Spark 2. Alexey Zinovyev, Java/BigData Trainer in EPAM
|
|
|
- Shauna Esther Adams
- 6 years ago
- Views:
Transcription

1 Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM


2 With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About
3 Secret Word from EPAM itsubbotnik Big Data Training 3
4 Contacts Alexey_Zinovyev@epam.com Facebook: vk.com/big_data_russia Big Data Russia vk.com/java_jvm Java & JVM langs Big Data Training 4

5 Sprk Dvlprs! Let s start! 5
6 < SPARK 2.0 6

7 Modern Java in 2016 Big Data in 2014 Big Data Training 7

8 Big Data in 2017 Big Data Training 8
9 Machine Learning EVERYWHERE Big Data Training 9

10 Machine Learning vs Traditional Programming Big Data Training 10

11 Big Data Training 11
12 Something wrong with HADOOP Big Data Training 12

13 Hadoop is not SEXY 13

14 Whaaaat? 14

15 Map Reduce Job Writing 15

16 MR code 16

17 Hadoop Developers Right Now 17


18 Iterative Calculations 10x 100x 18
19 MapReduce vs Spark 19



20 MapReduce vs Spark 20

21 MapReduce vs Spark 21
22 SPARK 2.0 DISCUSSION 22
23 Spark Family 23
24 Spark Family 24
25 Case #0 : How to avoid DStreams with RDD-like API? 25

26 Continuous Applications 26
27 Continuous Applications cases Updating data that will be served in real time Extract, transform and load (ETL) Creating a real-time version of an existing batch job Online machine learning 27
28 Write Batches 28
29 Catch Streaming 29
30 The main concept of Structured Streaming You can express your streaming computation the same way you would express a batch computation on static data. 30
31 // Read JSON once from S3 logsdf = spark.read.json("s3://logs") Batch // Transform with DataFrame API and save logsdf.select("user", "url", "date").write.parquet("s3://out") 31
32 // Read JSON continuously from S3 logsdf = spark.readstream.json("s3://logs") Real Time // Transform with DataFrame API and save logsdf.select("user", "url", "date").writestream.parquet("s3://out").start() 32

33 Unlimited Table 33
34 val lines = spark.readstream.format("socket").option("host", "localhost") WordCount from Socket.option("port", 9999).load() val words = lines.as[string].flatmap(_.split(" ")) val wordcounts = words.groupby("value").count() 34
35 val lines = spark.readstream.format("socket").option("host", "localhost") WordCount from Socket.option("port", 9999).load() val words = lines.as[string].flatmap(_.split(" ")) val wordcounts = words.groupby("value").count() 35
36 val lines = spark.readstream.format("socket").option("host", "localhost") WordCount from Socket.option("port", 9999).load() val words = lines.as[string].flatmap(_.split(" ")) val wordcounts = words.groupby("value").count() 36
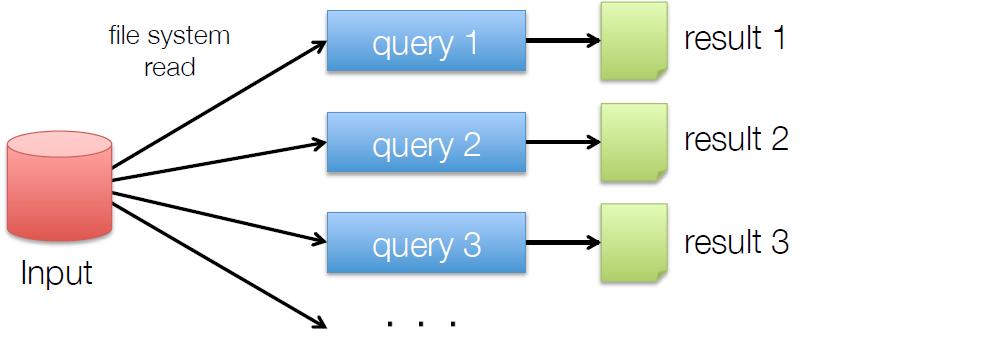
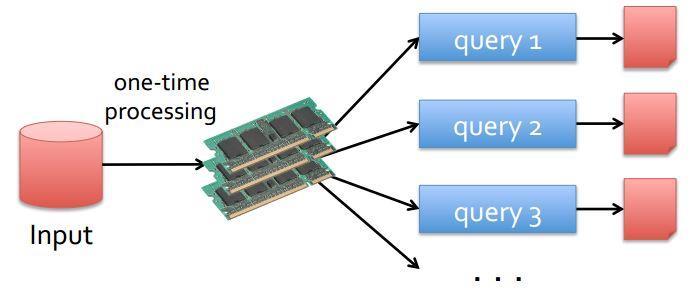
 WordCount from Socket.")
 Don t forget to start Streaming val words = lines.")
37 val lines = spark.readstream.format("socket").option("host", "localhost") WordCount from Socket.option("port", 9999).load() Don t forget to start Streaming val words = lines.as[string].flatmap(_.split(" ")) val wordcounts = words.groupby("value").count() 37

