Large-scale Information Processing
|
|
|
- Noah Price
- 6 years ago
- Views:
Transcription
1 Sommer 2013 Large-scale Information Processing Ulf Brefeld Knowledge Mining & Assessment
2 Anecdotal evidence... I think there is a world market for about five computers, Thomas J. Watson (Chairman of the Board of International Business Machines), it is very possible that... one machine would suffice to solve all the problems that are demanded of it from the whole country., Sir Charles Darwin (grandson of the naturalist of the same name, head of Britain's National Physical Laboratory), 1946 Originally one thought that if there were a half dozen large computers in this country, hidden away in research laboratories, this would take care of all requirements we had throughout the country., Howard H. Aiken (computer pioneer, IBM Mark I designer),

3 Today... 3
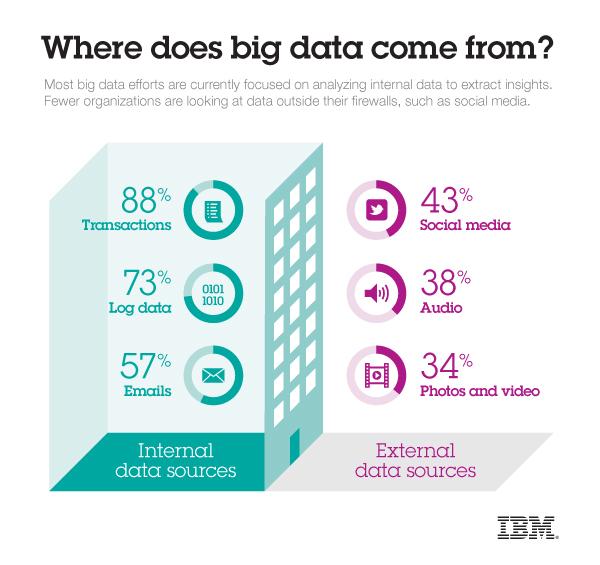
4 4

5 Quelle: IBM 5
6 Query Volumes Quelle: Google Trends 6

7 Market Segmentation A company launches three new campaigns There is 2GB of data from customers who bought one of the three in the past There is 5GB potential customer data Who will be interested in which campaign? 7
8 Topics 8


9 Index Structures Make data searchable Efficient data structres Inverted index Radix tries... 9

10 Unsupervised Machine Learning Clustering Find group structures Nearest neighbors Duplicate detection Outlier detection Find anomalies 10

11 Supervised Machine Learning Linear models Classification Regression Ranking Optimization Feature encodings/scaling Hashing tricks 11

12 Structured Prediction Variables inter-depend/correlate Sequences, trees, grids, etc. Named entity recognition, parsing Protein secondary structure prediction Image segmentation 12

13 Recommender Systems 13


")

14 Scenarios Single computer vs. cluster (Hadoop, MapReduce) Static data vs. data streams 14
15 Integrierte Veranstaltung TUCAN Termine: Dienstags, 15:20-17:00 Uhr, S105/24 Donnerstags, 11:40-13:20 Uhr, S103/100 4 SWS, 6 CP Mündliche Prüfung/Klausur Foliensatz plus Tafel... Sprechstunde n.v. 15
 Sinn und Zweck: Theoretisches Verständnis Praktische Vertiefungen Keine Abgabe/Korretur http://www.kma.informatik.tu-darmstadt.")
16 Übungen Tutor: Emmanouil Tzouridis Unregelmäßig (etwa jeder 4. Termin) Sinn und Zweck: Theoretisches Verständnis Praktische Vertiefungen Keine Abgabe/Korretur teaching/large-scale-information-processing/ 16
17 Further Readings Rajaraman & Ullman, Mining of Massive Datasets 17
18 Large-scale Information Processing, Sommer 2013 Hadoop MapReduce Ulf Brefeld Knowledge Mining & Assessment

19 The Web 19
20 The size of the Web 20

21 Reading the Web... Average size of a web page in 2011 was 965 kb 50 billion times 965 kb = 899 TB Read 900 TB of data with 100MB/sec Takes 4 months on a single computer We need more computers... * * according to tech.slashdot.org 21
22 Cluster Issues Reliability problems Computers fail every day Expected lifetime about 3 years (1000 days) If you had 1000 computers, one would fail per day Google had about 900,000 computers in 2011 On average 900 failed every day Cluster size varies * * according to datacenterknowledge.com 22
23 Hadoop Open Source Apache Project Commodity Hardware Cluster (cheap Linux PCs) Hadoop Core includes: Distributed File System (distributes data) Map/Reduce (distributes application) Written in Java Runs on Linux, Mac OS/X, Windows, Solaris, 23

24 Distributed File System Optimized for streaming reads of large files Files are broken into large blocks Blocks are typically 128 MB Default is 3 replicas for each block Clients read from closest replica Automatic re-replication 24
25 Map Reduce Data Flow Input Map Shuffle Reduce Output 25
26 Features Java, C++, and text-based APIs Text-based (streaming) great for scripting Higher level interfaces: Pig, Hive, Jaql,... Automatic re-execution on failure Framework re-executes failed tasks Locality optimizations Map tasks are scheduled close to the inputs when possible 26
27 What is it good for? Indexing Log analysis Image manipulation Sorting large-scale data Data Mining (though not optimal) - For real-time processing - For processing intensive tasks with little data 27
28 Important Functions Setup Setup mapper task Load data, connect to database, Map / Reduce Data processing (Mapper) Value aggregation (Reducer) Cleanup Free memory, disconnect database,... 28
29 Example: Word Count Hadoop s Hello World Input Output Key Value Key Value Mapper pos in file lines of text word 1 Reducer word set of counts word sum 29
30 Example: Word Count Its all about key-value pairs... Input Output Key Value Key Value Mapper pos in file lines of text word 1 Reducer word set of counts word sum 30
31 Example: Word Count Two phases: map and reduce Input Output Key Value Key Value Mapper pos in file lines of text word 1 Reducer word set of counts word sum 31
32 Example: Word Count Map: input lines of text, output words and their counts Input Output Key Value Key Value Mapper pos in file lines of text word 1 Reducer word set of counts word sum 32
33 Example: Word Count Reduce: sum up counts for each word Input Output Key Value Key Value Mapper pos in file lines of text word 1 Reducer word set of counts word sum 33
34 Word Count Data Flow the cat and the box M1 R1 curiosity kills the cat M2 Erwin and his cat M3 R2 Input Map Shuffle Reduce Output 34
35 Word Count Data Flow the cat and the box M1 cat:1 the:2 box:1 and:1 R1 curiosity kills the cat M2 Erwin and his cat M3 R2 Input Map Shuffle Reduce Output 35
36 Word Count Data Flow the cat and the box M1 curiosity kills the cat M2 the:1 cat:1 curiosity:1 kills:1 R1 Erwin and his cat M3 R2 Input Map Shuffle Reduce Output 36
37 Word Count Data Flow the cat and the box M1 R1 curiosity kills the cat M2 Erwin and his cat M3 cat:1 Erwin:1 and:1 his:1 R2 Input Map Shuffle Reduce Output 37
38 Word Count Data Flow the cat and the box curiosity kills the cat Erwin and his cat M1 M2 M3 cat:1 the:1 box:1 the:1 and:1 the:1 cat:1 curiosity:1 kills:1 cat:1 Erwin:1 and:1 his:1 R1 R2 box:1 cat:3 the:3 curiosity:1 and:2 kills:1 Erwin:1 his:1 Input Map Shuffle Reduce Output 38
39 Mapper private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(longwritable key, Text value, Context c) { String line = value.tostring(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasmoretokens()) { word.set(tokenizer.nexttoken()); context.write(word, one); 39
