Starting with Apache Spark, Best Practices and Learning from the Field
|
|
|
- Magnus Joseph
- 6 years ago
- Views:
Transcription

1

2 Starting with Apache Spark, Best Practices and Learning from the Field Felix Cheung, Principal Engineer + Spark Committer Spark@Microsoft
3
4 Best Practices Enterprise Solutions

5
6
7 Resilient - Fault tolerant
8
9 19,500+ commits
10 Tungsten AMPLab becoming RISELab Drizzle low latency execution, 3.5x lower than Spark Streaming Ernest performance prediction, automatically choose the optimal resource config on the cloud
11
12 Spark Core Deployment Scheduler Resource Manager (aka Cluster Manager) - Spark History Server, Spark UI

13
14 Parallelization, Partition Transformation Action Shuffle
15 Doing multiple things at the same time
16 A unit of parallelization
17 Manipulating data - immutable "Narrow" "Wide"

18

19
20 Processing: sorting, serialize/deserialize, compression Transfer: disk IO, network bandwidth/latency Take up memory, or spill to disk for intermediate results ("shuffle file")
21 Materialize results Execute the chain of transformations that leads to output lazy evaluation count collect -> take write
22 SQL DataFrame Dataset Data source Execution engine - Catalyst
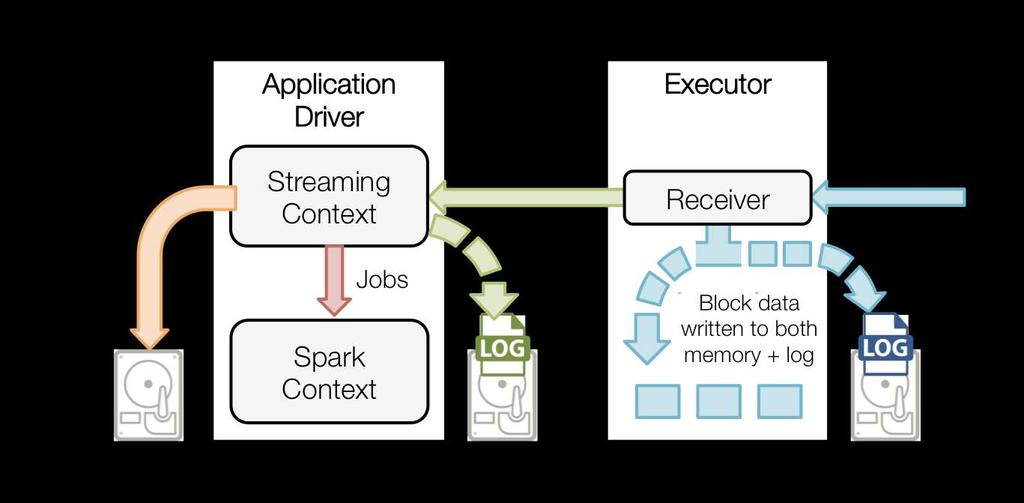
23 Execution Plan Predicate Pushdown
24 Strong typing Optimized execution
25 Dataset[Row] Partition = set of Row's

26 "format" - Parquet, CSV, JSON, or Cassandra, HBase
27
28 Ability to process expressions as early in the plan as possible
29 spark.read.jdbc(jdbcurl, "food", connectionproperties) // with pushdown spark.read.jdbc(jdbcurl, "food", connectionproperties).select("hotdog", "pizza", "sushi")
30 Streaming Discretized Streams (DStreams) Receiver DStream Direct DStream Basic and Advanced Sources
31 Source Reliability Receiver + Write Ahead Log (WAL) Checkpointing




32
33
34
35
36 Only for reliable messaging sources that supports read from position Stronger fault-tolerance, exactly-once* No receiver/wal less resource, lower overhead
37 Saving to reliable storage to recover from failure 1. Metadata checkpointing StreamingContext.checkpoint() 2. Data checkpointing dstream.checkpoint()
38 Machine Learning ML Pipeline Transformer Estimator Evaluator
39 DataFrame-based - leverage optimizations and support transformations a sequence of algorithms - PipelineStages

40 DataFrame Transformer Transformer Estimator Feature engineering Modeling
41 Feature transformer - take a DataFrame and its Column and append one or more new Column
42 StopWordsRemover Binarizer SQLTransformer VectorAssembler
43 Estimators An algorithm DataFrame -> Model A Model is a Transformer LinearRegression KMeans
44 Evaluator Metric to measure Model performance on held-out test data
45 Evaluator MulticlassClassificationEvaluator BinaryClassificationEvaluator RegressionEvaluator
