TUTORIAL: BIG DATA ANALYTICS USING APACHE SPARK
|
|
|
- Darlene Blair
- 6 years ago
- Views:
Transcription


1 TUTORIAL: BIG DATA ANALYTICS USING APACHE SPARK Sugimiyanto Suma Yasir Arfat Supervisor: Prof. Rashid Mehmood
2 Outline 2 Big Data Big Data Analytics Problem Basics of Apache Spark Practice basic examples of Spark Building and Running the Spark Applications Spark s Libraries Practice Data Analytics using applications. Performance tuning of Apache Spark: Cluster Resource Utilization Advance features of Apache Spark: When and How to use
3 Tutorial objective 3 Giving Spark s concepts Build and Run Spark Application Utilization of Apache Spark Standalone Cluster Analytics using Apache Spark with applications

4 Big data 4 Big data is defined by IBM as any data that cannot be captured, managed and/or processed using traditional data management components and techniques. Source:
5 Big data analytic 5 Big data analytics examines large amounts of data to uncover hidden patterns, correlations and other insights. With today s technology, it s possible to analyze our data and get answers from it almost immediately an effort that s slower and less efficient with more traditional business intelligence solutions. Source: sas.com


6 Big data analytic (cont.) 6 Cost reduction. Big data technologies such as Hadoop and cloud-based analytics bring significant cost advantages when it comes to storing large amounts of data plus they can identify more efficient ways of doing business. Faster, better decision making. With the speed of Hadoop and in-memory analytics, combined with the ability to analyze new sources of data, businesses are able to analyze information immediately and make decisions based on what they ve learned. New products and services. With the ability to gauge customer needs and satisfaction through analytics comes the power to give customers what they want. Davenport points out that with big data analytics, more companies are creating new products to meet customers needs. Source:


7 Problem 7 Data growing faster than processing speeds. The only solution is to parallelize the data on large clusters. Wide use in both enterprises and web industry. Source: cluster.jpg
8 Problem 8 Data growing faster than processing speeds. The only solution is to parallelize the data on large clusters. Wide use in both enterprises and web industry. How do we program these things? Source: cluster.jpg

9 Apache 9
10 History of Spark 10 Started in 2009 as a research project at UC Berkeley Hadoop was too inefficient for iterative type algorithms and interactive analysis that the researchers required Spark was initially the result of creating a platform to address those needs At inception, it was already providing speed gains over Hadoop on Map Reduce jobs Open sourced in 2010 Spark Streaming was incorporated as a core component in 2011 In 2013, Spark was transferred to the Apache Software foundation Spark 1.0 released in 2014, where it became the most actively developed and fastest growing Apache project in Apache s history July 26th, 2016 Spark 2.0 released with major improvements in every area over the 1.x branches Source:

11 Spark Community 11 Most active open source community in big data 200+ developers, 50+ companies contributing Source:
12 What is spark? 12 Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming. It eases developer to build an application to process and analyze big data in parallel on top of a cluster. It is an alternative of Hadoop Map Reduce to process big data in parallel. Source:


13 Sequential VS Parallel 13 We utilize more cores/processors/executors fference-serial-parallel-processing/



14 Why spark? 14 Dealing with huge data and parallelize it (speed up) Source:
 15 Hadoop execution flow Spark execution flow")
15 Why spark? (cont.) 15 Hadoop execution flow Spark execution flow Source: g/hype-around-apache-spark/
16 Spark Stack and what you can do 16 Spark SQL For SQL and unstructured data processing MLib Machine Learning Algorithms GraphX Graph Processing Spark Streaming Computation in parallel stream processing of live data streams Source:

