CHAPTER VII INDEXED K TWIN NEIGHBOUR CLUSTERING ALGORITHM 7.1 INTRODUCTION
|
|
|
- Edward Skinner
- 5 years ago
- Views:
Transcription
1 CHAPTER VII INDEXED K TWIN NEIGHBOUR CLUSTERING ALGORITHM 7.1 INTRODUCTION Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called cluster) are more similar (in some sense or another) to each other than those of other groups (clusters). These clusters presumably reflect some mechanisms at a work in the domain from which instances are drawn, a mechanism that causes some instances to bear a stronger resemblance to each other than they do the remaining instances. Clustering naturally requires different techniques to the classification and association learning. There are different methods used to express the result of clustering. The clusters identified may be exclusive, so that any instance belongs to only one group or they may be overlapping so that an instance may fall into several groups or they may be probabilistic, where by an instance belongs to each group with a certain probability or they may be hierarchical, such that there is crude division of instances into groups at the top level, and each of the group is filtered further perhaps all the way down to individual instances. Really, the choice among these possibilities should be detected by the nature of mechanisms that are thought to underlie the particular clustering phenomenon. The major conventional algorithm fails in optimizing data structure concepts because of overlapping clusters and heterogeneous members of the same cluster. The current chapter of this thesis proposes a new clustering algorithm called Indexed K Nearest Twin Neighbour Clustering Algorithm (IKNTN). 7.2 CLUSTERING TECHNIQUES Clustering is a useful technique for the discovery of data distribution and patterns in the underlying data. The goal of clustering is to discover both the dense and the sparse regions in a data set. Data clustering has been studied in the statistics, machine learning, and database communities with diverse emphases. The earlier approaches do not adequately consider the fact that the data set can be too large to fit into the main memory. In particular, they do not recognize that the problem must be viewed in terms of how to work with limited resources. The main emphasis has been to cluster with high accuracy as possible, while keeping the I/O cost high. Thus, it is not relevant to apply the classical algorithms in the context of data mining and it is necessary to investigate the principle of clustering to devise 145
2 efficient algorithms which meet the specific requirement of minimizing the I/O operation. It is to be noted that the basic principle of clustering hinges on a concept of distance metric or similarity metric. Since the data are invariably real numbers for statistical application and pattern recognition, a large class of metrics exists and one can define one s own metric depending on an explicit requirement. But in databases, there exist objects which cannot be ordered, and their attributes may be categorical in nature. Traditional clustering algorithms only handle numeric data which are not suitable for data mining purposes. This chapter deals with different clustering techniques for data mining called IKNTN Clustering Algorithm. During the last several years, there has been an increasing interest in devising efficient clustering algorithms for data mining. In a short span of 2 to 3 years a very large number of new and interesting algorithms have been proposed. The aim of this chapter is to present a novel clustering algorithm and this will be useful for optimizing the performance of data structure and for future research in the area of optimizing the performance of data structure and algorithms. The clustering algorithms for numerical data are again categorized into two classes: partition and hierarchical. There are three different partitioning algorithms namely PAM, CLARA, and CLARANS CLUSTERING PARADIGMS There are two main approaches available for clustering paradigms, namely hierarchical clustering and partitioning clustering. Besides, clustering algorithms differ among themselves in their ability to handle different types of attributes, numeric and categorical, in accuracy of clustering, and in their ability to handle disk-resident data PARTITIONING ALGORITHM Partitioning algorithms is constructed partitions of a database with N data points, into a set of k clusters. The construction involves determining the optimal partition with respect to an objective function. There is approximately /! ways of partitioning a set of N data points into k subsets. An exhaustive enumeration method that can find the global optimal partition is practically infeasible except when N and k are very small. The partitioning clustering algorithm usually adopts the Iterative Optimization paradigm also it is one of the main limitations of the partitioning algorithm. It starts with an initial partition and uses an iterative control strategy. It tries swapping data points to see if such a swapping improves the quality of clustering technique. When swapping does not yield any improvements in 146
3 clustering, it finds a locally optimal partition. This quality of clustering is very sensitive to the initially selected partition. Some of the most famous partitioning algorithms are k-means and k-medoid. In fields such as data structure, search and optimization method deals with how to find the best model(s) that makes minimum computation. Data mining concept especially the clustering concept can play very important role in optimizing the data structure concepts such as search. One of the biggest challenges in search, the search has to carryout throughout the data. So this increases the computational cost. A potential remedy to this problem is clustering the data and search done only within the predefined cluster. Clustered data structure may take less computational cost than the traditional data structure. IKNTN focuses on improvements to basic operations on data structures, specifically focus on the search operation performance on larger data, also introduces a new clustering algorithm specially designed to achieve optimal reduction of computational cost in any data structure. The chapters V and VI show the key role of data structure and its computational cost in LZW data compression algorithm. So in order to get the optimal reduction of computational cost, a novel clustering algorithm is designed and proposed. The IKNTN clustering algorithm solves the issues of traditional clustering algorithms like overlapping clusters and huge iteration. This algorithm runs with minimal computational cost compared with other partition clustering algorithms. 7.3 INDEXED K NEAREST TWIN NEIGHBOUR CLUSTERING ALGORITHM (IKNTN) Clustering is group of the same or similar elements gathered or occurring closely together. This section of the thesis discusses a novel algorithm called Indexed K Nearest Twin Neighbour Clustering Algorithm. This algorithm is branched under partitioning clustering algorithms. Apart from the traditional partitioning clustering algorithms, the proposed algorithm has several advantages i.e., the clusters formed by the proposed algorithm don t have any overlapping. This means that each cluster has its own independent boundary and also unlimited number or huge iteration to find the efficient cluster which is not required. The latter sections of this chapter deals with the proposed algorithm which is specially designed to optimize the performance of any kind of data structure or this algorithm reduces the computational complexity of any data structure currently in use. The proposed algorithm finds the nearest twin Neighbour and all nearest twins are clustered and then all individual Clusters are indexed. Each cluster has only nearest twin patterns or a cluster contains only a 147