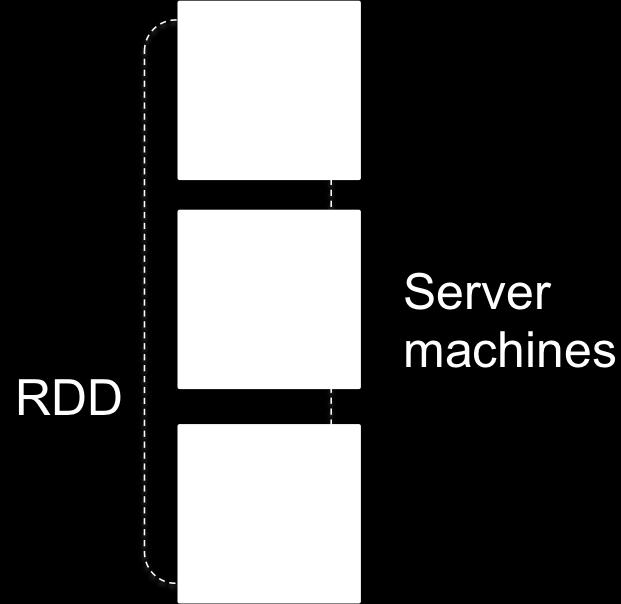
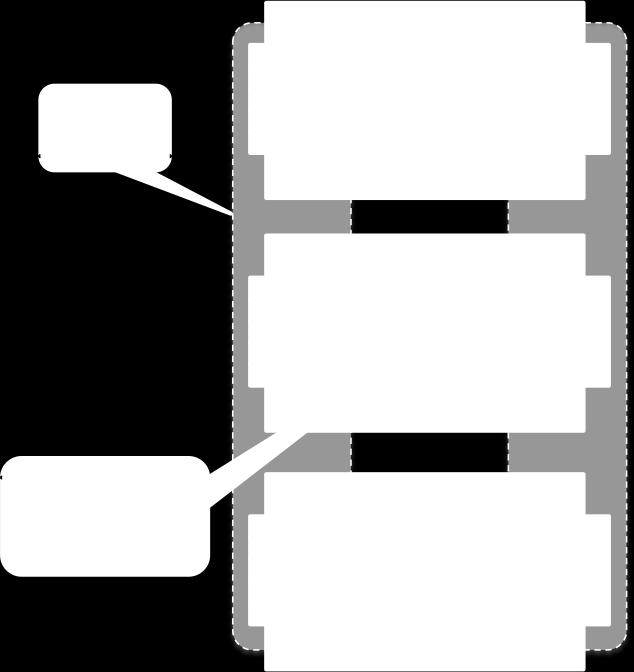
38 WordCount with Structured Streaming 38
39 Structured Streaming provides fast & scalable fault-tolerant end-to-end with exactly-once semantic stream processing ability to use DataFrame/DataSet API for streaming 39
40 Structured Streaming provides (in dreams) fast & scalable fault-tolerant end-to-end with exactly-once semantic stream processing ability to use DataFrame/DataSet API for streaming 40
41 Let s UNION streaming and static DataSets 41

42 Let s UNION streaming and static DataSets org.apache.spark.sql. AnalysisException: Union between streaming and batch DataFrames/Datasets is not supported; 42
43 Let s UNION streaming and static DataSets Go to UnsupportedOperationChecker.scala and check your operation 43
44 Case #1 : We should think about optimization in RDD terms 44

