TI2736-B Big Data Processing. Claudia Hauff
|
|
|
- Harry Heath
- 6 years ago
- Views:
Transcription

1 TI2736-B Big Data Processing Claudia Hauff
2 Intro Streams Streams Map Reduce HDFS Pig Pig Design Patterns Hadoop Ctd. Graphs Giraph Spark Zoo Keeper Spark
3 Learning objectives Implement the four introduced design patterns and choose the correct one according to the usage scenario Express common database operations as MapReduce jobs and argue about the pros & cons of the implementations Relational joins Union, Selection, Projection, Intersection 3
4 MapReduce design patterns local aggregation pairs & stripes order inversion secondary sorting 4
5 Design patterns Arrangement of components and specific techniques designed to handle frequently encountered situations across a variety of problem domains. Programmer s tasks (Hadoop does the rest): Prepare data Write mapper code Write reducer code Write combiner code Write partitioner code But: every task needs to be converted into the Mapper/ Reducer schema 5
6 Design patterns In parallel/distributed systems, synchronisation of intermediate results is difficult MapReduce paradigm offers one opportunity for cluster-wide synchronisation: shuffle & sort phase Programmers have little control over: Where a Mapper/Reducer runs When a Mapper/Reducer starts & ends Which key/value pairs are processed by which Mapper or Reducer 6
7 Controlling the data flow Complex data structures as keys and values (e.g. PairOfIntString) Execution of user-specific initialisation & termination code at each Mapper/Reducer State preservation in Mapper/Reducer across multiple input or intermediate keys (Java objects) User-controlled partitioning of the key space and thus the set of keys that a particular Reducer encounters 7
8 Controlling the data flow Complex data structures as keys and values (e.g. PairOfIntString) Execution of user-specific initialisation & termination code at each Mapper/Reducer State preservation in Mapper/Reducer across multiple input or intermediate keys (Java objects) User-controlled partitioning of the key space and thus the set of keys that a particular Reducer encounters 8
9 Design pattern I: Local aggregation 9
10 Local aggregation Moving data from Mappers to Reducers Data transfer over the network Local disk writes Local aggregation: reduces amount of intermediate data & increases algorithm efficiency Exploited concepts: Combiners State preservation Most popular: in-mapper combining 10
11 Our WordCount example (once more) map(docid a, doc d): foreach term t in doc: EmitIntermediate(t, count 1); reduce(term t, counts[c1, c2, ]) sum = 0; foreach count c in counts: sum += c; Emit(term t, count sum) 11
12 Local aggregation on two levels map(docid a, doc d): H = associative_array; foreach term t in doc: H{t}=H{t}+1; foreach term t in H: EmitIntermediate(t,count H{t}); 12
13 Local aggregation on two levels setup(): H = associative_array; map(docid a, doc d): foreach term t in doc: H{t}=H{t}+1; cleanup(): foreach term t in H: EmitIntermediate(t,count H{t}); 13
14 Correctness of local aggregation: the mean map(string t, int r): EmitIntermediate(string t, int r) combine(string t, ints [r1, r2,..]) sum = 0; count = 0; foreach int r in ints: sum += r; mapper output count += 1; grouped by key EmitIntermediate(string t, pair(sum,count)) reduce(string t, pairs [(s1,c1), (s2,c2),..]) sum = 0; count = 0; foreach pair (s,c) in pairs: sum += s; count += c; avg=sum/count; Emit(string t, int avg); 14 Mapper Combiner Reducer incorrect
