Data in the Cloud and Analytics in the Lake
|
|
|
- Jody White
- 5 years ago
- Views:
Transcription

1 Data in the Cloud and Analytics in the Lake
2 Introduction Working in Analytics for over 5 years Part the digital team at BNZ for 3 years Based in the Auckland office Preferred Languages SQL Python (PySpark) R Professional Scuba Diver PADI Divemaster Professional Waiter Fine Dining
3 Slide 2 Notes The Digital team 300 (and growing) people of out 4, million customers made up of a mix of personal and business clients. mildly large data As for myself. I have been at bnz for around 3 years. I do have a small confession, I am not a SAS coder so there wont be any code snippets this talk. My language of choice for Data Engineering and Data Science is Python. Diver Waiter


4 BNZ Digital Channels Product Pages Sales Funnels Account Balances Product Servicing Multi User Sites Login Portal Help and Support In Channel Messaging Quick Balances In Channel Sales Offers
5 Slide 3 Notes Okay so now that that s out of the way, a dive a bit deeper into the digital landscape of BNZ. We have five main ways our customer can interact with us digitally, which we refer to as channels. The unauthenticated Website before the password Product Pages, Help and Support, Landing Pages Internet Banking Reactive web app (we ll get back to this later) Mobile App Internet Banking for Business Business Banking Platform Multi User Sites Mobile App While our customer will generally just call it our website, internally its not so simple. So what does this mean?
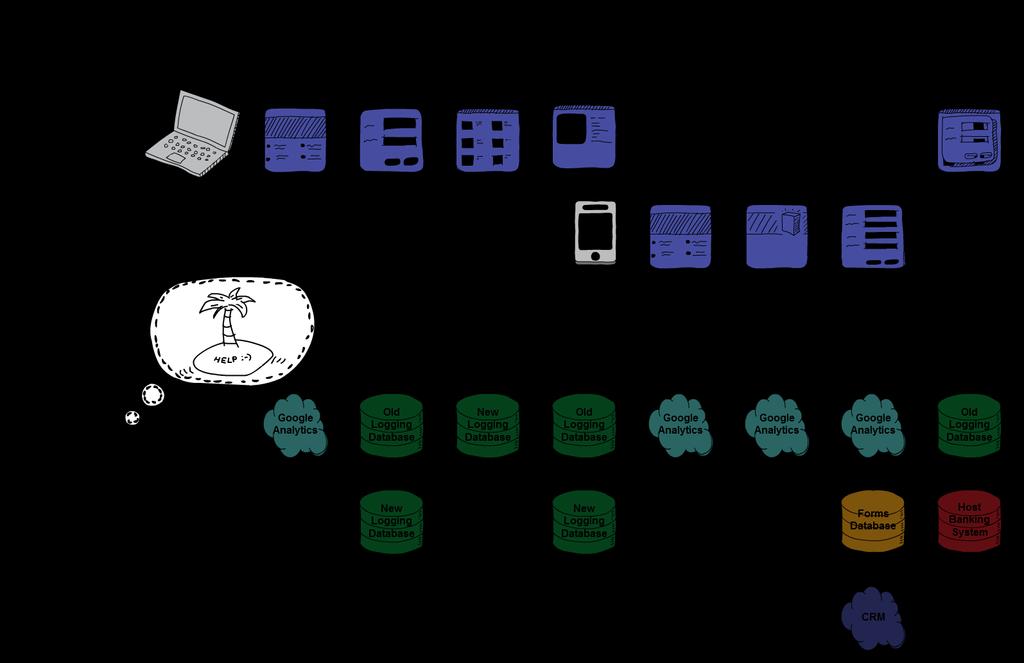
6 Business Challenges
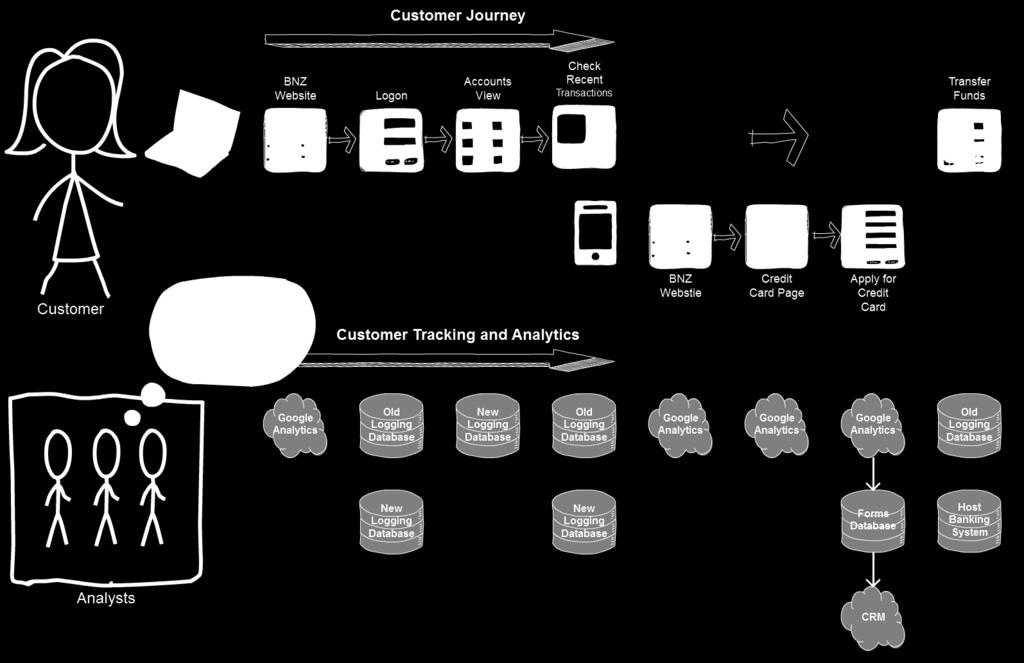
7 Slide 4 Notes Ask why you might apply for a Credit Card? Lets take a typical customer journey 1. Customer sit down at they laptop, opens a browser and clicks on the BNZ bookmark 2. They land on the home page 3. Click on the login button 4. Now they land on their account view, 5. Check their balances and notice they have significantly less than they expected 6. Open up their account and have a look at some recent transactions and realise their rates have were due and the automatic payment has gone out 7. Now they remember they got an about a credit card from us. 8. Open their mobile find the and click on the link 9. Land on the bnz website, navigate a few credit card pages 10.Fill out and application form and get a credit card. 11.Now they remember they logged in to pay their insurance so go back to their internet banking and make a transaction on their new card So far we have had: Two sets of data from Google Analytics Logging data spread across 4 different tables Forms data CRM data And raw data in our core banking systems
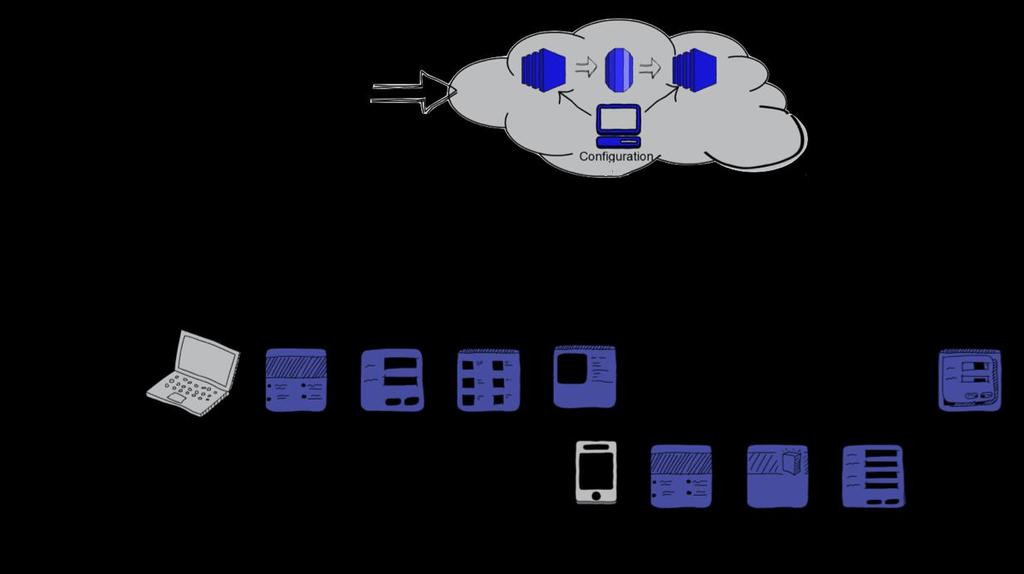

8 Customer Intelligence 360 Discover
9 Slide 5 Notes We decided to implement CI360 Discover as a single tool to capture data across all out digital channels Discover is a Cloud based analytics collection tool Provides not only the ability to capture data but to create data by configuring rules This can be done by analysts or business users and for the most part does not require developers
10 Risk vs The Cloud As in any large company, everything needs to managed within an accepted level of risk VS We needed to capture as much data as possible, even data we don t know we need yet Capture Everything Simplify risk requirements by excluding Personally Identifiable Information (PII) Exclude PII Use SAS Discover Form and Field Level Rules Control not based on content Analyse all the potential points where this could occur Analyses proved unfeasible Work with Risk to evaluate putting PII in the cloud