45 Single Thread collection 45

46 No perf issues, right? 46
47 The main concept more partitions = more parallelism 47

48 Do it parallel 48

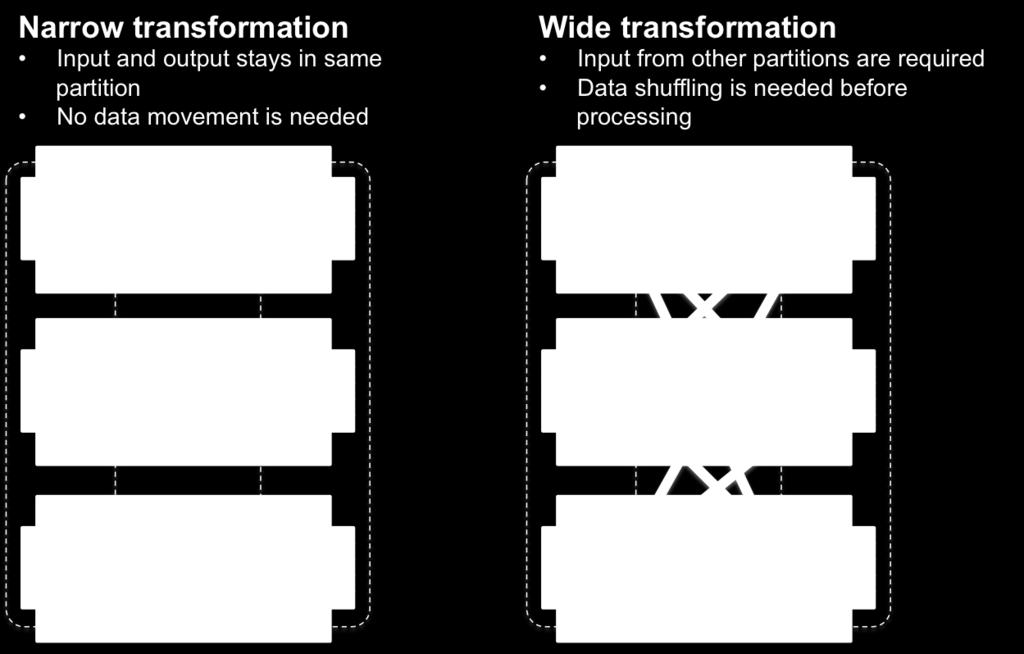
49 I d like NARROW 49
50 Map, filter, filter 50
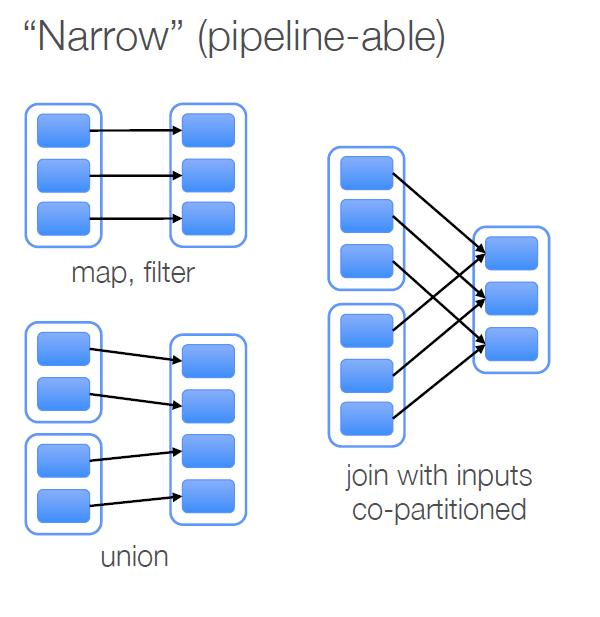
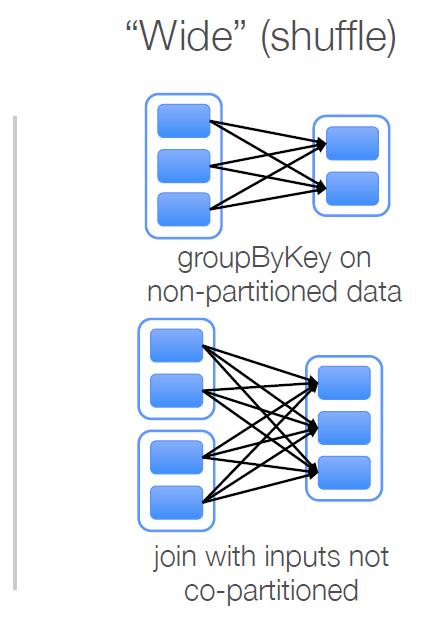
51 GroupByKey, join 51
52 Case #2 : DataFrames suggest mix SQL and Scala functions 52

53 History of Spark APIs 53
54 rdd.filter(_.age > 21) // RDD RDD df.filter("age > 21") // DataFrame SQL-style df.filter(df.col("age").gt(21)) // Expression style dataset.filter(_.age < 21); // Dataset API 54

55 History of Spark APIs 55
56 rdd.filter(_.age > 21) // RDD SQL df.filter("age > 21") // DataFrame SQL-style df.filter(df.col("age").gt(21)) // Expression style dataset.filter(_.age < 21); // Dataset API 56
57 rdd.filter(_.age > 21) // RDD Expression df.filter("age > 21") // DataFrame SQL-style df.filter(df.col("age").gt(21)) // Expression style dataset.filter(_.age < 21); // Dataset API 57

58 History of Spark APIs 58
59 rdd.filter(_.age > 21) // RDD DataSet df.filter("age > 21") // DataFrame SQL-style df.filter(df.col("age").gt(21)) // Expression style dataset.filter(_.age < 21); // Dataset API 59
60 Case #2 : DataFrame is referring to data attributes by name 60

