Apache Spark for RDBMS Practitioners: How I Learned to Stop Worrying and Love to Scale
|
|
|
- Arleen Brown
- 5 years ago
- Views:
Transcription


1 Apache Spark for RDBMS Practitioners: How I Learned to Stop Worrying and Love to Scale Luca Canali, CERN
2 About Luca Data Engineer and team lead at CERN Hadoop and Spark service, database services 18+ years of experience with data(base) services Performance, architecture, tools, internals Sharing and community Blog, notes, tools, contributions to Apache 2

 3 3")




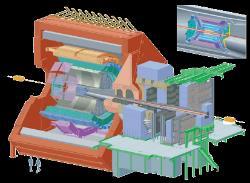

3 The Large Hadron Collider (LHC) 3 3
")
4 LHC and Data LHC data processing teams (WLCG) have built custom solutions able to operate at very large scale (data scale and world-wide operations) 4
5 Overview of Data at CERN Physics Data ~ 300 PB -> EB Big Data on Spark and Hadoop ~10 PB Analytics for accelerator controls and logging Monitoring use cases, this includes use of Spark streaming Analytics on aggregated logs Explorations on the use of Spark for high energy physics Relational databases ~ 2 PB Control systems, metadata for physics data processing, administration and general-purpose 5
6 Apache CERN Spark on YARN/HDFS In total ~1850 physical cores and 15 PB capacity Spark on Kubernetes Deployed on CERN cloud using OpenStack See also, at this conference: Experience of Running Spark on Kubernetes on OpenStack for High Energy Physics Workloads Cluster Name Configuration Software Version Accelerator logging 20 nodes (Cores 480, Mem - 8 TB, Storage 5 PB, 96GB in SSD) Spark General Purpose 48 nodes (Cores 892,Mem 7.5TB,Storage 6 PB) Spark Development cluster 14 nodes (Cores 196,Mem 768GB,Storage 2.15 PB) Spark ATLAS Event Index 18 nodes (Cores 288,Mem 912GB,Storage 1.29 PB) Spark

7 Motivations/Outline of the Presentation Report experience of using Apache Spark at CERN DB group Value of Spark for data coming from DBs Highlights of learning experience DBA/Dev Data Engineer Big Data 7
8 Goals Entice more DBAs and RDBMS Devs into entering Spark community Focus on added value of scalable platforms and experience on RDBMS/data practices SQL/DataFrame API very valuable for many data workloads Performance instrumentation of the code is key: use metric and tools beyond simple time measurement 8

9 Spark, Swiss Army Knife of Big Data One tool, many uses Data extraction and manipulation Large ecosystem of data sources Engine for distributed computing Runs SQL Streaming Machine Learning GraphX.. Image Credit: Vector Pocket Knife from Clipart.me 9

10 Problem We Want to Solve Running reports on relational DATA DB optimized for transactions and online Reports can overload storage system RDBMS specialized for random I/O, CPU, storage and memory HW and SW are optimized at a premium for performance and availability 10

11 Offload from RDBMS Building hybrid transactional and reporting systems is expensive Solution: offload to a system optimized for capacity In our case: move data to Hadoop + SQL-based engine Report Queries Transactions on RDBMS ETL Queries 11
12 Spark Read from RDBMS via JDBC val df = spark.read.format("jdbc").option("url","jdbc:oracle:thin:@server:port/service ).option("driver", "oracle.jdbc.driver.oracledriver").option("dbtable", "DBTABLE").option("user", XX").option("password", "YY").option("fetchsize",10000).option("sessionInitStatement",preambleSQL).load() Optional DB-specific Optimizations SPARK option("sessioninitstatement", """BEGIN execute immediate 'alter session set "_serial_direct_read"=true'; END;""") 12
13 Challenges Reading from RDMBs Important amount of CPU consumed by serializationdeserialization transferring to/from RDMS data format Particularly important for tables with short rows Need to take care of data partitioning, parallelism of the data extraction queries, etc A few operational challenges Configure parallelism to run at speed But also be careful not to overload the source when reading 13
14 Apache Sqoop to Copy Data Scoop is optimized to read from RDBMS Sqoop connector for Oracle DBs has several key optimizations We use it for incremental refresh of data from production RDBMS to HDFS data lake Typically we copy latest partition of the data Users run reporting jobs on offloaded data from YARN/HDFS 14
15 Sqoop to Copy Data (from Oracle) Sqoop has a rich choice of options to customize the data transfer sqoop import \ --connect jdbc:oracle:thin:@server.cern.ch:port/service --username.. -P \ -Doraoop.chunk.method=ROWID --direct \ --fetch-size \ --num-mappers XX \ --target-dir XXXX/mySqoopDestDir \ --table TABLESNAME \ Oracle-specific optimizations --map-column-java FILEID=Integer,JOBID=Integer,CREATIONDATE=String \ --compress --compression-codec snappy \ --as-parquetfile 15
16 Streaming and ETL Besides traditional ETL also streaming important and used by production use cases Streaming data into Apache Kafka 16
17 Spark and Data Formats Data formats are key for performance Columnar formats are a big boost for many reporting use cases Parquet and ORC Column pruning Easier compression/encoding Partitioning and bucketing also important 17
18 Data Access Optimizations Use Apache Parquet or ORC Profit of column projection, filter push down, compression and encoding, partition pruning Partition=1 Col1 Col2 Col3 Col4 Min Max Count.. 18

