Informa)on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies
|
|
|
- Fay Warren
- 5 years ago
- Views:
Transcription
1 Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies
2 Map-Reduce: Why? Need to process 100TB datasets On 1 node: 50MB/s = 23 days MTBF = 3 years On 1000 node cluster: 50MB/s = 33 min MTBF = 1 day Need framework for distribu)on Efficient, reliable, easy to use
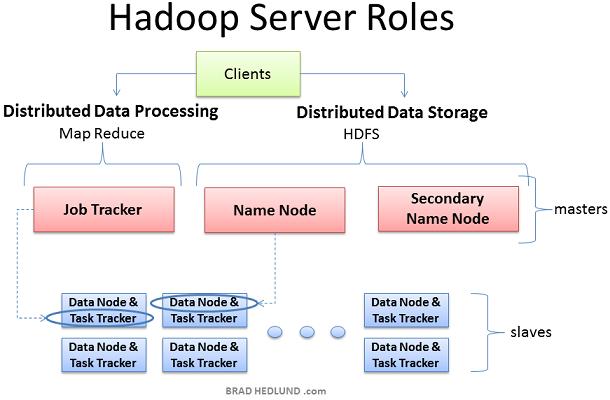
3 Hadoop: How? Commodity Hardware Cluster Distributed File System Modeled on GFS Distributed Processing Framework Using Map/Reduce metaphor Open Source, Java Apache Lucene subproject
4
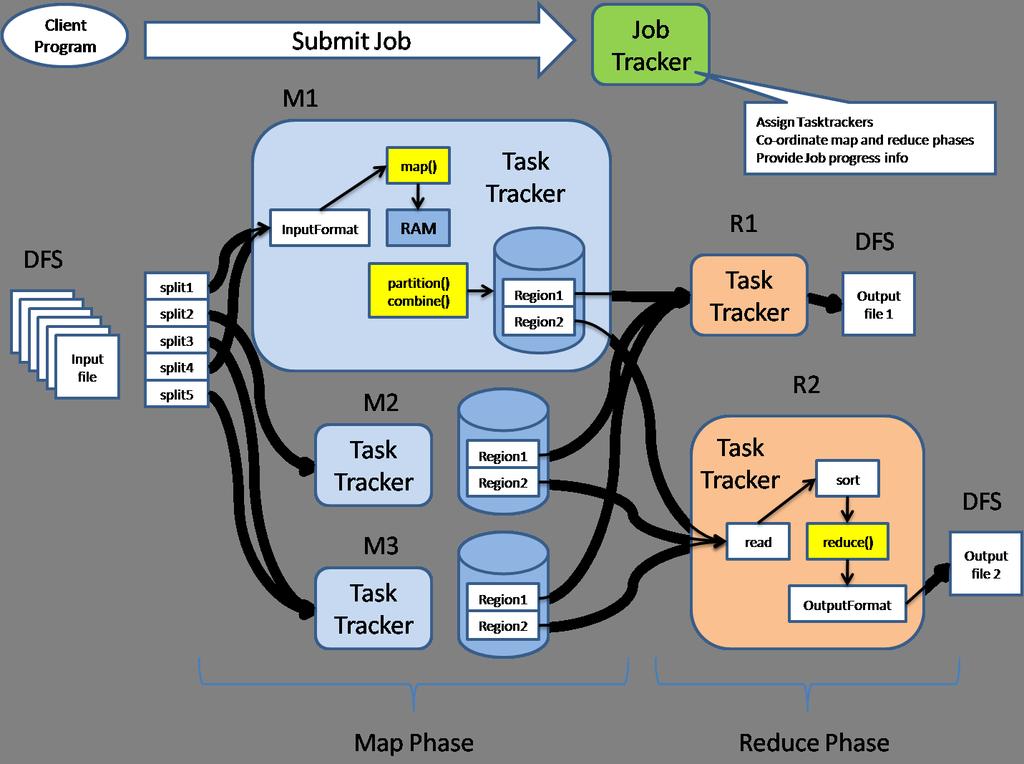
5 Map-Reduce Execu)on User Program (1) fork (1) fork (1) fork Master (2) assign map (2) assign reduce worker split 0 split 1 split 2 split 3 split 4 (3) read worker (4) local write (5) remote read worker worker (6) write output file 0 output file 1 worker Input files Map phase Intermediate files (on local disk) Reduce phase Output files
6 Distributed File System Single namespace for en)re cluster Managed by a single namenode. Hierarchal directories Op)mized for streaming reads of large files. Files are broken in to large blocks. Typically 64 or 128 MB Replicated to several datanodes, for reliability Clients can find loca)on of blocks Client talks to both namenode and datanodes Data is not sent through the namenode.
