Franck Mercier. Technical Solution Professional Data + AI Azure Databricks
|
|
|
- Reynold Kelly
- 5 years ago
- Views:
Transcription

1 Franck Mercier Technical Solution Professional Data + AI Azure Databricks



2 Thanks to our sponsors Global Gold Silver Bronze Microsoft JetBrains Rubrik Delphix Solution OMD And
3
4 Apache Spark An unified, open source, parallel, data processing framework for Big Data Analytics Spark SQL Interactive Queries Spark MLlib Machine Learning Spark Streaming Stream processing GraphX Graph Computation Spark Core Engine Yarn Mesos Standalone Scheduler Open-source data processing engine built around speed, ease of use, and sophisticated analytics In memory engine that is up to 100 times faster than Hadoop Largest open-source data project with contributors Highly extensible with support for Scala, Java and Python alongside Spark SQL, GraphX, Streaming and Machine Learning Library (Mllib)

5 Databricks, company overview
6 What is Azure Databricks? A fast, easy and collaborative Apache Spark based analytics platform optimized for Azure Best of Databricks Best of Microsoft Designed in collaboration with the founders of Apache Spark One-click set up; streamlined workflows Interactive workspace that enables collaboration between data scientists, data engineers, and business analysts. Native integration with Azure ser vices (Power BI, SQL DW, Cosmos DB, Blob Storage) Enterprise-grade Azure security (Active Director y integration, compliance, enterprise -grade SL As)
7 Azure Databricks Azure Databricks Collaborative Workspace IoT / streaming data Machine learning models DATA ENGINEER DATA SCIENTIST BUSINESS ANALYST Cloud storage Deploy Production Jobs & Workflows BI tools MULTI-STAGE PIPELINES JOB SCHEDULER NOTIFICATION & LOGS Data warehouses Optimized Databricks Runtime Engine Data exports Hadoop storage DATABRICKS I/O APACHE SPARK SERVERLESS Rest APIs Data warehouses Enhance Productivity Build on secure & trusted cloud Scale without limits
8 Collaborative Workspace Azure Databricks Collaborative Workspace DATA ENGINEER DATA SCIENTIST BUSINESS ANALYST Deploy Production Jobs & Workflows MULTI-STAGE PIPELINES JOB SCHEDULER NOTIFICATION & LOGS Optimized Databricks Runtime Engine DATABRICKS I/O APACHE SPARK SERVERLESS Rest APIs
9 Deploy Production Jobs & Workflows Azure Databricks Collaborative Workspace DATA ENGINEER DATA SCIENTIST BUSINESS ANALYST Deploy Production Jobs & Workflows MULTI-STAGE PIPELINES JOB SCHEDULER NOTIFICATION & LOGS Optimized Databricks Runtime Engine DATABRICKS I/O APACHE SPARK SERVERLESS Rest APIs
10 Optimized Databricks Runtime Engine Azure Databricks Collaborative Workspace DATA ENGINEER DATA SCIENTIST BUSINESS ANALYST Deploy Production Jobs & Workflows MULTI-STAGE PIPELINES JOB SCHEDULER NOTIFICATION & LOGS Optimized Databricks Runtime Engine DATABRICKS I/O APACHE SPARK SERVERLESS Rest APIs
11 B I G D ATA & A D VA N C E D A N A LY T I C S AT A G L A N C E Ingest Store Prep & Train Model & Serve Intelligence Business apps Data Factory (Data movement, pipelines & orchestration) Cosmos DB Custom apps Kafka Blobs Data Lake Databricks HDInsight Data Lake Analytics SQL SQL Database Predictive apps Event Hub IoT Hub Machine Learning SQL Data Warehouse Operational reports Sensors and devices Analysis Services Analytical dashboards


12 BIG DATA STORAGE Reduced Administration BIG DATA ANALYTICS K N O W I N G T H E V A R I O U S B I G D A T A S O L U T I O N S CONTROL EASE OF USE Azure Databricks Azure Data Lake Analytics Azure HDInsight Azure Marketplace HDP CDH MapR Any Hadoop technology, any distribution Workload optimized, managed clusters Frictionless & Optimized Spark clusters Data Engineering in a Job-as-a-service model IaaS Clusters Managed Clusters Big Data as-a-service Azure Data Lake Analytics Azure Data Lake Store Azure Storage
13
14 Modern Big Data Warehouse Ingest Store Prep & Train Model & Serve Intelligence Logs, files and media (unstructured) Data factory Azure storage Azure Databricks (Spark) Polybase Business / custom apps (Structured) Data factory Azure SQL Data Warehouse Analytical dashboards
15 Advanced Analytics on Big Data Ingest Store Prep & Train Model & Serve Intelligence Logs, files and media (unstructured) Data factory Azure storage Azure Databricks (Spark Mllib, SparkR, SparklyR) Azure Cosmos DB Web & mobile apps Polybase Business / custom apps (Structured) Data factory Azure SQL Data Warehouse Analytical dashboards
16 Real-time analytics on Big Data Ingest Store Prep & Train Model & Serve Intelligence Unstructured data Azure HDInsight (Kafka) Azure Event Hub Azure Databricks (Spark) Polybase Azure storage Azure SQL Data Warehouse Analytical dashboards
17
18 Availability Release Standard Premium General availability Data analytics: $0.49/DBU/hr + VM Data analytics: Data engineering: $0.24/DBU/hr + VM Data engineering: $0.67/DBU/hr + VM $0.43/DBU/hr + VM Includes: Compliance: SOC2, HIPAA, AAD Integration Data connectors (Blob Storage, Data Lake, SQL DW, Cosmos DB, Event Hub), GPU Instances Includes: Everything from standard + Fine grained control for notebooks & clusters, structured data controls JDBC/ODBC endpoint Governance logs.net Integration Integrations with Azure apps like Power BI, etc. Azure Databricks offers two distinct workloads : Data analytics: Data Analytics workload makes it easy for data scientists to explore, visualize, manipulate, and share data and insights interactively (Interactive clusters, Github integration, Revision history,.) Data engineering: Data Engineering workload makes it easy for data engineers to build and execute jobs Details : $CAD
19 Azure Databricks Core Concepts


20 P R O V I S I O N I N G A Z U R E D A T A B R I C K S W O R K S P A C E
21 G E N E R A L S P A R K C L U S T E R A R C H I T E C T U R E Driver Program SparkContext Cluster Manager Worker Node Worker Node Worker Node Data Sources (HDFS, SQL, NoSQL, )
22 D A T A B R I C K S F I L E S Y S T E M ( D B F S ) Is a distributed File System (DBFS) that is a layer over Azure Blob Storage Python Scala CLI dbutils DBFS Azure Blob Storage
23 A Z U R E D A T A B R I C K S C O R E A R T I F A C T S Azure Databricks
24 Demo
25 Secure Collaboration

.")