61 DataSet = RDD s types + DataFrame s Catalyst RDD API compile-time type-safety off-heap storage mechanism performance benefits of the Catalyst query optimizer Tungsten 61
62 DataSet = RDD s types + DataFrame s Catalyst RDD API compile-time type-safety off-heap storage mechanism performance benefits of the Catalyst query optimizer Tungsten 62
63 Structured APIs in SPARK 63
64 Unified API in Spark 2.0 DataFrame = Dataset[Row] Dataframe is a schemaless (untyped) Dataset now 64
65 case class User( String, footsize: Long, name: String) // DataFrame -> DataSet with Users val userds = Define case class spark.read.json("/home/tmp/datasets/users.json").as[user] userds.map(_.name).collect() userds.filter(_.footsize > 38).collect() ds.rdd // IF YOU REALLY WANT 65
66 case class User( String, footsize: Long, name: String) // DataFrame -> DataSet with Users val userds = Read JSON spark.read.json("/home/tmp/datasets/users.json").as[user] userds.map(_.name).collect() userds.filter(_.footsize > 38).collect() ds.rdd // IF YOU REALLY WANT 66
67 case class User( String, footsize: Long, name: String) // DataFrame -> DataSet with Users val userds = Filter by Field spark.read.json("/home/tmp/datasets/users.json").as[user] userds.map(_.name).collect() userds.filter(_.footsize > 38).collect() ds.rdd // IF YOU REALLY WANT 67
68 Case #3 : Spark has many contexts 68
69 Spark Session New entry point in spark for creating datasets Replaces SQLContext, HiveContext and StreamingContext Move from SparkContext to SparkSession signifies move away from RDD 69
70 val sparksession = SparkSession.builder.master("local").appName("spark session example").getorcreate() Spark Session val df = sparksession.read.option("header","true").csv("src/main/resources/names.csv") df.show() 70
71 No, I want to create my lovely RDDs 71
")
72 Where s parallelize() method? 72
73 case class User( String, footsize: Long, name: String) // DataFrame -> DataSet with Users val userds = spark.read.json("/home/tmp/datasets/users.json").as[user] RDD? userds.map(_.name).collect() userds.filter(_.footsize > 38).collect() ds.rdd // IF YOU REALLY WANT 73
74 Case #4 : Spark uses Java serialization A LOT 74
75 Two choices to distribute data across cluster Java serialization By default with ObjectOutputStream Kryo serialization Should register classes (no support of Serialazible) 75
76 The main problem: overhead of serializing Each serialized object contains the class structure as well as the values 76
77 The main problem: overhead of serializing Each serialized object contains the class structure as well as the values Don t forget about GC 77

78 Tungsten Compact Encoding 78
79 Encoder s concept Generate bytecode to interact with off-heap & Give access to attributes without ser/deser 79
80 Encoders 80

81 No custom encoders 81

82 Case #5 : Not enough storage levels 82
83 Caching in Spark Frequently used RDD can be stored in memory One method, one short-cut: persist(), cache() SparkContext keeps track of cached RDD Serialized or deserialized Java objects 83
84 Full list of options MEMORY_ONLY MEMORY_AND_DISK MEMORY_ONLY_SER MEMORY_AND_DISK_SER DISK_ONLY MEMORY_ONLY_2, MEMORY_AND_DISK_2 84
85 Spark Core Storage Level MEMORY_ONLY (default for Spark Core) MEMORY_AND_DISK MEMORY_ONLY_SER MEMORY_AND_DISK_SER DISK_ONLY MEMORY_ONLY_2, MEMORY_AND_DISK_2 85
86 Spark Streaming Storage Level MEMORY_ONLY (default for Spark Core) MEMORY_AND_DISK MEMORY_ONLY_SER (default for Spark Streaming) MEMORY_AND_DISK_SER DISK_ONLY MEMORY_ONLY_2, MEMORY_AND_DISK_2 86


87 Developer API to make new Storage Levels 87
88 What s the most popular file format in BigData? 88

89 Case #6 : External libraries to read CSV 89
90 data = sqlcontext.read.format("csv").option("header", "true").option("inferschema", "true") Easy to read CSV.load("/datasets/samples/users.csv") data.cache() data.createorreplacetempview( users") display(data) 90
91 Case #7 : How to measure Spark performance? 91