19 Parquet Metadata Exploration Tools for Parquet metadata exploration, useful for learning and troubleshooting Useful tools: parquet-tools parquet-reader Info at: ellaneous/blob/master/spark_note s/tools_parquet_diagnostics.md 19
20 SQL Now After moving the data (ETL), add the queries to the new system Spark SQL/DataFrame API is a powerful engine Optimized for Parquet (recently improved ORC) Partitioning, Filter push down Feature rich, code generation, also has CBO (cost based optimizer) Note: it s a rich ecosystem, options are available (we also used Impala and evaluated Presto) 20

21 Spark SQL Interfaces: Many Choices PySpark, spark-shell, Spark jobs in Python/Scala/Java Notebooks Jupyter Web service for data analysis at CERN swan.cern.ch Thrift server 21
22 Lessons Learned Reading Parquet is CPU intensive Parquet format uses encoding and compression Processing Parquet -> hungry of CPU cycles and memory bandwidth Test on dual socket CPU Up to 3.4 Gbytes/s reads 22
23 Benchmarking Spark SQL Running benchmarks can be useful (and fun): See how the system behaves at scale Stress-test new infrastructure Experiment with monitoring and troubleshooting tools TPCDS benchmark Popular and easy to set up, can run at scale See 23
24 Example from TPCDS Benchmark 24
25 Lessons Learned from Running TPCDS Useful for commissioning of new systems It has helped us capture some system parameter misconfiguration before prod Comparing with other similar systems Many of the long-running TPCDS queries Use shuffle intensively Can profit of using SSDs for local dirs (shuffle) There are improvements (and regressions) of TPCDS queries across Spark versions 25
26 Learning Something New About SQL Similarities but also differences with RDBMS: Dataframe abstraction, vs. database table/view SQL or DataFrame operation syntax // Dataframe operations val df = spark.read.parquet("..path..") df.select("id").groupby("id").count().show() // SQL df.createorreplacetempview("t1") spark.sql("select id, count(*) from t1 group by id").show() 26
27 ..and Something OLD About SQL Using SQL or DataFrame operations API is equivalent Just different ways to express the computation Look at execution plans to see what Spark executes Spark Catalyst optimizer will generate the same plan for the 2 examples == Physical Plan == *(2) HashAggregate(keys=[id#98L], functions=[count(1)]) +- Exchange hashpartitioning(id#98l, 200) +- *(1) HashAggregate(keys=[id#98L], functions=[partial_count(1)]) +- *(1) FileScan parquet [id#98l] Batched: true, Format: Parquet, Location: InMemoryFileIndex[file:/tmp/t1.prq], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<id:bigint> 27

28 Monitoring and Performance Troubleshooting Performance is key for data processing at scale Lessons learned from DB systems: Use metrics and time-based profiling It s a boon to rapidly pin-point bottleneck resources Instrumentation and tools are essential 28

