Introduction to Map/Reduce. Kostas Solomos Computer Science Department University of Crete, Greece
|
|
|
- Maria Dickerson
- 5 years ago
- Views:
Transcription

1 Introduction to Map/Reduce Kostas Solomos Computer Science Department University of Crete, Greece
2 What we will cover What is MapReduce? How does it work? A simple word count example (the Hello World! of MapReduce) 2
3 What is MapReduce? A programming model for processing large datasets in parallel on a cluster, by dividing the work into a set of independent tasks (introduced by Google in 2005) All we have to do is provide the implementation of two methods: map() reduce() even that, is but we can do much more optional! 3
4 How does it work? keys and values everything is expressed as (key, value) pairs e.g. the information that the word hello appears 4 times in a text, could be expressed as: ( hello, 4) Each map method receives a list of (key, value) pairs and emits a list of (key, value) pairs the intermediate output of the program Each reduce method receives, for each unique intermediate key k, a list of all intermediate values that were emitted for k. Then, it emits a list of (key, value) pairs the final output of the program 4
5 MapReduce Input Data 5
6 MapReduce Input Data Splitting 6
7 MapReduce Mapper Input Mapper 1 Mapper 2 Mapper 3 7
8 MapReduce Mapper Output Mapper 1 Mapper 2 Mapper 3 8
9 MapReduce Shuffling & Sorting (simplified) 9
10 MapReduce Reducing Reducer 1 Reducer 2 Reducer 3 10
11 MapReduce Reducing f1 v1 f2 v2 f2 v1 f3 v1 f4 v3 f3 v2 f5 v2 f1 v3 Reducer 1 Reducer 2 Reducer 3 11
12 Example: WordCount Input: A list of (file-name, line) pairs Output: A list of (word, frequency) pairs for each unique word appearing in the input Idea: Map: for each word w, emit a (w, 1) pair Reduce: for each (w, list(1,1,,1)), sum up the 1 s and emit a (w, )) pair 12
13 Example: WordCount Input fil hello. world tx t fil.tx t the big fish eat the little fish fil.tx t hello, fish and chips please! Output Map hello, 1 world, 1 the, 1 the, 1 little, 1 Map Map big, 1 fish, 1 eat, 1 fish, 1 Reduce and, 1 hello, 2 little, 1 the, 2 world, 1 p ar t big, 1 chips, 1 eat, 1 fish, 3 please, 1 p ar t hello, 1 and, 1 Reduce fish, 1 chips 1 please, 1 13
14 WordCount Mapper public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); } public void map(longwritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.tostring(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasmoretokens()) { word.set(tokenizer.nexttoken()); context.write(word, one); } } 14
15 WordCount Reducer public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> } public void reduce(text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } 15
16 Combiner: a local, mini-reducer An optional class that works like a reducer, run locally for the output of each mapper Goal: reduce the network traffic from mappers to reducers could be a bottleneck reduce the workload of the reducers WordCount Example: We could sum up the local 1 s corresponding to the same key and emit a temporary word count to the reducer fewer pairs are sent to the network the reducers save some operations 16
17 WordCount with Combiner Input fil hello. world tx t fil.tx t the big fish eat the little fish fil.tx t hello, fish and chips please! Output Map hello, 1 world, 1 Reduce the, 2 little, 1 Map big, 1 fish, 2 eat, 1 Map and, 1 hello, 2 little, 1 the, 2 world, 1 p ar t big, 1 chips, 1 eat, 1 fish, 3 please, 1 p ar t hello, 1 and, 1 Reduce fish, 1 chips 1 please, 1 17
18 Job configuration public int run(string[] args) throws Exception { Job job = new Job(getConf(), "WordCount"); job.setjarbyclass(wordcount.class); job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); job.setmapperclass(map.class); job.setreducerclass(reduce.class); job.setcombinerclass(reduce.class); job.setinputformatclass(textinputformat.class); job.setoutputformatclass(textoutputformat.class); job.setnumreducetasks(2); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitforcompletion(true); 18
19 Writable types Any key or value type has to implement the Writable interface Examples of Objects implementing Writable: Text (used for Strings) IntWritable, LongWritable, ShortWritable, DoubleWritable, VIntWritable, VLongWritable, (variable-length encodings) ByteWritable, BooleanWritable ArrayWritable Keys have to implement the WritableComparable interface, too if (key, value) pairs sent to a single reduce task include multiple keys, the reducer will process the keys in sorted order. You can also define and use your own types 19
20 A simple CustomWritable public class MyWritable implements Writable { private int counter; private long timestamp; public void write(dataoutput out) throws IOException { out.writeint(counter); out.writelong(timestamp); } public void readfields(datainput in) throws IOException { counter = in.readint(); timestamp = in.readlong(); } public static MyWritable read(datainput in) throws IOException { MyWritable MyWritable w = new MyWritable(); w.readfields(in); int counter return w; long timestamp } 20