92 You'd measure performance! 92
93 TPCDS 99 Queries 93
94 94





95 How to benchmark Spark 95
96 Special Tool from Databricks Benchmark Tool for SparkSQL 96

97 Spark 2 vs Spark
98 Case #8 : What s faster: SQL or DataSet API? 98

99 Job Stages in old Spark 99

100 Scheduler Optimizations 100

101 Catalyst Optimizer for DataFrames 101

102 Unified Logical Plan DataFrame = Dataset[Row] 102
103 Bytecode 103
104 DataSet.explain() == Physical Plan == Project [avg(price)#43,carat#45] +- SortMergeJoin [color#21], [color#47] :- Sort [color#21 ASC], false, 0 : +- TungstenExchange hashpartitioning(color#21,200), None : +- Project [avg(price)#43,color#21] : +- TungstenAggregate(key=[cut#20,color#21], functions=[(avg(cast(price#25 as bigint)),mode=final,isdistinct=false)], output=[color#21,avg(price)#43]) : +- TungstenExchange hashpartitioning(cut#20,color#21,200), None : +- TungstenAggregate(key=[cut#20,color#21], functions=[(avg(cast(price#25 as bigint)),mode=partial,isdistinct=false)], output=[cut#20,color#21,sum#58,count#59l]) : +- Scan CsvRelation(-----) +- Sort [color#47 ASC], false, 0 +- TungstenExchange hashpartitioning(color#47,200), None +- ConvertToUnsafe +- Scan CsvRelation(----) 104
105 Case #9 : Why does explain() show so many Tungsten things? 105
106 How to be effective with CPU Runtime code generation Exploiting cache locality Off-heap memory management 106
107 Tungsten s goal Push performance closer to the limits of modern hardware 107

108 Maybe something UNSAFE? 108
109 UnsafeRowFormat Bit set for tracking null values Small values are inlined For variable-length values are stored relative offset into the variablelength data section Rows are always 8-byte word aligned Equality comparison and hashing can be performed on raw bytes without requiring additional interpretation 109
110 Case #10 : Can I influence on Memory Management in Spark? 110


111 Case #11 : Should I tune generation s stuff? 111
112 Cached Data 112
113 During operations 113

114 For your needs 114
115 For Dark Lord 115
116 IN CONCLUSION 116
117 We have no ability join structured streaming and other sources to handle it one unified ML API GraphX rethinking and redesign Custom encoders Datasets everywhere integrate with something important 117
118 Roadmap Support other data sources (not only S3 + HDFS) Transactional updates Dataset is one DSL for all operations GraphFrames + Structured MLLib Tungsten: custom encoders The RDD-based API is expected to be removed in Spark


")














119 And we can DO IT! Push Events & Alarms ( , SNMP etc.) Real-Time ETL & CEP Search Index Social Real-Time Data-Marts Real-time Data Ingestion Batch Data-Marts External Batch Data Ingestion Batch ETL & Raw Area HDFS CFS as an option Titan & KairosDB store data in Cassandra Relations Graph Ontology Metadata Internal Scheduler Time-Series Data Real-time Dashboarding All Raw Data backup is stored here Events & Alarms Events & Alarms 119
120 First Part 120

121 Second Part 121
122 Contacts Alexey_Zinovyev@epam.com Facebook: vk.com/big_data_russia Big Data Russia vk.com/java_jvm Java & JVM langs 122