17 Execution Flow of Spark 17 Soucre: ocs/latest/cluster-overview.html
18 Terminology 18 Spark Context Represents the connection to a Spark cluster, and can be used to create RDDs, accumulators and broadcast variables on the cluster. Driver Program The process running the main() function of the application and creating the SparkContext Cluster Manager An external service to manage resources on the cluster (standalone manager, YARN, Apache Mesos) Deploy Mode Distinguishes where the driver process runs. "cluster" mode, the framework launches the driver inside of the cluster. "client" mode, the submitter launches the driver outside of the cluster. Source:
19 Terminology (cont.) 19 Worker Node: Nodes that run the application program in cluster Executor Process launched on a worker node, which runs the Tasks Keep data in memory or disk storage Task: A unit of work that will be sent to executor Job Consists multiple tasks Created based on an Action Stage: Each Job is divided into smaller set of tasks called Stages that is sequential and depend on each other Source:
20 Resilient Distributed Dataset (RDD) 20 RDD stands for resilient distributed dataset Resilient - if data is lost, data can be recreated Distributed - stored in nodes among the cluster Dataset - initial data comes from a file or can be created programmatically Partitioned collection of records Spread across the cluster Read-only Caching dataset in memory different storage levels available Source:
21 Resilient Distributed Dataset (Cont.) 21 Resilient Distributed Dataset (RDD) is a basic Abstraction in Spark Immutable, Partitioned collection of elements that can be operated in parallel Simply, RDD is a data type which can be parallelized. RDD main characteristics: A list of partitions A function for computing each split A list of dependencies on other RDDs Optionally, a partitioner for key-value RDDs (e.g. to say that the RDD is hashpartitioned) Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file) Custom RDD can also be implemented (by overriding functions) Source:
22 How basic operations works 22 RDD computations model 3 main steps: Create RDD Transformation Actions Source: 5/11/apache-spark.html
23 Type of Operations 23 Transformations map filter flatmap union, etc. Actions collect count take foreach, etc.
24 Working with RDDs 24 Source:
25 Creating RDDs 25 Two ways creating an RDD Initialize a collection of values val rdd = sc.parallelize(seq(1,2,3,4)) Load data file(s) from filesystem, HDFS, etc. val rdd = sc.textfile( file:///anytext.txt )
26 How the parallelization works 26 Suppose we are working with a standalone node with 4 cores. We want to increment by 1 each element in a list/array. We are running the job in sequential mode. val data = Seq(1,2,3,4) var res[] = {} for(i <- 1 to 4){ res[i] = data[i]+1 } res = (2,3,4,5) Execution time : 4 millisecond
27 How the parallelization works (cont.) 27 Suppose we are working with a standalone node with 4 cores. We want to increment by 1 each element in a list/array. We are going to parallelize the data among 2 cores. val rdd = sc.parallelize(seq(1,2,3,4)) val rddadd = rdd.map(i => i+1) core core-2 res: rddadd = (2,3,4,5) Execution time : 2 millisecond
28 How the parallelization works (cont.) 28 Suppose we are working with a standalone node with 4 cores. We are going to parallelize the data with core-based. val rdd = sc.parallelize(seq(1,2,3,4)) val rddadd = rdd.map(i => i+1) core core-2 core-3 core-4 res: rddadd = (2,3,4,5) Execution time : 1 millisecond
29 Spark Web UI 29 Stage details event timeline showing the timeline of task execution. Notice that only task is executed sequentially. There is only one task at a time.
 30 Stage details event timeline showing the timeline of task execution.")
30 Spark Web UI (cont.) 30 Stage details event timeline showing the timeline of task execution. Notice that there are two tasks are executed in parallel at a time.
 31 Stage details event timeline over four cores, parallelism has increased when we use")
31 Spark Web UI (cont.) 31 Stage details event timeline over four cores, parallelism has increased when we use more cores. It shows that it is running four tasks in parallel at a time.
32 Cluster Deployment 32 Local Node Standalone Deploy Mode Apache Mesos Hadoop YARN Amazon EC2

33 Cluster Deployment 33 Source:spark.apache.org/docs/latest/submitting-applications.html
34 Two ways working with spark 34 Interactively (Spark-shell) Standalone application (Spark-submit)