26 S E C U R E C O L L A B O R A T I O N Azure Databricks is integrated with AAD so Azure Databricks users are just regular AAD users With Azure Databricks colleagues can securely share key artifacts such as Clusters, Notebooks, Jobs and Workspaces There is no need to define users and their access control separately in Databricks. AAD users can be used directly in Azure Databricks for all user-based access control (Clusters, Jobs, Notebooks etc.). Databricks has delegated user authentication to AAD enabling single-sign on (SSO) and unified authentication. Notebooks, and their outputs, are stored in the Databricks account. However, AAD-based accesscontrol ensures that only authorized users can access them. Azure Databricks Access Control Authentication
27 D A T A B R I C K S A C C E S S C O N T R O L Access control can be defined at the user level via the Admin Console Databricks Access Control Workspace Access Control Cluster Access Control Jobs Access Control REST API Tokens Defines who can who can view, edit, and run notebooks in their workspace Allows users to who can attach to, restart, and manage (resize/delete) clusters. Allows Admins to specify which users have permissions to create clusters Allows owners of a job to control who can view job results or manage runs of a job (run now/cancel) Allows users to use personal access tokens instead of passwords to access the Databricks REST API
28 A Z U R E D A T A B R I C K S C O R E A R T I F A C T S Azure Databricks
29 Clusters Azure Databricks

30 C L U S T E R S Azure Databricks clusters are the set of Azure Linux VMs that host the Spark Worker and Driver Nodes Your Spark application code (i.e. Jobs) runs on the provisioned clusters. Azure Databricks clusters are launched in your subscription but are managed through the Azure Databricks portal. Azure Databricks provides a comprehensive set of graphical wizards to manage the complete lifecycle of clusters from creation to termination. You can create two types of clusters Standard and Serverless Pool (see next slide) While creating a cluster you can specify: Number of nodes Autoscaling and Auto Termination policy Spark Configuration details The Azure VM instance types for the Driver and Worker Nodes

31 S E R V E R L E S S P O O L ( B E T A ) A self-managed pool of cloud resources, auto-configured for interactive Spark workloads You specify only the minimum and maximum number of nodes in the cluster Azure Databricks provisions and adjusts the compute and local storage based on your usage. Limitation: Currently works only for SQL and Python. Benefits of Serverless Pool Auto-Configuration Elasticity Fine grained Sharing

32 C L U S T E R A C C E S S C O N T R O L There are two configurable types of permissions for Cluster Access Control: Individual Cluster Permissions - This controls a user s ability to attach notebooks to a cluster, as well as to restart/resize/terminate/start clusters. Cluster Creation Permissions - This controls a user s ability to create clusters Individual permissions can be configured on the Clusters Page by clicking on Permissions under the More Actions icon of an existing cluster There are 4 different individual cluster permission levels: No Permissions, Can Attach To, Can Restart, and Can Manage. Privileges are shown below Abilities No Permissions Can Attach To Can Restart Can Manage Attach notebooks to cluster x x x View Spark UI x x x View cluster metrics (Ganglia) x x x Terminate cluster x x Start cluster x x Tom Smith (tom@company.com) Restart cluster x x Resize cluster Modify permissions x x
33 Azure Databricks

34 J O B S Jobs are the mechanism to submit Spark application code for execution on the Databricks clusters Spark application code is submitted as a Job for execution on Azure Databricks clusters Jobs execute either Notebooks or Jars Azure Databricks provide a comprehensive set of graphical tools to create, manage and monitor Jobs.
35 C R E A T I N G A N D R U N N I N G J O B S ( 1 O F 2 ) When you create a new Job you have to specify: The Notebook or Jar to execute Cluster: The cluster on which the Job execute. This could be an exiting or new cluster. Schedule i.e. how often the Job runs. Jobs can also be run one time right away.
36 C R E A T I N G A N D R U N N I N G J O B S ( 2 O F 2 ) When you create a new job you can optionally specify advanced options: Maximum number of concurrent runs of the Job Timeout: Jobs still running beyond the specified duration are automatically killed Retry Policy: Specifies if and when failed jobs will be retried Permissions: Who can do what with jobs. This allows for Job definition and management to be securely shared with others (see next slide)
37 J O B A C C E S S C O N T R O L Enables job owners and administrators to grant fine grained permissions on their jobs With Jobs Access Controls job owners can choose which other users or groups can view results of the job. Owners can also choose who can manage runs of their job (i.e. invoke run now and cancel.) There are 5 different permission levels for jobs: No Permissions Can View Can Manage Run Is Owner and Can Manage Abilities No Permissions Can View Can Manage Run Is Owner Can Manage (admin) View job details and settings Yes Yes Yes Yes Yes View results, Spark UI, logs of a job run Yes Yes Yes Yes Run now Yes Yes Yes Cancel run Yes Yes Yes Edit job settings Yes Yes Modify permissions Yes Yes Delete job Yes Yes Change owner Yes Note: Can Manage permission is reserved for administrators.

38 V I E W I N G L I S T O F J O B S In the Portal you can view the list of all jobs you have access to You can click on Run Now icon run the job right away You can also delete a job from the list to
 Jobs History of old Job runs (for up to")
 V I E W I N G J O B S H I S")
39 In the Azure Databricks Jobs Portal you can view: The list of currently running (Active) Jobs History of old Job runs (for up to 60 days) The output of a particular Job run (including standard error, standard output, Spark UI logs) V I E W I N G J O B S H I S T O R Y
40 Azure Databricks

41 W O R K S P A C E S Workspaces enables users to organize and share their Notebooks, Libraries and Dashboards Icons indicate the type of the object contained in a folder By default, the workspace and all its contents are available to users.
42 W O R K S P A C E O P E R A T I O N S You can search the entire Databricks workspace In the Azure Databricks Portal, via the Workspaces drop down menu, you can: Create Folders, Notebooks and Libraries Import Notebooks into the Workspace Export the Workspace to a database archive Set Permissions. You can grant 4 levels of permissions Can Manage Can Read Can Edit Can Run

