Beyond MapReduce: Apache Spark Antonino Virgillito
|
|
|
- Sylvia Cross
- 6 years ago
- Views:
Transcription
1 Beyond MapReduce: Apache Spark Antonino Virgillito 1

2 Why Spark? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration s output is written to disk making it slow Hadoop execution flow Spark execution flow Not tied to 2 stage Map Reduce paradigm 1. Extract a working set 2. Cache it 3. Query it repeatedly

3 About Apache Spark Initially started at UC Berkeley in 2009 Fast and general purpose cluster computing system 10x (on disk) - 100x (In-Memory) faster Most popular for running Iterative Machine Learning Algorithms. Provides high level APIs in 3 different programming languages Scala, Java, Python Integration with Hadoop and its eco-system and can read existing data on HDFS

4 Spark Stack Spark SQL For SQL and unstructured data processing MLib Machine Learning Algorithms GraphX Graph Processing Spark Streaming stream processing of live data streams

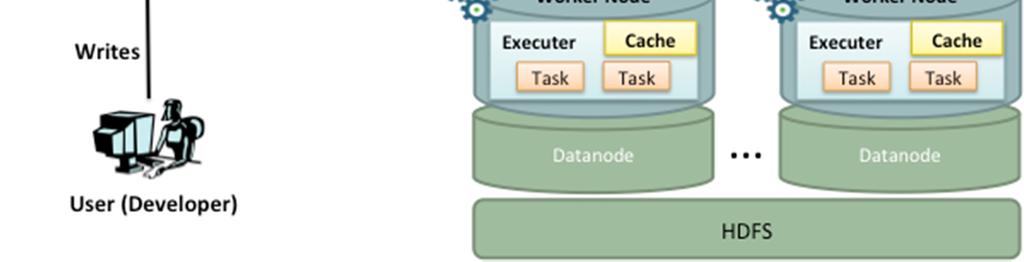
5 Execution Flow
6 Terminology Application Jar User Program and its dependencies except Hadoop & Spark Jars bundled into a Jar file Driver Program The process to start the execution (main() function) Cluster Manager An external service to manage resources on the cluster (standalone manager, YARN, Apache Mesos) Deploy Mode cluster : Driver inside the cluster client : Driver outside of Cluster
7 Terminology (contd.) Worker Node Node that run the application program in cluster Executor Process launched on a worker node, that runs the Tasks Keep data in memory or disk storage Task A unit of work that will be sent to executor Job Consists multiple tasks Created based on a Action SparkContext : represents the connection to a Spark cluster, and can be used to create RDDs, accumulators and broadcast variables on that cluster.
8 Resilient Distributed Datasets Resilient Distributed Datasets or RDD are the distributed memory abstractions that lets programmer perform inmemory parallel computations on large clusters. And that too in a highly fault tolerant manner. This is the main concept around which the whole Spark framework revolves around. Currently 2 types of RDDs: Parallelized collections: Created by calling parallelize method on an existing Scala collection. Developer can specify the number of slices to cut the dataset into. Ideally 2-3 slices per CPU. Hadoop Datasets: These distributed datasets are created from any file stored on HDFS or other storage systems supported by Hadoop (S3, Hbase etc). These are created using SparkContext s textfile method. Default number of slices in this case is 1 slice per file block. 8
9 Cluster Deployment Standalone Deploy Mode simplest way to deploy Spark on a private cluster Amazon EC2 EC2 scripts are available Very quick launching a new cluster Hadoop YARN
10 Spark Shell./bin/spark-shell --master local[2] The --master option specifies the master URL for a distributed cluster, or local to run locally with one thread, or local[n] to run locally with N threads. You should start by using local for testing../bin/run-example SparkPi 10 This will run 10 iterations to calculate the value of Pi
11 Basic operations scala> val textfile = sc.textfile("readme.md") textfile: spark.rdd[string] = spark.mappedrdd@2ee9b6e3 scala> textfile.count() // Number of items in this RDD ees0: Long = 126 scala> textfile.first() // First item in this RDD res1: String = # Apache Spark scala> val lineswithspark = textfile.filter(line => line.contains("spark")) lineswithspark: spark.rdd[string] = spark.filteredrdd@7dd4af09 Simplier - Single liner: scala> textfile.filter(line => line.contains("spark")).count() // How many lines contain "Spark"? res3: Long = 15
12 Map - Reduce scala> textfile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b) res4: Long = 15 scala> import java.lang.math scala> textfile.map(line => line.split(" ").size).reduce((a, b) => Math.max(a, b)) res5: Int = 15 scala> val wordcounts = textfile.flatmap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) wordcounts: spark.rdd[(string, Int)] = spark.shuffledaggregatedrdd@71f027b8 wordcounts.collect()
13 With Caching scala> lineswithspark.cache() res7: spark.rdd[string] = spark.filteredrdd@17e51082 scala> lineswithspark.count() res8: Long = 15 scala> lineswithspark.count() res9: Long = 15
14 With HDFS val lines = spark.textfile( hdfs://... ) val errors = lines.filter(line => line.startswith( ERROR )) println(total errors: + errors.count())