40 Mapper private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(longwritable key, Text value, Context c) { String line = value.tostring(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasmoretokens()) { word.set(tokenizer.nexttoken()); context.write(word, one); 40
41 Mapper private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(longwritable key, Text value, Context c) { String line = value.tostring(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasmoretokens()) { word.set(tokenizer.nexttoken()); context.write(word, one); 41
42 Mapper private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(longwritable key, Text value, Context c) { String line = value.tostring(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasmoretokens()) { word.set(tokenizer.nexttoken()); context.write(word, one); 42
43 Mapper private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(longwritable key, Text value, Context c) { String line = value.tostring(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasmoretokens()) { word.set(tokenizer.nexttoken()); context.write(word, one); 43
44 Mapper private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(longwritable key, Text value, Context c) { String line = value.tostring(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasmoretokens()) { word.set(tokenizer.nexttoken()); context.write(word, one); 44
45 Mapper private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(longwritable key, Text value, Context c) { String line = value.tostring(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasmoretokens()) { word.set(tokenizer.nexttoken()); context.write(word, one); 45
46 Mapper private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(longwritable key, Text value, Context c) { String line = value.tostring(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasmoretokens()) { word.set(tokenizer.nexttoken()); context.write(word, one); 46
47 Mapper private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(longwritable key, Text value, Context context) { String line = value.tostring(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasmoretokens()) { word.set(tokenizer.nexttoken()); context.write(word, one); 47
48 Reducer public void reduce(text key, Iterable<IntWritable> values,......context context) { int sum = 0; for (IntWritable val : values) { sum += val.get(); context.write(key, new IntWritable(sum)); 48
49 Reducer public void reduce(text key, Iterable<IntWritable> values,......context context) { int sum = 0; for (IntWritable val : values) { sum += val.get(); context.write(key, new IntWritable(sum)); 49
50 Reducer public void reduce(text key, Iterable<IntWritable> values,......context context) { int sum = 0; for (IntWritable val : values) { sum += val.get(); context.write(key, new IntWritable(sum)); 50
51 Reducer public void reduce(text key, Iterable<IntWritable> values,......context context) { int sum = 0; for (IntWritable val : values) { sum += val.get(); context.write(key, new IntWritable(sum)); 51
52 Reducer public void reduce(text key, Iterable<IntWritable> values,......context context) { int sum = 0; for (IntWritable val : values) { sum += val.get(); context.write(key, new IntWritable(sum)); 52
53 Reducer public void reduce(text key, Iterable<IntWritable> values,......context context) { int sum = 0; for (IntWritable val : values) { sum += val.get(); context.write(key, new IntWritable(sum)); 53
54 Main public static void main(string[] args) { Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); job.setmapperclass(map.class); job.setreducerclass(reduce.class); job.setinputformatclass(textinputformat.class); job.setoutputformatclass(textoutputformat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitforcompletion(true); 54
55 Main public static void main(string[] args) { Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); job.setmapperclass(map.class); job.setreducerclass(reduce.class); job.setinputformatclass(textinputformat.class); job.setoutputformatclass(textoutputformat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitforcompletion(true); 55
56 Main public static void main(string[] args) { Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); job.setmapperclass(map.class); job.setreducerclass(reduce.class); job.setinputformatclass(textinputformat.class); job.setoutputformatclass(textoutputformat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitforcompletion(true); 56
57 Main public static void main(string[] args) { Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); job.setmapperclass(map.class); job.setreducerclass(reduce.class); job.setinputformatclass(textinputformat.class); job.setoutputformatclass(textoutputformat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitforcompletion(true); 57
58 Main public static void main(string[] args) { Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); job.setmapperclass(map.class); job.setreducerclass(reduce.class); job.setinputformatclass(textinputformat.class); job.setoutputformatclass(textoutputformat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitforcompletion(true); 58
59 Main public static void main(string[] args) { Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); job.setmapperclass(map.class); job.setreducerclass(reduce.class); job.setinputformatclass(textinputformat.class); job.setoutputformatclass(textoutputformat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitforcompletion(true); 59
60 Main public static void main(string[] args) { Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); job.setmapperclass(map.class); job.setreducerclass(reduce.class); job.setinputformatclass(textinputformat.class); job.setoutputformatclass(textoutputformat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitforcompletion(true); 60
61 Main public static void main(string[] args) { Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); job.setmapperclass(map.class); job.setreducerclass(reduce.class); job.setinputformatclass(textinputformat.class); job.setoutputformatclass(textoutputformat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitforcompletion(true); 61

62 - Literatur Book (available online) Tutorials Machine learning with Hadoop 62
Introduction to Map/Reduce. Kostas Solomos Computer Science Department University of Crete, Greece