43 F O L D E R O P E R A T I O N S A N D A C C E S S C O N T R O L In the Azure Databricks Portal, via the Folder drop down menu, you can: Create Folders, Notebooks and Libraries within the folder Clone the folder to create a deep copy of the folder Rename or delete the folder Move the folder to another location Export a folder to save it and its contents as a Databricks archive Import a saved Databricks archive into the selected folder Set Permissions for the folder. As with Workspaces you can set 5 levels of permissions: No Permissions, Can Manage, Can Read, Can Edit, Can Run
44 Azure Databricks
45 A Z U R E D A T A B R I C K S N O T E B O O K S O V E R V I E W Notebooks are a popular way to develop, and run, Spark Applications Notebooks are not only for authoring Spark applications but can be run/executed directly on clusters Shift+Enter Notebooks support fine grained permissions so they can be securely shared with colleagues for collaboration (see following slide for details on permissions and abilities) Notebooks are well-suited for prototyping, rapid development, exploration, discovery and iterative development Notebooks typically consist of code, data, visualization, comments and notes
46 M I X I N G L A N G U A G E S I N N O T E B O O K S You can mix multiple languages in the same notebook Normally a notebook is associated with a specific language. However, with Azure Databricks notebooks, you can mix multiple languages in the same notebook. This is done using the language magic command: %python Allows you to execute python code in a notebook (even if that notebook is not python) %sql Allows you to execute sql code in a notebook (even if that notebook is not sql). %r Allows you to execute r code in a notebook (even if that notebook is not r). %scala Allows you to execute scala code in a notebook (even if that notebook is not scala). %sh Allows you to execute shell code in your notebook. %fs Allows you to use Databricks Utilities - dbutils filesystem commands. %md To include rendered markdown

47 N O T E B O O K O P E R A T I O N S A N D A C C E S S C O N T R O L You can create a new notebook from the Workspace or the folder drop down menu (see previous slides) From a notebook s drop down menu you can: Clone the notebook Rename or delete the notebook Move the notebook to another location Export a notebook to save it and its contents as a Databricks archive or IPython notebook or HTML or source code file. Set Permissions for the notebook As with Workspaces you can set 5 levels of permissions: No Permissions, Can Manage, Can Read, Can Edit, Can Run You can also set permissions from notebook UI itself by selecting the menu option.

48 V I S U A L I Z A T I O N Azure Databricks supports a number of visualization plots out of the box All notebooks, regardless of their language, support Databricks visualizations. When you run the notebook the visualizations are rendered inside the notebook in-place The visualizations are written in HTML. You can save the HTML of the entire notebook by exporting to HTML. If you use Matplotlib, the plots are rendered as images so you can just right click and download the image You can change the plot type just by picking from the selection
49 Azure Databricks




50 L I B R A R I E S O V E R V I E W Enables external code to be imported and stored into a Workspace
51


52 A Z U R E S Q L D W I N T E G R A T I O N Integration enables structured data from SQL DW to be included in Spark Analytics Azure SQL Data Warehouse is a SQL-based fully managed, petabyte-scale cloud solution for data warehousing You can bring in data from Azure SQL DW to perform advanced analytics that require both structured and unstructured data. Currently you can access data in Azure SQL DW via the JDBC driver. From within your spark code you can access just like any other JDBC data source. If Azure SQL DW is authenticated via AAD then Azure Databricks user can seamlessly access Azure SQL DW. Azure Databricks Azure SQL DW

53 P O W E R B I I N T E G R A T I O N Enables powerful visualization of data in Spark with Power BI Power BI Desktop can connect to Azure Databricks clusters to query data using JDBC/ODBC server that runs on the driver node. This server listens on port and it is not accessible outside the subnet where the cluster is running. Azure Databricks uses a public HTTPS gateway The JDBC/ODBC connection information can be obtained from the Cluster UI directly as shown in the figure. When establishing the connection, you can use a Personal Access Token to authenticate to the cluster gateway. Only users who have attach permissions can access the cluster via the JDBC/ ODBC endpoint. In Power BI desktop you can setup the connection by choosing the ODBC data source in the Get Data option.

54 C O S M O S D B I N T E G R A T I O N The Spark connector enables real-time analytics over globally distributed data in Azure Cosmos DB Azure Cosmos DB is Microsoft's globally distributed, multi-model database service for mission-critical applications With Spark connector for Azure Cosmos DB, Apache Spark can now interact with all Azure Cosmos DB data models: Documents, Tables, and Graphs. efficiently exploits the native Azure Cosmos DB managed indexes and enables updateable columns when performing analytics. utilizes push-down predicate filtering against fast-changing globally-distributed data Some use-cases for Azure Cosmos DB + Spark include: Streaming Extract, Transformation, and Loading of data (ETL) Data enrichment Trigger event detection Complex session analysis and personalization Visual data exploration and interactive analysis Notebook experience for data exploration, information sharing, and collaboration The connector uses the Azure DocumentDB Java SDK and moves data directly between Spark worker nodes and Cosmos DB data nodes
55 A Z U R E B L O B S T O R A G E I N T E G R A T I O N Data can be read from Azure Blob Storage using the Hadoop FileSystem interface. Data can be read from public storage accounts without any additional settings. To read data from a private storage account, you need to set an account key or a Shared Access Signature (SAS) in your notebook Setting up an account key spark.conf.set ( "fs.azure.account.key.{your Storage Account Name}.blob.core.windows.net", "{Your Storage Account Access Key}") Setting up a SAS for a given container: spark.conf.set( "fs.azure.sas.{your Container Name}.{Your Storage Account Name}.blob.core.windows.net", "{Your SAS For The Given Container}") Once an account key or a SAS is setup, you can use standard Spark and Databricks APIs to read from the storage account: val df = spark.read.parquet("wasbs://{your Container Name}@m{Your Storage Account name}.blob.core.windows.net/{your Directory Name}") dbutils.fs.ls("wasbs://{your ntainer Name}@{Your Storage Account Name}.blob.core.windows.net/{Your Directory Name}")
56 A Z U R E D A T A L A K E I N T E G R A T I O N To read from your Data Lake Store account, you can configure Spark to use service credentials with the following snippet in your notebook spark.conf.set("dfs.adls.oauth2.access.token.provider.type", "ClientCredential") spark.conf.set("dfs.adls.oauth2.client.id", "{YOUR SERVICE CLIENT ID}") spark.conf.set("dfs.adls.oauth2.credential", "{YOUR SERVICE CREDENTIALS}") spark.conf.set("dfs.adls.oauth2.refresh.url", " DIRECTORY ID}/oauth2/token") After providing credentials, you can read from Data Lake Store using standard APIs: val df = spark.read.parquet("adl://{your DATA LAKE STORE ACCOUNT NAME}.azuredatalakestore.net/{YOUR DIRECTORY NAME}") dbutils.fs.list("adl://{your DATA LAKE STORE ACCOUNT NAME}.azuredatalakestore.net/{YOUR DIRECTORY NAME}")
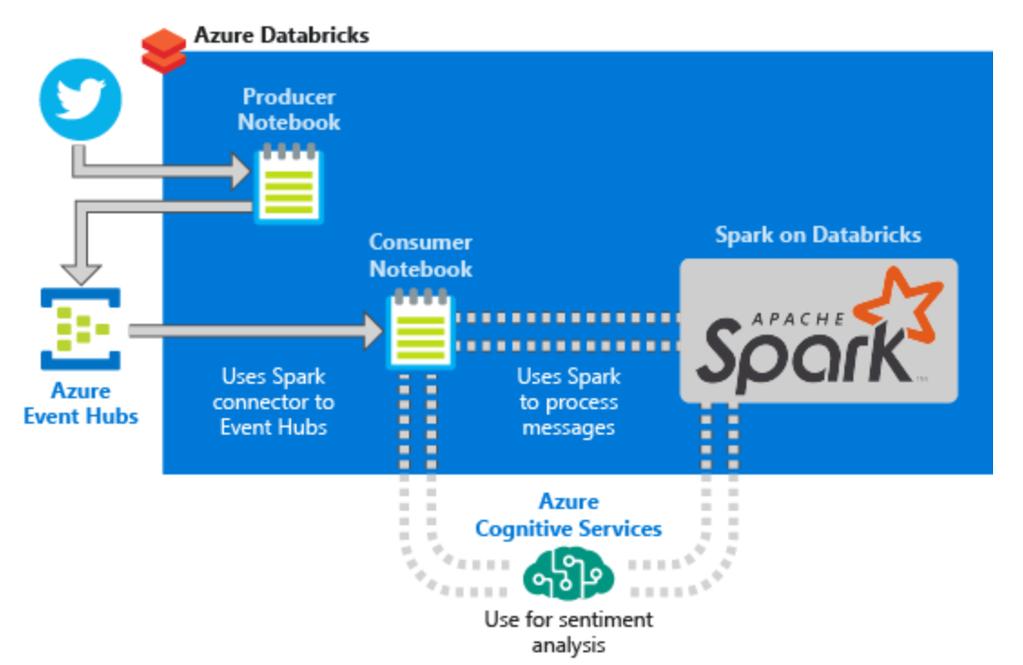
57 Integration sample
58
 Supports Model Selection (hyperparameter tuning) using Cross Validation and Train-Validation Split. Supports Java, Scala or Python apps using DataFrame-based API (as of Spark 2.0).")
59 S P A R K M A C H I N E L E A R N I N G ( M L ) O V E R V I E W Enables Parallel, Distributed ML for large datasets on Spark Clusters Offers a set of parallelized machine learning algorithms (see next slide) Supports Model Selection (hyperparameter tuning) using Cross Validation and Train-Validation Split. Supports Java, Scala or Python apps using DataFrame-based API (as of Spark 2.0). Benefits include: An uniform API across ML algorithms and across multiple languages Facilitates ML pipelines (enables combining multiple algorithms into a single pipeline). Optimizations through Tungsten and Catalyst Spark MLlib comes pre-installed on Azure Databricks 3 rd Party libraries supported include: H20 Sparkling Water, SciKit-learn and XGBoost