21 Output Format The OutputFormat and RecordWriter interfaces dictate how to write the results of a job back to the underlying permanent storage The default format (TextOutputFormat) will write (key, value) pairs as strings to individual lines of an output file (using the tostring() methods of the keys and values). The SequenceFileOutputFormat will keep the data in binary, so it can be later read quickly by the SequenceFileInputFormat. These classes make use of the write() method of the specific Writable classes used by your MapReduce pass. 21
22 Input Formats The InputFormat defines how to read data from a file into the Mapper instances. Hadoop comes with several implementations of InputFormat; e.g. TextInputFormat: The key it emits for each record is the byte offset of the line read (as a LongWritable), and the value is the contents of the line up to the terminating '\n' character (as a Text object) SequenceFileInputFormat, for reading particular binary file formats instead of reading input as text only, you read it as (key, value) pairs, as you have written them in a previous job These classes make use of the readfields() method of the specific Writable classes used by your MapReduce pass. 22
23 Partitioning Which reducer will receive the intermediate output keys and values? (key, value) pairs with the same key end up at the same partition The mappers partition data independently they never exchange information with one another Hadoop uses an interface called Partitioner to determine to which partition a (key, value) pair will go A single partition refers to all (key, value) pairs which will be sent to a single reduce task #partitions = #reduce tasks (each Reducer can process multiple reduce tasks) The Partitioner determines the load balancing of the reducers 23
24 The Partitioner interface The Partitioner interface defines the getpartition() method Input: a key, a value and the number of partitions Output: a partition id for the given key, value pair The default Partitioner is the HashPartitioner: int getpartition(k key, V value, int numpartitions) { return key.hashcode() % numpartitions; } Key key.hashcode() partitionid (0-2) numpartitions = 3 hello world map reduce
25 Fault tolerance The primary way that Hadoop achieves fault tolerance is through restarting tasks Individual task nodes (TaskTrackers) are in constant communication with the head node of the system (the JobTracker) If a TaskTracker fails to communicate with the JobTracker for a period of time (by default, 10 minutes), the JobTracker will assume that the TaskTracker in question has crashed. The JobTracker knows which map and reduce tasks were assigned to each TaskTracker. If the job is still in the map phase, then other TaskTrackers will be asked to re-execute all map tasks previously run by the failed TaskTracker. If the job is in the reduce phase, then other TaskTrackers will re-execute all map and reduce tasks that were assigned to the failed TaskTracker. 25
26 Speculative execution The same input can be processed multiple times in parallel, to exploit differences in machine capabilities by dividing the tasks across many nodes, it is possible for a few slow nodes to rate-limit the rest of the program When tasks complete, they announce this fact to the JobTracker Whichever copy of a task finishes first becomes the definitive copy If other copies were executing speculatively, Hadoop tells the TaskTrackers to abandon the tasks and discard their outputs. The Reducers then receive their inputs from whichever Mapper completed successfully, first. 26
27 MRv1: JobTracker and TaskTrackers Client Client JobTracker master TaskTracker TaskTracker TaskTracker map map map reduce reduce reduce slaves 27
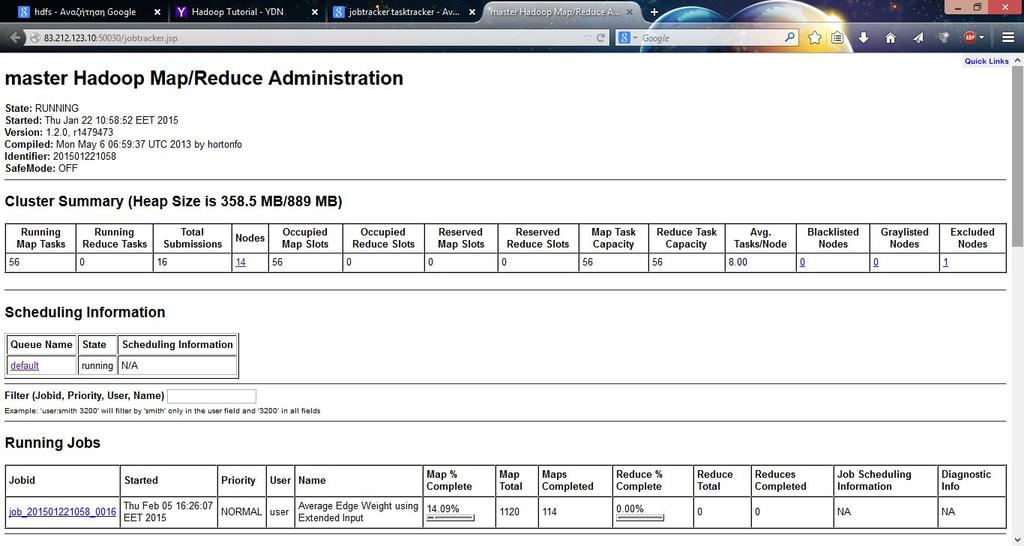
28 JobTracker UI 28
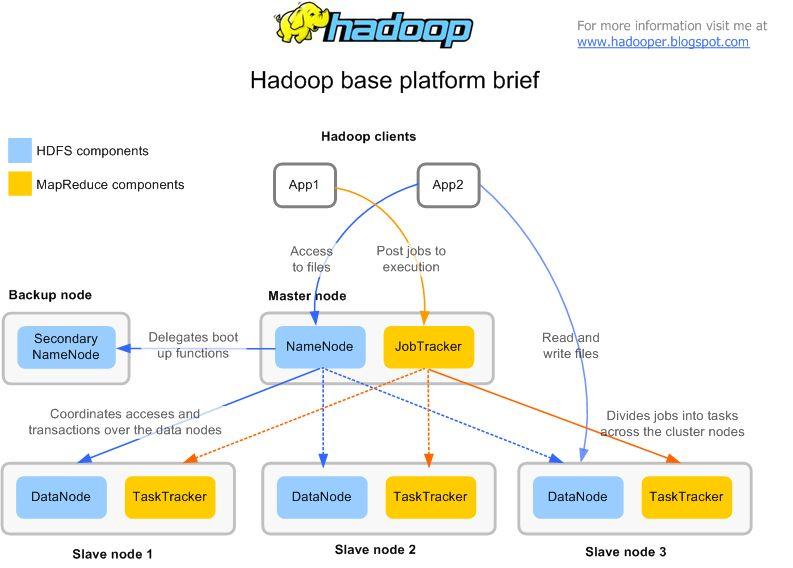
29 Hadoop Distributed File System (HDFS) HDFS is a distributed file system designed to hold very large amounts of data (terabytes or even petabytes), and provide high-throughput access to this information Files are stored in a redundant fashion across multiple machines to ensure their durability to failure and high availability to very parallel applications HDFS is a block-structured file system: individual files are broken into blocks of a fixed size (default 128MB) These blocks are stored across a cluster of one or more machines (DataNodes) The NameNode stores all the metadata for the file system 29

30 HDFS nodes 30
31 Interacting with HDFS Unix shell-like commands (ls, mkdir, rm, ) Important: start any HDFS command with `bin/hadoop dfs` Examples: bin/hadoop dfs ls /user/hduser/ lists the contents of the directory /user/hduser/ bin/hadoop dfs copyfromlocal ~/test.txt /user/hduser/input copies the local file test.txt to the HDFS directory Input 31
32 More HDFS shell commands cat, text, tail mv, cp, rm, rmr, mkdir copytolocal, movetolocal, get, getmerge copyfromlocal, movefromlocal, put count du, dus setrep 32
33 NameNode WebUI 33

34 Datanodes 34
35 35
36 Resources Large part of this tutorial was adapted from under a Creative Commons Attribution 3.0 Unported License. 36
UNIT V PROCESSING YOUR DATA WITH MAPREDUCE Syllabus
 UNIT V PROCESSING YOUR DATA WITH MAPREDUCE Syllabus Getting to know MapReduce MapReduce Execution Pipeline Runtime Coordination and Task Management MapReduce Application Hadoop Word Count Implementation.