123 Any questions? 123
Kafka pours and Spark resolves! Alexey Zinovyev, Java/BigData Trainer in EPAM
 Kafka pours and Spark resolves! Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With Spark since 2014 With EPAM since 2015 About Contacts E-mail
Kafka pours and Spark resolves! Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With Spark since 2014 With EPAM since 2015 About Contacts E-mail
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Structured Streaming. Big Data Analysis with Scala and Spark Heather Miller
 Structured Streaming Big Data Analysis with Scala and Spark Heather Miller Why Structured Streaming? DStreams were nice, but in the last session, aggregation operations like a simple word count quickly
Structured Streaming Big Data Analysis with Scala and Spark Heather Miller Why Structured Streaming? DStreams were nice, but in the last session, aggregation operations like a simple word count quickly
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
WHAT S NEW IN SPARK 2.0: STRUCTURED STREAMING AND DATASETS
 WHAT S NEW IN SPARK 2.0: STRUCTURED STREAMING AND DATASETS Andrew Ray StampedeCon 2016 Silicon Valley Data Science is a boutique consulting firm focused on transforming your business through data science
WHAT S NEW IN SPARK 2.0: STRUCTURED STREAMING AND DATASETS Andrew Ray StampedeCon 2016 Silicon Valley Data Science is a boutique consulting firm focused on transforming your business through data science
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
SparkSQL 11/14/2018 1
 SparkSQL 11/14/2018 1 Where are we? Pig Latin HiveQL Pig Hive??? Hadoop MapReduce Spark RDD HDFS 11/14/2018 2 Where are we? Pig Latin HiveQL SQL Pig Hive??? Hadoop MapReduce Spark RDD HDFS 11/14/2018 3
SparkSQL 11/14/2018 1 Where are we? Pig Latin HiveQL Pig Hive??? Hadoop MapReduce Spark RDD HDFS 11/14/2018 2 Where are we? Pig Latin HiveQL SQL Pig Hive??? Hadoop MapReduce Spark RDD HDFS 11/14/2018 3
New Developments in Spark
 New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
An Overview of Apache Spark
 An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
Agenda. Spark Platform Spark Core Spark Extensions Using Apache Spark
 Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
An Introduction to Apache Spark
 An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
MapReduce review. Spark and distributed data processing. Who am I? Today s Talk. Reynold Xin
 Who am I? Reynold Xin Stanford CS347 Guest Lecture Spark and distributed data processing PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD), UC Berkeley AMPLab Reynold
Who am I? Reynold Xin Stanford CS347 Guest Lecture Spark and distributed data processing PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD), UC Berkeley AMPLab Reynold
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Databases and Big Data Today. CS634 Class 22
 Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Accelerating Spark Workloads using GPUs
 Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Spark and distributed data processing
 Stanford CS347 Guest Lecture Spark and distributed data processing Reynold Xin @rxin 2016-05-23 Who am I? Reynold Xin PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD),
Stanford CS347 Guest Lecture Spark and distributed data processing Reynold Xin @rxin 2016-05-23 Who am I? Reynold Xin PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD),
Big Streaming Data Processing. How to Process Big Streaming Data 2016/10/11. Fraud detection in bank transactions. Anomalies in sensor data
 Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Asanka Padmakumara. ETL 2.0: Data Engineering with Azure Databricks
 Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Databricks, an Introduction
 Databricks, an Introduction Chuck Connell, Insight Digital Innovation Insight Presentation Speaker Bio Senior Data Architect at Insight Digital Innovation Focus on Azure big data services HDInsight/Hadoop,
Databricks, an Introduction Chuck Connell, Insight Digital Innovation Insight Presentation Speaker Bio Senior Data Architect at Insight Digital Innovation Focus on Azure big data services HDInsight/Hadoop,
Memory Management for Spark. Ken Salem Cheriton School of Computer Science University of Waterloo
 Memory Management for Spark Ken Salem Cheriton School of Computer Science University of aterloo here I m From hat e re Doing Flexible Transactional Persistence DBMS-Managed Energy Efficiency Non-Relational
Memory Management for Spark Ken Salem Cheriton School of Computer Science University of aterloo here I m From hat e re Doing Flexible Transactional Persistence DBMS-Managed Energy Efficiency Non-Relational
The Future of Real-Time in Spark
 The Future of Real-Time in Spark Reynold Xin @rxin Spark Summit, New York, Feb 18, 2016 Why Real-Time? Making decisions faster is valuable. Preventing credit card fraud Monitoring industrial machinery
The Future of Real-Time in Spark Reynold Xin @rxin Spark Summit, New York, Feb 18, 2016 Why Real-Time? Making decisions faster is valuable. Preventing credit card fraud Monitoring industrial machinery
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Data Platforms and Pattern Mining
 Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Intro To Spark. John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center. Copyright 2017
 Intro To Spark John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Performance First, use RAM Also, be smarter Spark Capabilities (i.e. Hadoop shortcomings) Ease of
Intro To Spark John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Performance First, use RAM Also, be smarter Spark Capabilities (i.e. Hadoop shortcomings) Ease of