29 Spark and Monitoring Tools Spark instrumentation Web UI REST API Eventlog Executor/Task Metrics Dropwizard metrics library Complement with OS tools For large clusters, deploy tools that ease working at cluster-level 29
30 WEB UI Part of Spark: Info on Jobs, Stages, Executors, Metrics, SQL,.. Start with: point web browser driver_host, port

31 Spark Executor Metrics System Metrics collected at execution time Exposed by WEB UI/ History server, EventLog, custom tools rndb/sparkmeasure 31
32 Spark Executor Metrics System What is available with Spark Metrics, SPARK Spark Executor Task Metric name executorruntime executorcputime executordeserializetime executordeserializecputime resultsize jvmgctime + I/OMetrics, Shuffle metrics, Short description Elapsed time the executor spent running this task. This includes time fetching shuffle data. The value is expressed in milliseconds. CPU time the executor spent running this task. This includes time fetching shuffle data. The value is expressed in nanoseconds. Elapsed time spent to deserialize this task. The value is expressed in milliseconds. CPU time taken on the executor to deserialize this task. The value is expressed in nanoseconds. The number of bytes this task transmitted back to the driver as the TaskResult. Elapsed time the JVM spent in garbage collection while executing this task. The value is expressed in milliseconds. 26 metrics available, see 32



33 Spark Metrics - Dashboards Dropwizard metrics Graphite sink Configure: --conf spark.metrics.conf=metrics.properties Use to produce dashboards to measure online: Number of active tasks, JVM metrics, CPU usage SPARK-25228, Spark task metrics SPARK-22190, etc. 33
34 More Use Cases: Scale Up! Spark proved valuable and flexible Ecosystem and tooling in place Opens to exploring more use cases and.. scaling up! 34
 Data reduction (for further analysis Histograms and plots of interest See also, at this conference: HEP Data Processing with Apache Spark and CERN s Next Generation Data")
35 Use Case: Spark for Physics Input: Physics data in CERN/HEP storage Spark APIs for Physics data analysis POC: processed 1 PB of data in 10 hours Read into Spark (spark-root connector) Apply computation at scale (UDF) Data reduction (for further analysis Histograms and plots of interest See also, at this conference: HEP Data Processing with Apache Spark and CERN s Next Generation Data Analysis Platform with Apache Spark 35