35 Two ways working with spark (cont.) 35 Interactively (spark-shell)
36 Two ways working with spark (cont.) 36 Standalone application (Spark-submit) spark-submit \ --class company.division.yourclass \ --master spark://<host>:7077 \ --name countingcows CountingCows-1.0.jar spark-submit --class company.division.yourclass --master spark://<host>: name countingcows CountingCows-1.0.jar
37 Simple example: Using Interactive 37 Mode import org.apache.spark._ val conf = new SparkConf().setAppName("ToyApp") val sc = new SparkContext(conf) val rdd = sc.parallelize(seq(10,20,30,40)) val rddadd = rdd.map(i => i+1) rddadd.collect() sc.stop() Create an RDD Transformation Action
38 Building And Running a filter 38 application cd /home/hduser/tutorial/simpleapp/filter 1. Create main class directory : mkdir -p src/main/scala 2. Create script file : vim src/main/scala/filter.scala 2.1 Use this code : import org.apache.spark._ object Filter{ def main(args: Array[String]){ val conf = new SparkConf().setAppName("Filter") val sc = new SparkContext(conf) val x = sc.parallelize(1 to , 2) val y = x.filter(e => e%2==1) y.foreach(println(_)) println("done.") sc.stop() } } Source:
39 Building And Running the filter 39 application 3. Create an sbt file : vim build.sbt 4. Use this application properties : name := "Filter" version := "1.0" scalaversion := "2.11.8" // librarydependencies += "org.apache.spark" %% "spark-core" % "2.2.0" 5. Compile and generate *.jar file : sbt compile sbt package 6. Spark-submit: spark-submit --master local --executor-memory 5g --driver-memory 5g target/scala-2.11/filter_ jar
40 Word count example 40 Working with spark-submit with a million records Case: count word appearance in whole document (commonly used to generate burst words) Submitting the application to single core (sequential) We will see the speedup when submitting to multi-cores (parallel)
41 Word count example (cont.) 41 import org.apache.spark._ object Toy{ def main(args: Array[String]){ val conf = new SparkConf().setAppName("ToyApp") val sc = new SparkContext(conf) val rdd = sc.textfile("file:///home/hduser/tutorial/simpleapp/wordcount big.txt") Create an RDD val start = System.nanoTime val rddlower = rdd.map(i => i.tolowercase().replaceall("[^a-za-z0-9_ ]","")).flatmap(i => i.split(" ")).map(word => (word,1)).reducebykey(_ + _) Transformation } } rddlower.coalesce(1).saveastextfile("file:///home/hduser/tutorial/big_clean.txt") val duration = (System.nanoTime - start) / 1e9d println("done.") println("execution time: "+duration) sc.stop() Action
42 Building Word Count application 42 with SBT cd /home/hduser/tutorial/simpleapp/wordcount 1. Create main class directory : mkdir -p src/main/scala 2. Create script file : vim src/main/scala/wordcount.scala 3. Use this code : import org.apache.spark._ object WordCount{ def main(args: Array[String]){ val conf = new SparkConf().setAppName("Word Count") val sc = new SparkContext(conf) val rdd = sc.textfile("file:///home/hduser/tutorial/simpleapp/wordcount/big.txt") val start = System.nanoTime val rddlower = rdd.map(i => i.tolowercase().replaceall("[^a-za-z0-9_ ]","")).flatmap(i => i.split(" ")).map(word => (word,1)).reducebykey(_ + _) rddlower.coalesce(1).saveastextfile("file:///home/hduser/tutorial/simpleapp/wordcount/result/wordcount") val duration = (System.nanoTime - start) / 1e9d println("done.") println("execution time: "+duration) sc.stop() } }
43 Building And Running the Word Count 43 application 3. Create an sbt file : vim build.sbt 4. Use this application properties : name := "WordCount" version := "1.0" scalaversion := "2.11.8" // librarydependencies += "org.apache.spark" %% "spark-core" % "2.2.0" 5. Compile and generate *.jar file : sbt compile sbt package 6. Submit to one core : spark-submit --master local target/scala-2.11/wordcount_ jar 7. Submit to all cores: Remove the previous result : rm -r /home/hduser/tutorial/simpleapp/wordcount/result/wordcount spark-submit --master local[*] target/scala-2.11/wordcount_ jar
44 Submitting application with spark-submit 44

45 Submitting application with spark-submit (cont.) 45

46 Submitting application with spark-submit (cont.) 46
47 47 Questions?

48 48 Break 30 minutes
49 Welcome Back TUTORIAL: BIG DATA ANALYTICS USING APACHE SPARK Sugimiyanto Suma Yasir Arfat Supervisor: Prof. Rashid Mehmood s
50 Outline 50 Big Data Big Data Analytics Problem Basics of Apache Spark Practice basic examples of Spark Building and Running the Spark Applications Spark s Libraries Practice Data Analytics using applications. Performance tuning of Apache Spark: Cluster Resource Utilization Advance features of Apache Spark: When and How to use
51 Big Data Analytics Component 51 (Gandomi & Haider 2015)

52 Big Data Analytics Using Apache Spark 52
53 Analysis Techniques 53 Natural Language Processing (NLP) Statistical Analysis Machine Learning...
54 Machine Learning 54 In 1959, Arthur Samuel, a pioneer in the field of computer gaming and artificial intelligence defined machine learning as: the field of study that gives computers the ability to learn without being explicitly programmed Finding a pattern from the given dataset (training) Estimate the value of unseen data
 55 A general machine learning pipeline")
55 Machine Learning (cont.) 55 A general machine learning pipeline (Rajdeep et al. 2017)
56 Machine Learning (cont.) 56 Unsupervised learning: A model does not require labelled data. No labels of outputs are given to the learning system. It finds structure on its own from the inputs given to. E.g. clustering, dimensionality reduction, and some forms of feature extraction, such as text processing. Supervised learning: These types of models use labelled data to learn. The system is presented with inputs and desired outputs by a human and the goal is to learn a model to map inputs to outputs. E.g. Recommendation engines, regression, and classification.
57 Machine Learning (cont.) 57 Classification generally refers to classifying thins into distinct categories or classes. We wish to assign classes based on a set of features. The features might represent variables related to an item or object, and event or context, or some combination of these. Binary classification (1 or 0). E.g. spam classifier (spam or nonspam). Multiclass classification (0 n). E.g. sentiment analysis (positive, negative, neutral).
58 58 Spark built-in libraries
59 Spark built-in libraries 59 MLlib Spark SQL