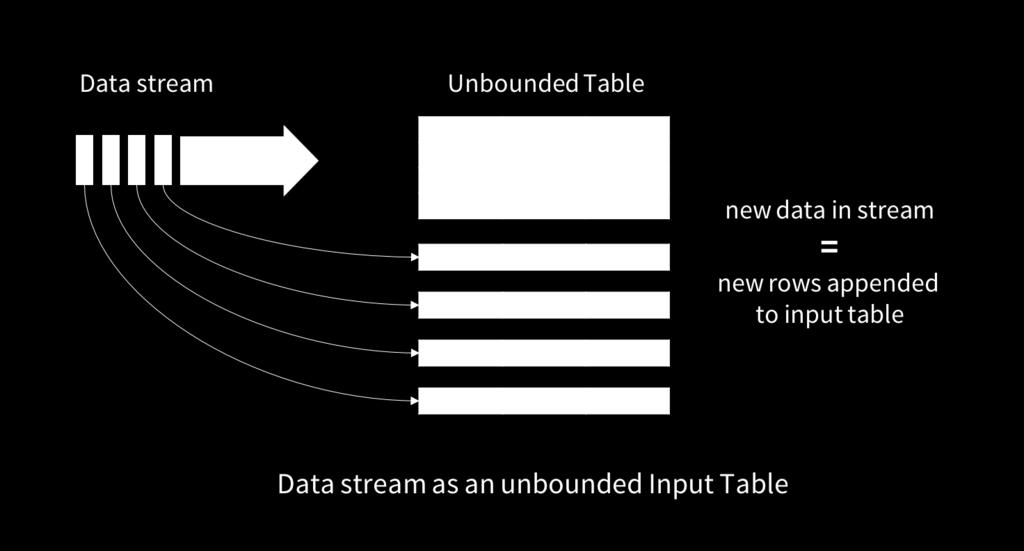
46 MLWriter/MLReader Pipeline persistence Include transformers, estimators, Params
47 Graph Graph Pregel Graph Algorithms Graph Queries
48 Directed multigraph with user properties on edges and vertices SEA NYC LAX
49 PageRank ConnectedComponents ranks = tripgraph.pagerank(resetprobability= 0.15, maxiter=5)
50 DataFrame-based Simplify loading graph data, wrangling Support Graph Queries
51 Pattern matching Mix pattern with SQL syntax motifs = g.find("(a)-[e]->(b); (b)- [e2]->(a);!(c)-[]->(a)").filter("a.id = 'MIA'")
52 Structured Streaming Structured Streaming Model Source Sink StreamingQuery
53 Extending same DataFrame to include incremental execution of unbounded input Reliability, correctness / exactly-once - checkpointing (2.1 JSON format)
54 Stream as Unbounded Input
55 Watermark (2.1) - handling of late data Streaming ETL, joining static data, partitioning, windowing
56 FileStreamSource KafkaSource MemoryStream (not for production) TextSocketSource MQTT
57 FileStreamSink (new formats in 2.1) ConsoleSink ForeachSink (Scala only) MemorySink as Temp View
58 staticdf = ( spark.read.schema(jsonschema).json(inputpath) )
59 streamingdf = ( spark.readstream.schema(jsonschema).option("maxfilespertrigger", 1).json(inputPath) ) # Take a list of files as a stream
60 streamingcountsdf = ( streamingdf.groupby( streamingdf.word, window( streamingdf.time, "1 hour")).count() )
61 query = ( streamingcountsdf.writestream.format("memory").queryname("word_counts").outputmode("complete").start() ) spark.sql("select count from word_counts order by time")
62
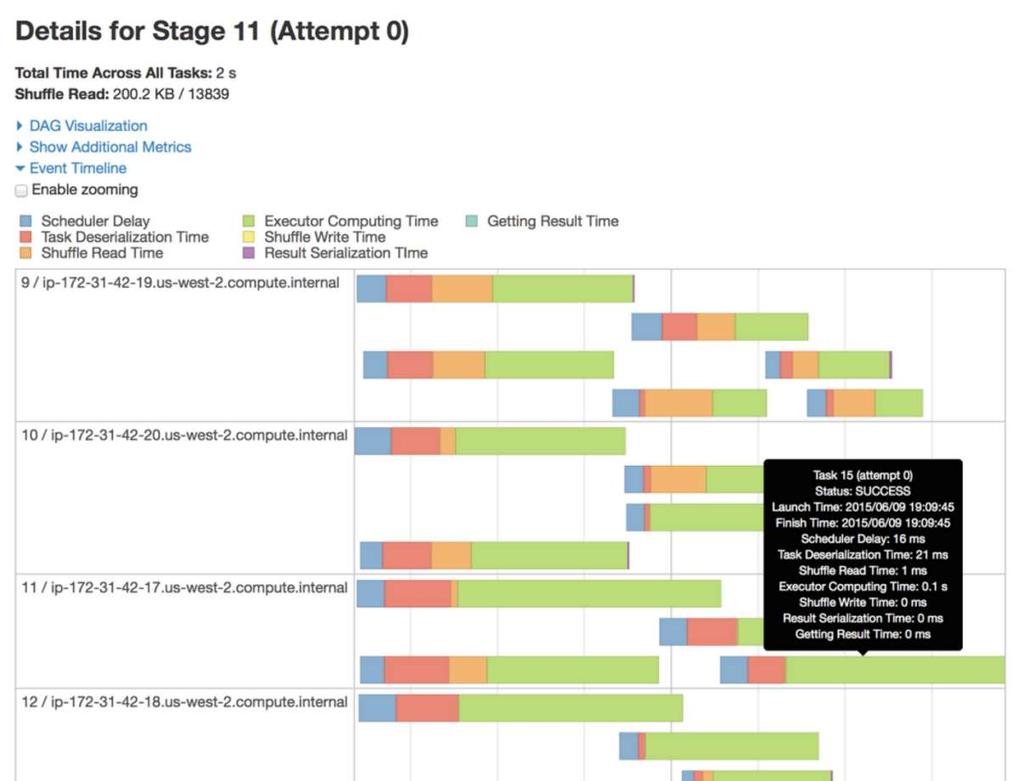
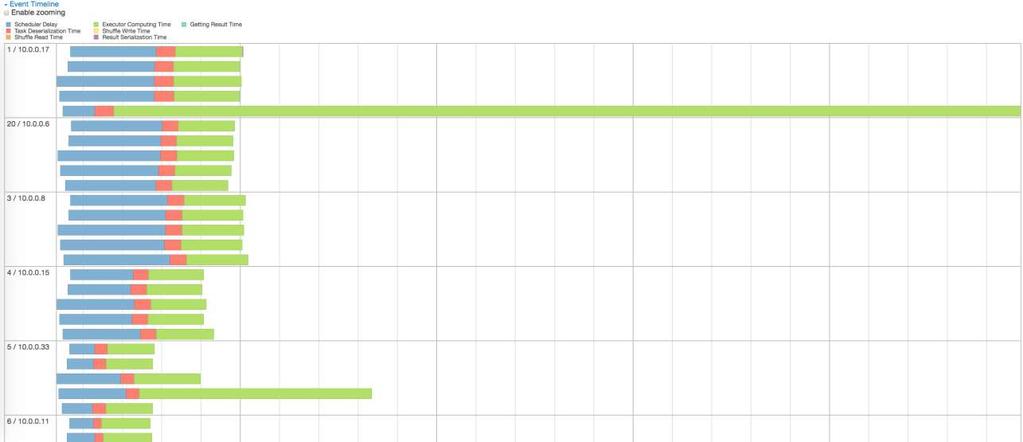
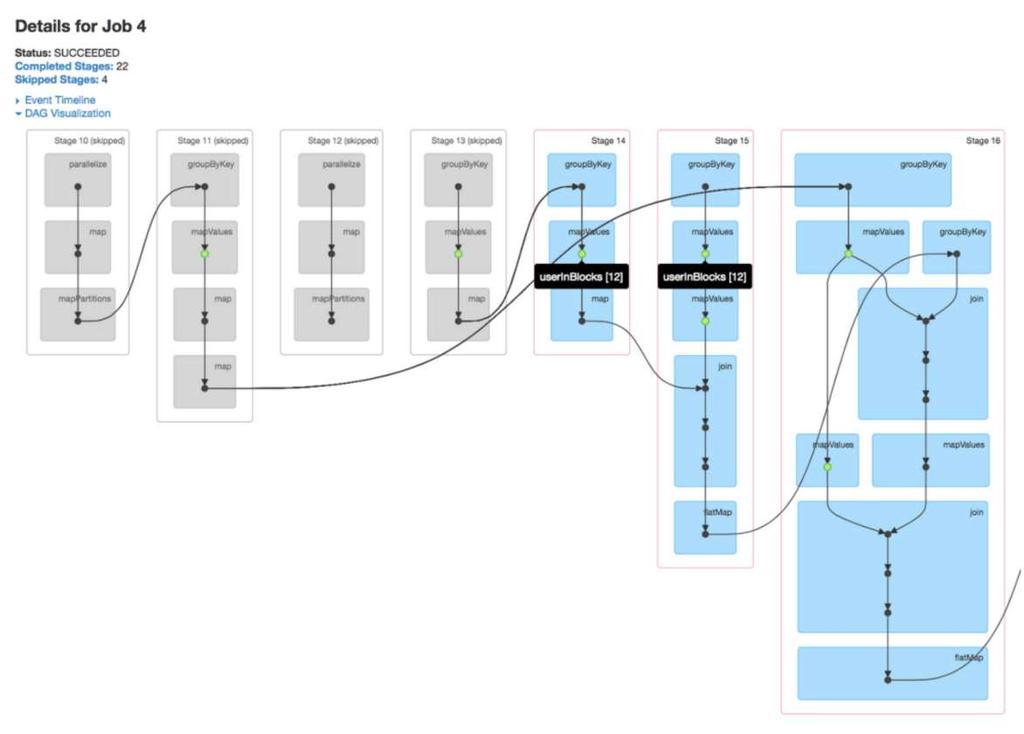
63 How much going in affects how much work it's going to take
64 Size does matter! CSV or JSON is "simple" but also tend to be big JSON-> Parquet (compressed) - 7x faster
65 Format also does matter Recommended format - Parquet Default data source/format VectorizedReader Better dictionary decoding
66 Parquet Columnar Format Column chunk co-located Metadata and headers for skipping
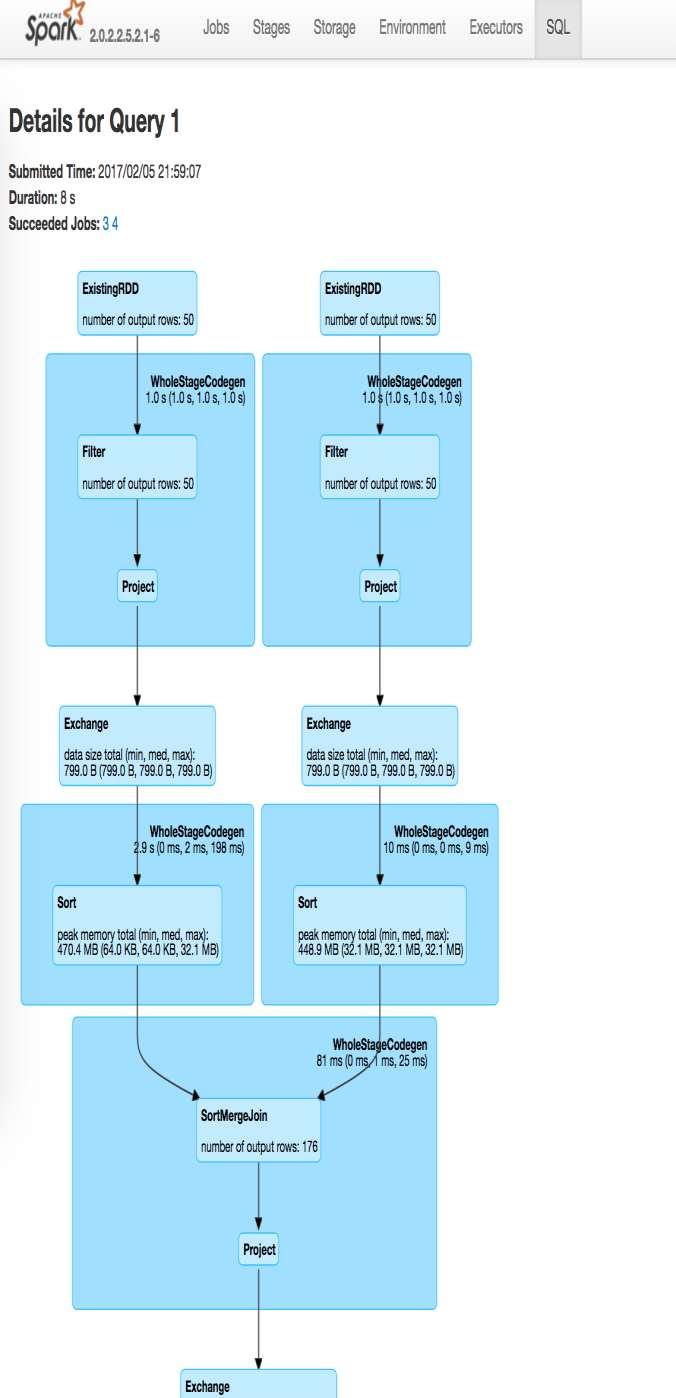
67 Recommend Parquet
68 Compression is a factor gzip <100MB/s vs snappy 500MB/s Tradeoffs: faster or smaller? Spark 2.0+ defaults to snappy
69 Sidenote: Table Partitioning Storage data into groups of partitioning columns Encoded path structure matches Hive table/event_date=
70 Spark UI Timeline view
71
72 Spark UI DAG view
73 Executor tab
74 SQL tab
75
76 Understanding Queries explain() is your friend but it could be hard to understand at times == Parsed Logical Plan == Aggregate [count(1) AS count#79l] +- Sort [speed_y#49 ASC], true +- Join Inner, (speed_x#48 = speed_y#49) :- Project [speed#2 AS speed_x#48, dist#3] : +- LogicalRDD [speed#2, dist#3] +- Project [speed#18 AS speed_y#49, dist#19] +- LogicalRDD [speed#18, dist#19]