UNIT V PROCESSING YOUR DATA WITH MAPREDUCE Syllabus Getting to know MapReduce MapReduce Execution Pipeline Runtime Coordination and Task Management MapReduce Application Hadoop Word Count Implementation.
Cloud Computing. Up until now
 Cloud Computing Lecture 9 Map Reduce 2010-2011 Introduction Up until now Definition of Cloud Computing Grid Computing Content Distribution Networks Cycle-Sharing Distributed Scheduling 1 Outline Map Reduce:
Cloud Computing Lecture 9 Map Reduce 2010-2011 Introduction Up until now Definition of Cloud Computing Grid Computing Content Distribution Networks Cycle-Sharing Distributed Scheduling 1 Outline Map Reduce:
Data-Intensive Computing with MapReduce
 Data-Intensive Computing with MapReduce Session 2: Hadoop Nuts and Bolts Jimmy Lin University of Maryland Thursday, January 31, 2013 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Computing with MapReduce Session 2: Hadoop Nuts and Bolts Jimmy Lin University of Maryland Thursday, January 31, 2013 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Large-scale Information Processing
 Sommer 2013 Large-scale Information Processing Ulf Brefeld Knowledge Mining & Assessment brefeld@kma.informatik.tu-darmstadt.de Anecdotal evidence... I think there is a world market for about five computers,
Sommer 2013 Large-scale Information Processing Ulf Brefeld Knowledge Mining & Assessment brefeld@kma.informatik.tu-darmstadt.de Anecdotal evidence... I think there is a world market for about five computers,
MapReduce Simplified Data Processing on Large Clusters
 MapReduce Simplified Data Processing on Large Clusters Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) MapReduce 1393/8/5 1 /
MapReduce Simplified Data Processing on Large Clusters Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) MapReduce 1393/8/5 1 /
Big Data Analysis using Hadoop. Map-Reduce An Introduction. Lecture 2
 Big Data Analysis using Hadoop Map-Reduce An Introduction Lecture 2 Last Week - Recap 1 In this class Examine the Map-Reduce Framework What work each of the MR stages does Mapper Shuffle and Sort Reducer
Big Data Analysis using Hadoop Map-Reduce An Introduction Lecture 2 Last Week - Recap 1 In this class Examine the Map-Reduce Framework What work each of the MR stages does Mapper Shuffle and Sort Reducer
Parallel Processing - MapReduce and FlumeJava. Amir H. Payberah 14/09/2018
 Parallel Processing - MapReduce and FlumeJava Amir H. Payberah payberah@kth.se 14/09/2018 The Course Web Page https://id2221kth.github.io 1 / 83 Where Are We? 2 / 83 What do we do when there is too much
Parallel Processing - MapReduce and FlumeJava Amir H. Payberah payberah@kth.se 14/09/2018 The Course Web Page https://id2221kth.github.io 1 / 83 Where Are We? 2 / 83 What do we do when there is too much
COMP4442. Service and Cloud Computing. Lab 12: MapReduce. Prof. George Baciu PQ838.
 COMP4442 Service and Cloud Computing Lab 12: MapReduce www.comp.polyu.edu.hk/~csgeorge/comp4442 Prof. George Baciu csgeorge@comp.polyu.edu.hk PQ838 1 Contents Introduction to MapReduce A WordCount example
COMP4442 Service and Cloud Computing Lab 12: MapReduce www.comp.polyu.edu.hk/~csgeorge/comp4442 Prof. George Baciu csgeorge@comp.polyu.edu.hk PQ838 1 Contents Introduction to MapReduce A WordCount example
Parallel Data Processing with Hadoop/MapReduce. CS140 Tao Yang, 2014
 Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example
Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (1/2) January 10, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (1/2) January 10, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Introduction to Map/Reduce & Hadoop
 Introduction to Map/Reduce & Hadoop Vassilis Christophides christop@csd.uoc.gr http://www.csd.uoc.gr/~hy562 University of Crete 1 Peta-Bytes Data Processing 2 1 1 What is MapReduce? MapReduce: programming
Introduction to Map/Reduce & Hadoop Vassilis Christophides christop@csd.uoc.gr http://www.csd.uoc.gr/~hy562 University of Crete 1 Peta-Bytes Data Processing 2 1 1 What is MapReduce? MapReduce: programming
Chapter 3. Distributed Algorithms based on MapReduce
 Chapter 3 Distributed Algorithms based on MapReduce 1 Acknowledgements Hadoop: The Definitive Guide. Tome White. O Reilly. Hadoop in Action. Chuck Lam, Manning Publications. MapReduce: Simplified Data
Chapter 3 Distributed Algorithms based on MapReduce 1 Acknowledgements Hadoop: The Definitive Guide. Tome White. O Reilly. Hadoop in Action. Chuck Lam, Manning Publications. MapReduce: Simplified Data
Clustering Documents. Case Study 2: Document Retrieval
 Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 21 th, 2015 Sham Kakade 2016 1 Document Retrieval Goal: Retrieve
Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 21 th, 2015 Sham Kakade 2016 1 Document Retrieval Goal: Retrieve
Clustering Documents. Document Retrieval. Case Study 2: Document Retrieval
 Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April, 2017 Sham Kakade 2017 1 Document Retrieval n Goal: Retrieve
Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April, 2017 Sham Kakade 2017 1 Document Retrieval n Goal: Retrieve
Big Data Analysis using Hadoop Lecture 3
 Big Data Analysis using Hadoop Lecture 3 Last Week - Recap Driver Class Mapper Class Reducer Class Create our first MR process Ran on Hadoop Monitored on webpages Checked outputs using HDFS command line
Big Data Analysis using Hadoop Lecture 3 Last Week - Recap Driver Class Mapper Class Reducer Class Create our first MR process Ran on Hadoop Monitored on webpages Checked outputs using HDFS command line
Java in MapReduce. Scope
 Java in MapReduce Kevin Swingler Scope A specific look at the Java code you might use for performing MapReduce in Hadoop Java program recap The map method The reduce method The whole program Running on
Java in MapReduce Kevin Swingler Scope A specific look at the Java code you might use for performing MapReduce in Hadoop Java program recap The map method The reduce method The whole program Running on
Introduction to Map/Reduce & Hadoop