 Introduction to Map/Reduce Kostas Solomos Computer Science Department University of Crete, Greece What we will cover What is MapReduce? How does it work? A simple word count example (the Hello World! of
Introduction to Map/Reduce Kostas Solomos Computer Science Department University of Crete, Greece What we will cover What is MapReduce? How does it work? A simple word count example (the Hello World! of
Parallel Processing - MapReduce and FlumeJava. Amir H. Payberah 14/09/2018
 Parallel Processing - MapReduce and FlumeJava Amir H. Payberah payberah@kth.se 14/09/2018 The Course Web Page https://id2221kth.github.io 1 / 83 Where Are We? 2 / 83 What do we do when there is too much
Parallel Processing - MapReduce and FlumeJava Amir H. Payberah payberah@kth.se 14/09/2018 The Course Web Page https://id2221kth.github.io 1 / 83 Where Are We? 2 / 83 What do we do when there is too much
MapReduce Simplified Data Processing on Large Clusters
 MapReduce Simplified Data Processing on Large Clusters Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) MapReduce 1393/8/5 1 /
MapReduce Simplified Data Processing on Large Clusters Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) MapReduce 1393/8/5 1 /
Clustering Documents. Case Study 2: Document Retrieval
 Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 21 th, 2015 Sham Kakade 2016 1 Document Retrieval Goal: Retrieve
Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 21 th, 2015 Sham Kakade 2016 1 Document Retrieval Goal: Retrieve
Clustering Documents. Document Retrieval. Case Study 2: Document Retrieval
 Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April, 2017 Sham Kakade 2017 1 Document Retrieval n Goal: Retrieve
Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April, 2017 Sham Kakade 2017 1 Document Retrieval n Goal: Retrieve
UNIT V PROCESSING YOUR DATA WITH MAPREDUCE Syllabus
 UNIT V PROCESSING YOUR DATA WITH MAPREDUCE Syllabus Getting to know MapReduce MapReduce Execution Pipeline Runtime Coordination and Task Management MapReduce Application Hadoop Word Count Implementation.
UNIT V PROCESSING YOUR DATA WITH MAPREDUCE Syllabus Getting to know MapReduce MapReduce Execution Pipeline Runtime Coordination and Task Management MapReduce Application Hadoop Word Count Implementation.
Java in MapReduce. Scope
 Java in MapReduce Kevin Swingler Scope A specific look at the Java code you might use for performing MapReduce in Hadoop Java program recap The map method The reduce method The whole program Running on
Java in MapReduce Kevin Swingler Scope A specific look at the Java code you might use for performing MapReduce in Hadoop Java program recap The map method The reduce method The whole program Running on
An Introduction to Apache Spark
 An Introduction to Apache Spark Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 1 / 67 Big Data small data big data Amir H. Payberah (SICS) Apache Spark
An Introduction to Apache Spark Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 1 / 67 Big Data small data big data Amir H. Payberah (SICS) Apache Spark
Parallel Data Processing with Hadoop/MapReduce. CS140 Tao Yang, 2014
 Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example
Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example
COMP4442. Service and Cloud Computing. Lab 12: MapReduce. Prof. George Baciu PQ838.
 COMP4442 Service and Cloud Computing Lab 12: MapReduce www.comp.polyu.edu.hk/~csgeorge/comp4442 Prof. George Baciu csgeorge@comp.polyu.edu.hk PQ838 1 Contents Introduction to MapReduce A WordCount example
COMP4442 Service and Cloud Computing Lab 12: MapReduce www.comp.polyu.edu.hk/~csgeorge/comp4442 Prof. George Baciu csgeorge@comp.polyu.edu.hk PQ838 1 Contents Introduction to MapReduce A WordCount example
Computer Science 572 Exam Prof. Horowitz Tuesday, April 24, 2017, 8:00am 9:00am
 Computer Science 572 Exam Prof. Horowitz Tuesday, April 24, 2017, 8:00am 9:00am Name: Student Id Number: 1. This is a closed book exam. 2. Please answer all questions. 3. There are a total of 40 questions.
Computer Science 572 Exam Prof. Horowitz Tuesday, April 24, 2017, 8:00am 9:00am Name: Student Id Number: 1. This is a closed book exam. 2. Please answer all questions. 3. There are a total of 40 questions.
Clustering Documents. Document Retrieval. Case Study 2: Document Retrieval
 Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox April 16 th, 2015 Emily Fox 2015 1 Document Retrieval n Goal: Retrieve
Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox April 16 th, 2015 Emily Fox 2015 1 Document Retrieval n Goal: Retrieve
FAQs. Topics. This Material is Built Based on, Analytics Process Model. 8/22/2018 Week 1-B Sangmi Lee Pallickara
 CS435 Introduction to Big Data Week 1-B W1.B.0 CS435 Introduction to Big Data No Cell-phones in the class. W1.B.1 FAQs PA0 has been posted If you need to use a laptop, please sit in the back row. August
CS435 Introduction to Big Data Week 1-B W1.B.0 CS435 Introduction to Big Data No Cell-phones in the class. W1.B.1 FAQs PA0 has been posted If you need to use a laptop, please sit in the back row. August
W1.A.0 W2.A.0 1/22/2018 1/22/2018. CS435 Introduction to Big Data. FAQs. Readings
 CS435 Introduction to Big Data 1/17/2018 W2.A.0 W1.A.0 CS435 Introduction to Big Data W2.A.1.A.1 FAQs PA0 has been posted Feb. 6, 5:00PM via Canvas Individual submission (No team submission) Accommodation
CS435 Introduction to Big Data 1/17/2018 W2.A.0 W1.A.0 CS435 Introduction to Big Data W2.A.1.A.1 FAQs PA0 has been posted Feb. 6, 5:00PM via Canvas Individual submission (No team submission) Accommodation
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 16. Big Data Management VI (MapReduce Programming)
") Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 16 Big Data Management VI (MapReduce Programming) Credits: Pietro Michiardi (Eurecom): Scalable Algorithm
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 16 Big Data Management VI (MapReduce Programming) Credits: Pietro Michiardi (Eurecom): Scalable Algorithm
Experiences with a new Hadoop cluster: deployment, teaching and research. Andre Barczak February 2018
 Experiences with a new Hadoop cluster: deployment, teaching and research Andre Barczak February 2018 abstract In 2017 the Machine Learning research group got funding for a new Hadoop cluster. However,