 Distributed model training")
36 Use Case: Machine Learning at Scale Data and models from Physics AUC= Input: labeled data and DL models Feature engineer ing at scale Hyperparameter optimization (Random/Grid search) Distributed model training Output: particle selector model 36
37 Summary and High-Level View of the Lessons Learned 37
38 Transferrable Skills, Spark - DB Familiar ground coming from RDBMS world SQL CBO Execution plans, hints, joins, grouping, windows, etc Partitioning Performance troubleshooting, instrumentation, SQL optimizations Carry over ideas and practices from DBs 38
39 Learning Curve Coming from DB Manage heterogeneous environment and usage: Python, Scala, Java, batch jobs, notebooks, etc Spark is fundamentally a library not a server component like a RDBMS engine Understand differences tables vs DataFrame APIs Understand data formats Understand clustering and environment (YARN, Kubernets, ) Understand tooling and utilities in the ecosystem 39
40 New Dimensions and Value With Spark you can easily scale up your SQL workloads Integrate with many sources (DBs and more) and storage (Cloud storage solutions or Hadoop) Run DB and ML workloads and at scale - CERN and HEP are developing solutions with Spark for use cases for physics data analysis and for ML/DL at scale Quickly growing and open community You will be able to comment, propose, implement features, issues and patches 40
41 Conclusions - Apache Spark very useful and versatile - for many data workloads, including DB-like workloads - DBAs and RDBMS Devs - Can profit of Spark and ecosystem to scale up some of their workloads from DBs and do more! - Can bring experience and good practices over from DB world 41
42 Acknowledgements Members of Hadoop and Spark service at CERN and HEP users community, CMS Big Data project, CERN openlab Many lessons learned over the years from the RDBMS community, notably Apache Spark community: helpful discussions and support with PRs Links More #SAISdev11 42
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Apache Spark 2.0 Performance Improvements Investigated With Flame Graphs. Luca Canali CERN, Geneva (CH)
") Apache Spark 2.0 Performance Improvements Investigated With Flame Graphs Luca Canali CERN, Geneva (CH) Speaker Intro Database engineer and team lead at CERN IT Hadoop and Spark service Database services
Apache Spark 2.0 Performance Improvements Investigated With Flame Graphs Luca Canali CERN, Geneva (CH) Speaker Intro Database engineer and team lead at CERN IT Hadoop and Spark service Database services
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Spark and HPC for High Energy Physics Data Analyses
 Spark and HPC for High Energy Physics Data Analyses Marc Paterno, Jim Kowalkowski, and Saba Sehrish 2017 IEEE International Workshop on High-Performance Big Data Computing Introduction High energy physics
Spark and HPC for High Energy Physics Data Analyses Marc Paterno, Jim Kowalkowski, and Saba Sehrish 2017 IEEE International Workshop on High-Performance Big Data Computing Introduction High energy physics
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Microsoft. Exam Questions Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo
 Version:Demo") Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 You have an Azure HDInsight cluster. You need to store data in a file format that
Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 You have an Azure HDInsight cluster. You need to store data in a file format that
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Hadoop File Formats and Data Ingestion. Prasanth Kothuri, CERN
 Prasanth Kothuri, CERN 2 Files Formats not just CSV - Key factor in Big Data processing and query performance - Schema Evolution - Compression and Splittability - Data Processing Write performance Partial
Prasanth Kothuri, CERN 2 Files Formats not just CSV - Key factor in Big Data processing and query performance - Schema Evolution - Compression and Splittability - Data Processing Write performance Partial
IBM Db2 Event Store Simplifying and Accelerating Storage and Analysis of Fast Data. IBM Db2 Event Store
 IBM Db2 Event Store Simplifying and Accelerating Storage and Analysis of Fast Data IBM Db2 Event Store Disclaimer The information contained in this presentation is provided for informational purposes only.
IBM Db2 Event Store Simplifying and Accelerating Storage and Analysis of Fast Data IBM Db2 Event Store Disclaimer The information contained in this presentation is provided for informational purposes only.
Exam Questions
 Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Asanka Padmakumara. ETL 2.0: Data Engineering with Azure Databricks
 Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
April Copyright 2013 Cloudera Inc. All rights reserved.