 Introduction to Map/Reduce & Hadoop V. CHRISTOPHIDES University of Crete & INRIA Paris 1 Peta-Bytes Data Processing 2 1 1 What is MapReduce? MapReduce: programming model and associated implementation for
Introduction to Map/Reduce & Hadoop V. CHRISTOPHIDES University of Crete & INRIA Paris 1 Peta-Bytes Data Processing 2 1 1 What is MapReduce? MapReduce: programming model and associated implementation for
Outline. What is Big Data? Hadoop HDFS MapReduce Twitter Analytics and Hadoop
 Intro To Hadoop Bill Graham - @billgraham Data Systems Engineer, Analytics Infrastructure Info 290 - Analyzing Big Data With Twitter UC Berkeley Information School September 2012 This work is licensed
Intro To Hadoop Bill Graham - @billgraham Data Systems Engineer, Analytics Infrastructure Info 290 - Analyzing Big Data With Twitter UC Berkeley Information School September 2012 This work is licensed
Recommended Literature
 COSC 6397 Big Data Analytics Introduction to Map Reduce (I) Edgar Gabriel Spring 2017 Recommended Literature Original MapReduce paper by google http://research.google.com/archive/mapreduce-osdi04.pdf Fantastic
COSC 6397 Big Data Analytics Introduction to Map Reduce (I) Edgar Gabriel Spring 2017 Recommended Literature Original MapReduce paper by google http://research.google.com/archive/mapreduce-osdi04.pdf Fantastic
CSE6331: Cloud Computing
 CSE6331: Cloud Computing Leonidas Fegaras University of Texas at Arlington c 2017 by Leonidas Fegaras Map-Reduce Fundamentals Based on: J. Simeon: Introduction to MapReduce P. Michiardi: Tutorial on MapReduce
CSE6331: Cloud Computing Leonidas Fegaras University of Texas at Arlington c 2017 by Leonidas Fegaras Map-Reduce Fundamentals Based on: J. Simeon: Introduction to MapReduce P. Michiardi: Tutorial on MapReduce
Session 1 Big Data and Hadoop - Overview. - Dr. M. R. Sanghavi
 Session 1 Big Data and Hadoop - Overview - Dr. M. R. Sanghavi Acknowledgement Prof. Kainjan M. Sanghavi For preparing this prsentation This presentation is available on my blog https://maheshsanghavi.wordpress.com/expert-talk-fdp-workshop/
Session 1 Big Data and Hadoop - Overview - Dr. M. R. Sanghavi Acknowledgement Prof. Kainjan M. Sanghavi For preparing this prsentation This presentation is available on my blog https://maheshsanghavi.wordpress.com/expert-talk-fdp-workshop/
Ghislain Fourny. Big Data 6. Massive Parallel Processing (MapReduce)
") Ghislain Fourny Big Data 6. Massive Parallel Processing (MapReduce) So far, we have... Storage as file system (HDFS) 13 So far, we have... Storage as tables (HBase) Storage as file system (HDFS) 14 Data
Ghislain Fourny Big Data 6. Massive Parallel Processing (MapReduce) So far, we have... Storage as file system (HDFS) 13 So far, we have... Storage as tables (HBase) Storage as file system (HDFS) 14 Data
Ghislain Fourny. Big Data Fall Massive Parallel Processing (MapReduce)
") Ghislain Fourny Big Data Fall 2018 6. Massive Parallel Processing (MapReduce) Let's begin with a field experiment 2 400+ Pokemons, 10 different 3 How many of each??????????? 4 400 distributed to many volunteers
Ghislain Fourny Big Data Fall 2018 6. Massive Parallel Processing (MapReduce) Let's begin with a field experiment 2 400+ Pokemons, 10 different 3 How many of each??????????? 4 400 distributed to many volunteers
Big Data: Architectures and Data Analytics
 Big Data: Architectures and Data Analytics July 14, 2017 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
Big Data: Architectures and Data Analytics July 14, 2017 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
Clustering Documents. Document Retrieval. Case Study 2: Document Retrieval
 Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox April 16 th, 2015 Emily Fox 2015 1 Document Retrieval n Goal: Retrieve
Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox April 16 th, 2015 Emily Fox 2015 1 Document Retrieval n Goal: Retrieve
Database Applications (15-415)
") Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
FAQs. Topics. This Material is Built Based on, Analytics Process Model. 8/22/2018 Week 1-B Sangmi Lee Pallickara
 CS435 Introduction to Big Data Week 1-B W1.B.0 CS435 Introduction to Big Data No Cell-phones in the class. W1.B.1 FAQs PA0 has been posted If you need to use a laptop, please sit in the back row. August
CS435 Introduction to Big Data Week 1-B W1.B.0 CS435 Introduction to Big Data No Cell-phones in the class. W1.B.1 FAQs PA0 has been posted If you need to use a laptop, please sit in the back row. August
Cloud Computing CS
 Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
itpass4sure Helps you pass the actual test with valid and latest training material.
 itpass4sure http://www.itpass4sure.com/ Helps you pass the actual test with valid and latest training material. Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Vendor : Cloudera
itpass4sure http://www.itpass4sure.com/ Helps you pass the actual test with valid and latest training material. Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Vendor : Cloudera
Map-Reduce Applications: Counting, Graph Shortest Paths
 Map-Reduce Applications: Counting, Graph Shortest Paths Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Map-Reduce Applications: Counting, Graph Shortest Paths Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Map Reduce. MCSN - N. Tonellotto - Distributed Enabling Platforms
 Map Reduce 1 MapReduce inside Google Googlers' hammer for 80% of our data crunching Large-scale web search indexing Clustering problems for Google News Produce reports for popular queries, e.g. Google
Map Reduce 1 MapReduce inside Google Googlers' hammer for 80% of our data crunching Large-scale web search indexing Clustering problems for Google News Produce reports for popular queries, e.g. Google
Computer Science 572 Exam Prof. Horowitz Tuesday, April 24, 2017, 8:00am 9:00am
 Computer Science 572 Exam Prof. Horowitz Tuesday, April 24, 2017, 8:00am 9:00am Name: Student Id Number: 1. This is a closed book exam. 2. Please answer all questions. 3. There are a total of 40 questions.