11 Slide 6 Notes dealt with their risk team at some point. In any company there is a need ensure an acceptable level of risk. customer data is increasingly being misused Increasing regulation (GDPR) for the horde of s on updated privacy policies On the other side we have Big Data (or in the case of NZ mildly large data) and data science use cases. capture everything we can. year on year trend analyses for an executive report. train a traditional models, implement real-time machine learning.. To make our lives easier and reduce risk we decided to try to exclude PII data
12 Implementation of SAS Discover Phase 1 One line of JavaScript (SDKs for the Mobile Apps) Phase 2 Track customer identities using a secure hash Get data from SAS CI360 Discover to our Cloudera Hadoop Cluster Reverse the hash and join with our customer data Build a Visual Analytics Suite
13 Slide 7 Notes Phase 1 - The famous one line of Javascript. To the surprise of the developer it proved to be pretty much just that. Channel by channel we quickly got tracking up and running and were able to see data arriving in the cloud - We started setting up basic rules to track behaviour. - At the same time we put the SDK into the mobile apps and connected a few prexisitng hooks to start captureing the various screens. - Difficulties Singe Page Apps. We have a bunch of single page apps that drive our digital channels. The retail internet banking channel and the way we present and submit forms across WWW. We quickly found that while we could capture the majority of event it still proved difficult to capture goals and screens within these apps without reverting to hard coded events Phase 2 - Create a service to start sending a unique hash to SAS Discover to uniquely identify users and implement this in each channel (ongoing) - Build a process to get the data from SAS Discover back to BNZ. For this we engaged our enterprise data team to build a robust pipeline from AWS to our on premis Cloudera Cluster. At the time of the initial plan SAS Discover was only able to output its data to an Oracle or PostgreSQL database, however we were fortunate to be one of the first organisation to be able to use the new API that enabled us to get data directly from the service itself. - Build a process to get the customer identifier, this involved building near real-time feeds between various source data systems to allow us to use this within an analytics pipeline. This is an interesting space where operational data is now being required by analytics tooling. - Build a Visual Analytics Suite. Using Tableau we are able to build out an ever increasing suite of visual analytics that can satisfy standard (80%) of the business question (this is also somewhat ongoing)

14 Final Implementation 1. All five of our channels are connected to CI Business users are able to create rules 3. The raw data flows back into to the data lake using Informatica via the CI360 REST API 4. Business users can use a suite of visual analytics in Tableau 5. The analytics team is also able to use the raw data
15 Slide 8 Notes 1. All five of our channels are connected to SAS Discover. We are able to track our users as they move between desktop channels or even use multiple devices at the same time. 2. Business users are able to create rules to group pages and screens together, and determine goals and business processes they want to track. 3. The raw data flows back into to the BNZ ecosystem using Informatica via the SAS Discover REST API. New data is available on an hourly basis with any extra business rules applied. 4. Business users can use a suite of visual analytics in Tableau to answer the majority of their question s. 5. The analytics team is also able to use the raw data to generate insights or build advanced models.