7 Distributed Processing User submits Map/Reduce job to JobTracker System: Splits job into lots of tasks Schedules tasks on nodes close to data Monitors tasks Kills and restarts if they fail/hang/disappear Pluggable file systems for input/output Local file system for tes)ng, debugging, etc
8 Map/Reduce Metaphor Data is a stream of keys and values Mapper Input: key1,value1 pair Output: key2, value2 pairs Reducer Called once per a key, in sorted order Input: key2, stream of value2 Output: key3, value3 pairs Launching Program Creates a JobConf to define a job. Submits JobConf and waits for comple)on.
9
10 MapReduce Programmers specify two func)ons: map (k, v) <k, v >* reduce (k, v ) <k, v >* All values with the same key are reduced together The run)me handles everything else Not quite usually, programmers also specify: par))on (k, number of par))ons) par))on for k Olen a simple hash of the key, e.g., hash(k ) mod n Divides up key space for parallel reduce opera)ons combine (k, v ) <k, v >* Mini-reducers that run in memory aler the map phase Used as an op)miza)on to reduce network traffic
11 k 1 v 1 k 2 v 2 k 3 v 3 k 4 v 4 k 5 v 5 k 6 v 6 map map map map a 1 b 2 c 3 c 6 a 5 c 2 b 7 c 8 combine combine combine combine a 1 b 2 c 9 a 5 c 2 b 7 c 8 par))oner par))oner par))oner par))oner Shuffle and Sort: aggregate values by keys a 1 5 b 2 7 c reduce reduce reduce r 1 s 1 r 2 s 2 r 3 s 3
12 Word Count Map(String docid, String text): for each word w in text: Emit(w, 1); Reduce(String term, Iterator<Int> values): int sum = 0; for each v in values: sum += v; Emit(term, value);
13 MapReduce: Index Construc)on Map over all documents Emit term as key, (docno, *) as value Emit other informa)on as necessary (e.g., term posi)on) Sort/shuffle: group pos)ngs by term Reduce Gather and sort the pos)ngs (e.g., by docno or *) Write pos)ngs to disk MapReduce does all the heavy liling!
14 Inverted Indexing with MapReduce Doc 1 one fish, two fish Doc 2 red fish, blue fish Doc 3 cat in the hat Map one 1 1 two 1 1 red 2 1 blue 2 1 cat 3 1 hat 3 1 fish 1 2 fish 2 2 Shuffle and Sort: aggregate values by keys Reduce cat 3 1 fish one 1 1 red 2 1 blue 2 1 hat 3 1 two 1 1
15 Inverted Indexing: Pseudo-Code
![Posi)onal Indexes Doc 1 one fish, two fish Doc 2 red fish, blue fish Doc 3 cat in the hat Map one 1 1 two 1 1 [1] [3] red 2 1 blue 2 1 [1] [3] cat 3 1 hat 3 1 [1] [2] fish](/docs-images/86/93629187/images/16-0.jpg "1 2 [2,4] fish 2 2 [2,4] Shuffle and Sort: aggregate values by keys Reduce cat 3 1 fish 1 2 [2,4] 2 2 one 1 1 red 2 1 [1] [1] [1] [2,4] blue 2 1 hat 3 1 two 1 1 [3] [2]")
16 Posi)onal Indexes Doc 1 one fish, two fish Doc 2 red fish, blue fish Doc 3 cat in the hat Map one 1 1 two 1 1 [1] [3] red 2 1 blue 2 1 [1] [3] cat 3 1 hat 3 1 [1] [2] fish 1 2 [2,4] fish 2 2 [2,4] Shuffle and Sort: aggregate values by keys Reduce cat 3 1 fish 1 2 [2,4] 2 2 one 1 1 red 2 1 [1] [1] [1] [2,4] blue 2 1 hat 3 1 two 1 1 [3] [2] [3]