60 M M L S P A R K Microsoft Machine Learning Library for Apache Spark (MMLSpark) lets you easily create scalable machine learning models for large datasets. It includes integration of SparkML pipelines with the Microsoft Cognitive Toolkit and OpenCV, enabling you to: Ingress and pre-process image data Featurize images and text using pre-trained deep learning models Train and score classification and regression models using implicit featurization
61 Spark ML Algorithms S P A R K M L A L G O R I T H M S
.")

62 D E E P L E A R N I N G Azure Databricks supports and integrates with a number of Deep Learning libraries and frameworks to make it easy to build and deploy Deep Learning applications Supports Deep Learning Libraries/frameworks including: Microsoft Cognitive Toolkit (CNTK). o Article explains how to install CNTK on Azure Databricks. TensorFlowOnSpark BigDL Offers Spark Deep Learning Pipelines, a suite of tools for working with and processing images using deep learning using transfer learning. It includes high-level APIs for common aspects of deep learning so they can be done efficiently in a few lines of code: Distributed Hyperparameter Tuning Transfer Learning
63

64 S P A R K S T R U C T U R E D S T R E A M I N G O V E R V I E W A unified system for end-to-end fault-tolerant, exactly-once stateful stream processing Unifies streaming, interactive and batch queries a single API for both static bounded data and streaming unbounded data. Runs on Spark SQL. Uses the Spark SQL Dataset/DataFrame API used for batch processing of static data. Runs incrementally and continuously and updates the results as data streams in. Supports app development in Scala, Java, Python and R. Supports streaming aggregations, event-time windows, windowed grouped aggregation, stream-to-batch joins. Features streaming deduplication, multiple output modes and APIs for managing/monitoring streaming queries. Built-in sources: Kafka, File source (json, csv, text, parquet)

 are required.")
65 A P A C H E K A F K A F O R H D I N S I G H T I N T E G R A T I O N Azure Databricks Structured Streaming integrates with Apache Kafka for HDInsight Apache Kafka for Azure HDInsight is an enterprise grade streaming ingestion service running in Azure. Azure Databricks Structured Streaming applications can use Apache Kafka for HDInsight as a data source or sink. No additional software (gateways or connectors) are required. Setup: Apache Kafka on HDInsight does not provide access to the Kafka brokers over the public internet. Kafka clusters and the Azure Databricks cluster must be located in the same Azure Virtual Network.
66 S P A R K G R A P H X O V E R V I E W A set of APIs for graph and graph-parallel computation. Unifies ETL, exploratory analysis, and iterative graph computation within a single system. Developers can: view the same data as both graphs and collections, transform and join graphs with RDDs, and write custom iterative graph algorithms using the Pregel API. Currently only supports using the Scala and RDD APIs. PageRank Connected components Label propagation SVD++ Algorithms Strongly connected components Triangle count
67
68 R D D S A N D D B I O C A C H E - D I F F E R E N C E S DBIO cache and RDDs are both caches that can be used together Availability Capability Comment RDD is part of Apache Spark Databricks IO cache is available only to Databricks customers. Type of data stored The RDD cache can be used to store the result of any subquery. The DBIO cache is designed to speed-up scans by creating local copies of remote data. It can improve the performance of a wide range of queries, but cannot be used to store results of arbitrary subqueries. Performance The data stored in the DBIO cache can be read and operated on faster than the data in the RDD cache. This is because the DBIO cache uses efficient decompression algorithms, and outputs data in the optimal format for further processing using whole-stage code generation. Automatic vs manual control When using the RDD cache it is necessary to manually choose tables or queries to be cached. When using the DBIO cache the data is added to the cache automatically whenever it has to be fetched from a remote source. This process is fully transparent and does not require any action from the user. Disk vs memory-based Unlike the RDD cache, the DBIO cache is stored entirely on the local disk. RDD: Resilient Distributed Dataset DBIO: Databricks IO