16 The Data Lake - Hadoop is Not a Thing Traditional Analytics Tools 1. A data storage mechanism: usually some sort of table made of columns containing a type of data 2. A way to import new data into the table 3. A way to manipulate the data, either through a visual editor or code 4. A way to view the output in a table or graph 5. A way to export data
17 Slide 9 Notes Building a data lake and one of the most common technologies to do this is Hadoop. We within digital we have been using our Cloudera Hadoop cluster in anger for about 2 years Hadoop is not a thing. I mean this in the way that it is not like the tools we are used to.


18 Hadoop is Lots of Little Things 1. Data Storage Mechanism: Data is stored in a distributed file system called HDFS. It works like any drive on your computer, you can put any type of file on it. It is predominantly a write once architecture. 2. Importing Data: Sqoop for reading and writing from relational databases Flume for dealing with streams WebHDFS for files via a REST API 3. Data Manipulation, is where Hadoop excels: MapReduce uses HDFS s native functionality Hive and Impala provide a familiar SQL interface Spark is a vastly powerful data engine that has Python and R APIs for Data Science and Machine Learning 4. Viewing the data: Web interfaces such as Cloudera Hue provide a simple user interface for the various tools 5. Due to the massive nature of much of the data on Hadoop, it s often best to just leave the data there.
19 Slide 10 Notes 1. Data Storage Mechanism. Data is stored in a distributed file system called HDFS. Unlike traditional analytics tools it works like a folder on your computer and can take any type of file. The most common files for the analyst to load are 1. CSVs or text files, but HDFS can support 2. unstructured tests such as log files, 3. JSONs or 4. images. 5. It also has some extra formats for storing data. In particular, Parquet files form the closest analogy to the traditional table, they are highly typed and the columns have specific names. Parquet also uses column instead of row based storage, which makes it ideal for the big wide tables that you often get in big data. 2. Importing Data. Hadoop has many ways to import data: 1. Sqoop for reading and writing from relational databases, 2. Flume for dealing with streams, and 3. WebHDFS for files via a REST API. 4. While some of these tools can perform minor transformations, they are only really good at landing the original data into HDFS. 3. When it comes to data manipulation, there is plenty of choice. MapReduce is a java based language that uses HDFS s native functionality. Hive has been built on this to provide a familiar SQL interface. Impala uses the table metadata from Hive but performs much faster, thanks to its in-memory engine. Finally, Spark is a vastly powerful data engine that has Python and R APIs for Data Science and Machine Learning. Learning each of these, their strengths and limitations and how to combine them into an analytics pipeline is much more complex than traditional tools. 4. A way to output the data. Cloudera Hue provides a quick way to interact directly with the cluster, but lacks much of the visual output we are used to from tools like SAS. Thankfully the SQL engines provide connectors to modern visualization tools like Tableau. 5. Due to the massive nature of much of the data on Hadoop, it s often best to just leave the data there.

20 Creating the Event Stream: Updates on Hadoop To maintain a small set of transitory data in the same table using partitions, on each run: 1. Picks up any new start facts, the partition with the partial facts and any new end fact 2. Writes any completed facts to the relevant monthly partition 3. Overwrite the temporary partition with any un-joined facts
21 Slide 11 Notes CI360 Discover outputs some standardized streams of data: Pages Session Forms Etc Most of these have two parts which I call: Starting Part/Fact: This is the immutable data at the time of the event. When it happened, where it was Ending Part/Fact: This is the information about the event as a whole, like loading time or number of pages viewed that we don t know until all the possible actions are finished


22 SAS Discover Data Architecture 1. Informatica retrieves new data from the CI360 REST API 2. Informatica writes the optimised data model to production 1. Create Event Streams. Most of the key event streams in SAS Discover have two parts: one stream records the event at the start, another processed later to describe the entire event. 2. Create Identity Map: Using the most recent partition of the identity tables and near real-time data feed from the Operational Data Store to decode the hashed customer identities. 3. Data Engineering team creates the Enrichment tables, using Spark and Alteryx to fill out the 360 degree view of our users. 4. Analytics team and data scientists able to use the data to answer solve business problems
23 Slide 12 Notes Informatica retrieves new data from the SAS Discover REST API Check for new data Informatica retrieves s3 bcket address and single use credentials for each new file Download the fact tables in chucks and appends to existing data Download the full identity map and appends a new partition in a time series Informatica writes the optimised data model to production Create Event Streams. Most of the key event streams in SAS Discover have two parts: one stream records the event at the start, when a person lands on a page. The other is processed later to describe the entire event, loading time and time spent on page. To get a complete view of the stream we need to join the data from both tables. However, the starting fact arrives up to four hours before the ending fact. Being able to react quickly is increasingly important, so we need a way to temporarily add the partial facts to the output stream. To do this, we make use of partitions. This allows us to maintain a small set of transitory data that is co-located in the same table as the final data. On each run, the process picks up any new start facts, the partition with the partial facts and any new end fact. It then writes any completed facts to the relevant monthly partition and any un-joined facts overwrite the previous partial partition (See Figure 7). Create Identity Map. The identity map is much easier. Informatica picks up the most recent partition of the identity tables, joins them together and then uses the near real-time data feed from the Operational Data Store to decode the hashed customer identities. SAS Discover allows us to have multiple levels of identities, so we need to flatten the identity table to allow one-to-one joining with our time series and enrichment tables. Data Engineering team creates the Enrichment tables. Now that we have an hourly feed of customer data, we need to add customer attributes such as segment, digital activation, or product holding. Our analytics team and data engineers use the other data within the raw zone to start to fill out the 360 o degree view of our users.