Experiences with a new Hadoop cluster: deployment, teaching and research Andre Barczak February 2018 abstract In 2017 the Machine Learning research group got funding for a new Hadoop cluster. However,
Map Reduce. MCSN - N. Tonellotto - Distributed Enabling Platforms
 Map Reduce 1 MapReduce inside Google Googlers' hammer for 80% of our data crunching Large-scale web search indexing Clustering problems for Google News Produce reports for popular queries, e.g. Google
Map Reduce 1 MapReduce inside Google Googlers' hammer for 80% of our data crunching Large-scale web search indexing Clustering problems for Google News Produce reports for popular queries, e.g. Google
Big Data Analysis using Hadoop. Map-Reduce An Introduction. Lecture 2
 Big Data Analysis using Hadoop Map-Reduce An Introduction Lecture 2 Last Week - Recap 1 In this class Examine the Map-Reduce Framework What work each of the MR stages does Mapper Shuffle and Sort Reducer
Big Data Analysis using Hadoop Map-Reduce An Introduction Lecture 2 Last Week - Recap 1 In this class Examine the Map-Reduce Framework What work each of the MR stages does Mapper Shuffle and Sort Reducer
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
CS 470 Spring Parallel Algorithm Development. (Foster's Methodology) Mike Lam, Professor
 Mike Lam, Professor") CS 470 Spring 2018 Mike Lam, Professor Parallel Algorithm Development (Foster's Methodology) Graphics and content taken from IPP section 2.7 and the following: http://www.mcs.anl.gov/~itf/dbpp/text/book.html
CS 470 Spring 2018 Mike Lam, Professor Parallel Algorithm Development (Foster's Methodology) Graphics and content taken from IPP section 2.7 and the following: http://www.mcs.anl.gov/~itf/dbpp/text/book.html
Map-Reduce in Various Programming Languages
 Map-Reduce in Various Programming Languages 1 Context of Map-Reduce Computing The use of LISP's map and reduce functions to solve computational problems probably dates from the 1960s -- very early in the
Map-Reduce in Various Programming Languages 1 Context of Map-Reduce Computing The use of LISP's map and reduce functions to solve computational problems probably dates from the 1960s -- very early in the
Guidelines For Hadoop and Spark Cluster Usage
 Guidelines For Hadoop and Spark Cluster Usage Procedure to create an account in CSX. If you are taking a CS prefix course, you already have an account; to get an initial password created: 1. Login to https://cs.okstate.edu/pwreset
Guidelines For Hadoop and Spark Cluster Usage Procedure to create an account in CSX. If you are taking a CS prefix course, you already have an account; to get an initial password created: 1. Login to https://cs.okstate.edu/pwreset
Big Data landscape Lecture #2
 Big Data landscape Lecture #2 Contents 1 1 CORE Technologies 2 3 MapReduce YARN 4 SparK 5 Cassandra Contents 2 16 HBase 72 83 Accumulo memcached 94 Blur 10 5 Sqoop/Flume Contents 3 111 MongoDB 12 2 13
Big Data landscape Lecture #2 Contents 1 1 CORE Technologies 2 3 MapReduce YARN 4 SparK 5 Cassandra Contents 2 16 HBase 72 83 Accumulo memcached 94 Blur 10 5 Sqoop/Flume Contents 3 111 MongoDB 12 2 13
1/30/2019 Week 2- B Sangmi Lee Pallickara
 Week 2-A-0 1/30/2019 Colorado State University, Spring 2019 Week 2-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING Term project deliverable
Week 2-A-0 1/30/2019 Colorado State University, Spring 2019 Week 2-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING Term project deliverable
September 2013 Alberto Abelló & Oscar Romero 1
 duce-i duce-i September 2013 Alberto Abelló & Oscar Romero 1 Knowledge objectives 1. Enumerate several use cases of duce 2. Describe what the duce environment is 3. Explain 6 benefits of using duce 4.
duce-i duce-i September 2013 Alberto Abelló & Oscar Romero 1 Knowledge objectives 1. Enumerate several use cases of duce 2. Describe what the duce environment is 3. Explain 6 benefits of using duce 4.
Big Data: Architectures and Data Analytics
 Big Data: Architectures and Data Analytics July 14, 2017 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
Big Data: Architectures and Data Analytics July 14, 2017 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
EE657 Spring 2012 HW#4 Zhou Zhao
 EE657 Spring 2012 HW#4 Zhou Zhao Problem 6.3 Solution Referencing the sample application of SimpleDB in Amazon Java SDK, a simple domain which includes 5 items is prepared in the code. For instance, the
EE657 Spring 2012 HW#4 Zhou Zhao Problem 6.3 Solution Referencing the sample application of SimpleDB in Amazon Java SDK, a simple domain which includes 5 items is prepared in the code. For instance, the
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
Hadoop 3.X more examples
 Hadoop 3.X more examples Big Data - 09/04/2018 Let s start with some examples! http://www.dia.uniroma3.it/~dvr/es2_material.zip Example: LastFM Listeners per Track Consider the following log file UserId
Hadoop 3.X more examples Big Data - 09/04/2018 Let s start with some examples! http://www.dia.uniroma3.it/~dvr/es2_material.zip Example: LastFM Listeners per Track Consider the following log file UserId
Chapter 3. Distributed Algorithms based on MapReduce
 Chapter 3 Distributed Algorithms based on MapReduce 1 Acknowledgements Hadoop: The Definitive Guide. Tome White. O Reilly. Hadoop in Action. Chuck Lam, Manning Publications. MapReduce: Simplified Data
Chapter 3 Distributed Algorithms based on MapReduce 1 Acknowledgements Hadoop: The Definitive Guide. Tome White. O Reilly. Hadoop in Action. Chuck Lam, Manning Publications. MapReduce: Simplified Data
Recommended Literature
 COSC 6397 Big Data Analytics Introduction to Map Reduce (I) Edgar Gabriel Spring 2017 Recommended Literature Original MapReduce paper by google http://research.google.com/archive/mapreduce-osdi04.pdf Fantastic
COSC 6397 Big Data Analytics Introduction to Map Reduce (I) Edgar Gabriel Spring 2017 Recommended Literature Original MapReduce paper by google http://research.google.com/archive/mapreduce-osdi04.pdf Fantastic
TI2736-B Big Data Processing. Claudia Hauff
 TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Pig Design Pattern Hadoop Mix Graphs Giraph Spark Zoo Keeper Spark But first Partitioner & Combiner
TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Pig Design Pattern Hadoop Mix Graphs Giraph Spark Zoo Keeper Spark But first Partitioner & Combiner
Outline Introduction Big Data Sources of Big Data Tools HDFS Installation Configuration Starting & Stopping Map Reduc.