69 Thank you
Modern Data Warehouse The New Approach to Azure BI
 Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
Asanka Padmakumara. ETL 2.0: Data Engineering with Azure Databricks
 Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Understanding the latent value in all content
 Understanding the latent value in all content John F. Kennedy (JFK) November 22, 1963 INGEST ENRICH EXPLORE Cognitive skills Data in any format, any Azure store Search Annotations Data Cloud Intelligence
Understanding the latent value in all content John F. Kennedy (JFK) November 22, 1963 INGEST ENRICH EXPLORE Cognitive skills Data in any format, any Azure store Search Annotations Data Cloud Intelligence
BIG DATA COURSE CONTENT
 BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Overview of Data Services and Streaming Data Solution with Azure
 Overview of Data Services and Streaming Data Solution with Azure Tara Mason Senior Consultant tmason@impactmakers.com Platform as a Service Offerings SQL Server On Premises vs. Azure SQL Server SQL Server
Overview of Data Services and Streaming Data Solution with Azure Tara Mason Senior Consultant tmason@impactmakers.com Platform as a Service Offerings SQL Server On Premises vs. Azure SQL Server SQL Server
Microsoft Azure Databricks for data engineering. Building production data pipelines with Apache Spark in the cloud
 Microsoft Azure Databricks for data engineering Building production data pipelines with Apache Spark in the cloud Azure Databricks As companies continue to set their sights on making data-driven decisions
Microsoft Azure Databricks for data engineering Building production data pipelines with Apache Spark in the cloud Azure Databricks As companies continue to set their sights on making data-driven decisions
Data Architectures in Azure for Analytics & Big Data
 Data Architectures in for Analytics & Big Data October 20, 2018 Melissa Coates Solution Architect, BlueGranite Microsoft Data Platform MVP Blog: www.sqlchick.com Twitter: @sqlchick Data Architecture A
Data Architectures in for Analytics & Big Data October 20, 2018 Melissa Coates Solution Architect, BlueGranite Microsoft Data Platform MVP Blog: www.sqlchick.com Twitter: @sqlchick Data Architecture A
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Exam Questions
 Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Alexander Klein. #SQLSatDenmark. ETL meets Azure
 Alexander Klein ETL meets Azure BIG Thanks to SQLSat Denmark sponsors Save the date for exiting upcoming events PASS Camp 2017 Main Camp 05.12. 07.12.2017 (04.12. Kick-Off abends) Lufthansa Training &
Alexander Klein ETL meets Azure BIG Thanks to SQLSat Denmark sponsors Save the date for exiting upcoming events PASS Camp 2017 Main Camp 05.12. 07.12.2017 (04.12. Kick-Off abends) Lufthansa Training &
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
HDInsight > Hadoop. October 12, 2017
 HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
Databricks, an Introduction
 Databricks, an Introduction Chuck Connell, Insight Digital Innovation Insight Presentation Speaker Bio Senior Data Architect at Insight Digital Innovation Focus on Azure big data services HDInsight/Hadoop,
Databricks, an Introduction Chuck Connell, Insight Digital Innovation Insight Presentation Speaker Bio Senior Data Architect at Insight Digital Innovation Focus on Azure big data services HDInsight/Hadoop,
Index. Scott Klein 2017 S. Klein, IoT Solutions in Microsoft s Azure IoT Suite, DOI /
 Index A Advanced Message Queueing Protocol (AMQP), 44 Analytics, 9 Apache Ambari project, 209 210 API key, 244 Application data, 4 Azure Active Directory (AAD), 91, 257 Azure Blob Storage, 191 Azure data
Index A Advanced Message Queueing Protocol (AMQP), 44 Analytics, 9 Apache Ambari project, 209 210 API key, 244 Application data, 4 Azure Active Directory (AAD), 91, 257 Azure Blob Storage, 191 Azure data
exam. Microsoft Perform Data Engineering on Microsoft Azure HDInsight. Version 1.0
 70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
Activator Library. Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success.
 Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
17/05/2017. What we ll cover. Who is Greg? Why PaaS and SaaS? What we re not discussing: IaaS
 What are all those Azure* and Power* services and why do I want them? Dr Greg Low SQL Down Under greg@sqldownunder.com Who is Greg? CEO and Principal Mentor at SDU Data Platform MVP Microsoft Regional
What are all those Azure* and Power* services and why do I want them? Dr Greg Low SQL Down Under greg@sqldownunder.com Who is Greg? CEO and Principal Mentor at SDU Data Platform MVP Microsoft Regional
Microsoft. Exam Questions Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo
 Version:Demo") Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 You have an Azure HDInsight cluster. You need to store data in a file format that
Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 You have an Azure HDInsight cluster. You need to store data in a file format that
Agenda. Spark Platform Spark Core Spark Extensions Using Apache Spark
 Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Data 101 Which DB, When. Joe Yong Azure SQL Data Warehouse, Program Management Microsoft Corp.
 Data 101 Which DB, When Joe Yong (joeyong@microsoft.com) Azure SQL Data Warehouse, Program Management Microsoft Corp. The world is changing AI increased by 300% in 2017 Data will grow to 44 ZB in 2020
Data 101 Which DB, When Joe Yong (joeyong@microsoft.com) Azure SQL Data Warehouse, Program Management Microsoft Corp. The world is changing AI increased by 300% in 2017 Data will grow to 44 ZB in 2020
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Developing Microsoft Azure Solutions (70-532) Syllabus
 Syllabus") Developing Microsoft Azure Solutions (70-532) Syllabus Cloud Computing Introduction What is Cloud Computing Cloud Characteristics Cloud Computing Service Models Deployment Models in Cloud Computing Advantages
Developing Microsoft Azure Solutions (70-532) Syllabus Cloud Computing Introduction What is Cloud Computing Cloud Characteristics Cloud Computing Service Models Deployment Models in Cloud Computing Advantages
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Developing Microsoft Azure Solutions
 Developing Microsoft Azure Solutions Duration: 5 Days Course Code: M20532 Overview: This course is intended for students who have experience building web applications. Students should also have experience
Developing Microsoft Azure Solutions Duration: 5 Days Course Code: M20532 Overview: This course is intended for students who have experience building web applications. Students should also have experience
Architecting Microsoft Azure Solutions (proposed exam 535)
") Architecting Microsoft Azure Solutions (proposed exam 535) IMPORTANT: Significant changes are in progress for exam 534 and its content. As a result, we are retiring this exam on December 31, 2017, and
Architecting Microsoft Azure Solutions (proposed exam 535) IMPORTANT: Significant changes are in progress for exam 534 and its content. As a result, we are retiring this exam on December 31, 2017, and