24 What we have learned For SAS CI360 Discover the one line of JavaScript was just that Sometimes, what looks like the harder path is the easier one The data lake isn t always smooth sailing Tracking customer interactions are only the first step of the process
25 Slide 13 Notes What s next: Building a scalable system to deliver a single customer view to deliver a consistent omni channel personalised experience
26 What s next Building an agile scalable pipeline to deliver a single customer view and enable a consistent omni channel personalised experience
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Asanka Padmakumara. ETL 2.0: Data Engineering with Azure Databricks
 Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
An Introduction to Big Data Formats
 Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Best practices for building a Hadoop Data Lake Solution CHARLOTTE HADOOP USER GROUP
 Best practices for building a Hadoop Data Lake Solution CHARLOTTE HADOOP USER GROUP 07.29.2015 LANDING STAGING DW Let s start with something basic Is Data Lake a new concept? What is the closest we can
Best practices for building a Hadoop Data Lake Solution CHARLOTTE HADOOP USER GROUP 07.29.2015 LANDING STAGING DW Let s start with something basic Is Data Lake a new concept? What is the closest we can
Oracle Big Data Connectors
 Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Datameer for Data Preparation:
 Datameer for Data Preparation: Explore, Profile, Blend, Cleanse, Enrich, Share, Operationalize DATAMEER FOR DATA PREPARATION: EXPLORE, PROFILE, BLEND, CLEANSE, ENRICH, SHARE, OPERATIONALIZE Datameer Datameer
Datameer for Data Preparation: Explore, Profile, Blend, Cleanse, Enrich, Share, Operationalize DATAMEER FOR DATA PREPARATION: EXPLORE, PROFILE, BLEND, CLEANSE, ENRICH, SHARE, OPERATIONALIZE Datameer Datameer
CIS 612 Advanced Topics in Database Big Data Project Lawrence Ni, Priya Patil, James Tench
 CIS 612 Advanced Topics in Database Big Data Project Lawrence Ni, Priya Patil, James Tench Abstract Implementing a Hadoop-based system for processing big data and doing analytics is a topic which has been
CIS 612 Advanced Topics in Database Big Data Project Lawrence Ni, Priya Patil, James Tench Abstract Implementing a Hadoop-based system for processing big data and doing analytics is a topic which has been
Virtuoso Infotech Pvt. Ltd.
 Virtuoso Infotech Pvt. Ltd. About Virtuoso Infotech Fastest growing IT firm; Offers the flexibility of a small firm and robustness of over 30 years experience collectively within the leadership team Technology
Virtuoso Infotech Pvt. Ltd. About Virtuoso Infotech Fastest growing IT firm; Offers the flexibility of a small firm and robustness of over 30 years experience collectively within the leadership team Technology
Modern Data Warehouse The New Approach to Azure BI
 Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
SQT03 Big Data and Hadoop with Azure HDInsight Andrew Brust. Senior Director, Technical Product Marketing and Evangelism
 Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
From Single Purpose to Multi Purpose Data Lakes. Thomas Niewel Technical Sales Director DACH Denodo Technologies March, 2019
 From Single Purpose to Multi Purpose Data Lakes Thomas Niewel Technical Sales Director DACH Denodo Technologies March, 2019 Agenda Data Lakes Multiple Purpose Data Lakes Customer Example Demo Takeaways
From Single Purpose to Multi Purpose Data Lakes Thomas Niewel Technical Sales Director DACH Denodo Technologies March, 2019 Agenda Data Lakes Multiple Purpose Data Lakes Customer Example Demo Takeaways
Azure Data Factory. Data Integration in the Cloud
 Azure Data Factory Data Integration in the Cloud 2018 Microsoft Corporation. All rights reserved. This document is provided "as-is." Information and views expressed in this document, including URL and
Azure Data Factory Data Integration in the Cloud 2018 Microsoft Corporation. All rights reserved. This document is provided "as-is." Information and views expressed in this document, including URL and
CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED DATA PLATFORM
 CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED PLATFORM Executive Summary Financial institutions have implemented and continue to implement many disparate applications
CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED PLATFORM Executive Summary Financial institutions have implemented and continue to implement many disparate applications
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Introduction to Big-Data
 Introduction to Big-Data Ms.N.D.Sonwane 1, Mr.S.P.Taley 2 1 Assistant Professor, Computer Science & Engineering, DBACER, Maharashtra, India 2 Assistant Professor, Information Technology, DBACER, Maharashtra,
Introduction to Big-Data Ms.N.D.Sonwane 1, Mr.S.P.Taley 2 1 Assistant Professor, Computer Science & Engineering, DBACER, Maharashtra, India 2 Assistant Professor, Information Technology, DBACER, Maharashtra,
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Data warehousing on Hadoop. Marek Grzenkowicz Roche Polska
 Data warehousing on Hadoop Marek Grzenkowicz Roche Polska Agenda Introduction Case study: StraDa project Source data Data model Data flow and processing Reporting Lessons learnt Ideas for the future Q&A
Data warehousing on Hadoop Marek Grzenkowicz Roche Polska Agenda Introduction Case study: StraDa project Source data Data model Data flow and processing Reporting Lessons learnt Ideas for the future Q&A
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
Data Analytics at Logitech Snowflake + Tableau = #Winning
 Welcome # T C 1 8 Data Analytics at Logitech Snowflake + Tableau = #Winning Avinash Deshpande I am a futurist, scientist, engineer, designer, data evangelist at heart Find me at Avinash Deshpande Chief
Welcome # T C 1 8 Data Analytics at Logitech Snowflake + Tableau = #Winning Avinash Deshpande I am a futurist, scientist, engineer, designer, data evangelist at heart Find me at Avinash Deshpande Chief