60 Machine Learning Library (MLlib) 60 Apache Spark's scalable machine learning library. Its goal is to make practical machine learning scalable and easy. Ease of use Performance (high-quality algorithms, 100x faster than MapReduce) Source: spark.apache.org/mllib/
61 MLlib (cont.) 61 MLlib contains many algorithms and utilities. ML algorithms include: Classification: logistic regression, naive Bayes,... Regression: generalized linear regression, survival regression,... Clustering: K-means, Gaussian mixtures (GMMs), ML workflow utilities include: Feature transformations: standardization, normalization, hashing,... Model evaluation and hyper-parameter tuning Other utilities include: Distributed linear algebra: SVD, PCA,... Statistics: summary statistics, hypothesis testing,.. For the complete list visit: Source: spark.apache.org/mllib/
62 Spark built-in libraries 62 MLlib Spark SQL
63 Spark SQL 63 Apache Spark's module for working with structured data Integrated Seamlessly mix SQL queries with Spark programs Source:spark.apache.org/sql/
64 Spark SQL (cont.) 64 Performance & Scalability Spark SQL includes a cost-based optimizer, columnar storage and code generation to make queries fast. At the same time, it scales to thousands of nodes and multi hour queries using the Spark engine, which provides full mid-query fault tolerance Uniform Data Access Connect to any data source the same way Source: spark.apache.org/sql/
 65 Standard Connectivity Connect through JDBC or")
65 Spark SQL (cont.) 65 Standard Connectivity Connect through JDBC or ODBC. Source:
66 Demo: Data Analytics Applications 66 Spark SQL and MLlib
67 Demo: Data Analytics application 67 Analyzing Twitter data to detect traffic event Detecting occurring events are essential in finding out what is happening in the city for decision-making or future planning purposes. It is a benefit for stakeholders such as government. Social media event detection could be an additional detection apart from sensor-based event detection, where the detection coverage is not limited by the number of installed sensor as in sensor-based detection.
68 Demo: Data Analytics application 68 Analyzing Twitter data to detect traffic event Crawling twitter data Preprocessing Data Cleansing & Transformation Tokenization Stop Word removal Supervised learning: binary classification (traffic, non-traffic), using > 1000 labeled data Feature Extraction (Bag-of-words representation) using Spark s HashingTF Logistic Regression with default threshold 0.5 (adjustable) Evaluation Metrics Well-known and common (prediction accuracy, Precision, Recall, F1- Measure)
69 69 cd /home/hduser/tutorial/analytic/eventdetection/app spark-submit --master spark://sugi-ideapad: class Tutor_DataExtraction --executor-memory 8g --driver-memory 8g --conf "spark.debug.maxtostringfields=5000" --num-executors 7 --executor-cores 7 target/scala- 2.11/tutorial_ jar spark-submit --master spark://sugi-ideapad: class Tutor_Classification --executor-memory 8g --driver-memory 8g --conf "spark.debug.maxtostringfields=5000" --num-executors 7 --executor-cores 7 target/scala- 2.11/tutorial_ jar
70 Performance Tuning of Apache Spark 70 Cluster Resource Utilization Spark Web UI Partitioning Profiler
71 Cluster Resource utilization 71 Spark executor in an application has the same fixed number of cores and same fixed heap size. The number of cores can be specified with the --executor-cores flag when invoking spark-submit, spark-shell, and pyspark from the command line, or by setting the spark.executor.cores property in the spark-defaults.conf file or on a SparkConf object. Similarly, the heap size can be controlled with the --executor-memory flag or the spark.executor.memory property. spark-shell --master spark://<host>:7077 -executor-cores 17 --executor-memory 5g spark-submit --class company.division.yourclass --master spark://<host>:7077 -executor-cores 17 --executor-memory 5g--name countingsheep CountingSheep-1.0.jar Source: blog.cloudera.com
72 Performance Tuning of Apache Spark 72 Cluster Resource Utilization Spark Web UI Partitioning Profiler
73 Spark Web UI 73 Source: (Malak & East 2016)
74 Performance Tuning of Apache Spark 74 Cluster Resource Utilization Spark Web UI Partitioning Profiler
75 Partitioning (to utilize all CPU cores) 75 Using the parameters to spark-shell or spark-submit, we can ensure that memory and CPUs are available on the cluster for our application. But that doesn t guarantee that all the available memory or CPUs will be used. Spark processes a stage by processing each partition separately. In fact, only one executor can work on a single partition, so if the number of partitions is less than the number of executors, the stage won t take advantage of the full resources available. Call RDD.partitions.size to find out how many partition your RDD has. The default partition size can be retrieved using sc.defaultparallelism One way to resolve this problem is to use the repartition method on the RDD to supply a recommended new number of partitions: Val rdd = rdd.repartition(10) Source: (Malak & East 2016)
76 Performance Tuning of Apache Spark 76 Cluster Resource Utilization Spark Web UI Partitioning Profiler