15 Correctness of local aggregation: the mean map(string t, int r): EmitIntermediate(string t, pair (r,1)) combine(string t, pairs [(s1,c1), (s2,c2),..]) sum = 0; count = 0; foreach (s,c) in pairs: sum += s; count += c; EmitIntermediate(string t, pair(sum,count)) reduce(string t, pairs [(s1,c1), (s2,c2),..]) sum = 0; count = 0; foreach pair (s,c) in pairs: sum += s; count += c; avg=sum/count; Emit(string t, int avg); 15 Mapper Combiner Reducer correct
16 Pros and cons: local aggregation vs. Combiners Advantages: Controllable when & how aggregation occurs More efficient (no disk spills, no object creation & destruction overhead) Disadvantages: Breaks functional programming paradigm (state preservation between map() calls) Algorithmic behaviour might depend on the order of map() input key/values (hard to debug) Scalability bottleneck (programming effort to avoid it) 16
17 Local aggregation: always useful? Efficiency improvements dependent on Size of intermediate key space Distribution of keys Number of key/value pairs emitted by individual map tasks WordCount Scalability limited by vocabulary size 17
18 Design pattern II: Pairs & Stripes 18
19 To motivate the next design pattern.. co-occurrence matrices Corpus: 3 documents Delft is a city. Amsterdam is a city. Hamlet is a dog. Co-occurrence matrix (on the document level) Applications: clustering, retrieval, stemming, text mining, stripe 19 delft is a city the dog amsterdam hamlet delft X is X a X city X the X dog X 0 1 amsterdam X 0 hamlet X pair - Square matrix of size n n (n: vocabulary size) - Unit can be document, sentence, paragraph,
20 To motivate the next design pattern.. co-occurrence matrices Corpus: 3 documents Delft is a city. Amsterdam is a city. Hamlet is a dog. Co-occurrence matrix (on the document level) Applications: clustering, retrieval, stemming, text mining, stripe delft is a city the dog amsterdam hamlet delft X is X a X city X the X dog X 0 1 amsterdam X 0 hamlet X n n Not just NLP/IR: think sales analyses (people 20 who buy X also buy Y) pair More general: estimating distributions - Square matrix of discrete of size joint events (n: vocabulary from a large size) number of observations. - Unit can be document, sentence, paragraph,
21 Pairs each pair is a cell in the matrix (complex key) map(docid a, doc d): foreach term w in d: emit co-occurrence count foreach term u in d: EmitIntermediate(pair(w,u),1) reduce(pair p, counts [c1, c2, ] s = 0; foreach c in counts: s += c; Emit(pair p, count s); 21 a single cell in the cooccurrence matrix
22 each stripe is a row in the matrix (complex value) Stripes map(docid a, doc d): foreach term w in d: H = associative_array; foreach term u in d: H{u}=H{u}+1; EmitIntermediate(term w, Stripe H); reduce(term w, stripes [H1,H2,..]) F = associative_array; foreach H in stripes: sum(f,h); Emit(term w, stripe F) emit terms co-occurring with term w one row in the co-occurrence matrix 22
23 Pairs & Stripes 2.3M documents Co-occurrence window: 2 19 nodes in the cluster 1 hour 2.6 billion intermediate key/value pairs; after combiner run: 1.1B final key/value pairs: 142M 11 minutes 653M intermediate key/value pairs; after combiner run: 29M final: 1.69M rows 23 Source: Jimmy Lin s MapReduce Design Patterns book
24 Stripes 2.3M documents Co-occurrence window: 2 Scaling up (on EC2) Source: 24 Jimmy Lin s MapReduce Design Patterns book