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
AWS Serverless Architecture Think Big
 MAKING BIG DATA COME ALIVE AWS Serverless Architecture Think Big Garrett Holbrook, Data Engineer Feb 1 st, 2017 Agenda What is Think Big? Example Project Walkthrough AWS Serverless 2 Think Big, a Teradata
MAKING BIG DATA COME ALIVE AWS Serverless Architecture Think Big Garrett Holbrook, Data Engineer Feb 1 st, 2017 Agenda What is Think Big? Example Project Walkthrough AWS Serverless 2 Think Big, a Teradata
IBM Data Replication for Big Data
 IBM Data Replication for Big Data Highlights Stream changes in realtime in Hadoop or Kafka data lakes or hubs Provide agility to data in data warehouses and data lakes Achieve minimum impact on source
IBM Data Replication for Big Data Highlights Stream changes in realtime in Hadoop or Kafka data lakes or hubs Provide agility to data in data warehouses and data lakes Achieve minimum impact on source
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data with Hadoop Ecosystem
 Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Oracle Big Data. A NA LYT ICS A ND MA NAG E MENT.
 Oracle Big Data. A NALYTICS A ND MANAG E MENT. Oracle Big Data: Redundância. Compatível com ecossistema Hadoop, HIVE, HBASE, SPARK. Integração com Cloudera Manager. Possibilidade de Utilização da Linguagem
Oracle Big Data. A NALYTICS A ND MANAG E MENT. Oracle Big Data: Redundância. Compatível com ecossistema Hadoop, HIVE, HBASE, SPARK. Integração com Cloudera Manager. Possibilidade de Utilização da Linguagem
The Technology of the Business Data Lake. Appendix
 The Technology of the Business Data Lake Appendix Pivotal data products Term Greenplum Database GemFire Pivotal HD Spring XD Pivotal Data Dispatch Pivotal Analytics Description A massively parallel platform
The Technology of the Business Data Lake Appendix Pivotal data products Term Greenplum Database GemFire Pivotal HD Spring XD Pivotal Data Dispatch Pivotal Analytics Description A massively parallel platform
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Solving the Really Big Tech Problems with IoT Data Security and Privacy
 Solving the Really Big Tech Problems with IoT Data Security and Privacy HPE Security Data Security March 16, 2017 IoT Everywhere - Promising New Value Manufacturing Energy / Utilities Banks / Financial
Solving the Really Big Tech Problems with IoT Data Security and Privacy HPE Security Data Security March 16, 2017 IoT Everywhere - Promising New Value Manufacturing Energy / Utilities Banks / Financial
How to choose the right approach to analytics and reporting
 SOLUTION OVERVIEW How to choose the right approach to analytics and reporting A comprehensive comparison of the open source and commercial versions of the OpenText Analytics Suite In today s digital world,
SOLUTION OVERVIEW How to choose the right approach to analytics and reporting A comprehensive comparison of the open source and commercial versions of the OpenText Analytics Suite In today s digital world,
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem. Zohar Elkayam
 Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Oracle Big Data SQL. Release 3.2. Rich SQL Processing on All Data
 Oracle Big Data SQL Release 3.2 The unprecedented explosion in data that can be made useful to enterprises from the Internet of Things, to the social streams of global customer bases has created a tremendous
Oracle Big Data SQL Release 3.2 The unprecedented explosion in data that can be made useful to enterprises from the Internet of Things, to the social streams of global customer bases has created a tremendous
Scalable Tools - Part I Introduction to Scalable Tools
 Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
KNIME for the life sciences Cambridge Meetup
 KNIME for the life sciences Cambridge Meetup Greg Landrum, Ph.D. KNIME.com AG 12 July 2016 What is KNIME? A bit of motivation: tool blending, data blending, documentation, automation, reproducibility More
KNIME for the life sciences Cambridge Meetup Greg Landrum, Ph.D. KNIME.com AG 12 July 2016 What is KNIME? A bit of motivation: tool blending, data blending, documentation, automation, reproducibility More
Stages of Data Processing
 Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Hadoop Online Training
 Hadoop Online Training IQ training facility offers Hadoop Online Training. Our Hadoop trainers come with vast work experience and teaching skills. Our Hadoop training online is regarded as the one of the
Hadoop Online Training IQ training facility offers Hadoop Online Training. Our Hadoop trainers come with vast work experience and teaching skills. Our Hadoop training online is regarded as the one of the
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
Spotfire Data Science with Hadoop Using Spotfire Data Science to Operationalize Data Science in the Age of Big Data
 Spotfire Data Science with Hadoop Using Spotfire Data Science to Operationalize Data Science in the Age of Big Data THE RISE OF BIG DATA BIG DATA: A REVOLUTION IN ACCESS Large-scale data sets are nothing
Spotfire Data Science with Hadoop Using Spotfire Data Science to Operationalize Data Science in the Age of Big Data THE RISE OF BIG DATA BIG DATA: A REVOLUTION IN ACCESS Large-scale data sets are nothing
Information empowerment for your evolving data ecosystem
 Information empowerment for your evolving data ecosystem Highlights Enables better results for critical projects and key analytics initiatives Ensures the information is trusted, consistent and governed
Information empowerment for your evolving data ecosystem Highlights Enables better results for critical projects and key analytics initiatives Ensures the information is trusted, consistent and governed
Exam Questions
 Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Data 101 Which DB, When. Joe Yong Azure SQL Data Warehouse, Program Management Microsoft Corp.