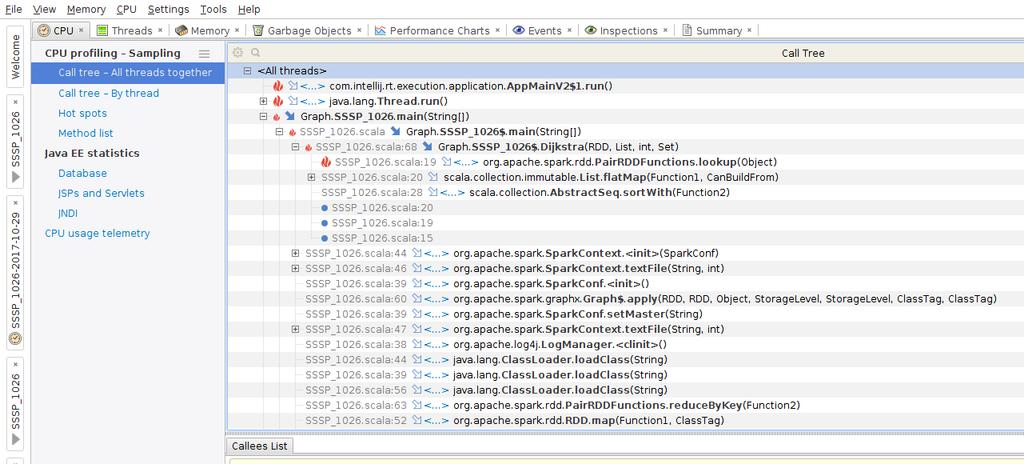
77 YourKit Profiler 77
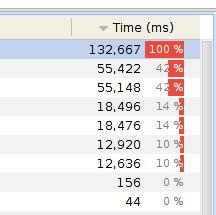
78 YourKit Profiler(cont.) 78
79 79 Advance Features of Apache Spark
80 Advance Features of Apache Spark 80 Shared Variables Accumulators Broadcast Variable RDD Persistence
81 Shared Variables 81 Normally, when a function passed to a Spark operation (such as map or reduce) is executed on a remote cluster node, it works on separate copies of all the variables used in the function. These variables are copied to each machine, and no updates to the variables on the remote machine are propagated back to the driver program. Supporting general, read-write shared variables across tasks would be inefficient. However, Spark does provide two limited types of shared variables for two common usage patterns: broadcast variables and accumulators. Broadcast variables used to efficiently, distribute large values. Accumulators used to aggregate the information of particular collection. Source: e_spark/advanced_spark_programming.htm
82 Accumulators 82 Accumulators are variables that are only added to through an associative and commutative operation and can therefore be efficiently supported in parallel. They can be used to implement counters (as in MapReduce) or sums. Spark natively supports accumulators of numeric types, and programmers can add support for new types. Source: e_spark/advanced_spark_programming.htm
83 Accumulators (cont.) 83 scala> val accum = sc.longaccumulator("my Accumulator") accum: org.apache.spark.util.longaccumulator = LongAccumulator(id: 0, name: Some(My Accumulator), value: 0) scala> sc.parallelize(array(1, 2, 3, 4)).foreach(x => accum.add(x))... 10/09/29 18:41:08 INFO SparkContext: Tasks finished in s scala> accum.value res2: Long = 10 Source: dd-programming-guide.html#accumulators
 84 Source: (Malak &")
84 Accumulators (cont.) 84 Source: (Malak & East 2016)
85 Advance Features of Apache Spark 85 Shared Variables Accumulators Broadcast Variable RDD Persistence
86 Broadcast Variables 86 Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. They can be used, for example, to give every node a copy of a large input dataset in an efficient manner. Spark also attempts to distribute broadcast variables using efficient broadcast algorithms to reduce communication cost. Source:
87 Broadcast Variables (cont.) 87 scala> val broadcastvar = sc.broadcast(array(1, 2, 3)) broadcastvar: org.apache.spark.broadcast.broadcast[array[int]] = Broadcast(0) scala> broadcastvar.value res0: Array[Int] = Array(1, 2, 3) Source:
88 Advance Features of Apache Spark 88 Shared Variables Accumulators Broadcast Variable RDD Persistence
89 RDD Persistence 89 One of the most important capabilities in Spark is persisting (or caching) a dataset in memory across operations. When you persist an RDD, each node stores any partitions of it, that it computes in memory and reuses them in other actions on that dataset (or datasets derived from it). This allows future actions to be much faster (often by more than 10x). Caching is a key tool for iterative algorithms and fast interactive use. Spark s cache is fault-tolerant if any partition of an RDD is lost, it will automatically be recomputed using the transformations that originally created it. An RDD can be persisted using: Persist() : each persisted RDD can be stored using a different storage level, allowing you, for example, to persist the dataset on disk, persist it in memory but as serialized Java objects (to save space), replicate it across nodes. Cache() : a shorthand for using the default storage level, which is StorageLevel.MEMORY_ONLY (store deserialized objects in memory) Source:
90 RDD Persistence (cont.) 90 The different storage level is set by passing a StorageLevel object (Scala, Java, Python) to persist(). Full set of storage level: Source: d-programming-guide.html#rdd-persistence
91 References 91 blog.cloudera.com Gandomi, A. & Haider, M., Beyond the hype: Big data concepts, methods, and analytics. International Journal of Information Management, 35(2), pp Available at: Available online. Accessed at 2017/10/ Matt Hamblen, Just what IS a smart city?, computerworld.com, Oct 1, 2015 Malak, M.S. & East, R., Spark GraphX In action, Manning Publications. Rajdeep, D., Ghotra, M.S. & Pentreath, N., Machine Learning with Spark, Birmingham, Mumbai: Packt Publishing.