4 group of nearest twin patterns. After the process of clustering, the search is performed only within the particular cluster with the help of cluster Index. The primary objective of the proposed clustering algorithm is to optimize the ability of data structure for a huge data set; especially this algorithm gives optimal reduction in any search, insertion or deletion using any fundamental data structure. The first phase of the algorithm is sorting the given dataset or data points in ascending or descending order. The sorting phase has a key role in the proposed algorithm. This phase partially brings the nearest data points to the neighboring position. For example, it is to be assumed that, are the data points to be clustered using the IKNTN algorithm is shown in the Figure 7.1. After sorting phase, the data points are rearranged or it seems to be a sorted manner, then the data set must follow 1<< order if it is in arranged in an ascending order. Then the neighboring values of may be approximately equal to +1 that is 1 +1 where indicates the element in the data set. So after this preprocessing stage the efficiency of the IKNTN algorithm is much improved. Sorting phase has a very important role in the computational complexity of this algorithm, if the algorithm is designed with low complexity sorting algorithm, then the cost of the algorithm is also reduced. Next step is to find the minimal length data available in the data set D and the minimal length which is stored in the variable L is shown in the figure-7.1. If the L and number of Clusters K are related i.e., if L increases then K increases or if L decreases then K reduces, this step can be combined with the sorting phase and then the additional computation is reduced. The next step is initializing the value for K, where K indicates the number of cluster, initially the K is initialized with zero. During the invention of new cluster from the data set, the value of K will be incremented. This algorithm does not define the total number of clusters at the initial stage, i.e., there is a possibility of generating a new cluster when processing the last data point, where represents the size of the data set. Next the algorithm starts iteration and fetches the first two data points D and D from the sorted or preprocessed data set and the Euclidean Distance of both data points are calculated but only the L length of the data points are used for calculating the Euclidean Distance i.e., shown in the Algorithm 7.1 line number 21. The Euclidean_Distance function returns the distance between two data points D and D respectively and it is stored in the variable ED. If the ED equals 0.0 then the algorithm is considered as both data points D and D as Twin Neighbour, if both the elements are twin grouped into Cluster, initially =0 then. Initially the size of is zero, but after formation of all available clusters for data points in D no empty cluster is 148
5 available or the minimum number of members inside each clusters is at least one. The size of each cluster is represented as h =0,1,2,.. 1. D is added to the cluster. If both elements are D and D, Euclidean Distance is not zero then are the elements not twin, then only a new index is generated with D for the cluster using the formula given in the figure 7.1. The new index is assigned to [] and a new cluster is created by incrementing. The iteration is continued up to. The algorithm creates K number of clusters with unique index (shown in the figure 7.3). 1. Algorithm IKNTN(D) 2. Sort the elements of D i where =1 3. Find the min D and store to L 4. Initialize K=0 5. For i =1 to D 6. ED=Euclidean_Distance(D,D,L) 7. If ED = 0.0 then // Twin Neighbour 8. Add D to the th Cluster // use appropriate data structure 9. Else 10. Index[K]= Calculate_Index(D,L)//Assigns the K th Cluster index and generate an index table 11. Increment K by one 12. End if 13. End for 14. Read the pattern X is be searched 15. In= Calculate_Index(X,L) 16. Search for the In in the Index table and store Index in N 17. If search fails X is not exist 18. Else Search in the N th Cluster using appropriate data structure 19. End if 20. Function Euclidean_Distance(D,D,L) 21. Return D D ) 22. End function 23. Function Calculate_Index(D,L) 24. h D ) ) 25. End function Figure 7.1 Indexed K Nearest Twin Neighbour Algorithm 149
6 Figure 7.2 Data points before clustering The next phase of the algorithm is the search to perform the lookup operation, and the lookup value is read and stored in the X, the index values for the X using the formula are to be found as shown in figure 7.1. If the algorithm finds the index in index table [], then the search is performed in the particular cluster, else the element does not exist in the data set. The computational complexity of the algorithm purely based on the data structure employed with the IKNTN algorithm. The figure 7.2 shows the data points and the figure 7.3 illustrates the IKNTN clustering algorithm (after clustering the data points using IKNTN). Figure 7.3 Example of IKNTN clustering algorithm (Data points after clustering) 150
7 7.3.1 COMPUTATIONAL COMPLEXITY ANALYSIS OF IKNTN ALGORITHM The IKNTN algorithm has three phases such as sorting, clustering and searching. The computational complexity is calculated by the sum of computation required for all these three phases. In the first phase, computation is calculated depending on the sorting algorithm used with the phase. For example, if the quick sort is applied then the computational cost ) refer Theorem 3.8., if Binary insertion sort (BIS) means ) 1)! required. In the next two phases, Computational complexity is purely based on the data structure employed with the algorithm. This thesis experiments four primary data structures with IKNTN, namely BST, Linear Array, Hash table and Binary insertion sort with Binary search. Definition -1 Number of clusters is K. Length of each cluster is represented as where = 1,2,3. D is the data set and size of the data set is D, each data point in the data set is represented as D i where =1,2,3. 151
8 Figure 7.4 Illustrates Indexed clusters using IKNTN algorithm 152
9 LINEAR ARRAY IMPLEMENTATION OF IKNTN ALGORITHM 7.5 Linear array representation of IKNTN clustering algorithm In the proposed IKNTN clustering algorithm, the linear array is employed with each cluster that is shown in the figure 7.5. Each time a new member is found in D, the algorithm inserts the member or data point to the particular cluster that has the same twin Neighbour. Otherwise it will create a new cluster and store the data point or the member in that cluster. In 153