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
The Evolution of Big Data Platforms and Data Science
 IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Spark 2. Alexey Zinovyev, Java/BigData Trainer in EPAM
 Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Oracle Big Data Fundamentals Ed 2
 Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Activator Library. Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success.
 Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Starting with Apache Spark, Best Practices and Learning from the Field
 Starting with Apache Spark, Best Practices and Learning from the Field Felix Cheung, Principal Engineer + Spark Committer Spark@Microsoft Best Practices Enterprise Solutions Resilient - Fault tolerant
Starting with Apache Spark, Best Practices and Learning from the Field Felix Cheung, Principal Engineer + Spark Committer Spark@Microsoft Best Practices Enterprise Solutions Resilient - Fault tolerant
What is Gluent? The Gluent Data Platform
 What is Gluent? The Gluent Data Platform The Gluent Data Platform provides a transparent data virtualization layer between traditional databases and modern data storage platforms, such as Hadoop, in the
What is Gluent? The Gluent Data Platform The Gluent Data Platform provides a transparent data virtualization layer between traditional databases and modern data storage platforms, such as Hadoop, in the
Bringing Data to Life
 Bringing Data to Life Data management and Visualization Techniques Benika Hall Rob Harrison Corporate Model Risk March 16, 2018 Introduction Benika Hall Analytic Consultant Wells Fargo - Corporate Model
Bringing Data to Life Data management and Visualization Techniques Benika Hall Rob Harrison Corporate Model Risk March 16, 2018 Introduction Benika Hall Analytic Consultant Wells Fargo - Corporate Model
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Scale out databases for CERN use cases
 Journal of Physics: Conference Series PAPER OPEN ACCESS Scale out databases for CERN use cases To cite this article: Zbigniew Baranowski et al 2015 J. Phys.: Conf. Ser. 664 042002 Related content - Accelerating
Journal of Physics: Conference Series PAPER OPEN ACCESS Scale out databases for CERN use cases To cite this article: Zbigniew Baranowski et al 2015 J. Phys.: Conf. Ser. 664 042002 Related content - Accelerating
Apache Hive for Oracle DBAs. Luís Marques
 Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation)
 (Development, Administration & REAL TIME Projects Implementation)") HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
Agenda. AWS Database Services Traditional vs AWS Data services model Amazon RDS Redshift DynamoDB ElastiCache
 Databases on AWS 2017 Amazon Web Services, Inc. and its affiliates. All rights served. May not be copied, modified, or distributed in whole or in part without the express consent of Amazon Web Services,
Databases on AWS 2017 Amazon Web Services, Inc. and its affiliates. All rights served. May not be copied, modified, or distributed in whole or in part without the express consent of Amazon Web Services,
exam. Microsoft Perform Data Engineering on Microsoft Azure HDInsight. Version 1.0
 70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
Microsoft. Exam Questions Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo
 Version:Demo") Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 HOTSPOT You install the Microsoft Hive ODBC Driver on a computer that runs Windows
Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 HOTSPOT You install the Microsoft Hive ODBC Driver on a computer that runs Windows
Employing HPC DEEP-EST for HEP Data Analysis. Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN)
, Maria Girone (CERN)") Employing HPC DEEP-EST for HEP Data Analysis Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN) 1 Outline The DEEP-EST Project Goals and Motivation HEP Data Analysis on HPC with Apache Spark on HPC
Employing HPC DEEP-EST for HEP Data Analysis Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN) 1 Outline The DEEP-EST Project Goals and Motivation HEP Data Analysis on HPC with Apache Spark on HPC
Increase Value from Big Data with Real-Time Data Integration and Streaming Analytics
 Increase Value from Big Data with Real-Time Data Integration and Streaming Analytics Cy Erbay Senior Director Striim Executive Summary Striim is Uniquely Qualified to Solve the Challenges of Real-Time
Increase Value from Big Data with Real-Time Data Integration and Streaming Analytics Cy Erbay Senior Director Striim Executive Summary Striim is Uniquely Qualified to Solve the Challenges of Real-Time
Elastify Cloud-Native Spark Application with PMEM. Junping Du --- Chief Architect, Tencent Cloud Big Data Department Yue Li --- Cofounder, MemVerge