17 Inverted Indexing: Pseudo-Code What s the problem?
18 Scalability Botleneck Ini)al implementa)on: terms as keys, pos)ngs as values Reducers must buffer all pos)ngs associated with key (to sort) What if we run out of memory to buffer pos)ngs?
19 Another Try (key) (values) (keys) (values) fish 1 2 [2,4] fish 1 [2,4] 34 1 [23] fish 9 [9] 21 3 [1,8,22] 35 2 [8,41] 80 3 [2,9,76] fish fish fish 21 [1,8,22] 34 [23] 35 [8,41] 9 1 [9] fish 80 [2,9,76] How is this different? Let the framework do the sor)ng Term frequency implicitly stored Directly write pos)ngs to disk!

20 Another Approach
21 The indexing problem MapReduce it? Scalability is paramount Must be rela)vely fast, but need not be real )me Fundamentally a batch opera)on Incremental updates may or may not be important For the web, crawling is a challenge in itself The retrieval problem Must have sub-second response )me For the web, only need rela)vely few results
22 Retrieval with MapReduce? MapReduce is fundamentally batch-oriented Op)mized for throughput, not latency Startup of mappers and reducers is expensive MapReduce is not suitable for real-)me queries! Use separate infrastructure for retrieval
23 Term vs. Document Par))oning D T 1 D Term Par))oning T 2 T 3 T Document Par))oning T D 1 D 2 D 3
24 Parallel Queries Algorithm Assume standard inner-product formula)on: score( Algorithm sketch: Load queries into memory in each mapper Map over pos)ngs, compute par)al term contribu)ons and store in accumulators Emit accumulators as intermediate output Reducers merge accumulators to compute final document scores q, d) = w t, qwt, d t V
25 Parallel Queries: Map blue Mapper query id = 1, blue fish Compute score contribu)ons for term key = 1, value = { 9:2, 21:1, 35:1 } fish Mapper query id = 1, blue fish Compute score contribu)ons for term key = 1, value = { 1:2, 9:1, 21:3, 34:1, 35:2, 80:3 }
26 Parallel Queries: Reduce key = 1, value = { 9:2, 21:1, 35:1 } key = 1, value = { 1:2, 9:1, 21:3, 34:1, 35:2, 80:3 } Reducer Element-wise sum of associa)ve arrays key = 1, value = { 1:2, 9:3, 21:4, 34:1, 35:3, 80:3 } Query: blue fish doc 21, score=4 doc 2, score=3 doc 35, score=3 doc 80, score=3 doc 1, score=2 doc 34, score=1 Sort accumulators to generate final ranking
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Information Retrieval Processing with MapReduce
 Information Retrieval Processing with MapReduce Based on Jimmy Lin s Tutorial at the 32nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2009) This
Information Retrieval Processing with MapReduce Based on Jimmy Lin s Tutorial at the 32nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2009) This
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Developing MapReduce Programs
 Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Today s Lecture. CS 61C: Great Ideas in Computer Architecture (Machine Structures) Map Reduce
 Map Reduce") CS 61C: Great Ideas in Computer Architecture (Machine Structures) Map Reduce 8/29/12 Instructors Krste Asanovic, Randy H. Katz hgp://inst.eecs.berkeley.edu/~cs61c/fa12 Fall 2012 - - Lecture #3 1 Today
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Map Reduce 8/29/12 Instructors Krste Asanovic, Randy H. Katz hgp://inst.eecs.berkeley.edu/~cs61c/fa12 Fall 2012 - - Lecture #3 1 Today
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Overview. Why MapReduce? What is MapReduce? The Hadoop Distributed File System Cloudera, Inc.
 MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
Search Engines. Informa1on Retrieval in Prac1ce. Annotations by Michael L. Nelson
 Search Engines Informa1on Retrieval in Prac1ce Annotations by Michael L. Nelson All slides Addison Wesley, 2008 Indexes Indexes are data structures designed to make search faster Text search has unique
Search Engines Informa1on Retrieval in Prac1ce Annotations by Michael L. Nelson All slides Addison Wesley, 2008 Indexes Indexes are data structures designed to make search faster Text search has unique
MapReduce, Apache Hadoop
 NDBI040: Big Data Management and NoSQL Databases hp://www.ksi.mff.cuni.cz/ svoboda/courses/2016-1-ndbi040/ Lecture 2 MapReduce, Apache Hadoop Marn Svoboda svoboda@ksi.mff.cuni.cz 11. 10. 2016 Charles University
NDBI040: Big Data Management and NoSQL Databases hp://www.ksi.mff.cuni.cz/ svoboda/courses/2016-1-ndbi040/ Lecture 2 MapReduce, Apache Hadoop Marn Svoboda svoboda@ksi.mff.cuni.cz 11. 10. 2016 Charles University
CS6200 Informa.on Retrieval. David Smith College of Computer and Informa.on Science Northeastern University
 CS6200 Informa.on Retrieval David Smith College of Computer and Informa.on Science Northeastern University Indexing Process Indexes Indexes are data structures designed to make search faster Text search
CS6200 Informa.on Retrieval David Smith College of Computer and Informa.on Science Northeastern University Indexing Process Indexes Indexes are data structures designed to make search faster Text search
Map- reduce programming paradigm
 Map- reduce programming paradigm Some slides are from lecture of Matei Zaharia, and distributed computing seminar by Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet. In pioneer days they
Map- reduce programming paradigm Some slides are from lecture of Matei Zaharia, and distributed computing seminar by Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet. In pioneer days they
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
MapReduce, Apache Hadoop
 Czech Technical University in Prague, Faculty of Informaon Technology MIE-PDB: Advanced Database Systems hp://www.ksi.mff.cuni.cz/~svoboda/courses/2016-2-mie-pdb/ Lecture 12 MapReduce, Apache Hadoop Marn
Czech Technical University in Prague, Faculty of Informaon Technology MIE-PDB: Advanced Database Systems hp://www.ksi.mff.cuni.cz/~svoboda/courses/2016-2-mie-pdb/ Lecture 12 MapReduce, Apache Hadoop Marn
Introduction to MapReduce. Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng.
 Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Laarge-Scale Data Engineering
 Laarge-Scale Data Engineering The MapReduce Framework & Hadoop Key premise: divide and conquer work partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 result combine Parallelisation challenges How
Laarge-Scale Data Engineering The MapReduce Framework & Hadoop Key premise: divide and conquer work partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 result combine Parallelisation challenges How
Introduc)on to. CS60092: Informa0on Retrieval
on to. CS60092: Informa0on Retrieval") Introduc)on to CS60092: Informa0on Retrieval Ch. 4 Index construc)on How do we construct an index? What strategies can we use with limited main memory? Sec. 4.1 Hardware basics Many design decisions in
Introduc)on to CS60092: Informa0on Retrieval Ch. 4 Index construc)on How do we construct an index? What strategies can we use with limited main memory? Sec. 4.1 Hardware basics Many design decisions in
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
L22: SC Report, Map Reduce
 L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
TP1-2: Analyzing Hadoop Logs
 TP1-2: Analyzing Hadoop Logs Shadi Ibrahim January 26th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
TP1-2: Analyzing Hadoop Logs Shadi Ibrahim January 26th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
The MapReduce Abstraction
 The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (2/2) January 12, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (2/2) January 12, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Map Reduce.