25 Pairs & Stripes: two ends of a spectrum Pairs each co-occurring event is recorded Stripes all co-occurring events wrt. the conditioning event are recorded Middle ground: divide key space into buckets and treat each as a sub-stripe. If one bucket in total: stripes, if #buckets==vocabulary: pairs. 25
26 Design pattern III: Order inversion 26
27 From absolute counts to relative frequencies 27

28 From absolute counts to relative frequencies: Stripes Marginal can be computed easily in one job. Second Hadoop job to compute the relative frequencies. 28
 is removed - properly sequence the data: (1) compute marginal, (2) for each joint count, compute relative")
29 From absolute counts to relative frequencies: Pairs 2 options to make Pairs work: - build in-memory associative array; but advantage of pairs approach (no memory bottleneck) is removed - properly sequence the data: (1) compute marginal, (2) for each joint count, compute relative frequency 29
30 From absolute counts to relative frequencies: Pairs 30
31 From absolute counts to relative frequencies: Pairs Properly sequence the data: - Custom partitioner: partition based on left part of pair - Custom key sorting: * before anything else - Combiner usage (or in-memory mapper) required for (w,*) - Preserving state of marginal 31 Design pattern: order inversion
32 From absolute counts to relative frequencies: Pairs Example data flow for pairs approach: 32
33 Order inversion Goal: compute the result of a computation (marginal) in the reducer before the data that requires it is processed (relative frequencies) Key insight: convert sequencing of computation into a sorting problem Ordering of key/value pairs and key partitioning controlled by the programmer Create a notion of before and after Major benefit: reduced memory footprint 33
34 Design pattern IV: Secondary sorting 34
35 Secondary sorting Order inversion pattern: sorting by key What about sorting by value (a secondary sort)? Hadoop does not allow it 35
36 Secondary sorting Solution: move part of the value into the intermediate key and let Hadoop do the sorting m 1! (t 1,r 1234 ) (m 1,t 1 )! r 1234 Also called value-to-key conversion (m 1,t 1 )! [(r )] (m 1,t 2 )! [(r )] (m 1,t 3 )! [(r ] 36
37 Secondary sorting Solution: move part of the value into the intermediate key and let Hadoop do the sorting m 1! (t 1,r 1234 ) (m 1,t 1 )! r 1234 Also called value-to-key conversion (m 1,t 1 )! [(r )] (m 1,t 2 )! [(r )] (m 1,t 3 )! [(r ] 37 Requires: - Custom key sorting: first by left element (sensor id), and then by right element (timestamp) - Custom partitioner: partition based on sensor id only - State across reduce() calls tracked (complex key)
38 Database operations 38
39 Databases. link table with billions of entries Scenario Database tables can be written out to file, one tuple per line MapReduce jobs can perform standard database operations Useful for operations that pass over most (all) tuples Example Find all paths of length 2 in the table Hyperlinks Result should be tuples (u,v,w) where a link exists between (u,v) and between (v,w) 39

40 Databases. link table with billions of entries Scenario Database tables can be written out to file, one tuple per line MapReduce jobs can perform standard database operations Useful for operations that pass over most (all) tuples Example Find all paths of length 2 in the table Hyperlinks Result should be tuples (u,v,w) where a link exists between (u,v) and between (v,w) FROM 1 TO 1 FROM 2 TO 2 join Hyperlinks with itself url1 url2 url3 url2 url3 url5 url1 url2 url3 url2 url3 url5 (url1,url2,url3) (url2,url3,url5) 40