10 the linear array implementation each cluster is uniquely maintained with different array data structures. The algorithm prefers hash table to build cluster index table. Theorem 7.1 Linear Array Implementation of IKNTN Algorithm takes + )+ + 1 )) h Proof: After fetching each data points D i during clustering phase single insertion is made to the corresponding cluster is shown in the figure 7.4, insertion to the linear array approximately required less than O(1) time, and to fulfill single iteration approximately O(1), then the total cost per iteration is approximately calculated as O(1). Then total computational complexity of clustering phase is D * O (1) that is simplified as O ( D ). So the total cost is )+ for the sorting and clustering phase. Next the average computation required for the search in linear representation of clusters has to be calculated. Search in an array requires So the total average cost is calculated by The above equation is simplified as ) 7.2) So the average cost per search is shown in Figure 7.2. Then the total cost is calculated as 1 7.3) Computation time required per indexing 1) because hash table preferred So the total computation required for indexing is 1)= ) Then the total computational cost including three phases of the algorithm is calculated as follows: + )+ + 1 )) 7.4) 154
11 BST IMPLEMENTATION OF IKNTN ALGORITHM Figure 7.6 BST Structure before Clustering Figure 7.7 Example BST Structure after Clustering using IKNTN Algorithm In the proposed IKNTN clustering algorithm, the BST array is employed with each cluster that is shown in the figure 7.7. Each time a new member is found in the D the algorithm inserts the member or data point to the particular cluster which has the same twin Neighbour. Otherwise it will create a new cluster and store the data point or the member in 155
12 that cluster. Each time a new cluster is identified in the data set for which the algorithm automatically creates a new binary search tree (BST) data structure. In the BST implementation each cluster is uniquely maintained with unique BST data structure. This approach also prefers hash table to build cluster index table. The figure 7.6 shows the BST data structure before clustering and figure 7.7 shows the BST data structure employed in each cluster during IKNTN clustering algorithm. Theorem 7.2 BST implementation of IKNTN algorithm takes ) )++ 1 log )) ))+ + 1 log ) h Proof: After fetching each data points D i during clustering phase single insertion is made to the corresponding cluster which is shown in the figure 7.7 Insertion to the BST approximately requires less than ) time, and to fulfill single iteration is approximately calculated as follows: To build a BST requires approximately log ) ) So the total average cost for constructing clusters using BST is calculated as follows: ) + + By simplifying the above equation, the following is obtained. 7.6) 156
13 So total cost is calculated as follows: 7.7) Next have to calculate the search complexity using BST. The search complexity per cluster is ) Then the average computation is calculated by ) 7.8) So the total computation required including indexing using hashing is ) )+ 1 log )) ))+ + 1 log )7.9) HASH TABLE IMPLEMENTATION OF IKNTN ALGORITHM In the proposed IKNTN clustering, algorithm is implemented using chained hash table. It is used with each cluster that is shown in the figure 7.8. Each time a new member is found in the D for which the algorithm inserts the member or data point to the particular cluster that has the same twin Neighbour, and the clusters function with the help of chained hash table. Otherwise it will create a new cluster and store the data point or the member in that cluster. Each time a new cluster is identified in the data set, the algorithm automatically creates a new Chained hash table. In this implementation, each cluster is uniquely maintained with unique hash table. In this approach, both clusters and index tables are maintained with hash table but with small variance: clusters are maintained with the chained hash table and index is maintained with the ordinary hash table. The figure 7.8 shows the chained data structure before clustering and figure 7.9 shows the chained data structure employed in each cluster during IKNTN clustering algorithm Theorem 7.3 Chained hash table implementation of IKNTN algorithm takes ) ) ) Proof: After fetching each data points D i during clustering phase single insertion is made to the corresponding cluster which is shown in the figure
14 Insertion to the BST approximately requires less than ) time, and to fulfill single iteration approximately is calculated as follows To build a Chained Hash table requires approximately h Theorem So the total average cost is of constructing clusters using Chained hash table is calculated as follows: ) By simplifying the above equation the following is obtained: So total cost is calculated as follows 7.11) 7.12) Next have to calculate the search complexity using Chained Hashed Table. The search complexity per cluster is 1+ ) Then the average computation is calculated by 1+ ) ) 7.13) So the total computation required including indexing using hashing is ) ) ) 7.14) 158
15 Figure 7.8 Chain Hash Table Before Clustering Figure 7.9 Chain Hash Table after Clustering 159
16 BIS IMPLEMENTATION OF IKNTN ALGORITHM BIS is incorporated within the proposed IKNTN clustering algorithm implementation, the BIS is used with each cluster that is shown in the figure 7.8. Each time a new member is found in the D, the algorithm inserts the member or data point to the particular cluster that has the same twin neighbour, the clusters function with the help of BIS. Otherwise it will create a new cluster and store the data point or the member in that cluster. Each time a new cluster is identified in the data set, the algorithm automatically creates a new data structure for BIS. In this implementation each cluster is uniquely maintained with unique data structure. In this approach only the index table is maintained with hash table and clusters are maintained with BIS. The figure 7.10 shows the chained data structure before clustering and figure 7.11 shows the chained data structure employed in each cluster during IKNTN clustering algorithm Theorem 7.4 BIS implementation of IKNTN algorithm takes 1 )++ 1 log) )) ))+ + 1 log )Computation per search Proof: After fetching each data points D i during clustering phase single insertion is made to the corresponding cluster which shown in the figure 7.6. Insertion to the BIS with BS approximately requires less than ) time and to fulfill single iteration approximately is calculated as based on the theorem 7.2. )++ log log ) ) )) )) ) 160
17 Figure 7.10 Illustrates BIS and Binary search Figure 7.11 illustrates BIS with Binary search clustering using IKNTN algorithm 161
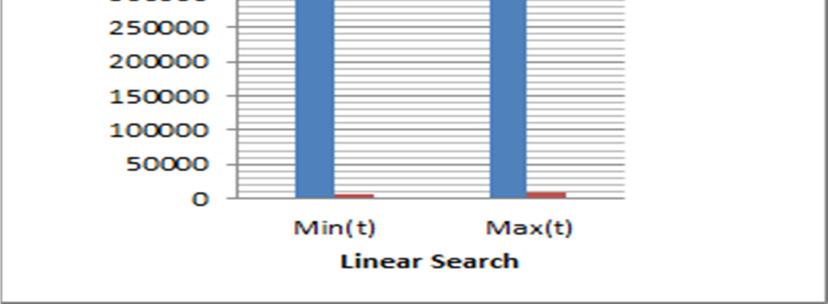
