l.r.tiwari college of engineering Abstract-
Bigtable: A Distributed Storage System for Structured Data
 Bigtable: A Distributed Storage System for Structured Data Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber {fay,jeff,sanjay,wilsonh,kerr,m3b,tushar,fikes,gruber}@google.com
Bigtable: A Distributed Storage System for Structured Data Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber {fay,jeff,sanjay,wilsonh,kerr,m3b,tushar,fikes,gruber}@google.com
MapReduce & BigTable
 CPSC 426/526 MapReduce & BigTable Ennan Zhai Computer Science Department Yale University Lecture Roadmap Cloud Computing Overview Challenges in the Clouds Distributed File Systems: GFS Data Process & Analysis:
CPSC 426/526 MapReduce & BigTable Ennan Zhai Computer Science Department Yale University Lecture Roadmap Cloud Computing Overview Challenges in the Clouds Distributed File Systems: GFS Data Process & Analysis:
CS5412: OTHER DATA CENTER SERVICES
 1 CS5412: OTHER DATA CENTER SERVICES Lecture V Ken Birman Tier two and Inner Tiers 2 If tier one faces the user and constructs responses, what lives in tier two? Caching services are very common (many
1 CS5412: OTHER DATA CENTER SERVICES Lecture V Ken Birman Tier two and Inner Tiers 2 If tier one faces the user and constructs responses, what lives in tier two? Caching services are very common (many
Outline. Spanner Mo/va/on. Tom Anderson
 Spanner Mo/va/on Tom Anderson Outline Last week: Chubby: coordina/on service BigTable: scalable storage of structured data GFS: large- scale storage for bulk data Today/Friday: Lessons from GFS/BigTable
Spanner Mo/va/on Tom Anderson Outline Last week: Chubby: coordina/on service BigTable: scalable storage of structured data GFS: large- scale storage for bulk data Today/Friday: Lessons from GFS/BigTable
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
CSE-E5430 Scalable Cloud Computing Lecture 9
 CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
Bigtable: A Distributed Storage System for Structured Data
 4 Bigtable: A Distributed Storage System for Structured Data FAY CHANG, JEFFREY DEAN, SANJAY GHEMAWAT, WILSON C. HSIEH, DEBORAH A. WALLACH, MIKE BURROWS, TUSHAR CHANDRA, ANDREW FIKES, and ROBERT E. GRUBER
4 Bigtable: A Distributed Storage System for Structured Data FAY CHANG, JEFFREY DEAN, SANJAY GHEMAWAT, WILSON C. HSIEH, DEBORAH A. WALLACH, MIKE BURROWS, TUSHAR CHANDRA, ANDREW FIKES, and ROBERT E. GRUBER
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Lecture: The Google Bigtable
 Lecture: The Google Bigtable h#p://research.google.com/archive/bigtable.html 10/09/2014 Romain Jaco3n romain.jaco7n@orange.fr Agenda Introduc3on Data model API Building blocks Implementa7on Refinements
Lecture: The Google Bigtable h#p://research.google.com/archive/bigtable.html 10/09/2014 Romain Jaco3n romain.jaco7n@orange.fr Agenda Introduc3on Data model API Building blocks Implementa7on Refinements
CS5412: DIVING IN: INSIDE THE DATA CENTER
 1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs
1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs
big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures
 mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures") Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
Extreme Computing. NoSQL.
 Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
Google File System and BigTable. and tiny bits of HDFS (Hadoop File System) and Chubby. Not in textbook; additional information
 and Chubby. Not in textbook; additional information") Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
Bigtable: A Distributed Storage System for Structured Data
 Bigtable: A Distributed Storage System for Structured Data Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber ~Harshvardhan
Bigtable: A Distributed Storage System for Structured Data Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber ~Harshvardhan
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Google Data Management
 Google Data Management Vera Goebel Department of Informatics, University of Oslo 2009 Google Technology Kaizan: continuous developments and improvements Grid computing: Google data centers and messages
Google Data Management Vera Goebel Department of Informatics, University of Oslo 2009 Google Technology Kaizan: continuous developments and improvements Grid computing: Google data centers and messages
CA485 Ray Walshe NoSQL
 NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
Google big data techniques (2)
") Google big data techniques (2) Lecturer: Jiaheng Lu Fall 2016 10.12.2016 1 Outline Google File System and HDFS Relational DB V.S. Big data system Google Bigtable and NoSQL databases 2016/12/10 3 The Google
Google big data techniques (2) Lecturer: Jiaheng Lu Fall 2016 10.12.2016 1 Outline Google File System and HDFS Relational DB V.S. Big data system Google Bigtable and NoSQL databases 2016/12/10 3 The Google
CS5412: DIVING IN: INSIDE THE DATA CENTER
 1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman We ve seen one cloud service 2 Inside a cloud, Dynamo is an example of a service used to make sure that cloud-hosted applications can scale
1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman We ve seen one cloud service 2 Inside a cloud, Dynamo is an example of a service used to make sure that cloud-hosted applications can scale
Programming model and implementation for processing and. Programs can be automatically parallelized and executed on a large cluster of machines
 A programming model in Cloud: MapReduce Programming model and implementation for processing and generating large data sets Users specify a map function to generate a set of intermediate key/value pairs
A programming model in Cloud: MapReduce Programming model and implementation for processing and generating large data sets Users specify a map function to generate a set of intermediate key/value pairs
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Google File System 2
 Google File System 2 goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design
Google File System 2 goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design
Infrastructure system services
 Infrastructure system services Badri Nath Rutgers University badri@cs.rutgers.edu Processing lots of data O(B) web pages; each O(K) bytes to O(M) bytes gives you O(T) to O(P) bytes of data Disk Bandwidth
Infrastructure system services Badri Nath Rutgers University badri@cs.rutgers.edu Processing lots of data O(B) web pages; each O(K) bytes to O(M) bytes gives you O(T) to O(P) bytes of data Disk Bandwidth
Design & Implementation of Cloud Big table
 Design & Implementation of Cloud Big table M.Swathi 1,A.Sujitha 2, G.Sai Sudha 3, T.Swathi 4 M.Swathi Assistant Professor in Department of CSE Sri indu College of Engineering &Technolohy,Sheriguda,Ibrahimptnam
Design & Implementation of Cloud Big table M.Swathi 1,A.Sujitha 2, G.Sai Sudha 3, T.Swathi 4 M.Swathi Assistant Professor in Department of CSE Sri indu College of Engineering &Technolohy,Sheriguda,Ibrahimptnam
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
! Design constraints. " Component failures are the norm. " Files are huge by traditional standards. ! POSIX-like
 Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
NPTEL Course Jan K. Gopinath Indian Institute of Science
 Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
CS /29/18. Paul Krzyzanowski 1. Question 1 (Bigtable) Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams
 Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams") Question 1 (Bigtable) What is an SSTable in Bigtable? Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams It is the internal file format used to store Bigtable data. It maps keys
Question 1 (Bigtable) What is an SSTable in Bigtable? Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams It is the internal file format used to store Bigtable data. It maps keys
Distributed Systems Pre-exam 3 review Selected questions from past exams. David Domingo Paul Krzyzanowski Rutgers University Fall 2018
 Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams David Domingo Paul Krzyzanowski Rutgers University Fall 2018 November 28, 2018 1 Question 1 (Bigtable) What is an SSTable in
Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams David Domingo Paul Krzyzanowski Rutgers University Fall 2018 November 28, 2018 1 Question 1 (Bigtable) What is an SSTable in
Big Data Processing Technologies. Chentao Wu Associate Professor Dept. of Computer Science and Engineering
 Big Data Processing Technologies Chentao Wu Associate Professor Dept. of Computer Science and Engineering wuct@cs.sjtu.edu.cn Schedule (1) Storage system part (first eight weeks) lec1: Introduction on