41 Database operations: relational joins reduce side joins map side joins one-to-one one-to-many many-to-many 41
42 Relational joins Popular application: data-warehousing Often data is relational (sales transactions, product inventories,..) Different strategies to perform relational joins on two datasets (tables in a DB) S and T depending on data set size, skewness and join type (k 1,s 1, S 1 ) key to join on (k 1,t 1, T 1 ) (k 2,s 2, S 2 )tupleid (k 3,t 2, T 2 ) (k 3,s 3, S 3 ) tuple attributes (k 8,t 3, T 3 ) S may be user profiles, T logs of online activity 42 k s are the foreign keys
43 Relational joins: reduce side database tables exported to file Idea: map over both datasets and emit the join key as intermediate key and the tuple as value One-to-one join: at most one tuple from S and T share the same join key Four possibilities for the values in reduce(): - a tuple from S - a tuple from T - (1) a tuple from S, (2) a tuple from T - (1) a tuple from T, (2) a tuple from S reducer emits key/value if the value list contains 2 elements 43

44 Relational joins: reduce side Idea: map over both datasets and emit the join key as intermediate key and the tuple as value One-to-many join: the primary key in S can join to many keys in T 44
45 Relational joins: reduce side Idea: map over both datasets and emit the join key as intermediate key and the tuple as value Many-to-many join: many tuples in S can join to many tuples in T Possible solution: employ the one-to-many approach. Works well if S has only a few tuples per join (requires data knowledge). 45

 MAPPER Map over the other dataset (3) No reducer MAPPER necessary 46 no shuffling")
46 Relational joins: map side Problem of reduce-side joins: both datasets are shuffled across the network In map side joins we assume that both datasets are sorted by join key; they can be joined by scanning both datasets simultaneously Partition & sort both datasets k, i < 5 k, 5 apple i<10 k, i 10 Mapper: (1) MAPPER Read smaller dataset piecewise into memory (2) MAPPER Map over the other dataset (3) No reducer MAPPER necessary 46 no shuffling across the network!
47 Relational joins: comparison Problem of reduce-side joins: both datasets are shuffled across the network Map-side join: no data is shuffled through the network, very efficient Preprocessing steps take up more time in map-side join (partitioning files, sorting by join key) Usage scenarios: Reduce-side: adhoc queries Map-side: queries as part of a longer workflow; preprocessing steps are part of the workflow (can also be Hadoop jobs) 47
48 Database operations: the rest 48
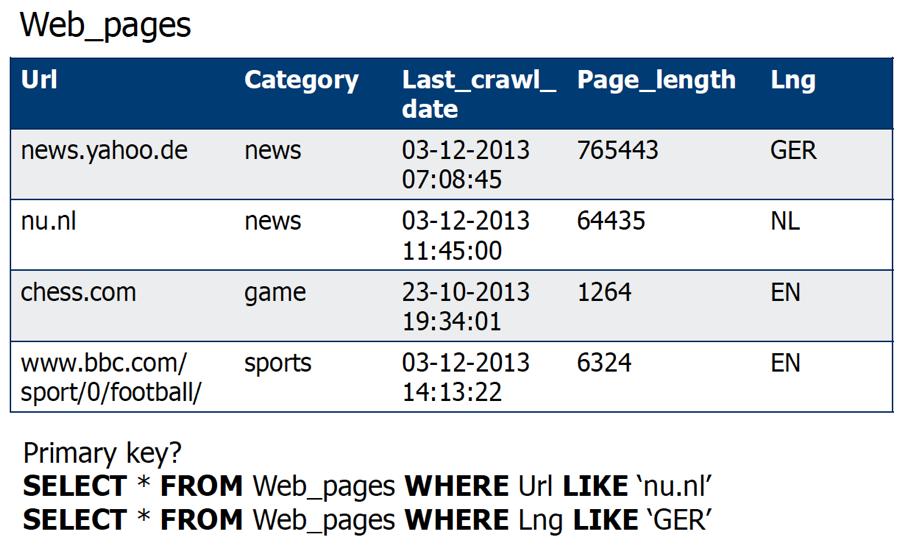
49 Selections 49
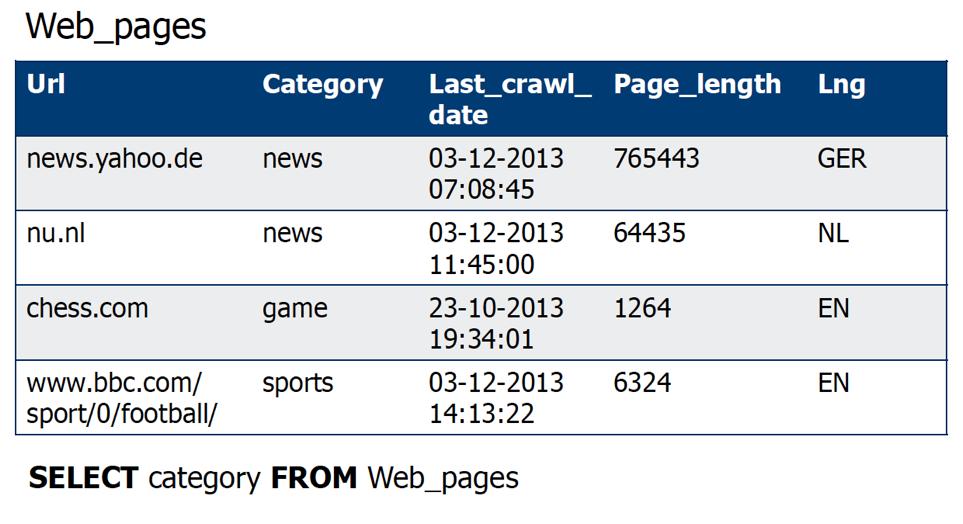
50 Projections 50
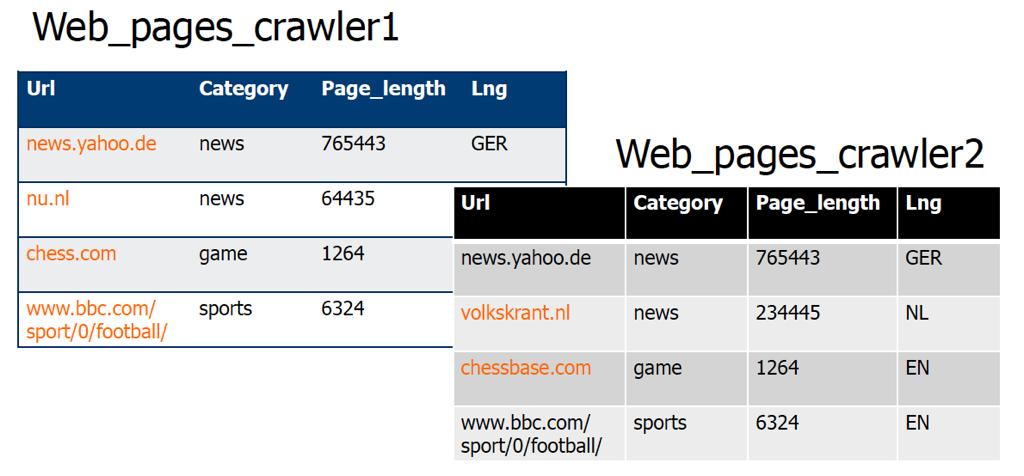
51 Union 51
52 Intersection 52
53 Summary Design patterns for MapReduce Common database operations 53
54 Recommended reading Mining of Massive Datasets by Rajaraman & Ullman. Available online. Chapter 2. The last part of this lecture (database operations) has been drawn from this chapter. Data-Intensive Text Processing with MapReduce by Lin et al. Available online. Chapter 3. The lecture is mostly based on the content of this chapter. 54
55 THE END
Lecture 7: MapReduce design patterns! Claudia Hauff (Web Information Systems)!