CSC 261/461 Database Systems Lecture 24. Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101
 CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
Integrate MATLAB Analytics into Enterprise Applications
 Integrate Analytics into Enterprise Applications Aurélie Urbain MathWorks Consulting Services 2015 The MathWorks, Inc. 1 Data Analytics Workflow Data Acquisition Data Analytics Analytics Integration Business
Integrate Analytics into Enterprise Applications Aurélie Urbain MathWorks Consulting Services 2015 The MathWorks, Inc. 1 Data Analytics Workflow Data Acquisition Data Analytics Analytics Integration Business
Přehled novinek v SQL Server 2016
 Přehled novinek v SQL Server 2016 Martin Rys, BI Competency Leader martin.rys@adastragrp.com https://www.linkedin.com/in/martinrys 20.4.2016 1 BI Competency development 2 Trends, modern data warehousing
Přehled novinek v SQL Server 2016 Martin Rys, BI Competency Leader martin.rys@adastragrp.com https://www.linkedin.com/in/martinrys 20.4.2016 1 BI Competency development 2 Trends, modern data warehousing
20532D: Developing Microsoft Azure Solutions
 20532D: Developing Microsoft Azure Solutions Course Details Course Code: Duration: Notes: 20532D 5 days Elements of this syllabus are subject to change. About this course This course is intended for students
20532D: Developing Microsoft Azure Solutions Course Details Course Code: Duration: Notes: 20532D 5 days Elements of this syllabus are subject to change. About this course This course is intended for students
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Azure Data Factory. Data Integration in the Cloud
 Azure Data Factory Data Integration in the Cloud 2018 Microsoft Corporation. All rights reserved. This document is provided "as-is." Information and views expressed in this document, including URL and
Azure Data Factory Data Integration in the Cloud 2018 Microsoft Corporation. All rights reserved. This document is provided "as-is." Information and views expressed in this document, including URL and
BI ENVIRONMENT PLANNING GUIDE
 BI ENVIRONMENT PLANNING GUIDE Business Intelligence can involve a number of technologies and foster many opportunities for improving your business. This document serves as a guideline for planning strategies
BI ENVIRONMENT PLANNING GUIDE Business Intelligence can involve a number of technologies and foster many opportunities for improving your business. This document serves as a guideline for planning strategies
The age of Big Data Big Data for Oracle Database Professionals
 The age of Big Data Big Data for Oracle Database Professionals Oracle OpenWorld 2017 #OOW17 SessionID: SUN5698 Tom S. Reddy tom.reddy@datareddy.com About the Speaker COLLABORATE & OpenWorld Speaker IOUG
The age of Big Data Big Data for Oracle Database Professionals Oracle OpenWorld 2017 #OOW17 SessionID: SUN5698 Tom S. Reddy tom.reddy@datareddy.com About the Speaker COLLABORATE & OpenWorld Speaker IOUG
Developing Microsoft Azure Solutions (70-532) Syllabus
 Syllabus") Developing Microsoft Azure Solutions (70-532) Syllabus Cloud Computing Introduction What is Cloud Computing Cloud Characteristics Cloud Computing Service Models Deployment Models in Cloud Computing Advantages
Developing Microsoft Azure Solutions (70-532) Syllabus Cloud Computing Introduction What is Cloud Computing Cloud Characteristics Cloud Computing Service Models Deployment Models in Cloud Computing Advantages
MATLAB. Senior Application Engineer The MathWorks Korea The MathWorks, Inc. 2
 1 Senior Application Engineer The MathWorks Korea 2017 The MathWorks, Inc. 2 Data Analytics Workflow Business Systems Smart Connected Systems Data Acquisition Engineering, Scientific, and Field Business
1 Senior Application Engineer The MathWorks Korea 2017 The MathWorks, Inc. 2 Data Analytics Workflow Business Systems Smart Connected Systems Data Acquisition Engineering, Scientific, and Field Business
Microsoft. Exam Questions Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo
 Version:Demo") Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 HOTSPOT You install the Microsoft Hive ODBC Driver on a computer that runs Windows
Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 HOTSPOT You install the Microsoft Hive ODBC Driver on a computer that runs Windows
What is Gluent? The Gluent Data Platform
 What is Gluent? The Gluent Data Platform The Gluent Data Platform provides a transparent data virtualization layer between traditional databases and modern data storage platforms, such as Hadoop, in the
What is Gluent? The Gluent Data Platform The Gluent Data Platform provides a transparent data virtualization layer between traditional databases and modern data storage platforms, such as Hadoop, in the
Techno Expert Solutions
 Course Content of Microsoft Windows Azzure Developer: Course Outline Module 1: Overview of the Microsoft Azure Platform Microsoft Azure provides a collection of services that you can use as building blocks
Course Content of Microsoft Windows Azzure Developer: Course Outline Module 1: Overview of the Microsoft Azure Platform Microsoft Azure provides a collection of services that you can use as building blocks
Analyzing Flight Data
 IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
Stages of Data Processing
 Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Hortonworks Data Platform
 Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Data 101 Which DB, When Joe Yong Sr. Program Manager Microsoft Corp.
 17-18 March, 2018 Beijing Data 101 Which DB, When Joe Yong Sr. Program Manager Microsoft Corp. The world is changing AI increased by 300% in 2017 Data will grow to 44 ZB in 2020 Today, 80% of organizations
17-18 March, 2018 Beijing Data 101 Which DB, When Joe Yong Sr. Program Manager Microsoft Corp. The world is changing AI increased by 300% in 2017 Data will grow to 44 ZB in 2020 Today, 80% of organizations
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
The Evolution of Big Data Platforms and Data Science
 IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Oracle Big Data Connectors
 Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
28 February 1 March 2018, Trafo Baden. #techsummitch
 #techsummitch 28 February 1 March 2018, Trafo Baden #techsummitch Transform your data estate with cloud, data and AI #techsummitch The world is changing Data will grow to 44 ZB in 2020 Today, 80% of organizations
#techsummitch 28 February 1 March 2018, Trafo Baden #techsummitch Transform your data estate with cloud, data and AI #techsummitch The world is changing Data will grow to 44 ZB in 2020 Today, 80% of organizations
Microsoft Perform Data Engineering on Microsoft Azure HDInsight.
 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight http://killexams.com/pass4sure/exam-detail/70-775 QUESTION: 30 You are building a security tracking solution in Apache Kafka to parse
Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight http://killexams.com/pass4sure/exam-detail/70-775 QUESTION: 30 You are building a security tracking solution in Apache Kafka to parse