15 Standalone (Java) /* SimpleApp.java */ import org.apache.spark.api.java.*; import org.apache.spark.sparkconf; import org.apache.spark.api.java.function.function; public class SimpleApp { public static void main(string[] args) { String logfile = "YOUR_SPARK_HOME/README.md"; // Should be some file on your system SparkConf conf = new SparkConf().setAppName("Simple Application").setMaster("local"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> logdata = sc.textfile(logfile).cache(); long numas = logdata.filter(new Function<String, Boolean>() { public Boolean call(string s) { return s.contains("a"); } }).count(); long numbs = logdata.filter(new Function<String, Boolean>() { public Boolean call(string s) { return s.contains("b"); } }).count(); } } System.out.println("Lines with a: " + numas + ", lines with b: " + numbs); 15
16 Job Submission $SPARK_HOME/bin/spark-submit \ --class "SimpleApp" \ --master local[4] \ target/scala-2.10/simple-project_ jar
17 Configuration val conf = new SparkConf().setMaster("local").setAppName("CountingSheep").set("spark.executor.memory", "1g") val sc = new SparkContext(conf)
L6: Introduction to Spark Spark
 L6: Introduction to Spark Spark Feng Li feng.li@cufe.edu.cn School of Statistics and Mathematics Central University of Finance and Economics Revised on December 20, 2017 Today we are going to learn...
L6: Introduction to Spark Spark Feng Li feng.li@cufe.edu.cn School of Statistics and Mathematics Central University of Finance and Economics Revised on December 20, 2017 Today we are going to learn...
2/26/2017. RDDs. RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is used to run an application
are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is used to run an application
RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 1 RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application
1 RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application
Big Data Analytics. C. Distributed Computing Environments / C.2. Resilient Distributed Datasets: Apache Spark. Lars Schmidt-Thieme
 Big Data Analytics C. Distributed Computing Environments / C.2. Resilient Distributed Datasets: Apache Spark Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute of Computer
Big Data Analytics C. Distributed Computing Environments / C.2. Resilient Distributed Datasets: Apache Spark Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute of Computer
Distributed Systems. Distributed computation with Spark. Abraham Bernstein, Ph.D.
 Distributed Systems Distributed computation with Spark Abraham Bernstein, Ph.D. Course material based on: - Based on slides by Reynold Xin, Tudor Lapusan - Some additions by Johannes Schneider How good
Distributed Systems Distributed computation with Spark Abraham Bernstein, Ph.D. Course material based on: - Based on slides by Reynold Xin, Tudor Lapusan - Some additions by Johannes Schneider How good
Big Data Analytics with Apache Spark. Nastaran Fatemi
 Big Data Analytics with Apache Spark Nastaran Fatemi Apache Spark Throughout this part of the course we will use the Apache Spark framework for distributed data-parallel programming. Spark implements a
Big Data Analytics with Apache Spark Nastaran Fatemi Apache Spark Throughout this part of the course we will use the Apache Spark framework for distributed data-parallel programming. Spark implements a
An Introduction to Apache Spark
 An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
08/04/2018. RDDs. RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application contains
are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application contains
The detailed Spark programming guide is available at:
 Aims This exercise aims to get you to: Analyze data using Spark shell Monitor Spark tasks using Web UI Write self-contained Spark applications using Scala in Eclipse Background Spark is already installed
Aims This exercise aims to get you to: Analyze data using Spark shell Monitor Spark tasks using Web UI Write self-contained Spark applications using Scala in Eclipse Background Spark is already installed
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Introduction to Apache Spark. Patrick Wendell - Databricks
 Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
COSC 6339 Big Data Analytics. Introduction to Spark. Edgar Gabriel Fall What is SPARK?
 COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
2/4/2019 Week 3- A Sangmi Lee Pallickara
 Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
An Introduction to Big Data Analysis using Spark
 An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Reactive App using Actor model & Apache Spark. Rahul Kumar Software
 Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application
Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Data-intensive computing systems
 Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Cloud, Big Data & Linear Algebra
 Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Guidelines For Hadoop and Spark Cluster Usage
 Guidelines For Hadoop and Spark Cluster Usage Procedure to create an account in CSX. If you are taking a CS prefix course, you already have an account; to get an initial password created: 1. Login to https://cs.okstate.edu/pwreset
Guidelines For Hadoop and Spark Cluster Usage Procedure to create an account in CSX. If you are taking a CS prefix course, you already have an account; to get an initial password created: 1. Login to https://cs.okstate.edu/pwreset
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 21 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Streaming
Data processing in Apache Spark Pelle Jakovits 21 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Streaming
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
CSC 261/461 Database Systems Lecture 24. Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101
 CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
Introduction to Apache Spark
 Introduction to Apache Spark Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Introduction to Apache Spark Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 8 October, 2014, Tartu Outline Introduction to Spark Resilient Distributed Data (RDD) Available data operations Examples Advantages and Disadvantages Frameworks
Data processing in Apache Spark Pelle Jakovits 8 October, 2014, Tartu Outline Introduction to Spark Resilient Distributed Data (RDD) Available data operations Examples Advantages and Disadvantages Frameworks
TUTORIAL: BIG DATA ANALYTICS USING APACHE SPARK
 TUTORIAL: BIG DATA ANALYTICS USING APACHE SPARK Sugimiyanto Suma Yasir Arfat Supervisor: Prof. Rashid Mehmood Outline 2 Big Data Big Data Analytics Problem Basics of Apache Spark Practice basic examples
TUTORIAL: BIG DATA ANALYTICS USING APACHE SPARK Sugimiyanto Suma Yasir Arfat Supervisor: Prof. Rashid Mehmood Outline 2 Big Data Big Data Analytics Problem Basics of Apache Spark Practice basic examples
Apache Spark: Hands-on Session A.A. 2016/17
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Apache Spark: Hands-on Session A.A. 2016/17 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Apache Spark: Hands-on Session A.A. 2016/17 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Apache Spark: Hands-on Session A.A. 2017/18
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Apache Spark: Hands-on Session A.A. 2017/18 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Apache Spark: Hands-on Session A.A. 2017/18 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Big Data Infrastructures & Technologies Hadoop Streaming Revisit.
 Big Data Infrastructures & Technologies Hadoop Streaming Revisit ENRON Mapper ENRON Mapper Output (Excerpt) acomnes@enron.com blake.walker@enron.com edward.snowden@cia.gov alex.berenson@nyt.com ENRON Reducer
Big Data Infrastructures & Technologies Hadoop Streaming Revisit ENRON Mapper ENRON Mapper Output (Excerpt) acomnes@enron.com blake.walker@enron.com edward.snowden@cia.gov alex.berenson@nyt.com ENRON Reducer
Apache Spark Internals
 Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
In-Memory Processing with Apache Spark. Vincent Leroy
 In-Memory Processing with Apache Spark Vincent Leroy Sources Resilient Distributed Datasets, Henggang Cui Coursera IntroducBon to Apache Spark, University of California, Databricks Datacenter OrganizaBon
In-Memory Processing with Apache Spark Vincent Leroy Sources Resilient Distributed Datasets, Henggang Cui Coursera IntroducBon to Apache Spark, University of California, Databricks Datacenter OrganizaBon
Distributed Computing with Spark and MapReduce
 Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture with Apache Spark
 Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR
Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Getting Started with Spark
 Getting Started with Spark Shadi Ibrahim March 30th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
Getting Started with Spark Shadi Ibrahim March 30th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
Spark Tutorial. General Instructions
 CS246: Mining Massive Datasets Winter 2018 Spark Tutorial Due Thursday January 25, 2018 at 11:59pm Pacific time General Instructions The purpose of this tutorial is (1) to get you started with Spark and
CS246: Mining Massive Datasets Winter 2018 Spark Tutorial Due Thursday January 25, 2018 at 11:59pm Pacific time General Instructions The purpose of this tutorial is (1) to get you started with Spark and
Spark. Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica.
 Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Apache Spark. CS240A T Yang. Some of them are based on P. Wendell s Spark slides
 Apache Spark CS240A T Yang Some of them are based on P. Wendell s Spark slides Parallel Processing using Spark+Hadoop Hadoop: Distributed file system that connects machines. Mapreduce: parallel programming
Apache Spark CS240A T Yang Some of them are based on P. Wendell s Spark slides Parallel Processing using Spark+Hadoop Hadoop: Distributed file system that connects machines. Mapreduce: parallel programming
Spark Standalone 模式应用程序开发 Spark 大数据博客 -
 在本博客的 Spark 快速入门指南 (Quick Start Spark) 文章中简单地介绍了如何通过 Spark s hell 来快速地运用 API 本文将介绍如何快速地利用 Spark 提供的 API 开发 Standalone 模式的应用程序 Spark 支持三种程序语言的开发 :Scala ( 利用 SBT 进行编译 ), Java ( 利用 Maven 进行编译 ) 以及 Python
在本博客的 Spark 快速入门指南 (Quick Start Spark) 文章中简单地介绍了如何通过 Spark s hell 来快速地运用 API 本文将介绍如何快速地利用 Spark 提供的 API 开发 Standalone 模式的应用程序 Spark 支持三种程序语言的开发 :Scala ( 利用 SBT 进行编译 ), Java ( 利用 Maven 进行编译 ) 以及 Python
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
An Overview of Apache Spark
 An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
/ Cloud Computing. Recitation 13 April 14 th 2015
 15-319 / 15-619 Cloud Computing Recitation 13 April 14 th 2015 Overview Last week s reflection Project 4.1 Budget issues Tagging, 15619Project This week s schedule Unit 5 - Modules 18 Project 4.2 Demo
15-319 / 15-619 Cloud Computing Recitation 13 April 14 th 2015 Overview Last week s reflection Project 4.1 Budget issues Tagging, 15619Project This week s schedule Unit 5 - Modules 18 Project 4.2 Demo
Apache Spark. Easy and Fast Big Data Analytics Pat McDonough
 Apache Spark Easy and Fast Big Data Analytics Pat McDonough Founded by the creators of Apache Spark out of UC Berkeley s AMPLab Fully committed to 100% open source Apache Spark Support and Grow the Spark
Apache Spark Easy and Fast Big Data Analytics Pat McDonough Founded by the creators of Apache Spark out of UC Berkeley s AMPLab Fully committed to 100% open source Apache Spark Support and Grow the Spark
Spark and Spark SQL. Amir H. Payberah. SICS Swedish ICT. Amir H. Payberah (SICS) Spark and Spark SQL June 29, / 71
 Spark and Spark SQL June 29, / 71") Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Spark Programming Essentials
 Spark Programming Essentials Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Spark Programming Essentials Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
Agenda. Spark Platform Spark Core Spark Extensions Using Apache Spark
 Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
An exceedingly high-level overview of ambient noise processing with Spark and Hadoop
 IRIS: USArray Short Course in Bloomington, Indian Special focus: Oklahoma Wavefields An exceedingly high-level overview of ambient noise processing with Spark and Hadoop Presented by Rob Mellors but based
IRIS: USArray Short Course in Bloomington, Indian Special focus: Oklahoma Wavefields An exceedingly high-level overview of ambient noise processing with Spark and Hadoop Presented by Rob Mellors but based
Databases and Big Data Today. CS634 Class 22
 Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Datacenter Simulation Methodologies: Spark
 This work is supported by NSF grants CCF-1149252, CCF-1337215, and STARnet, a Semiconductor Research Corporation Program, sponsored by MARCO and DARPA. Datacenter Simulation Methodologies: Spark Tamara
This work is supported by NSF grants CCF-1149252, CCF-1337215, and STARnet, a Semiconductor Research Corporation Program, sponsored by MARCO and DARPA. Datacenter Simulation Methodologies: Spark Tamara
// Create a configuration object and set the name of the application SparkConf conf=new SparkConf().setAppName("Spark Exam 2 - Exercise
.setAppName(Spark Exam 2 - Exercise") import org.apache.spark.api.java.*; import org.apache.spark.sparkconf; public class SparkDriver { public static void main(string[] args) { String inputpathpm10readings; String outputpathmonthlystatistics;