 D. Praveen Kumar Junior Research Fellow Department of Computer Science & Engineering Indian Institute of Technology (Indian School of Mines) Dhanbad, Jharkhand, India Head of IT & ITES, Skill Subsist Impels
D. Praveen Kumar Junior Research Fellow Department of Computer Science & Engineering Indian Institute of Technology (Indian School of Mines) Dhanbad, Jharkhand, India Head of IT & ITES, Skill Subsist Impels
Outline. What is Big Data? Hadoop HDFS MapReduce Twitter Analytics and Hadoop
 Intro To Hadoop Bill Graham - @billgraham Data Systems Engineer, Analytics Infrastructure Info 290 - Analyzing Big Data With Twitter UC Berkeley Information School September 2012 This work is licensed
Intro To Hadoop Bill Graham - @billgraham Data Systems Engineer, Analytics Infrastructure Info 290 - Analyzing Big Data With Twitter UC Berkeley Information School September 2012 This work is licensed
Computer Science 572 Exam Prof. Horowitz Monday, November 27, 2017, 8:00am 9:00am
 Computer Science 572 Exam Prof. Horowitz Monday, November 27, 2017, 8:00am 9:00am Name: Student Id Number: 1. This is a closed book exam. 2. Please answer all questions. 3. There are a total of 40 questions.
Computer Science 572 Exam Prof. Horowitz Monday, November 27, 2017, 8:00am 9:00am Name: Student Id Number: 1. This is a closed book exam. 2. Please answer all questions. 3. There are a total of 40 questions.
Steps: First install hadoop (if not installed yet) by, https://sl6it.wordpress.com/2015/12/04/1-study-and-configure-hadoop-for-big-data/
 by, https://sl6it.wordpress.com/2015/12/04/1-study-and-configure-hadoop-for-big-data/") SL-V BE IT EXP 7 Aim: Design and develop a distributed application to find the coolest/hottest year from the available weather data. Use weather data from the Internet and process it using MapReduce. Steps:
SL-V BE IT EXP 7 Aim: Design and develop a distributed application to find the coolest/hottest year from the available weather data. Use weather data from the Internet and process it using MapReduce. Steps:
Hadoop 2.X on a cluster environment
 Hadoop 2.X on a cluster environment Big Data - 05/04/2017 Hadoop 2 on AMAZON Hadoop 2 on AMAZON Hadoop 2 on AMAZON Regions Hadoop 2 on AMAZON S3 and buckets Hadoop 2 on AMAZON S3 and buckets Hadoop 2 on
Hadoop 2.X on a cluster environment Big Data - 05/04/2017 Hadoop 2 on AMAZON Hadoop 2 on AMAZON Hadoop 2 on AMAZON Regions Hadoop 2 on AMAZON S3 and buckets Hadoop 2 on AMAZON S3 and buckets Hadoop 2 on
Big Data Analytics: Insights and Innovations
 International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 6, Issue 10 (April 2013), PP. 60-65 Big Data Analytics: Insights and Innovations
International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 6, Issue 10 (April 2013), PP. 60-65 Big Data Analytics: Insights and Innovations
Big Data: Architectures and Data Analytics
 Big Data: Architectures and Data Analytics June 26, 2018 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
Big Data: Architectures and Data Analytics June 26, 2018 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
MapReduce. Arend Hintze
 MapReduce Arend Hintze Distributed Word Count Example Input data files cat * key-value pairs (0, This is a cat!) (14, cat is ok) (24, walk the dog) Mapper map() function key-value pairs (this, 1) (is,
MapReduce Arend Hintze Distributed Word Count Example Input data files cat * key-value pairs (0, This is a cat!) (14, cat is ok) (24, walk the dog) Mapper map() function key-value pairs (this, 1) (is,
PARLab Parallel Boot Camp
 PARLab Parallel Boot Camp Cloud Computing with MapReduce and Hadoop Matei Zaharia Electrical Engineering and Computer Sciences University of California, Berkeley What is Cloud Computing? Cloud refers to
PARLab Parallel Boot Camp Cloud Computing with MapReduce and Hadoop Matei Zaharia Electrical Engineering and Computer Sciences University of California, Berkeley What is Cloud Computing? Cloud refers to
Java & Inheritance. Inheritance - Scenario
 Java & Inheritance ITNPBD7 Cluster Computing David Cairns Inheritance - Scenario Inheritance is a core feature of Object Oriented languages. A class hierarchy can be defined where the class at the top
Java & Inheritance ITNPBD7 Cluster Computing David Cairns Inheritance - Scenario Inheritance is a core feature of Object Oriented languages. A class hierarchy can be defined where the class at the top
MapReduce and Hadoop. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica MapReduce and Hadoop Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica MapReduce and Hadoop Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Cloud Programming on Java EE Platforms. mgr inż. Piotr Nowak
 Cloud Programming on Java EE Platforms mgr inż. Piotr Nowak dsh distributed shell commands execution -c concurrent --show-machine-names -M --group cluster -g cluster /etc/dsh/groups/cluster needs passwordless
Cloud Programming on Java EE Platforms mgr inż. Piotr Nowak dsh distributed shell commands execution -c concurrent --show-machine-names -M --group cluster -g cluster /etc/dsh/groups/cluster needs passwordless
Big Data: Architectures and Data Analytics
 Big Data: Architectures and Data Analytics June 26, 2018 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
Big Data: Architectures and Data Analytics June 26, 2018 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
MapReduce & YARN Hands-on Lab Exercise 1 Simple MapReduce program in Java
 MapReduce & YARN Hands-on Lab Exercise 1 Simple MapReduce program in Java Contents Page 1 Copyright IBM Corporation, 2015 US Government Users Restricted Rights - Use, duplication or disclosure restricted
MapReduce & YARN Hands-on Lab Exercise 1 Simple MapReduce program in Java Contents Page 1 Copyright IBM Corporation, 2015 US Government Users Restricted Rights - Use, duplication or disclosure restricted
Big Data Analytics. 4. Map Reduce I. Lars Schmidt-Thieme
 Big Data Analytics 4. Map Reduce I Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany original slides by Lucas Rego
Big Data Analytics 4. Map Reduce I Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany original slides by Lucas Rego
Introduction to HDFS and MapReduce
 Introduction to HDFS and MapReduce Who Am I - Ryan Tabora - Data Developer at Think Big Analytics - Big Data Consulting - Experience working with Hadoop, HBase, Hive, Solr, Cassandra, etc. 2 Who Am I -
Introduction to HDFS and MapReduce Who Am I - Ryan Tabora - Data Developer at Think Big Analytics - Big Data Consulting - Experience working with Hadoop, HBase, Hive, Solr, Cassandra, etc. 2 Who Am I -
Topics covered in this lecture
 9/5/2018 CS435 Introduction to Big Data - FALL 2018 W3.B.0 CS435 Introduction to Big Data 9/5/2018 CS435 Introduction to Big Data - FALL 2018 W3.B.1 FAQs How does Hadoop mapreduce run the map instance?