Computer Science 572 Exam Prof. Horowitz Tuesday, April 24, 2017, 8:00am 9:00am Name: Student Id Number: 1. This is a closed book exam. 2. Please answer all questions. 3. There are a total of 40 questions.
W1.A.0 W2.A.0 1/22/2018 1/22/2018. CS435 Introduction to Big Data. FAQs. Readings
 CS435 Introduction to Big Data 1/17/2018 W2.A.0 W1.A.0 CS435 Introduction to Big Data W2.A.1.A.1 FAQs PA0 has been posted Feb. 6, 5:00PM via Canvas Individual submission (No team submission) Accommodation
CS435 Introduction to Big Data 1/17/2018 W2.A.0 W1.A.0 CS435 Introduction to Big Data W2.A.1.A.1 FAQs PA0 has been posted Feb. 6, 5:00PM via Canvas Individual submission (No team submission) Accommodation
Introduction to HDFS and MapReduce
 Introduction to HDFS and MapReduce Who Am I - Ryan Tabora - Data Developer at Think Big Analytics - Big Data Consulting - Experience working with Hadoop, HBase, Hive, Solr, Cassandra, etc. 2 Who Am I -
Introduction to HDFS and MapReduce Who Am I - Ryan Tabora - Data Developer at Think Big Analytics - Big Data Consulting - Experience working with Hadoop, HBase, Hive, Solr, Cassandra, etc. 2 Who Am I -
1/30/2019 Week 2- B Sangmi Lee Pallickara
 Week 2-A-0 1/30/2019 Colorado State University, Spring 2019 Week 2-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING Term project deliverable
Week 2-A-0 1/30/2019 Colorado State University, Spring 2019 Week 2-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING Term project deliverable
An Introduction to Apache Spark
 An Introduction to Apache Spark Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 1 / 67 Big Data small data big data Amir H. Payberah (SICS) Apache Spark
An Introduction to Apache Spark Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 1 / 67 Big Data small data big data Amir H. Payberah (SICS) Apache Spark
Hadoop 2.8 Configuration and First Examples
 Hadoop 2.8 Configuration and First Examples Big Data - 29/03/2017 Apache Hadoop & YARN Apache Hadoop (1.X) De facto Big Data open source platform Running for about 5 years in production at hundreds of
Hadoop 2.8 Configuration and First Examples Big Data - 29/03/2017 Apache Hadoop & YARN Apache Hadoop (1.X) De facto Big Data open source platform Running for about 5 years in production at hundreds of
2. MapReduce Programming Model
 Introduction MapReduce was proposed by Google in a research paper: Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System
Introduction MapReduce was proposed by Google in a research paper: Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System
IntWritable w1 = new IntWritable(163); IntWritable w2 = new IntWritable(67); assertthat(comparator.compare(w1, w2), greaterthan(0));
; IntWritable w2 = new IntWritable(67); assertthat(comparator.compare(w1, w2), greaterthan(0));") factory for RawComparator instances (that Writable implementations have registered). For example, to obtain a comparator for IntWritable, we just use: RawComparator comparator = WritableComparator.get(IntWritable.class);
factory for RawComparator instances (that Writable implementations have registered). For example, to obtain a comparator for IntWritable, we just use: RawComparator comparator = WritableComparator.get(IntWritable.class);
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing. Lecture 6: MapReduce in Parallel Computing
 ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
Cloud Computing. Leonidas Fegaras University of Texas at Arlington. Web Data Management and XML L12: Cloud Computing 1
 Cloud Computing Leonidas Fegaras University of Texas at Arlington Web Data Management and XML L12: Cloud Computing 1 Computing as a Utility Cloud computing is a model for enabling convenient, on-demand
Cloud Computing Leonidas Fegaras University of Texas at Arlington Web Data Management and XML L12: Cloud Computing 1 Computing as a Utility Cloud computing is a model for enabling convenient, on-demand
Map-Reduce Applications: Counting, Graph Shortest Paths
 Map-Reduce Applications: Counting, Graph Shortest Paths Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Map-Reduce Applications: Counting, Graph Shortest Paths Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 16. Big Data Management VI (MapReduce Programming)
") Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 16 Big Data Management VI (MapReduce Programming) Credits: Pietro Michiardi (Eurecom): Scalable Algorithm
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 16 Big Data Management VI (MapReduce Programming) Credits: Pietro Michiardi (Eurecom): Scalable Algorithm
UNIT-IV HDFS. Ms. Selva Mary. G
 UNIT-IV HDFS HDFS ARCHITECTURE Dataset partition across a number of separate machines Hadoop Distributed File system The Design of HDFS HDFS is a file system designed for storing very large files with
UNIT-IV HDFS HDFS ARCHITECTURE Dataset partition across a number of separate machines Hadoop Distributed File system The Design of HDFS HDFS is a file system designed for storing very large files with
Big Data: Architectures and Data Analytics
 Big Data: Architectures and Data Analytics June 26, 2018 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
Big Data: Architectures and Data Analytics June 26, 2018 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
Big Data: Architectures and Data Analytics
 Big Data: Architectures and Data Analytics June 26, 2018 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
Big Data: Architectures and Data Analytics June 26, 2018 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
Steps: First install hadoop (if not installed yet) by, https://sl6it.wordpress.com/2015/12/04/1-study-and-configure-hadoop-for-big-data/
 by, https://sl6it.wordpress.com/2015/12/04/1-study-and-configure-hadoop-for-big-data/") SL-V BE IT EXP 7 Aim: Design and develop a distributed application to find the coolest/hottest year from the available weather data. Use weather data from the Internet and process it using MapReduce. Steps:
SL-V BE IT EXP 7 Aim: Design and develop a distributed application to find the coolest/hottest year from the available weather data. Use weather data from the Internet and process it using MapReduce. Steps:
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hortonworks HDPCD. Hortonworks Data Platform Certified Developer. Download Full Version :
 Hortonworks HDPCD Hortonworks Data Platform Certified Developer Download Full Version : https://killexams.com/pass4sure/exam-detail/hdpcd QUESTION: 97 You write MapReduce job to process 100 files in HDFS.