 Elastify Cloud-Native Spark Application with PMEM Junping Du --- Chief Architect, Tencent Cloud Big Data Department Yue Li --- Cofounder, MemVerge Table of Contents Sparkling: The Tencent Cloud Data Warehouse
Elastify Cloud-Native Spark Application with PMEM Junping Du --- Chief Architect, Tencent Cloud Big Data Department Yue Li --- Cofounder, MemVerge Table of Contents Sparkling: The Tencent Cloud Data Warehouse
Accelerate Big Data Insights
 Accelerate Big Data Insights Executive Summary An abundance of information isn t always helpful when time is of the essence. In the world of big data, the ability to accelerate time-to-insight can not
Accelerate Big Data Insights Executive Summary An abundance of information isn t always helpful when time is of the essence. In the world of big data, the ability to accelerate time-to-insight can not
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
IBM Big SQL Partner Application Verification Quick Guide
 IBM Big SQL Partner Application Verification Quick Guide VERSION: 1.6 DATE: Sept 13, 2017 EDITORS: R. Wozniak D. Rangarao Table of Contents 1 Overview of the Application Verification Process... 3 2 Platform
IBM Big SQL Partner Application Verification Quick Guide VERSION: 1.6 DATE: Sept 13, 2017 EDITORS: R. Wozniak D. Rangarao Table of Contents 1 Overview of the Application Verification Process... 3 2 Platform
Hadoop. Introduction to BIGDATA and HADOOP
 Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Tatsuhiro Chiba, Takeshi Yoshimura, Michihiro Horie and Hiroshi Horii IBM Research
 Tatsuhiro Chiba, Takeshi Yoshimura, Michihiro Horie and Hiroshi Horii IBM Research IBM Research 2 IEEE CLOUD 2018 / Towards Selecting Best Combination of SQL-on-Hadoop Systems and JVMs à à Application
Tatsuhiro Chiba, Takeshi Yoshimura, Michihiro Horie and Hiroshi Horii IBM Research IBM Research 2 IEEE CLOUD 2018 / Towards Selecting Best Combination of SQL-on-Hadoop Systems and JVMs à à Application
Migrate from Netezza Workload Migration
 Migrate from Netezza Automated Big Data Open Netezza Source Workload Migration CASE SOLUTION STUDY BRIEF Automated Netezza Workload Migration To achieve greater scalability and tighter integration with
Migrate from Netezza Automated Big Data Open Netezza Source Workload Migration CASE SOLUTION STUDY BRIEF Automated Netezza Workload Migration To achieve greater scalability and tighter integration with
Principal Software Engineer Red Hat Emerging Technology June 24, 2015
 USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
CloudExpo November 2017 Tomer Levi
 CloudExpo November 2017 Tomer Levi About me Full Stack Engineer @ Intel s Advanced Analytics group. Artificial Intelligence unit at Intel. Responsible for (1) Radical improvement of critical processes
CloudExpo November 2017 Tomer Levi About me Full Stack Engineer @ Intel s Advanced Analytics group. Artificial Intelligence unit at Intel. Responsible for (1) Radical improvement of critical processes
Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData
 Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData ` Ronen Ovadya, Ofir Manor, JethroData About JethroData Founded 2012 Raised funding from Pitango in 2013 Engineering in Israel,
Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData ` Ronen Ovadya, Ofir Manor, JethroData About JethroData Founded 2012 Raised funding from Pitango in 2013 Engineering in Israel,
Accelerating Spark Workloads using GPUs
 Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
BIG DATA COURSE CONTENT
 BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay Mellanox Technologies
 Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
Overview. About CERN 2 / 11
 Overview CERN wanted to upgrade the data monitoring system of one of its Large Hadron Collider experiments called ALICE (A La rge Ion Collider Experiment) to ensure the experiment s high efficiency. They
Overview CERN wanted to upgrade the data monitoring system of one of its Large Hadron Collider experiments called ALICE (A La rge Ion Collider Experiment) to ensure the experiment s high efficiency. They
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
The Future of Real-Time in Spark
 The Future of Real-Time in Spark Reynold Xin @rxin Spark Summit, New York, Feb 18, 2016 Why Real-Time? Making decisions faster is valuable. Preventing credit card fraud Monitoring industrial machinery
The Future of Real-Time in Spark Reynold Xin @rxin Spark Summit, New York, Feb 18, 2016 Why Real-Time? Making decisions faster is valuable. Preventing credit card fraud Monitoring industrial machinery
PUBLIC SAP Vora Sizing Guide
 SAP Vora 2.0 Document Version: 1.1 2017-11-14 PUBLIC Content 1 Introduction to SAP Vora....3 1.1 System Architecture....5 2 Factors That Influence Performance....6 3 Sizing Fundamentals and Terminology....7