Big Data Processing Technologies Chentao Wu Associate Professor Dept. of Computer Science and Engineering wuct@cs.sjtu.edu.cn Schedule (1) Storage system part (first eight weeks) lec1: Introduction on
CSE 124: Networked Services Lecture-16
 Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
GFS: The Google File System. Dr. Yingwu Zhu
 GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
W b b 2.0. = = Data Ex E pl p o l s o io i n
 Hypertable Doug Judd Zvents, Inc. Background Web 2.0 = Data Explosion Web 2.0 Mt. Web 2.0 Traditional Tools Don t Scale Well Designed for a single machine Typical scaling solutions ad-hoc manual/static
Hypertable Doug Judd Zvents, Inc. Background Web 2.0 = Data Explosion Web 2.0 Mt. Web 2.0 Traditional Tools Don t Scale Well Designed for a single machine Typical scaling solutions ad-hoc manual/static
The Google File System (GFS)
") 1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Lessons Learned While Building Infrastructure Software at Google
 Lessons Learned While Building Infrastructure Software at Google Jeff Dean jeff@google.com Google Circa 1997 (google.stanford.edu) Corkboards (1999) Google Data Center (2000) Google Data Center (2000)
Lessons Learned While Building Infrastructure Software at Google Jeff Dean jeff@google.com Google Circa 1997 (google.stanford.edu) Corkboards (1999) Google Data Center (2000) Google Data Center (2000)
Distributed Data Management. Christoph Lofi Institut für Informationssysteme Technische Universität Braunschweig
 Distributed Data Management Christoph Lofi Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Exams 25 minutes oral examination 20.-24.02.2012 19.-23.03.2012
Distributed Data Management Christoph Lofi Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Exams 25 minutes oral examination 20.-24.02.2012 19.-23.03.2012
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
Percolator. Large-Scale Incremental Processing using Distributed Transactions and Notifications. D. Peng & F. Dabek
 Percolator Large-Scale Incremental Processing using Distributed Transactions and Notifications D. Peng & F. Dabek Motivation Built to maintain the Google web search index Need to maintain a large repository,
Percolator Large-Scale Incremental Processing using Distributed Transactions and Notifications D. Peng & F. Dabek Motivation Built to maintain the Google web search index Need to maintain a large repository,
11 Storage at Google Google Google Google Google 7/2/2010. Distributed Data Management
 11 Storage at Google Distributed Data Management 11.1 Google Bigtable 11.2 Google File System 11. Bigtable Implementation Wolf-Tilo Balke Christoph Lofi Institut für Informationssysteme Technische Universität
11 Storage at Google Distributed Data Management 11.1 Google Bigtable 11.2 Google File System 11. Bigtable Implementation Wolf-Tilo Balke Christoph Lofi Institut für Informationssysteme Technische Universität
The Google File System
 October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
Distributed Systems. 05r. Case study: Google Cluster Architecture. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 05r. Case study: Google Cluster Architecture Paul Krzyzanowski Rutgers University Fall 2016 1 A note about relevancy This describes the Google search cluster architecture in the mid
Distributed Systems 05r. Case study: Google Cluster Architecture Paul Krzyzanowski Rutgers University Fall 2016 1 A note about relevancy This describes the Google search cluster architecture in the mid
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.
![DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.](/thumbs/86/93978710.jpg "DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.") CHALLENGES Transparency: Slide 1 DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems ➀ Introduction ➁ NFS (Network File System) ➂ AFS (Andrew File System) & Coda ➃ GFS (Google File System)
CHALLENGES Transparency: Slide 1 DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems ➀ Introduction ➁ NFS (Network File System) ➂ AFS (Andrew File System) & Coda ➃ GFS (Google File System)
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
DIVING IN: INSIDE THE DATA CENTER
 1 DIVING IN: INSIDE THE DATA CENTER Anwar Alhenshiri Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs it to
1 DIVING IN: INSIDE THE DATA CENTER Anwar Alhenshiri Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs it to
Distributed System. Gang Wu. Spring,2018
 Distributed System Gang Wu Spring,2018 Lecture7:DFS What is DFS? A method of storing and accessing files base in a client/server architecture. A distributed file system is a client/server-based application
Distributed System Gang Wu Spring,2018 Lecture7:DFS What is DFS? A method of storing and accessing files base in a client/server architecture. A distributed file system is a client/server-based application
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
The Google File System
 The Google File System By Ghemawat, Gobioff and Leung Outline Overview Assumption Design of GFS System Interactions Master Operations Fault Tolerance Measurements Overview GFS: Scalable distributed file
The Google File System By Ghemawat, Gobioff and Leung Outline Overview Assumption Design of GFS System Interactions Master Operations Fault Tolerance Measurements Overview GFS: Scalable distributed file