 Data 101 Which DB, When Joe Yong (joeyong@microsoft.com) Azure SQL Data Warehouse, Program Management Microsoft Corp. The world is changing AI increased by 300% in 2017 Data will grow to 44 ZB in 2020
Data 101 Which DB, When Joe Yong (joeyong@microsoft.com) Azure SQL Data Warehouse, Program Management Microsoft Corp. The world is changing AI increased by 300% in 2017 Data will grow to 44 ZB in 2020
Increase Value from Big Data with Real-Time Data Integration and Streaming Analytics
 Increase Value from Big Data with Real-Time Data Integration and Streaming Analytics Cy Erbay Senior Director Striim Executive Summary Striim is Uniquely Qualified to Solve the Challenges of Real-Time
Increase Value from Big Data with Real-Time Data Integration and Streaming Analytics Cy Erbay Senior Director Striim Executive Summary Striim is Uniquely Qualified to Solve the Challenges of Real-Time
Bringing Data to Life
 Bringing Data to Life Data management and Visualization Techniques Benika Hall Rob Harrison Corporate Model Risk March 16, 2018 Introduction Benika Hall Analytic Consultant Wells Fargo - Corporate Model
Bringing Data to Life Data management and Visualization Techniques Benika Hall Rob Harrison Corporate Model Risk March 16, 2018 Introduction Benika Hall Analytic Consultant Wells Fargo - Corporate Model
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Real-time Streaming Applications on AWS Patterns and Use Cases
 Real-time Streaming Applications on AWS Patterns and Use Cases Paul Armstrong - Solutions Architect (AWS) Tom Seddon - Data Engineering Tech Lead (Deliveroo) 28 th June 2017 2016, Amazon Web Services,
Real-time Streaming Applications on AWS Patterns and Use Cases Paul Armstrong - Solutions Architect (AWS) Tom Seddon - Data Engineering Tech Lead (Deliveroo) 28 th June 2017 2016, Amazon Web Services,
What is Gluent? The Gluent Data Platform
 What is Gluent? The Gluent Data Platform The Gluent Data Platform provides a transparent data virtualization layer between traditional databases and modern data storage platforms, such as Hadoop, in the
What is Gluent? The Gluent Data Platform The Gluent Data Platform provides a transparent data virtualization layer between traditional databases and modern data storage platforms, such as Hadoop, in the
The Evolution of a Data Project
 The Evolution of a Data Project The Evolution of a Data Project Python script The Evolution of a Data Project Python script SQL on live DB The Evolution of a Data Project Python script SQL on live DB SQL
The Evolution of a Data Project The Evolution of a Data Project Python script The Evolution of a Data Project Python script SQL on live DB The Evolution of a Data Project Python script SQL on live DB SQL
Oracle Big Data Fundamentals Ed 2
 Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Syncsort DMX-h. Simplifying Big Data Integration. Goals of the Modern Data Architecture SOLUTION SHEET
 SOLUTION SHEET Syncsort DMX-h Simplifying Big Data Integration Goals of the Modern Data Architecture Data warehouses and mainframes are mainstays of traditional data architectures and still play a vital
SOLUTION SHEET Syncsort DMX-h Simplifying Big Data Integration Goals of the Modern Data Architecture Data warehouses and mainframes are mainstays of traditional data architectures and still play a vital
Read & Download (PDF Kindle) Pro Apache Hadoop
 Pro Apache Hadoop") Read & Download (PDF Kindle) Pro Apache Hadoop Pro Apache Hadoop, Second Edition brings you up to speed on Hadoop â the framework of big data. Revised to cover Hadoop 2.0, the book covers the very latest
Read & Download (PDF Kindle) Pro Apache Hadoop Pro Apache Hadoop, Second Edition brings you up to speed on Hadoop â the framework of big data. Revised to cover Hadoop 2.0, the book covers the very latest
HDInsight > Hadoop. October 12, 2017
 HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Data 101 Which DB, When Joe Yong Sr. Program Manager Microsoft Corp.