 Map Reduce dacosta@irit.fr Divide and conquer at PaaS Second Third Fourth 100 % // Fifth Sixth Seventh Cliquez pour 2 Typical problem Second Extract something of interest from each MAP Third Shuffle and
Map Reduce dacosta@irit.fr Divide and conquer at PaaS Second Third Fourth 100 % // Fifth Sixth Seventh Cliquez pour 2 Typical problem Second Extract something of interest from each MAP Third Shuffle and
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Map-Reduce and Adwords Problem
 Map-Reduce and Adwords Problem Map-Reduce and Adwords Problem Miłosz Kadziński Institute of Computing Science Poznan University of Technology, Poland www.cs.put.poznan.pl/mkadzinski/wpi Big Data (1) Big
Map-Reduce and Adwords Problem Map-Reduce and Adwords Problem Miłosz Kadziński Institute of Computing Science Poznan University of Technology, Poland www.cs.put.poznan.pl/mkadzinski/wpi Big Data (1) Big
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CMSC 723: Computational Linguistics I Session #12 MapReduce and Data Intensive NLP. University of Maryland. Wednesday, November 18, 2009
 CMSC 723: Computational Linguistics I Session #12 MapReduce and Data Intensive NLP Jimmy Lin and Nitin Madnani University of Maryland Wednesday, November 18, 2009 Three Pillars of Statistical NLP Algorithms
CMSC 723: Computational Linguistics I Session #12 MapReduce and Data Intensive NLP Jimmy Lin and Nitin Madnani University of Maryland Wednesday, November 18, 2009 Three Pillars of Statistical NLP Algorithms
Index construc-on. Friday, 8 April 16 1
 Index construc-on Informa)onal Retrieval By Dr. Qaiser Abbas Department of Computer Science & IT, University of Sargodha, Sargodha, 40100, Pakistan qaiser.abbas@uos.edu.pk Friday, 8 April 16 1 4.3 Single-pass
Index construc-on Informa)onal Retrieval By Dr. Qaiser Abbas Department of Computer Science & IT, University of Sargodha, Sargodha, 40100, Pakistan qaiser.abbas@uos.edu.pk Friday, 8 April 16 1 4.3 Single-pass
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
MapReduce Algorithm Design
 MapReduce Algorithm Design Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul Big
MapReduce Algorithm Design Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul Big
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
MapReduce Simplified Data Processing on Large Clusters
 MapReduce Simplified Data Processing on Large Clusters Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) MapReduce 1393/8/5 1 /
MapReduce Simplified Data Processing on Large Clusters Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) MapReduce 1393/8/5 1 /
Apache Hive. CMSC 491 Hadoop-Based Distributed Compu<ng Spring 2016 Adam Shook
 Apache Hive CMSC 491 Hadoop-Based Distributed Compu
Apache Hive CMSC 491 Hadoop-Based Distributed Compu
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed Systems. CS422/522 Lecture17 17 November 2014
 Distributed Systems CS422/522 Lecture17 17 November 2014 Lecture Outline Introduction Hadoop Chord What s a distributed system? What s a distributed system? A distributed system is a collection of loosely
Distributed Systems CS422/522 Lecture17 17 November 2014 Lecture Outline Introduction Hadoop Chord What s a distributed system? What s a distributed system? A distributed system is a collection of loosely
Data-Intensive Distributed Computing
 Data-Intensive Distributed Computing CS 45/65 43/63 (Winter 08) Part 3: Analyzing Text (/) January 30, 08 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides are
Data-Intensive Distributed Computing CS 45/65 43/63 (Winter 08) Part 3: Analyzing Text (/) January 30, 08 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides are
Informa(on Retrieval
 Introduc*on to Informa(on Retrieval CS276: Informa*on Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Lecture 4: Index Construc*on Plan Last lecture: Dic*onary data structures Tolerant retrieval
Introduc*on to Informa(on Retrieval CS276: Informa*on Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Lecture 4: Index Construc*on Plan Last lecture: Dic*onary data structures Tolerant retrieval
Agenda. Request- Level Parallelism. Agenda. Anatomy of a Web Search. Google Query- Serving Architecture 9/20/10