9/5/2018 CS435 Introduction to Big Data - FALL 2018 W3.B.0 CS435 Introduction to Big Data 9/5/2018 CS435 Introduction to Big Data - FALL 2018 W3.B.1 FAQs How does Hadoop mapreduce run the map instance?
Introduction to Map/Reduce & Hadoop
 Introduction to Map/Reduce & Hadoop Vassilis Christophides christop@csd.uoc.gr http://www.csd.uoc.gr/~hy562 University of Crete 1 Peta-Bytes Data Processing 2 1 1 What is MapReduce? MapReduce: programming
Introduction to Map/Reduce & Hadoop Vassilis Christophides christop@csd.uoc.gr http://www.csd.uoc.gr/~hy562 University of Crete 1 Peta-Bytes Data Processing 2 1 1 What is MapReduce? MapReduce: programming
Hadoop 2.8 Configuration and First Examples
 Hadoop 2.8 Configuration and First Examples Big Data - 29/03/2017 Apache Hadoop & YARN Apache Hadoop (1.X) De facto Big Data open source platform Running for about 5 years in production at hundreds of
Hadoop 2.8 Configuration and First Examples Big Data - 29/03/2017 Apache Hadoop & YARN Apache Hadoop (1.X) De facto Big Data open source platform Running for about 5 years in production at hundreds of
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing. Lecture 6: MapReduce in Parallel Computing
 ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
Informa)on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies
on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies") Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node:
Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node:
MRUnit testing framework is based on JUnit and it can test Map Reduce programs written on 0.20, 0.23.x, 1.0.x, 2.x version of Hadoop.
 MRUnit Tutorial Setup development environment 1. Download the latest version of MRUnit jar from Apache website: https://repository.apache.org/content/repositories/releases/org/apache/ mrunit/mrunit/. For
MRUnit Tutorial Setup development environment 1. Download the latest version of MRUnit jar from Apache website: https://repository.apache.org/content/repositories/releases/org/apache/ mrunit/mrunit/. For
Introduction to Hadoop. Scott Seighman Systems Engineer Sun Microsystems
 Introduction to Hadoop Scott Seighman Systems Engineer Sun Microsystems 1 Agenda Identify the Problem Hadoop Overview Target Workloads Hadoop Architecture Major Components > HDFS > Map/Reduce Demo Resources
Introduction to Hadoop Scott Seighman Systems Engineer Sun Microsystems 1 Agenda Identify the Problem Hadoop Overview Target Workloads Hadoop Architecture Major Components > HDFS > Map/Reduce Demo Resources
Big Data: Architectures and Data Analytics
 Big Data: Architectures and Data Analytics January 22, 2018 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
Big Data: Architectures and Data Analytics January 22, 2018 Student ID First Name Last Name The exam is open book and lasts 2 hours. Part I Answer to the following questions. There is only one right answer
PIGFARM - LAS Sponsored Computer Science Senior Design Class Project Spring Carson Cumbee - LAS
 PIGFARM - LAS Sponsored Computer Science Senior Design Class Project Spring 2017 Carson Cumbee - LAS What is Big Data? Big Data is data that is too large to fit into a single server. It necessitates the
PIGFARM - LAS Sponsored Computer Science Senior Design Class Project Spring 2017 Carson Cumbee - LAS What is Big Data? Big Data is data that is too large to fit into a single server. It necessitates the
Hadoop 3 Configuration and First Examples
 Hadoop 3 Configuration and First Examples Big Data - 26/03/2018 Apache Hadoop & YARN Apache Hadoop (1.X) De facto Big Data open source platform Running for about 5 years in production at hundreds of companies
Hadoop 3 Configuration and First Examples Big Data - 26/03/2018 Apache Hadoop & YARN Apache Hadoop (1.X) De facto Big Data open source platform Running for about 5 years in production at hundreds of companies
Cloud Computing. Up until now
 Cloud Computing Lecture 9 Map Reduce 2010-2011 Introduction Up until now Definition of Cloud Computing Grid Computing Content Distribution Networks Cycle-Sharing Distributed Scheduling 1 Outline Map Reduce:
Cloud Computing Lecture 9 Map Reduce 2010-2011 Introduction Up until now Definition of Cloud Computing Grid Computing Content Distribution Networks Cycle-Sharing Distributed Scheduling 1 Outline Map Reduce:
Session 1 Big Data and Hadoop - Overview. - Dr. M. R. Sanghavi
 Session 1 Big Data and Hadoop - Overview - Dr. M. R. Sanghavi Acknowledgement Prof. Kainjan M. Sanghavi For preparing this prsentation This presentation is available on my blog https://maheshsanghavi.wordpress.com/expert-talk-fdp-workshop/
Session 1 Big Data and Hadoop - Overview - Dr. M. R. Sanghavi Acknowledgement Prof. Kainjan M. Sanghavi For preparing this prsentation This presentation is available on my blog https://maheshsanghavi.wordpress.com/expert-talk-fdp-workshop/
2. MapReduce Programming Model
 Introduction MapReduce was proposed by Google in a research paper: Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System
Introduction MapReduce was proposed by Google in a research paper: Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. OSDI'04: Sixth Symposium on Operating System
Data-Intensive Computing with MapReduce
 Data-Intensive Computing with MapReduce Session 2: Hadoop Nuts and Bolts Jimmy Lin University of Maryland Thursday, January 31, 2013 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Computing with MapReduce Session 2: Hadoop Nuts and Bolts Jimmy Lin University of Maryland Thursday, January 31, 2013 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University
![CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University](/thumbs/87/96206398.jpg "CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University") CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [MAPREDUCE & HADOOP] Does Shrideep write the poems on these title slides? Yes, he does. These musing are resolutely on track For obscurity shores, from whence
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [MAPREDUCE & HADOOP] Does Shrideep write the poems on these title slides? Yes, he does. These musing are resolutely on track For obscurity shores, from whence
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Map/Reduce & Hadoop
 Introduction to Map/Reduce & Hadoop V. CHRISTOPHIDES University of Crete & INRIA Paris 1 Peta-Bytes Data Processing 2 1 1 What is MapReduce? MapReduce: programming model and associated implementation for
Introduction to Map/Reduce & Hadoop V. CHRISTOPHIDES University of Crete & INRIA Paris 1 Peta-Bytes Data Processing 2 1 1 What is MapReduce? MapReduce: programming model and associated implementation for
Attacking & Protecting Big Data Environments
 Attacking & Protecting Big Data Environments Birk Kauer & Matthias Luft {bkauer, mluft}@ernw.de #WhoAreWe Birk Kauer - Security Researcher @ERNW - Mainly Exploit Developer Matthias Luft - Security Researcher
Attacking & Protecting Big Data Environments Birk Kauer & Matthias Luft {bkauer, mluft}@ernw.de #WhoAreWe Birk Kauer - Security Researcher @ERNW - Mainly Exploit Developer Matthias Luft - Security Researcher
Recommended Literature
 COSC 6339 Big Data Analytics Introduction to Map Reduce (I) Edgar Gabriel Fall 2018 Recommended Literature Original MapReduce paper by google http://research.google.com/archive/mapreduce-osdi04.pdf Fantastic
COSC 6339 Big Data Analytics Introduction to Map Reduce (I) Edgar Gabriel Fall 2018 Recommended Literature Original MapReduce paper by google http://research.google.com/archive/mapreduce-osdi04.pdf Fantastic
Prototyping Data Intensive Apps: TrendingTopics.org
 Prototyping Data Intensive Apps: TrendingTopics.org Pete Skomoroch Research Scientist at LinkedIn Consultant at Data Wrangling @peteskomoroch 09/29/09 1 Talk Outline TrendingTopics Overview Wikipedia Page
Prototyping Data Intensive Apps: TrendingTopics.org Pete Skomoroch Research Scientist at LinkedIn Consultant at Data Wrangling @peteskomoroch 09/29/09 1 Talk Outline TrendingTopics Overview Wikipedia Page
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Improved MapReduce k-means Clustering Algorithm with Combiner
 2014 UKSim-AMSS 16th International Conference on Computer Modelling and Simulation Improved MapReduce k-means Clustering Algorithm with Combiner Prajesh P Anchalia Department Of Computer Science and Engineering
2014 UKSim-AMSS 16th International Conference on Computer Modelling and Simulation Improved MapReduce k-means Clustering Algorithm with Combiner Prajesh P Anchalia Department Of Computer Science and Engineering
Parallel Computing. Prof. Marco Bertini
 Parallel Computing Prof. Marco Bertini Apache Hadoop Chaining jobs Chaining MapReduce jobs Many complex tasks need to be broken down into simpler subtasks, each accomplished by an individual MapReduce
Parallel Computing Prof. Marco Bertini Apache Hadoop Chaining jobs Chaining MapReduce jobs Many complex tasks need to be broken down into simpler subtasks, each accomplished by an individual MapReduce
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Programmatic ETL. Christian Thomsen, Aalborg University. ebiss 2017
 Programmatic ETL Christian Thomsen, Aalborg University Agenda Introduction to pygrametl a framework for programmatic ETL Explicit parallelism in pygrametl A case-study Open-sourcing pygrametl ETLMR CloudETL
Programmatic ETL Christian Thomsen, Aalborg University Agenda Introduction to pygrametl a framework for programmatic ETL Explicit parallelism in pygrametl A case-study Open-sourcing pygrametl ETLMR CloudETL
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Processing big data with modern applications: Hadoop as DWH backend at Pro7. Dr. Kathrin Spreyer Big data engineer
 Processing big data with modern applications: Hadoop as DWH backend at Pro7 Dr. Kathrin Spreyer Big data engineer GridKa School Karlsruhe, 02.09.2014 Outline 1. Relational DWH 2. Data integration with
Processing big data with modern applications: Hadoop as DWH backend at Pro7 Dr. Kathrin Spreyer Big data engineer GridKa School Karlsruhe, 02.09.2014 Outline 1. Relational DWH 2. Data integration with
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Big Data: Tremendous challenges, great solutions
 Big Data: Tremendous challenges, great solutions Luc Bougé ENS Rennes Alexandru Costan INSA Rennes Gabriel Antoniu INRIA Rennes Survive the data deluge! Équipe KerData 1 Big Data? 2 Big Picture The digital
Big Data: Tremendous challenges, great solutions Luc Bougé ENS Rennes Alexandru Costan INSA Rennes Gabriel Antoniu INRIA Rennes Survive the data deluge! Équipe KerData 1 Big Data? 2 Big Picture The digital
TI2736-B Big Data Processing. Claudia Hauff
 TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Pig Design Patterns Hadoop Ctd. Graphs Giraph Spark Zoo Keeper Spark Learning objectives Implement
TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Pig Design Patterns Hadoop Ctd. Graphs Giraph Spark Zoo Keeper Spark Learning objectives Implement
Spark and Cassandra. Solving classical data analytic task by using modern distributed databases. Artem Aliev DataStax
 Spark and Cassandra Solving classical data analytic task by using modern distributed databases Artem Aliev DataStax Spark and Cassandra Solving classical data analytic task by using modern distributed
Spark and Cassandra Solving classical data analytic task by using modern distributed databases Artem Aliev DataStax Spark and Cassandra Solving classical data analytic task by using modern distributed