92 Useful Resources 92
93 93 Thank you for attending HPCSaudi Tutorial

94 Contact 94 Prof. Rashid Mehmood Director of Research, Training, and Consultancy HPC Center, King Abdul Aziz University, Jeddah, Saudi Arabia
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Beyond MapReduce: Apache Spark Antonino Virgillito
 Beyond MapReduce: Apache Spark Antonino Virgillito 1 Why Spark? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration
Beyond MapReduce: Apache Spark Antonino Virgillito 1 Why Spark? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark
 An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
2/4/2019 Week 3- A Sangmi Lee Pallickara
 Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Machine Learning With Spark
 Ons Dridi R&D Engineer 13 Novembre 2015 Centre d Excellence en Technologies de l Information et de la Communication CETIC Presentation - An applied research centre in the field of ICT - The knowledge developed
Ons Dridi R&D Engineer 13 Novembre 2015 Centre d Excellence en Technologies de l Information et de la Communication CETIC Presentation - An applied research centre in the field of ICT - The knowledge developed
Big Data Analytics with Apache Spark. Nastaran Fatemi
 Big Data Analytics with Apache Spark Nastaran Fatemi Apache Spark Throughout this part of the course we will use the Apache Spark framework for distributed data-parallel programming. Spark implements a
Big Data Analytics with Apache Spark Nastaran Fatemi Apache Spark Throughout this part of the course we will use the Apache Spark framework for distributed data-parallel programming. Spark implements a
MLI - An API for Distributed Machine Learning. Sarang Dev
 MLI - An API for Distributed Machine Learning Sarang Dev MLI - API Simplify the development of high-performance, scalable, distributed algorithms. Targets common ML problems related to data loading, feature
MLI - An API for Distributed Machine Learning Sarang Dev MLI - API Simplify the development of high-performance, scalable, distributed algorithms. Targets common ML problems related to data loading, feature
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
COSC 6339 Big Data Analytics. Introduction to Spark. Edgar Gabriel Fall What is SPARK?
 COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
08/04/2018. RDDs. RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application contains
are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application contains
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
2/26/2017. RDDs. RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is used to run an application
are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is used to run an application
RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 1 RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application
1 RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Cloud, Big Data & Linear Algebra
 Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Apache Spark and Scala Certification Training
 About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Guidelines For Hadoop and Spark Cluster Usage
 Guidelines For Hadoop and Spark Cluster Usage Procedure to create an account in CSX. If you are taking a CS prefix course, you already have an account; to get an initial password created: 1. Login to https://cs.okstate.edu/pwreset
Guidelines For Hadoop and Spark Cluster Usage Procedure to create an account in CSX. If you are taking a CS prefix course, you already have an account; to get an initial password created: 1. Login to https://cs.okstate.edu/pwreset
Applied Spark. From Concepts to Bitcoin Analytics. Andrew F.
 Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
An Introduction to Big Data Analysis using Spark
 An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
EPL660: Information Retrieval and Search Engines Lab 11
 EPL660: Information Retrieval and Search Engines Lab 11 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science Introduction to Apache Spark Fast and general engine for
EPL660: Information Retrieval and Search Engines Lab 11 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science Introduction to Apache Spark Fast and general engine for
Distributed Computing with Spark and MapReduce
 Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Spark and Spark SQL. Amir H. Payberah. SICS Swedish ICT. Amir H. Payberah (SICS) Spark and Spark SQL June 29, / 71
 Spark and Spark SQL June 29, / 71") Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
 About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Introduction to Apache Spark. Patrick Wendell - Databricks
 Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
CS435 Introduction to Big Data FALL 2018 Colorado State University. 10/24/2018 Week 10-B Sangmi Lee Pallickara
 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
Machine Learning for Large-Scale Data Analysis and Decision Making A. Distributed Machine Learning Week #9
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Distributed Machine Learning Week #9 Today Distributed computing for machine learning Background MapReduce/Hadoop & Spark Theory
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Distributed Machine Learning Week #9 Today Distributed computing for machine learning Background MapReduce/Hadoop & Spark Theory
Distributed Computing with Spark
 Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
빅데이터기술개요 2016/8/20 ~ 9/3. 윤형기