77
78 == Physical Plan == *HashAggregate(keys=[], functions=[count(1)], output=[count#79l]) +- Exchange SinglePartition +- *HashAggregate(keys=[], functions=[partial_count(1)], output=[count#83l]) +- *Project +- *Sort [speed_y#49 ASC], true, 0 +- Exchange rangepartitioning(speed_y#49 ASC, 200) +- *Project [speed_y#49] +- *SortMergeJoin [speed_x#48], [speed_y#49], Inne :- *Sort [speed_x#48 ASC], false, 0 : +- Exchange hashpartitioning(speed_x#48, 200 : +- *Project [speed#2 AS speed_x#48] : +- *Filter isnotnull(speed#2) : +- Scan ExistingRDD[speed#2,dist#3] +- *Sort [speed_y#49 ASC], false, 0 +- Exchange hashpartitioning(speed_y#49, 200
79 UDF Write you own custom transforms But... Catalyst can't see through it (yet?!) Always prefer to use builtin transforms as much as possible
80 UDF vs Builtin Example Remember Predicate Pushdown? val isseattle = udf { (s: String) => s == "Seattle" } cities.where(isseattle('name)) *Filter UDF(name#2) +- *FileScan parquet [id#128l,name#2] Batched: true, Format: ParquetFormat, InputPaths: file:/users/b/cities.parquet, PartitionFilters: [], PushedFilters: [], ReadSchema: struct<id:bigint,name:string>
81 UDF vs Builtin Example cities.where('name === "Seattle") *Project [id#128l, name#2] +- *Filter (isnotnull(name#2) && (name#2 = Seattle)) +- *FileScan parquet [id#128l,name#2] Batched: true, Format: ParquetFormat, InputPaths: file:/users/b/cities.parquet, PartitionFilters: [], PushedFilters: [IsNotNull(name), EqualTo(name,Seattle)], ReadSchema: struct<id:bigint,name:string>
82 UDF in Python from pyspark.sql.types import IntegerType sqlcontext.udf.register("stringlengthint", lambda x: len(x), IntegerType()) sqlcontext.sql("select stringlengthint('test')").take(1) Avoid! Why? Pickling, transfer, extra memory to run Python interpreter - Hard to debug errors!
83 Going for Performance Stored in compressed Parquet Partitioned table Predicate Pushdown Avoid UDF
84 Shuffling for Join Can be very expensive
85 Optimizing for Join Partition! Narrow transform if left and right partitioned with same scheme
86 Optimizing for Join Broadcast Join (aka Map-Side Join in Hadoop) Smaller table against large table - avoid shuffling large table Default 10MB auto broadcast
87 BroadcastHashJoin left.join(right, Seq("id"), "leftanti").explain == Physical Plan == *BroadcastHashJoin [id#50], [id#60], LeftAnti, BuildRight :- LocalTableScan [id#50, left#51] +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint))) +- LocalTableScan [id#60]
88 Repartition To numpartitions or by Columns Increase parallelism will shuffle coalesce() combine partitions in place
89 Cache cache() or persist() Flush least-recently-used (LRU) - Make sure there is enough memory! MEMORY_AND_DISK to avoid expensive recompute (but spill to disk is slow)