Hortonworks HDPCD Hortonworks Data Platform Certified Developer Download Full Version : https://killexams.com/pass4sure/exam-detail/hdpcd QUESTION: 97 You write MapReduce job to process 100 files in HDFS.
Actual4Dumps. Provide you with the latest actual exam dumps, and help you succeed
 Actual4Dumps http://www.actual4dumps.com Provide you with the latest actual exam dumps, and help you succeed Exam : HDPCD Title : Hortonworks Data Platform Certified Developer Vendor : Hortonworks Version
Actual4Dumps http://www.actual4dumps.com Provide you with the latest actual exam dumps, and help you succeed Exam : HDPCD Title : Hortonworks Data Platform Certified Developer Vendor : Hortonworks Version
Hadoop 3 Configuration and First Examples
 Hadoop 3 Configuration and First Examples Big Data - 26/03/2018 Apache Hadoop & YARN Apache Hadoop (1.X) De facto Big Data open source platform Running for about 5 years in production at hundreds of companies
Hadoop 3 Configuration and First Examples Big Data - 26/03/2018 Apache Hadoop & YARN Apache Hadoop (1.X) De facto Big Data open source platform Running for about 5 years in production at hundreds of companies
Cloud Computing. Leonidas Fegaras University of Texas at Arlington. Web Data Management and XML L3b: Cloud Computing 1
 Cloud Computing Leonidas Fegaras University of Texas at Arlington Web Data Management and XML L3b: Cloud Computing 1 Computing as a Utility Cloud computing is a model for enabling convenient, on-demand
Cloud Computing Leonidas Fegaras University of Texas at Arlington Web Data Management and XML L3b: Cloud Computing 1 Computing as a Utility Cloud computing is a model for enabling convenient, on-demand
Programming Models MapReduce
 Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Guidelines For Hadoop and Spark Cluster Usage
 Guidelines For Hadoop and Spark Cluster Usage Procedure to create an account in CSX. If you are taking a CS prefix course, you already have an account; to get an initial password created: 1. Login to https://cs.okstate.edu/pwreset
Guidelines For Hadoop and Spark Cluster Usage Procedure to create an account in CSX. If you are taking a CS prefix course, you already have an account; to get an initial password created: 1. Login to https://cs.okstate.edu/pwreset
Cloud Programming on Java EE Platforms. mgr inż. Piotr Nowak
 Cloud Programming on Java EE Platforms mgr inż. Piotr Nowak dsh distributed shell commands execution -c concurrent --show-machine-names -M --group cluster -g cluster /etc/dsh/groups/cluster needs passwordless
Cloud Programming on Java EE Platforms mgr inż. Piotr Nowak dsh distributed shell commands execution -c concurrent --show-machine-names -M --group cluster -g cluster /etc/dsh/groups/cluster needs passwordless
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
CS 470 Spring Parallel Algorithm Development. (Foster's Methodology) Mike Lam, Professor
 Mike Lam, Professor") CS 470 Spring 2018 Mike Lam, Professor Parallel Algorithm Development (Foster's Methodology) Graphics and content taken from IPP section 2.7 and the following: http://www.mcs.anl.gov/~itf/dbpp/text/book.html
CS 470 Spring 2018 Mike Lam, Professor Parallel Algorithm Development (Foster's Methodology) Graphics and content taken from IPP section 2.7 and the following: http://www.mcs.anl.gov/~itf/dbpp/text/book.html
Experiences with a new Hadoop cluster: deployment, teaching and research. Andre Barczak February 2018
 Experiences with a new Hadoop cluster: deployment, teaching and research Andre Barczak February 2018 abstract In 2017 the Machine Learning research group got funding for a new Hadoop cluster. However,
Experiences with a new Hadoop cluster: deployment, teaching and research Andre Barczak February 2018 abstract In 2017 the Machine Learning research group got funding for a new Hadoop cluster. However,
Big Data Analytics. 4. Map Reduce I. Lars Schmidt-Thieme
 Big Data Analytics 4. Map Reduce I Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany original slides by Lucas Rego
Big Data Analytics 4. Map Reduce I Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany original slides by Lucas Rego
Recommended Literature
 COSC 6339 Big Data Analytics Introduction to Map Reduce (I) Edgar Gabriel Fall 2018 Recommended Literature Original MapReduce paper by google http://research.google.com/archive/mapreduce-osdi04.pdf Fantastic
COSC 6339 Big Data Analytics Introduction to Map Reduce (I) Edgar Gabriel Fall 2018 Recommended Literature Original MapReduce paper by google http://research.google.com/archive/mapreduce-osdi04.pdf Fantastic
Big Data: Architectures and Data Analytics
 Big Data: Architectures and Data Analytics January 22, 2018 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
Big Data: Architectures and Data Analytics January 22, 2018 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
A Guide to Running Map Reduce Jobs in Java University of Stirling, Computing Science
 A Guide to Running Map Reduce Jobs in Java University of Stirling, Computing Science Introduction The Hadoop cluster in Computing Science at Stirling allows users with a valid user account to submit and
A Guide to Running Map Reduce Jobs in Java University of Stirling, Computing Science Introduction The Hadoop cluster in Computing Science at Stirling allows users with a valid user account to submit and
TI2736-B Big Data Processing. Claudia Hauff
 TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Pig Design Pattern Hadoop Mix Graphs Giraph Spark Zoo Keeper Spark But first Partitioner & Combiner
TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Pig Design Pattern Hadoop Mix Graphs Giraph Spark Zoo Keeper Spark But first Partitioner & Combiner
ExamTorrent. Best exam torrent, excellent test torrent, valid exam dumps are here waiting for you
 ExamTorrent http://www.examtorrent.com Best exam torrent, excellent test torrent, valid exam dumps are here waiting for you Exam : Apache-Hadoop-Developer Title : Hadoop 2.0 Certification exam for Pig
ExamTorrent http://www.examtorrent.com Best exam torrent, excellent test torrent, valid exam dumps are here waiting for you Exam : Apache-Hadoop-Developer Title : Hadoop 2.0 Certification exam for Pig
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
MapReduce-style data processing
 MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MRUnit testing framework is based on JUnit and it can test Map Reduce programs written on 0.20, 0.23.x, 1.0.x, 2.x version of Hadoop.
 MRUnit Tutorial Setup development environment 1. Download the latest version of MRUnit jar from Apache website: https://repository.apache.org/content/repositories/releases/org/apache/ mrunit/mrunit/. For
MRUnit Tutorial Setup development environment 1. Download the latest version of MRUnit jar from Apache website: https://repository.apache.org/content/repositories/releases/org/apache/ mrunit/mrunit/. For
September 2013 Alberto Abelló & Oscar Romero 1
 duce-i duce-i September 2013 Alberto Abelló & Oscar Romero 1 Knowledge objectives 1. Enumerate several use cases of duce 2. Describe what the duce environment is 3. Explain 6 benefits of using duce 4.
duce-i duce-i September 2013 Alberto Abelló & Oscar Romero 1 Knowledge objectives 1. Enumerate several use cases of duce 2. Describe what the duce environment is 3. Explain 6 benefits of using duce 4.
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
MapReduce & YARN Hands-on Lab Exercise 1 Simple MapReduce program in Java
 MapReduce & YARN Hands-on Lab Exercise 1 Simple MapReduce program in Java Contents Page 1 Copyright IBM Corporation, 2015 US Government Users Restricted Rights - Use, duplication or disclosure restricted
MapReduce & YARN Hands-on Lab Exercise 1 Simple MapReduce program in Java Contents Page 1 Copyright IBM Corporation, 2015 US Government Users Restricted Rights - Use, duplication or disclosure restricted
Big Data Analytics: Insights and Innovations
 International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 6, Issue 10 (April 2013), PP. 60-65 Big Data Analytics: Insights and Innovations
International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 6, Issue 10 (April 2013), PP. 60-65 Big Data Analytics: Insights and Innovations
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Exam Name: Cloudera Certified Developer for Apache Hadoop CDH4 Upgrade Exam (CCDH)
") Vendor: Cloudera Exam Code: CCD-470 Exam Name: Cloudera Certified Developer for Apache Hadoop CDH4 Upgrade Exam (CCDH) Version: Demo QUESTION 1 When is the earliest point at which the reduce method of
Vendor: Cloudera Exam Code: CCD-470 Exam Name: Cloudera Certified Developer for Apache Hadoop CDH4 Upgrade Exam (CCDH) Version: Demo QUESTION 1 When is the earliest point at which the reduce method of
15/03/2018. Combiner
 Combiner 2 1 Standard MapReduce applications The (key,value) pairs emitted by the Mappers are sent to the Reducers through the network Some pre-aggregations could be performed to limit the amount of network
Combiner 2 1 Standard MapReduce applications The (key,value) pairs emitted by the Mappers are sent to the Reducers through the network Some pre-aggregations could be performed to limit the amount of network
Computing as a Utility. Cloud Computing. Why? Good for...
 Computing as a Utility Cloud Computing Leonidas Fegaras University of Texas at Arlington Cloud computing is a model for enabling convenient, on-demand network access to a shared pool of configurable computing
Computing as a Utility Cloud Computing Leonidas Fegaras University of Texas at Arlington Cloud computing is a model for enabling convenient, on-demand network access to a shared pool of configurable computing
Processing Distributed Data Using MapReduce, Part I
 Processing Distributed Data Using MapReduce, Part I Computer Science E-66 Harvard University David G. Sullivan, Ph.D. MapReduce A framework for computation on large data sets that are fragmented and replicated
Processing Distributed Data Using MapReduce, Part I Computer Science E-66 Harvard University David G. Sullivan, Ph.D. MapReduce A framework for computation on large data sets that are fragmented and replicated
Hadoop 3.X more examples
 Hadoop 3.X more examples Big Data - 09/04/2018 Let s start with some examples! http://www.dia.uniroma3.it/~dvr/es2_material.zip Example: LastFM Listeners per Track Consider the following log file UserId
Hadoop 3.X more examples Big Data - 09/04/2018 Let s start with some examples! http://www.dia.uniroma3.it/~dvr/es2_material.zip Example: LastFM Listeners per Track Consider the following log file UserId
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
EE657 Spring 2012 HW#4 Zhou Zhao
 EE657 Spring 2012 HW#4 Zhou Zhao Problem 6.3 Solution Referencing the sample application of SimpleDB in Amazon Java SDK, a simple domain which includes 5 items is prepared in the code. For instance, the
EE657 Spring 2012 HW#4 Zhou Zhao Problem 6.3 Solution Referencing the sample application of SimpleDB in Amazon Java SDK, a simple domain which includes 5 items is prepared in the code. For instance, the
Vendor: Cloudera. Exam Code: CCD-410. Exam Name: Cloudera Certified Developer for Apache Hadoop. Version: Demo
 Vendor: Cloudera Exam Code: CCD-410 Exam Name: Cloudera Certified Developer for Apache Hadoop Version: Demo QUESTION 1 When is the earliest point at which the reduce method of a given Reducer can be called?
Vendor: Cloudera Exam Code: CCD-410 Exam Name: Cloudera Certified Developer for Apache Hadoop Version: Demo QUESTION 1 When is the earliest point at which the reduce method of a given Reducer can be called?