Map- reduce programming paradigm
 Map- reduce programming paradigm Some slides are from lecture of Matei Zaharia, and distributed computing seminar by Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet. In pioneer days they
Map- reduce programming paradigm Some slides are from lecture of Matei Zaharia, and distributed computing seminar by Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet. In pioneer days they
Map-Reduce Applications: Counting, Graph Shortest Paths
 Map-Reduce Applications: Counting, Graph Shortest Paths Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Map-Reduce Applications: Counting, Graph Shortest Paths Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Introduction to Hadoop
 Hadoop 1 Why Hadoop Drivers: 500M+ unique users per month Billions of interesting events per day Data analysis is key Need massive scalability PB s of storage, millions of files, 1000 s of nodes Need cost
Hadoop 1 Why Hadoop Drivers: 500M+ unique users per month Billions of interesting events per day Data analysis is key Need massive scalability PB s of storage, millions of files, 1000 s of nodes Need cost
MapReduce: Recap. Juliana Freire & Cláudio Silva. Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec
 MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
Processing Distributed Data Using MapReduce, Part I
 Processing Distributed Data Using MapReduce, Part I Computer Science E-66 Harvard University David G. Sullivan, Ph.D. MapReduce A framework for computation on large data sets that are fragmented and replicated
Processing Distributed Data Using MapReduce, Part I Computer Science E-66 Harvard University David G. Sullivan, Ph.D. MapReduce A framework for computation on large data sets that are fragmented and replicated
Data Partitioning and MapReduce
 Data Partitioning and MapReduce Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies,
Data Partitioning and MapReduce Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies,
CS / Cloud Computing. Recitation 3 September 9 th & 11 th, 2014
 CS15-319 / 15-619 Cloud Computing Recitation 3 September 9 th & 11 th, 2014 Overview Last Week s Reflection --Project 1.1, Quiz 1, Unit 1 This Week s Schedule --Unit2 (module 3 & 4), Project 1.2 Questions
CS15-319 / 15-619 Cloud Computing Recitation 3 September 9 th & 11 th, 2014 Overview Last Week s Reflection --Project 1.1, Quiz 1, Unit 1 This Week s Schedule --Unit2 (module 3 & 4), Project 1.2 Questions
MAPREDUCE - PARTITIONER
 MAPREDUCE - PARTITIONER http://www.tutorialspoint.com/map_reduce/map_reduce_partitioner.htm Copyright tutorialspoint.com A partitioner works like a condition in processing an input dataset. The partition
MAPREDUCE - PARTITIONER http://www.tutorialspoint.com/map_reduce/map_reduce_partitioner.htm Copyright tutorialspoint.com A partitioner works like a condition in processing an input dataset. The partition
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
Internet Measurement and Data Analysis (13)
") Internet Measurement and Data Analysis (13) Kenjiro Cho 2016-07-11 review of previous class Class 12 Search and Ranking (7/4) Search systems PageRank exercise: PageRank algorithm 2 / 64 today s topics
Internet Measurement and Data Analysis (13) Kenjiro Cho 2016-07-11 review of previous class Class 12 Search and Ranking (7/4) Search systems PageRank exercise: PageRank algorithm 2 / 64 today s topics
Lecture 7: MapReduce design patterns! Claudia Hauff (Web Information Systems)!
!") Big Data Processing, 2014/15 Lecture 7: MapReduce design patterns!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm
Big Data Processing, 2014/15 Lecture 7: MapReduce design patterns!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm
Using Big Data for the analysis of historic context information
 0 Using Big Data for the analysis of historic context information Francisco Romero Bueno Technological Specialist. FIWARE data engineer francisco.romerobueno@telefonica.com Big Data: What is it and how
0 Using Big Data for the analysis of historic context information Francisco Romero Bueno Technological Specialist. FIWARE data engineer francisco.romerobueno@telefonica.com Big Data: What is it and how
MapReduce programming model
 MapReduce programming model technology basics for data scientists Spring - 2014 Jordi Torres, UPC - BSC www.jorditorres.eu @JordiTorresBCN Warning! Slides are only for presenta8on guide We will discuss+debate
MapReduce programming model technology basics for data scientists Spring - 2014 Jordi Torres, UPC - BSC www.jorditorres.eu @JordiTorresBCN Warning! Slides are only for presenta8on guide We will discuss+debate
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
PARALLEL DATA PROCESSING IN BIG DATA SYSTEMS
 PARALLEL DATA PROCESSING IN BIG DATA SYSTEMS Great Ideas in ICT - June 16, 2016 Irene Finocchi (finocchi@di.uniroma1.it) Title keywords How big? The scale of things Data deluge Every 2 days we create as
PARALLEL DATA PROCESSING IN BIG DATA SYSTEMS Great Ideas in ICT - June 16, 2016 Irene Finocchi (finocchi@di.uniroma1.it) Title keywords How big? The scale of things Data deluge Every 2 days we create as
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
BigData and MapReduce with Hadoop
 BigData and MapReduce with Hadoop Ivan Tomašić 1, Roman Trobec 1, Aleksandra Rashkovska 1, Matjaž Depolli 1, Peter Mežnar 2, Andrej Lipej 2 1 Jožef Stefan Institute, Jamova 39, 1000 Ljubljana 2 TURBOINŠTITUT
BigData and MapReduce with Hadoop Ivan Tomašić 1, Roman Trobec 1, Aleksandra Rashkovska 1, Matjaž Depolli 1, Peter Mežnar 2, Andrej Lipej 2 1 Jožef Stefan Institute, Jamova 39, 1000 Ljubljana 2 TURBOINŠTITUT