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
 About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
Analyzing Flight Data
 IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Parallel Processing Spark and Spark SQL
 Parallel Processing Spark and Spark SQL Amir H. Payberah amir@sics.se KTH Royal Institute of Technology Amir H. Payberah (KTH) Spark and Spark SQL 2016/09/16 1 / 82 Motivation (1/4) Most current cluster
Parallel Processing Spark and Spark SQL Amir H. Payberah amir@sics.se KTH Royal Institute of Technology Amir H. Payberah (KTH) Spark and Spark SQL 2016/09/16 1 / 82 Motivation (1/4) Most current cluster
CS435 Introduction to Big Data FALL 2018 Colorado State University. 10/24/2018 Week 10-B Sangmi Lee Pallickara
 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
Lightning Fast Cluster Computing. Michael Armbrust Reflections Projections 2015 Michast
 Lightning Fast Cluster Computing Michael Armbrust - @michaelarmbrust Reflections Projections 2015 Michast What is Apache? 2 What is Apache? Fast and general computing engine for clusters created by students
Lightning Fast Cluster Computing Michael Armbrust - @michaelarmbrust Reflections Projections 2015 Michast What is Apache? 2 What is Apache? Fast and general computing engine for clusters created by students
Spark supports several storage levels
 1 Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the
1 Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the
15/04/2018. Spark supports several storage levels. The storage level is used to specify if the content of the RDD is stored
 Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the RDD,
Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the RDD,
Intro To Spark. John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center. Copyright 2017
 Intro To Spark John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Spark Capabilities (i.e. Hadoop shortcomings) Performance First, use RAM Also, be smarter Ease of
Intro To Spark John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Spark Capabilities (i.e. Hadoop shortcomings) Performance First, use RAM Also, be smarter Ease of
Distributed Systems. 22. Spark. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Evolution From Shark To Spark SQL:
 Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
/ Cloud Computing. Recitation 13 April 17th 2018
 15-319 / 15-619 Cloud Computing Recitation 13 April 17th 2018 Overview Last week s reflection Team Project Phase 2 Quiz 11 OLI Unit 5: Modules 21 & 22 This week s schedule Project 4.2 No more OLI modules
15-319 / 15-619 Cloud Computing Recitation 13 April 17th 2018 Overview Last week s reflection Team Project Phase 2 Quiz 11 OLI Unit 5: Modules 21 & 22 This week s schedule Project 4.2 No more OLI modules
빅데이터기술개요 2016/8/20 ~ 9/3. 윤형기
 빅데이터기술개요 2016/8/20 ~ 9/3 윤형기 (hky@openwith.net) D4 http://www.openwith.net 2 Hive http://www.openwith.net 3 What is Hive? 개념 a data warehouse infrastructure tool to process structured data in Hadoop. Hadoop
빅데이터기술개요 2016/8/20 ~ 9/3 윤형기 (hky@openwith.net) D4 http://www.openwith.net 2 Hive http://www.openwith.net 3 What is Hive? 개념 a data warehouse infrastructure tool to process structured data in Hadoop. Hadoop
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Spark Streaming. Big Data Analysis with Scala and Spark Heather Miller
 Spark Streaming Big Data Analysis with Scala and Spark Heather Miller Where Spark Streaming fits in (1) Spark is focused on batching Processing large, already-collected batches of data. For example: Where
Spark Streaming Big Data Analysis with Scala and Spark Heather Miller Where Spark Streaming fits in (1) Spark is focused on batching Processing large, already-collected batches of data. For example: Where
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 8 October, 2014, Tartu Outline Introduction to Spark Resilient Distributed Data (RDD) Available data operations Examples Advantages and Disadvantages Frameworks
Data processing in Apache Spark Pelle Jakovits 8 October, 2014, Tartu Outline Introduction to Spark Resilient Distributed Data (RDD) Available data operations Examples Advantages and Disadvantages Frameworks
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
15.1 Data flow vs. traditional network programming
 CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
Starting with Apache Spark, Best Practices and Learning from the Field
 Starting with Apache Spark, Best Practices and Learning from the Field Felix Cheung, Principal Engineer + Spark Committer Spark@Microsoft Best Practices Enterprise Solutions Resilient - Fault tolerant
Starting with Apache Spark, Best Practices and Learning from the Field Felix Cheung, Principal Engineer + Spark Committer Spark@Microsoft Best Practices Enterprise Solutions Resilient - Fault tolerant
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 21 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Streaming
Data processing in Apache Spark Pelle Jakovits 21 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Streaming
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
COSC 6339 Big Data Analytics. Introduction to Spark. Edgar Gabriel Fall What is SPARK?
 COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Submitted to: Dr. Sunnie Chung. Presented by: Sonal Deshmukh Jay Upadhyay
 Submitted to: Dr. Sunnie Chung Presented by: Sonal Deshmukh Jay Upadhyay Submitted to: Dr. Sunny Chung Presented by: Sonal Deshmukh Jay Upadhyay What is Apache Survey shows huge popularity spike for Apache
Submitted to: Dr. Sunnie Chung Presented by: Sonal Deshmukh Jay Upadhyay Submitted to: Dr. Sunny Chung Presented by: Sonal Deshmukh Jay Upadhyay What is Apache Survey shows huge popularity spike for Apache