!") Big Data Processing, 2014/15 Lecture 7: MapReduce design patterns!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm
Big Data Processing, 2014/15 Lecture 7: MapReduce design patterns!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm
MapReduce Design Patterns
 MapReduce Design Patterns MapReduce Restrictions Any algorithm that needs to be implemented using MapReduce must be expressed in terms of a small number of rigidly defined components that must fit together
MapReduce Design Patterns MapReduce Restrictions Any algorithm that needs to be implemented using MapReduce must be expressed in terms of a small number of rigidly defined components that must fit together
Developing MapReduce Programs
 Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
MapReduce Algorithm Design
 MapReduce Algorithm Design Contents Combiner and in mapper combining Complex keys and values Secondary Sorting Combiner and in mapper combining Purpose Carry out local aggregation before shuffle and sort
MapReduce Algorithm Design Contents Combiner and in mapper combining Complex keys and values Secondary Sorting Combiner and in mapper combining Purpose Carry out local aggregation before shuffle and sort
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Map-Reduce and Adwords Problem
 Map-Reduce and Adwords Problem Map-Reduce and Adwords Problem Miłosz Kadziński Institute of Computing Science Poznan University of Technology, Poland www.cs.put.poznan.pl/mkadzinski/wpi Big Data (1) Big
Map-Reduce and Adwords Problem Map-Reduce and Adwords Problem Miłosz Kadziński Institute of Computing Science Poznan University of Technology, Poland www.cs.put.poznan.pl/mkadzinski/wpi Big Data (1) Big
MapReduce Patterns, Algorithms, and Use Cases
 MapReduce Patterns, Algorithms, and Use Cases In this article I digested a number of MapReduce patterns and algorithms to give a systematic view of the different techniques that can be found on the web
MapReduce Patterns, Algorithms, and Use Cases In this article I digested a number of MapReduce patterns and algorithms to give a systematic view of the different techniques that can be found on the web
MapReduce Algorithms
 Large-scale data processing on the Cloud Lecture 3 MapReduce Algorithms Satish Srirama Some material adapted from slides by Jimmy Lin, 2008 (licensed under Creation Commons Attribution 3.0 License) Outline
Large-scale data processing on the Cloud Lecture 3 MapReduce Algorithms Satish Srirama Some material adapted from slides by Jimmy Lin, 2008 (licensed under Creation Commons Attribution 3.0 License) Outline
Algorithms for MapReduce. Combiners Partition and Sort Pairs vs Stripes
 Algorithms for MapReduce 1 Assignment 1 released Due 16:00 on 20 October Correctness is not enough! Most marks are for efficiency. 2 Combining, Sorting, and Partitioning... and algorithms exploiting these
Algorithms for MapReduce 1 Assignment 1 released Due 16:00 on 20 October Correctness is not enough! Most marks are for efficiency. 2 Combining, Sorting, and Partitioning... and algorithms exploiting these
Data Partitioning and MapReduce
 Data Partitioning and MapReduce Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies,
Data Partitioning and MapReduce Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies,
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (2/2) January 12, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (2/2) January 12, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
MapReduce: Algorithm Design for Relational Operations
 MapReduce: Algorithm Design for Relational Operations Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Projection π Projection in MapReduce Easy Map over tuples, emit
MapReduce: Algorithm Design for Relational Operations Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Projection π Projection in MapReduce Easy Map over tuples, emit
Announcements. Parallel Data Processing in the 20 th Century. Parallel Join Illustration. Introduction to Database Systems CSE 414
 Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Announcements. Optional Reading. Distributed File System (DFS) MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm
 MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm") Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Data-Intensive Distributed Computing
 Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 1: MapReduce Algorithm Design (4/4) January 16, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 1: MapReduce Algorithm Design (4/4) January 16, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Laboratory Session: MapReduce
 Laboratory Session: MapReduce Algorithm Design in MapReduce Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Laboratory Session: MapReduce 1 / 63 Preliminaries Preliminaries Pietro Michiardi (Eurecom)
Laboratory Session: MapReduce Algorithm Design in MapReduce Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Laboratory Session: MapReduce 1 / 63 Preliminaries Preliminaries Pietro Michiardi (Eurecom)
MapReduce Patterns. MCSN - N. Tonellotto - Distributed Enabling Platforms
 MapReduce Patterns 1 Intermediate Data Written locally Transferred from mappers to reducers over network Issue - Performance bottleneck Solution - Use combiners - Use In-Mapper Combining 2 Original Word
MapReduce Patterns 1 Intermediate Data Written locally Transferred from mappers to reducers over network Issue - Performance bottleneck Solution - Use combiners - Use In-Mapper Combining 2 Original Word
Part A: MapReduce. Introduction Model Implementation issues
 Part A: Massive Parallelism li with MapReduce Introduction Model Implementation issues Acknowledgements Map-Reduce The material is largely based on material from the Stanford cources CS246, CS345A and
Part A: Massive Parallelism li with MapReduce Introduction Model Implementation issues Acknowledgements Map-Reduce The material is largely based on material from the Stanford cources CS246, CS345A and
Hadoop Map Reduce 10/17/2018 1
 Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Anurag Sharma (IIT Bombay) 1 / 13
 1 / 13") 0 Map Reduce Algorithm Design Anurag Sharma (IIT Bombay) 1 / 13 Relational Joins Anurag Sharma Fundamental Research Group IIT Bombay Anurag Sharma (IIT Bombay) 1 / 13 Secondary Sorting Required if we need
0 Map Reduce Algorithm Design Anurag Sharma (IIT Bombay) 1 / 13 Relational Joins Anurag Sharma Fundamental Research Group IIT Bombay Anurag Sharma (IIT Bombay) 1 / 13 Secondary Sorting Required if we need
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
TI2736-B Big Data Processing. Claudia Hauff
 TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Software Virtual machine-based: Cloudera CDH 5.8, based on CentOS Saves us from a manual Hadoop installation (especially difficult on Windows)
TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Software Virtual machine-based: Cloudera CDH 5.8, based on CentOS Saves us from a manual Hadoop installation (especially difficult on Windows)
TI2736-B Big Data Processing. Claudia Hauff
 TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Ctd. Graphs Pig Design Patterns Hadoop Ctd. Giraph Zoo Keeper Spark Spark Ctd. Learning objectives
TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Ctd. Graphs Pig Design Patterns Hadoop Ctd. Giraph Zoo Keeper Spark Spark Ctd. Learning objectives
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
MapReduce Algorithm Design
 MapReduce Algorithm Design Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul Big
MapReduce Algorithm Design Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul Big
1. Introduction to MapReduce
 Processing of massive data: MapReduce 1. Introduction to MapReduce 1 Origins: the Problem Google faced the problem of analyzing huge sets of data (order of petabytes) E.g. pagerank, web access logs, etc.