import org.apache.spark.api.java.*; import org.apache.spark.sparkconf; public class SparkDriver { public static void main(string[] args) { String inputpathpm10readings; String outputpathmonthlystatistics;
Machine Learning With Spark
 Ons Dridi R&D Engineer 13 Novembre 2015 Centre d Excellence en Technologies de l Information et de la Communication CETIC Presentation - An applied research centre in the field of ICT - The knowledge developed
Ons Dridi R&D Engineer 13 Novembre 2015 Centre d Excellence en Technologies de l Information et de la Communication CETIC Presentation - An applied research centre in the field of ICT - The knowledge developed
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Big Data Analytics with Hadoop and Spark at OSC
 Big Data Analytics with Hadoop and Spark at OSC 09/28/2017 SUG Shameema Oottikkal Data Application Engineer Ohio SuperComputer Center email:soottikkal@osc.edu 1 Data Analytics at OSC Introduction: Data
Big Data Analytics with Hadoop and Spark at OSC 09/28/2017 SUG Shameema Oottikkal Data Application Engineer Ohio SuperComputer Center email:soottikkal@osc.edu 1 Data Analytics at OSC Introduction: Data
EPL660: Information Retrieval and Search Engines Lab 11
 EPL660: Information Retrieval and Search Engines Lab 11 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science Introduction to Apache Spark Fast and general engine for
EPL660: Information Retrieval and Search Engines Lab 11 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science Introduction to Apache Spark Fast and general engine for
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
2/26/2017. Spark MLlib is the Spark component providing the machine learning/data mining algorithms. MLlib APIs are divided into two packages:
 Spark MLlib is the Spark component providing the machine learning/data mining algorithms Pre-processing techniques Classification (supervised learning) Clustering (unsupervised learning) Itemset mining
Spark MLlib is the Spark component providing the machine learning/data mining algorithms Pre-processing techniques Classification (supervised learning) Clustering (unsupervised learning) Itemset mining
a Spark in the cloud iterative and interactive cluster computing
 a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
Distributed Computing with Spark
 Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
本文转载自 :
 本文转载自 :http://blog.cloudera.com/blog/2014/04/how-to-run-a-simple-apache-spark-appin-cdh-5/ (Editor s note this post has been updated to reflect CDH 5.1/Spark 1.0) Apache Spark is a general-purpose, cluster
本文转载自 :http://blog.cloudera.com/blog/2014/04/how-to-run-a-simple-apache-spark-appin-cdh-5/ (Editor s note this post has been updated to reflect CDH 5.1/Spark 1.0) Apache Spark is a general-purpose, cluster
 About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
Big Data Analytics at OSC
 Big Data Analytics at OSC 04/05/2018 SUG Shameema Oottikkal Data Application Engineer Ohio SuperComputer Center email:soottikkal@osc.edu 1 Data Analytics at OSC Introduction: Data Analytical nodes OSC
Big Data Analytics at OSC 04/05/2018 SUG Shameema Oottikkal Data Application Engineer Ohio SuperComputer Center email:soottikkal@osc.edu 1 Data Analytics at OSC Introduction: Data Analytical nodes OSC
Spark supports several storage levels
 1 Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the
1 Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Pyspark standalone code
 COSC 6339 Big Data Analytics Introduction to Spark (II) Edgar Gabriel Spring 2017 Pyspark standalone code from pyspark import SparkConf, SparkContext from operator import add conf = SparkConf() conf.setappname(
COSC 6339 Big Data Analytics Introduction to Spark (II) Edgar Gabriel Spring 2017 Pyspark standalone code from pyspark import SparkConf, SparkContext from operator import add conf = SparkConf() conf.setappname(
Scalable Tools - Part I Introduction to Scalable Tools
 Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Scaling Up & Out. Haidar Osman