 빅데이터기술개요 2016/8/20 ~ 9/3 윤형기 (hky@openwith.net) D4 http://www.openwith.net 2 Hive http://www.openwith.net 3 What is Hive? 개념 a data warehouse infrastructure tool to process structured data in Hadoop. Hadoop
빅데이터기술개요 2016/8/20 ~ 9/3 윤형기 (hky@openwith.net) D4 http://www.openwith.net 2 Hive http://www.openwith.net 3 What is Hive? 개념 a data warehouse infrastructure tool to process structured data in Hadoop. Hadoop
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
Accelerating Spark Workloads using GPUs
 Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Introduction to Apache Spark
 Introduction to Apache Spark Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Introduction to Apache Spark Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Spark. Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica.
 Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Introduction to Spark
 Introduction to Spark Outlines A brief history of Spark Programming with RDDs Transformations Actions A brief history Limitations of MapReduce MapReduce use cases showed two major limitations: Difficulty
Introduction to Spark Outlines A brief history of Spark Programming with RDDs Transformations Actions A brief history Limitations of MapReduce MapReduce use cases showed two major limitations: Difficulty
Distributed Machine Learning" on Spark
 Distributed Machine Learning" on Spark Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Outline Data flow vs. traditional network programming Spark computing engine Optimization Example Matrix Computations
Distributed Machine Learning" on Spark Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Outline Data flow vs. traditional network programming Spark computing engine Optimization Example Matrix Computations
Data-intensive computing systems
 Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Big Streaming Data Processing. How to Process Big Streaming Data 2016/10/11. Fraud detection in bank transactions. Anomalies in sensor data
 Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
L6: Introduction to Spark Spark
 L6: Introduction to Spark Spark Feng Li feng.li@cufe.edu.cn School of Statistics and Mathematics Central University of Finance and Economics Revised on December 20, 2017 Today we are going to learn...
L6: Introduction to Spark Spark Feng Li feng.li@cufe.edu.cn School of Statistics and Mathematics Central University of Finance and Economics Revised on December 20, 2017 Today we are going to learn...
Using Existing Numerical Libraries on Spark
 Using Existing Numerical Libraries on Spark Brian Spector Chicago Spark Users Meetup June 24 th, 2015 Experts in numerical algorithms and HPC services How to use existing libraries on Spark Call algorithm
Using Existing Numerical Libraries on Spark Brian Spector Chicago Spark Users Meetup June 24 th, 2015 Experts in numerical algorithms and HPC services How to use existing libraries on Spark Call algorithm
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Webinar Series TMIP VISION
 Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
About the Tutorial. Audience. Prerequisites. Copyright and Disclaimer. PySpark
 About the Tutorial Apache Spark is written in Scala programming language. To support Python with Spark, Apache Spark community released a tool, PySpark. Using PySpark, you can work with RDDs in Python
About the Tutorial Apache Spark is written in Scala programming language. To support Python with Spark, Apache Spark community released a tool, PySpark. Using PySpark, you can work with RDDs in Python
Databases and Big Data Today. CS634 Class 22
 Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Reactive App using Actor model & Apache Spark. Rahul Kumar Software
 Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application
Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Scalable Tools - Part I Introduction to Scalable Tools
 Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
An Overview of Apache Spark
 An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
Pyspark standalone code
 COSC 6339 Big Data Analytics Introduction to Spark (II) Edgar Gabriel Spring 2017 Pyspark standalone code from pyspark import SparkConf, SparkContext from operator import add conf = SparkConf() conf.setappname(
COSC 6339 Big Data Analytics Introduction to Spark (II) Edgar Gabriel Spring 2017 Pyspark standalone code from pyspark import SparkConf, SparkContext from operator import add conf = SparkConf() conf.setappname(
Twitter data Analytics using Distributed Computing
 Twitter data Analytics using Distributed Computing Uma Narayanan Athrira Unnikrishnan Dr. Varghese Paul Dr. Shelbi Joseph Research Scholar M.tech Student Professor Assistant Professor Dept. of IT, SOE
Twitter data Analytics using Distributed Computing Uma Narayanan Athrira Unnikrishnan Dr. Varghese Paul Dr. Shelbi Joseph Research Scholar M.tech Student Professor Assistant Professor Dept. of IT, SOE
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Higher level data processing in Apache Spark
 Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Getting Started with Spark
 Getting Started with Spark Shadi Ibrahim March 30th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
Getting Started with Spark Shadi Ibrahim March 30th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
Spark Streaming. Guido Salvaneschi
 Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Dell In-Memory Appliance for Cloudera Enterprise
 Dell In-Memory Appliance for Cloudera Enterprise Spark Technology Overview and Streaming Workload Use Cases Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