18 7.3.2 SPACE COMPLEXITY OF IKNTN ALGORITHM Space complexity of the algorithm is calculated by the total usage of main memory by the execution time. The algorithm uses five variables such as,,,,,, So the algorithm occupies one unit for each variable, for five variables it requires five units of memory and the data set D fully resides in the memory during the clustering. The size of the dataset is D. So the total space required is +5, the size of the index table is K. i.e. approximately +), and the sorting phase and search phase require the additional variables. Then the clusters occupy the same size of memory utilized by the Data set D. Then total memory or space required is 2 +). 7.4 EXPERIMENTAL RESULTS The data strucures and algorithms which are used for the experimentation of the data structures specially employed with the LZW compression algorithm is discussed in the Chapter IV, they are Linear array with linear search, BST, Chained Hash table and BIS with Binary search. Each algorithm is exprerimented before and after clustering, for this expreimentation, name data set is used, and the size of the data set is The selected data structure and algorithm is executed 100 times to find out the Minimum time taken (Min(t)) and Maximum Time taken (Max(t)). The experimental results are shown in the figure 7.12 (before clustering) and figure 7.13 (after Clustering) and table 7.1. Linear search achives , BST achieves (shown in the figure 7.14 (before clustering) and figure 7.15 (after clustering)); Hash table achieves (shown in the figure 7.16 (before clustering) and figure 7.17 (after clustering)) and BIS with Binary Search percentage of improvement after clustering is shown in the figure 7.18 (before clustering) and figure 7.19 (after clustering) with IKNTN algorithm. The experimentation results prove the ability of IKNTN algorithm in order to reduce the computational complexity of the existing data structure and algorithms. T is the total time required for search all elements in the dataset D. Where is the time requiring for the search operation for the element. = 7.16) 162
19 Then the average time required for searching individual element is calculated as #$@R# = X# Y#$ A#@$Bℎ = 87.17) The total time save is achieved after clustering with IKNTN for data structures and algorithms is shown in the figure 7.22, and the comparative analysis is shown in the figure 7.20 and figure Figure 7.12 Time taken by Linear Array with Linear Search Before Clustering (in nanoseconds) Figure 7.13 Time taken by Linear Array with Linear Search After Clustering (in nanoseconds) Figure 7.14 Time taken by BST Before Clustering (in nanoseconds) 163
20 Figure 7.15 Time taken by BST after Clustering (in nanoseconds) Figure 7.16 Time taken by Hash table before Clustering (in nanoseconds) Figure 7.17 Time taken by Hash table after Clustering (in nanoseconds) 164
21 Figure 7.18 Time taken by BIS with Binary Search before Clustering (in nanoseconds) Figure 7.19 Time taken by BIS with Binary Search after Clustering (in nanoseconds) Table 7.1 Time taken by Aata Structure and Algorithms Before and Afrter IKNTN Clustering Algorithm Data Structures or algorithm used for experimentation Min(t) Max(t) Linear array with Before Clustering Linear Search After clustering using IKNTN BST Before Clustering After clustering using IKNTN Hash Table Before Clustering After clustering using IKNTN BIS with Binary Before Clustering Search After clustering using IKNTN






 166")
22 Figure 7.21 Time complexity analysis of data structure and algorithms before and afrter IKNTN clustering Algorithm Figure 7.20 Time complexity analysis of data structure and algorithms before and afrter IKNTN Figure 7.22 Data structures and algorithms time reducion after IKNTN clustering Algorithm (in Percentage) 166
23 7.5 SUMMARY A novel Clustering algorithm which is proposed in this chapter is called Indexed K Nearest Twin Neighbour (IKNTN) Clustering algorithm. The proposed algorithm effctively clusteres all the possible Nearest Twin Neighbour with the help of Euclidean distance and each cluster is uniquily indexed using a novel indexing method. The algorithm is specially designed to optimize the perfomence of data structure. Data structure and algorithm which are experimented with the IKNTN clustering algorithms are Linear array with Linear search, BST, Chained Hash Table and BIS with Binary Search. The experimentation result shows , , and percentages of time complexity reduction on Linear array with Linear search, BST chained Hash table achieves and BIS with Binary search respectively. The experimentation result shows the effectiveness and efficiency of the IKNTN clustering algorithm. So the proposed IKNTN algorithm is the best for optimizing any kind of search and the performance of data structure. The computational complexity of data structures and algorithms is reduced after clustering with IKNTN algorithm. The next phases of this thesis use the IKNTN Clustering algorithm to reduce the time complexity of LZW data compression algorithm. 167
Discovery of Agricultural Patterns Using Parallel Hybrid Clustering Paradigm
 IOSR Journal of Engineering (IOSRJEN) ISSN (e): 2250-3021, ISSN (p): 2278-8719 PP 10-15 www.iosrjen.org Discovery of Agricultural Patterns Using Parallel Hybrid Clustering Paradigm P.Arun, M.Phil, Dr.A.Senthilkumar
IOSR Journal of Engineering (IOSRJEN) ISSN (e): 2250-3021, ISSN (p): 2278-8719 PP 10-15 www.iosrjen.org Discovery of Agricultural Patterns Using Parallel Hybrid Clustering Paradigm P.Arun, M.Phil, Dr.A.Senthilkumar
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
CHAPTER 3 A FAST K-MODES CLUSTERING ALGORITHM TO WAREHOUSE VERY LARGE HETEROGENEOUS MEDICAL DATABASES
 70 CHAPTER 3 A FAST K-MODES CLUSTERING ALGORITHM TO WAREHOUSE VERY LARGE HETEROGENEOUS MEDICAL DATABASES 3.1 INTRODUCTION In medical science, effective tools are essential to categorize and systematically
70 CHAPTER 3 A FAST K-MODES CLUSTERING ALGORITHM TO WAREHOUSE VERY LARGE HETEROGENEOUS MEDICAL DATABASES 3.1 INTRODUCTION In medical science, effective tools are essential to categorize and systematically
3 No-Wait Job Shops with Variable Processing Times
 3 No-Wait Job Shops with Variable Processing Times In this chapter we assume that, on top of the classical no-wait job shop setting, we are given a set of processing times for each operation. We may select
3 No-Wait Job Shops with Variable Processing Times In this chapter we assume that, on top of the classical no-wait job shop setting, we are given a set of processing times for each operation. We may select
International Journal of Scientific Research & Engineering Trends Volume 4, Issue 6, Nov-Dec-2018, ISSN (Online): X
: X") Analysis about Classification Techniques on Categorical Data in Data Mining Assistant Professor P. Meena Department of Computer Science Adhiyaman Arts and Science College for Women Uthangarai, Krishnagiri,
Analysis about Classification Techniques on Categorical Data in Data Mining Assistant Professor P. Meena Department of Computer Science Adhiyaman Arts and Science College for Women Uthangarai, Krishnagiri,
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Introduction to Clustering
 Introduction to Clustering Ref: Chengkai Li, Department of Computer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) What is Cluster Analysis? Finding groups of
Introduction to Clustering Ref: Chengkai Li, Department of Computer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) What is Cluster Analysis? Finding groups of
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Decreasing a key FIB-HEAP-DECREASE-KEY(,, ) 3.. NIL. 2. error new key is greater than current key 6. CASCADING-CUT(, )
 3.. NIL. 2. error new key is greater than current key 6. CASCADING-CUT(, )") Decreasing a key FIB-HEAP-DECREASE-KEY(,, ) 1. if >. 2. error new key is greater than current key 3.. 4.. 5. if NIL and.
Decreasing a key FIB-HEAP-DECREASE-KEY(,, ) 1. if >. 2. error new key is greater than current key 3.. 4.. 5. if NIL and.
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
SOMSN: An Effective Self Organizing Map for Clustering of Social Networks
 SOMSN: An Effective Self Organizing Map for Clustering of Social Networks Fatemeh Ghaemmaghami Research Scholar, CSE and IT Dept. Shiraz University, Shiraz, Iran Reza Manouchehri Sarhadi Research Scholar,
SOMSN: An Effective Self Organizing Map for Clustering of Social Networks Fatemeh Ghaemmaghami Research Scholar, CSE and IT Dept. Shiraz University, Shiraz, Iran Reza Manouchehri Sarhadi Research Scholar,
CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS
 CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS CHAPTER 4 CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS 4.1 Introduction Optical character recognition is one of
CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS CHAPTER 4 CLASSIFICATION WITH RADIAL BASIS AND PROBABILISTIC NEURAL NETWORKS 4.1 Introduction Optical character recognition is one of
Accelerating Unique Strategy for Centroid Priming in K-Means Clustering
 IJIRST International Journal for Innovative Research in Science & Technology Volume 3 Issue 07 December 2016 ISSN (online): 2349-6010 Accelerating Unique Strategy for Centroid Priming in K-Means Clustering
IJIRST International Journal for Innovative Research in Science & Technology Volume 3 Issue 07 December 2016 ISSN (online): 2349-6010 Accelerating Unique Strategy for Centroid Priming in K-Means Clustering
NORMALIZATION INDEXING BASED ENHANCED GROUPING K-MEAN ALGORITHM
 NORMALIZATION INDEXING BASED ENHANCED GROUPING K-MEAN ALGORITHM Saroj 1, Ms. Kavita2 1 Student of Masters of Technology, 2 Assistant Professor Department of Computer Science and Engineering JCDM college
NORMALIZATION INDEXING BASED ENHANCED GROUPING K-MEAN ALGORITHM Saroj 1, Ms. Kavita2 1 Student of Masters of Technology, 2 Assistant Professor Department of Computer Science and Engineering JCDM college
A Review on Cluster Based Approach in Data Mining
 A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
Data Mining: Concepts and Techniques. Chapter March 8, 2007 Data Mining: Concepts and Techniques 1
 Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
Image Mining: frameworks and techniques
 Image Mining: frameworks and techniques Madhumathi.k 1, Dr.Antony Selvadoss Thanamani 2 M.Phil, Department of computer science, NGM College, Pollachi, Coimbatore, India 1 HOD Department of Computer Science,
Image Mining: frameworks and techniques Madhumathi.k 1, Dr.Antony Selvadoss Thanamani 2 M.Phil, Department of computer science, NGM College, Pollachi, Coimbatore, India 1 HOD Department of Computer Science,
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
CHAPTER 6 MODIFIED FUZZY TECHNIQUES BASED IMAGE SEGMENTATION
 CHAPTER 6 MODIFIED FUZZY TECHNIQUES BASED IMAGE SEGMENTATION 6.1 INTRODUCTION Fuzzy logic based computational techniques are becoming increasingly important in the medical image analysis arena. The significant
CHAPTER 6 MODIFIED FUZZY TECHNIQUES BASED IMAGE SEGMENTATION 6.1 INTRODUCTION Fuzzy logic based computational techniques are becoming increasingly important in the medical image analysis arena. The significant
Data Mining and Data Warehousing Classification-Lazy Learners
 Motivation Data Mining and Data Warehousing Classification-Lazy Learners Lazy Learners are the most intuitive type of learners and are used in many practical scenarios. The reason of their popularity is
Motivation Data Mining and Data Warehousing Classification-Lazy Learners Lazy Learners are the most intuitive type of learners and are used in many practical scenarios. The reason of their popularity is
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Learning
 Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Unsupervised Learning Partitioning Methods
 Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
D-GridMST: Clustering Large Distributed Spatial Databases
 D-GridMST: Clustering Large Distributed Spatial Databases Ji Zhang Department of Computer Science University of Toronto Toronto, Ontario, M5S 3G4, Canada Email: jzhang@cs.toronto.edu Abstract: In this
D-GridMST: Clustering Large Distributed Spatial Databases Ji Zhang Department of Computer Science University of Toronto Toronto, Ontario, M5S 3G4, Canada Email: jzhang@cs.toronto.edu Abstract: In this
A Comparative study of Clustering Algorithms using MapReduce in Hadoop
 A Comparative study of Clustering Algorithms using MapReduce in Hadoop Dweepna Garg 1, Khushboo Trivedi 2, B.B.Panchal 3 1 Department of Computer Science and Engineering, Parul Institute of Engineering
A Comparative study of Clustering Algorithms using MapReduce in Hadoop Dweepna Garg 1, Khushboo Trivedi 2, B.B.Panchal 3 1 Department of Computer Science and Engineering, Parul Institute of Engineering
Kapitel 4: Clustering
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
3. Cluster analysis Overview
 Université Laval Multivariate analysis - February 2006 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Université Laval Multivariate analysis - February 2006 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
CLUSTERING. CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16
 CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
Clustering. (Part 2)
") Clustering (Part 2) 1 k-means clustering 2 General Observations on k-means clustering In essence, k-means clustering aims at minimizing cluster variance. It is typically used in Euclidean spaces and works
Clustering (Part 2) 1 k-means clustering 2 General Observations on k-means clustering In essence, k-means clustering aims at minimizing cluster variance. It is typically used in Euclidean spaces and works
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu [Kumar et al. 99] 2/13/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu [Kumar et al. 99] 2/13/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu
Prof. Sushant S Sundikar 1
 UNIT 5 The related activities of sorting, searching and merging are central to many computer applications. Sorting and merging provide us with a means of organizing information take advantage of the organization
UNIT 5 The related activities of sorting, searching and merging are central to many computer applications. Sorting and merging provide us with a means of organizing information take advantage of the organization
Chapter DM:II. II. Cluster Analysis
 Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
An Enhanced K-Medoid Clustering Algorithm
 An Enhanced Clustering Algorithm Archna Kumari Science &Engineering kumara.archana14@gmail.com Pramod S. Nair Science &Engineering, pramodsnair@yahoo.com Sheetal Kumrawat Science &Engineering, sheetal2692@gmail.com
An Enhanced Clustering Algorithm Archna Kumari Science &Engineering kumara.archana14@gmail.com Pramod S. Nair Science &Engineering, pramodsnair@yahoo.com Sheetal Kumrawat Science &Engineering, sheetal2692@gmail.com
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Supervised vs.unsupervised Learning
 Supervised vs.unsupervised Learning In supervised learning we train algorithms with predefined concepts and functions based on labeled data D = { ( x, y ) x X, y {yes,no}. In unsupervised learning we are
Supervised vs.unsupervised Learning In supervised learning we train algorithms with predefined concepts and functions based on labeled data D = { ( x, y ) x X, y {yes,no}. In unsupervised learning we are
Advanced Algorithms and Data Structures
 Advanced Algorithms and Data Structures Prof. Tapio Elomaa tapio.elomaa@tut.fi Course Prerequisites A seven credit unit course Replaced OHJ-2156 Analysis of Algorithms We take things a bit further than
Advanced Algorithms and Data Structures Prof. Tapio Elomaa tapio.elomaa@tut.fi Course Prerequisites A seven credit unit course Replaced OHJ-2156 Analysis of Algorithms We take things a bit further than
COS 226 Algorithms and Data Structures Fall Final Solutions. 10. Remark: this is essentially the same question from the midterm.
