CLUSTERING. CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16
|
|
|
- Hilda McLaughlin
- 5 years ago
- Views:
Transcription


1 CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16
2 1. K-medoids: REFERENCES K-means: CLARA: 4. Book: Data Mining Concepts and Techniques, Jiawei Han, Micheline Kamber,Morgan Kaufman,2011 Chapter : 10, Page:
3 PART 1
4 OVERVIEW What is clustering? Similarity Measures Requirements of good clustering algorithm K-mean clustering K-medoids clustering - PAM K-medoids clustering - CLARA Applications of K-means and K-medoids
5 WHAT IS CLUSTERING? A way of grouping together data samples that are similar in some way - according to some criteria that you pick. A form of unsupervised learning It can also be called a method of data exploration.
6 SIMILARITY MEASURES A good clustering method will produce high quality clusters with 1.high intra-class similarity 2.low inter-class similarity The quality of a clustering result depends on: 1. similarity measure used by the method and its implementation. 2. its ability to discover some or all of the hidden patterns.
7 REQUIREMENTS OF GOOD CLUSTERING ALGORITHM Scalability Discovery of clusters with arbitrary shape Able to deal with noise and outliers Insensitive to order of input records High dimensionality Incorporation of user-specified constraints
8 CLUSTERING ALGORITHMS 1.K-Means 2.K-medoids 2.1 Basic K-medoids 2.2 PAM 2.3 CLARA
9 K-MEANS CLUSTERING First used by James Mcqueen in 1967 Unsupervised Learning Goal : Find the groups in the given data where no of groups is denoted by K Groups made on Feature similarity Results expected: Centroids used to label data Labels for training data Uses : Behavioral segmentation, Inventory categorization,sorting sensor measurements
10 K-MEANS PROCESS Input Data set K i.e no of clusters Data Assignment Step Each centroid represents one cluster Each data point is assigned to its nearest cluster based on squared Euclidean distance Centroid Update Step Recompute the centroids by taking the mean of the data points assigned to that particular centroid The algorithms repeats the two steps until end condition is met: No change in clusters

11 K-MEANS PROCESS
12 K-MEANS ALGORITHM Input : K (No of Clusters to form) and Input Data Set Initialize: Randomly assign K cluster centroids µ 1, µ 2,.µ K, є R n Repeat{ for i = 1 to m c (i) :=index(1 to K) of cluster centroid closest to x (i) (datapoint) for k = 1 to K µ K :=average mean of points assigned to cluster K } Stop when convergence criteria is meet.
13 CHOOSING NUMBER OF CLUSTERS K Elbow- Join method Metric used is mean distance between data points and their cluster centroid.
14 K-MEANS EXAMPLE

15 K-MEANS EXAMPLE
16 ADVANTAGES AND DISADVANTAGES Advantages 1. Easyto implement. 2. With a large number of variables, K-Means may be computationally faster than hierarchical clustering (if K is small) Disadvantages 1. Difficult to predict the number of clusters (K-Value). 2. Can converge on local minima 3. Sensitive to outliers
17 K-MEDOIDS CLUSTERING The mean in k-means clustering is sensitive to outliers. Since an object with an extremely high value may substantially distort the distribution of data. Hence we move to k-medoids. Instead of taking mean of cluster we take the most centrally located point in cluster as it s center. These are called medoids.


18 K-MEANS & K-MEDOIDS Clustering- Outliers Comparison
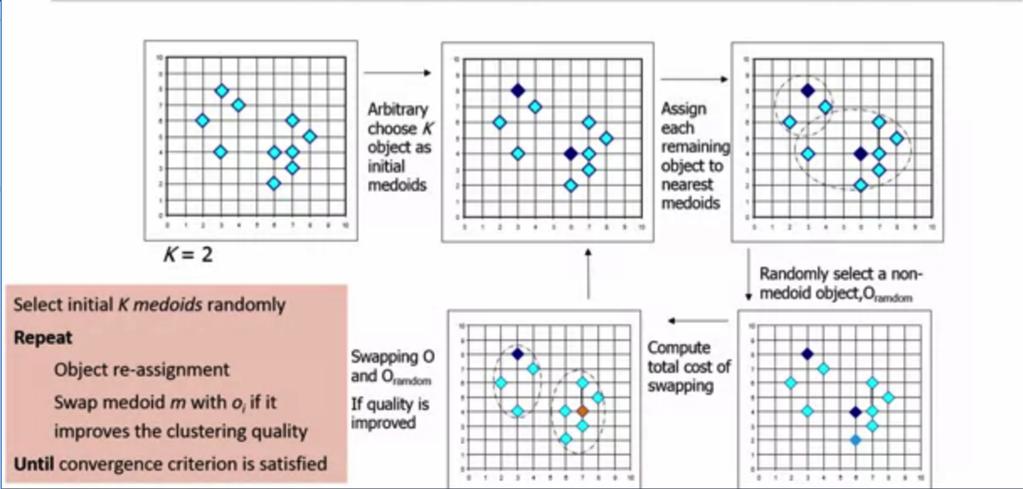
19 K-MEDOIDS - BASIC ALGORITHM Input : Number of K (the clusters to form) Initialize: Select K points as the initial representative objects i.e initial K-medoids of our K clusters. Repeat: Assign each point to the cluster with the closest medoid m. Randomly select a non-representative object o i Compute the total cost of swapping S, the medoid m with o i If S < 0: Swap m with o i to form new set of medoids. Stop when convergence criteria is meet.
20 K-MEDOIDS - BASIC FlOWCHART
21 K-MEDOIDS - PAM ALGORITHM PAM stands for Partitioning Around Medoids. GOAL: To find Clusters that have minimum average dissimilarity between objects that belong to same cluster. ALGORITHM: 1. Start with initial set of medoids. 2. Iteratively replace one of the medoids with a non-medoid if it reduces total sum of SSE of resulting cluster. SSE is calculated as below: Where k is number of clusters and x is a data point in cluster C i and M i is medoid of C i
22 TYPICAL PAM EXAMPLE
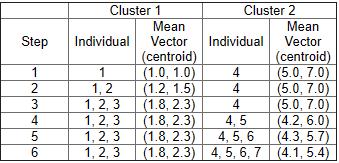
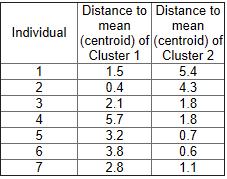
23 K-MEDOIDS (PAM) EXAMPLE For K = 2 Randomly Select m1 = (3,4) and m2 =(7,4) Using Manhattan as similarity metric we get, C1 = ( o1, o2, o3, o4 ) C2 = ( o5, o6, o7, o8, o9, o10)
24 K-MEDOIDS (PAM) EXAMPLE Compute absolute error as follows, E = (o1-o2) + (o3-o2) + (o4-o2) + (o5-o8) +(o6-o8)+(o7-o8) +(o9-o8) + (o10-o8) E = (3+4+4) + ( ) Therefore, E = 20
25 K-MEDOIDS (PAM) EXAMPLE Swapping o8 with o7 Compute absolute error as follows, E = (o1-o2) + (o3-o2) + (o4-o2) + (o5-o7) +(o6-o7)+(o8-o7) +(o9-o7) + (o10-o7) E = (3+4+4) + ( ) Therefore, E = 22
26 K-MEDOIDS (PAM) EXAMPLE Let s now calculate cost function S for this swap, S = E for (o2,07) - E for (o2, o8) S = Therefore S > 0, This swap is undesirable.
27 ADVANTAGES and DISADVANTAGES of PAM Advantages: PAM is more flexible as it can use any similarity measure. PAM is more robust than k-means as it handles noise better. Disadvantages: PAM algorithm for K-medoid clustering works well for dataset but cannot scale well for large data set due to high computational overhead. PAM COMPLEXITY : O(k(n-k) 2 ) this is because we compute distance of n-k points with each k point, to decide in which cluster it will fall and after this we try to replace each of the medoid with a non medoid and find it s distance with n-k points. To overcome this we make use of CLARA.
28 CLARA - CLUSTERING LARGE APPLICATIONS Improvement over PAM Finds medoids in a sample from the dataset [Idea]: If the samples are sufficiently random, the medoids of the sample approximate the medoids of the dataset [Heuristics]: 5 samples of size 40+2k gives satisfactory results Works well for large datasets (n=1000, k=10)
29 CLARA ALGORITHM 1. Split randomly the data sets in multiple subsets with fixed size (sampsize) 2. Compute PAM algorithm on each subset and choose the corresponding k representative objects (medoids). Assign each observation of the entire data set to the closest medoid. 3. Calculate the mean (or the sum) of the dissimilarities of the observations to their closest medoid. This is used as a measure of the goodness of the clustering. 4. Retain the sub-dataset for which the mean (or sum) is minimal. A further analysis is carried out on the final partition.
30 COMPARISON CLARA vs PAM Strength: - deals with larger data sets than PAM - CLARA Outperforms PAM in terms of running time and quality of clustering Weakness: - Efficiency depends on the sample size - A good clustering based on samples will not necessarily represent a good clustering of the whole

31 APPLICATIONS Social Network Document Clustering
32 GENERAL APPLICATIONS OF CLUSTERING 1. Recognition 2. Spatial Data Analysis a. create thematic maps in GIS by clustering feature spaces b. detect spatial clusters and explain them in spatial data mining 1. Image Processing 2. Economic Science (especially market research) 3. WWW a. Document classification b. Cluster Weblog data to discover groups of similar access patterns
33 PART 2
34 TRAFFIC ANOMALY DETECTION USING K-MEANS CLUSTERING Authors: Gerhard Munz, Sa Li, Georg Carle, Computer Networks and Internet, Wilhelm Schickard Institute for Computer Science, University of Tuebingen, Germany Published in GI/ITG Workshop MMBnet, 2007.
35 NETWORK DATA MINING Knowledge about monitoring data. Helps in determining dominant characteristics and outliers. Deployed to define rules or patterns that are typical for specific kinds of traffic helps to analyze new sets of monitoring data(labeling).
36 NOVEL NDM APPROACH K-means clustering of monitoring data Aggregate and transform flow records into datasets for equally spaced time intervals Raw Data and Extracted Features Total number of packets sent Total number of bytes sent Number of different source-destination pairs
37 K-means Clustering Distance metric used is
38 CLASSIFICATION AND OUTLIER DETECTION Classification Outlier detection
39 CLASSIFICATION AND OUTLIER DETECTION Combined approach
40 RESULTS : PING FLOOD DETECTION
41 CONCLUSIONS The resulting cluster centroids can be used to detect anomalies in new on-line monitoring data with a small number of distance calculations. Applying the clustering algorithm separately for different services improves the detection quality. The algorithm is scalable. Optimum number of clusters K is difficult to decide.

42
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Learning Partitioning Methods
 Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Data Mining: Concepts and Techniques. Chapter March 8, 2007 Data Mining: Concepts and Techniques 1
 Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
Cluster Analysis. CSE634 Data Mining
 Cluster Analysis CSE634 Data Mining Agenda Introduction Clustering Requirements Data Representation Partitioning Methods K-Means Clustering K-Medoids Clustering Constrained K-Means clustering Introduction
Cluster Analysis CSE634 Data Mining Agenda Introduction Clustering Requirements Data Representation Partitioning Methods K-Means Clustering K-Medoids Clustering Constrained K-Means clustering Introduction
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Data Mining. Dr. Raed Ibraheem Hamed. University of Human Development, College of Science and Technology Department of Computer Science
 Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Data Mining Algorithms
 for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
K-Means. Oct Youn-Hee Han
 K-Means Oct. 2015 Youn-Hee Han http://link.koreatech.ac.kr ²K-Means algorithm An unsupervised clustering algorithm K stands for number of clusters. It is typically a user input to the algorithm Some criteria
K-Means Oct. 2015 Youn-Hee Han http://link.koreatech.ac.kr ²K-Means algorithm An unsupervised clustering algorithm K stands for number of clusters. It is typically a user input to the algorithm Some criteria
APPLICATION OF MULTIPLE RANDOM CENTROID (MRC) BASED K-MEANS CLUSTERING ALGORITHM IN INSURANCE A REVIEW ARTICLE
 BASED K-MEANS CLUSTERING ALGORITHM IN INSURANCE A REVIEW ARTICLE") APPLICATION OF MULTIPLE RANDOM CENTROID (MRC) BASED K-MEANS CLUSTERING ALGORITHM IN INSURANCE A REVIEW ARTICLE Sundari NallamReddy, Samarandra Behera, Sanjeev Karadagi, Dr. Anantha Desik ABSTRACT: Tata
APPLICATION OF MULTIPLE RANDOM CENTROID (MRC) BASED K-MEANS CLUSTERING ALGORITHM IN INSURANCE A REVIEW ARTICLE Sundari NallamReddy, Samarandra Behera, Sanjeev Karadagi, Dr. Anantha Desik ABSTRACT: Tata
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Kapitel 4: Clustering
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Unsupervised Learning. Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team
 Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest)
") Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Efficient and Effective Clustering Methods for Spatial Data Mining. Raymond T. Ng, Jiawei Han
 Efficient and Effective Clustering Methods for Spatial Data Mining Raymond T. Ng, Jiawei Han 1 Overview Spatial Data Mining Clustering techniques CLARANS Spatial and Non-Spatial dominant CLARANS Observations
Efficient and Effective Clustering Methods for Spatial Data Mining Raymond T. Ng, Jiawei Han 1 Overview Spatial Data Mining Clustering techniques CLARANS Spatial and Non-Spatial dominant CLARANS Observations
PAM algorithm. Types of Data in Cluster Analysis. A Categorization of Major Clustering Methods. Partitioning i Methods. Hierarchical Methods
 Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering
 INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Community Detection. Jian Pei: CMPT 741/459 Clustering (1) 2
 2") Clustering Community Detection http://image.slidesharecdn.com/communitydetectionitilecturejune0-0609559-phpapp0/95/community-detection-in-social-media--78.jpg?cb=3087368 Jian Pei: CMPT 74/459 Clustering
Clustering Community Detection http://image.slidesharecdn.com/communitydetectionitilecturejune0-0609559-phpapp0/95/community-detection-in-social-media--78.jpg?cb=3087368 Jian Pei: CMPT 74/459 Clustering
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
New Approach for K-mean and K-medoids Algorithm
 New Approach for K-mean and K-medoids Algorithm Abhishek Patel Department of Information & Technology, Parul Institute of Engineering & Technology, Vadodara, Gujarat, India Purnima Singh Department of
New Approach for K-mean and K-medoids Algorithm Abhishek Patel Department of Information & Technology, Parul Institute of Engineering & Technology, Vadodara, Gujarat, India Purnima Singh Department of
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Clustering. Chapter 10 in Introduction to statistical learning
 Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
A Comparative study of Clustering Algorithms using MapReduce in Hadoop
 A Comparative study of Clustering Algorithms using MapReduce in Hadoop Dweepna Garg 1, Khushboo Trivedi 2, B.B.Panchal 3 1 Department of Computer Science and Engineering, Parul Institute of Engineering
A Comparative study of Clustering Algorithms using MapReduce in Hadoop Dweepna Garg 1, Khushboo Trivedi 2, B.B.Panchal 3 1 Department of Computer Science and Engineering, Parul Institute of Engineering
What is Cluster Analysis? COMP 465: Data Mining Clustering Basics. Applications of Cluster Analysis. Clustering: Application Examples 3/17/2015
 // What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
// What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
What to come. There will be a few more topics we will cover on supervised learning
 Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Cluster Analysis: Basic Concepts and Methods
 HAN 17-ch10-443-496-9780123814791 2011/6/1 3:44 Page 443 #1 10 Cluster Analysis: Basic Concepts and Methods Imagine that you are the Director of Customer Relationships at AllElectronics, and you have five
HAN 17-ch10-443-496-9780123814791 2011/6/1 3:44 Page 443 #1 10 Cluster Analysis: Basic Concepts and Methods Imagine that you are the Director of Customer Relationships at AllElectronics, and you have five
Exploratory data analysis for microarrays
 Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
Introduction to Mobile Robotics
 Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
CHAPTER 4 K-MEANS AND UCAM CLUSTERING ALGORITHM
 CHAPTER 4 K-MEANS AND UCAM CLUSTERING 4.1 Introduction ALGORITHM Clustering has been used in a number of applications such as engineering, biology, medicine and data mining. The most popular clustering
CHAPTER 4 K-MEANS AND UCAM CLUSTERING 4.1 Introduction ALGORITHM Clustering has been used in a number of applications such as engineering, biology, medicine and data mining. The most popular clustering
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Cluster Analysis chapter 7. cse634 Data Mining. Professor Anita Wasilewska Compute Science Department Stony Brook University NY
 Cluster Analysis chapter 7 cse634 Data Mining Professor Anita Wasilewska Compute Science Department Stony Brook University NY Sources Cited [1] Driver, H. E. and A. L. Kroeber (1932) Quantitative expression
Cluster Analysis chapter 7 cse634 Data Mining Professor Anita Wasilewska Compute Science Department Stony Brook University NY Sources Cited [1] Driver, H. E. and A. L. Kroeber (1932) Quantitative expression
A Review on Cluster Based Approach in Data Mining
 A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
COSC 6339 Big Data Analytics. Fuzzy Clustering. Some slides based on a lecture by Prof. Shishir Shah. Edgar Gabriel Spring 2017.
 COSC 6339 Big Data Analytics Fuzzy Clustering Some slides based on a lecture by Prof. Shishir Shah Edgar Gabriel Spring 217 Clustering Clustering is a technique for finding similarity groups in data, called
COSC 6339 Big Data Analytics Fuzzy Clustering Some slides based on a lecture by Prof. Shishir Shah Edgar Gabriel Spring 217 Clustering Clustering is a technique for finding similarity groups in data, called
k-means Clustering Todd W. Neller Gettysburg College Laura E. Brown Michigan Technological University
 k-means Clustering Todd W. Neller Gettysburg College Laura E. Brown Michigan Technological University Outline Unsupervised versus Supervised Learning Clustering Problem k-means Clustering Algorithm Visual
k-means Clustering Todd W. Neller Gettysburg College Laura E. Brown Michigan Technological University Outline Unsupervised versus Supervised Learning Clustering Problem k-means Clustering Algorithm Visual
Iteration Reduction K Means Clustering Algorithm
 Iteration Reduction K Means Clustering Algorithm Kedar Sawant 1 and Snehal Bhogan 2 1 Department of Computer Engineering, Agnel Institute of Technology and Design, Assagao, Goa 403507, India 2 Department
Iteration Reduction K Means Clustering Algorithm Kedar Sawant 1 and Snehal Bhogan 2 1 Department of Computer Engineering, Agnel Institute of Technology and Design, Assagao, Goa 403507, India 2 Department
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme
 Entscheidungsunterstützungssysteme") Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme Why do we need to find similarity? Similarity underlies many data science methods and solutions to business problems. Some
Clustering (Basic concepts and Algorithms) Entscheidungsunterstützungssysteme Why do we need to find similarity? Similarity underlies many data science methods and solutions to business problems. Some
[7.3, EA], [9.1, CMB]
![[7.3, EA], [9.1, CMB]](/thumbs/76/73876791.jpg "[7.3, EA], [9.1, CMB]") K-means Clustering Ke Chen Reading: [7.3, EA], [9.1, CMB] Outline Introduction K-means Algorithm Example How K-means partitions? K-means Demo Relevant Issues Application: Cell Neulei Detection Summary
K-means Clustering Ke Chen Reading: [7.3, EA], [9.1, CMB] Outline Introduction K-means Algorithm Example How K-means partitions? K-means Demo Relevant Issues Application: Cell Neulei Detection Summary
Clustering. Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
Clustering. (Part 2)
") Clustering (Part 2) 1 k-means clustering 2 General Observations on k-means clustering In essence, k-means clustering aims at minimizing cluster variance. It is typically used in Euclidean spaces and works
Clustering (Part 2) 1 k-means clustering 2 General Observations on k-means clustering In essence, k-means clustering aims at minimizing cluster variance. It is typically used in Euclidean spaces and works
COSC 6397 Big Data Analytics. Fuzzy Clustering. Some slides based on a lecture by Prof. Shishir Shah. Edgar Gabriel Spring 2015.
 COSC 6397 Big Data Analytics Fuzzy Clustering Some slides based on a lecture by Prof. Shishir Shah Edgar Gabriel Spring 215 Clustering Clustering is a technique for finding similarity groups in data, called
COSC 6397 Big Data Analytics Fuzzy Clustering Some slides based on a lecture by Prof. Shishir Shah Edgar Gabriel Spring 215 Clustering Clustering is a technique for finding similarity groups in data, called
Exploratory Analysis: Clustering
 Exploratory Analysis: Clustering (some material taken or adapted from slides by Hinrich Schutze) Heejun Kim June 26, 2018 Clustering objective Grouping documents or instances into subsets or clusters Documents
Exploratory Analysis: Clustering (some material taken or adapted from slides by Hinrich Schutze) Heejun Kim June 26, 2018 Clustering objective Grouping documents or instances into subsets or clusters Documents
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering
 Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Comparative Study of Subspace Clustering Algorithms
 Comparative Study of Subspace Clustering Algorithms S.Chitra Nayagam, Asst Prof., Dept of Computer Applications, Don Bosco College, Panjim, Goa. Abstract-A cluster is a collection of data objects that
Comparative Study of Subspace Clustering Algorithms S.Chitra Nayagam, Asst Prof., Dept of Computer Applications, Don Bosco College, Panjim, Goa. Abstract-A cluster is a collection of data objects that
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
Keywords Clustering, Goals of clustering, clustering techniques, clustering algorithms.
 Volume 3, Issue 5, May 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com A Survey of Clustering
Volume 3, Issue 5, May 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com A Survey of Clustering
Multivariate analyses in ecology. Cluster (part 2) Ordination (part 1 & 2)
 Ordination (part 1 & 2)") Multivariate analyses in ecology Cluster (part 2) Ordination (part 1 & 2) 1 Exercise 9B - solut 2 Exercise 9B - solut 3 Exercise 9B - solut 4 Exercise 9B - solut 5 Multivariate analyses in ecology Cluster
Multivariate analyses in ecology Cluster (part 2) Ordination (part 1 & 2) 1 Exercise 9B - solut 2 Exercise 9B - solut 3 Exercise 9B - solut 4 Exercise 9B - solut 5 Multivariate analyses in ecology Cluster
An Enhanced K-Medoid Clustering Algorithm
 An Enhanced Clustering Algorithm Archna Kumari Science &Engineering kumara.archana14@gmail.com Pramod S. Nair Science &Engineering, pramodsnair@yahoo.com Sheetal Kumrawat Science &Engineering, sheetal2692@gmail.com
An Enhanced Clustering Algorithm Archna Kumari Science &Engineering kumara.archana14@gmail.com Pramod S. Nair Science &Engineering, pramodsnair@yahoo.com Sheetal Kumrawat Science &Engineering, sheetal2692@gmail.com
Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Mine Blood Donors Information through Improved K- Means Clustering Bondu Venkateswarlu 1 and Prof G.S.V.Prasad Raju 2
 Mine Blood Donors Information through Improved K- Means Clustering Bondu Venkateswarlu 1 and Prof G.S.V.Prasad Raju 2 1 Department of Computer Science and Systems Engineering, Andhra University, Visakhapatnam-
Mine Blood Donors Information through Improved K- Means Clustering Bondu Venkateswarlu 1 and Prof G.S.V.Prasad Raju 2 1 Department of Computer Science and Systems Engineering, Andhra University, Visakhapatnam-
CS4445 Data Mining and Knowledge Discovery in Databases. A Term 2008 Exam 2 October 14, 2008
 CS4445 Data Mining and Knowledge Discovery in Databases. A Term 2008 Exam 2 October 14, 2008 Prof. Carolina Ruiz Department of Computer Science Worcester Polytechnic Institute NAME: Prof. Ruiz Problem
CS4445 Data Mining and Knowledge Discovery in Databases. A Term 2008 Exam 2 October 14, 2008 Prof. Carolina Ruiz Department of Computer Science Worcester Polytechnic Institute NAME: Prof. Ruiz Problem
Machine Learning. Unsupervised Learning. Manfred Huber
 Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Classification. Vladimir Curic. Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University
 Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Chapter 6 Continued: Partitioning Methods
 Chapter 6 Continued: Partitioning Methods Partitioning methods fix the number of clusters k and seek the best possible partition for that k. The goal is to choose the partition which gives the optimal
Chapter 6 Continued: Partitioning Methods Partitioning methods fix the number of clusters k and seek the best possible partition for that k. The goal is to choose the partition which gives the optimal
Analyzing Outlier Detection Techniques with Hybrid Method
 Analyzing Outlier Detection Techniques with Hybrid Method Shruti Aggarwal Assistant Professor Department of Computer Science and Engineering Sri Guru Granth Sahib World University. (SGGSWU) Fatehgarh Sahib,
Analyzing Outlier Detection Techniques with Hybrid Method Shruti Aggarwal Assistant Professor Department of Computer Science and Engineering Sri Guru Granth Sahib World University. (SGGSWU) Fatehgarh Sahib,
Clustering. Robert M. Haralick. Computer Science, Graduate Center City University of New York
 Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Lecture on Modeling Tools for Clustering & Regression
 Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Enhancing K-means Clustering Algorithm with Improved Initial Center
 Enhancing K-means Clustering Algorithm with Improved Initial Center Madhu Yedla #1, Srinivasa Rao Pathakota #2, T M Srinivasa #3 # Department of Computer Science and Engineering, National Institute of
Enhancing K-means Clustering Algorithm with Improved Initial Center Madhu Yedla #1, Srinivasa Rao Pathakota #2, T M Srinivasa #3 # Department of Computer Science and Engineering, National Institute of
Road map. Basic concepts
 Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
Clustering Basic concepts Road map K-means algorithm Representation of clusters Hierarchical clustering Distance functions Data standardization Handling mixed attributes Which clustering algorithm to use?
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Slides From Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Normalization based K means Clustering Algorithm
 Normalization based K means Clustering Algorithm Deepali Virmani 1,Shweta Taneja 2,Geetika Malhotra 3 1 Department of Computer Science,Bhagwan Parshuram Institute of Technology,New Delhi Email:deepalivirmani@gmail.com
Normalization based K means Clustering Algorithm Deepali Virmani 1,Shweta Taneja 2,Geetika Malhotra 3 1 Department of Computer Science,Bhagwan Parshuram Institute of Technology,New Delhi Email:deepalivirmani@gmail.com
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clust Clus e t ring 2 Nov
 Clustering 2 Nov 3 2008 HAC Algorithm Start t with all objects in their own cluster. Until there is only one cluster: Among the current clusters, determine the two clusters, c i and c j, that are most
Clustering 2 Nov 3 2008 HAC Algorithm Start t with all objects in their own cluster. Until there is only one cluster: Among the current clusters, determine the two clusters, c i and c j, that are most
The k-means Algorithm and Genetic Algorithm
 The k-means Algorithm and Genetic Algorithm k-means algorithm Genetic algorithm Rough set approach Fuzzy set approaches Chapter 8 2 The K-Means Algorithm The K-Means algorithm is a simple yet effective
The k-means Algorithm and Genetic Algorithm k-means algorithm Genetic algorithm Rough set approach Fuzzy set approaches Chapter 8 2 The K-Means Algorithm The K-Means algorithm is a simple yet effective
Data Mining. Clustering. Hamid Beigy. Sharif University of Technology. Fall 1394
 Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
K-Means Clustering With Initial Centroids Based On Difference Operator
 K-Means Clustering With Initial Centroids Based On Difference Operator Satish Chaurasiya 1, Dr.Ratish Agrawal 2 M.Tech Student, School of Information and Technology, R.G.P.V, Bhopal, India Assistant Professor,
K-Means Clustering With Initial Centroids Based On Difference Operator Satish Chaurasiya 1, Dr.Ratish Agrawal 2 M.Tech Student, School of Information and Technology, R.G.P.V, Bhopal, India Assistant Professor,
CS Introduction to Data Mining Instructor: Abdullah Mueen
 CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
Intelligent Image and Graphics Processing
 Intelligent Image and Graphics Processing 智能图像图形处理图形处理 布树辉 bushuhui@nwpu.edu.cn http://www.adv-ci.com Clustering Clustering Attach label to each observation or data points in a set You can say this unsupervised
Intelligent Image and Graphics Processing 智能图像图形处理图形处理 布树辉 bushuhui@nwpu.edu.cn http://www.adv-ci.com Clustering Clustering Attach label to each observation or data points in a set You can say this unsupervised
Application of K-Means Clustering Methodology to Cost Estimation
 Application of K-Means Clustering Methodology to Cost Estimation Mr. Jacob J. Walzer, Kalman & Co., Inc. 2018 Professional Development & Training Workshop 6/2018 Background There are many ways to analyze
Application of K-Means Clustering Methodology to Cost Estimation Mr. Jacob J. Walzer, Kalman & Co., Inc. 2018 Professional Development & Training Workshop 6/2018 Background There are many ways to analyze
Information Retrieval and Organisation
 Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
An Unsupervised Technique for Statistical Data Analysis Using Data Mining
 International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 5, Number 1 (2013), pp. 11-20 International Research Publication House http://www.irphouse.com An Unsupervised Technique
International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 5, Number 1 (2013), pp. 11-20 International Research Publication House http://www.irphouse.com An Unsupervised Technique
K+ Means : An Enhancement Over K-Means Clustering Algorithm
 K+ Means : An Enhancement Over K-Means Clustering Algorithm Srikanta Kolay SMS India Pvt. Ltd., RDB Boulevard 5th Floor, Unit-D, Plot No.-K1, Block-EP&GP, Sector-V, Salt Lake, Kolkata-700091, India Email:
K+ Means : An Enhancement Over K-Means Clustering Algorithm Srikanta Kolay SMS India Pvt. Ltd., RDB Boulevard 5th Floor, Unit-D, Plot No.-K1, Block-EP&GP, Sector-V, Salt Lake, Kolkata-700091, India Email:
Flat Clustering. Slides are mostly from Hinrich Schütze. March 27, 2017
 Flat Clustering Slides are mostly from Hinrich Schütze March 7, 07 / 79 Overview Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? / 79 Outline Recap Clustering:
Flat Clustering Slides are mostly from Hinrich Schütze March 7, 07 / 79 Overview Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? / 79 Outline Recap Clustering:
Machine Learning - Clustering. CS102 Fall 2017
 Machine Learning - Fall 2017 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Data Mining Looking for
Machine Learning - Fall 2017 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Data Mining Looking for
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
d(2,1) d(3,1 ) d (3,2) 0 ( n, ) ( n ,2)......
 d(3,1 ) d (3,2) 0 ( n, ) ( n ,2)......") Data Mining i Topic: Clustering CSEE Department, e t, UMBC Some of the slides used in this presentation are prepared by Jiawei Han and Micheline Kamber Cluster Analysis What is Cluster Analysis? Types
Data Mining i Topic: Clustering CSEE Department, e t, UMBC Some of the slides used in this presentation are prepared by Jiawei Han and Micheline Kamber Cluster Analysis What is Cluster Analysis? Types
Clustering: K-means and Kernel K-means
 Clustering: K-means and Kernel K-means Piyush Rai Machine Learning (CS771A) Aug 31, 2016 Machine Learning (CS771A) Clustering: K-means and Kernel K-means 1 Clustering Usually an unsupervised learning problem
Clustering: K-means and Kernel K-means Piyush Rai Machine Learning (CS771A) Aug 31, 2016 Machine Learning (CS771A) Clustering: K-means and Kernel K-means 1 Clustering Usually an unsupervised learning problem
Clustering Techniques
 Clustering Techniques Marco BOTTA Dipartimento di Informatica Università di Torino botta@di.unito.it www.di.unito.it/~botta/didattica/clustering.html Data Clustering Outline What is cluster analysis? What
Clustering Techniques Marco BOTTA Dipartimento di Informatica Università di Torino botta@di.unito.it www.di.unito.it/~botta/didattica/clustering.html Data Clustering Outline What is cluster analysis? What