Dell In-Memory Appliance for Cloudera Enterprise Spark Technology Overview and Streaming Workload Use Cases Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
a Spark in the cloud iterative and interactive cluster computing
 a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
Outline. CS-562 Introduction to data analysis using Apache Spark
 Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Spark Programming Essentials
 Spark Programming Essentials Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Spark Programming Essentials Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Matrix Computations and " Neural Networks in Spark
 Matrix Computations and " Neural Networks in Spark Reza Zadeh Paper: http://arxiv.org/abs/1509.02256 Joint work with many folks on paper. @Reza_Zadeh http://reza-zadeh.com Training Neural Networks Datasets
Matrix Computations and " Neural Networks in Spark Reza Zadeh Paper: http://arxiv.org/abs/1509.02256 Joint work with many folks on paper. @Reza_Zadeh http://reza-zadeh.com Training Neural Networks Datasets
Today s content. Resilient Distributed Datasets(RDDs) Spark and its data model
 Spark and its data model") Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Data Platforms and Pattern Mining
 Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
/ Cloud Computing. Recitation 13 April 14 th 2015
 15-319 / 15-619 Cloud Computing Recitation 13 April 14 th 2015 Overview Last week s reflection Project 4.1 Budget issues Tagging, 15619Project This week s schedule Unit 5 - Modules 18 Project 4.2 Demo
15-319 / 15-619 Cloud Computing Recitation 13 April 14 th 2015 Overview Last week s reflection Project 4.1 Budget issues Tagging, 15619Project This week s schedule Unit 5 - Modules 18 Project 4.2 Demo
Using Numerical Libraries on Spark
 Using Numerical Libraries on Spark Brian Spector London Spark Users Meetup August 18 th, 2015 Experts in numerical algorithms and HPC services How to use existing libraries on Spark Call algorithm with
Using Numerical Libraries on Spark Brian Spector London Spark Users Meetup August 18 th, 2015 Experts in numerical algorithms and HPC services How to use existing libraries on Spark Call algorithm with
Shark: Hive (SQL) on Spark
 on Spark") Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Khadija Souissi. Auf z Systems November IBM z Systems Mainframe Event 2016
 Khadija Souissi Auf z Systems 07. 08. November 2016 @ IBM z Systems Mainframe Event 2016 Acknowledgements Apache Spark, Spark, Apache, and the Spark logo are trademarks of The Apache Software Foundation.
Khadija Souissi Auf z Systems 07. 08. November 2016 @ IBM z Systems Mainframe Event 2016 Acknowledgements Apache Spark, Spark, Apache, and the Spark logo are trademarks of The Apache Software Foundation.
CSC 261/461 Database Systems Lecture 24. Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101
 CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
Analyzing Flight Data
 IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 8 October, 2014, Tartu Outline Introduction to Spark Resilient Distributed Data (RDD) Available data operations Examples Advantages and Disadvantages Frameworks
Data processing in Apache Spark Pelle Jakovits 8 October, 2014, Tartu Outline Introduction to Spark Resilient Distributed Data (RDD) Available data operations Examples Advantages and Disadvantages Frameworks
Integration of Machine Learning Library in Apache Apex
 Integration of Machine Learning Library in Apache Apex Anurag Wagh, Krushika Tapedia, Harsh Pathak Vishwakarma Institute of Information Technology, Pune, India Abstract- Machine Learning is a type of artificial
Integration of Machine Learning Library in Apache Apex Anurag Wagh, Krushika Tapedia, Harsh Pathak Vishwakarma Institute of Information Technology, Pune, India Abstract- Machine Learning is a type of artificial
An exceedingly high-level overview of ambient noise processing with Spark and Hadoop
 IRIS: USArray Short Course in Bloomington, Indian Special focus: Oklahoma Wavefields An exceedingly high-level overview of ambient noise processing with Spark and Hadoop Presented by Rob Mellors but based
IRIS: USArray Short Course in Bloomington, Indian Special focus: Oklahoma Wavefields An exceedingly high-level overview of ambient noise processing with Spark and Hadoop Presented by Rob Mellors but based
Fast, Interactive, Language-Integrated Cluster Computing
 Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 21 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Streaming
Data processing in Apache Spark Pelle Jakovits 21 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Streaming
A very short introduction
 A very short introduction General purpose compute engine for clusters batch / interactive / streaming used by and many others History developed in 2009 @ UC Berkeley joined the Apache foundation in 2013
A very short introduction General purpose compute engine for clusters batch / interactive / streaming used by and many others History developed in 2009 @ UC Berkeley joined the Apache foundation in 2013
Stream Processing on IoT Devices using Calvin Framework
 Stream Processing on IoT Devices using Calvin Framework by Ameya Nayak A Project Report Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Science Supervised
Stream Processing on IoT Devices using Calvin Framework by Ameya Nayak A Project Report Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Science Supervised