SAP Vora 2.0 Document Version: 1.1 2017-11-14 PUBLIC Content 1 Introduction to SAP Vora....3 1.1 System Architecture....5 2 Factors That Influence Performance....6 3 Sizing Fundamentals and Terminology....7
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Oracle Big Data Connectors
 Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Microsoft Azure Databricks for data engineering. Building production data pipelines with Apache Spark in the cloud
 Microsoft Azure Databricks for data engineering Building production data pipelines with Apache Spark in the cloud Azure Databricks As companies continue to set their sights on making data-driven decisions
Microsoft Azure Databricks for data engineering Building production data pipelines with Apache Spark in the cloud Azure Databricks As companies continue to set their sights on making data-driven decisions
Databricks Delta: Bringing Unprecedented Reliability and Performance to Cloud Data Lakes
 Databricks Delta: Bringing Unprecedented Reliability and Performance to Cloud Data Lakes AN UNDER THE HOOD LOOK Databricks Delta, a component of the Databricks Unified Analytics Platform*, is a unified
Databricks Delta: Bringing Unprecedented Reliability and Performance to Cloud Data Lakes AN UNDER THE HOOD LOOK Databricks Delta, a component of the Databricks Unified Analytics Platform*, is a unified
4th National Conference on Electrical, Electronics and Computer Engineering (NCEECE 2015)
") 4th National Conference on Electrical, Electronics and Computer Engineering (NCEECE 2015) Benchmark Testing for Transwarp Inceptor A big data analysis system based on in-memory computing Mingang Chen1,2,a,
4th National Conference on Electrical, Electronics and Computer Engineering (NCEECE 2015) Benchmark Testing for Transwarp Inceptor A big data analysis system based on in-memory computing Mingang Chen1,2,a,
Scalable Tools - Part I Introduction to Scalable Tools
 Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
 About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Hadoop Online Training
 Hadoop Online Training IQ training facility offers Hadoop Online Training. Our Hadoop trainers come with vast work experience and teaching skills. Our Hadoop training online is regarded as the one of the
Hadoop Online Training IQ training facility offers Hadoop Online Training. Our Hadoop trainers come with vast work experience and teaching skills. Our Hadoop training online is regarded as the one of the
Modern Data Warehouse The New Approach to Azure BI
 Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
Autonomous Database Level 100
 Autonomous Database Level 100 Sanjay Narvekar December 2018 1 Safe Harbor Statement The following is intended to outline our general product direction. It is intended for information purposes only, and
Autonomous Database Level 100 Sanjay Narvekar December 2018 1 Safe Harbor Statement The following is intended to outline our general product direction. It is intended for information purposes only, and
Flash Storage Complementing a Data Lake for Real-Time Insight
 Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
HiTune. Dataflow-Based Performance Analysis for Big Data Cloud
 HiTune Dataflow-Based Performance Analysis for Big Data Cloud Jinquan (Jason) Dai, Jie Huang, Shengsheng Huang, Bo Huang, Yan Liu Intel Asia-Pacific Research and Development Ltd Shanghai, China, 200241
HiTune Dataflow-Based Performance Analysis for Big Data Cloud Jinquan (Jason) Dai, Jie Huang, Shengsheng Huang, Bo Huang, Yan Liu Intel Asia-Pacific Research and Development Ltd Shanghai, China, 200241
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Evolution of the Logging Service Hands-on Hadoop Proof of Concept for CALS-2.0
 Evolution of the Logging Service Hands-on Hadoop Proof of Concept for CALS-2.0 Chris Roderick Marcin Sobieszek Piotr Sowinski Nikolay Tsvetkov Jakub Wozniak Courtesy IT-DB Agenda Intro to CALS System Hadoop
Evolution of the Logging Service Hands-on Hadoop Proof of Concept for CALS-2.0 Chris Roderick Marcin Sobieszek Piotr Sowinski Nikolay Tsvetkov Jakub Wozniak Courtesy IT-DB Agenda Intro to CALS System Hadoop
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem. Zohar Elkayam
 Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
AWS Serverless Architecture Think Big
 MAKING BIG DATA COME ALIVE AWS Serverless Architecture Think Big Garrett Holbrook, Data Engineer Feb 1 st, 2017 Agenda What is Think Big? Example Project Walkthrough AWS Serverless 2 Think Big, a Teradata
MAKING BIG DATA COME ALIVE AWS Serverless Architecture Think Big Garrett Holbrook, Data Engineer Feb 1 st, 2017 Agenda What is Think Big? Example Project Walkthrough AWS Serverless 2 Think Big, a Teradata