The Evolution of Big Data Platforms and Data Science
 IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
Higher level data processing in Apache Spark
 Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Spark Streaming. Guido Salvaneschi
 Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Shark: SQL and Rich Analytics at Scale. Michael Xueyuan Han Ronny Hajoon Ko
 Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
An Introduction to Apache Spark Big Data Madison: 29 July William Red Hat, Inc.
 An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
IOTA ARCHITECTURE: DATA VIRTUALIZATION AND PROCESSING MEDIUM DR. KONSTANTIN BOUDNIK DR. ALEXANDRE BOUDNIK
 IOTA ARCHITECTURE: DATA VIRTUALIZATION AND PROCESSING MEDIUM DR. KONSTANTIN BOUDNIK DR. ALEXANDRE BOUDNIK DR. KONSTANTIN BOUDNIK DR.KONSTANTIN BOUDNIK EPAM SYSTEMS CHIEF TECHNOLOGIST BIGDATA, OPEN SOURCE
IOTA ARCHITECTURE: DATA VIRTUALIZATION AND PROCESSING MEDIUM DR. KONSTANTIN BOUDNIK DR. ALEXANDRE BOUDNIK DR. KONSTANTIN BOUDNIK DR.KONSTANTIN BOUDNIK EPAM SYSTEMS CHIEF TECHNOLOGIST BIGDATA, OPEN SOURCE
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
Data Analytics Job Guarantee Program
 Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Data Analytics and Machine Learning: From Node to Cluster
 Data Analytics and Machine Learning: From Node to Cluster Presented by Viswanath Puttagunta Ganesh Raju Understanding use cases to optimize on ARM Ecosystem Date BKK16-404B March 10th, 2016 Event Linaro
Data Analytics and Machine Learning: From Node to Cluster Presented by Viswanath Puttagunta Ganesh Raju Understanding use cases to optimize on ARM Ecosystem Date BKK16-404B March 10th, 2016 Event Linaro
In-Memory Processing with Apache Spark. Vincent Leroy
 In-Memory Processing with Apache Spark Vincent Leroy Sources Resilient Distributed Datasets, Henggang Cui Coursera IntroducBon to Apache Spark, University of California, Databricks Datacenter OrganizaBon
In-Memory Processing with Apache Spark Vincent Leroy Sources Resilient Distributed Datasets, Henggang Cui Coursera IntroducBon to Apache Spark, University of California, Databricks Datacenter OrganizaBon
Hive and Shark. Amir H. Payberah. Amirkabir University of Technology (Tehran Polytechnic)
") Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Spark Streaming: Hands-on Session A.A. 2017/18
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Spark Streaming: Hands-on Session A.A. 2017/18 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Spark Streaming: Hands-on Session A.A. 2017/18 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Workload Characterization and Optimization of TPC-H Queries on Apache Spark
 Workload Characterization and Optimization of TPC-H Queries on Apache Spark Tatsuhiro Chiba and Tamiya Onodera IBM Research - Tokyo April. 17-19, 216 IEEE ISPASS 216 @ Uppsala, Sweden Overview IBM Research
Workload Characterization and Optimization of TPC-H Queries on Apache Spark Tatsuhiro Chiba and Tamiya Onodera IBM Research - Tokyo April. 17-19, 216 IEEE ISPASS 216 @ Uppsala, Sweden Overview IBM Research
THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION
 Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Impala. A Modern, Open Source SQL Engine for Hadoop. Yogesh Chockalingam
 Impala A Modern, Open Source SQL Engine for Hadoop Yogesh Chockalingam Agenda Introduction Architecture Front End Back End Evaluation Comparison with Spark SQL Introduction Why not use Hive or HBase?
Impala A Modern, Open Source SQL Engine for Hadoop Yogesh Chockalingam Agenda Introduction Architecture Front End Back End Evaluation Comparison with Spark SQL Introduction Why not use Hive or HBase?
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
1 Big Data Hadoop. 1. Introduction About this Course About Big Data Course Logistics Introductions
 Big Data Hadoop Architect Online Training (Big Data Hadoop + Apache Spark & Scala+ MongoDB Developer And Administrator + Apache Cassandra + Impala Training + Apache Kafka + Apache Storm) 1 Big Data Hadoop
Big Data Hadoop Architect Online Training (Big Data Hadoop + Apache Spark & Scala+ MongoDB Developer And Administrator + Apache Cassandra + Impala Training + Apache Kafka + Apache Storm) 1 Big Data Hadoop
Real-time data processing with Apache Flink
 Real-time data processing with Apache Flink Gyula Fóra gyfora@apache.org Flink committer Swedish ICT Stream processing Data stream: Infinite sequence of data arriving in a continuous fashion. Stream processing:
Real-time data processing with Apache Flink Gyula Fóra gyfora@apache.org Flink committer Swedish ICT Stream processing Data stream: Infinite sequence of data arriving in a continuous fashion. Stream processing:
Index. Raul Estrada and Isaac Ruiz 2016 R. Estrada and I. Ruiz, Big Data SMACK, DOI /
 Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
EPL660: Information Retrieval and Search Engines Lab 11
 EPL660: Information Retrieval and Search Engines Lab 11 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science Introduction to Apache Spark Fast and general engine for
EPL660: Information Retrieval and Search Engines Lab 11 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science Introduction to Apache Spark Fast and general engine for
Spark and Spark SQL. Amir H. Payberah. SICS Swedish ICT. Amir H. Payberah (SICS) Spark and Spark SQL June 29, / 71
 Spark and Spark SQL June 29, / 71") Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Lambda Architecture with Apache Spark
 Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR
Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR