Chapter 3. Distributed Algorithms based on MapReduce
|
|
|
- Hilary Matthews
- 5 years ago
- Views:
Transcription
1 Chapter 3 Distributed Algorithms based on MapReduce 1
2 Acknowledgements Hadoop: The Definitive Guide. Tome White. O Reilly. Hadoop in Action. Chuck Lam, Manning Publications. MapReduce: Simplified Data Processing on Large Clusters. Jeff Dean, Sanjay Ghemawat, Google, Inc. MapReduce: Simplified Data Processing on Large Clusters. Slides from Dan Weld s class at U. Washington. MapReduce: Simplified Data Processing on Large Clusters. Conroy Whitney, 4th year CS Web Development 2
3 Chapter Outline What is MapReduce Motivation Functions Work flow & data flow Hello World in MapReduce Details of your own MapReduce programs Implementation 3
4 What is MapReduce Origin from Google [OSDI 04] MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat Programming model for parallel data processing Hadoop can run MapReduce programs written in various languages, e.g., Java, Ruby, Python, C++ For large-scale data processing Exploits large set of commodity computers Executes process in distributed manner Offers high availability 4
5 Motivation Typical big data problem challenges: How do we break up a large problem into smaller tasks that can be executed in parallel? How do we assign tasks to workers distributed across a potentially large number of machines? How do we ensure that the workers get the data they need? How do we coordinate synchronization among the different workers? How do we share partial results from one worker that is needed by another? How do we accomplish all of the above in the face of software errors and hardware faults? 5



6 Typical Big Data Problem Iterate over a large number of records Extract something of interest from each record Shuffle and sort intermediate results Aggregate intermediate results Generate final output Map Reduce Key idea: provide a functional abstraction for these two operations 6
7 Data Structures <key, value> pairs are the basic data structure in MapReduce Keys and values can be: integers, float, strings, raw bytes They can also be arbitrary data structures The design of MapReduce algorithms involves: Imposing the key-value structure on arbitrary datasets E.g.: for a collection of Web pages, input keys may be URLs and values may be the HTML content In some algorithms, input keys are not used (e.g., wordcount), in others they uniquely identify a record Keys can be combined in complex ways to design various algorithms 7

8 A Brief View of MapReduce 8
9 Map and Reduce Functions Programmers specify two functions: map (k1, v1) list [<k2, v2>] Map transforms the input into key-value pairs to process reduce (k2, list [v2]) [<k3, v3>] Reduce aggregates the list of values for each key All values with the same key are sent to the same reducer list [<k2, v2>] will be grouped according to key k2 as (k2, list [v2]) The MapReduce environment takes in charge of everything else A complex program can be decomposed as a succession of Map and Reduce tasks 9

10 Shuffle & Sort Functions Shuffle Input to the Reducer is the sorted output of the mappers. In this phase the framework fetches the relevant partition of the output of all the mappers, via HTTP. Sort The framework groups Reducer inputs by keys (since different Mappers may have output the same key) in this stage. 10
11 Brief Data Flow Data distribution: 1. Input files are split into M pieces on distributed file system MB blocks 2. Intermediate files created from map tasks are written to local disk 3. Output files are written to distributed file system Assigning tasks Many copies of user program are started Tries to utilize data localization by running map tasks on machines with data One instance becomes the Master Master finds idle machines and assigns them tasks 11
12 Brief Work Flow Application writer specifies A pair of functions called Map and Reduce and a set of input files and submits the job Workflow Input phase generates a number of FileSplits from input files (one per Map task) The Map phase executes a user function to transform input kv-pairs into a new set of kv-pairs The framework sorts & Shuffles the kv-pairs to output nodes The Reduce phase combines all kv-pairs with the same key into new kv-pairs The output phase writes the resulting pairs to files All phases are distributed with many tasks doing the work Framework handles scheduling of tasks on cluster Framework handles recovery when a node fails 12
13 Everything Else? Handles scheduling Assigns workers to map and reduce tasks Handles data distribution Moves processes to data Handles synchronization Gathers, sorts, and shuffles intermediate data Handles errors and faults Detects worker failures and restarts Everything happens on top of a distributed file system (HDFS) You don t know: Where mappers and reducers run When a mapper or reducer begins or finishes Which input a particular mapper is processing Which intermediate key a particular reducer is processing 13

14 Hello World in MapReduce 14
15 Hello World in MapReduce 15
16 Hello World in MapReduce Input: Key-value pairs: (docid, doc) of a file stored on the distributed filesystem docid : unique identifier of a document doc: is the text of the document itself Mapper: Takes an input key-value pair, tokenize the line Emits intermediate key-value pairs: the word is the key and the integer is the value The framework: Guarantees all values associated with the same key (the word) are brought to the same reducer The reducer: Receives all values associated to some keys Sums the values and writes output key-value pairs: the key is the word and the value is the number of occurrences 16
17 Mapper Reducer Run this program as a MapReduce job 17
18 Where the Magic Happens Implicit between the map and reduce phases is a parallel group by operation on intermediate keys Intermediate data arrive at each reducer in order, sorted by the key No ordering is guaranteed across reducers Output keys from reducers are written back to HDFS The output may consist of r distinct files, where r is the number of reducers Such output may be the input to a subsequent MapReduce phase Intermediate keys (used in shuffle and sort) are transient: They are not stored on the distributed filesystem They are spilled to the local disk of each machine in the cluster 18
19 Write your own WordCount in Java 19
20 Section Outline Program overview Mapper Reducer Main (The Driver) Combiner Partitioner Serialization and Writable Counters Input and Output Compression 20
21 Write your own WordCount in Java Program Overview 21
22 MapReduce Program A MapReduce program consists of the following 3 parts: Driver main (would trigger the map and reduce methods) Mapper Reducer It is better to include the map reduce and main methods in 3 different classes Check detailed information of all classes at: es-noframe.html
23 Write your own WordCount in Java Mapper 23
24 Mapper public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); } public void map(object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasmoretokens()) { word.set(itr.nexttoken()); context.write(word, one); } }
25 Mapper Explanation Maps input key/value pairs to a set of intermediate key/value pairs. //Map class header public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ Class Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT> KEYIN,VALUEIN -> (k1, v1) -> (docid, doc) KEYOUT,VALUEOUT ->(k2, v2) -> (word, 1) // IntWritable: A serializable and comparable object for integer private final static IntWritable one = new IntWritable(1); //Text: stores text using standard UTF8 encoding. It provides methods to serialize, deserialize, and compare texts at byte level private Text word = new Text(); //hadoop supported data types for the key/value pairs, in package org.apache.hadoop
26 Mapper Explanation (Cont ) //Map method header public void map(object key, Text value, Context context) throws IOException, InterruptedException{ } Object key/text value: Data type of the input Key and Value to the mapper Context: An inner class of Mapper, used to store the context of a running task. Here it is used to collect data output by either the Mapper or the Reducer, i.e. intermediate outputs or the output of the job Exceptions: IOException, InterruptedException This function is called once for each key/value pair in the input split. Your application should override this to do your job.
27 Mapper Explanation (Cont ) //Use a string tokenizer to split the document into words StringTokenizer itr = new StringTokenizer(value.toString()); //Iterate through each word and a form key value pairs while (itr.hasmoretokens()) { //Assign each work from the tokenizer(of String type) to a Text word word.set(itr.nexttoken()); //Form key value pairs for each word as <word, one> using context context.write(word, one); } Map function produces Map.Context object Map.context() takes (k, v) elements Any (WritableComparable, Writable) can be used
28 Write your own WordCount in Java Reducer 28
29 Reducer public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); } public void reduce(text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{ int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); }
30 Reducer Explanation //Reduce Header similar to the one in map with different key/value data type public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> //data from map will be < word,{1,1,..}>, so we get it with an Iterator and thus we can go through the sets of values public void reduce(text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{ //Initaize a variable sum as 0 int sum = 0; //Iterate through all the values with respect to a key and sum up all of them for (IntWritable val : values) { } sum += val.get(); // Form the final key/value pairs results for each word using context } result.set(sum); context.write(key, result);
31 Write your own WordCount in Java Main (The Driver) 31
32 Main (The Driver) Given the Mapper and Reducer code, the short main() starts the MapReduction running The Hadoop system picks up a bunch of values from the command line on its own Then the main() also specifies a few key parameters of the problem in the Job object Job is the primary interface for a user to describe a map-reduce job to the Hadoop framework for execution (such as what Map and Reduce classes to use and the format of the input and output files) Other parameters, i.e. the number of machines to use, are optional and the system will determine good values for them if not specified Then the framework tries to faithfully execute the job as-is described by Job
33 Main (The Driver) public static void main(string[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setjarbyclass(wordcount.class); job.setmapperclass(tokenizermapper.class); job.setreducerclass(intsumreducer.class); job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true)? 0 : 1); }
34 Main Explanation //Creating a Configuration object and a Job object, assigning a job name for identification purposes Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); Job Class: It allows the user to configure the job, submit it, control its execution, and query the state. Normally the user creates the application, describes various facets of the job via Job and then submits the job and monitor its progress. //Setting the job's jar file by finding the provided class location job.setjarbyclass(wordcount.class); //Providing the mapper and reducer class names job.setmapperclass(tokenizermapper.class); job.setreducerclass(intsumreducer.class); //Setting configuration object with the Data Type of output Key and Value for map and reduce job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class);
35 Main Explanation (Cont ) //The hdfs input and output directory to be fetched from the command line FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); //Submit the job to the cluster and wait for it to finish System.exit(job.waitForCompletion(true)? 0 : 1);
36 Make It Running! Configure environment variables export JAVA_HOME= export PATH=${JAVA_HOME}/bin:${PATH} export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar Compile WordCount.java and create a jar: $ hadoop com.sun.tools.javac.main WordCount.java $ jar cf wc.jar WordCount*.class Put files to HDFS $ hdfs dfs put YOURFILES input Run the application $ hadoop jar wc.jar WordCount input output Check the results $ hdfs dfs cat output/*
37 Make It Running! Given two files: file1: Hello World Bye World file2: Hello Hadoop Goodbye Hadoop The first map emits: < Hello, 1> < World, 1> < Bye, 1> < World, 1> The second map emits: < Hello, 1> < Hadoop, 1> < Goodbye, 1> < Hadoop, 1> The output of the job is: < Bye, 1> < Goodbye, 1> < Hadoop, 2> < Hello, 2> < World, 2>
38 Write your own WordCount in Java Combiner 38
39 Combiners Often a Map task will produce many pairs of the form (k,v 1 ), (k,v 2 ), for the same key k E.g., popular words in the word count example Combiners are a general mechanism to reduce the amount of intermediate data, thus saving network cost They could be thought of as mini-reducers Warning! The use of combiners must be thought carefully Optional in Hadoop: the correctness of the algorithm cannot depend on computation (or even execution) of the combiners A combiner operates on each map output key. It must have the same output key-value types as the Mapper class. A combiner can produce summary information from a large dataset because it replaces the original Map output Works only if reduce function is commutative and associative In general, reducer and combiner are not interchangeable

40 Combiners in WordCount Combiner combines the values of all keys of a single mapper node (single machine): Much less data needs to be copied and shuffled! If combiners take advantage of all opportunities for local aggregation we have at most m V intermediate key-value pairs m: number of mappers V: number of unique terms in the collection Note: not all mappers will see all terms
41 Combiners in WordCount In WordCount.java, you only need to add the follow line to Main: job.setcombinerclass(intsumreducer.class); This is because in this example, Reducer and Combiner do the same thing Note: Most cases this is not true! You need to write an extra combiner class Given two files: file1: Hello World Bye World file2: Hello Hadoop Goodbye Hadoop The first map emits: < Hello, 1> < World, 2> < Bye, 1> The second map emits: < Hello, 1> < Hadoop, 2> < Goodbye, 1>
42 Write your own WordCount in Java Partitioner 42
43 Partitioner Partitioner controls the partitioning of the keys of the intermediate map-outputs. The key (or a subset of the key) is used to derive the partition, typically by a hash function. The total number of partitions is the same as the number of reduce tasks for the job. This controls which of the m reduce tasks the intermediate key (and hence the record) is sent to for reduction. System uses HashPartitioner by default: hash(key) mod R Sometimes useful to override the hash function: E.g., hash(hostname(url)) mod R ensures URLs from a host end up in the same output file and will be stored in one file Job sets Partitioner implementation (in Main)
44 MapReduce: Recap Programmers must specify: map (k 1, v 1 ) [(k 2, v 2 )] reduce (k 2, [v 2 ]) [<k 3, v 3 >] All values with the same key are reduced together Optionally, also: combine (k 2, [v 2 ]) [<k 3, v 3 >] Mini-reducers that run in memory after the map phase Used as an optimization to reduce network traffic partition (k 2, number of partitions) partition for k 2 Often a simple hash of the key, e.g., hash(k 2 ) mod n Divides up key space for parallel reduce operations The execution framework handles everything else
45 MapReduce: Recap (Cont ) Divides input into fixed-size pieces, input splits Hadoop creates one map task for each split Map task runs the user-defined map function for each record in the split Size of splits Small size is better for load-balancing: faster machine will be able to process more splits But if splits are too small, the overhead of managing the splits dominate the total execution time For most jobs, a good split size tends to be the size of a HDFS block, 64MB(default) Data locality optimization Run the map task on a node where the input data resides in HDFS This is the reason why the split size is the same as the block size
46 MapReduce: Recap (Cont ) Map tasks write their output to local disk (not to HDFS) Map output is intermediate output Once the job is complete the map output can be thrown away So storing it in HDFS with replication would be overkill If the node of map task fails, Hadoop will automatically rerun the map task on another node Reduce tasks don t have the advantage of data locality Input to a single reduce task is normally the output from all mappers Output of the reduce is stored in HDFS for reliability The number of reduce tasks is not governed by the size of the input, but is specified independently

47 MapReduce: Recap (Cont ) When there are multiple reducers, the map tasks partition their output: One partition for each reduce task The records for every key are all in a single partition Partitioning can be controlled by a user-defined partitioning function
48 Write your own WordCount in Java Serialization and Writable 48
49 Serialization Process of turning structured objects into a byte stream for transmission over a network or for writing to persistent storage Deserialization is the reverse process of serialization Requirements Compact To make efficient use of storage space Fast The overhead in reading and writing of data is minimal Extensible We can transparently read data written in an older format Interoperable We can read or write persistent data using different language
50 Writable Interface Hadoop defines its own box classes for strings (Text), integers (IntWritable), etc. Writable is a serializable object which implements a simple, efficient, serialization protocol public interface Writable { void write(dataoutput out) throws IOException; void readfields(datainput in) throws IOException; } All values must implement interface Writable All keys must implement interface WritableComparable context.write(writablecomparable, Writable) You cannot use java primitives here!!
51 Writable Wrappers There are Writable wrappers for all the Java primitive types except shot and char (both of which can be stored in an IntWritable) get() for retrieving and set() for storing the wrapped value Variable-length formats If a value is between -122 and 127, use only a single byte Otherwise, use first byte to indicate whether the value is positive or negative and how many bytes follow
52 Writable Examples Text Writable for UTF-8 sequences Can be thought of as the Writable equivalent of java.lang.string Maximum size is 2GB Use standard UTF-8 Text is mutable (like all Writable implementations, except NullWritable) Different from java.lang.string You can reuse a Text instance by calling one of the set() method NullWritable Zero-length serialization Used as a placeholder A key or a value can be declared as a NullWritable when you don t need to use that position
53 Stripes Implementation A stripe key-value pair a { b: 1, c: 2, d: 5, e: 3, f: 2 }: Key: the term a Value: the stripe { b: 1, c: 2, d: 5, e: 3, f: 2 } In Java, easy, use map (hashmap) How to represent this stripe in MapReduce? MapWritable: the wrapper of Java map in MapReduce put(writable key, Writable value) get(object key) containskey(object key) containsvalue(object value) entryset(), returns Set<Map.Entry<Writable,Writable>>, used for iteration More details please refer to e/hadoop/io/mapwritable.html
54 Pairs Implementation Key-value pair (a, b) count Value: count Key: (a, b) In Java, easy, implement a pair class How to store the key in MapReduce? You must customize your own key, which must implement interface WritableComparable! First start from a easier task: when the value is a pair, which must implement interface Writable
55 Multiple Output Values If we are to output multiple values for each key E.g., a pair of String objects, or a pair of int How do we do that? WordCount output a single number as the value Remember, our object containing the values needs to implement the Writable interface We could use Text Value is a string of comma separated values Have to convert the values to strings, build the full string Have to parse the string on input (not hard) to get the values
56 Implement a Custom Writable Suppose we wanted to implement a custom class containing a pair of String objects. Call it StringPair. How would we implement this class? Needs to implement the WritableComparable interface Instance variables to hold the values Construct functions A method to set the values (two String objects) A method to get the values (two String objects) write() method: serialize the member variables (i.e., two String) objects in turn to the output stream readfields() method: deserialize the member variables (i.e., two String) in turn from the input stream As in Java: hashcode(), equals(), tostring() compareto() method: specify how to compare two objects of the self-defind class

; } set() method public void set(int left, int right) { first = left;")
57 Implement a Custom Writable Implement the Writable interface public class IntPair implements Writable { Instance variables to hold the values private int first, second; Construct functions public IntPair() { } public IntPair(int first, int second) { set(first, second); } set() method public void set(int left, int right) { first = left; second = right; }
; out.writeint(second); } Write the two integers to the output stream in turn readfields() method public void readfields(datainput in) throws IOException { first = in.")
58 Implement a Custom Writable get() method public int getfirst() { return first; } public int getsecond() { return second; } write() method public void write(dataoutput out) throws IOException { out.writeint(first); out.writeint(second); } Write the two integers to the output stream in turn readfields() method public void readfields(datainput in) throws IOException { first = in.readint(); second = in.readint(); } Read the two integers from the input stream in turn
 return first.")
59 Implement a Custom WritableComparable In some cases such as secondary sort, we also need to override the hashcode() method. Because we need to make sure that all key-value pairs associated with the first part of the key are sent to the same reducer! public int hashcode() return first.hashcode(); } By doing this, partitioner will only use the hashcode of the first part. You can also write a paritioner to do this job
60 Implement a Custom Writable In some cases such as secondary sort, we also need to override the hashcode() method. Because we need to make sure that all key-value pairs associated with the first part of the key are sent to the same reducer! public int hashcode() return first.hashcode(); } By doing this, partitioner will only use the hashcode of the first part. You can also write a paritioner to do this job 60
61 Write your own WordCount in Java Counters 61
62 MapReduce Counters Instrument Job s metrics Gather statistics Quality control confirm what was expected. E.g., count invalid records Application level statistics. Problem diagnostics Try to use counters for gathering statistics instead of log files Framework provides a set of built-in metrics For example bytes processed for input and output User can create new counters Number of records consumed Number of errors or warnings
63 Built-in Counters Hadoop maintains some built-in counters for every job. Several groups for built-in counters File System Counters number of bytes read and written Job Counters documents number of map and reduce tasks launched, number of failed tasks Map-Reduce Task Counters mapper, reducer, combiner input and output records counts, time and memory statistics
64 User-Defined Counters You can create your own counters Counters are defined by a Java enum serves to group related counters E.g., enum Temperature { MISSING, MALFORMED } Increment counters in Reducer and/or Mapper classes Counters are global: Framework accurately sums up counts across all maps and reduces to produce a grand total at the end of the job
65 Implement User-Defined Counters Retrieve Counter from Context object Framework injects Context object into map and reduce methods Increment Counter s value Can increment by 1 or more
 Enumerate all counters after job is completed for (CounterGroup group : counters) { System.out.println(\"* Counter Group: \" + group.getdisplayname() + \" (\" + group.getname() + \")\"); System.")
66 Implement User-Defined Counters Get Counters from a finished job in Java Counter counters = job.getcounters() Get the counter according to name Counter c1 = counters.findcounter(temperature.missing) Enumerate all counters after job is completed for (CounterGroup group : counters) { System.out.println("* Counter Group: " + group.getdisplayname() + " (" + group.getname() + ")"); System.out.println(" number of counters in this group: " + group.size()); for (Counter counter : group) { System.out.println(" - " + counter.getdisplayname() + ": " + counter.getname() + ": "+counter.getvalue()); } }
67 Write your own WordCount in Java Input and Output 67
68 MapReduce SequenceFile File operations based on binary format rather than text format SequenceFile class prvoides a persistent data structure for binary key-value pairs, e.g., Key: timestamp represented by a LongWritable Value: quantity being logged represented by a Writable Use SequenceFile in MapReduce: job.setinputformatclass(sequencefileoutputformat.class); job.setoutputformatclass(sequencefileoutputformat.class); In Mapreduce by default TextInputFormat
69 MapReduce Input Formats InputSplit A chunk of the input processed by a single map Each split is divided into records Split is just a reference to the data (doesn t contain the input data) RecordReader Iterate over records Used by the map task to generate record key-value pairs As a MapReduce application programmer, we do not need to deal with InputSplit directly, as they are created in InputFormat In MapReduce, by default TextInputFormat and LineRecordReader


70 MapReduce InputFormat
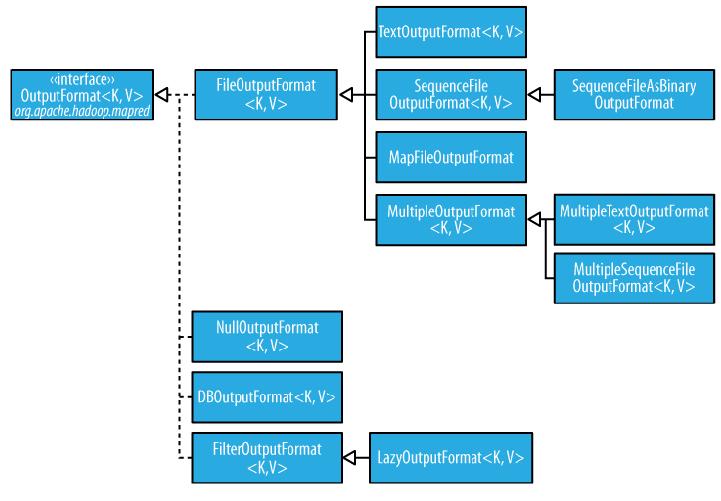
71 MapReduce OutputFormat
72 Write your own WordCount in Java Compression 72
73 Compression Two major benefits of file compression Reduce the space needed to store files Speed up data transfer across the network When dealing with large volumes of data, both of these savings can be significant, so it pays to carefully consider how to use compression in Hadoop

74 Compression Formats Compression formats Splittable column Indicates whether the compression format supports splitting Whether you can seek to any point in the stream and start reading from some point further on Splittable compression formats are especially suitable for MapReduce
75 Compression and Input Splits When considering how to compress data that will be processed by MapReduce, it is important to understand whether the compression format supports splitting Example of not-splitable compression problem A file is a gzip-compressed file whose compressed size is 1 GB Creating a split for each block won t work since it is impossible to start reading at an arbitrary point in the gzip stream, and therefore impossible for a map task to read its split independently of the others
: obtain a CompressionInputStream, which allows you to read uncompressed data from")
76 Codecs A codec is the implementation of a compressiondecompression algorithm CompressionCodec createoutputstream(outputstream out): create a CompressionOutputStream to which you write your uncompressed data to have it written in compressed form to the underlying stream createinputstream(inputstream in): obtain a CompressionInputStream, which allows you to read uncompressed data from the underlying stream
77 Use Compression in MapReduce If the input files are compressed, they will be decompressed automatically as they are read by MapReduce, using the filename extension to determine which codec to use. We do not need to do anything unless to guarantee that the filename extension is correct In order to compress the output of a MapReduce job, you need to: Set the mapreduce.output.fileoutputformat.compress property to true Set the mapreduce.output.fileoutputformat.compress.codec property to the classname of the compression codec Use the static method of FileOutputFormat to set these properties
 throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, \"word count\"); job.")
; FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); FileOutputFormat.")
78 Use Compression in MapReduce In WordCount.java, you can do: public static void main(string[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setjarbyclass(wordcount.class); job.setmapperclass(tokenizermapper.class); job.setreducerclass(intsumreducer.class); job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); FileOutputFormat.setCompressOutput(job, true); FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class); System.exit(job.waitForCompletion(true)? 0 : 1); }
79 Implementations 79


80 Create Local Files Create folder /home/hadoop/file and 2 local files file1.txt and file2.txt 80


81 Upload Local Files Create the input folder on HDFS and upload the local input files into the input folder 81


82 Run Programs Compiled jar files "/usr/hadoop/hadoop-examples jar Runtime information 82


83 Check Results Check the output folder Check the output file 83
84 End of Chapter 3 84
COMP4442. Service and Cloud Computing. Lab 12: MapReduce. Prof. George Baciu PQ838.
 COMP4442 Service and Cloud Computing Lab 12: MapReduce www.comp.polyu.edu.hk/~csgeorge/comp4442 Prof. George Baciu csgeorge@comp.polyu.edu.hk PQ838 1 Contents Introduction to MapReduce A WordCount example
COMP4442 Service and Cloud Computing Lab 12: MapReduce www.comp.polyu.edu.hk/~csgeorge/comp4442 Prof. George Baciu csgeorge@comp.polyu.edu.hk PQ838 1 Contents Introduction to MapReduce A WordCount example
Java in MapReduce. Scope
 Java in MapReduce Kevin Swingler Scope A specific look at the Java code you might use for performing MapReduce in Hadoop Java program recap The map method The reduce method The whole program Running on
Java in MapReduce Kevin Swingler Scope A specific look at the Java code you might use for performing MapReduce in Hadoop Java program recap The map method The reduce method The whole program Running on
Introduction to Map/Reduce. Kostas Solomos Computer Science Department University of Crete, Greece
 Introduction to Map/Reduce Kostas Solomos Computer Science Department University of Crete, Greece What we will cover What is MapReduce? How does it work? A simple word count example (the Hello World! of
Introduction to Map/Reduce Kostas Solomos Computer Science Department University of Crete, Greece What we will cover What is MapReduce? How does it work? A simple word count example (the Hello World! of
MapReduce Simplified Data Processing on Large Clusters
 MapReduce Simplified Data Processing on Large Clusters Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) MapReduce 1393/8/5 1 /
MapReduce Simplified Data Processing on Large Clusters Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) MapReduce 1393/8/5 1 /
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing. Lecture 6: MapReduce in Parallel Computing
 ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
Parallel Data Processing with Hadoop/MapReduce. CS140 Tao Yang, 2014
 Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example
Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 16. Big Data Management VI (MapReduce Programming)
") Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 16 Big Data Management VI (MapReduce Programming) Credits: Pietro Michiardi (Eurecom): Scalable Algorithm
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 16 Big Data Management VI (MapReduce Programming) Credits: Pietro Michiardi (Eurecom): Scalable Algorithm
UNIT V PROCESSING YOUR DATA WITH MAPREDUCE Syllabus
 UNIT V PROCESSING YOUR DATA WITH MAPREDUCE Syllabus Getting to know MapReduce MapReduce Execution Pipeline Runtime Coordination and Task Management MapReduce Application Hadoop Word Count Implementation.
UNIT V PROCESSING YOUR DATA WITH MAPREDUCE Syllabus Getting to know MapReduce MapReduce Execution Pipeline Runtime Coordination and Task Management MapReduce Application Hadoop Word Count Implementation.
Experiences with a new Hadoop cluster: deployment, teaching and research. Andre Barczak February 2018
 Experiences with a new Hadoop cluster: deployment, teaching and research Andre Barczak February 2018 abstract In 2017 the Machine Learning research group got funding for a new Hadoop cluster. However,
Experiences with a new Hadoop cluster: deployment, teaching and research Andre Barczak February 2018 abstract In 2017 the Machine Learning research group got funding for a new Hadoop cluster. However,
Parallel Processing - MapReduce and FlumeJava. Amir H. Payberah 14/09/2018
 Parallel Processing - MapReduce and FlumeJava Amir H. Payberah payberah@kth.se 14/09/2018 The Course Web Page https://id2221kth.github.io 1 / 83 Where Are We? 2 / 83 What do we do when there is too much
Parallel Processing - MapReduce and FlumeJava Amir H. Payberah payberah@kth.se 14/09/2018 The Course Web Page https://id2221kth.github.io 1 / 83 Where Are We? 2 / 83 What do we do when there is too much
Developing MapReduce Programs
 Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Big Data Analysis using Hadoop. Map-Reduce An Introduction. Lecture 2
 Big Data Analysis using Hadoop Map-Reduce An Introduction Lecture 2 Last Week - Recap 1 In this class Examine the Map-Reduce Framework What work each of the MR stages does Mapper Shuffle and Sort Reducer
Big Data Analysis using Hadoop Map-Reduce An Introduction Lecture 2 Last Week - Recap 1 In this class Examine the Map-Reduce Framework What work each of the MR stages does Mapper Shuffle and Sort Reducer
Cloud Programming on Java EE Platforms. mgr inż. Piotr Nowak
 Cloud Programming on Java EE Platforms mgr inż. Piotr Nowak dsh distributed shell commands execution -c concurrent --show-machine-names -M --group cluster -g cluster /etc/dsh/groups/cluster needs passwordless
Cloud Programming on Java EE Platforms mgr inż. Piotr Nowak dsh distributed shell commands execution -c concurrent --show-machine-names -M --group cluster -g cluster /etc/dsh/groups/cluster needs passwordless
Data-Intensive Computing with MapReduce
 Data-Intensive Computing with MapReduce Session 2: Hadoop Nuts and Bolts Jimmy Lin University of Maryland Thursday, January 31, 2013 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Computing with MapReduce Session 2: Hadoop Nuts and Bolts Jimmy Lin University of Maryland Thursday, January 31, 2013 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
MapReduce and Hadoop. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica MapReduce and Hadoop Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica MapReduce and Hadoop Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The
Recommended Literature
 COSC 6397 Big Data Analytics Introduction to Map Reduce (I) Edgar Gabriel Spring 2017 Recommended Literature Original MapReduce paper by google http://research.google.com/archive/mapreduce-osdi04.pdf Fantastic
COSC 6397 Big Data Analytics Introduction to Map Reduce (I) Edgar Gabriel Spring 2017 Recommended Literature Original MapReduce paper by google http://research.google.com/archive/mapreduce-osdi04.pdf Fantastic
Big Data Analysis using Hadoop Lecture 3
 Big Data Analysis using Hadoop Lecture 3 Last Week - Recap Driver Class Mapper Class Reducer Class Create our first MR process Ran on Hadoop Monitored on webpages Checked outputs using HDFS command line
Big Data Analysis using Hadoop Lecture 3 Last Week - Recap Driver Class Mapper Class Reducer Class Create our first MR process Ran on Hadoop Monitored on webpages Checked outputs using HDFS command line
2. MapReduce Programming Model
 Introduction MapReduce was proposed by Google in a research paper: Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System
Introduction MapReduce was proposed by Google in a research paper: Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (2/2) January 12, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (2/2) January 12, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
IntWritable w1 = new IntWritable(163); IntWritable w2 = new IntWritable(67); assertthat(comparator.compare(w1, w2), greaterthan(0));
; IntWritable w2 = new IntWritable(67); assertthat(comparator.compare(w1, w2), greaterthan(0));") factory for RawComparator instances (that Writable implementations have registered). For example, to obtain a comparator for IntWritable, we just use: RawComparator comparator = WritableComparator.get(IntWritable.class);
factory for RawComparator instances (that Writable implementations have registered). For example, to obtain a comparator for IntWritable, we just use: RawComparator comparator = WritableComparator.get(IntWritable.class);
Map Reduce. MCSN - N. Tonellotto - Distributed Enabling Platforms
 Map Reduce 1 MapReduce inside Google Googlers' hammer for 80% of our data crunching Large-scale web search indexing Clustering problems for Google News Produce reports for popular queries, e.g. Google
Map Reduce 1 MapReduce inside Google Googlers' hammer for 80% of our data crunching Large-scale web search indexing Clustering problems for Google News Produce reports for popular queries, e.g. Google
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
Big Data Analytics: Insights and Innovations
 International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 6, Issue 10 (April 2013), PP. 60-65 Big Data Analytics: Insights and Innovations
International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 6, Issue 10 (April 2013), PP. 60-65 Big Data Analytics: Insights and Innovations
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
Clustering Documents. Document Retrieval. Case Study 2: Document Retrieval
 Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April, 2017 Sham Kakade 2017 1 Document Retrieval n Goal: Retrieve
Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April, 2017 Sham Kakade 2017 1 Document Retrieval n Goal: Retrieve
Compile and Run WordCount via Command Line
 Aims This exercise aims to get you to: Compile, run, and debug MapReduce tasks via Command Line Compile, run, and debug MapReduce tasks via Eclipse One Tip on Hadoop File System Shell Following are the
Aims This exercise aims to get you to: Compile, run, and debug MapReduce tasks via Command Line Compile, run, and debug MapReduce tasks via Eclipse One Tip on Hadoop File System Shell Following are the
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Clustering Documents. Case Study 2: Document Retrieval
 Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 21 th, 2015 Sham Kakade 2016 1 Document Retrieval Goal: Retrieve
Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 21 th, 2015 Sham Kakade 2016 1 Document Retrieval Goal: Retrieve
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Cloud Computing CS
 Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (1/2) January 10, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (1/2) January 10, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
A Guide to Running Map Reduce Jobs in Java University of Stirling, Computing Science
 A Guide to Running Map Reduce Jobs in Java University of Stirling, Computing Science Introduction The Hadoop cluster in Computing Science at Stirling allows users with a valid user account to submit and
A Guide to Running Map Reduce Jobs in Java University of Stirling, Computing Science Introduction The Hadoop cluster in Computing Science at Stirling allows users with a valid user account to submit and
MapReduce Algorithms
 Large-scale data processing on the Cloud Lecture 3 MapReduce Algorithms Satish Srirama Some material adapted from slides by Jimmy Lin, 2008 (licensed under Creation Commons Attribution 3.0 License) Outline
Large-scale data processing on the Cloud Lecture 3 MapReduce Algorithms Satish Srirama Some material adapted from slides by Jimmy Lin, 2008 (licensed under Creation Commons Attribution 3.0 License) Outline
Large-scale Information Processing
 Sommer 2013 Large-scale Information Processing Ulf Brefeld Knowledge Mining & Assessment brefeld@kma.informatik.tu-darmstadt.de Anecdotal evidence... I think there is a world market for about five computers,
Sommer 2013 Large-scale Information Processing Ulf Brefeld Knowledge Mining & Assessment brefeld@kma.informatik.tu-darmstadt.de Anecdotal evidence... I think there is a world market for about five computers,
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
15/03/2018. Combiner
 Combiner 2 1 Standard MapReduce applications The (key,value) pairs emitted by the Mappers are sent to the Reducers through the network Some pre-aggregations could be performed to limit the amount of network
Combiner 2 1 Standard MapReduce applications The (key,value) pairs emitted by the Mappers are sent to the Reducers through the network Some pre-aggregations could be performed to limit the amount of network
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Ghislain Fourny. Big Data 6. Massive Parallel Processing (MapReduce)
") Ghislain Fourny Big Data 6. Massive Parallel Processing (MapReduce) So far, we have... Storage as file system (HDFS) 13 So far, we have... Storage as tables (HBase) Storage as file system (HDFS) 14 Data
Ghislain Fourny Big Data 6. Massive Parallel Processing (MapReduce) So far, we have... Storage as file system (HDFS) 13 So far, we have... Storage as tables (HBase) Storage as file system (HDFS) 14 Data
Cloud Computing. Up until now
 Cloud Computing Lecture 9 Map Reduce 2010-2011 Introduction Up until now Definition of Cloud Computing Grid Computing Content Distribution Networks Cycle-Sharing Distributed Scheduling 1 Outline Map Reduce:
Cloud Computing Lecture 9 Map Reduce 2010-2011 Introduction Up until now Definition of Cloud Computing Grid Computing Content Distribution Networks Cycle-Sharing Distributed Scheduling 1 Outline Map Reduce:
MapReduce Algorithm Design
 MapReduce Algorithm Design Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul Big
MapReduce Algorithm Design Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul Big
Hadoop 3.X more examples
 Hadoop 3.X more examples Big Data - 09/04/2018 Let s start with some examples! http://www.dia.uniroma3.it/~dvr/es2_material.zip Example: LastFM Listeners per Track Consider the following log file UserId
Hadoop 3.X more examples Big Data - 09/04/2018 Let s start with some examples! http://www.dia.uniroma3.it/~dvr/es2_material.zip Example: LastFM Listeners per Track Consider the following log file UserId
Ghislain Fourny. Big Data Fall Massive Parallel Processing (MapReduce)
") Ghislain Fourny Big Data Fall 2018 6. Massive Parallel Processing (MapReduce) Let's begin with a field experiment 2 400+ Pokemons, 10 different 3 How many of each??????????? 4 400 distributed to many volunteers
Ghislain Fourny Big Data Fall 2018 6. Massive Parallel Processing (MapReduce) Let's begin with a field experiment 2 400+ Pokemons, 10 different 3 How many of each??????????? 4 400 distributed to many volunteers
Data-Intensive Distributed Computing
 Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 1: MapReduce Algorithm Design (4/4) January 16, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 1: MapReduce Algorithm Design (4/4) January 16, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
MapReduce: Recap. Juliana Freire & Cláudio Silva. Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec
 MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/90/104368640.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Guidelines For Hadoop and Spark Cluster Usage
 Guidelines For Hadoop and Spark Cluster Usage Procedure to create an account in CSX. If you are taking a CS prefix course, you already have an account; to get an initial password created: 1. Login to https://cs.okstate.edu/pwreset
Guidelines For Hadoop and Spark Cluster Usage Procedure to create an account in CSX. If you are taking a CS prefix course, you already have an account; to get an initial password created: 1. Login to https://cs.okstate.edu/pwreset
Attacking & Protecting Big Data Environments
 Attacking & Protecting Big Data Environments Birk Kauer & Matthias Luft {bkauer, mluft}@ernw.de #WhoAreWe Birk Kauer - Security Researcher @ERNW - Mainly Exploit Developer Matthias Luft - Security Researcher
Attacking & Protecting Big Data Environments Birk Kauer & Matthias Luft {bkauer, mluft}@ernw.de #WhoAreWe Birk Kauer - Security Researcher @ERNW - Mainly Exploit Developer Matthias Luft - Security Researcher
L22: SC Report, Map Reduce
 L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
Introduction to MapReduce
 732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
Processing Distributed Data Using MapReduce, Part I
 Processing Distributed Data Using MapReduce, Part I Computer Science E-66 Harvard University David G. Sullivan, Ph.D. MapReduce A framework for computation on large data sets that are fragmented and replicated
Processing Distributed Data Using MapReduce, Part I Computer Science E-66 Harvard University David G. Sullivan, Ph.D. MapReduce A framework for computation on large data sets that are fragmented and replicated
Hadoop 2.X on a cluster environment
 Hadoop 2.X on a cluster environment Big Data - 05/04/2017 Hadoop 2 on AMAZON Hadoop 2 on AMAZON Hadoop 2 on AMAZON Regions Hadoop 2 on AMAZON S3 and buckets Hadoop 2 on AMAZON S3 and buckets Hadoop 2 on
Hadoop 2.X on a cluster environment Big Data - 05/04/2017 Hadoop 2 on AMAZON Hadoop 2 on AMAZON Hadoop 2 on AMAZON Regions Hadoop 2 on AMAZON S3 and buckets Hadoop 2 on AMAZON S3 and buckets Hadoop 2 on
Programming Models MapReduce
 Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
CSE Lecture 11: Map/Reduce 7 October Nate Nystrom UTA
 CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
Parallel Nested Loops
 Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Partition-Based. Parallel Nested Loops. Median. More Join Thoughts. Parallel Office Tools 9/15/2011
 Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
Vendor: Hortonworks. Exam Code: HDPCD. Exam Name: Hortonworks Data Platform Certified Developer. Version: Demo
 Vendor: Hortonworks Exam Code: HDPCD Exam Name: Hortonworks Data Platform Certified Developer Version: Demo QUESTION 1 Workflows expressed in Oozie can contain: A. Sequences of MapReduce and Pig. These
Vendor: Hortonworks Exam Code: HDPCD Exam Name: Hortonworks Data Platform Certified Developer Version: Demo QUESTION 1 Workflows expressed in Oozie can contain: A. Sequences of MapReduce and Pig. These
Map-Reduce Applications: Counting, Graph Shortest Paths
 Map-Reduce Applications: Counting, Graph Shortest Paths Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Map-Reduce Applications: Counting, Graph Shortest Paths Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Java & Inheritance. Inheritance - Scenario
 Java & Inheritance ITNPBD7 Cluster Computing David Cairns Inheritance - Scenario Inheritance is a core feature of Object Oriented languages. A class hierarchy can be defined where the class at the top
Java & Inheritance ITNPBD7 Cluster Computing David Cairns Inheritance - Scenario Inheritance is a core feature of Object Oriented languages. A class hierarchy can be defined where the class at the top
Outline Introduction Big Data Sources of Big Data Tools HDFS Installation Configuration Starting & Stopping Map Reduc.
 D. Praveen Kumar Junior Research Fellow Department of Computer Science & Engineering Indian Institute of Technology (Indian School of Mines) Dhanbad, Jharkhand, India Head of IT & ITES, Skill Subsist Impels
D. Praveen Kumar Junior Research Fellow Department of Computer Science & Engineering Indian Institute of Technology (Indian School of Mines) Dhanbad, Jharkhand, India Head of IT & ITES, Skill Subsist Impels
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
The MapReduce Abstraction
 The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
CS-2510 COMPUTER OPERATING SYSTEMS
 CS-2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application Functional
CS-2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application Functional
Introduction to Map/Reduce & Hadoop
 Introduction to Map/Reduce & Hadoop V. CHRISTOPHIDES University of Crete & INRIA Paris 1 Peta-Bytes Data Processing 2 1 1 What is MapReduce? MapReduce: programming model and associated implementation for
Introduction to Map/Reduce & Hadoop V. CHRISTOPHIDES University of Crete & INRIA Paris 1 Peta-Bytes Data Processing 2 1 1 What is MapReduce? MapReduce: programming model and associated implementation for
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
Introduction to MapReduce (cont.)
") Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
CSE6331: Cloud Computing
 CSE6331: Cloud Computing Leonidas Fegaras University of Texas at Arlington c 2017 by Leonidas Fegaras Map-Reduce Fundamentals Based on: J. Simeon: Introduction to MapReduce P. Michiardi: Tutorial on MapReduce
CSE6331: Cloud Computing Leonidas Fegaras University of Texas at Arlington c 2017 by Leonidas Fegaras Map-Reduce Fundamentals Based on: J. Simeon: Introduction to MapReduce P. Michiardi: Tutorial on MapReduce
About the Tutorial. Audience. Prerequisites. Disclaimer & Copyright. Avro
 About the Tutorial Apache Avro is a language-neutral data serialization system, developed by Doug Cutting, the father of Hadoop. This is a brief tutorial that provides an overview of how to set up Avro
About the Tutorial Apache Avro is a language-neutral data serialization system, developed by Doug Cutting, the father of Hadoop. This is a brief tutorial that provides an overview of how to set up Avro
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Map Reduce Group Meeting
 Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
MapReduce. Arend Hintze
 MapReduce Arend Hintze Distributed Word Count Example Input data files cat * key-value pairs (0, This is a cat!) (14, cat is ok) (24, walk the dog) Mapper map() function key-value pairs (this, 1) (is,
MapReduce Arend Hintze Distributed Word Count Example Input data files cat * key-value pairs (0, This is a cat!) (14, cat is ok) (24, walk the dog) Mapper map() function key-value pairs (this, 1) (is,
1/30/2019 Week 2- B Sangmi Lee Pallickara
 Week 2-A-0 1/30/2019 Colorado State University, Spring 2019 Week 2-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING Term project deliverable
Week 2-A-0 1/30/2019 Colorado State University, Spring 2019 Week 2-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING Term project deliverable
Map-Reduce Applications: Counting, Graph Shortest Paths
 Map-Reduce Applications: Counting, Graph Shortest Paths Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Map-Reduce Applications: Counting, Graph Shortest Paths Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Introduction to Map/Reduce & Hadoop
 Introduction to Map/Reduce & Hadoop Vassilis Christophides christop@csd.uoc.gr http://www.csd.uoc.gr/~hy562 University of Crete 1 Peta-Bytes Data Processing 2 1 1 What is MapReduce? MapReduce: programming
Introduction to Map/Reduce & Hadoop Vassilis Christophides christop@csd.uoc.gr http://www.csd.uoc.gr/~hy562 University of Crete 1 Peta-Bytes Data Processing 2 1 1 What is MapReduce? MapReduce: programming
Database Applications (15-415)
") Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Recommended Literature
 COSC 6339 Big Data Analytics Introduction to Map Reduce (I) Edgar Gabriel Fall 2018 Recommended Literature Original MapReduce paper by google http://research.google.com/archive/mapreduce-osdi04.pdf Fantastic
COSC 6339 Big Data Analytics Introduction to Map Reduce (I) Edgar Gabriel Fall 2018 Recommended Literature Original MapReduce paper by google http://research.google.com/archive/mapreduce-osdi04.pdf Fantastic
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Hadoop Map Reduce 10/17/2018 1
 Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Cloud Computing. Leonidas Fegaras University of Texas at Arlington. Web Data Management and XML L12: Cloud Computing 1
 Cloud Computing Leonidas Fegaras University of Texas at Arlington Web Data Management and XML L12: Cloud Computing 1 Computing as a Utility Cloud computing is a model for enabling convenient, on-demand
Cloud Computing Leonidas Fegaras University of Texas at Arlington Web Data Management and XML L12: Cloud Computing 1 Computing as a Utility Cloud computing is a model for enabling convenient, on-demand
MapReduce Design Patterns
 MapReduce Design Patterns MapReduce Restrictions Any algorithm that needs to be implemented using MapReduce must be expressed in terms of a small number of rigidly defined components that must fit together
MapReduce Design Patterns MapReduce Restrictions Any algorithm that needs to be implemented using MapReduce must be expressed in terms of a small number of rigidly defined components that must fit together
Parallel Programming Concepts
 Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
itpass4sure Helps you pass the actual test with valid and latest training material.
 itpass4sure http://www.itpass4sure.com/ Helps you pass the actual test with valid and latest training material. Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Vendor : Cloudera
itpass4sure http://www.itpass4sure.com/ Helps you pass the actual test with valid and latest training material. Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Vendor : Cloudera
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Clustering Documents. Document Retrieval. Case Study 2: Document Retrieval
 Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox April 16 th, 2015 Emily Fox 2015 1 Document Retrieval n Goal: Retrieve
Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox April 16 th, 2015 Emily Fox 2015 1 Document Retrieval n Goal: Retrieve
Map Reduce.
 Map Reduce dacosta@irit.fr Divide and conquer at PaaS Second Third Fourth 100 % // Fifth Sixth Seventh Cliquez pour 2 Typical problem Second Extract something of interest from each MAP Third Shuffle and
Map Reduce dacosta@irit.fr Divide and conquer at PaaS Second Third Fourth 100 % // Fifth Sixth Seventh Cliquez pour 2 Typical problem Second Extract something of interest from each MAP Third Shuffle and
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Motivation. Map in Lisp (Scheme) Map/Reduce. MapReduce: Simplified Data Processing on Large Clusters
 Map/Reduce. MapReduce: Simplified Data Processing on Large Clusters") Motivation MapReduce: Simplified Data Processing on Large Clusters These are slides from Dan Weld s class at U. Washington (who in turn made his slides based on those by Jeff Dean, Sanjay Ghemawat, Google,
Motivation MapReduce: Simplified Data Processing on Large Clusters These are slides from Dan Weld s class at U. Washington (who in turn made his slides based on those by Jeff Dean, Sanjay Ghemawat, Google,
FAQs. Topics. This Material is Built Based on, Analytics Process Model. 8/22/2018 Week 1-B Sangmi Lee Pallickara
 CS435 Introduction to Big Data Week 1-B W1.B.0 CS435 Introduction to Big Data No Cell-phones in the class. W1.B.1 FAQs PA0 has been posted If you need to use a laptop, please sit in the back row. August
CS435 Introduction to Big Data Week 1-B W1.B.0 CS435 Introduction to Big Data No Cell-phones in the class. W1.B.1 FAQs PA0 has been posted If you need to use a laptop, please sit in the back row. August
Big Data: Architectures and Data Analytics
 Big Data: Architectures and Data Analytics July 14, 2017 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
Big Data: Architectures and Data Analytics July 14, 2017 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
Map Reduce & Hadoop Recommended Text:
 Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
An Introduction to Apache Spark
 An Introduction to Apache Spark Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 1 / 67 Big Data small data big data Amir H. Payberah (SICS) Apache Spark
An Introduction to Apache Spark Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 1 / 67 Big Data small data big data Amir H. Payberah (SICS) Apache Spark
Outline. Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins
 MapReduce 1 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins 2 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce
MapReduce 1 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins 2 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce
Laarge-Scale Data Engineering
 Laarge-Scale Data Engineering The MapReduce Framework & Hadoop Key premise: divide and conquer work partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 result combine Parallelisation challenges How
Laarge-Scale Data Engineering The MapReduce Framework & Hadoop Key premise: divide and conquer work partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 result combine Parallelisation challenges How
Hortonworks HDPCD. Hortonworks Data Platform Certified Developer. Download Full Version :
 Hortonworks HDPCD Hortonworks Data Platform Certified Developer Download Full Version : https://killexams.com/pass4sure/exam-detail/hdpcd QUESTION: 97 You write MapReduce job to process 100 files in HDFS.
Hortonworks HDPCD Hortonworks Data Platform Certified Developer Download Full Version : https://killexams.com/pass4sure/exam-detail/hdpcd QUESTION: 97 You write MapReduce job to process 100 files in HDFS.
CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University
![CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University](/thumbs/87/96206398.jpg "CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University") CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [MAPREDUCE & HADOOP] Does Shrideep write the poems on these title slides? Yes, he does. These musing are resolutely on track For obscurity shores, from whence
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [MAPREDUCE & HADOOP] Does Shrideep write the poems on these title slides? Yes, he does. These musing are resolutely on track For obscurity shores, from whence