 17-18 March, 2018 Beijing Data 101 Which DB, When Joe Yong Sr. Program Manager Microsoft Corp. The world is changing AI increased by 300% in 2017 Data will grow to 44 ZB in 2020 Today, 80% of organizations
17-18 March, 2018 Beijing Data 101 Which DB, When Joe Yong Sr. Program Manager Microsoft Corp. The world is changing AI increased by 300% in 2017 Data will grow to 44 ZB in 2020 Today, 80% of organizations
Bring Context To Your Machine Data With Hadoop, RDBMS & Splunk
 Bring Context To Your Machine Data With Hadoop, RDBMS & Splunk Raanan Dagan and Rohit Pujari September 25, 2017 Washington, DC Forward-Looking Statements During the course of this presentation, we may
Bring Context To Your Machine Data With Hadoop, RDBMS & Splunk Raanan Dagan and Rohit Pujari September 25, 2017 Washington, DC Forward-Looking Statements During the course of this presentation, we may
Data-Intensive Distributed Computing
 Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 5: Analyzing Relational Data (1/3) February 8, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 5: Analyzing Relational Data (1/3) February 8, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Logi Info v12.5 WHAT S NEW
 Logi Info v12.5 WHAT S NEW Introduction Logi empowers companies to embed analytics into the fabric of their organizations and products enabling anyone to analyze data, share insights, and make informed
Logi Info v12.5 WHAT S NEW Introduction Logi empowers companies to embed analytics into the fabric of their organizations and products enabling anyone to analyze data, share insights, and make informed
Big Data com Hadoop. VIII Sessão - SQL Bahia. Impala, Hive e Spark. Diógenes Pires 03/03/2018
 Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
Oracle Big Data Fundamentals Ed 1
 Oracle University Contact Us: +0097143909050 Oracle Big Data Fundamentals Ed 1 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, learn to use Oracle's Integrated Big Data
Oracle University Contact Us: +0097143909050 Oracle Big Data Fundamentals Ed 1 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, learn to use Oracle's Integrated Big Data
Hortonworks Data Platform
 Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Lambda Architecture for Batch and Stream Processing. October 2018
 Lambda Architecture for Batch and Stream Processing October 2018 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only.
Lambda Architecture for Batch and Stream Processing October 2018 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only.
Oracle Data Integrator 12c: Integration and Administration
 Oracle University Contact Us: Local: 1800 103 4775 Intl: +91 80 67863102 Oracle Data Integrator 12c: Integration and Administration Duration: 5 Days What you will learn Oracle Data Integrator is a comprehensive
Oracle University Contact Us: Local: 1800 103 4775 Intl: +91 80 67863102 Oracle Data Integrator 12c: Integration and Administration Duration: 5 Days What you will learn Oracle Data Integrator is a comprehensive
exam. Microsoft Perform Data Engineering on Microsoft Azure HDInsight. Version 1.0
 70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
Hadoop Overview. Lars George Director EMEA Services
 Hadoop Overview Lars George Director EMEA Services 1 About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer HBase and Whirr O Reilly Author HBase The Definitive
Hadoop Overview Lars George Director EMEA Services 1 About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer HBase and Whirr O Reilly Author HBase The Definitive
Big Data on AWS. Peter-Mark Verwoerd Solutions Architect
 Big Data on AWS Peter-Mark Verwoerd Solutions Architect What to get out of this talk Non-technical: Big Data processing stages: ingest, store, process, visualize Hot vs. Cold data Low latency processing
Big Data on AWS Peter-Mark Verwoerd Solutions Architect What to get out of this talk Non-technical: Big Data processing stages: ingest, store, process, visualize Hot vs. Cold data Low latency processing
Ian Choy. Technology Solutions Professional
 Ian Choy Technology Solutions Professional XML KPIs SQL Server 2000 Management Studio Mirroring SQL Server 2005 Compression Policy-Based Mgmt Programmability SQL Server 2008 PowerPivot SharePoint Integration
Ian Choy Technology Solutions Professional XML KPIs SQL Server 2000 Management Studio Mirroring SQL Server 2005 Compression Policy-Based Mgmt Programmability SQL Server 2008 PowerPivot SharePoint Integration
Index. Scott Klein 2017 S. Klein, IoT Solutions in Microsoft s Azure IoT Suite, DOI /
 Index A Advanced Message Queueing Protocol (AMQP), 44 Analytics, 9 Apache Ambari project, 209 210 API key, 244 Application data, 4 Azure Active Directory (AAD), 91, 257 Azure Blob Storage, 191 Azure data
Index A Advanced Message Queueing Protocol (AMQP), 44 Analytics, 9 Apache Ambari project, 209 210 API key, 244 Application data, 4 Azure Active Directory (AAD), 91, 257 Azure Blob Storage, 191 Azure data
Hue Application for Big Data Ingestion
 Hue Application for Big Data Ingestion August 2016 Author: Medina Bandić Supervisor(s): Antonio Romero Marin Manuel Martin Marquez CERN openlab Summer Student Report 2016 1 Abstract The purpose of project
Hue Application for Big Data Ingestion August 2016 Author: Medina Bandić Supervisor(s): Antonio Romero Marin Manuel Martin Marquez CERN openlab Summer Student Report 2016 1 Abstract The purpose of project
Hadoop, Yarn and Beyond
 Hadoop, Yarn and Beyond 1 B. R A M A M U R T H Y Overview We learned about Hadoop1.x or the core. Just like Java evolved, Java core, Java 1.X, Java 2.. So on, software and systems evolve, naturally.. Lets
Hadoop, Yarn and Beyond 1 B. R A M A M U R T H Y Overview We learned about Hadoop1.x or the core. Just like Java evolved, Java core, Java 1.X, Java 2.. So on, software and systems evolve, naturally.. Lets
Integrate MATLAB Analytics into Enterprise Applications
 Integrate Analytics into Enterprise Applications Aurélie Urbain MathWorks Consulting Services 2015 The MathWorks, Inc. 1 Data Analytics Workflow Data Acquisition Data Analytics Analytics Integration Business
Integrate Analytics into Enterprise Applications Aurélie Urbain MathWorks Consulting Services 2015 The MathWorks, Inc. 1 Data Analytics Workflow Data Acquisition Data Analytics Analytics Integration Business
Improving the ROI of Your Data Warehouse
 Improving the ROI of Your Data Warehouse Many organizations are struggling with a straightforward but challenging problem: their data warehouse can t affordably house all of their data and simultaneously
Improving the ROI of Your Data Warehouse Many organizations are struggling with a straightforward but challenging problem: their data warehouse can t affordably house all of their data and simultaneously
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Copyright 2012, Oracle and/or its affiliates. All rights reserved.