Oracle Big Data SQL. Release 3.2. Rich SQL Processing on All Data
 Oracle Big Data SQL Release 3.2 The unprecedented explosion in data that can be made useful to enterprises from the Internet of Things, to the social streams of global customer bases has created a tremendous
Oracle Big Data SQL Release 3.2 The unprecedented explosion in data that can be made useful to enterprises from the Internet of Things, to the social streams of global customer bases has created a tremendous
Integrate MATLAB Analytics into Enterprise Applications
 Integrate Analytics into Enterprise Applications Dr. Roland Michaely 2015 The MathWorks, Inc. 1 Data Analytics Workflow Access and Explore Data Preprocess Data Develop Predictive Models Integrate Analytics
Integrate Analytics into Enterprise Applications Dr. Roland Michaely 2015 The MathWorks, Inc. 1 Data Analytics Workflow Access and Explore Data Preprocess Data Develop Predictive Models Integrate Analytics
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
70-532: Developing Microsoft Azure Solutions
 70-532: Developing Microsoft Azure Solutions Exam Design Target Audience Candidates of this exam are experienced in designing, programming, implementing, automating, and monitoring Microsoft Azure solutions.
70-532: Developing Microsoft Azure Solutions Exam Design Target Audience Candidates of this exam are experienced in designing, programming, implementing, automating, and monitoring Microsoft Azure solutions.
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
SQL Server 2017 Power your entire data estate from on-premises to cloud
 SQL Server 2017 Power your entire data estate from on-premises to cloud PREMIER SPONSOR GOLD SPONSORS SILVER SPONSORS BRONZE SPONSORS SUPPORTERS Vulnerabilities (2010-2016) Power your entire data estate
SQL Server 2017 Power your entire data estate from on-premises to cloud PREMIER SPONSOR GOLD SPONSORS SILVER SPONSORS BRONZE SPONSORS SUPPORTERS Vulnerabilities (2010-2016) Power your entire data estate
The Future of Real-Time in Spark
 The Future of Real-Time in Spark Reynold Xin @rxin Spark Summit, New York, Feb 18, 2016 Why Real-Time? Making decisions faster is valuable. Preventing credit card fraud Monitoring industrial machinery
The Future of Real-Time in Spark Reynold Xin @rxin Spark Summit, New York, Feb 18, 2016 Why Real-Time? Making decisions faster is valuable. Preventing credit card fraud Monitoring industrial machinery
Azure Data Factory VS. SSIS. Reza Rad, Consultant, RADACAD
 Azure Data Factory VS. SSIS Reza Rad, Consultant, RADACAD 2 Please silence cell phones Explore Everything PASS Has to Offer FREE ONLINE WEBINAR EVENTS FREE 1-DAY LOCAL TRAINING EVENTS VOLUNTEERING OPPORTUNITIES
Azure Data Factory VS. SSIS Reza Rad, Consultant, RADACAD 2 Please silence cell phones Explore Everything PASS Has to Offer FREE ONLINE WEBINAR EVENTS FREE 1-DAY LOCAL TRAINING EVENTS VOLUNTEERING OPPORTUNITIES
70-532: Developing Microsoft Azure Solutions
 70-532: Developing Microsoft Azure Solutions Objective Domain Note: This document shows tracked changes that are effective as of January 18, 2018. Create and Manage Azure Resource Manager Virtual Machines
70-532: Developing Microsoft Azure Solutions Objective Domain Note: This document shows tracked changes that are effective as of January 18, 2018. Create and Manage Azure Resource Manager Virtual Machines
CloudSwyft Learning-as-a-Service Course Catalog 2018 (Individual LaaS Course Catalog List)
") CloudSwyft Learning-as-a-Service Course Catalog 2018 (Individual LaaS Course Catalog List) Microsoft Solution Latest Sl Area Refresh No. Course ID Run ID Course Name Mapping Date 1 AZURE202x 2 Microsoft
CloudSwyft Learning-as-a-Service Course Catalog 2018 (Individual LaaS Course Catalog List) Microsoft Solution Latest Sl Area Refresh No. Course ID Run ID Course Name Mapping Date 1 AZURE202x 2 Microsoft
Energy Management with AWS
 Energy Management with AWS Kyle Hart and Nandakumar Sreenivasan Amazon Web Services August [XX], 2017 Tampa Convention Center Tampa, Florida What is Cloud? The NIST Definition Broad Network Access On-Demand
Energy Management with AWS Kyle Hart and Nandakumar Sreenivasan Amazon Web Services August [XX], 2017 Tampa Convention Center Tampa, Florida What is Cloud? The NIST Definition Broad Network Access On-Demand
Talend Big Data Sandbox. Big Data Insights Cookbook
 Overview Pre-requisites Setup & Configuration Hadoop Distribution Download Demo (Scenario) Overview Pre-requisites Setup & Configuration Hadoop Distribution Demo (Scenario) About this cookbook What is
Overview Pre-requisites Setup & Configuration Hadoop Distribution Download Demo (Scenario) Overview Pre-requisites Setup & Configuration Hadoop Distribution Demo (Scenario) About this cookbook What is
Index. Raul Estrada and Isaac Ruiz 2016 R. Estrada and I. Ruiz, Big Data SMACK, DOI /
 Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Azure Data Lake Store
 Azure Data Lake Store Analytics 101 Kenneth M. Nielsen Data Solution Architect, MIcrosoft Our Sponsors About me Kenneth M. Nielsen Worked with SQL Server since 1999 Data Solution Architect at Microsoft
Azure Data Lake Store Analytics 101 Kenneth M. Nielsen Data Solution Architect, MIcrosoft Our Sponsors About me Kenneth M. Nielsen Worked with SQL Server since 1999 Data Solution Architect at Microsoft
Oskari Heikkinen. New capabilities of Azure Data Factory v2
 Oskari Heikkinen New capabilities of Azure Data Factory v2 Oskari Heikkinen Lead Cloud Architect at BIGDATAPUMP Microsoft P-TSP Azure Advisors Numerous projects on Azure Worked with Microsoft Data Platform
Oskari Heikkinen New capabilities of Azure Data Factory v2 Oskari Heikkinen Lead Cloud Architect at BIGDATAPUMP Microsoft P-TSP Azure Advisors Numerous projects on Azure Worked with Microsoft Data Platform
WHITEPAPER. MemSQL Enterprise Feature List
 WHITEPAPER MemSQL Enterprise Feature List 2017 MemSQL Enterprise Feature List DEPLOYMENT Provision and deploy MemSQL anywhere according to your desired cluster configuration. On-Premises: Maximize infrastructure
WHITEPAPER MemSQL Enterprise Feature List 2017 MemSQL Enterprise Feature List DEPLOYMENT Provision and deploy MemSQL anywhere according to your desired cluster configuration. On-Premises: Maximize infrastructure
Integrate MATLAB Analytics into Enterprise Applications
 Integrate Analytics into Enterprise Applications Lyamine Hedjazi 2015 The MathWorks, Inc. 1 Data Analytics Workflow Preprocessing Data Business Systems Build Algorithms Smart Connected Systems Take Decisions
Integrate Analytics into Enterprise Applications Lyamine Hedjazi 2015 The MathWorks, Inc. 1 Data Analytics Workflow Preprocessing Data Business Systems Build Algorithms Smart Connected Systems Take Decisions
The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Dublin Apache Kafka Meetup, 30 August 2017.
 Dublin Apache Kafka Meetup, 30 August 2017 The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Joseph @pleia2 * ASF projects 1 Elizabeth K. Joseph, Developer Advocate Developer Advocate