Processing of massive data: MapReduce 1. Introduction to MapReduce 1 Origins: the Problem Google faced the problem of analyzing huge sets of data (order of petabytes) E.g. pagerank, web access logs, etc.
Basic MapReduce Algorithm Design
 Chapter 3 Basic MapReduce Algorithm Design This is a post-production manuscript of: Jimmy Lin and Chris Dyer. Data-Intensive Text Processing with MapReduce. Morgan & Claypool Publishers, 2010. This version
Chapter 3 Basic MapReduce Algorithm Design This is a post-production manuscript of: Jimmy Lin and Chris Dyer. Data-Intensive Text Processing with MapReduce. Morgan & Claypool Publishers, 2010. This version
DATA MINING II - 1DL460
 DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU
 Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU !2 MapReduce Overview! Sometimes a single computer cannot process data or takes too long traditional serial programming is not always
Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU !2 MapReduce Overview! Sometimes a single computer cannot process data or takes too long traditional serial programming is not always
MapReduce and Hadoop. Debapriyo Majumdar Indian Statistical Institute Kolkata
 MapReduce and Hadoop Debapriyo Majumdar Indian Statistical Institute Kolkata debapriyo@isical.ac.in Let s keep the intro short Modern data mining: process immense amount of data quickly Exploit parallelism
MapReduce and Hadoop Debapriyo Majumdar Indian Statistical Institute Kolkata debapriyo@isical.ac.in Let s keep the intro short Modern data mining: process immense amount of data quickly Exploit parallelism
Techno Expert Solutions An institute for specialized studies!
 Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
April Final Quiz COSC MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model.
 Explain briefly the main ideas and components of the MapReduce programming model.") 1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
2/26/2017. Note. The relational algebra and the SQL language have many useful operators
 The relational algebra and the SQL language have many useful operators Selection Projection Union, intersection, and difference Join (see Join design patterns) Aggregations and Group by (see the Summarization
The relational algebra and the SQL language have many useful operators Selection Projection Union, intersection, and difference Join (see Join design patterns) Aggregations and Group by (see the Summarization
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
MapReduce: Recap. Juliana Freire & Cláudio Silva. Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec
 MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
The relational algebra and the SQL language have many useful operators
 The relational algebra and the SQL language have many useful operators Selection Projection Union, intersection, and difference Join (see Join design patterns) Aggregations and Group by (see the Summarization
The relational algebra and the SQL language have many useful operators Selection Projection Union, intersection, and difference Join (see Join design patterns) Aggregations and Group by (see the Summarization
15/03/2018. Counters
 Counters 2 1 Hadoop provides a set of basic, built-in, counters to store some statistics about jobs, mappers, reducers E.g., number of input and output records E.g., number of transmitted bytes Ad-hoc,
Counters 2 1 Hadoop provides a set of basic, built-in, counters to store some statistics about jobs, mappers, reducers E.g., number of input and output records E.g., number of transmitted bytes Ad-hoc,
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Informa)on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies
on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies") Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node:
Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node:
PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets
 2011 Fourth International Symposium on Parallel Architectures, Algorithms and Programming PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets Tao Xiao Chunfeng Yuan Yihua Huang Department
2011 Fourth International Symposium on Parallel Architectures, Algorithms and Programming PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets Tao Xiao Chunfeng Yuan Yihua Huang Department
MapReduce and Hadoop
 Università degli Studi di Roma Tor Vergata MapReduce and Hadoop Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference Big Data stack High-level Interfaces Data Processing
Università degli Studi di Roma Tor Vergata MapReduce and Hadoop Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference Big Data stack High-level Interfaces Data Processing
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
A Review Paper on Big data & Hadoop
 A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 07) Week 4: Analyzing Text (/) January 6, 07 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 07) Week 4: Analyzing Text (/) January 6, 07 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Page 1. Goals for Today" Background of Cloud Computing" Sources Driving Big Data" CS162 Operating Systems and Systems Programming Lecture 24
 Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Lecture 11: Graph algorithms! Claudia Hauff (Web Information Systems)!