90 Streaming Use Structured Streaming (2.1+) If not... If reliable messaging (Kafka) use Direct DStream
91 Metadata - Config Position from streaming source (aka offset) - could get duplicates! (at-least-once) Pending batches
92 Persist stateful transformations - data lost if not saved Cut short execution that could grow indefinitely
93 Direct DStream Checkpoint also store offset Turn off auto commit - do when in good state for exactlyonce
94 Checkpointing Stream/ML/Graph/SQL - more efficient indefinite/iterative - recovery Generally not versioning-safe Use reliable distributed file system (caution on object store )
95
96
97 Hadoop External Data Source Hourly Hive FrontEnd WebLog Spark SQL HDFS Hive Metastore BI Tools
98 Near-RealTime (end-to-end roundtrip: 8-20 sec) Spark ML FrontEnd Kafka Spark Streaming HDFS Offline Analysis
99
100 BI Tools SQL Appliance Spark SQL Hive BI Tools RDBMS
101
102 Visualization Kafka Spark Streaming Spark ML BI Tools Message Bus Storage Data Lake Hive Metastore External Data Source Spark SQL Spark ML
103
104 SQL SQL Visualization Spark SQL Kafka Spark Streaming Hive BI Tools Flume HDFS Presto Data Science Notebook
105
106 Message Bus Spark Streaming Spark SQL Spark SQL Storage SQL Data Factory
107 Moving
108
109
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Asanka Padmakumara. ETL 2.0: Data Engineering with Azure Databricks
 Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Apache Hive for Oracle DBAs. Luís Marques
 Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Spark 2. Alexey Zinovyev, Java/BigData Trainer in EPAM
 Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
Kafka pours and Spark resolves! Alexey Zinovyev, Java/BigData Trainer in EPAM
 Kafka pours and Spark resolves! Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With Spark since 2014 With EPAM since 2015 About Contacts E-mail
Kafka pours and Spark resolves! Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With Spark since 2014 With EPAM since 2015 About Contacts E-mail
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Apache Spark Tutorial
 Apache Spark Tutorial Reynold Xin @rxin BOSS workshop at VLDB 2017 Apache Spark The most popular and de-facto framework for big data (science) APIs in SQL, R, Python, Scala, Java Support for SQL, ETL,
Apache Spark Tutorial Reynold Xin @rxin BOSS workshop at VLDB 2017 Apache Spark The most popular and de-facto framework for big data (science) APIs in SQL, R, Python, Scala, Java Support for SQL, ETL,
Time Series Storage with Apache Kudu (incubating)
") Time Series Storage with Apache Kudu (incubating) Dan Burkert (Committer) dan@cloudera.com @danburkert Tweet about this talk: @getkudu or #kudu 1 Time Series machine metrics event logs sensor telemetry