 Scaling Up & Out Haidar Osman 1- Crash course in Scala - Classes - Objects 2- Actors - The Actor Model - Examples I, II, III, IV 3- Apache Spark - RDD & DAG - Word Count Example 2 1- Crash course in Scala
Scaling Up & Out Haidar Osman 1- Crash course in Scala - Classes - Objects 2- Actors - The Actor Model - Examples I, II, III, IV 3- Apache Spark - RDD & DAG - Word Count Example 2 1- Crash course in Scala
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 7: Parallel Computing Cho-Jui Hsieh UC Davis May 3, 2018 Outline Multi-core computing, distributed computing Multi-core computing tools
STA141C: Big Data & High Performance Statistical Computing Lecture 7: Parallel Computing Cho-Jui Hsieh UC Davis May 3, 2018 Outline Multi-core computing, distributed computing Multi-core computing tools
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
COMP 322: Fundamentals of Parallel Programming. Lecture 37: Distributed Computing, Apache Spark
 COMP 322: Fundamentals of Parallel Programming Lecture 37: Distributed Computing, Apache Spark Vivek Sarkar, Shams Imam Department of Computer Science, Rice University vsarkar@rice.edu, shams@rice.edu
COMP 322: Fundamentals of Parallel Programming Lecture 37: Distributed Computing, Apache Spark Vivek Sarkar, Shams Imam Department of Computer Science, Rice University vsarkar@rice.edu, shams@rice.edu
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Apache Spark and Scala Certification Training
 About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
Stream Processing on IoT Devices using Calvin Framework
 Stream Processing on IoT Devices using Calvin Framework by Ameya Nayak A Project Report Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Science Supervised
Stream Processing on IoT Devices using Calvin Framework by Ameya Nayak A Project Report Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Science Supervised
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
About the Tutorial. Audience. Prerequisites. Copyright and Disclaimer. PySpark
 About the Tutorial Apache Spark is written in Scala programming language. To support Python with Spark, Apache Spark community released a tool, PySpark. Using PySpark, you can work with RDDs in Python
About the Tutorial Apache Spark is written in Scala programming language. To support Python with Spark, Apache Spark community released a tool, PySpark. Using PySpark, you can work with RDDs in Python
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
An Introduction to Apache Spark Big Data Madison: 29 July William Red Hat, Inc.
 An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
/ Cloud Computing. Recitation 13 April 12 th 2016
 15-319 / 15-619 Cloud Computing Recitation 13 April 12 th 2016 Overview Last week s reflection Project 4.1 Quiz 11 Budget issues Tagging, 15619Project This week s schedule Unit 5 - Modules 21 Project 4.2
15-319 / 15-619 Cloud Computing Recitation 13 April 12 th 2016 Overview Last week s reflection Project 4.1 Quiz 11 Budget issues Tagging, 15619Project This week s schedule Unit 5 - Modules 21 Project 4.2
TensorFlowOnSpark Scalable TensorFlow Learning on Spark Clusters Lee Yang, Andrew Feng Yahoo Big Data ML Platform Team
 TensorFlowOnSpark Scalable TensorFlow Learning on Spark Clusters Lee Yang, Andrew Feng Yahoo Big Data ML Platform Team What is TensorFlowOnSpark Why TensorFlowOnSpark at Yahoo? Major contributor to open-source
TensorFlowOnSpark Scalable TensorFlow Learning on Spark Clusters Lee Yang, Andrew Feng Yahoo Big Data ML Platform Team What is TensorFlowOnSpark Why TensorFlowOnSpark at Yahoo? Major contributor to open-source
Spark supports several storage levels
 1 Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the
1 Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the
15/04/2018. Spark supports several storage levels. The storage level is used to specify if the content of the RDD is stored
 Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the RDD,
Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the RDD,