!") Lecture 11: Graph algorithms!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the scenes of MapReduce:
Lecture 11: Graph algorithms!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the scenes of MapReduce:
Graphs (Part II) Shannon Quinn
 Shannon Quinn") Graphs (Part II) Shannon Quinn (with thanks to William Cohen and Aapo Kyrola of CMU, and J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Parallel Graph Computation Distributed computation
Graphs (Part II) Shannon Quinn (with thanks to William Cohen and Aapo Kyrola of CMU, and J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Parallel Graph Computation Distributed computation
Hadoop. Course Duration: 25 days (60 hours duration). Bigdata Fundamentals. Day1: (2hours)
. Bigdata Fundamentals. Day1: (2hours)") Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Big Data and Scripting map reduce in Hadoop
 Big Data and Scripting map reduce in Hadoop 1, 2, connecting to last session set up a local map reduce distribution enable execution of map reduce implementations using local file system only all tasks
Big Data and Scripting map reduce in Hadoop 1, 2, connecting to last session set up a local map reduce distribution enable execution of map reduce implementations using local file system only all tasks
MapReduce: A Programming Model for Large-Scale Distributed Computation
 CSC 258/458 MapReduce: A Programming Model for Large-Scale Distributed Computation University of Rochester Department of Computer Science Shantonu Hossain April 18, 2011 Outline Motivation MapReduce Overview
CSC 258/458 MapReduce: A Programming Model for Large-Scale Distributed Computation University of Rochester Department of Computer Science Shantonu Hossain April 18, 2011 Outline Motivation MapReduce Overview
Parallel Nested Loops
 Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Partition-Based. Parallel Nested Loops. Median. More Join Thoughts. Parallel Office Tools 9/15/2011
 Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
Overview. Why MapReduce? What is MapReduce? The Hadoop Distributed File System Cloudera, Inc.
 MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
L22: SC Report, Map Reduce
 L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
Homework 3: Wikipedia Clustering Cliff Engle & Antonio Lupher CS 294-1
 Introduction: Homework 3: Wikipedia Clustering Cliff Engle & Antonio Lupher CS 294-1 Clustering is an important machine learning task that tackles the problem of classifying data into distinct groups based
Introduction: Homework 3: Wikipedia Clustering Cliff Engle & Antonio Lupher CS 294-1 Clustering is an important machine learning task that tackles the problem of classifying data into distinct groups based
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Hadoop ecosystem. Nikos Parlavantzas
 1 Hadoop ecosystem Nikos Parlavantzas Lecture overview 2 Objective Provide an overview of a selection of technologies in the Hadoop ecosystem Hadoop ecosystem 3 Hadoop ecosystem 4 Outline 5 HBase Hive
1 Hadoop ecosystem Nikos Parlavantzas Lecture overview 2 Objective Provide an overview of a selection of technologies in the Hadoop ecosystem Hadoop ecosystem 3 Hadoop ecosystem 4 Outline 5 HBase Hive
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
MapReduce for Data Warehouses 1/25
 MapReduce for Data Warehouses 1/25 Data Warehouses: Hadoop and Relational Databases In an enterprise setting, a data warehouse serves as a vast repository of data, holding everything from sales transactions
MapReduce for Data Warehouses 1/25 Data Warehouses: Hadoop and Relational Databases In an enterprise setting, a data warehouse serves as a vast repository of data, holding everything from sales transactions
HiTune. Dataflow-Based Performance Analysis for Big Data Cloud
 HiTune Dataflow-Based Performance Analysis for Big Data Cloud Jinquan (Jason) Dai, Jie Huang, Shengsheng Huang, Bo Huang, Yan Liu Intel Asia-Pacific Research and Development Ltd Shanghai, China, 200241
HiTune Dataflow-Based Performance Analysis for Big Data Cloud Jinquan (Jason) Dai, Jie Huang, Shengsheng Huang, Bo Huang, Yan Liu Intel Asia-Pacific Research and Development Ltd Shanghai, China, 200241
Laarge-Scale Data Engineering
 Laarge-Scale Data Engineering The MapReduce Framework & Hadoop Key premise: divide and conquer work partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 result combine Parallelisation challenges How
Laarge-Scale Data Engineering The MapReduce Framework & Hadoop Key premise: divide and conquer work partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 result combine Parallelisation challenges How
CSE 344 MAY 2 ND MAP/REDUCE
 CSE 344 MAY 2 ND MAP/REDUCE ADMINISTRIVIA HW5 Due Tonight Practice midterm Section tomorrow Exam review PERFORMANCE METRICS FOR PARALLEL DBMSS Nodes = processors, computers Speedup: More nodes, same data
CSE 344 MAY 2 ND MAP/REDUCE ADMINISTRIVIA HW5 Due Tonight Practice midterm Section tomorrow Exam review PERFORMANCE METRICS FOR PARALLEL DBMSS Nodes = processors, computers Speedup: More nodes, same data
Data Platforms and Pattern Mining
 Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
MapReduce. Kiril Valev LMU Kiril Valev (LMU) MapReduce / 35
 MapReduce / 35") MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
2.3 Algorithms Using Map-Reduce
 28 CHAPTER 2. MAP-REDUCE AND THE NEW SOFTWARE STACK one becomes available. The Master must also inform each Reduce task that the location of its input from that Map task has changed. Dealing with a failure
28 CHAPTER 2. MAP-REDUCE AND THE NEW SOFTWARE STACK one becomes available. The Master must also inform each Reduce task that the location of its input from that Map task has changed. Dealing with a failure
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Shark: Hive (SQL) on Spark
 on Spark") Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
The MapReduce Abstraction
 The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Lecture Map-Reduce. Algorithms. By Marina Barsky Winter 2017, University of Toronto
 Lecture 04.02 Map-Reduce Algorithms By Marina Barsky Winter 2017, University of Toronto Example 1: Language Model Statistical machine translation: Need to count number of times every 5-word sequence occurs
Lecture 04.02 Map-Reduce Algorithms By Marina Barsky Winter 2017, University of Toronto Example 1: Language Model Statistical machine translation: Need to count number of times every 5-word sequence occurs
Copyright 2012, Oracle and/or its affiliates. All rights reserved.