Time Series Storage with Apache Kudu (incubating) Dan Burkert (Committer) dan@cloudera.com @danburkert Tweet about this talk: @getkudu or #kudu 1 Time Series machine metrics event logs sensor telemetry
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Security and Performance advances with Oracle Big Data SQL
 Security and Performance advances with Oracle Big Data SQL Jean-Pierre Dijcks Oracle Redwood Shores, CA, USA Key Words SQL, Oracle, Database, Analytics, Object Store, Files, Big Data, Big Data SQL, Hadoop,
Security and Performance advances with Oracle Big Data SQL Jean-Pierre Dijcks Oracle Redwood Shores, CA, USA Key Words SQL, Oracle, Database, Analytics, Object Store, Files, Big Data, Big Data SQL, Hadoop,
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Apache Spark for RDBMS Practitioners: How I Learned to Stop Worrying and Love to Scale
 Apache Spark for RDBMS Practitioners: How I Learned to Stop Worrying and Love to Scale Luca Canali, CERN About Luca Data Engineer and team lead at CERN Hadoop and Spark service, database services 18+ years
Apache Spark for RDBMS Practitioners: How I Learned to Stop Worrying and Love to Scale Luca Canali, CERN About Luca Data Engineer and team lead at CERN Hadoop and Spark service, database services 18+ years
Distributed Systems. 22. Spark. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
April Copyright 2013 Cloudera Inc. All rights reserved.
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
빅데이터기술개요 2016/8/20 ~ 9/3. 윤형기
 빅데이터기술개요 2016/8/20 ~ 9/3 윤형기 (hky@openwith.net) D4 http://www.openwith.net 2 Hive http://www.openwith.net 3 What is Hive? 개념 a data warehouse infrastructure tool to process structured data in Hadoop. Hadoop
빅데이터기술개요 2016/8/20 ~ 9/3 윤형기 (hky@openwith.net) D4 http://www.openwith.net 2 Hive http://www.openwith.net 3 What is Hive? 개념 a data warehouse infrastructure tool to process structured data in Hadoop. Hadoop
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
Apache Kudu. Zbigniew Baranowski
 Apache Kudu Zbigniew Baranowski Intro What is KUDU? New storage engine for structured data (tables) does not use HDFS! Columnar store Mutable (insert, update, delete) Written in C++ Apache-licensed open
Apache Kudu Zbigniew Baranowski Intro What is KUDU? New storage engine for structured data (tables) does not use HDFS! Columnar store Mutable (insert, update, delete) Written in C++ Apache-licensed open
Big Streaming Data Processing. How to Process Big Streaming Data 2016/10/11. Fraud detection in bank transactions. Anomalies in sensor data
 Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Structured Streaming. Big Data Analysis with Scala and Spark Heather Miller
 Structured Streaming Big Data Analysis with Scala and Spark Heather Miller Why Structured Streaming? DStreams were nice, but in the last session, aggregation operations like a simple word count quickly