Map-Reduce in Various Programming Languages
 Map-Reduce in Various Programming Languages 1 Context of Map-Reduce Computing The use of LISP's map and reduce functions to solve computational problems probably dates from the 1960s -- very early in the
Map-Reduce in Various Programming Languages 1 Context of Map-Reduce Computing The use of LISP's map and reduce functions to solve computational problems probably dates from the 1960s -- very early in the
Big Data for Engineers Spring Resource Management
 Ghislain Fourny Big Data for Engineers Spring 2018 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models
Ghislain Fourny Big Data for Engineers Spring 2018 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models
Hadoop 2.X on a cluster environment
 Hadoop 2.X on a cluster environment Big Data - 05/04/2017 Hadoop 2 on AMAZON Hadoop 2 on AMAZON Hadoop 2 on AMAZON Regions Hadoop 2 on AMAZON S3 and buckets Hadoop 2 on AMAZON S3 and buckets Hadoop 2 on
Hadoop 2.X on a cluster environment Big Data - 05/04/2017 Hadoop 2 on AMAZON Hadoop 2 on AMAZON Hadoop 2 on AMAZON Regions Hadoop 2 on AMAZON S3 and buckets Hadoop 2 on AMAZON S3 and buckets Hadoop 2 on
MAPREDUCE - PARTITIONER
 MAPREDUCE - PARTITIONER http://www.tutorialspoint.com/map_reduce/map_reduce_partitioner.htm Copyright tutorialspoint.com A partitioner works like a condition in processing an input dataset. The partition
MAPREDUCE - PARTITIONER http://www.tutorialspoint.com/map_reduce/map_reduce_partitioner.htm Copyright tutorialspoint.com A partitioner works like a condition in processing an input dataset. The partition
Map- reduce programming paradigm
 Map- reduce programming paradigm Some slides are from lecture of Matei Zaharia, and distributed computing seminar by Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet. In pioneer days they
Map- reduce programming paradigm Some slides are from lecture of Matei Zaharia, and distributed computing seminar by Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet. In pioneer days they
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Computing. Prof. Marco Bertini
 Parallel Computing Prof. Marco Bertini Apache Hadoop Chaining jobs Chaining MapReduce jobs Many complex tasks need to be broken down into simpler subtasks, each accomplished by an individual MapReduce
Parallel Computing Prof. Marco Bertini Apache Hadoop Chaining jobs Chaining MapReduce jobs Many complex tasks need to be broken down into simpler subtasks, each accomplished by an individual MapReduce
Vendor: Hortonworks. Exam Code: HDPCD. Exam Name: Hortonworks Data Platform Certified Developer. Version: Demo
 Vendor: Hortonworks Exam Code: HDPCD Exam Name: Hortonworks Data Platform Certified Developer Version: Demo QUESTION 1 Workflows expressed in Oozie can contain: A. Sequences of MapReduce and Pig. These
Vendor: Hortonworks Exam Code: HDPCD Exam Name: Hortonworks Data Platform Certified Developer Version: Demo QUESTION 1 Workflows expressed in Oozie can contain: A. Sequences of MapReduce and Pig. These
Topics covered in this lecture
 9/5/2018 CS435 Introduction to Big Data - FALL 2018 W3.B.0 CS435 Introduction to Big Data 9/5/2018 CS435 Introduction to Big Data - FALL 2018 W3.B.1 FAQs How does Hadoop mapreduce run the map instance?
9/5/2018 CS435 Introduction to Big Data - FALL 2018 W3.B.0 CS435 Introduction to Big Data 9/5/2018 CS435 Introduction to Big Data - FALL 2018 W3.B.1 FAQs How does Hadoop mapreduce run the map instance?
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Laarge-Scale Data Engineering
 Laarge-Scale Data Engineering The MapReduce Framework & Hadoop Key premise: divide and conquer work partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 result combine Parallelisation challenges How
Laarge-Scale Data Engineering The MapReduce Framework & Hadoop Key premise: divide and conquer work partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 result combine Parallelisation challenges How
Distributed Systems. CS422/522 Lecture17 17 November 2014
 Distributed Systems CS422/522 Lecture17 17 November 2014 Lecture Outline Introduction Hadoop Chord What s a distributed system? What s a distributed system? A distributed system is a collection of loosely
Distributed Systems CS422/522 Lecture17 17 November 2014 Lecture Outline Introduction Hadoop Chord What s a distributed system? What s a distributed system? A distributed system is a collection of loosely
Outline Introduction Big Data Sources of Big Data Tools HDFS Installation Configuration Starting & Stopping Map Reduc.
 D. Praveen Kumar Junior Research Fellow Department of Computer Science & Engineering Indian Institute of Technology (Indian School of Mines) Dhanbad, Jharkhand, India Head of IT & ITES, Skill Subsist Impels
D. Praveen Kumar Junior Research Fellow Department of Computer Science & Engineering Indian Institute of Technology (Indian School of Mines) Dhanbad, Jharkhand, India Head of IT & ITES, Skill Subsist Impels
KillTest *KIJGT 3WCNKV[ $GVVGT 5GTXKEG Q&A NZZV ]]] QORRZKYZ IUS =K ULLKX LXKK [VJGZK YKX\OIK LUX UTK _KGX
![KillTest *KIJGT 3WCNKV[ $GVVGT 5GTXKEG Q&A NZZV ]]] QORRZKYZ IUS =K ULLKX LXKK [VJGZK YKX\OIK LUX UTK _KGX](/thumbs/87/96360053.jpg "KillTest *KIJGT 3WCNKV[ $GVVGT 5GTXKEG Q&A NZZV ]]] QORRZKYZ IUS =K ULLKX LXKK [VJGZK YKX\OIK LUX UTK _KGX") KillTest Q&A Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Version : DEMO 1 / 4 1.When is the earliest point at which the reduce method of a given Reducer can be called?
KillTest Q&A Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Version : DEMO 1 / 4 1.When is the earliest point at which the reduce method of a given Reducer can be called?
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
Big Data Exercises. Fall 2017 Week 5 ETH Zurich. MapReduce
 Big Data Exercises Fall 2017 Week 5 ETH Zurich MapReduce Reading: White, T. (2015). Hadoop: The Definitive Guide (4th ed.). O Reilly Media, Inc. [ETH library] (Chapters 2, 6, 7, 8: mandatory, Chapter 9:
Big Data Exercises Fall 2017 Week 5 ETH Zurich MapReduce Reading: White, T. (2015). Hadoop: The Definitive Guide (4th ed.). O Reilly Media, Inc. [ETH library] (Chapters 2, 6, 7, 8: mandatory, Chapter 9:
INTRODUCTION TO HADOOP
 Hadoop INTRODUCTION TO HADOOP Distributed Systems + Middleware: Hadoop 2 Data We live in a digital world that produces data at an impressive speed As of 2012, 2.7 ZB of data exist (1 ZB = 10 21 Bytes)
Hadoop INTRODUCTION TO HADOOP Distributed Systems + Middleware: Hadoop 2 Data We live in a digital world that produces data at an impressive speed As of 2012, 2.7 ZB of data exist (1 ZB = 10 21 Bytes)
Overview. Why MapReduce? What is MapReduce? The Hadoop Distributed File System Cloudera, Inc.
 MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What