 COS 226 Algorithms and Data Structures Fall 2011 Final Solutions 1 Analysis of algorithms (a) T (N) = 1 10 N 5/3 When N increases by a factor of 8, the memory usage increases by a factor of 32 Thus, T
COS 226 Algorithms and Data Structures Fall 2011 Final Solutions 1 Analysis of algorithms (a) T (N) = 1 10 N 5/3 When N increases by a factor of 8, the memory usage increases by a factor of 32 Thus, T
Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques
 24 Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques Ruxandra PETRE
24 Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques Ruxandra PETRE
Semi-Supervised Clustering with Partial Background Information
 Semi-Supervised Clustering with Partial Background Information Jing Gao Pang-Ning Tan Haibin Cheng Abstract Incorporating background knowledge into unsupervised clustering algorithms has been the subject
Semi-Supervised Clustering with Partial Background Information Jing Gao Pang-Ning Tan Haibin Cheng Abstract Incorporating background knowledge into unsupervised clustering algorithms has been the subject
Nearest Neighbor Predictors
 Nearest Neighbor Predictors September 2, 2018 Perhaps the simplest machine learning prediction method, from a conceptual point of view, and perhaps also the most unusual, is the nearest-neighbor method,
Nearest Neighbor Predictors September 2, 2018 Perhaps the simplest machine learning prediction method, from a conceptual point of view, and perhaps also the most unusual, is the nearest-neighbor method,
Lecture Notes for Chapter 7. Introduction to Data Mining, 2 nd Edition. by Tan, Steinbach, Karpatne, Kumar
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, nd Edition by Tan, Steinbach, Karpatne, Kumar What is Cluster Analysis? Finding groups
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, nd Edition by Tan, Steinbach, Karpatne, Kumar What is Cluster Analysis? Finding groups
The Application of K-medoids and PAM to the Clustering of Rules
 The Application of K-medoids and PAM to the Clustering of Rules A. P. Reynolds, G. Richards, and V. J. Rayward-Smith School of Computing Sciences, University of East Anglia, Norwich Abstract. Earlier research
The Application of K-medoids and PAM to the Clustering of Rules A. P. Reynolds, G. Richards, and V. J. Rayward-Smith School of Computing Sciences, University of East Anglia, Norwich Abstract. Earlier research
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Chapter 8. 8 Minimization Techniques. 8.1 Introduction. 8.2 Single-Output Minimization Design Constraints
 8 Minimization Techniques 8.1 Introduction The emphasis is on clean, irredundant, minimal designs has been dramatically affected by the evolution of LSI [VLSI] technology. There are instances where a minimal
8 Minimization Techniques 8.1 Introduction The emphasis is on clean, irredundant, minimal designs has been dramatically affected by the evolution of LSI [VLSI] technology. There are instances where a minimal
PAM algorithm. Types of Data in Cluster Analysis. A Categorization of Major Clustering Methods. Partitioning i Methods. Hierarchical Methods
 Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Handout 9: Imperative Programs and State
 06-02552 Princ. of Progr. Languages (and Extended ) The University of Birmingham Spring Semester 2016-17 School of Computer Science c Uday Reddy2016-17 Handout 9: Imperative Programs and State Imperative
06-02552 Princ. of Progr. Languages (and Extended ) The University of Birmingham Spring Semester 2016-17 School of Computer Science c Uday Reddy2016-17 Handout 9: Imperative Programs and State Imperative
What is Cluster Analysis? COMP 465: Data Mining Clustering Basics. Applications of Cluster Analysis. Clustering: Application Examples 3/17/2015
 // What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
// What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
What to come. There will be a few more topics we will cover on supervised learning
 Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Mobile Human Detection Systems based on Sliding Windows Approach-A Review
 Mobile Human Detection Systems based on Sliding Windows Approach-A Review Seminar: Mobile Human detection systems Njieutcheu Tassi cedrique Rovile Department of Computer Engineering University of Heidelberg
Mobile Human Detection Systems based on Sliding Windows Approach-A Review Seminar: Mobile Human detection systems Njieutcheu Tassi cedrique Rovile Department of Computer Engineering University of Heidelberg
Association Rule Mining and Clustering
 Association Rule Mining and Clustering Lecture Outline: Classification vs. Association Rule Mining vs. Clustering Association Rule Mining Clustering Types of Clusters Clustering Algorithms Hierarchical:
Association Rule Mining and Clustering Lecture Outline: Classification vs. Association Rule Mining vs. Clustering Association Rule Mining Clustering Types of Clusters Clustering Algorithms Hierarchical:
Particle Swarm Optimization applied to Pattern Recognition
 Particle Swarm Optimization applied to Pattern Recognition by Abel Mengistu Advisor: Dr. Raheel Ahmad CS Senior Research 2011 Manchester College May, 2011-1 - Table of Contents Introduction... - 3 - Objectives...
Particle Swarm Optimization applied to Pattern Recognition by Abel Mengistu Advisor: Dr. Raheel Ahmad CS Senior Research 2011 Manchester College May, 2011-1 - Table of Contents Introduction... - 3 - Objectives...
PARALLEL CLASSIFICATION ALGORITHMS
 PARALLEL CLASSIFICATION ALGORITHMS By: Faiz Quraishi Riti Sharma 9 th May, 2013 OVERVIEW Introduction Types of Classification Linear Classification Support Vector Machines Parallel SVM Approach Decision
PARALLEL CLASSIFICATION ALGORITHMS By: Faiz Quraishi Riti Sharma 9 th May, 2013 OVERVIEW Introduction Types of Classification Linear Classification Support Vector Machines Parallel SVM Approach Decision
3. Cluster analysis Overview
 Université Laval Analyse multivariable - mars-avril 2008 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Université Laval Analyse multivariable - mars-avril 2008 1 3.1. Overview 3. Cluster analysis Clustering requires the recognition of discontinuous subsets in an environment that is sometimes discrete (as
Introduction to Mobile Robotics
 Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Data Mining. Clustering. Hamid Beigy. Sharif University of Technology. Fall 1394
 Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Data Mining Algorithms
 for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
CS 340 Lec. 4: K-Nearest Neighbors
 CS 340 Lec. 4: K-Nearest Neighbors AD January 2011 AD () CS 340 Lec. 4: K-Nearest Neighbors January 2011 1 / 23 K-Nearest Neighbors Introduction Choice of Metric Overfitting and Underfitting Selection
CS 340 Lec. 4: K-Nearest Neighbors AD January 2011 AD () CS 340 Lec. 4: K-Nearest Neighbors January 2011 1 / 23 K-Nearest Neighbors Introduction Choice of Metric Overfitting and Underfitting Selection
22 Elementary Graph Algorithms. There are two standard ways to represent a
 VI Graph Algorithms Elementary Graph Algorithms Minimum Spanning Trees Single-Source Shortest Paths All-Pairs Shortest Paths 22 Elementary Graph Algorithms There are two standard ways to represent a graph
VI Graph Algorithms Elementary Graph Algorithms Minimum Spanning Trees Single-Source Shortest Paths All-Pairs Shortest Paths 22 Elementary Graph Algorithms There are two standard ways to represent a graph
6.854J / J Advanced Algorithms Fall 2008
 MIT OpenCourseWare http://ocw.mit.edu 6.854J / 18.415J Advanced Algorithms Fall 2008 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms. 18.415/6.854 Advanced
MIT OpenCourseWare http://ocw.mit.edu 6.854J / 18.415J Advanced Algorithms Fall 2008 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms. 18.415/6.854 Advanced
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Lecture 25 Notes Spanning Trees
 Lecture 25 Notes Spanning Trees 15-122: Principles of Imperative Computation (Spring 2016) Frank Pfenning 1 Introduction The following is a simple example of a connected, undirected graph with 5 vertices
Lecture 25 Notes Spanning Trees 15-122: Principles of Imperative Computation (Spring 2016) Frank Pfenning 1 Introduction The following is a simple example of a connected, undirected graph with 5 vertices
International Journal of Advanced Research in Computer Science and Software Engineering
 Volume 3, Issue 3, March 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Special Issue:
Volume 3, Issue 3, March 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Special Issue:
CHAPTER-6 WEB USAGE MINING USING CLUSTERING
 CHAPTER-6 WEB USAGE MINING USING CLUSTERING 6.1 Related work in Clustering Technique 6.2 Quantifiable Analysis of Distance Measurement Techniques 6.3 Approaches to Formation of Clusters 6.4 Conclusion
CHAPTER-6 WEB USAGE MINING USING CLUSTERING 6.1 Related work in Clustering Technique 6.2 Quantifiable Analysis of Distance Measurement Techniques 6.3 Approaches to Formation of Clusters 6.4 Conclusion
CS521 \ Notes for the Final Exam
 CS521 \ Notes for final exam 1 Ariel Stolerman Asymptotic Notations: CS521 \ Notes for the Final Exam Notation Definition Limit Big-O ( ) Small-o ( ) Big- ( ) Small- ( ) Big- ( ) Notes: ( ) ( ) ( ) ( )
CS521 \ Notes for final exam 1 Ariel Stolerman Asymptotic Notations: CS521 \ Notes for the Final Exam Notation Definition Limit Big-O ( ) Small-o ( ) Big- ( ) Small- ( ) Big- ( ) Notes: ( ) ( ) ( ) ( )
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Trees. 3. (Minimally Connected) G is connected and deleting any of its edges gives rise to a disconnected graph.