 1 Big Data Connectors: High Performance Integration for Hadoop and Oracle Database Melli Annamalai Sue Mavris Rob Abbott 2 Program Agenda Big Data Connectors: Brief Overview Connecting Hadoop with Oracle
1 Big Data Connectors: High Performance Integration for Hadoop and Oracle Database Melli Annamalai Sue Mavris Rob Abbott 2 Program Agenda Big Data Connectors: Brief Overview Connecting Hadoop with Oracle
MapReduce-II. September 2013 Alberto Abelló & Oscar Romero 1
 MapReduce-II September 2013 Alberto Abelló & Oscar Romero 1 Knowledge objectives 1. Enumerate the different kind of processes in the MapReduce framework 2. Explain the information kept in the master 3.
MapReduce-II September 2013 Alberto Abelló & Oscar Romero 1 Knowledge objectives 1. Enumerate the different kind of processes in the MapReduce framework 2. Explain the information kept in the master 3.
Data-Intensive Distributed Computing
 Data-Intensive Distributed Computing CS 45/65 43/63 (Winter 08) Part 3: Analyzing Text (/) January 30, 08 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides are
Data-Intensive Distributed Computing CS 45/65 43/63 (Winter 08) Part 3: Analyzing Text (/) January 30, 08 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides are
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Pig Latin: A Not-So-Foreign Language for Data Processing
 Pig Latin: A Not-So-Foreign Language for Data Processing Christopher Olston, Benjamin Reed, Utkarsh Srivastava, Ravi Kumar, Andrew Tomkins (Yahoo! Research) Presented by Aaron Moss (University of Waterloo)
Pig Latin: A Not-So-Foreign Language for Data Processing Christopher Olston, Benjamin Reed, Utkarsh Srivastava, Ravi Kumar, Andrew Tomkins (Yahoo! Research) Presented by Aaron Moss (University of Waterloo)
Scaling Up 1 CSE 6242 / CX Duen Horng (Polo) Chau Georgia Tech. Hadoop, Pig
 Chau Georgia Tech. Hadoop, Pig") CSE 6242 / CX 4242 Scaling Up 1 Hadoop, Pig Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
CSE 6242 / CX 4242 Scaling Up 1 Hadoop, Pig Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
CS / Cloud Computing. Recitation 3 September 9 th & 11 th, 2014
 CS15-319 / 15-619 Cloud Computing Recitation 3 September 9 th & 11 th, 2014 Overview Last Week s Reflection --Project 1.1, Quiz 1, Unit 1 This Week s Schedule --Unit2 (module 3 & 4), Project 1.2 Questions
CS15-319 / 15-619 Cloud Computing Recitation 3 September 9 th & 11 th, 2014 Overview Last Week s Reflection --Project 1.1, Quiz 1, Unit 1 This Week s Schedule --Unit2 (module 3 & 4), Project 1.2 Questions
Towards Automatic Optimization of MapReduce Programs (Position Paper) Shivnath Babu Duke University
 Shivnath Babu Duke University") Towards Automatic Optimization of MapReduce Programs (Position Paper) Shivnath Babu Duke University Roadmap Call to action to improve automatic optimization techniques in MapReduce frameworks Challenges
Towards Automatic Optimization of MapReduce Programs (Position Paper) Shivnath Babu Duke University Roadmap Call to action to improve automatic optimization techniques in MapReduce frameworks Challenges
Pig A language for data processing in Hadoop
 Pig A language for data processing in Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Apache Pig: Introduction Tool for querying data on Hadoop
Pig A language for data processing in Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Apache Pig: Introduction Tool for querying data on Hadoop