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Data Storage in the Cloud
 Data Storage in the Cloud KHALID ELGAZZAR GOODWIN 531 ELGAZZAR@CS.QUEENSU.CA Outline 1. Distributed File Systems 1.1. Google File System (GFS) 2. NoSQL Data Store 2.1. BigTable Elgazzar - CISC 886 - Fall
Data Storage in the Cloud KHALID ELGAZZAR GOODWIN 531 ELGAZZAR@CS.QUEENSU.CA Outline 1. Distributed File Systems 1.1. Google File System (GFS) 2. NoSQL Data Store 2.1. BigTable Elgazzar - CISC 886 - Fall
Ghislain Fourny. Big Data 5. Wide column stores
 Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
CS 138: Google. CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
GFS: The Google File System
 GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
Ghislain Fourny. Big Data 5. Column stores
 Ghislain Fourny Big Data 5. Column stores 1 Introduction 2 Relational model 3 Relational model Schema 4 Issues with relational databases (RDBMS) Small scale Single machine 5 Can we fix a RDBMS? Scale up
Ghislain Fourny Big Data 5. Column stores 1 Introduction 2 Relational model 3 Relational model Schema 4 Issues with relational databases (RDBMS) Small scale Single machine 5 Can we fix a RDBMS? Scale up
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
Recap. CSE 486/586 Distributed Systems Google Chubby Lock Service. Paxos Phase 2. Paxos Phase 1. Google Chubby. Paxos Phase 3 C 1
 Recap CSE 486/586 Distributed Systems Google Chubby Lock Service Steve Ko Computer Sciences and Engineering University at Buffalo Paxos is a consensus algorithm. Proposers? Acceptors? Learners? A proposer
Recap CSE 486/586 Distributed Systems Google Chubby Lock Service Steve Ko Computer Sciences and Engineering University at Buffalo Paxos is a consensus algorithm. Proposers? Acceptors? Learners? A proposer
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
Google File System. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google fall DIP Heerak lim, Donghun Koo
 Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
CS /30/17. Paul Krzyzanowski 1. Google Chubby ( Apache Zookeeper) Distributed Systems. Chubby. Chubby Deployment.
 Distributed Systems. Chubby. Chubby Deployment.") Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
CS 138: Google. CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
HBase. Леонид Налчаджи
 HBase Леонид Налчаджи leonid.nalchadzhi@gmail.com HBase Overview Table layout Architecture Client API Key design 2 Overview 3 Overview NoSQL Column oriented Versioned 4 Overview All rows ordered by row
HBase Леонид Налчаджи leonid.nalchadzhi@gmail.com HBase Overview Table layout Architecture Client API Key design 2 Overview 3 Overview NoSQL Column oriented Versioned 4 Overview All rows ordered by row
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
The MapReduce Abstraction
 The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
GFS Overview. Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures
 GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
Recap. CSE 486/586 Distributed Systems Google Chubby Lock Service. Recap: First Requirement. Recap: Second Requirement. Recap: Strengthening P2
 Recap CSE 486/586 Distributed Systems Google Chubby Lock Service Steve Ko Computer Sciences and Engineering University at Buffalo Paxos is a consensus algorithm. Proposers? Acceptors? Learners? A proposer
Recap CSE 486/586 Distributed Systems Google Chubby Lock Service Steve Ko Computer Sciences and Engineering University at Buffalo Paxos is a consensus algorithm. Proposers? Acceptors? Learners? A proposer
Big Table. Dennis Kafura CS5204 Operating Systems
 Big Table Dennis Kafura CS5204 Operating Systems 1 Introduction to Paper summary with this lecture. is a Google product Google = Clever "We settled on this data model after examining a variety of potential
Big Table Dennis Kafura CS5204 Operating Systems 1 Introduction to Paper summary with this lecture. is a Google product Google = Clever "We settled on this data model after examining a variety of potential
GFS-python: A Simplified GFS Implementation in Python
 GFS-python: A Simplified GFS Implementation in Python Andy Strohman ABSTRACT GFS-python is distributed network filesystem written entirely in python. There are no dependencies other than Python s standard
GFS-python: A Simplified GFS Implementation in Python Andy Strohman ABSTRACT GFS-python is distributed network filesystem written entirely in python. There are no dependencies other than Python s standard
Goal of the presentation is to give an introduction of NoSQL databases, why they are there.
 1 Goal of the presentation is to give an introduction of NoSQL databases, why they are there. We want to present "Why?" first to explain the need of something like "NoSQL" and then in "What?" we go in
1 Goal of the presentation is to give an introduction of NoSQL databases, why they are there. We want to present "Why?" first to explain the need of something like "NoSQL" and then in "What?" we go in
NPTEL Course Jan K. Gopinath Indian Institute of Science
 Storage Systems NPTEL Course Jan 2012 (Lecture 41) K. Gopinath Indian Institute of Science Lease Mgmt designed to minimize mgmt overhead at master a lease initially times out at 60 secs. primary can request
Storage Systems NPTEL Course Jan 2012 (Lecture 41) K. Gopinath Indian Institute of Science Lease Mgmt designed to minimize mgmt overhead at master a lease initially times out at 60 secs. primary can request