 1 Big Data Connectors: High Performance Integration for Hadoop and Oracle Database Melli Annamalai Sue Mavris Rob Abbott 2 Program Agenda Big Data Connectors: Brief Overview Connecting Hadoop with Oracle
1 Big Data Connectors: High Performance Integration for Hadoop and Oracle Database Melli Annamalai Sue Mavris Rob Abbott 2 Program Agenda Big Data Connectors: Brief Overview Connecting Hadoop with Oracle
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Benchmarks Prove the Value of an Analytical Database for Big Data
 White Paper Vertica Benchmarks Prove the Value of an Analytical Database for Big Data Table of Contents page The Test... 1 Stage One: Performing Complex Analytics... 3 Stage Two: Achieving Top Speed...
White Paper Vertica Benchmarks Prove the Value of an Analytical Database for Big Data Table of Contents page The Test... 1 Stage One: Performing Complex Analytics... 3 Stage Two: Achieving Top Speed...
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Oracle Data Integrator 12c: Integration and Administration
 Oracle University Contact Us: +34916267792 Oracle Data Integrator 12c: Integration and Administration Duration: 5 Days What you will learn Oracle Data Integrator is a comprehensive data integration platform
Oracle University Contact Us: +34916267792 Oracle Data Integrator 12c: Integration and Administration Duration: 5 Days What you will learn Oracle Data Integrator is a comprehensive data integration platform
Azure DevOps. Randy Pagels Intelligent Cloud Technical Specialist Great Lakes Region
 Azure DevOps Randy Pagels Intelligent Cloud Technical Specialist Great Lakes Region What is DevOps? People. Process. Products. Build & Test Deploy DevOps is the union of people, process, and products to
Azure DevOps Randy Pagels Intelligent Cloud Technical Specialist Great Lakes Region What is DevOps? People. Process. Products. Build & Test Deploy DevOps is the union of people, process, and products to
Modernizing Business Intelligence and Analytics
 Modernizing Business Intelligence and Analytics Justin Erickson Senior Director, Product Management 1 Agenda What benefits can I achieve from modernizing my analytic DB? When and how do I migrate from
Modernizing Business Intelligence and Analytics Justin Erickson Senior Director, Product Management 1 Agenda What benefits can I achieve from modernizing my analytic DB? When and how do I migrate from
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Flexible Network Analytics in the Cloud. Jon Dugan & Peter Murphy ESnet Software Engineering Group October 18, 2017 TechEx 2017, San Francisco
 Flexible Network Analytics in the Cloud Jon Dugan & Peter Murphy ESnet Software Engineering Group October 18, 2017 TechEx 2017, San Francisco Introduction Harsh realities of network analytics netbeam Demo
Flexible Network Analytics in the Cloud Jon Dugan & Peter Murphy ESnet Software Engineering Group October 18, 2017 TechEx 2017, San Francisco Introduction Harsh realities of network analytics netbeam Demo
Data Processing with Apache Beam (incubating) and Google Cloud Dataflow
 and Google Cloud Dataflow") Data Processing with Apache Beam (incubating) and Google Cloud Dataflow Jelena Pjesivac-Grbovic Staff software engineer Cloud Big Data In collaboration with Frances Perry, Tayler Akidau, and Dataflow team
Data Processing with Apache Beam (incubating) and Google Cloud Dataflow Jelena Pjesivac-Grbovic Staff software engineer Cloud Big Data In collaboration with Frances Perry, Tayler Akidau, and Dataflow team
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG
 BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
Big Data analytics in insurance
 Big Data analytics in insurance Who we are Experts At Your Service > Over 50 specialists in IT infrastructure > Certified, experienced, passionate Based In Switzerland > 100% self-financed Swiss company
Big Data analytics in insurance Who we are Experts At Your Service > Over 50 specialists in IT infrastructure > Certified, experienced, passionate Based In Switzerland > 100% self-financed Swiss company
USERS CONFERENCE Copyright 2016 OSIsoft, LLC
 Bridge IT and OT with a process data warehouse Presented by Matt Ziegler, OSIsoft Complexity Problem Complexity Drives the Need for Integrators Disparate assets or interacting one-by-one Monitoring Real-time
Bridge IT and OT with a process data warehouse Presented by Matt Ziegler, OSIsoft Complexity Problem Complexity Drives the Need for Integrators Disparate assets or interacting one-by-one Monitoring Real-time
Is Your Data Viable? Preparing Your Data for SAS Visual Analytics 8.2
 Paper SAS1826-2018 Is Your Data Viable? Preparing Your Data for SAS Visual Analytics 8.2 Gregor Herrmann, SAS Institute Inc. ABSTRACT We all know that data preparation is crucial before you can derive
Paper SAS1826-2018 Is Your Data Viable? Preparing Your Data for SAS Visual Analytics 8.2 Gregor Herrmann, SAS Institute Inc. ABSTRACT We all know that data preparation is crucial before you can derive
Switching to Sheets from Microsoft Excel Learning Center gsuite.google.com/learning-center
 Switching to Sheets from Microsoft Excel 2010 Learning Center gsuite.google.com/learning-center Welcome to Sheets Now that you've switched from Microsoft Excel to G Suite, learn how to use Google Sheets
Switching to Sheets from Microsoft Excel 2010 Learning Center gsuite.google.com/learning-center Welcome to Sheets Now that you've switched from Microsoft Excel to G Suite, learn how to use Google Sheets
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423