 G is connected and deleting any of its edges gives rise to a disconnected graph.") Trees 1 Introduction Trees are very special kind of (undirected) graphs. Formally speaking, a tree is a connected graph that is acyclic. 1 This definition has some drawbacks: given a graph it is not trivial
Trees 1 Introduction Trees are very special kind of (undirected) graphs. Formally speaking, a tree is a connected graph that is acyclic. 1 This definition has some drawbacks: given a graph it is not trivial
Cluster quality assessment by the modified Renyi-ClipX algorithm
 Issue 3, Volume 4, 2010 51 Cluster quality assessment by the modified Renyi-ClipX algorithm Dalia Baziuk, Aleksas Narščius Abstract This paper presents the modified Renyi-CLIPx clustering algorithm and
Issue 3, Volume 4, 2010 51 Cluster quality assessment by the modified Renyi-ClipX algorithm Dalia Baziuk, Aleksas Narščius Abstract This paper presents the modified Renyi-CLIPx clustering algorithm and
Performance Analysis of Data Mining Classification Techniques
 Performance Analysis of Data Mining Classification Techniques Tejas Mehta 1, Dr. Dhaval Kathiriya 2 Ph.D. Student, School of Computer Science, Dr. Babasaheb Ambedkar Open University, Gujarat, India 1 Principal
Performance Analysis of Data Mining Classification Techniques Tejas Mehta 1, Dr. Dhaval Kathiriya 2 Ph.D. Student, School of Computer Science, Dr. Babasaheb Ambedkar Open University, Gujarat, India 1 Principal
2. Background. 2.1 Clustering
 2. Background 2.1 Clustering Clustering involves the unsupervised classification of data items into different groups or clusters. Unsupervised classificaiton is basically a learning task in which learning
2. Background 2.1 Clustering Clustering involves the unsupervised classification of data items into different groups or clusters. Unsupervised classificaiton is basically a learning task in which learning
Clustering. Robert M. Haralick. Computer Science, Graduate Center City University of New York
 Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Module 2: Classical Algorithm Design Techniques
 Module 2: Classical Algorithm Design Techniques Dr. Natarajan Meghanathan Associate Professor of Computer Science Jackson State University Jackson, MS 39217 E-mail: natarajan.meghanathan@jsums.edu Module
Module 2: Classical Algorithm Design Techniques Dr. Natarajan Meghanathan Associate Professor of Computer Science Jackson State University Jackson, MS 39217 E-mail: natarajan.meghanathan@jsums.edu Module
Web Page Classification using FP Growth Algorithm Akansha Garg,Computer Science Department Swami Vivekanad Subharti University,Meerut, India
 Web Page Classification using FP Growth Algorithm Akansha Garg,Computer Science Department Swami Vivekanad Subharti University,Meerut, India Abstract - The primary goal of the web site is to provide the
Web Page Classification using FP Growth Algorithm Akansha Garg,Computer Science Department Swami Vivekanad Subharti University,Meerut, India Abstract - The primary goal of the web site is to provide the
Edge Classification in Networks
 Charu C. Aggarwal, Peixiang Zhao, and Gewen He Florida State University IBM T J Watson Research Center Edge Classification in Networks ICDE Conference, 2016 Introduction We consider in this paper the edge
Charu C. Aggarwal, Peixiang Zhao, and Gewen He Florida State University IBM T J Watson Research Center Edge Classification in Networks ICDE Conference, 2016 Introduction We consider in this paper the edge
Ant Colonies, Self-Organizing Maps, and A Hybrid Classification Model
 Proceedings of Student/Faculty Research Day, CSIS, Pace University, May 7th, 2004 Ant Colonies, Self-Organizing Maps, and A Hybrid Classification Model Michael L. Gargano, Lorraine L. Lurie, Lixin Tao,
Proceedings of Student/Faculty Research Day, CSIS, Pace University, May 7th, 2004 Ant Colonies, Self-Organizing Maps, and A Hybrid Classification Model Michael L. Gargano, Lorraine L. Lurie, Lixin Tao,
Data Mining. Dr. Raed Ibraheem Hamed. University of Human Development, College of Science and Technology Department of Computer Science
 Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Data Mining and Machine Learning: Techniques and Algorithms
 Instance based classification Data Mining and Machine Learning: Techniques and Algorithms Eneldo Loza Mencía eneldo@ke.tu-darmstadt.de Knowledge Engineering Group, TU Darmstadt International Week 2019,
Instance based classification Data Mining and Machine Learning: Techniques and Algorithms Eneldo Loza Mencía eneldo@ke.tu-darmstadt.de Knowledge Engineering Group, TU Darmstadt International Week 2019,
Cluster Analysis. Angela Montanari and Laura Anderlucci
 Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Redefining and Enhancing K-means Algorithm
 Redefining and Enhancing K-means Algorithm Nimrat Kaur Sidhu 1, Rajneet kaur 2 Research Scholar, Department of Computer Science Engineering, SGGSWU, Fatehgarh Sahib, Punjab, India 1 Assistant Professor,
Redefining and Enhancing K-means Algorithm Nimrat Kaur Sidhu 1, Rajneet kaur 2 Research Scholar, Department of Computer Science Engineering, SGGSWU, Fatehgarh Sahib, Punjab, India 1 Assistant Professor,
Improving the Efficiency of Fast Using Semantic Similarity Algorithm
 International Journal of Scientific and Research Publications, Volume 4, Issue 1, January 2014 1 Improving the Efficiency of Fast Using Semantic Similarity Algorithm D.KARTHIKA 1, S. DIVAKAR 2 Final year
International Journal of Scientific and Research Publications, Volume 4, Issue 1, January 2014 1 Improving the Efficiency of Fast Using Semantic Similarity Algorithm D.KARTHIKA 1, S. DIVAKAR 2 Final year
An Unsupervised Approach for Combining Scores of Outlier Detection Techniques, Based on Similarity Measures
 An Unsupervised Approach for Combining Scores of Outlier Detection Techniques, Based on Similarity Measures José Ramón Pasillas-Díaz, Sylvie Ratté Presenter: Christoforos Leventis 1 Basic concepts Outlier
An Unsupervised Approach for Combining Scores of Outlier Detection Techniques, Based on Similarity Measures José Ramón Pasillas-Díaz, Sylvie Ratté Presenter: Christoforos Leventis 1 Basic concepts Outlier