Workload Characterization and Optimization of TPC-H Queries on Apache Spark
 Workload Characterization and Optimization of TPC-H Queries on Apache Spark Tatsuhiro Chiba and Tamiya Onodera IBM Research - Tokyo April. 17-19, 216 IEEE ISPASS 216 @ Uppsala, Sweden Overview IBM Research
Workload Characterization and Optimization of TPC-H Queries on Apache Spark Tatsuhiro Chiba and Tamiya Onodera IBM Research - Tokyo April. 17-19, 216 IEEE ISPASS 216 @ Uppsala, Sweden Overview IBM Research
Hue Application for Big Data Ingestion
 Hue Application for Big Data Ingestion August 2016 Author: Medina Bandić Supervisor(s): Antonio Romero Marin Manuel Martin Marquez CERN openlab Summer Student Report 2016 1 Abstract The purpose of project
Hue Application for Big Data Ingestion August 2016 Author: Medina Bandić Supervisor(s): Antonio Romero Marin Manuel Martin Marquez CERN openlab Summer Student Report 2016 1 Abstract The purpose of project
TPCX-BB (BigBench) Big Data Analytics Benchmark
 Big Data Analytics Benchmark") TPCX-BB (BigBench) Big Data Analytics Benchmark Bhaskar D Gowda Senior Staff Engineer Analytics & AI Solutions Group Intel Corporation bhaskar.gowda@intel.com 1 Agenda Big Data Analytics & Benchmarks Industry
TPCX-BB (BigBench) Big Data Analytics Benchmark Bhaskar D Gowda Senior Staff Engineer Analytics & AI Solutions Group Intel Corporation bhaskar.gowda@intel.com 1 Agenda Big Data Analytics & Benchmarks Industry
zspotlight: Spark on z/os
 zspotlight: Spark on z/os Avijit Chatterjee, Ph.D. achatter@us.ibm.com, @ChatterAvijit STSM, IBM Competitive Project Office 1 CEOs are increasingly focused on customers as individuals leveraging contextual
zspotlight: Spark on z/os Avijit Chatterjee, Ph.D. achatter@us.ibm.com, @ChatterAvijit STSM, IBM Competitive Project Office 1 CEOs are increasingly focused on customers as individuals leveraging contextual
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG
 BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
SSDs that Think. Noam Mizrahi Vice President, Technology and Architecture CTO Office, Marvell
 SSDs that Think Intelligent SSDs Can Handle a Larger Computing Load at the Edge Noam Mizrahi Vice President, Technology and Architecture CTO Office, Marvell People have been mining forever 18xx 19xx Gold
SSDs that Think Intelligent SSDs Can Handle a Larger Computing Load at the Edge Noam Mizrahi Vice President, Technology and Architecture CTO Office, Marvell People have been mining forever 18xx 19xx Gold
Stream Processing Platforms Storm, Spark,.. Batch Processing Platforms MapReduce, SparkSQL, BigQuery, Hive, Cypher,...
 Data Ingestion ETL, Distcp, Kafka, OpenRefine, Query & Exploration SQL, Search, Cypher, Stream Processing Platforms Storm, Spark,.. Batch Processing Platforms MapReduce, SparkSQL, BigQuery, Hive, Cypher,...
Data Ingestion ETL, Distcp, Kafka, OpenRefine, Query & Exploration SQL, Search, Cypher, Stream Processing Platforms Storm, Spark,.. Batch Processing Platforms MapReduce, SparkSQL, BigQuery, Hive, Cypher,...
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Adaptive Executive Layer with Pentaho Data Integration
 Adaptive Executive Layer with Pentaho Data Integration An Introduction to AEL and the AEL Spark Engine Jonathan Jarvis Senior Solutions Engineer / Engineering Services June 26th, 2018 Agenda AEL Overview
Adaptive Executive Layer with Pentaho Data Integration An Introduction to AEL and the AEL Spark Engine Jonathan Jarvis Senior Solutions Engineer / Engineering Services June 26th, 2018 Agenda AEL Overview
Do-It-Yourself 1. Oracle Big Data Appliance 2X Faster than
 Oracle Big Data Appliance 2X Faster than Do-It-Yourself 1 Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such
Oracle Big Data Appliance 2X Faster than Do-It-Yourself 1 Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Security and Performance advances with Oracle Big Data SQL
 Security and Performance advances with Oracle Big Data SQL Jean-Pierre Dijcks Oracle Redwood Shores, CA, USA Key Words SQL, Oracle, Database, Analytics, Object Store, Files, Big Data, Big Data SQL, Hadoop,
Security and Performance advances with Oracle Big Data SQL Jean-Pierre Dijcks Oracle Redwood Shores, CA, USA Key Words SQL, Oracle, Database, Analytics, Object Store, Files, Big Data, Big Data SQL, Hadoop,
Jupyter and Spark on Mesos: Best Practices. June 21 st, 2017
 Jupyter and Spark on Mesos: Best Practices June 2 st, 207 Agenda About me What is Spark & Jupyter Demo How Spark+Mesos+Jupyter work together Experience Q & A About me Graduated from EE @ Tsinghua Univ.
Jupyter and Spark on Mesos: Best Practices June 2 st, 207 Agenda About me What is Spark & Jupyter Demo How Spark+Mesos+Jupyter work together Experience Q & A About me Graduated from EE @ Tsinghua Univ.