Structured Streaming Big Data Analysis with Scala and Spark Heather Miller Why Structured Streaming? DStreams were nice, but in the last session, aggregation operations like a simple word count quickly
Agenda. Spark Platform Spark Core Spark Extensions Using Apache Spark
 Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera
L3: Spark & RDD. CDS Department of Computational and Data Sciences. Department of Computational and Data Sciences
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
exam. Microsoft Perform Data Engineering on Microsoft Azure HDInsight. Version 1.0
 70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Exam Questions
 Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Hive and Shark. Amir H. Payberah. Amirkabir University of Technology (Tehran Polytechnic)
") Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Technical Sheet NITRODB Time-Series Database
 Technical Sheet NITRODB Time-Series Database 10X Performance, 1/10th the Cost INTRODUCTION "#$#!%&''$!! NITRODB is an Apache Spark Based Time Series Database built to store and analyze 100s of terabytes
Technical Sheet NITRODB Time-Series Database 10X Performance, 1/10th the Cost INTRODUCTION "#$#!%&''$!! NITRODB is an Apache Spark Based Time Series Database built to store and analyze 100s of terabytes
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
Tatsuhiro Chiba, Takeshi Yoshimura, Michihiro Horie and Hiroshi Horii IBM Research
 Tatsuhiro Chiba, Takeshi Yoshimura, Michihiro Horie and Hiroshi Horii IBM Research IBM Research 2 IEEE CLOUD 2018 / Towards Selecting Best Combination of SQL-on-Hadoop Systems and JVMs à à Application
Tatsuhiro Chiba, Takeshi Yoshimura, Michihiro Horie and Hiroshi Horii IBM Research IBM Research 2 IEEE CLOUD 2018 / Towards Selecting Best Combination of SQL-on-Hadoop Systems and JVMs à à Application
Shark: SQL and Rich Analytics at Scale. Michael Xueyuan Han Ronny Hajoon Ko
 Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Analyzing Flight Data
 IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
Databricks, an Introduction
 Databricks, an Introduction Chuck Connell, Insight Digital Innovation Insight Presentation Speaker Bio Senior Data Architect at Insight Digital Innovation Focus on Azure big data services HDInsight/Hadoop,
Databricks, an Introduction Chuck Connell, Insight Digital Innovation Insight Presentation Speaker Bio Senior Data Architect at Insight Digital Innovation Focus on Azure big data services HDInsight/Hadoop,
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Impala. A Modern, Open Source SQL Engine for Hadoop. Yogesh Chockalingam
 Impala A Modern, Open Source SQL Engine for Hadoop Yogesh Chockalingam Agenda Introduction Architecture Front End Back End Evaluation Comparison with Spark SQL Introduction Why not use Hive or HBase?