CHAPTER 7 CONCLUSION AND FUTURE WORK
 CHAPTER 7 CONCLUSION AND FUTURE WORK 7.1 Conclusion Data pre-processing is very important in data mining process. Certain data cleaning techniques usually are not applicable to all kinds of data. Deduplication
CHAPTER 7 CONCLUSION AND FUTURE WORK 7.1 Conclusion Data pre-processing is very important in data mining process. Certain data cleaning techniques usually are not applicable to all kinds of data. Deduplication
Improving Cluster Method Quality by Validity Indices
 Improving Cluster Method Quality by Validity Indices N. Hachani and H. Ounalli Faculty of Sciences of Bizerte, Tunisia narjes hachani@yahoo.fr Faculty of Sciences of Tunis, Tunisia habib.ounalli@fst.rnu.tn
Improving Cluster Method Quality by Validity Indices N. Hachani and H. Ounalli Faculty of Sciences of Bizerte, Tunisia narjes hachani@yahoo.fr Faculty of Sciences of Tunis, Tunisia habib.ounalli@fst.rnu.tn
A k-means Clustering Algorithm on Numeric Data
 Volume 117 No. 7 2017, 157-164 ISSN: 1311-8080 (printed version); ISSN: 1314-3395 (on-line version) url: http://www.ijpam.eu ijpam.eu A k-means Clustering Algorithm on Numeric Data P.Praveen 1 B.Rama 2
Volume 117 No. 7 2017, 157-164 ISSN: 1311-8080 (printed version); ISSN: 1314-3395 (on-line version) url: http://www.ijpam.eu ijpam.eu A k-means Clustering Algorithm on Numeric Data P.Praveen 1 B.Rama 2
Data Analytics on RAMCloud
 Data Analytics on RAMCloud Jonathan Ellithorpe jdellit@stanford.edu Abstract MapReduce [1] has already become the canonical method for doing large scale data processing. However, for many algorithms including
Data Analytics on RAMCloud Jonathan Ellithorpe jdellit@stanford.edu Abstract MapReduce [1] has already become the canonical method for doing large scale data processing. However, for many algorithms including
Cluster quality 15. Running time 0.7. Distance between estimated and true means Running time [s]
![Cluster quality 15. Running time 0.7. Distance between estimated and true means Running time [s]](/thumbs/78/77996585.jpg "Cluster quality 15. Running time 0.7. Distance between estimated and true means Running time [s]") Fast, single-pass K-means algorithms Fredrik Farnstrom Computer Science and Engineering Lund Institute of Technology, Sweden arnstrom@ucsd.edu James Lewis Computer Science and Engineering University of
Fast, single-pass K-means algorithms Fredrik Farnstrom Computer Science and Engineering Lund Institute of Technology, Sweden arnstrom@ucsd.edu James Lewis Computer Science and Engineering University of
A CSP Search Algorithm with Reduced Branching Factor
 A CSP Search Algorithm with Reduced Branching Factor Igor Razgon and Amnon Meisels Department of Computer Science, Ben-Gurion University of the Negev, Beer-Sheva, 84-105, Israel {irazgon,am}@cs.bgu.ac.il
A CSP Search Algorithm with Reduced Branching Factor Igor Razgon and Amnon Meisels Department of Computer Science, Ben-Gurion University of the Negev, Beer-Sheva, 84-105, Israel {irazgon,am}@cs.bgu.ac.il
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Efficient and Effective Clustering Methods for Spatial Data Mining. Raymond T. Ng, Jiawei Han
 Efficient and Effective Clustering Methods for Spatial Data Mining Raymond T. Ng, Jiawei Han 1 Overview Spatial Data Mining Clustering techniques CLARANS Spatial and Non-Spatial dominant CLARANS Observations
Efficient and Effective Clustering Methods for Spatial Data Mining Raymond T. Ng, Jiawei Han 1 Overview Spatial Data Mining Clustering techniques CLARANS Spatial and Non-Spatial dominant CLARANS Observations
AN IMPROVED HYBRIDIZED K- MEANS CLUSTERING ALGORITHM (IHKMCA) FOR HIGHDIMENSIONAL DATASET & IT S PERFORMANCE ANALYSIS
 FOR HIGHDIMENSIONAL DATASET & IT S PERFORMANCE ANALYSIS") AN IMPROVED HYBRIDIZED K- MEANS CLUSTERING ALGORITHM (IHKMCA) FOR HIGHDIMENSIONAL DATASET & IT S PERFORMANCE ANALYSIS H.S Behera Department of Computer Science and Engineering, Veer Surendra Sai University
AN IMPROVED HYBRIDIZED K- MEANS CLUSTERING ALGORITHM (IHKMCA) FOR HIGHDIMENSIONAL DATASET & IT S PERFORMANCE ANALYSIS H.S Behera Department of Computer Science and Engineering, Veer Surendra Sai University
A Program demonstrating Gini Index Classification
 A Program demonstrating Gini Index Classification Abstract In this document, a small program demonstrating Gini Index Classification is introduced. Users can select specified training data set, build the
A Program demonstrating Gini Index Classification Abstract In this document, a small program demonstrating Gini Index Classification is introduced. Users can select specified training data set, build the
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Lecture Notes on Spanning Trees
 Lecture Notes on Spanning Trees 15-122: Principles of Imperative Computation Frank Pfenning Lecture 26 April 25, 2013 The following is a simple example of a connected, undirected graph with 5 vertices
Lecture Notes on Spanning Trees 15-122: Principles of Imperative Computation Frank Pfenning Lecture 26 April 25, 2013 The following is a simple example of a connected, undirected graph with 5 vertices
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering
 INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
A SURVEY OF IMAGE MINING TECHNIQUES AND APPLICATIONS
 A SURVEY OF IMAGE MINING TECHNIQUES AND APPLICATIONS R. Vijayalatha Research Scholar, Manonmaniam Sundaranar University, Tirunelveli (India) ABSTRACT In the area of Data Mining, Image Mining technology
A SURVEY OF IMAGE MINING TECHNIQUES AND APPLICATIONS R. Vijayalatha Research Scholar, Manonmaniam Sundaranar University, Tirunelveli (India) ABSTRACT In the area of Data Mining, Image Mining technology
Datasets Size: Effect on Clustering Results
 1 Datasets Size: Effect on Clustering Results Adeleke Ajiboye 1, Ruzaini Abdullah Arshah 2, Hongwu Qin 3 Faculty of Computer Systems and Software Engineering Universiti Malaysia Pahang 1 {ajibraheem@live.com}
1 Datasets Size: Effect on Clustering Results Adeleke Ajiboye 1, Ruzaini Abdullah Arshah 2, Hongwu Qin 3 Faculty of Computer Systems and Software Engineering Universiti Malaysia Pahang 1 {ajibraheem@live.com}