 Agenda CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instructors: Randy H. Katz David A. PaHerson hhp://inst.eecs.berkeley.edu/~cs61c/fa10 Request and Data Level Parallelism Administrivia
Agenda CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instructors: Randy H. Katz David A. PaHerson hhp://inst.eecs.berkeley.edu/~cs61c/fa10 Request and Data Level Parallelism Administrivia
Your First Hadoop App, Step by Step
 Learn Hadoop in one evening Your First Hadoop App, Step by Step Martynas 1 Miliauskas @mmiliauskas Your First Hadoop App, Step by Step By Martynas Miliauskas Published in 2013 by Martynas Miliauskas On
Learn Hadoop in one evening Your First Hadoop App, Step by Step Martynas 1 Miliauskas @mmiliauskas Your First Hadoop App, Step by Step By Martynas Miliauskas Published in 2013 by Martynas Miliauskas On
CCA-410. Cloudera. Cloudera Certified Administrator for Apache Hadoop (CCAH)
") Cloudera CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Download Full Version : http://killexams.com/pass4sure/exam-detail/cca-410 Reference: CONFIGURATION PARAMETERS DFS.BLOCK.SIZE
Cloudera CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Download Full Version : http://killexams.com/pass4sure/exam-detail/cca-410 Reference: CONFIGURATION PARAMETERS DFS.BLOCK.SIZE
CS 378 Big Data Programming
 CS 378 Big Data Programming Lecture 11 more on Data Organiza:on Pa;erns CS 378 - Fall 2016 Big Data Programming 1 Assignment 5 - Review Define an Avro object for user session One user session for each
CS 378 Big Data Programming Lecture 11 more on Data Organiza:on Pa;erns CS 378 - Fall 2016 Big Data Programming 1 Assignment 5 - Review Define an Avro object for user session One user session for each
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
International Journal of Advance Engineering and Research Development. A Study: Hadoop Framework
 Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Data-Intensive Distributed Computing
 Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 1: MapReduce Algorithm Design (4/4) January 16, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 1: MapReduce Algorithm Design (4/4) January 16, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
Distributed Computations MapReduce. adapted from Jeff Dean s slides
 Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
Algorithms for MapReduce. Combiners Partition and Sort Pairs vs Stripes
 Algorithms for MapReduce 1 Assignment 1 released Due 16:00 on 20 October Correctness is not enough! Most marks are for efficiency. 2 Combining, Sorting, and Partitioning... and algorithms exploiting these
Algorithms for MapReduce 1 Assignment 1 released Due 16:00 on 20 October Correctness is not enough! Most marks are for efficiency. 2 Combining, Sorting, and Partitioning... and algorithms exploiting these
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
Introduction to MapReduce
 Introduction to MapReduce Based on slides by Juliana Freire Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Required Reading! Data-Intensive Text Processing with MapReduce,
Introduction to MapReduce Based on slides by Juliana Freire Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Required Reading! Data-Intensive Text Processing with MapReduce,
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
MapReduce-style data processing
 MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
Cloud Programming. Programming Environment Oct 29, 2015 Osamu Tatebe
 Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
Announcements. Optional Reading. Distributed File System (DFS) MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm
 MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm") Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Introduction to MapReduce
 Introduction to MapReduce Based on slides by Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec How much data? Google processes 20 PB a day (2008) Internet Archive Wayback Machine has 3 PB + 100
Introduction to MapReduce Based on slides by Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec How much data? Google processes 20 PB a day (2008) Internet Archive Wayback Machine has 3 PB + 100
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
Parallel Data Processing with Hadoop/MapReduce. CS140 Tao Yang, 2014
 Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example
Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Announcements. Parallel Data Processing in the 20 th Century. Parallel Join Illustration. Introduction to Database Systems CSE 414
 Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Lecture 12 DATA ANALYTICS ON WEB SCALE
 Lecture 12 DATA ANALYTICS ON WEB SCALE Source: The Economist, February 25, 2010 The Data Deluge EIGHTEEN months ago, Li & Fung, a firm that manages supply chains for retailers, saw 100 gigabytes of information
Lecture 12 DATA ANALYTICS ON WEB SCALE Source: The Economist, February 25, 2010 The Data Deluge EIGHTEEN months ago, Li & Fung, a firm that manages supply chains for retailers, saw 100 gigabytes of information
MapReduce: Simplified Data Processing on Large Clusters
 MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
Hadoop MapReduce Framework
 Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce
Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 07) Week 4: Analyzing Text (/) January 6, 07 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 07) Week 4: Analyzing Text (/) January 6, 07 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
STATS Data Analysis using Python. Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns
 STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
MapReduce Design Patterns
 MapReduce Design Patterns MapReduce Restrictions Any algorithm that needs to be implemented using MapReduce must be expressed in terms of a small number of rigidly defined components that must fit together
MapReduce Design Patterns MapReduce Restrictions Any algorithm that needs to be implemented using MapReduce must be expressed in terms of a small number of rigidly defined components that must fit together
MapReduce. Tom Anderson
 MapReduce Tom Anderson Last Time Difference between local state and knowledge about other node s local state Failures are endemic Communica?on costs ma@er Why Is DS So Hard? System design Par??oning of
MapReduce Tom Anderson Last Time Difference between local state and knowledge about other node s local state Failures are endemic Communica?on costs ma@er Why Is DS So Hard? System design Par??oning of
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Map-Reduce and Related Systems
 Map-Reduce and Related Systems Acknowledgement The slides used in this chapter are adapted from the following sources: CS246 Mining Massive Data-sets, by Jure Leskovec, Stanford University, http://www.mmds.org
Map-Reduce and Related Systems Acknowledgement The slides used in this chapter are adapted from the following sources: CS246 Mining Massive Data-sets, by Jure Leskovec, Stanford University, http://www.mmds.org
Introduction to MapReduce
 Introduction to MapReduce Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Single-node architecture CPU Memory Data Analysis, Machine Learning, Statistics Disk How much
Introduction to MapReduce Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Single-node architecture CPU Memory Data Analysis, Machine Learning, Statistics Disk How much
NoSQL. Based on slides by Mike Franklin and Jimmy Lin
 NoSQL Based on slides by Mike Franklin and Jimmy Lin 1 Big Data (some old numbers) Facebook: 130TB/day: user logs 200-400TB/day: 83 million pictures Google: > 25 PB/day processed data Gene sequencing:
NoSQL Based on slides by Mike Franklin and Jimmy Lin 1 Big Data (some old numbers) Facebook: 130TB/day: user logs 200-400TB/day: 83 million pictures Google: > 25 PB/day processed data Gene sequencing:
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Batch Inherence of Map Reduce Framework
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 6, June 2015, pg.287
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 6, June 2015, pg.287
Database Applications (15-415)
") Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016
CS-2510 COMPUTER OPERATING SYSTEMS
 CS-2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application Functional
CS-2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application Functional
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
Programming Models MapReduce
 Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Parallel Programming Concepts
 Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model