Impala A Modern, Open Source SQL Engine for Hadoop Yogesh Chockalingam Agenda Introduction Architecture Front End Back End Evaluation Comparison with Spark SQL Introduction Why not use Hive or HBase?
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Hacking PostgreSQL Internals to Solve Data Access Problems
 Hacking PostgreSQL Internals to Solve Data Access Problems Sadayuki Furuhashi Treasure Data, Inc. Founder & Software Architect A little about me... > Sadayuki Furuhashi > github/twitter: @frsyuki > Treasure
Hacking PostgreSQL Internals to Solve Data Access Problems Sadayuki Furuhashi Treasure Data, Inc. Founder & Software Architect A little about me... > Sadayuki Furuhashi > github/twitter: @frsyuki > Treasure
Oracle Big Data Connectors
 Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Parallel Processing Spark and Spark SQL
 Parallel Processing Spark and Spark SQL Amir H. Payberah amir@sics.se KTH Royal Institute of Technology Amir H. Payberah (KTH) Spark and Spark SQL 2016/09/16 1 / 82 Motivation (1/4) Most current cluster
Parallel Processing Spark and Spark SQL Amir H. Payberah amir@sics.se KTH Royal Institute of Technology Amir H. Payberah (KTH) Spark and Spark SQL 2016/09/16 1 / 82 Motivation (1/4) Most current cluster
Databricks Delta: Bringing Unprecedented Reliability and Performance to Cloud Data Lakes
 Databricks Delta: Bringing Unprecedented Reliability and Performance to Cloud Data Lakes AN UNDER THE HOOD LOOK Databricks Delta, a component of the Databricks Unified Analytics Platform*, is a unified
Databricks Delta: Bringing Unprecedented Reliability and Performance to Cloud Data Lakes AN UNDER THE HOOD LOOK Databricks Delta, a component of the Databricks Unified Analytics Platform*, is a unified
Data Analytics Job Guarantee Program
 Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Apache Spark and Scala Certification Training
 About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Activator Library. Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success.
 Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData
 Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData ` Ronen Ovadya, Ofir Manor, JethroData About JethroData Founded 2012 Raised funding from Pitango in 2013 Engineering in Israel,
Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData ` Ronen Ovadya, Ofir Manor, JethroData About JethroData Founded 2012 Raised funding from Pitango in 2013 Engineering in Israel,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
SparkStreaming. Large scale near- realtime stream processing. Tathagata Das (TD) UC Berkeley UC BERKELEY
 UC Berkeley UC BERKELEY") SparkStreaming Large scale near- realtime stream processing Tathagata Das (TD) UC Berkeley UC BERKELEY Motivation Many important applications must process large data streams at second- scale latencies
SparkStreaming Large scale near- realtime stream processing Tathagata Das (TD) UC Berkeley UC BERKELEY Motivation Many important applications must process large data streams at second- scale latencies
Backtesting with Spark
 Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Spark Streaming. Guido Salvaneschi
 Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
An Overview of Apache Spark
 An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
Microsoft. Exam Questions Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo
 Version:Demo") Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 You have an Azure HDInsight cluster. You need to store data in a file format that
Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 You have an Azure HDInsight cluster. You need to store data in a file format that
Lightning Fast Cluster Computing. Michael Armbrust Reflections Projections 2015 Michast
 Lightning Fast Cluster Computing Michael Armbrust - @michaelarmbrust Reflections Projections 2015 Michast What is Apache? 2 What is Apache? Fast and general computing engine for clusters created by students
Lightning Fast Cluster Computing Michael Armbrust - @michaelarmbrust Reflections Projections 2015 Michast What is Apache? 2 What is Apache? Fast and general computing engine for clusters created by students
BIG DATA COURSE CONTENT
 BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
COSC 6339 Big Data Analytics. Introduction to Spark. Edgar Gabriel Fall What is SPARK?
 COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
Shark: SQL and Rich Analytics at Scale. Yash Thakkar ( ) Deeksha Singh ( )
 Deeksha Singh ( )") Shark: SQL and Rich Analytics at Scale Yash Thakkar (2642764) Deeksha Singh (2641679) RDDs as foundation for relational processing in Shark: Resilient Distributed Datasets (RDDs): RDDs can be written at
Shark: SQL and Rich Analytics at Scale Yash Thakkar (2642764) Deeksha Singh (2641679) RDDs as foundation for relational processing in Shark: Resilient Distributed Datasets (RDDs): RDDs can be written at
Microsoft. Exam Questions Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo
 Version:Demo") Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 HOTSPOT You install the Microsoft Hive ODBC Driver on a computer that runs Windows
Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 HOTSPOT You install the Microsoft Hive ODBC Driver on a computer that runs Windows
Oracle Big Data SQL. Release 3.2. Rich SQL Processing on All Data
 Oracle Big Data SQL Release 3.2 The unprecedented explosion in data that can be made useful to enterprises from the Internet of Things, to the social streams of global customer bases has created a tremendous
Oracle Big Data SQL Release 3.2 The unprecedented explosion in data that can be made useful to enterprises from the Internet of Things, to the social streams of global customer bases has created a tremendous
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Apache Flink. Alessandro Margara
 Apache Flink Alessandro Margara alessandro.margara@polimi.it http://home.deib.polimi.it/margara Recap: scenario Big Data Volume and velocity Process large volumes of data possibly produced at high rate
Apache Flink Alessandro Margara alessandro.margara@polimi.it http://home.deib.polimi.it/margara Recap: scenario Big Data Volume and velocity Process large volumes of data possibly produced at high rate
Flash Storage Complementing a Data Lake for Real-Time Insight
 Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
An Introduction to Apache Spark
 An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
Hadoop Online Training
 Hadoop Online Training IQ training facility offers Hadoop Online Training. Our Hadoop trainers come with vast work experience and teaching skills. Our Hadoop training online is regarded as the one of the
Hadoop Online Training IQ training facility offers Hadoop Online Training. Our Hadoop trainers come with vast work experience and teaching skills. Our Hadoop training online is regarded as the one of the
Techno Expert Solutions An institute for specialized studies!
 Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
An Introduction to Apache Spark Big Data Madison: 29 July William Red Hat, Inc.
 An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
The Future of Real-Time in Spark
 The Future of Real-Time in Spark Reynold Xin @rxin Spark Summit, New York, Feb 18, 2016 Why Real-Time? Making decisions faster is valuable. Preventing credit card fraud Monitoring industrial machinery
The Future of Real-Time in Spark Reynold Xin @rxin Spark Summit, New York, Feb 18, 2016 Why Real-Time? Making decisions faster is valuable. Preventing credit card fraud Monitoring industrial machinery
Index. bfs() function, 225 Big data characteristics, 2 variety, 3 velocity, 3 veracity, 3 volume, 2 Breadth-first search algorithm, 220, 225
 function, 225 Big data characteristics, 2 variety, 3 velocity, 3 veracity, 3 volume, 2 Breadth-first search algorithm, 220, 225") Index A Anonymous function, 66 Apache Hadoop, 1 Apache HBase, 42 44 Apache Hive, 6 7, 230 Apache Kafka, 8, 178 Apache License, 7 Apache Mahout, 5 Apache Mesos, 38 42 Apache Pig, 7 Apache Spark, 9 Apache
Index A Anonymous function, 66 Apache Hadoop, 1 Apache HBase, 42 44 Apache Hive, 6 7, 230 Apache Kafka, 8, 178 Apache License, 7 Apache Mahout, 5 Apache Mesos, 38 42 Apache Pig, 7 Apache Spark, 9 Apache
Apache Ignite - Using a Memory Grid for Heterogeneous Computation Frameworks A Use Case Guided Explanation. Chris Herrera Hashmap
 Apache Ignite - Using a Memory Grid for Heterogeneous Computation Frameworks A Use Case Guided Explanation Chris Herrera Hashmap Topics Who - Key Hashmap Team Members The Use Case - Our Need for a Memory
Apache Ignite - Using a Memory Grid for Heterogeneous Computation Frameworks A Use Case Guided Explanation Chris Herrera Hashmap Topics Who - Key Hashmap Team Members The Use Case - Our Need for a Memory
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation)
 (Development, Administration & REAL TIME Projects Implementation)") HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
Adaptive Executive Layer with Pentaho Data Integration
 Adaptive Executive Layer with Pentaho Data Integration An Introduction to AEL and the AEL Spark Engine Jonathan Jarvis Senior Solutions Engineer / Engineering Services June 26th, 2018 Agenda AEL Overview
Adaptive Executive Layer with Pentaho Data Integration An Introduction to AEL and the AEL Spark Engine Jonathan Jarvis Senior Solutions Engineer / Engineering Services June 26th, 2018 Agenda AEL Overview