Dublin Apache Kafka Meetup, 30 August 2017 The SMACK Stack: Spark*, Mesos*, Akka, Cassandra*, Kafka* Elizabeth K. Joseph @pleia2 * ASF projects 1 Elizabeth K. Joseph, Developer Advocate Developer Advocate
Azure Data Lake Analytics Introduction for SQL Family. Julie
 Azure Data Lake Analytics Introduction for SQL Family Julie Koesmarno @MsSQLGirl www.mssqlgirl.com jukoesma@microsoft.com What we have is a data glut Vernor Vinge (Emeritus Professor of Mathematics at
Azure Data Lake Analytics Introduction for SQL Family Julie Koesmarno @MsSQLGirl www.mssqlgirl.com jukoesma@microsoft.com What we have is a data glut Vernor Vinge (Emeritus Professor of Mathematics at
#techsummitch
 www.thomasmaurer.ch #techsummitch Justin Incarnato Justin Incarnato Microsoft Principal PM - Azure Stack Hyper-scale Hybrid Power of Azure in your datacenter Azure Stack Enterprise-proven On-premises
www.thomasmaurer.ch #techsummitch Justin Incarnato Justin Incarnato Microsoft Principal PM - Azure Stack Hyper-scale Hybrid Power of Azure in your datacenter Azure Stack Enterprise-proven On-premises
Alexander Klein. ETL in the Cloud
 Alexander Klein ETL in the Cloud Sponsors help us to run this event! THX! You Rock! Sponsor Gold Sponsor Silver Sponsor Bronze Sponsor You Rock! Sponsor Session 13:45 Track 1 Das super nerdige Solisyon
Alexander Klein ETL in the Cloud Sponsors help us to run this event! THX! You Rock! Sponsor Gold Sponsor Silver Sponsor Bronze Sponsor You Rock! Sponsor Session 13:45 Track 1 Das super nerdige Solisyon
Blurring the Line Between Developer and Data Scientist
 Blurring the Line Between Developer and Data Scientist Notebooks with PixieDust va barbosa va@us.ibm.com Developer Advocacy IBM Watson Data Platform WHY ARE YOU HERE? More companies making bet-the-business
Blurring the Line Between Developer and Data Scientist Notebooks with PixieDust va barbosa va@us.ibm.com Developer Advocacy IBM Watson Data Platform WHY ARE YOU HERE? More companies making bet-the-business
We are ready to serve Latest IT Trends, Are you ready to learn? New Batches Info
 We are ready to serve Latest IT Trends, Are you ready to learn? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : Storage & Database Services : Introduction
We are ready to serve Latest IT Trends, Are you ready to learn? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : Storage & Database Services : Introduction
Lambda Architecture for Batch and Stream Processing. October 2018
 Lambda Architecture for Batch and Stream Processing October 2018 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only.
Lambda Architecture for Batch and Stream Processing October 2018 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only.
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Spark 2. Alexey Zinovyev, Java/BigData Trainer in EPAM
 Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
SQL Server 2019 Big Data Clusters
 SQL Server 2019 Big Data Clusters Ben Weissman @bweissman > SOLISYON GMBH > FÜRTHER STRAßE 212 > 90429 NÜRNBERG > +49 911 990077 20 Who am I? Ben Weissman @bweissman b.weissman@solisyon.de http://biml-blog.de/
SQL Server 2019 Big Data Clusters Ben Weissman @bweissman > SOLISYON GMBH > FÜRTHER STRAßE 212 > 90429 NÜRNBERG > +49 911 990077 20 Who am I? Ben Weissman @bweissman b.weissman@solisyon.de http://biml-blog.de/
SQL Server Machine Learning Marek Chmel & Vladimir Muzny
 SQL Server Machine Learning Marek Chmel & Vladimir Muzny @VladimirMuzny & @MarekChmel MCTs, MVPs, MCSEs Data Enthusiasts! vladimir@datascienceteam.cz marek@datascienceteam.cz Session Agenda Machine learning
SQL Server Machine Learning Marek Chmel & Vladimir Muzny @VladimirMuzny & @MarekChmel MCTs, MVPs, MCSEs Data Enthusiasts! vladimir@datascienceteam.cz marek@datascienceteam.cz Session Agenda Machine learning
SQT03 Big Data and Hadoop with Azure HDInsight Andrew Brust. Senior Director, Technical Product Marketing and Evangelism
 Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Khadija Souissi. Auf z Systems November IBM z Systems Mainframe Event 2016
 Khadija Souissi Auf z Systems 07. 08. November 2016 @ IBM z Systems Mainframe Event 2016 Acknowledgements Apache Spark, Spark, Apache, and the Spark logo are trademarks of The Apache Software Foundation.
Khadija Souissi Auf z Systems 07. 08. November 2016 @ IBM z Systems Mainframe Event 2016 Acknowledgements Apache Spark, Spark, Apache, and the Spark logo are trademarks of The Apache Software Foundation.
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Azure Learning Circles
 Azure Learning Circles Azure Management Session 1: Logs, Diagnostics & Metrics Presented By: Shane Creamer shanec@microsoft.com Typical Customer Narratives Most customers know how to operate on-premises,
Azure Learning Circles Azure Management Session 1: Logs, Diagnostics & Metrics Presented By: Shane Creamer shanec@microsoft.com Typical Customer Narratives Most customers know how to operate on-premises,
Developing Microsoft Azure Solutions (70-532) Syllabus
 Syllabus") Developing Microsoft Azure Solutions (70-532) Syllabus Cloud Computing Introduction What is Cloud Computing Cloud Characteristics Cloud Computing Service Models Deployment Models in Cloud Computing Advantages
Developing Microsoft Azure Solutions (70-532) Syllabus Cloud Computing Introduction What is Cloud Computing Cloud Characteristics Cloud Computing Service Models Deployment Models in Cloud Computing Advantages
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Olivia Klose Technical Evangelist. Sascha Dittmann Cloud Solution Architect
 Olivia Klose Technical Evangelist Sascha Dittmann Cloud Solution Architect What is Apache Spark? Apache Spark is a fast and general engine for large-scale data processing. An unified, open source, parallel,
Olivia Klose Technical Evangelist Sascha Dittmann Cloud Solution Architect What is Apache Spark? Apache Spark is a fast and general engine for large-scale data processing. An unified, open source, parallel,
Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect
 Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect Igor Roiter Big Data Cloud Solution Architect Working as a Data Specialist for the last 11 years 9 of them as a Consultant specializing
Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect Igor Roiter Big Data Cloud Solution Architect Working as a Data Specialist for the last 11 years 9 of them as a Consultant specializing
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
App Service Overview. Rand Pagels Azure Technical Specialist - Application Development US Great Lakes Region
 App Service Overview Quickly create powerful cloud apps using a fully-managed platform Rand Pagels Azure Technical Specialist - Application Development US Great Lakes Region Security & Management Platform
App Service Overview Quickly create powerful cloud apps using a fully-managed platform Rand Pagels Azure Technical Specialist - Application Development US Great Lakes Region Security & Management Platform